DataService-操作手册
DATA SERVER 功能
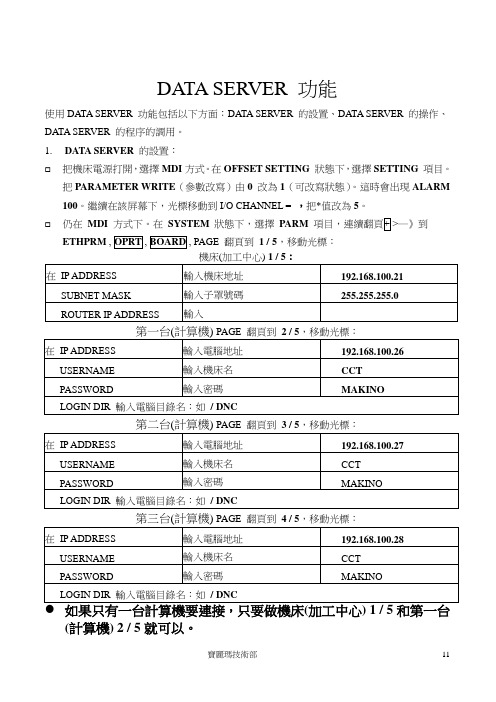
DATA SERVER 功能使用DATA SERVER 功能包括以下方面:DATA SERVER 的設置、DATA SERVER 的操作、DATA SERVER 的程序的調用。
1.DATA SERVER的設置:☐把機床電源打開,選擇MDI方式。
在OFFSET SETTING狀態下,選擇SETTING項目。
把PARAMETER WRITE(參數改寫)由0 改為1(可改寫狀態)。
這時會出現ALARM 100。
繼續在該屏幕下,光標移動到I/O CHANNEL = ,把*值改為5。
☐仍在MDI方式下。
在SYSTEM狀態下,選擇PARM─》到ETHPRM, PAGE 翻頁到1 / 5,移動光標:PAGE 翻頁到 3 / 5,移動光標:PAGE 翻頁到 4 / 5,移動光標:(計算機) 2 / 5就可以。
●●●●至此,DATA SERVER 參數設置完畢。
返回到OFFSET SETTING,選擇SETTING項目,把PARAMETER WRITE(參數改寫)由1改為0。
關機再開機即可執行DATA SERVER 操作。
2.選擇使用計算機的方法,在EDITOR模式─》PROG─》─》按上下鍵,選擇使用2 / 5 ,3 / 5 ,4 / 5的計算機就可以,一般用第一台(計算機) 2 / 5就可以。
3.DATA SERVER 為屏幕字母所對應的軟鍵)●GET命令(從電腦HOST PC 到機床DATA SERVER 傳輸程序)EDITOR模式─》PROG ─》輸入程式名字xxxx,Oxxxx(xxxx電腦程式名,Oxxxx轉入DATA SERVER 后的程式名)COMPLETE●DELETE命令(從機床HD-DIR 的FILE刪除)EDITOR模式─》PROG─》─》XXXX─》COMPLETE●PUT命令(從機床DATA SERVER到電腦HOST PC傳輸程序)EDITOR模式─》PROG─》─》XXXX─》COMPLETE4.DATA SERVER程式的調用DATA SERVER(160Mb)調用(加工程式大于32K)先查看DATA SERVER 程式,EDITOR模式─》PROG─》─》查看需要的加工程式,然後查看子程式調用程式;EDITOR模式─》PROG─》─》輸入O2001(CALL SUB如果沒有該程式,則建立一個以下的程式;EDITOR模式─》PROG─》─》輸入O2001 INSERT,再輸入EOB,INSERT,再輸入以下程式。
DATASEVER

FANUC DATA SEVER 安装方式一、 F ANUC 系统参数设定:1.P20 = 5 ;I/O CHANNEL = DATA SERVER I/O DEVICE2.P900 # 0 = 0 ;DATA SERVER AVAILABLE3.P911 = 64 ;“ @ ”4.P912 = 58 ;“ : ”5.P913 = 47 ;“ / ”6.P914 = 92 ;“ ¥ ”7.P915 = 45 ;“ ˉ ”8.P916 = 95 ;“ ─ ”二、 进入DATA SERVER 设定画面方式:1.进入SYSTEM →DS-SET 画面方式:将模式( MODE )切换到MDI功能键↓软键 ►↓一直按出现画面的软键↓选择2.设定画面:( HOST COMPUTER ):IP ADDRESS :PC 在网络的地址。
例如:128.8.220.200USER NAME :进入DATA SERVER 的使用者帐号(以使用者为) 例如:AWEAPASSWORD :进入DATA SERVER 的密码。
在尚未储存前,PASSWORD 值会显示出来,且随时可覆盖。
HOST DIRECTORY :PC 侧与DATA SERVER 相连的工作目录。
例如:“\USER ”(以使用者为主)( DATA SERVER ):MAC ADDRESS :DATA SERVER 上有ADR 号码例如:08001902EC23(每个号码须依据DATA SERVER 上的卡号设定) IP ADDRESS :DATA SERVER 在网络的地址例如:120.8.220.119(前三个数字须一样,末尾数字须不一样) MASK ADDRESS :网络掩码设定:255.255.255.03.设定操作模式:MODE 切换至MDI 模式,按功能键SYSTEM ,按下屏幕右方软键►,向右翻页再按下屏幕下方的灰色软键 ( [STRING] [LOCK] [INPUT] [CHECK] [SET]A .用游标上下移动所要输入设定值的地址,输入完后按屏幕下方灰色软键[INPUT],按下INPUT 后设定值会闪烁,此时按屏幕下方灰色软键[SET] 后设定值不再闪烁,表示输入完成。
DataService-操作手册

DataService-操作手册DataServices培训总结-操作手册目录一、DS简介 ........ 错误!未定义书签。
二、DS数据加载方式 (5)三、DS进行数据抽取模型开发的基本过程 (6)四、DS创建数据源系统和目标系统的数据存储 (7)1、Oracl e数据库作为数据源系统.. 72、ECC作为数据源系统 (7)3、HANA数据库作为目标系统 (8)五、全量加载过程 (9)1、创建Project和Job (9)2、导入源表的元数据到资源库 (9)3、创建Data Flow (10)4、设置源表和目标表 (10)5、手工执行Job (12)六、基于表比较的增量加载 (12)1、在Job下定义工作流 (12)2、在工作流中定义数据流 (13)3、加入Table_Comparison控件.. 134、设置Table_Comparison控件.. 14七、基于时间戳的增量加载 (15)1、在Job下定义工作流 (15)2、定义Script控件 (15)3、定义处理新增数据的数据流和处理更新数据的数据流 (16)八、DS中常用控件介绍 (18)1、Key_Generation (18)2、Case (19)3、Merge (20)4、Validation (21)5、设置过滤器和断点 (22)九、定义Job定期执行 (23)1、登录Data Services ManagementConsole (23)2、定义Batch Job Schedules (24)十、其他注意事项 (26)据映射,转换和控制逻辑的数据管理应用程序,创建包含工作流(作业执行定义)和数据流(数据转换定义)的应用程序◆R epository:应用程序设计器使用的本地资源库用来存储Data Services对象(如项目,作业,工作流,和数据流)的定义和源和目标的元数据◆J ob server:作业服务器启动数据移动的从多个不同种类的源集成数据的引擎,执行复杂的数据转换,并管理从ERP系统和其他源的抽取和事务二、DS数据加载方式◆全量加载◆增量上载a)基于表比较作业在执行时读取数据源和目标中的全部数据,在服务器的内存中进行比较,计算数据差异b)时间戳增量需要在数据源中添加时间戳字段,一般为创建时间和最后修改时间,在抽取作业中定义对两个时间戳字段进行对比,符合条件的创建时间条目进行插入,符合条件的修改时间条目进行更新c)利用数据库CDC(changed data capture)首先需要开启数据库的CDC服务,为数据库实例启用CDC功能,为源表启用CDC功能。
