MooseFS使用总结
Linux平台上MFS(MooseFS)的部署v0.5

Linux平台上MFS(MooseFS)的部署目录1 概述 (3)2 实验环境 (3)3 安装和配置MFS Master (4)3.1 安装master (4)3.2 配置master (4)3.3 启动和停止master服务 (5)4 安装和配置ChunkServer (5)4.1 安装ChunkServer (5)4.2 配置ChunkServer (5)4.3 启动和停止ChunkServer服务 (6)5 安装和配置MFS Client (6)5.1 安装FUSE (6)5.2 安装MFS Client (7)5.3 使用MFS (7)5.4 设置副本数量 (7)5.5 设置空间回收时间 (8)6 破坏性测试 (9)6.1 测试数据存储服务器 (9)6.2 测试元数据服务器 (9)1 概述MFS(MooseFS)是一个Linux/Unix平台上开源的分布式文件系统。
它可以把文件复制成多份(如3份)分别放置在多个数据服务器(ChunkServer)上,实现文件的冗余。
而且可以动态的增加ChunkServer,实现动态存储容量扩展,甚至可以支持PB级的存储容量。
2 实验环境●硬件和软件环境:✓PC:Intel(R) Core(TM)2 Quad CPU Q9550@ 2.83GHz, 8G RAM✓OS: CentOS 5.2 (x86_64), Kernel: 2.6.18-92.el5xen✓MFS: MooseFS v1.5.12表2-1 安装MFS所需软件列表3 安装和配置MFS Master3.1 安装master●创建用户# useradd mfs -s /sbin/nologin●安装master# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs # make# make install3.2 配置master●创建目录# mkdir -p /var/run/mfs# chown mfs:mfs /var/run/mfs●更改配置文件/usr/local/mfs/etc/mfsmaster.cfg:#WORKING_USER = mfs#WORKING_GROUP = mfs#LOCK_FILE = /var/run/mfs/mfsmaster.pid#DATA_PATH = /usr/local/mfs/var/mfs#SYSLOG_IDENT = mfsmaster#BACK_LOGS = 50#REPLICATIONS_DELAY_INIT = 300#REPLICATIONS_DELAY_DISCONNECT = 3600#MATOCS_LISTEN_HOST = *#MATOCS_LISTEN_PORT = 9420#MATOCU_LISTEN_HOST = *#MATOCU_LISTEN_PORT = 9421#CHUNKS_LOOP_TIME = 300#CHUNKS_DEL_LIMIT = 100#CHUNKS_REP_LIMIT = 153.3 启动和停止master服务●启动master服务# /usr/local/mfs/sbin/mfsmaster start●停止master服务# /usr/local/mfs/sbin/mfsmaster -s●查看master日志/var/log/messages# tail -f /var/log/messages4 安装和配置ChunkServer4.1 安装ChunkServer●创建用户# useradd mfs -s /sbin/nologin●安装ChunkServer# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs # make# make install4.2 配置ChunkServer●创建目录# mkdir -p /var/run/mfs# chown mfs:mfs /var/run/mfs●创建共享存储的挂载点,建议分配整个磁盘分区# mount /dev/xvdb1 /data# chown mfs:mfs /data●更改配置文件/usr/local/mfs/etc/mfschunkserver.cfg:#WORKING_USER = mfs#WORKING_GROUP = mfs#DATA_PATH = /usr/local/mfs/var/mfs#LOCK_FILE = /var/run/mfs/mfschunkserver.pid#SYSLOG_IDENT = mfschunkserver#BACK_LOGS = 50#MASTER_RECONNECTION_DELAY = 30MASTER_HOST = 10.8.2.41MASTER_PORT = 9420#MASTER_TIMEOUT = 60#CSSERV_LISTEN_HOST = *#CSSERV_LISTEN_PORT = 9422#CSSERV_TIMEOUT = 60#CSTOCS_TIMEOUT = 60#HDD_CONF_FILENAME = /usr/local/mfs/etc/mfshdd.cfg●更改配置文件/usr/local/mfs/etc/mfshdd.cfg, 增加文件系统挂载点:/data1/data2注意:配置的挂载点必须让mfs用户有读写权限,如没有,用如下命令赋权限:# chown mfs:mfs /data14.3 启动和停止ChunkServer服务●启动chunkserver服务# /usr/local/mfs/sbin/mfschunkserver start●停止chunkserver服务# /usr/local/mfs/sbin/mfschunkserver -s●查看chunkserver日志/var/log/messages# tail -f /var/log/messages5 安装和配置MFS Client5.1 安装FUSE●增加环境变量并使其生效export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATHexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib:.export PATH=$PATH:/usr/local/mfs/bin:.●安装fuse# tar xvzf fuse-2.7.4.tar.gz# cd fuse-2.7.4# ./configure# make# make install5.2 安装MFS Client●创建用户# useradd mfs -s /sbin/nologin●安装MFS Client# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs --enable-mfsmount# make# make install5.3 使用MFS●如果报错fuse: device not found, 请先fuse mount.# modprobe fuse●挂载MFS文件系统# mkdir /mfsdata# /usr/local/mfs/bin/mfsmount -h 10.8.2.41 -w /mfsdata●使用MFS# dd if=/dev/urandom of=/mfsdata/test.dat bs=1M count=200# md5sum /mfsdata/test.dat522c27c45064c2d0463c168593f5bead /mfsdata/test.dat5.4 设置副本数量●查看目录现在的副本数量:# mfsgetgoal /mfsdata/mfsdata: 1# mfsfileinfo /mfsdata/test.dat/mfsdata/test.dat:chunk 0: 0000000000000013_00000004 / (id:19 ver:4)copy 1: 10.8.2.44:9422chunk 1: 0000000000000014_00000003 / (id:20 ver:3)copy 1: 10.8.2.42:9422chunk 2: 0000000000000015_00000003 / (id:21 ver:3)copy 1: 10.8.2.42:9422chunk 3: 0000000000000016_00000001 / (id:22 ver:1)copy 1: 10.8.2.42:9422●更改目录现在的副本数量:# mfsrsetgoal 3 /mfsdata/mfsdata/:inodes with goal changed: 3 (3)inodes with goal not changed: 0 (0)inodes with permission denied: 0 (0)●查看更改后目录的副本数量:# mfsgetgoal /mfsdata/mfsdata: 3# mfsfileinfo /mfsdata/test.dat/mfsdata/test.dat:chunk 0: 0000000000000013_00000004 / (id:19 ver:4)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 1: 0000000000000014_00000003 / (id:20 ver:3)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 2: 0000000000000015_00000003 / (id:21 ver:3)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 3: 0000000000000016_00000001 / (id:22 ver:1)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:94225.5 设置空间回收时间●查看目录当前回收时间:# mfsgettrashtime /mfsdata/mfsdata: 86400●设置目录当前回收时间为600秒:# mfsrsettrashtime 600 /mfsdata/mfsdata:inodes with trashtime changed: 3 (3)inodes with trashtime not changed: 0 (0)inodes with permission denied: 0 (0)●查看更改后空间回收时间:# mfsgettrashtime /mfsdata/mfsdata: 6006 破坏性测试6.1 测试数据存储服务器现在用4个服务器组成了MFS的存储平台,其中一个是master,其余三个服务器是chunkserver.先停止一个chunkserver服务,然后在某个MFS客户端往挂接点的目录(/mfsdata)里复制数据或者创建目录/文件、或者读取文件、或者删除文件,观察操作是否能正常进行。
分布式文件系统MFS(moosefs)实现存储共享
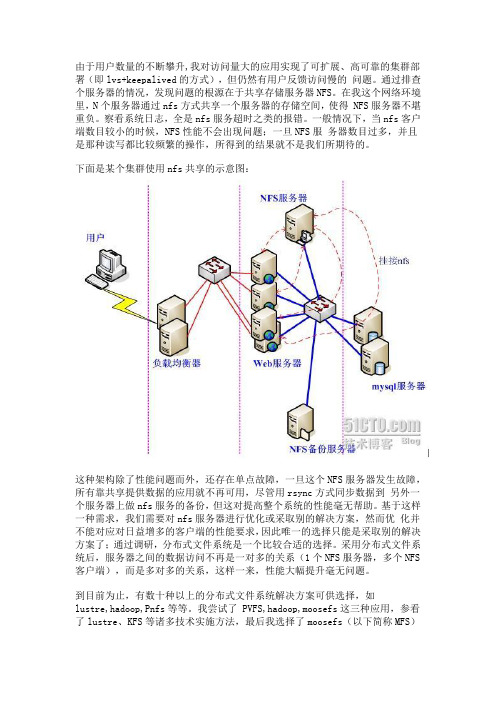
由于用户数量的不断攀升,我对访问量大的应用实现了可扩展、高可靠的集群部署(即lvs+keepalived的方式),但仍然有用户反馈访问慢的问题。
通过排查个服务器的情况,发现问题的根源在于共享存储服务器NFS。
在我这个网络环境里,N个服务器通过nfs方式共享一个服务器的存储空间,使得 NFS服务器不堪重负。
察看系统日志,全是nfs服务超时之类的报错。
一般情况下,当nfs客户端数目较小的时候,NFS性能不会出现问题;一旦NFS服务器数目过多,并且是那种读写都比较频繁的操作,所得到的结果就不是我们所期待的。
下面是某个集群使用nfs共享的示意图:这种架构除了性能问题而外,还存在单点故障,一旦这个NFS服务器发生故障,所有靠共享提供数据的应用就不再可用,尽管用rsync方式同步数据到另外一个服务器上做nfs服务的备份,但这对提高整个系统的性能毫无帮助。
基于这样一种需求,我们需要对nfs服务器进行优化或采取别的解决方案,然而优化并不能对应对日益增多的客户端的性能要求,因此唯一的选择只能是采取别的解决方案了;通过调研,分布式文件系统是一个比较合适的选择。
采用分布式文件系统后,服务器之间的数据访问不再是一对多的关系(1个NFS服务器,多个NFS 客户端),而是多对多的关系,这样一来,性能大幅提升毫无问题。
到目前为止,有数十种以上的分布式文件系统解决方案可供选择,如lustre,hadoop,Pnfs等等。
我尝试了 PVFS,hadoop,moosefs这三种应用,参看了lustre、KFS等诸多技术实施方法,最后我选择了moosefs(以下简称MFS)这种分布式文件系统来作为我的共享存储服务器。
为什么要选它呢?我来说说我的一些看法:1、实施起来简单。
MFS的安装、部署、配置相对于其他几种工具来说,要简单和容易得多。
看看lustre 700多页的pdf文档,让人头昏吧。
2、不停服务扩容。
MFS框架做好后,随时增加服务器扩充容量;扩充和减少容量皆不会影响现有的服务。
MooseFS使用总结

