遗传算法C++
遗传算法旅行商问题c语言代码

遗传算法是一种模拟自然选择过程的优化算法,可以用于解决各种复杂的组合优化问题。
其中,旅行商问题是一个经典的组合优化问题,也是一个典型的NP难题,即寻找最优解的时间复杂度是指数级的。
在本文中,我们将讨论如何使用遗传算法来解决旅行商问题,并给出相应的C语言代码实现。
我们将介绍旅行商问题的数学模型,然后简要介绍遗传算法的原理,最后给出C语言代码实现。
旅行商问题是指一个旅行商要拜访n个城市,恰好拜访每个城市一次,并返回出发城市,要求总路程最短。
数学上可以用一个n*n的距离矩阵d[i][j]表示城市i到城市j的距离,问题可以形式化为求解一个排列p={p1,p2,...,pn},使得目标函数f(p)=Σd[p[i]][p[i+1]]+d[p[n]][p[1]]最小。
这个问题是一个组合优化问题,其搜索空间是一个n维的离散空间。
遗传算法是一种基于生物进化过程的优化算法,主要包括选择、交叉、变异等操作。
在使用遗传算法解决旅行商问题时,可以将每个排列p看作一个个体,目标函数f(p)看作个体的适应度,通过选择、交叉和变异等操作来搜索最优解。
以下是遗传算法解决旅行商问题的C语言代码实现:1. 我们需要定义城市的距离矩阵和其他相关参数,例如城市的数量n,种裙大小pop_size,交叉概率pc,变异概率pm等。
2. 我们初始化种裙,即随机生成pop_size个排列作为初始种裙。
3. 我们进入遗传算法的迭代过程。
在每一代中,我们首先计算种裙中每个个体的适应度,然后通过选择、交叉和变异操作来更新种裙。
4. 选择操作可以采用轮盘赌选择法,即根据个体的适应度来进行选择,适应度越高的个体被选中的概率越大。
5. 交叉操作可以采用部分映射交叉方法,即随机选择两个个体,然后随机选择一个交叉点,将交叉点之后的基因片段进行交换。
6. 变异操作可以采用变异率为pm的单点变异方法,即随机选择一个个体和一个位置,将该位置的基因值进行随机变异。
7. 我们重复进行迭代操作,直到达到停止条件(例如达到最大迭代次数或者适应度达到阈值)。
基于C语言的遗传算法应用研究

基于C语言的遗传算法应用研究介绍遗传算法是一种受生物学启发的优化算法,通过模拟进化过程来寻找最优解。
它被广泛应用于解决各种复杂问题,如组合优化、函数优化、机器学习等领域。
在本文中,我们将讨论基于C语言的遗传算法的应用研究。
遗传算法的原理遗传算法的原理是基于自然选择和遗传机制。
它模拟了生物进化过程中的选择、复制和变异等操作。
算法通过对一个种群进行迭代操作来逐步优化解的质量,直到找到全局最优解或最优近似解。
遗传算法主要包含以下几个关键步骤: 1. 初始化种群:随机生成一组个体作为初始种群。
2. 评估适应度:根据问题的定义,对每个个体计算适应度值。
3.选择操作:根据适应度值选择优秀的个体作为父代。
4. 交叉操作:通过交叉操作,将父代的基因进行混合,生成新的子代。
5. 变异操作:对子代进行变异,引入新的基因信息。
6. 更新种群:用新的个体替代原来的个体,形成新的种群。
7. 终止条件:根据预先设定的终止条件,决定算法是否结束。
C语言在遗传算法中的应用C语言作为一种通用的高级编程语言,具有高效、灵活和可移植的特点,非常适合在遗传算法中实现。
以下是C语言在遗传算法中的几个关键应用。
种群表示C语言可以使用数组或结构体等数据结构来表示遗传算法的种群。
每个个体可以用一个固定长度的二进制串或其他数据类型来表示。
C语言提供了强大的数组操作功能,使得种群的处理和操作更加简便和高效。
适应度函数C语言可以定义适应度函数来评估每个个体的适应度值。
适应度函数根据问题的特定要求来计算一个个体的适应度值,作为选择操作的依据。
C语言提供了丰富的数学函数库,使得适应度函数的计算更加方便。
选择操作C语言可以使用多种选择算法来选择优秀的个体作为父代。
例如,可以使用轮盘赌选择、锦标赛选择等方法来实现选择操作。
C语言提供了条件语句和随机数生成等功能,使得选择操作的实现简单而灵活。
交叉操作C语言可以通过交叉操作将父代的基因混合,生成新的子代。
遗传算法的C语言程序案例
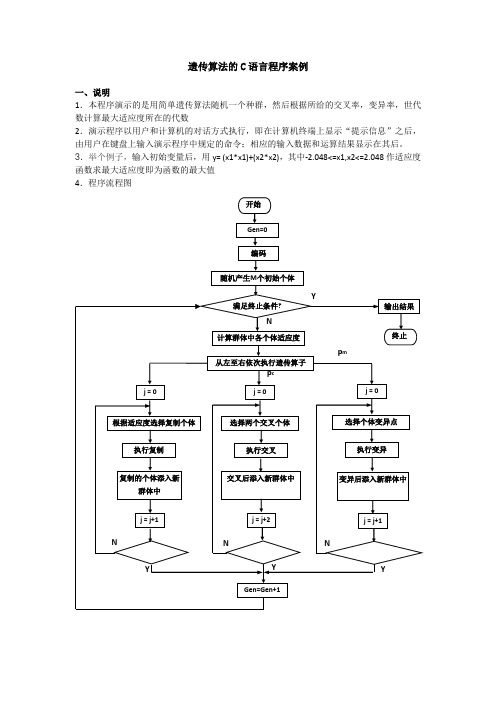
遗传算法的C语言程序案例一、说明1.本程序演示的是用简单遗传算法随机一个种群,然后根据所给的交叉率,变异率,世代数计算最大适应度所在的代数2.演示程序以用户和计算机的对话方式执行,即在计算机终端上显示“提示信息”之后,由用户在键盘上输入演示程序中规定的命令;相应的输入数据和运算结果显示在其后。
3.举个例子,输入初始变量后,用y= (x1*x1)+(x2*x2),其中-2.048<=x1,x2<=2.048作适应度函数求最大适应度即为函数的最大值4.程序流程图5.类型定义int popsize; //种群大小int maxgeneration; //最大世代数double pc; //交叉率double pm; //变异率struct individual{char chrom[chromlength+1];double value;double fitness; //适应度};int generation; //世代数int best_index;int worst_index;struct individual bestindividual; //最佳个体struct individual worstindividual; //最差个体struct individual currentbest;struct individual population[POPSIZE];3.函数声明void generateinitialpopulation();void generatenextpopulation();void evaluatepopulation();long decodechromosome(char *,int,int);void calculateobjectvalue();void calculatefitnessvalue();void findbestandworstindividual();void performevolution();void selectoperator();void crossoveroperator();void mutationoperator();void input();void outputtextreport();6.程序的各函数的简单算法说明如下:(1).void generateinitialpopulation ()和void input ()初始化种群和遗传算法参数。
遗传算法的C语言实现(二)-----以求解TSP问题为例

遗传算法的C语⾔实现(⼆)-----以求解TSP问题为例上⼀次我们使⽤遗传算法求解了⼀个较为复杂的多元⾮线性函数的极值问题,也基本了解了遗传算法的实现基本步骤。
这⼀次,我再以经典的TSP问题为例,更加深⼊地说明遗传算法中选择、交叉、变异等核⼼步骤的实现。
⽽且这⼀次解决的是离散型问题,上⼀次解决的是连续型问题,刚好形成对照。
⾸先介绍⼀下TSP问题。
TSP(traveling salesman problem,旅⾏商问题)是典型的NP完全问题,即其最坏情况下的时间复杂度随着问题规模的增⼤按指数⽅式增长,到⽬前为⽌还没有找到⼀个多项式时间的有效算法。
TSP问题可以描述为:已知n个城市之间的相互距离,某⼀旅⾏商从某⼀个城市出发,访问每个城市⼀次且仅⼀次,最后回到出发的城市,如何安排才能使其所⾛的路线最短。
换⾔之,就是寻找⼀条遍历n个城市的路径,或者说搜索⾃然⼦集X={1,2,...,n}(X的元素表⽰对n个城市的编号)的⼀个排列P(X)={V1,V2,....,Vn},使得Td=∑d(V i,V i+1)+d(V n,V1)取最⼩值,其中,d(V i,V i+1)表⽰城市V i到V i+1的距离。
TSP问题不仅仅是旅⾏商问题,其他许多NP完全问题也可以归结为TSP问题,如邮路问题,装配线上的螺母问题和产品的⽣产安排问题等等,也使得TSP问题的求解具有更加⼴泛的实际意义。
再来说针对TSP问题使⽤遗传算法的步骤。
(1)编码问题:由于这是⼀个离散型的问题,我们采⽤整数编码的⽅式,⽤1~n来表⽰n个城市,1~n的任意⼀个排列就构成了问题的⼀个解。
可以知道,对于n个城市的TSP问题,⼀共有n!种不同的路线。
(2)种群初始化:对于N个个体的种群,随机给出N个问题的解(相当于是染⾊体)作为初始种群。
这⾥具体采⽤的⽅法是:1,2,...,n作为第⼀个个体,然后2,3,..n分别与1交换位置得到n-1个解,从2开始,3,4,...,n分别与2交换位置得到n-2个解,依次类推。
遗传算法C语言源代码(一元函数和二元函数)

C语言遗传算法代码以下为遗传算法的源代码,计算一元代函数的代码和二元函数的代码以+++++++++++++++++++++++++++++++++++++为分割线分割开来,请自行选择适合的代码,使用时请略看完代码的注释,在需要更改的地方更改为自己需要的代码。