DataService-操作手册

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
DataServer 程序使用说明

Mdsplus-Matlab接口说明与使用IDL 是the Interactive Data Language的简写,一般的可以用命令行界面完成一定的功能。
IDL用户可以通过设定FILE→PREFERENCES→PATH,加入C:\PROGRAME FILE\MDSPLUS\IDL这个路径,并激活之,那么就可以读写MDSPLUS的数据了。
1、路径设置与要求:(1)安装了java(2)安装了mdsplus(参见mdsplus安装说明)(3)安装了IDL(4)在IDL的path参数设置中加入../mdsplus/idl,“..”是mdsplus安装路径。
2、2、接口函数:(1)mdsconnect(para): connect to server(2)[a,b]=mdsopen(tree,shot): open tree(3)[a,status]=mdsvalue(signal path or tag): retrieve data (see next slide)(4)mdsput(node,d1): put 1D data into treemdsput(node,exp,d1,d2,d3…): put mD data into tree(5)mdssetdefault: change current location in open tree(6)mdsgetmsg: print MDSplus error message corresponding to status code(7)mdstcl: direct tree access/editing(8)mdsclose: close tree(9)mdsdisconnect: disconnect from server3、举例说明:(1)访问EAST数据(普通只需如下基本功能)IDL> mdsconnect,’’IDL> mdsopen,’east’,60000IDL> y=mdsvalue('\ip'), or y=mdsvalue('\east’)IDL> x=mdsvalue('dim_of(\ip)')IDL> plot,x,yIDL> mdstcl,'set tree main/shot = -1'IDL> mdstcl,'dir'IDL> mdstcl,'decompile :device'IDL> mdstcl,'set def .ufiles'IDL> mdstcl,'dir'IDL>mdsclose(2)访问CMOD数据(特殊用户需要更多如下功能)IDL> mdsconnect,’’IDL> mdsopen,'cmod',1000531010IDL> y=mdsvalue('\magnetics::ip')IDL> x=mdsvalue('dim_of(\magnetics::ip)')IDL> plot,x,yIDL> x=mdsvalue('getnci("***","NID_NUMBER")') ; Find out how many nodes IDL> x=mdsvalue("getnci(\magnetics::ip,'FULLPATH')") ; Find full path of ip IDL> x=mdsvalue('getnci("***","NID_NUMBER","SIGNAL")') ; find out how many signal nodesIDL> units=mdsvalue('units_of(\magnetics::ip)')IDL> print,unitsampereIDL> print,mdsvalue('decompile(`getnci(\magnetics::ip,"RECORD"))')Build_Signal(Build_With_Units(\MAGNETICS::MAG_ROGOWSKI.SIGNALS:RO G_CD + 3000F0 * \MAGNETICS::BTOR, "ampere"), *, DIM_OF(\MAGNETICS::BTOR))IDL> y=mdsvalue('\MAGNETICS::MAG_HARDWARE:TR16_3:INPUT_15') IDL> plot,yIDL>y=mdsvalue('raw_of(\MAGNETICS::MAG_HARDWARE:TR16_3:INPUT_15) ')IDL> plot,yIDL>print,mdsvalue('units_of(\MAGNETICS::MAG_HARDWARE:TR16_3:INPUT _15)')voltsIDL>print,mdsvalue('units_of(raw_of(\MAGNETICS::MAG_HARDWARE:TR16_3: INPUT_15))')countsIDL>print,mdsvalue('decompile(`getnci(\magnetics::ip,"RECORD"))')Build_Signal(Build_With_Units(\MAGNETICS::MAG_ROGOWSKI.SIGNALS:RO G_CD + 3000F0 * \MAGNETICS::BTOR, "ampere"), *, DIM_OF(\MAGNETICS::BTOR))IDL>print,mdsvalue('getnci(\MAGNETICS::MAG_ROGOWSKI.SIGNALS:ROG_C