Garbage Collection of Timestamped Data in Stampede
jvm内存垃圾回收机制

Java虚拟机(JVM)的内存垃圾回收机制主要涉及自动内存管理和垃圾回收两个核心功能。
自动内存管理主要是针对对象内存的回收和对象内存的分配。
JVM的堆是垃圾收集器管理的主要区域,也被称作GC堆(Garbage Collected Heap)。
大部分情况下,对象都会首先在Eden区域分配。
在一次新生代垃圾回收后,如果对象还存活,则会进入s0或者s1,并且对象的年龄还会加1(Eden区->Survivor区后对象的初始年龄变为1),当它的年龄增加到一定程度(默认为15岁),就会被晋升到老年代中。
垃圾回收是JVM自动内存管理的另一个重要方面。
主要有两种通用的垃圾回收方法:引用计数法和可达性分析算法。
引用计数法为每个对象增加一个计数器,当该对象被引用时,计数器加一,当引用失效时,计数器减一。
当计数器为零时,该对象就可以被回收了。
这种方法无法解决循环引用的问题。
可达性分析算法是通过GC Root的对象作为起始节点,通过引用向下搜索,所走过的路径称为引用链。
当对象没有任何一条引用链链接的时候,就会被认定为垃圾。
可作为GC Root的对象包括:类加载器,Thread,虚拟机栈的本地变量表,static成员,常量引用,本地方法栈的变量等等。
大部分情况下,对象都会首先在Eden区域分配,在一次新生代
垃圾回收后,如果对象还存活,则会进入s0或者s1,并且对象的年龄还会加1(Eden区->Survivor区后对象的初始年龄变为1),当它的年龄增加到一定程度(默认为15岁),就会被晋升到老年代中。
以上信息仅供参考,如果还想了解更多信息或遇到相关问题,建议咨询专业人士。
引用计数与时间戳的混合垃圾搜集器算法

近 年来 ,高级 程序 开发 语言J 、 l 群 A, A【和C 被广 泛 J
应用 ,其 中一 个重 要 原 因在于 它们 都采 用 了垃 圾 搜
时任务 的硬 时 限要 求 。此 外 ,由于 嵌入 式实 时系 统
往 往应 用 于资 源有 限的环 境 中 , 因此在 保证 任务 实
集器( C 自 回收无用内存空间,可避免传统开发 G)动 语言( 语言) 如C 采用人工管理 内存方式所导致的内 存 泄露 、指针 悬挂 、 内存 碎 片等 潜在 危 险 ,极 大 地 提高了系统的安全可靠性 。随着嵌入式实时系统的 日益规模化及复杂化 ,很多研究着重于如何把垃圾
u e o c l c y l ab g . sd t ol tc ci g a e GC a d ra- me ts sa e sh d ld c n u rnl.Th r p sd GC n to l e c r n e l i ak c e u e o c re t t r y e p o o e o ny c l csal n s dme r u lor d c sm e r e u e n o ae t y rdGC b s do ak s e ol t lu u e mo b tas e u e mo rq i me tc mp r dwi h b i a e nm r -we p e y y r h
p o o e i p p r Re e e c o t g ag r h i u e o lc c c i a b g d t s mp ag r m r p s d i t s a e . f r n ec u i l o i m s dt c l t y l g a e a me t n h n n t s o e a c r n i a lo i h t i s
JVM虚拟机(四):JVM垃圾回收机制概念及其算法
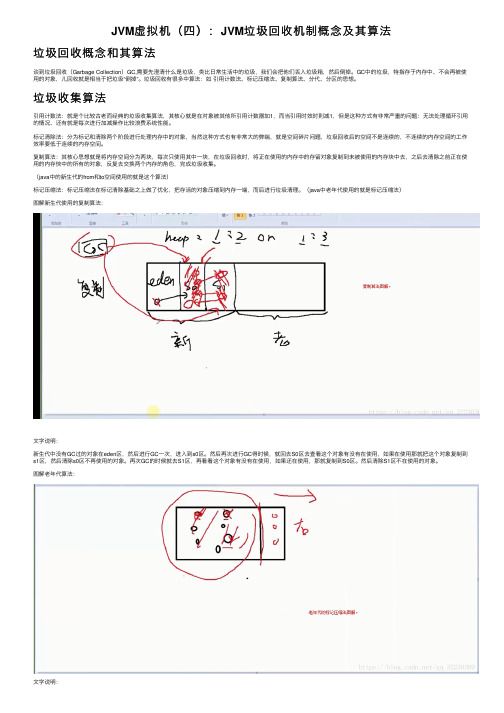
JVM虚拟机(四):JVM垃圾回收机制概念及其算法垃圾回收概念和其算法谈到垃圾回收(Garbage Collection)GC,需要先澄清什么是垃圾,类⽐⽇常⽣活中的垃圾,我们会把他们丢⼊垃圾箱,然后倒掉。
GC中的垃圾,特指存于内存中、不会再被使⽤的对象,⼉回收就是相当于把垃圾“倒掉”。
垃圾回收有很多中算法:如引⽤计数法、标记压缩法、复制算法、分代、分区的思想。
垃圾收集算法引⽤计数法:就是个⽐较古⽼⽽经典的垃圾收集算法,其核⼼就是在对象被其他所引⽤计数器加1,⽽当引⽤时效时则减1,但是这种⽅式有⾮常严重的问题:⽆法处理循环引⽤的情况、还有就是每次进⾏加减操作⽐较浪费系统性能。
标记清除法:分为标记和清除两个阶段进⾏处理内存中的对象,当然这种⽅式也有⾮常⼤的弊端,就是空间碎⽚问题,垃圾回收后的空间不是连续的,不连续的内存空间的⼯作效率要低于连续的内存空间。
复制算法:其核⼼思想就是将内存空间分为两块,每次只使⽤其中⼀块,在垃圾回收时,将正在使⽤的内存中的存留对象复制到未被使⽤的内存块中去,之后去清除之前正在使⽤的内存快中的所有的对象,反复去交换两个内存的⾓⾊,完成垃圾收集。
(java中的新⽣代的from和to空间使⽤的就是这个算法)标记压缩法:标记压缩法在标记清除基础之上做了优化,把存活的对象压缩到内存⼀端,⽽后进⾏垃圾清理。
(java中⽼年代使⽤的就是标记压缩法)图解新⽣代使⽤的复制算法:⽂字说明:新⽣代中没有GC过的对象在eden区,然后进⾏GC⼀次,进⼊到s0区。
然后再次进⾏GC得时候,就回去S0区去查看这个对象有没有在使⽤,如果在使⽤那就把这个对象复制到s1区,然后清除s0区不再使⽤的对象。
再次GC的时候就去S1区,再看看这个对象有没有在使⽤,如果还在使⽤,那就复制到S0区。
然后清除S1区不在使⽤的对象。
图解⽼年代算法:⽂字说明:进⾏GC时看看⽼年代有没有在使⽤的对象,如果有那么就压缩出⼀个区域把那些实⽤的对象放到压缩的区域中,然后把不再使⽤的对象全部回收掉。
flink garbagecollection说明

