How to configure job scheduler (OpenPBS) for computer cluster
HPC作业调度系统openPBS说明

认的设置就行,这里说一下要注意的几个选项。 --enable-docs 这个选项是用来安装 PBS 的文档的,默认是 disable 的。 --enable-debug 这个选项允许 PBS 进行 debug,默认也是 disable 的。 --set-default-server=your_server_name,指定默认的 server --set-server-home=your_pbs_Home_path, 指 定 PBS_HOME 的 路 径 , 默 认 是 在 /usr/spool/PBS
openpbs 的安装及使用
【一】 简介 PBS是Portable Batch System的简称,是一个管理任务和计算机资源的系统。它能接受由shell
脚本和控制属性组成的任务,并且保存任务直到任务被运行,运行完任务后会把结果送回提交作 业的用户。
openpbs就是开源可以免费使用的PBS。 openpbs既可以运行在单机系统上,也可以运行在机群上,适应性很强。
set queue medium max_running = 10 set queue medium resources_max.cput = 02:00:00 set queue medium resources_min.cput = 00:20:01 set queue medium resources_default.cput = 02:00:00 set queue medium enabled = True set queue medium started = True # # Create and define queue small # create queue small set queue small queue_type = Execution set queue small Priority = 100 set queue small max_running = 10 set queue small resources_max.cput = 00:20:00 set queue small resources_default.cput = 00:20:00 set queue small enabled = True set queue small started = True # # Create and define queue default # create queue default set queue default queue_type = Route set queue default max_running = 10 set queue default route_destinations = small set queue default route_destinations += medium set queue default route_destinations += long set queue default route_destinations += verylong set queue default enabled = True set queue default started = True # # Set server attributes. # set server scheduling = True set server max_user_run = 6 set server acl_host_enable = True set server acl_hosts = * set server default_queue = default set server log_events = 63 set server mail_from = adm set server query_other_jobs = True set server resources_default.cput = 01:00:00 set server resources_default.neednodes = 1 set server resources_default.nodect = 1 set server resources_default.nodes = 1
曙光作业管理-调度系统安装配置手册

Torque + Maui配置手册之抛砖引玉篇本文将以应用于实际案例(南航理学院、复旦大学物理系、宁波气象局)中的作业调度系统为例,简单介绍一下免费开源又好用的Torque+Maui如何在曙光服务器上进行安装和配置,以及针对用户特定需求的常用调度策略的设定情况,以便可以起到抛砖引玉的作用,使更多的人关注MAUI这个功能强大的集群调度器(后期将推出SGE+MAUI版本)。
本文中的涉及的软件版本Torque 版本:2.1.7 maui版本:3.2.6p17。
1. 集群资源管理器Torque1.1.从源代码安装Torque其中pbs_server安装在node33上,TORQUE有两个主要的可执行文件,一个是主节点上的pbs_server,一个是计算节点上的pbs_mom,机群中每一个计算节点(node1~node16)都有一个pbs_mom负责与pbs_server通信,告诉pbs_server该节点上的可用资源数以及作业的状态。
机群的NFS共享存储位置为/home,所有用户目录都在该目录下。
1.1.1.解压源文件包在共享目录下解压缩torque# tar -zxf torque-2.1.17.tar.gz假设解压的文件夹名字为: /home/dawning/torque-2.1.71.1.2.编译设置#./configure --enable-docs --with-scp --enable-syslog其中,默认情况下,TORQUE将可执行文件安装在/usr/local/bin和/usr/local/sbin下。
其余的配置文件将安装在/var/spool/torque下默认情况下,TORQUE不安装管理员手册,这里指定要安装。
默认情况下,TORQUE使用rcp来copy数据文件,官方强烈推荐使用scp,所以这里设定--with-scp.默认情况下,TORQUE不允许使用syslog,我们这里使用syslog。
Oracle_BI_Scheduler配置及iBot开发文档
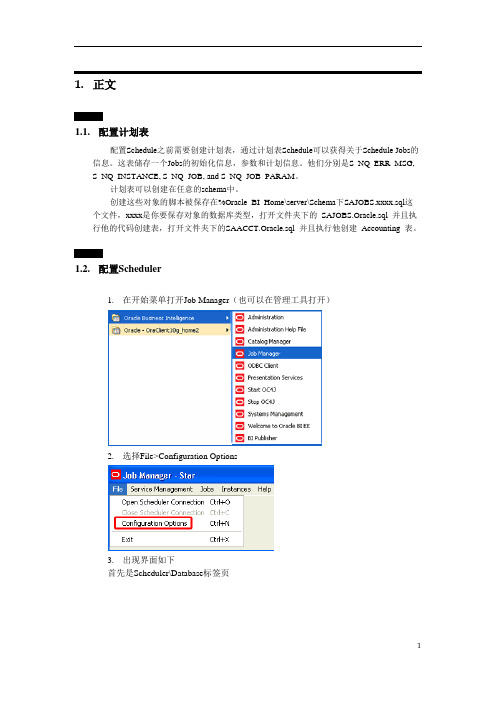
1.正文1.1.配置计划表配置Schedule之前需要创建计划表,通过计划表Schedule可以获得关于Schedule Jobs的信息。
这表储存一个Jobs的初始化信息,参数和计划信息。
他们分别是S_NQ_ERR_MSG, S_NQ_INSTANCE, S_NQ_JOB, and S_NQ_JOB_PARAM。
计划表可以创建在任意的schema中。
创建这些对象的脚本被保存在%Oracle_BI_Home\server\Schema下SAJOBS.xxxx.sql这个文件,xxxx是你要保存对象的数据库类型,打开文件夹下的SAJOBS.Oracle.sql 并且执行他的代码创建表,打开文件夹下的SAACCT.Oracle.sql 并且执行他创建Accounting 表。
1.2.配置Scheduler1.在开始菜单打开Job Manager(也可以在管理工具打开)2.选择File>Configuration Options3.出现界面如下首先是Scheduler\Database标签页其中的数据库和用户名和下面的4个表名是对应的。
这四张表就建在这个数据库的用户下。
下来是General标签页检查一下Scheduler的脚本是不是在那个地址,一般情况下,如果是用默认安装BIEE 的话,就不用改这个地方的地址了,然后设置一下管理员密码。
其实配置到这一步就可以点击OK,Oracle BI Scheduler服务就可以启动了接下来在Mali标签页配置发件人邮箱其中要注意正确设置SMTP服务项。
转到iBots界面,在这个界面只要确认一下Log就可以了最后还有一点配置,添加一段对用户的密码验证文件:打开D:\OracleBIData\web\config\instanceconfig.xml,看有没有一段代码<Alerts><ScheduleServer>localhost</ScheduleServer></Alerts>中间是你的主机名,在它下面添加代码<CredentialStore><CredentialStorage type="file" path="D:\OracleBIData\web\config\credentialstore.xml"/> </CredentialStore>保存后打开命令提示符,执行下面语句cryptotools credstore -add -infile d:/OracleBIData/web/config/credentialstore.xml回车后在alias项输入Admin,回车后提示是否要对文件加密,可以选择N,提示是否替换源文件,选择Y。
如何使用Android的JobScheduler进行后台任务调度

如何使用Android的JobScheduler进行后台任务调度Android的JobScheduler是一个用于调度和管理后台任务的系统服务。
它能够帮助开发者有效地管理应用程序的后台任务,提高应用程序的性能和电池寿命。
本文将介绍如何使用Android的JobScheduler进行后台任务调度。
一、什么是JobSchedulerJobScheduler是Android系统为了更好地管理后台任务而引入的一个系统服务。
通过JobScheduler,开发者可以在特定的条件下执行后台任务,例如设备连接到充电器、设备连接到WiFi网络等。
JobScheduler主要用于解决在Android系统中的后台任务调度问题,以减少对电池寿命和设备性能的影响。
二、如何使用JobScheduler1. 添加依赖库在项目的build.gradle文件中,添加如下依赖库:```groovyimplementation 'com.firebase:firebase-jobdispatcher:0.8.5'```2. 创建JobServiceJobService是一个继承自android.app.job.JobService的抽象类,需要实现抽象方法onStartJob()和onStopJob()。
onStartJob()方法用于执行后台任务,onStopJob()方法用于取消后台任务。
下面是一个示例:```javapublic class MyJobService extends JobService {@Overridepublic boolean onStartJob(JobParameters params) {// 在这里执行后台任务return false;}@Overridepublic boolean onStopJob(JobParameters params) {// 在这里取消后台任务return false;}}```3. 创建Job在应用程序的代码中,创建一个Job实例,指定需要执行的任务细节、执行条件等。
python的scheduler用法

python的scheduler用法scheduler(调度器)是Python中常用的一个模块,可以用于定时执行任务。
它非常适用于一些需要定时执行的操作,例如定时发送电子邮件、定时备份数据、定时爬取网页等。
本文将详细介绍python 的scheduler用法。
一、安装scheduler模块在开始使用scheduler之前,我们需要先安装该模块。
可以使用pip命令在命令行中进行安装,具体命令如下:pip install scheduler二、引入scheduler模块在编写Python代码时,我们需要引入scheduler模块,以便可以使用该模块提供的功能。
引入scheduler模块的代码如下:```pythonimport scheduler三、创建scheduler对象在使用scheduler模块之前,我们需要先创建一个scheduler对象,以便进行后续的任务调度。
创建scheduler对象的代码如下:```pythons=scheduler.scheduler()四、定义任务函数在使用scheduler进行任务调度时,我们需要定义要执行的任务。
可以通过定义函数的方式来实现。
下面是一个示例:```pythondef task():print("执行任务...")五、添加任务在scheduler对象中,我们可以通过调用`add_job`方法来添加任务。
该方法接受两个参数,第一个参数是要执行的函数名称,第二个参数是触发器类型(可以是日期时间、间隔时间等)。
```pythons.add_job(task,'interval',seconds=10)上述代码表示每隔10秒执行一次task函数。
六、开始调度任务在添加完任务后,我们需要调用scheduler对象的`start`方法来开始执行任务调度。
代码如下:```pythons.start()七、结束调度任务如果我们想要手动结束任务调度,可以调用scheduler对象的`shutdown`方法。
调度工具odi使用流程

调度工具odi使用流程英文回答:ODI (Oracle Data Integrator) is a powerful data integration and ETL (Extract, Transform, Load) tool developed by Oracle. It allows users to efficiently manage and execute data integration processes, such as extracting data from various sources, transforming it into a desired format, and loading it into a target system.The process of using ODI typically involves the following steps:1. Designing the Data Integration Process: This involves creating a data integration project in ODI Studio, which is a graphical development environment. In this step, you define the source and target systems, map the data elements between them, and create the necessary transformations and mappings.2. Setting up the Connectivity: ODI supports various types of data sources, such as databases, files, and web services. To connect to these sources, you need toconfigure the necessary connection information, such as the server name, username, password, and port number.3. Defining the Data Flows: Once the connectivity is established, you can define the data flows in ODI Studio. This involves creating mappings, which specify how the data should be transformed from the source to the target. Youcan use ODI's built-in transformation functions, or create custom transformations using SQL or PL/SQL.4. Testing and Debugging: After defining the data flows, it is important to test and debug them to ensure they work as expected. ODI provides various debugging tools, such as data preview, breakpoints, and error handling, to help identify and fix any issues.5. Executing the Data Integration Process: Once thedata flows are tested and debugged, you can execute thedata integration process in ODI. This can be done manuallyor scheduled to run at specific times. ODI provides a scheduling tool called the ODI Scheduler, which allows you to define the execution frequency, dependencies, and other parameters.6. Monitoring and Maintenance: After the data integration process is executed, it is important to monitor its progress and performance. ODI provides various monitoring and logging features, such as real-time status updates, error logs, and performance metrics, to help you track and optimize the data integration process.Overall, ODI is a comprehensive data integration tool that simplifies the process of extracting, transforming, and loading data. It provides a user-friendly interface, powerful transformation capabilities, and robust scheduling and monitoring features. Whether you are a data integration developer or a data analyst, ODI can greatly streamline your data integration workflows.中文回答:ODI(Oracle Data Integrator)是由Oracle开发的一款强大的数据集成和ETL(Extract, Transform, Load)工具。
Python定时任务框架APScheduler详解

Python定时任务框架APScheduler详解APScheduler最近想写个任务调度程序,于是研究了下 Python 中的任务调度⼯具,⽐较有名的是:Celery,RQ,APScheduler。
Celery:⾮常强⼤的分布式任务调度框架RQ:基于Redis的作业队列⼯具APScheduler:⼀款强⼤的任务调度⼯具RQ 参考 Celery,据说要⽐ Celery 轻量级。
在我看来 Celery 和 RQ 太重量级了,需要单独启动进程,并且依赖第三⽅数据库或者缓存,适合嵌⼊到较⼤型的 python 项⽬中。
其次是 Celery 和 RQ ⽬前的最新版本都不⽀持动态的添加定时任务(celery 官⽅不⽀持,可以使⽤第三⽅的或者实现),所以对于⼀般的项⽬推荐⽤ APScheduler,简单⾼效。