D,"FULLPATH")')IDL>print,mdsvalue('decompile(`getnci(\magnetics::MAG_ROGOWSKI.SIGNALS: ROG_CD,"RECORD"))')Build_With_Units(\MAGNETICS::MAG_HARDWARE:TR16_1:INPUT_09 * 1063.18F3, "ampere")IDL>print,mdsvalue('getnci(\MAGNETICS::MAG_HARDWARE:TR16_1:INPUT_0 9,"FULLPATH")')IDL>print,mdsvalue('decompile(`getnci(\magnetics::MAG_ROGOWSKI.SIGNALS: ROG_C,"RECORD"))',status=s)% MDSV ALUE: Error evaluating expression*IDL> print,s265388144IDL> print,mdsvalue('getmsg($)',s)TreeNNF : Node Not FoundIDL>y=mdsgetmsg(s)IDL>print,yTreeNNF : Node Not FoundIDL> mdscloseIDL> mdsopen,'main',-1IDL> mdsput,'signal','sind(1:1000)'IDL> plot,mdsvalue('signal')IDL> mdscloseIDL> mdstcl,'set tree main/shot=-1'IDL> mdstcl,'dir'IDL> mdstcl,'decompile :device'IDL> mdstcl,'set def .ufiles'IDL> mdstcl,'dir'IDL>mdsclose4、附一个英文使用说明Accessing MDSplus / MDS- Data with IDLTo access MDSplus and/or MDS- data, you must either be on a data server node, or have MDSplus installed on your "client" computer (click here for MDSplus installation information).For any errors, go here. (Browser back arrow to return.)Quick IDL Examples for Specific Experiments:Using Generic MDSplus IDL Routines•HIT•TIP•ZaP•TCSUsing UW IDL Library Routines•HIT•TIP•ZaP•TCSBasic Format for IDL Data Read (Site Independent):1.If not on a data server"connect" to it with mdsconnect(only needsto be done once per IDL session)2.Open the shot file with mdsopen3.Read the data with mdsvalue4.Continue reading data with mdsvalue5.Open other shots with mdsopen6.Read more data with mdsvalue, etc.General Examples:(Commands you type are in color, any comments appear after the ";".)To access data, you need to either be on the data server node or "connect" to it with the mdsconnect command (this only needs to be done once per IDL session, you can put this in your idl_startup procedure):IDL> mdsconnect, 'name_of_data_server'To read MDSplus data:Next open the shot with mdsopen:IDL> mdsopen, 'tree_name', shot_numberFinally, read your data with mdsvalue:IDL> y = mdsvalue('node_name')IDL> y = mdsvalue('dim_of(node_name)')For MDSplus, shot number 0 (zero) is the most recent shot.To read MDS- data (note use of quotes):IDL> y = mdsvalue('mdsv1("tree_name",*,shot_number,"data_name")')For MDS-, shot number -1 (minus one) is the most recent shot.Quick IDL Examples for Specific Experiments:In the following examples, use the data server and tree name appropriate to your dataExample IDL scripts are given. You could cut and paste them to the IDL command line or download and execute them with the "@" command, e.g.:IDL> @hitexampleQuick HIT IDL Example:Example: hitexample.proIDL> ; connect to serverIDL> mdsopen,'hitdata', 0 ; open most recent shotIDL> y = mdsvalue('\i_p'); read