Skyline 靶向方法优化
Skyline 靶向方法优化

Skyline 靶向方法优化本教程将介绍 Skyline 靶向蛋白质组环境中可用于优化选择性反应监测(简称 SRM;亦称为“多反应监测”,简称 MRM)质谱仪实验方法的功能。
当给定蛋白质的一组理想目标肽段没有或未知时,Skyline 能够简单创建可测量范围十分广泛的各种肽段的方法,以在样品基质中搜寻最适合测量的肽段。
然后,将这些首次测试的结果导入Skyline,Skyline 可以帮助您优化方法,以改进下一轮的测量。
我们将这称为“靶向方法优化周期”,该方法经常以下图体现:通过循环此周期,您可以从比较笼统的假设开始,包括您想监测的 100 多个蛋白质,快速缩小清单至最佳肽段、子离子和仪器设置以便达到您的实验目标。
本教程将引导您逐步完成此优化周期的两个半循环,以便让您知晓如何进行更多的循环来创建充分优化的定量方法。
入门指南要开始本教程,请下载下列 ZIP 文件:https:///tutorials/MethodRefine.zip将文件解压到您的电脑的某个文件夹,比如:C:\Users\brendanx\Documents这将创建一个新文件夹:C:\Users\brendanx\Documents\MethodRefine现在通过双击,或使用一个正在运行的Skyline的“文件”菜单下的“打开”命令来打开新文件夹中的WormUnrefined.sky 文件。
结果数据选择文档中的第一个肽段 (YLGAYLLATLGGNASPSAQDVLK)。
Skyline 将同时显示图谱库中的MS/MS图谱和相应的在 MacCoss 实验室仪器上获得的肽段的子离子 y3 – y15 的时间-强度色谱图数据:请注意,与每个肽段相关联的 MS/MS谱图库通常来自于离子阱质谱仪进行的实验。
在左侧的肽视图中,Skyline在肽段序列的左侧显示绿色、黄色和红色点。
它们为峰质量图标,其含义分别如下:∙绿色— Skyline 选择的最佳峰的所有离子对形成一共洗脱峰。
Skyline非数据依赖型采集-skylinems

Skyline 非数据依赖型采集非数据依赖型采集 (DIA)1,2是一项可用于进行大规模靶向蛋白质组学实验的先进技术。
靶向采集方法,例如选择性反应监测 (SRM) 和平行反应监测 (PRM),仅可适用于一些无采集时序安排的肽段或在有时序安排的情况下,适用于每次质谱仪运行下的数十至数百个肽段。
与SRM相比,DIA可以检测更多数量的肽段(数千或甚至整个蛋白质组),并且不严重影响检测方法的敏感性、选择性和再现性。
DIA 的另一优势是,待测量的肽段不需要提前或计划指定,反而在广泛的母离子质荷比中,任何需要的肽段的子离子色谱图均可以在采集后从 DIA 运行中提取。
2010年10月,Skyline首次用于从DIA 数据中提取色谱图。
自此以来,这一功能已得到了很大的改进。
当前版本的 Skyline可用于多种常见的DIA数据分析方法和流程。
Skyline 亦支持所有可以进行 DIA 的仪器,包括 AB SCIEX,Agilent,Bruker和Waters 的 Q-TOF 仪器和Thermo 的Q-Orbitrap 仪器。
若要使 DIA 实验富有成效,那么开始便需要在某种色谱仪和质谱仪上采用数据依赖型(D DA)的方法进行初始的数据的采集。
如果这些初始鸟枪法的检测和DIA实验在同一仪器上进行,这会大有帮助。
但如果使用相似的多肽破碎技术和色谱分析发法,同一试验方法则亦可能在不同的仪器平台之间转移。
在这些初始的 DDA 实验中,样本可以被分离或进行简化从而达到更高的蛋白质组覆盖率。
多肽-谱图匹配软件将用于分析DDA 数据,而生成的多肽序列 (ID)、谱图和保留时间会被用来创建一个谱图库和保留时间 (iRT) 库(在 S kyline 中)或创建一个加长的离子对列表(含有片段离子子集的相似信息)或者被称为“化验物库”(在其他工具中)。
这些子离子相对丰度值和标准化的保留时间 (iRT) 可以用于任何数量的后续 DIA 实验,但这些 DIA 实验需使用相同的仪器和保留时间校准的标准肽段。
Skyline小分子目标

Skyline 小分子目标Skyline 靶向蛋白质组学环境提供充足的视觉信息,可查看您导入 Skyline 文档的原始质谱仪数据。
Skyline 最初系为蛋白质组学而开发的,现在其应用已延伸到普遍小分子领域。
许多教程都可以帮助您使用 Skyline 进行各种类型的数据分析(例如:SRM、MS1 筛选、DIA、靶向 MS/MS 等等)。
本教程将集中讲述使用 Skyline 进行小分子的定向分析。
在本教程中,您将为一组与蛋氨酸途径相关的化合物建立一项多反应监测 (MRM) 实验。
Skyline 旨在提供一个不分质谱仪供应商并且可用于靶向定量质谱研究的平台。
这个平台可以导入在不同仪器供应商的质谱仪上采集的原始数据,如,Agilent、SCIEX、Bruker、Shimadzu、Th ermo-Scientific 和 Waters。
这将能极大地促进不同仪器之间的比较和大型多站点研究。
这种方法在蛋白质组学领域中已使用多年,所以在将其用于定向小分子时同样奏效。
开始首先,请下载下列 ZIP 文件:https:///tutorials/SmallMolecule.zip将其中的文件解压到您电脑上的文件夹,如:C:\Users\bspratt\Documents这将创建一个新文件夹:C:\Users\bspratt\Documents\SmallMolecule这里会包含本教程需要的所有文件。
现在打开 Skyline,然后您将看到一个新的空文档。
将一个小分子离子对列表导入 Skyline 文档将小分子离子对列表导入 Skyline 文档最简单的方法是,打开一个空白文档,使用编辑>插入>离子对列表菜单项。
[注释:文件>导入>离子对列表菜单项还不能用于非蛋白质组数据。
它无法在一个小分子离子对列表中猜出哪些列是做什么的。
]Skyline 至少需要知道每个母离子和子离子的电荷状态和离子公式或质荷比。
基于最近邻过滤的数据流Skyline算法