MooseFS使用总结2010-12-08 12:55阿炯流行的开源分布式文件系统比较我现在有海量的数据文件(1000万个文件)需要存储,需要让其他计算机可以很容易地访问,数据无价,我还希望这个文件系统带冗余功能。
我首先注意到的是Ubuntu Enterprise Cloud 的提供者:Eucalyptus。
它提供了和AWS(Amazon Web Service)几乎完全兼容的云计算接口,看起来似乎是个云存储的靠谱解决方案。
Eucalyptus模仿Amazon的S3服务,提供了一个叫做Walrus的存储服务组件。
可是经过一番探索,我发现Eucalyptus想说爱你不容易。
一方面是因为Eucalyptus配置起来很麻烦,缺乏文档,网上几乎找不到任何相关帮助;另一方面,虽然理论上Eucalyptus和AWS的EC2/S3兼容,但实际上并非如此,很多在AWS上可以用的工具,在Eucalyptus上就无法使用最关键是,直到最后我把Walrus配置完成之后,才发现Walrus根本不像我想的那样,是一个带冗余的云存储系统。
而只是一个实现了S3接口的单机软件而已。
实际上Walrus 和Eucalyptus的另一个组件sc(storage controller)没有任何关联,Walrus只是提供了和S3一致的接口,而它的实现方式,既不带冗余,也不能分开部署在多台服务器上。
于是我开始寻找一个真正的分布式文件系统,来解决我的存储难题。
一找才发现,市面上各种分布式文件系统品种繁多,层出不穷。
列举几个主要的:mogileFS:Key-Value型元文件系统,不支持FUSE,应用程序访问它时需要API,主要用在web领域处理海量小图片,效率相比mooseFS高很多。
FastDFS:国人在mogileFS的基础上进行改进的key-value型文件系统,同样不支持FUSE,提供比mogileFS更好的性能。
mooseFS:支持FUSE,相对比较轻量级,对master服务器有单点依赖,用c编写,性能相对较好,国内用的人比较多glusterFS:支持FUSE,比mooseFS庞大。
MooseFS 命令

MFS主节点命令:Mfscgiserv开启http/cgi 服务监控MFSMfsmaster开启、重启、停止MFS master进程Mfsmaster.cfg MFS master 进程的配置文件Mfsexport.cfg MFS控制对文件系统访问的文件Mfsmaster.lock MFS master进程的运行文件PID文件.mfsmaster.lock MFS master进程的锁文件metadata.mfs metadata.mfs.back MFS文件系统元数据镜像changelog.*.mfs MFS 文件系统元数据变化日志data.stats MFS的master图表状态MfsmetadumpMfsmetarestore重放MFS元数据变化日志dump MFS镜像文件MFS备份节点命令:Mfsmetalogger开启、重启、停止MFS metalogger进程Mfsmetalogger.cfg MFS metalogger的配置文件Mfsmetalogger.lock MFS metalogger进程的运行文件PID文件.mfsmetalogger.lock MFS metalogger进程的锁文件Changelog_nl.*.mfs MooseFS filesystem metadata change logs (backup of master change log files)MFS数据节点命令:Mfschunkserver开启、重启、停止Mfs chunkserver进程-t 等待一个lockfile的时间长短(默认60秒)Mfschunkserver.cfg MFS chunkserver进程的配置文件Mfshdd.cfg 列表用于mfs存储的目录,一个一行;MFS挂载节点命令:mssetgoalmfsgetgoalmfsgettrashtimemssettrashtimemfscheckfilemfsfileinfomfsappendchunksmfsdirinfomfsfilerepairmfsmakesnapshotmfsgeteattrmfsseteattrmfsdeleattr。
moosefs使用文档

