判别分析与聚类分析方法
聚类分析 判别分析

聚类分析
聚类分析又称群分析,是研究如何将客观事物合理 分类的一种数学方法。它是根据事物本身的特点对 被研究对象进行分类,使同一类中的个体有较大的 相似性,不同类中的个体有较大的差异。 聚类分许根据分类对象的不同,可分为样本聚类和 变量聚类。 样本聚类又称Q型聚类,它是根据被观测的对象的各 种特征,对各变量进行分类。 变量聚类又称R型聚类,反映同一事物特点的变量有 很多,我们往往选择部分变量对事物的某一方面进 行研究。 9
判别分析
在生产实践中经常会遇到这样的问题:根据子样的 某些特性指标决定它的分类。例如天气预报,要预 报明天是晴还是不晴,通常是将已掌握的多项当地 和外地的气象资料进行分析判别。把天气资料作为 子样用它的某些指标来决定它属于“晴朗天气”还 是“不晴朗天气”。再如:判断一个病人是否患有 肝病,就要检查病人的多项指标。这些问题都根据 不同总体的统计特性来判断子样的归属,成为判别 分析。
Q型聚类实例分析
例:一组有关12盎司啤酒成分和价格的数据, 变量包括beername(啤酒名称)、calorie (热量 卡路里) 、sodium (纳含量) 、alcohol (酒精 含量) 、cost (价格)。 要求根据12盎司啤酒的各成分含量及12盎司 啤酒的价格对20种啤酒进行分类。由于没有 要求具体分成几类,所以不能应用快速聚类 的方法,要使用分层聚类的办法。
聚类分析与判别 分析
聚类分析和判别分析是研究事物分类的 两种基本方法,他们被广泛地应用于自 然科学、社会科学研究及工农业生产的 各个领域。 这两种分析方法也是用与数学建模中, 一般数学建模的数据量都很大,很多, 很繁琐,应用它们聚类分析和判别分析 可以把大而多的数据简单化,有利于我 们进行建模。 聚类分析:快速聚类 分层聚类情况已经知道,就 可由这些已知的信息用判别分析的方法来建立判别函数。 对建立的判别函数的要求是用它来判别新的观测对象的 归类时。错判率要减到最小。 判别函数的一般形式是 Y=a1x1+a2x2+……+anxn 这里Y是判别分数,x1、x2、…xn为反映研究对象特 Y x1 x2 …xn 征的变量, a1、a2、…an为各变量的系数。 根据已知观测量的分类和表明观测量特征的变量值推导 出判别函数。在进行判别时,把各个观测量的值代入判 别函数中,得出判别分数,最后确定该属于哪一类。
聚类分析与判别分析区别

表示
:
cos
!
ij
=
p
a
=
1
!
x
ia
x
ja
p
a
=
1
!
x
2
・
p
a
=
1
!
x
2
"
ia
ja
1
≤
cos
!
ij
≤
1
当
cos
!
ij
=1
,
说明两个样品
x
i
与
x
j
完全相似
;
cos
!
ij
接
近
1
,
说
明
两
个
样
品
x
i
与
x
j
相
似
密
切
;
cos
!
ij
=0
,
说明
x
i
与
x
j
完全不一样
;
cos
!
