printConfig.xml的说明
PythonXML解析

PythonXML解析XML是一种常见的数据交换格式,许多网络应用和API都使用XML来传输数据。
Python提供了许多库来解析和处理XML数据。
本文将介绍使用Python解析XML的方法及其相关技巧。
一、什么是XMLXML(可扩展标记语言)是一种用于描述数据的标记语言,它采用类似HTML的标签来标记数据,从而使数据更加结构化。
XML常用于表示数据的层次结构,如树形结构或层级结构。
二、Python中的XML解析方法在Python中,常用的XML解析库有两种:ElementTree和lxml。
这两种库都提供了方便的API来处理XML数据。
1. ElementTreeElementTree是Python标准库中内置的一个XML解析库。
使用ElementTree可以方便地解析和操作XML文件。
下面是一个简单的示例代码,演示了如何使用ElementTree解析XML数据:```pythonimport xml.etree.ElementTree as ET# 解析XML文件tree = ET.parse('data.xml')root = tree.getroot()# 遍历XML节点for child in root:print(child.tag, child.attrib)# 访问XML节点的属性和文本内容for elem in tree.iter():print(elem.tag, elem.attrib, elem.text)```2. lxmllxml是一个基于C语言的强大的XML和HTML处理库,性能较好。
使用lxml可以进行高效的XML解析和处理。
下面是一个简单的示例代码,演示了如何使用lxml解析XML数据:```pythonfrom lxml import etree# 解析XML文件tree = etree.parse('data.xml')root = tree.getroot()# 遍历XML节点for child in root:print(child.tag, child.attrib)# 访问XML节点的属性和文本内容for elem in tree.iter():print(elem.tag, elem.attrib, elem.text)```三、XML解析技巧1. 遍历XML节点使用ElementTree和lxml库可以很方便地遍历XML节点。
PHP操作XML详解

[高端技术] PHP操作XML详解XML是一种流行的半结构化文件格式,以一种类似数据库的格式存储数据。
在实际应用中,一些简单的、安全性较低的数据往往使用XML文件的格式进行存储。
这样做的好处一方面可以通过减少与数据库的交互性操作提高读取效率,另一方面可以有效利用XML的优越性降低程序的编写难度。
PHP提供了一整套的读取XML文件的方法,很容易的就可以编写基于XML的脚本程序。
本章将要介绍PHP与XML的操作方法,并对几个常用的XML类库做一些简要介绍。
1 XML简介XML是“可扩展性标识语言(eXtensible Markup Language)”的缩写,是一种类似于HTML 的标记性语言。
但是与HTML不同,XML主要用于描述数据和存放数据,而HTML主要用于显示数据。
XML是一种“元标记”语言,开发者可以根据自己的需要创建标记的名称。
例如,下面的XML 代码可以用来描述一条留言。
复制代码1.<thread>2.<title>Welcome</title>3.<author>Simon</author>4.<content>Welcome to XML guestbook!!</content>5.</thread>其中,<thread>与</thread>标签标记了这是一段留言。
在留言中有标题、作者、内容,完整的表述了一条留言信息。
在一个XML文件的顶部,通常使用<?xml version=”1.0″?>来标识XML数据的开始和XML 数据使用标准的版本信息。
在浏览器中访问XML文件可以看到层次分明的XML数据信息,如图1所示。
XML的发展非常迅速,近些年来很多软件开发商都开始采用XML的开发标准进行应用程序的开发。
并且,很多新兴技术都架构在XML数据之上。
这意味着XML将与HTML一样成为Web技术不可或缺的一部分。
U8开发之打印控件

U8打印控件摘要打印控件是面向单据,列表,报表等多种业务场景的提供预览,打印,输出功能的公共控件。
什么是打印控件?打印控件Print Control是一个独立的,但同时又具有一定针对性的报表打印控件,它根据指定的XML格式文件(或字符串)对指定的XML数据文件(或字符串)进行格式化输出,本身基本不做任何数据的处理,不涉及任何业务逻辑,也不与任何数据库进行交互。
也就是说,一旦你对控件指定了源格式XML和数据XML,那么通过控件得到的打印预览输出和打印输出也就唯一确定了。
从这一点来看,本控件类似于IE、Mozilla等浏览器对纯HTML文本进行的解释。
Print Control的格式化输出依赖与上述的两个XML文件(或字符串,下同,以后不再注明),任何报表或者其他类似文件,如果希望使用本控件来打印的话,都必须先将格式和数据分别组织成满足本控件预定义格式的XML文件。
Print Control以ocx的形式封装,是一个进程内的COM Server,并支持嵌入到WEB中使用。
目标本文的目标是介绍使用打印控件进行开发的基本流程已经各个接口,属性,事件的使用方法。
目标人群是使用打印控件的二开人员。
打印控件可以做什么?绑定XML文件页面设置打印预览打印输出文件如何使用打印控件?1.环境准备打印控件的编译和调适,需要安装VC6和2个sdk1个是Microsoft SDK(Windows SDK November 2001)1个是FRAMEWORK 2.0 SDK安装完后在VC6进行如下设置:Tools→Options→Directories→选中Include files→加入2个sdk的路径:再在此界面中选中Library Files 加入2个sdk的lib路径:然后就可以在VC6中打开PrintControl的工程,进行编译了。
打印控件的调试工程一般如下:在一个文件夹中搁入U8PrintDataXML.log,U8PrintStyleXML.log,logPrintCtlTestor.exe然后Project→Settings→Debug,指向那个文件夹即可:然后在工程中找到此函数CPrintControlCtrl::SetDataStyleXML(此为打印控件入口函数)和long CPrintControlCtrl::PrintPreview()下断点,然后F5运行。
xml结构描述文件

