用SAS的mixed过程拟合林分的线性差分生长模型
proc mixed 误差项 sas 混合模型 公式

proc mixed 误差项sas 混合模型公式全文共四篇示例,供读者参考第一篇示例:PROC MIXED是SAS中用于混合模型分析的过程,混合模型是一种能够处理多层次结构或者重复测量数据的统计模型。
在混合模型中,我们可以同时考虑固定效应和随机效应,进而对不同层次的变量进行分析。
在混合模型中,误差项扮演着非常重要的角色,它是模型中必不可少的一个组成部分。
本文将介绍关于PROC MIXED中误差项的相关知识,并给出相应的混合模型公式。
误差项在混合模型中是指未被模型中的自变量所解释的部分,也就是模型中未被考虑的随机误差。
在混合模型中,我们通常假设误差项服从正态分布,并且具有均值为0、方差为σ^2的特性。
误差项的存在使得我们能够量化模型中的不确定性,评估模型的拟合程度,并且进行相关的统计推断。
在PROC MIXED中,我们可以通过指定各种固定效应和随机效应来构建混合模型。
常见的混合模型可以被表达为如下的公式:Y = Xβ + Zγ + εY表示观测到的因变量向量,X是固定效应矩阵,β是固定效应参数向量,Z是随机效应矩阵,γ是随机效应参数向量,ε是误差项向量。
在该公式中,固定效应表示各个因素对因变量的整体影响,而随机效应则表示了在样本中的个体差异。
误差项则是模型中未被解释的残差部分。
在具体的数据分析过程中,我们需要根据研究的实际情况来构建混合模型。
在进行实验设计时,我们需要考虑实验中的重复测量数据或者样本数据的层次结构。
在这种情况下,混合模型能够更好地分析不同层次之间的关系,并且考虑到各个层次的变异性。
通过PROC MIXED进行混合模型分析时,我们可以通过设定不同的协方差结构来进一步扩展模型的适用范围。
可以选择不同的协方差结构来描述不同层次的数据之间的相关性。
PROC MIXED还提供了丰富的选项来进行模型拟合和参数估计,包括最大似然估计、重复测量设计、协变量调整等功能。
第二篇示例:混合模型是一种在统计分析中常用的模型,特别是当研究对象存在多个层次或重复测量时。
sas各过程笔记+描述性统计+线性回归+logistic回归+生存+判别+聚类+主成分+因子分析
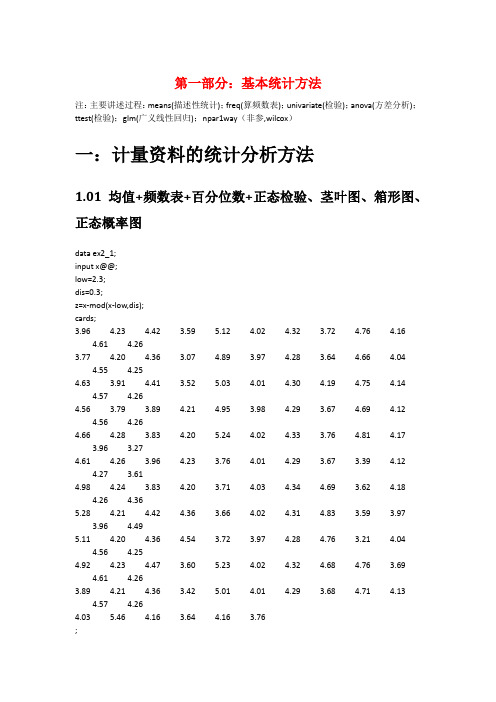
第一部分:基本统计方法注:主要讲述过程:means(描述性统计);freq(算频数表);univariate(检验);anova(方差分析);ttest(检验);glm(广义线性回归);npar1way(非参,wilcox)一:计量资料的统计分析方法1.01均值+频数表+百分位数+正态检验、茎叶图、箱形图、正态概率图data ex2_1;input x@@;low=2.3;dis=0.3;z=x-mod(x-low,dis);cards;3.964.23 4.42 3.595.12 4.02 4.32 3.72 4.76 4.164.61 4.263.774.20 4.36 3.07 4.89 3.97 4.28 3.64 4.66 4.044.55 4.254.63 3.91 4.41 3.525.03 4.01 4.30 4.19 4.75 4.144.57 4.264.56 3.79 3.89 4.21 4.95 3.98 4.29 3.67 4.69 4.124.56 4.264.66 4.28 3.83 4.205.24 4.02 4.33 3.76 4.81 4.173.96 3.274.61 4.26 3.96 4.23 3.76 4.01 4.29 3.67 3.39 4.124.27 3.614.98 4.24 3.83 4.20 3.71 4.03 4.34 4.69 3.62 4.184.26 4.365.28 4.21 4.42 4.36 3.66 4.02 4.31 4.83 3.59 3.973.964.495.11 4.20 4.36 4.54 3.72 3.97 4.28 4.76 3.21 4.044.56 4.254.92 4.23 4.47 3.605.23 4.02 4.32 4.68 4.76 3.694.61 4.263.894.21 4.36 3.425.01 4.01 4.29 3.68 4.71 4.134.57 4.264.035.46 4.16 3.64 4.16 3.76;/*freq语句,算频数表*/proc freq;tables z;run;proc means data=ex2_1n mean std stderr clm;var x;run;data ex2_1;input x f@@;cards;3.07 23.27 33.47 93.67 143.87 224.07 304.27 214.47 154.67 104.87 65.07 45.27 2;run;proc means;freq f;var x;run;/*把freq f改成weight f就是把f当权重或频数来算,f则在0,1之间*//*计算x的95%的置信区间*/proc univariate data=ex2_1;var x;output out=pctpctlpre=ppctlpts=2.5 97.5;run;proc print data=pct;run;/*正态检验、茎叶图、箱形图、正态概率图*/proc univariate data=ex2_1normalplot;var x;run;/*Extreme Observation显示的值是最小的5个极值和最大的5个极值*/1.02几何均值data ex2_5;input x f@@;y=log10(x);cards;10 420 340 1080 10160 11320 15640 141280 2;proc means noprint;/*调用means过程,不显示结果*/var y;freq f;output out=b/*结果输出到数据集b中*/mean=logmean;/*把数据集b中均数的变量名mean改为logmean*/run;data c;/*新建数据集c*/set b;/*调用数据集b*/g=10**logmean;/*计算变量logmean的反对数,该值就是x的几何均数,将该值赋值给变量g*/ proc print data=c;var g;run;/*这个是计算平通平均数的值*/proc means data=ex2_5;var x;freq f;run;1.03已知均值和方差求置信区间-单样本+单样本与总体/*单样本*/data ex3_2;n=10;mean=166.95;std=3.64;t=tinv(0.975,n-1);pts=t*std/sqrt(n);lclm=mean-pts;uclm=mean+pts;proc print;var lclm uclm;run;/*单样本与总体均值*/data ex3_5;n=36;/*样本量*/s_m=130.83;/*样本均值*/std=25.74;/*样本标准差*/p_m=140;/*总体均值*/df=n-1;/*自由度*/t=(s_m-p_m)/(std/sqrt(n));p=(1-probt(abs(t),df))*2;/*根据t值计算p值*/run;proc print;var t p;run;1.06双样本均值相等检验+两组分开+两组一起算+两组样本量不同/*双样本分开算*/data ex3_4;n1=29;n2=32;m1=20.10;m2=16.89;s1=7.02;s2=8.46;ss1=s1**2*(n1-1);ss2=s2**2*(n2-1);sc2=(ss1+ss2)/(n1+n2-2);se=sqrt(sc2*(1/n1+1/n2));t=tinv(0.975,n1+n2-2);lclm=(m1-m2)-t*se;uclm=(m1-m2)+t*se;proc print;var t se lclm uclm;run;/*双样本相减后再算*//*用MEANS作配对资料两个样本均数比较的t检验*/data ex3_6;input x1 x2 @@;d=x1-x2;cards;0.840 0.5800.591 0.5090.674 0.5000.632 0.3160.687 0.3370.978 0.5170.750 0.4540.730 0.5121.200 0.9970.870 0.506;proc means t prt;var d;run;/*用UNIVARIATE过程作配对资料两样本均数比较的t检验*/ proc univariate data=ex3_6;var d;run;/*双样本两组样本量不同*/data ex3_7;input x@@;if _n_<21 then c=1;/*当观测数小于21时,变量c的值为1,表示试验组*/else c=2;/*其余变量c的值为2,表示对照组*/cards;-0.70 -5.60 2.00 2.80 0.70 3.50 4.00 5.80 7.10 -0.502.50 -1.60 1.703.00 0.404.50 4.60 2.50 6.00 -1.403.70 6.50 5.00 5.20 0.80 0.20 0.60 3.40 6.60 -1.106.00 3.80 2.00 1.60 2.00 2.20 1.20 3.10 1.70 -2.00;proc ttest;/*调用ttest过程*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;1.08-1.13anova方差分析过程+一维分组+二维分组+三维分组/*只有一组分组因素*/data ex4_2;input x c @@;cards;3.53 1 2.42 2 2.86 3 0.89 44.59 1 3.36 2 2.28 3 1.06 44.34 1 4.32 2 2.39 3 1.08 42.66 1 2.34 2 2.28 3 1.27 43.59 1 2.68 2 2.48 3 1.63 43.13 1 2.95 2 2.28 3 1.89 43.30 1 2.36 2 3.48 3 1.31 44.04 1 2.56 2 2.42 3 2.51 43.53 1 2.52 2 2.41 3 1.88 43.56 1 2.27 2 2.66 3 1.41 43.85 1 2.98 2 3.29 3 3.19 44.07 1 3.72 2 2.70 3 1.92 41.37 12.65 2 2.66 3 0.94 43.93 1 2.22 2 3.68 3 2.11 42.33 1 2.90 2 2.65 3 2.81 42.98 1 1.98 2 2.66 3 1.98 44.00 1 2.63 2 2.32 3 1.74 43.55 1 2.86 2 2.61 3 2.16 42.64 1 2.93 23.64 3 3.37 42.56 1 2.17 2 2.58 3 2.97 43.50 1 2.72 2 3.65 3 1.69 43.25 1 1.56 2 3.21 3 1.19 42.96 13.11 2 2.23 3 2.17 44.30 1 1.81 2 2.32 3 2.28 43.52 1 1.77 2 2.68 3 1.72 43.93 1 2.80 2 3.04 3 2.47 44.19 1 3.57 2 2.81 3 1.02 42.96 1 2.97 23.02 3 2.52 44.16 1 4.02 2 1.97 3 2.10 42.59 1 2.31 2 1.68 33.71 4;proc anova;/*调用anova过程*/class c;/*定义分组变量为c*/model x=c;/*定义模型,分析g对x的影响*/means c/dunnett;/*用LSD法对多组均数过行两两比较*/means c/hovtest;/*作方差齐性检验,默认levene法,p值大于0.05,则认为是g组方差相等*/run;quit;/*有两组分组因素*/data ex4_4;input x a b@@;cards;0.82 1 10.65 2 10.51 3 10.73 1 20.54 2 20.23 3 20.43 1 30.34 2 30.28 3 30.41 1 40.21 2 40.31 3 40.68 1 50.43 2 50.24 3 5;proc anova;class a b;/*定义分组变量a和b*/model x=a b;/*定义模型,分析a和b对x影响*/means a/snk;/*用SNK法对变量a的多组均数进行两两比较*/run;quit;1.15嵌套设计资料的方差分析glm过程一级因素+二组因素(glm过程要先class再model)/*嵌套设计资料的方差分析*/data ex11_6;input x a b @@;cards;82 1 184 1 191 1 288 1 285 1 383 1 365 2 461 2 462 2 559 2 556 2 660 2 671 3 767 3 775 3 878 3 885 3 989 3 9;proc glm;/*调用glm过程*/class a b;/*定义分组变量为a和b*/model x=a a(b);/*定义模型,以a为一组因素,b为二级因素*/run;quit;1.17重复测量资料的方差分析data ex12_2;input t1 t2 g@@;/*确定变量名称,t1和t2分别为两个时间点的分析变量,g为处理因素变量,b为区组变量*/cards;130 114 1124 110 1136 126 1128 116 1122 102 1118 100 1116 98 1138 122 1126 108 1124 106 1118 124 2132 122 2134 132 2114 96 2118 124 2128 118 2118 116 2132 122 2120 124 2134 128 2;proc glm;/*调用glm过程*/class g;/*定义分组变量g*/model t1 t2=g;/*定义模型,分析g对变量t1和t2的影响*/repeated time 2/*命名重复因子为time,有2个水平*/contrast(1)/*表示以第一时间点为对照点*//summary;/*考察不同时间点与对照时间点比较的结果*/run;quit;data ex12_3;input t0-t4 g@@;cards;120 108 112 120 117 1118 109 115 126 123 1119 112 119 124 118 1121 112 119 126 120 1127 121 127 133 126 1121 120 118 131 137 2122 121 119 129 133 2128 129 126 135 142 2117 115 111 123 131 2118 114 116 123 133 2131 119 118 135 129 3129 128 121 148 132 3123 123 120 143 136 3123 121 116 145 126 3125 124 118 142 130 3;proc glm;class g;model t0-t4=g;repeated time 5/*命名重复因子为time,有2个水平*/contrast(1);run;quit;二:计数资料的统计分析方法2.1四格表资料的卡方检验data ex7_1;input r c f@@;/*确定变量名称,r为行变量,c为列变量,f为频数变量*/ cards;1 1 991 2 52 1 752 2 21;proc freq;/*调用freq过程*/weight f;/*定义f为频数变量*/tables r*c/*作r*c的列联表*//chisq/*对列联表作卡方检验*/expected;/*输出每个格的理论频数*/run;2.5阳性事件发生的概率(二项分布)data ex6_1;do x=6 to 8;/*建立循环,变量x从6到8*/p1=probbnml(0.7,10,x);/*计算二项分布随机变量不大于x的概率*/p2=probbnml(0.7,10,x-1);/*计算二项分布随机变量不大于x-1的概率*/p=p1-p2;*/计算出现x的概率*/output;/*结果输出*/end;proc print;var x p;run;2.6正态分布法计算总体率的可信区间data ex6_3;n=100;x=55;p=x/n;sp=sqrt(p*(1-p)/n);u=probit(0.975);usp=u*sp;lclm=p-usp;uclm=p+usp;proc print;var n p sp lclm uclm;run;2.7样本率与总体率的比较(直接法——单侧检验)data ex6_4;d=probbnml(0.55,10,8);p=1-d;proc print;var p;run;2.8样本率与总体率的比较(直接法——双侧检验)data ex6_5;p01=probbnml(0.6,10,9);p02=probbnml(0.6,10,8);p0=p01-p02;/*计算出现9的概率*/do i=0to10;/*建立循环,变量i从0到10*/p11=probbnml(0.6,10,i);p12=probbnml(0.6,10,i-1);p1=p11-p12;/*计算出现i的概率*/if i=0then p1=p11; /*定义出现0的概率*/if p1<=p0 then output; /*如果出现i的概率小于出现9的概率,则保留在数据集中*/ end;proc means sum;var p1;run;2.9两个样本率比较的z检验data ex6_7;n1=120;n2=110;x1=36;x2=22;p1=x1/n1;p2=x2/n2;pc=(x1+x2)/(n1+n2);/*计算合并发生率*/sp=sqrt(pc*(1-pc)*(1/n1+1/n2));/*计算两个率相差的标准误差*/u=(p1-p2)/sp;/*计算u值*/p=(1-probnorm(abs(u)))*2;/*计算p值*/format u p 5.4;/*输出格式为小数点后保留4位*/proc print;var pc sp u p;run;2.10.Poisson分布的样本均数与总体均数比较(直接法)data ex6_12;n=120;/*确定样本例数*/pai=0.008; /*确定总体率*/lam=n*pai; /*计算总体均数lamda*/x=4; /*确定实际发生数*/p=1-poisson(lam,x-1);/*计算实际发生数所对应的概率*/proc print;var lam p;run;2.11 Poisson分布的样本均数与总体均数比较(正态近似法)data ex6_12;n=25000;/*样本量*/x=123; /*样本均数*/pi=0.003; /*确定总体率*/lam=n*pi; /*计算总体均数*/u=(x-lam)/sqrt(lam*(1-pi)); /*计算u值*/p=1-probnorm(abs(u)); /*计算u值所对应的p值*/proc print;var lam u p;run;2.14负二项分布的参数估计data ex6_16;input x f@@;cards;0 301 142 83 44 25 06 2;proc univariate;var x;freq f;output out=mv2var=v;run;data k;set mv2;k=mu**2/(v-mu);proc print;var mu k;run;三、非参数统计方法3.2单个样本中位数和总体中位数比较data ex8_2;input x1@@;median=45.30;/*假设中位数为45.30*/d=x1-median; /*计算x1和假设中位数的差值*/cards;44.21 45.30 46.39 49.47 51.05 53.1653.26 54.37 57.16 67.37 71.05 87.37;proc univariate; /*调用univariate过程度*/var d;run;proc means median; /*调用means过程计算x1实际的中位数*/var x1;run;3.3两个独立样本比较的Wilcoxon秩和检验(R对应函数wilcox.test())data ex8_3;input x c @@;/*确定变量名称,x、c分别为分析变量和分组变量(类别多于两类一样的写法)*/2.78 13.23 14.20 14.87 15.12 16.21 17.18 18.05 18.56 19.60 13.23 23.50 24.04 24.15 24.28 24.34 24.47 24.64 24.75 24.82 24.95 25.10 2;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;3.4等级资料的两样本比较data ex8_4;input c g f@@;/*确定变量名称,f为频数,c为分类,g为要分析的变量(分类多种类似)*/ cards;1 1 11 2 81 3 161 4 101 5 42 1 22 2 232 3 112 5 0;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/freq f;/*确定频数变量为f*/var g;/*定义分析变量g*/class c;/*定义分组变量c*/run;第二部分:多元统计分析方法注:主要讲述过程:reg(回归),corr(相关分析),nlin(对数曲线回归),logistic(逻辑回归),phreg(条件logistic回归分析+cox回归),life test(生存分析),discrim(判别分析),stepdisc(逐步回归),cluster(聚类),varclus(指标聚类),princomp(主成分分析),factor(因子分析),cancorr(典型相关分析)一:回归和相关分析1.1两个变量的直线回归分析data ex9_1;input x y;/*确定变量名称*/cards;13 3.5411 3.019 3.096 2.488 2.5610 3.3612 3.187 2.65;proc reg;/*调用reg过程*/model y=x;/*定义模型,以y为应变量,以x为自变量*//*在model语句后面加上选项,得到一些有用的统计量,常用的有:stb(输出标准化偏回归系数)、p(输出每个观测的实际值、预测值和残差)、cli(输出每个观测预测值均数的双侧95%置信区间)、clm(输出每个观测预测值的双侧95%置信范围)*//*例如:model y=x /stb p cli */plot y*x;/*画出散点图*/run;1.2两个变量的直线相关分析data ex9_5;input x y;cards;43 217.2274 316.1851 231.1158 220.9650 254.7065 293.8454 263.2857 271.7367 263.4669 276.5380 341.1548 261.0038 213.2085 315.1254 252.08;proc corr;/*若要求作spearman相关分析,则可以写成proc corr spearman */ var x y;run;/*得到一个相关系数矩阵*/1.4加权直线加回data ex9_9;input x y;w=1/(x*x); /*设置权重变量w*/cards;0.11 4.000.12 5.100.21 9.500.30 9.000.34 17.200.44 14.000.56 18.900.60 29.400.69 22.100.80 41.50;proc reg;weight w;/*定义权重变量w*/model y=x;/*定义模型,以y为因变量,以x为自变量*/run;1.5两个直线回归系数的比较data ex9_12;input x y c@@;cards;13 3.54 111 3.01 19 3.09 16 2.48 18 2.56 110 3.36 112 3.18 17 2.65 110 3.01 29 2.83 211 2.92 212 3.09 215 3.98 216 3.89 28 2.21 27 2.39 210 2.74 215 3.36 2;proc glm;class c;model y=x c x*c;/*定义模型,分析x、c以及x和c的交互作用对y的影响,即判断两总体直线回归系数是否相同*/run;proc glm;class c;model y=x c;/*上一步已排除协变量的影响,然后再分析两分析变量是否来自同一总体*/run;1.6两个变量的对数曲线回归data ex9_13;input x y;cards;0.005 34.110.050 57.990.500 94.495.000 128.5025.000 169.98;proc nlin;/*调用nlin过程*/parms a=0 b=0; /*定义初始值*/model y=a+b*log10(x); /*定义对数模型,以y为因变以量,x为自变量*/ run;1.7两个变量的指数曲线回归分析data ex9_14;input x y;cards;2 545 507 4510 3714 3519 2526 2031 1634 1838 1345 852 1153 860 465 6;proc nlin;parms a=4 b=0.03;/*定义初始值*/model y=exp(a+b*x);/*定义指数模型,以y为因变量,x为自变量*/run;1.8多元回归data ex15_1;input x1-x4 y@@;/*确定变量名称,x1,x2,x3,x4分别为自变量,y为应变量*/ cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4;/*也可以写成model y=x1 x2 x3 x4;*/run;1.9逐步回归data ex12_2;input x1-x4 y@@;cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4/selection=stepwise/*定义模型,以y因变量,x1-x4为变量进行多元回归分析*/ sle=0.10/*定义入先变量的界值*/sls=0.10;/*定义剔除变量的界值*/run;三:logistic回归3.1 两个变量logistic回归分析data ex16_1;input y x1 x2 f@@;/*确定变量名称,y为发病情况,x1为吸烟情况,x2为饮酒情况,f为发生频数*/cards;1 0 0 631 0 1 631 1 0 441 1 1 2650 0 0 1360 0 1 1070 1 0 570 1 1 151;proc logistic;/*调用logistic过程*/freq f;/*定义频数变量f*/model y=x1 x2;/*定义模型,以y为因变量,x1和x2为自变量*/run;3.2 1:M配对资料的条件logistic回归分析data