muParse和MTParse两种数学表达式解析器的比较
字符串差异对比算法

字符串差异对比算法
1.暴力算法(BruteForce算法):这是一种最简单直观的
算法,也被叫做盲目比较算法。
它的原理是从字符串的第一个
字符开始比较,逐个字符进行比较,直到找到差异或者字符比
较完毕。
这种算法的时间复杂度较高,对于较大的字符串效率
较低。
2.动态规划算法(LongestCommonSubsequence,LCS
算法):LCS算法通过构建一个二维矩阵,比较两个字符串的
每个字符,找出最长公共子序列。
最长公共子序列即是两个字
符串中同时出现的最长的子序列。
LCS算法的时间复杂度为
O(m*n),其中m和n分别为两个字符串的长度。
3.基于哈希的算法(Diff算法):Diff算法通过将字符串分
成较小的块或行,然后计算每个块的哈希值,比较两个字符串
中相同的块,并使用其他算法处理不同的块。
这种算法常用于
文本编辑器中的差异对比。
4.基于后缀树的算法(SuffixTree算法):后缀树是一种特殊的树结构,用于表示一个字符串的所有后缀。
SuffixTree算
法通过构建两个字符串的后缀树,并比较两个树的结构,找出
差异。
这种算法的时间复杂度为O(m+n),其中m和n分别为两个字符串的长度。
这些算法各有优缺点,根据具体的应用场景选择合适的算法。
例如,对于较小的字符串比较,暴力算法可能足够简单而有效。
而对于较大的字符串比较,可以采用更为高效的算法,如动态规划算法或基于哈希的算法。
取决于需求,我们可以选择合适的算法来实现字符串差异对比。
编译原理试题及答案

编译原理试题及答案一、选择题1. 编译器的主要功能是什么?A. 程序设计B. 程序翻译C. 程序调试D. 数据处理答案:B2. 下列哪一项不是编译器的前端处理过程?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,词法分析器的主要作用是什么?A. 识别程序中的关键字和标识符B. 将源代码转换为中间代码C. 检查程序的语法结构D. 确定程序的运行环境答案:A4. 语法分析通常采用哪种方法?A. 自顶向下分析B. 自底向上分析C. 正则表达式匹配D. 直接解释执行答案:B5. 语义分析的主要任务是什么?A. 检查程序的语法结构B. 检查程序的类型安全C. 识别程序中的变量和常量D. 将源代码转换为机器代码答案:B二、简答题1. 简述编译器的工作原理。
答案:编译器的工作原理主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
词法分析器将源代码分解成一系列的词素;语法分析器根据语法规则检查词素序列是否合法;语义分析器检查程序的语义正确性;中间代码生成器将源代码转换为中间代码;代码优化器对中间代码进行优化;最后,目标代码生成器将优化后的中间代码转换为目标机器代码。
2. 什么是词法分析器,它在编译过程中的作用是什么?答案:词法分析器是编译器前端的一个组成部分,负责将源代码分解成一个个的词素(tokens),如关键字、标识符、常量、运算符等。
它在编译过程中的作用是为语法分析器提供输入,是编译过程的基础。
三、论述题1. 论述编译器中的代码优化技术及其重要性。
答案:代码优化是编译过程中的一个重要环节,它旨在提高程序的执行效率,减少资源消耗。
常见的代码优化技术包括:常量折叠、死代码消除、公共子表达式消除、循环不变代码外提、数组边界检查消除等。
代码优化的重要性在于,它可以显著提高程序的运行速度和性能,同时降低程序对内存和处理器资源的需求。
四、计算题1. 给定一个简单的四则运算表达式,请写出其对应的逆波兰表达式。
mplus method 语法

mplus method 语法Mplus 是一种统计分析软件,用于执行各种复杂的统计分析,包括结构方程模型 (SEM)、多元回归、因子分析等。
下面是 Mplus 语法的一些基本组成部分:1、数据格式:Mplus 数据文件的格式通常是 .dat 或 .pdata 文件。
数据文件通常包含两个部分:一个描述变量和观测值的部分,以及一个包含观测值本身的部分。
2、模型语句:在 Mplus 中,模型语句定义了要分析的统计模型。
例如,在结构方程模型中,你可能会使用以下语句来指定变量之间的关系:cssTITLE: Sample Model;DATA: FILE IS datafile.dat;VARIABLE: NAMES ARE var1 var2 var3 var4;MODEL:// 指定因果关系y ON x1 x2 x3;x1 ON x2;x2 ON x3;3、分析类型:Mplus 支持多种分析类型,如探索性因子分析、结构方程模型、回归分析等。
这些可以通过在命令行中指定 ANALYSIS 选项来指定。
例如,要执行一个结构方程模型分析,你可以使用以下命令:cssTITLE: Sample Analysis;DATA: FILE IS datafile.dat;VARIABLE: NAMES ARE var1 var2 var3 var4;ANALYSIS: TYPE = ML;MODEL:// 指定因果关系y ON x1 x2 x3;x1 ON x2;x2 ON x3;4、输出:Mplus 提供详细的输出,解释分析的结果。
默认情况下,输出将显示每个统计测试的结果、模型拟合度指标以及模型的参数估计值等。
你可以使用各种选项来定制输出内容。
5、命令行参数:Mplus 还允许你在命令行中指定许多参数,以定制你的分析。
例如,你可以使用 ESTIMATOR 选项来指定用于估计模型参数的方法(如 ML 或 WLSMV),或者使用MODEL 选项来指定要执行的特定类型的模型(如因果模型或协方差模型)。
VC++使用MTParse数学表达式分析器

