西南交大数据库实验报告
西南交通大学数值分析上机实验报告

数值分析上机实习报告学号:姓名:专业:联系电话:任课教师:序 (3)一、必做题 (4)1、问题一 (4)1.1 问题重述 (4)1.2 实验方法介绍 (4)1.3 实验结果 (5)2、问题二 (7)2.1 问题重述 (7)2.2 实验原理 (7)雅各比算法:将系数矩阵A分解为:A=L+U+D,则推到的最后迭代公式为: (8)2.3 实验结果 (8)二、选做题 (10)3、问题三 (10)3.1 问题重述 (10)3.2 实验原理 (10)3.3 实验结果 (11)总结 (11)序伴随着计算机技术的飞速发展,所有的学科都走向定量化和准确化,从而产生了一系列的计算性的学科分支,而数值计算方法就是解决计算问题的桥梁和工具。
数值计算方法,是一种研究并解决数学问题的数值近似解方法,是在计算机上使用的解数学问题的方法。
为了提高计算能力,需要结合计算能力与计算效率,因此,用来解决数值计算的软件因为高效率的计算凸显的十分重要。
数值方法是用来解决数值问题的计算公式,而数值方法的有效性需要根据其方法本身的好坏以及数值本身的好坏来综合判断。
数值计算方法计算的结果大多数都是近似值,但是理论的严密性又要求我们不仅要掌握将基本的算法,还要了解必要的误差分析,以验证计算结果的可靠性。
数值计算一般涉及的计算对象是微积分,线性代数,常微分方程中的数学问题,从而对应解决实际中的工程技术问题。
在借助MA TLAB、JA V A、C++ 和VB软件解决数学模型求解过程中,可以极大的提高计算效率。
本实验采用的是MATLAB软件来解决数值计算问题。
MA TLAB是一种用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境,其对解决矩阵运算、绘制函数/数据图像等有非常高的效率。
本文采用MATLAB对多项式拟合、雅雅格比法与高斯-赛德尔迭代法求解方程组迭代求解,对Runge-Kutta 4阶算法进行编程,并通过实例求解验证了其可行性,使用不同方法对计算进行比较,得出不同方法的收敛性与迭代次数的多少,比较各种方法的精确度和解的收敛速度。
(精选)西南交大数电实验报告

实验二、三:quartusⅡ原理图设计1.实验原理图2.实验仿真波形实验四:Verilog描述组合逻辑电路1.一位数值比较器1.1源代码module compare(a_gt,a_eq,a_lt,a,b);input a,b;output a_gt,a_eq,a_lt;assign a_gt=a&~b;assign a_eq=a&b|~a&~b;assign a_lt=~a&b;endmodule1.2代码生成原理图2.七段译码器2.1源代码module decode4_7(codeout,indec);input[3:0] indec;output[6:0] codeout;reg[6:0] codeout;always@(indec)begincase(indec)4'd0:codeout=7'b1111110;4'd1:codeout=7'b0110000;4'd2:codeout=7'b1101101;4'd3:codeout=7'b1111001;4'd4:codeout=7'b0110011;4'd5:codeout=7'b1011011;4'd6:codeout=7'b1011111;4'd7:codeout=7'b1110000;4'd8:codeout=7'b1111111;4'd9:codeout=7'b1111011;default: codeout=7'b1001111;endcaseendendmodule2.2代码生成原理图3.总原理图4.实验仿真波形图实验五:集成触发器的应用1.原理图2.实验仿真波形图实验六:移位寄存器实验1.原理图2.实验仿真波形图实验七:十进制可逆计数器1.十进制可逆计数器1.1 十进制可逆计数器源代码module s2014111909(clk,ud,q,co);input clk,ud;output reg [3:0] q;output co;assign co=((q==9)&&ud)||((q==0)&&(!ud));always @(posedge clk)beginif(ud)beginif(q>8) q<=0;else q<=q+1'd1;endelsebeginif(q==0) q<=4'd9;else q<=q-1'd1;endendendmodule1.2 代码生成原理图1.3 实验仿真波形图2.总原理图3.波形图实验八:脉冲宽度调制(PMW)实验1.实验代码module s1909(clk,h,l,out);input clk;input[3:0] h,l;output reg out;reg[6:0]pwmcnt;reg[11:0]fcnt;wire [6:0] z;reg clk1;assign z=h*10+l;always@(posedge clk)beginif(fcnt>=12'd2499)begin clk1<=~clk1; fcnt<=0;endelsebegin fcnt<=fcnt+1;endendalways@(posedge clk1)beginif(pwmcnt<z)begin out=1;endelse if(pwmcnt>=7'd99)begin pwmcnt=0;out=0;endelse begin out=0;endpwmcnt=pwmcnt+1;endendmodule2.波形图(注:专业文档是经验性极强的领域,无法思考和涵盖全面,素材和资料部分来自网络,供参考。
大二数据库实验报告

大二数据库实验报告1.引言1.1 概述概述部分的内容应该对整个实验和实验报告进行简要介绍和概括。
可以从以下几个方面进行撰写:概述部分主要从以下几个方面进行撰写:1. 引入数据库实验的背景:可以描述数据库实验是大学计算机科学专业中重要的实践环节之一,通过实验可以加深对数据库管理系统的理解和应用,并提高学生的实践能力和问题解决能力。
2. 对实验目标的概述:可以说明本次实验的主要目的是通过设计和实现一个小规模数据库系统,熟悉数据库的基本操作和编程接口,掌握数据库设计和管理的基本要点。
3. 对实验内容的概述:可以简要介绍实验涉及的主要内容,如数据库的概念和基本原理、关系型数据库的设计和实现、SQL语言的基本操作、数据库表的创建和查询等方面。
同时,可以提及实验所使用的工具和技术,如MySQL数据库管理系统、SQL编程语言等。
4. 对实验报告结构的概述:可以提及实验报告的整体结构,介绍本报告的章节组成和每个章节的主要内容,以帮助读者了解报告的组织架构和阅读顺序。
以上是概述部分的内容撰写建议,可以结合实际情况进行适当调整和扩充。
文章结构部分的内容:本实验报告共包含三个主要部分,即引言、正文和结论。
首先,引言部分(Chapter 1)是整篇实验报告的开篇之章,用于引入该实验的背景和目的,使读者对实验的内容有一个初步的了解。
在引言部分,我们将首先对本次实验进行概述(1.1 概述),介绍该实验的基本背景、研究领域和应用场景。
然后,我们将对本报告的文章结构进行介绍(1.2 文章结构),概括性地列出报告的主要章节和各个章节的内容概要。
最后,我们将明确本次实验的目的(1.3 目的),说明在本次实验中我们需要实现的具体目标和解决的问题。
接下来,正文部分(Chapter 2)是实验报告的核心,包含了本次实验的详细过程、实验设计、实验结果以及相应的分析和讨论。
在正文部分的第一个要点(2.1 第一个要点)中,我们将详细介绍本次实验的背景和相关的理论知识,对数据库的概念、结构和操作进行深入阐述。
数据库实验报告

数据库实验报告一、实验目的本次数据库实验的主要目的是深入了解数据库的基本概念和操作,掌握数据库管理系统的使用方法,提高对数据的管理和处理能力。
通过实际操作,我们希望能够熟练运用SQL 语句进行数据的查询、插入、更新和删除,以及创建和管理数据库表、索引和视图等对象。
二、实验环境本次实验使用的数据库管理系统是 MySQL 80,操作系统为Windows 10。
实验在个人计算机上进行,使用 MySQL Workbench 作为数据库管理工具。
三、实验内容1、数据库创建使用 CREATE DATABASE 语句创建了一个名为“student_management”的数据库,用于存储学生管理相关的数据。
2、表的创建在“student_management”数据库中,创建了以下几张表:“students”表,包含学生的学号(student_id)、姓名(name)、性别(gender)、年龄(age)等字段。
“courses”表,包含课程的课程号(course_id)、课程名称(course_name)、学分(credit)等字段。
“enrolls”表,用于关联学生和课程,包含学生学号(student_id)、课程号(course_id)和成绩(grade)等字段。
3、数据插入使用 INSERT INTO 语句向上述表中插入了一些示例数据,以方便后续的查询和操作。
4、数据查询通过 SELECT 语句进行了多种查询操作,例如:查询所有学生的信息。
查询特定性别学生的信息。
查询选修了某门课程的学生名单及成绩。
5、数据更新使用 UPDATE 语句对部分学生的年龄或成绩进行了修改。
6、数据删除使用 DELETE 语句删除了一些不再需要的数据记录。
7、索引创建为“students”表的“student_id”字段和“courses”表的“course_id”字段创建了索引,以提高查询效率。
8、视图创建创建了一个名为“student_course_grade_view”的视图,用于展示学生的学号、姓名、课程名称和成绩。
数据库实验报告(实验六)(合集五篇)

数据库实验报告(实验六)(合集五篇)第一篇:数据库实验报告(实验六)实验六SQL语言数据查询语言DQL一、实验内容了解SQL语言的SELECT语句对数据的查询,学会在Navicat for MySQL中用SELECT语句对表中的数据进行简单查询、连接查询、嵌套查询和组合查询。
启动Navicat for MySQL,用SELECT语句进行简单查询操作,具体实验步骤如下:(实验步骤里的内容)1启动Navicat for MySQL,登录到本地数据库服务器后,连接到test数据库上。
用Create Table建立Student表、Course表和Choose表:2.用INSERT语句分别向Student表中插入3个元组、Course表中插入3个元组、Choose表中插入7个元组:3.用SELECT语句,查询计算机学院学生的学号和姓名。
4.用SELECT语句的between…and…表示查询条件,查询年龄在20~23岁的学生信息。
5.用SELECT语句的COUNT()聚集函数,统计Student表中学生总人数。
6.分别用SELECT语句的max()、min()、sum()、avg()四个聚集函数,计算Choose表中C1课程的最高分、最低分、总分、平均分。
7.用SELECT语句对空值(NULL)的判断条件,查询Course表中先修课称编号为空值的课程编号和课程名称。
8.用SELECT语句的连接查询,查询学生的学号、姓名、选修的课程名及成绩。
9.用SELECT的存在量词EXISTS,查询与“张三”在同一个学院学习的学生信息。
10.用SELECT语句的嵌套查询,查询选修C1课程的成绩低于“张三”的学生的学号和成绩。
11.用SELECT语句的组合查询(UNION),查询选修了C1课程或者选修了C3课程的学生学号。
12.用SELECT语句的组合查询(UNION)与DISTINCT短语,查询选修了C1课程或者选修了C3课程的学生学号,并取消重复的数据。
数值分析上机实习报告(西南交通大学)