su 更改用户输入密码(由$转变为#)#cd /usr/src将安装包放入指定文件需要赋予用户权限[root@localhost src]# chown -R mfs:mfs /usr/src将fuse-2.8.5.tar.gzmfs-1.6.27-1.tar.gzzlib-1.2.8.tar.gz放入/usr/src安装FUSE 软件包#tar -zxvf fuse-2.8.5.tar.gz#cd fuse-2.8.5#./configure#make#make install安装MooseFS#groupadd mfs#useradd -g mfs mfs#cd /usr/src#tar -zxvf mfs-1.6.27-1.tar.gz出现错误解决:需要安装zlib[root@localhost src]# tar -zxvf zlib-1.2.8.tar.gz [root@localhost src]# cd zlib-1.2.8[root@localhost zlib-1.2.8]# sudo ./configure#make#make install出现错误解决:[root@s001 mfs-1.6.17]# ldconfig -p | grep fuse[root@s001 mfs-1.6.17]# rpm -qa | grep fuseyum install fuse-devel继续安装MooseFS#cd mfs-1.6.27#./configure --prefix=/usr --sysconfdir=/etc \--localstatedir=/var/lib --with-default-user=mfs \--with-default-group=mfs#make#make install修改文件时需要赋予权限[root@localhost mfs]# chown -R mfs:mfs /etc/mfs注意:关闭元数据服务器,务必使用 /usr/sbin/mfsmaster –s 这种方式,如果直接使用kill 杀死进程,将导致下次启动时出现找不到相关文件,而不能正常启动服务器。
分布式文件系统MFS(moosefs)实现存储共享

分布式文件系统MFS(moosefs)实现存储共享分布式文件系统MFS(MooseFS)实现存储共享分布式文件系统(Distributed File System,简称DFS)是一种将数据分散存储在多个计算机节点上的文件系统。
每个节点都可以独立地执行读写操作,从而提高了文件系统的性能和可扩展性。
MFS (MooseFS)是一款流行的DFS系统,具有高性能、高可靠性和易于部署的特点。
本文将重点介绍MFS实现存储共享的原理和方法。
一、MFS简介MFS是一种开源、跨平台的DFS系统,支持Linux、Windows和Mac等操作系统。
它由Master节点和多个Chunk节点组成。
Master节点负责管理文件系统的元数据,而Chunk节点负责存储实际的文件数据。
MFS利用网络将文件数据分散存储在不同的Chunk节点上,从而实现了存储共享的功能。
二、MFS存储共享原理MFS采用了分片(Sharding)和复制(Replication)的策略来实现存储共享。
分片是指将一个文件划分为多个固定大小的块(Chunk),并将这些块存储在不同的Chunk节点上。
每个Chunk节点只负责存储自己所拥有的块,而不负责整个文件的存储。
这种方式可以提高数据的读写速度,同时也提高了系统的容错性和可用性。
复制是指将每个块复制到多个Chunk节点上,以实现数据的冗余存储。
当某个Chunk节点发生故障时,其他拥有相同块的节点可以继续提供服务,从而保证数据的可靠性和可用性。
MFS可以根据用户的需求设置块的复制数,以权衡系统的性能和容错性。
三、MFS存储共享方法在使用MFS实现存储共享时,需要按照以下步骤进行配置和操作:1. 安装和配置MooseFS首先,需要在每个节点上安装MooseFS软件,并进行必要的配置。
在Master节点上,需要指定Chunk节点的IP地址和端口号,以及元数据的存储路径。
在Chunk节点上,需要指定Master节点的IP地址和端口号。
文本操作模块-fs模块(五)

文本操作模块-fs模块(五)fs模块是一个比较庞大的模块,在前面也介绍了该模块中最核心的一点东西,虽然核心的这点东西,在整个fs模块中占据的比例比较小,但是如果只是我们平常使用的话,基本已经够用了,其他的一些方法,属于能力提升时需要学习的的内容了,所以在后面就不再继续了,本篇属于fs模块中的最后一篇,也不是把fs模块中的其他API都给一一列举出来,这里再说最后一个我看来很重要的方法,监听文件或者目录的的方法watchFile。
概总这里之所以在最后把这个watchFile方法写入到这里,是因为在前端的一个流行的构建工具grunt中,有一个grunt-contrib-watch模块,可以用于监听整个项目中,文件是否有变化,不知道有没有人去看过该部分的源码,是如何实现这个模块的呢?(我是还没有去看过,基础学习完成之后,再去研究下)所以,这里提前看下,fs模块中的watchFile是如何实现的,等以后去看grunt中的watch模块时,就可以更得心应手了,所以,想法和我相同的朋友们,就继续看下去吧。
fs.watchFile方法该方法是用于监听指定文件的一个方法,其使用方法为[javascript] view plain copy 在CODE上查看代码片派生到我的代码片fs.watchFile(filename,[option],listener);其中:1:filename:必须,需要被监听的文件的完整的路径以及文件名2:option:可选,option支持两个参数,persistent属性和interval属性:interval属性用于指定每隔多少毫秒监听一次文件的是否发生了改变,以及发生了什么改变,默认为5007(毫秒)persistent属性,用于指定了,当指定了被监视的文件后,是否停止当前正在运行的应用程序,默认为true3:listener:必须,被监听文件发生改变时调用的回调函数回调函数传入两个参数callback(curr,prev),它们都是fs.Stats的实例,关于该实例的详细介绍,请参考前篇文章,curr表示修改之后的的信息对象,prev表示本次修改之前的信息对象。
第八章 分布式文件系统MooseFS

master <-> metaloggers module: listen on *:9419
master <-> chunkservers module: listen on *:9420
main master server module: listen on *:9421
# deprecated, to be removed in MooseFS 1.7
# LOCK_FILE = /var/run/mfs/mfsmetalogger.lock
启动元数据日志服务器
[root@mytest2 etc]# /usr/local/mfs/sbin/mfsmetalogger start
#元数据日志服务器运行时在系统日志输出的标识。
# SYSLOG_IDENT = mfsmetalogger
# LOCK_MEMORY = 0
# NICE_LEVEL = -19
#从元数据服务器(master)抓回文件,然后进行存放的路径。
# DATA_PATH = /usr/local/mfs/var/mfs
#存放备份日志的总个数为50并轮转。
# BACK_LOGS = 50
#元数据备份文件下载请求频率。默认为24小时。即每隔1天从源数据服务器下载一个metadata.mfs.back文件。当元数据服务器关闭或者出现故障的时候,此文件消失。如果要恢复
整个MFS,则需从元数据日志服务器取得该文件。请特别注意这个文件,它与日志文件一起,才能够恢复整个被破坏的分布式文件系统。
mfsmaster daemon initialized properly
MooseFS分析

