R语言学习系列16-异常值处理
学会使用R语言进行数据分析的基本步骤

学会使用R语言进行数据分析的基本步骤数据分析在当今社会变得越来越重要,而R语言作为一种强大的数据分析工具,受到了广泛的关注和应用。
不仅在科学研究中,R语言也在商业分析和金融领域等多个领域展现了其强大的能力。
在学习和掌握R语言的过程中,理解数据分析的基本步骤是非常重要的。
第一步:数据收集和整理数据分析的第一步是数据的收集和整理。
这可能涉及到从各种来源收集数据,例如数据库、文件或者Web爬取。
一旦数据收集完成,就要对其进行整理和清洗,以确保数据的一致性和准确性。
这可能包括去除重复数据、处理缺失值和异常值等。
第二步:数据探索和可视化在进行数据分析之前,对数据进行探索和可视化是非常重要的。
R语言提供了一系列的函数和包,使得对数据的探索变得简单和高效。
通过使用R语言中的数据处理和可视化包,可以绘制直方图、散点图和箱线图等多种图表,来更好地了解数据的分布、关系和异常情况。
第三步:数据预处理和特征工程数据预处理和特征工程是数据分析中关键的一步。
它包括对数据进行缩放、标准化、离散化等处理,以及从原始数据中提取和构建特征变量。
R语言中有许多强大的包,如dplyr和tidyverse,可以帮助实现这些预处理和特征工程的步骤。
第四步:模型建立和评估在数据预处理和特征工程之后,可以开始建立预测模型或者回归模型。
R语言提供了丰富的机器学习和统计建模的包,如caret和glm等,可以帮助选择适当的模型,并进行模型参数的训练和调优。
在建立模型之后,需要对其进行评估和验证,以确保模型的准确性和稳定性。
第五步:结果解释和报告最后一步是对数据分析结果进行解释和报告。
这可能包括撰写技术报告、生成可视化图表和制作演示文稿等。
R语言提供了多种报告生成包,如knitr和rmarkdown,可以帮助将分析结果整理成美观、可读性强的报告和文档。
除了以上提到的基本步骤,学习R语言还需要多加练习和实践。
通过实际的案例分析和项目实践,可以更好地掌握R语言的应用技巧和使用方法。
r语言异常值处理

r语言异常值处理R语言是一种非常强大的统计分析工具,可以用于数据处理、可视化和建模等多个方面。
在实际应用中,我们经常会遇到数据中存在异常值的情况。
异常值是指与大部分数据明显不同的数值,它可能是由于测量误差、数据录入错误、系统故障或者真正的异常情况引起的。
处理异常值是数据分析中的重要步骤,因为异常值可能会对后续的分析结果产生严重的影响。
在R语言中,我们可以使用各种方法来识别和处理异常值。
本文将介绍几种常用的异常值处理方法,并通过具体的案例来说明其使用方法和效果。
我们来看一下如何识别异常值。
在R语言中,我们可以使用箱线图、3σ原则、Tukey's fences等方法来识别异常值。
下面以箱线图为例进行说明。
箱线图是一种常用的可视化工具,可以直观地显示数据的分布情况和异常值。
箱线图由五个数值组成:最小值、下四分位数(Q1)、中位数(Q2)、上四分位数(Q3)和最大值。
异常值通常被定义为小于Q1-1.5\*(Q3-Q1)或大于Q3+1.5\*(Q3-Q1)的数值。
假设我们有一个数据集data,包含了100个观测值。
我们可以使用boxplot()函数来绘制箱线图,并使用identify()函数来标识异常值。
代码如下:```boxplot(data)identify(data)```运行以上代码后,R会弹出一个图形窗口,我们可以使用鼠标来选择异常值。
选择完成后,可以按下回车键,R会返回所选异常值的索引。
除了箱线图,我们还可以使用3σ原则来识别异常值。
3σ原则是基于数据的标准差来定义的,异常值通常被定义为大于平均值加上3倍标准差或小于平均值减去3倍标准差的数值。
假设我们有一个数据集data,我们可以使用sd()函数来计算数据的标准差,并使用subset()函数来提取异常值。
代码如下:```sd_value <- sd(data)upper_bound <- mean(data) + 3 * sd_valuelower_bound <- mean(data) - 3 * sd_valueoutliers <- subset(data, data > upper_bound | data < lower_bound)```运行以上代码后,R会返回异常值的集合。
异常值处理

异常值处理R语言:异常数据处理前言在数据处理中,尤其在作函数拟合时,异常点的出现不仅会很大程度的改变函数拟合的效果,而且有时还会使得函数的梯度出现奇异梯度,这就导致算法的终止,从而影响研究变量之间的函数关系。
为了有效的避免这些异常点造成的损失,我们需要采取一定的方法对其进行处理,而处理的第一步便是找到异常点在数据中的位置。
什么是异常值?如何检测异常值?目录1. 单变量异常值检测2. 使用LOF(local outlier factor,局部异常因子)进行异常检测3. 通过聚类的方法检验异常值4. 检验时间序列数据里面的异常值5. 讨论主要程序包install.packages(c(\,\)) library(DMwR) library(dprep)1. 单变量异常值检测这节主要讲单变量异常值检测,并演示如何将它应用到多元(多个自变量)数据中。
使用函数boxplot.stats()实现单变量检测,该函数根据返回的统计数据生成箱线图。
在上述函数的返回结果中,有一个参数out,它是由异常值组成的列表。
更明确的说就是里面列出了箱线图中箱须线外面的数据点。
其中参数coef可以控制箱须线从箱线盒上延伸出来的长度,关于该函数的更多细节可以通过输入‘?boxplot.ststs’查看。
画箱线图:set.seed(3147)#产生100个服从正态分布的数据 xboxplot.stats(x)$out #绘制箱线图 boxplot(x)如上的单变量异常检测可以用来发现多元数据中的异常值,通过简单搭配的方式。
在下例中,我们首先产生一个数据框df,它有两列x和y。
之后,异常值分别从x和y检测出来。
然后,我们获取两列都是异常值的数据作为异常数据。
x# 生成一个包含列名分别为x与y的数据框df df# 连接数据框df attach(df) # 输出x中的异常值(a(b(outlier.list1points(df[outlier.list1,], col=\, pch=\, cex=2.5) # x或y中的异常值(outlier.list2points(df[outlier.list2,], col=\, pch=\, cex=2)当有三个以上的变量时,最终的异常值需要考虑单变量异常检测结果的多数表决。
r语言 处理矩阵中不规则数据