Apscheduler是⼀个基于Quartz的python定时任务框架,相关的 api 接⼝调⽤起来⽐较⽅便,⽬前其提供了基于⽇期、固定时间间隔以及corntab类型的任务,并且可持久化任务;同时它提供了多种不同的调⽤器,⽅便开发者根据⾃⼰的需求进⾏使⽤,也⽅便与数据库等第三⽅的外部持久化储存机制进⾏协同⼯作,⾮常强⼤。
安装最简单的⽅法是使⽤ pip 安装:$ pip install apscheduler或者下载源码安装:$ python setup.py install⽬前版本:3.6.3基本概念APScheduler 具有四种组件:triggers(触发器)jobstores (job 存储)executors (执⾏器)schedulers (调度器)triggers:触发器管理着 job 的调度⽅式。
jobstores:⽤于 job 数据的持久化。
默认 job 存储在内存中,还可以存储在各种数据库中。
除了内存⽅式不需要序列化之外(⼀个例外是使⽤ ProcessPoolExecutor),其余都需要 job 函数参数可序列化。
作业提交系统Torque个人安装

PBS是功能最为齐全,历史最悠久,支持最广泛的本地集群调度器之一。
PBS的目前包括openPBS,PBS Pro和T orque三个主要分支。
其中OpenPBS是最早的PBS系统,目前已经没有太多后续开发,PBS pro 是PBS的商业版本,功能最为丰富。
T orque是Clustering公司接过了OpenPBS,并给与后续支持的一个开源版本。
下面是本人安装torque的过程。
一、Torque安装在master(管理结点上)1、解压安装包[root@master tmp]# tar zxvf torque-2.3.0.tar.gz2、进入到解压后的文件夹./configure --with-default-server=mastermakemake install3、(1)[root@master torque-2.3.0]#./torque.setup <user><user>必须是个普通用户(2)[root@master torque-2.3.0]#make packages把产生的 tpackages , torque-package-clients-linux-x86-64.sh,torque-package-mom-linux-x86-64.sh 拷贝到所有节点。
(3)[root@master torque-2.3.0]# ./torque-package-clients-linux-x86_64.sh --install[root@master torque-2.3.0]# ./torque-package-mom-linux-x86_64.sh --install(4)编辑/var/spool/torque/server_priv/nodes(需要自己建立)加入如下内容master np=4node01 np=4........node09 np=4(5)启动pbs_server,pbs_sched,pbs_mom,并把其写到/etc/rc.local里使其能开机自启动。
Hootsuite - Magento Plugin 用户指南说明书
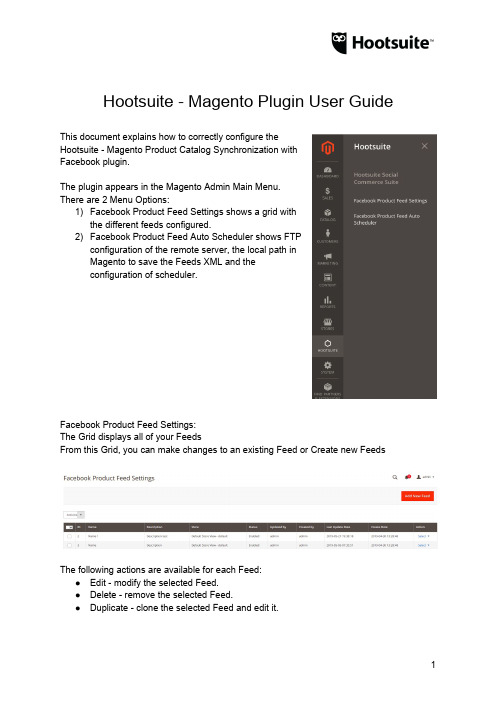
Hootsuite - Magento Plugin User Guide This document explains how to correctly configure theHootsuite - Magento Product Catalog Synchronization withFacebook plugin.The plugin appears in the Magento Admin Main Menu.There are 2 Menu Options:1)Facebook Product Feed Settings shows a grid withthe different feeds configured.2)Facebook Product Feed Auto Scheduler shows FTPconfiguration of the remote server, the local path inMagento to save the Feeds XML and theconfiguration of scheduler.Facebook Product Feed Settings:The Grid displays all of your FeedsFrom this Grid, you can make changes to an existing Feed or Create new FeedsThe following actions are available for each Feed:●Edit - modify the selected Feed.●Delete - remove the selected Feed.●Duplicate - clone the selected Feed and edit it.●Process - runs the Feed and generates an XML file in real time.The following bulk action options are available for multiple Feeds:●Delete - remove all selected Feeds.●Process - runs all selected Feeds, and generate distinct XML in real time.Feed Management:●Facebook Catalog Product Feed option lets you manage the Feed details○Title (Required) - unique short description.○Description - long text that describes the function of the feed.○Store (Required) - generates a Feed based on underlying Store catalog.○Status (Required) - flag to enable or disable the Feed for processing.●Filter Configuration lets Users set the selection criteria for what products for aparticular store catalog are included in the resulting XML file generated.●Attribute Mapping lets Users specify what Magento store Product attributes to bemapped to Facebook Attributes on the resulting XML file. Facebook Requiredattributes cannot be updated and must be mapped to a choice Magento Attribute.Optional Attributes may be exempt if desired and if included will need to be mapped to a corresponding Magento store product attribute.Scheduling the Facebook Product Feed:The following need to be defined to schedule a process to auto generate the Feed XML file●Remote Path Setting, allows you to configure the FTP remote server in which thefeeds will be uploaded.○Server - FTP host domain.○Path - remote directory onFTP server where thegenerated XML file will besent.○Test Connection - toconfirm connect criteriaprovided is accurate.●Local Path Setting, lets a User specify adirectory under the Magento rootdirectory where the generated XML filewill be sent.●Scheduler, lets a User configure thefrequency of the background processto auto generate the Feed XML file。
blockingscheduler用法

blockingscheduler用法blockingscheduler是Python中一个用于调度阻塞任务的模块,它允许你在多线程或多进程环境中运行阻塞任务,并且能够在任务之间自动切换,提高程序的运行效率。
以下是blockingscheduler的使用方法:1. 安装blockingscheduler模块使用pip命令进行安装:```pip install blockingscheduler```2. 导入blockingscheduler模块```pythonimport blockingscheduler```3. 创建一个Scheduler对象```pythonscheduler = blockingscheduler.Scheduler()```4. 向Scheduler对象添加任务使用add_task方法向Scheduler对象添加任务。
add_task方法接受一个函数作为参数,并返回一个Task对象。
```pythontask = scheduler.add_task(func, *args, **kwargs)```函数func是要执行的任务,*args和**kwargs是用于传递给任务函数的参数。
5. 运行Scheduler对象调用Scheduler对象的run方法,开始运行所有的任务。
run 方法将会阻塞当前线程或进程,直到所有任务完成。
```pythonscheduler.run()```6. 配置Scheduler对象调用Scheduler对象的configure方法,可以配置Scheduler的一些属性,例如调度间隔、并发数量等。
```pythonscheduler.configure(interval=1, max_workers=4)```interval参数指定了调度间隔的时间(单位为秒),max_workers参数指定了并发数量。
默认值为1和4。
7. 更高级的使用方法blockingscheduler还提供了其他的一些功能,例如取消任务、获取任务的结果等。
backgroundscheduler用法

backgroundscheduler用法1.介绍在P yt ho n的任务调度模块`sc he du le`中,`B ac kg ro un dS ch edu l er`是一个强大的工具,它可以帮助我们在后台运行定时任务。
本文将介绍如何使用`B ac kg r ou nd Sc he du le r`来实现任务的调度和执行。
2.安装与导入首先,我们需要安装`sc he du le`模块,可以使用pi p命令进行安装:```p i pi ns ta ll sc he dul e```安装完成后,我们需要在Py th on脚本中导入`B ac kg ro un dS ch edu l er`类:```p yt ho nf r om sc he du le im por t Ba ck gr ou nd Sc hed u le r```3.创建和设置调度器使用`B ac kg ro un dSc h ed ul er`之前,我们需要先创建一个调度器对象,并对其进行一些设置。
下面是创建和设置调度器的示例代码:```p yt ho ns c he du le r=Ba ck gro u nd Sc he du le r()设置scheduler为非守护进程,以保证后台任务可以正常运行```4.添加任务在`Ba ck gr ou nd Sc he d ul er`中,我们可以添加多个任务并设置其执行的时间间隔。
下面是添加任务的示例代码:```p yt ho nd e ft as k():p r in t("执行任务")每10秒执行一次任务```5.启动和停止调度器当我们添加了任务后,就可以启动调度器来运行这些任务了。
下面是启动和停止调度器的示例代码:```p yt ho n启动调度器停止调度器s c he du le r.sh ut dow n(w ai t=Fa ls e)```6.完整示例下面是一个使用`Bac k gr ou nd Sc he du ler`的完整示例代码:```p yt ho nf r om sc he du le im por t Ba ck gr ou nd Sc hed u le rd e ft as k():p r in t("执行任务")s c he du le r=Ba ck gro u nd Sc he du le r()s c he du le r.da em oni c=F al ses c he du le r.ad d_job(ta sk,'in te rv al',se co nd s=10)s c he du le r.st ar t()i n pu t("按下任意键停止任务...")s c he du le r.sh ut dow n(w ai t=Fa ls e)```7.总结`B ac kg ro un dS ch edu l er`是一个功能强大的任务调度模块,可以帮助我们方便地在后台执行定时任务。
jobschedulehelper解析 -回复

jobschedulehelper解析-回复Jobschedulehelper是一个用于调度和管理作业(Job)的Java库。
它提供了一组强大的工具和函数,可以帮助开发者更高效地处理作业调度和管理的任务。
本文将逐步回答以下问题:Jobschedulehelper是什么?它如何工作?它提供了哪些功能?如何使用Jobschedulehelper来进行作业调度和管理?Jobschedulehelper是什么?Jobschedulehelper是一个Java库,用于调度和管理作业。
它是基于Quartz框架的封装,提供了一组方便的工具和函数来简化作业调度和管理的任务。
它可以帮助开发者更快速、高效地实现作业调度和管理功能。
它如何工作?Jobschedulehelper基于Quartz框架,通过使用Quartz的调度器(Scheduler)来实现作业的调度和管理。
它提供了一个简单的接口,可以轻松地创建和配置作业,并指定它们的调度规则。
Jobschedulehelper 内部封装了Quartz的相关逻辑,使开发者无需深入理解Quartz的细节,就可以完成作业调度和管理的任务。
它提供了哪些功能?Jobschedulehelper提供了丰富的功能,包括灵活的作业调度、作业触发器管理、作业状态监控等。
具体功能如下:1. 作业调度:Jobschedulehelper允许开发者定义和配置作业的调度规则,例如定时触发、简单重复触发、日历触发等。
开发者可以根据需求灵活地设定作业的调度时间和间隔。
2. 作业触发器管理:Jobschedulehelper提供了简单易用的接口,用于管理作业的触发器。
开发者可以方便地创建、更新、暂停、恢复和删除作业的触发器,灵活地控制作业的触发条件。
3. 作业状态监控:Jobschedulehelper提供了作业状态的监控功能。
开发者可以实时了解作业的运行状态、触发时间、完成时间等信息,帮助排查和解决作业调度中的问题。
MICROS B2B配置与设置说明书

B2B Configuration & SetupB2B Configuration & SetupMICROS retains the right to update or change the contents of thisdocument without prior notice.MICROS assumes no responsibility by the contents of this document.© Copyright MICROS 5/4/2012All rights reserved. No part of this publication may be reproduced,photocopied, stored on a retrieval system, or transmitted without theexpress prior written consent of the publisher.All other brand and product names are trademarks or registeredtrademarks of their respective companies.Price quotes are links between vendors, articles, and units and are created automatically by the system whenan article is ordered or received for the first time.Table of ContentsCONFIGURATION & SETUP 4B2B G ENERAL T AB (4)I TEM C ATALOG T AB (5)O RDERING T AB (6)R ECEIVING T AB (7)O RDER A CKNOWLEDGEMENT T AB (8)VENDOR COST CENTER PROFILE SETUP 9MIA2 SERVICE 10ORDERING AND ORDER ACKNOWLEDGEMENT 12MANUAL PROCESSES 14LINKING OF NEW VENDOR PURCHASE ITEMS (VPIS) 16ACCEPTING PRICE VARIANCES 17RECEIVING 18VENDOR RATING 18V IEWING V ARIANCE IN S USPENDED R ECEIPTS (19)A PPLYING R EASON C ODES (19)V IEWING V ENDOR R ATING D ETAIL (20)B2B DISCREPANCY 21CURRENT B2B AVAILABILITY 22I NTERFACES D EVELOPED: (22)V ENDORS U SING THE MYINVENTORY S TANDARD I NTERFACE: (22)I NTERFACES IN DEVELOPMENT: (22)Configuration & SetupThe B2B Interface is configured per individual Vendor in myinventory → Master Data → Vendors. Search for the desired Vendor and select that Vendor to edit the B2B Configuration settings.