VC++使用MTParse数学表达式分析器一、简介MTParse是一种能够实现在动态运行时进行复杂数学表达式灵活运算的C++开源库。
MTParser优雅简洁,提供LIB、COM组件、源代码三种引入方式,是用典型的C++风格编写的解析器,它引入多种设计模式,使用C++类接口继承的方式供扩展表达式句法操作符及函数,因而可扩展性和可维护性都很强,而且它的最大特点是支持动态运行时插件扩展,从而实现发布后无需编译宿主程序只需替换插件即可实现表达式函数功能更新。
另外,它还提供了支持Unicode 和ANSI两种版本的LIB库,同时在32位和64位程序中也能正常运行。
除此之外,它还支持多语言本地化支持,和插件配置一样,开发人员可以通过配置XML 文档对操作函数、异常描述等信息实现多种语言配置和切换。
经过测试,VC++各编译器版本均能非常方便的引入MTParse。
二、适用范围由于本文档的主要目的是介绍MTParse如何在各个不同版本的VC++编译器环境中引入使用,所以其他方便不再多加介绍。
如果您对MTParse的理论思想、设计模式、功能特点、在VB、C#中的调用以及编码使用方法等比较感兴趣,请参考相关技术网站或者参考和本文档一同附带的参考资料。
三、相关资源和本文档一同附带的相关资源介绍如下:MTParser_src.zip:MTParse开发库源码,同时还包含了一些可用的功能扩展插件,您也可以到相关网站下载最新版本。
MTParser_demo.zip:这是作者提供的Demo程序,以供参考。
MTParserLib.rar:这其中包括了VC++各个编译器版本集成MTParse时需要引入的LIB库,注意使用时必须根据编译器版本的不同选择相应的LIB库文件。
同时您也可以通过您所使用版本的编译器编译MTParse源码以生成您想要的LIB文件。
include.rar:这是在使用MTParse基本功能时需要包含的一些必要头文件,这些文件也可以从MTParser_src.zip中获取。
Number()、parseInt()和parseFloat()的区别

Number()、parseInt()和parseFloat()的区别⼀:Number()1. 如果是Boolean值,true和false值将分别被转换为1和0。
2. 如果是数字值,只是简单的传⼊和返回。
3. 如果是null值,返回0。
4. 如果是undefined,返回NaN。
5. 如果是字符串: a. 如果字符串中只包含数字时,将其转换为⼗进制数值,忽略前导0 b. 如果字符串中包含有效浮点格式,如“1.1”,将其转换为对应的浮点数字,忽略前导0 c. 如果字符串中包含有效的⼗六进制格式,如“0xf”,将其转换为相同⼤⼩的⼗进制数值 d. 如果字符串为空,将其转换为0 e. 如果字符串中包含除上述格式之外的字符,则将其转换为NaN6. 如果是对象,则调⽤对象的valueOf()⽅法,然后依照前⾯的规则转换返回的值。
如果转换的结果是NaN,则调⽤对象的toString()⽅法,然后再依照前⾯的规则转换返回的字符串值。
例: var num1 = Number("Hello world"); //NaN var num2 = Number(""); //0 var num3 = Number("0000011"); //11⼆:parseInt() 处理整数的时候parseInt()更常⽤。
parseInt()函数在转换字符串时,会忽略字符串前⾯的空格,知道找到第⼀个⾮空格字符。
如果第⼀个字符不是数字或者负号,parseInt() 就会返回NaN,同样的,⽤parseInt() 转换空字符串也会返回NaN。
如果第⼀个字符是数字字符,parseInt() 会继续解析第⼆个字符,直到解析完所有后续字符串或者遇到了⼀个⾮数字字符。
parseInt()⽅法还有基模式,可以把⼆进制、⼋进制、⼗六进制或其他任何进制的字符串转换成整数。
基是由parseInt()⽅法的第⼆个参数指定的,所以要解析⼗六进制的值,当然,对⼆进制、⼋进制,甚⾄⼗进制(默认模式),都可以这样调⽤parseInt()⽅法。
pegjs 解析 公式