+++++++++++++++++++++++++++++++一元函数代码++++++++++++++++++++++++++++#include <>#include<>#include<>#include<>#define POPSIZE 1000#define maximization 1#define minimization 2#define cmax 100#define cmin 0#define length1 20#define chromlength length1 //染色体长度//注意,你是求最大值还是求最小值int functionmode=minimization;//变量的上下限的修改开始float min_x1=-2;//变量的下界float max_x1=-1;//变量的上界//变量的上下限的修改结束int popsize; //种群大小int maxgeneration; //最大世代数double pc; //交叉率double pm; //变异率struct individual{char chrom[chromlength+1];double value;double fitness; //适应度};int generation; //世代数int best_index;int worst_index;struct individual bestindividual; //最正确个体struct individual worstindividual; //最差个体struct individual currentbest;struct individual population[POPSIZE];//函数声明void generateinitialpopulation();void generatenextpopulation();void evaluatepopulation();long decodechromosome(char *,int,int);void calculateobjectvalue();void calculatefitnessvalue();void findbestandworstindividual();void performevolution();void selectoperator();void crossoveroperator();void mutationoperator();void input();void outputtextreport();void generateinitialpopulation( ) //种群初始化{int i,j;for (i=0;i<popsize; i++){for(j=0;j<chromlength;j++){population[i].chrom[j]=(rand()%20<10)?'0':'1';}population[i].chrom[chromlength]='\0';}}void generatenextpopulation() //生成下一代{selectoperator();crossoveroperator();mutationoperator();}void evaluatepopulation() //评价个体,求最正确个体{calculateobjectvalue();calculatefitnessvalue();findbestandworstindividual();}long decodechromosome(char *string ,int point,int length) //给染色体解码{int i;long decimal=0;char*pointer;for(i=0,pointer=string+point;i<length;i++,pointer++)if(*pointer-'0'){decimal +=(long)pow(2,i);}return (decimal);}void calculateobjectvalue() //计算函数值{int i;long temp1,temp2;double x1;for (i=0; i<popsize; i++){temp1=decodechromosome(population[i].chrom,0,length1);x1=(max_x1-min_x1)*temp1/(1024*1024-1)+min_x1;//目标函数修改开始population[i].value=(pow(x1,5)-3*x1-1)*(pow(x1,5)-3*x1-1);//目标函数修改结束}}void calculatefitnessvalue()//计算适应度{int i;double temp;for(i=0;i<popsize;i++){if(functionmode==maximization){if((population[i].value+cmin)>0.0){temp=cmin+population[i].value;}else{temp=0.0;}}else if (functionmode==minimization){if(population[i].value<cmax){temp=cmax-population[i].value;}else{ temp=0.0;}}population[i].fitness=temp;}}void findbestandworstindividual( ) //求最正确个体和最差个体{int i;double sum=0.0;bestindividual=population[0];worstindividual=population[0];for (i=1;i<popsize; i++){if (population[i].fitness>){bestindividual=population[i];best_index=i;}else if (population[i].fitness<){worstindividual=population[i];worst_index=i;}sum+=population[i].fitness;}if (generation==0){currentbest=bestindividual;}else{if(>=){currentbest=bestindividual;}}}void performevolution() //演示评价结果{if (>){currentbest=population[best_index];}else{population[worst_index]=currentbest;}}void selectoperator() //比例选择算法{int i,index;double p,sum=0.0;double cfitness[POPSIZE];struct individual newpopulation[POPSIZE];for(i=0;i<popsize;i++){sum+=population[i].fitness;}for(i=0;i<popsize; i++){cfitness[i]=population[i].fitness/sum;}for(i=1;i<popsize; i++){cfitness[i]=cfitness[i-1]+cfitness[i];}for (i=0;i<popsize;i++){p=rand()%1000/1000.0;index=0;while (p>cfitness[index]){index++;}newpopulation[i]=population[index];}for(i=0;i<popsize; i++){population[i]=newpopulation[i];}}void crossoveroperator() //交叉算法{int i,j;int index[POPSIZE];int point,temp;double p;char ch;for (i=0;i<popsize;i++){index[i]=i;}for (i=0;i<popsize;i++){point=rand()%(popsize-i);temp=index[i];index[i]=index[point+i];index[point+i]=temp;}for (i=0;i<popsize-1;i+=2){p=rand()%1000/1000.0;if (p<pc){point=rand()%(chromlength-1)+1;for (j=point; j<chromlength;j++){ch=population[index[i]].chrom[j];population[index[i]].chrom[j]=population[index[i+1]].chrom[j];population[index[i+1]].chrom[j]=ch;}}}}void mutationoperator() //变异操作{int i,j;double p;for (i=0;i<popsize;i++){for(j=0;j<chromlength;j++){p=rand()%1000/1000.0;if (p<pm){population[i].chrom[j]=(population[i].chrom[j]=='0')?'1':'0';}}}void input() //数据输入{ //printf("初始化全局变量:\n");//printf(" 种群大小(50-500):");//scanf("%d", &popsize);popsize=500;if((popsize%2) != 0){//printf( " 种群大小已设置为偶数\n");popsize++;};//printf(" 最大世代数(100-300):");//scanf("%d", &maxgeneration);maxgeneration=200;//printf(" 交叉率(0.2-0.99):");//scanf("%f", &pc);pc=0.95;//printf(" 变异率(0.001-0.1):");//scanf("%f", &pm);pm=0.03;}void outputtextreport()//数据输出{int i;double sum;double average;sum=0.0;for(i=0;i<popsize;i++){sum+=population[i].value;}average=sum/popsize;printf("当前世代=%d\n当前世代平均函数值=%f\n当前世代最优函数值=%f\n",generation,average,population[best_index].value);}void main() //主函数{ int i;long temp1,temp2;double x1,x2;generation=0;input();generateinitialpopulation();evaluatepopulation();while(generation<maxgeneration)generation++;generatenextpopulation();evaluatepopulation();performevolution();outputtextreport();}printf("\n");printf(" 统计结果: ");printf("\n");//printf("最大函数值等于:%f\n",);printf("其染色体编码为:");for (i=0;i<chromlength;i++){printf("%c",[i]);}printf("\n");temp1=decodechromosome(currentbest.chrom,0,length1);x1=(max_x1-min_x1)*temp1/(1024*1024-1)+min_x1;printf("x1=%lf\n",x1);//这是需要修改的地方printf("最优值等于:%f\n",(pow(x1,5)-3*x1-1)*(pow(x1,5)-3*x1-1));}+++++++++++++++++++++++++二元函数代码+++++++++++++++++++++++++++++++++++++++++ #include <>#include<>#include<>#include<>#define POPSIZE 500#define maximization 1#define minimization 2#define cmax 100#define cmin 0#define length1 20#define length2 20#define chromlength length1+length2 //染色体长度//-----------求最大还是最小值int functionmode=maximization;//-----------//-----------变量上下界float min_x1=0;float max_x1=3;float min_x2=1;float max_x2=5;//-----------int popsize; //种群大小int maxgeneration; //最大世代数double pc; //交叉率double pm; //变异率struct individual{char chrom[chromlength+1];double value;double fitness; //适应度};int generation; //世代数int best_index;int worst_index;struct individual bestindividual; //最正确个体struct individual worstindividual; //最差个体struct individual currentbest;struct individual population[POPSIZE];//函数声明void generateinitialpopulation();void generatenextpopulation();void evaluatepopulation();long decodechromosome(char *,int,int);void calculateobjectvalue();void calculatefitnessvalue();void findbestandworstindividual();void performevolution();void selectoperator();void crossoveroperator();void mutationoperator();void input();void outputtextreport();void generateinitialpopulation( ) //种群初始化{int i,j;for (i=0;i<popsize; i++){for(j=0;j<chromlength;j++){population[i].chrom[j]=(rand()%40<20)?'0':'1';}population[i].chrom[chromlength]='\0';}}void generatenextpopulation() //生成下一代{selectoperator();crossoveroperator();mutationoperator();}void evaluatepopulation() //评价个体,求最正确个体{calculateobjectvalue();calculatefitnessvalue();findbestandworstindividual();}long decodechromosome(char *string ,int point,int length) //给染色体解码{int i;long decimal=0;char*pointer;for(i=0,pointer=string+point;i<length;i++,pointer++)if(*pointer-'0'){decimal +=(long)pow(2,i);}return (decimal);}void calculateobjectvalue() //计算函数值{int i;long temp1,temp2;double x1,x2;for (i=0; i<popsize; i++){temp1=decodechromosome(population[i].chrom,0,length1);temp2=decodechromosome(population[i].chrom,length1,length2);x1=(max_x1-min_x1)*temp1/(1024*1024-1)+min_x1;x2=(max_x2-min_x2)*temp2/(1024*1024-1)+min_x2;//-----------函数population[i].value=x1*x1+sin(x1*x2)-x2*x2;//-----------}}void calculatefitnessvalue()//计算适应度{int i;double temp;for(i=0;i<popsize;i++){if(functionmode==maximization){if((population[i].value+cmin)>0.0){temp=cmin+population[i].value;}else{temp=0.0;}}else if (functionmode==minimization){if(population[i].value<cmax){temp=cmax-population[i].value;}else{ temp=0.0;}}population[i].fitness=temp;}}void findbestandworstindividual( ) //求最正确个体和最差个体{int i;double sum=0.0;bestindividual=population[0];worstindividual=population[0];for (i=1;i<popsize; i++){if (population[i].fitness>){bestindividual=population[i];best_index=i;}else if (population[i].fitness<){worstindividual=population[i];worst_index=i;}sum+=population[i].fitness;}if (generation==0){currentbest=bestindividual;}else{if(>=){currentbest=bestindividual;}}}void performevolution() //演示评价结果{if (>){currentbest=population[best_index];}else{population[worst_index]=currentbest;}}void selectoperator() //比例选择算法{int i,index;double p,sum=0.0;double cfitness[POPSIZE];struct individual newpopulation[POPSIZE];for(i=0;i<popsize;i++){sum+=population[i].fitness;}for(i=0;i<popsize; i++){cfitness[i]=population[i].fitness/sum;}for(i=1;i<popsize; i++){cfitness[i]=cfitness[i-1]+cfitness[i];}for (i=0;i<popsize;i++){p=rand()%1000/1000.0;index=0;while (p>cfitness[index]){index++;}newpopulation[i]=population[index];}for(i=0;i<popsize; i++){population[i]=newpopulation[i];}}void crossoveroperator() //交叉算法{int i,j;int index[POPSIZE];int point,temp;double p;char ch;for (i=0;i<popsize;i++){index[i]=i;}for (i=0;i<popsize;i++){point=rand()%(popsize-i);temp=index[i];index[i]=index[point+i];index[point+i]=temp;}for (i=0;i<popsize-1;i+=2){p=rand()%1000/1000.0;if (p<pc){point=rand()%(chromlength-1)+1;for (j=point; j<chromlength;j++){ch=population[index[i]].chrom[j];population[index[i]].chrom[j]=population[index[i+1]].chrom[j];population[index[i+1]].chrom[j]=ch;}}}}void mutationoperator() //变异操作{int i,j;double p;for (i=0;i<popsize;i++){for(j=0;j<chromlength;j++){p=rand()%1000/1000.0;if (p<pm){population[i].chrom[j]=(population[i].chrom[j]=='0')?'1':'0';}}}}void input() //数据输入{ //printf("初始化全局变量:\n");//printf(" 种群大小(50-500):");//scanf("%d", &popsize);popsize=200;if((popsize%2) != 0){//printf( " 种群大小已设置为偶数\n");popsize++;};//printf(" 最大世代数(100-300):");//scanf("%d", &maxgeneration);maxgeneration=200;//printf(" 交叉率(0.2-0.99):");//scanf("%f", &pc);pc=0.9;//printf(" 变异率(0.001-0.1):");//scanf("%f", &pm);pm=0.003;}void outputtextreport()//数据输出{int i;double sum;double average;sum=0.0;for(i=0;i<popsize;i++){sum+=population[i].value;}average=sum/popsize;printf("当前世代=%d\n当前世代平均函数值=%f\n当前世代最优函数值=%f\n",generation,average,population[best_index].value);}void main() //主函数{ int i;long temp1,temp2;double x1,x2;generation=0;input();generateinitialpopulation();evaluatepopulation();while(generation<maxgeneration){generation++;generatenextpopulation();evaluatepopulation();performevolution();outputtextreport();}printf("\n");printf(" 统计结果: ");printf("\n");//printf("最大函数值等于:%f\n",);printf("其染色体编码为:");for (i=0;i<chromlength;i++){printf("%c",[i]);}printf("\n");temp1=decodechromosome(currentbest.chrom,0,length1);temp2=decodechromosome(currentbest.chrom,length1,length2);x1=(max_x1-min_x1)*temp1/(1024*1024-1)+min_x1;x2=(max_x2-min_x2)*temp2/(1024*1024-1)+min_x2;printf("x=%lf,y=%lf\n",x1,x2);//-----------修改函数printf("最大值=%f\n",x1*x1+sin(x1*x2)-x2*x2);//-----------}。
遗传算法实验报告

实验一 二进制编码函数优化一、实验目的根据给出的数学模型,利用遗传算法求解,并用C 语言编程实现。
采用二进制编码方式,通过不断调整种群规模、进化代数、交叉因子和变异因子等参数,对目标函数进行优化求解。
重点:掌握二进制编码的编程过程。
二、实验仪器Acer Aspire V5-472G ,Windows 7 旗舰版,64位操作系统 Intel(R) Core(TM) i5-3337 CPU @1.8GHz 1.80 GHz Microsoft Visual C++ 6.0 Microsoft Office Excel 2016三、实验内容及步骤采用二进制编码方式优化如下测试函数: (1) De Jong 函数F1:极小点f 1(0, 0, 0)=0。
(2) De Jong 函数F2:极小点f 2(1,1) = 0。
(3) De Jong 函数F3:对于]0.5,12.5[--∈i x 区域内的每一个点,它都取全局极小值30),,,,(543213-=x x x x x f 。
要求:对每一个测试函数,分析不同的种群规模(20~100)、交叉概率(0.4~0.99)和变异概率(0.0001~0.1)对优化结果的影响,试确定最佳参数组合。
四、实验报告(1) 根据De Jong函数F1:极小点f1(0, 0, 0)=0。
给定Cmax=100,MaxGeneration=100,在此基础上改变A:Popsize(20、60、100)、B:Pc(0.3、0.6、0.9)、C:Pm(0.1、0.05、0.001)等参数,设计一个3因素3水平的正交实验,根据正交实验表进行实验。
将正交实验因素和实验结果整合成一个正交实验表,如表1.1.1所示。
其中M表示best达到0的最小迭代数,N代表Average的收敛性,收敛为1,不收敛为0。
对实验结果M、N两项参数进行分析,得到均值响应表,如表1.1.2所示。
表1.1.1 函数F1正交实验表表1.1.2 函数F1均值响应表通过分析均值响应表,得到较优的组合为A1B1C2和A1B1C1。
(完整版)遗传算法c语言代码

srand((unsigned)time(NULL));
for(i=0;i<num;i++)
{
bianyip[i]=(rand()%100);
bianyip[i]/=100;
}
//确定可以变异的染色体
t=0;
for(i=0;i<num;i++)
{
if(bianyip[i]<pm)
printf("\n******************是否想再一次计算(y or n)***********************\n");
fflush(stdin);
scanf("%c",&choice);
}while(choice=='y');
return 0;
}
{
flag=0;
break;
}
}
if(flag)
{
group[i].city[j]=t;
j++;
}
}
}
printf("************初始种群如下****************\n");
for(i=0;i<num;i++)
{
for(j=0;j<cities;j++)
printf("%4d",group[i].city[j]);
{
group[i].p=1-(double)group[i].adapt/(double)biggestsum;
biggestp+=group[i].p;
C语言人工智能算法实现神经网络和遗传算法

C语言人工智能算法实现神经网络和遗传算法人工智能(Artificial Intelligence)是当今科技领域中备受关注的热门话题,而C语言作为一种广泛应用的编程语言,也可以用于实现人工智能算法。
本文将详细介绍如何用C语言来实现神经网络和遗传算法,以展示其在人工智能领域的应用。
1. 神经网络神经网络是一种模仿人脑的学习和决策过程的计算模型。
它由多个神经元组成的层级结构构成,每个神经元接收来自上一层神经元输出的信号,并根据一定的权重和激活函数来计算输出。
下图展示了一个简单的神经网络结构:[图1:神经网络结构图]为了实现一个神经网络,我们需要在C语言中定义神经网络的结构体,并实现前馈传播和反向传播算法。
首先,我们需要定义神经网络的层级结构,可以使用数组或链表来表达。
每个神经元需要存储权重、偏差和激活函数等信息。
我们可以使用结构体来表示神经元的属性,例如:```Ctypedef struct Neuron {double* weights; // 权重数组double bias; // 偏差double output; // 输出} Neuron;```然后,定义神经网络的结构体:```Ctypedef struct NeuralNetwork {int numLayers; // 层数int* layerSizes; // 每层神经元数量的数组Neuron** layers; // 神经元层级的数组} NeuralNetwork;```接下来,我们需要实现神经网络的前馈传播算法。
前馈传播算法用于将输入数据从输入层传递到输出层,并计算网络的输出。
算法的伪代码如下所示:```Cfor each layer in network {for each neuron in layer {calculate neuron's weighted sum of inputs;apply activation function to obtain neuron's output;}}```最后,需要实现神经网络的反向传播算法,用于根据期望输出来调整网络的权重和偏差。
遗传算法

遗传算法的基本运算过程如下:a)初始化:设置进化代数计数器t=0,设置最大进化代数T,随机生成M个个体作为初始群体P(0)。
b)个体评价:计算群体P(t)中各个个体的适应度。
c)选择运算:将选择算子作用于群体。
选择的目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。
选择操作是建立在群体中个体的适应度评估基础上的。
d)交叉运算:将交叉算子作用于群体。
遗传算法中起核心作用的就是交叉算子。
e)变异运算:将变异算子作用于群体。
即是对群体中的个体串的某些基因座上的基因值作变动。
群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。
f)终止条件判断:若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。
每个个体实际上是染色体(chromosome)带有特征的实体。
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。
因此,在一开始需要实现从表现型到基因型的映射即编码工作。
由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
遗传算法 c语言代码

以下是一个简单的遗传算法的C语言代码示例:c#include <stdio.h>#include <stdlib.h>#include <time.h>#include <math.h>#define POPULATION_SIZE 100#define GENE_LENGTH 10#define MAX_GENERATIONS 1000#define MUTATION_RATE 0.01#define CROSSOVER_RATE 0.8typedef struct Individual {char genes[GENE_LENGTH];double fitness;} Individual;double calculate_fitness(Individual* individual) {// 计算适应度函数,这里使用简单的二进制字符串中1的个数作为适应度 int count = 0;for (int i = 0; i < GENE_LENGTH; i++) {if (individual->genes[i] == '1') {count++;}}return count;}void initialize_population(Individual* population) {// 初始化种群for (int i = 0; i < POPULATION_SIZE; i++) {for (int j = 0; j < GENE_LENGTH; j++) {population[i].genes[j] = rand() % 2 ? '0' : '1';}population[i].fitness = calculate_fitness(&population[i]); }}void selection(Individual* population, Individual* parents) {// 选择操作,采用轮盘赌算法选择两个父代个体double total_fitness = 0;for (int i = 0; i < POPULATION_SIZE; i++) {total_fitness += population[i].fitness;}double rand1 = rand() / (double)RAND_MAX * total_fitness;double rand2 = rand() / (double)RAND_MAX * total_fitness;double cumulative_fitness = 0;int parent1_index = -1, parent2_index = -1;for (int i = 0; i < POPULATION_SIZE; i++) {cumulative_fitness += population[i].fitness;if (rand1 < cumulative_fitness && parent1_index == -1) {parent1_index = i;}if (rand2 < cumulative_fitness && parent2_index == -1) {parent2_index = i;}}parents[0] = population[parent1_index];parents[1] = population[parent2_index];}void crossover(Individual* parents, Individual* offspring) {// 交叉操作,采用单点交叉算法生成两个子代个体int crossover_point = rand() % GENE_LENGTH;for (int i = 0; i < crossover_point; i++) {offspring[0].genes[i] = parents[0].genes[i];offspring[1].genes[i] = parents[1].genes[i];}for (int i = crossover_point; i < GENE_LENGTH; i++) {offspring[0].genes[i] = parents[1].genes[i];offspring[1].genes[i] = parents[0].genes[i];}offspring[0].fitness = calculate_fitness(&offspring[0]);offspring[1].fitness = calculate_fitness(&offspring[1]);}void mutation(Individual* individual) {// 变异操作,以一定概率翻转基因位上的值for (int i = 0; i < GENE_LENGTH; i++) {if (rand() / (double)RAND_MAX < MUTATION_RATE) {individual->genes[i] = individual->genes[i] == '0' ? '1' : '0'; }}individual->fitness = calculate_fitness(individual);}void replace(Individual* population, Individual* offspring) {// 替换操作,将两个子代个体中适应度更高的一个替换掉种群中适应度最低的一个个体int worst_index = -1;double worst_fitness = INFINITY;for (int i = 0; i < POPULATION_SIZE; i++) {if (population[i].fitness < worst_fitness) {worst_index = i;worst_fitness = population[i].fitness;}}if (offspring[0].fitness > worst_fitness || offspring[1].fitness > worst_fitness) {if (offspring[0].fitness > offspring[1].fitness) {population[worst_index] = offspring[0];} else {population[worst_index] = offspring[1];}}}。
遗传算法

对于一个求函数最大值的优化问题(求函数最小值也类同),一般可以描述为下列数学规划模型:
遗传算法
式中x为决策变量,式2-1为目标函数式,式2-2、2-3为约束条件,U是基本空间,R是U的子集。满足约束条件的解X称为可行解,集合R表示所有满足约束条件的解所组成的集合,称为可行解集合。
2005年,江雷等针对并行遗传算法求解TSP问题,探讨了使用弹性策略来维持群体的多样性,使得算法跨过局部收敛的障碍,向全局最优解方向进化。
编辑本段一般算法
遗传算法是基于生物学的,理解或编程都不太难。下面是遗传算法的一般算法:
创建一个随机的初始状态
初始种群是从解中随机选择出来的,将这些解比喻为染色体或基因,该种群被称为第一代,这和符号人工智能系统的情况不一样,在那里问题的初始状态已经给定了。
(2)许多传统搜索算法都是单点搜索算法,容易陷入局部的最优解。遗传算法同时处理群体中的多个个体,即对搜索空间中的多个解进行评估,减少了陷入局部最优解的风险,同时算法本身易于实现并行化。
(3)遗传算法基本上不用搜索空间的知识或其它辅助信息,而仅用适应度函数值来评估个体,在此基础上进行遗传操作。适应度函数不仅不受连续可微的约束,而且其定义域可以任意设定。这一特点使得遗传算法的应用范围大大扩展。
遗传算法C语言代码

遗传算法C语言代码遗传算法C语言代码遗传算法C语言代码// GA.cpp : Defines the entry point for the console application.///*这是一个非常简单的遗传算法源代码,是由Denis Cormier (North Carolina State University)开发的,Sita S.Raghavan (University of North Carolina at Charlotte)修正。
代码保证尽可能少,实际上也不必查错。
对一特定的应用修正此代码,用户只需改变常数的定义并且定义“评价函数”即可。
注意代码的设计是求最大值,其中的目标函数只能取正值;且函数值和个体的适应值之间没有区别。
该系统使用比率选择、精华模型、单点杂交和均匀变异。
如果用 Gaussian变异替换均匀变异,可能得到更好的效果。
代码没有任何图形,甚至也没有屏幕输出,主要是保证在平台之间的高可移植性。
读者可以从, 目录 coe/evol中的文件prog.c中获得。
要求输入的文件应该命名为‘gadata.txt’;系统产生的输出文件为‘galog.txt’。
输入的文件由几行组成:数目对应于变量数。
且每一行提供次序——对应于变量的上下界。
如第一行为第一个变量提供上下界,第二行为第二个变量提供上下界,等等。
*/#include <stdio.h>#include <stdlib.h>#include <math.h>/* Change any of these parameters to match your needs *///请根据你的需要来修改以下参数#define POPSIZE 50 /* population size 种群大小*/#define MAXGENS 1000 /* max. number of generations 最大基因个数*/const int NVARS = 3; /* no. of problem variables 问题变量的个数*/#define PXOVER 0.8 /* probability of crossover 杂交概率*/#define PMUTATION 0.15 /* probability of mutation 变异概率*/#define TRUE 1#define FALSE 0int generation; /* current generation no. 当前基因个数*/int cur_best; /* best individual 最优个体*/FILE *galog; /* an output file 输出文件指针*/struct genotype /* genotype (GT), a member of the population 种群的一个基因的结构体类型*/{double gene[NVARS]; /* a string of variables 变量*/double fitness; /* GT's fitness 基因的适应度*/double upper[NVARS]; /* GT's variables upper bound 基因变量的上界*/double lower[NVARS]; /* GT's variables lower bound 基因变量的下界*/double rfitness; /* relative fitness 比较适应度*/double cfitness; /* cumulative fitness 积累适应度*/};struct genotype population[POPSIZE+1]; /* population 种群*/struct genotype newpopulation[POPSIZE+1]; /* new population; 新种群*//* replaces the old generation *///取代旧的基因/* Declaration of procedures used by this genetic algorithm *///以下是一些函数声明void initialize(void);double randval(double, double);void evaluate(void);void keep_the_best(void);void elitist(void);void select(void);void crossover(void);void Xover(int,int);void swap(double *, double *);void mutate(void);void report(void);/**************************************** ***********************//* Initialization function: Initializes the values of genes *//* within the variables bounds. It also initializes (to zero) *//* all fitness values for each member of the population. It *//* reads upper and lower bounds of each variable from the *//* input file `gadata.txt'. It randomlygenerates values *//* between these bounds for each gene of each genotype in the *//* population. The format of the input file `gadata.txt' is *//* var1_lower_bound var1_upper bound */ /* var2_lower_bound var2_upper bound ... */ /**************************************** ***********************/void initialize(void){FILE *infile;int i, j;double lbound, ubound;if ((infile = fopen("gadata.txt","r"))==NULL){fprintf(galog,"\nCannot open input file!\n");exit(1);}/* initialize variables within the bounds *///把输入文件的变量界限输入到基因结构体中for (i = 0; i < NVARS; i++){fscanf(infile, "%lf",&lbound);fscanf(infile, "%lf",&ubound);for (j = 0; j < POPSIZE; j++){population[j].fitness = 0;population[j].rfitness = 0;population[j].cfitness = 0;population[j].lower[i] = lbound;population[j].upper[i]= ubound;population[j].gene[i] = randval(population[j].lower[i],population[j].upper[i]);}}fclose(infile);}/**************************************** *******************//* Random value generator: Generates a value within bounds *//**************************************** *******************///随机数产生函数double randval(double low, double high) {double val;val = ((double)(rand()%1000)/1000.0)*(high - low) + low;return(val);}/*************************************************************//* Evaluation function: This takes a user defined function. *//* Each time this is changed, the code has to be recompiled. *//* The current function is: x[1]^2-x[1]*x[2]+x[3] *//**************************************** *********************///评价函数,可以由用户自定义,该函数取得每个基因的适应度void evaluate(void){int mem;int i;double x[NVARS+1];for (mem = 0; mem < POPSIZE; mem++){for (i = 0; i < NVARS; i++)x[i+1] = population[mem].gene[i];population[mem].fitness = (x[1]*x[1]) - (x[1]*x[2]) + x[3];}}/**************************************** ***********************//* Keep_the_best function: This function keeps track of the *//* best member of the population. Note that the last entry in *//* the array Population holds a copy of the best individual *//**************************************** ***********************///保存每次遗传后的最佳基因void keep_the_best(){int mem;int i;cur_best = 0;/* stores the index of the best individual*///保存最佳个体的索引for (mem = 0; mem < POPSIZE; mem++){if (population[mem].fitness > population[POPSIZE].fitness){cur_best = mem;population[POPSIZE].fitness = population[mem].fitness;}}/* once the best member in the population is found, copy the genes *///一旦找到种群的最佳个体,就拷贝他的基因for (i = 0; i < NVARS; i++)population[POPSIZE].gene[i] = population[cur_best].gene[i];}/**************************************** ************************//* Elitist function: The best member of the previous generation *//* is stored as the last in the array. If the best member of *//* the current generation is worse then the best member of the *//* previous generation, the latter one would replace the worst *//* member of the current population *//**************************************** ************************///搜寻杰出个体函数:找出最好和最坏的个体。
遗传算法(GeneticAlgorithms)

遗传算法(GeneticAlgorithms)遗传算法前引:1、TSP问题1.1 TSP问题定义旅⾏商问题(Traveling Salesman Problem,TSP)称之为货担郎问题,TSP问题是⼀个经典组合优化的NP完全问题,组合优化问题是对存在组合排序或者搭配优化问题的⼀个概括,也是现实诸多领域相似问题的简化形式。
1.2 TSP问题解法传统精确算法:穷举法,动态规划近似处理算法:贪⼼算法,改良圈算法,双⽣成树算法智能算法:模拟退⽕,粒⼦群算法,蚁群算法,遗传算法等遗传算法:性质:全局优化的⾃适应概率算法2.1 遗传算法简介遗传算法的实质是通过群体搜索技术,根据适者⽣存的原则逐代进化,最终得到最优解或准最优解。
它必须做以下操作:初始群体的产⽣、求每⼀个体的适应度、根据适者⽣存的原则选择优良个体、被选出的优良个体两两配对,通过随机交叉其染⾊体的基因并随机变异某些染⾊体的基因⽣成下⼀代群体,按此⽅法使群体逐代进化,直到满⾜进化终⽌条件。
2.2 实现⽅法根据具体问题确定可⾏解域,确定⼀种编码⽅法,能⽤数值串或字符串表⽰可⾏解域的每⼀解。
对每⼀解应有⼀个度量好坏的依据,它⽤⼀函数表⽰,叫做适应度函数,⼀般由⽬标函数构成。
确定进化参数群体规模、交叉概率、变异概率、进化终⽌条件。
案例实操我⽅有⼀个基地,经度和纬度为(70,40)。
假设我⽅飞机的速度为1000km/h。
我⽅派⼀架飞机从基地出发,侦察完所有⽬标,再返回原来的基地。
在每⼀⽬标点的侦察时间不计,求该架飞机所花费的时间(假设我⽅飞机巡航时间可以充分长)。
已知100个⽬标的经度、纬度如下表所列:3.2 模型及算法求解的遗传算法的参数设定如下:种群⼤⼩M=50;最⼤代数G=100;交叉率pc=1,交叉概率为1能保证种群的充分进化;变异概率pm=0.1,⼀般⽽⾔,变异发⽣的可能性较⼩。
编码策略:初始种群:⽬标函数:交叉操作:变异操作:选择:算法图:代码实现:clc,clear, close allsj0=load('data12_1.txt');x=sj0(:,1:2:8); x=x(:);y=sj0(:,2:2:8); y=y(:);sj=[x y]; d1=[70,40];xy=[d1;sj;d1]; sj=xy*pi/180; %单位化成弧度d=zeros(102); %距离矩阵d的初始值for i=1:101for j=i+1:102d(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*...cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));endendd=d+d'; w=50; g=100; %w为种群的个数,g为进化的代数for k=1:w %通过改良圈算法选取初始种群c=randperm(100); %产⽣1,...,100的⼀个全排列c1=[1,c+1,102]; %⽣成初始解for t=1:102 %该层循环是修改圈flag=0; %修改圈退出标志for m=1:100for n=m+2:101if d(c1(m),c1(n))+d(c1(m+1),c1(n+1))<...d(c1(m),c1(m+1))+d(c1(n),c1(n+1))c1(m+1:n)=c1(n:-1:m+1); flag=1; %修改圈endendendif flag==0J(k,c1)=1:102; break %记录下较好的解并退出当前层循环endendendJ(:,1)=0; J=J/102; %把整数序列转换成[0,1]区间上实数即染⾊体编码for k=1:g %该层循环进⾏遗传算法的操作for k=1:g %该层循环进⾏遗传算法的操作A=J; %交配产⽣⼦代A的初始染⾊体c=randperm(w); %产⽣下⾯交叉操作的染⾊体对for i=1:2:wF=2+floor(100*rand(1)); %产⽣交叉操作的地址temp=A(c(i),[F:102]); %中间变量的保存值A(c(i),[F:102])=A(c(i+1),[F:102]); %交叉操作A(c(i+1),F:102)=temp;endby=[]; %为了防⽌下⾯产⽣空地址,这⾥先初始化while ~length(by)by=find(rand(1,w)<0.1); %产⽣变异操作的地址endB=A(by,:); %产⽣变异操作的初始染⾊体for j=1:length(by)bw=sort(2+floor(100*rand(1,3))); %产⽣变异操作的3个地址%交换位置B(j,:)=B(j,[1:bw(1)-1,bw(2)+1:bw(3),bw(1):bw(2),bw(3)+1:102]);endG=[J;A;B]; %⽗代和⼦代种群合在⼀起[SG,ind1]=sort(G,2); %把染⾊体翻译成1,...,102的序列ind1num=size(G,1); long=zeros(1,num); %路径长度的初始值for j=1:numfor i=1:101long(j)=long(j)+d(ind1(j,i),ind1(j,i+1)); %计算每条路径长度endend[slong,ind2]=sort(long); %对路径长度按照从⼩到⼤排序J=G(ind2(1:w),:); %精选前w个较短的路径对应的染⾊体endpath=ind1(ind2(1),:), flong=slong(1) %解的路径及路径长度xx=xy(path,1);yy=xy(path,2);plot(xx,yy,'-o') %画出路径以上整个代码中没有调⽤GA⼯具箱。
第七讲遗传算法

四、遗传算法应用举例 1
于是,得第三代种群S3: s1=11100(28), s2=01001(9) s3=11000(24), s4=10011(19)
四、遗传算法应用举例 1
第三代种群S3中各染色体的情况
染色体
适应度 选择概率 估计的 选中次数
四、遗传算法应用举例 1
首先计算种群S1中各个体
s1= 13(01101), s2= 24(11000) s3= 8(01000), s4= 19(10011)
的适应度f (si) 。 容易求得
f (s1) = f(13) = 132 = 169 f (s2) = f(24) = 242 = 576 f (s3) = f(8) = 82 = 64 f (s4) = f(19) = 192 = 361
群体的染色体都将逐渐适应环境,不断进化,最后收敛到 一族最适应环境的类似个体,即得到问题最优解。
一、遗传算法概述
与传统的优化算法相比,遗传算法主要有以下几 个不同之处
遗传算法不是直接作用在参变量集上而是利用参变量集 的某种编码 遗传算法不是从单个点,而是从一个点的群体开始搜索; 遗传算法利用适应值信息,无须导数或其它辅助信息; 遗传算法利用概率转移规则,而非确定性规则。
否
结束程序
计算每个个体的适应值
以概率选择遗传算子
选择一个个体 选择两个个体进行 选择一个个体进行 复制到新群体 交叉插入到新群体 变异插入到新群体
得到新群体
四、遗传算法应用举例 1
例1 利用遗传算法求解区间[0,31]上的二次函数 y=x2的最大值。
Y
y=x2
31 X
四、遗传算法应用举例 1
分析
s1’’=11001(25), s2’’=01100(12) s3’’=11011(27), s4’’=10000(16)
(完整版)遗传算法简介及代码详解

遗传算法简述及代码详解声明:本文内容整理自网络,认为原作者同意转载,如有冒犯请联系我。
遗传算法基本内容遗传算法为群体优化算法,也就是从多个初始解开始进行优化,每个解称为一个染色体,各染色体之间通过竞争、合作、单独变异,不断进化。
遗传学与遗传算法中的基础术语比较染色体:又可以叫做基因型个体(individuals)群体/种群(population):一定数量的个体组成,及一定数量的染色体组成,群体中个体的数量叫做群体大小。
初始群体:若干染色体的集合,即解的规模,如30,50等,认为是随机选取的数据集合。
适应度(fitness):各个个体对环境的适应程度优化时先要将实际问题转换到遗传空间,就是把实际问题的解用染色体表示,称为编码,反过程为解码/译码,因为优化后要进行评价(此时得到的解是否较之前解优越),所以要返回问题空间,故要进行解码。
SGA采用二进制编码,染色体就是二进制位串,每一位可称为一个基因;如果直接生成二进制初始种群,则不必有编码过程,但要求解码时将染色体解码到问题可行域内。
遗传算法的准备工作:1) 数据转换操作,包括表现型到基因型的转换和基因型到表现型的转换。
前者是把求解空间中的参数转化成遗传空间中的染色体或者个体(encoding),后者是它的逆操作(decoding)2) 确定适应度计算函数,可以将个体值经过该函数转换为该个体的适应度,该适应度的高低要能充分反映该个体对于解得优秀程度。
非常重要的过程。
遗传算法基本过程为:1) 编码,创建初始群体2) 群体中个体适应度计算3) 评估适应度4) 根据适应度选择个体5) 被选择个体进行交叉繁殖6) 在繁殖的过程中引入变异机制7) 繁殖出新的群体,回到第二步实例一:(建议先看实例二)求 []30,0∈x 范围内的()210-=x y 的最小值1) 编码算法选择为"将x 转化为2进制的串",串的长度为5位(串的长度根据解的精度设 定,串长度越长解得精度越高)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
if(constraint_check(x)==1)
for(k=1; k<=N; k++) CHROMOSOME[j][k]=x[k];
if(constraint_check(y)==1)
for(k=1; k<=N; k++) CHROMOSOME[jj][k]=y[k];
for(k=1; k<=N; k++) temp[k]=CHROMOSOME[j][k];
break;
}
}
}
for(i=1; i<=POP_SIZE; i++)
for(k=1; k<=N; k++)
CHROMOSOME[k]=temp[k];
}
for(i=0; i<POP_SIZE; i++){
label=0; a=OBJECTIVE[0];
for(j=i+1; j<=POP_SIZE; j++)
if((TYPE*a)<(TYPE*OBJECTIVE[j][0])) {
a=OBJECTIVE[j][0];
initialization();
evaluation(0);
for(i=1; i<=GEN; i++) {
selection();
crossover();
mutation();
evaluation(i);
printf("\nGeneration NO.%d\n", i);
label=j;
}
if(label!=0) {
for(k=0; k<=M; k++) {
a=OBJECTIVE[k];
OBJECTIVE[k]=OBJECTIVE[label][k];
OBJECTIVE[label][k]=a;
}
x1 = CHROMOSOME[1];
x2 = CHROMOSOME[2];
x3 = CHROMOSOME[3];
OBJECTIVE[1] = sqrt(x1)+sqrt(x2)+sqrt(x3);
}
for(i=1;i<=POP_SIZE;i++)
OBJECTIVE[0]= OBJECTIVE[1];
if(constraint_check(x)==0) goto mark;
for(j=1; j<=N; j++) CHROMOSOME[j]=x[j];
}
}
main()
{
int i, j;
double a;
q[0]=0.05; a=0.05;
for(i=1; i<=POP_SIZE; i++) {a=a*0.95; q=q+a;}
{
double r, temp[POP_SIZE+1][N+1];
int i, j, k;
for(i=1; i<=POP_SIZE; i++) {
r=myu(0, q[POP_SIZE]);
for(j=0; j<=POP_SIZE; j++) {
if(r<=q[j]) {
else {
printf(")\nf=(");
for(j=1; j<=M; j++) {
if(j<M) printf("%3.4f,", OBJECTIVE[0][j]);
else printf("%3.4f", OBJECTIVE[0][j]);
}
static void crossover()
{
int i, j, jj, k, pop;
double r, x[N+1], y[N+1];
pop=POP_SIZE/2;
for(i=1; i<=pop; i++) {
if(myu(0,1)>P_CROSSOVER) continue;
double OBJECTIVE[POP_SIZE+1][m+1];
double q[POP_SIZE+1];
static void objective_function(void)
{
double x1,x2,x3;
int i;
for(i = 1; i <= POP_SIZE; i++) {
for(j=1; j<=N; j++) {
a=CHROMOSOME[j];
CHROMOSOME[j]=CHROMOSOME[label][j];
CHROMOSOME[label][j]=a;
}
}
}
}
static void selection()
}
static int constraint_check(double x[])
{
double a;
int n;
for(n=1;n<=N;n++) if(x[n]<0) return 0;
a = x[1]*x[1]+2*x[2]*x[2]+3*x[3]*x[3];
if(a>1) return 0;
int i, j, k, label;
objective_function();
if(gen==0){
for(k=0; k<=M; k++) OBJECTIVE[0][k]=OBJECTIVE[1][k];//
for(j = 1; j <= N; j++) CHROMOSOME[0][j]=CHROMOSOME[1][j];
else direction[k]=0;
infty=myu(0,INFTY);
while(infty>precision) {
for(j=1; j<=N; j++) y[j]=x[j]+infty*direction[j];
if(constraint_check(y)==1) {
// Genetic Algorithm for nonlinear programming
// Written by Microsoft Visual C++
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "aa.h"
printf("x=(");
for(j=1; j<=N; j++) {
if(j<N) printf("%3.4f,",CHROMOSOME[0][j]);
else printf("%3.4f",CHROMOSOME[0][j]);
}
if(M==1) printf(")\nf=%3.4f\n", OBJECTIVE[0][1]);
static void initialization(void);
static void evaluation(int gen);
static void selection(void);
static void crossover(void);
static void mutation(void);
return 1;
}
static void initialization(void)
{
double x[N+1]; // N is the number of variables
int i,j;
for(i=1; i<=POP_SIZE; i++){
mark:
for(j=1; j<=N; j++) x[j]=myu(0,1);
}
printf(") Aggregating Value=%3.4f\n",OBJECTIVE[0][0]);
}
}
printf("\n");
return 1;
}
static void evaluation(int gen)
{
double a;
static void objective_function(void);
static int constraint_check(double x[]);
#define N 3 // number of variables
#define M 1 // number of objectives
for(k=1; k<=N; k++) CHROMOSOME[k]=y[k];
break;
}
infty=myu(0,infty);
}
}
}
}
}
static void mutation(void)
{
int i, j, k;
double x[N+1], y[N+1], infty, direction[N+1];