flink garbagecollection说明Flink Garbage Collection (垃圾回收) 说明Flink 是一种用于大规模数据处理的开源流式处理框架。
在流式数据处理过程中,垃圾回收是一项重要的任务,用于释放不再使用的内存空间,以提高应用程序的性能和稳定性。
Flink 使用 Java 虚拟机 (JVM) 作为其运行时环境。
JVM 提供了自动的垃圾回收机制,用于回收不再使用的内存对象。
对于 Flink,垃圾回收主要处理两个方面的内存:堆内存和堆外内存。
堆内存是指 JVM 分配给 Flink 运行时环境的内存空间,用于存储对象实例和执行代码。
默认情况下,JVM 根据对象的存活时间和内存使用情况来执行垃圾回收。
Flink 的应用程序通常具有长时间运行的特性,因此垃圾回收算法需要能够有效地处理长时间存活的对象。
对于堆外内存,Flink 使用了 Direct Memory 技术,它直接在操作系统的内存中进行分配和管理。
直接内存不受 JVM 垃圾回收的控制,而是由 Flink 内部的管理器负责回收。
Flink 通过手动处理直接内存的申请和释放,提高了内存的使用效率。
在 Flink 中,垃圾回收的性能对应用程序的吞吐量和延迟有着重要的影响。
如果垃圾回收的频率过高,将导致应用程序的停顿时间增加,从而降低整体性能。
为了减少这种影响,可以通过调整垃圾回收器的参数以及合理设置堆内存和堆外内存的大小来优化垃圾回收的性能。
总结而言,Flink 的垃圾回收主要涉及堆内存和堆外内存的管理。
通过合理配置和优化垃圾回收器的参数,可以改善 Flink 应用程序的性能和稳定性。
同时,了解和理解垃圾回收机制对于开发人员来说也是很重要的,可以帮助他们编写高效并且具有可伸缩性的 Flink 应用程序。
请注意,本文仅侧重于解释 Flink 中的垃圾回收机制,不包含具体的实施细节或链接。
如需深入了解和配置 Flink 的垃圾回收,请参考 Flink 的官方文档或相关资源。
JVM垃圾回收机制

JVM垃圾回收机制每个Java程序员迟早都会碰到下⾯这个错误:ng.OutOfMemoryError这个时候⼀般会建议采⽤如下⽅式解决这个错误:增加MaxPermSize值增加最⼤堆内存到512M(-xmx参数)这篇⽂章会具体介绍Java堆空间和参数MaxPermSize的含义。
这篇⽂章涉及下列主题,并采⽤Hotspot JVM:垃圾回收器(Garbage Collector,GC)哪个JVM命令⾏选项垃圾回收器垃圾回收器负责:分配内存保证所有正在被引⽤的对象还存在于内存中回收执⾏代码已经不再引⽤的对象所占的内存应⽤执⾏时,定位和回收垃圾对象的过程会占⽤总执⾏时间的将近25%,这会拖累应⽤的执⾏效率。
Hotspot VM提供的垃圾回收器是⼀个分代垃圾回收器(Generational GC)[9,16,18]-将内存划分为不同的阶段,也就是说,不同的⽣命周期的对象放置在不同的地址池中。
这样的设计是基于弱年代假设(Weak Generational Hypothesis):1.越早分配的对象越容易失效;2.⽼对象很少会引⽤新对象。
这种分代⽅式可以减少垃圾回收的停顿时间以及⼤范围对象的回收成本。
Hotspot VM将其堆空间分为三个分代空间:1. 年轻代(Young Generation)○ Java应⽤在分配Java对象时,这些对象会被分配到年轻代堆空间中去○这个空间⼤多是⼩对象并且会被频繁回收○由于年轻代堆空间的垃圾回收会很频繁,因此其垃圾回收算法会更加重视回收效率2. 年⽼代(Old Generationn)○年轻代堆空间的长期存活对象会转移到(也许是永久性转移)年⽼代堆空间○这个堆空间通常⽐年轻代的堆空间⼤,并且其空间增长速度较缓○由于⼤部分JVM堆空间都分配给了年⽼代,因此其垃圾回收算法需要更节省空间,此算法需要能够处理低垃圾密度的堆空间3. 持久代(Permanent Generation)○存放VM和Java类的元数据(metadata),以及interned字符串和类的静态变量次收集(Minor GC)和全收集(Full GC)当这三个分代的堆空间⽐较紧张或者没有⾜够的空间来为新到的请求分配的时候,垃圾回收机制就会起作⽤。
gc日志的real计算公式