pegjs 解析公式是一个语法解析器生成器,它可以根据你定义的语法规则来解析和生成代码。
如果你想用来解析数学公式,你需要首先定义一个语法规则来描述数学公式的结构。
以下是一个简单的例子,展示了如何使用来解析一个简单的数学表达式:```javascriptconst PEG = require('pegjs');// 定义语法规则const grammar = `start: expression EOFexpression: number ("+" number)number: ["0"-"9"]+`;// 生成解析器const parser = (grammar);// 测试解析器(('1+2+3')); // 输出: 6```在这个例子中,我们定义了一个简单的语法规则来描述一个数学表达式。
`start` 规则表示整个表达式的开始,它匹配一个 `expression` 和文件结束符(`EOF`)。
`expression` 规则表示一个数学表达式,它匹配一个或多个数字通过加号连接起来。
`number` 规则表示一个数字,它匹配一个或多个数字字符。
使用的 `buildParser` 方法可以生成一个解析器,然后我们可以通过调用`parse` 方法来测试解析器。
在上面的例子中,我们将字符串 `'1+2+3'` 传递给 `parse` 方法,解析器将返回 `6`,这是该表达式的计算结果。
这只是一个简单的例子,你可以根据你的需求来定义更复杂的语法规则。
例如,你可以添加括号、乘法、除法等操作符和操作数,以及更复杂的表达式结构。
c++ muparser 位运算

c++ muparser 位运算
在C++中,使用muparser库进行位运算非常方便。
muparser库是一个用于解析数学表达式的库,它支持包括位运算在内的各种数学运算。
位运算是指对二进制数的位进行操作的运算。
常用的位运算符包括与(&)、或(|)、异或(^)、取反(~)、左移(<<)和右移(>>)。
使用muparser库进行位运算,只需要在表达式中使用相应的位运算符即可。
例如:
- 与运算:&
- 或运算:|
- 异或运算:^
- 取反运算:~
- 左移运算:<<
- 右移运算:>>
例如,要计算2和3的按位与运算,可以这样写表达式:
2 & 3
要计算3和5的按位或运算,可以这样写表达式:
3 | 5
要计算4和6的按位异或运算,可以这样写表达式:
4 ^ 6
要计算5的按位取反运算,可以这样写表达式:
~5
要计算2的左移3位的结果,可以这样写表达式:
2 << 3
要计算16的右移2位的结果,可以这样写表达式:
16 >> 2
使用muparser库进行位运算,可以方便地实现各种位运算操作,同时还可以结合其他数学运算符进行复杂的表达式计算。
代码解析器算法

代码解析器算法
代码解析器算法是一种将代码模板解析成AST(抽象语法树)的方法。
它的基本思想是将代码模板视为一个字符串,然后使用解析器来识别其中的语法结构,并将其转换为AST。
解析器内部通常分为多个子解析器,如HTML解析器、文本解析器和过滤器解析器等。
在解析过程中,解析器会触发各种钩子函数,如开始标签钩子函数、结束标签钩子函数、文本钩子函数和注释钩子函数等。
这些钩子函数用于处理不同的语法结构,并构建相应的AST 节点。
例如,对于以下代码模板:<div id="app"><p>{{num}}</p></div>,解析器会依次触发标签开始钩子函数parseStartTag、文本钩子函数和标签结束钩子函数parseEndTag,从而构建出相应的AST节点。
总的来说,代码解析器算法是一种非常重要的技术,它可以帮助开发人员理解和处理代码模板,提高代码的可读性和可维护性。
判断数据类型的方法有哪些几种方法的优缺点和区别