ij
接近
0
,
说
明
x
i
与
x
j
差别大。把所有两两样品的相似系数都
通过聚类分析可以达到简化数据的目的
,
将
众多的样品先聚集成比较好处理的几个类别或子
集
,
然后再进行后续的多元分析。
比如在回归分析
中
,
有时不对原始数据进行拟合
,
而是对这些子集
的中心作拟合
,
可能会更有意义。又比如
,
为了研
究不同消费者群体的消费行为特征
,
「聚类分析与判别分析」

「聚类分析与判别分析」聚类分析和判别分析是数据挖掘和统计学中常用的两种分析方法。
聚类分析是一种无监督学习方法,通过对数据进行聚类,将相似的样本归为一类,不同的样本归入不同的类别。
判别分析是一种有监督学习方法,通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
本文将对聚类分析和判别分析进行详细介绍。
聚类分析是一种数据探索技术,其目标是在没有任何先验知识的情况下,将相似的样本聚集在一起,形成互相区别较大的样本群。
聚类算法根据样本的特征,将样本分为若干个簇。
常见的聚类算法有层次聚类、k-means聚类和密度聚类。
层次聚类是一种自下而上或自上而下的层次聚合方法,通过测量样本间的距离或相似性,不断合并或分裂簇,最终形成一个聚类树状结构。
k-means聚类将样本划分为k个簇,通过优化目标函数最小化每个样本点与其所在簇中心点的距离来确定簇中心。
密度聚类基于样本点的密度来判断是否属于同一簇,通过划定一个密度阈值来确定簇的分界。
聚类分析在很多领域中都有广泛的应用,例如市场分割、医学研究和社交网络分析。
在市场分割中,聚类分析可以将消费者按照其购买行为和偏好进行分组,有助于企业制定更精准的营销策略。
在医学研究中,聚类分析可以将不同患者分为不同的亚型,有助于个性化的治疗和药物开发。
在社交网络分析中,聚类分析可以将用户按照其兴趣和行为进行分组,有助于推荐系统和社交媒体分析。
相比之下,判别分析是一种有监督学习方法,其目标是通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
判别分析的目标是找到一个决策边界,使得同一类别内的样本尽可能接近,不同类别之间的样本尽可能远离。
常见的判别分析算法有线性判别分析(LDA)和逻辑回归(Logistic Regression)。
LDA是一种经典的线性分类方法,它通过对数据进行投影,使得同类样本在投影空间中的方差最小,不同类样本的中心距离最大。
逻辑回归是一种常用的分类算法,通过构建一个概率模型,将未知样本划分为不同的类别。
SPSS统计分析第八章聚类分析与判别分析

SPSS统计分析第八章聚类分析与判别分析聚类分析与判别分析是SPSS统计分析中非常重要的两个方法。
聚类分析是寻找数据之间的相似性,将相似的数据划分为一个簇,从而实现对数据的归类和分组。
判别分析则是寻找数据之间的差异性,帮助我们理解不同因素对于数据的影响程度,从而实现对数据的分类预测。
首先,我们来介绍聚类分析。
聚类分析是根据数据之间的相似性进行归类的一种方法,通过度量数据之间的相似性,将相似的数据归为一类。
它在寻找数据内在组织结构和特点上具有很大的作用。
在SPSS中进行聚类分析的步骤如下:1.载入数据集:在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行聚类分析的数据集。
2.选择聚类变量:在"分析"->"分类"->"聚类"中,选择需要进行聚类分析的变量。
可以选择一个或多个变量作为聚类变量,决定了聚类的维度。
3.设置聚类参数:在设置参数的对话框中,可以选择使用不同的距离测度和聚类算法。
距离测度可以选择欧氏距离、曼哈顿距离、切比雪夫距离等,而聚类算法可以选择层次聚类、K均值聚类等。
根据具体的数据特点,选择合适的参数。
4.进行聚类分析:点击"确定"按钮,SPSS会自动进行聚类分析,并生成聚类的结果。
聚类结果可以通过树状图、散点图等形式展示,便于我们对数据的理解和分析。
接下来,我们来介绍判别分析。
判别分析是一种通过建立数学模型,根据不同的预测变量对数据进行分类和预测的方法。
判别分析可以帮助我们理解不同因素对于数据分类的重要性,从而进行有针对性的分析和预测。
在SPSS中进行判别分析的步骤如下:1.载入数据集:同样,在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行判别分析的数据集。
聚类分析和判别分析

18