xml结构描述文件XML(可扩展标记语言)是一种用于描述数据结构和数据的文本格式。
它具有易于阅读、易于编写和易于解析的特点,因此在许多领域得到了广泛的应用。
下面将详细介绍XML结构描述文件的相关知识。
1.XML结构简介XML是基于XML规范的一种树状结构。
它由一系列的元素组成,每个元素包括开始标签、结束标签和中间的内容。
XML文件由一个根元素开始,然后分为多个子元素,子元素也可以分为多个孙元素。
这种层次结构使得XML具有良好的可读性和易于理解。
2.XML的基本语法XML的基本语法包括以下几点:- 开始标签:每个元素都以开始标签表示,例如```<element>```。
- 结束标签:每个元素都以结束标签表示,例如```</element>```。
两个斜杠(```/```)表示结束标签。
- 空格:XML元素可以包含空格,以提高可读性。
- 注释:XML允许在元素中添加注释,以提供对代码的说明。
注释以```<!--```开始,以```-->```结束。
- CDATA段:CDATA段用于包含不解析的特殊字符,以避免XML解析器将其解析为标签或属性。
CDATA段以```<![CDATA[```开始,以```]]>```结束。
3.XML的应用场景XML广泛应用于以下场景:- 数据存储:XML文件可以用于存储结构化数据,便于数据的备份和传输。
- 数据交换:XML具有良好的可读性和易于解析性,可用于不同系统之间的数据交换。
- 配置文件:许多软件使用XML文件作为配置文件,以便于用户自定义设置。
- 文档编写:XML可应用于文档编写,如使用TEI(Text Encoding Initiative)规范对文本进行编码。
4.XML的优势与局限性XML的优势:- 结构清晰:XML采用树状结构,使数据层次关系一目了然。
- 易于阅读和编写:XML采用类似于HTML的语法,易于阅读和编写。
c语言解析xml源码

c语言解析xml源码
C语言解析XML源码是一个相当复杂的任务,因为XML是一种
具有层次结构的标记语言,它需要逐级解析并处理标签、属性和文
本内容。
在C语言中,通常会使用第三方库来解析XML,比较常用
的有libxml2和expat等。
首先,我们需要使用适当的方法读取XML文件的内容,可以使
用C语言的文件操作函数来实现。
然后,我们需要逐个读取XML文
件中的标签、属性和文本内容,这就需要用到字符串处理函数和逻
辑判断。
接着,我们需要建立数据结构来存储XML文件的层次结构,通常会使用树形结构来表示XML的层次关系。
在这个过程中,我们
需要考虑如何处理XML文件中的命名空间、实体引用等特殊情况。
一般来说,使用libxml2或expat等库可以大大简化解析XML
的过程。
这些库提供了丰富的API来处理XML文件,包括读取、解析、遍历和修改XML文档等功能。
使用这些库,我们可以更方便地
实现XML文件的解析和处理,而不需要从零开始编写解析XML的代码。
在实际编写C语言解析XML的源码时,需要考虑到错误处理、
内存管理、性能优化等方面。
特别是在处理大型XML文件时,需要考虑到内存占用和解析效率的问题。
因此,在编写解析XML的源码时,需要仔细考虑各种情况,并进行充分的测试和优化。
总之,解析XML的源码编写是一个复杂而且需要细致处理的任务,需要充分理解XML的结构和规范,同时使用合适的工具和技术来简化解析过程。
希望这个回答能够帮助你更好地理解C语言解析XML源码的过程。
.Net读取配置文件xml
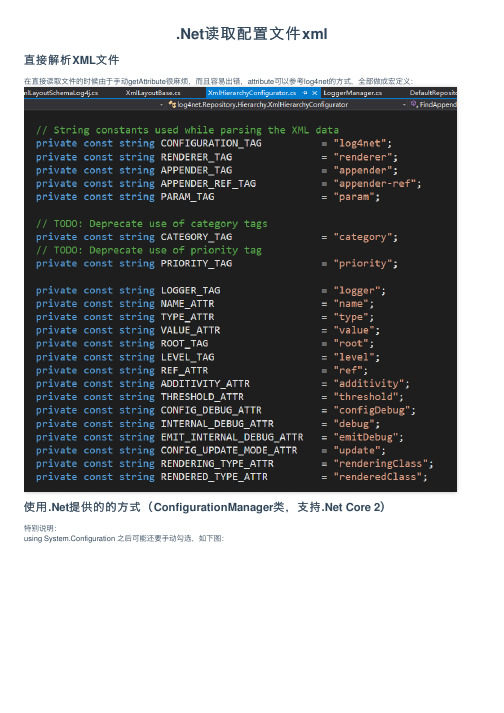
.Net读取配置⽂件xml直接解析XML⽂件在直接读取⽂件的时候由于⼿动getAttribute很⿇烦,⽽且容易出错,attribute可以参考log4net的⽅式,全部做成宏定义:使⽤.Net提供的的⽅式(ConfigurationManager类,⽀持.Net Core 2)特别说明:using System.Configuration 之后可能还要⼿动勾选,如下图:使⽤.Net 提供的⽅法读取有时候会很⽅便,可以直接将配置信息填写在app.config ⽂件中例如下⾯的配置⽂件读取的时候:<?xml version="1.0" encoding="utf-8" ?><configuration><startup><supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" /></startup><appSettings><add key="name" value="kun"/><add key="name2" value="kun"/></appSettings><connectionStrings><add name="WingtipToys" connectionString="Data Source=(LocalDB)\v11.0;Initial Catalog=WingtipToys;Integrated Security=True;Pooling=False" /> </connectionStrings></configuration>static void ReadAllSettings(){try{var appSettings = ConfigurationManager.AppSettings;if (appSettings.Count == 0){Console.WriteLine("AppSettings is empty.");}else{foreach (var key in appSettings.AllKeys.Where((key) => key == "name")){Console.WriteLine("Key: {0} Value: {1}", key, appSettings[key]);}}}catch (ConfigurationErrorsException){Console.WriteLine("Error reading app settings");}}static void ReadSetting(string key){try{var appSettings = ConfigurationManager.AppSettings;string result = appSettings[key] ?? "Not Found";Console.WriteLine(result);}catch (ConfigurationErrorsException){Console.WriteLine("Error reading app settings");}}读取数据库连接信息也可以只⽤⼀句代码:var connectionString = ConfigurationManager.ConnectionStrings["WingtipToys"].ConnectionString;对于这种简单key/Value⽅式的配置,使⽤ConfigurationManager类还是很⽅便的。
xml解析配置步骤