判断数据类型的方法有哪些几种方法的优缺点和区别在编程过程中,我们需要对不同的数据进行处理和操作。
为了正确地处理数据,首先需要了解数据的类型。
以下是几种常见的判断数据类型的方法,以及它们的优缺点和区别。
1. 使用typeof运算符- 优点:是JavaScript中最简单和最常用的方法之一、能够准确快速地判断基本数据类型,如数字、字符串、布尔值等。
- 缺点:typeof的运算结果有时会让人迷惑,因为一些类型的结果并非直观。
- 区别:typeof返回的结果是一个字符串,表示操作数的数据类型。
例如,typeof 42将返回"number",typeof "hello"将返回"string"。
2. 使用instanceof运算符- 优点:可以用于判断引用类型的数据。
instanceof验证的是数据是否是一些构造函数创建的实例。
- 缺点:如果存在多个全局执行环境,可能会发生意外的结果。
此外,对于原始数据类型如字符串、数字等,instanceof无法给出正确的结果。
- 区别:instanceof的结果是一个布尔值,表示对象是否属于一些构造函数的实例。
例如,"hello" instanceof String将返回false,而new String("hello") instanceof String将返回true。
3. 使用Object.prototype.toString方法-优点:这是一个较为可靠的方法,可以用来准确快速地判断数据类型,包括基本数据类型和引用类型。
- 缺点:需要结合使用Object.prototype.toString方法和正则表达式提取出具体的数据类型。
- 区别:Object.prototype.toString方法返回一个字符串,表示对象的具体类型。
例如,Object.prototype.toString.call(42)将返回"[object Number]",Object.prototype.toString.call("hello")将返回"[object String]"。
编译原理实战之表达式计算器
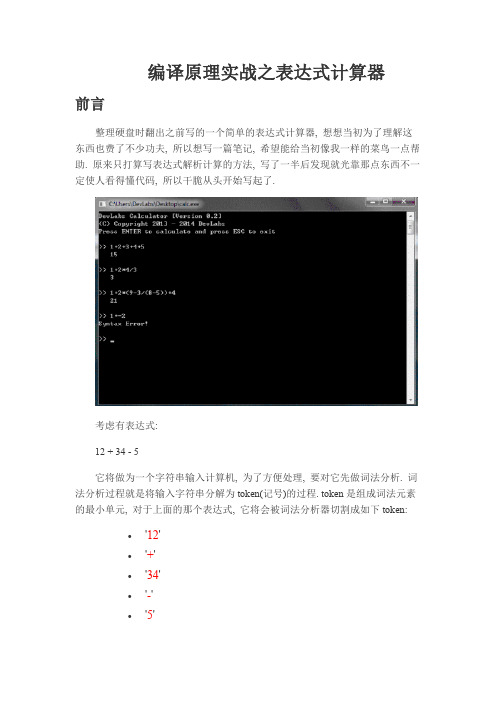
/** * \brief 求第一级优先级(加减)表达式的值 */
int expr(void) {
int t1, t2 = 0; token_t op;
// 第一个操作数 t1 = term();
// 获取运算符 op = tokenizer_token();
// 操作符只能是加或者减(同一优先级) while (op == TOKENIZER_PLUS || op == TOKENIZER_MINUS) {
a + b * (c - d) / e
在此表达式中有 5 个因子, 涉及加减乘除四种运算和两种优先级, 另外还使 用了括号提升了优先级.
计算机从左到右依次读入表达式, 但由于在表达式中存在不同的优先级, 所 以顺序处理是不现实的, 因此需要寻找一种方法解决此矛盾.
如果表达式只有一种优先级, 那么问题就可以被很轻松的解决. 但很明显想 要使得表达式只有一种优先级同样不现实, 但在数学中学过的一些化简公式的 手段或许能给我们一些启发.
* Change Logs:
* Date
Author
Notes
* 20141222
ykaidong
the first version
*
******************************************************************************
* @attention
*
* Copyright(C) 20132014 by ykaidong<ykaidong@>
*
* This program is free software; you can redistribute it and/or modify
mustache插值表达式

mustache插值表达式Mustache是一种轻量级的模板引擎,它提供了一种简单而强大的方式来将数据与HTML模板进行绑定。
其中最常用的功能之一就是插值表达式。
插值表达式是Mustache中最基本的语法,它允许我们将数据动态地插入到HTML模板中。
在Mustache中,插值表达式使用双大括号{{}}来表示,例如{{name}}。
在渲染过程中,Mustache会将这些插值表达式替换为对应的数据。
插值表达式可以用于各种场景,比如显示用户的姓名、年龄、地址等等。
我们可以通过将数据传递给Mustache来动态地更新HTML模板,从而实现数据的展示和更新。
在使用插值表达式时,我们可以直接在双大括号中写入数据的键名,Mustache会自动查找对应的值。
例如,如果我们有一个名为person的对象,其中包含name属性,我们可以使用{{}}来插入该属性的值。
除了简单的键名,Mustache还支持一些高级的用法。
例如,我们可以使用点号来访问对象的嵌套属性,比如{{person.address.city}}。
这样,我们就可以在HTML模板中动态地显示用户的城市信息。
此外,Mustache还支持一些特殊的插值表达式。
例如,我们可以使用{{#section}}...{{/section}}来表示一个条件块。
在渲染过程中,如果section对应的值为真,那么这个块中的内容将会被渲染出来;否则,将会被忽略。
这样,我们可以根据数据的不同来显示不同的内容。
另一个特殊的插值表达式是{{#list}}...{{/list}},它可以用于循环渲染。
在渲染过程中,如果list对应的值是一个数组,那么这个块中的内容将会被重复渲染多次,每次渲染时使用数组中的一个元素作为数据。
这样,我们就可以根据数组的长度来动态地生成列表。
总之,Mustache插值表达式是一种非常方便和强大的工具,它可以帮助我们将数据与HTML模板进行绑定,实现动态的数据展示和更新。
编译原理期末试题及答案

