模式识别综述作业
基于模式识别的视频内容分析技术综述

基于模式识别的视频内容分析技术综述随着互联网和数码媒体的快速发展,视频资源的数量和规模不断增长。
然而,由于视频数据本身的多样性和复杂性,直接利用人力进行视频内容分析变得困难且低效。
因此,基于模式识别的视频内容分析技术应运而生,其通过利用计算机视觉、模式识别和机器学习等相关领域的方法与技术,实现对视频内容的自动分析与理解。
本文将对基于模式识别的视频内容分析技术进行综述,探讨其应用领域、关键技术以及挑战与未来发展方向。
一、视频内容分析的应用领域基于模式识别的视频内容分析技术已广泛应用于各个领域,包括视频监控、视频搜索与检索、视频目标识别与跟踪、视频内容理解与解释等。
其中,视频监控是最早应用该技术的领域之一。
通过使用模式识别算法,可以实现对监控视频中的异常情况、目标物体和行为的检测与分析。
视频搜索与检索则是基于视频内容的相关性进行检索,利用模式识别技术将视频内容与用户查询进行匹配,提供相关的搜索结果。
视频目标识别与跟踪则是利用模式识别技术对视频中的目标物体进行检测、识别与跟踪,常用于智能交通、视频安防等领域。
此外,视频内容理解与解释是基于模式识别的视频分析的一个重要研究方向,旨在实现对视频内容的高层次理解与解释,如视频语义理解、情感分析等。
二、视频内容分析的关键技术基于模式识别的视频内容分析技术的核心是计算机视觉、模式识别和机器学习等相关领域的技术,下面将介绍其中的一些关键技术。
1. 视频特征提取与表示视频特征提取是视频内容分析的首要任务,通过将视频的低层次视觉特征转换为高层次的语义特征,实现对视频内容的理解。
常用的视频特征包括颜色特征、纹理特征、形状特征等。
视频特征的表示方式有多种,如Bag of Visual Words模型、时空金字塔模型等。
2. 视频目标检测与识别视频目标检测与识别是视频内容分析的重要任务,其目标是检测和识别视频中的目标物体。
常用的方法包括基于深度学习的目标检测方法,如Faster R-CNN、SSD等。
模式识别大作业

模式识别大作业引言:转眼之间,研一就结束了。
这学期的模式识别课也接近了尾声。
我本科是机械专业,编程和算法的理解能力比较薄弱。
所以虽然这学期老师上课上的很精彩,但是这学期的模式识别课上的感觉还是有点吃力。
不过这学期也加强了编程的练习。
这次的作业花了很久的时间,因为平时自己的方向是主要是图像降噪,自己在看这一块图像降噪论文的时候感觉和模式识别的方向结合的比较少。
我看了这方面的模式识别和图像降噪结合的论文,发现也比较少。
在思考的过程中,我想到了聚类的方法。
包括K均值和C均值等等。
因为之前学过K均值,于是就选择了K均值的聚类方法。
然后用到了均值滤波和自适应滤波进行处理。
正文:k-means聚类算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。
一般都采用均方差作为标准测度函数。
k-means 算法接受输入量k ;然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
均值滤波是常用的非线性滤波方法 ,也是图像处理技术中最常用的预处理技术。
它在平滑脉冲噪声方面非常有效,同时它可以保护图像尖锐的边缘。
均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板包括了其周围的临近像素(以目标象素为中心的周围8个象素,构成一个滤波模板,即去掉目标象素本身)。
再用模板中的全体像素的平均值来代替原来像素值。
即对待处理的当前像素点(x,y),选择一个模板,该模板由其近邻的若干像素组成,求模板中所有像素的均值,再把该均值赋予当前像素点(x,y),作为处理后图像在该点上的灰度个g(x,y),即个g(x,y)=1/m ∑f(x,y)m为该模板中包含当前像素在内的像素总个数。
模式识别_作业1

作业一:作业二:对如下5个6维模式样本,用最小聚类准则进行系统聚类分析: x 1: 0, 1, 3, 1, 3, 4 x 2: 3, 3, 3, 1, 2, 1 x 3: 1, 0, 0, 0, 1, 1 x 4: 2, 1, 0, 2, 2, 1 x 5: 0, 0, 1, 0, 1, 01、 计算D (0)=⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛0 12 3 5 2612 0 7 15 243 7 0 24 55 15 24 0 2326 24 5 23 0,因为x3与x5的距离最近,则将x3与x5分为一类。
同时可以求出x1,x2,x4与x3,5的距离,如x1到x3,5的距离为x1到x3的距离与x1与x5的距离中取最小的一个距离。
2、 则D (1)=⎪⎪⎪⎪⎪⎪⎭⎫ ⎝⎛0 7 15 2470 24 515 24 0 2324 5 23 0,同样现在该矩阵中x4与x3,5的距离最近,则可以将x3,4,5分为一类,这样分类结束,总共可以将x1,x2,x3,x4,x5分为三类,其中:x1为第一类;x2为第二类;x3和x4和x5为第三类。
• 作业三:(K-均值算法)• 选k=2,z 1(1)=x 1,z 2(1)=x 10,用K-均值算法进行聚类分析由图可以看出这二十个点的坐标:x1(0,0),x2(1,0),x3(0,1),x4(1,1),x5(2,1),x6(1,2),x7(2,2),x8( 3,2),x9(6,6),x10(7,6),x11(8,6),x12(6,7),x13(7,7),x14(8,7),x 15(9,7),x16(7,8),x17(8,8),x18(9,8),x19(8,9),x20(9,9)。
1、选2个初始聚类中心,z1(1)=x1,z2(1)=x10.2、求取其它十八个点分别到x1与x10的距离:x2到x1的距离为1;x2到x10的距离为6x3到x1的距离为1;x3到x10的距离为x4到x1的距离为;x4到x10的距离为x5到x1的距离为;x5到x10的距离为5x6到x1的距离为;x6到x10的距离为x7到x1的距离为2;x7到x10的距离为x8到x1的距离为;x8到x10的距离为4x9到x1的距离为6;x9到x10的距离为1x11到x1的距离为10;x11到x10的距离为1x12到x1的距离为;x12到x10的距离为x13到x1的距离为7;x13到x10的距离为1x14到x1的距离为;x14到x10的距离为x15到x1的距离为;x15到x10的距离为x16到x1的距离为;x16到x10的距离为2x17到x1的距离为8;x17到x10的距离为x18到x1的距离为;x18到x10的距离为2x19到x1的距离为;x19到x10的距离为x20到x1的距离为9;x20到x10的距离为所以其中x2到x8距离x1近些,则可以将x2到x8与x1分为一类,而x9与x11到x20与x10分为另一类;3、通过将第一类中的所有x1到x8的坐标求取平均来计算该类别的中心坐标,求取新的类别的中心坐标z1(2)= (5/4,9/8),同理可以求出另一类的中心坐标z2(2)= (92/12,22/3)4、然后重新计算各点距离这二点中心坐标的距离,最后可以得出x1到x8仍然为第一类,x9到x20仍然为第二类。
模式识别发展及现状综述