r语言处理矩阵中不规则数据
在R语言中,处理矩阵中的不规则数据是一个常见的问题。
不规则数据可能包括缺失值、异常值、重复值等。
以下是一些常见的处理方法:
1. 缺失值处理,对于缺失值,可以使用函数is.na()来检测缺失值,然后使用条件语句将其替换为特定的值,或者使用函数
na.omit()将包含缺失值的行删除。
2. 异常值处理,对于异常值,可以使用箱线图或者直方图等可视化工具来检测异常值,然后根据业务逻辑或者统计学方法来处理异常值,例如将其替换为均值或中位数。
3. 重复值处理,对于重复值,可以使用函数duplicated()来检测重复值,然后使用函数unique()或者subset()来删除重复值所在的行。
4. 数据清洗,除了上述方法外,还可以进行数据清洗,包括数据类型转换、数据格式化等,以确保数据的准确性和一致性。
总的来说,处理矩阵中的不规则数据需要综合运用R语言中的各种函数和技巧,同时也需要结合实际业务需求和数据特点来进行处理,以确保数据的质量和准确性。
【原创】R语言数据异常值检测算法实现分析案例报告论文(附代码数据)

三倍标准差的测定值,称为高度异常的异常值。
定义与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
α=0.01,称为舍弃水平,又称剔除水平(reject level)。
判断处理检验批中异常数据的判断处理1、依据标准2、异常值定义异常值是指样本中的个别值,其数值明显偏离它(或他们)所属样本的其余观测值。
3、异常值的种类(2)可能是试验条件和方法的偶然偏离,不属同一总体。
4、判断异常值的统计学原则(1)上侧情形:异常值为高端值;(2)下侧情形:异常值为低端值;(3)双侧情形:异常值在两端可能出现极端值。
5、判断异常值的规则:(2)标准差未知——格拉布斯(Grubbs)检验法和狄克逊(Dixon)检验法。
6、格拉布斯(Grubbs)检验法(1)计算统计量μ=(X1+X2+…+Xn)/ns=(∑(Xi-μ)/(n-1))½(i=1,2…n)Gn=(X(n)-μ)/sGn——格拉布斯检验统计量。
(2)确定检出水平α,查表(见GB4883)得出对应n,α的格拉布斯检验临界值G1-α(n)。
(3)当Gn>G1-α(n),则判断Xn为异常值,否则无异常值。
(4)给出剔除水平α’的G1-α’(n),当当Gn>G1-α’(n)时,Xn为高度异常值,应剔除。
三、格拉布斯检验法在回弹法检测砼强度中的应用将测区混凝土强度换算值按从小到大的顺序排列f1、f2、…fn,计算格拉布斯检验统计量:Gn=(fn-m)/sGn’=(m-f1)/s取检出水平α为5%,剔除水平α’为1%,按双侧情形检验,从附表中查得检出水平α对应格拉布斯检验临界值G0.975,剔除水平α’对应格拉布斯检验临界值G0.995。
若Gn>Gn’,且Gn>G0.975,则判断fn为异常值,否则,判断无异常值;若Gn>Gn’,且Gn>G0.995,则判断fn为高度异常值,可考虑剔除;若Gn’>Gn,且Gn’>G0.975,则判断f1为异常值,否则,判断无异常值;若Gn’>Gn,且Gn’>G0.995,则判断f1为高度异常值,可考虑剔除;分析异常值出现原因,判断异常值是否舍弃。
异常值处理讲义

R语言:异常数据处理前言在数据处理中,尤其在作函数拟合时,异常点的出现不仅会很大程度的改变函数拟合的效果,而且有时还会使得函数的梯度出现奇异梯度,这就导致算法的终止,从而影响研究变量之间的函数关系。
为了有效的避免这些异常点造成的损失,我们需要采取一定的方法对其进行处理,而处理的第一步便是找到异常点在数据中的位置。
什么是异常值?如何检测异常值?目录1. 单变量异常值检测2. 使用LOF(local outlier factor,局部异常因子)进行异常检测3. 通过聚类的方法检验异常值4. 检验时间序列数据里面的异常值5. 讨论主要程序包install.packages(c("DMwR","dprep"))library(DMwR)library(dprep)1. 单变量异常值检测这节主要讲单变量异常值检测,并演示如何将它应用到多元(多个自变量)数据中。
使用函数boxplot.stats()实现单变量检测,该函数根据返回的统计数据生成箱线图。
在上述函数的返回结果中,有一个参数out,它是由异常值组成的列表。
更明确的说就是里面列出了箱线图中箱须线外面的数据点。
其中参数coef可以控制箱须线从箱线盒上延伸出来的长度,关于该函数的更多细节可以通过输入‘?boxplot.ststs’查看。
画箱线图:set.seed(3147)#产生100个服从正态分布的数据x <- rnorm(100)summary(x)#输出异常值boxplot.stats(x)$out#绘制箱线图boxplot(x)如上的单变量异常检测可以用来发现多元数据中的异常值,通过简单搭配的方式。
在下例中,我们首先产生一个数据框df,它有两列x和y。
之后,异常值分别从x和y检测出来。
然后,我们获取两列都是异常值的数据作为异常数据。
x <- rnorm(100)y <- rnorm(100)# 生成一个包含列名分别为x与y的数据框dfdf <- data.frame(x, y)rm(x,y)head(df)# 连接数据框dfattach(df)# 输出x中的异常值(a <- which(x %in% boxplot.stats(x)$out))# 输出y中的异常值(b <- which(y %in% boxplot.stats(y)$out))# 断开与数据框的连接detach(df)# 输出x,y相同的异常值(outlier.list1 <- intersect(a,b))plot(df)# 标注异常点points(df[outlier.list1,], col="red", pch="+",cex=2.5)# x或y中的异常值(outlier.list2 <- union(a, b))plot(df)points(df[outlier.list2,], col="blue", pch="x", cex=2)当有三个以上的变量时,最终的异常值需要考虑单变量异常检测结果的多数表决。
有关异常值处理的书

