经验分布函数
经验分布函数定义

经验分布函数(Empirical Distribution Function)1. 定义经验分布函数(Empirical Distribution Function,简称EDF)是统计学中一种描述样本数据分布的非参数方法。
它用于估计总体的累积分布函数(Cumulative Distribution Function,简称CDF)。
经验分布函数是一个阶梯函数,它以样本数据点为基础,给出了每个数据点在总体中的累积概率。
2. 用途经验分布函数可以帮助我们理解和描述样本数据的分布情况。
通过观察经验分布函数的形状和特征,我们可以得到关于总体分布的一些直观感受,并进行进一步的推断和分析。
具体应用包括但不限于以下几个方面:2.1 数据探索与可视化经验分布函数可以通过绘制阶梯图来展示样本数据的累积概率情况。
这种可视化方式直观地展示了数据在整个总体中所占比例的变化情况,帮助我们发现异常值、离群点等重要信息。
2.2 总体推断与假设检验在统计推断中,经验分布函数也常常被用于进行总体参数的估计和假设检验。
通过比较两个经验分布函数的差异,我们可以判断两个样本是否来自同一总体。
经验分布函数还可以用于估计总体分位数、密度函数等未知参数。
2.3 模型检验与拟合经验分布函数还可以用于模型检验和拟合。
在构建概率模型时,我们需要判断所选模型是否能够较好地拟合数据。
通过比较经验分布函数和理论分布函数的差异,我们可以评估模型的优劣,并选择最佳拟合模型。
3. 工作方式经验分布函数的计算步骤如下:3.1 数据排序将样本数据按照从小到大的顺序进行排序。
3.2 计算累积概率对于每个数据点,计算其在整个样本中的累积概率。
具体计算公式为:F n(x)=该数据点前面的数据个数总样本量其中,F n(x)表示第n个观测值在整个样本中的累积概率,x表示观测值。
3.3 绘制阶梯图根据计算得到的累积概率,绘制阶梯图。
将每个数据点的横坐标设置为该数据点的值,纵坐标设置为对应的累积概率。
经验分布函数及其应用

经验分布函数及其应用经验分布函数定义定义:设12n x x x ⋯,,,是总体(离散型、或连续型,分布函数F(x)未知)的n 个独立观测值,按大小顺序可排成12***n x x x ≤≤⋯≤ 。
若1**k k x x x +<< ,则不超过x 的观测值的频率为函数,就等于在n 次重复独立试验中事件{}x ξ≤的频率。
()110,=,,1,2,,11,k k nn x x k x x x k n nx x x F ***+*⎧≤⎪⎪<≤=-⎨⎪>⎩*⎪…… 我们称此函数()n F x 为总体的经验分布函数或样本分布函数。
简单性质:1.对于每一组观测值1,2,i i x i ξ*=*=,……,n ,()n F x *单调,非降,左连续且在1,2,i x x i =*=,……,n 点有间断点,在每个点的跳跃值都是1n 。
2.显然()01n F x ≤≤,具有分布函数的其他性质。
3.()n F x *为样本12n x x x ⋯,,,的函数,是一统计量,即为一随机变量,由于12n x x x ⋯,,,相互独立且有相同的分布函数()F x ,因而它等价于n 次独立重复试验的伯努利概型中事件{}x ξ≤发生k 次其余n k - 次不发生的额概率,即有:{}{}()()1()k n k k k n n k P F x C F x F x n -⎧⎫==-⎨⎬⎩⎭4.格列汶科定理设总体ξ 的分布函数为()F x ,经验分布函数为()n F x *,对于任何实数x ,记 ()()sup n x n F x F x D -∞<<*+∞=-则有lim 01n n P D →∞⎧⎫⎪⎪==⎨⎬⎪⎪⎩⎭ 其中n D 也为一统计量用来衡量()n F x *与()F x 之间在所有的x 的值上的最大差异程度,格列汶科定理证明了统计量n D 以概率为1地收敛于0,也就是如下所要说的经验分布函数的收敛性问题。
r语言经验分布函数