xml解析配置步骤XML(可扩展标记语言)是一种用于存储和传输数据的标记语言,它被广泛用于配置文件中。
解析XML配置文件是将XML文件中的数据提取出来并进行解析的过程。
在本篇文章中,我们将介绍XML解析配置的具体步骤。
1.导入相关类库在开始解析XML之前,我们需要导入相关类库来处理XML数据。
Java 中常用的XML解析器有DOM、SAX和StAX。
DOM解析器将整个XML文档读入内存,形成一个树形结构,可以对节点进行增删改查操作。
SAX解析器逐行读取XML文档,通过事件驱动机制对XML文档进行解析和处理。
StAX 解析器以流式方式解析XML文档,可以同时进行读取和写入操作。
根据具体需求,选择适合的XML解析器并导入相关类库。
2.创建解析器对象在使用DOM或SAX解析器之前,需要先创建解析器对象。
对于DOM解析器,使用DocumentBuilder类的newInstance(方法创建解析器实例。
对于SAX解析器,创建SAXParserFactory对象,并调用其newSAXParser(方法创建解析器实例。
对于StAX解析器,使用XMLInputFactory类的newInstance(方法创建解析器实例。
3.解析XML文件使用解析器对象解析XML文件。
对于DOM解析器,可以使用parse(方法解析XML文件,该方法接受一个File对象、一个InputStream对象或一个URL对象作为参数。
对于SAX解析器,需要创建一个继承自DefaultHandler的类来处理XML文件的解析事件,然后调用解析器的parse(方法,传入XML文件和事件处理类。
对于StAX解析器,需要创建一个XMLStreamReader对象,使用createXMLStreamReader(方法传入XML文件进行解析。
4.获取根元素在DOM解析中,可以使用getDocumentElement(方法获取XML文档的根元素。
在SAX解析中,需要重写startDocument(方法,在该方法中获取XML文档的根元素。
xml标准文件说明

北京xx有限公司XML标准文件说明1. 绪论 (2)1.1 开发者和开发目标 (2)1.2 术语 (3)2. 文档 (4)2.1 格式良好的(Well-Formed)XML文档 (4)2.2 字符 (5)2.3 通用句法成分 (5)2.4 字符数据和标记 (6)2.5 注释 (7)2.6 处理指令 (7)2.7 CDATA段 (8)2.8 序言(prolog)和文档类型声明 (8)2.9 独立文档声明 (10)2.10 空白域处理 (11)2.11 行尾处理 (11)2.12 语言标识 (12)2.13字符集错误 (13)2.14标签分类 (13)2.15标签要求 (13)2.16 xml嵌套子元素 (13)2.17 xml嵌套子元素 (14)2.18 整体结构 (15)3. 逻辑结构 (15)3.1 起始标记,结束标记和空元素标记 (16)3.2 元素类型声明 (17)3.2.1 元素内容 (18)3.2.2 混合型内容(Mixed Content) (19)3.3 属性表声明 (19)3.3.1 属性类型 (20)3.3.2 属性缺省值 (21)3.3.3 属性-值对的规范化(Attribute-Value Normalization) (22)3.4 条件段(Conditional Sections) (22)5. 一致性(Conformance) (23)5.1 进行验证和不进行验证的处理器(Validating and Non-Validating Processors) (23)5.2 使用XML处理器 (24)6. 符号(Notation) (24)7 完整的XML DEMO (25)1. 绪论可扩展标记语言,缩写为XML,描述了一类称为XML文档的数据对象,同时也部分地描述了处理这些数据对象的计算机程序的行为。
XML是SGML(标准通用标记语言[ISO 8879])针对应用的一个子集,或者说是SGML的一种受限形式。
java 引用外部配置文件的方法

java 引用外部配置文件的方法Java作为一种广泛应用的编程语言,经常需要引用外部配置文件来获取程序的设置参数。
本文将介绍几种常用的方法来实现这个目的。
一、使用Properties类Properties类是Java提供的一个用于处理配置文件的工具类,它可以读取和写入配置文件的键值对。
使用Properties类引用外部配置文件的步骤如下:1. 创建一个Properties对象。
2. 使用load()方法读取配置文件,将配置文件的内容加载到Properties对象中。
3. 使用getProperty()方法根据键名获取配置项的值。
下面是一个示例代码:```javaimport java.io.FileInputStream;import java.io.IOException;import java.util.Properties;public class ConfigReader {public static void main(String[] args) {Properties properties = new Properties();try {FileInputStream fis = newFileInputStream("config.properties");properties.load(fis);fis.close();} catch (IOException e) {e.printStackTrace();}String url = properties.getProperty("url");String username = properties.getProperty("username"); String password = properties.getProperty("password"); System.out.println("url: " + url);System.out.println("username: " + username);System.out.println("password: " + password);}}```在这个例子中,我们使用了一个名为config.properties的配置文件,其中包含了url、username和password三个配置项的值。
使用XML解析器编程之源代码讲解

使用XML解析器编程之源代码讲解XML解析器用于解析XML文档,获取其中的数据和结构信息。
在解析器的源代码中,通常会包含以下几个重要的组成部分:解析器的初始化、解析器的核心方法以及节点处理。
一、解析器的初始化解析器的初始化主要包括创建解析器对象、设置解析器的配置参数、构建解析树等操作。
1.创建解析器对象创建一个解析器对象,可以是一个类的实例或者一个可以引用的解析器对象。
解析器对象通常包含解析XML的方法以及处理节点的方法。
2.设置解析器的配置参数解析器的配置参数可以包括解析方式、XML文档的编码方式、解析错误的处理方式等。
通过设置这些参数,可以让解析器按照设定的方式进行解析。
3.构建解析树解析器会将XML文档转换成解析树的形式,方便后续的处理。
解析树可以通过遍历解析器对象的属性或调用特定的方法来获取。
二、解析器的核心方法解析器的核心方法主要包括获取XML文档、解析XML文档、获取节点信息等操作。
1.获取XML文档解析器需要读取XML文档的内容,可以通过文件输入流、网络请求或者其他方式来获取。
获取到的XML文档需要进行解析才能得到其中的数据和结构信息。
2.解析XML文档解析XML文档的过程通常采用递归的方式进行。
解析器会从根节点开始,逐个解析子节点和子节点的属性,直到解析完整个XML文档。
3.获取节点信息解析器需要提供获取节点信息的方法,例如获取节点的名称、属性、值等。
节点信息可以通过解析树来获取,也可以通过特定的解析方法来获取。
三、节点处理节点处理是解析器中的一个重要环节,主要包括节点类型判断、节点内容处理、节点属性处理等操作。
1.节点类型判断解析器需要判断节点的类型,包括元素节点、文本节点、注释节点等。
不同类型的节点需要采用不同的处理方式。
2.节点内容处理解析器需要对节点的内容进行处理,例如获取节点的文本值、去除节点的空格、转换节点的格式等。
3.节点属性处理解析器需要对节点的属性进行处理,包括获取属性值、添加、修改、删除属性等操作。
generatorconfig.xml注释