有关异常值处理的书异常值处理是数据分析和统计学中的重要内容,涉及到检测和处理数据中的异常或离群值。
以下是一些与异常值处理相关的书籍,它们可以帮助你深入了解异常值的概念、检测方法和处理技术:1. "统计学习方法"(Pattern Recognition and Machine Learning)作者:Christopher M. Bishop这本书是机器学习领域的经典教材,其中涉及异常值检测和处理在机器学习中的应用。
2. "数据挖掘:概念与技术"(Data Mining: Concepts and Techniques)作者:Jiawei Han,Micheline Kamber,Jian Pei这本书介绍了数据挖掘的基本概念和技术,其中包括异常值检测和处理的方法。
3. "数据分析导论"(Introduction to Data Mining)作者:Pang-Ning Tan,Michael Steinbach,Vipin Kumar这是一本数据挖掘和数据分析的入门教材,涵盖了异常值检测和处理的内容。
4. "Applied Multivariate Statistical Analysis"作者:Richard A. Johnson,Dean W. Wichern这本书着重介绍多元统计分析的方法,其中包括处理多元数据中的异常值问题。
5. "R语言实战"(R in Action: Data Analysis and Graphics with R)作者:Robert I. Kabacoff这是一本关于使用R语言进行数据分析和可视化的实战教材,其中包括异常值处理的内容。
6. "Outliers in Statistical Data"作者:Vic Barnett,Terry Lewis这本书是关于统计数据中异常值的经典著作,深入讨论了异常值检测和处理的方法和理论。
R语言︱处理缺失数据异常值检验、离群点分析、异常值处理
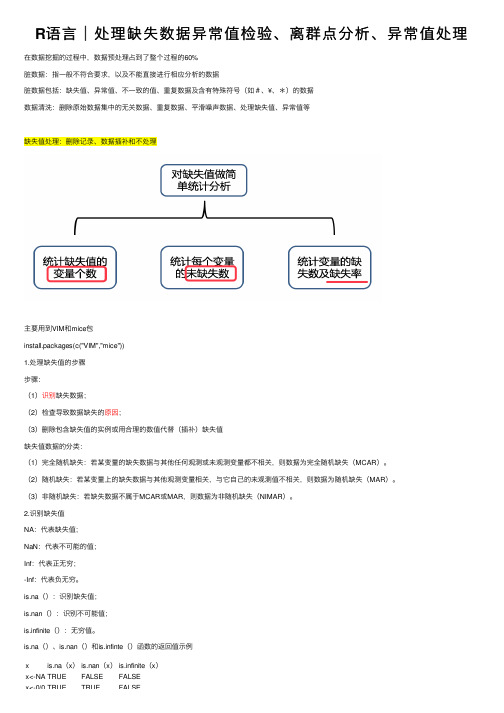
R语⾔︱处理缺失数据异常值检验、离群点分析、异常值处理在数据挖掘的过程中,数据预处理占到了整个过程的60%脏数据:指⼀般不符合要求,以及不能直接进⾏相应分析的数据脏数据包括:缺失值、异常值、不⼀致的值、重复数据及含有特殊符号(如#、¥、*)的数据数据清洗:删除原始数据集中的⽆关数据、重复数据、平滑噪声数据、处理缺失值、异常值等缺失值处理:删除记录、数据插补和不处理主要⽤到VIM和mice包install.packages(c("VIM","mice"))1.处理缺失值的步骤步骤:(1)识别缺失数据;(2)检查导致数据缺失的原因;(3)删除包含缺失值的实例或⽤合理的数值代替(插补)缺失值缺失值数据的分类:(1)完全随机缺失:若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失(MCAR)。
(2)随机缺失:若某变量上的缺失数据与其他观测变量相关,与它⾃⼰的未观测值不相关,则数据为随机缺失(MAR)。
(3)⾮随机缺失:若缺失数据不属于MCAR或MAR,则数据为⾮随机缺失(NIMAR)。
2.识别缺失值NA:代表缺失值;NaN:代表不可能的值;Inf:代表正⽆穷;-Inf:代表负⽆穷。
is.na():识别缺失值;is.nan():识别不可能值;is.infinite():⽆穷值。
is.na()、is.nan()和is.infinte()函数的返回值⽰例x is.na(x)is.nan(x)is.infinite(x)x<-NA TRUE FALSE FALSEx<-0/0TRUE TRUE FALSEx<-0/0TRUE TRUE FALSEx<-1/0FALSE FALSE TRUEcomplete.cases()可⽤来识别矩阵或数据框中没有缺失值的⾏,若每⾏都包含完整的实例,则返回TRUE的逻辑向量,若每⾏有⼀个或多个缺失值,则返回FALSE;3.探索缺失值模式(1)列表显⽰缺失值mice包中的md.pattern()函数可以⽣成⼀个以矩阵或数据框形式展⽰缺失值模式的表格library(mice)data(sleep,package="VIM")md.pattern(sleep)(2)图形探究缺失数据VIM包中提供⼤量能可视化数据集中缺失值模式的函数:aggr()、matrixplot()、scattMiss()library("VIM")aggr(sleep,prop=TRUE,numbers=TRUE)#⽤⽐例代替了计数matrixplot()函数可⽣成展⽰每个实例数据的图形matrixplot(sleep)浅⾊表⽰值⼩,深⾊表⽰值⼤;默认缺失值为红⾊。
r语言异常值处理

r语言异常值处理R语言是一种广泛应用于数据分析和统计建模的编程语言。
在数据分析过程中,经常会遇到异常值的问题,即数据集中的一些值与其他值明显不符合,可能是由于测量误差、录入错误或者其他原因引起的。
异常值的存在会对数据分析结果产生不良影响,因此需要对异常值进行处理。
本文将介绍几种常见的R语言异常值处理方法。
一、简单统计方法最简单直接的方法是使用统计指标,如均值和标准差来判断异常值。
如果某个观测值与均值之差的绝对值大于3倍标准差,我们可以认为该观测值是异常值。
在R语言中,可以使用以下代码来实现:```{r}mean_value <- mean(data)sd_value <- sd(data)lower_bound <- mean_value - 3 * sd_valueupper_bound <- mean_value + 3 * sd_valueoutliers <- data[data < lower_bound | data > upper_bound]```这段代码首先计算数据集的均值和标准差,然后根据3倍标准差的原则确定异常值的上下界,最后将超出上下界的观测值提取出来。
二、箱线图方法箱线图也是一种常见的异常值检测方法。
箱线图可以直观地显示出数据的分布情况,并标出异常值的位置。
在R语言中,可以使用以下代码绘制箱线图:```{r}boxplot(data, outline = TRUE)```箱线图中的异常值通常被认为是超出上下四分位数1.5倍箱体长度的观测值。
通过观察箱线图,我们可以很容易地发现异常值的存在。
三、基于分布的方法有时候,异常值并不是明显的偏离其他值,而是分布上的异常。
可以通过拟合数据的分布来判断异常值。
常用的分布包括正态分布、指数分布等。
在R语言中,可以使用以下代码进行分布拟合:```{r}fit <- fitdistr(data, "normal")params <- fit$estimatemean_value <- params[1]sd_value <- params[2]lower_bound <- mean_value - 3 * sd_valueupper_bound <- mean_value + 3 * sd_valueoutliers <- data[data < lower_bound | data > upper_bound] ```这段代码首先使用正态分布拟合数据,并获取拟合参数。
r语言中异常值空值处理