plasma currentIDL> t = mdsvalue('dim_of(\i_p)') ; read plasma current timebaseQuick TIP IDL Example:Example: tipexample.proIDL> ; connect to serverIDL> mdsopen,'tipdata', 0 ; open most recent shotIDL> y = mdsvalue('\det1'); read detector 1 dataIDL> t = mdsvalue('dim_of(\det1)') ; read detector 1 timebaseQuick ZaP IDL Example:Example: zapexample.proIDL> ; connect to serverIDL> mdsopen,'zapmain', 0 ; open most recent shotIDL> y = mdsvalue('\i_p'); read plasma currentIDL> t = mdsvalue('dim_of(\i_p)') ; read plasma current timebaseQuick TCS IDL Example: (NOTE THIS IS FOR MDS- DATA)Example: tcsexample.proIDL> ; connect to serverIDL> y = mdsvalue('mdsv1("TCSDAT",*,-1,"S.XFT16")'); read data (latest shot)IDL> t = mdsvalue('mdsv1("TCSDAT",*,-1,"S.XFT16_TM")') ; read timebase Quick IDL Examples Using UW IDL Routines:IMPORTANT NOTE:These routines will look for the environment variable "idl_treename" to use for opening the MDSplus tree. This will default to "HITDATA" if the environment variable "idl_treename"is undefined.STRONG SUGGESTION:Put this line in your idl_startup file, (or set it up manually in your login file).setenv,'idl_treename=XXXXX'where "XXXXX" is HITDATA (default), TIPDATA, ZAPMAIN, TCSDAT, etc.Data Servers:In the following examples, use the data server and tree name appropriate to your dataAccessing Version Controlled UW IDL Libraries:You will need to have the UW IDL libraries in your IDL path.Accessing Non-Version Controlled UW IDL Libraries:The UW IDL libraries are also available from cvs (see your system manager for details) or as a zip file by clicking here.MDS- IDL Routine Compatibility:Several of the MDS- IDL routines have been ported to MDSplus, including data, get_shot, set_shot, and (coming soon) units.Example Scripts Using UW IDL Routines:Example IDL scripts are given. You could cut and paste them to the IDL command line or download and execute them with the "@" command, e.g.:IDL> @uwhitexampleQuick HIT UW IDL Example:Example: uwhitexample.proIDL> ; connect to server[IDL> setenv,'idl_treename=hitdata' ; set treename to HITDATA: This is the DEFAULT, this line OPTIONAL]IDL> ss,0 ; open most recent shotIDL> y=data('\i_p',timebase=t) ; read plasma current and timebaseQuick TIP UW IDL Example:Example: uwtipexample.proIDL> ; connect to serverIDL> setenv,'idl_treename=tipdata' ; set treename to TIPDATAIDL> ss,0 ; open most recent shotIDL> y=data('\det1',timebase=t) ; read DET1 and timebaseQuick ZaP UW IDL Example:Example: uwzapexample.proIDL> ; connect to serverIDL> setenv,'idl_treename=zapmain' ; set treename to ZAPMAINIDL> ss,0 ; open most recent shotIDL> y=data('\det1',timebase=t) ; read DET1 and timebaseQuick TCS UW IDL Example:Example: uwtcsexample.proIDL> ; connect to serverIDL> setenv,'idl_treename=tcsdat' ; set treename to TCSDAT IDL> ss,0 ; open most recent shotIDL> y=data('s.xft16',timebase=t) ; read XFT16 and timebase。