基于最近邻过滤的数据流Skyline算法王艳杰;薛安荣;吴正寅【摘要】Lazy of Skyline query algorithm is poor in data processing. So this paper proposes an improved algorithm called Nearest Neighbor-based Skyline Computation(NNSC) by using the idea of Nearest Neighbor(NN) filtering. It defines a threshold by using Euclidean distance in pre-processing stage. If the Euclidean distance of the recently inserted object is greater than which of the threshold, it will be processed ahead of time to improve the algorithm efficiency and reduce resource consumption. Experimental results show that NNSC can reduce the time and space complexity, and its performance is improved significantly for positive correlated data.%在Skyline查询算法中,Lazy算法的数据处理能力较弱.针对该问题,利用最近邻过滤的思想,提出改进的NNSC算法.在预处理阶段,利用欧氏距离定义一个阈值,如果新插入数据对象的欧氏距离大于阈值,提前处理该对象,以提高算法利用率,减少资源的消耗.实验结果证明,NNSC可降低时空复杂度,对于正相关数据,性能提升效果明显.【期刊名称】《计算机工程》【年(卷),期】2011(037)021【总页数】3页(P43-45)【关键词】数据流;Skyline算法;NNSC算法;最近邻过滤;欧氏距离【作者】王艳杰;薛安荣;吴正寅【作者单位】江苏大学计算机科学与通信工程学院,扛苏镇江212013;江苏大学计算机科学与通信工程学院,扛苏镇江212013;江苏大学计算机科学与通信工程学院,扛苏镇江212013【正文语种】中文【中图分类】TP3111 概述Skyline查询就是返回给定数据集中所有不被其他点支配的点。
基于Skyline服务的Top-k选择方法

基于Skyline服务的Top-k选择方法杨莉;张文生;许国艳【期刊名称】《计算机应用与软件》【年(卷),期】2016(033)011【摘要】为缩小 Skyline 服务集,提高服务选择的效率,提出一种 Skyline 服务Top-k 选择方法。
首先,用数据推理的方式为 Skyline服务的 Top-k 选择提供理论依据,并提出 Skyline 服务 Top-k 选择的相关命题;然后,基于这些命题,提出 Skyline 服务 Top-k 选择算法,该算法可以得到被选择可能性最大的 Top-k Skyline 服务集;最后,通过实验证明,该方法能有效降低服务选择的时间,而不影响服务组合的最终结果。
%A Top-k selection algorithm based on Skyline service is proposed to decrease the size of Skyline services set and increase the ef-ficiency of service selection.Firstly,the theoretical foundation of the proposed algorithm is provided by mathematical reasoning,and then some related propositions are presented;Secondly,with the proposed propositions,the Skyline service Top-k selection algorithm is put for-ward,which is able to obtain the Top-k Skyline service set which was most likely to be selected ;Finally,the experiment is conducted to prove that the proposed algorithm is useful to decrease service selection time with no impact on service composition.【总页数】5页(P253-257)【作者】杨莉;张文生;许国艳【作者单位】河海大学信息中心江苏南京 210098;华东宜兴抽水蓄能有限公司江苏宜兴 214205;河海大学计算机与信息学院江苏南京 211100【正文语种】中文【中图分类】TP3【相关文献】1.基于Skyline的动态可信服务选择方法 [J], 王海艳;丁飞2.基于服务质量的Top-k Web服务选择方法 [J], 王海;朱正东;李增智3.DFTS:面向大数据集的Top-k Skyline查询算法 [J], 魏亮;林子雨;赖永炫4.海量数据上有效的top-k Skyline查询算法 [J], 韩希先;宋翠;戈韵如;高宏;李建中5.Efficient User Preferences-Based Top-k Skyline Using MapReduce [J], Linlin Ding;Xiao Zhang;Mingxin Sun;Aili Liu;Baoyan Song;因版权原因,仅展示原文概要,查看原文内容请购买。
Skyline 数据非依赖性采集说明书