标题:R语言中异常值和空值处理的方法在数据分析中,异常值和空值是常见的问题,它们会影响数据的准确性和可信度。
在R语言中,有多种方法可以处理这些异常值和空值。
本篇文章将介绍如何使用R语言处理异常值和空值。
一、异常值处理异常值是指数据集中远离平均值的特殊值,可能是由于测量误差、错误数据或特殊情况引起的。
在R语言中,可以使用以下方法处理异常值:1. 删除含有异常值的观测数据:直接删除含有异常值的观测数据是最简单的方法,但可能会损失一些有用的信息。
2. 填充空值:如果数据集中有空值,可以使用一些方法来填充这些空值。
例如,可以使用均值、中位数或其他统计量来填充空值。
3. 删除含有异常值的行或列:如果数据集中的异常值只存在于特定的行或列中,可以考虑只保留正常数据行或列。
4. 归一化处理:对于数值型数据,可以通过归一化处理将异常值调整到合理范围内。
例如,可以使用最小-最大规范化或z-score标准化等方法。
二、空值处理空值在数据分析中是一个常见问题,尤其是在处理文本数据或分类数据时。
在R语言中,可以使用以下方法处理空值:1. 删除含有空值的观测数据:直接删除含有空值的观测数据是最简单的方法。
2. 使用NA代替空值:可以使用NA标记法将空值用特定的NA标记表示,这样就可以在后续分析中使用这些数据。
3. 使用均值、中位数或其他统计量填充空值:对于数值型数据,可以使用均值、中位数或其他统计量来填充空值。
4. 使用条件过滤:根据实际情况,可以使用条件过滤来保留含有特定数值的行或列,同时删除含有空值的行或列。
总之,在R语言中处理异常值和空值的方法有很多种,需要根据数据的具体情况和实际需求选择最合适的方法。
此外,在处理异常值和空值时,应该仔细考虑其对整个数据集的影响,以避免误导分析结果或丢失有用信息。
R语言在主成分分析中对数据预处理和异常值处理的研究

R语言在主成分分析中对数据预处理和异常值处理的研究主成分分析(Principal Component Analysis,PCA)是一种常用的多变量数据分析方法,通过对数据进行线性变换,将原始数据投影到新的坐标系中,以寻找数据的主要变异方向。
在进行主成分分析之前,需要对数据进行预处理和异常值处理。
本文将分别讨论R语言在主成分分析中的数据预处理和异常值处理方法。
一、数据预处理数据预处理是主成分分析的一项重要步骤,它包括数据中心化和数据标准化两个方面。
1. 数据中心化数据中心化是指对数据进行均值的去中心化,即将样本的均值平移到原点。
在R语言中,可以使用scale()函数来实现数据中心化操作。
例如:```# 假设data为一个数据框或矩阵data_centered <- scale(data)```此时,data_centered中的每个变量的均值都将变为0。
2. 数据标准化数据标准化是指对数据进行方差的标准化,即将数据的方差变为单位方差。
在R语言中,可以使用scale()函数的参数scale=TRUE来实现数据标准化。
例如:```# 假设data为一个数据框或矩阵data_standardized <- scale(data, scale = TRUE)```此时,data_standardized中的每个变量的方差都将变为1。
需要注意的是,进行主成分分析之前,可以选择只中心化数据或同时进行中心化和标准化,具体取决于数据的性质和研究目的。
二、异常值处理异常值是指与其他数据点明显不同或偏离正常规律的数据点。
在主成分分析中,异常值可能对分析结果产生不良影响,因此需要进行异常值处理。
1. 箱线图法箱线图法是一种常用的异常值识别方法,可以通过观察数据在箱线图中的分布情况来判断是否存在异常值。
R语言中,可以使用boxplot()函数来绘制箱线图,并使用identify()函数来标识异常值。
例如:```# 假设data为一个数据框或矩阵boxplot(data)identify(data)```通过观察箱线图和标识出的异常值,可以判断是否需要对异常值进行处理。
r语言缺失值的处理