generatorconfig.xml注释一、概述generatorconfig.xml是Eclipse插件开发中常用的配置文件,用于配置插件的生成器(Generator)相关参数。
为了更好地理解和使用该文件,以下是对文件中各个元素的注释说明。
二、元素注释1. 根元素(/generatorconfig): 这是generatorconfig.xml文件的根元素,包含了整个配置文件的信息。
2. 插件信息(plugin): 用于标识生成器的插件信息,包括插件名称、版本等。
3. 生成器配置(generator): 这是生成器的核心配置,包含了生成器的名称、版本、描述等信息,以及生成器的输入和输出设置。
4. 输入设置(input): 用于指定生成器的输入参数和数据源,包括文件、数据库、API等。
5. 输出设置(output): 用于指定生成器的输出目录、文件名、文件格式等。
6. 插件依赖(dependency): 用于指定生成器所需的插件依赖,包括插件名称、版本等。
7. 任务配置(task): 用于指定生成器的任务执行方式,包括任务名称、任务类型、任务参数等。
8. 属性设置(property): 用于设置生成器的属性值,包括生成器名称、版本号、描述等。
9. 快捷键设置(key): 用于设置生成器的快捷键,方便用户快速执行生成器操作。
三、注意事项1. 在使用输入和输出设置时,需要注意文件路径的正确性和安全性,避免出现文件权限问题或路径错误。
2. 在使用插件依赖时,需要确保所需的插件已经正确安装并引入到项目中。
3. 在配置任务时,需要根据实际需求选择适当的任务类型和参数,以确保生成器的正确执行。
4. 在使用属性设置时,需要注意属性的唯一性和正确性,避免出现属性冲突或命名错误的情况。
5. 在编写注释时,需要注意语法和格式的正确性,以确保注释的清晰和易读。
四、总结以上是对generatorconfig.xml文件的注释说明,希望能帮助开发者更好地理解和使用该文件,提高插件开发的效率和准确性。
详解XML中的标签与元素的使用

详解XML中的标签与元素的使用标签我们来了解一下XML 最重要的部分之一,XML 标签。
XML 标签是XML 的基础。
它们定义了XML 中某个元素的范围。
它们也可以用来插入注释,声明解析环境需的设置以及插入特定的指令。
大体上可以按照如下方式归类XML 标签:开始标签每个开始的非空XML 元素都被标记为开始标签。
下面是一个开始标签的例子:结束标签每个有开始标签的元素都应该使用结束标签闭合。
下面是一个结束标签的例子:注意,结束标签在元素名的前面包含一个斜线("/")。
空标签出现在开始标签和结束标签之间的文本被称作内容。
没有内容的元素被称为空元素。
空元素使用下面两种方式表示:空元素标签可以用于任何没有内容的元素。
XML 标签规则以下是使用XML 标签需要遵循的规则:规则1XML 标签区分大小写。
下面这行代码是一个错误语法示例,因为两个标签大小写不一样,在XML 中会被视为错误的语法。
下面的代码展示了正确的方法,这里开始和结束标签的名称使用了相同的大小写。
规则2XML 标签必须按照适当的顺序闭合,比如,在另一个元素内部开启的XML 标签必须在外部元素闭合之前闭合。
例如:元素XML 元素可以被定义为XML 的构建块。
元素可以表现为承载文本,元素,属性,媒体对象或这有这些的容器。
每个XML 文档都包含一个或多个元素,其范围由开始和结束标签界定,或者用一个空元素标签表示空元素。
语法下面是编写一个XML 元素的语法:这里element-name:表示元素的名称。
开始和结束标签之间的_名称_必须匹配。
attribute1, attribute2:就是由空格分隔的元素属性。
属性(attribute)定义了元素的属性(propert y)。
它关联一个名称和字符串值。
属性被写作如下形式:name = "value"属性_名称_后紧跟一个= 号以及使用双引号(" ")或者单引号(' ')包裹的字符串值。
xml结构描述文件

xml结构描述文件【最新版】目录1.XML 结构描述文件的概念与作用2.XML 结构描述文件的基本组成3.XML 结构描述文件的应用案例4.XML 结构描述文件的优缺点正文XML 结构描述文件是一种用于描述其他 XML 文档结构的文本文件,通常采用 XML 语法编写。
它可以用来定义 XML 文档的元素、属性、以及元素之间的关系,从而确保 XML 文档的结构和内容的一致性。
XML 结构描述文件在数据交换、数据存储和数据处理等方面具有广泛的应用。
XML 结构描述文件的基本组成主要包括以下几个方面:1.元素(Element):元素是 XML 结构描述文件的基本构成单位,它可以表示一个数据项或者一个数据集合。
元素由开始标签、结束标签和中间的内容组成。
2.属性(Attribute):属性是用来描述元素的性质或特征的,它由属性名和属性值组成,通常位于元素的开始标签中。
3.注释(Comment):注释是用来对 XML 结构描述文件中的某些内容进行解释或说明的,它以"<!--"开始,以"-->"结束。
4.命名空间(Namespace):命名空间用于避免元素和属性名称的冲突,它由一个统一资源标识符(URI)和一个可选的前缀组成。
XML 结构描述文件的应用案例包括但不限于以下几种情况:1.用于描述 XML 文档的结构,例如 XML Schema(XML 模式)就是一种用于定义 XML 文档结构的 XML 结构描述文件。
2.用于描述数据交换的格式,例如 Web 服务中的 WSDL(Web 服务描述语言)文件,用于描述 Web 服务的接口和数据交换格式。
3.用于描述配置文件的结构,例如 Java 中的 XML 配置文件,用于描述 Java 应用程序的配置信息。
XML 结构描述文件的优点主要体现在以下几个方面:1.可读性强:XML 结构描述文件采用纯文本格式编写,易于阅读和理解。
printjs库的configuration各项配置的解释