模式识别发展及现状综述
目前,模式识别已经成为数据处理和分析技术中一个重要的组成部分,它在不同的应用领域中得到了广泛的应用,比如生物识别,自动机器人,
语音识别等。
模式识别是一种使机器获得能力,以识别和理解事物的能力,它把视觉,听觉,触觉等信息的处理过程变成可实现的机器任务,从而从
大量的信息中提取有用的信息,达到其中一种有意义的目的。
模式识别的研究有着悠久的历史,其发展历程大致可分为四个阶段:
传统模式识别,统计机器学习、深度学习和智能,每一阶段都为模式识别
技术的发展奠定了基础。
传统模式识别可以追溯到1900年以前,主要是通过规则来识别特征
或分类样本。
在传统模式识别阶段,主要有基于特征的模式识别、基于模
型的模式识别和基于结构的模式识别。
基于特征的模式识别主要是提取具
有代表性的特征,并根据特征判断类别之间的差异;基于模型的模式识别
则是根据建立的模型,通过最小二乘法或最小化误差函数,识别特征;基
于结构的模式识别则是抽取数据中的空间结构特征,从而实现类样本的聚
类分离。
随着计算机处理速度的不断提高,统计机器学习技术也取得了很大的
进展。
模式识别作业题(2)

=α
∏ p( x | μ ) p( μ )
i =1 i
N
=α
∏
i =1
N
⎡ 1 ⎢ exp ⎢ − 2πσ ⎢ ⎣
( xi − μ )
2σ
2
2
⎤ ⎡ 1 ⎥ ⎢ ⎥ • 2πσ exp ⎢ − 0 ⎥ ⎢ ⎦ ⎣
( μ − μ0 ) ⎤⎥ ⎥ 2σ ⎥ 0 ⎦
2 2
= α exp ⎢ − [⎜
''
⎡ 1 ⎛ N ⎛ 1 1 ⎞ 2 μ + − 2 ⎟ ⎜ 2 2 σ 02 ⎟ 2 ⎜ ⎢ ⎝σ σ ⎝ ⎠ ⎣
2 1 N +C ( x − μ ) ∑ 2 i =1 i
似然函数 μ 求导
∂L( μ ) N = ∑ x -N μ =0 i ∂μ i =1
∧
所以 μ 的最大似然估计: μ =
1 N
∑ xi
i =1
N
贝叶斯估计: p( μ |X)=
p( X | μ ) p( μ )
∫ p( X | μ ) p(μ )du
2 σn =
σ 02σ 2 2 Nσ 0 +σ 2
其中, mN =
1 N
∑x ,μ
i =1 i
N
n
就是贝叶斯估计。
7 略
得证。 3、使用最小最大损失判决规则的错分概率是最小吗?为什么?
答:不是最小的。首先要明确当我们谈到最小最大损失判决规则时,先验概率是未知的, 而先验概率的变化会导致错分概率变化, 故错分概率也是一个变量。 使用最小最大损 失判决规则的目的就是保证在先验概率任意变化导致错分概率变化时, 错分概率的最 坏(即最大)情况在所有判决规则中是最好的(即最小)。 4、 若 λ11 = λ22 =0, λ12 = λ21 ,证明此时最小最大决策面是来自两类的错误率相等。 证明:最小最大决策面满足 ( λ11 - λ22 )+( λ21 - λ11 ) 容易得到
电子信息工程中的图像处理与模式识别技术研究综述

电子信息工程中的图像处理与模式识别技术研究综述1. 引言图像处理与模式识别技术是电子信息工程中一项重要的研究领域。
随着科技的不断进步,图像处理与模式识别技术在各个领域都得到了广泛应用。
本文将对电子信息工程中的图像处理与模式识别技术进行综述,探讨其研究现状和未来发展方向。
2. 图像处理技术2.1 数字图像的获取与存储数字图像的获取是图像处理的前提,本节将介绍各种数字图像获取的方法以及图像的存储方式。
2.2 图像增强与滤波图像增强是提高图像质量的关键步骤,本节将介绍图像增强的常见方法以及滤波技术在图像处理中的应用。
2.3 图像分割与特征提取图像分割是将图像划分为不同区域的过程,本节将介绍图像分割的常用算法以及特征提取的方法。
2.4 图像压缩与编码图像压缩与编码是降低图像数据量的关键技术,本节将介绍常用的图像压缩与编码算法。
3. 模式识别技术3.1 模式识别的基本概念本节将介绍模式识别的基本概念,包括模式识别的定义、分类以及模式识别系统的一般框架。
3.2 特征提取与选择特征是模式识别中的关键要素,本节将介绍特征提取的方法以及特征选择的技术。
3.3 模式分类与识别模式分类与识别是模式识别技术的核心,本节将介绍常用的模式分类与识别算法。
3.4 监督学习与无监督学习监督学习和无监督学习是模式识别中常用的学习方法,本节将介绍监督学习和无监督学习的原理及应用。
4. 图像处理与模式识别在电子信息工程中的应用4.1 视觉传感技术图像处理与模式识别技术在视觉传感技术中得到了广泛应用,本节将介绍视觉传感技术在机器视觉、无人驾驶等领域的应用。
4.2 医学影像处理医学影像处理是电子信息工程中的重要应用领域,本节将介绍医学影像处理中图像处理和模式识别技术的应用。
4.3 安防监控与人脸识别安防监控和人脸识别是电子信息工程中常见的应用场景,本节将介绍图像处理和模式识别技术在安防监控和人脸识别中的应用。
5. 图像处理与模式识别技术的挑战与展望虽然图像处理与模式识别技术在各个领域都得到了广泛应用,但仍面临着一些挑战。
模式识别理论及其应用综述