数值分析上机实习报告姓名:学号:专业:大地测量学与测量工程电话:序言1.所用程序语言:本次数值分析上机实习采用Visual c#作为程序设计语言,利用Visual c#可视化的编程实现方法,采用对话框形式进行设计计算程序界面,并将结果用表格或文档的格式给出。
2.程序概述:(1)第一题是采用牛顿法和steffensen法分别对两个题进行分析,编好程序后分别带入不同的初值,观察与真实值的差别,分析出初值对结果的影响,分析两种方法的收敛速度。
(2)第二题使用Visual c#程序设计语言完成了“松弛因子对SOR法收敛速度的影响”,通过在可视化界面下输入不同的n和w值,点击按钮直接可看到迭代次数及计算结果,观察了不同的松弛因子w对收敛速度的影响。
目录一.用牛顿法,及牛顿-Steffensen法............ 错误!未定义书签。
1. 计算结果.................................... 错误!未定义书签。
2. 结果分析 (5)3. 程序清单 (5)二.松弛因子对SOR法收敛速度的影响 (8)1. 迭代次数计算结果 (8)2. 计算X()结果 (10)3. 对比分析 (12)4. 程序清单: (12)三.实习总结 (14)实验课题(一)用牛顿法,及牛顿-Steffensen法题目:分别用牛顿法,及牛顿-Steffensen法(1)求ln(x+sin x)=0的根。
初值x0分别取0.1, 1,1.5, 2, 4进行计算。
(2)求sin x=0的根。
初值x0分别取1,1.4,1.6, 1.8,3进行计算。
分析其中遇到的现象与问题。
1、计算结果由于比较多每种方法中只选取了其中两个的图片例在下面:2、结果分析通过对以上的牛顿法和steffensen法的练习,我发现在初值的选取很重要,好的初值选出后可以很快的达到预定的精度,要是选的不好就很慢,而且在有的时候得出的还是非数字,所以初始值的选取很重要。
西南交大数据结构实验报告

目录实验一一元稀疏多项式的计算1实验三停车场管理10实验四算术表达式求值16实验七哈夫曼编/译码器实验指导书23实验八最短路径实验指导书34实验十部排序算法比拟实验指导书42实验一一元稀疏多项式的计算*include <stdio.h>*include <stdlib.h>*include <conio.h>typedef struct Item{double coef;int e*pn;struct Item *ne*t;}Item,*Polyn;*define CreateItem(p) p=(Item *)malloc(sizeof(Item));*define DeleteItem(p) free((void *)p);/************************************************************//* 判断选择函数*/ /************************************************************/int Select(char *str){ char ch;printf("%s\n",str);printf("Input Y or N:");do{ ch=getch();}while(ch!='Y'&&ch!='y'&&ch!='N'&&ch!='n');printf("\n");if(ch=='Y'||ch=='y') return(1);else return(0);}/************************************************************//* 插入位置定位函数*/ /**************************************************************/int InsertLocate(Polyn h,int e*pn,Item **p){ Item *pre,*q;pre=h;q=h->ne*t;while(q&&q->e*pn<e*pn){ pre=q;q=q->ne*t;}if(!q){ *p=pre;return(1);}else if(q->e*pn==e*pn){ *p=q;return(0);}else{ *p=pre;return(-1);}}/************************************************************//* 插入结点函数*/ /************************************************************/void insert(Item *pre,Item *p){ p->ne*t=pre->ne*t;pre->ne*t=p;}/************************************************************//* 输入多项式*//************************************************************/Polyn Input(void){double coef;int e*pn,flag;Item *h,*p,*q,*pp;CreateItem(h);//产生头结点h->ne*t=NULL;printf("input coef and e*pn(if end ,e*pn=-1)\n");while(1){ printf("coef=");scanf("%lf",&coef);printf("e*pn=");scanf("%d",&e*pn); //输入多项式的系数和指数if(e*pn==-1) break; //假设指数为-1,表示输入完毕if(InsertLocate(h,e*pn,&pp))//返回值非0表示插入新结点{ CreateItem(p);p->coef=coef;p->e*pn=e*pn;insert(pp,p); //按顺序在插入}else if(Select("has the same e*pn,Replace older value"))pp->coef=coef; //指数一样,替换系数}return h;}/************************************************************//* 撤消多项式*//************************************************************/void Destroy(Polyn h){Item *p=h,*q;while(p!=NULL){ q=p;p=p->ne*t;DeleteItem(q);}}/************************************************************//* 输出多项式*/ /************************************************************/void Output(Polyn h,char *title){int flag=1;Item *p=h->ne*t;printf("%s=",title);while(p){ if(flag) //表示是否是多项式的第一项{ flag=0;if(p->e*pn==0) printf("%.2lf",p->coef);else printf("%.2lf*^%d",p->coef,p->e*pn);}else{ if(p->coef>0) printf("+");if(p->e*pn==0) printf("%.2lf",p->coef);else printf("%.2lf*^%d",p->coef,p->e*pn);}p=p->ne*t;}printf("\n");}/************************************************************//* 判断两个多项式项的关系*/ /************************************************************/int Itemp(Item *,Item y){ if(*.e*pn<y.e*pn)return(-1);else if(*.e*pn==y.e*pn)return(0);else return(1);}int menu(void){ int num;system("cls");printf("now the choice you can make:\n");printf(" (1)create P(*)\n");printf(" (2)create Q(*)\n");printf(" (3)p(*)+Q(*)\n");printf(" (4)P(*)-Q(*)\n");printf(" (5)p(*)*Q(*)\n");printf(" (6)print P(*)\n");printf(" (7)print Q(*)\n");printf(" (8)print P(*)+Q(*)\n");printf(" (9)print P(*)-Q(*)\n");printf(" (10)print P(*)*Q(*)\n");printf(" (11)Quit\n");printf("please select 1,2,3,4,5,6,7,8,9,10,11:");do{scanf("%d",&num);}while(num<1 || num>11);return(num);}/************************************************************//* 判断多项式是否存在*/ /************************************************************/int PolynNotEmpty(Polyn h,char *p){ if(h==NULL){ printf("%s is not e*ist!\n",p);getchar();return 0;}else return(1);}/************************************************************//* 两多项式多项式相加*/ /************************************************************/Polyn AddPolyn(Polyn h1,Polyn h2){Item *head,*last,*pa=h1->ne*t,*pb=h2->ne*t,*s; CreateItem(head); //头结点,不动last=head;while(pa&&pb){ switch(Itemp(*pa,*pb)){case -1:CreateItem(s);s->coef=pa->coef;s->e*pn=pa->e*pn;last->ne*t=s;last=last->ne*t;pa=pa->ne*t;break;case 1:CreateItem(s);s->coef=pb->coef;s->e*pn=pb->e*pn;last->ne*t=s;last=last->ne*t;pb=pb->ne*t;break;case 0:if(pa->coef+pb->coef) //相加不为0,写入{CreateItem(s);s->coef=pa->coef+pb->coef;s->e*pn=pa->e*pn;last->ne*t=s;last=last->ne*t;}pa=pa->ne*t;pb=pb->ne*t; break;}}if(pa) //a未到尾last->ne*t=pa;else if(pb)last->ne*t=pb;else //两者皆到尾last->ne*t=NULL;return head;}Polyn SubtractPolyn(Polyn h1,Polyn h2){Item *head,*last,*last1,*pa=h1->ne*t,*pb=h2->ne*t,*s;CreateItem(head);last=head;while(pa&&pb){ switch(Itemp(*pa,*pb)){ case -1:CreateItem(s);s->coef=pa->coef;s->e*pn=pa->e*pn;last->ne*t=s;last=last->ne*t;pa=pa->ne*t;break;case 1:CreateItem(s);s->coef=pb->coef*(-1);s->e*pn=pb->e*pn;last->ne*t=s;last=last->ne*t;pb=pb->ne*t;break;case 0:if(pa->coef-pb->coef) //相加不为0,写入{CreateItem(s);s->coef=pa->coef-pb->coef;s->e*pn=pa->e*pn;last->ne*t=s;last=last->ne*t;}pa=pa->ne*t;pb=pb->ne*t; break;}}if(pa) //a未到尾last->ne*t=pa;else if(pb) //pb未到尾,后面附负值{while(pb){CreateItem(s);s->coef=pb->coef*(-1);s->e*pn=pb->e*pn;last->ne*t=s;last=last->ne*t;pb=pb->ne*t;}last->ne*t=pb;}else //两者皆到尾last->ne*t=NULL;return head;}/************************************************************//* 两多项式多项式相乘*//************************************************************/Polyn MultPolyn(Polyn h1,Polyn h2) //两个多项式相乘{ int e*pn;Item *head,*pa,*pb=h2->ne*t,*s,*pp;double coef;CreateItem(head);head->ne*t=NULL;while(pb) //双层循环,每项都乘到{ pa=h1->ne*t;while(pa){ e*pn=pa->e*pn+pb->e*pn;coef=pa->coef*pb->coef;if(InsertLocate(head,e*pn,&pp))//返回值非0表示插入新结点{ CreateItem(s);s->coef=coef;s->e*pn=e*pn;insert(pp,s); //按顺序在插入}elsepp->coef=pp->coef+coef; //找到有一样指数,直接加上去pa=pa->ne*t;}pb=pb->ne*t;}return head;}/************************************************************//* 主函数*//************************************************************/void main(){ int num;Polyn h1=NULL; //p(*)Polyn h2=NULL; //Q(*)Polyn h3=NULL; //P(*)+Q(*)Polyn h4=NULL; //P(*)-Q(*)Polyn h5=NULL; //P(*)*Q(*)while(1){ num=menu();getchar();switch(num){ case 1: //输入第一个多项式,假设多项式存在,首先撤消然后再输入if(h1!=NULL){ if(Select("P(*) is not Empty,Create P(*) again")){ Destroy(h1);h1=Input();}}else h1=Input();break;case 2: //输入第二个多项式,假设多项式存在,首先撤消然后再输入if(h2!=NULL){ if(Select("Q(*) is not Empty,Create Q(*) again")){ Destroy(h2);h2=Input();}}else h2=Input();break;case 3: //两多项式相加if(PolynNotEmpty(h1,"p(*)")&&PolynNotEmpty(h2,"Q(*)")){ h3=AddPolyn(h1,h2);Output(h1,"P(*)");Output(h2,"Q(*)");Output(h3,"P(*)+Q(*)");printf("P(*)+Q(*) has finished!\n");getchar();}break;case 4: //两多项式相减if(PolynNotEmpty(h1,"p(*)")&&PolynNotEmpty(h2,"Q(*)")){ h4=SubtractPolyn(h1,h2);Output(h1,"P(*)");Output(h2,"Q(*)");Output(h4,"P*)-Q(*)");printf("P(*)-Q(*) has finished!\n");getchar();}break;case 5: //两多项式相乘if(PolynNotEmpty(h1,"p(*)")&&PolynNotEmpty(h2,"Q(*)")){ h5=MultPolyn(h1,h2);Output(h1,"P(*)");Output(h2,"Q(*)");Output(h5,"P(*)*Q(*)");printf("P(*)*Q(*) has finished!\n");getchar();}break;case 6: //显示第一个多项式if(PolynNotEmpty(h1,"p(*)")){ Output(h1,"P(*)");getchar();}break;case 7: //显示第二个多项式if(PolynNotEmpty(h2,"Q(*)")){ Output(h2,"Q(*)");getchar();}break;case 8: //显示相加结果多项式if(PolynNotEmpty(h3,"P(*)+Q(*)")){ Output(h1,"P(*)");Output(h2,"Q(*)");Output(h3,"P(*)+Q(*)");getchar();}break;case 9: //显示相减结果多项式if(PolynNotEmpty(h4,"P(*)-Q(*)")){ Output(h1,"P(*)");Output(h2,"Q(*)");Output(h4,"P(*)-Q(*)");getchar();}break;case 10: //显示相乘结果多项式if(PolynNotEmpty(h5,"P(*)*Q(*)")){ Output(h1,"P(*)");Output(h2,"Q(*)");Output(h5,"P(*)*Q(*)");getchar();}break;case 11: //完毕程序运行。
数据库实验报告实验小结(3篇)