Skyline 数据非依赖性采集数据非依赖性采集 (DIA)1,2是一种用于大型靶向蛋白质组学实验的先进技术。
在没有采集预定的情况下,选择反应监测 (SRM) 和平行反应监测 (PRM) 等靶向采集方法仅能测量少量肽段;在每次质谱运行进行预定的情况下,这些采集方法可测量数十到数百个肽段。
而使用 DIA 时可以测量更多的肽段(数千个乃至整个蛋白质组),相对于 SRM,采用这种方法时在灵敏度、选择性和再现性方面的牺牲并不大。
DIA 的另一个优点是无需预先指定或预定所要测量的肽段,而是可以在运行 DIA 进行采集后,提取广泛的母离子质荷比范围内任何所需肽段的子离子色谱图。
自 2010 年 10 月 Skyline 首次支持根据 DIA 数据提取色谱图以来,这项支持一直在定期改进。
从 21.1 版开始,Skyline 支持多种常用的 DIA 数据分析策略和工作流程。
Skyline 还支持所有具备 DIA 功能的仪器,其中包括 SCIEX、Agilent、Bruker 和 Waters 公司的 Q-TOF 仪器以及Thermo 公司的 Q-Orbitrap 仪器。
采用一种有效的 DIA 工作流程时,一开始就能在特定的仪器和色谱设置下运行任意多次初步数据依赖性采集 (DDA)。
它有利于在运行 DIA 的同一台仪器上执行这些初步 Shotgun 测量。
但是,如果使用类似的分段技术和色谱法,也可以在仪器平台之间转移靶向分析。
对于这些初步的 DDA 测量,为达到更高的蛋白质组覆盖率,样品可能会被分馏或以其他方式简化。
DDA 运行使用肽段谱图匹配管道进行处理,然后(在 Skyline 中)利用得到的肽段ID 的谱图和保留时间来创建谱图库和保留时间 (iRT) 库,或是(在其他工具中)创建叫做“分析库”的扩展离子对列表(具备碎片离子子集的相似信息)。
这些碎片离子相对丰度和归一化保留时间 (iRT) 库可用于后续任意多次使用相同仪器和标准肽段进行保留时间校准的 DIA 运行。
一种基于Skyline的服务选择方法

一种基于Skyline的服务选择方法在云环境中,服务选择是一项重要的任务,可以极大地影响云应用程序的性能和质量。
因此,研究如何选择最优的服务对于优化云应用程序的性能和可靠性至关重要。
Skyline是一种基于多维数据的查询处理方法,被广泛应用于服务选择。
基于Skyline的服务选择方法可以为用户提供高效和可靠的服务选择。
基于Skyline的服务选择方法的基本思想是,将所有可用的服务看作一个点云,然后利用Skyline算法找到最优的服务组合,以满足用户的需求。
Skyline算法可以使用多种技术来实现,例如暴力搜索、分治策略、高效数据结构等,其核心思想是找到所有不劣解或非支配点。
在服务选择中,Skyline算法可以用来查找所有非支配服务或最优解的子集。
除了Skyline算法之外,基于Skyline的服务选择方法还包括确定服务筛选条件、定义评估指标和评估服务性能等方面。
服务筛选条件可能包括成本、可用性、相应时间、QoS(质量服务)和安全性等。
评估指标可能包括服务响应时间、延迟、可用性、性能和成本等。
评估服务的性能和质量的方法包括测试、模拟和预测等。
基于Skyline的服务选择方法已经在许多实际应用中得到了应用。
举例来说,一个基于Skyline的服务选择方法被用于选择最佳的Web服务组合以优化类似Google的搜索引擎。
在这个应用中,选择最优的Web服务组合意味着提高搜索引擎的性能和响应时间,以及减轻网络带宽的负担。
另一个应用是通过选择最优的服务来提高移动应用程序的性能和响应时间。
总的来说,基于Skyline的服务选择方法是一种高效和可靠的服务选择技术,可以为用户提供高质量的服务。
它可以通过选择最优的服务组合来满足用户的需求和优化应用程序性能和质量。
在未来,这种技术有望在更多的应用场景中得到广泛应用,成为优化云应用性能和可靠性的重要手段中的一种。
一种基于索引的高效k-支配Skyline算法

关键词
syie决 策 支 持 ; 一 配 s yie基 于 索 引 kl ; n k支 kl ; n T 31 P 1 D I :1. 74 S . .0 6 2 1 . 1 3 O 号 0 3 2 / P J 1 1 .0 0 0 2 6
中圈 法 分 类 号
An I e s d Ef i intk・ m i a k ln g r t nd x Ba e f c e Do n ntS y i e Al o ihm
Ab ta t Duet hei p t n ef e e a pp iato n ol i ulic ie i c so a n sr c o t m or a c ors v r la lc i nsi v v ng m t— rt ra de ii n m ki g,
s lnequ r s r c ie o fa t n i n i he r s a c il fda a a ea a am i i g i e ky i e y ha e ev d a l to t e to n t e e r h fe d o t b s nd d t n n n r — c nty a s H o v r s t e er. we e ,a henumbe me son n r a e,t o sbiiy t or do n ntr — rofdi n i s i c e s he p s i lt o f m mi a e l ton hi t e a apo nt sv r ow. Asa r s t h umbe ky i e p nt c me o a i s p be we n d t i s i e y l e ul ,t e n rofs ln oi sbe o st o nu e ou o p ov d n e uli f r a i n. Fo t a f fnd ng m o e i or a n r m r s t r i e a y us f n o m to r he s ke o i i r mp t nt a d mo e me n n u ky i i t n h gh d me i n d t e ,a e c c pt c le 愚 d m i a t ky i e a i gf ls lne po n s i i i nso a a s t n w on e a ld 一 o n n s ln
MapReduce框架下的Skyline结果优化算法

S k y l i ne r e s u l t o p t i mi z a t i o n a l g o r i t hm ba s e d o n
M a o Re d uc e f r a me wo r k
MA X u e . s e n , , WA N G X i a o . j i e , HA N J i a n g — h o n g ,WA N G Y i n g — g u a n
户提供精确 的信息 。M a p R e d u c e作为并 行计 算框 架 , 已广 泛应 用 于大 数据 处理 中。本 文提 出 了 Ma p R e — d u c e 框架下基于 支配个数 的结果优 化算法 ( MR — D MN) , 解决 了大数据 环境下 的 S k y l i n e结果集 优化 问题。
( 1 。 S c h o o l o f C o mp u t e r& I n f o r ma t i o n , He f e i U n i v e r s i t y o f T e c h n o l o g y , He f e i 2 3 0 0 0 9 , C h i n a ;
p r o b l e m o f o p t i mi z a t i o n o f S k y l i n e r e s u l t s e t i n b i g d a t a e n v i r o n me n t s . L o t s o f e x p e r i me n t s s h o w t h a t t h e lg a o r i t h m h a s g o o d t i me a n d s p a c e e f f i c i e n c y .
药物靶点的筛选与优化