**For a list of all Vendors for which the Interface is currently developed, see page 22B2B General TabMandatory Fields:-Vendor ID (supplied by Vendor) -Buyer GLNOptional Fields:-Location Number (supplied by Vendor) -Vendor GLN (supplied by Vendor)-“Vendor is B2B Solutions Provider” (not used by myinventory)-“Send Notifications to Cost Center E-Mail Address”-sends an e-mail to the Cost Center instead of the Originator (for Ordering only)**Note: Only the tabs that correspond to required functionality will need to be filled out. For example, if Order Cycles will not be used, the “B2B Order Cycles” tab does not need to be filled out. For each required tab, the user will need to configure FTP Server settings so that myinventory can effectively communicate with and transfer files to and from the Vendor.Item Catalog TabMandatory Fields:- File Path for Item Catalog (obtained from Hosting)- File Mask (from Vendor)- Item Catalog Import Template**Ensure that the REMOTE PATH has the identifying path filled in. In the example below “/HMSH/Outbound” is identifying that on the FTP server the path is “HMSH > Outbound” and not just “Outbound”.**Note: In some cases the FILE MASK ending may be “.edi” and not .832. This can be identified when you log into the FTP server and see the ending of the file.Optional Fields:-“-Enable “Process Order Guides (Article Catalog) via Automation Server” – when MIA2 Job “B2B Import Item Catalogs” is configured, myinventory will automatically check for and import Item Catalogs from the Vendor, as scheduledOrdering TabMandatory Fields:- File Path for Orders (obtained from Hosting)- File Mask (from Vendor)- Purchase Order Export Template- Enable “Use B2B Order” (Turns the B2B ordering function on)****Ensure that the REMOTE PATH has the identifying path filled in. In the example below “/HMSH/Inbound” is identifying that on the FTP server the path is HMSH > Inbound and not just InboundOptional Fields:-“Force B2B Qty” – Cost Centers will be unable to change the quantites in B2B Receipts from the Vendor-“Order processing via B2B only” –If this option is enabled, Users will only be able to order Vendor Purchase Items that are linked to the Vendor B2B Catalog-“Use Order Cycles” – Vendor will adhere to established Order Cycles-“User prepared Purchase Orders” – Mandatory if using Central Ordering—If this option is not enabled, Vendor will not appear in Central Ordering module-“Use myinventory Automation” – when the MIA2 Job “B2B Send Purchase Orders” is enabled, myinventory will search for and submit Orders via B2B automatically, as scheduled-“Send one file per day” – one Order will be filed with this Vendor once a day – not recommended for customers with multiple Cost Centers each placing a separate Order with the same Vendor-“Only one Order per day/Order Cycle” – only one Order per day/Order Cycle may be submitted for the Vendor, Cost Center, and Delivery DateReceiving TabMandatory Fields:-File Path (obtained from Hosting)-File Mask (from Vendor)-Receipt Import template-Enable “Use B2B Receiving”Optional Fields:-“Process Invoices via Automation Server” – works in conjunction with the MIA2 Job “B2B Import Invoices/Credit Notes”-“Book Receipt Immediately” – myinventory will automatically Book the Receipt once it is sent by the Vendor instead of storing it in Suspended Receipts to be Booked manually-“Make Invoice after booking Receipt” – available only when previous option is ticked. Books B2B Receipts for this Vendor as Invoices automatically-“Send Interal Notification To” – Users added here will receive an email when a new B2B Receipt has been sent -“B2B Receipt is Invoice” – B2B Receipt will act as an Invoice-“No manual created Receipts” – Users cannot create Receipts, they can only receive via B2B-“Use Price Quotes in B2B Receipt” – When this option is enabled , the system will use the Price defined for the Vendor Purchase Item instead of the Price on the Invoice-Invoice Acknowledgement Section – to be filled out if customer wants to send an Acknowledgement to the Vendor that the B2B Invoice has been successfully importedOrder Acknowledgement TabMandatory Fields:- File Path for Orders (from Hosting)- File Mask (from Vendor)- Order Acknowledgement Import Template- “Process Order Acknowledgement via Automation Server” –when MIA2 Job “B2B Import Order Acknowledgements” is set up, myinventory will automatically process the Order Acknowledgement from the Vendor, as scheduledVendor Cost Center Profile SetupEnsure that the Role Rights/User Rights are enabled first by navigating to:myinventory → Maintenance →Role/User Management→Master DataTo assign a Customer Number to a Cost Center, navigate to:myinventory → Maintenance → Vendor Cost Center ProfileSelect the Vendor and click Refresh.*Note – These are the account Numbers that are associated to the specific Store. The Vendor uses these Customer Numbers to identify which Store/Cost Center the Order is coming from.** This Customer Number has nothing to do with the Customer Number in Master Data > Vendor.MIA2 ServiceThe MIA2 (m y i nventory A utomation) Service is responsible for the transfer of B2B Files. The service transfers order files to the Vendor FTP and receives Order Acknowledgments, Price Catalogs, and Invoices. Without the help of the MIA2 Service, of all these actions must be performed manually by the user. These MIA2 Jobs are configured by navigating to: myinventory→Maintenance→MIA2 Scheduler. Select “Create Job” and choose the appropriate B2B-related Jobs. Under “Execution Rules”, choose “Periodically, every [n] minutes”. The frequency with which these jobs run depends on how the customer’s business operates, how many Vendors are utilizing the B2B Interface, how often Orders/Receipts are created and sent, etc.B2B Import Invoices/Credit Notes -- Imports Invoices/Credit Notes if myinventory Automation is enabled for B2B Receiving (Recommended Execution rules: Periodically, every day)B2B Import Item Catalogs -- Imports Item Catalog for Vendors using myinventory Automation (Recommended Execution rules: Periodically, every week)B2B Send Purchase Order -- Sends Purchase Orders to Vendor if 'Use myinventory Automation' is enabled for Vendor (Recommended Execution rules: Periodically, every 15-30 minutes)B2B Send Purchase Orders Status Report -- Sends Purchase Order Status Report to configured User if 'Use myinventory Automation' is enabled for Vendor. Only useful with Central Ordering with one order per Vendor and Day (Recommended Execution rules: Periodically, every day)B2B Import Order Acknowledgements -- Imports Purchase Order Acknowledgements if Vendor has 'Use myinventory Automation' enabled (Recommended Execution rules: Periodically, every 15-30 minutes)Ordering and Order AcknowledgementThe User will not recognize any change in the Ordering process; after the Order is placed, the system will generate a file for every Order and transfer the file to the Vendor FTP Server.To enable the Central Ordering Module, navigate to:Maintenance →Role/User Management →Purchase → “Purchase Manager for Prepared Orders” ArrayOnce enabled, Users with the above Role/User Right enabled can view the Order Status of each Order through the Central Ordering module by navigating to:myinventory → Maintenance → Central OrderingThe Order Acknowledgment process can be reviewed only through the Central Ordering module:Manual ProcessesThe following processes can be completed manually if 1) the MIA2 Job is not configured for this process, or 2) the User wants to perform the task without waiting for the scheduled MIA2 Job to runThe following processes can be performed manually in myinventory B2B Solutions: -Load Item Catalog -Load Invoices -Load Order CyclesEnsure that the Job Executes successfully:Linking of New Vendor Purchase Items (VPIs)You can link the new Vendor Items to myinventory Vendor Purchase Items by navigating to: myinventory B2B Solutions and clicking on “Link” beside the Unlinked Items.Vendor Purchase Items can also be linked to Vendor Items directly through Vendor Purchase Catalog, by clicking “Link” next to the desired Vendor Purchase Item. The user will then be brought to the above screen, where the matching Vendor Item can be selected, if one exists.Accepting Price Variances***Reminder: Until all Unlinked VPIs are linked, the Invoices that contain the items will not process. They will remain in the buffer until these links are reconciled.Once Unlinked VPIs have been linked, the Invoices must be Processed. In order to do this, the User must navigate to the main B2B Solutions module, where he or she can click on the link that reads “[n ] Invoices in Buffer”. myinventory will direct the User to a page that shows all of the documents that can be processed, in this case, 2. To process the Invoices and push them out of the buffer, the User will click the “Process” button at the bottom of the screen.Once “Process” has been clicked, a notification window will indicate “Action has been initiated”. When the User clicks “OK” in the window, he or she will be taken back to the B2B screen where they can view the status of the action. “Execution completed successfully” indicates the Invoice has been successfully processed and can now be booked.Place a check mark next to any/all of the prices that you are accepting. Select “Accept Price(s)” at the bottom of the screen, to accept the price from the B2B Catalog and update the price for those items in Vendor Purchase Catalog.ReceivingOnce Unlinked VPIs have been linked, and Invoices have been Processed and removed from the Buffer, the B2B Invoice/Credit Note will move to the Receiving module of myinventory. If “Book Receipt Immediately” is enabled in Master Data→Vendor→B2B Receiving, myinventory will automatically Book the Receipt without any need for User interaction.If this option is not enabled, the B2B Receipt will remain in the Suspended Receipts area until a User opens the Receipt and clicks “Book” to finalize the Receipt.Vendor RatingEach Vendor can be configured to use Vendor Rating, which will enable the user to see all variances in Price and Quantity between an Order from that Vendor and a Receipt created from that Order.