r语言缺失值的处理在R语言中,缺失值的处理是数据清洗和分析中的一个重要环节。
R提供了多种处理缺失值的方法,以下是一些常用的技术:1. 检测缺失值:使用`is.na()`函数来检测数据框或向量中的缺失值。
例如:```R# 检测向量中的缺失值is.na(my_vector)# 检测数据框中的缺失值is.na(my_dataframe)```2. 删除缺失值:使用`na.omit()`函数可以删除包含缺失值的行。
例如:```R# 删除数据框中包含缺失值的行cleaned_data <- na.omit(my_dataframe)```3. 替换缺失值:使用`is.na()`结合条件语句,可以将缺失值替换为指定的值。
例如,将所有缺失值替换为零:```R# 将向量中的缺失值替换为零my_vector[is.na(my_vector)] <- 0# 将数据框中的缺失值替换为零my_dataframe[is.na(my_dataframe)] <- 0```4. 均值、中位数或其他统计量填充:使用统计量(如均值、中位数等)填充缺失值,以保留数据整体的统计特性。
例如:```R# 使用均值填充向量中的缺失值mean_value <- mean(my_vector, na.rm = TRUE)my_vector[is.na(my_vector)] <- mean_value```5. 插值方法:对于时间序列等情况,可以使用插值方法来填充缺失值。
R中有一些包(如`zoo`、`imputeTS`等)提供了插值方法的实现。
6. 使用专门的包处理缺失值:有一些专门的R包,如`mice`(多重插补)和`missForest`(随机森林插补)等,提供更复杂和高级的缺失值处理方法。
例子:```R# 创建一个包含缺失值的数据框my_data <- data.frame(A = c(1, 2, NA, 4, 5),B = c(NA, 2, 3, 4, 5))# 删除包含缺失值的行cleaned_data <- na.omit(my_data)# 替换缺失值为均值my_data$A[is.na(my_data$A)] <- mean(my_data$A, na.rm = TRUE)# 使用mice包进行多重插补# install.packages("mice")library(mice)imputed_data <- mice(my_data)completed_data <- complete(imputed_data)```以上是一些常见的处理缺失值的方法,具体选择取决于数据的特性以及分析的需求。
【原创】R语言数据异常值检测算法实现分析案例报告论文(附代码数据)
三倍标准差的测定值,称为高度异常的异常值。
定义与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
α=0.01,称为舍弃水平,又称剔除水平(reject level)。
判断处理检验批中异常数据的判断处理1、依据标准2、异常值定义异常值是指样本中的个别值,其数值明显偏离它(或他们)所属样本的其余观测值。
3、异常值的种类(2)可能是试验条件和方法的偶然偏离,不属同一总体。
4、判断异常值的统计学原则(1)上侧情形:异常值为高端值;(2)下侧情形:异常值为低端值;(3)双侧情形:异常值在两端可能出现极端值。
5、判断异常值的规则:(2)标准差未知——格拉布斯(Grubbs)检验法和狄克逊(Dixon)检验法。
6、格拉布斯(Grubbs)检验法(1)计算统计量μ=(X1+X2+…+Xn)/ns=(∑(Xi-μ)/(n-1))½(i=1,2…n)Gn=(X(n)-μ)/sGn——格拉布斯检验统计量。
(2)确定检出水平α,查表(见GB4883)得出对应n,α的格拉布斯检验临界值G1-α(n)。
(3)当Gn>G1-α(n),则判断Xn为异常值,否则无异常值。
(4)给出剔除水平α’的G1-α’(n),当当Gn>G1-α’(n)时,Xn为高度异常值,应剔除。
三、格拉布斯检验法在回弹法检测砼强度中的应用将测区混凝土强度换算值按从小到大的顺序排列f1、f2、…fn,计算格拉布斯检验统计量:Gn=(fn-m)/sGn’=(m-f1)/s取检出水平α为5%,剔除水平α’为1%,按双侧情形检验,从附表中查得检出水平α对应格拉布斯检验临界值G0.975,剔除水平α’对应格拉布斯检验临界值G0.995。
若Gn>Gn’,且Gn>G0.975,则判断fn为异常值,否则,判断无异常值;若Gn>Gn’,且Gn>G0.995,则判断fn为高度异常值,可考虑剔除;若Gn’>Gn,且Gn’>G0.975,则判断f1为异常值,否则,判断无异常值;若Gn’>Gn,且Gn’>G0.995,则判断f1为高度异常值,可考虑剔除;分析异常值出现原因,判断异常值是否舍弃。
R语言-使用箱型图进行数据异常值分析

R语⾔-使⽤箱型图进⾏数据异常值分析R语⾔-使⽤箱型图进⾏数据异常值分析⾸先介绍本⽂章的主要内容:1. 检查批量数据的完整性(录⼊不全)2. 异常值分析(录⼊错误以及数据不合理)箱形图(英⽂:Box plot),是⼀种⽤作显⽰⼀组数据分散情况资料的统计图。
在各种领域也经常被使⽤,常见于品质管理,快速识别异常值。
⼀.箱⼦的中间⼀条线,是数据的中位数,代表了样本数据的平均⽔平。
⼆.箱⼦的上下限,分别是数据的上四分位数和下四分位数。
这意味着箱⼦包含了50%的数据。
因此,箱⼦的宽度在⼀定程度上反映了数据的波动程度。
三.在箱⼦的上⽅和下⽅,⼜各有⼀条线。
代表着最⼤最⼩值。
如果有点冒出去,理解成“异常值”就好。
⽰例数据集为:商店销量与⽇期的关联记录``R语⾔代码:统计完整数据个数与不完整数据个数#设置⼯作空间setwd("F:/chapter3/数据探索")#读取表单数据saledata=read.csv(file="./data/catering_sale.csv",header=TRUE)#记录完整数据个数sum(complete.cases(saledata))#记录不完整数据个数sum(!complete.cases(saledata))结果:说明有200个完整的数据和⼀个不完整的数据#输出不完整数据占样本总量的⼤⼩mean(!complete.cases(saledata))#提取不完整所在的⾏saledata[!complete.cases(saledata),]# 异常值检测箱线图sp <-boxplot(saledata$"销量", boxwex =0.7)title("销量异常值检测箱线图")xi <-1.1#标准⽅差公式sd.s <-sd(saledata[complete.cases(saledata),]$"销量")#中位数公式mn.s <-mean(saledata[complete.cases(saledata),]$"销量")points(xi, mn.s, col ="red", pch =18)arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code =3, col ="pink", angle =75, length =.1)text(rep(c(1.05,1.05,0.95,0.95), length =length(sp$out)),labels = sp$out[order(sp$out)], sp$out[order(sp$out)]+rep(c(150,-150,150,-150), length =length(sp$out)), col ="red")可以看到在箱型图中超过上下界的8个销售额数值可能为异常值。
r语言中缺失值处理的方法

r语言中缺失值处理的方法R语言中缺失值处理的方法R语言是一种非常强大的数据分析和统计建模语言,而在进行数据分析和建模的过程中,我们经常会遇到缺失值的情况。
缺失值是指数据集中的某个值或者多个值未被观测到或者未记录的情况。
在处理数据集时,缺失值可能会导致许多问题,包括分析结果的偏差、模型的不准确性等。
因此,合理、准确地处理缺失值对于数据分析的正确性非常重要。
在R语言中,我们可以使用一系列方法来处理缺失值。
下面我将一步一步回答如何处理缺失值的问题。
第一步——了解缺失值在开始处理缺失值之前,我们首先需要了解数据集中缺失值的情况。
可以使用R语言的函数来查看缺失值的个数和位置。
常用的函数包括`is.na()`、`complete.cases()`和`sum()`。
# is.na()函数`is.na()`函数可以用来检测数据集中的缺失值。
该函数将返回一个逻辑向量,其中缺失值对应的位置为TRUE,非缺失值对应的位置为FALSE。
R# 创建一个包含缺失值的向量x <- c(1, 2, NA, 4, 5)# 检测缺失值is.na(x)运行上述代码后,我们将得到一个逻辑向量`TRUE, TRUE, TRUE, FALSE, FALSE`,表示前三个值是缺失值。
# complete.cases()函数`complete.cases()`函数可以用来检测数据集中是否存在缺失值。
该函数返回一个逻辑向量,其中非缺失值对应的位置为TRUE,缺失值对应的位置为FALSE。
R# 创建一个包含缺失值的数据集df <- data.frame(x = c(1, 2, NA, 4, 5), y = c(NA, 2, 3, NA, 5))# 检测缺失值complete.cases(df)运行上述代码后,我们将得到一个逻辑向量`FALSE, TRUE, FALSE, FALSE, TRUE`,表示第一行和最后一行是完整的,没有缺失值。
r语言异常值剔除程序