MooseFS分析点滴云1.官方说明1.1. 关于MooseFSMooseFS是一个容错的网络分布式文件系统。
将数据分散在多个物理服务器中,但对于用户其实是作为一个可见资源。
对于标准的文件操作MooseFS充当类似Unix操作系统中的文件系统:1、层次结构(目录树)2、POSIX文件存储属性(权限,最后访问和修改时间)3、支持特殊文件(块设备和字符设备,管道和套接字)4、符号链接(指向目标文件的文件指针,目标文件不一定在MooseFS 上)和硬链接(MooseFS相同的数据文件可以有不同的文件名)5、提供基于IP地址和/或密码两种方式,实现文件系统的授权访问1.2. MooseFS的特性1、高可靠性(分布在不同的电脑,可以存储的数据的多个副本拷贝)2、通过安装新的计算机/磁盘容量进行动态扩展3、删除的文件保留一个可配置的一段时间内(文件系统级别的“垃圾桶”)4、在文件被读写时都能保持的一致性快照1.3. 体系架构MooseFS由四部分组成:管理服务器(master server):单机管理整个文件系统,存储为每个文件元数据(大小,属性和文件的位置信息,包括非常规文件的所有信息,例如目录,插座,管道和设备等)。
数据服务器(chunk servers):任何数量的数据服务器上存储文件的数据,并且同步数据(如果某文件在一个以上的服务器上存在的话)。
元数据备份服务器(metalogger server):任何数量的服务器,所有这些存储元数据变动记录,定期下载主元数据文件;用于主服务器宕机后,提升管理服务器的有效价值。
访问MooseFS中文件的客户机:任意数量的机器,使用mfsmount 过程与管理服务器进行通信(接收和修改文件元数据)和块服务器(实际的文件数据交换)。
mfsmount是基于FUSE机制(文件系统用户空间的),所以MooseFS针对所有采用FUSE实现机制的操作系统(Linux, FreeBSD, MacOS X等)都是有效的。
php mongogridfs 用法

文章主题:深入探讨PHP Mongogridfs的用法一、引言在Web开发中,文件存储和管理是一个常见的需求。
而在PHP开发中,Mongogridfs是一个非常有用的工具,它可以帮助我们高效地管理和存储文件。
在本文中,我们将深入探讨PHP Mongogridfs的用法,帮助大家更好地理解和使用这一工具。
二、PHP Mongogridfs简介Mongogridfs是MongoDB的一个子系统,它用于存储和管理大文件。
与传统的数据库系统不同,Mongogridfs以分块的方式存储文件,使得它更适合存储大文件,并且可以在分布式系统中进行扩展。
在PHP中,我们可以通过Mongogridfs扩展来方便地使用Mongogridfs,实现对文件的高效管理和存储。
三、基本用法1. 安装Mongogridfs扩展要在PHP中使用Mongogridfs,首先需要安装Mongogridfs扩展。
可以通过PECL来进行安装,或者在Windows环境下,直接下载DLL 文件。
安装完成后,需要在php.ini中开启该扩展。
2. 连接MongoDB在使用Mongogridfs之前,需要先连接MongoDB。
可以使用MongoDB官方提供的驱动,也可以使用其他第三方的MongoDB库。
确保在连接MongoDB时,设置了正确的认证信息和权限。
3. 存储文件使用Mongogridfs存储文件非常简单。
我们可以使用Mongogridfs提供的函数,如storeFile()来将文件存储到MongoDB中。
在存储文件时,可以设置文件的元数据,方便后续的检索和管理。
4. 读取文件读取文件同样非常方便。
可以使用Mongogridfs提供的函数,如findOne()或find()来获取文件的内容,并根据需要进行处理。
在读取文件时,可以根据文件的元数据进行检索,以便快速地获取需要的文件。
5. 删除文件当文件不再需要时,可以使用Mongogridfs提供的函数,如delete()来删除文件。
fs使用方法 -回复

fs使用方法-回复FS是一个强大的文件系统,用于管理和组织操作系统中的文件和文件夹。
本文将逐步介绍FS的使用方法,帮助读者更好地了解和使用这个功能强大的工具。
第一步:了解FS的基本概念和原理在开始使用FS之前,我们需要先了解一些基本的概念和原理。
FS是一个层次化的文件系统,通过将文件和文件夹组织在树状结构中,使我们能够方便地找到和管理它们。
树状结构的顶层被称为根目录,它包含了所有其他文件和文件夹的入口点。
每个文件或文件夹都有一个唯一的路径来表示其在整个系统中的位置。
FS还提供了一系列的操作和功能,使我们能够创建、复制、删除、移动和重命名文件和文件夹。
此外,还可以设置文件和文件夹的权限,以确保只有授权用户能够访问或修改它们。
第二步:学习基本的FS命令在开始使用FS之前,我们需要先学习一些基本的FS命令。
这些命令可以在命令行界面(CLI)或脚本中使用。
以下是一些常用的FS命令:1. ls:列出当前目录中的文件和文件夹。
2. cd:切换当前目录到指定的目录。
3. pwd:显示当前目录的路径。
4. mkdir:创建一个新的文件夹。
5. touch:创建一个新的文件。
6. cp:复制文件或文件夹。
7. rm:删除文件或文件夹。
8. mv:移动或重命名文件或文件夹。
9. chmod:设置文件或文件夹的权限。
请注意,FS命令的语法可能因操作系统和FS版本的不同而有所差异。
在使用这些命令之前,请务必阅读相关文档或使用help命令获取更多信息。
第三步:使用FS进行常见的操作现在我们已经熟悉了FS的基本原理和命令,让我们来学习如何使用FS进行一些常见的操作。
1. 创建文件夹:使用mkdir命令可以创建一个新的文件夹。
例如,要在当前目录下创建名为"documents"的文件夹,可以执行以下命令:mkdir documents。
2. 创建文件:使用touch命令可以创建一个新的空文件。
例如,要在当前目录下创建名为"readme.txt"的文件,可以执行以下命令:touch readme.txt。
MooseFS各个配置文件的参数

MooseFS各个配置文件的参数1.元数据服务(master server)位置:PREFIX/ etcmfsmaster.cfg是主配置文件,mfsexports.cfg是被挂接目录及权限设置。
1.1 mfsmaster.cfg的配置:凡是用#注释掉的变量均使用其默认值,这里来解释一下这些变量:#WORKING_USER和WORKING_GROUP:是运行master server的用户和组;#SYSLOG_IDENT:是master server在syslog中的标识,也就是说明这是由master serve 产生的;#LOCK_MEMORY:是否执行mlockall()以避免mfsmaster 进程溢出(默认为0);#NICE_LEVE:运行的优先级(如果可以默认是-19; 注意: 进程必须是用root启动);#EXPORTS_FILENAME:被挂接目录及其权限控制文件的存放位置#DATA_PA TH:数据存放路径,此目录下大致有三类文件,changelog,sessions和stats;#BACK_LOGS:metadata的改变log文件数目(默认是50);#REPLICATIONS_DELAY_INIT:延迟复制的时间(默认是300s);#REPLICATIONS_DELAY_DISCONNECT:chunkserver断开的复制延迟(默认是3600);# MATOML_LISTEN_HOST:metalogger监听的IP地址(默认是*,代表任何IP);# MATOML_LISTEN_PORT:metalogger监听的端口地址(默认是9419);# MATOCS_LISTEN_HOST:用于chunkserver连接的IP地址(默认是*,代表任何IP);# MATOCS_LISTEN_PORT:用于chunkserver连接的端口地址(默认是9420);# MATOCU_LISTEN_HOST:用于客户端挂接连接的IP地址(默认是*,代表任何IP);# MATOCU_LISTEN_PORT:用于客户端挂接连接的端口地址(默认是9421);# CHUNKS_LOOP_TIME :chunks的回环频率(默认是:300秒);# CHUNKS_DEL_LIMIT :在一个loop设备中可以删除chunks的最大数(默认:100)# REPLICATIONS_DELAY_DISCONNECT chunkserver断开后的复制延时(默认:3600秒)# CHUNKS_WRITE_REP_LIMIT:在一个循环里复制到一个chunkserver的最大chunk 数目(默认是1)# CHUNKS_READ_REP_LIMIT :在一个循环里从一个chunkserver复制的最大chunk 数目(默认是5)# REJECT_OLD_CLIENTS:弹出低于1.6.0的客户端挂接(0或1,默认是0)注意mfsexports访问控制对于那些老客户是没用的以上是对master server的mfsmaster.cfg配置文件的解释,对于这个文件不需要做任何修改就可以工作。
GlusterFS-Lustre-MooseFS实践总结

GlusterFS/Lustre/MooseFS实践总结作者:酷抉小生时间:2014/11/22文档摘要:该文档是根据个人对一些开源分布式系统的一些实践总结。
相关描述:✧关注酷抉小生的个人网站酷抉网:/✧PDF文档获取:百度网盘/s/1hqePCqw✧PDF文档及相关资料下载请到百度搜索✧欢迎加入storm-分布式-IT技术交流群(191321336,群中有详细的资料),一起讨论技术,一起分享代码,一起分享设计;✧目录GlusterFS/Lustre/MooseFS实践总结 (1)1 文档说明 (1)2 系统实践总结 (1)2.1 GlusterFS (1)2.1.1 系统概况 (1)2.1.2 系统搭建 (1)2.1.3 系统可用性 (1)2.1.4 系统性能 (2)2.1.5 系统适性 (2)2.1.6 二次开发 (2)2.1.7 实际应用 (2)2.2 Lustre (3)2.2.1 系统概况 (3)2.2.2 系统搭建 (3)2.2.3 系统可用性 (3)2.2.4 系统性能 (3)2.2.5 系统适性 (4)2.2.6 二次开发 (4)2.2.7 实际应用 (4)2.3 MooseFS (4)2.3.1 系统概况 (4)2.3.2 系统搭建 (4)2.3.3 系统可用性 (4)2.3.4 系统性能 (5)2.3.5 系统适性 (5)2.3.6 二次开发 (5)2.3.7 实际应用 (5)3 其他DFS概览 (6)4 总结 (6)5 啰嗦几句 (6)6 参考文献 (7)1 文档说明该文档为个人对一些开源分布式文件系统实践之后的总结,主要包括系统安装分析、可用性、可靠性、扩展性等方面。
由于个人工作及个人好爱原因,最近对几个开源分布式文件系统进行了实践,包括环境的搭建、性能的测试及功能的测试等等,总觉得要把这些实践过后的经验记录下来,希望能给其他人一些帮助。
根据这些总结,希望能对一些分布式文件系统爱好者或者开发者在进行原型开发时能有所帮助,主要是一些性能指标的分析。
MooseFS分布式文件系统部署手册

MooseFS分布式文件系统部署手册目录1、架构规划 (2)2、主控服务器Master server 安装 (2)3、备份服务器Backup server (metalogger) 安装 (4)4、存储块服务器Chunk servers安装 (5)5、客户端Users’ computers 安装 (6)6、安装MooseFS 在同一个主机 (8)7、MooseFS 基础用法 (10)8、停止MooseFS (12)9、维护Moosfs (13)9.1、MooseFS chunkservers的维护 (13)9.2、MooseFS元数据的备份 (13)9.3、MooseFS master的恢复 (13)9.4、从备份恢复MooseFS master (13)9.5、起停顺序 (14)10、监控 (14)11、故障处理 (14)11.1、disk显示报错 (14)11.2、MFS master启动失败 (14)11.3、写入数据卡住 (15)12、文件删除回收处理 (15)12.1、回收站查看 (15)12.2、恢复文件 (15)正文:1、架构规划fuse 版本:/projects/fuse/wget/project/fuse/fuse-2.X/2.9.3/fuse-2.9.3.tar.gz?r=ht tp%3A%2F%%2Fprojects%2Ffuse%2F&ts=1410357693&use_mirro r=cznicwget /project/fuse/fuse-2.X/2.9.3/fuse-2.9.3.tar.gzMooseFS:/projects/moosefs/∙ 主控服务器Master server: 172.16.8.100∙ 主控备份服务器Metalogger server: 172.16.8.101∙ 存储块服务器Chunk servers: 172.16.8.203172.16.8.204∙ 客户端主机(clients): 172.16.8.2052、主控服务器Master server 安装yum install lrzsz gcc vim wget telnet tcpdump zlib* fuse-devel -yfuse:wget/project/fuse/fuse-2.X/2.9.3/fuse-2.9.3.tar.gz?r=ht tp%3A%2F%%2Fprojects%2Ffuse%2F&ts=1410357693&use_mirro r=cznicwget /project/fuse/fuse-2.X/2.9.3/fuse-2.9.3.tar.gz MooseFS:http://pro.hit.gemius.pl/hitredir/id=.WCbG2t.7Ln5k1s3Q9xPg8cPfX.wVMc5kyXfrKcJT DH.c7/url=/tl_files/mfscode/mfs-1.6.27-5.tar.gztar xzvf fuse-2.9.3.tar.gzcd fuse-2.9.3./configure&&make &&make installcd ..useradd mfstar -zxvf mfs-1.6.27-5.tar.gzcd mfs-1.6.27./configure --prefix=/usr --sysconfdir=/etc \--localstatedir=/var/lib --with-default-user=mfs \--with-default-group=mfs --disable-mfschunkserver--disable-mfsmountmake&&make install###自动生成样例配置文件,这些样例文件是以/etc/*.distcd /etc/mfscp mfsmaster.cfg.dist mfsmaster.cfgcp mfsmetalogger.cfg.dist mfsmetalogger.cfgcp mfsexports.cfg.dist mfsexports.cfgmkdir -p /usr/etc/mfs/ln -s /etc/mfs/mfsmaster.cfg /usr/etc/mfs/mfsmaster.cfgln -s /etc/mfs/mfsexports.cfg /usr/etc/mfs/mfsexpln -s /etc/mfs/mfstopology.cfg /usr/etc/mfs/mfstopology.cfgln -s /etc/mfs/mfshdd.cfg /usr/etc/mfs/mfshdd.cfg##Mfsmaster.cfg 配置文件包含主控服务器master 相关的设置,在这里我们暂时不打算对其进行修改。
My_MooseFS与MogileFS性能测试对比

MooseFS与MogileFS的性能测试对比1.1.测试过程测试1 Java_Write_15w_100KMogileFS和MooseFS启动15个进程进行写数据,对比执行所需时间;测试2 Siege_Read_c100_60mins_1storage在192.168.80.15上使用Siege模拟100个并发用户通过http访问前端Nginx,持续60分钟随机访问50万个文件,这50万个文件均只存储在同一个Storage(Chunk)节点下;测试3 Siege_Read_c200_60mins_1storage在192.168.80.15上使用Siege模拟200个并发用户通过http访问前端Nginx,持续60分钟随机访问50万个文件,这50万个文件均只存储在同一个Storage(Chunk)节点下;测试4 Siege_Read_c300_60mins_1storage在192.168.80.15上使用Siege模拟300个并发用户通过http访问前端Nginx,持续60分钟随机访问50万个文件,这50万个文件均只存储在同一个Storage(Chunk)节点下;1.2.测试结果写操作(Replication份数均为3):文件系统助记号并发数完成时间测试1 MogileFS Java_Write_15w_100K 15 69分钟测试1 MooseFS Java_Write_15w_100K 15 140分钟若MooseFS设置的Replication份数为1,通过15个并发写15万数据只需要48分钟可见MooseFS的写操作速度受到份数设置的影响,如下图:读操作:MogileFS:助记号成功率平均反应时间(秒)平均每秒处理个数(个/秒)平均每秒流量(MBytes/秒)平均并发数(个)磁盘平均tps(个)磁盘平均读速度(Blocks/秒)测试2 Siege_Read_c100_60mins_1storage99.8% 0.70 82.96 8.09 58.24 252.221 17180.2测试3 Siege_Read_c200_60mins_1storage99.8% 1.57 96.38 9.39 151.74 275.235 19811.9测试4 Siege_Read_c300_60m_1storage98.9% 1.53 147.83 14.27 225.73 420.278 27329.0MooseFS:助记号成功率平均反应时间(秒)平均每秒处理个数(个/秒)平均每秒流量(MBytes/秒)平均并发数(个)磁盘平均tps(个)磁盘平均读速度(Blocks/秒)100.00 % 3.64 24.14 2.36 87.83 114.046 5762.24 测试2 Siege_Read_c100_60mins_1storage测试3 Siege_Read97.04 % 6.76 24.43 2.39 165.22 114.582 5793.09_c200_60mins_1storage测试4 Siege_Read88.92 % 7.66 25.14 2.46 192.65 116.7 5982.61_c300_60m_1storage1.3.结果分析●写操作测试同样Replication份数的情况下,MooseFS比MogileFS要慢较多。
FS总结文档

协议栈消息
• sip是软件的最重要一部分,所以知道他的 消息处理方式非常重要的。 • sip的基本消息invite、info、200、ack等不再 详述,在3261里面有详细的描述 • 这里描述fs如何接收和处理sip消息? • fs的协议栈使用的是nokia的sofia协议栈。发 送sip消息和接收sip消息都根据rfc的标准处 理
event
• fs启动时创建了x*10000,x(根据cpu数量 确定,大于2,小于60)的event-dispatchqueue,并创建一个线程处理收到的event事 件
event-1
• event是通过类型进行区分,例如有: SWITCH_EVENT_CHANNEL_CREATE、
SWITCH_EVENT_CHANNEL_HANGUP等。
状态机
• 介绍:fs通过状态来驱动呼叫的变换,通过 要实现的状态state和当前运行的状态 running-state两个状态实现呼叫业务的实现。 • mod-sofia模块注册了各个状态的状态机函 数,还有公用的core-state-machine的各个状 态对应的注册函数。 • 当state和running-state不一致时,运行状态 机
状态机-3
• 状态机的运行需要session数据,所以在跑状 态机之前必须申请session,用来管理这次呼 叫,并申请一个channel,用来管理申请的 channel • 当sofia创建一个session时,会把 sofia_endpoint_interface到session中,在 machine_state中则可以调用mod-sofia模块 注册在sofia-endpoint-interface的函数进行处 理
mod-sofia模块
[转]深入浅出mongoose-----包括mongoose基本所有操作,非常实用!!!!!
![[转]深入浅出mongoose-----包括mongoose基本所有操作,非常实用!!!!!](https://img.taocdn.com/s3/m/8396c59782d049649b6648d7c1c708a1284a0ac8.png)
[转]深⼊浅出mongoose-----包括mongoose基本所有操作,⾮常实⽤深⼊浅出mongoosemongoose是nodeJS提供连接 mongodb的⼀个库. 此外还有mongoskin, mongodb(mongodb官⽅出品). 本⼈,还是⽐较青睐mongoose的, 因为他遵循的是⼀种, 模板式⽅法, 能够对你输⼊的数据进⾏⾃动处理. 有兴趣的同学可以去看看.初⼊mongooseinstall mongooseI’ve said that. 使⽤mongoose你需要有 nodeJS和mongodb数据库. 这两个东西, 前端宝宝们应该很清楚了》下载mongoose:npm install mongoose --saveconnect mongoose下载好数据库之后,我们来碰碰运⽓, 看你能不能连接上database. ⾸先,打开你的mongodb;mongod; //这⾥我已经将mongodb放在环境变量中了数据库成功打开后: 在js⽂件中写⼊:'use strict';const mongoose = require('mongoose');mongoose.connect('mongodb://localhost:27017/test');const con = mongoose.connection;con.on('error', console.error.bind(console, '连接数据库失败'));con.once('open',()=>{//成功连接})(其实,懂得童鞋,你只要copy就⾏了.) OK,运⽓好的同学,此刻嘴⾓扬起45°的微笑. 运⽓差的同学, 出门左转google. 简单连接mongoose后,我们来看⼀看mongoose的基本构造吧.understand mongoosemongoose实际上,可以说是Oracle和mongodb的⼀个混合产物,但归根接地还是mongodb的. 这⾥我要祭出,我珍藏很久的对⽐图. 熟悉其他数据库的同学应该能很快明⽩的.Oracle MongoDB Mongoose数据库实例(database instance)MongoDB实例Mongoose模式(schema)数据库(database)mongoose表(table)集合(collection)模板(Schema)+模型(Model)⾏(row)⽂档(document)实例(instance)rowid_id_idJoin DBRef DBRef通过上⾯的阐述,我们⼤概能知道了在Mongoose⾥⾯有哪⼏个基本概念.Schema: 相当于⼀个数据库的模板. Model可以通过mongoose.model 集成其基本属性内容. 当然也可以选择不继承.Model: 基本⽂档数据的⽗类,通过集成Schema定义的基本⽅法和属性得到相关的内容.instance: 这就是实实在在的数据了. 通过 new Model()初始化得到.他们各⾃间是怎样的关系呢?下图可以清晰的说明, 以上3中实际上就是⼀个继承⼀个得到最后的数据.我们先看⼀个demo吧:'use strict';const mongoose = require('mongoose');const con = mongoose.connection;con.on('error', console.error.bind(console, '连接数据库失败'));con.once('open',()=>{//定义⼀个schemalet Schema = mongoose.Schema({category:String,name:String});Schema.methods.eat = function(){console.log("I've eatten one "+);}//继承⼀个schemalet Model = mongoose.model("fruit",Schema);//⽣成⼀个documentlet apple = new Model({category:'apple',name:'apple'});//存放数据apple.save((err,apple)=>{if(err) return console.log(err);apple.eat();//查找数据Model.find({name:'apple'},(err,data)=>{console.log(data);})});})到这⾥, 实际上, mongoose我们已经就学会了. 剩下就是看⼀看官⽅⽂档的API–CRUD相关操作. 如果,⼤家觉得意犹未尽的话,可以继续看下⾯的深⼊浅出. ⽽且, 下⾯会附上实际应⽤中, mongoose的写法.深⼊浅出mongoose这⾥,我们根据上⾯的3个概念深⼊的展开⼀下.Schema这实际上是,mongoose中最重要的⼀个theroy. schema 是⽤来定义 documents的基本字段和集合的. 在mongoose中,提供了Schema的类。
Centos下MooseFS(MFS)分布式存储共享环境部署记录

Centos下MooseFS(MFS)分布式存储共享环境部署记录分布式⽂件系统(Distributed File System)是指⽂件系统管理的物理存储资源不⼀定直接连接在本地节点上,⽽是通过计算机⽹络与节点相连,分布式⽂件系统的实际基于客户机/服务器模式。
⽬前常见的分布式⽂件系统有很多种,⽐如Hadoop、Moosefs、HDFS、FastDFS、PNFS(Parallel NFS)、Lustre、TFS、GFS等等⼀系列。
在众多的分布式⽂件系统解决⽅案中,MFS是搭建⽐较简单、使⽤起来也不需要过多的修改web程序,⾮常⽅便。
⼀、MooseFS是什么MooseFS(即Moose File System,简称MFS)是⼀个具有容错性的⽹络分布式⽂件系统,它将数据分散存放在多个物理服务器或单独磁盘或分区上,确保⼀份数据有多个备份副本,对于访问MFS的客户端或者⽤户来说,整个分布式⽹络⽂件系统集群看起来就像⼀个资源⼀样,也就是说呈现给⽤户的是⼀个统⼀的资源。
MooseFS就相当于UNIX的⽂件系统(类似ext3、ext4、nfs),它是⼀个分层的⽬录树结构。
MFS存储⽀持POSIX标准的⽂件属性(权限,最后访问和修改时间),⽀持特殊的⽂件,如块设备,字符设备,管道、套接字、链接⽂件(符合链接、硬链接);MFS⽀持FUSE(⽤户空间⽂件系统Filesystem in Userspace,简称FUSE),客户端挂载后可以作为⼀个普通的Unix⽂件系统使⽤MooseFS。
MFS可⽀持⽂件⾃动备份的功能,提⾼可⽤性和⾼扩展性。
MogileFS不⽀持对⼀个⽂件内部的随机或顺序读写,因此只适合做⼀部分应⽤,如图⽚服务,静态HTML服务、⽂件服务器等,这些应⽤在⽂件写⼊后基本上不需要对⽂件进⾏修改,但是可以⽣成⼀个新的⽂件覆盖原有⽂件。
⼆、MooseFS的特性1)⾼可靠性,每⼀份数据可以设置多个备份(多分数据),并可以存储在不同的主机上2)⾼可扩展性,可以很轻松的通过增加主机的磁盘容量或增加主机数量来动态扩展整个⽂件系统的存储量3)⾼可容错性,可以通过对mfs进⾏系统设置,实现当数据⽂件被删除后的⼀段时间内,依旧存放于主机的回收站中,以备误删除恢复数据4)⾼数据⼀致性,即使⽂件被写⼊、访问时,依然可以轻松完成对⽂件的⼀致性快照5)通⽤⽂件系统,不需要修改上层应⽤就可以使⽤(那些需要专门api的dfs很⿇烦!)。
MooseFS维护技巧集锦