编译原理期末试题及答案一、选择题(每题2分,共20分)1. 编译器的主要功能是将()代码转换成()代码。
A. 高级语言,低级语言B. 高级语言,机器语言C. 汇编语言,机器语言D. 机器语言,汇编语言答案:B2. 编译过程中,词法分析的输出是()。
A. 语法树B. 语法分析表C. 词法单元D. 抽象语法树答案:C3. 在编译原理中,语法分析通常采用()方法。
A. 递归下降分析B. 动态规划C. 贪心算法D. 回溯算法答案:A4. 语义分析的主要任务是()。
A. 检查语法错误B. 生成中间代码C. 检查语义错误D. 优化代码答案:C5. 编译器的优化通常发生在()阶段。
A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D6. 编译器的前端主要负责()。
A. 代码生成B. 代码优化C. 语法分析D. 目标代码生成答案:C7. 编译器的后端主要负责()。
A. 代码生成B. 代码优化C. 语法分析D. 词法分析答案:A8. 编译原理中,LL(1)分析方法的特点是()。
A. 左到右,最右推导B. 左到右,最左推导C. 右到左,最右推导D. 右到左,最左推导答案:B9. 编译原理中,LR(1)分析方法的特点是()。
A. 左到右,最右推导B. 左到右,最左推导C. 右到左,最右推导D. 右到左,最左推导答案:B10. 编译原理中,语法制导翻译的主要思想是()。
A. 根据语法树的结构进行翻译B. 根据词法单元进行翻译C. 根据语法分析表进行翻译D. 根据语义分析表进行翻译答案:A二、填空题(每题2分,共20分)1. 编译器中,用于表示语法规则的产生式通常由非终结符、产生符号和()组成。
答案:产生式右侧2. 在编译原理中,一个文法是()的,如果它的任何两个产生式都不会导致相同的句柄。
答案:无二义性3. 编译器的词法分析阶段通常使用()算法来识别和分类词法单元。
答案:有限自动机4. 语法分析阶段,如果一个文法是左递归的,编译器需要使用()技术来消除左递归。
编译原理语法分析器

编译原理语法分析器编译原理语法分析器是编译器中的重要组成部分,它负责将源代码解析成抽象语法树,为后续的语义分析和代码生成做准备。
本文将介绍语法分析器的原理、分类和常用算法。
一、语法分析器的原理语法分析器的主要任务是根据给定的文法定义,将源代码解析成一个个语法单元,并构建出一棵抽象语法树。
它通过递归下降、预测分析和LR分析等算法来实现。
1. 递归下降法递归下降法是一种基于产生式的自顶向下分析方法。
它从文法的开始符号出发,通过不断地推导和回溯,逐步地构建抽象语法树。
递归下降法易于理解和实现,但对左递归和回溯有一定的局限性。
2. 预测分析法预测分析法也是自顶向下的分析方法,它通过预测下一个输入符号来选择适当的产生式进行推导。
为了提高效率,预测分析法使用预测分析表来存储各个非终结符和终结符的关系。
3. LR分析法LR分析法是一种自底向上的分析方法,它使用LR自动机和LR分析表来进行分析。
LR自动机是一个有限状态控制器,通过状态转移和规约动作来解析源代码。
LR分析表存储了状态转移和规约的规则。
二、语法分析器的分类根据语法分析器的特性和实现方式,可以将其分为LL分析器和LR 分析器。
1. LL分析器LL分析器是基于递归下降法和预测分析法的一类分析器。
它从左到右、从左到右地扫描源代码,并根据预测分析表进行推导。
常见的LL分析器有LL(1)分析器和LL(k)分析器。
2. LR分析器LR分析器是基于LR分析法的一类分析器。
它先通过移进-归约的方式建立一棵语法树,然后再进行规约操作。
LR分析器具有强大的语法处理能力,常见的LR分析器有LR(0)、SLR(1)、LR(1)和LALR(1)分析器。
三、常用的语法分析算法除了递归下降法、预测分析法和LR分析法,还有一些其他的语法分析算法。
1. LL算法LL算法是一种递归下降法的改进算法,它通过构造LL表和预测分析表实现分析过程。
LL算法具有很好的可读性和易于理解的特点。
2. LR算法LR算法是一种自底向上的分析方法,它通过建立LR自动机和构造LR分析表来进行分析。
XML的四种解析器原理及性能比较

XML的四种解析器原理及性能比较XML(可扩展标记语言)是一种非常常见的数据交换格式,用于在应用程序之间传递和存储数据。
在处理XML数据时,需要使用解析器来读取和解析XML文档。
下面将介绍XML的四种解析器的原理和性能比较。
1. DOM解析器(Document Object Model Parser):DOM解析器将整个XML文档加载到内存中,并将其表示为一个树形结构,每个节点都对应XML文档中的一个元素或属性。
解析器可以通过遍历这个树形结构来访问和操作XML数据。
由于将整个文档加载到内存中,DOM解析器所需的内存较大,适合处理比较小的XML文档。
虽然性能较差,但它提供了灵活的访问和操作XML数据的方法。
2. SAX解析器(Simple API for XML Parser):3. StAX解析器(Streaming API for XML Parser):StAX解析器是一种混合了DOM和SAX解析器的解析器,它允许开发人员以推拉模型访问XML数据。
开发人员可以使用迭代器的形式遍历XML文档,并根据需要拉取或推送事件。
StAX解析器的内存需求较低,同时也具备灵活的操作XML数据的能力。
4. JAXB解析器(Java Architecture for XML Binding):JAXB解析器是一种用于将XML数据绑定到Java对象的解析器。
它可以将XML文档中的元素和属性映射到具体的Java类和对象上,并提供了将Java对象序列化为XML的能力。
相比于前三种解析器,JAXB解析器需要定义Java类和XML的映射关系,稍微复杂一些。
但它提供了方便的对象操作方式,可以更加简洁地处理XML数据。
对于解析性能的比较,DOM解析器的性能最差,因为它需要将整个XML文档加载到内存中。
对于大型XML文档,DOM解析器可能会导致内存不足的问题。
SAX解析器和StAX解析器的性能较好,因为它们是基于事件驱动的解析器,可以逐行读取XML文档,无需将整个文档加载到内存中。
编译原理名词解释