ex16_3;input i y x1-x6 @@;/*确定变量名称,i为区组变量,y为病人情况,1为病例,0为对照,x1-x6为危险因素*/t=2-y;/*定义时间变量*/cards;1 1 3 5 1 1 1 01 0 1 1 1 3 3 01 0 1 1 1 3 3 02 1 13 1 1 3 02 0 1 1 13 2 02 0 1 2 13 2 03 1 14 1 3 2 03 0 1 5 1 3 2 03 0 14 1 3 2 04 1 1 4 1 2 1 14 0 2 1 1 3 2 05 1 2 4 2 3 2 0 5 0 1 2 1 3 3 05 0 2 3 1 3 2 06 1 1 3 1 3 2 1 6 0 1 2 1 3 2 06 0 1 3 2 3 3 07 1 2 1 1 3 2 1 7 0 1 1 1 3 3 07 0 1 1 1 3 3 08 1 1 2 3 2 2 0 8 0 1 5 1 3 2 08 0 1 2 1 3 1 09 1 3 4 3 3 2 0 9 0 1 1 1 3 3 09 0 1 4 1 3 1 010 1 1 4 1 3 3 1 10 0 1 4 1 3 3 010 0 1 2 1 3 1 011 1 3 4 1 3 2 0 11 0 3 4 1 3 1 011 0 1 5 1 3 1 012 1 1 4 3 3 3 0 12 0 1 5 1 3 2 012 0 1 5 1 3 3 013 1 1 4 1 3 2 0 13 0 1 1 1 3 1 013 0 1 1 1 3 2 014 1 1 3 1 3 2 1 14 0 1 1 1 3 1 014 0 1 2 1 3 3 015 1 1 4 1 3 2 0 15 0 1 5 1 3 3 015 0 1 5 1 3 3 016 1 1 4 2 3 1 0 16 0 2 1 1 3 3 016 0 1 1 3 3 2 017 1 2 3 1 3 2 0 17 0 1 1 2 3 2 017 0 1 2 1 3 2 018 1 1 4 1 3 2 0 18 0 1 1 1 2 1 0 18 0 1 2 1 3 2 019 0 1 1 1 2 1 019 0 2 2 2 3 1 020 1 1 4 2 3 2 120 0 1 5 1 3 3 020 0 1 4 1 3 2 021 1 1 5 1 2 1 021 0 1 4 1 3 2 021 0 1 2 1 3 2 122 1 1 2 2 3 1 022 0 1 2 1 3 2 022 0 1 1 1 3 3 023 1 1 3 1 2 2 023 0 1 1 1 3 1 123 0 1 1 2 3 2 124 1 1 2 2 3 2 124 0 1 1 1 3 2 024 0 1 1 2 3 2 025 1 1 4 1 1 1 125 0 1 1 1 3 2 025 0 1 1 1 3 3 0;proc phreg;/*调用phreg过程*/model t*y(0)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,x1-x6为自变量*//selection=stepwise/*选择逐步回归方法筛选变量*/sle=0.1sls=0.1/*入选和剔除的界值均为0.1*/ties=discrete;/*用离散logistic模型替代比例危险模型*/strata i;/*定义区组变量*/run;2.3 应变量为多分类资料的logistic回归data ex16_5;input x1 x2 y f;/*x1是两个社区,x2是性别,Y是获取健康知识途径(传统大众媒介=1,网络=2,社区宣传=3,f为频数)*/cards;0 0 1 200 0 2 350 0 3 260 1 1 100 1 2 270 1 3 571 0 1 421 02 171 1 1 161 12 121 1 3 26;proc logistic;freq f;/*定义频数变量为f*/model y(ref='3')/*定义模型,以y为因变量,ref语句指时参照的类别为“社区宣传”,最后得到结果均为与“社区宣传”相对应*/=x1 x2/*定义x1和x2为自变量*//link=glogit;/*指定多分类应变量回归模型*/run;四:生存分析4.1乘积极限法估计生存率,例17-2甲、乙两种手术方法的生存率估计data ex17_2;input t d@@;/*确定变量名称,t为时间变量,d为截尾变量*/cards;1 13 15 15 15 16 16 16 17 18 110 110 114 017 119 020 022 026 034 134 044 159 1;proc lifetest;/*调用lifetest过程*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.2寿命表法估计生存率data ex17_3;input t d f@@;cards;0 0 00 1 4561 0 391 1 2262 0 222 1 1523 0 233 1 1714 0 244 1 1355 0 1075 1 1256 0 1336 1 837 0 1027 1 748 0 688 1 519 0 649 1 4210 0 4510 1 4311 0 5311 1 3412 0 3312 1 1813 0 2714 0 3314 1 615 0 2015 1 0;proc lifetest method=life/*调用lifetest过程,指定用寿命表法估计生存率*/ width=1;/*表示每间隔1估计生存率*/freq f;/*表示以f为频数变量*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.3生存曲线比较的log-rank检验及制作生存曲线data ex17_4;input t d g @@;cards;1 1 13 1 15 1 15 1 15 1 16 1 16 1 16 1 17 1 18 1 110 1 110 1 114 0 117 1 119 0 120 0 122 0 126 0 131 0 134 1 134 0 144 1 159 1 11 1 21 1 22 1 23 1 23 1 24 1 24 1 24 1 26 1 26 1 28 1 29 1 29 1 210 1 211 1 212 1 213 1 215 1 217 1 218 1 2;proc lifetest plot=(s);/*调用lifetest过程并做生存曲线图*/ time t*d(0);strata g;/*定义变量g为分组变量*/run;4.4.cox回归分析data ex17_5;input x1-x6 t y @@;cards;54 0 0 1 1 0 52 057 0 1 0 0 0 51 058 0 0 0 1 1 35 143 1 1 1 1 0 103 048 0 1 0 0 0 7 140 0 1 0 0 0 60 044 0 1 0 0 0 58 036 0 0 0 1 1 29 139 1 1 1 0 1 70 042 0 1 0 0 1 67 042 0 1 0 0 0 66 042 1 0 1 1 0 87 051 1 1 1 0 0 85 055 0 1 0 0 1 82 052 1 1 1 0 1 74 0 48 1 1 1 0 0 63 0 54 1 0 1 1 1 101 0 38 0 1 0 0 0 100 0 40 1 1 1 0 1 66 1 38 0 0 0 1 0 93 0 19 0 0 0 1 0 24 1 67 1 0 1 1 0 93 0 37 0 0 1 1 0 90 0 43 1 0 0 1 0 15 149 0 0 0 1 0 3 150 1 1 1 1 1 87 0 53 1 1 1 0 0 120 0 32 1 1 1 0 0 120 0 46 0 1 0 0 1 120 043 1 0 1 1 0 120 044 1 0 1 1 0 120 0 62 0 0 0 1 0 120 0 40 1 1 1 0 1 40 1 50 1 0 0 1 0 26 1 33 1 1 0 0 0 120 0 57 1 1 1 0 0 120 0 48 1 0 0 1 0 120 0 28 0 0 0 1 0 3 1 54 1 0 1 1 0 120 1 35 0 1 0 1 1 7 1 47 0 0 0 1 0 18 1 49 1 0 1 1 0 120 0 43 0 1 0 0 0 120 0 48 1 1 0 0 0 15 1 44 0 0 0 1 0 4 1 60 1 1 1 0 0 120 0 40 0 0 0 1 0 16 1 32 0 1 0 0 1 24 1 44 0 0 0 1 1 19 1 48 1 0 0 1 0 120 0 72 0 1 0 1 0 24 1 42 0 0 0 1 0 2 1 63 1 0 1 1 0 120 0 55 0 1 1 0 0 12 1 39 0 0 0 1 0 5 1 44 0 0 0 1 0 120 0 42 1 1 1 0 0 120 061 0 1 0 1 0 40 145 1 0 1 1 0 108 038 0 1 0 0 0 24 162 0 0 0 1 0 16 1;proc phreg;model t*y(1)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,变量值1表示截尾数据,x1-x6为危险因素*//selection=stepwisesle=0.05sls=0.05;run;五:判别和聚类分析5.1判别分析data ex18_4;input x1-x4 g; /*确定变量名称,x1-x4为用于进行判别分析的指标,g为分组变量*/ cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc discrim;class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(结果横向是真实值,竖向的预测值)5.2逐步判别分析data ex18_5;input x1-x4 g;cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc stepdisc /*调用stepdisc过程*/slentry=0.2/*确定入选标准为0.2*/slstay=0.3;/*确定剔除标准为0.3*/class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(筛选出变量后,调用discrim过程对筛选出的变量作判别分析,即先做5.2再做5.1)5.3作样品聚类和指标聚类data ex19_3;input x1-x9;cards;46 25 5 2138 1.68 0.35 8.11 4 4 35 12 20 3510 2.76 1.43 6.84 3 3 52 25 20 2784 2.19 0.54 4.11 3 3 32 7 20 2451 1.93 0.47 11.45 9 6 38 22 0 3247 2.56 0.80 11.68 5 5 51 31 30 3710 2.92 0.37 11.60 2 2 40 9 10 3194 2.51 0.40 11.40 5 5 34 17 20 4658 3.67 0.46 11.35 3 3 50 29 0 5019 3.95 0.47 13.45 10 8 42 20 20 7482 5.89 0.12 13.11 0 0 57 30 15 3800 2.99 0.19 10.76 2 236 15 20 2478 1.95 0.25 10.00 0 037 12 0 3827 3.01 0.82 10.50 4 4 52 32 0 2984 2.35 0.16 11.15 3 3 52 32 10 3749 2.95 0.72 11.45 11 10 42 27 30 4941 3.89 0.73 13.80 7 6 44 27 20 3948 3.11 0.33 13.65 16 14 40 21 5 3360 2.64 0.37 11.40 0 0 38 21 5 2936 2.31 0.69 11.40 1 1 44 27 20 6851 5.39 0.99 12.28 7 6 43 27 0 3926 3.09 0.47 11.95 0 0 26 10 3 4381 3.45 0.52 11.80 7 5 37 18 20 7142 5.62 0.85 11.81 5 5 28 9 20 2612 2.06 0.37 11.65 1 1 25 9 30 2638 2.08 0.78 12.25 1 1 34 14 20 4322 3.40 0.41 15.00 5 5 50 32 20 2862 2.25 0.69 8.80 2 2;proc cluster/*调用cluster过程*/method=average;/*采用类平均法进行聚类*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;proc treegraphics haxis=axis1 horizontal;/*调用tree过程输出聚类图,并将图横向输出*/ run;/*对各个指标聚类,即对9个变量聚类*/proc varclus;/*调用varclus过程*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;六、主成分分析和因子分析6.1主成分分析data ex20_1;input x1-x6;cards;92 77 80 95 99 12697 75 77 80 95 12595 80 70 78 89 12075 75 73 88 98 11092 68 72 79 88 11390 85 80 70 78 10372 93 75 77 80 10088 70 76 72 81 10264 70 69 85 93 10570 73 70 87 84 10078 69 75 73 89 9778 72 71 68 75 9675 64 63 76 73 9284 66 77 55 65 7670 64 51 60 67 8858 72 75 62 52 7582 73 40 50 48 6145 65 42 47 43 60;proc princomp;/*调用princomp过程,对6个变量做主成分分析,结果包括主成分累积贡献率,特征向量矩阵*/run;6.2因子分析data ex20_2;input x1-x9;cards;4.34 389 99.06 1.23 25.46 93.15 3.56 97.51 61.663.45 271 88.28 0.85 23.55 94.31 2.44 97.94 73.334.38 385 103.97 1.21 26.54 92.53 4.02 98.484.18 377 99.48 1.19 26.89 93.86 2.92 99.41 63.164.32 378 102.01 1.19 27.63 93.18 1.99 99.71 80.004.13 349 97.55 1.10 27.34 90.63 4.38 99.03 63.164.57 361 91.66 1.14 24.89 90.60 2.73 99.69 73.534.31 209 62.18 0.52 31.74 91.67 3.65 99.48 61.114.06 425 83.27 0.93 26.56 93.81 3.09 99.48 70.734.43 458 92.39 0.95 24.26 91.12 4.21 99.76 79.074.13 496 95.43 1.03 28.75 93.43 3.50 99.10 80.494.10 514 92.99 1.07 26.31 93.24 4.22 100.00 78.954.11 490 80.90 0.97 26.90 93.68 4.97 99.77 80.533.53 344 79.66 0.68 31.87 94.77 3.59 100.00 81.974.16 508 90.98 1.01 29.43 95.75 2.77 98.72 62.864.17 545 92.98 1.08 26.92 94.89 3.14 99.41 82.354.16 507 95.10 1.01 25.82 94.41 2.80 99.35 60.614.86 540 93.17 1.07 27.59 93.47 2.77 99.80 70.215.06 552 84.38 1.10 27.56 95.15 3.10 98.63 69.234.03 453 72.69 0.90 26.03 91.94 4.50 99.05 60.424.15 529 86.53 1.05 22.40 91.52 3.84 98.58 68.423.94 515 91.01 1.02 25.44 94.88 2.56 99.36 73.914.12 552 89.14 1.10 25.70 92.65 3.87 95.52 66.674.42 597 90.18 1.18 26.94 93.03 3.76 99.28 73.813.05 437 78.81 0.87 23.05 94.46 4.03 96.223.94 477 87.34 0.95 26.78 91.784.57 94.28 87.344.14 638 88.57 1.27 26.53 95.16 1.67 94.50 91.673.87 583 89.82 1.16 22.66 93.43 3.55 94.49 89.074.08 552 90.19 1.10 22.53 90.36 3.47 97.88 87.144.14 551 90.81 1.09 23.06 91.65 2.47 97.72 87.134.04 574 81.36 1.14 26.65 93.74 1.61 98.20 93.023.93 515 76.87 1.02 23.88 93.82 3.09 95.46 88.373.90 555 80.58 1.10 23.08 94.38 2.06 96.82 91.793.62 554 87.21 1.10 22.50 92.43 3.22 97.16 87.773.75 586 90.31 1.12 23.73 92.47 2.07 97.74 93.893.77 627 86.47 1.24 23.22 91.17 3.40 98.98 89.80;proc factor/*调用factor过程*/n=4;/*确定因子数为4,如果不写就默认为3*/run;proc factorn=4rotate=quartimax;/*因子旋转的方法为四次方最大正交旋转*/run;七、典型相关分析(具体解释看ppt“SAS-典型相关分析(可以先上本章_再上对应分析)”)data ex21_1;input x1-x4 y1-y4;cards;1210 120.7 23.4 59.8 11.3 67.6 1.92 2.71 1040 121.2 22.9 59.0 10.1 66.5 1.92 2.60 1620 121.5 24.6 59.5 9.5 67.8 1.95 2.64 1690 122.5 24.4 60.7 11.0 69.2 2.08 2.64 1150 122.7 27.2 64.5 10.5 69.1 2.19 2.84 1150 123.2 20.0 56.1 10.4 59.3 1.83 2.61 1460 123.3 24.9 58.4 10.5 69.0 2.01 2.72 1190 123.4 21.8 59.0 10.6 67.4 1.90 2.71 1840 123.9 23.5 60.2 9.6 67.1 2.00 2.84 1250 124.5 25.2 63.0 11.2 67.8 2.05 2.78 1480 124.8 22.3 58.1 10.7 67.9 2.05 2.73 1310 124.9 22.0 58.0 10.5 67.8 1.98 2.68 1660 125.3 24.7 60.0 10.8 69.3 1.95 2.80 1580 125.6 22.8 59.0 9.4 69.1 2.00 2.65 1460 125.8 25.7 61.0 10.2 69.6 1.95 2.70 1240 126.0 30.2 68.0 9.2 67.1 2.14 2.88 1100 126.2 25.2 60.5 9.8 68.4 1.98 2.72 1250 126.8 23.6 58.5 10.2 67.5 1.94 2.74 1270 127.1 23.0 57.7 10.8 69.8 1.90 2.78 1300 127.6 24.3 59.0 10.3 67.9 1.93 2.84 1350 127.7 24.1 60.0 11.0 69.7 2.03 2.77 1250 128.3 21.6 55.5 10.4 68.5 1.83 2.70 1720 128.5 27.1 62.0 11.4 71.2 2.03 2.75 1480 128.5 22.6 57.4 10.0 67.3 2.04 2.83 1380 129.4 24.9 60.5 11.5 69.8 2.04 2.76 1170 129.0 26.7 63.7 9.6 67.4 2.13 2.98 1640 129.8 26.1 62.0 9.8 71.0 2.00 2.84 1640 131.6 28.7 62.8 9.7 70.7 1.89 2.89 1150 130.2 25.0 58.6 10.5 71.8 1.96 2.78 1430 130.5 26.1 60.7 10.8 68.6 2.05 2.77 1150 130.6 23.4 54.4 11.8 69.2 1.96 2.78 1150 131.4 25.5 63.2 10.2 70.4 2.05 2.84 1320 131.6 25.6 58.9 10.9 70.2 2.06 2.86 1360 131.7 27.4 62.0 10.9 73.5 1.99 2.70 1460 132.0 26.3 61.5 11.1 71.2 2.17 2.13 1380 132.2 25.7 61.4 10.1 70.1 1.96 2.83 1300 132.5 24.5 57.0 10.8 71.8 2.02 2.84 1220 132.7 27.0 61.3 10.1 72.2 2.08 2.80 1320 132.9 25.2 60.5 11.2 73.1 2.01 2.73 1910 133.1 30.1 67.0 9.0 87.1 2.15 2.97 1800 133.5 26.5 62.5 9.8 71.7 2.07 2.82 1560 133.6 24.8 58.5 10.3 72.2 1.93 2.79 1840 134.0 26.0 60.5 10.4 73.0 1.98 2.741590 134.4 25.5 60.7 9.6 69.9 1.99 2.81 1430 134.1 26.6 63.0 11.2 72.2 2.06 2.90 1760 134.6 32.5 66.0 9.9 87.4 2.61 2.98 1470 135.3 27.9 61.8 10.1 73.3 2.20 2.78 1580 135.6 28.1 65.8 9.8 73.1 2.05 2.89 1580 136.5 28.2 62.0 11.8 72.9 2.17 2.92 1840 137.1 27.6 62.8 9.5 72.4 2.11 2.91 1810 137.4 28.3 62.5 9.4 74.2 2.06 3.00 1850 138.1 29.5 62.4 9.7 72.3 2.12 4.02 2120 140.0 34.9 68.8 9.5 87.9 2.74 4.15 1760 140.7 32.0 64.4 10.2 74.0 2.17 4.05 1800 141.0 32.5 63.8 9.5 88.2 2.65 4.08 1260 141.7 29.1 65.0 9.7 88.2 2.68 2.90 1860 142.4 19.3 70.0 10.1 89.6 2.71 4.06 1800 144.7 27.0 58.3 10.8 74.8 2.10 2.82 1470 136.8 26.3 61.4 10.0 72.2 2.07 2.93 1260 121.1 22.9 59.0 10.6 66.3 2.05 2.76 1570 132.7 25.3 58.6 11.5 73.6 2.16 2.78 1290 125.0 25.7 60.5 10.1 68.8 2.00 2.69 1580 133.2 27.3 60.7 9.6 71.7 2.11 2.85 1690 132.8 28.6 64.7 9.6 72.9 2.19 4.08 1670 131.6 25.4 59.7 10.6 69.8 2.14 2.76 1300 133.1 25.9 58.0 10.1 69.7 2.12 2.83 1610 134.0 25.8 59.6 9.4 70.8 2.10 2.88 1580 134.3 26.3 61.2 10.2 72.2 2.14 2.84 1570 129.1 27.7 62.2 11.1 72.9 2.09 2.93 1660 140.1 32.1 67.0 9.3 87.1 2.15 4.03 1040 132.6 27.9 62.0 10.3 72.5 2.08 2.81 1290 128.3 23.6 58.5 9.3 69.0 1.97 2.76 1980 145.8 34.5 68.0 9.8 89.7 2.68 4.25 1210 133.3 25.6 61.5 9.9 71.0 2.11 2.82 1300 134.3 25.6 61.0 10.5 73.2 2.02 2.83 1310 138.1 27.8 61.2 9.9 73.5 2.09 2.78 1590 135.6 25.9 59.6 9.6 72.8 2.10 2.91 1270 128.3 24.1 58.5 10.3 69.2 1.92 2.77 1310 129.7 24.7 61.7 10.1 69.4 2.03 2.80 2280 143.6 37.6 70.0 9.7 88.8 2.17 4.18 1580 136.6 32.3 67.2 10.3 87.1 2.66 4.04 2370 147.4 38.8 73.0 10.8 90.7 2.82 4.38 ;proc cancorr;/*调用cancorr过程*/var x1-x4;/*定义一组变组变量*/with y1-y3;/*定义另一组变量*/。
SAS系统和数据分析一元线性回归分析