24 30 36 42 48 54 60 66 72
0.69
0.77 0.59 0.65 0.51 0.73 0.53 0.36 0.52 0.34
1.33
1.41 1.25 1.19 0.93 1.13 0.82 0.52 1.03 0.49
0.48
0.52 0.30 0.49 0.16 0.35 0.16 0.19 0.30 0.18
i i
( xi x ) 2 ( yi y ) 2
i i
i
当变量的测量值相差悬殊时,要先进行 标准化. 如R为极差, s 为标准差, 则标 准化的数据为每个观测值减去均值后 再除以R或s. 当观测值大于0时, 有人 采用Lance和Williams的距离
1 | xi yi | x y p i i i
Number of Cases in each Cluster Cluster 1 2 3 4 1.000 1.000 2.000 15.000 19.000 .000
Valid Missing
结果解释
参照专业知识,将儿童生长发育分期定为: 第一期,出生后至满月,增长率最高; 第二期,第2个月起至第3个月,增长率次之; 第三期,第3个月起至第8个月,增长率减缓; 第四期,第8个月后,增长率显著减缓。
k-均值聚类:案例
为研究儿童生长发育的分期,调查1253名1月至7岁儿 童的身高(cm)、体重(kg)、胸围(cm)和坐高(cm) 资料。资料作如下整理:先把1月至7岁划成19个月份段, 分月份算出各指标的平均值,将第1月的各指标平均值与出 生时的各指标平均值比较,求出月平均增长率(%),然后 第2月起的各月份指标平均值均与前一月比较,亦求出月平 均增长率(%),结果见下表。欲将儿童生长发育分为四期, 故指定聚类的类别数为4,请通过聚类分析确定四个儿童生 长发育期的起止区间。
聚类分析与判别分析

第一节聚类分析统计思想一、聚类分析的基本思想1.什么是聚类分析俗语说,物以类聚、人以群分。
当有一个分类指标时,分类比较容易。
但是当有多个指标,要进行分类就不是很容易了。
比如,要想把中国的县分成若干类,可以按照自然条件来分:考虑降水、土地、日照、湿度等各方面;也可以考虑收入、教育水准、医疗条件、基础设施等指标;对于多指标分类,由于不同的指标项对重要程度或依赖关系是相互不同的,所以也不能用平均的方法,因为这样会忽视相对重要程度的问题。
所以需要进行多元分类,即聚类分析。
最早的聚类分析是由考古学家在对考古分类中研究中发展起来的,同时又应用于昆虫的分类中,此后又广泛地应用在天气、生物等方面。
对于一个数据,人们既可以对变量(指标)进行分类(相当于对数据中的列分类),也可以对观测值(事件,样品)来分类(相当于对数据中的行分类)。
2.R型聚类和Q型聚类对变量的聚类称为R型聚类,而对观测值聚类称为Q型聚类。
这两种聚类在数学上是对称的,没有什么不同。
聚类分析就是要找出具有相近程度的点或类聚为一类;如何衡量这个“相近程度”?就是要根据“距离”来确定。
这里的距离含义很广,凡是满足4个条件(后面讲)的都是距离,如欧氏距离、马氏距离…,相似系数也可看作为距离。
二、如何度量距离的远近:统计距离和相似系数1.统计距离距离有点间距离好和类间距离2.常用距离统计距离有多种,常用的是明氏距离。
3.相似系数当对个指标变量进行聚类时,用相似系数来衡量变量间的关联程度,一般地称为变量和间的相似系数。
常用的相似系数有夹角余弦、相关系数等。
夹角余弦:相关系数:对于分类变量的研究对象的相似性测度,一般称为关联测度。
第二节如何进行聚类分析一、系统聚类1.系统聚类的基本步骤2.最短距离法3.最长距离法4.重心法和类平均法5.离差平方和法二、SPSS中的聚类分析1、事先要确定分多少类:K均值聚类法;2、事先不用确定分多少类:分层聚类;分层聚类由两种方法:分解法和凝聚法。
聚类分析及判别分析案例
聚类分析及判别分析案例⼀、案例背景随着现代⼈⼒资源管理理论的迅速发展,绩效考评技术⽔平也在不断提⾼。
绩效的多因性、多维性,要求对绩效实施多标准⼤样本科学有效的评价。
对企业来说,对上千⼈进⾏多达50~60个标准的考核是很常见的现象。
但是,⽬前多标准⼤样本⼤型企业绩效考评问题仍然困扰着许多⼈⼒资源管理从业⼈员。
为此,有必要将当今国际上最流⾏的视窗统计软件SPSS应⽤于绩效考评之中。
在分析企业员⼯绩效⽔平时,由于员⼯绩效⽔平的指标很多,各指标之间还有⼀定的关联性,缺乏有效的⽅法进⾏⽐较。
⽬前较理想的⽅法是⾮参数统计⽅法。