模式识别理论及其应用综述
模式识别是指通过对已知模式的学习,从输入数据中自动识别并分类相似的模式或对象。
它是一种基于统计和机器学习的技术,可以应用于多个领域,例如图像处理、语音识别、自然语言处理等。
在模式识别中,最常用的技术是机器学习算法。
机器学习算法是一种通过对大量训练数据的学习,从中发现规律和模式,然后应用这些规律和模式来解决问题的方法。
常用的机器学习算法包括支持向量机、决策树、神经网络等。
在图像处理领域,模式识别可以用于图像分类和目标检测。
例如,当我们要对图像库中的图像进行分类时,可以使用模式识别技术来自动识别和分类不同类型的图像。
在目标检测方面,模式识别可以帮助我们在图像中快速准确地检测和定位目标。
在语音识别领域,模式识别可以用于语音识别和语音合成。
语音识别是将语音信号转化为文本或命令的过程,而语音合成则是将文本转化为语音信号的过程。
模式识别可以通过对大量语音数据的学习,发现语音信号的特征和模式,从而实现准确的语音识别和语音合成。
在自然语言处理领域,模式识别可以用于文本分类和信息提取。
文本分类是将文本数据根据其内容分类到不同的类别中,例如将新闻文章分类到不同的主题类别中。
信息提取是从大量文本中提取出指定信息的过程,例如从新闻文章中提取出人物、地点和事件等信息。
模式识别可以通过对大量文本数据的学习,发现文本的特征和模式,从而实现准确的文本分类和信息提取。
总之,模式识别是一种基于统计和机器学习的技术,可以应用于多个领域,例如图像处理、语音识别、自然语言处理等。
它可以通过对大量数据的学习,发现数据中的规律和模式,从而实现准确的模式识别和分类。
模式识别大作业
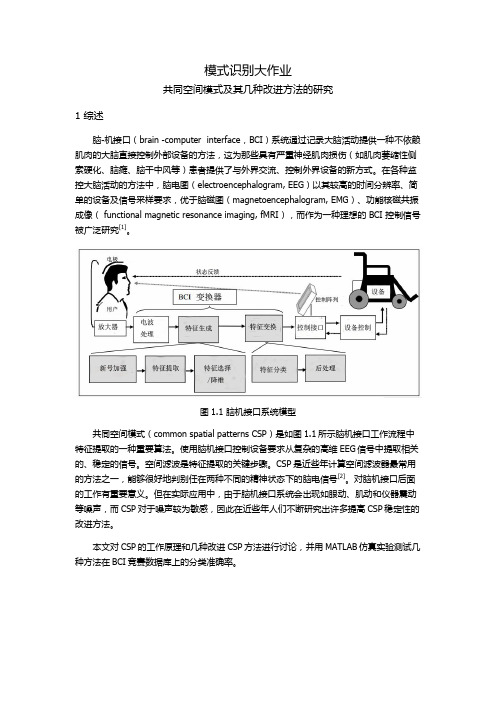
模式识别大作业共同空间模式及其几种改进方法的研究1 综述脑-机接口(brain -computer interface,BCI)系统通过记录大脑活动提供一种不依赖肌肉的大脑直接控制外部设备的方法,这为那些具有严重神经肌肉损伤(如肌肉萎缩性侧索硬化、脑瘫、脑干中风等)患者提供了与外界交流、控制外界设备的新方式。
在各种监控大脑活动的方法中,脑电图(electroencephalogram, EEG)以其较高的时间分辨率、简单的设备及信号采样要求,优于脑磁图(magnetoencephalogram, EMG)、功能核磁共振成像( functional magnetic resonance imaging, fMRI),而作为一种理想的 BCI 控制信号被广泛研究[1]。
图1.1 脑机接口系统模型共同空间模式(common spatial patterns CSP)是如图1.1所示脑机接口工作流程中特征提取的一种重要算法。
使用脑机接口控制设备要求从复杂的高维EEG信号中提取相关的、稳定的信号。
空间滤波是特征提取的关键步骤。
CSP是近些年计算空间滤波器最常用的方法之一,能够很好地判别任在两种不同的精神状态下的脑电信号[2]。
对脑机接口后面的工作有重要意义。
但在实际应用中,由于脑机接口系统会出现如眼动、肌动和仪器震动等噪声,而CSP对于噪声较为敏感,因此在近些年人们不断研究出许多提高CSP稳定性的改进方法。
本文对CSP的工作原理和几种改进CSP方法进行讨论,并用MATLAB仿真实验测试几种方法在BCI竞赛数据库上的分类准确率。
2 经典共同空间模式CSP 算法的目标是创建公共空间滤波器,最大化第一类方差,最小化另一类方差,采用同时对角化两类任务协方差矩阵的方式,区别出两种任务的最大化公共空间特征[3]。
定义一个N x T的矩阵E来表示原始EEG信号数据段,其中N表示电极数目即空间导联数目,T表示每个通道的采样点数目。
模式识别作业(全)

模式识别大作业一.K均值聚类(必做,40分)1.K均值聚类的基本思想以及K均值聚类过程的流程图;2.利用K均值聚类对Iris数据进行分类,已知类别总数为3。
给出具体的C语言代码,并加注释。
例如,对于每一个子函数,标注其主要作用,及其所用参数的意义,对程序中定义的一些主要变量,标注其意义;3.给出函数调用关系图,并分析算法的时间复杂度;4.给出程序运行结果,包括分类结果(只要给出相对应的数据的编号即可)以及循环迭代的次数;5.分析K均值聚类的优缺点。
二.贝叶斯分类(必做,40分)1.什么是贝叶斯分类器,其分类的基本思想是什么;2.两类情况下,贝叶斯分类器的判别函数是什么,如何计算得到其判别函数;3.在Matlab下,利用mvnrnd()函数随机生成60个二维样本,分别属于两个类别(一类30个样本点),将这些样本描绘在二维坐标系下,注意特征值取值控制在(-5,5)范围以内;4.用样本的第一个特征作为分类依据将这60个样本进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志(正确分类的样本点用“O”,错误分类的样本点用“X”)画出来;5.用样本的第二个特征作为分类依据将这60个样本再进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志画出来;6.用样本的两个特征作为分类依据将这60个样本进行分类,统计正确分类的百分比,并在二维坐标系下将正确分类的样本点与错误分类的样本点用不同标志画出来;7.分析上述实验的结果。
8.60个随即样本是如何产生的的;给出上述三种情况下的两类均值、方差、协方差矩阵以及判别函数;三.特征选择(选作,15分)1.经过K均值聚类后,Iris数据被分作3类。
从这三类中各选择10个样本点;2.通过特征选择将选出的30个样本点从4维降低为3维,并将它们在三维的坐标系中画出(用Excell);3.在三维的特征空间下,利用这30个样本点设计贝叶斯分类器,然后对这30个样本点利用贝叶斯分类器进行判别分类,给出分类的正确率,分析实验结果,并说明特征选择的依据;。
电气设备局部放电模式识别研究综述

