6统计假设测验
统计假设测验的基本原理

第六章 统计假设测验的基本原理一、统计假设测验基本概念由一个样本或一系列样本所得的结果去推断总体,即统计推断。
统计推断包括参数估计和假设测验两个方面。
参数估计是由样本结果对总体参数作出点估计和区间估计。
点估计是以统计数估计相应的参数,例如以x 估计μ;区间估计是以一定的概率作保证估计总体参数位于某两个数值之间。
但是试验工作更关心的是有关估计值的利用,即利用估计值去作统计假设测验。
此法首先是根据试验目的对试验总体提出两种彼此对立的假设,然后由样本的实际结果,经过一定的计算,作出在概率意义上应接受哪种假设的推断。
由于此种测验法首先对总体提出假设,所以称为统计假设测验。
二、统计假设测验基本方法(一)提出假设统计假设测验首先要对研究总体提出假设。
假设一般有两种,一种是无效假设,记作H 0;另一种是备择假设,记作H A 。
无效假设是设处理效应为零,试验结果所得的差异乃误差所致。
备择假设是和无效假设相反的一种假设,即认为试验结果所得的差异是由于真实处理效应所引起。
1、单个平均数的假设 假设一个样本平均数x 是从一个已知总体(总体平均数为0μ)中随机抽出的,记作H 0:0μμ=,对H A :0μμ≠。
例如,有一个小麦品种产量总体是正态分布的,总体平均667m 2产量0μ为360kg ,标准差σ为40kg 。
但此品种经多年种植后出现退化,必须对其进行改良,改良的品种种植16个小区,得其平均667m 2产量王为380kg 。
试问这个改良品种在产量性状上是否和原品种相同。
此乃单个平均数的假设测验,是要测验改良品种的总体平均667m 2产量μ是否还是360kg 。
记为H 0:0μμ=(360kg ),H A :0μμ≠。
2、两个平均数相比较的假设 假设两个样本平均数1x 和2x 是从两个具有平均数相等的总体中随机抽出的,记为H 0:12μμ=,H A :12μμ≠。
例如要测验两个小麦品种的总体平均产量是否相等,两种农药的杀虫效果是否一样等等。
田间试验与统计分析试卷

田间试验与统计分析试卷99级田间试验与统计分析期末试卷A一.是非题:判断结果填入括弧,以√表示正确,以×表示错误。
(本大题分10小题,每小题1分,共10分)1.χ2应用于独立性测验,当观察的χ2<χ2α,ν时,即认为两个变数独立;当观察的χ2≥χ2α,ν时,即认为两个变数相关。
(X )2.如果无效假设H 0正确,通过测验却被否定,是α错误;若假设H 0错误,测验后却被接受,是β错误(√)3.统计假设测验H 0:μ≥μ0,H A :μ<μ0时,否定区域在右尾。
(√)4.成对数据资料的比较假设测验,是假设每个样本中的各观察值来源于同一总体。
(X )5.凡是经过方差分析F 测验,处理效应差异显著的资料,必须进一步作多重比较,判断各个处理均数彼此间的差异显著性。
(√)6.对于一双变数资料(x,y ),若决定系数r 2=0.8371,则表示了在y 总变异的平方和由x 不同而引起变异平方占83.71%;或在x 总变异的平方和由x 不同而引起变异平方占83.71%。
(X )7.研究作物产量(y )与施肥(x )的关系得线性回归方程=58.375+1.1515x(r=0.2731**),在一定的区间(x 观察值范围内),产量随施肥量的增加而增加的。
(X )8.综合性试验中各因素的各水平不构成平衡处理组合,而是将若干因素某些水平结合在一起形成少数几个处理组合。
(√)9.误差的同质性假定,是指假定各个处理的εij 都具有N (0,σ2)的。
(X )10.在标准正态分布曲线下,其概率P(0≤u ≤1)=0.6827。
(X )二.选择题:(本大题分5小题,每小题2分,共20分)1.若变数x 与y 回归系数估计值为b ,则c 1x 与c 2y 的回归系数估计值为A. bB. c 1c 2bC.b c c 1D.b c c 122.某地小叶杨观赏林100个林带的土壤中发生螨虫危害,在100个林带中以不复置(不放回)随机抽测10个林带,根据调查结果计算出该抽样的误差平方和=129.96,则该抽样误差值是 A. 1.14 B. 1.20 C. 3.80D. 0.423.已知?服从于N (10,31),以样本容量n 1=4随机抽得样本,得?1,再以样本容量n 2=2随机抽得样本,得?2,则所有(?1-?2)服从 A. N (10,493)B. N (0,1)C. N (0,493)D. N (10,31)4.试验因素对试验指标所起的增加或减少的作用是A.试验效应B.主效C.简单效应D.因素内不同水平间的互作5.分子均方ν1=1,分母均方ν2=11时,F 0.05=4.84,根据F 分布统计值与t 分布统计值间的关系,可推算出ν=11时t 0.05=A. 4.84B. 9.68C. 2.20D. 23.436.统计假设测验是根据“小概率事件实际上不可能发生“的原理A.接受无效假设的过程B. 否定无效假设的过程C. 接受或否定无效假设的过程D. 接受和否定备择假设的过程7.成对数据按成组数据的方法比较,容易使统计推断发生A. 第一类错误B. 第二类错误C. 第一类错误和第二类错误D. 第一类错误或第二类错误8.测验H 0:σ2=С,对H A :σ2≠С,则实得χ2下列那一种情况下否定H 0A. χ2<χ2α,ν或χ2>χ21-α,νB. χ2>χ2α,ν或χ2<χ21-α,νC. χ2<χ2α/2,ν和χ2>χ2(1-α/2),νD. χ2>χ2α/2,ν和χ2<χ2(1-α/2),ν9. ?如果两个直线回归样本均来自同一正态总体N (α+βX ,σ2),离回归方差分别为S 2y1/x1,S 2y2/x2,则两个样本合并离回归方差为2/2/2211x y x y S S +B.)1()1(2121-+-+n n Q QC.42121-++n n Q QD.)2()2(2121-+-+n n U U10.由N (300,502)总体中随机抽取两个独立样本,S 12=49.52,S 22=53.42,F值为A. 0.9270B. 0.8593C. 1.0788D. 1.1638三.填空题:(本大题分5小题,1、2、3、4、5小题各4分,6小题10分,共30分)1.有一样本资料,其样本容量n=30、平均数y =10,平均数标准误S ?=1,则其总体平均数μ的99%置信限为(10-1.0*301U ,10+11U )。
6 假设检验