本⽂将列举某企业的具体情况确定适当的考核标准,采⽤主成分分析以及聚类分析⽅法,⽐较出各员⼯绩效⽔平,从⽽为企业绩效管理提供⼀定的科学依据。
最后采⽤判别分析建⽴判别函数,同时与原分类进⾏⽐较。
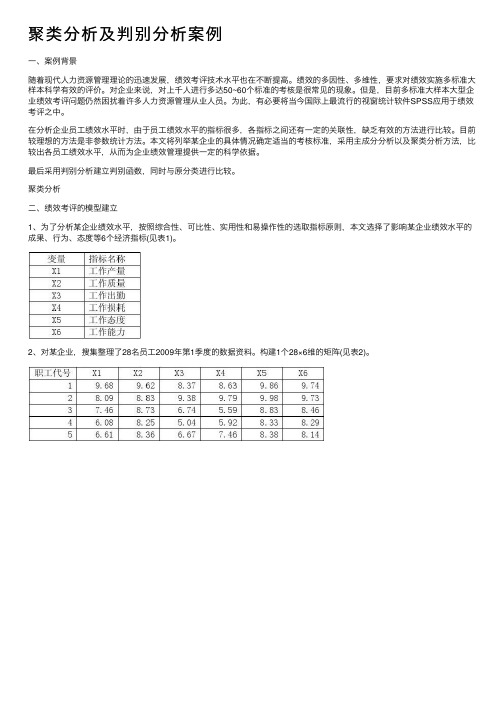
聚类分析⼆、绩效考评的模型建⽴1、为了分析某企业绩效⽔平,按照综合性、可⽐性、实⽤性和易操作性的选取指标原则,本⽂选择了影响某企业绩效⽔平的成果、⾏为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员⼯2009年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应⽤SPSS数据统计分析系统⾸先对变量进⾏及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备⽤。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227 -.295Zscore(X2) .228 -.221Zscore(X3) .224 -.297Zscore(X4) .177 -.173Zscore(X5) .186 .572Zscore(X6) .185 .587提取⽅法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值⼤于1,分别为3.944和1.08,所以选取两个主成分。
根据累计贡献率超过80%的⼀般选取原则,主成分1和主成分2的累计贡献率已达到了83.74%的⽔平,表明原来6个变量反映的信息可由两个主成分反映83.74%。
第六章 聚类分析与判别分析

y0 1E-06 1E-06 1E-06 1E-06 1E-06 华北 华北 长江中下游 长江中下游 长江中下游
15.6
23.9 9.48 13.5
8.88
15.2 6.43 7.47
31
22.38 13.14 19.11
21.01
9.66 10.43 20.49
11.8
13.9 8.3 10.3
0.16
1.19 1.11 1.76
j
k l
114
74.96 5.6
41.44
50.13 50.88
33.2
13.9 5.21
11.2
9.62 3.89
48.72
16.14 12.94
30.77
10.18 9.49
14.9
14.5 6.77
11.1
1.ቤተ መጻሕፍቲ ባይዱ1 1.27
每 个聚 类 中 的案 例 数 聚类 1 2 3 4 5 6 7 8 有效 缺失 1.000 1.000 3.000 2.000 1.000 1.000 2.000 1.000 12.000 .000
第六章 聚类分析与判别分析
介绍: 1、聚类分析 2、判别分析
分类学是人类认识世界的基础科学。聚类分析和判别分析是 研究事物分类的基本方法,广泛地应用于自然科学、社会科 学、工农业生产的各个领域。
主要分类 快速样本聚类
事先指定用于聚类分析的类数
系统聚类
不指定最终的类数,结论将在聚类过程中寻求
从聚类结果可知,地区a为一类;地区b、c、k为 一类;地区d、h为一类;地区e和g为一类;地区f为 一类;地区j为一类;地区l为一类
系统聚类(分层聚类分析)
现代地理学中的数学方法 (3)

聚类分析是根据样本之间的亲疏关系 (相似程度或差异程度)进行分类的,其 基本思想是:把相似度高的样本划归为同 一类,把差异程度大的样本划分到不同的 类。聚类分析的方法有:系统聚类法,K均值法,图论聚类法,模糊聚类法,等等 。本节主要介绍系统聚类法。
第3节
聚类分析与判别分析
聚类分析和判别分析,是定量化的研究分 类问题的统计学方法。这两种方法都是研究事 物分类的数学方法,但二者是有区别的。 聚类分析,事先并不知道样本有多少类, 也不知道每一个样本来自哪一类,而是根据样 本的自身属性确定亲疏关系,并按这种亲疏关 系程度对样本进行分类。 而判别分析,则是在事先已知样本分类的 前提下,对给定的新样本进行归类。它是根据 已知对象的观测指标和所属类别,判断未知对 象所属类别的方法。
12 13 14 15 16 17 18 19 20 21
51.274 68.831 77.301 76.948 99.265 118.505 141.473 137.761 117.612 122.781
1.041 0.836 0.623 1.022 0.654 0.661 0.737 0.598 1.245 0.731