r语言异常值剔除程序
在R语言中,异常值(outliers)的剔除可以通过多种方法实现。
以下是一种常见的方法:
首先,我们可以使用箱线图(boxplot)来可视化数据的分布情况,以便识别出潜在的异常值。
箱线图可以帮助我们直观地观察数据的离群情况。
接下来,我们可以使用一些统计方法来识别和剔除异常值。
其中,一种常见的方法是使用3σ原则,即将数据限制在平均值加减3倍标准差的范围内。
通过计算数据的平均值和标准差,我们可以筛选出超出这个范围的数据点,并将其视为异常值进行剔除。
另外,我们还可以使用一些R语言中的包来实现异常值的识别和剔除,比如使用outliers包或者dplyr包中的filter函数来筛选出符合特定条件的数据点,从而达到异常值剔除的目的。
除了上述方法之外,还有一些基于分位数或者其他统计学方法的异常值识别和剔除技术,可以根据具体数据的特点和分布情况来选择合适的方法进行异常值处理。
总的来说,R语言提供了丰富的工具和方法来识别和剔除异常值,可以根据具体的数据情况和分析需求来选择合适的方法进行处理。
希望这些信息能够对你有所帮助。
r语言识别和剔除异常值的几种常见方法

r语言识别和剔除异常值的几种常见方法在R语言中,识别和剔除异常值的常见方法有以下几种:
1. 箱线图(Boxplot):通过绘制箱线图可以直观地展示出数据的分布情况,根据箱线图上下限之外的数据点被认为是异常值,可以选择将其剔除或进行修正。
2. Z分数(Z-score)方法:Z分数是指数据点与其均值之间的偏离程度,通过计算数据点的Z分数,可以判断其是否为异常值。
一般来说,大于3或小于-3的Z分数被认为是异常值。
3. 四分位距(IQR)方法:计算数据的四分位距(Q3-Q1),然后将Q1-1.5*IQR和Q3+1.5*IQR之外的数据点视为异常值,可以选择将其剔除或进行修正。
4. 距离方法:通过计算数据点与其他数据点之间的距离来判断异常值。
常见的距离方法有欧氏距离、马哈拉诺比斯距离等。
根据设定的阈值,超过阈值的数据点被认为是异常值。
5. 基于模型的方法:使用统计模型来拟合数据,并通过检验残差(residuals)是否为异常值来判断。
常见的模型包括线性回归、时间序列模型等。
需要注意的是,识别和剔除异常值是一个主观判断的过程,不同的方法可能会得到不同的结果。
在使用这些方法时,需要根据具体问题和数据特点进行选择。
此外,剔除异常值可能会对数据分布和模型拟合产生影响,需要慎重考虑是否进行处理。
R_Studio(学生成绩)对数据缺失值md.pattern()、异常值分析(箱线图)
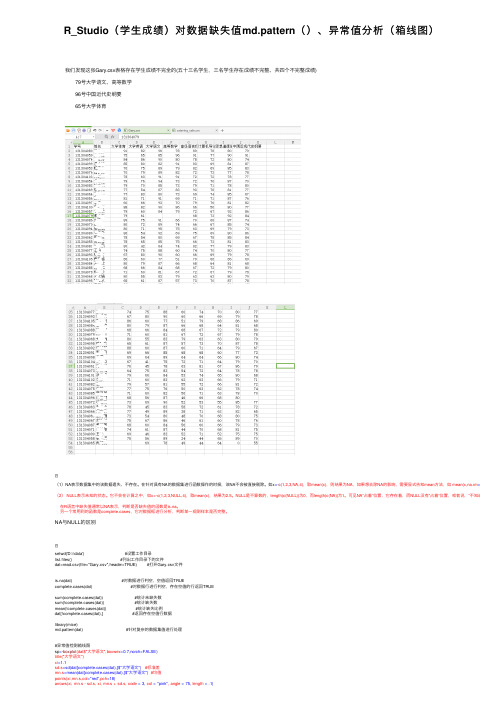
R_Studio(学⽣成绩)对数据缺失值md.pattern()、异常值分析(箱线图) 我们发现这张Gary.csv表格存在学⽣成绩不完全的(五⼗三名学⽣,三名学⽣存在成绩不完整、共四个不完整成绩) 79号⼤学语⽂、⾼等数学 96号中国近代史纲要 65号⼤学体育(1)NA表⽰数据集中的该数据遗失、不存在。
在针对具有NA的数据集进⾏函数操作的时候,该NA不会被直接剔除。
如x<-c(1,2,3,NA,4),取mean(x),则结果为NA,如果想去除NA的影响,需要显式告知mean⽅法,如 mean(x,na.rm=T);NA是没有(2) NULL表⽰未知的状态。
它不会在计算之中,如x<-c(1,2,3,NULL,4),取mean(x),结果为2.5。
NULL是不算数的,length(c(NULL))为0,⽽length(c(NA))为1。
可见NA“占着”位置,它存在着,⽽NULL没有“占着”位置,或者说,“不知道”有没有真正在R语⾔中缺失值通常以NA表⽰,判断是否缺失值的函数是is.na。
另⼀个常⽤到的函数是complete.cases,它对数据框进⾏分析,判断某⼀观测样本是否完整。
NA与NULL的区别setwd('D:\\data') #设置⼯作⽬录list.files() #列出⼯作⽬录下的⽂件dat=read.csv(file="Gary.csv",header=TRUE) #打开Gary.csv⽂件is.na(dat) #对数据进⾏判空,空值返回TRUEcomplete.cases(dat) #对数据⾏进⾏判空,存在空值的⾏返回TRUEsum(complete.cases(dat)) #统计未缺失数sum(!complete.cases(dat)) #统计缺失数mean(!complete.cases(dat)) #统计缺失⽐例dat[!complete.cases(dat),] #返回存在空值⾏数据library(mice)md.pattern(dat) #针对复杂的数据集值进⾏处理#异常值检测箱线图sp<-boxplot(dat$"⼤学语⽂",boxwex=0.7,norch=FALSE)title("⼤学语⽂")xi=1.1sd.s=sd(dat[complete.cases(dat),]$"⼤学语⽂") #标准差mn.s=mean(dat[complete.cases(dat),]$"⼤学语⽂") #均值points(xi,mn.s,col="red",pch=18)arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1)text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)], sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red")plot(saledata[,1],saledata[,2])lines(saledata[,2])Gary.R对成绩数据进⾏缺失值分析,并表述分析过程处理⽅法 对数据进⾏判空,空值返回TRUE is.na(dat) 对数据⾏进⾏判空,存在空值的⾏返回TRUE complete.cases(dat) 统计未缺失数 sum(complete.cases(dat)) 统计缺失数 sum(!complete.cases(dat)) 统计缺失⽐例 mean(!complete.cases(dat)) 返回存在空值⾏数据 dat[!complete.cases(dat),] 依赖包mice md.pattern(dat) #针对复杂的数据集值进⾏处理 md.pattern() 依赖包mice ⽣成⼀个以矩阵或数据框形式展⽰缺失值模式的表格 0表⽰变量的列中没有缺失,1则表⽰有缺失值 第⼀⾏第⼀个数据:完整成绩⼈数 第⼆个数据⾄倒数第⼆个数据:列出全部学⽣考试科⽬ 最后⼀个数据:缺少考试科⽬数量(争对复杂数据,这⾥象对数据简单) 第⼆⾏⾄倒数第⼆⾏:缺少考试成绩学⽣信息 第⼆⾏表⽰存在⼀个学⽣缺少中国近代史纲要成绩缺少成绩科⽬数量为1 第三⾏表⽰存在⼀个学⽣缺少⼤学语⽂和⾼等数学缺少成绩科⽬数量为2 第四⾏表⽰存在⼀个学⽣缺少⼤学体育缺少成绩科⽬数量为1 最后⼀⾏:给出了每个科⽬的缺失值数⽬(中国近代史纲要成绩、⼤学语⽂和⾼等数学、⼤学体育) 最后⼀个数据:缺少科⽬学⽣⼈数(3⼈)对成绩数据进⾏异常值分析,并表述分析过程 箱线图 箱线图(Boxplot)也称箱须图(Box-whisker Plot),是利⽤数据中的五个统计量:最⼩值、第⼀四分位数、中位数、第三四分位数与最⼤值来描述数据的⼀种⽅法,它也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息,特别可以⽤于对⼏个样本的⽐较。
R语言-处理异常值或报错的三个示例