**Note: B2B is not required for this Vendor Rating functionality to work. Any Vendor can have this configuration enabled.To enable Vendor Rating for a Vendor, navigate to:myinventory→Master Data→VendorsSelect the desired Vendor, and in the “Delivery Settings” tab, tick the box next to “Use Vendor Rating.”In the “Vendor Rating Setup”, choose from one of three options:- “Optional” – User has the option of providing a reason for the variance in Price or Quantity- “Rating on Modified Position” – User is required to select a reason for all Items where the Quantity or Price has changed- “Rating is mandatory” – the User is required to enter information for everything Received from selected Vendor. Receipt cannot be booked until this information is supplied.**Note: Vendor Rating Reason Codes can be configured in myinventory→Master Data→Reason Codes. The Reason Code category should be “Purchase.”Viewing Variance in Suspended ReceiptsWhen a Receipt is sent from the Vendor via B2B, the user can access it through Suspended Receipts. If an Order was originally placed through myinventory via B2B, any changes in Price or Quantity will appear in the Suspended Receipt. If the User has the ability to make changes to the Price or Quantity, any variances from the ordered Price and Quantity as a result of those manual changes will appear as well.Two columns on the left will indicate if there are variances in Price or Quantity that differ from the original Order (only Items with a change in Quantity will appear in red):OD= OverdeliveredUD= UnderdeliveredOP = OverpricedUP = UnderpricedApplying Reason CodesIn some cases, a User may be required to or wish to enter a Reason Code for a discrepancy in Price or Quantity. To do so, click on Add Rating at the bottom of the Suspended Receipts screen.Choose a Reason Code. Select “Apply to all Items” to apply this Reason Code to all of the Items on the Receipt, or select “Apply only on selected Items” to apply this Reason Code only to the Items that have the checkbox ticked next to them. Additional information may be entered if the User wishes to enter more notes about the Price or Quantity discrepancy.Viewing Vendor Rating DetailThe User may view the discrepancies between the Order and the Receipt in more detail by clicking on “Vendor Rating” in the top menu bar of the Suspended Receipt. This detail will also appear when the User Books the Receipt.For each Item on the Receipt, the User can view the Quantity Variance and Price Variance between the Original Order and the Delivered Order. This information can be e-mailed (if Vendor e-mail is specified) or Printed.B2B DiscrepancyWhen viewing a B2B Receipt, there is an option in the Menu Bar called “B2B Discrepancy”:When the User clicks on this option, a window will appear that shows the variances in Quantity and Price between the B2B Order, the B2B Receipt, and the Booked Receipt:The B2B Discrepancy window will indicate: Cost Center, Item Number, Item Name, Issue Type, Ordered Quantity, Variance Quantity, Ordered Price, B2B Receipt Price, Booked Price, Variance Value, Foreign Currency (FC), Reference, Order Number (PO Number of the Order that was placed for the items on this receipt), Delivery Note Number, Delivery Date, Invoice Number, Receipt Number, and Invoice Date. Depending on the configuration and use of the myinventory system, some of these fields may not be populated with data.The User has the option of leaving a Note for the Vendor by checking the box next to “Note to Vendor” and filling in the text box below. The B2B Discrepancy information and Note to Vendor can be printed or e-mailed to the Vendor, provided an e-mail address was specified for the Vendor in Master Data Vendors.Current B2B AvailabilityInterfaces Developed:•Sysco US•Sysco Canada•US Food•Roma Vistar•PFG•Ben E. KeithVendors Using the myinventory Standard Interface: •Coastal•Reinhart US•GFS Canada•GFS US•DMA•ItradenetworkInterfaces in development:•Edward Don。
pbs作业管理系统

scheduling = True max_user_run = 20 default_queue = default query_other_jobs = True
2011-3-15
22
Scheduler调度行为配置 Scheduler调度行为配置
• Scheduler的行为由配置目录下的 sched_priv/sched_config文件进行控制 • Sort_by关键字控制调度算法可以选择的选项为
Server端设置 Server端设置
• 初始化server: (第一次运行或者重新配置) /usr/local/sbin/pbs_server –t create • Server配置目录 /var/spool/pbs/server_priv/ • 节点属性声明:/var/spool/pbs/server_priv/nodes node2 R220A np=2 node3 R220A np=2 node4 dualcore np=4 node5 dualcore np=4 node6 R4280A np=4 node7 R4280A np=4
create queue default set queue default set queue default set queue default set queue default set set set set server server server server queue_type = execution max_running = 20 enabled = True started = True
内 容
• 任务管理系统概述 • PBS作业调度系统 • 作业调度系统的使用
2011-3-15
7
PBS作业调度系统 PBS作业调度系统
Command Scheduler (Kron)说明书

Command Scheduler (Kron)•Finding Feature Information,page1•Restrictions for Command Scheduler,page1•Information About Command Scheduler(Kron),page2•How to Configure Command Scheduler(Kron),page2•Configuration Examples for Command Scheduler(Kron),page5•Additional References,page6•Feature Information for Command Scheduler(Kron),page7Finding Feature InformationYour software release may not support all the features documented in this module.For the latest caveats andfeature information,see Bug Search Tool and the release notes for your platform and software release.Tofind information about the features documented in this module,and to see a list of the releases in which eachfeature is supported,see the feature information table at the end of this module.Use Cisco Feature Navigator to find information about platform support and Cisco software image support.To access Cisco Feature Navigator,go to /go/cfn.An account on is not required.Restrictions for Command SchedulerThe EXEC CLI specified in a Command Scheduler policy list must neither generate a prompt nor can it beterminated using mand Scheduler is designed as a fully automated facility,and no manualintervention is permitted.Command Scheduler (Kron) Information About Command Scheduler (Kron)Information About Command Scheduler (Kron)Command SchedulerThe Command Scheduler(KRON)Policy for System Startup feature enables support for the CommandScheduler upon system startup.The Command Scheduler allows customers to schedule fully-qualified EXEC mode CLI commands to runonce,at specified intervals,at specified calendar dates and times,or upon system startup.Originally designedto work with Cisco Networking Services commands,Command Scheduler now has a broader application.Using the Cisco Networking Services image agent feature,remote devices residing outside a firewall or usingNetwork Address Translation(NAT)addresses can use Command Scheduler to launch CLI at intervals,toupdate the image running in the device.Command Scheduler has two basic processes.A policy list is configured containing lines of fully-qualifiedEXEC CLI commands to be run at the same time or same interval.One or more policy lists are then scheduledto run after a specified interval of time,at a specified calendar date and time,or upon system startup.Eachscheduled occurrence can be set to run either once only or on a recurring basis.How to Configure Command Scheduler (Kron)Configuring Command Scheduler Policy Lists and OccurrencesAn occurrence for Command Scheduler is defined as a scheduled event.Policy lists are configured to runafter a specified interval of time,at a specified calendar date and time,or upon system startup.Policy listscan be run once,as a one-time event,or as recurring events over time.Command Scheduler occurrences can be scheduled before the associated policy list has been configured,buta warning will advise you to configure the policy list before