64.609 62.804 60.102 68.001 60.702 63.304 54.206 55.901 54.503 49.102
968.33 957.14 824.37 1 255.42 1 251.03 1 246.47 814.21 1 124.05 805.67 1 313.11
181.38 194.04 188.09 211.55 220.91 242.16 193.46 228.44 175.23 236.29
表4.3.1 8种系统聚类方法的距离参数值(下页)
聚类分析与判别分析

10.2.4 层次聚类R型聚类
判别分析先层根据次已聚知类类别R的型事物聚的类性质是建对立函研数究式,对然象后对的未观知类察别变的新量事进物进行行分判断类以,将之它归使入已具知有的类共别同中。特征的变量 在判取别分在析一中有起如,下假以定便: 可以从不同类中分别选出具有代表性的变量作为分析,从而减少分析 如但果两变观 者察的量值不的的同个在个数于数多:或层。文次其件聚非类计常可算庞以大对公,不式则同宜的与使聚Q用类型快类速数聚聚产类类生分一计析系算方列法的公。聚式类解相,似而快,速不聚类同只的能产是生R固型定类聚数类的聚是类对解,变类量数需进要行用户事 先指距定。离的计算,Q型聚类是对样本间进行距离的计算。
观测变量的平均值和方差不相关。 快速聚类分析的实质是K-Mean聚类。
10.2.5 层次聚类R型聚类应用实例 不同在于,因素分析在合并变量的时候,是同时考虑所有变量之间的关系;
层次聚类分析中的Q型聚类可使具有共同特点的样本聚齐在一起,以便对不同类的样本进行分析。 聚类分析的方法主要有两种,一种是“快速聚类分析”; 而变量的聚类分析,则采用层次式的判别方式,根据个别变量之间的亲疏程度逐次进行聚类。
10.2 层次聚类
Ø 层次聚类Q型聚类 Ø 层次聚类Q型聚类应用实例 Ø 层次聚类R型聚类 Ø层次聚类R型聚类应用实例
10.2.1 层次聚类Q型聚类
层次聚类分析中的Q型聚类可使具有共同特点的样本聚齐在一起,以便对 不同类的样本进行分析。层次聚类分析中,测量样本之间的亲疏程度,一种是 样本数据与小类,小类与小类之间的亲疏程度。
该例可以借用层次聚类Q型聚类的实例,分析某班级中语文成绩、数学成绩、化 学成绩和外语成绩四门,哪些课程属于同一个类。
10.3 快速聚类
Ø快速聚类分析的概念 Ø 快速聚类分析的计算过程及公式 Ø快速聚类分析应用实例
聚类分析与判别分析比较实证研究
聚类分析与判别分析的比较聚类分析统计是比较各个事物间的性质,根据需要将性质相近的事物归为同一类,而将性质相差较大的归入不同的类。
它的本质是建立一种分类方法,他能够将一批样本数据按照他们性质上的亲密程度在没有先验知识的情况下自动进行分类。
聚类分析方法主要有两种:一种是快速聚类分析方法,一种是层次聚类分析方法。
层次聚类分析按其分类对象的不同分为Q型聚类分析它是根据被观测的样品的各种特征,将特征相似的样品归并为一类;R型聚类分析是根据被观测的变量之间的相似性,将其特征相似的变量归并为一类。
快速样本聚类适合聚成的类数已确定和大样本的聚类分析;而分层聚类则事先无法确定类别数,但给出的统计量可以帮助确定最好的分类结果。
后者对大样本分析受限制。
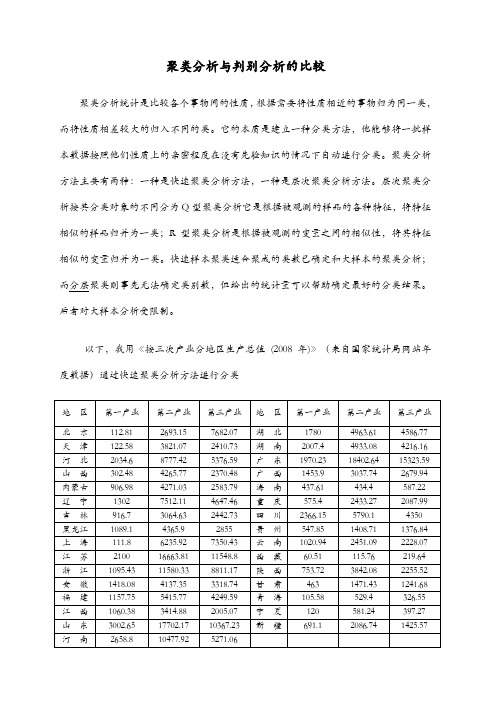
以下,我用《按三次产业分地区生产总值(2008年)》(来自国家统计局网站年度数据)通过快速聚类分析方法进行分类结果分析:从输出结果可以看出,当样本层次聚类分析成3个类时,样本的类归属情况:第一类包括7个省:北京、上海、安徽、福建、湖南、湖北、四川;第二类包含17个省:天津、山西、内蒙古、吉林、黑龙江、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆;第三类包含4省:河北、辽宁、浙江、河南;第四类包含3个省:江苏、山东、广东判别分析是另一种处理分类分体的统计方法。
它是先根据已知类别的事物的性质,建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。
判别分析的内容十分丰富,按照已知分类的多少,分成两组判别喝多组判别;按照判别方法分为逐步判别和序贯判别;按照判别则分为距离判别、贝叶斯判别和费歇判别等。
通过聚类分析我们已经知道以上31个省的分类情况,现在将福建、江西、山东、河南四个省的聚类结果删除掉。
然后进行判别分析。