第1篇一、实验背景随着信息技术的飞速发展,数据库技术已成为现代信息技术的基础。
数据库实验课程旨在使学生掌握数据库的基本概念、原理、技术和应用,提高学生解决实际问题的能力。
本次实验以SQL Server数据库为平台,通过一系列实验操作,加深对数据库基本知识的理解。
二、实验目的1. 熟悉SQL Server数据库的安装与配置;2. 掌握数据库的基本概念、原理和设计方法;3. 熟练运用SQL语言进行数据库的创建、查询、修改和删除操作;4. 学会使用数据库管理工具进行数据库的管理和维护。
三、实验内容1. SQL Server数据库的安装与配置2. 数据库的创建、修改和删除3. 表的创建、修改和删除4. 数据的插入、查询、修改和删除5. 视图的创建、修改和删除6. 存储过程的创建、修改和删除7. 触发器的创建、修改和删除8. 用户和角色的管理四、实验过程及结果1. SQL Server数据库的安装与配置(1)安装SQL Server:按照官方安装教程进行安装,选择适合的安装类型。
(2)配置SQL Server:配置SQL Server实例,设置数据库引擎服务、SQL Server代理等。
2. 数据库的创建、修改和删除(1)创建数据库:使用CREATE DATABASE语句创建数据库。
(2)修改数据库:使用ALTER DATABASE语句修改数据库。
(3)删除数据库:使用DROP DATABASE语句删除数据库。
3. 表的创建、修改和删除(1)创建表:使用CREATE TABLE语句创建表。
(2)修改表:使用ALTER TABLE语句修改表。
(3)删除表:使用DROP TABLE语句删除表。
4. 数据的插入、查询、修改和删除(1)插入数据:使用INSERT INTO语句插入数据。
(2)查询数据:使用SELECT语句查询数据。
(3)修改数据:使用UPDATE语句修改数据。
(4)删除数据:使用DELETE语句删除数据。
数据结构实验报告西南交大