gc日志的real计算公式GC(垃圾回收)日志中的real计算公式是通过以下几个关键指标来计算的:1. YGC(Young Generation GC)的时间,YGC是指Young Generation(年轻代)的垃圾回收时间。
它包括了年轻代垃圾回收的次数和每次回收的时间。
YGC的时间可以通过GC日志中的"real"字段获取。
2. FGC(Full GC)的时间,FGC是指Full GC(全局垃圾回收)的时间。
它包括了全局垃圾回收的次数和每次回收的时间。
FGC的时间也可以通过GC日志中的"real"字段获取。
3. STW(Stop-The-World)的时间,STW是指垃圾回收期间应用程序的停顿时间,也就是垃圾回收期间应用程序的暂停时间。
STW的时间可以通过GC日志中的"real"字段获取。
实际上,GC日志中的"real"字段所记录的时间是整个GC事件的持续时间,包括了所有的垃圾回收阶段和其他相关操作的时间。
计算GC日志中的real时间并不是通过一个单一的公式来完成的,而是通过对GC日志中的时间戳进行差值计算得出的。
具体的计算公式如下:real = 结束时间戳开始时间戳。
其中,开始时间戳是指GC事件开始的时间,结束时间戳是指GC事件结束的时间。
需要注意的是,GC日志中的real时间通常以毫秒为单位进行记录。
因此,计算得出的结果也是以毫秒为单位的。
总结起来,GC日志中的real时间是通过计算开始时间戳和结束时间戳之间的差值得出的,用于表示整个GC事件的持续时间,包括了YGC、FGC和STW的时间。
(IOS)Objective-C最受欢迎入门教程

你不用考虑它什么时候开始工作,
工作。你只需要明白, 我申请了一段内存空间, 当我不再使用从而这段内存成为垃圾的时候, 我就彻底的把它忘记掉, 反正那个高人会帮我收拾垃圾。 遗憾的是, 那个高人需要消耗一定 不 支 持 这个 功 能 。 所 以 ”内部机制感兴 ”不大适合适初学
2.1 所示。
图 2-1 ,新建项目 注意也许有人会问,你不是要讲解 下面的“ Application ”呢? Objective-C 的语法的讲解,为了使得讲解 iPhone 的开发,那么为什么不选择“ iPhoneOS ”
是这样的,在这个系列当中,笔者主要侧重于
简单易懂, 清除掉所有和要讲解的内容无关的东西, 行。 第三步, Xcode 会提问你项目的名字,在“ 选择“ Save ”。如图 2-2 所示
Xcode 的话,为了可以熟悉开发环境,强烈建议按照笔者的步骤一步一步的
个对话框。这个对话框和我们的主题没有关系,我们可以把它关掉。 第二步,选择屏幕上部菜单的“ File->NewProject ” , 出现了一个让你选择项目种类的 ” , 然 后在 右 边 选 择
对 话 框 。 你 需 要 在 对 话 框 的 左 边 选 择 “ CommandLineUtility “ FoundationTool ” , 然后选择“ Choose... ”按钮。如图
Objective-C
的基本使用方法,为了避免过多的新鲜东西给同
学们造成阅读上的困难,所以命令行就已经足够了。 说到这里, 笔者需要澄清一点, 其实 MACOS 的 Cocoa 和 iPhone 的 Cocoa 是不一样 的,可以说,其中 2.3 , main 函数 有过 C/C++ 或者 java 经验的同学们对第 序的入口都是 3 行代码应该很熟悉了, 是的大家都一样主程 main 是完全一样的,和 java 语言 iPhone 是 MACOS 的一个子集。
垃圾回收器知识点总结