得出结果如上图,福建,江西,山东,河南四省的判别结果与之前分类结果一样。
典型判别式函数系数函数1 2 3第一产业.000 .002 .001第二产业.001 -.001 .000第三产业.000 .001 .000(常量) -3.744 -1.017 -.516非标准化系数由此图得出三个函数(X1,X2,X3分别为第一产业、第二产业、第三产业)D1=-3.744+0.001X2D2==1.017+0.002X1-0.001X2+0.001X3D3=-0.516+0.001X1通过聚类分析和判别分析,我们得到了31省的分类结果。
判别分析与聚类分析

判别分析(Discriminant Analysis)一、概述:判别问题又称识别问题,或者归类问题。
判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。
根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。
所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。
训练样本的要求:类别明确,测量指标完整准确。
一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。
判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。
半定量指标界于二者之间,可根据不同情况分别采用以上方法。
类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。
如何来表征相同属性、相同的特征指标呢?同一类别的个体之间距离小,不同总体的样本之间距离大。
距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距绝对距离马氏距离:(Manhattan distance)设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为(,)X与总体(类别)A的距离D X Y=(,)为D X A=明考斯基距离(Minkowski distance):明科夫斯基距离欧几里德距离(欧氏距离)二、Fisher两类判别一、训练样本的测量值A类训练样本编号 1x 2xm x1 11A x 12A x 1A m x 221A x22A x2A m xA n1A An x 2A An xA An m x 均数1A x2A xAm xB 类训练样本编号 1x 2x m x1 11B x 12B x 1B m x 221B x22B x2B m xB n1B Bn x 2B Bn x B Bn m x 均数1B x2B xBm x二、建立判别函数(Discriminant Analysis Function)为:1122m m Y C X C X C X =+++其中:1C 、2C 和m C 为判别系数(Discriminant Coefficient ) 可解如下方程组得判别系数。
聚类分析和判别分析

西安科技大学
数学建模
Mathematical Modeling
1. 系统聚类法核心思想
设有 n 个样品,每个样品测得 m 项指标。系统 聚类法的基本思想是:首先定义样品间的距离(或 相似系数)和类与类之间的距离。初始将 n 个样品 看成 n 类(每一类包含一个样品) ,这时类间的距离 与样品间的距离是等价的;然后将距离最近的两类 合并成为新类,并计算新类与其它类的类间距离, 再按最小距离准则并类。这样每次缩小一类,直到 所有的样品都并成一类为止。
聚类分析和判别分析 张守刚
西安科技大学
数学建模
Mathematical Modeling
• 总体来说,聚类分析就是把没有分类信息 的资料按照相似程度进行归类; • 两类:系统聚类法和非系统聚类法,系统 聚类法是应用最广泛的一种方法; • 聚类分析的核心是确定“度量==分类的准 则”;
聚类分析和判别分析
聚类分析和判别分析
张守刚
西安科技大学
数学建模
Mathematical Modeling
• 逐步判别法:与逐步回归法思想类似,都 是逐步引入变量,每引入一个“最重要” 的变量进入判别式,同时也考虑较早引入 判别式的某些变量,若其判别能力不显著 了,就剔除,知道判别式中没有不重要的 变量需要剔除,且没有重要的变量需要引 入为止。这个筛选过称的本质就是假设检 验。
聚类分析和判别分析
张守刚
西安科技大学