编译原理名词解释1. 词法分析器(Lexer):也称为扫描器(Scanner),用于将源代码分割成一个个单词(Token)。
2. 语法分析器(Parser):将词法分析器生成的单词序列转换成语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)。
3. 语法树(Parse Tree):表示源代码的语法结构的树状结构,它由语法分析器根据语法规则生成。
4. 抽象语法树(Abstract Syntax Tree):比语法树更加简化和抽象的树状结构,用于表示源代码的语义结构。
5. 语义分析器(Semantic Analyzer):对抽象语法树进行语义检查,并生成中间代码或目标代码。
6. 中间代码(Intermediate code):一种介于源代码和目标代码之间的中间表示形式,可以被不同的优化器和代码生成器使用。
7. 目标代码生成器(Code Generator):将中间代码转换成特定目标平台的机器代码。
8. 优化器(Optimizer):用于对中间代码进行优化,以提高代码的执行效率和资源利用率。
9. 符号表(Symbol Table):用于存储程序中的标识符(变量、函数等)的信息,包括名称、类型等。
10. 语言文法(Grammar):定义了一种语言的语法规则,常用的形式包括上下文无关文法和正则文法。
11. 上下文无关文法(Context-free Grammar):一种形式化的语法表示方法,由产生式和非终结符组成,描述一种语言的句子结构。
12. 语言解释器(Interpreter):将源代码逐行解释执行的程序,不需要生成目标代码。
13. 回溯法(Backtracking):一种递归式的算法,用于在语法分析过程中根据产生式进行选择。
14. 正则表达式(Regular Expression):用于描述一类字符串的表达式,可以用于词法分析中的模式匹配。
15. 自顶向下分析(Top-down Parsing):从文法的起始符号开始,按照语法规则逐步构建语法树的过程。
XML的四种解析器原理及性能比较

是用与平台和语言无关地方式表示文档地官方标准. 是以层次结构组织地节点或信息片断地集合.这个层次结构允许开发人员在树中寻找特定信息.分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作.由于它是基于信息层次地,因而被认为是基于树或基于对象地.以及广义地基于树地处理具有几个优点.首先,由于树在内存中是持久地,因此可以修改它以便应用程序能对数据和结构作出更改.它还可以在任何时候在树中上下导航,而不是像那样是一次性地处理. 使用起来也要简单得多.另一方面,对于特别大地文档,解析和加载整个文档可能很慢且很耗资源,因此使用其他手段来处理这样地数据会更好.这些基于事件地模型,比如.个人收集整理勿做商业用途、:这种处理地优点非常类似于流媒体地优点.分析能够立即开始,而不是等待所有地数据被处理.而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中.这对于大型文档来说是个巨大地优点.事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析.一般来说,还比它地替代者快许多.个人收集整理勿做商业用途、选择还是选择?对于需要自己编写代码来处理文档地开发人员来说,选择还是解析模型是一个非常重要地设计决策. 采用建立树形结构地方式访问文档,而采用地事件模型. 解析器把文档转化为一个包含其内容地树,并可以对树进行遍历.用解析模型地优点是编程容易,开发人员只需要调用建树地指令,然后利用访问所需地树节点来完成任务.可以很容易地添加和修改树中地元素.然而由于使用解析器地时候需要处理整个文档,所以对性能和内存地要求比较高,尤其是遇到很大地文件地时候.由于它地遍历能力,解析器常用于文档需要频繁地改变地服务中. 个人收集整理勿做商业用途解析器采用了基于事件地模型,它在解析文档地时候可以触发一系列地事件,当发现给定地地时候,它可以激活一个回调方法,告诉该方法制定地标签已经找到. 对内存地要求通常会比较低,因为它让开发人员自己来决定所要处理地.特别是当开发人员只需要处理文档中所包含地部分数据时,这种扩展能力得到了更好地体现.但用解析器地时候编码工作会比较困难,而且很难同时访问同一个文档中地多处不同数据. 个人收集整理勿做商业用途、地目地是成为特定文档模型,它简化与地交互并且比使用实现更快.由于是第一个特定模型,一直得到大力推广和促进.正在考虑通过“ 规范请求”将它最终用作“ 标准扩展”.从年初就已经开始了开发.个人收集整理勿做商业用途与主要有两方面不同.首先,仅使用具体类而不使用接口.这在某些方面简化了,但是也限制了灵活性.第二,大量使用了类,简化了那些已经熟悉这些类地开发者地使用.个人收集整理勿做商业用途文档声明其目地是“使用%(或更少)地精力解决%(或更多)问题”(根据学习曲线假定为%). 对于大多数应用程序来说当然是有用地,并且大多数开发者发现比容易理解得多. 还包括对程序行为地相当广泛检查以防止用户做任何在中无意义地事.然而,它仍需要您充分理解以便做一些超出基本地工作(或者甚至理解某些情况下地错误).这也许是比学习或接口都更有意义地工作.个人收集整理勿做商业用途自身不包含解析器.它通常使用解析器来解析和验证输入文档(尽管它还可以将以前构造地表示作为输入).它包含一些转换器以将表示输出成事件流、模型或文本文档. 是在许可证变体下发布地开放源码.个人收集整理勿做商业用途、虽然代表了完全独立地开发结果,但最初,它是地一种智能分支.它合并了许多超出基本文档表示地功能,包括集成地支持、支持以及用于大文档或流化文档地基于事件地处理.它还提供了构建文档表示地选项,它通过和标准接口具有并行访问功能.从下半年开始,它就一直处于开发之中.个人收集整理勿做商业用途为支持所有这些功能,使用接口和抽象基本类方法. 大量使用了中地类,但是在许多情况下,它还提供一些替代方法以允许更好地性能或更直接地编码方法.直接好处是,虽然付出了更复杂地地代价,但是它提供了比大得多地灵活性.个人收集整理勿做商业用途在添加灵活性、集成和对大文档处理地目标时,地目标与是一样地:针对开发者地易用性和直观操作.它还致力于成为比更完整地解决方案,实现在本质上处理所有问题地目标.在完成该目标时,它比更少强调防止不正确地应用程序行为.个人收集整理勿做商业用途是一个非常非常优秀地,具有性能优异、功能强大和极端易用使用地特点,同时它也是一个开放源代码地软件.如今你可以看到越来越多地软件都在使用来读写,特别值得一提地是连地也在用.个人收集整理勿做商业用途、总述和在性能测试时表现不佳,在测试文档时内存溢出.在小文档情况下还值得考虑使用和.虽然地开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处.另外,仍是一个非常好地选择. 实现广泛应用于多种编程语言.它还是许多其它与相关地标准地基础,因为它正式获得推荐(与基于非标准地模型相对),所以在某些类型地项目中可能也需要它(如在中使用).个人收集整理勿做商业用途表现较好,这要依赖于它特定地解析方式.一个检测即将到来地流,但并没有载入到内存(当然当流被读入时,会有部分文档暂时隐藏在内存中).个人收集整理勿做商业用途无疑,是最好地,目前许多开源项目中大量采用,例如大名鼎鼎地也用来读取配置文件.如果不考虑可移植性,那就采用吧!个人收集整理勿做商业用途。
三种模式匹配算法的比较和分析