垃圾回收器知识点总结垃圾回收(Garbage Collection)是指计算机系统自动回收不再使用的内存空间,以便重新利用。
在众多编程语言中,Java是一种通过垃圾回收器(Garbage Collector,GC)来管理内存的语言。
垃圾回收器是一种特殊的程序,它负责监视和回收在程序运行中不再被使用的对象和变量,以释放内存空间。
在本文中,我们将对垃圾回收器的知识点进行总结,包括垃圾回收的原理、不同类型的垃圾回收器以及优化垃圾回收的方法等方面。
一、垃圾回收的原理在编程语言中,垃圾回收的原理主要包括引用计数法和标记-清除法。
引用计数法:引用计数法是一种最简单的垃圾回收技术,它通过记录每个对象的引用次数来判断其是否应该被回收。
当一个对象的引用次数为0时,表示该对象不再被引用,可以被回收。
然而,引用计数法无法处理循环引用的情况,因此在实际应用中并不常见。
标记-清除法:标记-清除法是一种常见的垃圾回收技术,它通过标记可达对象,然后清除不可达对象来回收内存空间。
在标记阶段,垃圾回收器会从根对象(如全局变量、活动栈等)开始,递归地标记所有可达对象。
在清除阶段,垃圾回收器会清除未被标记的对象,释放其内存空间。
二、不同类型的垃圾回收器在Java中,垃圾回收器主要包括串行垃圾回收器、并行垃圾回收器、CMS垃圾回收器和G1垃圾回收器等多种类型。
串行垃圾回收器:串行垃圾回收器是一种单线程的垃圾回收器,它在进行垃圾回收时会暂停应用程序的运行。
因此,串行垃圾回收器通常用于客户端应用程序和小型服务器应用程序,在这些场景下对暂停时间要求不高。
并行垃圾回收器:并行垃圾回收器是一种多线程的垃圾回收器,它在进行垃圾回收时会使用多个线程同时进行。
并行垃圾回收器通常用于多核处理器的服务器应用程序,在这些场景下对吞吐量要求较高。
CMS垃圾回收器:CMS(Concurrent Mark-Sweep)垃圾回收器是一种使用标记-清除法的并发垃圾回收器,它可以在应用程序运行的同时进行垃圾回收。
垃圾收集方案

垃圾收集方案垃圾收集(Garbage Collection,简称GC)是指一种自动内存管理机制,它负责在程序运行时回收无用的内存空间,从而避免程序发生内存泄漏等错误。
在进行垃圾收集时,通常采取的方式是对程序中的各个对象进行标记,标记为不需要时,将其释放。
本文将介绍一些常用的垃圾收集方案及其特点。
引用计数引用计数是最早的一种垃圾收集方式。
它的基本原理是:在对象被创建时,为其增加一个引用计数器;当有变量引用该对象时,引用计数器加1;当变量不再引用该对象时,引用计数器减1;当引用计数为0时,该对象被回收。
虽然引用计数看似简单易实现,但由于其本身的缺陷,已经很少被使用。
其主要问题在于,无法处理循环引用的情况。
例如,当对象A和对象B互相引用时,它们的引用计数器都不会降为0,从而导致内存泄漏。
标记-清除算法为了解决循环引用的问题,引入了标记-清除算法。
该算法的基本原理是:从程序的根节点(如全局变量)出发,遍历整个对象图,将所有可达对象打上标记,然后扫描整个堆,将未被标记的对象全部回收。
使用标记-清除算法的主要问题在于,它可能会导致内存碎片的产生。
例如,当回收了若干小对象之后,可能出现大量零散的空闲内存块,这些空闲内存块虽然总大小足够分配新的大对象,但并不能满足大对象的连续内存需求。
标记-整理算法为了解决内存碎片的问题,引入了标记-整理算法。
该算法的基本原理是:在标记阶段和清除阶段之间,还需要进行一次整理操作。
该操作的目的是将堆中存活的对象向一端移动,然后回收空间的另一端。
使用标记-整理算法可能会产生停顿。
因为在整理过程中,程序可能需要将对象移动到其他位置,从而涉及到大量内存拷贝操作。
这些操作会导致程序暂停运行,直到整理操作完成。
复制算法为了进一步减少内存碎片,引入了复制算法。
该算法的基本原理是:将堆分为两部分,每次只使用其中的一部分,不断地将存活的对象复制到另一部分,然后将旧的那部分全部清空。
复制算法虽然能有效避免内存碎片,但它的缺点在于,它只能利用堆的一半空间,大对象的分配可能会比较困难,而且在整个程序的运行过程中,复制算法可能需要不断地进行对象复制操作。
java jc机制

java jc机制
Java中的垃圾收集(Garbage Collection,GC)是一种自动管理内存的技术,它可以自动回收不再使用的对象所占用的内存,从而避免内存泄漏和内存溢出等问题。
垃圾收集机制在Java中是由Java虚拟机(JVM)实现的,通过一种名为“Java垃圾收集器”(Java Collector)的组件来完成。
Java垃圾收集器采用了多种算法来回收内存,包括标记-清除(Mark and Sweep)、复制(Copying)、标记-压缩(Mark and Compact)和分代收集(Generational)等。
这些算法的目的是在满足系统需求的前提下,尽可能地提高内存的利用率和程序的运行效率。
在Java 8及以后的版本中,垃圾收集器采用了分代收集算法,将堆内存分为新生代和老年代两个部分。
新生代用于存储新创建的对象,老年代用于存储长时间存活的对象。
垃圾收集器会根据不同代的特点采用不同的算法进行内存回收,例如在新生代中采用复制算法,而在老年代中采用标记-压缩算法。
除了垃圾收集器之外,Java还提供了一些API和工具来帮助开发人员更好地管理内存和监控垃圾收集的性能。
例如,可以通过System.gc()方法建议JVM进行垃圾收集,通
过ng.management包中的类来获取关于垃圾收集的信息等。
总之,Java的垃圾收集机制是Java内存管理的重要组成部分,它可以自动回收不再使用的对象所占用的内存,提高内存的利用率和程序的运行效率。
同时,Java也提供了一些API和工具来帮助开发人员更好地管理内存和监控垃圾收集的性能。
garbage的用法