printjs库的configuration各项配置的解释
PrintJS是一个用于打印网页内容的JavaScript库,它的configuration可以包括多个参数以定制打印功能。
下面是对PrintJS的一些常见配置参数的解释:
1. printable: 确定要打印的元素或选择器,可以是单独的元素、元素数组或选择器字符串。
2. type: 指定打印的类型,可以是'pdf'、'image'或'html'。
默认为'pdf'。
3. header: 设置打印时的页头,默认为空。
4. footer: 设置打印时的页脚,默认为空。
5. scale: 用于缩放打印内容的比例,默认为100%。
6. paper: 用于指定纸张大小和方向的配置对象。
例如,可以设置'paper: {size: 'A4', orientation: 'portrait'}'。
7. css: 用于指定要应用于打印内容的CSS样式,可以是一个样式字符串或样式对象。
8. printEventName: 用于指定触发打印事件的事件名称,默认为'click'。
9. sourceNode: 用于指定要打印的HTML元素的选择器字符串或DOM节点。
10. margin: 用于设置打印内容的边距,可以是一个数
字或一个包含上、右、下、左四个方向的边距的对象。
11. fit: 用于指定是否将内容缩放以适应纸张大小,默认为false。
如果设置为true,则会自动缩放内容以适应纸张大小。
php操作xml入门之xml基本介绍及xml标签元素

php操作xml入门之xml根本介绍及xml标签元素以xml实例来讲解:代码如下:?xml version="1.0" encoding="utf-8" standalone="no" ?classstudentname小乔/namesex女/sexage23/age/studentstudentname周瑜/namesex男/sexage27/age/student/class一、xml声明:?xml version="1.0" encoding="utf-8" standalone="no" ?〔1〕、xml声明要放在文档的第一行;〔2〕、encoding:文档字符编码,如utf-8、gb2312等。
〔3〕、standalone:值为yes或者no,可有可无,表示文档定义是否独立,即与其它文档是否有关联。
默认为no。
二、根元素包在最外层的class/class为根元素,每个xml 文档都必需有且只能有一个根元素。
三、xml 元素/标签/节点student/student、name/name、sex/sex、age/age等都是xml的元素,元素也称为标签或节点。
当然,根元素也是一元素。
假设标签中没有内容,如name/name之间没有实体内容,那么可以简写为name /。
即使是写成name/name,扫瞄器翻开时,也是显示name /四、标签中的空格与换行标签中消灭的空格与换行,xml 文档会将空格与换行当作原始内容来处理。
所以,在编程时要特殊留意。
五、xml标签的命名标准〔1〕区分大小写;〔2〕不能以数字或“_”开头;〔3〕不能以xml、XML、Xml等特殊字符开头;〔4〕不能包含空格;〔5〕不能包含冒号。
更多信息请查看IT技术专栏。
Python之xml文档及配置文件处理(ElementTree模块、ConfigParser模块)

Python之xml⽂档及配置⽂件处理(ElementTree模块、ConfigParser模块)本节内容1. 前⾔2. XML处理模块3. ConfigParser/configparser模块4. 总结⼀、前⾔我们在中我们描述了Python数据持久化的⼤体概念和基本处理⽅式,通过这些知识点我们已经能够处理⼤部分Python数据序列化/反序列化的需求。
本节我们来介绍下另外两个模块,它们都有各⾃特殊的⽤途,且提供了功能更加强⼤的api:模块名称 | 描述| - | -xml.etree.ElementTree(简称ET) | ⼀个简单、轻量级的XML处理器,⽤于创建、解析、处理XML数据ConfigParser(Python 3.x中已改名为configparser) | 配置⽂件解析器,⽤于创建、解析、处理类似Windows系统上的INI配置⽂件⼆、xml处理模块:xml.etree.ElementTree1. XML简介XML,全称eXtensible Markup Language,即可扩展标记语⾔。
它可以⽤来标记数据、定义数据类型,是⼀种允许⽤户对⾃⼰的标记语⾔进⾏定义的源语⾔。
XML的结构与HMTL(超⽂本标记语⾔)结构很相似,但是HTML是⽤来显⽰数据的,⽽XML主要⽤来传输和存储数据。
来看⼀个XML实例,它表⽰的是⼀个植物列表:<?xml version="1.0" encoding="utf-8"?><CATALOG><PLANT id='001'><NAME>Sanguinaria canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT><PLANT id='002'><NAME>Aquilegia canadensis</NAME><LIGHT>Mostly Shady</LIGHT></PLANT><PLANT id='003'><NAME>Phlox divaricata</B=NAME><LIGHT>Sun or Shade</LIGHT></PLANT></CATALOG>由上⾯的XML实例,可以看出XML数据有以下⼏个特征:XML是由多个标签对组成,如: <CATALOG></CATALOG>,<PLANT></PLANT>等标签是可以有属性的,如:<PLANT id='001'></PLANT>中的id就是PLANT标签的⼀个属性标签对应的数据放在标签对中间,如:<NAME>Sanguinaria canadensis</NAME>标签可以嵌套,如下所⽰:<CATALOG><PLANT><NAME></NAME></PLANT></CATALOG>2. XML tree 和 elements的概念和相关类介绍XML是⼀种层级化的数据格式,因此它最⾃然的表⽰⽅式是⼀个(倒置的)树形结构。
python的内置模块xml模块方法xml解析详解以及使用