电气设备局部放电模式识别研究综述一、本文概述电气设备局部放电(Partial Discharge, PD)是设备绝缘老化和失效的重要前兆,其早期检测和准确识别对于保障设备的安全运行和延长使用寿命具有重要意义。
随着科技的不断进步,对电气设备局部放电的模式识别研究已成为当前电气工程领域的热点之一。
本文旨在综述近年来电气设备局部放电模式识别的研究进展,分析不同方法的优缺点,并展望未来的研究方向。
通过对国内外相关文献的梳理和评价,本文期望为电气设备局部放电模式识别的研究和应用提供有益的参考和借鉴。
在本文中,首先将对电气设备局部放电的基本概念、产生机理和危害进行简要介绍,为后续的模式识别研究奠定基础。
接着,将重点回顾和总结电气设备局部放电模式识别的传统方法,如脉冲电流法、超声波法、化学法等,并分析它们的适用范围和局限性。
随后,将详细介绍近年来新兴的电气设备局部放电模式识别技术,如基于机器学习的方法、基于深度学习的方法以及基于的方法等,并探讨它们在提高识别准确率和效率方面的优势。
将对电气设备局部放电模式识别的未来研究方向进行展望,包括多源信息融合、智能化识别系统、在线监测与预警等方面。
通过本文的综述,期望能够为电气设备局部放电模式识别的研究和实践提供全面的视角和深入的理解,为推动该领域的发展做出一定的贡献。
二、局部放电检测技术与原理局部放电是指在电气设备绝缘结构中,部分区域发生的非贯穿性放电现象。
这种放电虽然不会立即导致设备绝缘击穿,但长期累积会对绝缘材料造成损伤,最终导致设备故障。
因此,对局部放电的有效检测与模式识别对于电气设备的预防性维护和安全运行至关重要。
电气测量法:这是最常用的方法,包括脉冲电流法、介质损耗法、局部放电超声波检测法等。
其中,脉冲电流法通过测量局部放电产生的脉冲电流来检测放电的存在和强度;介质损耗法则通过分析绝缘材料介质损耗的变化来间接判断放电情况。
化学检测法:通过检测局部放电过程中产生的气体成分和浓度变化来判断放电的强度和频率。
模式识别综述

模式识别综述
刘迪;李耀峰
【期刊名称】《黑龙江科技信息》
【年(卷),期】2012(000)028
【摘要】模式识别(Pattern Recognition)又称图形识别,就是通过计算机用数学技术方法来研究模式的自动处理和判读。
通常把环境与客体统称为“模式”。
随着计算机技术的发展,人类有可能研究复杂的信息处理过程。
信息处理过程的一个重要形式是生命体对环境及客体的识别。
对人类来说,特别重要的是对光学信息(通过视觉器官来获得)和声学信息(通过听觉器官来获得)的识别。
这是模式识别的两个重要方面。
模式识别研究主要集中在两方面,一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。
本文主要阐述了模式识别的基本原理、方法及各种技术,以及在相关领域的应用,并且对模式识别领域的前景做出展望。
【总页数】1页(P120-120)
【作者】刘迪;李耀峰
【作者单位】东北电力大学信息工程学院,吉林吉林132012;吉林供电公司,吉林吉
林132012
【正文语种】中文
【中图分类】TP391.4
【相关文献】
1.基于模式识别的电力系统暂态稳定评估综述 [J], 王志刚
2.轨道角动量模式识别方法综述 [J], 冯文艳;付栋之;王云龙;张沛
3.多功能雷达工作模式识别方法综述 [J], 阳榴;朱卫纲;吕守业;赵宏宇;赫岩
4.基于模式识别的电力系统暂态稳定评估综述 [J], 王志刚[1]
5.DNA甲基化差异模式识别方法综述 [J], 赵倩;张雪;张彦;林正奎;孙野青
因版权原因,仅展示原文概要,查看原文内容请购买。
华南理工大学《模式识别》大作业报告

华南理工大学《模式识别》大作业报告题目:模式识别导论实验学院计算机科学与工程专业计算机科学与技术(全英创新班)学生姓名黄炜杰学生学号 201230590051指导教师吴斯课程编号145143课程学分2 分起始日期 2015年5月18日实验内容【实验方案设计】Main steps for the project is:1.To make it more challenging, I select the larger dataset, Pedestrian, rather than thesmaller one. But it may be not wise to learning on such a large dataset, so Inormalize the dataset from 0 to 1 first and perform a k-means sampling to select the most representative samples. After that feature selection is done so as to decrease the amount of features. At last, a PCA dimension reduction is used to decrease the size of the dataset.2.Six learning algorithms including K-Nearest Neighbor, perception, decision tree,support vector machine, multi-layer perception and Naïve Bayesian are used to learn the pattern of the dataset.3.Six learning algorithm are combing into six multi-classifiers system individually,using bagging algorithm.实验过程:NormalizationThe input dataset is normalized to the range of [0, 1] so that make it suitable for performing k-means clustering on it, and also increase the speed of learning algorithms.SamplingThere are too much sample in the dataset, only a smallpart of them are enough to learn a good classifier. To select the most representative samples, k-means clustering is used to cluster the sample into c group and select r% of them.There are 14596 samples initially, but 1460 may be enough, so r=10. The selection of c should follow three criterions:a) Less drop of accuracyb) Little change about ratio of two classesc) Smaller c, lower time complexitySo I design two experiments to find the best parameter c:Experiment 1:Find out the training accuracy of different amountof cluster. The result is shown in the figure on the left. X-axis is amount of cluster and Y-axis is accuracy. Red line denotes accuracy before sampling and blue line denotes accuracy after sampling. As it’s shown in the figure, c=2, 5, 7, 9, 13 may be good choice since they have relative higher accuracy.Experiment 2:Find out the ratio of sample amount of two class. The result is shown in the figure on the right. X-axis is amount of cluster and Y-axis is the ratio. Red line denotes ratio before sampling and blue line denotes ratio after sampling. As it’s shown in the figure, c=2, 5, 9 may be good choice since the ratio do not change so much.As a result, c=5 is selected tosatisfy the three criterions.Feature selection3780 features is much more than needed to train a classifier, so I select a small part of them before learning. The target is to select most discriminative features, that is to say, select features that have largest accuracy in each step. But there are six learning algorithm in our project, it’s hard to decide which learning algorithm this feature selection process should depend on and it may also has high time complexity. So relevance, which is the correlation between feature and class is used as a discrimination measurement to select the best feature sets. But only select the most relevant features may introduce rich redundancy. So a tradeoff between relevance and redundancy should be made. An experiment about how to make the best tradeoff is done:the best amount of features isFind out the training accuracy of different amountof features. The result is shown below. X-axis is amount of features and Y-axis is accuracy. Red line denotes accuracyPCATo make the dataset smaller, features with contribution rate of PCA ≥ 85% is selected. So we finally obtain a dataset with 1460 samples and 32 features. The size of the dataset drops for 92.16% but accuracy only has 0.61% decease. So these preprocessing steps are successful to decrease the size of the dataset.Learning6 models are used in the learning steps: K-Nearest Neighbor, perception, decision tree, support vector machine, multi-layer perception and Naïve Bayesian. I designed a RBF classifier and MLP classifier at first but they are too slow for the reason that matrix manipulation hasn’t been designed carefully, so I use the function in the library instead. Parameter determination for these classifiers are:①K-NNWhen k≥5,the accuracy trends to be stable, so k=5②Decision treeMaxcrit is used as binary splitting criterion.③MLP5 units for hidden is enough。
基于模式识别的声纹识别技术研究综述