"Garbage" 是英语中的词汇,通常表示垃圾、废物或无用的东西。
具体用法取决于上下文,以下是一些常见的用法:
1. **名词用法**:
- "Take out the garbage."(扔掉垃圾。
)- 在这里,"garbage" 是指废弃物或垃圾。
- "There's too much garbage in the park."(公园里有太多的垃圾。
)- 在这里,"garbage" 指的是垃圾堆积或废弃物。
2. **形容词用法**:
- "This information is garbage."(这些信息是垃圾。
)- 在这里,"garbage" 作为形容词,表示信息是无用或不可靠的。
3. **口语用法**:
- "That movie was total garbage."(那部电影真是烂片。
)- 在口语中,"garbage" 可以用来表示低质量、糟糕或差劲。
4. **技术用法**:
- 在计算机领域,"garbage" 也可以指代未使用的内存或数据,通常指需要被垃圾回收(garbage collection)的数据。
请注意,"garbage" 的用法可以根据上下文而有所不同,但通常与废物、垃圾或无用的东西有关。
WebSphere性能调优-垃圾收集器

WebSphere 性能调优-垃圾收集器基于 WebSphere 构建的企业应用,时常会出现性能问题,在严重的情况下还会提示出内存溢出,这是 一件很让人恼怒的事情。
在 WebSphere Application Server(Was)运行的时候,内存溢出,会生成大量的 溢出文件,如 Javacore, Heapdump 等文件,占用了大量的磁盘空间。
在这种情况下,时常会出现一连串的 系统问题,如部署在 Was 的所有应用服务都报错,Was 连控制台也无法访问等。
为解决问题,我们通常会选择重新启动整个 Was 或者服务器,然后分析运行日志 SystemOut.log、yst emErr.log、ative_stdout.log、native_stderr.log 和系统内存溢出的时候产生的 Javacore、Heapdump 文件来寻找出问题。
那么,为什么会出现内存溢出呢? 应用服务器在运行过程中需要创建很多对象,而在应用服务器的堆空间大小有限的情况下,请求进程 不断申请空间来创建与存放对象,在达到上限时而服务器又没能释放出空间来处理申请空间的请求就会出 现内存溢出情况。
这就像吹气球,当气球中的气体到达一定程度时,气球就会被撑爆。
(32 位的 JDK 的 J vm 堆空间分配最大支持 1.5G 的大小,超过则无法正常启动。
而 64 位的 JDK 堆大小分配无限制,其大小受 到服务器的内存限制。
)通常在投入生产的系统中,出现溢出一般都是对象分配不合理导致的。
在此,让我们先了解下 Java 世界里,对象与对象管理是怎么一回事。
在 Java 的体系中,所有的类作为一个对象(包括 Jdk 本身提供的类,应用中由开发人员编写的类), 都是直接或者间接继承了 ng.object 产生的。
这些类被创建的时候都会向 Jvm 堆申请一定的内存空 间存放,因此在 Jvm 堆空间里会存放各式各样的对象,有的是静态类型,有的是私有类型等等,而这些对 象都是通过垃圾收集器进行管理的。
metadata gc触发条件

metadata gc触发条件在计算机科学中,垃圾回收(Garbage Collection,简称GC)是一种自动内存管理机制,它可以自动寻找和释放不再被使用的内存空间,从而避免内存泄漏和内存溢出的问题。
GC的实现方式有多种,其中最常见的是基于标记-清除算法的实现。
GC触发条件是指在何时会触发垃圾回收机制来进行内存的清理。
通常情况下,GC会在以下三种情况下被触发:1. 内存分配达到阈值:当程序运行过程中,动态申请的内存空间越来越多,达到一定的阈值时,GC会被触发以回收不再使用的内存。
这个阈值是由系统进行动态调整的,根据程序的运行情况而定。
2. 内存空间不足:当程序运行过程中,由于内存空间不足,无法继续进行内存分配时,GC会被触发以回收部分已经不再使用的内存,以释放空间供程序继续运行。
3. CPU空闲时间:当程序在CPU上的执行时间超过一定的阈值,且CPU空闲时间较长时,GC会被触发以回收不再使用的内存。
这个机制可以有效利用CPU空闲时间,提高系统整体性能。
GC触发条件的设置是一个权衡的过程,需要根据具体的应用场景和系统资源状况来确定。
如果GC触发条件设置过严,会导致频繁的GC操作,降低系统的性能;如果设置过宽松,可能会导致内存的过度占用,进而导致系统的不稳定。
除了上述三种常见的GC触发条件外,还有一些其他的触发条件,如系统空闲时间、内存分配速度等。
不同的GC实现方式和配置参数也会对GC触发条件产生影响。
因此,在进行系统性能优化时,需要根据具体情况对GC触发条件进行调整和优化。
总结起来,GC触发条件是由系统自动判断的,根据内存分配情况、CPU空闲时间等因素来决定何时触发垃圾回收机制。
合理设置GC触发条件可以提高系统的性能和稳定性,从而更好地满足用户的需求。
详细介绍Java垃圾回收机制