实验一一元稀疏多项式的计算“my.h”#pragma once#include<stdio.h>#include<stdlib.h>#include<string.h>#include<conio.h>#define CLS system("cls");#define PAUSE system("pause");typedef struct Item{double num;int e;struct Item *next;}item,*link;int menu(void);int judge(link,char*);void remove(link);link copy1(link,link);link copy2(link,link);int search(link,int,double);void sort(link);link add(link,link);link subtract(link,link);link multiply(link,link);link input(void);void output(link,char*);“e xecute.cpp”#include"my.h"/**********复制剩余的数据(用于加法)****************/link copy1(link pre,link h){link l;l=(link)malloc(sizeof(item));l->num=h->num;l->e=h->e;l->next=NULL;pre->next=l;return h->next;}/**********复制剩余的数据(用于减法)****************/link copy2(link pre,link h){link l;l=(link)malloc(sizeof(item));l->num=-h->num;l->e=h->e;l->next=NULL;pre->next=l;return h->next;}/****搜索链表中是否已有相同次数的项,同次数项更新系数(用于乘法)****/int search(link h,int e,double num){h=h->next;while(h){if(h->e==e){h->num+=num;return 0;}h=h->next;}return 1;}/********将多项式按次数递增排序(用于乘法)********/void sort(link head){link pre,back,tp_pre,tp_back;for(pre=head,back=pre->next;back->next;pre=pre->next,back=pre->next)for(tp_pre=back,tp_back=tp_pre->next;tp_back;tp_pre=tp_pre->next,tp_back=tp_pre->next) if(tp_back->e<back->e){tp_pre->next=tp_back->next;pre->next=tp_back;tp_back->next=back;break;}}/****************两个多项式相加***************/link add(link h1,link h2){if(h1==NULL||h2==NULL||h1->num==0||h2->num==0){ printf("无多项式!\n");PAUSE;return NULL;}link head,l,pre;head=(link)malloc(sizeof(item));head->num=0;head->next=NULL;pre=head;for(h1=h1->next,h2=h2->next;h1||h2;){if(!h1){while(h2){h2=copy1(pre,h2);pre=pre->next;++head->num;}break;}if(!h2){while(h1){h1=copy1(pre,h1);pre=pre->next;++head->num;}break;}if(h1->e<h2->e){h1=copy1(pre,h1);pre=pre->next;++head->num;}else if(h1->e==h2->e){if(h1->num!=-h2->num){l=(link)malloc(sizeof(item));l->num=h1->num+h2->num;l->e=h1->e;l->next=NULL;pre->next=l;pre=pre->next;++head->num;}h1=h1->next;h2=h2->next;}else{h2=copy1(pre,h2);pre=pre->next;++head->num;}}printf("多项式相加完成!\n");PAUSE;CLS;return head;}/****************两个多项式相减***************/link subtract(link h1,link h2){if(h1==NULL||h2==NULL||h1->num==0||h2->num==0){ printf("无多项式!\n");PAUSE;return NULL;}link head,l,pre;head=(link)malloc(sizeof(item));head->num=0;head->next=NULL;pre=head;for(h1=h1->next,h2=h2->next;h1||h2;){if(!h1){while(h2){h2=copy2(pre,h2);pre=pre->next;++head->num;}break;}if(!h2){while(h1){h1=copy1(pre,h1);pre=pre->next;++head->num;}break;}if(h1->e<h2->e){h1=copy1(pre,h1);pre=pre->next;++head->num;}else if(h1->e==h2->e){if(h1->num!=h2->num){l=(link)malloc(sizeof(item));l->num=h1->num-h2->num;l->e=h1->e;l->next=NULL;pre->next=l;pre=pre->next;++head->num;}h1=h1->next;h2=h2->next;}else{h2=copy2(pre,h2);pre=pre->next;++head->num;}}printf("多项式相减完成!\n");PAUSE;CLS;return head;}/****************两个多项式相乘***************/link multiply(link h1,link h2){if(h1==NULL||h2==NULL||h1->num==0||h2->num==0){ printf("无多项式!\n");PAUSE;return NULL;}link head,end,temp,now;double num;int e;head=(link)malloc(sizeof(item));head->num=0;head->next=NULL;end=head;for(h1=h1->next;h1;h1=h1->next)for(now=h2->next;now;now=now->next){num=h1->num*now->num;e=h1->e+now->e;if(search(head,e,num)){temp=(link)malloc(sizeof(item));temp->num=num;temp->e=e;temp->next=NULL;end->next=temp;end=end->next;++head->num;}}sort(head);printf("多项式相乘完成!\n");PAUSE;CLS;return head;}“io.cpp”#include"my.h"/******************输入并按次数递增的顺序存储数据*********************/link input(void){link head,pre,back,l;double num;int e,flag;head=(link)malloc(sizeof(item));head->next=NULL;head->num=0;do{printf("请输入系数:");scanf("%lf",&num);printf("请输入指数:");scanf("%d",&e);CLS;if(!num) break;if(head->num==0){ //空链表时建立第一个节点l=(link)malloc(sizeof(item));l->num=num;l->e=e;l->next=NULL;head->next=l;++head->num;}else{ //保证存储数据时按次数递增的顺序存储flag=1;for(pre=head,back=pre->next;back;pre=pre->next,back=pre->next){if(e==back->e){ //链表中已有相同次数的项,修改系数即可back->num+=num;flag=0;break;}if(e<back->e){ //找到链表中第一个大于输入数据的节点,在此节点前插入新书局节点l=(link)malloc(sizeof(item));l->num=num;l->e=e;pre->next=l;l->next=back;++head->num;flag=0;break;}}if(flag){ //若新输入的数据次数比链表中的所有数据次数都大,则将此数据项接到链表末尾l=(link)malloc(sizeof(item));l->num=num;l->e=e;l->next=NULL;pre->next=l;++head->num;}}}while(1);return head;}/****************输出数据******************/void output(link h,char *title){printf("%s=",title);if(h==NULL||h->num==0){ //空链表时的输出printf("无多项式!\n");PAUSE;return;}while(h->next){h=h->next;if(h->num==1)if(h->e==0)printf("%g",h->num);elseprintf("x^%d",h->e);else if(h->e==0)printf("%g",h->num);elseprintf("%gx^%d",h->num,h->e);if(h->next&&h->next->num>0)putch('+');}putch('\n');PAUSE;}“m ain.cpp”#include"my.h"int main(void){link p,q,sum,sub,mul;p=q=sum=sub=mul=NULL;while(1){switch(menu()){case 1:if(judge(p,"P(x)")) p=input();break;case 2:if(judge(q,"Q(x)")) q=input();break;case 3:if(judge(sum,"P(x)+Q(x)")) sum=add(p,q);break;case 4:if(judge(sub,"P(x)-Q(x)")) sub=subtract(p,q);break;case 5:if(judge(mul,"P(x)*Q(x)")) mul=multiply(p,q);break;case 6:output(p,"P(x)");break;case 7:output(q,"Q(x)");break;case 8:output(sum,"P(x)+Q(x)");break;case 9:output(sub,"P(x)-Q(x)");break;case 10:output(mul,"P(x)*Q(x)");break;case 11:exit(0);}}}“menu.cpp”#include"my.h"static char string[11][20]={"1--createP(x)","2--create Q(x)","3--p(x)+Q(x)","4--P(x)-Q(x)","5--p(x)*Q(x)","6--printP(x)","7--printQ(x)","8--printP(x)+ Q(x)","9--print P(x)-Q(x)","10--print P(x)*Q(x)","11—Quit"};/*****************主菜单显示****************/int menu(void){int i;while(1){CLS;for(i=0;i<11;++i)puts(string[i]);printf("请选择:");scanf("%d",&i);if(i>=1&&i<=11){CLS;return i;}elseprintf("输入不合法,请重新输入!\n");PAUSE;}}/****************用于判断链表是否存在******************/int judge(link h,char *str){char ch;if(h==NULL||h->num==0)return 1;else{printf("%s is not Empty,Create %s again?\nInput Y or N:",str,str);while(1){ch=getch();if(ch=='y'||ch=='Y'){remove(h);CLS;return 1;}else if(ch=='n'||ch=='N')return 0;}CLS;}}/***************删除链表*******************/void remove(link head){link pre,back;for(pre=head,back=pre->next;back;pre=back,back=back->next) free(pre);free(pre);head=NULL;}实验四算术表达式求值“my.h”#pragma once#include<stdio.h>#include<stdlib.h>#include<conio.h>#include<math.h>#define CLS system("cls");#define PAUSE system("pause");#define N 50union Element{double num;char symbol;};typedef struct Node{Element data;Node *next;}Queue,*qNode,stackNode,*stack;typedef struct queueRecord{Queue *front;Queue *rear;}*qRecord;/********************************stack.cpp********************************/int isStackEmpty(stack top);stack creat_stack();void push(stack top,Element data); Element pop(stack top);Element top(stack top);/********************************queue.cpp********************************/int isQueueEmpty(qRecord queue); qRecord creat_queue();void Enqueue(qRecord queue,Element data); Element Dequeue(qRecord queue);/********************************input.cpp********************************/ void input(qRecord,stack);void output(qRecord);/********************************calculate.cpp********************************/ double calculate(qRecord,stack);/********************************menu.cpp********************************/int menu();void screen();“calculate.cpp”#include "my.h"double calculate(qRecord queue,stack stack){ Element a,b,temp;temp.num = 0;temp.symbol = NULL;while(!isQueueEmpty(queue)){temp = Dequeue(queue);if(temp.symbol == NULL)push(stack,temp);else{b = pop(stack);a = pop(stack);switch(temp.symbol){case '+': a.num+=b.num;push(stack,a);break;case '-': a.num-=b.num;push(stack,a);;break;case '*': a.num*=b.num;push(stack,a);;break;case '/': a.num/=b.num;push(stack,a);;break;}temp.num = 0;temp.symbol = NULL;}}return pop(stack).num;}“input.cpp”#include "my.h"int compare(Element a,Element b){ //a为栈顶的元素,b为新进入的元素int i,j;switch(a.symbol){case '+': i = 1;break;case '-': i = 1;break;case '*': i = 2;break;case '/': i = 2;break;case '(': i = 0;break;}switch(b.symbol){case '+': j = 1;break;case '-': j = 1;break;case '*': j = 2;break;case '/': j = 2;break;case '(': j = 3;break;case ')': j = 1;break;}if(i >= j)return 1;elsereturn 0;}void input(qRecord queue,stack stack){char ch;int j;Element temp;printf("请输入表达式:");temp.num = 0;for(ch = getchar();ch != '\n';ch = getchar()){if(ch-'0' >= 0 && ch-'0' <= 9){temp.num += (ch-'0')/10.0;temp.num *= 10;temp.symbol = NULL;continue;}if(ch == '.'){for(j = 0,ch = getchar();ch-'0' >= 0 && ch-'0' <= 9;ch = getchar()) temp.num += (ch-'0')/pow(10,++j);temp.symbol = NULL;Enqueue(queue,temp);temp.num = 0;if(ch == '\n')break;}if(ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == '(' || ch == ')'){ if(temp.num != 0){Enqueue(queue,temp);temp.num = 0;}temp.symbol = ch;while(!isStackEmpty(stack) && compare(top(stack),temp))Enqueue(queue,pop(stack));if(temp.symbol != ')')push(stack,temp);elsepop(stack);temp.num = 0;}}if(temp.num != 0 && temp.symbol == NULL)Enqueue(queue,temp);while(!isStackEmpty(stack))Enqueue(queue,pop(stack));}void output(qRecord queue){qNode q;if(isQueueEmpty(queue)){printf("表达式为空!\n");return;}printf("后缀表达式为:");for(q = queue->front;q != NULL;q = q->next) if(q->data.symbol == NULL)printf("%g ",q->data.num);elseprintf("%c ",q->data.symbol);putch('\n');}“main.cpp”#include "my.h"void main(){stack stack = creat_stack();qRecord queue = creat_queue();double result;screen();while(1){switch(menu()){case 1:input(queue,stack);PAUSE;break;case 2:output(queue);PAUSE;break;case 3:if(!isQueueEmpty(queue))result = calculate(queue,stack);printf("计算结果=%g\n",result);PAUSE;CLS;screen();break;case 4:exit(0);}}}“menu.cpp”#include "my.h"int menu(){int i;while(1){i = getch() - '0';if(i >= 1 && i <= 4)return i;}}void screen(){printf("1.输入表达式\n");printf("2.输出表达式\n");printf("3.得出结果\n");printf("4.退出\n");}“queue.cpp”#include "my.h"int isQueueEmpty(qRecord queue){if(queue->front == NULL)return 1;elsereturn 0;}qRecord creat_queue(){qRecord queue = (qRecord)malloc(sizeof(queueRecord));queue->front = queue->rear = NULL;return queue;}void Enqueue(qRecord queue,Element data){if(isQueueEmpty(queue)){queue->rear = (qNode)malloc(sizeof(Queue));queue->front = queue->rear;}else{queue->rear->next = (qNode)malloc(sizeof(Queue));queue->rear = queue->rear->next;}queue->rear->data = data;queue->rear->next = NULL;}Element Dequeue(qRecord queue){qNode temp = queue->front;Element data = temp->data;queue->front = queue->front->next;free(temp);return data;}“stack.cpp”#include "my.h"int isStackEmpty(stack top){if(top->next == NULL)return 1;elsereturn 0;}stack creat_stack(){stack st = (stack)malloc(sizeof(stackNode));st->next = NULL;return st;}void push(stack top,Element data){stack temp = (stack)malloc(sizeof(stackNode));temp->data = data;temp->next = top->next;top->next = temp;}Element pop(stack top){stack temp = top->next;Element data = temp->data;top->next = temp->next;free(temp);return data;}Element top(stack top){return top->next->data;}实验七哈夫曼编/译码器实验指导书“my.h”#pragma once#include<stdio.h>#include<stdlib.h>#include<conio.h>#include<math.h>“Huffman.cpp”#include<stdio.h> /* for size_t, printf() */#include<conio.h> /* for getch() */#include<ctype.h> /* for tolower() */#include<malloc.h> /* for malloc(), calloc(), free() */#include<string.h> /* for memmove(), strcpy() */#include<stdlib.h>/*树结构和全局结构指针*/#define NODENUM 26#define CLS system("cls");#define PAUSE system("pause");/*----------哈夫曼树结点结构-------------*/struct node{char ch;int weight;int parent;int lchild,rchild;} *ht; //指向哈夫曼树的存储空间的指针变量/*----------字符编码结点结构-------------*/struct HuffmanCoding{char ch;char coding[NODENUM];};/*--------哈夫曼树遍历时栈的结点结构------*/struct stacknode{int NodeLevel;int NodeElem;};/*---------------常量文件名---------------*/const char *TableFileName = "HfmTbl.txt"; //哈夫曼树数据文件const char *CodeFileName = "CodeFile.txt"; //字符编码数据文件const char *SourceFileName = "SrcText.txt"; //需编码的字符串文件const char *EnCodeFileName = "EnCodeFile.txt"; //编码数据文件const char *DecodeFileName = "DecodeFile.txt"; //译码字符文件/************************************************************/ /* 释放哈夫曼树数据空间函数*/ /************************************************************/ void free_ht(){if(ht != NULL){free(ht);ht = NULL;}}/************************************************************/ /* 从文件读取哈夫曼树数据函数*/ /************************************************************/ int ReadFromFile(){//int i;int m;FILE *fp;if((fp=fopen(TableFileName,"rb"))==NULL){printf("cannot open %s\n", TableFileName);getch();return 0;}fread(&m,sizeof(int),1,fp); //m为数据个数free_ht();ht=(struct node *)malloc(m*sizeof(struct node));fread(ht,sizeof(struct node),m,fp);fclose(fp);return m;}/************************************************************/ /* 吃掉无效的垃圾字符函数函数*/ /* 从键盘读字符数据时使用,避免读到无效字符*/ /************************************************************/ void EatCharsUntilNewLine(){while(getchar()!='\n') continue;}/************************************************************//* 选择权值最小的两个根结点函数*//************************************************************/void Select(struct node ht[],int n, int *s1,int *s2){int i,j;for(i = 0 ; i <= n && ht[i].parent != -1 ; ++i);for(j = i + 1 ; j < n ; ++j)if(ht[j].weight < ht[i].weight && ht[j].parent==-1)i = j;*s1 = i;for(i = 0 ; i <= n && (ht[i].parent != -1 || i==*s1); ++i);for(j = i + 1 ; j <= n ; ++j)if(ht[j].weight < ht[i].weight && j != *s1 && ht[j].parent==-1)i = j;*s2 = i;}/************************************************************//* 创建哈夫曼树和产生字符编码的函数*//************************************************************/void Initialization(){int i=0,n,m,j,f,s1,s2,start;char cd[NODENUM];struct HuffmanCoding code[NODENUM];FILE *fp;printf("输入字符总数n:");scanf("%d",&n);EatCharsUntilNewLine();m=2*n-1;ht=(struct node *)malloc(m*sizeof(struct node)); //申请哈夫曼树的存储空间//输入字符和权值for(i=0;i<n;i++){printf("请输入第%d个字符和权值:",i+1);scanf("%c",&ht[i].ch);scanf("%d",&ht[i].weight);ht[i].parent=ht[i].lchild=ht[i].rchild=-1;EatCharsUntilNewLine();}//剩余空间处理,初始化哈夫曼树for(i=n;i<m;i++){ht[i].ch='*';ht[i].weight=0;ht[i].parent=ht[i].lchild=ht[i].rchild=-1;}//建立哈夫曼树for(i=n;i<m;i++){Select(ht,i-1,&s1,&s2);ht[s1].parent=i;ht[s2].parent=i;ht[i].lchild=s1;ht[i].rchild=s2;ht[i].weight=ht[s1].weight+ht[s2].weight;}//把哈夫曼树的数据存储到文件中if((fp=fopen(TableFileName,"wb"))==NULL){printf("cannot open %s\n", TableFileName);getch();return;}fwrite(&m,sizeof(int),1,fp);fwrite(ht,sizeof(struct node),m,fp);fclose(fp);/*********************************************************/ /* 产生字符编码*/ /* 从叶结点开始,沿父结点上升,直到根结点,若沿*//* 父结点的左分支上升,则得编码字符“0”,若沿父结*/ /* 点的右分支上升,则得编码字符“1”*/ /*********************************************************///把字符编码数据存储到文件中if(!(fp=fopen(CodeFileName,"wb"))){printf("cannot open %s\n", CodeFileName);getch();return;}cd[n-1]=0;for(i=0;i<n;i++){start=n-1;for(j=i,f=ht[i].parent;f!=-1;j=f,f=ht[f].parent)if(ht[f].lchild==j)cd[--start]='0';elsecd[--start]='1';code[i].ch=ht[i].ch;strcpy(code[i].coding,&cd[start]);}fwrite(&n,sizeof(int),1,fp);fwrite(code,sizeof(struct HuffmanCoding),n,fp);fclose(fp);free_ht();printf("\nInitial successfule!\n");getch();}/************************************************************/ /* 哈夫曼编码的函数*/ /************************************************************/ void Encode(void){int i,j,n;char Encodestr[256];struct HuffmanCoding code[NODENUM];FILE *fp1, *fp2;//读字符编码数据fp1 = fopen(CodeFileName,"rb");fread(&n,sizeof(int),1,fp1);fread(code,sizeof(struct HuffmanCoding),n,fp1);//读需编码的字符串,把读入的文本串存储到文件中EatCharsUntilNewLine();printf("请输入要编码的字符串:");gets(Encodestr);fputs(Encodestr,fp1);fclose(fp1);//打开存储编码的数据文件,字符编码fp2=fopen(EnCodeFileName,"wb");printf("编码结果:\n");for(i=0; Encodestr[i]!='\0';++i)for(j=0;j<n;j++)if(Encodestr[i]==code[j].ch){printf("%s",code[j].coding);fwrite(code[j].coding,sizeof(code[j].coding),1,fp2);break;}fclose(fp2);printf("\n编码完成!\n");PAUSE;}/************************************************************/ /* 哈夫曼译码的函数*/ /************************************************************/ void Decode(){FILE *CFP, *TFP;char DeCodeStr[256];char ch;int f,m;m=ReadFromFile();//打开编码数据文件,打开存储译码的数据文件TFP=fopen(DecodeFileName,"wb");CFP=fopen(EnCodeFileName,"rb");//字符译码/********************************************************/ /* 方法:依次从编码数据文件中读取编码字符,并从*/ /* 哈夫曼树开始,若是数字字符“0”,则沿其左分*/ /* 支下降到孩子结点;若是数字字符“1”,则沿其*/ /* 右分支下降到孩子结点;如此反复,直到页结点,*/ /* 则输出页结点对应的字符到译码数据文件中,并*/ /* 显式。
西南交大数据库实验报告