DataService操作手册

DataServices培训总结-操作手册目录一、DS简介 ................................................二、DS数据加载方式 ........................................三、DS进行数据抽取模型开发的基本过程 ......................四、DS创建数据源系统和目标系统的数据存储 ..................1、Oracle数据库作为数据源系统..........................2、ECC作为数据源系统 ..................................3、HANA数据库作为目标系统 .............................五、全量加载过程...........................................1、创建Project和Job ..................................2、导入源表的元数据到资源库............................3、创建Data Flow ......................................4、设置源表和目标表....................................5、手工执行Job ........................................六、基于表比较的增量加载...................................1、在Job下定义工作流..................................2、在工作流中定义数据流................................3、加入Table_Comparison控件...........................4、设置Table_Comparison控件...........................七、基于时间戳的增量加载...................................1、在Job下定义工作流..................................2、定义Script控件.....................................3、定义处理新增数据的数据流和处理更新数据的数据流......八、DS中常用控件介绍 ......................................1、Key_Generation......................................2、Case................................................3、Merge...............................................4、Validation..........................................5、设置过滤器和断点....................................九、定义Job定期执行.......................................1、登录Data Services Management Console ...............2、定义Batch Job Schedules ............................十、其他注意事项...........................................一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
DataService操作手册

DataServices培训总结-操作手册目录一、DS简介 ................................................二、DS数据加载方式 ........................................三、DS进行数据抽取模型开发的基本过程......................四、DS创建数据源系统和目标系统的数据存储..................1、Oracle数据库作为数据源系统..........................2、ECC作为数据源系统 ..................................3、HANA数据库作为目标系统 .............................五、全量加载过程...........................................1、创建Project和Job ..................................2、导入源表的元数据到资源库............................3、创建Data Flow ......................................4、设置源表和目标表....................................5、手工执行Job ........................................六、基于表比较的增量加载...................................1、在Job下定义工作流..................................2、在工作流中定义数据流................................3、加入Table_Comparison控件...........................4、设置Table_Comparison控件...........................七、基于时间戳的增量加载...................................1、在Job下定义工作流..................................2、定义Script控件.....................................3、定义处理新增数据的数据流和处理更新数据的数据流......