基于模式识别的声纹识别技术研究综述声纹识别技术是一种通过对个体声音特征进行提取和分析,以确定其身份的生物识别技术。
它利用了人的语音特征,通过声音信号的频率、共振等特性,将来自不同人的声音进行鉴别和识别。
在过去几十年里,声纹识别技术得到了广泛的关注和研究,并在实际应用中取得了重要的突破。
本文将对基于模式识别的声纹识别技术进行综述,并探讨其在实际应用中的挑战和前景。
1. 声纹识别技术的原理和模型声纹识别技术基于声音信号的特征,在算法上可以分为两个主要步骤:声音特征提取和模式识别。
声音特征提取通过数学模型和算法,将声音信号转换为数字化的特征向量,以便后续的分析和识别。
常用的声音特征包括梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等。
模式识别阶段通过对特征向量进行分类和匹配,将其与已知的声纹模型进行比较,从而确定身份。
2. 基于模式识别的声纹识别算法在基于模式识别的声纹识别技术中,有多种常用的算法和方法。
其中,高斯混合模型(GMM)是一种常用的声纹建模方法,它通过对声纹特征向量进行高斯建模和聚类,以实现声纹的分类和识别。
支持向量机(SVM)和隐马尔可夫模型(HMM)也被广泛应用于声纹识别领域。
此外,最近兴起的深度学习技术如卷积神经网络(CNN)和循环神经网络(RNN)也在声纹识别中表现出良好的效果。
3. 声纹识别技术的应用领域声纹识别技术在多个领域有着广泛的应用。
在安全领域,声纹识别技术可以用于身份验证和访问控制,例如在银行、政府机构等场所的门禁系统中应用。
在司法领域,声纹识别技术能够用于犯罪分析和调查,帮助警方快速锁定嫌疑人。
此外,声纹识别技术还可以应用于电话客服、语音助理等领域,提高交互体验和服务质量。
4. 挑战和未来发展方向声纹识别技术在实际应用中仍面临一些挑战。
首先,环境噪声和通讯压缩等因素会对声音信号的质量和特征提取造成影响。
其次,声纹识别技术在大规模应用中的实时性和准确性也需要进一步提高。
模式识别作业第三章2

第三章作业3.5 已知两类训练样本为1:(0 0 0 )',(1 0 0)' ,(1 0 1)',(1 1 0)'ω2:(0 0 1)',(0 1 1)' ,(0 1 0)',(1 1 1)'ω设0)'(-1,-2,-2,)1(=W,用感知器算法求解判别函数,并绘出判别界面。
解:matlab程序如下:clear%感知器算法求解判别函数x1=[0 0 0]';x2=[1 0 0]';x3=[1 0 1]';x4=[1 1 0]';x5=[0 0 1]';x6=[0 1 1]';x7=[0 1 0]';x8=[1 1 1]';%构成增广向量形式,并进行规范化处理x=[0 1 1 1 0 0 0 -1;0 0 0 1 0 -1 -1 -1;0 0 1 0 -1 -1 0 -1;1 1 1 1 -1 -1 -1 -1];plot3(x1(1),x1(2),x1(3),'ro',x2(1),x2(2),x2(3),'ro',x3(1),x3(2),x3(3) ,'ro',x4(1),x4(2),x4(3),'ro');hold on;plot3(x5(1),x5(2),x5(3),'rx',x6(1),x6(2),x6(3),'rx',x7(1),x7(2),x7(3) ,'rx',x8(1),x8(2),x8(3),'rx');grid on;w=[-1,-2,-2,0]';c=1;N=2000;for k=1:Nt=[];for i=1:8d=w'*x(:,i);if d>0w=w;t=[t 1];elsew=w+c*x(:,i);t=[t -1];endendif i==8&t==ones(1,8)w=wsyms x yz=-w(1)/w(3)*x-w(2)/w(3)*y-1/w(3);ezmesh(x,y,z,[0.5 1 2]);axis([-0.5,1.5,-0.5,1.5,-0.5,1.5]);title('感知器算法')break;elseendend运行结果:w =3-2-31判别界面如下图所示:若有样本123[,,]'x x x x =;其增广]1,,,[321x x x X =;则判别函数可写成: 1323')(321+*-*-*=*=x x x X w X d若0)(>X d ,则1ω∈x ,否则2ω∈x3.6 已知三类问题的训练样本为123:(-1 -1)', (0 0)' , :(1 1)'ωωω试用多类感知器算法求解判别函数。
模式识别文献综述

模式识别基础概念文献综述一.前言模式识别诞生于20世纪20年代。
随着20世纪40年代计算机的出现,20世纪50年代人工智能的兴起,模式识别在20世纪60年代迅速发展成为一门学科。
在20世纪60年代以前,模式识别主要限于统计学领域的理论研究,计算机的出现增加了对模式识别实际应用的需求,也推动了模式识别理论的发展。
经过几十年的研究,取得了丰硕的成果,已经形成了一个比较完善的理论体系,主要包括统计模式识别、结构模式识别、模糊模式识别、神经网络模式识别和多分类器融合等研究内容。
模式识别就是研究用计算机实现人类的模式识别能力的一门学科,目的是利用计算机将对象进行分类。
这些对象与应用领域有关,它们可以是图像、信号,或者任何可测量且需要分类的对象,对象的专业术语就是模式(pattern)。
按照广义的定义,存在于时间和空间中可观察的事物,如果可以区别它们是否相同或相似,都可以成为模式。
二.模式识别基本概念<一>.模式识别系统模式识别的本质是根据模式的特征表达和模式类的划分方法,利用计算机将模式判属特定的类。
因此,模式识别需要解决五个问题:模式的数字化表达、模式特性的选择、特征表达方法的确定、模式类的表达和判决方法的确定。
一般地,模式识别系统由信息获取、预处理、特征提取和选择、分类判决等4部分组成,如图1-1所示。
观察对象→→→→→→→→→类→类别号信息获取预处理特征提取和选择分类判决图1-1模式识别系统的组成框图<二>.线性分类器对一个判别函数来说,应该被确定的是两个内容:其一为方程的形式;其二为方程所带的系数。
对于线性判别函数来说方程的形式是线性的,方程的维数为特征向量的维数,方程组的数量则决定于待判别对象的类数。
对M类问题就应该有M个线性判别函数;对两类问题如果采用“+”“-”判别,则判别函数可以只有一个。
既然方程组的数量、维数和形式已定,则对判别函数的设计就是确定函数的各系数,也就是线性方程的各权值。
模式识别中的特征提取方法综述