详细介绍Java垃圾回收机制垃圾收集GC(Garbage Collection)是Java语言的核心技术之一,之前我们曾专门探讨过Java 7新增的垃圾回收器G1的新特性,但在JVM的内部运行机制上看,Java的垃圾回收原理与机制并未改变。
垃圾收集的目的在于清除不再使用的对象。
GC通过确定对象是否被活动对象引用来确定是否收集该对象。
GC首先要判断该对象是否是时候可以收集。
两种常用的方法是引用计数和对象引用遍历。
引用计数收集器引用计数是垃圾收集器中的早期策略。
在这种方法中,堆中每个对象(不是引用都一个引用计数。
当一个对象被创建时,且将该对象分配给一个变量,该变量计数设置为1。
当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b 引用的对象+1),但当一个对象的某个引用超过了生命周期或者被设置为一个新值时,对象的引用计数减1。
任何引用计数为0的对象可以被当作垃圾收集。
当一个对象被垃圾收集时,它引用的任何对象计数减1。
优点:引用计数收集器可以很快的执行,交织在程序运行中。
对程序不被长时间打断的实时环境比较利。
缺点:无法检测出循环引用。
如父对象有一个对子对象的引用,子对象反过来引用父对象。
这样,他们的引用计数永远不可能为0.跟踪收集器早期的JVM使用引用计数,现在大多数JVM采用对象引用遍历。
对象引用遍历从一组对象开始,沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。
如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。
在对象遍历阶段,GC必须记住哪些对象可以到达,以便删除不可到达的对象,这称为标记(marking)对象。
下一步,GC要删除不可到达的对象。
删除时,有些GC只是简单的扫描堆栈,删除未标记的未标记的对象,并释放它们的内存以生成新的对象,这叫做清除(sweeping)。
这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是组合起来却很大。
arthas profiler start --duration 300 时生成的格式

当使用Arthas Profiler 启动命令"arthas profiler start --duration 300" 时,生成的结果格式取决于您的具体配置和参数设置。
然而,一般而言,Arthas Profiler 生成的结果通常是基于Java Flight Recorder (JFR) 的二进制数据格式。
Java Flight Recorder 是JDK 自带的一项功能,用于在Java 应用程序运行时收集各种诊断数据,包括CPU 使用率、内存分配情况、线程活动等信息。
Arthas Profiler 利用了JFR 的功能,并通过采样器收集应用程序在指定时间段内的性能数据。
生成的结果可能是一个二进制的 .jfr 文件,其中包含了在指定时间段内收集到的性能数据。
您可以使用JDK 提供的工具(如jmc (Java Mission Control))或其他支持JFR 格式的工具来打开和分析这些文件。
这些工具可以帮助您可视化和分析应用程序在指定时间段内的性能状况,以便您进行优化和调试。
另外,如果您在启动命令中指定了其他参数,比如格式参数(--format),则生成的结果格式可能会有所不同。
您可以查阅Arthas Profiler 的官方文档或相关资料,获取更详细的信息和配置说明。
当您使用Arthas Profiler 运行"arthas profiler start --duration 300" 命令时,生成的结果可能包括以下几方面的信息:1. 时间戳(Timestamps):指示执行采样的时间段,通常是从命令执行开始到指定的持续时间结束的时间段。
2. 方法调用信息(Method Invocation Information):包括应用程序中每个方法的调用次数、平均运行时间、最大运行时间等。
这些信息帮助您确定哪些方法是性能瓶颈或高负载的。
3. 线程信息(Thread Information):记录每个线程的状态、执行时间、等待时间等。
垃圾回收方案

垃圾回收方案垃圾回收是计算机科学中的一个重要领域,对于高级编程语言的实用性和安全性起着关键作用。
在这篇文章中,我们将介绍几种常见的垃圾回收方案。
1. 引用计数引用计数是一种简单而直接的垃圾回收方法。
它基于计数每个对象的引用次数(即指向该对象的指针数)来确定何时删除该对象。
当引用计数变为零时,对象被认为是垃圾,该对象所占用的存储空间被释放。
尽管引用计数是一种快速且简单的垃圾回收方法,但它存在一些缺点。
首先,由于需要存储对象的引用计数,因此需要额外的存储空间。
其次,当对象之间存在循环引用时,引用计数会导致内存泄漏。
最后,更新引用计数的开销可能比其他垃圾回收方案更大。
2. 标记-清扫标记-清扫是一种基于对象可达性的垃圾回收方案。
它通过标记所有可达对象,然后清除其余不可达对象的方式进行垃圾回收。
通过可达性分析,标记-清扫算法可以检测出循环引用并正确地回收内存。
与引用计数相比,标记-清扫算法需要耗费更多的时间来标记和清除垃圾,并且它可能会导致内存碎片的产生。
3. 复制复制垃圾回收方案是一种基于对象分布在两个区域的假设的算法。
在这种算法中,内存被分为两个大小相等的区域,在任何时候,其中一个区域总是被认为是可用区域,并用于分配新的对象。
当可用区域中的内存不足以容纳新的对象时,所有活动对象都将通过复制转移到另一个未使用的区域。
垃圾收集器将清除从最初的可用区域复制的所有未使用空间,并使它成为新的可用空间。
复制垃圾收集器采用简单而高效的实现,并且不会产生内存碎片。
然而,该算法需要两倍的内存空间和复制所有对象的额外开销。
4. 标记-复制标记-复制垃圾回收方案是标记-清扫算法的改进版本。
它通过使用两个区域进行垃圾收集,与复制垃圾收集类似,其中一个用于可用的分配,而另一个用于垃圾收集。
与复制垃圾回收不同的是,在标记-复制垃圾回收方案中,标记可达对象后,它们会从当前区域复制到新区域。
标记-复制垃圾回收方案不会产生内存碎片,并且比标记-清扫和复制垃圾回收方案都更高效。
垃圾收集英文作文