第三十一课一元线性回归分析回归分析是一种统计分析方法,它利用两个或两个以上变量之间的关系,由一个或几个变量来预测另一个变量。
在SAS/STA T中有多个进行回归的过程,如REG、GLM等,REG过程常用于进行一般线性回归模型分析。
一、回归模型1. 基本概念回归模型是一种正规工具,它表示统计关系中两个基本的内容:①用系统的形式表示因变量Y随一个或几个自变量X变化的趋势;②表现观察值围绕统计关系曲线的散布情况。
这两个特点是由下列假设决定的:●在与抽样过程相联系的观察值总体中,对应于每一个X值,存在Y的一个概率分布;这些概率分布的均值以一些系统的方式随X变化。
●图31.1是用透视的方法来显示回归曲线。
Y对给定X具有概率分布这一概念总是与统计关系中的经验分布形式上相对应;同样,描述概率分布的均值与X之间关系的回归曲线,与统计关系中Y系统地随X变化的一般趋势相对应。
图31.1线性回归模型的图示在回归模型中,X称为“自变量”,Y称为“因变量”;这只是传统的称法,并不表明在给定的情况下Y因果地依赖于X,无论统计关系多么密切,回归模型不一定是因果关系,在某些应用中,比如我们由温度表水银柱高度(自变量)来估计温度(因变量)时,自变量实际上依赖于因变量。
此外,回归模型的自变量可以多于一个。
2. 回归模型的构造(1)自变量的选择构造回归模型时必须考虑到易处理性,所以在有关的任何问题中,回归模型只能(或只应该)包括有限个自变量或预测变量。
(2) 回归方程的函数形式选择回归方程函数形式与选择自变量紧密相关。
有时有关理论可能指出适当的函数形式。
然而,通常我们预先并不能知道回归方程的函数形式,要在收集和分析数据后,才能确定函数形式。
我们经常使用线性和二次回归函数来作为未知性质回归方程的最初近似值。
图31.2(a)表示复杂回归函数可以由线性回归函数近似的情况,图31.2(b)表示复杂回归函数可以由两个线性回归函数分段近似的情况。
sas第7章