模式识别中的特征提取方法综述特征提取是模式识别中的关键步骤,它用于将原始数据转换为具有辨识能力的表征形式。
特征提取方法的选择对于模式识别的性能有着重要的影响。
本文将综述一些常用的特征提取方法,并进行比较和分析。
一、统计特征统计特征是最简单常用的特征提取方法之一。
它通过对输入数据的统计分析,提取数据的平均值、方差、偏度、峰度等统计量作为特征。
统计特征方法简单直观,对于一些简单的问题具有较好的效果。
但在处理复杂的模式识别问题时,统计特征提取的表征能力有限。
二、频域特征频域特征是通过对信号进行傅立叶变换或小波变换,提取信号的频域特征来刻画其频谱特性。
常用的频域特征包括频谱密度、频率分量等。
频域特征对于信号的周期性和频率分布有较好的表征能力,适用于音频信号、图像信号等。
三、时域特征时域特征是通过对信号在时间上的变化进行分析和提取,来表征信号的时域性质。
常用的时域特征包括平均值、方差、标准差等。
时域特征适用于时间序列数据,如语音信号、心电信号等。
四、图像特征图像特征是针对图像数据设计的特征提取方法。
常用的图像特征包括颜色特征、纹理特征、形状特征等。
颜色特征提取可以通过颜色直方图、颜色矩等方法进行;纹理特征可以通过灰度共生矩阵、小波纹理等方法进行;形状特征可以通过边缘检测、轮廓描述符等方法进行。
五、频谱图特征频谱图特征是将信号分帧、进行快速傅立叶变换后,提取每帧频谱图的特征。
常用的频谱图特征包括梅尔频谱系数(MFCC)、功率谱等。
频谱图特征广泛应用于语音识别、音乐分类等领域。
六、深度学习特征深度学习是近年来兴起的一种特征学习方法,通过神经网络模型自动学习数据的特征表示。
常用的深度学习特征提取方法包括卷积神经网络(CNN)、循环神经网络(RNN)等。
深度学习特征具有较强的非线性拟合能力和表征能力,已在图像识别、自然语言处理等领域取得了显著的进展。
七、主成分分析特征主成分分析(PCA)是一种最常用的降维方法,它通过线性变换将原始数据映射到低维子空间。
模式识别作业-小论文

《模式识别》学习心得模式识别(Pattern Recognition)技术也许是最具有挑战性的一门技术了,模式识别有时又被称为分类技术,因为模式识别说到底就是对数据进行分类。
说到识别,最为常用的便是模仿人的视觉的图像识别(当然还有语音识别),也许你会想当然地认为那还不简单,觉得我们用我们的眼睛可以轻而易举地识别出各种事物,但是当你想用计算机中的程序来实现它时,于是你便会觉得很沮丧,甚至于有无从下手的感觉,至此你再也不会觉得电脑有多聪明,你会觉得电脑是多么的低能。
是的,现在的电脑智能,即人工智能还远不如蟑螂的智能,这其中最为根本的原因是模式识别技术还是处于较为低层次的发展阶段,很多的识别技术还无法突破,甚至有人还断言,再过30年也不会有本质的飞跃。
当然,世事总是让人难以预料,我们也用不着这么地悲观,科学技术总是向前发展的,没有人可以阻档得了的。
在这里,我把我对模式识别技术的学习和研究心得拿出来与大家分享一下。
模式识别具有较长的历史,在20世纪60年代以前,模式识别主要是限于统计学领域中的理论研究,还无法有较强的数学理论支持,20世纪80年代神经网络等识别技术得到了突破,计算机硬件技术更是有了长足的发展,模式识别技术便得到了较为广泛的应用,光学字符识别(OCR)是模式识别技术最早得到成功应用的技术,之后的应用还有如DNA序列分析、化学气味识别、图像理解力、人脸检测、表情识别、手势识别、语音识别、图像信息检索、数据挖掘等。
模式识别是一门与数学结合非常紧密的科学,所应用到的数学知识非常多,最基本的便是概率论和数理统计了,模式识别技术到处都充满了概率和统计的思想,我们经常所说的识别率,其实就是概率的表达:在大数据量(严格地说应当是数据量无穷大)测试中识别成功的概率,还有常用的贝叶斯决策分类器便是运用了概率公式。
模式识别还用到了线性代数,因为运用线性代数可以较为方便表达具有多特征的事物,我们一般会用向量来表达一个事物的特征,对于向量的计算是一定会用到线性代数的知识的。
模式识别与智能系统综述

模式识别与智能系统综述1 简介模式识别与智能系统是一个交叉学科领域,涉及统计学、机器学习、等多个学科的知识。
其主要研究内容是如何使用计算机对复杂的数据进行分析和处理,从而实现对数据中隐藏的模式和规律的识别和理解。
本文将对模式识别与智能系统的基本概念、发展历程、应用领域和未来发展趋势进行综述。
2 基本概念2.1 模式识别模式识别是指通过对数据进行分析和处理,识别出数据中的模式和规律的任务。
它可以应用于各个领域,包括图像识别、语音识别、生物信息学等。
模式识别的基本方法包括特征提取、分类器设计和学习算法等。
2.2 智能系统智能系统是指模拟人类智能行为的计算机系统。
它通过学习和不断优化算法,模拟人类的思维和决策过程。
智能系统可以应用于自动驾驶、智能推荐系统、语音助手等领域。
3 发展历程3.1 早期阶段模式识别和智能系统的研究起源于上世纪50年代。
当时,研究者们开始使用计算机来处理图像和语音等数据,试图从中识别出有用的信息。
然而,由于计算机性能的限制和算法的不完善,早期的模式识别和智能系统往往表现出较低的准确率和鲁棒性。
3.2 中期阶段随着计算机技术的快速发展和机器学习算法的不断改进,模式识别和智能系统在中期阶段取得了长足的进展。
在这个阶段,研究者们提出了许多经典的模式识别算法,如支持向量机、随机森林等。
同时,深度学习技术的引入进一步提高了模式识别和智能系统的性能。
3.3 当代阶段当前,模式识别和智能系统正处于快速发展的当代阶段。
随着大数据和云计算等技术的兴起,模式识别和智能系统在各个领域都取得了重大突破。
例如,在医疗领域,智能系统可以通过分析大量的医学影像数据,帮助医生诊断疾病。
在金融领域,模式识别可以用于识别金融欺诈行为。
未来,随着技术的进一步发展,模式识别和智能系统将发挥越来越重要的作用。
4 应用领域4.1 图像和视觉识别图像和视觉识别是模式识别和智能系统的重要应用领域之一。
它可以应用于人脸识别、目标检测、图像分类等任务。
模式识别理论及其应用综述