仓库和业务员是多对多的关系,由进货这个联系来连接,其主件为仓库编号和业务员编号,仓库和业务员两个实体分别以一对多的形式指向进货表。
连锁商店与收银员是一对多的关系,由连锁商店指向收银员一对多。由于一个连锁商店只有一个经理,所以讲经理作为连锁商店的属性放入属性表中。
图如下公司公司编号地址仓库仓库编号仓库地址公司编号fk连锁商店商店编号商店名公司编号fk商品商品编号数量销售商店编号fk商品编号fk销量收银员收银员编号性别商店编号fk销售价格价格升降标价商品编号fk价格fk日期业务员业务员编号姓名进货业务员编号fk仓库编号fk日期解答思路
西南交通大学
实验报告
实验课程名称:___ __数据库应用系统__
产品和仓位之间是多对多的关系,由入库这个联系来连接,其主件为产品编号和仓位号,产品和仓位两个实体分别以一对多的形式指向入库表。
车间和仓位是一对多的关系,由车间指向仓位一对多,车间号作为仓位属性的外件。
产品,销售员和客户三者之间的关系是多对多,中间由订单这个联系来连接,其主件为产品编号,销售员编号和客户编号,三个实体分别以一对多的形式指向订单表。
4、碰到价格之类的因素,有可能会出现前后价格不统一而导致整个数据库出现问题的情况,可以加上参考价格和实际价格来加以区分。
5、在实体之间关系复杂时要仔细思考每个实体的特点及题意,一步步确定它们之间的关系,综合考虑制成图。
6、在制图时要在不违背常理和题意的基础上,遵循越简单越好的原则,这样可以节省空间,减少不必要的数据维护,时整个数据看起来不至于冗杂。
职工的属性有姓名,性别,月薪,聘期;商店的属性有地址和商店名;商品的属性有规格,单价和商品名。
数据库实验实验报告

数据库实验实验报告一、实验目的本次数据库实验的主要目的是通过实际操作和实践,深入理解数据库的基本概念、原理和技术,掌握数据库的设计、创建、管理和操作的方法和技能,提高解决实际问题的能力和综合素质。
二、实验环境本次实验使用的数据库管理系统是 MySQL 80,操作系统为Windows 10。
实验在个人计算机上进行,使用了 MySQL Workbench 作为数据库管理和开发工具。
三、实验内容(一)数据库设计1、需求分析根据给定的业务场景和需求,对数据库进行了详细的需求分析。
确定了需要存储的实体、属性和关系,绘制了 ER 图,为后续的数据库设计提供了清晰的蓝图。
2、概念结构设计基于需求分析的结果,进行了概念结构设计。
确定了实体、属性和实体之间的关系,使用 ER 图进行了直观的表示。
3、逻辑结构设计将概念结构设计转换为逻辑结构设计,确定了表的结构、字段的数据类型、主键和外键等。
创建了相应的数据表,并进行了完整性约束的定义。
(二)数据库创建1、使用 SQL 语句创建数据库和数据表在 MySQL 中,使用 CREATE DATABASE 语句创建了数据库,使用 CREATE TABLE 语句创建了数据表,并按照设计要求定义了表的结构和约束。
2、插入数据使用 INSERT INTO 语句向数据表中插入了大量的测试数据,以确保数据库的完整性和可用性。
(三)数据库管理1、数据查询使用 SELECT 语句进行了各种复杂的查询操作,包括单表查询、多表连接查询、子查询、聚合函数的使用等,掌握了不同查询方式的特点和应用场景。
2、数据更新使用 UPDATE 语句对数据表中的数据进行了更新操作,掌握了如何正确修改数据以满足业务需求。
3、数据删除使用 DELETE 语句对数据表中的数据进行了删除操作,了解了删除数据时需要注意的事项,以避免误删除重要数据。
(四)数据库优化1、索引优化在数据表的关键字段上创建了索引,提高了数据查询的效率。
西南交大ERP实验报告——SD