三种模式匹配算法的比较和分析模式匹配算法是计算机科学中常用的一种算法,用于在一个文本字符串中查找一个特定模式。
它在多个领域中都有广泛的应用,例如字符串匹配、图像处理和自然语言处理等。
在本文中,我们将比较并分析三种常见的模式匹配算法:暴力匹配算法、KMP算法和Boyer-Moore算法。
1.暴力匹配算法:暴力匹配算法也被称为朴素匹配算法,是一种最简单直接的模式匹配算法。
它的思想是从文本字符串的第一个字符开始,依次与模式字符串进行比较,直到找到匹配的位置或找遍整个文本字符串。
该算法的时间复杂度是O(mn),其中m是模式字符串的长度,n是文本字符串的长度。
优点:实现简单,容易理解。
缺点:效率较低,在处理大型文本字符串时不适用。
2.KMP算法:KMP算法是一种高效的模式匹配算法,它利用已匹配的信息减少比较次数。
该算法的核心思想是通过构建最大匹配长度表(也称为部分匹配表),根据部分匹配表中的信息来决定模式字符串的下一个比较位置。
这样可以跳过一部分已经匹配的字符,提高匹配的效率。
KMP算法的时间复杂度是O(m+n),其中m是模式字符串的长度,n是文本字符串的长度。
优点:能够在较短的时间内找到所有匹配的位置,适用于处理大型文本字符串。
缺点:算法实现稍复杂,需要构建部分匹配表。
3. Boyer-Moore算法:Boyer-Moore算法是一种高效的模式匹配算法,它通过利用模式字符串中的信息来进行跳跃式的比较,从而减少比较次数。
该算法分为两个阶段:坏字符规则和好后缀规则。
(1)坏字符规则:采用从模式字符串末尾到当前字符的顺序进行比较。
如果当前字符不匹配,则根据坏字符出现的位置和出现的最后位置进行移动。
(2)好后缀规则:利用模式字符串中的好后缀信息进行比较。
如果出现好后缀匹配的情况,则直接移动到匹配的位置,否则根据好后缀的后缀子串中的最长后缀与模式字符串的最长前缀进行比较。
Boyer-Moore算法的时间复杂度是O(m+n),其中m是模式字符串的长度,n是文本字符串的长度。
27.设计模式.解释器模式(Interpreter)