药物靶点的筛选与优化药物靶点是药物研发的核心问题之一。
一个好的靶点可以帮助药物更好地达到治疗效果。
而如何筛选和优化靶点,则是一个需要借助多种技术手段和方法的复杂过程。
一、靶点的筛选靶点的筛选是药物研发的第一步。
大部分新药研发项目都是基于靶点进行展开的。
有多种方法可以用于筛选靶点,其中最基础且常见的是基因测序技术。
通过分析人体的基因组、转录组和表观组等信息,可以挖掘出潜在的靶点。
基因测序技术虽然可以大大加速靶点筛选的过程,但仍然存在很多问题。
首先,人类基因组的复杂性使得筛选出的靶点往往只有一部分具有实际意义。
此外,在筛选的过程中,往往会受到样本数量的限制,使得筛选效果受到很大影响。
因此,靶点的筛选过程需要综合运用多种技术手段和方法。
其次,目前靶点的筛选工作较为艰难,因为需要考虑到药物的有效性和安全性。
这意味着我们需要在可行性和风险之间做出平衡,并进行较为精确的测量和分析。
二、靶点的优化靶点的优化则是药物研发的第二个重要步骤。
在靶点筛选的基础上,研究人员需要通过各种实验手段和数学模型来优化找到的靶点,以提高药物的疗效性和安全性。
一种常见的靶点优化技术是颜色标记。
这种技术可以有效地将药物相关的细胞和分子标记出来,以便研究人员更好地理解药物的作用机制。
此外,还可以使用分子动力学模拟技术来了解分子之间在不同时间尺度下的相互作用,进一步优化靶点。
靶点的优化需要不断地进行实验验证,进行反复比较和经验调整。
例如,在优化开发抗菌药物时,研究人员需要实验几百种不同细菌的感受性,并进行不断的优化和改进,以得到更好的效果。
三、靶点研究的未来随着技术的发展和人类对药物研发的深入认识,靶点的筛选和优化技术也将不断发展和改进。
例如,目前已经出现了许多基于人工智能的靶点筛选方法,它们可以通过大量的数据分析和机器学习来发现新的靶点。
这种方法可以大大节省时间和人力,也可以消除人为误差。
此外,越来越多的研究表明,靶点筛选和优化都需要参考整个身体的生理情况,而不仅仅是针对某个特定器官或细胞。
分治算法求解二维点集合的skyline

分治算法求解二维点集合的skyline在计算机科学中,分治算法是一种常见的问题解决方法,它将一个大问题分解成多个小问题,分别解决这些小问题,最后将它们的解合并起来得到最终结果。
在本文中,我们将讨论如何使用分治算法来求解二维点集合的skyline问题。
首先,让我们来了解一下什么是skyline。
在二维平面上,给定一组点的坐标,我们称其中某些点为skyline,如果这些点的坐标在该组点中是可见的,也就是说,这些点的横坐标和纵坐标都不小于其他点的横坐标和纵坐标。
换句话说,skyline是在二维平面上能够被看到的点的集合。
接下来,我们将介绍如何使用分治算法来求解二维点集合的skyline问题。
首先,我们将二维点集合按照横坐标进行排序,然后将其分成两个子集合,分别递归求解每个子集合的skyline。
最后,将两个子集合的skyline合并起来,得到最终的skyline。
在分解问题的过程中,我们需要考虑如何合并子问题的解。
对于每个子集合的skyline,我们可以用一个扫描线的方法来求解。
具体来说,我们可以将横坐标和纵坐标分别存储在两个优先队列中,然后按照横坐标从小到大的顺序依次处理每个点,更新优先队列中的点,直到得到该子集合的skyline。
最后,将两个子集合的skyline合并起来,我们可以得到整个二维点集合的skyline。
在合并的过程中,我们需要考虑两个子集合的skyline的交点,也就是说,如果两个子集合的skyline的某个点在某个子集合中是可见的,那么它在合并后的skyline中也是可见的。
综上所述,我们可以使用分治算法来求解二维点集合的skyline问题。
通过将问题分解成多个子问题,递归求解每个子问题的skyline,最后合并子问题的解,我们可以得到最终的skyline。
这种方法的时间复杂度为O(nlogn),其中n是点的个数,因此在实际应用中,分治算法是一个高效的解决方案。
Mapreduce下改进Skyline的高效算法

Mapreduce下改进Skyline的高效算法刘建邦;刘旭敏【摘要】Existing Mapreduce-based Skyline algorithms is inefficient facing large scale database,to solve this problem,an MapReduce with balanced point skyline( MRBPS)algorithm is proposed,using incomparability of dataset,map points to different regions with a computed balancedpoint,simplified multi-dimensional comparison to one dimensional comparison,reduce number of tests in Map and Reduce Task. Systematic experiments prove that the algorithm is efficient in large scale database,and more efficient and reliable than existing algorithms.%目前基于 MapReduce 的 Skyline 算法随着维度增大会陷入维度灾难,不能高效地解决大数据条件下的计算问题。
提出高效算法 MRBPS,利用数据间的互不支配特性,通过一个优化轴点对数据集建立区域标识,在 Map 和 Reduce 阶段优先比较每个点的区域标识,将多维比较简化为一维比较,提高了计算效率,通过系统实验证明:此算法在大数据量时能够明显提高计算效率,与现有算法相比具有高效性和可靠性。
【期刊名称】《传感器与微系统》【年(卷),期】2016(035)011【总页数】4页(P116-119)【关键词】Skyline查询;MapReduce;大数据【作者】刘建邦;刘旭敏【作者单位】首都师范大学信息工程学院,北京 100048;首都师范大学信息工程学院,北京 100048【正文语种】中文【中图分类】TP311Skyline查询又称Pareto查询,主要目的是找出数据集中所有不被其他点支配的数据点集,广泛应用于多目标决策和数据挖掘等领域,是数据库领域的一个研究热点,同时,随着大数据时代的到来,人们开始关注并行Skyline计算,Mapreduce隐藏了并行计算的细节,如数据的分布式存储,任务的调度,机器间通信和容错处理,具有良好的容错性和可靠性,非常适用于大数据的处理。
组合Skyline的求解与更新算法