ERP实验报告实验项目名称SAP-Sales and Distribution Case Study 实验室7308所属课程名称ERP实验日期201*年5月18日班级2011级物流管理三班学号********姓名****实验目的及意义:Explains an integrated sales and distribution process in detail and thus fosters a thorough understanding of each process step and underlying SAP functionality.实验内容:Start the sales order process by creating a new customer (The Bike Zone) in Orlando. Then, will receive an inquiry which you will process into a quotation.Once the quotation is accepted by the customer you create a sales order referencing the quotation. As you will have enough bikes in stock, you deliver the products sold to your customer, create an invoice and receive the payment. The graphic below displays the complete process (17 tasks).Study 9:Create New Customer实验步骤:(1)在以下的账户管理信息中输入以下的数据:(2)在“Payment Transaction”标签下填入以下信息:(3)打开“Sales Area Data”标签,然后填入表格中的信息:(4) 在“Sales Area Data”标签下的“Shipping”标签中输入表格中的信息:(5)(6)在“Billing Documents”标签下填入以下信息:(7)点击”保存“按钮生成以下的表格:SD 10:Create Contact Person for Customer 实验步骤:按照提示顺序打开文件每一步,”保存“后生成以下的表格:SD 11:Change Customer(1)按照提示顺序则会打开以下的表格:(2)在“Sales Area Data”界面中,选择“the Partner Function”表格,然后出现以下的表:(3)在下一个空白行,在“PF”列输入“CP”,然后点击搜索按钮“”,得出以下的表:(4)“CP”行中的数据会自动键入如下所示:(5)点击“”确认按钮,得到以下的数据信息:SD 12: Create Customer Inquiry实验步骤:(1)按照顺序步骤打开以下的表格,并向以下的界面中键入相应的信息:(2)点击“”将产生一个表格,然后点击“Sold-to party”的搜索按钮“”将产生以下的表格,并在“Search term”中输入以下信息:(3)点击“”,将产生以下的表格,再双击“The Bike Zone”:(4)在以下的表格中填入相应的信息如下所示:(5)点击“”后双击选择“Deluxe Touring Bike(black),重复以上动作双击“Professional Touring Bike(black),最后选择确认按钮“”,得到了这个订单的价格:(6)将“order probabilities”“30%”改成“75%”,然后单击确认按钮“”,点击“保存”按钮,将会出现新的数据。
西南交通大学研究 数值分析上机实习报告2012

数值分析上机实习报告要求1.应提交一份完整的实习报告。
具体要求如下:(1)要有封面,封面上要标明姓名、学号、专业和联系电话;(2)要有序言,说明所用语言及简要优、特点,说明选用的考量;(3)要有目录,指明题目、程序、计算结果,图标和分析等内容所在位置,作到信息简明而完全;(4)要有总结,全方位总结机编程计算的心得体会;(5)尽量使报告清晰明了,一般可将计算结果、图表及对比分析放在前面,程序清单作为附录放在后面,程序中关键部分要有中文说明或标注,指明该部分的功能和作用。
2.程序需完好保存到期末考试后的一个星期,以便老师索取用于验证、询问或质疑部分内容。
3.认真完成实验内容,可以达到既学习计算方法又提高计算能力的目的,还可以切身体会书本内容之精妙所在,期间可以得到很多乐趣。
4.拷贝或抄袭他人结果是不良行为,将视为不合格。
5.报告打印后按要求的时间提交给任课老师。
上机实习必须在规定的时间内完成,可要求在考前或考后一个星期内提交。
不合格者和不交者不通过数值分析2012年上机试题1. 已知:a=-5,b=5, 以下是某函数f(x)的一些点(x k,y k), 其中x k=a+0.1(k-1) ,k=1,..,101x k=a+0.1k,请用插值类方法给出函数f(x)的一个解决方案和具体结果。
并通过实验考虑下列问题实验前分析:所给的节点一共有101个,用Lagrange插值发最高可以做次数100的插值多项式做低次插值是需要进行分组,间插值区域分成互不重叠的区间。
分组时须按区间位置高低的顺序依次划分,有可能最后余下的区间节点数不足够做n次的Lagrange插值多项式,需要特殊处理。
分完组后在分得的区间套用插值公式得到:(1)(2)(),,,m n n n L L L ,那么最后的插值多项式是分段的多项式:(1)1(2)2()(),(),()(),n nn m nmL x x I L x x I L x L x x I ⎧∈⎪∈⎪=⎨⎪⎪∈⎩实验结果:下面列出其中某些次的插值多项式5()L x 的系数(1) Ln(x)的次数n 越高,逼近f(x)的程度越好? 答:不是,比如2()1/(1)f x x =+时1201()1()1()()nn j j j n jx Ln x x x x x ωω+=+='+-∑当n →∞时只在 3.63x ≤内收敛,在这区间外是发散的。
数据库实验报告范本(3篇)

第1篇实验名称:数据库设计与实现实验日期:2023年4月15日实验班级:计算机科学与技术专业1班实验学号:12345678一、实验目的1. 理解数据库设计的基本原理和方法。
2. 掌握数据库概念结构、逻辑结构和物理结构的设计。
3. 学会使用数据库设计工具进行数据库设计。
4. 能够使用SQL语句进行数据库的创建、查询、更新和删除等操作。
二、实验内容1. 数据库概念结构设计- 分析需求,确定实体和实体间的关系。
- 设计E-R图,表示实体、属性和关系。
2. 数据库逻辑结构设计- 将E-R图转换为关系模式。
- 设计关系模式,确定主键、外键等约束。
3. 数据库物理结构设计- 选择合适的数据库管理系统(DBMS)。
- 设计数据库表结构,包括字段类型、长度、索引等。
- 设计存储策略,如数据文件、索引文件等。
4. 数据库实现- 使用DBMS创建数据库。
- 创建表,输入数据。
- 使用SQL语句进行查询、更新和删除等操作。
三、实验步骤1. 数据库概念结构设计- 分析需求,确定实体和实体间的关系。
- 设计E-R图,表示实体、属性和关系。
2. 数据库逻辑结构设计- 将E-R图转换为关系模式。
- 设计关系模式,确定主键、外键等约束。
3. 数据库物理结构设计- 选择合适的数据库管理系统(DBMS)。
- 设计数据库表结构,包括字段类型、长度、索引等。
- 设计存储策略,如数据文件、索引文件等。
4. 数据库实现- 使用DBMS创建数据库。
- 创建表,输入数据。
- 使用SQL语句进行查询、更新和删除等操作。
四、实验结果与分析1. 数据库概念结构设计- 实体:学生、课程、教师、成绩。
- 关系:学生与课程之间有选课关系,教师与课程之间有授课关系。
2. 数据库逻辑结构设计- 学生表(学号,姓名,性别,年龄,班级号)。
- 课程表(课程号,课程名,学分,教师号)。
- 教师表(教师号,姓名,性别,年龄,职称)。
- 成绩表(学号,课程号,成绩)。
数据库学习实验报告(3篇)

第1篇一、实验目的本次实验旨在通过实际操作,加深对数据库基础知识的理解,掌握数据库的基本操作,包括数据库的创建、表的设计、数据的插入、查询、修改和删除等。
通过本次实验,提高对SQL语言的实际应用能力,为后续深入学习数据库知识打下坚实的基础。
二、实验环境1. 操作系统:Windows 102. 数据库管理系统:MySQL 5.73. 开发工具:MySQL Workbench三、实验内容1. 数据库的创建与删除2. 表的设计与数据类型3. 数据的插入、查询、修改和删除4. 索引与视图的应用四、实验步骤1. 数据库的创建与删除(1)创建数据库```sqlCREATE DATABASE db_student;```(2)删除数据库```sqlDROP DATABASE db_student;```2. 表的设计与数据类型(1)创建学生表```sqlCREATE TABLE student (id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(50),age INT,gender ENUM('男', '女'),class VARCHAR(50));```(2)创建课程表```sqlCREATE TABLE course (id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(50),credit INT);```3. 数据的插入、查询、修改和删除(1)插入数据```sqlINSERT INTO student (name, age, gender, class) VALUES ('张三', 20, '男', '计算机科学与技术');INSERT INTO course (name, credit) VALUES ('高等数学', 4);```(2)查询数据```sql-- 查询所有学生信息SELECT FROM student;-- 查询年龄大于20岁的学生信息SELECT FROM student WHERE age > 20;-- 查询课程名称为“高等数学”的课程信息SELECT FROM course WHERE name = '高等数学';```(3)修改数据```sql-- 修改学生张三的年龄为21岁UPDATE student SET age = 21 WHERE name = '张三';-- 修改课程“高等数学”的学分UPDATE course SET credit = 5 WHERE name = '高等数学';```(4)删除数据```sql-- 删除学生张三的信息DELETE FROM student WHERE name = '张三';-- 删除课程“高等数学”的信息DELETE FROM course WHERE name = '高等数学'; ```4. 索引与视图的应用(1)创建索引```sql-- 创建学生表id字段的索引CREATE INDEX idx_student_id ON student(id); -- 创建课程表name字段的索引CREATE INDEX idx_course_name ON course(name); ```(2)创建视图```sql-- 创建包含学生姓名和课程名称的视图CREATE VIEW student_course_view ASSELECT , FROM studentJOIN course ON student.class = course.id;```(3)查询视图数据```sql-- 查询视图中的数据SELECT FROM student_course_view;```五、实验总结通过本次实验,我深入了解了数据库的基本操作,掌握了SQL语言的运用。
数据库原理实验报告