SAS 统计分析与应用 从入门到精通
6、GLM过程 、 过程
二、多元线性回归
GLM过程用来分析符合一般线性模型(General Linear Modeling) 的数据,利用该过程也可以实现一元线性回归和多元线性回归,其语句 格式为: PROC GLM DATA=数据集名 <选项>; MODEL 因变量名=自变量名列表 </选项>; BY 分组变量名; RUN; 其中,PROC语句和MODEL语句是必须的,其他语句可以根据用 户需要进行选用。
SAS 统计分析与应用 从入门到精通
1、可化为线性的曲线回归 、
三、曲线回归
由于曲线回归没有固定的模型和方法,因而很难进行处理和分析。但 是对于一些基本的曲线模型,我们可以通过变换将它们转化为线性模型, 继而利用线性回归的方法进行分析。
SAS 统计分析与应用 从入门到精通
2、REG 过程 、
三、曲线回归
2、模型的检验 、
一、一元线性回归
SAS 统计分析与应用 从入门到精通
2、模型的检验 、
一、一元线性回归
SAS 统计分析与应用 从入门到精通
3、利用回归方程进行预测 、
一、一元线性回归
SAS 统计分析与应用 从入门到精通
4、REG过程 、 过程
一、一元线性回归
REG过程是SAS系统中提供的用于一般线性回归的过程,通过此 过程可以实现一元回归分析,包括模型的建立和检验等。REG过程中 有很多的语句和选项,其中用于一元回归的基本语句格式为: PROC REG DATA=数据集名 <选项>; MODEL 因变量名=自变量名 </选项>; PLOT 纵轴变量名*横轴变量名 <=符号> </选项>; BY 分组变量名; RUN; 其中,PROC语句和MODEL语句是必须的,其他语句可以根据用 户需要进行选用。
SASGLM过程.