python的内置模块xml模块⽅法xml解析详解以及使⽤⼀、XML介绍xml是实现不同语⾔或程序直接进⾏数据交换的协议,跟json差不多,单json使⽤起来更简单,不过现在还有很多传统公司的接⼝主要还是xmlxml跟html都属于是标签语⾔我们主要学习的是ElementTree是python的XML处理模块,它提供了⼀个轻量级的对象模型,在使⽤ElementTree模块时,需要import xml.etree.ElementTre ElementTree相当于整个xml节点树,⽽Element表⽰节点数中的⼀个单独节点我们看下下⾯的xml⽂本,标签分为2种。
1、⾃闭和标签 <rank updated="yes">2</rank>2、⾮闭合标签 <neighbor direction="E" name="Austria" /><data><country name="Liechtenstein"><rank updated="yes">2</rank><year updated="yes">2010</year><gdppc>141100</gdppc><neighbor direction="E" name="Austria"/><neighbor direction="W" name="Switzerland"/></country><country name="Singapore"><rank updated="yes">5</rank><year updated="yes">2013</year><gdppc>59900</gdppc><neighbor direction="N" name="Malaysia"/></country><country name="Panama"><rank updated="yes">69</rank><year updated="yes">2013</year><gdppc>13600</gdppc><neighbor direction="W" name="Costa Rica"/><neighbor direction="E" name="Colombia"/></country></data>⼆、xml.etree.ElementTree 模块的具体应⽤1、打印根标签的名字import xml.etree.ElementTree as ET #导⼊模块,名字太长了,把这个模块名重命名为ETtree = ET.parse("xml_lesson.xml")#parse解析,⽤ET模块下的parse这个⽅法把xml⽂件解析开,解析开拿到⼀个tree,tree就是⼀个对象root = tree.getroot()#这个对象可以调⽤⽅法,getroot就是根的意思print(root.tag)#root这个对象有⼀个属性tag,tag的值就是根标签的名字C:\python35\python3.exe D:/pyproject/day21模块/xml_testdata什么是标签,什么是属性,举个例⼦<country name="Liechtenstein">conuntry是标签name="Liechtenstein" 是这个标签的属性<neighbor direction="W" name="Costa Rica" />neighbor是标签direction="W" name="Costa Rica" 这2个都是标签的属性2、⽤for循环查看下root下⾯是什么东西for n in root:print(n)C:\python35\python3.exe D:/pyproject/day21模块/xml_test<Element 'country' at 0x0000000000E339F8><Element 'country' at 0x0000000000E38408><Element 'country' at 0x0000000000E38598>这3个地址指向的就是对象,打印下这三个标签的名字,⽤tag这个属性就可以了for n in root:print(n.tag)C:\python35\python3.exe D:/pyproject/day21模块/xml_testcountrycountrycountry在打印下country下⾯的标签for n in root:for i in n:print(i.tag)C:\python35\python3.exe D:/pyproject/day21模块/xml_testrankyeargdppcneighborneighborrankyeargdppcneighborrankyeargdppcneighborneighbor3、打印标签的属性 attrib打印country的属性for n in root:print(n.attrib)C:\python35\python3.exe D:/pyproject/day21模块/xml_test{'name': 'Liechtenstein'}{'name': 'Singapore'}{'name': 'Panama'}在打印下country⾥⾯的对象的属性for n in root:for i in n:print(i.attrib)C:\python35\python3.exe D:/pyproject/day21模块/xml_test {'updated': 'yes'}{'updated': 'yes'}{}{'name': 'Austria', 'direction': 'E'}{'name': 'Switzerland', 'direction': 'W'}{'updated': 'yes'}{'updated': 'yes'}{}{'name': 'Malaysia', 'direction': 'N'}{'updated': 'yes'}{'updated': 'yes'}{}{'name': 'Costa Rica', 'direction': 'W'}{'name': 'Colombia', 'direction': 'E'}4、text 标签实际包裹的内容for n in root:for i in n:print(i.text)C:\python35\python3.exe D:/pyproject/day21模块/xml_test 22010141100NoneNone5201359900None69201313600NoneNone5、iter想取到每个属性中的year的text值就应该⽤iter⽅法这样取for n in root.iter("year"):print(n.tag,n.text)C:\python35\python3.exe D:/pyproject/day21模块/xml_testyear 2010year 2013year 20136、对xml⽂件数据进⾏修改操作import xml.etree.ElementTree as ET #导⼊模块,名字太长了,把这个模块名重命名为ETtree = ET.parse("xml_lesson.xml")#parse解析,⽤ET模块下的parse这个⽅法把xml⽂件解析开,#解析开拿到⼀个tree,tree就是⼀个对象root = tree.getroot()#这个对象可以调⽤⽅法,getroot就是根的意思# print(root.tag)#root这个对象有⼀个属性tag,tag的值就是根标签的名字for n in root.iter("year"):new_year=int(n.text)+1n.text=str(new_year)#修改year标签的text属性n.set("updated1","yes")#给year这个标签增加⼀个属性tree.write("xml_lesson.xml")#直接把修改的写⼊到⽂件中<data><country name="Liechtenstein"><rank updated="yes">2</rank><year updated="yes" updated1="yes">2012</year><gdppc>141100</gdppc><neighbor direction="E" name="Austria"/><neighbor direction="W" name="Switzerland"/></country><country name="Singapore"><rank updated="yes">5</rank><year updated="yes" updated1="yes">2015</year><gdppc>59900</gdppc><neighbor direction="N" name="Malaysia"/></country><country name="Panama"><rank updated="yes">69</rank><year updated="yes" updated1="yes">2015</year><gdppc>13600</gdppc><neighbor direction="W" name="Costa Rica"/><neighbor direction="E" name="Colombia"/></country></data>7、对xml⽂件进⾏删除操作,⽐如删除排名⼤于50的国家,需要取到每个conutry中的rank的text import xml.etree.ElementTree as ET #导⼊模块,名字太长了,把这个模块名重命名为ETtree = ET.parse("xml_lesson.xml")#parse解析,⽤ET模块下的parse这个⽅法把xml⽂件解析开,#解析开拿到⼀个tree,tree就是⼀个对象root = tree.getroot()#这个对象可以调⽤⽅法,getroot就是根的意思# print(root.tag)#root这个对象有⼀个属性tag,tag的值就是根标签的名字for n in root.findall("country"):#找到所有的countryrank=int(n.find("rank").text)#找到所有的rank的text值if rank > 50:#判断值⼤于50的root.remove(n)#就删除country这个标签tree.write("xml_lesson.xml")#写⼊⽂件删除之后,⽂件⾥⾯只有2个country了<data><country name="Liechtenstein"><rank updated="yes">2</rank><year updated="yes" updated1="yes">2012</year><gdppc>141100</gdppc><neighbor direction="E" name="Austria" /><neighbor direction="W" name="Switzerland" /></country><country name="Singapore"><rank updated="yes">5</rank><year updated="yes" updated1="yes">2015</year><gdppc>59900</gdppc><neighbor direction="N" name="Malaysia" /></country></data>8、如何通过模块创建xml⽂件呢import xml.etree.ElementTree as ET #导⼊模块,名字太长了,把这个模块名重命名为ETnew_xml=ET.Element("namelist")#创建了⼀个根节点#相当于创建了<namelist></namelist>name=ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})#创建⼀个⼦标签name,然后增加⼀个属性age=ET.SubElement(name,"age",attrib={"checked":"no"})sex=ET.SubElement(name,"sex")sex.text="28"et=ET.ElementTree(new_xml)#⽣成⽂档对象et.write("test.xml",encoding="utf8",xml_declaration=True)查看下⽣成的text.xml这个⽂件内容<namelist><name enrolled="yes"><age checked="no"/><sex>28</sex></name></namelist>。
AndroidManifest.xml文件详解