( 签训 练样 本) 监 督学 习( 签训 练样 标 对非 未标
本) ,监督学 习和非监督学习又可分为参数
模式识 别理 论
及 其 应 用 综述
熊超 浙江理工大学公共 计算机教 学部
学工作者近 几十年来的努 力,已经取得 了
模 式识 删技 术近 年 来得 到 了迅 速 的 发展 。 本文托其理论基础 与应 并作 了详细的介鳝 与 l
模 式识 剐 ;应 舶 ; 发_ 状 况 ;综 述 晨
统计模式识别方法和结构( 句法) 模式识别方 法 。统计 模式 识 别是 对 模 式 的 统 计 分 类 方 法 ,即结合统计概率论 的贝叶斯决策 系统 进行模式识别的技 术 ,又称为决 策理论识 别方 法 。利 用 模 式 与 子 模式 分 层 结构 的树
状 信 息 所 完 成 的 模 式识 别 工 作 ,就 是 结 构 模 式 识 别或 句 法 模式 识 别 。 13 .模式 识 别系统 不论 是 以 哪 种 模式 识 别方 法 为 基 础 的 模 式 识 别 系统 , 本 上都 是 由两个 过程 组 成 基 的,即设计与实现。设计是指用一定数量的 样本 ( 叫做 训练 集或 学 习集 )进 行 分类 器的 设 计 。实现 是指 用 所设计 的 分 类器对 待识 别 的样 本进 行分 类决 策 。基于 统计 方 法的 模式
征提取 , 选择模块找到合适的特征来表示输 人模 式 ,分类 器被 训练 分割 特 征空 间 。在 分 类模式 中, 被训练的分类器根据测量的特征
将 输 入模 式分 配 到某 个 模式 类 。 统 计 模式 识 别 的 决 策过 程 可 以总 结如
识 别 系统 如 图所 示 :
现代统计学 习理论—— V C理论的建立 ,该 理 论不 仅在 严格 的数学 基 础上 圆满地 回答 了
模式识别-图像特征综述