数据库原理实验报告目录一、实验目的 (2)1. 熟悉数据库的基本概念和原理 (2)2. 掌握数据库的设计方法和技巧 (3)3. 学会使用SQL语言进行数据操作和管理 (5)二、实验内容 (6)1. 数据库基本概念 (7)2. 数据库设计 (9)3. SQL语言基础 (9)4. SQL语句练习 (11)5. 数据库管理与维护 (12)三、实验步骤与结果 (13)1. 数据库基本概念 (15)数据库的定义和特点 (16)关系型数据库的基本结构 (17)数据库管理系统(DBMS)的功能和组成部分 (19)2. 数据库设计 (20)需求分析 (22)概念模型设计 (23)逻辑模型设计 (25)物理模型设计 (26)3. SQL语言基础 (27)SQL语言的基本语法 (28)SQL语句的分类和功能 (30)SQL语句的操作对象 (31)4. SQL语句练习 (32)5. 数据库管理与维护 (34)数据库备份与恢复 (35)数据库优化与调整 (36)数据库安全与权限管理 (38)四、实验总结与展望 (39)1. 本实验的主要收获和体会 (40)2. 在实际工作中遇到的困难和问题及解决方法 (41)3. 对未来学习和工作的展望 (42)一、实验目的本次数据库原理实验的主要目的是加深对数据库管理系统原理的理解,掌握数据库的基本操作,并学会使用SQL语言进行数据库的查询、插入、更新和删除等操作。
通过实际操作,培养学生的数据库设计能力和解决实际问题的能力,为后续的数据库课程学习和职业生涯打下坚实的基础。
实验还旨在提高学生的动手实践能力和团队协作精神,为未来的学习和工作积累宝贵的经验。
1. 熟悉数据库的基本概念和原理数据库是存储数据的集合,这些数据可以是关于企业、组织或个人的信息。
它提供了一个有组织的数据存储环境,可以高效、有序地存储和管理大量的数据。
在现代信息技术中,数据库管理系统(DBMS)作为支持数据存储和操作的核心软件工具发挥着至关重要的作用。
西南交大c实验报告
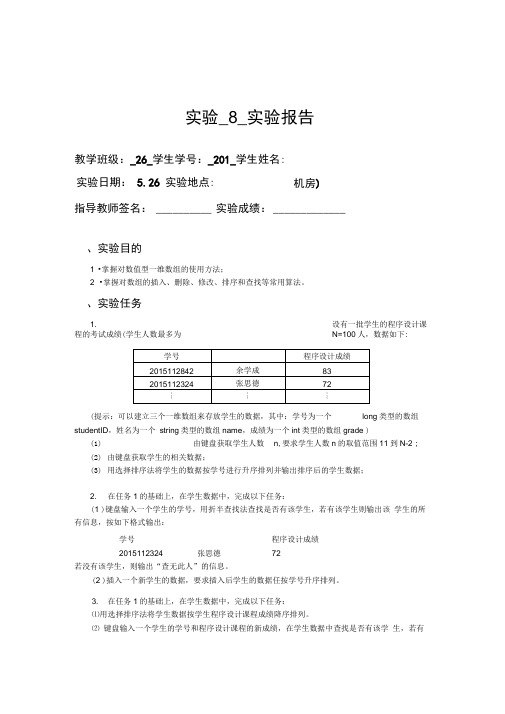
实验_8_实验报告教学班级:_26_学生学号:_201_学生姓名:指导教师签名: __________ 实验成绩: _____________、实验目的1 •掌握对数值型一维数组的使用方法;2 •掌握对数组的插入、删除、修改、排序和查找等常用算法。
、实验任务1.设有一批学生的程序设计课程的考试成绩(学生人数最多为N=100人,数据如下:(提示:可以建立三个一维数组来存放学生的数据,其中:学号为一个 long 类型的数组studentID ,姓名为一个 string 类型的数组name ,成绩为一个int 类型的数组grade )(1)由键盘获取学生人数 n ,要求学生人数n 的取值范围11到N-2 ;(2) 由键盘获取学生的相关数据;(3) 用选择排序法将学生的数据按学号进行升序排列并输出排序后的学生数据; 2.在任务1的基础上,在学生数据中,完成以下任务:(1 )键盘输入一个学生的学号,用折半查找法查找是否有该学生,若有该学生则输出该 学生的所有信息,按如下格式输出:若没有该学生,则输出“查无此人”的信息。
(2 )插入一个新学生的数据,要求插入后学生的数据任按学号升序排列。
3. 在任务1的基础上,在学生数据中,完成以下任务: ⑴用选择排序法将学生数据按学生程序设计课程成绩降序排列。
⑵ 键盘输入一个学生的学号和程序设计课程的新成绩,在学生数据中查找是否有该学 生,若有实验日期: 5.26 实验地点:机房)学号2015112324张思德程序设计成绩72该学生则用键盘输入的新成绩替换该学生的原成绩,否则输出“查无此人”的信息。
三、实验结果(源程序+注释)//输入并升序排列学生的成绩#in clude<iostream>#in clude<stri ng>#in clude<ioma nip>using n amespace std;void mai n(){cout << "Name:" << en dl;cout << "Number:20" << endl;long stude ntlD[100], tran s1;〃定义两个长整型变量,其中一个是数组stri ng name[100], tran s2;// 定义两个字符串类变量,其中一个是数组int grade[100], n, i, j,trans3;cout << "请输入学生人数n (11 w n < 98)" << endl;cin >> n;//从键盘输入学生的人数for (i = 0; i <= n - 1; i++)// 利用循环结构录入各学生的信息{cout << "请依次输入第"<< i + 1 << " 个学生的学号、、成绩"<< endl; cin >> stude ntlD[i] >>n ame[i] >> grade[i];}for (i = 0; i <= n - 1; i++)// 利用嵌套循环和条件语句将信息按学号进行升序排列{for (j = i + 1; j <= n -1; j++){if (stude ntlD[i] > stude ntID[j]){tran s1 = stude ntlD[i]; stude ntlD[i] = stude ntlD[j]; stude ntlD[j]= tran s1;trans2 = n ame[i]; n ame[i] = n ame[j]; n ame[j] = tran s2;trans3 = grade[i]; grade[i] = grade[j]; grade[j] = tran s3;}}}cout << "按学号升序排序后学生的成绩信息为:"<< endl;cout << setw(10) << " 学号"<< setw(10) << "" << setw(10) << " 成绩"<< endl;// 限定输出结果格式for (i = 0; i <= n - 1; i++)// 按特定格式输出排列后的学生信息{cout << setw(10) << studentID[i] << setw(10) << name[i] << setw(10) << grade[i]<< en dl;}/*键盘输入一个学生的学号,用折半查找法查找是否有该学生*/int bot = n - 1, mid, top = 0;long nu mber;cout << "请输入待查学生的学号"<< endl;cin >> nu mber;while (top <= bot)〃折半查找法查找信息库中某个学号的学生{mid = (bot + top) / 2;if (stude ntlD[mid] == nu mber) break;else if (stude ntlD[mid] > nu mber) top = mid + 1;else if (stude ntlD[mid] < nu mber) bot = mid - 1;}if (bot >= top)//当这个学生存在时,以特定格式输出该学生的信息{cout << "该学生的信息为:"<< endl;cout << setw(10) << " 学号"<< setw(10) << "" << setw(10) << " 成绩"<< endl;cout << setw(10) << number << setw(10) << name[mid] << setw(10) << grade[mid] << en dl;}else if(top>=bot) cout << " 查无此人"<< endl;//当该学生不存在时,显示"查无此人”/*插入一个新学生的数据,要求插入后学生的数据按学号升序排列*/cout << "请依次输入要插入的学生学号、、成绩信息:"<< endl;cin >> stude ntlD[ n] >> n ame[ n] >> grade[ n];〃录入要插入的学生的信息for (i = 0; i <= n; i++)〃利用嵌套循环和条件语句,将插入后学生的数据按学号升序排列{for (j = i + 1; j <= n; j++){if (studentID[i] > studentID[j]){tran si = stude ntlD[i]; stude ntlD[i] = stude ntlD[j]; stude ntlD[j]= tran si;trans2 = n ame[i]; n ame[i] = n ame[j]; n ame[j] = tran s2;trans3 = grade[i]; grade[i] = grade[j]; grade[j] = tran s3;}}}cout << "插入并排序后学生的成绩信息为:"<< endl;cout << setw(10) << " 学号"<< setw(10) << "" << setw(10) << " 成绩"<< endl;// 限定提示语句的输出格式for (i = 0; i <= n; i++){cout << setw(10) << studentlD[i] << setw(10) << name[i] << setw(10) << grade[i]<< endl;//输出排序结果}#in clude<iostream> #in clude<stri ng> #in clude<ioma nip> using n amespace std; void mai n() {cout << "Name:" << en dl; cout << "Number:201" << endl;long stude ntlD[100], tran s1;〃 定义两个长整型变量,其中一个是数组 stri ng name[100], tran s2;〃 定义两个字符串类变量,其中一个是数组 int grade[100], n, i, j, trans3;cout << "请输入学生人数 n (11 w n < 98)" << endl; cin >> n;□成缔、姓客、成詡誌/*在任务1的基础上,在学生数据中,完成以下任务:⑴用选择排序法将学生数据按学生程序设计课程成绩降序排列。
数据库实验报告(完整版)