it is scheduled to run.Before You BeginPerform this task to set up Command Scheduler policy lists of EXEC Cisco Networking Services commandsand configure a Command Scheduler occurrence to specify the time or interval after which the Cisco NetworkingServices commands will run.Command Scheduler Policy ListsPolicy lists consist of one or more lines of fully-qualified EXEC CLI commands.All commands in a policylist are executed when the policy list is run by Command Scheduler using the kron occurrence command.Use separate policy lists for CLI commands that are run at different times.No editor function is available,and the policy list is run in the order in which it was configured.To delete an entry,use the no form of thecli command followed by the appropriate EXEC command.If an existing policy list name is used,new entriesare added to the end of the policy list.To view entries in a policy list,use the show running-config command.If a policy list is scheduled to run only once,it will not be displayed by the show running-config commandafter it has run.Policy lists can be configured after the policy list has been scheduled,but each policy list must be configuredbefore it is scheduled to run.Command Scheduler OccurencesThe clock time must be set on the routing device before a Command Scheduler occurrence is scheduled torun.If the clock time is not set,a warning message will appear on the console screen after the kron occurrence command has been e the clock command or Network Time Protocol (NTP)to set the clock time.The EXEC CLI to be run by Command Scheduler must be tested on the routing device to determine if it will run without generating a prompt or allowing execution interruption by keystrokes.Initial testing is important because Command Scheduler will delete the entire policy list if any CLI syntax fails.Removing the policylist ensures that any CLI dependencies will not generate more errors.If you use the conditional keyword with the kron policy-list command,execution of the commands will stop when an error isencountered.Note •No more than 31policy lists can be scheduled to run at the same time.•If a one-time occurrence is scheduled,the occurrence will not be displayed by the showrunning-config command after the occurrence has run.>SUMMARY STEPS1.enable2.configure terminal3.kron policy-list list-name [conditional ]4.cli command5.exit6.kron occurrence occurrence-name [user username ]{in [[numdays:]numhours:]nummin |athours:min [[month ]day-of-month ][day-of-week ]}{oneshot |recurring |system-startup }7.policy-list list-name8.exit9.show kron scheduleDETAILED STEPS Purpose Command or ActionEnables privileged EXEC mode.enableStep 1Example:Device>enable •Enter your password if prompted.Enters global configuration mode.configure terminalExample:Device#configure terminal Step 2Command Scheduler (Kron)Configuring Command Scheduler Policy Lists and OccurrencesPurpose Command or ActionSpecifies a name for a new or existing Command Scheduler policy list and enters kron-policy configuration mode.kron policy-list list-name [conditional ]Example:Device(config)#kron policy-listcns-weekly Step 3•If the list-name is new,a new policy list structure is created.•If the list-name exists,the existing policy list structure is accessed.The policy list is run in configured order with no editor function.•If the optional conditional keyword is used,execution of thecommands stops when an error is encountered.Specifies the fully-qualified EXEC command and associated syntax to be added as an entry in the specified Command Scheduler policy list.cli commandExample:Device(config-kron-policy)#cli cnsStep 4•Each entry is added to the policy list in the order in which it is configured.image retrieve server•Repeat this step to add other EXEC CLI commands to a policy list to be executed at the same time or interval.https://10.19.2.3/cnsweek/statushttps://10.19.2.3/cnsstatus/week/EXEC commands that generate a prompt or can be terminatedusing keystrokes will cause an error.Note Exits kron-policy configuration mode and returns the device to global configuration mode.exitExample:Device(config-kron-policy)#exit Step 5Specifies a name and schedule for a new or existing Command Scheduler occurrence and enters kron-occurrence configuration mode.kron occurrence occurrence-name [userusername ]Step 6{in [[numdays:]numhours:]nummin |at•Use the in keyword to specify a delta time interval with a timer that starts when this command is configured.hours:min [[month ]day-of-month ][day-of-week ]}{oneshot |recurring |system-startup }•Use the at keyword to specify a calendar date and time.Example:Device(config)#kron occurrence mayuser sales at 6:30may 20oneshot •Choose either the oneshot or recurring keyword to schedule Command Scheduler occurrence once or repeatedly.Add the optional system-startup keyword for the occurrence to be at system startup.Specifies a Command Scheduler policy list.policy-list list-name Step 7Example:Device(config-kron-occurrence)#policy-list sales-may •Each entry is added to the occurrence list in the order in which it isconfigured.If the CLI commands in a policy list generate a prompt or can beterminated using keystrokes,an error will be generated and thepolicy list will be deleted.Note Command Scheduler (Kron)Configuring Command Scheduler Policy Lists and OccurrencesPurpose Command or ActionExits kron-occurrence configuration mode and returns the device to global configuration mode.exitExample:Device(config-kron-occurrence)#exit Step 8•Repeat this step to exit global configuration mode.(Optional)Displays the status and schedule information of CommandScheduler occurrences.show kron scheduleExample:Device#show kron scheduleStep 9ExamplesIn the following example,output information is displayed about the status and schedule of all configuredCommand Scheduler occurrences:Device#show kron scheduleKron Occurrence Schedulecns-weekly inactive,will run again in 7days 01:02:33may inactive,will run once in 32days 20:43:31at 6:30on May 20Troubleshooting TipsUse the debug kron command in privileged EXEC mode to troubleshoot Command Scheduler commande any debugging command with caution because the volume of output generated can slow or stop the device's operations.Configuration Examples for Command Scheduler (Kron)Example: Command Scheduler Policy Lists and OccurrencesIn the following example,a Command Scheduler policy named cns-weekly is configured to run two sets of EXEC CLI involving Cisco Networking Services commands.The policy is then scheduled with two otherpolicies to run every seven days,one hour and thirty minutes.kron policy-list cns-weeklycli cns image retrieve server http://10.19.2.3/week/status http://10.19.2.5/status/week/cli cns config retrieve page /testconfig/config.asp no-persistexitkron occurrence week in 7:1:30recurringpolicy-list cns-weeklypolicy-list itd-weeklypolicy-list mkt-weeklyCommand Scheduler (Kron)Troubleshooting TipsIn the following example,a Command Scheduler policy named sales-may is configured to run a CiscoNetworking Services command to retrieve a specified image from a remote server.The policy is then scheduled to run only once on May 20,at 6:30a.m.kron policy-list sales-maycli cns image retrieve server 10.19.2.3status 10.19.2.3exitkron occurrence may at 6:30May 20oneshotpolicy-list sales-mayIn the following example,a Command Scheduler policy named image-sunday is configured to run a Cisco Networking Services command to retrieve a specified image from a remote server.The policy is then scheduled to run every Sunday at 7:30a.m.kron policy-list image-sundaycli cns image retrieve server 10.19.2.3status 10.19.2.3exitkron occurrence sunday user sales at 7:30sunday recurringpolicy-list image-sundayIn the following example,a Command Scheduler policy named file-retrieval is configured to run a Cisco Networking Services command to retrieve a specific file from a remote server.The policy is then scheduled to run on system startup.kron policy-list file-retrievalcli cns image retrieve server 10.19.2.3status 10.19.2.3exitkron occurrence system-startuppolicy-list file-retrievalAdditional References Related DocumentsDocument Title Related TopicCisco IOS Master Commands List,All ReleasesCisco IOS commands Cisco IOS Cisco NetworkingServices Command Reference Cisco Networking Services commands:complete command syntax,command mode,command history,defaults,usage guidelines,andexamples.Cisco CNS Configuration EngineAdministrator Guide,1.3Cisco Networking Services Configuration Engine Standards and RFCsTitleStandard/RFC --No new or modified standards/RFCs are supported by this feature,and support for existingstandards/RFCs has not been modified by this mand Scheduler (Kron)Additional ReferencesMIBsMIBs Link MIBTo locate and download MIBs for selected platforms,Cisco software