八、DS中常用控件介绍 ......................................1、Key_Generation......................................2、Case................................................3、Merge...............................................4、Validation..........................................5、设置过滤器和断点....................................九、定义Job定期执行.......................................1、登录Data Services Management Console...............2、定义Batch Job Schedules ............................十、其他注意事项...........................................一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
DataService操作手册

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
DataService-操作手册

DataServices培训总结-操作手册目录一、DS简介 (3)二、DS数据加载方式 (4)三、DS进行数据抽取模型开发的基本过程 (5)四、DS创建数据源系统和目标系统的数据存储 (6)1、Oracle数据库作为数据源系统 (6)2、ECC作为数据源系统 (6)3、HANA数据库作为目标系统 (7)五、全量加载过程 (8)1、创建Project和Job (8)2、导入源表的元数据到资源库 (8)3、创建Data Flow (8)4、设置源表和目标表 (9)5、手工执行Job (10)六、基于表比较的增量加载 (11)1、在Job下定义工作流 (11)页脚内容12、在工作流中定义数据流 (11)3、加入Table_Comparison控件 (12)4、设置Table_Comparison控件 (13)七、基于时间戳的增量加载 (13)1、在Job下定义工作流 (13)2、定义Script控件 (14)3、定义处理新增数据的数据流和处理更新数据的数据流 (15)八、DS中常用控件介绍 (16)1、Key_Generation (16)2、Case (17)3、Merge (18)4、Validation (19)5、设置过滤器和断点 (20)九、定义Job定期执行 (21)1、登录Data Services Management Console (21)2、定义Batch Job Schedules (22)十、其他注意事项 (24)页脚内容2一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行页脚内容3Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
DataService操作手册

DataServices培训总结-操作手册目录一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采纳数据批量处置的方式,按期执行后台作业,将数据从多个业务系统中抽掏出来,并进行必要的处置(转换,归并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:治理操纵台是网页版DS治理工具,能够进行一些系统配置和概念Job执行◆Designer:Designer是一个具有易于利用的图形用户界面的开发工具。
它许诺开发人员定义包括数据映射,转换和操纵逻辑的数据治理应用程序,创建包括工作流(作业执行概念)和数据流(数据转换概念)的应用程序◆Repository:应用程序设计器利用的本地资源库用来存储Data Services对象(如项目,作业,工作流,和数据流)的概念和源和目标的元数据◆Job server:作业效劳器启动数据移动的从多个不同种类的源集成数据的引擎,执行复杂的数据转换,并治理从ERP系统和其他源的抽取和事务二、DS数据加载方式◆全量加载◆增量上载a)基于表比较作业在执行时读取数据源和目标中的全数数据,在效劳器的内存中进行比较,计算数据不同b)时刻戳增量需要在数据源中添加时刻戳字段,一样为创建时刻和最后修改时刻,在抽取作业中概念对两个时刻戳字段进行对照,符合条件的创建时刻条款进行插入,符合条件的修改时刻条款进行更新c)利用数据库CDC(changed data capture)第一需要开启数据库的CDC效劳,为数据库实例启用CDC功能,为源表启用CDC功能。
在这种模式下,DS的增量更新再也不直接访问源表,而是在与源表相关的变更记录表中读取增量三、DS进行数据抽取模型开发的大体进程◆为数据源创建数据存储◆导入源表的元数据到资源库◆为SAP HANA目标系统创建数据存储◆新建DS项目和批量作业◆新建DS数据流:概念源表和目标表,概念变量、编辑Query和Map_CDC_Operation ◆执行批量作业四、DS创建数据源系统和目标系统的数据存储1、Oracle数据库作为数据源系统登录Data Services Designer,在本地对象库的数据存储页签中单击鼠标右键,选择新建菜单创建数据存储“EAM_TEST”,在弹出的对话框中输入EAM数据库的连接信息2、ECC作为数据源系统一样在创建DataStore时,输入ECC的连接信息3、HANA数据库作为目标系统在创建DataStore时,输入HANA数据库的连接信息五、全量加载进程1、创建Project和Job在本地对象库的project页签中单击鼠标右键,选择新建菜单,创建项目“ERP_DS”。
SAP DataService-中文操作手册