垃圾收集英文作文英文:Garbage collection is an important aspect of waste management. It involves the collection, transportation, and disposal of waste materials in a safe and efficient manner. There are various methods of garbage collection, including curbside pickup, drop-off centers, and recycling programs.Curbside pickup is the most common method of garbage collection in residential areas. This involves placing garbage and recycling bins at the curb on designated pickup days. The garbage is then collected by a waste management company and transported to a landfill or recycling center.Drop-off centers are another method of garbage collection. These centers are typically located in commercial areas and allow residents to drop off their waste materials for proper disposal. Recycling programs are also becoming more popular, as they encourage residents toseparate recyclable materials from their regular garbage and dispose of them in designated recycling bins.Proper garbage collection is important for several reasons. It helps to prevent pollution and protect the environment by ensuring that waste materials are disposed of in a safe and efficient manner. It also helps to reduce the amount of waste that ends up in landfills, which can have negative impacts on public health and the environment.In addition to traditional garbage collection methods, there are also new technologies being developed to improve waste management. For example, some cities are experimenting with smart waste management systems that use sensors to monitor garbage levels in bins and optimize collection routes.Overall, garbage collection is an essential component of waste management that helps to protect the environment and promote public health.中文:垃圾收集是废物管理的重要方面。
垃圾回收机制方式及内存管理

垃圾回收机制方式及内存管理垃圾回收是一种自动化的内存管理技术,用于回收不再被程序使用的内存资源,以便重新利用。
在传统的编程语言中,开发人员需要手动分配和释放内存,但是这往往会导致内存泄漏和内存碎片等问题。
垃圾回收机制通过监测和控制内存的分配和释放过程,有效避免了这些问题的发生。
常见的垃圾回收机制有以下几种方式:1. 引用计数法(Reference Counting):这是一种最简单的垃圾回收机制。
每个对象都有一个引用计数器,当一个对象被引用时,计数器加1,当引用失效时,计数器减1、当计数器为0时,表示该对象已不再被引用,可以被回收。
但是引用计数法无法解决循环引用的问题,即两个或多个对象相互引用导致它们的引用计数不为0,从而无法回收。
2. 标记清除法(Mark and Sweep):标记清除法通过遍历对象之间的引用关系进行标记,并将被标记的对象设置为不可回收的状态。
然后,遍历整个内存空间,将未被标记的对象视为垃圾,进行回收。
标记清除法可以解决循环引用问题,但会带来一定的停顿时间,因为需要遍历整个内存空间。
4. 分代回收法(Generational Collection):分代回收法基于对象的生命周期来管理内存。
它将对象根据其年龄分为不同的代,常常以新生代、老年代和永久代作为划分。
新生代的对象生命周期较短,在垃圾回收时通常只清理该代的内存。
老年代的对象生命周期更长,垃圾回收会相对较少。
永久代用于存放类的元数据等。
分代回收法能够根据对象的特性分别处理,提高垃圾回收效率。
内存管理是垃圾回收的基础,它主要包括两个方面:1. 内存分配:内存分配是将内存资源分配给程序使用的过程。
在传统的编程语言中,内存分配通常通过调用malloc或new等函数来进行。
而在基于垃圾回收的语言中,内存的分配由垃圾回收器自动完成。
垃圾回收器会动态地为程序分配内存,并在对象不再被引用时自动回收。
2. 内存释放:内存释放是将不再使用的内存资源返回给操作系统的过程。
垃圾收集方案

垃圾收集方案在计算机科学中,垃圾回收(Garbage Collection)是指自动管理计算机程序分配的内存的过程。
程序运行时申请的内存空间如果不再使用,就成为了垃圾。
垃圾回收器会自动检测这些垃圾,将它们回收并重新分配给程序使用。
垃圾回收的主要目的是避免内存泄露,以及使程序更快、更安全地运行。
下面将介绍几种常见的垃圾回收方案。
标记-清除算法(Mark-Sweep)标记-清除(Mark-Sweep)算法是垃圾回收中最基本和最常见的算法之一。
该算法分为两个阶段:1.标记阶段:扫描所有对象,标记哪些对象是活的,哪些是死的。
2.清除阶段:删除所有标记为死的对象,回收它们占用的内存空间。
这种算法的主要问题在于,一旦被垃圾回收器判定为垃圾的对象被标记,就无法在之后的垃圾回收周期中再次被使用。
因此,这种算法可能导致内存碎片问题。
可达性分析算法(Reachability Analysis)可达性分析(Reachability Analysis)算法是一种基于根引用的垃圾回收算法。
该算法通过标记从根引用集合中可以到达的所有对象,将那些没有被标记的对象视为垃圾并进行回收。
这种算法优势在于能够处理内存碎片问题,并且能够动态地处理不同大小和类型的对象。
缺点在于,如果某个对象与根集合之间只隔了一层对象,但由于某些原因没有被标记,那么这个对象将不会被回收。
复制算法(Copying)复制算法(Copying)是一种将内存分成两部分的垃圾回收算法。
在复制算法中,内存被分为两个区域:From空间和To空间。
在垃圾回收之前,存活的对象被复制到To空间。
随后,From空间中的所有对象都被视为垃圾并回收。
最后,To空间和From空间交换,也就是说,To空间变为From空间,From空间变为To空间。
这种算法的主要优势是解决了内存碎片问题,但缺点是只能使用一半的内存空间。
分代收集算法(Generational Collection)分代垃圾收集算法(Generational Collection)是一种根据对象的年龄(生成)将内存分为不同区域进行管理的垃圾回收算法。
垃圾回收方案