releases,and feature sets,use Cisco MIB Locator found at the following URL:/go/mibsNo new or modified MIBs are supported by thisfeature,and support for existing MIBs has not beenmodified by this feature.Technical AssistanceLinkDescription /cisco/web/support/index.html The Cisco Support and Documentation website provides online resources to download documentation,software,and e these resources to install andconfigure the software and to troubleshoot and resolvetechnical issues with Cisco products and technologies.Access to most tools on the Cisco Support andDocumentation website requires a user IDand password.Feature Information for Command Scheduler (Kron)The following table provides release information about the feature or features described in this module.This table lists only the software release that introduced support for a given feature in a given software release train.Unless noted otherwise,subsequent releases of that software release train also support that e Cisco Feature Navigator to find information about platform support and Cisco software image support.To access Cisco Feature Navigator,go to /go/cfn .An account on is not required.Table 1: Feature Information for Command Scheduler (Kron)Feature Information Releases Feature NameThe Command Scheduler feature provides the ability to schedule some EXEC CLI commands to run at specific times or at specified intervals.The following commands were introduced or modified by this feature:cli ,debug kron ,kron occurrence ,kron policy-list ,policy-list ,show kron schedule .Cisco IOS XE Release 2.112.3(1)12.2(33)SRA12.2(33)SRC12.2(33)SB12.2(33)SXI12.2(50)SY Command Scheduler (Kron)Command Scheduler (Kron)Feature Information for Command Scheduler (Kron)Feature InformationReleases Feature Name The Command Scheduler (Kron)Policy for System Startup featureenables support for the CommandScheduler feature upon systemstartup.Cisco IOS XE Release 3.8S 12.2(33)SRC 12.2(50)SY 12.2(33)SB12.4(15)TCommand Scheduler (Kron)Policy for System Startup Command Scheduler (Kron)Feature Information for Command Scheduler (Kron)。
Python定时任务工具之APScheduler使用方式

Python定时任务⼯具之APScheduler使⽤⽅式APScheduler (advanceded python scheduler)是⼀款Python开发的定时任务⼯具。
⽂档地址特点:不依赖于Linux系统的crontab系统定时,独⽴运⾏可以动态添加新的定时任务,如下单后30分钟内必须⽀付,否则取消订单,就可以借助此⼯具(每下⼀单就要添加此订单的定时任务)对添加的定时任务可以做持久保存1 安装pip install apscheduler2 组成APScheduler 由以下四部分组成:triggers 触发器指定定时任务执⾏的时机job stores 存储器可以将定时持久存储executors 执⾏器在定时任务该执⾏时,以进程或线程⽅式执⾏任务schedulers 调度器常⽤的有BackgroundScheduler(后台运⾏)和BlockingScheduler( 阻塞式 )3 使⽤⽅式from apscheduler.schedulers.background import BlockingScheduler#创建定时任务的调度器对象scheduler = BlockingScheduler()# 创建执⾏器executors = {'default': ThreadPoolExecutor(20),}# 定义定时任务def my_job(param1, param2): # 参数通过add_job()args传递传递过来print(param1) # 100print(param2) # python# 向调度器中添加定时任务scheduler.add_job(my_job, 'date', args=[100, 'python'], executors=executors)# 启动定时任务调度器⼯作scheduler.start()4 调度器 Scheduler负责管理定时任务BlockingScheduler : 作为独⽴进程时使⽤from apscheduler.schedulers.blocking import BlockingSchedulerscheduler = BlockingScheduler()scheduler.start() # 此处程序会发⽣阻塞BackgroundScheduler : 在框架程序(如Django、Flask)中使⽤.from apscheduler.schedulers.background import BackgroundSchedulerscheduler = BackgroundScheduler()scheduler.start() # 此处程序不会发⽣阻塞AsyncIOScheduler : 当你的程序使⽤了asyncio的时候使⽤。
IBM Workload Scheduler 快速入门指南说明书

IBM Workload Scheduler Quick Start GuideVersion 9.4Quick Start GuideThis guide describes a quick and easy way to install the product.National Language Version:To obtain the Quick Start Guide in other languages, print the language-specific PDF from the installation media.Product overviewIBM Workload Scheduler is the state-of-the-art production workload manager for distributed platforms, designed to help you meet your present and future data processing challenges. It is part of the IBM Workload Automation product family.3Step 3: Review the installation architectureThe diagram shows the IBM Workload Scheduler components and user interfaces that you can install, in both the static and dynamic configurations. Components that interface with other products in the family are also shown. For more details, see IBM Workload Scheduler: Planning and Installation .User InterfacesCommand-line client (remote)Dynamic agentsCommand lineWeb browserCommand-line client (remote)Fault-tolerant AgentsCommand lineWeb browserIBM®4Step 4: Planning your installationFor information about how to install IBM Workload Scheduler, see the IBM Workload Scheduler: Planning and Installation.Plan your installation as follows:v Consider dividing into domains the network of computers on which you want to manage the workload.v Manage the RDBMS requirements of your system using a supported version of DB2®or Oracle. If you choose DB2, you can also choose to install the bundled instance.v Decide if you want to use a dynamic or a static environment or both.v Access and control IBM Workload Scheduler through the available user interfaces.v From these plans, determine where you need to install the product components.For information about how to install IBM Workload Scheduler for z/OS Agent, see IBM Workload Scheduler for z/OS: Planning and Installation.5Step 5: Installing and configuringUsing the supplied launchpad, install and configure the master domain manager and its backup, following the instructionsin the IBM Workload Scheduler: Planning and Installation. A backup is a master domain manager that you can switch to if there are problems with your current master domain manager. Its use is not required.Install and configure a dynamic domain manager and its backup for each domain in which you want to run dynamicscheduling. Use the launchpad to install them, following the instructions in the IBM Workload Scheduler: Planning andInstallation. Install and configure a domain manager and its backup for each domain in which you want to run staticscheduling. To install them, follow the instructions in the IBM Workload Scheduler: Planning and Installation.Depending on the type of scheduling you plan to perform, install:v For dynamic scheduling: Dynamic agentsv For static scheduling: Fault-tolerant agentsIBM Workload Scheduler can be fully controlled from the command line on the master domain manager, which isautomatically installed with it, but to use the other interfaces, you must install an extra component:Dynamic Workload Console and its connectorInstall this to perform scheduling object database management, plan management, workload monitoring, eventmanagement operations, and the running of reports. Follow the instructions in the IBM Workload Scheduler:Planning and Installation.Command-line clientInstall this to perform operations on the objects in the database from any computer other than the master domainmanager, where it is already installed by default. See the IBM Workload Scheduler: Planning and Installation.6Step 6: Getting startedRead the IBM Workload Scheduler: User's Guide and Reference. For information about dynamic scheduling, see IBM WorkloadScheduler: Scheduling Workload Dynamically. Optionally visit the Workload Automation YouTube channel, which iscontinuously updated with video demos that show new features and capabilities. Then, when you are ready, create your own real scheduling objects in the database, and a scheduling plan, and start running it.IBM Workload Scheduler Version 9.4 Licensed Materials - Property of IBM®. © Copyright IBM Corp. 2001, 2016. U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.© Copyright HCL Technologies Limited 2016.IBM, the IBM logo, and ®are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the web at /legal/copytrade.shtml.Part Number:CF4F7MLPrinted in Ireland。
PBS脚本JobSubmissionandScheduling(PBSScripts)

PBS脚本JobSubmissionandScheduling(PBSScripts)参考:⼀介绍超算系统使⽤作业队列来管理计算任务的执⾏。
将计算任务提交到作业队列后,它们将在队列中等待,直到有可⽤的适当的计算资源。
常见的排队系统为PBS(Portable Batch System.)。
要将作业提交到PBS队列,⽤户可以创建PBS作业脚本(PBS job scripts)。
PBS作业脚本包含有关计算所需资源的信息,以及⽤于执⾏计算的命令。
⼆ PBS Script格式PBS作业脚本是⼀个⼩型⽂本⽂件,其中包含有关作业所需资源的信息,包括时间,节点数和内存。
PBS脚本还包含让超算系统执⾏的命令(commands needed to begin executing the desired computation)。
⽐如linux系统命令(由超算的操作系统决定)。
PBS作业脚本⽰例:1 #!/bin/bash -l2 #PBS -l walltime=8:00:00,nodes=1:ppn=8,mem=10gb3 #PBS -m abe4#*************************5 cd ~/program_directory6 module load intel7 module load ompi/intel8 mpirun -np 8 program_name < inputfile > outputfilePBS脚本的第⼀⾏定义了将使⽤哪种shell读取脚本(系统将如何读取⽂件)。
建议使第⼀⾏#!/ bin / bash -l⽤于PBS查询系统的命令以 #PBS 开头。
上⾯的⽰例脚本中的第⼆⾏包含PBS资源请求。
该⽰例作业将需要8个⼩时,每个节点8个处理器核(ppn),以及10 GB的内存(mem)。
资源请求必须包含适当的值;如果请求的时间,处理器或内存不适合硬件,则该作业将⽆法运⾏。
openpbs