DataServices培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (2)三、DS进行数据抽取模型开发的基本过程 (3)四、DS创建数据源系统和目标系统的数据存储 (3)1、Oracle数据库作为数据源系统 (3)2、ECC作为数据源系统 (4)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (6)3、创建Data Flow (6)4、设置源表和目标表 (7)5、手工执行Job (7)六、基于表比较的增量加载 (8)1、在Job下定义工作流 (8)2、在工作流中定义数据流 (8)3、加入Table_Comparison控件 (9)4、设置Table_Comparison控件 (9)七、基于时间戳的增量加载 (10)1、在Job下定义工作流 (10)2、定义Script控件 (10)3、定义处理新增数据的数据流和处理更新数据的数据流 (11)八、DS中常用控件介绍 (13)1、Key_Generation (13)2、Case (13)3、Merge (14)4、Validation (15)5、设置过滤器和断点 (15)九、定义Job定期执行 (16)1、登录Data Services Management Console (16)2、定义Batch Job Schedules (17)十、其他注意事项 (18)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:◆Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
data servo 操作步骤使用说明

data servo 操作步骤――基于windows xp系统记得使用Data servo之前计算机必须关闭windows防火墙:关闭防火墙步骤:控制面板――>windows防火墙,选择关闭。
在storage模式下才可以进行ATA卡和NC之间的操作,在FTP模式下才可以进行NC和PC之间的操作,它们之间的操作还和CNC的模式有关,而ATA卡和PC的通讯和CNC的状态无关,也和FTP模式还是存储模式无关。
Data servo只能进行参数,加工程序和刀补螺补的传输操作,梯形图和其余的则不行。
以下以0i-TC,8.4”显示器为例操作一、FTP模式操作步骤:(FTP模式看计算机HOST中的文件)用系统自带....的互联网信息服务器(IIS)来实现连接1.连接步骤计算机侧:(xp系统和2000系统在第三步的处理上稍有差别)1)先检查系统是否安装了IIS软件。
从控制面板――>管理工具,双击管理工具,看其中是否有“Internet信息服务快捷方式”(Internet service manager),若有,跳至3),若没有继续2)安装IIS。
若是2000系统,需要插入光盘安装,若是xp系统,直接控制面板――>添加或删除程序――>添加/删除windows组件,进入之后选定IIS,点亮图框右下方Detail按钮之后,点击Detail按键,进入选择安装FTP servo 选项,OK即可。
安装完之后,点击FINISH键完成安装3)设定IIS。
从控制面板――>管理工具――>Internet 信息服务快捷方式,双击该快捷方式,进入画面,不断双击左侧Internet信息服务栏下方的图标以展开目录树,直到最后一个“默认FTP站点”右键单击“默认FTP站点”项,选择属性。
可以进行相关用户、权限、目录等的设定,设定完之后确认即可。
4) 设定相关的ip地址和子网掩码CNC侧:1)在以太网选项中设定相关的ip地址和子网掩码,保证其中数据服务器的ip地址/子网掩码和计算机设定的一致,而机床(系统)的ip和上述两者不同。
sap data service designer使用

sap data service designer使用下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!SAP数据服务设计师是SAP公司提供的一款数据集成工具,通过它可以方便地实现数据的抽取、转换和加载(ETL)操作。
dataservice操作手册

D a t a S e r v i c e s培训总结-操作手册目录一、DS简介 (2)二、DS数据加载方式 (3)三、DS进行数据抽取模型开发的基本过程 (4)四、DS创建数据源系统和目标系统的数据存储 (4)1、Oracle数据库作为数据源系统 (4)2、ECC作为数据源系统 (5)3、HANA数据库作为目标系统 (5)五、全量加载过程 (5)1、创建Project和Job (5)2、导入源表的元数据到资源库 (5)3、创建Data Flow (5)4、设置源表和目标表 (6)5、手工执行Job (6)六、基于表比较的增量加载 (6)1、在Job下定义工作流 (6)2、在工作流中定义数据流 (6)3、加入Table_Comparison控件 (7)4、设置Table_Comparison控件 (7)七、基于时间戳的增量加载 (7)1、在Job下定义工作流 (7)2、定义Script控件 (7)3、定义处理新增数据的数据流和处理更新数据的数据流8八、DS中常用控件介绍 (9)1、Key_Generation (9)2、Case (9)3、Merge (9)4、Validation (9)5、设置过滤器和断点 (9)九、定义Job定期执行 (10)1、登录Data Services Management Console (10)2、定义Batch Job Schedules (10)十、其他注意事项 (11)一、DS简介SAP BusinessObjects Data Services是通过SAP HANA认证的ETL 工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到HANA数据库中。
DS的组件之间的关系:Management Consol:管理控制台是网页版DS管理工具,可以进行一些系统配置和定义Job执行◆Designer:Designer是一个具有易于使用的图形用户界面的开发工具。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
培训总结-操作手册
目录
一、简介
是通过认证的工具。
采用数据批量处理的方式,定期执行后台作业,将数据从多个业务系统中抽取出来,并进行必要的处理(转换,合并,过滤,清洗),然后再加载到数据库中。
的组件之间的关系:
:
管理控制台是网页版管理工具,可以进行一些系统配置和定义执行
◆:
是一个具有易于使用的图形用户界面的开发工具。