order=formated :要求人为指定数据显示格 式
order= freq:要求按观察值频次降序排列
统计计算 Statistical Computation
统计计算
GLM过程 Statistical Computation
Class 分类变量;/*此为第二条语句,后面 需model配合*/
Model 因变量 Y=自变量 X [/NOINT| INT|intercept|NounI |solution| tolerrance| E
|E1 |E2|E3|E4 |SS1 |SS2|SS3
|SS4|P|CLM|CLI|ALPHA= |
XPX|INVERSE|SINGULAR=1E-8或
0|ZETA=1E-8或0] 统计计算 Statistical Computation
统计计算
概述 Statistical Computation
本章目录
COGNTLRMAS中T 语‘对照句说的明格。式10个(汉续字),20个
字符’ 向量 L及元素[/E|E=effect或默认 为MS|ETYPE=n|SINGULAR=number];
采用GLM过程进行 回归和方差分析
1、 GLM应用背景 2、 GLM原理简介 3、 GLM的功能 4、 GLM的格式 5、 GLM作一元线性
回归
6、 GLM作多元线性回归 7 、GLM作多项式回归 8、虚拟变量的设置 9、多个随机实验组协方差 分析 ( GLM应用) Sas软件----GLM过程
表|P=变量表[RESIDUAL=变量表|R=变量 表]];
sas进行多元非线性回归+sas中方差分析解读

SAS进行多元非线性回归多元非线性回归方程重要方法是转化为线性回归方程.转化时应首先选择适合的非线性回归形式,并将其线性化。
对于实际问题,首先应对原始数据进行作图或通过观察,选择适当函数进行拟合。
已知1978~2006年全国GDP(y),第一产业x1、第二产业x2、工业生产总值x3、第三产业生产总值x4,请建立y对x1~x4的回归模型。
[plain]viewplaincopyprint?1. dataex;2. inputyx1-x4@@;3. y1=log(y);z1=log(x1);z2=log(x2);z3=log(x3);z4=log(x4);/*对数据做变化,取对数后再做回归分析*/4. cards;5. 16.84535.60927.44366.37353.79256. 21.3836.632910.05858.75844.69167. 23.17166.581911.14249.66235.44738. 25.72897.097412.318110.66416.31349. 28.62477.797313.510111.2887.317310. 32.31039.195214.634312.08648.480811. 36.403710.068816.166412.982210.168512. 45.077412.084419.730115.583813.262913. 51.474913.139522.25217.452816.083414. 63.413517.454327.536321.419321.122915. 82.348419.430435.629428.867827.288616. 92.714321.203139.383233.019432.12817. 101.463324.377240.579634.337836.506518. 117.417824.194148.475941.011444.747819. 147.521326.615162.683452.289358.221920. 188.895830.161382.385367.892176.349221. 253.057735.8777111.32491.4335105.85622. 320.407245.578137.4362102.6372137.39323. 397.570158.3757167.9238130.2389171.270624. 475.869168.732197.5005157.0486209.636625. 534.596970.7519222.8439174.1697241.001126. 580.03671.3285238.4684187.0766270.239127. 656.409874.1104268.3988206.0297313.900628. 728.077478.3636297.0933217.9077352.620529. 812.846979.1826328.0378229.521405.626530. 929.485883.2886393.6734268.2806452.523831. 1133.8828103.3327504.571341.5303525.979132. 1519.90112.59655.27469.28752.0433. 1790.66123.25774.66584.41892.7534. ;35. p rocreg;/*reg调用回归模块*/36. m odely1=z1z2z3z4/cli;/*表示以z1z2z3z4为自变量,y1为应变量建立回归模型,/cli表示要求预测区间。
SAS经济时间序列分各种模型分析

SAS经济时间序列分各种模型分析目录实验一分析太阳黑子数序列 (3)实验二模拟AR模型 (4)实验三模拟MA模型和ARMA模型 (6)实验四分析化工生产量数据 (8)实验五模拟ARIMA模型和季节ARIMA模型 (10)实验六分析美国国民生产总值的季度数据 (13)实验七分析国际航线月度旅客总数数据 (16)实验八干预模型的建模 (19)实验九传递函数模型的建模 (22)实验十回归与时序相结合的建模 (25)太阳黑子年度数据 (28)美国国民收入数据 (29)化工生产过程的产量数据 (30)国际航线月度旅客数据 (30)洛杉矶臭氧每小时读数的月平均值数据 (31)煤气炉数据 (35)芝加哥某食品公司大众食品周销售数据 (37)牙膏市场占有率周数据 (39)某公司汽车生产数据 (44)加拿大山猫数据 (44)实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:ods html;ods listing close;5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
7、提交程序,观察输出结果。
初步识别序列为AR(2)模型。
8、估计和诊断。
输入如下程序:9、提交程序,观察输出结果。
假设通过了白噪声检验,且模型合理,则进行预测。
10、进行预测,输入如下程序:11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。
sas 混合效应模型 拟合度

sas 混合效应模型拟合度全文共四篇示例,供读者参考第一篇示例:SAS(Statistical Analysis System)是一个强大的统计分析软件,它可以用来分析各种不同类型的数据。
混合效应模型是一种常用的统计模型,用于处理具有多层次结构的数据,比如在医学研究或者教育研究中经常遇到的长期跟踪研究数据。
拟合度是评价模型拟合数据的好坏程度的指标,通常用来判断模型是否能够较好地解释数据的变异。
在SAS中,混合效应模型可以通过PROC MIXED或者PROC GLIMMIX等过程来实现。
这些过程可以拟合包含随机效应的模型,并且可以评估拟合度以确定模型是否适合数据。
除了统计指标,混合效应模型的拟合度还可以通过图形化方法进行评估。
比如可以绘制残差图来查看模型是否存在偏差,或者绘制预测值和实际值的对比图来考察模型的预测能力。
在使用混合效应模型进行数据分析时,了解拟合度是非常重要的。
如果模型的拟合度较差,那么模型对数据的解释能力就会降低,进而影响到研究结论的可靠性。
在进行数据分析前,我们应该仔细评估模型的拟合度,确保选取到合适的模型来解释数据。
SAS的混合效应模型提供了一个强大的工具,可以用来处理各种多层次数据结构的统计分析问题。
评估模型的拟合度是确保分析结果可靠的重要环节,我们应该充分利用SAS的功能来进行详细的模型评估,以确保我们对数据的解释是准确和可靠的。
【字数:354】第二篇示例:SAS 混合效应模型是一种统计分析方法,可以同时考虑固定效应和随机效应,广泛应用于研究数据分析中。
在实际应用中,研究者经常会关心混合效应模型的拟合度,即模型对数据的拟合程度。
本文将介绍混合效应模型的概念及其在SAS 软件中的实现方式,并探讨如何评估混合效应模型的拟合度。
一、混合效应模型的概念混合效应模型是一种复杂的统计模型,适用于研究中存在多层次结构或随机效应的数据。
在混合效应模型中,数据可以分为两种效应:固定效应和随机效应。
线性混合模型对作物育种无重复试验数据分析的 实证研究

图 1 具有 99 个品系的试验 1 田间分布图 Fig .1 Field layout of trial 1 with 99 lines
3
CK2 S1 … S5 CK2 … … … CK2 S46 … S50 CK2
图 2 具有 50 个品系的试验 2 田间分布图 Fig .2 Field layout of trial 2 with 50 lines
[8-10] [6] [7]
。
近年来,随着线性混合模型理论的完善和统计分析软件的不断发展,为传统上不能进行统计分析的有关试 验提供了可能的分析途径。 根据线性混合模型分析原理,对以往不能进行统计分析的无重复试验数据提出统计分析方法,并利用 该方法和SAS软件对作物育种两种典型无重复试验设计的数据进行分析,展示对无重复试验应用线性混合 模型分析的程序和过程,为植物育种无重复试验分析的实现和广泛应用提供依据,进而达到改进无重复试 验在科学研究中应用成效的目的。解决植物育种无重复田间试验品系效应估计及其效应差异显著性统计测 验的问题。
Empirical Study on Analyzing Unreplicated Trials Data of Crop Breeding Based on Linear Mixed Model
Abstract;【Objective】The study provied a new method for analysing unreplicated datas ,and show how to use the PROC MIXED Program that provieded by SAS to analyse the unreplicated datas.【Method】Using linear mixed models to analyze unreplicated experimental data that come from crop breeding,the corresponding program and process for analyzing the data of unreplicated trials based on an international standard statistical software(SAS). The data characteristics of unreplicated trials and the drawbacks of classical analysis of variance being indicated,using the principle of covariance structures of linear mixed models to analyze unreplicated trial data , the information criteria of model fit was used for selecting the covariance structure model. .【Result】The empirical study showed that the linear mixed model analysis provided estimates and tests of line effects for the data of unreplicated plant breeding trials; The outcome in ranking and selection of the lines tested based on the estimates was different from that based on the observed value of the lines;The choice of covariance models had important impact on the results of analysis of unreplicated trials. 【Conclusion】The unreplicated experimental data could be analyzed using the PROC MIXED procedure in SAS based on the principle of the linear mixed model, so that the method can resolve the inferior comparable problems of unreplicated breeding lines and the problems of unreplicated trail data cannot be performed in significant test . Key words:Unreplicated trial; Model selection; Covariance structure; Information criterion
【原创】机器学习:在SAS中运行随机森林数据分析报告论文(附代码数据)