常用的α 值为0.01, 0.05, 0.1
由研究者事先确定。
拒绝域 1/2 1 - 接受域
拒绝域 1/2
临界值
H0
临界值
假设检验的步骤
根据问题要求提出 原假设(H0 )和备择假设(H1); 确定适当的检验统计量及相应的抽样分布;
计算检验统计量的值;
选取显著性水平,确定原假设的接受域和拒绝域; 作出统计决策。
举例2
某品牌洗发水在产品说明书中称:平均净含 量不少于500ml。相关机构要通过抽检其中 一批产品来验证是否属实。试陈述用于检验
的原假设和备择假设。
设该品牌洗发水的平均净含量真值是μ。 如果μ<500,表明说明书的内容不属实。
H0 :μ ≥ 500 (净含量符合说明书)
H1 :μ < 500 (净含量不符合说明书)
举例3
一家研究机构估计,某城市中家庭拥有汽车 的比率超过30%。为验证这一估计是否正确, 该机构随机抽取了一个样本进行检验。试陈
述用于检验的原假设和备择假设。
设该城市家庭拥有汽车的比率真值是 p。 研究者想收集证据予以证明:比率不超过30% H0 :p ≤ 30% (比率不超过30%)
H1 :p > 30% (比率超过30%)
例题
一种罐装饮料每罐的容量是255ml,标准差是
5ml。为检验每罐容量是否符合要求,质检人员
在某天的产品中随机抽取40罐进行检验,测得平 均容量为255.8ml。取显著性水平 =0.05,检 验该天生产的饮料容量是否符合标准要求。
设饮料的平均容量为μ。 H0 :μ = 255 (容量符合要求) H1 :μ≠255 (容量不符合要求)
6假设检验基础

3、选择检验方法并计算统计量:要根据所分析资料的类 选择检验方法并计算统计量: 型和统计推断的目的要求选用不同的检验方法。 型和统计推断的目的要求选用不同的检验方法。 4、确定P值:P值是指由H0所规定的总体中做随机抽样, 确定P 值是指由H 所规定的总体中做随机抽样, 获得等于及大于(或等于及小于)现有统计量的概率。 获得等于及大于(或等于及小于)现有统计量的概率。当 求得检验统计量的值后, 求得检验统计量的值后,一般可通过特制的统计用表直接 查出P 查出P值。
H0:µ = µ0
t= s
H1 : µ ≠ µ0 (单侧µ > µ0或µ < µ0 )
n ~ t(ν ), ν = n − 1
X − µ0
二、配对设计资料的t检验 配对设计资料的t 配对设计是研究者为了控制可能存在的主要非处理因素而 采用的一种试验设计方法。 采用的一种试验设计方法。 形式: 形式:1、将受试对象配成特征相近的对子,同对的两个受试 将受试对象配成特征相近的对子, 对象随机分别接受不同处理; 对象随机分别接受不同处理; 2、同一样品分成两份,随机分别接受不同处理(或测量); 同一样品分成两份,随机分别接受不同处理(或测量); 3、同一受试对象处理前后,数据作对比。 同一受试对象处理前后,数据作对比。
单双侧的确定一是根据专业知识, 单双侧的确定一是根据专业知识,已知东北某县囱 门月龄闭合值不会低于一般值; 门月龄闭合值不会低于一般值;二是研究者只关心东北 某县值是否高于一般人群值,应当用单侧检验。一般认 某县值是否高于一般人群值,应当用单侧检验 一般认 为双侧检验较为稳妥,故较为常用。 为双侧检验较为稳妥,故较为常用。
已知: 已知:µ0 = 14.1 X = 14.3 s = 5.08 n = 36
应用统计学6-假设检验(1)

t 检验
(单边和双边)
χ2检验
(单边和双边)
名称 条件
H0
统计量及其分布
拒绝域 |u| >u1-α/2 u >u1-α u < - u1-α |t| >tα/2 t >tα t < -tα
2 χ 2 > χα / 2 ( n − 1)或
0 u 总体 µ ≤ µ0 2 检 方差σ 均 验 已知 µ ≥ µ 0 值 检 验 t 总体 µ = µ 0 µ ≤ µ0 2 检 方差σ 验 未知 µ ≥ µ 0
正确
α 错误和 β 错误的关系
当H0、H1给定,n固定时,无法同时使α和β变小 α和β的关系就像翘翘板,α小β就大, α大β就小
β α
使α、β 同时变小的办法就是增大样本容量。
“不能拒绝H0”
一般地说,哪一类错误所带来的后果越严重,危害越大, 在假设检验中就应当把哪一类错误作为Fra bibliotek要的控制目标。
通常β不易计算,所以通常我们 主要控制α,尽量减小β
µ ≥ µ0 µ < µ0
µ ≤ µ0 µ > µ0
双边检验
抽样分布
拒绝域 α/2
H0 :µ = µ0
H1 :µ ≠ µ0
置信水平 拒绝域 1-α α/2 接受域 H0值
临界值
临界值
左单边检验
抽样分布
拒绝域
H0 :µ ≥ µ0
H1 :µ < µ0
置信水平
α
1-α 接受域 H0值
临界值
右单边检验
由于α 事先确定,所以拒绝H0 是有说服力的, 而β通常未知,所以如果我们决定“接受H0 “,我们并不 确定这个决策的置信度,所以通常我们不采用“接受H0 “的说法,而是采用“不能拒绝H0 “的说法。
概率论与数理统计 南京大学 6 第六章假设检验 (6.1.1) 假设检验的基本概念