组合Skyline的求解与更新算法董雷刚;刘国华【期刊名称】《计算机工程》【年(卷),期】2017(043)006【摘要】针对现有组合Skyline查询算法剪枝效率低、对低维数据集计算速度不理想的问题,提出一种快速求解与更新组合Skyline的算法.定义支配区的相关概念,给出相应剪枝规则裁剪无用的数据组合.对于数据集添加数据点和删除数据点的情况,在原有查询结果的基础上根据数据点所在分区实施不同的操作,从而实现查询结果的快速更新.实验结果表明,该算法可有效提高剪枝效率,加快运算速度.%Existing algorithms for querying combinatorial Skyline have low pruning efficiency and unsatisfactory computing speed for low-dimensional data set.Aiming at these problems,this paper proposes a fast algorithm for solving and updating combinatorial Skyline.It defines the related concept of dominant area and presents some pruning rules to prune lots of useless data.For points added or deleted,based on existing result,it takes corresponding operations according to the data partition,so as to update query results quickly.Experimental results show that the proposed algorithm can improve pruning efficiency and computation speed effectively.【总页数】8页(P195-201,206)【作者】董雷刚;刘国华【作者单位】东华大学信息科学与技术学院,上海201620;大庆师范学院计算机科学与信息技术学院,黑龙江大庆163712;东华大学计算机科学与技术学院,上海201620【正文语种】中文【中图分类】TP311【相关文献】1.基于近似的skyline算法的Web服务组合方法 [J], 段静珊;周彦晖2.二维Packing问题拟人型算法中的动作空间更新过程求解 [J], 胡文蓓;饶昊3.求解组合优化问题的组合遗传算法 [J], 欧永斌;彭佳红4.求解复杂函数优化问题的种群动态更新狼群算法 [J], 胡锦强5.求解复杂函数优化问题的种群动态更新狼群算法 [J], 胡锦强因版权原因,仅展示原文概要,查看原文内容请购买。
MRM靶向定量技术

K9-R17%
案例1:验证胰腺癌血清
发现4个潜在 Biomarker
BJC 2017.11.09 On Line
案例3:MRM+EPI提升定量能力 一针定量4组样品
J Proteome Res, 2013. 12(9): p. 3912-9.
案例4:低丰度肽段验证
200+蛋白 1200+离子对 建立Scheduled MRM 方法
选
择
碎
裂
选
择
应用
最早用于制药行业定量小分子
优点
MRM(多反应监测)技术原理 如何应用于肽段绝对定量 如何应用于小分子定量 应用案例分析
与传统鸟枪法的区别
Shotgun技 术
用于定量的缺点
重现 性差
70%
纳升喷雾不稳定
Msms谱图假阳性
MRM技术解决问题
从1拖10改为专门监测某些肽段
轻标10fmol 重标100fmol 轻标1fmol 重标100fmol
实际样品上样时,重标也 是100fmol
大规模样品MRM如何做
局限性 60分钟梯度18s峰宽
0.01*X*6<18
Scheduled 解决办法 MRM
只在某个时间窗口 内扫描特定离子对
离子对个数
保留时间
监测800条肽段,500个蛋白,稳定定量200个蛋白
心血管疾病
1
Fast and effective
2
creation of your
presentation
3
4
糖尿病
恶性肿瘤
Mass Spectrometry based Metabolomics
Oncometabolite
MapReduce 模型下基于 R 树索引的 Skyline 查询算法