数学建模
Mathematical Modeling
案例1
• 中国统计年鉴,2005,主要城市日照时数。 变量有: City—城市名称; 月份—Jan、Feb、……、Dec。 注:聚类可分为变量聚类和观测量聚类, 本案例采用变量聚类方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
⎪⎩∞
如果G P 和Gq 是近邻 否则
聚类方法比较
综合特性最好的聚类方法为类平均法或Ward 最小方差法,而最差的则为最短距离法。 Ward最小方差法倾向于寻找观察数相同的类。 类平均法偏向寻找等方差的类。 拉长的或无规则的类使用最短距离法比其他 方法好。 非参数问题的聚类方法为密度估计法。
5
类的统计量
3
修改后的程序
data newiris;/*测试新数据*/
input sepallen sepalwid petallen petalwid @@;
cards;
56 30 41 13
51 35 14 23
67 25 18 15
run;
proc discrim data=iris pool=test outstat=plotiris testdata=newiris testout=plotp;
样品聚类法2:动态(快速)聚类法
K-means cluster ①选择若干个观察作为“凝聚点”或称类的中心点,作
proc candisc <选项列表>; class 变量; by 变量表; freq 变量; var 变量表; weight 变量; run;
candisc选项
out=数据集名——生成一个包含原始数据和 典型变量得分的SAS数据集。 ncan=——指定将被计算的典型变量的个数。
实例分析
Fisher鸢尾花(Iris)数据 修改后的程序chap8_01B
∑ ( ) k exp i =1
−
0.5Di2
( x, Gi
)
广义平方距离
Di2 (x)
=
d
2 i
(
x)
+
gi
+
hi
gi
=
⎧log ⎨
Σi
⎩0
若各组协方差阵Σi不全相等 若各组协方差阵Σi全相等
判别准则:h(i D= ⎧⎨⎩与−2dlo0稍g p有i 不若若各同各组组)先先验验概概率率pip不i全全相相等等
两类聚类问题
1. 对样品的聚类: 统计指标是类与类之间的距 离,它是把每一个样品看成高维空间中的 一个点,类与类之间用某种原则规定它们 的距离,将距离近的点聚合成一类,距离 远的点聚合成另一类。
2. 对变量的聚类: 统计指标是变量间相似系 数,根据这个统计指标将比较相似的变量 归为一类,而把不怎么相似的变量归为另 一类。
第八章
判别和聚类分析
第八章 判别和聚类分析
第一节 判别分析 第二节 聚类分析
第一节 判别分析
判别分析: 根据已掌握的一批分类明确的 样品,建立一个判别函数,使得用此判别 函数进行判别时错判事例最少,进而能用 此判别函数对给定的新样品判别它来自哪 个总体。
距离判别分析方法 Fisher线性函数判别方法
class species;
var petallen petalwid sepalwid sepallen; proc print data=plotp;/*判别结论新数据*/ proc print data=plotiris;/*输出数据包含二次判别函数*/
run;
SAS典型Fisher判别分析 candisc
4
样品间的距离
设有n组样品,每组样品有m个变量,第i样
品第k变量数据为xik,
1
∑ ( ) Euclid距离:dij
= ⎜⎛ m ⎝ k =1
xik
− x jk
2 ⎟⎞ 2 ⎠
1
∑ Minkowski距离:dij
= ⎜⎛ m ⎝ k =1
xik − x jk
g ⎟⎞ ⎠
g
Mahalanobis距离: dij = (xi − x j )′S −1(xi − x j ) S为样品的协方差矩阵
均匀核估计法
d * (xi , x j )
=
⎧(1 / ⎩⎨∞
f
(xi )
+1/
f
(x j )) / 2
Wong混合法
如果d (xi , x j ) ≤ r 否则
d *(xp , xq ) =
⎧ ⎪
(
D
p
⎨
+
Dq
+
( p + q)d 2 (x p , xq ) / 4)v / 2 ( p + q)1+v / 2
−2(x − u1 + u2
2
u1
+ 2
u2
)′V
−1 (u1
)′V −1(u1 − u2 )
−
u2
)
判别准则: 若 w( y) ≥ 0,则判定y属于G1.