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog机器学习:在SAS中运行随机森林数据分析报告为了在SAS中运行随机森林,我们必须使用PROC HPFOREST指定目标变量,并概述天气变量是“类别”还是“定量”。
实例1为了进行此分析,我们使用了目标(Repsone变量),该目标是分类的(SAS 语言中标称的),如下面的图像代码中所描述的黄色和红色:运行代码后,我们得到了一系列表格,这些表格将详细分析数据。
例如,模型信息让我们知道,随机选择了3个变量来测试每个节点或每个树中可能的分割(黄色)。
我们还可以看到,运行的最大树数为100,如蓝色下划线所示。
该模型信息还告诉我们,“袋中部分”设置为默认值的60%,使OBB的比率为40%。
请注意,“修剪分数”默认设置为“ 0”,因为将其最接近设置为“ 1”,然后树木将具有的最低生长水平。
换句话说是不修剪。
HPFOREST自动仅使用在任何观察值下均没有缺失记录的有效变量。
但是,我们还可以看到,在研究样本的213个国家中,有213个被利用。
这是因为我已经利用了一组没有缺失值的县。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog接下来,我们可以看到模型生成带有“基线拟合统计量”的表。
就本研究中的数据而言,我们可以看到该模型识别出38%的误分类,换句话说是62%的准确分类。
这表示大部分样本已在每个随机选择的样本中正确分类。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog在下表中分析森林的适合度时,我们可以看到误分类率已经达到了最低点,树号为100.这表明在OOB样本中使用该模型进行测试时,误分类率仅在22%。
最后,我们看到SAS POC HPFOREST为我们提供了“损失减少变量的重要性”表。
下表概述了每个变量如何有助于模型的可预测性的重要性等级。
如下图所示,酒精变量排名最高。
SAS中的描述性统计过程

SAS中的描述性统计过程(2012-08—01 18:07:01)转载▼分类:数据分析挖掘标签:杂谈SAS中的描述性统计过程描述性统计指标的计算可以用四个不同的过程来实现,它们分别是means过程、summary过程、univariate过程以及tabulate过程。
它们在功能范围和具体的操作方法上存在一定的差别,下面我们大概了解一下它们的异同点。
相同点:他们均可计算出均数、标准差、方差、标准误、总和、加权值的总和、最大值、最小值、全距、校正的和未校正的离差平方和、变异系数、样本分布位置的t检验统计量、遗漏数据和有效数据个数等,均可应用by语句将样本分割为若干个更小的样本,以便分别进行分析。
不同点:(1)means过程、summary过程、univariate过程可以计算样本的偏度(skewness)和峰度(kurtosis),而tabulate过程不计算这些统计量;(2)univariate过程可以计算出样本的众数(mode),其它三个过程不计算众数;(3)summary过程执行后不会自动给出分析的结果,须引用output语句和print过程来显示分析结果,而其它三个过程则会自动显示分析的结果;(4)univariate过程具有统计制图的功能,其它三个过程则没有;(5)tabulate过程不产生输出资料文件(存储各种输出数据的文件),其它三个均产生输出资料文件.统计制图的过程均可以实现对样本分布特征的图形表示,一般情况下可以使用的有chart过程、plot过程、gchart过程和gplot过程。
大家有没有发现前两个和后两个只有一个字母‘g’(代表graph)的差别,其实它们之间(只差一个字母g的过程之间)的统计描述功能是相同的,区别仅在于绘制出的图形的复杂和美观程度.chart过程和plot过程绘制的图形类似于我们用文本字符堆积起来的图形,只能概括地反映出资料分布的大体形状,实际上这两个过程绘制的图形并不能称之为图形,因为他根本就没有涉及一般意义上图形的任何一种元素(如颜色、分辨率等)。
使用SAS进行变量筛选、模型诊断、多元线性回归分析

使用SAS进行变量筛选、模型诊断、多元线性回归分析在其他地方看到的帖子,自己动手做了实验并结合自己的理解做了修订第一节多元线性回归分析的概述回归分析中所涉及的变量常分为自变量与因变量。
当因变量是非时间的连续性变量(自变量可包括连续性的和离散性的)时,欲研究变量之间的依存关系,多元线性回归分析是一个有力的研究工具。
多元回归分析的任务就是用数理统计方法估计出各回归参数的值及其标准误差;对各回归参数和整个回归方程作假设检验;对各回归变量(即自变量)的作用大小作出评价;并利用已求得的回归方程对因变量进行预测、对自变量进行控制等等。
值得注意的是∶一般认为标准化回归系数的绝对值越大,所对应的自变量对因变量的影响也就越大。
但是,当自变量彼此相关时,回归系数受模型中其他自变量的影响,若遇到这种情况,解释标准化回归系数时必须采取谨慎的态度。
当然,更为妥善的办法是通过回归诊断(The Diagnosis of Regression),了解哪些自变量之间有严重的多重共线性(Multicoll-inearity),从而,舍去其中作用较小的变量,使保留下来的所有自变量之间尽可能互相独立。
此时,利用标准化回归系数作出解释,就更为合适了。
关于自变量为定性变量的数量化方法设某定性变量有k个水平(如ABO血型系统有4个水平),若分别用1、2、…、k代表k个水平的取值,是不够合理的。
因为这隐含着承认各等级之间的间隔是相等的,其实质是假定该因素的各水平对因变量的影响作用几乎是相同的。
比较妥当的做法是引入k-1个哑变量(Dummy Variables),每个哑变量取值为0或1。
现以ABO血型系统为例,说明产生哑变量的具体方法。
当某人为A型血时,令X1=1、X2=X3=0;当某人为B型血时,令X2=1、X1=X3=0;当某人为AB型血时,令X3=1、X1=X2=0;当某人为O型血时,令X1=X2=X3=0。
这样,当其他自变量取特定值时,X1的回归系数b1度量了E(Y/A型血)-E(Y/O型血)的效应;X2的回归系数b2度量了E(Y/B型血)-E(Y/O型血)的效应;X3的回归系数b3度量了E(Y/AB型血)-E(Y/O型血)的效应。
一般混合线性模型SAS的MIXED过程实现_混合线性模型及其SAS软件实现_一_

一般混合线性模型SAS的M IXED过程实现———混合线性模型及其SAS软件实现(一)山西医科大学卫生统计教研室(030001) 张岩波 何大卫 刘桂芬 王琳娜 郭明英 【提 要】 目的 系统结构数据在医学领域广泛存在,其统计分析方法各异,可统称之为混合模型。
本文研讨其实现方法。
方法 以多水平模型例证一般混合线性模型的SAS M IX ED实现过程。
结果 以JSP数据为实例显示SAS的拟合结果与M Ln相一致。
结论 SAS M IXED可灵活地拟合包括多水平模型的各类混合模型。
【关键词】 系统结构数据 混合线性模型 多水平模型 M IX ED过程 近些年,国内医学统计学界对系统结构数据有了较多的认识,并进行了大量实效的研究和应用。
徐勇勇教授对系统结构数据做了全面的表述〔1〕。
由于常规的统计方法分析这类数据时忽略了误差结构,因此分析方法多采用以下模型:混合线性模型(Mixed lin-ear,M LM)、分层线性模型(Hierarchical linear, H LM)、广义线性混合模型(Generalized linear mixed, GLM M)、分层广义线性模型(Hierarchical generalized linear,HGLM)、多水平模型(Multilevel,M LM)、方差成分模型(Variance components,VCM)、随机系数模型(Random coefficients,RCM)等,以下且统称之为混合模型。
分析模型相应的软件有自行开发的软件(如陈长生博士针对重复测量数据自行开发的REP软件)及国外开发的专业软件,如M Ln(或M lw iN)软件,其他还有BUGS、H LM、VARCL等软件。
由于至今各种方法仍处于发展完善阶段,加之工具软件的限制,大大制约了此类方法的实际应用。
目前国内SAS软件已相当普及,其新增的M IXED模块及宏程序GLIM-M IX、NLINM IX可以有效、灵活地拟合各类混合模型,无疑为上述数据提供了有力的分析工具〔2,3〕。
SAS宏程序%HPGLIMMIX在大样本数据广义线性混合模型参数估计中的应用

-计算机应用-SAS 宏程序% HPGLIMMIX 在大样本数据广义线性混合模型参数估计中的应用**基金项目:国家重点研发计划精准医学研究重点专项(2017 YFC0907200,2017 YFC0907201)#共同第一作者△通信作者:赵亚玲,E-mail : zhaoyl666 @ xjtu. edu. cn ;颜虹,E-mail : yanhonge@ xjtu. edu. cn西安交通大学医学部公共卫生学院流行病与卫生统计学系(710061)吴晨璐#米白冰#陈方尧裴磊磊史青云赵亚玲△ 颜虹^【提 要】 目的 SAS 软件中目前实现广义线性混合模型的过程步主要包括PROC GLIMMIX 和PROC NLMIXED ,两种方法在实际应用中各有侧重。
本文介绍一个可以提高广义线性混合模型运行效率的SAS 宏程序%HPGLIMMIX 的使用方法及其结果解读。
方法通过实例数据,介绍% HPGLIMMIX 分析正态分布和二项分布数据的过 程,并展示采用%HPGLIMMIX 分析大样本数据的性能优势。
结果对于小样本正态分布和二项分布数据,采用% HPGLIMMIX 和GLIMMIX 、NLMIXED 分析的用法基本一致。
对于大样本数据,% HPGLIMMIX 可进行模型拟合并可有 效节省时间及计算资源。
结论 %HPGLIMMIX 可有效提升大样本数据的广义线性混合模型拟合的效率。
NLMIXED 过 程可以快速准确地进行参数估计。
【关键词】 广义线性混合模型 % HPGLIMMIX GLIMMIX NLMIXED SAS 宏【中图分类号】R195. 1 【文献标识码】A DOI 10. 3969/j. issn. 1002 -3674.2021.01.036队列和临床试验等医学研究中经常遇到重复测量 的纵向数据。
此类数据不满足观测时点间的独立性假 设,故不宜采用传统的线性模型(linear models , LM ),而应采用纳入随机效应项的混合模型(mixed model , MM )进行分析[1]。
sas分类模型的混淆矩阵性能评估