MapReduce 模型下基于 R 树索引的 Skyline 查询算法李建伟;王康平;黄岚;王贵参【期刊名称】《吉林大学学报(理学版)》【年(卷),期】2016(054)004【摘要】提出一种 MapReduce 并行计算模型下基于 R 树索引的 Skyline 查询算法,解决了海量空间数据集下执行 Skyline 查询效率低的问题。
通过建立 R 树索引实现空间数据不同粒度的范围剪枝,有效降低了分布式 Skyline 查询需扫描的数据规模,提高了在 MapReduce 模型下Skyline 查询的执行效率。
在不同数据分布下进行对比实验的结果表明,该方法比已有算法在执行效率上更具优势。
%We proposed a Skyline query algorithm based on R-tree index in MapReduce parallel computing model,which solved the low execution efficiency problems of Skyline query in the massive spatial data sets.Through the establishment of R-tree index to realize spatial data of different size range pruning,the algorithm effectively reduced the size of the data required to scan the distributed Skyline query, and improved the execution efficiency of Skyline query in MapReduce model. Comparative tests in different data distribution shows the proposed method has more advantages on efficiency than the existing algorithms.【总页数】6页(P833-838)【作者】李建伟;王康平;黄岚;王贵参【作者单位】吉林大学计算机科学与技术学院,长春 130012;吉林大学计算机科学与技术学院,长春 130012;吉林大学计算机科学与技术学院,长春 130012;吉林大学计算机科学与技术学院,长春 130012【正文语种】中文【中图分类】TP391【相关文献】1.基于MapReduce的增广动态Skyline查询处理方法 [J], 丁琳琳;崔子强;尹显坤;王俊陆;宋宝燕2.基于MapReduce的Skyline-join查询算法 [J], 孙大烈;李建中3.基于MapReduce的Skyline查询处理算法 [J], 崔文相;肖迎元;郝刚;王洪亚;邓华锋4.基于MapReduce的连续概率Skyline查询 [J], 单观敏;董一鸿;何贤芒5.基于 MapReduce 的 Skyline 查询优化算法∗ [J], 杨启; 王芳; 黄树成因版权原因,仅展示原文概要,查看原文内容请购买。
定向PRM
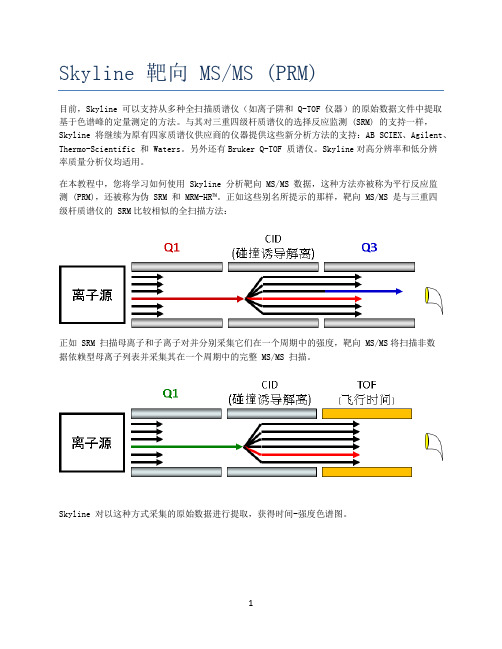
Skyline 靶向 MS/MS (PRM)目前,Skyline 可以支持从多种全扫描质谱仪(如离子阱和 Q-TOF 仪器)的原始数据文件中提取基于色谱峰的定量测定的方法。
与其对三重四级杆质谱仪的选择反应监测 (SRM) 的支持一样,Skyline 将继续为原有四家质谱仪供应商的仪器提供这些新分析方法的支持:AB SCIEX、Agilent、Thermo-Scientific 和 Waters。
另外还有Bruker Q-TOF 质谱仪。
Skyline对高分辨率和低分辨率质量分析仪均适用。
在本教程中,您将学习如何使用 Skyline 分析靶向 MS/MS 数据,这种方法亦被称为平行反应监测 (PRM),还被称为伪 SRM 和 MRM-HR™。
正如这些别名所提示的那样,靶向 MS/MS 是与三重四级杆质谱仪的 SRM比较相似的全扫描方法:正如 SRM 扫描母离子和子离子对并分别采集它们在一个周期中的强度,靶向 MS/MS将扫描非数据依赖型母离子列表并采集其在一个周期中的完整 MS/MS 扫描。
Skyline 对以这种方式采集的原始数据进行提取,获得时间-强度色谱图。
由此产生的色谱图提供的定量数据,与目前在Skyline 用户界面进行的三重四级杆SRM实验数据类似。
当类似仪器上的时间不可选时,靶向 MS/MS 可作为三重四级杆的替代。
即便如此,这种靶向MS/MS 相比传统 SRM在选择性上有优势,并且可以进行数据库搜索,以帮助验证所提取的色谱峰。
而且,靶向 MS/MS 也可用于对各种全扫描仪器进行质量控制,即使它们主要用于数据依赖型采集(DDA)。
这一质量控制方法将会单独在其他教程中进行介绍。
本教程将探讨靶向 MS/MS 在低分辨率 Thermo LTQ 和高分辨率 Agilent Q-TOF 上进行靶向定量测定的用法。
入门指南如要开始本教程,请下载下列 ZIP 文件:https:///tutorials/TargetedMSMS_2.zip将其中的文件解压到您的电脑文件夹,如:C:\Users\brendanx\Documents这将创建一个新文件夹:C:\Users\brendanx\Documents\TargetedMSMS其中包含本教程所需的所有文件。
靶向测序覆盖度优化.pptx