它允许开发人员定义包括数据映射,转换和控制逻辑的数据管理应用程序,创建包含工作流(作业执行定义)和数据流(数据转换定义)的应用程序
◆:
应用程序设计器使用的本地资源库用来存储对象(如项目,作业,工作流,和数据流)的定义和源和目标的元数据
◆:
作业服务器启动数据移动的从多个不同种类的源集成数据的引擎,执行复杂的数据转换,并管理从系统和其他源的抽取和事务
二、数据加载方式
◆全量加载
◆增量上载
a)基于表比较
作业在执行时读取数据源和目标中的全部数据,在服务器的内存中进行比较,计算数据差异
b)时间戳增量
需要在数据源中添加时间戳字段,一般为创建时间和最后修改时间,在抽取作业中定义对两个时间戳字段进行对比,符合条件的创建时间条目进行插入,符合条件的修改时间条目进行更新
c)利用数据库()
首先需要开启数据库的服务,为数据库实例启用功能,为源表启用功能。
在这种模式下,的增量更新不再直接访问源表,而是在与源表相关的变更记录表中读取增量
三、进行数据抽取模型开发的基本过程
◆为数据源创建数据存储
◆导入源表的元数据到资源库
◆为目标系统创建数据存储
◆新建项目和批量作业
◆新建数据流:定义源表和目标表,定义变量、编辑和
◆执行批量作业
四、创建数据源系统和目标系统的数据存储
1、数据库作为数据源系统
登录,在本地对象库的数据存储页签中单击鼠标右键,选择新建菜单
创建数据存储“”,在弹出的对话框中输入数据库的连接信息
2、作为数据源系统
同样在创建时,输入的连接信息
3、数据库作为目标系统
在创建时,输入数据库的连接信息
五、全量加载过程
1、创建和
在本地对象库的页签中单击鼠标右键,选择新建菜单,创建项目“”。
双击该项目,在“”,可以在该项目下创建
2、导入源表的元数据到资源库
在本地对象库的数据存储页签中,选择源系统的数据存储,单击鼠标邮件,选择“”,输入需要导入到资源库的表名称。
导入成功后,在数据存储的目录下可以看到导入的表
3、创建
单击“”,在右边空白区域单击鼠标邮件,选择“”-“”
4、设置源表和目标表
单击创建的,将需要导入到数据库中的源表拖入到区域中,将区域右侧的工具条中的模版表拖入区域创建模版表
输入模版表名称、目标系统的数据存储、数据库存放抽取数据表的用户名。
连接源表和目标表
双击模版表,设置“”中的“”
5、手工执行
选择,单击鼠标右键,选择“”
执行成功之后,在数据库中的下可以看到“T161T”,可以查看数据表的内容。
执行过程信息和结果可以在监控器中查看。
六、基于表比较的增量加载
1、在下定义工作流
2、在工作流中定义数据流
在数据流中定义源表和模版表,执行,执行成功之后,在目标系统数据存储的目录下可以看到创建的模版表
3、加入控件
选择模版表,单击鼠标邮件,选择“”。
模版表会更新为目录下的数据表。
通过将转换-数据集成中的“”控件拖入到数据流中的方式添加“”控件
将源表连接“”控件,“”控件连接目标表。
4、设置控件
双击“”控件,设置相关参数:比较的目标表、表的主键,需要比较的字段。
当需要比较的字段为空时,会比较所有字段。
建议按照需要填写需要比较的字段,可以加快处理速度。
保存后执行。
七、基于时间戳的增量加载
1、在下定义工作流
在工作流中定义控件,读取数据抽取后最新的创建时间和更改时间,定义一个处理新增数据的数据流和一个处理更新数据的数据流
2、定义控件
在控件中需要使用变量存放读取的最新的创建时间和最新的更改时间。
选择,在工具栏选择“”按钮,创建全局变量
双击“”控件,编写语句,从数据库表中读取最新的创建时间和更改时间
3、定义处理新增数据的数据流和处理更新数据的数据流
双击“”数据流,加载源表,,控件和目标表
双击,在输出字段中增加“”和“”两个字段。
“”字段使用函数()进行赋值,“”赋值为‘I’
在中设置条件
双击控件,设置
同样的方式定义“”数据流,在的条件中定义为
在的数据结果中增加“”和“”两个字段。
“”字段使用函数()进行赋值,“”赋值为‘U’
保存后,执行。
可以通过修改源系统数据测试基于时间戳的增量加载。
八、中常用控件介绍
1、
在源表基础上为目标表重新生成主键
在中增加“”字段,赋值为0。
在控件中设置目标表、主键字段、主键值增加量
2、
将源表根据规则进行拆分
双击控件,设置拆分条件
当 = 1时,输出1,当 =2时,输出2
3、
将具有同样数据结构的源表进行合并
在中增加输出字段,赋值为1。
在1中增加输出字段,赋值为2。
在中将两个表的内容合并输出。
4、
提取数据源表中的正确数据,将错误数据单独存放在其他表中
双击控件,设置“”
5、设置过滤器和断点
过滤器和断点结合使用,用于设置的条件
选择源表到目标表的连接线,单击鼠标右键,选择,设置条件(当满足某种条件时进入断点,或者在满足过滤条件的同时执行多少条数据后时进入断点)
选择,单击鼠标右键,选择
工具栏上的按钮可以控制执行下一条数据、继续执行、终止
过程中进入断点后,可以一次查看数据加载结果
九、定义定期执行
1、登录
单击工具栏的“”按钮
进入的登录界面
单击进入界面
2、定义
在页签选择
进入批量执行的设置界面
可以设置每周的某一天执行(一周执行一次)或则每月的某一天执行(一个月执行一次),也可以设置为每天都执行。
都选“”则会定期循环执行,否则只执行一次。
可以设置一天执行一次,也可以一天执行多次,设置开始执行时间。
上图中如果设置为一天多次执行,开始时间为上午1点,持续时间为600分钟,间隔时间为360分钟,则会在一天的上午1点和上午6点各执行一次。
如果设置时间间隔为240分钟,则会在一天的上午1点、上午5点和上午9点各执行一次。
(总持续时间不超过10小时)。
十、其他注意事项
1、客户端安装包需要注意和服务器版本一致
2、在第一次登录信息时,无法成功。
也失败,需要在文件
中添加对应的地址和域名
3、连接数据库作为数据源时,需要在客户端上安装客户端,
设置文件,设置环境变量之后重启服务器;连接数据库时,需要安装客户端
4、在连接作为数据源时,需要开启系统跨客户端编辑权限
5、在中新建作为存放抽取表的,将给赋权限,包括查询和创
建的权限
6、全量抽取时,目标表不能使用导入表,需要使用模版表,
模版表每次会删除重建,导入表会出现主键重复的错误提示7、基于时间戳的增量加载,源表中需要有创建时间和更改时
间两个字段,分别处理新增和修改的数据
8、如果只是设置过滤器而没有设置断点,在进行时,会执行
成功,过滤器有效。
如果不进行,直接执行,设置的过滤器不起作用
21 / 21。