sas分类模型的混淆矩阵性能评估跑完分类模型(Logistic回归、决策树、神经网络等),我们经常面对一大堆模型评估的报表和指标,如Confusion Matrix、ROC、Lift、Gini、K-S之类(这个单子可以列很长),往往让很多在业务中需要解释它们的朋友头大:“这个模型的Lift是4,表明模型运作良好。
——啊,怎么还要解释ROC,ROC如何如何,表明模型表现良好……”如果不明白这些评估指标的背后的直觉,就很可能陷入这样的机械解释中,不敢多说一句,就怕哪里说错。
本文就试图用一个统一的例子(SAS Logistic回归),从实际应用而不是理论研究的角度,对以上提到的各个评估指标逐一点评,并力图表明:1.这些评估指标,都是可以用白话(plain English, 普通话)解释清楚的;2.它们是可以手算出来的,看到各种软件包输出结果,并不是一个无法探究的“黑箱”;3.它们是相关的。
你了解一个,就很容易了解另外一个。
本文从混淆矩阵(Confusion Matrix,或分类矩阵,Classification Matrix)开始,它最简单,而且是大多数指标的基础。
数据本文使用一个在信用评分领域非常有名的免费数据集,German Credit Dataset,你可以在UCI Machine Learning Repository找到(下载;数据描述)。
另外,你还可以在SAS系统的Enterprise Miner的演示数据集中找到该数据的一个版本(dmagecr.sas7bdat)。
以下把这个数据分为两部分,训练数据train和验证数据valid,所有的评估指标都是在valid数据中计算(纯粹为了演示评估指标,在train数据里计算也未尝不可),我们感兴趣的二分变量是good_bad,取值为{good, bad}:Train data good_bad Frequency Percent-------------------------------------------bad 154 25.67 good 446 74.33Valid data good_bad Frequency Percent--------------------------------------------bad 146 36.50 good 254 63.50信用评分指帮助贷款机构发放消费信贷的一整套决策模型及其支持技术。
用SAS的mixed过程拟合林分的线性差分生长模型

用SAS的mixed过程拟合林分的线性差分生长模型【摘要】本研究的目的在于研究如何用SAS的proc mixed过程拟合线性代数差分模型。
所用数据来源于148个集约经营火炬松人工林。
直接拟合了一个胸高断面积的收获模型,而非代数差分生长模型。
模型拟合过程如下:i).同时确定随林分变化的参数和最优拟合的方差结构模型;ii).依据AIC、BIC和极大似然比检验化简期望模型;iii).用代数差分法将拟合的收获模型转化为代数差分生长模型。
【关键词】线性代数差分模型;mixed过程;模型筛选;林分生长与收获预估0.前言在林分生长与收获预估的模型中,差分生长模型得到了广泛的应用。
线性差分模型基本上为Schumacher模型的变型,广泛应用于林分蓄积、胸高断面积的建模,以及单位面积株数和优势木树高生长模型。
差分生长模型拟合方法有“直接最小二乘估计法”和“分类变量回归法”[1]。
一般认为后者可以获得近似无偏的估计,而前者则导致检验统计量如RMSE的失真[2]。
传统上差分生长模型的拟合主要是直接拟合差分生长模型,然后根据拟合统计量如RMSE、R2等确定最优拟合模型。
与传统方法不同,本文直接拟合生长模型,在获得参数估计值后,再用代数差分法导出相应的代数差分生长模型。
这样做的优越之处在于非常便于对期望模型和方差结构模型进行筛选。
更为重要的是,可以通过模型拟合识别最适合的随林分变化参数。
本文详细讨论了如何用“分类变量回归法”和SAS的mixed过程拟合代数差分生长模型,可简述如下:i).直接以生长收获模型为对象,同时确定一个随林分变化的参数和最优拟合方差结构模型;ii). 保持方差结构模型不变,根据拟合统计量逐步化简期望模型;iii).在确定最优拟合的期望模型后,运用代数差分法导出相对应的代数差分生长模型。
所有拟合与筛选均用SAS的mixed过程完成,并给出了详细的SAS代码和代码解释。
1.方法与材料1.1数据数据来源于148个集约经营的火炬松实验人工林逐年观测的固定样地数据(样地约0.152公顷)。
一般混合线性模型SAS的MIXED过程实现_混合线性模型及其SAS软件实现_一_
一般混合线性模型SAS的M IXED过程实现———混合线性模型及其SAS软件实现(一)山西医科大学卫生统计教研室(030001) 张岩波 何大卫 刘桂芬 王琳娜 郭明英 【提 要】 目的 系统结构数据在医学领域广泛存在,其统计分析方法各异,可统称之为混合模型。
本文研讨其实现方法。
方法 以多水平模型例证一般混合线性模型的SAS M IX ED实现过程。
结果 以JSP数据为实例显示SAS的拟合结果与M Ln相一致。
结论 SAS M IXED可灵活地拟合包括多水平模型的各类混合模型。
【关键词】 系统结构数据 混合线性模型 多水平模型 M IX ED过程 近些年,国内医学统计学界对系统结构数据有了较多的认识,并进行了大量实效的研究和应用。
徐勇勇教授对系统结构数据做了全面的表述〔1〕。
由于常规的统计方法分析这类数据时忽略了误差结构,因此分析方法多采用以下模型:混合线性模型(Mixed lin-ear,M LM)、分层线性模型(Hierarchical linear, H LM)、广义线性混合模型(Generalized linear mixed, GLM M)、分层广义线性模型(Hierarchical generalized linear,HGLM)、多水平模型(Multilevel,M LM)、方差成分模型(Variance components,VCM)、随机系数模型(Random coefficients,RCM)等,以下且统称之为混合模型。
分析模型相应的软件有自行开发的软件(如陈长生博士针对重复测量数据自行开发的REP软件)及国外开发的专业软件,如M Ln(或M lw iN)软件,其他还有BUGS、H LM、VARCL等软件。
由于至今各种方法仍处于发展完善阶段,加之工具软件的限制,大大制约了此类方法的实际应用。
目前国内SAS软件已相当普及,其新增的M IXED模块及宏程序GLIM-M IX、NLINM IX可以有效、灵活地拟合各类混合模型,无疑为上述数据提供了有力的分析工具〔2,3〕。
用Mixed和Nlmixed过程建立混合生长模型

用Mixed和Nlmixed过程建立混合生长模型
李永慈;唐守正
【期刊名称】《林业科学研究》
【年(卷),期】2004(017)003
【摘要】本文用5块不同密度样地的树高生长资料,根据线性和非线性混合模型理论,利用SAS的Mixed过程和Nlmixed过程,分别拟合线性混合模型和非线性混合树高生长模型.根据预测值和固定效应同时绘制出不同密度下的高生长曲线和平均高生长曲线,充分显示了混合模型的优势,即它可以同时反映总体的平均变化趋势和个体之间的差异.
【总页数】5页(P279-283)
【作者】李永慈;唐守正
【作者单位】北京林业大学资源与环境学院,北京,100083;中国林业科学研究院资源信息研究所,北京,100091
【正文语种】中文
【中图分类】S758.5
【相关文献】
1.带时依协变量的重复测量资料的混合线性模型分析及其MIXED过程实现 [J], 张莉娜
2.一般混合线性模型SAS的MIXED过程实现──混合线性模型及其SAS软件实现(一) [J], 张岩波;何大卫;刘桂芬;王琳娜;郭明英
3.重复测量数据的混合模型及其MIXED过程实现 --混合线性模型及其SAS软件
实现(二) [J], 张岩波;何大卫;刘桂芬;张晋昕;郭静
4.混合层建立对一次强阵风天气过程的影响 [J], 汪靖;赵玉洁;吴振玲;蔡子颖
5.混合教学模式下监测与评价学生学习过程研究框架的建立 [J], 颜莹;李小武;季洪梅;石锋
因版权原因,仅展示原文概要,查看原文内容请购买。
SAS系统中线性回归模型的选择

3 4
荆州师范学院学报 (自然科学版)
2003 年 4 月
选择法( rwquare) 、修正 R2 选择法 (adirsq) 、Mallows 的 Cp 选择法 (cp) .
2 模型选择的一般标准
在 SAS 程序的输出中 ,有下列几类检验参数值 :第一类 , 复测定系数 R2 ( R2 ≤1) 、F 检验值及 prob > F 的值 ,它们是衡量回归效果好坏的指标. 一般来说 R2 越接近于 1 ,回归效果越好 ;prob > F 的值小于 0. 05 (或 0. 01) ,说明在 α= 0. 05 (或 0. 01) 水平上线性关系显著 (或极显著) , 否则线性关系不显著. 第二类 , 各回归系 数的 t 检验值和 prob > | T| 的值. prob > | T| 的值小于 0. 05 (或 0. 01) ,说明回归系数在α= 0. 05 (或 0. 01) 水 平上是显著的 (或极显著) ,否则不显著. 第三类 ,预测残差平方 press 的值 ,它可用来比较不同方法所建立的 模型的优劣. press 越小 ,模型越好.
响应变量的方差也就是误差的方差对所有观测均为常数记为在以上的假设下可由最小二乘估计求得未知参数的估计值应使误差平方和sse用均方误差mse估计sas系统中reg线性回归过程共有九种模型方法它们分别是全回归模型none逐步引入法for2ward逐步剔除法backward逐步筛选法stepwise最大增量法maxr最小增量法minr荆州师范学院学报自然科学版vol126no122003jingzhouteacherscollegenaturalscienceapr
对所取得的实验数据 ,首先用全回归模型建模 ,若能同时通过第一 、第二类检验 ,则此模型是很好的线性 回归模型 ,否则 ,不是线性的 ,要用特殊回归模型来做. 在许多情况下 ,所建立的模型能通过第一类检验 ,而不 能通过第二类检验 ,这与变量间的多重相关性有关. 这时可计算变量间的相关系数矩阵 , 用主成分方法生成 另一数据集 ,再建立回归模型. 其次 ,所有的模型都是有实际意义的 , 在建模过程中要结合实际情况进行分 析 ,综合比较 ,最终找出较好的模型.
基于1stOpt+软件的树高测量模型1)