多类线性判别函数
wj
(x)
=
x 'V
−1u j
−
1 2
uj
'V
−1u j
)
判别规则:判给函数值最大的类。
注:这里V用 pooled covariance 计算
线性判别
45
40
35
30
25
20
10
20
30
40
50
60
70
协方差不同:二次判别函数
Zi(x)=-0.5 D2i(x)
判别准则: 若Zk(y)最大,则判定y属于Gk.
当各组方差相等,退化为线性判别函数
二次判别
45
40
35
30
25
20
10
20
30
40
50
60
70
2
误判的概率
样品x来自G1 , 被误判来自G2
设有k个组 G1,G2 ,L,Gk,每一组的先验概率pi已 知,且在x处的组Gi密度fi(x)可以估计。样品
属于组Gi的后验概率为:
∑ p(Gi | x) =
pi f i(x)
k i =1
pi
fi
(x)
设每组内样品为多维正态分布,那么
( ) fi (x)
=
(2π ) − p / 2
Σi
−1/ 2
exp
−
0.5d
2 i
(
x,
Gi
)
d
2 i
(
x,
Gi
)
=
(
x
−
μi
)′Σ
−1 i
(x
−
μi
)
Bayes判别
后验估计
∑ ( ( ) ) p(Gi | x) =
pi
exp
−
0.5d
2 i
(
x,
Gi
)
Σi
−1/ 2
p k
i=1 i
exp
−
0.5d
2 i
(
x,
Gi
)
Σi
−1/ 2
( ) = exp − 0.5Di2 (x,Gi )
样品聚类法1:系统(递阶)聚类法
系统聚类法(Hierarchical clustering method) 是目前使用最多的一种方法。 基本思想是首先将n个样品看成n类,然后规 定样品之间的距离和类与类之间的距离。
将距离最近的两类合并为一个新类,再计算 新类和其他类之间的距离,从中找出最近的 两类合并,继续下去,最后所有的样品全在 一类。将上述并类过程画成聚类图,便可以 决定分多少类,每类各有什么样品。
伪F统计量: 伪F值大表示对应分类显著。 (峰顶好)
伪t2统计量: 伪t2值大表示上一次分类显著。(谷底 好)
立方聚类准则CCC(Cubic Clustering Criterion): CCC大表示对应分类显著。 (峰顶好)
综合分析: CCC统计量和伪F统计量的局部峰值所 对应的聚类数,与这个聚类数伪t2统计量的一个 较小值和下一个聚类数的一个较大伪t2统计量相 吻合。
距离判别分析
Mahalanobis距离(统计距离)
Euclid Vs Mahalanobis
按照Mahalanobis距离判别
0.08 0.07 0.06 0.05 0.04 0.03 0.02 0.01
0 50 55 60 65 70 75 80 85 90 95 100
1
理论基础: 贝叶斯公式
Ward最小方差法一般是在多元正态混合型、 等球形协方差、等抽样概率假设下合并类。
密度估计法
非参数概率密度的聚类方法。
k最近邻估计法
d * (xi ,
xj
)
=
⎧(1/ ⎩⎨∞
f
(xi )
+1/
f
(x j
)) /
2
如果d (xi , x j ) ≤ max(rk (xi ), rk (x j )) 否则
run ;
选项及语句
method=normal | npar——当指定method= normal时,基 于类内服从多元正态分布,并导出线性或二次判别函数;当 指定method=npar时,采用非参数方法。 pool= no| test | yes——pool=test要求对组内协方差阵的齐性 的似然比检验进行Bartlett修正,线性判别函数会直接给 出,而二次型判别函数需通过建立输出数据集方式获得。 Outstat=数据集名——指定输出数据集名 testdata=数据集名——指定欲分类观测的一般SAS数据集 testout=数据集名——生成一个输出SAS数据集。 listerr表示要求仅仅输出由后验概率产生错误分类的那些样 品点的有关信息 crosslisterr表示要求以交叉表的形式输出实际类别与分类结 果之间一致和不一致的有关信息。 priors语句——指定先验概率
1. 基本用法 2. 判别新数据集 3. 较多选项