客观 主观
H0真
H0不真
拒绝H0
第一类错 误(弃真)
不 H0真) P(第一类错误)= P(不拒绝H0 | H0不真) P(第二类错误)=
一般情况下,犯两类错误的概率存在此消彼 长的关系,不能同时达到最小,我们通常的 做法是首先控制犯第一类错误的概率,然后 尽量降低犯第二类错误的概率。 (奈曼-皮 尔逊原则)
假设检验的基本概念
2019/1/6
假设检验=假设+检验。
首先对总体提出某种推断或猜测,即假设;
然后通过试验,抽取样本,根据样本信息 对“假设”的正确性进行判断,即检验。
例1 :某厂生产的一种保健食品。已知在正常的情况 下,每瓶保健品的重量(单位:千克)服从均值为 25.0的正态分布(方差为0.01 )。某天开工后, 随机抽取9瓶,测得其平均重量为24.94,试问 该天生产是否正常?
H0: =25;
H1: 25
例2 :某厂生产一批产品,要求次品率不超过5%。 随机抽取50件,发现有4件次品,问产品能 否出厂?
H0:p0.05;
H1: p>0.05
原假设:记为H0 备择假设(或对立假设):记为H1 。
简单假设:只含一个结论。 复合假设:包含多个结论。
假设检验中的两类错误
统计学第六章测试题

第六章 测试题A.参数估计B.统计推断C.区间估计D.假设检验 2.假设检验的概率依据是( )。
A.小概率原理B.最大似然原理C.大数定理D.中心极限定理3.下面有关小概率原则说法中正确的是( ) A 小概率原则事件就是不可能事件B 它是指当一个事件的概率不大于充分小的界限α(0<α<1)时,可认为该事件为不可能事件C 基于”小概率原则”完全可以对某一事件发生与否作出正确判断D 总体推断中可以不予考虑的事件4.通常研究者想收集证据予以支持的假设称为( ) A.原假设 B.备择假设 C.合理假设 D.正常假设5.当原假设为0μμ≥时,此时的假设检验称为( )A.双侧检验B.右侧检验C. 左侧检验D.显著性检验 6.研究表明,司机驾车时因接打手机而发生事故的比例超过20%,用来检验这一结论的原假设和备择假设应是( ) A.%20:0≥μH %20:1<μH B.%20:0≤μH %20:1>μH C.%20:0≤P H %20:1>P H D.%20:0≥P H %20:1<P H7.如果是总体方差已知,正态分布、小样本数据的均值检验,应该采用( )A. t 检验B. z 检验C. P 检验D. 以上都不对 8.在假设检验中,原假设和备选假设( )A 都有可能成立B 都有可能不成立C 只有一个成立而且必有一个成立D 原假设一定成立,备选假设不一定成立9.一种零件的标准长度5Cm ,要检验某天生产的零件是否符合标准要求,建立的原假设和备选假设就为( ) A .0:5H μ=,1:5H μ≠ B .0:5H μ≠,1:5H μ>C .0:5H μ≤,1:5H μ> D .0:5H μ≥,1:5H μ<10.若检验的假设为00H μμ≥:,10H μμ<:,则拒绝域为( )A .z z α<- B .z z α>C ./2z z α<-或/2z z α<- D .z z α>或z z α<-二、简答题1.假设检验的理论依据及推理的思想方法判断的理论依据:假设检验的理论依据是小概率事件原理。
第六部分假设检验

Z
接受域
统计量Z Z , 则就拒 绝原假设H 0 , 反之, Z Z , 则应接受原假 设H 0
拒绝域
第六部分 假设检验
四、统计检验中的名词 5、双边检验和单边检验
1)双边检验 如果拒绝域选择为统计量分布的两侧, 那么, 当显著性水平为时, 每侧拒 绝域的概率应各为 / 2.现在假定所用统计量分布以0点为对称, 则临界值 Z / 2和显著性水平有如下的关系式 : P( Z Z / 2 ) 双边检验的假设如下 : H 0 : 0 H1 : 0 若 Z Z / 2 , 则应拒绝H 0 ; 若 Z Z / 2 , 则应接受H 0
10 C10 如果H 0成立,P( 10) 10 10 7 C100
抽10人都为非本地人的概率极小, 而这样的小概率事件在 现实中发生了, 只能拒绝原假设, 接受备择假设。
第六部分 假设检验
四、统计检验中的名词 1、假定 在运用各种统计技术时,首先需要假定,例如总体 是否要求满足正态分布或其他形态的分布,总体间的方 差是否要求相等,或抽样是否要求独立等。除了这些具 体要求外,还有一个不言而喻的假定,那就是抽样必须 是随机抽样。
第六部分 假设检验
五、假设检验的步骤 1、根据实际问题作出假设。包括原假设 H 0和备择假设 H1 两部分; 2、根据样本构成合适的、能反映 H 0 的统计量,并在 H 0 条件下确定统计量的分布; 3、根据问题的需要,给出小概率 的大小,并求出拒 绝域和临界值; 4、根据上述检验标准,用样本统计量的观测值进行判 断。若样本统计量的值落入拒绝域,则拒绝 H 0 ,否则 接受 H 0
大学统计学 第6章 假设检验与方差分析