min mk(S
)
=f
k
+g
T k
S+21
ST
G
k
S 。
s .t.‖S‖≤hk
当信赖域模型中的范数‖S ‖≤hk 取 2 范数 时,得到 LM-UGO 算法的数学模型:
min mk( S)
=f
k
+g
T k
S+21
SGT
k
S 。
s.t.‖S‖2 ≤hk
2.3 1stOpt(LM -UGO)法
1stOpt 是七维高科有限公司开发的数学优化分
由 1stOpt 自身随机给出,通过其独特的全局优化算
法,最终得出最优解。
2.4 SPSS 软件的最小二乘法
SPSS 软件作为集数据处理、图表编辑、统计分
析以及数据接口于一体的大型通用专业统计分析软
件,具备强大的频数分布分析、相关分析、回归分析
等功能[14] 。 而普通最小二乘法是线性回归模型最
重要的参数估计方法之一[15] 。 因此 数据来源 在旺业甸实验林场标准样地,利用电子经纬仪
测得 181 株落叶松立木实测数据。 剔除有明显误差 的数据后, 将 全 部 样 木 数 据 作 为 建 模 样 本, 按 照 胸 径、树高、材积进行统计,样木数据基本情况统计如 表 1 所示。
表 1 样木数据基本情况统计
统计量
最大值 最小值 平均值
using new evaluation method .The fitting result using LM -UGO was better than that using traditional SPSS method .After inspected by F, the relationship of F of two methods were : F >F >F , LM-UGO SPSS最小二乘法 0.05(1,179) and R2 >0.9, CV <50%, and the value of TRE and MSE were both less than ±3%.The results can meet the requirements of assessment index range and the relevant provisions of the Forestry Survey Technology .
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用SAS的mixed过程拟合林分的线性差分生长模型【摘要】本研究的目的在于研究如何用SAS的proc mixed过程拟合线性代数差分模型。
所用数据来源于148个集约经营火炬松人工林。
直接拟合了一个胸高断面积的收获模型,而非代数差分生长模型。
模型拟合过程如下:i).同时确定随林分变化的参数和最优拟合的方差结构模型;ii).依据AIC、BIC和极大似然比检验化简期望模型;iii).用代数差分法将拟合的收获模型转化为代数差分生长模型。
【关键词】线性代数差分模型;mixed过程;模型筛选;林分生长与收获预估0.前言在林分生长与收获预估的模型中,差分生长模型得到了广泛的应用。
线性差分模型基本上为Schumacher模型的变型,广泛应用于林分蓄积、胸高断面积的建模,以及单位面积株数和优势木树高生长模型。
差分生长模型拟合方法有“直接最小二乘估计法”和“分类变量回归法”[1]。
一般认为后者可以获得近似无偏的估计,而前者则导致检验统计量如RMSE的失真[2]。
传统上差分生长模型的拟合主要是直接拟合差分生长模型,然后根据拟合统计量如RMSE、R2等确定最优拟合模型。
与传统方法不同,本文直接拟合生长模型,在获得参数估计值后,再用代数差分法导出相应的代数差分生长模型。
这样做的优越之处在于非常便于对期望模型和方差结构模型进行筛选。
更为重要的是,可以通过模型拟合识别最适合的随林分变化参数。
本文详细讨论了如何用“分类变量回归法”和SAS的mixed过程拟合代数差分生长模型,可简述如下:i).直接以生长收获模型为对象,同时确定一个随林分变化的参数和最优拟合方差结构模型;ii). 保持方差结构模型不变,根据拟合统计量逐步化简期望模型;iii).在确定最优拟合的期望模型后,运用代数差分法导出相对应的代数差分生长模型。
所有拟合与筛选均用SAS的mixed过程完成,并给出了详细的SAS代码和代码解释。
1.方法与材料1.1数据数据来源于148个集约经营的火炬松实验人工林逐年观测的固定样地数据(样地约0.152公顷)。
SAS的数据集basal的内容如表(1)。
表1 模型拟合的基本数据结构Table 1 data structure for mode fittingage=林分年龄;fert=经营措施,分别取值为H=施加除草剂以控制竞争植物、F=施肥以增加土壤肥力、HF=除草剂和施肥并用、C=对照;code=样地代码,每个样地有一个唯一代码;logba=样地胸高断面积的自然对数值;logdh=样地优势木树高的自然对数值;iage=林分年龄的倒数;logtpa=样地株数的自然对数值。
共有148个样地数据,1491个记录。
1.2数学模型所考虑的胸高断面积收获的数学模型为E(lny)=α+αlnN+αlnH+α+α (1)这里lny、lnH和lnN分别对应logba、logdh和logtpa;1/t对应iage,其余为模型参数。
通过不同假设,以上模型可以导出很多广泛应用的差分生长模型。
例如假设α0为随林分变化的参数,运用代数差分法可以导出Pienaar和Shiver (1986)的胸高断面积模型[3];假设α4=0且α0为随林分变化的参数则可导出Forss等人(1996)提出的差分生长模型[4];假设α4=0和α2=0且α3为随林分变化的参数,则可以导出Souter (1986)的模型[5]。
1.3参数估计方法从以上代数差分法的讨论中,总是假设模型(1)中有一个参数随林分变化而变化,因而使用“分类变量回归法”以便考虑这一特点。
如果用SAS的reg过程,必须构造特殊的数据结构。
用SAS的reg过程拟合线性差分生长模型有两点不足之处:1).需要构造复杂的数据文件。
以本研究的为例,数据文件中需要增加额外的148个变量;2).reg过程无法考虑重复观测数据的自相关性和异质方差结构。
由于所考虑的胸高断面积模型均为线性模型,而且数据为典型的重复观测数据,因而模型的拟合与筛选均用SAS的proc mixed过程。
1.4模型筛选和筛选指标选用模型筛选包括期望模型和最优拟合的自相关与异质方差结构模型的筛选。
Ngo和Brand(1997)推荐了两种模型选择方法[6]。
一种方法就是首先列出所有可用的数学期望模型和所有可能的方差结构模型,拟合二者间的所有组合,然后根据模型拟合指标选择最优拟合模型。
另一种方法为Wolfinger和Diggle提出的方法,即首先考虑最复杂的期望模型,并保持期望模型不变,然后选择最优拟合的方差结构模型。
一旦选出最优拟合的方差模型,保持方差模型不变,再逐步简化期望模型。
模型筛选指标较多,但常用的指标为极大似然比检验(LRT)、AIC、BIC(或称为SBC)。
LRT用于嵌套的模型,而AIC和BIC用于非嵌套模型。
2.结果与分析2.1残差的方差结构模型为考虑经营措施对胸高断面积生长过程的影响,将模型(1)改写如下:(2)这里参数?为不同经营措施对截距和各项回归系数的影响,下标k分别取值为C、F、H和HF,对应四种经营措施;由于差分生长模型需要确定一个随林分变化而变化的参数,因而模型拟合的首要任务就是识别该参数。
假设“1/t”的回归系数随林分变化而变化,那么模型(2)则可以表示如下:这里βi为随林分变化的参数。
根据以往的研究,所考虑的方差模型为:CS模型(同一林分不同年龄的观测值方差相同,而且相关系数为常数)、AR(1)模型(不同年龄观测值的方差相同,但相关系数为一阶自相关模型)、ARH(1)模型(相关系数为一阶自相关模型,但不同年龄观测值的方差相异)和ARMA(1,1)模型(不同年龄观测值的方差相同,但相关系数为一阶自相关移动平均模型)。
由于模型(2)中共有5个参数可以考虑为随林分而变化的参数(b0~b4),因而相对应地共有5个期望模型,加上所考虑的4个方差结构模型,所有组合共计为20个模型。
首先拟合这20个模型,根据拟合统计量AIC、BIC确定随林分变化的参数及最优拟合的方差结构模型,这部分与Ngo和Brand的方法一致;然后保持方差结构模型不变,根据LRT、AIC、BIC剔除回归效果不显著的因子,包括经营措施效果等,即化简期望模型。
而这一部分则与Wolfinger和Diggle的方法一致。
方差结构筛选的基本SAS代码如下:以上代码及以后代码中的粗体字为SAS系统关键词。
class语句声明了3个分类变量,分别为fert、code及age。
model语句中既包含离散型的分类变量,又包含连续型变量(如logba、logtp等,即未在class语句中声明的变量)。
以上代码的model语句意义如下:i).代码中model语句中的分类变量表示该变量对回归模型截距的影响。
例如model语句中fert表示不同经营措施下的logba的回归模型的截距不同,随fert 变量的取值变化而变化。
ii).如果一个连续型变量与一个分类变量的乘积出现model语句中,且仅以该形式出现,如code*iage,则表示该连续型变量的回归系数随分类变量的取值变化而变化。
code是一个分类变量,每个取值对应一个样地,而iage为一个连续型变量,那么code*iage则表示每个样地的iage项的回归系数均不相同,各有其取值。
iii).如果一个连续型变量与一个分类变量的乘积出现,而且该连续型变量同时独立出现在模型中,同样表示该连续型变量的回归系数随分类变量的取值变化而变化,但与ii)的意义有所不同。
例如logdh和fert*logdh同时出现在model 语句中,表示logdh的回归系数随fert取值的变化而变化,而且每个fert取值的回归系数均表示为两个分量之和。
一个分量为参照回归系数,另一个分量为与参照回归系数相比的增量(可负可正)。
mixed过程按照英文字母的排列顺序,以fert的最后一个取值(即HF)为参照,其回归系数即为参照回归系数。
而fert 其它取值的回归系数则表示为参照回归系数(即HF)和与之相比增量之和。
以上model语句的对应的数学模型如下:以上四个模型分别对应经营措施C、F、H和HF的回归模型。
参数α0、α1、α2、α4为在HF经营措施下,林分胸高断面积的回归系数(参照回归系数);参数φi,k为k经营措施的第i个回归系数与HF相对应的回归系数相比之增量(k 取值为C、H和F)。
以对照C的lnH的系数为例,其回归系数为α2+φ2,C。
这里φ2,C就是C的lnH的回归系数与HF的lnH的回归系数相比的增量。
以上代码中,fert*logtpa、fert*logdh及fert*logdh*iage分别对应各项回归系数与HF 的回归系数相比的增量,即φ;logtpa、logdh及logdh*iage则对应参照回归系数,即HF的回归系数α0、α1、α2和α4等。
依据模型拟合统计量AIC和BIC值(其值越小,拟合效果越好)选择模型,指定1/t的回归系数为随林分变化的参数和arh(1)为方差结构模型时,AIC和BIC均取得了最小值,分别为-3629.9和-3585.0。
因而arh(1)为最优拟合的方差结构模型,并且可以确认1/t的回归系数为随林分变化的参数。
2.2最优拟合的期望模型保持arh(1)结构不变,根据AIC、BIC及极大似然比检验的p值进行期望模型的筛选。
模型(3)的拟合结果表明,经营措施H和HF各个参数差异并不显著,φ0,H、φ1,H、φ2,H 和φ4,H是否为0的t检验p值均大于0.05,说明经营措施H的各项回归系数与HF并无显著差别。
将二者的回归系数合并为一,仅保留截距不同,可拟合如下模型:(4)这里bi,k=αi,k+φi,k(i=0,1,2,4;k=C,F,H和HF);b1,p、b2,p、b4,p为经营措施H和HF的回归系数,b0,H和b0,HF则分别为二者的截距。
模型(3)便于比较不同经营措施的效果异同,而模型(4)则便于化简期望模型,即判断一个回归因子对胸高断面积的影响是否显著。
注意模型(3)和(4)的唯一区别仅在于将模型(3)中第3个和第4个模型合并为一个而已(仅截距不同)。
为拟合以上模型,新引进了一个分类变量“f”,其取值分别为C、F和H,其中经营措施H和HF的样地“f”变量值均为H。
拟合模型(4)的SAS代码如下:模型(4)的AIC、BIC的值均小于模型(3)的AIC和BIC值,LRT检验p 值为0.1573,表明模型(4)与模型(3)拟合效果基本相当,但模型(4)更为简洁。
由于参数的t检验结果表明仅对照C的lnH/t参数与0相比差异显著,因而剔除F、H和HF的lnH/t项(相应的模型称为模型5)。
相对应地,在SAS的数据文件中引入了一个新变量“check”,当且仅当林分的经营措施为C取值为1,其它情形均取值为0。