OpenPBS Users ManualHow to Write a PBS Batch ScriptPBS scripts are rather simple. An MPI example for user your-user-name: Example: MPI Code#PBS -N a_name_for_my_parallel_job#PBS -l nodes=7,walltime=1:00:00#PBS -S /bin/sh#PBS -q cac#PBS -M your-email-address#PBS -m abe#PBS -o /users/your-user-name/output#PBS -e /users/your-user-name/errors#echo "I ran on:"cat $PBS_NODEFILE#export GMPICONF=/users/your-user-name/.gmpi/$PBS_JOBID##cd to your execution directory firstcd ~##use mpirun to run my MPI binary with 7 nodes for 1 hourmpirun -np 14 ./your-mpi-programThe PBS script parameters are as follows:#PBS -N testjob Name of the job in the queue is "testjob".#PBS -l nodes=7,walltime=1:00:00 Reserve 7 machines (14processors), for 1 hour.#PBS -S /path/to/shell Script is /bin/sh (see below)#PBS -q default Submit to the queue named default.#PBS -M your-email-address Email me at this address.#PBS -m abe Email me when the job a borts, b egins, and e nds. #PBS -o /users/your-user-name/output Write stdout to this file.#PBS -e /users/your-user-name/errors Write stderr to this file.For complete information on PBS flags, use "man qsub". For furtherinformation on PBS, use "man pbs".The MPI (mpirun) parameters are as follows:-np Number pf processes.-stdin <filename> Use "filename" as standard input.-t Test but do not execute.Example: OpenMP CodeIf you're running OpenMP code (w/ 1 or 2 processes on these machines): #PBS -N myparalleljob#PBS -l nodes=1,walltime=90:00#PBS -S /bin/sh#PBS -q cac#PBS -M your-email-address#PBS -m abe#PBS -o /users/your-user-name/output#PBS -e /users/your-user-name/errors#echo "I ran on:"cat $PBS_NODEFILE#export GMPICONF=/home/your-user-name/.gmpi/$PBS_JOBIDexport NCPUS=2## cd to your execution directory firstcd ~./a.outYou may find it necessary to add the following to OpenMP jobs, should you run low on stack space due to the default stack size of 2 MB:export MPSTKZ 8MIf you have a serial code just set 'nodes=1'.For example:#PBS -N testjob#PBS -l nodes=1,walltime=24:00#PBS -q queue-name#PBS -M your-email-address#PBS -m abe#PBS -o /users/your-user-name/output#PBS -e /users/your-user-name/errors## cd to your execution directory firstcd ~/myrundirexecutable < input1 > output1 &Or if you want to maximize your use of a node by running two serial processes on the node (one process per CPU):#PBS -N testjob#PBS -S /bin/sh#PBS -l nodes=1,walltime=24:00#PBS -q queue-name#PBS -M your-email-address#PBS -m abe#PBS -o /users/your-user-name/output#PBS -e /users/your-user-name/errors# <input# cd to your execution directory firstcd ~/myrundirexecutable < input1 > output1 &executable < input2 > output2 &wait # make sure you wait, else the slower job will abortUse "qstat -f -Q" to see a list of the currently active queues on the machine you're using. They may differ from the list above.In this script, stdout and stderr will be directed into file JobName.o##. JobName was specified by the -N flag in the script file.How to Submit a PBS Batch ScriptTo submit an PBS script simply type:qsub scriptnamewhere scriptname is the name of your PBS script. Note that PBS runs your script under the your shell, unless otherwise told to do so. One benefit of running under /bin/sh is the csh is arguably broken in how it handles terminal-disconnected jobs (same goes for tcsh). Using csh or tcsh is fine, but you will receive error warnings at the beginning of your output file:Warning: no access to stty (Bad file descriptor).Thus no job control in this shell.How to Check the Status of a PBS Batch JobTo check the status of your job in the queue, type:qstatNote: This will show only your jobs. To see all jobs in the queue, type:qstat -aHow to Cancel a PBS Batch JobIf you realize that you made a mistake in your script file or if you've made modifications to your program since you submitted your job and you want to cancel your job, first get the "Job ID" by typing qstat.For example:qdel 203orqdel 203How to Query the PBS QueuesTo see the names of the available queues and their current parameters, type: qstat -f -QThe notable parameters in the output are Queue and resources_max.cput for the CPU limits.How do I choose myrinet nodes when running my OpenPBS job.In the above scripts you may have noticed the following#PBS -l nodes=10,walltime=24:00In order to make sure your myrinet code is run on nodes in cluster that have a myrinet card installed you will want to add the following to the above line.#PBS –l nodes=10:myrinetor#PBS –l nodes=10:ppn=2:myrinetThis would cause pbs to only choose and use10 nodes with the pbs attribute myrinet. The latter example would cause pbs to only choose and use 10 nodes with 2 processors each and a myrinet card node attribute.Node Attribute Discriptions:Please note that by default, all jobs are run using the “general” node attribute unless you specify it as explained above.General:Nodes that can run jobs that do not require a myrinet card installed Myrinet:Nodes with myrinet cards installedMyritest:Nodes that can run test jobs that require a myrinet cardTest:Nodes that can run test jobs that do not require a myrinet card Fatnode:Nodes that can run jobs that require larger amounts of memory and more cpus. Currently those nodes are 4 cpu/12G memory nodesHow do I specify the number of processors I want to use per node?You would specify the number of processors using the ppn(processor per node) attribute as such#PBS –l nodes=10:ppn=2Your job would then be run using 20 processors. If you specified ppn=1 then your job would be run using only 10 processors. It is actually best to specify less nodes with a larger number of if you need to run singular jobs so that you can use both cpu’s on a compute node. I.E.To run 10 processes, it would be best to use something like this#PBS –l nodes=5:ppn=2Where do I go to for more information?The best place to get information about PBS Script variables is by using the man page for qsub ie.man qsubFor more information about deleting your job, access the qdel man pageqdelmanFor more information about job status information, access the qstat man page qstatManMaui Users ManualMaui IntroductionThe Maui Scheduler was designed to offer improved job management and scheduling to users while allowing users to continue 'business as usual'. In fact, users do not need to change anything in the way they submit and track jobs when Maui is installed. However, if a user chooses, there are many new features and commands which can be utilized to improve the user's ability to run jobs when, where, and how they want.The Maui Scheduler, as its name suggests, is a scheduler. It is not a resource manager. A resource manager, such as PBS, Loadleveler, or LSF, manages the job queue and manages the compute nodes. A scheduler tells the resource manager what to do, when to run jobs, and where. Users typically submit jobs and query the state of the machine and jobs through the resource manager. When Maui is running, users can continue to issue the exact same resource manager commands as before. However, Maui also offers commands which provide additional information and capabilities.Maui capabilities include many internal mechanisms to improve overall scheduling performance, allowing users to run more jobs on the same system and get their results back more quickly. Additionally, Maui allows users to create resource reservations which guarantee resource availability at particular times. Quality of service features are also enabled which allow a user to request improved job turnaround time, access to additional resources, or exemptions to particular policies automatically. (The site administrator may choose to make some of these capabilities only available at a higher'job cost')Maui OverviewMaui is an advanced cluster scheduler capable of optimizing scheduling and node allocation decisions. It allows site administrators extensive control over which jobs are considered eligible for for scheduling, how the jobs are prioritized, and where these jobs are run. Maui supports advance reservations, QOS levels, backfill, and allocation management. Each of these features, if enabled, may require some adjustment on the part of the user to optimize system performance.BackfillBackfill is a scheduling approach which allows some jobs to be run 'out of order' so long as they do not delay the highest priority jobs in the queue. In order to determine whether or not a job will be delayed, each job must supply an estimate of how long it will need to run. This estimate, known as a wallclock limit, is an estimation of the wall time (or elapsed time) from job start to job finish. It is often wise to slightly overestimate thislimit because the scheduler may be configured to kill jobs which exceed their wallclock limits. However, overestimating a job's wallclock time by too much will prevent the scheduler from being able to optimize the job queue as much as possible. The more accurate the wallclock limit, the more 'holes' Maui can find to start your job early.Maui also provides the command showbf to allow users to see exactly