AndroidManifest.xml文件详解每个应用程序在它的根目录中都必须要有一个AndroidManifest.xml文件。
这个清单把应用程序的基本信息提交给Android系统,在应用程序的代码能够运行之前,这个信息系统必须建立。
以下是清单文件要做的一些事情:1.用Java包给应用程序命名。
这个包名是应用程序的唯一标识;2.描述应用程序的组件---组成应用程序的Activity、Service、Broadcast Receiver以及Content Provider。
它要用每个组件的实现类来命名,并向外发布对应组件功能(例如,组件所能处理的Intent消息)。
这些声明会让Android系统了解应用程序中组件,以及这些组件被加载的条件。
3.判断哪些进程是主应用程序组件。
4.声明应用程序所必须的权限,以便能够访问被保护的API,以及能够跟其他应用程序进行交互。
5.为了跟应用程序组件进行交互,还声明了其他要求有的权限。
6.列出了能够提供应用程序运行时的分析和其他信息的Instrumentation类。
只有在开发和测试应用程序时才在清单文件中声明这些类,在应用程序被发布之前,要删除这些类。
7.声明应用程序所要求的最小的Android API级别。
8.列出应用程序必须链接的外部库。
Manifest文件的结构下图中包含了清单文件的一般性结构,并且包含所有能包含的元素。
每个元素所带有的全部元素会在它们各自的文档中介绍。
<?xml version="1.0" encoding="utf-8"?><manifest><uses-permission/><permission/><permission-tree/><permission-group/><instrumentation/><uses-sdk/><uses-configuration/><uses-feature/><supports-screens/><compatible-screens/><supports-gl-texture/><application><activity><intent-filter><action/><category/><data/></intent-filter><meta-data/></activity><activity-alias><intent-filter>. . . </intent-filter><meta-data/></activity-alias><service><intent-filter>. . . </intent-filter><meta-data/></service><receiver><intent-filter>. . . </intent-filter><meta-data/></receiver><provider><grant-uri-permission/><meta-data/></provider><uses-library/></application></manifest>以下按字母顺序列出了清单文件中的所有元素,这些元素时Android系统法定元素,不能添加自定义的元素或属性。
用户密码打印配置指南说明书