数据库实验报告班级:07111103学号:**********姓名:***实验一:[实验内容1 创建和修改数据库]分别使用SQL Server Management Studio和Transact-SQL语句,按下列要求创建和修改用户数据库。
1.创建一个数据库,要求如下:(1)数据库名"testDB"。
(2)数据库中包含一个数据文件,逻辑文件名为testDB_data,磁盘文件名为testDB_data.mdf,文件初始容量为5MB,最大容量为15MB,文件容量递增值为1MB。
(3)事务日志文件,逻辑文件名为TestDB_log, 磁盘文件名为TestDB_log.ldf,文件初始容量为5MB, 最大容量为10MB,文件容量递增值为1MB。
2.对该数据库做如下修改:(1)添加一个数据文件,逻辑文件名为TestDB2_data,实际文件为TestDB2_data.ndf,文件初始容量为1MB,最大容量为6MB,文件容量递增值为1MB。
(2)将日志文件的最大容量增加为15MB,递增值改为2MB。
方法一:使用SQL Server Management Studio创建和修改数据库TestDB方法二:使用Transact-SQL语句创建和修改数据库TestDB方法一过于简单,暂不做讨论。
下面学习方法二。
首先,在sql sever 2008中单击新建查询。
然后键入下面的代码。
建立新的数据库。
1. 创建一个数据库,要求如下:2.对该数据库做如下修改:对刚刚的操作进行验证数据均已更新完毕。
[实验内容2 数据表的创建、修改和查询]1.熟悉有关数据表的创建和修改等工作,并了解主键、外键以及约束的创建和应用,熟练掌握使用SQL Server Management Studio和CREATE TABLE、ALTER TABLE等Transact-SQL语句对数据表的操作方法字段名数据类型字段长度注释项目编码char 10 主键名称varchar负责人编码char 10客户int开始日期datetime结束日期datetime员工数据表(Employee)字段名数据类型字段长度注释方法一:使用SQL Server Management Studio创建数据表并添加约束方法二:使用Transact-SQL语句创建数据表并添加约束2.向数据库TestDB中的两个数据表"项目数据表"和"员工数据表"中添加记录3.在查询分析器中书写Transact-SQL语句完成数据查询。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
代表团属性有人数;动员属性有姓名和性别;比赛项目属性有参赛人数和日期。
6.6:图如下
解答思路:
本题共有7个实体,分别为公司,仓库,连锁商店,收银员,商品,销售价格和业务员,它们的主件分别为公司编号,仓库编号,商店编号,收银员编号,商品编号,价格和业务员编号。各实体关系如下:
西南交通大学
实验报告
实验课程名称:___ __数据库应用系统__
专业班级:_____ _______________
学号:_____________________
学生姓名:______________________
实验指导教师:_______ ______________
课程名称
数据库应用系统
班级
各实体属性如上表。
总
结
首次接触IDEFIX图,很多操作和原理都不明白,通过自我的实践和讲评,让我渐渐对E-R图和软件操作IDEFIX图有了基本的了解,特别是在自己绘制IDEFIX图时遇到很多困难,通过种种试验和讲解,我有了以下的总结感想:
1、实体间的关系一般有一对一,一对多,多对多三种,而不同的关系在IDEFIX图中各自的表达方式也不同。具体分为一对多直接用关系连接,而多对多关系中间要通过一个联系来连接。
公司和车队是一对多的关系,由公司指向车队一对多,公司号作为车队属性的外件。
车队分别和车辆及司机均为一对多的关系,由车队分别指向车辆和司机一对多。
车辆和维修公司是多对多的关系,由维修这个联系来连接,其主件为车辆号和维修公司号,车辆和维修公司两个实体分别以一对多的形式指向维修表。
根据题意,车辆和司机分别在不同的保险公司投保,即每个保险公司只能有一个司机或一辆车投保,因此车辆和司机分别和保险公司是一对多的关系,由车辆和司机指向保险公司一对多。
2、在表达一对多关系时,关系圆点指向多的一方。而对于一对一的关系,也可以直接将其中一个实体加入另一个实体的属性里,表达出一对一的唯一关系。
3、在多对多的关系中,双方实体不要添加重复的相关属性,以免造成数据累赘。
3、在考虑诸如订单,进货之类的事件时,一定要考虑到可能会出现重复而导致无法输入数据的情况,一般加上订单编号之类的属性能避免重复导致异常。
产品和仓位之间是多对多的关系,由入库这个联系来连接,其主件为产品编号和仓位号,产品和仓位两个实体分别以一对多的形式指向入库表。
车间和仓位是一对多的关系,由车间指向仓位一对多,车间号作为仓位属性的外件。
产品,销售员和客户三者之间的关系是多对多,中间由订单这个联系来连接,其主件为产品编号,销售员编号和客户编号,三个实体分别以一对多的形式指向订单表。
实验日期
2013/10/21
姓名
学号
实验成绩
实验名称
应用Visio建立ER模型
实
验
目
的
1、掌握数据库的分析和设计步骤及方法。
2、掌握数据库概念模型ER图的绘制方法。
3、掌握ER图转换为关系的方法和关系分析方法。
实
验
条
件
1、计算机操作系统要求在Windows XP以上。
2、并要求软件Microsoft office Visio 2003及其以后版本。
系与专业之间是一对多的关系,由系指向专业一对多,系编号作为专业属性的外件。
系与宿舍区之间也是一对多的关系,由宿舍指向系一对多,因为一个系只能住同一宿舍区,但一个宿舍区可以有多个专业的学生住。
专业与班级之间是一对多的关系,由专业指向班级一对多,专业编号作为班级属性的外件。
班级与学生之间也是一对多的关系,由班级指向学生一对多,班级号作为学生属性的外件。
实
验
内
容
1、根据课后习题6.2---6.9,对题目进行理解和分析。
2、用Visio绘制,设计出ER模型。
3、对实验结果进行记录,并形成完整的实验报告。
实
验
步
骤
及
结
果
步骤一打开Visio,指向“数据库模型图”;
步骤二在“数据库”菜单上,在“选项”中选择“文档”,选择“IDEFIX”;
步骤三在“文件”菜单上,选择“页面设置”,指向“横向”;
职工的属性有姓名,性别,月薪,聘期;商店的属性有地址和商店名;商品的属性有规格,单价和商品名。
6.3:图如下
解答思路:
本体有三个实体,分别是公司,仓库,职工,其主件分别为公司编号、仓库编号和职工编号,各关系如下:
公司和仓库是一对多的关系,由公司指向仓库一对多,公司编号作为仓库属性的外件。
仓库和职工也是一对多的关系,由仓库指向职工一对多,仓库编号作为职工属性的外件。
学生与学会之间是多对多的关系,由参加这个联系来连接,其主件为学号和学会编号。学生与学会这两个实体分别以一对多的形式指向参加表。
系的属性有系名和人数;专业的属性有专业名称;班级的属性有班级人数;学生的属性有姓名和性别;学会的属性有人数和地址;宿舍区的属性有地址和宿舍人数。
6.8:图如下
答题思路:
本体共有五个实体,分别为产品,仓位,车间,销售员和客户,主件分别为产品编号,仓位号,车间号,销售员编号和客户编号。各关系如下:
公司的属性有公司名和地址;仓库的属性有仓库名和地址;职工的属性有姓名,性别,聘期和工资。
6.5:图如下
解答思路:
本体有三个实体,分别为代表团,运动员和比赛项目,各自的主件分别为代表团编号,运动员编号,项目编号。各关系如下:
代表团与运动员之间为一对多的关系,由代表团指向运动员一对多,代表团编号作为运动员属性的外件。
公司分别和仓库及连锁商店均是一对多的关系,由公司分别指向仓库和连锁商店一对多,公司编号作为外件。
仓库和业务员是多对多的关系,由进货这个联系来连接,其主件为仓库编号和业务员编号,仓库和业务员两个实体分别以一对多的形式指向进货表。
连锁商店与收银员是一对多的关系,由连锁商店指向收银员一对多。由于一个连锁商店只有一个经理,所以讲经理作为连锁商店的属性放入属性表中。
步骤四依次解答各题
6.2:图如下
解答思路:
该题共有三个实体,分别为:职工、商店、商品,它们的主件分别为职工编号,商店编号和商品编号。三者关系如下:
职工和商店之间是一对多的关系,由商店指向职工一对多,商店编号作为职工属性里的外件。
商店与商品是多对多的关系,中间通过销售这个联系连接,商店和商品两个实体都分别用一对多的形式指向销售表,而销售的主件就为商店编号和商品编号。
连锁商店与商品是多对多的关系,由销售这个联系来连接,其主件为商店编号和商品编号,连锁商店和商品分别以一对多的形式指向销售表。
商品与销售价格是多对多的关系,由标价这个联系来连接,其主件为商品编号和价格,商品和销售价格分别以一对多的形式指向标价表。
各实体的属性如上表所示。
6.7:图如下
解答思路:
本体有六个实体,分别为系、专业、班级、学生、学会和宿舍区,个实体主件分别为系编号,专业编号,班号,学号,学会编号和宿舍区号。各关系如下:
4、碰到价格之类的因素,有可能会出现前后价格不统一而导致整个数据库出现问题的情况,可以加上参考价格和实际价格来加以区分。
5、在实体之间关系复杂时要仔细思考每个实体的特点及题意,一步步确定它们之间的关系,综合考虑制成图。
6、在制图时要在不违背常理和题意的基础上,遵循越简单越好的原则,这样可以节省空间,减少不必要的数据维护,时整个数据看起来不至于冗杂。
产品,客户和仓位三者之间也是多对多关系,中间由出库这个联系来连接,其主件为产品编号,客户编号和仓位号,三个实体分别以一对多的形式指向出库表。
各实体的属性如上表所示。
6.9:图如下
解答思路:
根据题意,本题共有六个实体,分别为公司,车队,车辆,司机,保险公司和维修公司,主件分别为公司号,车队号,车辆号,司机编号,保险公司号和维修公司号。各实体之间关系如下: