查找表与二叉排序树
二叉排序树

9
第9章
第三节
二、二叉排序树(插入)
查找
动态查找表
二叉排序树是一种动态查找表
当树中不存在查找的结点时,作插入操作
新插入的结点一定是叶子结点(只需改动一个 结点的指针) 该叶子结点是查找不成功时路径上访问的最后 一个结点的左孩子或右孩子(新结点值小于或 大于该结点值) 10
第9章
第三节
查找
19
在二叉排序树中查找关 键字值等于37,88,94
3
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)中结点结构定义 二叉排序树通常采用二叉链表的形式进行存 储,其结点结构定义如下:
typedef struct BiNode { int data; BiNode *lChild, *rChild; }BiNode,*BitTree;
4
第9章
第三节
查找
动态查找表
2、二叉排序树的定义 定义二叉排序树所有用到的变量 BitTree root; int
//查找是否成功(1--成功,0--不成功) //查找位置(表示在BisCount层中的第几个位置
BisSuccess;
int
int
BisPos;
BisCount;
//查找次数(相当于树的层数)
7
第9章
第三节
查找
动态查找表
二、二叉排序树(查找函数)
else { BisSuccess = 0; root=GetNode(k);//查找不成功,插入新的结点}
} BiNode * GetNode(int k) { BiNode *s; s = new BiNode; s->data = k; s->lChild = NULL; s->rChild = NULL; return(s);}
查找排序PPT课件

low=1; high=n;
while(low<=high)
{ mid=(low+high)/2;
if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/
若k==r[mid].key,查找成功 若k<r[mid].key,则high=mid-1 若k>r[mid].key,则low=mid+1
❖重复上述操作,直至low>high时,查找失败 特点:比顺序查找方法效率高。最坏的情况下,需要比较 log2n次。
8
折半查找举例: 已知如下11个元素的有序表:
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low mid
high=mid-1
( 08, 14, 23, 37, 46, 55, 68, 79,
low=mid+1
high
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
5
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
分析: 查找第1个元素所需的比较次数为1; 查找第2个元素所需的比较次数为2; …… 查找第n个元素所需的比较次数为n;
总计全部比较次数为:1+2+…+n = (1+n)n/2 因为是计算某一个元素的平均查找次数,还应当除以n, (假设查找任一元素的概率相同) 即: ASL=(1+n)/2 ,时间效率为 O(n)
第九章 查找表

第九章查找表查找表是由同一类型的数据元素(或记录)构成的集合。
对查找表经常进行的操作:1)查询某个“特定的”数据元素是否在查找表中;2)检索某个“特定的”数据元素的各种属性;3)在查找表中插入一个数据元素;4)从查找表中删去某个数据元素。
静态查找表仅作上述1)和2)操作的查找表动态查找表有时在查询之后,还需要将“查询”结果为“不在查找表中”的数据元素插入查找表;或者,从查找表中删除其“查询”结果为“在查找表中”的数据元素关键字是数据元素(或记录)中某个数据项的值,用以标识(识别)一个数据元素(或记录)若此关键字可以识别唯一的一个记录,则称之谓“主关键字”若此关键字能识别若干记录,则称之谓“次关键字”查找根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素或(记录)若查找表中存在这样一个记录,则称“查找成功”,查找结果:给出整个记录的信息,或指示该记录在查找表中的位臵;否则称“查找不成功”,查找结果:给出“空记录”或“空指针”如何进行查找?取决于查找表的结构,即:记录在查找表中所处的位臵。
然而,查找表本身是一种很松散的结构,因此,为了提高查找的效率,需要在查找表中的元素之间人为地附加某种确定的关系,换句话说,用另外一种结构来表示查找表。
本章讨论的重点:查找表的各种表示方法及其相应的查找算法9.1 静态查找表ADT StaticSearchTable {数据对象D:D是具有相同特性的数据元素的集合。
每个数据元素含有类型相同的关键字,可唯一标识数据元素。
数据关系R:数据元素同属一个集合。
基本操作P:Create(&ST, n);操作结果:构造一个含n个数据元素的静态查找表ST。
Destroy(&ST);初始条件:静态查找表ST存在;操作结果:销毁表ST。
Search(ST, key);初始条件:静态查找表ST存在,key为和查找表中元素的关键字类型相同的给定值;操作结果:若ST中存在其关键字等于key的数据元素,则函数值为该元素的值或在表中的位臵,否则为“空”。
数据结构查找表

如何进行查找
在一个结构中查找某个数据元素的过程,依赖于数据 元素在结构中的地位,即依赖于数据元素的组织关系 (人为的)。
在计算机中进行查找的方法随数据结构不同而不同。 即随查找表的不同而不同。
9.1 静态查找表
顺序表的查找 有序表的查找 静态树表的查找
查找表的结构 查找过程描述 查找性能分析 查找方法比较
n ASLbs log 2 ( 1) 1 s
9.2 动态查找表
动态查找表的ADT
动态查找表的特点是,表结构本身是在查找过程中动态生成的。即, 对于给定值key,若表中存在其关键字等于key的记录,则查找成 功返回;否则,插入关键字等于key的记录。
P226: SearchDSTable(DT,key ); InsertDSTable(&DT,e ); DeleteDSTable(&DT, e );
给定值进行比较的关键字个数最多也不超过log2 n 1
折半查找的ASL
假设有序表的长度为n=2h-1,则描述折半查找的判定树是深度 为h的满二叉树。 该树中层次为1的结点有1个,层次为2的结点有2个,…,层次 为h的结点有2h-1个。 假设有序表中每个记录的查找概率相等(Pi = 1/n)。
05 low 13 19 21 37 56 64 75 80 88 92 high
mid
high low
mid (low high) / 2
例子
给定值key = 21的查找过程: 给定值key = 85的查找过程:
下界low>上界high,查找不成功。
int Search_Bin( SSTable ST,KeyType key ){ low = 1; high = ST.length; while( low <= high ){ mid = ( low + high ) /2; if EQ( key , ST.elem[mid].key ) return mid; else if LT( key , ST.elem[mid].key ) high = mid-1; else low = mid +1; } return 0; }
王道数据结构 第七章 查找思维导图-高清脑图模板
每次调整的对象都是“最小不平衡子树”
插入操作
在插入操作,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡
在A的左孩子的左子树中插入导致不平衡
由于在结点A的左孩子(L)的左子树(L)上插入了新结点,A的平衡因子由1增
至2,导致以A为根的子树失去平衡,需要一次向右的旋转操作。
LL
将A的左孩子B向右上旋转代替A成为根节点 将A结点向右下旋转成为B的右子树的根结点
RR平衡旋转(左单旋转)
而B的原左子树则作为A结点的右子树
在A的左孩子的右子树中插入导致不平衡
由于在结点A的左孩子(L)的右子树(R)上插入了新结点,A的平衡因子由1增
LR
至2,导致以A为根的子树失去平衡,需要两次旋转操作,先左旋转再右旋转。
将A的左孩子B的右子树的根结点C向左上旋转提升至B结点的位置
本质:永远保证 子树0<关键字1<子树1<关键字2<子树2<...
当左兄弟很宽裕时,用当前结点的前驱、前驱的前驱来填补空缺 当右兄弟很宽裕时,用当前结点的后继、后继的后继来填补空缺
兄弟够借。若被删除关键字所在结点删除前的关键字个数低于下限,且与此结点 右(或左)兄弟结点的关键字还很宽裕,则需要调整该结点、右(或左)兄弟结 点及其双亲结点及其双亲结点(父子换位法)
LL平衡旋转(右单旋转)
而B的原右子树则作为A结点的左子树
在A的右孩子的右子树中插入导致不平衡
由于在结点A的右孩子(R)的右子树(R)上插入了新结点,A的平衡因子由-1
减至-2,导致以A为根的子树失去平衡,需要一次向左的旋转操作。
RR
将A的右孩子B向左上旋转代替A成为根节点 将A结点向左下旋转成为B的左子树的根结点
二叉排序树

就维护表的有序性而言,二叉排序树无须移 动结点,只需修改指针即可完成插入和删 除操作,且其平均的执行时间均为O(lgn), 因此更有效。二分查找所涉及的有序表是 一个向量,若有插入和删除结点的操作, 则维护表的有序性所花的代价是O(n)。当 有序表是静态查找表时,宜用向量作为其 存储结构,而采用二分查找实现其查找操 作;若有序表里动态查找表,则应选择二 叉排序树作为其存储结构。
if(q->lchild) //*q的左子树非空,找*q的左子 树的最右节点r. {for(q=q->lchild;q->rchild;q=q->rchild); q->rchild=p->rchild; } if(parent->lchild==p)parent->lchild=p>lchild; else parent->rchild=p->lchild; free(p); /释放*p占用的空间 } //DelBSTNode
下图(a)所示的树,是按如下插入次序构成的: 45,24,55,12,37,53,60,28,40,70 下图(b)所示的树,是按如下插入次序构成的: 12,24,28,37,40,45,53,55,60,70
在二叉排序树上进行查找时的平均查找长度和二叉树的形态 有关: ①在最坏情况下,二叉排序树是通过把一个有序表的n 个结点依次插入而生成的,此时所得的二叉排序树蜕化为 棵深度为n的单支树,它的平均查找长度和单链表上的顺 序查找相同,亦是(n+1)/2。 ②在最好情况下,二叉排序树在生成的过程中,树的形 态比较匀称,最终得到的是一棵形态与二分查找的判定树 相似的二叉排序树,此时它的平均查找长度大约是lgn。 ③插入、删除和查找算法的时间复杂度均为O(lgn)。 (3)二叉排序树和二分查找的比较 就平均时间性能而言,二叉排序树上的查找和二分查找 差不多。
数据结构二叉排序树

05
13
19
21
37
56
64
75
80
88
92
low mid high 因为r[mid].key<k,所以向右找,令low:=mid+1=4 (3) low=4;high=5;mid=(4+5) div 2=4
05
13
19
low
21
37
56
64
75
80
88
92
mid high
因为r[mid].key=k,查找成功,所查元素在表中的序号为mid 的值
平均查找长度:为确定某元素在表中某位置所进行的比 较次数的期望值。 在长度为n的表中找某一元素,查找成功的平均查找长度:
ASL=∑PiCi
Pi :为查找表中第i个元素的概率 Ci :为查到表中第i个元素时已经进行的比较次数
在顺序查找时, Ci取决于所查元素在表中的位置, Ci =i,设每个元素的查找概率相等,即Pi=1/n,则:
RL型的第一次旋转(顺时针) 以 53 为轴心,把 37 从 53 的左上转到 53 的左下,使得 53 的左 是 37 ;右是 90 ,原 53 的左变成了 37 的右。 RL型的第二次旋转(逆时针)
一般情况下,假设由于二叉排序树上插入结点而失去 平衡的最小子树的根结点指针为a(即a是离插入结点最 近,且平衡因子绝对值超过1的祖先结点),则失去平衡 后进行调整的规律可归纳为下列四种情况: ⒈RR型平衡旋转: a -2 b -1 h-1 a1
2.查找关键字k=85 的情况 (1) low=1;high=11;mid=(1+11) / 2=6
05
13
19
21
数据结构中的查找算法总结

数据结构中的查找算法总结静态查找是数据集合稳定不需要添加删除元素的查找包括:1. 顺序查找2. 折半查找3. Fibonacci4. 分块查找静态查找可以⽤线性表结构组织数据,这样可以使⽤顺序查找算法,再对关键字进⾏排序就可以使⽤折半查找或斐波那契查找等算法提⾼查找效率,平均查找长度:折半查找最⼩,分块次之,顺序查找最⼤。
顺序查找对有序⽆序表均适⽤,折半查找适⽤于有序表,分块查找要求表中元素是块与块之间的记录按关键字有序动态查找是数据集合需要添加删除元素的查找包括: 1. ⼆叉排序树 2. 平衡⼆叉树 3. 散列表 顺序查找适合于存储结构为顺序存储或链接存储的线性表。
顺序查找属于⽆序查找算法。
从数据结构线形表的⼀端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相⽐较,若相等则表⽰查找成功 查找成功时的平均查找长度为: ASL = 1/n(1+2+3+…+n) = (n+1)/2 ; 顺序查找的时间复杂度为O(n)。
元素必须是有序的,如果是⽆序的则要先进⾏排序操作。
⼆分查找即折半查找,属于有序查找算法。
⽤给定值value与中间结点mid的关键字⽐较,若相等则查找成功;若不相等,再根据value 与该中间结点关键字的⽐较结果确定下⼀步查找的⼦表 将数组的查找过程绘制成⼀棵⼆叉树排序树,如果查找的关键字不是中间记录的话,折半查找等于是把静态有序查找表分成了两棵⼦树,即查找结果只需要找其中的⼀半数据记录即可,等于⼯作量少了⼀半,然后继续折半查找,效率⾼。
根据⼆叉树的性质,具有n个结点的完全⼆叉树的深度为[log2n]+1。
尽管折半查找判定⼆叉树并不是完全⼆叉树,但同样相同的推导可以得出,最坏情况是查找到关键字或查找失败的次数为[log2n]+1,最好的情况是1次。
时间复杂度为O(log2n); 折半计算mid的公式 mid = (low+high)/2;if(a[mid]==value)return mid;if(a[mid]>value)high = mid-1;if(a[mid]<value)low = mid+1; 折半查找判定数中的结点都是查找成功的情况,将每个结点的空指针指向⼀个实际上不存在的结点——外结点,所有外界点都是查找不成功的情况,如图所⽰。
Java常见的七种查找算法

Java常见的七种查找算法1. 基本查找也叫做顺序查找,说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。
从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
示例代码:public class A01_BasicSearchDemo1 {public static void main(String[] args){//基本查找/顺序查找//核心://从0索引开始挨个往后查找//需求:定义一个方法利用基本查找,查询某个元素是否存在//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}int[] arr ={131,127,147,81,103,23,7,79};int number =82;System.out.println(basicSearch(arr, number));}//参数://一:数组//二:要查找的元素//返回值://元素是否存在public static boolean basicSearch(int[] arr,int number){//利用基本查找来查找number在数组中是否存在for(int i =0; i < arr.length; i++){if(arr[i]== number){return true;}}return false;}}2. 二分查找也叫做折半查找,说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。
但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。
用给定值先与中间结点比较。
比较完之后有三种情况:•相等说明找到了•要查找的数据比中间节点小说明要查找的数字在中间节点左边•要查找的数据比中间节点大说明要查找的数字在中间节点右边代码示例:package com.itheima.search;public class A02_BinarySearchDemo1 {public static void main(String[] args){//二分查找/折半查找//核心://每次排除一半的查找范围//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}int[] arr ={7,23,79,81,103,127,131,147};System.out.println(binarySearch(arr,150));}public static int binarySearch(int[] arr,int number){//1.定义两个变量记录要查找的范围int min =0;int max = arr.length-1;//2.利用循环不断的去找要查找的数据while(true){if(min > max){return-1;}//3.找到min和max的中间位置int mid =(min + max)/2;//4.拿着mid指向的元素跟要查找的元素进行比较if(arr[mid]> number){//4.1 number在mid的左边//min不变,max = mid - 1;max = mid -1;}else if(arr[mid]< number){//4.2 number在mid的右边//max不变,min = mid + 1;min = mid +1;}else{//4.3 number跟mid指向的元素一样//找到了return mid;}}}}3. 插值查找在介绍插值查找之前,先考虑一个问题:为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?其实就是因为方便,简单,但是如果我能在二分查找的基础上,让中间的mid点,尽可能靠近想要查找的元素,那不就能提高查找的效率了吗?二分查找中查找点计算如下:mid=(low+high)/2, 即mid=low+1/2*(high-low);我们可以将查找的点改进为如下:mid=low+(key-a[low])/(a[high]-a[low])*(high-low),这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
数据结构:第9章 查找2-二叉树和平衡二叉树

return(NULL); else
{if(t->data==x) return(t);
if(x<(t->data) return(search(t->lchild,x));
else return(search(t->lchild,x)); } }
——这种既查找又插入的过程称为动态查找。 二叉排序树既有类似于折半查找的特性,又采用了链表存储, 它是动态查找表的一种适宜表示。
注:若数据元素的输入顺序不同,则得到的二叉排序树形态 也不同!
讨论1:二叉排序树的插入和查找操作 例:输入待查找的关键字序列=(45,24,53,45,12,24,90)
二叉排序树的建立 对于已给定一待排序的数据序列,通常采用逐步插入结点的方 法来构造二叉排序树,即只要反复调用二叉排序树的插入算法 即可,算法描述为: BiTree *Creat (int n) //建立含有n个结点的二叉排序树 { BiTree *BST= NULL;
for ( int i=1; i<=n; i++) { scanf(“%d”,&x); //输入关键字序列
– 法2:令*s代替*p
将S的左子树成为S的双亲Q的右子树,用S取代p 。 若C无右子树,用C取代p。
例:请从下面的二叉排序树中删除结点P。
F P
法1:
F
P
C
PR
C
PR
CL Q
CL QL
Q SL
S PR
QL S
SL
法2:
F
PS
C
PR
CL Q
QL SL S SL
二叉树
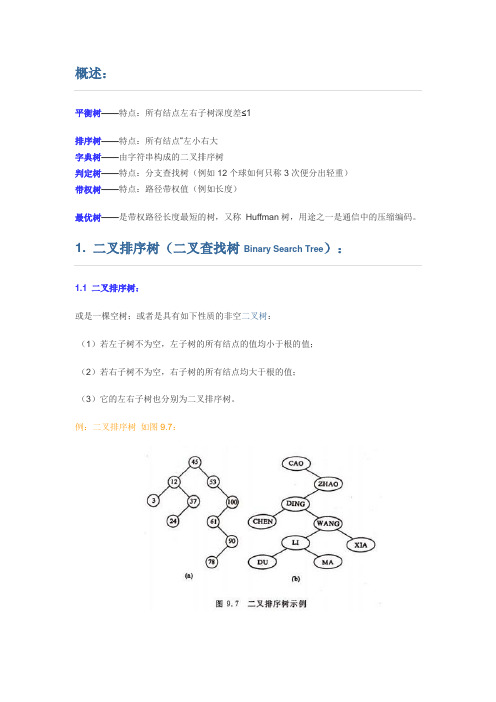
平衡树——特点:所有结点左右子树深度差≤1排序树——特点:所有结点―左小右大字典树——由字符串构成的二叉排序树判定树——特点:分支查找树(例如12个球如何只称3次便分出轻重)带权树——特点:路径带权值(例如长度)最优树——是带权路径长度最短的树,又称Huffman树,用途之一是通信中的压缩编码。
1.1 二叉排序树:或是一棵空树;或者是具有如下性质的非空二叉树:(1)若左子树不为空,左子树的所有结点的值均小于根的值;(2)若右子树不为空,右子树的所有结点均大于根的值;(3)它的左右子树也分别为二叉排序树。
例:二叉排序树如图9.7:二叉排序树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉排序树的存储结构。
中序遍历二叉排序树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉排序树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。
每次插入的新的结点都是二叉排序树上新的叶子结点,在进行插入操作时,不必移动其它结点,只需改动某个结点的指针,由空变为非空即可。
搜索,插入,删除的复杂度等于树高,期望O(logn),最坏O(n)(数列有序,树退化成线性表).虽然二叉排序树的最坏效率是O(n),但它支持动态查询,且有很多改进版的二叉排序树可以使树高为O(logn),如SBT,AVL,红黑树等.故不失为一种好的动态排序方法.2.2 二叉排序树b中查找在二叉排序树b中查找x的过程为:1. 若b是空树,则搜索失败,否则:2. 若x等于b的根节点的数据域之值,则查找成功;否则:3. 若x小于b的根节点的数据域之值,则搜索左子树;否则:4. 查找右子树。
[cpp]view plaincopyprint?1.Status SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p){2. //在根指针T所指二叉排序樹中递归地查找其关键字等于key的数据元素,若查找成功,3. //则指针p指向该数据元素节点,并返回TRUE,否则指针P指向查找路径上访问的4. //最好一个节点并返回FALSE,指针f指向T的双亲,其初始调用值为NULL5. if(!T){ p=f; return FALSE;} //查找不成功6. else if EQ(key, T->data.key) {P=T; return TRUE;} //查找成功7. else if LT(key,T->data.key)8. return SearchBST(T->lchild, key, T, p); //在左子树继续查找9. else return SearchBST(T->rchild, key, T, p); //在右子树继续查找10.}2.3 在二叉排序树插入结点的算法向一个二叉排序树b中插入一个结点s的算法,过程为:1. 若b是空树,则将s所指结点作为根结点插入,否则:2. 若s->data等于b的根结点的数据域之值,则返回,否则:3. 若s->data小于b的根结点的数据域之值,则把s所指结点插入到左子树中,否则:4. 把s所指结点插入到右子树中。
数据结构_第9章_查找2-二叉树和平衡二叉树

F
PS
C
PR
CL Q
QL SL S SL
10
3
18
2
6 12
6 删除10
3
18
2
4 12
4
15
15
三、二叉排序树的查找分析
1) 二叉排序树上查找某关键字等于给定值的结点过程,其实 就是走了一条从根到该结点的路径。 比较的关键字次数=此结点的层次数; 最多的比较次数=树的深度(或高度),即 log2 n+1
-0 1 24
0 37
0 37
-0 1
需要RL平衡旋转 (绕C先顺后逆)
24
0
-012
13
3573
0
01
37
90
0 53 0 53
0 90
作业
已知如下所示长度为12的表:
(Jan, Feb, Mar, Apr, May, June, July, Aug, Sep, Oct, Nov, Dec)
(1) 试按表中元素的顺序依次插入一棵初始为空的二叉 排序树,画出插入完成之后的二叉排序树,并求其在 等概率的情况下查找成功的平均查找长度。
2) 一棵二叉排序树的平均查找长度为:
n i1
ASL 1
ni Ci
m
其中:
ni 是每层结点个数; Ci 是结点所在层次数; m 为树深。
最坏情况:即插入的n个元素从一开始就有序, ——变成单支树的形态!
此时树的深度为n ; ASL= (n+1)/2 此时查找效率与顺序查找情况相同。
最好情况:即:与折半查找中的判ห้องสมุดไป่ตู้树相同(形态比较均衡) 树的深度为:log 2n +1 ; ASL=log 2(n+1) –1 ;与折半查找相同。
数据结构 查找

生成二叉排序树过程。
10 3 2 7 8 18 12
注:二叉排序树与关键字排列顺序有关,排列顺 序不一样,得到的二叉排序树也不一样。
二叉排序树的建立的算法
反复调用二叉排序树的插入算法即可 Bitree Creat (int n) { //建立含有n个结点的二叉排序树
Bitree T= NULL;
for ( int i=1; i<=n; i++) {
else if LT(key,p->key) p->lchild=s;
else p->rchild=s
return TRUE; }
//被插结点*s为右孩子
else return FALSE;
}// Insert BST
//树中已有关键字相同的结点,不再插入
4)二叉排序树的建立
例:关键字序列{ 10、18、3、8、12、2、7、3 }
5)二叉排序树上的删除
对于二叉排序树,删去树上一个结点相当于删去有序 序列中的一个记录,在删除某个结点之后依旧要保持二叉 排序树的特性。
如何在二叉排序树上删去一个结点呢?
设在二叉排序树上被删结点为*p(指向结点的指针为 p),其双亲结点为*f,设*p是*f的左孩子。 f F p P c PR C q Q s CL S QL SL
low
( 08,
( 08,
mid
14,
14,
high
55, 68, 79,
79,
23,
23,
37,
37,
46,
46,
91 )
low
55,
mid
68,
high
91 )
low mid
天大《数据结构》学习笔记六

这就是“冲突”。 (a)设计一个“好的”哈希函数:“好的”标准:(I)计算简便。(II)冲突少。 (b)给出解决冲突的方法。
5.3 构造哈希函数的方法举例:
构造哈希函数时应考虑到实际问题的需要,即表的长度,和键值的范围。如表长为 M,则 0<=h(k)<M. (1)除留余数法: 已知表长为 M,令 P 为接近 M 的质数,a 为常数(表头地址),则造 h(k)=k MOD p +a. 如:键值的范围为 000001 到 859999,M=6000 表头地址为 1000000,选 P=5987。 H(k)=k MOD 5987+1000000 如 k=179148 则 h(k)=1005525 (2)移位法: 如键值 k=32834872, M=1000
}
三、索引顺序查找(分块查找):
索引表:
本块最大 起始:
22
48
86
1
7
13
[1]
[7][13]来自22 12 13 8 9 20 33 42 44 38 24 48 60 58 74 49 86 53
块内无序,但块间有序:
数据结构—学习笔记六
查找方法:
(I)先决定在哪一块内(在索引表内) (II)再从此块内查找。
六、键树 如键集为:{CAI,CAO,LI,LAN,CHA……} 6.1 存入如下:
将此树转换为二叉树: 查某键时,按每个字母去查。此字母与二叉树上的当前行字母不匹配,则横向移动, 查下一;如匹配,则竖向移动,查下一个。 6.2 算法:(K.ch[num-1]为结束符$) { p=t->first; I=0;
328 348 + 72 748
数据结构—学习笔记六
第6章_查找和排序_查找

分块查找的 分块查找的ASL
设文件r[1:n]分成 块,每块记录个数 分成b块 每块记录个数 每块记录个数s=n/b 设文件 分成
若用对分查找确定块 (b+1)ASL= lg2(b+1)-1+(s+1)/2= lg2(n/s+1)+s/2 若用顺序查找确定块 ASL= (b+1)/2+(s+1)/2= (s2+2s+n)/(2s)
线性表的查找 顺序查找 二分查找 分块查找 二叉排序树查找 哈希技术
平均查找长度ASL 平均查找长度ASL
在查找过程中对关键字需要执行的平均 比较次数 是衡量一个查找算法次序优劣的标准
1.顺序查找
从表的一端开始顺序扫描线性表,依次 从表的一端开始顺序扫描线性表, 将扫描到的结点关键字与给定值K比较, 将扫描到的结点关键字与给定值K比较, 若当前扫描到的结点关键字与k 若当前扫描到的结点关键字与k相等则查 找成功;若扫描结束后, 找成功;若扫描结束后,仍未找到关键 字等于K的结点,则查找失败。 字等于K的结点,则查找失败。 顺序查找方法可用链式存储结构和 顺序查找方法可用链式存储结构和顺序 方法可用链式存储结构和顺序 存储结构实现 实现。 存储结构实现。
顺序查找算法
在原表长n的基础上增加一个元素n+1, 在原表长n的基础上增加一个元素n+1, 值送入此元素的关键字项中, 将K值送入此元素的关键字项中,称为 监视哨” “监视哨”。 顺序查找算法中所设的监视哨 顺序查找算法中所设的监视哨是为了简 监视哨是为了简 边界条件而引入的附加结点 化循环的边界条件而引入的附加结点( 化循环的边界条件而引入的附加结点(元 素),其作用是使循环中省去判定防止下 标越界的条件从而节省了比较的时间 比较的时间。 标越界的条件从而节省了比较的时间。
树、二叉树、查找算法总结

树、⼆叉树、查找算法总结树的定义形式化定义树:T={D,R }。
D是包含n个结点的有限集合(n≥0)。
当n=0时为空树,否则关系R满⾜以下条件:l 有且仅有⼀个结点d0∈D,它对于关系R来说没有前驱结点,结点d0称作树的根结点。
l 除根结点外,每个结点有且仅有⼀个前驱结点。
l D中每个结点可以有零个或多个后继结点。
递归定义树是由n(n≥0)个结点组成的有限集合(记为T)。
其中:l 如果n=0,它是⼀棵空树,这是树的特例;l 如果n>0,这n个结点中存在⼀个唯⼀结点作为树的根结点(root),其余结点可分为m (m≥0)个互不相交的有限⼦集T1、T2、…、Tm,⽽每个⼦集本⾝⼜是⼀棵树,称为根结点root的⼦树。
ð 树中所有结点构成⼀种层次关系!树的基本术语度结点的度:⼀个结点的⼦树的个数树的度:各节点的度的最⼤值。
通常将度为m的树成为m次树或m叉树结点分⽀结点:度不为0的结点(也称⾮终端结点)度为1的结点成为单分⽀结点,度为2的结点称为双分⽀结点叶结点:度为0的结点路径与路径长度路径:两个结点di和dj的结点序列(di,di1,di2,…,dj)。
其中<dx,dy>是分⽀。
路径长度:等于路径所通过的结点数⽬减1(即路径上的分⽀数⽬)结点的层次和树⾼度层次:根结点层次为1,它的孩⼦结点层次为2。
以此类推。
树的⾼度(深度):结点中的最⼤层次;有序树和⽆序树有序树:若树中各结点的⼦树是按照⼀定的次序从左向右安排的,且相对次序是不能随意变换的⽆序树:和上⾯相反森林只要把树的根结点删去就成了森林。
反之,只要给n棵独⽴的树加上⼀个结点,并把这n棵树作为该结点的⼦树,则森林就变成了⼀颗树。
树的性质性质1:树中的结点数等于所有结点的度数之和加1。
证明:树的每个分⽀记为⼀个度,度数和=分⽀和,⽽再给根节点加个分⽀性质2:度为m的树中第i层上⾄多有mi-1个结点(i≥1)。
性质3 ⾼度为h的m次树⾄多有个结点。
数据结构6

int binSearch(int a[],int n,int k) { int low,high,mid; low=0; high=n-1; while ( low<=high ) { mid=(low+high)/2; if (a[mid]==k) return(mid) ; else if(a[mid]<k) low=mid+1 ; else high=mid-1 ; } return(-1); }
通过在初始为空的树中不断插入数x来建立二叉排序树,步骤: 通过在初始为空的树中不断插入数x来建立二叉排序树,步骤: (1)若二叉排序树为空,则插入结点应为根结点 若二叉排序树为空, (2)若二叉排序树非空,根据关键字比较的结果确定是在左 若二叉排序树非空, 子树还是在右子树中继续查找插入位置, 子树还是在右子树中继续查找插入位置,直至某个结点的 左子树或右子树空为止,则插入结点应为该结点的左孩子 左子树或右子树空为止, 或右孩子。 或右孩子。
二、查找算法及实现
在给定的二叉排序树t中查找给定待查关键字k 在给定的二叉排序树t中查找给定待查关键字k: 从根结点出发 1.如果树t为空,那么查找失败。算法结束;否则, 1.如果树t为空,那么查找失败。算法结束;否则,转2。 如果树 2.如果t >data等于k 则查找成功。算法结束。否则转3 2.如果t->data等于k,则查找成功。算法结束。否则转3。 如果 等于 3.如果k<t->data,那么t=t->lchild(到左子树查找), 3.如果k<t->data,那么t=t->lchild(到左子树查找) 如果k<t t=t 到左子树查找 (1)。 t=t到右子树查找), ),转 转(1)。否则 t=t->rchild (到右子树查找),转 (1)。
查找表

2、二叉排序树的查找算法 、二叉排序树的查找算法 若二叉树为空,则查找不成功 否则,1 否则,1)若给定值等于根结点的关键字,则 查找成功。 2)若给定值小于根结点的关键字,则 继续在左子树上进行查找。 3)若给定值大于根结点的关键字,则 继续在右子树上进行查找。 继续在右子树上进行查找。
算法描述如下: Status searchBST(BiTree T,keyType,BiTree f,BiTree &p){ if (!T) {p=f; return false;}//查找不成功 else if (key=T→data) (key=T→ {P=T;return Tree;}//查找成功 else if (key<T→data) (key<T→ searchBST (T→lchild,key,T,P);//在左子树中继续查找 (T→lchild,key,T,P);// else searchBST(T→rchild,key,T,P);// searchBST(T→rchild,key,T,P);//在右子树中继续查找 }//searchBST
h
三、静态查找树表 不等概率查找的情况下,折半查找不是最好 的查找方法 四、索引顺序表(分块查找) 四、索引顺序表(分块查找) 对比顺序表和有序表的查找性能之差别 顺序表 有序表 表的特征 无序表 有序表 存储结构 顺序结构或 顺序结构 链表结构 插删操作 易于进行 需移动元素 ASL值 ASL值 大 小
3、二叉排序树的插入算法 、二叉排序树的插入算法 Status InsertBST(BiTree &T,ElemType e){ if (!SearchBST (T,e.key,null,p)){ S=(BiTree)malloc(sizeof(BiTNode)); S→data=e; S →lchild=S →rchild=Null; if (!P) T=S; else if (e.key<P →data.key) P →lchild=S;//插入S为左孩子 插入S else P →rchild=S;//插入S为右孩子 插入S Return True;} else return false;}//Insert BST
查找表——精选推荐

查找表基本概念:查找表:由同⼀类型的数据元素(或记录)构成的集合。
关键字(键):⽤来表⽰数据元素的数据项成为关键字,简称键,其值称为键值主关键字:可唯⼀标识哥哥数据元素的关键字查找:根据给定的某个K值,再查找表寻找⼀个其键值等于K的数据元素。
静态查找表:进⾏的是引⽤型运算动态查找表:进⾏的是加⼯型运算静态查找表:查找表⽤顺序表表⽰:(见P163)const int maxsize=20 //静态查找表的表长typedef struct {TableElem elem[maxsize+1]; /*⼀维数组, 0号单元留空*/int n; /*最后⼀个元素的下标,也即表长*/}SqTable ;typedef struct {keytype key ; /*关键字域 */… /*其它域*/} TableElem ;⼀、过程从表中最后⼀个记录开始顺序进⾏查找,若当前记录的关键字=给定值,则查找成功;否则,继续查上⼀记录…;若直⾄第⼀个记录尚未找到需要的记录,则查找失败。
⼆、算法⽅法⼀:使⽤⼀种设计技巧:设⽴岗哨int SearchSqtable(Sqtable T, KeyType key){ /*在顺序表R中顺序查找其关键字等于key的元素。
若找到,则函数值为该元素在表中的位置,否则为0*/T.elem[0].key=key;i=T.n;while ( T.elem[i].key!=key ) i- - ;return i ;}三、算法分析成功查找: ASL=∑ni=1Pi Ci(设每个记录的查找概率相等)=1/n ∑ni=1(n-i+1)=(n+1)/2不成功查找: ASL=n+1▲顺序查找优点:简单,对表⽆要求;▲顺序查找缺点:⽐较次数多1、⼆分查找思想:每次找中项.中项是,则找到;.否则,根据此中项的关键字与给定关键字的关系,决定在表的前或后半部继续找。
关键点。
可使下次查找范围缩⼩⼀半。
⼆分查找基本思想:每次将处于查找区间中间位置上的数据元素与给定值K⽐较,若不等则缩⼩查找区间并在新的区间内重复上述过程,直到查找成功或查找区间长度为0(查找不成功)为⽌⼆分查找算法:int SearchBin ( SqTable T, KeyType key ) {/*在有序表R中⼆分查找其关键字等于K的数据元素;若找到,则返回该元素在表中的位置,否则返回0 */int low,high;low=1 ; high=T.n ;while ( low<=high ){ mid=(low+high)/2 ;if (key==T.elem[mid].key) return mid;else if (key< T.elem[mid].key ) high =mid-1 ;else low=mid+1 ;}return (0) ;}分块查找⼀、查找过程:1.先建⽴最⼤(或⼩)关键字表——索引表(有序)即将每块中最⼤(或最⼩)关键字及指⽰块⾸记录在表中位置的指针依次存⼊⼀张表中,此表称为索引表;2.查找索引表,以确定所查元素所在块号;将查找关键字k与索引表中每⼀元素(即各块中最⼤关键字)进⾏⽐较,以确定所查元素所在块号;3.在相应块中按顺序查找关键字为k的记录。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
8Байду номын сангаас
7
18
25
35
42
二叉排序树的删除(续)
第二种方法∶
如果被删除结点p没有左子树,则用p的右子女代替 p即可(同第一种方法的)。
38
Insert Key=7
7<20
7<10
10
6
1155
7>6
2
8
7<8
7
20
40 30
25
35
39
Insert Key=18
20
10
6
1155
40 30
2
8
18
25
35
7
40
二叉排序树的删除
为了删除一个二叉树中的结点,必须首先找到这个结点, 然后选择下面给出两种方法删除之,以保证删除后仍满 足二叉排序树的定义。
哈夫曼树可定义为: struct HtTree { struct HtNode ht[MAXNODE]; int root;/* 树根在数组中的下标*/ }; typedef struct HtTree *PHtTree;
23
本讲主要内容:
字典及抽象数据结构 二分查找算法 二叉排序树的建构与维护 文件索引结构简介
函数指针的声明是基于函数声明的基础上,把函数名的部 分替换为(*变量名)。
19
例子1:
例如: int (*fp) (int i,intj); 就声名了一个函数指针。该函数指针可以指向带两个
整数变量且返回一个整数值的函数。
int add(int a, int b )
{ return(a+b); }
n
ASL pici i 1
27
抽象数据类型
ADT Dictionary
Dictionary表示抽象数据类型字典, DicElement 表示字典元素类型, KeyType 表示元素中关键码的类型, Position 表示字典中元素的位置。
operations
Dictionary createEmptyDictionary ( void )
20
10
40
6
1155 30
2
8
25
35
二叉排序树的存储结构(链式)
struct BinSearchNode;
typedef struct BinSearchNode * PBinSearchNode;
struct BinSearchNode
{
KeyType key;
/* 关键码值*/
PBinSearchNode llink, rlink; /* 二叉树的左、右指针 */
45 23 周夏司 50
39
46 16 李景文 10
43
47 2
叶佩霖 50
35
48 29 郭舒文 60
51
49 17 杜文杰 60
52
50 9
阮萃茵 70
29
51 3
龙国才 0
35
52 21 陈俊珊 45
45
53 13 李欣怡 75
55
55 4
刘星 50
29
57 28 郭凌典 25
48
59 14 李敏妍 90
};
typedef struct BinSearchNode * BinSearchTree /*二叉排序树*/
typedef BinSearchTree * PBinSearchTree;
36
二叉排序树的检索
二叉排序树中查找某个结点的过程和二分法检索相似, 也是逐步缩小检索范围的过程。
if (node.value == key) found else if ( key > node.value) binSearch(key, node.rightChild); else binSearch(key, node.leftChild);
则查找成功并返回此位置,否则确定新的查找区间, 继续二分查找.
30
二分查找算法:
31
二分查找性能分析
二分法检索每经过一次比较就将检索范围缩小 一半,第i次比较可能涉及的元素<=2i -1。
二分法检索的最大检索长度为:log2(n+1) 设检索每个元素的概率相同,平均检索长度
ASL 算法复杂度:log2(n)
25
…
字典与查找表
—— 由一些具有相同可辨认特性的数据元素构成的集合。
主关键字 关键字
26
…
字典的检索(searching)
根据给定的某个值,在查找表中确定一个其关 键字等于给定值的数据条目。
顺序检索、二分检索。
衡量一个字典检索算法效率的主要标准是检索过程 中对关键码的平均比较次数:
第一种方法∶
(1) 如果被删除结点p没有左子树,则用p的右子女代替p即可。 (2) 否则,在p的左子树中,找出关键码最大的一个结点r (r处 于p的左子树中最右下角的位置,r一定无右子女),将r的右指 针指向p的右子女,用p的左子女代替p结点。
41
Delete Key=10
20
10
6
1155
40 30
顺序检索的算法复杂度为O(n),平均比较次数为n/2。
29
字典的二分查找
二分查找(binary search)
要求:
查找表为有序表,即表中 结点按关键字有序排列,并且采用顺序存储结构。
基本思想:
1. 确定搜索区间的中点位置: 2. 然后将待查的key值与range[mid].key比较:若相等,
8
哈夫曼树(总体加权路径最小)
给定m个权值{ w1 , w2 ,…, wm }
① 构造由m棵二叉树组成的树林F = {T1,T2,…,Tm},其中每棵
树Ti 只有一个根结点,且根结点的权值为wi;
② 在树林中选取两棵根结点权值最小的和次小的二叉树作为左
右子树构造一棵新的二叉树,其根结点的权值为左右子树根 结点权值之和。
查找表与二叉排序树
用优先队列生成Huffman树
2007/05/07
优先队列的概念
根节点的值小于(或大于)左、右子节点的值 所有结点按广度优先的顺序依次存放,没有空缺。
2
3
5
9
10
7
8
14
12
11
16
Data Structures and Algorithm Analysis in C :CHAPTER 6: PRIORITY QUEUES (HEAPS)
2
优先队列可以采用顺序存储方式
第k层第i个节点: heap[ 2k-1 + i ]
左儿子: heap[ k * 2 ]
右儿子: heap[ k * 2 +1 ]
?
3
优先队列的ADT
Operations
PriorityQueue createEmptyPriQueue( void) //创建一个空优先队列。
in fp = add;
//fp指向add函数
int i = (*fp)(12,15);
20
函数指针作为参数
声明一个函数指针作为 函数oper()的参数。
21
在优先队列中引入函数指针
—— 提高抽象数据类型的通用性,实现软件分层
22
在线性结构上实现哈夫曼树
struct HtNode //* 哈夫曼树结点的结构 { int ww; int parent, llink, rlink; };
24
字典的基本概念
字典是一个由数据记录(record)构成的顺序表, 其中记录中有一个特殊的字段,称为关键码。每条 记录都有唯一的不重复的关键码取值。字典中的元 素之间能够根据其关键码进行比较与排序,对字典 元素的插入、删除和检索等操作一般也以关键码为 依据进行。 字典可以看成是由关键码值k到数据记录r的一个对 应。唯一的关键码取值可以唯一对应一条数据记录。
end ADT PriorityQueue
4
优先队列的类型声明
5
创建一个优先队列
6
优先队列中插入元素
location of the end of H
7
优先队列中删除元素
Get the minimum and the last element Child = i*2 +1;
Swap down else
11
哈夫曼树的类型定义
weight
12
哈夫曼算法(初始化)
13
用优先队列实现
哈夫曼算法(构造树)
14
问题分析:
优先队列的作用?
找最小值、次小值结点。
优先队列操作流程?
所有叶结点先入队。 弹出两个头部最小结点。 构造一棵子树。 子树头节点入队。
15
16
优先队列元素的数据类型?
74
61 27 唐慰夷 30
49
62 11 吴宇翔 0
47
71 10 何英华 0
51
78 30 梁迪欣 80
69
34
动态查找表结构
—— 二叉排序树(又称二叉搜索树)
以关键码值为结点的二叉树
如果任一结点的左子树非空, 则左子树中的所有结点的关键 码都小于根结点的关键码;
如果任一结点的右子树非空, 则右子树中的所有结点的关键 码都大于根结点的关键码。
32
二叉判定树
纪录二分查找的过程并扩充外部结点形成扩充二叉树 在等概率的前提下可使平均查找长度达到最小。
key
5