User Password Printing Configuration GuideOracle Banking APIsRelease 20.1.0.0.0Part No. F30660-01May 2020User Password Printing Configuration GuideMay 2020Oracle Financial Services Software LimitedOracle ParkOff Western Express HighwayGoregaon (East)Mumbai, Maharashtra 400 063IndiaWorldwide Inquiries:Phone: +91 22 6718 3000Fax:+91 22 6718 3001/financialservices/Copyright © 2006, 2020, Oracle and/or its affiliates. All rights reserved.Oracle and Java are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are “commercial computer software” pursuant to the applica ble Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government.This software or hardware is developed for general use in a variety of information management applications. It is not developed or intended for use in any inherently dangerous applications, including applications that may create a risk of personal injury. If you use this software or hardware in dangerous applications, then you shall be responsible to take all appropriate failsafe, backup, redundancy, and other measures to ensure its safe use. Oracle Corporation and its affiliates disclaim any liability for any damages caused by use of this software or hardware in dangerous applications.This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited.The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing.This software or hardware and documentation may provide access to or information on content, products and services from third parties. Oracle Corporation and its affiliates are not responsible for and expressly disclaim all warranties of any kind with respect to third-party content, products, and services. Oracle Corporation and its affiliates will not be responsible for any loss, costs, or damages incurred due to your access to or use of third-party content, products, or services.Table of Contents1.Preface .............................................................................................................................................. 1–1 1.1Intended Audience ...................................................................................................................... 1–1 1.2Documentation Accessibility ....................................................................................................... 1–1 1.3Access to Oracle Support ........................................................................................................... 1–1 1.4Structure ..................................................................................................................................... 1–11.5Related Information Sources ...................................................................................................... 1–12.OBAPI User Password Print Configuration................................................................................... 2–1 2.1Configure Password Encryption/Decryption Provider ................................................................ 2–1 2.2Configure Password Printing adapter ......................................................................................... 2–2Preface1. Preface 1.1 Intended AudienceThis document is intended for the following audience:∙Customers∙Partners1.2 Documentation AccessibilityFor information about Oracle's commitment to accessibility, visit the Oracle Accessibility Program website at /pls/topic/lookup?ctx=acc&id=docacc.1.3 Access to Oracle SupportOracle customers have access to electronic support through My Oracle Support. For information, visit/pls/topic/lookup?ctx=acc&id=info or visit/pls/topic/lookup?ctx=acc&id=trs if you are hearing impaired.1.4 StructureThis manual is organized into the following categories:Preface gives information on the intended audience. It also describes the overall structure of the User Manual.The subsequent chapters describes following details:∙Introduction∙Preferences & Database∙Configuration / Installation.1.5 Related Information SourcesFor more information on Oracle Banking APIs Release 20.1.0.0.0, refer to the following documents: ∙Oracle Banking APIs Installation Manuals2. OBAPI User Password Print Configuration 2.1 Configure Password Encryption/Decryption Provider1. When you create any new user or reset password for any existing user, user credential getsstored in system using two way cryptography so that same to be available for passwordprinting2. To override existing cryptography implementation, you need to perform following steps:Add provider that implementscom.ofss.digx.app.sms.crypto.IUserCryptographyProvider. Here you can addencryption and decryption implementation for Password.Example:package com.ofss.digx.app.sms.crypto;public class CustomUserCryptographyProvider implementsIUserCryptographyProvider {@Overridepublic String decrypt(String value) {// TODO Auto-generated method stubreturn null;}@Overridepublic String encrypt(String value) {// TODO Auto-generated method stubreturn null;}}∙Add one entry in Preferences.xml if not present for name ‘UserConfig’Example:<Preference name="UserConfig’"PreferencesProvider="com.ofss.digx.infra.config.impl.DBBasedPropertyProvider"parent="jdbcpreference" propertyFileName="select prop_id, prop_value fromdigx_fw_config_all_b where category_id = 'UserConfig’'" syncTimeInterval="36000000" /> ∙Add one entry in database table digx_fw_config_all_b for category_id =’UserConfig’ and prop_id =’USER_CRYPTO_PROVIDER’Insert into DIGX_FW_CONFIG_ALL_B (PROP_ID, CATEGORY_ID, PROP_VALUE,FACTORY_SHIPPED_FLAG, PROP_COMMENTS, SUMMARY_TEXT, CREATED_BY,CREATION_DATE, LAST_UPDATED_BY, LAST_UPDATED_DATE, OBJECT_STATUS,OBJECT_VERSION_NUMBER)values ('USER_CRYPTO_PROVIDER','UserConfig','com.ofss.digx.app.sms.crypto.CustomUserCryptographyProvider ','N',null,'Customprovider for Password Encryption anddecryption','ofssuser',sysdate,'ofssuser',sysdate,'A',1);Note: If above configuration is done, it will use CustomUserCryptographyProvider forpassword encryption and decryption and same encrypted password will be stored inDIGX_UM_PWD_PRINTINFO table. Currently by defaulterCryptographyProvider provider will used if no configuration is done.2.2 Configure Password Printing adapter1. After successfully storing password in System, same will be available for printing toadministrator.2. Currently when admin performs password printing for user, password printing data stored insystem in blob using adapter.3. To override existing password printing implementation, you need to perform following steps: ∙Add adapter that implementser.printinformation.provider.IUserInformationPrintAdapter. Here you can add implementation for printing document for a user.PasswordPrintInformationDTO object will contain username, password and otherdocuments(Password Letter/Welcome Letter).Example:package er.printinformation.provider;importer.printInformation.PasswordPrintInformation DTO;import com.ofss.digx.infra.exceptions.Exception;public class CustomUserInformationPrintAdapter implementsIUserInformationPrintAdapter {@Overridepublic void print(PasswordPrintInformationDTO userprintDTO) throws Exception {// TODO Auto-generated method stub}}∙Add one entry in Preferences.xml if not present for name ‘UserPrintConfig’Example:<Preference name="UserPrintConfig’"PreferencesProvider="com.ofss.digx.infra.config.impl.DBBasedPropertyProvider"parent="jdbcpreference" propertyFileName="select prop_id, prop_value fromdigx_fw_config_all_b where category_id = 'UserPrintConfig’'" syncTimeInterval="36000000"/>Add one entry in database table digx_fw_config_all_b for category_id =’UserPrintConfig’ and prop_id =’USER_INFORMATION_PRINT_PROVIDER’Insert into DIGX_FW_CONFIG_ALL_B (PROP_ID, CATEGORY_ID, PROP_VALUE,FACTORY_SHIPPED_FLAG, PROP_COMMENTS, SUMMARY_TEXT, CREATED_BY, CREATION_DATE, LAST_UPDATED_BY, LAST_UPDATED_DATE, OBJECT_STATUS, OBJECT_VERSION_NUMBER)values('USER_INFORMATION_PRINT_PROVIDER','UserPrintConfig','com.ofss.digx.app.sms.user.printinformation.provider.CustomUserInformationPrintAdapter','N',null,'Custom adapter for User Password Information Printing','ofssuser',sysdate,'ofssuser',sysdate,'A',1); Note: If above configuration is done, it will use CustomUserInformationPrintAdapter for user Password Information printing. Currently by defaulterInformationPrintAdapter adapter will used if does not found any configuration.Home。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目前三个报表支持自定义格式。
一是住院结算单对应的节点是zdy_jsd_widt,zdy_jsd_heigt,zdy_dyj_ZhiZhangName
二是门诊和住院的报销汇总报表。对应的节点是w1,h1,name1.
三是门诊结算单,对应的节点是w2,h2,name2.
升级的时候把printconfig.xml放到升级根目录下。
这个xml文档是解决结算单不能自定义格式的问题。例如门诊结算单打印的时候出来很多空白纸张。可以在打印printConfig.xml文档找到W2,H2,name2的节点,把刚才创建的自定义纸张写入这些参数中。w2表示宽度,H2表示高度,name2表示自定义纸张的名称。
还有一点就是在客户机子上修改这个文件后,就要把服务器的这个升级文件删掉,否则客户打开电脑的时候会自动更新,这样会把你原来设置的覆盖掉。
现在这三个报表默认的A4的纸张。