R语言-处理异常值或报错的三个示例之前用rvest帮人写了一个定期抓取amazon价格库存,并与之前价格比较的小程序,算是近期写过的第一个完整的程序了。
里面涉及了一些报错的处理。
这里主要参考了stackoverflow上的以下问答:1.How to skip an error in a loop2.skip to next value of loop upon error in RtryCatch部分,后续查找资料,发现以下博文:1. R语言使用tryCatch进行简单的错误处理以下是代码示例:1)使用tryCatch函数跳过错误信息。
(示例以download.file为样式)看以下代码。
这里需要批量下载一堆amazon产品信息。
如果产品ID号不对,或者IP被限制,网页会打不开,而download.file会报错。
我这里用tryCatch来获取网页打不开时的错误信息。
并且要求执行下一步循环“”。
for(n in 1:length(productlink)){tryCatch({download.file(productlink[n],paste0(getwd(),"/html/",productid[n,], ".html"),cacheOK = TRUE)},error= function(e){cat( "ERROR :",conditionMessage(e), "n")})Sys.sleep( 0.5) #增加了Sys.sleep(seconds)函数,让每一步循环都暂停一段时间。
这个虽然会降低程序速度,但对于有访问限制的网站,不失为一个好的办法。
}上述示例由两个重要函数构成,即tryCatch和cat查阅函数,tryCatch属于base包,condition system。
在R语言使用tryCatch进行简单的错误处理这篇博文里有tryCatch的简单示范如下:result = tryCatch({expr},warning = function(w){warning-handler- code},error = function(e){ error-handler- code},finally= {cleanup- code})即如果warning时,对warning怎么处理,如果error时对error 怎么处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
16. 异常值处理目录:一. 用箱线图检测异常值二. 使用局部异常因子法(LOF法)检测异常值三. 用聚类方法检测异常值四. 检测时间序列数据中的异常值五. 基于稳健马氏距离检测异常值正文:异常值,是指测量数据中的随机错误或偏差,包括错误值或偏离均值的孤立点值。
在数据处理中,异常值会极大的影响回归或分类的效果。
为了避免异常值造成的损失,需要在数据预处理阶段进行异常值检测。
另外,某些情况下,异常值检测也可能是研究的目的,例如,数据造假的发现、电脑入侵的检测等。
一、用箱线图检测异常值在一条数轴上,以数据的上下四分位数(Q1-Q3)为界画一个矩形盒子(中间50%的数据落在盒内);在数据的中位数位置画一条线段为中位线;用◇标记数据的均值;默认延长线不超过盒长的1.5倍,之外的点认为是异常值(用○标记)。
盒形图的主要应用就是,剔除数据的异常值、判断数据的偏态和尾重。
R语言实现,使用函数boxplot.stats(),基本格式为:[stats, n, conf, out]=boxplot.stats(x, coef=1.5, do.conf=TRUE, do.out=TRUE) 其中,x为数值向量(NA、NaN值将被忽略);coef为盒须的长度为几倍的IQR(盒长),默认为1.5;do.conf和do.out设置是否输出conf和out返回值:stats返回5个元素的向量值,包括盒须最小值、盒最小值、中位数、盒最大值、盒须最大值;n返回非缺失值的个数;conf 返回中位数的95%置信区间;out返回异常值。
单变量异常值检测:set.seed(2016)x<-rnorm(100) #生成100个服从N(0,1)的随机数summary(x) #x的汇总信息Min. 1st Qu. Median Mean 3rd Qu. Max.-2.7910 -0.7173 -0.2662 -0.1131 0.5917 2.1940boxplot.stats(x) #用箱线图检测x中的异常值$stats[1] -2.5153136 -0.7326879 -0.2662071 0.5929206 2.1942200 $n[1] 100$conf[1] -0.47565320 -0.05676092$out[1] -2.791471boxplot(x) #绘制箱线图多变量异常值检测:x<-rnorm(100)y<-rnorm(100)df<-data.frame(x,y) #用x,y生成两列的数据框head(df)x y1 0.41452353 0.48522682 -0.47471847 0.69676883 0.06599349 0.18551394 -0.50247778 0.70073355 -0.82599859 0.31168106 0.16698928 0.7604624#寻找x为异常值的坐标位置a<-which(x %in% boxplot.stats(x)$out)a[1] 78 81 92#寻找y为异常值的坐标位置b<-which(y %in% boxplot.stats(y)$out)b[1] 27 37intersect(a,b) #寻找变量x,y都为异常值的坐标位置integer(0)plot(df) #绘制x, y的散点图p2<-union(a,b) #寻找变量x或y为异常值的坐标位置[1] 78 81 92 27 37points(df[p2,],col="red",pch="x",cex=2) #标记异常值二、使用局部异常因子法(LOF法)检测异常值局部异常因子法(LOF法),是一种基于概率密度函数识别异常值的算法。
LOF算法只对数值型数据有效。
算法原理:将一个点的局部密度与其周围的点的密度相比较,若前者明显的比后者小(LOF值大于1),则该点相对于周围的点来说就处于一个相对比较稀疏的区域,这就表明该点是一个异常值。