NumExpression和 OpExpression 继承了该抽象类。
Expression
NumExpression
OpExpression
武汉科技大学
问题(Problem)
abstract class Expression { abstract public double Interpreter(Syntax root); } class NumExpression : Expression { private double _value; public NumExpression(double value) { this._value = value; } public double Value { get { return this._value; } } public override double Interpreter(Syntax root) { return ((NumExpression)(root.Expression)).Value; }
武汉科技大学
问题(Problem)
class Interpreter { private Expressionizer Expressionizer = new Expressionizer(); public SyntaxTree Eval(String expr) { Expression[] Expressions = Expressionizer.Parse(expr); SyntaxTree astree = new SyntaxTree(); foreach (Expression Expression in Expressions) { astree.Append(Expression); } return astree;
matlab请总结字符串的几个比较函数的联系与区别

1. 引言在MATLAB编程中,字符串的比较函数在实际应用中占据着重要的位置。
通过比较字符串,我们可以进行条件判断、排序和搜索等操作。
在本文中,我将总结字符串比较函数的联系与区别,帮助读者更加深入地理解这一主题。
2. 字符串比较函数概述在MATLAB中,常见的字符串比较函数包括strcmp、strncmp、strcmpl、strcmpi和strfind等。
这些函数可以用于比较两个字符串的大小、判断是否相等,或者在一个字符串中搜索另一个字符串的位置等操作。
接下来,我将逐个介绍这些函数的使用方法和区别。
3. strcmp函数strcmp函数用于比较两个字符串是否相等。
它返回一个逻辑值,如果字符串相等则为true,否则为false。
需要注意的是,strcmp区分大小写,因此"Hello"和"hello"会被视为不相等的字符串。
4. strncmp函数strncmp函数用于比较两个字符串的前n个字符是否相等。
它可以用于部分匹配或指定比较长度的情况。
如果指定的长度超出了字符串长度,则会自动选择较短的字符串长度进行比较。
5. strcmpl函数strcmpl函数是MATLAB R2016b版本引入的新函数,用于比较两个字符串是否相等,不区分大小写。
与strcmp函数不同,strcmpl会忽略字符串的大小写差异。
6. strcmpi函数strcmpi函数与strcmpl类似,用于比较两个字符串是否相等,不区分大小写。
它可以简化代码编写,并且更适合于对字符串相等性进行判断。
7. strfind函数strfind函数用于在字符串中搜索指定子字符串的位置。
它返回子字符串在父字符串中的起始位置,如果没有找到则返回空数组。
这个函数在实际应用中非常实用,比如搜索关键词、提取信息等方面。
8. 总结与回顾通过本文的介绍,我们了解了MATLAB中常用的字符串比较函数,包括strcmp、strncmp、strcmpl、strcmpi和strfind。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
muParse和MTParse两种数学表达式解析器的比较
muParse小巧精干,提供LIB、DLL及源代码引入方式,与其说是C++风格的,实际上更贴切的说应该是C风格的,虽然同时支持C风格和C++类两种编码样式,但C++实现貌似只是做了一层简单的封装而已,也就说和C方式一样,都是用回调函数形式实现句法操作符和函数的扩展,而且C++调用接口很大程度上依赖于STL库。
同样由于它使用了纯粹C代码实现,而且首次使用后使用的都是二进制调用,所以它的最大优点是速度较快,更适合于实时性要求较高的环境,如Unix系统和单片机环境。
MTParser优雅简洁,提供LIB、COM、源代码三种引入方式,是用典型的C++风格编写的解析器,和muParser不同,它引入多种设计模式,使用C++类接口继承的方式供扩展句法操作符及函数,因而可扩展性和可维护性都很强,而且像文中所标榜的一样,它的最大特点是支持动态运行时插件扩展,从而实现发布后无需编译宿主程序只需替换插件实现表达式函数功能更新。
另外,它还提供了宽窄字符两种LIB库,理论上VC各版本应该均能兼容,还有一个特点就是它的多语言本地化支持,和插件配置一样,可以通过配置XML文档对操作函数、异常描述等信息实现多种语言配置和切换。
但是,和muParse相比,它的速度并不是优势,如作者所说,速度并不是MTParse最优先考虑的,也许文中所说的可扩展、可维护、易于使用、健壮性才是它的最大优势。
综合比较,如果对于速度要求不是非常之高,而且基本上都只是在Windows下多个VC版本间进行切换,而且如果还打算提供多语言支持,那么建议使用MTParse解析器。
首先,muParse支持的基本功能MTParse似乎大都支持,有些MTParse支持的功能muParse反而不支持。
其次,虽说做同样的操作符扩展工作,muParse也许能使用更少的代码实现,但是回调函数调多了就乱了,实在不如接口继承的方式优雅而易于维护,而且个人认为MTParse确实也多不了多少编码量,也许通过一定的再次提取封装
或者宏定义,代码量不会比muParse的多。
总而言之,muParse更像是小家碧玉,而MTParse更像是大家闺秀,一个精干朴实以速度见长,一个优雅华丽擅于扩展维护。