R语言经验分布函数介绍R语言是一种广泛应用于统计学和数据分析的编程语言,它提供了丰富的函数和包来处理数据。
其中,经验分布函数(Empirical Distribution Function, EDF)是R语言中一种常用的数据分布函数,用于描述样本中各个取值的累积分布情况。
本文将深入探讨R语言中经验分布函数的原理、应用以及相关的注意事项。
经验分布函数:原理与定义经验分布函数是根据一组有限样本数据,通过统计分析得到的描述该样本分布情况的函数。
其定义如下:F̂n(x)=1n∑Ini=1(X i≤x)其中,F̂n(x)是经验分布函数,X i是样本中的第i个观测值,n是样本中的观测值数量,I(A)是指示函数,若事件A发生则为1,否则为0。
经验分布函数表示的是小于等于x的观测值占总观测值数量的比例。
经验分布函数具有以下特点: 1. 经验分布函数在x取值范围内单调不减。
2. 经验分布函数的值域在[0,1]之间。
3. 经验分布函数在观测值出现时的增量为1/n。
经验分布函数的计算在R语言中,可以使用ecdf()函数计算经验分布函数。
以下是一个简单的例子:# 创建一个包含观测值的向量x <- c(1, 3, 2, 5, 4)# 计算经验分布函数ecdf_x <- ecdf(x)# 打印经验分布函数的值print(ecdf_x(3))输出结果为0.6,表示在样本中大约有60%的值小于等于3。
除了使用ecdf()函数,还可以使用cumsum()函数自行计算经验分布函数。
以下是一个示例:# 创建一个包含观测值的向量x <- c(1, 3, 2, 5, 4)# 对观测值排序sorted_x <- sort(x)# 计算经验分布函数ecdf_x <- cumsum(rep(1, length(sorted_x)))/length(sorted_x)# 打印经验分布函数的值print(ecdf_x[which(sorted_x == 3)])输出结果同样为0.6。
经验分布和分布函数

经验分布和分布函数在统计学中,经验分布和分布函数是两个重要的概念。
经验分布是指根据一组观测数据得到的概率分布函数的估计,而分布函数则是用于描述一个随机变量的概率分布的函数。
经验分布是通过对观测数据进行统计分析来估计真实概率分布的方法之一。
在实际应用中,我们通常无法获得全部的数据,而只能通过抽样得到一部分数据。
因此,我们需要通过对抽样数据进行分析来得到总体的概率分布。
经验分布的计算方法很简单,只需要统计抽样数据中每个取值出现的频率即可。
然后将这些频率按照大小顺序累加,就得到了经验分布。
经验分布是对真实分布的一种估计,它可以用来描述抽样数据的分布特征。
分布函数是用来描述一个随机变量的概率分布的函数。
它定义为随机变量小于等于某个特定值的概率。
分布函数通常用大写字母F表示,其数学表达式为F(x) = P(X ≤ x),其中X表示随机变量,x表示一个实数。
分布函数是概率论中最基本的概念之一,它能够完整地描述一个随机变量的概率分布。
分布函数具有以下性质:1) F(x)是一个非减函数;2) F(x)的取值范围在0到1之间;3) F(x)在x趋于负无穷时趋于0,x趋于正无穷时趋于1。
经验分布和分布函数在统计学中有着广泛的应用。
它们可以用来描述随机变量的分布特征,从而对随机变量进行概率推断和统计推断。
例如,在假设检验中,我们可以通过计算经验分布和分布函数来判断某个假设的可行性。
另外,在参数估计中,我们也可以利用经验分布和分布函数来估计未知参数的值。
此外,经验分布和分布函数还可以用来进行模型拟合和预测,从而对未来的观测数据进行预测和分析。
经验分布和分布函数是统计学中两个重要的概念。
它们可以用来描述随机变量的分布特征,进行参数估计和假设检验。
在实际应用中,我们可以通过对观测数据进行统计分析来计算经验分布和分布函数,从而对随机变量的概率分布进行估计和推断。
经验分布和分布函数的应用范围广泛,对于统计学的研究和实践都具有重要的意义。
4-经验分布函数与卡方分布