靶向测序覆盖度优化.pptx靶向测序覆盖度优化将测序覆盖率定义为与已知参考碱基比对的平均读取数即:numberofreadsxreadlength/targetsize为了最大程度地提高靶向重测序的研究效率,并确保高度敏感突变检测获得足够的覆盖度,应考虑三个关键因素:1、目标区域的总长度;2、富集效率(readspassingfilte百分比及mapping百分比);3、目标区域覆盖深度范围;目标区域的总长度靶向区域的总长度等于富集分析中靶向的基因组序列的总长度(bp)。
例:TruSeqExomeEnrichmentKit靶向测序总长度:62Mb((包含:5''UTR,codingexons,3''UTR,microRNAs,microRNAtargets,andotherselectedandconservedregionsofinterest)95mer探针捕获300–400bp文库(插入片段180–280bp),文库大小350bp靶区域150bp60bpadapters插入片段230bp60bpadapters95mer探针?65?的readsmap 到靶区域当350bp的DNA文库(插入片段=230bp)被生物素化TruSeq探针富集,每个探针都会拉下整个文库每个95mer探针均靶向目标区域,保守的假定探针需要与插入片段(230bp)的95个碱基全部杂交,插入片段最左侧位置为探针最右侧位置上游的230bp处,插入片段最右侧位置为探针最左侧位置下游230bp处。
则:Pulldown=2Insert–Probe=2230–95=365bp。
根据经验证据表明80mer的探针内最多可容许15个错配,意味着探针拉下的区域可能会更大,上述为保守估计。
虚线表示富集片段的覆盖深度,超过65?的过滤Reads被映射到参考基因组上将overlap靶区域,超过80?的过滤Reads被映射到靶区域中的150个碱基上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Skyline 靶向方法优化本教程将介绍 Skyline 靶向蛋白质组环境中可用于优化选择性反应监测(简称 SRM;亦称为“多反应监测”,简称 MRM)质谱仪实验方法的功能。
当给定蛋白质的一组理想目标肽段没有或未知时,Skyline 能够简单创建可测量范围十分广泛的各种肽段的方法,以在样品基质中搜寻最适合测量的肽段。
然后,将这些首次测试的结果导入Skyline,Skyline 可以帮助您优化方法,以改进下一轮的测量。
我们将这称为“靶向方法优化周期”,该方法经常以下图体现:通过循环此周期,您可以从比较笼统的假设开始,包括您想监测的 100 多个蛋白质,快速缩小清单至最佳肽段、子离子和仪器设置以便达到您的实验目标。
本教程将引导您逐步完成此优化周期的两个半循环,以便让您知晓如何进行更多的循环来创建充分优化的定量方法。
入门指南要开始本教程,请下载下列 ZIP 文件:https:///tutorials/MethodRefine.zip将文件解压到您的电脑的某个文件夹,比如:C:\Users\brendanx\Documents这将创建一个新文件夹:C:\Users\brendanx\Documents\MethodRefine现在通过双击,或使用一个正在运行的Skyline的“文件”菜单下的“打开”命令来打开新文件夹中的WormUnrefined.sky 文件。
结果数据选择文档中的第一个肽段 (YLGAYLLATLGGNASPSAQDVLK)。
Skyline 将同时显示图谱库中的MS/MS图谱和相应的在 MacCoss 实验室仪器上获得的肽段的子离子 y3 – y15 的时间-强度色谱图数据:请注意,与每个肽段相关联的 MS/MS谱图库通常来自于离子阱质谱仪进行的实验。
在左侧的肽视图中,Skyline在肽段序列的左侧显示绿色、黄色和红色点。
它们为峰质量图标,其含义分别如下:∙绿色— Skyline 选择的最佳峰的所有离子对形成一共洗脱峰。
∙黄色—至少一半的离子对形成一共洗脱峰。
∙红色—不到一半的离子对形成一共洗脱峰。
色谱图数据最初从 39 Thermo 原始文件导入该文档。
若要了解为何此文档中对这些肽段的一次测量需要 39次单独进样,首先请注意 Skyline 窗口右下角的数字。
您可以看到该文档包含 225 个肽段和 2096 个离子对,涵盖各肽段的 y3 – y(n-1)子离子(其中 n 是整个肽段序列中氨基酸的个数)。
您正在查看的 Skyline 文档旨在帮助您确定在特定目标基质中哪些肽段是可以测量的,以及哪些是可测肽段的最佳离子对。
每个肽段都拥有大量的离子对可以使我们获得对给定的峰确实是在测量目标肽段的置信度。
这种置信度是通过计算所研究的肽段的离子对峰强度和相同肽段的谱图库1, 2之间的点积值相关性来测定的。
未优化的方法若要了解本文档中测量肽段所需的离子对列表生成方法,请按照如下步骤操作:∙在“文件”菜单上,选择“导出”,并单击“离子对列表”。
∙选择“多个方法”。
∙在“每次进样允许的最多离子对数”中输入“59”。
“导出离子对列表”表单应如下所示:∙单击“确定”按钮。
∙找到下一表单中的 MethodRefine 文件夹。
∙在“文件名”中输入“worm”。
∙单击“保存”按钮。
如果您使用 Windows Explorer 查看 MethodRefine 文件夹的内容,您将看到现在它包含了 39 个新的 CSV 文件 (worm_0001.csv – worm_0039.csv)。
每个文件大小约为 4K,且包含一个最多不超过 59个离子对的列表,用于导入到一个未安排时序的 Thermo TSQ 方法。
选择 59 这个数字可能显得有点奇怪,但是这对于获得与原始实验匹配的离子对列表很有必要。
原始实验选择的数字为 60。
遗憾的是,Skyline 曾经存在一个只能允许少于最大值的离子对数量的漏洞(现已修复)。
导入多个进样数据如果您想要学习如何导入这个实验的初始仪器输出文件的方法,您必须下载另一个 ZIP 格式的补充文件 (36M)。
该 ZIP 文件包含MacCoss 实验室收集的 39 个 Thermo 原始文件(161M,未压缩),用于测定您在上节刚刚导出的离子对列表。