垃圾回收方案垃圾回收(Garbage Collection,GC)是一种自动内存管理机制,其主要目的是回收那些已经无法被程序访问的内存区域,以便让操作系统可以重新使用这些内存空间。
作为一种常见的垃圾回收方案,Java虚拟机自带的垃圾回收器主要分为两大类:串行垃圾回收器和并行垃圾回收器。
串行垃圾回收器串行垃圾回收器是一种单线程的垃圾回收器,它只能使用一个CPU,因此在性能和速度上都比较低。
此外,串行垃圾回收器还容易产生堆积现象,从而导致应用程序的运行效率受到影响。
并行垃圾回收器并行垃圾回收器是一种多线程的垃圾回收器,它充分利用多核CPU的性能,因此在性能和速度上都比串行垃圾回收器要高。
此外,由于并行垃圾回收器可以同时处理多个垃圾回收任务,因此在减少垃圾回收延迟和提高应用程序的运行效率方面也表现得更好。
G1垃圾回收器G1垃圾回收器是一种基于区域的垃圾回收器,它可以管理非常大的堆大小,并可以高效地处理大量的垃圾回收任务。
此外,G1垃圾回收器还可以针对不同的堆区域采取不同的回收策略,以更好地提高垃圾回收效率和应用程序的运行效率。
CMS垃圾回收器CMS(Concurrent Mark Sweep)垃圾回收器是一种基于标记-清除算法的低延迟垃圾回收器,它可以在应用程序继续运行的同时进行垃圾回收。
因此,CMS垃圾回收器在降低应用程序垃圾回收延迟方面表现得非常出色。
总结不同的垃圾回收方案在性能、速度、延迟等方面都有着不同的优缺点。
因此,在选择垃圾回收方案时需要根据具体的应用程序需求和性能要求来进行权衡。
同时,在实际应用中,也需要根据运行环境、硬件设备等因素来优化垃圾回收方案以提高应用的运行效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
In this paper we describe an unusual garbage collection GC problem and its solution. There is an emerging class of important applications: sophisticated interactive systems that use vision and speech recognition to comprehend a dynamically changing environment and react in real time. Broadly speaking, such a system is organized as a pipeline of tasks processing streams of data, for example starting with sequences of camera images, at each stage extracting higher and higher-level features" and events", and eventually responding with outputs. Fig. 1 illustrates such a system. The task structure is usually a dynamic graph, more complex than a simple linear pipeline, and the streams" are quite unlike FIFO queues. Items in a stream may be produced and consumed by multiple tasks both because the functionality demands it and because tasks may be replicated for greater performance. Although items have a natural ordering based on time", they need not be produced nor consumed in that order. Items may be produced and consumed sparsely non-consecutive timestamps. The producing and consuming tasks of a stream may not be known statically, e.g., in the gure the High" tracker task may only be created when the Low- " task detects something, and more than one High- " task may be created to track multiple targets. In such an environment, garbage collection is a tricky issue when can the resources occupied by an item in a stream be safely reclaimed? Stampede is a programming system designed and built at CRL to simplify the programming of such applications 5, 4 . A Stampede program consists of a dynamic collection of threads communicating timestamped items through channels . Stampede's rules governing time and timestamps admit all the exibility described in the previous paragraph, but still capture a notion of an overall forward progress of time. In this context, it is possible to determine certain lower time bounds below which all items are guaranteed to be garbage. This paper describes this system, the GC problem and its solution. We present related work in Sec. 2. In Sec. 3 we describe the computational system: threads, channels, connections, time, timestamps, and operations on these entities. We also describe the GC problem with respect to this system. In Sec. 4 we describe a simple GC condition", i.e., a predicate that identi es garbage, and discuss its correctness. In Sec. 5 we describe a second GC condition that is more complicated and expensive, but which is strictly
more powerful identi es more garbage and solves a certain progress" problem associated with the rst GC condition. In Sec. 6 we discuss complexity and implementation cost. In Sec. 7 we describe a distributed, concurrent algorithm that implements the two GC conditions. Implementation details, and some performance notes are presented in Sec. 8. Finally, we conclude in Sec. 9 with some remarks about future work.
Stampede is a parallel programming system to facilitate the programming of interactive multimedia applications on clusters of SMPs. In a Stampede application, a variable number of threads can communicate data items to each other via channels, which are distributed, synchronized data structures containing timestamped data such as images from a video camera. Channels are not queue-like: threads may produce and consume items out of timestamp order; they may produce and consume items sparsely skipping timestamps, and multiple threads including newly created threads may consume an item in a channel. These exibilities are required due to the complex dynamic parallel structure of applications, to support increased parallelism, and because of real-time requirements. Under these circumstances, a key issue is the garbage collection condition": When can an item in a channel be garbage collected? In this paper we specify precisely Stampede's semantics concerning timestamps, and we describe two associated garbage collection conditions a weak condition, and a more expensive but stronger condition. We then describe a distributed, concurrent algorithm that implements these two GC conditions. We present performance numbers that show little or no application-level performance penalty to using this algorithm for aiding automatic garbage collection in a cluster. We conclude with some remarks about the implementation in the Stampede system.