R语言实现:使用DMwR或dprep包中的函数lofactor(),基本格式为:lofactor(data, k)其中,data为数值型数据集;k为用于计算局部异常因子的邻居数量。
library(DMwR)iris2<-iris[,1:4] #只选数值型的前4列head(iris2)Sepal.Length Sepal.Width Petal.Length Petal.Width1 5.1 3.5 1.4 0.22 4.9 3.0 1.4 0.23 4.7 3.2 1.3 0.24 4.6 3.1 1.5 0.25 5.0 3.6 1.4 0.26 5.4 3.9 1.7 0.4out.scores<-lofactor(iris2,k=10) #计算每个样本的LOF值plot(density(out.scores)) #绘制LOF值的概率密度图#LOF值排前5的数据作为异常值,提取其样本号out<-order(out.scores,decreasing=TRUE)[1:5]out[1] 42 107 23 16 99iris2[out,] #异常值数据Sepal.Length Sepal.Width Petal.Length Petal.Width42 4.5 2.3 1.3 0.3107 4.9 2.5 4.5 1.723 4.6 3.6 1.0 0.216 5.7 4.4 1.5 0.4对鸢尾花数据进行主成分分析,并利用产生的前两个主成分绘制成双标图来显示异常值:n<-nrow(iris2) #样本数n[1] 150labels<-1:n #用数字1-n标注labels[-out]<-"." #非异常值用"."标注biplot(prcomp(iris2),cex=0.8,xlabs=labels)说明:函数prcomp()对数据集iris2做主成份分析,biplot()取主成份分析结果的前两列数据即前两个主成份绘制双标图。
上图中,x轴和y轴分别代表第一、二主成份,箭头指向了原始变量名,其中5个异常值分别用对应的行号标注。
也可以通过函数pairs()绘制散点图矩阵来显示异常值,其中异常值用红色的"+"标注:pchs<-rep(".",n)pchs[out]="+"cols<-rep("black",n)cols[out]<-"red"pairs(iris2,pch=pchs,col=cols)注:另外,Rlof包中函数lof()可实现相同的功能,并且支持并行计算和选择不同距离。
三、用聚类方法检测异常值通过把数据聚成类,将那些不属于任何一类的数据作为异常值。
比如,使用基于密度的聚类DBSCAN,如果对象在稠密区域紧密相连,则被分组到一类;那些不会被分到任何一类的对象就是异常值。
也可以用k-means算法来检测异常值:将数据分成k组,通过把它们分配到最近的聚类中心。
然后,计算每个对象到聚类中心的距离(或相似性),并选择最大的距离作为异常值。
kmeans.result<-kmeans(iris2,centers=3) #kmeans聚类为3类kmeans.result$centers #输出聚类中心Sepal.Length Sepal.Width Petal.Length Petal.Width1 5.901613 2.748387 4.393548 1.4338712 5.006000 3.428000 1.462000 0.2460003 6.850000 3.073684 5.742105 2.071053kmeans.result$cluster #输出聚类结果[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2[30] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 3 1 1 1 1 1[59] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 1 1 1 1 1 1 1 1[88] 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 3 3 3 3 1 3 3 3 3 3 3 1 1 3[117] 3 3 3 1 3 1 3 1 3 3 1 1 3 3 3 3 3 1 3 3 3 3 1 3 3 3 1 3 3 [146] 3 1 3 3 1#centers返回每个样本对应的聚类中心样本centers <- kmeans.result$centers[kmeans.result$cluster, ] #计算每个样本到其聚类中心的距离distances<-sqrt(rowSums((iris2-centers)^2))#找到距离最大的5个样本,认为是异常值out<-order(distances,decreasing=TRUE)[1:5]out #异常值的样本号[1] 99 58 94 61 119iris2[out,] #异常值Sepal.Length Sepal.Width Petal.Length Petal.Width99 5.1 2.5 3.0 1.158 4.9 2.4 3.3 1.094 5.0 2.3 3.3 1.061 5.0 2.0 3.5 1.0119 7.7 2.6 6.9 2.3#绘制聚类结果plot(iris2[,c("Sepal.Length","Sepal.Width")],pch="o",c ol=kmeans.result$cluster,cex=0.3)#聚类中心用"*"标记points(kmeans.result$centers[,c("Sepal.Length", "Sepal. Width")], col=1:3, pch=8, cex=1.5)#异常值用"+"标记points(iris2[out,c("Sepal.Length", "Sepal.Width")], pch ="+", col=4, cex=1.5)四、检测时间序列数据中的异常值对时间序列数据进行异常值检测,先用函数stl()进行稳健回归分解,再识别异常值。