what resources are available for immediate use. This can allow users to configure a job that will be able to run a soon as it is submitted by utilizing only available resources.Backfill scheduling significantly improves the ability of the scheduler to utilize the available resources. Consequently, using backfill scheduling increases system utilization and throughput while decreasing average job queue time. Fortunately, backfill is a very forgiving algorithm, allowing even jobs with very poor wallclock estimates to benefit from it. However, better estimates will increase the amount of improvement backfill scheduling can provide for your jobs.Allocation ManagementMaui possesses interfaces to a number of allocation management systems such as PNNL's QBank. These systems allow each user to be given a portion of the total compute resources available on the system. These systems work by associating each user with one or more accounts. When a job is submitted, the user specifies which account should be charged for the resources consumed by the job. Default accounts may be specified to automate the account specification process in most cases. If such a system is being used at your site, your system administrators will inform you as to if and how accounts should be specified.Advance ReservationsAdvance reservations allow a site to set aside certain resources for specific uses over a given timeframe. Access to a given reservation is controlled by a reservation-specific access control list (ACL) which determines who or what can use the reserved resources. It is important to note that while reservation ACL's allow particular jobs to utilize reserved resources, they do not force the job to utilize these resources. Maui will attempt to locate the best possible combination of available resources whether these are reserved or unreserved. For example, in the figure below, note that job X, which meets access criteria for both reservation A and B, allocates a portion of its resources from each reservation and the remainder from resources outside of both reservations.While by default, reservations make resources available to jobs which meet particular criteria, Maui can be configured to constrain jobs to only run within accessiblereservations. Specifically, jobs can be forced to run only within reserved resources on a job by job basis.Quality of Service (QOS)The Maui QOS features allow a site to grant special privileges to particular users. These benefits can include access to additional resources, exemptions from certain policies, access to special capabilities, and improved job prioritization. Each site determines which advantages are important to make available and to whom. If you are granted special QOS access, you can specify the QOS to use for your job using the QOS keyword.StatisticsMaui tracks a large number of statistics to help users determine how well and how often their jobs are running. The showstats command provides detailed statistics on a per user, per group, and per account basis. Additionally, the command showgrid can be used to determine what types of jobs get the best scheduling performance allowing users to'tune' their jobs to obtain optimal turnaround time.DiagnosisMaui provides the checkjob command to allow users to view a detailed status of each job they have submitted. This command show all job attribute and state information and also provides an analysis of whether or not the job can run. If the job is unable to run, this command will provide a breakdown of these reasons why. The showstart command provides an estimate of job start time beyond this.If your job still will not start, contact your system administrator. He will have access to additional commands and detailed Maui logs which will reveal exactly why the job cannot run.Workload InformationMaui offers an extensive array of job prioritization options to allow sites to control exactly how jobs run through the job queue. If your site administrators have chosen to take advantage of this, the job ordering shown by your resource manager queue listing command (i.e., llq, qstat) will not reflect this. Maui provides the showq command to display a relevant listing of both active and idle jobs.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Portable Batch SystemOpenPBS Release 2.3Administrator GuideTranslator: 裴建中(北京工业大学)Email: pjz0311@QQ: 250386348注:翻译这一管理员指南仅仅是想和大家共同学习和交流与集群相关的知识,并无他意。
文中带有下划线的句子是我觉得理解的不好的地方,其后同时保留了原来的英文以便大家理解,请留意。
文中翻译不当的地方敬请各位批评更正。
1.介绍此文档用来为系统管理员提供构建、安装、配置并且管理PBS所需的一些信息。
很可能有一些重要的信息项被漏掉了。
这类文档中没有更加完善的了,到目前为止,它已经被好几个不同的管理员在不同的站点进行了更新,当然仍是比较欠缺。
1.1. 什么是PBS?PBS是一个批处理作业和计算机系统资源管理软件包。
它原本是按照POSIX 1003.2d批处理环境来开发的。
这样,它就可以接受批处理作业、shell脚本和控制属性,作业运行前对其储存并保护,然后运行作业,并且把输出转发回提交者。
PBS可以被安装并配置运行在单机系统或多个系统组来支持作业处理。
由于PBS的灵活性,多个系统可以以多种方式组合。
1.2. PBS的组件PBS包括四个主要的组件:命令组件、作业服务器、作业执行组件和作业调度器。
这里给出每一部分的简要描述来帮助你在安装过程中做出决定。
命令组件:PBS支持与POSIX1003.2d相一致的命令行和图形接口两种命令方式。
这些命令用于提交、监视、修改和删除作业。
命令可以被安装在任何PBS支持的系统类型上,并且不需要在本地安装任何其它的PBS组件。
共有三种类型的命令:任何已授权用户可以使用的命令;操作员命令;管理员命令;操作员和管理员命令需要不同的访问权限。
作业服务器:作业服务器是PBS的中心。
在本文档中,它一般被称作服务器或被称为可执行文件的名字pbs_server。
所有命令和其它守护进程都通过IP网络和服务器通信。
服务器的主要功能就是提供基本的批处理服务,例如接收/创建一个批处理作业,修改作业,保护作业免受系统宕机的影响并运行作业。
作业执行器:作业执行器是一个守护进程,它真正地把作业放入执行队列。
这一进程,pbs_mon,被非正式地命名为Mom,正如它是所有正在执行的作业的母亲(mother)一样。
当Mom从一个服务器那里接收一个作业拷贝时就将它放入执行队列。
Mom创建一个和用户登陆会话尽可能一致的新的会话。
例如,如果用户的登陆shell是csh,那么Mom就创建一个会话,在此会话中.login和.cshrc一样运行。
当服务器指示需要那么做时,Mom也负责把作业的输出返回给用户。
作业调度器:作业调度器是另一个守护进程,这一进程包括site’policy[1],这一策略控制着哪一个作业被运行,在那个节点运行,什么时候运行。
因为每一个site对于什么是好的或者有效的策略都有它自己的想法,PBS允许每一个site来创建它自己的调度器。
当运行的时候,调度器就可以和不同的Moms进行通信来获知系统资源的状态;和服务器进行通信来获知要执行的作业的有效性。
与服务器之间的接口是通过和命令组件一样的API。
实际上,调度器仅仅作为服务器的批处理管理器出现的。
除了上面主要的部分之外,PBS也提供了一个应用编程接口,API,命令组件用它来和服务器进行通信。
这一API在和PBS一起完成的第三部分的man pages中描述。
A site[1]如果愿意可以利用这些API来实现新的命令。
1.3.发布信息1.3.1.T ar文件PBS是以一个单一的tar文件来提供的。
这个tar文件包括:以后记和文本两种形式提供的本文档一个“配置”脚本,所有的源码,头文件和用于构建并安装PBS的make文件。
当解压tar文件时,将会在上面的信息之上创建一个顶层目录。
这一顶层目录将被命名为发布版本加补丁级别。
例如,对于发布版本 2.1和补丁级别13,这一目录将被命名为pbs_v2.1p13。
建议这些文件在解压时带上-p参数以便保留权限位。
1.3.2.附加要求PBS使用一个由GNU的autoconf生成的配置脚本来产生make文件。
如果你有一个POSIX make程序,那么由配置脚本生成的make文件将尝试利用POSIX的make特性。
当构建时如果你的make不能够处理这个make文件那么你可能用的是一个被破坏的make。
要是在构建时make失败,就试一下GNU的make。
如果使用了基于GUI的Tcl或基于调度器的Tcl,就需要有Tcl的头文件和库。
Tcl的官方网站是:/, ftp:///pub/tcl/tcl8_0PBS已经不再使用Tcl8.0之前的版本。
必须使用Tcl和Tk8.0或更高的版本。
如果使用了BaSL调度器,将需要yacc和lex(或者GNU bison和flex)。
对于bison和flex 的有关站点是:/software/software.html :/pub/gnu为了格式化包含在这一发布版本的这一文档,我们强烈推荐使用GNU groff包。
最新的groff版本1.11.1,它可以在这里找到:/software/groff/groff.html2.安装这一部分试图来解释构建和安装PBS的步骤。
PBS安装可以通过GNU的autoconf过程来完成。
这一安装过程与其他许多“典型”软件包相比需要更多的手工配置。
因为有一些涉及site policy的选项,所以安装就不能被自动的决定。
如果PBS运行在基于intel x86的红帽Linux上,可以使用RPM包来安装。
对于安装说明请看2.4.9部分。
为了获得一个可用的PBS安装,需要有下面的步骤:1. 阅读这一指南并为主机和PBS的大概配置做一个计划。
见1.2节和3.0到3.2节。
2. 决定PBS源码和(构建)目标文件的放置位置。
见2.2节。
3. 把发布的文件解压为源码树。
见2.2节。
4. 选择“配置”选项并从目标书的顶层来运行configure。
见2.2到2.4节。
5. 在目标树的顶层通过make来编译PBS。
见2.2到2.3部分。
6. 在目标树的顶层通过make install来安装PBS的模块。
需要root权限。
见2.2节。
7. 如果PBS正在管理一个多个节点的联合体或者像IBM SP这样的并行系统时,创建一个节点描述文件。
见第3章批处理系统配置。
节点可以在服务器通过qmgr命令启动之后加入,即使这时节点文件还没有创建。
8. 启动(bring up)并配置服务器。
见3.1到3.5节。
9. 配置并启动Moms。
见3.6节。
10.通过调度一些作业来测试。
见qrun(8B)man page.11.配置并启动调度程序。
通过授权(enabling)调度来设置服务器为活动状态。
见第四章2.1.计划PBS能够支持很广泛的配置。
它可以被安装并用于控制简单或大型系统中的作业。
它可以在多个系统之间用于作业负载均衡。
可以用于把一个集群或并行系统的节点分配给并行和串行作业。
或者它能够处理上述的混合情况。
在进一步介绍之前,我们需要定义一些术语。
PBS如何使用这些术语和你可能期望的有所区别。
节点:一个带有一个单操作系统映像(image),一个统一虚拟内存映像,一个或多个cpu和一个或多个IP地址的计算机系统。
通常,术语执行机被用作节点。
一个像SGI Origin 2000这样在一个单一操作系统拷贝下运行的多个处理单元的盒子对PBS来说就是一个节点而不管SGI的术语是什么。
一个像IBM SP这样包含多个单元的盒子,每一个都有它自己的操作系统的拷贝,就是多个节点的集合。
(A box like the SGI Origin 2000, with contains multiple processing units running under a single OS copy is one node to PBS regardless of SGI’s terminology. A bos like the IBM SP which contains many units, each w ith their own copy of the OS, is a collection of many nodes.)一个机群节点声明为包含一个或多个虚拟处理器。
使用术语“虚拟”是因为在一个物理节点中声明的虚拟处理器的数量可以等于或大于或小于实际处理器的数量。
现在分配的是这些虚拟处理器而不是整个的物理节点。
一个机群节点的虚拟处理器(VPs)可以以独占的方式或临时共享的方式分配。
分时节点不会被认为包含有虚拟节点并且这些节点没有分配作业也没有被作业所使用。
联合体(Complex):由一个批处理系统管理的主机的集合。
一个联合体可以由在某一时间仅分配有一个作业的节点组成或者由分配有多个马上要执行的作业的节点组成,或者是两者的组合。
集群:由多个集群节点组成的联合体。
集群节点:一个这样的节点——它的虚拟处理器在某一时间专门分配给一个作业(见独占节点部分),或者多个作业(见临时共享节点)。
这一节点类型也可以被称作空间共享。
如果一个集群节点有多于一个虚拟处理器,这些虚拟节点可以被分配给不同的作业或者用于满足单个作业的需要。
然而,单个节点上的所有处理器将被按照同一种方式来分配,例如,所有虚拟处理器将被分配为独占的或者临时共享的。
在多个作业中分时共享的主机被称为“timeshared”。
独占节点:一个独占节点就是在某一时间只能用于一个并且只能是一个作业。
对于一个作业的整个持续时间,一个节点集可以以独占的方式分配给这个作业。
这是提高消息传递程序性能的典型做法。
临时共享节点:一个临时共享节点,它的虚拟处理器被多个作业临时共享。
如果几个作业需要多个临时共享节点,某些虚拟处理器可能分配给两个作业,某些可能对其中一个作业是唯一的(some VPs may be allocated commonly to both jobs and some may be unique to one of the jobs)。
当一个虚拟处理器以分时共享为基础分配时,它将一直保持分时共享状态直到所有使用它的作业都终止为止。
然后这个虚拟处理器就可以以分时共享或者独占的使用方式再一次分配。
分时共享:在我们的上下文中,分时共享总是允许多个作业同时在一个执行主机或节点上运行。
一个分时共享节点就是作业可以分时共享的节点。
通常使用术语主机与分时共享相联接而不是节点,正如分时共享主机。
如果使用了术语节点而没有分时前缀,这个节点就是可以以独占方式或者分时共享方式分配的集群节点。
如果一个主机或节点被指示为分时共享,它将永远不会被服务器分配为独占的或者临时共享的。