P (i )log P (i ) i
MEAN
1
L
iP (i ) i
3.
频谱法 设图像
f(x ,y ) 的傅立叶变换为:
F(u ,v )
2
f(x ,y ) exp{j 2(ux vy )} dxdy
其二维傅立叶变换的功率谱可写成:
F(u ,v ) F(u ,v )F *(u ,v )
S
其中,积分沿着该闭合曲线进行,将其离散化,上面公式变为:
1 (xdy ydx ) 2
S
1 2
[xi(y i 1 y i ) y i(xi 1 xi )]
i 1
Nb
1 2
[x i y i i
1
Nb
1
x i 1y i ]
N b 为边界点的数目
4. 长轴与短轴
f(x ,y ) f(x ,y ) f(x x ,y y )
f(x ,y )
称为灰度差分。
一般采用下列参数来描述纹理图像的特性: (1) 对比度
CON
i P (i ) i
2
(2) 角度方向二阶矩
ASM
[P (i )] i
2
(3) 熵 (4)平均值
ENT
区域 R 的边界 B 是由 R 的所有边界点按 4-方向或 8-方向连接组成的,区域的其它点称 为区域的内部点。 下: 可以分别定义 4-方向连通边界B 4 和 8-方向连通边界 B 如 8
B4 (x ,y ) R | N 8(x ,y ) R 0
由于周长的表示方法不同,因而计算方法也不同,常用的简便方法如下: (1)把图像的像素看作单位面积的小方块时,则图 像中的区域和背景均由小方块组成。区 域的周 长为区域和背景缝隙的长度。 (2)把像素看作一个个点时,则周长用链码表示, 求周长也即计算链码长度。即周长表示 为:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别综述模式识别是人类的一项基本智能,在日常生活中,人们经常在进行“模式识别”。
随着20世纪40年代计算机的出现以及50年代人工智能的兴起,人们也希望能用计算机来代替或扩展人类的部分脑力劳动。
模式识别在20世纪60年代初迅速发展并成为一门新学科。
1 模式识别基本概念与研究任务模式识别(Pattern Recognition)是对感知信号(图像、视频、声音等)进行分析,对其中的物体对象或行为进行判别和解释的过程。
模式识别能力普遍存在于人和动物的认知系统,是人和动物获取外部环境知识,并与环境进行交互的重要基础。
我们现在所说的模式识别一般是指用机器实现模式识别过程,是人工智能领域的一个重要分支。
早期的模式识别研究是与人工智能和机器学习密不可分的,如Rosenblatt的感知机和Nilsson的学习机就与这三个领域密切相关。
后来,由于人工智能更关心符号信息和知识的推理,而模式识别更关心感知信息的处理,二者逐渐分离形成了不同的研究领域。
介于模式识别和人工智能之间的机器学习在20世纪80年代以前也偏重于符号学习,后来人工神经网络重新受到重视,统计学习逐渐成为主流,与模式识别中的学习问题渐趋重合,重新拉近了模式识别与人工智能的距离。
模式识别与机器学习的方法也被广泛用于感知信号以外的数据分析问题(如文本分析、商业数据分析、基因表达数据分析等),形成了数据挖掘领域。
有两种基本的模式识别方法,统计模式识别方法和结构(句法)模式识别方法。
统计模式识别是对模式的统计分类方法,即结合统计概率论的贝叶斯决策系统进行模式识别的技术,又称为决策理论识别方法。
利用模式与子模式分层结构的树状信息所完成的模式识别工作,就是结构模式识别或句法模式识别。
模式识别的主要任务和核心研究内容是模式分类。
分类器设计是在训练样本集合上进行优化(如使每一类样本的表达误差最小或使不同类别样本的分类误差最小)的过程,也就是一个机器学习过程。
由于模式识别的对象是存在于感知信号中的物体和现象,它研究的内容还包括信号、图像、视频的处理、分割、形状和运动分析等,以及面向应用(如文字识别、语音识别、生物认证、医学图像分析、遥感图像分析等)的方法和系统研究。
2 模式识别的发展历史现代模式识别是在20世纪40年代电子计算机发明以后逐渐发展起来的。
作为统计模式识别基础的多元统计分析和鉴别分析也在电子计算机出现之前提出来了。
1957年IBM 的C.K. Chow将统计决策方法用于字符识别。
然而,“模式识别”这个词被广泛使用并形成一个领域则是在20世纪60年代以后。
1966年由IBM组织在波多黎各召开了第一次以“模式识别”为题的学术会议。
Nagy的综述和Kanal的综述分别介绍了1968年以前和1968-1974的研究进展。
70年代几本很有影响的模式识别教材(如Fukunaga, Duda & Hart)的相继出版和1972年第一届国际模式识别大会(ICPR)的召开标志着模式识别领域的形成。
同时,国际模式识别协会(IAPR)在1974年的第二届国际模式识别大会上开始筹建,在1978年的第四届大会上正式成立。
统计模式识别的主要方法,包括Bayes决策、概率密度估计(参数方法和非参数方法)、特征提取(变换)和选择、聚类分析等,在20世纪60年代以前就已经成型。
由于统计方法不能表示和分析模式的结构,70年代以后结构和句法模式识别方法受到重视。
尤其是付京荪(K.S. Fu)提出的句法结构模式识别理论在70-80年代受到广泛的关注。
但是,句法模式识别中的基元提取和文法推断(学习)问题直到现在还没有很好地解决,因而没有太多的实际应用。
20世纪80年代Back-propagation (BP) 算法的重新发现和成功应用推动了人工神经网络研究和应用的热潮。
神经网络方法与统计方法相比具有不依赖概率模型、参数自学习、泛化性能良好等优点,至今仍在模式识别中广泛应用。
然而,神经网络的设计和实现依赖于经验,泛化性能不能确保最优。
90年代支持向量机(SVM)的提出吸引了模式识别界对统计学习理论和核方法(Kernel methods)的极大兴趣。
与神经网络相比,支持向量机的优点是通过优化一个泛化误差界限自动确定一个最优的分类器结构,从而具有更好的泛化性能。
而核函数的引入使很多传统的统计方法从线性空间推广到高维非线性空间,提高了表示和判别能力。
结合多个分类器的方法从90年代前期开始在模式识别界盛行,后来受到模式识别界和机器学习界的共同重视。
多分类器结合可以克服单个分类器的性能不足,有效提高分类的泛化性能。
这个方向的主要研究问题有两个:给定一组分类器的最佳融合和具有互补性的分类器组的设计。
其中一种方法,Boosting ,现已得到广泛应用,被认为是性能最好的分类方法。
进入21世纪,模式识别研究的趋势可以概括为以下四个特点。
一是Bayes 学习理论越来越多地用来解决具体的模式识别和模型选择问题,产生了优异的分类性能。
二是传统的问题,如概率密度估计、特征选择、聚类等不断受到新的关注,新的方法或改进/混合的方法不断提出。
三是模式识别领域和机器学习领域的相互渗透越来越明显,如特征提取和选择、分类、聚类、半监督学习等问题成为二者共同关注的热点。
四是由于理论、方法和性能的进步,模式识别系统开始大规模地用于现实生活,如车牌识别、手写字符识别、生物特征识别等。
3 模式识别的基本方法模式识别过程包括以下几个步骤:信号预处理、模式分割、特征提取、模式分类、上下文后处理。
预处理通过消除信号/图像/视频中的噪声来改善模式和背景间的可分离性;模式分割是将对象模式从背景分离或将多个模式分开的过程; 特征提取是从模式中提取表示该模式结构或性质的特征并用一个数据结构(通常为一个多维特征矢量)来表示;在特征表示基础上,分类器将模式判别为属于某个类别或赋予其属于某些类别的概率; 后处理则是利用对象模式与周围模式的相关性验证模式类别的过程。
3.1 Bayes 决策Bayes 决策是统计模式识别的基础。
将模式表示为一个特征矢量X (多维线性空间中的一个点) ,给定M 个类别的条件概率密度,M 1,2,),i P(X|ωi =,则模式属于各个类别的后验概率可根据 Bayes 公式计算:∑===M j j j i i i i i x p P x p P x p x p P x p 1)|()()|()()()|()()|(ωωωωωωω其中)P(ωi 是第i 类的先验概率。
根据 Bayes 决策规则,模式x 被判别为后验概率最大的类别(最小错误率决策)或期望风险最小的类别(最小代价决策)。
后验概率或鉴别函数把特征空间划分为对应各个类别的决策区域。
模式分类可以在概率密度估计的基础上计算后验概率密度,也可以不需要概率密度而直接近似估计后验概率或鉴别函数(直接划分特征空间)。
3.2 概率密度估计概率密度估计和聚类一样,是一个非监督学习过程。
研究概率密度估计主要有三个意义:分类、聚类(分割)、异常点监测(Novelty detection)。
在估计每个类别概率密度函数的基础上,可以用Bayes决策规则来分类。
概率密度模型经常采用高斯混合密度模型(Gaussian mixture model, GMM),其中每个密度成分可以看作是一个聚类。
异常点监测又称为一类分类(One-class classification),由于只有一类模式的训练样本,在建立这类模式的概率密度模型的基础上,根据相对于该模型的似然度来判断异常模式。
高斯混合密度估计常用的Expectation-Maximization (EM)算法被普遍认为存在三个问题:估计过程易陷于局部极值点,估计结果依赖于初始化值,不能自动确定密度成分的个数。
对于成分个数的确定,提出了一系列的模型选择准则,如Bayes准则[15]、最小描述长度(MDL)、 Bayesian Information Criterion (BIC)、Akaike Information Criterion (AIC)、最小消息长度(MML)等。
概率密度估计的另一种新方法是稀疏核函数描述(支持向量描述)。
Schölkopf 等人采用类似支持向量机的方法,用一个核特征空间的超平面将样本分为两类,使超平面外的样本数不超过一个事先给定的比例。
该超平面的函数是一个样本子集(支持向量)的核函数的加权平均,可以像支持向量机那样用二次规划算法求得。
Tax和Duin的方法是用核空间的一个球面来区分区域内和区域外样本,同样地可以用二次规划进行优化。
3.3 特征选择特征选择和特征变换都是为了达到维数削减的目的,在降低分类器复杂度的同时可以提高分类的泛化性能。
二者也经常结合起来使用,如先选择一个特征子集,然后对该子集进行变换。
近年来由于适应越来越复杂(特征维数成千上万,概率密度偏离高斯分布)的分类问题的要求,不断提出新的特征选择方法,形成了新的研究热点。
特征选择的方法按照特征选择过程与分类器之间的交互程度可以分为过滤式(Filter)、 Wrapper、嵌入式、混合式几种类型。
过滤式特征选择是完全独立于分类器的,这也是最常见的一种特征选择方式,选择过程计算量小,但是选择的特征不一定很适合分类。
在Wrapper 方法中,特征子集的性能使用一个分类器在验证样本上的正确率来衡量,这样选择的特征比较适合该分类器,但不一定适合其他的分类器。
由于在特征选择过程中要评价很多特征子集(子集的数量呈指数级增长),即使采用顺序前向搜索,Wrapper的计算量都是很大的,只适合特征维数不太高的情况。
Wrapper的另一个问题是当训练样本较少时会造成过拟合,泛化性能变差。
特征选择的基本原则是选择类别相关(Relevant)的特征而排除冗余的特征。
这种类别相关性和冗余性通常用互信息(Mutual information, MI)来度量。
特征与类别之间的互信息很好地度量了特征的相关性,而特征与特征之间的互信细则度量他们之间的相似性(冗余性)。
因此,基于互信息的特征选择方法一般遵循这样一种模式:在顺序前向搜索中寻找与类别互信息最大而与前面已选特征互信息最小的特征。
另外提出的条件互信息用来度量在一个已选特征的条件下另一个新的候选特征对分类的相关性。
通过分析一种相关度,Symmetrical Uncertainty (SU)与特征的Markov blanket之间的关系,设计一种快速的两步特征选择方法:先根据单个特征与类别之间的相关度选出相关特征,第二步对相关特征根据特征-类别相关度和特征-特征相关度进行筛选。
3.4 分类器设计模式分类是模式识别研究的核心内容,迄今为止提出了大量的分类方法。
Jain等人把分类器分为三种类型:基于相似度(或距离度量)的分类器、基于概率密度的分类器、基于决策边界的分类器。