MooseFS维护技巧集锦一、启动MooseFS集群最安全的启动MooseFS集群(避免任何读或写的错误数据或类似的问题)的方式是按照以下命令步骤:∙启动mfsmaster进程∙启动所有的mfschunkserver进程∙启动mfsmetalogger进程(如果配置了mfsmetalogger)当所有的chunkservers连接到MooseFS master后,任何数目的客户端可以利用mfsmount去挂接被export的文件系统。
(可以通过检查master的日志或是CGI监视器来查看是否所有的chunkserver被连接)。
二、停止MooseFS集群安全的停止MooseFS集群:∙在所有的客户端卸载MooseFS 文件系统(用umount命令或者是其它等效的命令)∙用mfschunkserver –s命令停止chunkserver进程∙用mfsmetalogger –s命令停止metalogger进程∙用mfsmaster –s命令停止master进程三、MooseFS chunkservers的维护假如每个文件的goal(目标)都不小于2,并且没有under-goal文件(这些可以用mfsgetgoal –r和mfsdirinfo命令来检查),那么一个单一的chunkserver在任何时刻都可能做停止或者是重新启动。
以后每当需要做停止或者是重新启动另一个chunkserver的时候,要确定之前的chunkserver被连接,而且要没有under-goal chunks。
四、MooseFS元数据的备份通常元数据有两部分的数据∙主要元数据文件metadata.mfs,当mfsmaster运行的时候会被命名为metadata.mfs.back ∙元数据改变日志changelog.*.mfs,存储了过去的N小时的文件改变(N的数值是由BACK_LOGS参数设置的,参数的设置在mfschunkserver.cfg配置文件中)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
MooseFS使用总结2010-12-08 12:55 阿炯流行的开源分布式文件系统比较我现在有海量的数据文件(1000万个文件)需要存储,需要让其他计算机可以很容易地访问,数据无价,我还希望这个文件系统带冗余功能。
我首先注意到的是Ubuntu Enterprise Cloud的提供者:Eucalyptus。
它提供了和AWS(Amazon Web Service)几乎完全兼容的云计算接口,看起来似乎是个云存储的靠谱解决方案。
Eucalyptus模仿Amazon的S3服务,提供了一个叫做Walrus的存储服务组件。
可是经过一番探索,我发现Eucalyptus想说爱你不容易。
一方面是因为Eucalyptus配置起来很麻烦,缺乏文档,网上几乎找不到任何相关帮助;另一方面,虽然理论上Eucalyptus和AWS的EC2/S3兼容,但实际上并非如此,很多在AWS上可以用的工具,在Eucalyptus上就无法使用最关键是,直到最后我把Walrus配置完成之后,才发现Walrus根本不像我想的那样,是一个带冗余的云存储系统。
而只是一个实现了S3接口的单机软件而已。
实际上Walrus和Eucalyptus的另一个组件sc(storage controller)没有任何关联,Walrus只是提供了和S3一致的接口,而它的实现方式,既不带冗余,也不能分开部署在多台服务器上。
于是我开始寻找一个真正的分布式文件系统,来解决我的存储难题。
一找才发现,市面上各种分布式文件系统品种繁多,层出不穷。
列举几个主要的:mogileFS:Key-Value 型元文件系统,不支持FUSE,应用程序访问它时需要API,主要用在web领域处理海量小图片,效率相比mooseFS高很多。
FastDFS:国人在mogileFS的基础上进行改进的key-value型文件系统,同样不支持FUSE,提供比mogileFS更好的性能。
mooseFS:支持FUSE,相对比较轻量级,对master服务器有单点依赖,用c编写,性能相对较好,国内用的人比较多glusterFS:支持FUSE,比mooseFS庞大。
ceph:支持FUSE,客户端已经进入了linux-2.6.34内核,也就是说可以像ext3/rasierFS一样,选择ceph为文件系统。
彻底的分布式,没有单点依赖,用C编写,性能较好。
基于不成熟的btrfs,其本身也非常不成熟。
lustre:Oracle公司的企业级产品,非常庞大,对内核和ext3深度依赖。
NFS:老牌网络文件系统,具体不了解,反正NFS最近几年没发展,肯定不能用。
本来我打算用mogileFS,因为它用的人最多,而且我的主要需求都是在web方面。
但是研究了它的api之后发现,Key-Value型文件系统没有目录结构,导致不能用list某个子目录的所有文件,不能直接像本地文件系统一样操作,干什么事情都需要一个api,让人十分不爽。
mogileFs这种做法,可能是受同一个开发团队的另一个大名鼎鼎的产品memcached的侦听端口+api模式影响,也有可能是mogileFS刚开始设计的时候,FUSE还没有开始流行。
总之要找一个支持FUSE的分布式文件系统,最后就在mooseFS, glusterFS, ceph中选择。
从技术上来看,ceph肯定是最棒的,用c编写,进入linux-2.6.34内核,基于btrfs文件系统,保证了它的高性能,而多台master的结构彻底解决了单点依赖问题,从而实现了高可用。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
而glusterFS比较适合大型应用,口碑相对较差,因此也不考虑。
最后我选择了缺点和优点同样明显的mooseFS。
虽然它有单点依赖,它的master非常占内存。
但是根据我的需求,mooseFS已经足够满足我的存储需求。
国内mooseFS的人比较多,并且有很多人用在了生产环境,更加坚定了我的选择。
一、MFS介绍:Distinctive features of MooseFS are:MooseFS优越特性如下:- higher reliability (data can be stored in several copies on separate computers)高可用性(数据可以存储在多个机器上的多个副本)- dynamically expanding disk space by attaching new computers/disks可动态扩展随时新增加机器或者是磁盘- possibility of storing deleted files for a defined period of time ("trash bin" service on a file system level) 可回收在指定时间内删除的文件(“垃圾回收站”是一个系统级别的服务)- possibility of creating snapshot of a file, which means coherent copy of the whole file, even while the file is being written.可以对整个文件甚至在正在写入的文件创建文件的快照。
MFS文件系统结构: 包含4种角色:管理服务器managing server (master) :负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复.多节点拷贝。
single computer managing the whole filesystem,storing metadata for every file (information on size, attributes and file localisation(s), including all information about non-regular files, i.e.directories, sockets, pipes and devices).单个机器管理整个文件系统,用来存储记录每一个文件的Metadata(记录文件的大小、文件的属性、文件的位置,也包括非规则文件的系统,如目录、sockets、管道和设备)元数据日志服务器Metalogger server(Metalogger):负责备份master服务器的变化日志文件,文件类型为changelog_ml.*.mfs,以便于在master server出问题的时候接替其进行工作。
数据存储服务器data servers (chunkservers) :负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输。
客户机挂载使用client computers :通过fuse内核接口挂接远程管理服务器上所管理的数据存储服务器,.看起来共享的文件系统和本地unix文件系统使用一样的效果。
说说mfs优势:一)、Free(GPL)0. 通用文件系统,不需要修改上层应用就可以使用(支持fuse)。
1. 可以在线扩容,体系架构可伸缩性极强。
2. 部署简单。
3. 体系架构高可用,除开master组件无单点故障。
4. 文件对象高可用,可设置任意的文件冗余程度,而绝对不会影响读或者写的性能。
5. 提供Windows回收站的功能。
6. 提供类似Java语言的GC(垃圾回收)。
7. 提供netapp,emc,ibm等商业存储的snapshot特性。
8. google filesystem的一个c实现。
9. 提供web gui监控接口。
10. 提高随机读或写的效率。
11. 提高海量小文件的读写效率。
可能的瓶颈:0). master本身的性能瓶颈。
mfs系统master存在单点故障如何解决?网上有人提供moosefs+drbd+heartbeat 来保证master单点问题?不过在使用过程中不可能完全不关机和间歇性的网络中断!短期对策:按业务切分1). 体系架构存储文件总数的可遇见的上限。
(mfs把文件系统的结构缓存到master的内存中,个人认为文件越多,master的内存消耗越大,8g对应2500kw的文件数,2亿文件就得64GB内存)。
短期对策:按业务切分2). 单点故障解决方案的健壮性。
二、mfs各元素主要配置文件1、master主服务器Metadata is stored in memory of the managing server and simultaneously is being saved on disk (as aperiodically updated binary file and immediately updated incremental logs). The main binary file as well as the logs are replicated to metaloggers (if present).Metadata元数据存储在master服务器的内存中,同时也保存在磁盘上(作为一个定期更新的二进制文件,并实时的更新changelog日志)。
如果存在metaloggers的话,主要的二进制文件以及日志也复制到metaloggers中。
How much CPU/RAM resources are used?消耗多少CPU和内存资源In our environment (ca. 500 TiB, 25 million files, 2 million folders distributed on 26 million chunks on 70 machines) the usage of chunkserver CPU (by constant file transfer) is about 15-20% and chunkserver RAM usually consumes about 100MiB (independent of amount of data).在我们的测试环境中(大约500 TiB的数据,250万份文件,200万文件夹,分成260万块分布在70机器上),chunkserver的CPU使用情况为(持续的文件传输)约为15-20%同时chunkserver内存使用100MiB(和数据量的多少无关)。
The master server consumes about 30% of CPU (ca. 1500 operations per second) and 8GiB RAM. CPU load depends on amount of operations and RAM on number of files and folders.master服务器消耗约30%的CPU(每秒钟约1500次操作)和8G的内存。