您下载的原始 MethodRefine.zip 文件包含高性能数据缓存文件 WormUnrefined.skyd,该文件已经具有 Skyline 所要求这些文件具有的所有数据。
如果您想继续使用现有数据缓存文件,您可以跳至下一节。
如果您想亲自重新导入数据,请下载 ZIP 文件:https:///tutorials/MethodRefineSupplement.zip将文件解压缩到您之前使用的文件夹。
这将创建一个新文件夹,如:C:\Users\brendanx\Documents\MethodRefineSupplement在 Skyline 中,按照以下步骤操作,删除以前缓存的数据:∙在“编辑”菜单中,单击“管理结果”。
∙单击“删除”按钮。
∙单击“确定”按钮。
色谱图表和峰质量图标已经从 Skyline 界面中删除。
∙在“文件”菜单中,单击“保存”(Ctrl-S)。
现在您可以亲自导入原始数据了。
您无需一次导入所有数据。
这对于在数据采集完成之前,对从这些较大,未优化的文档中导出的所有离子对列表进行检查是有帮助的。
在本教程中,您将分两批导入数据。
首先,执行下列步骤:∙在“文件”菜单中,选择“导入”,并单击“结果”。
∙选择“添加一个新的重复测定”。
∙在“名称”中输入“未调整”。
∙单击“确定”按钮。
∙找到 MethodRefineSupplement 文件夹。
∙单击“worm_0001.RAW”文件。
∙按 Shift 并单击“worm_0015.RAW”文件,选择前面的 15 个文件。
∙单击“打开”按钮。
Skyline 将开始导入 15 个文件,您可以在 Skyline 窗口的底部状态栏中查看显示的进度,以及峰质量图标返回至肽段视图中的肽段,如下所示:Skyline 将该数据缓存至高性能数据文件中时,您可以继续随意检查结果。
您甚至可以开始优化文档,但是对于本教程,您应该执行下列步骤来完成导入所有 39 个结果文件:∙在“文件”菜单中,选择“导入”,并单击“结果”。
∙选择“将文件添加至当前重复测定”。
∙单击“确定”按钮。
∙找到MethodRefineSupplement 文件夹。
∙单击“worm_0016.RAW”文件。
∙按 Shift 并单击“worm_0039.RAW”文件,选择剩下的所有文件。
∙单击“打开”按钮。
Skyline 完成导入后,您就可以使用与本教程来源匹配的数据缓存文件进行下一节的操作。
简单手动优化开始优化文档的一种方法是通过目测检查每个肽段,并根据 Skyline 提供的丰富信息决定将要保留和删除的内容。
这就是 ASMS 2009 海报中本教程的 Skyline 文档最初优化的方法。
浏览这些肽段只需要不到一小时,并选择和库谱图相匹配的轮廓清晰的峰的三个最佳离子对。
查看本教程的 Skyline 文档时,您可能会问到关于第一个肽段的问题,即 Skyline 是否错过了比当前放大显示的峰更好的峰。
要回答这个问题,您可以执行下列步骤,进行缩小:∙在“视图”菜单中,选择“自动缩放”,并单击“无”(Shift-F11)。
您应该在此暂停,花些时间记住以下快捷键:∙“视图/自动缩放/最佳峰”- F11∙“视图/自动缩放/无”- Shift - F11这些快捷方式允许您在当前选择的峰特写视图和您正在检查的仪器测量的离子对的整个时间范围之间迅速切换。
对于文档中的第一个肽段,整个范围如下所示:乍一看这很像有大量噪音的数据,但是如果您想看更多的细节,您可以对标有保留时间的任何较大峰附近单击并拖曳出一个方框来放大该区域。
如果您确认这些都不包含这个肽段的真正测量值,您可以按删除键从文档中删除这个肽段。
保留时间预测在检查色谱图峰时,了解肽段的预期保留时间也是很有用的。
特定序列保留时间计算器 (SSRCalc) 3.03已集成到 Skyline 以实现这项功能。
若要观察 SSRCalc 得分和测量的肽段保留时间之间的关系线性回归图,请执行下列步骤:∙在“视图”菜单上,选择“保留时间”,并单击“线性回归”(Shift-F8)。
Skyline 将显示如下图形:注意位于当前已优化的回归线上的红色点。
该点显示了SSRCalc 分值和当前所选肽段的出峰时间。
您在 Skyline 文档树中选择不同的肽段时,突出点将会相应改变。
该图默认使用 r = 0.9 的阈值开始优化回归,然后从中逐步删除点并相应标注它们为异常值,直至达到设定的阈值。
您可通过执行如下操作调整阈值:∙右键单击图,并单击“设置阈值”。
∙在“阈值”中输入“0.95”。
∙单击“确定”按钮。
Skyline 将重新计算回归,将更多的肽段标记为异常值,将图变成:您可通过执行如下操作来创建新的线性方程式以进行保留时间预测:∙右键单击图,并单击“创建回归”。
Skyline 显示“编辑保留时间回归”表单,该表单有预先填入来自保留时间回归图的信息,其中包括已优化的回归数据(145 个肽段),以及相同的斜率、截距和时间窗口。
Skyline 建议的时间窗口为从回归残差获得的 4 个标准偏差,这应该包含 145 个肽段中的 95%。
Skyline 还将选择与数据最匹配(r 最接近 1.0)的计算器。
目前仅有的选择是用孔径大小为 100 或300 埃的反相填料色谱柱数据训练过的 SSRCalc 3.0。
在 MacCoss 实验室中,我们使用 90 埃孔径的填料,SSRCalc 3.0 (100Å) 通常会提供最佳匹配。
若接受 Skyline 所建议的值,单击“确定”按钮。
Skyline 会将所选肽段的预测的保留时间的指示符添加至色谱图中,如下所示(您可能需要将回归图移开以便进行观察):该指示符周围的阴影矩形显示了您在“编辑保留时间回归”表格中选择的窗口(16.2 分钟)。
任何阴影矩形外的值均大于预测值的 2 个标准偏差。
缺失数据在离开保留时间回归图返回本文档进行手动细调之前,请注意 x 轴上的许多异常值点。
这表示Skyline 未找到所研究的肽段的任何峰。
若要了解原因,请移动鼠标至最左侧,直至鼠标变为手形,然后单击鼠标左键。
Skyline 将以红色突出显示该点并滚动肽段视图,以显示新选择的肽段 (YLAEVASEDR)。
按 Esc 键返回肽段视图,如下所示:这里有7个肽段没有红色峰质量图标,表示这些肽段在导入的RAW文件中无法进行定量。
如果我们是首次将原始文件导入本文档,这可能会令人觉得奇怪。