35%
16
30%
14
12
25%
10
20%
8
`
15%
6
10%
4
2
5%
0
0%
50-60
70-80
90-100
统计学导论
第六章 假设检验与方差分析
第一节 假设检验的基本原理 第二节 总体均值的假设检验 第三节 总体比例的假设检验 第四节 单因子方差分析 第五节 双因子方差分析 第六节 Excel在假设检验与方差分析
记为 H1:。150
整理课件
6-7
三、检验统计量
所谓检验统计量,就是根据所抽取的样本计 算的用于检验原假设是否成立的随机变量。
检验统计量中应当含有所要检验的总体参数, 以便在“总体参数等于某数值”的假定下研 究样本统计量的观测结果。
检验统计量还应该在“H0成立”的前提下有 已知的分布,从而便于计算出现某种特定的 观测结果的概率。
为 =x 149.8克,样本标准差s=0.872克。问该
生产线的装袋净重的期望值是否为150克(即 问生产线是否处于控制状态)?
整理课件
6-4
所谓假设检验,就是事先对总体的参数 或总体分布形式做出一个假设,然后利用抽 取的样本信息来判断这个假设(原假设)是 否合理,即判断总体的真实情况与原假设是 否存在显著的系统性差异,所以假设检验又 被称为显著性检验。
量所得结果落入接受域的概率。
问题,对于 和 大小的选择有
不同的考虑。例如,在例 6-1 中,如果检验者站在卖方 的立场上,他较为关心的是不要犯第一类错误,即不 要发生产品本来合格却被错误地拒收这样的事情,这
时, 要较小。反之,如果检验者站在买者的立场上,
(卫生统计学)第六章 假设检验基础

药前后患儿血清中免疫球蛋白IgG(mg/dl)含量
编号 1 2 3 4 5 6 7 8 9 10 11 12
用药前 1206.4 921.69 1294.08 945.36 721.36 692.32 980.01 691.01 910.39 568.56 1105.52 757.43
用药后 1678.44 1293.36 1711.66 1416.70 1204.55 1147.30 1379.59 1091.46 1360.34 1091.83 1728.03 1398.86
目的
H0
H1
双侧检验 是否μ1≠μ2
μ1=μ2
μ1≠μ2
单侧检验 是否μ1>μ2
μ1=μ2
μ1>μ2
或是否μ1<μ2
μ1=μ2
μ1<μ2
返回
选定检验方法和计算检验统计量
要根据研究设计的类型和统计推断的目的选用不同的检验方法。如 成组设计的两样本均数的比较用t检验(小样本)或Z检验(大样本), 两样本方差的比较用F检验。
(卫生统计学)第六章 假设检验基础
第一节、假设检验的概念与原理 一、假设检验的思维逻辑
1.小概率原理 小概率事件在一次随机试验中几乎是不可能发生
2.假设检验处理问题的特点 ⑴从全局的范围,即从总体上对问题作出判断 ⑵不可能对总体的每个个体均作观察
二、假设检验步骤
例6-1 已知北方农村儿童前囟门闭合月龄为14.1月。某研究者从东北某县抽取36名 儿童,得囟门闭合月龄均值为14.3月,标准差为5.08月。问该县儿童前囟门闭合月 龄的均数是否大于一般儿童?
四、方差齐性检验 homogeneity of variance test
医药数理统计第六章习题(检验假设和t检验)

第四章抽样误差与假设检验练习题一、单项选择题1. 样本均数的标准误越小说明A. 观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计总体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大2. 抽样误差产生的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当3. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布4. 假设检验的目的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L~9.1×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%答案:E D C D E二、计算与分析1.为了解某地区小学生血红蛋白含量的平均水平,现随机抽取该地小学生450人,算得其血红蛋白平均数为101.4g/L,标准差为1.5g/L,试计算该地小学生血红蛋白平均数的95%可信区间。
[参考答案]样本含量为450,属于大样本,可采用正态近似的方法计算可信区间。
101.4X=, 1.5S=,450n=,0.07S===95%可信区间为下限:/2.101.4 1.960.07101.26 XX u Sα=-⨯=-(g/L)上限:/2.101.4 1.960.07101.54 XX u Sα+=+⨯=(g/L)即该地成年男子红细胞总体均数的95%可信区间为101.26g/L~101.54g/L。
贾俊平统计学第6章假设检验

正态分布
01
正态分布是一种常见的概率分布 ,其概率密度函数呈钟形曲线, 具有对称性、连续性和可加性等 性质。
02
正态分布广泛存在于自然界和人 类社会中,许多随机变量都服从 或近似服从正态分布。
t分布
t分布是正态分布在自由度不同时的 另一种表现形式,其形状与正态分布 相似,但尾部概率不同。
在假设检验中,t分布在样本量较小或 总体标准差未知时常常被用来代替正 态分布进行统计分析。
界值,判断是否拒绝原假设。
双侧Z检验
总结词
双侧Z检验是用于检验一个总体均数是否与已知值存在显著差异的统计方法。
详细描述
双侧Z检验的步骤与单侧Z检验类似,但需要计算双尾Z值,并根据临界值判断是否拒绝原假设。例如,要检验某 产品的质量是否合格,可以提出原假设为产品质量合格,备择假设为产品质量不合格,然后通过计算Z值和临界 值,判断是否拒绝原假设。
03
样本统计量与抽样分布
样本均值和样本方差
样本均值
表示样本数据的平均水平,计算公式为 $bar{x} = frac{1}{n}sum_{i=1}^{n} x_i$,其中 $n$ 为样本容量, $x_i$ 为第 $i$ 个样本数据。
样本方差
表示样本数据的离散程度,计算公式为 $S^2 = frac{1}{n-1}sum_{i=1}^{n} (x_i - bar{x})^2$,其中 $S^2$ 为样本方差,$bar{x}$ 为样本均值。
假设检验的逻辑
小概率事件原理
如果一个事件在多次试验中发生的概 率很小,那么在一次试验中该事件就 不太可能发生。
反证法
先假设原假设成立,然后根据样本数 据和统计原理,推导出与已知事实或 概率相矛盾的结论,从而拒绝原假设 。
实验一、统计假设测验及方差分析--6
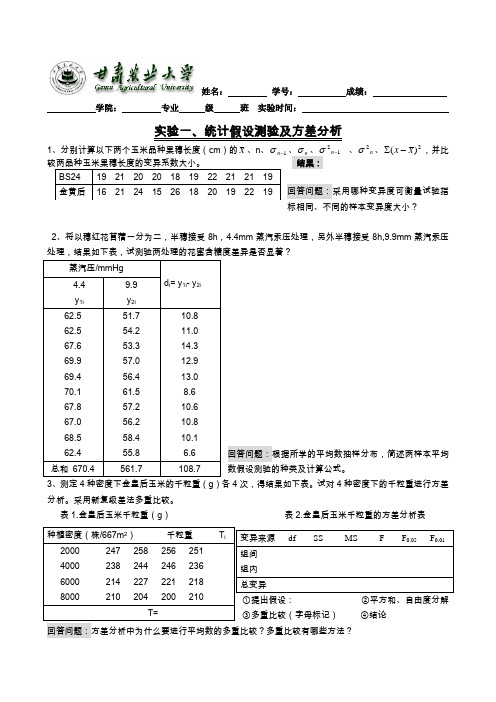
姓名: 学号: 成绩:
学院: 专业 级 班 实验时间: 实验一、统计假设测验及方差分析
1、分别计算以下两个玉米品种果穗长度(cm )的x 、n 、1-n σ、n σ、12-n σ、n 2σ、2)(x x -∑,并比
结果:
回答问题:采用哪种变异度可衡量试验指标相同、不同的样本变异度大小?
2、将以穗红花苜蓿一分为二,半穗接受8h ,4.4mm 蒸汽汞压处理,另外半穗接受8h,9.9mm 蒸汽汞压处
回答问题:根据所学的平均数抽样分布,简述两样本平均数假设测验的种类及计算公式。
3、测定4种密度下金皇后玉米的千粒重(g )各4次,得结果如下表。
试对4种密度下的千粒重进行方差分析。
采用新复级差法多重比较。
表1.金皇后玉米千粒重(g ) 表2.金皇后玉米千粒重的方差分析表。
应用统计学第六章参数假设检验

•临界值
•样本统计量
右侧检验示意图 (显著性水平与拒绝域 )
•抽样分布
•置信水平
•1 - a •接受域
•拒绝域
•a
•H0值
•样本统计量 •临界值
•观察到 的样本 统计量
•4 给出拒绝域
•在确定显著性水平后,可以确定检验的拒绝域W. 如在上面例1中, 取α=0.05, 要使对任意的θ≥110 有
•P155
•临界值
•H0值
•观察
到的样
本统计
•临界值
•样本统计量
双侧检验示意图 (显著性水平与拒绝域 )
•抽样分布
•拒绝域 •a/2
•1 - a •接受域
•置信水平 •拒绝域 • a/2
•临界值
•H0值
•临界值 •样本统计量
•观察 到的样 本统计
双侧检验示意图 (显著性水平与拒绝域 )
•抽样分布
•拒绝域 •a/2
•假设检验的思想:
•1、有一个明确的命题或假设 H;
•2、当 H 成立时,考虑某一变量 X 的性质,在女 士品茶问题中,考虑 X 为该女士说对的杯数,注意 此时 X 的分布已知;
•3、以 x 表示 X 的观测值,考虑 P(X=x)=px,px 越 小,试验结果越不利于 H;
•4、根据规定的小概率事件,做出最后的决策。
•若该女士只说对了 3 杯,又会得到怎样的结论?
•参数假设检验举例
例1:根据1989年的统计资料,某地女性新生儿的平 均体重为3190克。为判断该地1990年的女性新生儿 体重与1989年相比有无显著差异,从该地1990年的 女性新生儿中随机抽取30人,测得其平均体重为 3210克。从样本数据看,1990年女新生儿体重比 1989年略高,但这种差异可能是由于抽样的随机性 带来的,也许这两年新生儿的体重并没有显著差异 。究竟是否存在显著差异?可以先假设这两年新生 儿的体重没有显著差异,然后利用样本信息检验这 个假设能否成立。这是一个关于总体均值的假设检 验问题。
统计理论6_数值变量的假设检验

数值变量的假设检验版权所有:多多医善•数值变量统计分析概述•u检验•t检验•方差分析数值变量统计分析概述◆假设检验的基本思想◆反证法:先假设要比较的事物是相同的,再在这种假设成立的情况下,进行逻辑推理:①如果推理出的是一个小概率事件,一般情况下是不可能成立的,则反推到假设有误,从而否定假设②如果推理出的不是一个小概率事件,则在一次抽样中是可能发生的,则反推假设是成立的,从而接受假设——但这种否定或接受能力是可能出错的版权所有:多多医善数值变量统计分析概述◆数值变量比较的研究设计:自变量为分类变量、因变量为数值变量◆匹配方式举例①同一研究对象某种处理前后②同一研究对象两种处理方法③不同研究对象按照特定条件进行配对版权所有:多多医善•样本均数与总体均数比较的u检验•两样本均数比较的u检验样本均数与总体均数比较的u检验◆样本均数与总体均数比较的u检验:因变量为数值变量◆亦称为单样本u检验(one sample u test)◆适用条件①总体标准差σ已知的情况②或样本含量较大(比如n>100)时,因为n较大,υ也较大,则t分布很接近u分布版权所有:多多医善•t检验应用条件•样本均数与总体均数比较的t检验•完全随机设计t检验•匹配设计t检验t检验应用条件◆当样本含量较小(如n<50)时,t分布和u分布有较大的出入,所以小样本的样本均数与总体均数的比较以及两个样本均数的比较要用t检验◆适用条件①样本来自正态总体或近似正态总体;②两样本总体方差相等。
版权所有:多多医善完全随机设计t检验◆两样本均数比较的t检验:自变量为二分类变量,因变量为数值变量◆例测得14名慢性支气管炎病人与11名健康人的尿中17酮类固醇(mol/24h)排出量如下,试比较两组人的尿中17酮类固醇的排出量有无不同•原始调查数据如下:•病人X1(n=14):10.05 18.75 18.99 15.94 13.96 17.67 20.51 17.2214.69 15.10 9.42 8.21 7.24 24.60•健康人X2(n=11):17.95 30.46 10.88 22.38 12.89 23.01 13.89 19.4015.83 26.72 17.29从哪一步开始统计分析?版权所有:多多医善完全随机设计t检验◆两样本均数比较的t检验:自变量为二分类变量,因变量为数值变量◆例测得14名慢性支气管炎病人与11名健康人的尿中17酮类固醇(mol/24h)排出量如下,试比较两组人的尿中17酮类固醇的排出量有无不同事先准备:了解数据、是否满足正态分布、是否具备方差齐性满足正态性分布满足方差齐性版权所有:多多医善完全随机设计t 检验◆两样本均数比较的t 检验:自变量为二分类变量,因变量为数值变量◆例测得14名慢性支气管炎病人与11名健康人的尿中17酮类固醇(mol/24h )排出量如下,试比较两组人的尿中17酮类固醇的排出量有无不同•原始调查数据如下:•病人X 1(n=14):10.05 18.75 18.99 15.94 13.96 17.67 20.51 17.22 14.69 15.10 9.42 8.21 7.24 24.60•健康人X 2(n=11):17.95 30.46 10.88 22.38 12.89 23.01 13.89 19.40 15.83 26.72 17.29(1)建立检验假设(α =0.05)H 0:μ1=μ2,即病人与健康人的尿中17酮类固醇的排出量相同H 1:μ1≠μ2,即病人与健康人的尿中17酮类固醇的排出量不同版权所有:多多医善完全随机设计t检验两样本均数比较的t检验:自变量为二分类变量,因变量为数值变量讨论:1、如果不满足正态分布怎么办?2、如果满足正态分布但方差不齐怎么办?版权所有:多多医善完全随机设计t检验◆两样本均数比较的t检验:自变量为二分类变量,因变量为数值变量◆如果不满足正态分布:①尝试进行数据转换,如果转换后的数据符合正态分布,则用转换后的数据进一步分析;②如果通过转换仍无法满足正态分布,可采用秩和检验。
6.假设检验方法--均值 (1)

• 其中, 为样本平均数; 为两样本来自总体方差. • 例10 在参加了全国统一考试后,已知考生成绩服从正态 分布。甲省抽取153名考生,平均成绩为57.41分,该省标准差 为5.77分;乙省抽取686名考生,平均成绩为55.95分,该省标准 差为5.17分,问两省在该次考试中,平均分是否有显著性差 异?(0.01)
• 2. 小概率事
在随机事件中,概率很小的事件被称 为小概率事件,习惯上约定在0.05以下, 即当P(A)< 5%时,则称A为小概率事件。 在统计推断中认为,小概率事件在一次试 验或观察中是不可能发生的。
3.显著性水平
• 两种水平 (1)α=0.05,显著性水平为0.05,即统计 推断时可能犯错误的概率5%,也就是在95% 的可靠程度上进行检验; (2) α=0.01,显著性水平为0.01,即统计 推断时可能犯错误的概率1%,也就是在99% 的可靠程度上进行检验。
统计假设检验方法
统计假设检验是统计推断的重要方法,根据一定原理,利用样本信息,根 据一定概率,对总体参数或分布的某一假设作出拒绝或保留的决断.基本 思想是假设检验(类似于反正法)在一前提假设下进行推断;基本原则是小 概率事件原理(即,小概率事件在一次试验中实际上是不可能发生的);根 据研究对象分布情况我们所选的统计量不同,相对应的检验方法有Z检验、 t检验、F检验、卡方检验。本章主要介绍: 1、理解统计假设检验的一般原理 2、掌握单\双总体均值\方差假设检验的方法
1.假设 • 虚无假设(零假设):是关于当前样本所属的 总体(指参数)与假设总体(指参数)无区别 的假设,一般H0表示。 • 备择假设(研究假设):是关于当前样本所属 的总体(指参数)与假设总体(指参数)相反 的假设,一般用H1表示。 由于直接检验备择假设的真实性困难,假设检 验一般都是从虚无假设出发,通过虚无假设的 不真实性来证明备假设的真实性。
《卫生统计学》第6章假设检验

配对设计(paired design)是一种比较特殊 的设计方式,能够很好地控制非实验因素对 结果的影响,有自身配对和异体配对之分。
配对设计资料的分析着眼于每一对观察值之 差,这些差值构成一组资料,用检验推断差 值的总体均数是否为“0”。
.
1. 建立检验假设,确定检验水准
H0 : d 0 H1 : d 0 2. 计算统计量
方差不相等。
.
第三节 大样本资料的z检验
1.单样本资料的 Z 检验(非正态、大样本)
X 近似地服从正态分布,
X
~
N
,
2
n
H0: μ=μ0
或
H0 成立时,统计量
H1: μ≠μ0 (双侧) H1:μ>μ0 (单侧) H1:μ<μ0 (单侧)
Z X 0 ~ N ( 0,1 )
S/ n
.
2.两独立样本资料的 Z 检验(非正态、大样本)
t' X1 X2 S12 S22 n1 n2
0.5592 0.1467
2.733
0.51102 0.11072
12
12
( S12 n1
( S12 )2
S22 )2 n2
(
S
2 2
)2
( 0.51102 0.11072 )2
12
12
( 0.65102 )2 ( 0.11072 )2
12.03 12
.
4. Poisson分布资料的z检验
Z X1 X2 X1 X2
Z X1 X2 X1 X2 n1 n2
.
例 6-10 某市在对不同性别成年人(18 岁以上)意外伤害死亡情况有 无差异的研究中,监测数据显示该市 2002 年男女疾病监测各 10 万人,因 意外伤害死亡的人数男女分别为 51 人和 23 人。试问,2002 年不同性别每 10 万人口意外伤害死亡平均人数是否相等?
应用统计硕士(MAS)考试过关必做习题集(含名校考研真题详解)统计学(第6章 假设检验)【圣才出品】

第6章假设检验一、单项选择题1.在假设检验时,若增大样本容量,则犯两类错误的概率为()。
[浙江工商大学2017研]A.都增大B.都减小C.都不变D.一个增大一个减小【答案】B【解析】当样本量一定时,犯两类错误的概率呈现出此消彼长的关系。
当样本容量增大时,抽样误差减小,样本越来越接近总体,犯两类错误的概率均会减小。
2.如果原假设为真,所得到的样本结果会像实际观测结果那么极端或者更极端的概率称为()。
[山东大学2016研]A.临界值B.统计量C.P值D.实际显著性水平【答案】C【解析】如果原假设0H为真,所得到的样本结果会像实际观测结果那么极端或更极端的概率,称为P值,也称为观察到的显著性水平。
3.在假设检验中,如果我们相信原假设是真的,而犯第二类错误又不会造成太大的影响,此时,检验的显著性水平应该取( )。
[中央财经大学2015研]A .大些B .小些C .无法确定D .等于0.05【答案】B【解析】由于犯一类错误的概率和犯第二类错误的概率是此消彼长的关系,题中我们相信原假设为真,并且第二类错误的并不会造成较大影响,因此如果要拒绝原假设应该提高更显著的证据,所以犯第一类错误的概率应取小些。
而在假设检验中检验的显著性水平即为犯第一类错误的概率,故显著性水平应该取小些。
4.甲、乙两人服从标准正态分布的随机数发生器分别产出30个随机数字作为样本,求得平均数1x ,2x 样本方差S 21,S 22,则( )。
[中山大学2014研]A .12=x x ,S 21=S 22B .作两样本t 检验,必然接受零假设,得出两总体均值无差别的结论C .由甲、乙两样本求出的两总体方差比值()2212/σσ的95%置信区间,必然包含0D .分别由甲、乙两样本求出的各自总体均数的95%置信区间,可能没有交集【答案】D【解析】A 项,由于样本是随机的,抽出不同的样本得到的均值与方差往往是不同的。
B 项,同样由于样本的随机性,根据样本得到的估计值很可能不同于总体真值,因而两样本的t检验不一定接受零假设。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
=0.05或 =0.01。
Intelligence Emotional Adversity
Quotient (IQ) 智商 情商 逆商
What is hypothesis?
是指对总体的某些未知的或不完全
知道的性质所提出的待考察的命题.
第一节
统计假设测验的基本原理
一、统计假设的基本概念
二、统计假设测验的基本方法
三、两尾测验与一尾测验。 四、假设测验的两类错误
问题引入:
如果要比较某小麦新品种的产量
和原地方品种的产量哪个更好?
Good morning, everyone!
神舟八号与天空一号成功对接!
坠入爱河与万有引力 有无关系?
Science and Religion
In the early modern period these tendencies culminated in the idea that God directly imposed his wrm of natural laws. This view was reinforced by a new matter theory—the corpuscular hypothesis, or what we would call atomic theory— according to which nature was made up of minute and inert (i.e. causally impotent) particles。 (粒子假说与相信上帝介入有关)
y =330,
那么新品种样本所属总体与 当地品种这
个总体是否有显著差异呢?
(一) 对所研究的总体首先提出一个无效假设
测验单个平均数,则假设该样本是从一已知总体(总体平均
数为指定值 0 )中随机抽出的,即 H 0 : 0 。如上例,即
假定新品种的总体平均数 等于原品种的总体平均数 随机误差;对应假设则为 H A : 0 。
计假设
(二) 在承认上述无效假设的前提下,
获得平均数的抽样分布,计算该假设正确
的概率
(三) 根据“小概率事件实际上不可
能发生”原理接受或否定假设
设某地区的当地小麦品种一般667m2产300kg,即 当地品种这个总体的平均数 0=300(kg),并从多年种植 结果获得其标准差=75(kg),而现有某新品种通过25个 小区的试验,计得其样本平均产量为每667m2330kg, 即
出的,记作: 0 : 0 。例如: H
(1) 某一小麦品种的产量具有原地方品种的产量, 这指新品种的产量表现乃原地方品种产量表现的一个随 机样本,其平均产量 等于某一指定值 0 ,故记 为 H 0 : 0 。
(2) 某一棉花品种的纤维长度( )具有工业上某一
指定的标准(C ),这可记为 H 0 : C 。
y P{ 1.96 y y 1.96 y } 0.95
y
P{
y
1.96} 0.025
P{
y
y
1.96} 0.025
P{ y ( 1.96 y )} 0.025
P{ y ( 1.96 y )} 0.025
u
y
y
330 300 2 15
因为假设是新品种产量有大于或小于当地品种产量的可能
性,所以需用两尾测验。 查附表,当u=2时,P(概率)界于0.04和0.05之间,即这一 试验结果: 0 =30(kg),属于抽样误差的概率小于5%。 y
2. 计算接受区和否定区 在假设H0为正确的条件下,根据 y 的 抽样分布划出一个区间,如 y 在这一区间内则接受H0,如 y 在 这一区间外则否定H0 。 如何确定这一区间呢? 根据上章所述 y 和 u y 的分布,可知:
新总体与母总体在特征参数上存在函数关系。以平均 数抽样分布为例,这种关系可表示为以下两个方面。 (1) 该抽样分布的平均数 y 与母总体的平均数相等。
y
(2) 该抽样分布的方差与母总体方差间存在如下关系:
2 y 2 n 相应地, y n
的东西。真正科学的态度,对待一切未知的解释不了的东西和过 时的理论,应该坦坦荡荡,承认其存在,和平共处,保持言论的 自由。真正科学的态度,应该是努力去散播正确的言论,让人们 真正科学的态度,应该是容许各种言论和理论并行,诸子百家,
接受已有的科学,让陷入歪门邪道的人自己了解真想,走出黑暗。
百花齐放,互相辩论,而不是挥舞着所谓的科学大棒,横扫一切,
所以在测验时需先计算1.96 y 或2.58 y ,然后从 y 加
上和减去1.96 y 或2.58 y,即得两个否定区域的临界值。
如上述小麦新品种例,
0.03
fN(y)
0 =300, y 15 ,
1.96 y =29.4(kg)。因之, 它的两个2.5%概率 的否定区域为
先承认无效假设,从已知总体中抽取样本容量为n=25的 样本,该样本平均数的抽样分布具正态分布形状,平均 数 y =300(kg),标准误 y
n 75 25
=15(kg)。
通过试验,如果新品种的平均产量很接近300 kg,例如
301kg或299kg等,则试验结果当然与假设相符,于是应
因此,在 y 的抽样分布中,落在( 1.96 y, 1.96 y )
区间内的有95%,落在这一区间外的只有5%。
如果以5%概率作为接受或否定H0的界限,则上述区间 ( 1.96 y, 1.96 y )为接受假设的区域,简称接受区
( acceptance region );
0.01 0.02
接 受区域 否 区域 定
2.5%
否 区域 定
2.5%
y ≤300-29.4和 y ≥300+29.4,即
大于329.4(kg)和小于 270.6(kg)的概率只有 5%(见图5.1)。
0.00 255 270 285 300 315 330 345
y
270.6
329.4
图5.1 5%显著水平假设测验图示 (表示接受区域和否定区域)
和 y 1.96 y
y 1为否定 .96 y
假设的区域,简称否定区( rejection region )。 同理,若以1%作为接受或否定H0的界限,则 ( 2.58 y, 2.58 y )为接受区域, 2.58 y 和 y
y 2.58 y 为否定区域。
(三) 根据“小概率事件实际上不可能发生”原理接受或否定假设 当 y 由随机误差造成的概率小于5%或1%时,就可认 为它不可能属于抽样误差,从而否定假设。 如果因随机误差而得到某差数的概率P<0.05,则称这个差 数是显著的。如果因随机误差而得到某差数的概率P<0.01,则
称这个差数是极显著的。而这种假设测验也叫显著性测验。
0
=300kg,而样本平均数和之间的差数:330-300=30(kg)属 如果测验两个平均数,则假设两个样本的总体平均数相等,
即
H 0 : ,也就是假设两个样本平均数的差数 1 2
y1 y 2 属随机误差,而非真实差异;其对应假设则为 H A : 1 2 。
(二) 在承认上述无效假设的前提下,获得平均数的 抽样分布,计算假设正确的概率
30)才逐渐接近于正态分布。 若两个样本抽自于两个非正态总体,当n1和n2相当大、而
2 12与 2 相差不太远时,也可近似地应用正态接近方法估计
平均数差数出现的概率,当然这种估计的可靠性得依两总体
偏离正态的程度和相差大小而转移。
第五章
统计假设测验
第一节 统计假设测验的基本原理
第二节 平均数的假设测验 第三节 二项资料的百分数假设测验 第四节 参数的区间估计
(二) 两个平均数相比较的假设
两个样本乃从两个具有相等参数的总体中随机抽出 的,记为 H 0 : 1 2 或 H 0 : 1 2 0 。例如: (1)两个小麦品种的产量是相同的。 (2)两种杀虫药剂对于某种害虫的药效是相等的。 上述两种假设称为无效假设(null hypothesis)。因为假设 总体参数(平均数)与某一指定值相等或假设两个总体参数相 等,即假设其没有效应差异,或者说实得差异是由误差造 成的。
和无效假设相对应的应有一个统计假设,叫对应 假设或备择假设( alternative hypothesis ),记作
H A : 0
或
H A : 1 2 。
如果否定了无效假设,则必接受备择假设;同理,
如果接受了无效假设,当然也就否定了备择假设。
二、统计假设测验的基本方法
(一)
对所研究的总体首先提出一个统
想当然的以现有的有限理论去解释整个宇宙的一切。
Review
抽样分布 样本平均数的抽样分布 样本平均数差数的抽样分布 中心极限定理(central
limit
theorem)
central limit theorem
假设被研究的随机变量X,可以表示为许 多相互独立的随机变量Xi的和。如果Xi 的数量很大,而且每个别的Xi对于X所起 的作用又很小,则X可以被认为服从获近 似第服从正态分布。
无论原总体是什么分布,只要样
本足够大,样本平均数就近似服 从正态分布.
Example: Body Temperature
mean temperature: 98.6℉(℃ = 5×(℉32)/9 ) Standard deviation :0.62 ℉ n: 106 Find the probability of getting a mean of 98.2 ℉ or lower