ab
(a b)2(a b 1)
三大抽样分布
1、 2分布(卡方分布)
定义1 设 X1, X 2标准正态分布N (0,1),则称
n
X
2 i
~
2(n)
自由度为n
i1
n = 1 时,其密度函数为
f
(
x)
1
x e ,
1 2
x 2
x0
Fn
(
x)
0.4, 0.6,
69 x 72 72 x 82
n5
0.8, 82 x 90 1, x 90.
0, x x(1) ,
经验分布 函数
Fn
(
x)
k n
,
1,
x(k) x x(k1) , k 1,2, , n 1,
0.4 0.3 0.2 0.1
n=2
n=3 n=5 n = 10
n = 15
5 10 15 20 25
2 (n) 分布的性质
1 E 2(n) n, Var 2(n) 2n
2
若X1
2(n1 ), X2
2
(n2
)
,
X1
,
X
相互独立,
2
则 X1+X2~ 2(n1+n2 )
(3)Fn( x)的值依赖于样本观察值,对不同的样本,不同次 的实现值经验分布函数不同.故经验分布函数是次序统计量
X(1),
,
X
(
的函
n)
数,
不含
未知
参
数,是
证明经验分布函数依概率收敛到分布函数

证明经验分布函数依概率收敛到分布函数是概率论中一个重要的定理,也是推动概率论向前发展的基石。
该定理表明,当样本数量趋于无穷大时,每个样本的频率的期望值收敛到概率分布函数的期望值。
证明这一定理的关键在于,每个样本的频率服从参数为概率分布函数的标准误差函数,即每个样本的频率和概率分布函数的期望值之间的误差服从标准正态分布。
另外,为了证明该定理,我们还需要使用大数定律,根据大数定律,当样本数量趋于
无穷大时,每个样本频率的期望值将收敛到概率分布函数的期望值。
此外,还可以使用置信度定理和中心极限定理来证明该定理。
置信度定理表明,在一
定的置信水平下,样本的频率服从概率分布函数的期望值;而中心极限定理表明,当样本
数量趋于无穷大时,每个样本的频率的期望值收敛到概率分布函数的期望值。
综上所述,通过大数定律,置信度定理和中心极限定理,可以证明经验分布函数依概
率收敛到分布函数。
这一定理不仅在概率论中有重要意义,而且在实际应用中也具有重要
意义,可为各种统计分析提供有效的数据支持。
经验分布函数简介

经验分布函数简介1 概念如果我们想知道某个随机变量X的分布F,这在⼀般情况下当然是⽆法准确知道的,但如果我们⼿上有它的⼀些独⽴同分布的样本,可不可以利⽤这些样本?⼀个很简单的办法就是,把这些样本的“频率”近似为随机变量的“概率”。
经验分布函数(empirical distribution function):给每个点1/n的概率质量,得到CDF:ˆFn(x)=∑n i=1I(X i≤x)n2 性质经验分布函数,有什么性质?它可以很好地近似真实的分布函数吗?我们给出如下⼏个定理。
定理:对于任意给定的x,有E(ˆF n(x))=F(x);V(ˆF n(x))=F(x)(1−F(x))n→0;MSE=F(x)(1−F(x))n→0;ˆFn(x)P⟶F(x)。
Glivenko-Cantelli定理:X1,…,X n∼F,那么supx|ˆF n(x)−F(x)|P ⟶0更准确地说,上式其实是⼏乎必然收敛的。
Dvoretzky-Kiefer-Wolfowitz (DKW) Inequity:X1,…,X n∼F,那么∀ϵ>0,有P supx|ˆF n(x)−F(x)|>ϵ≤2e−2nϵ2利⽤DKW不等式,可以构造出F的⾮参数的1−α置信带:定义L(x)=max ˆFn(x)−ϵn,0,U(x)=maxˆFn(x)+ϵn,0,其中ϵn=12n log(2α),那么有P[L(x)≤F(x)≤U(x),∀x]≥1−α3 应⽤经验分布函数有什么⽤?它可以⽤来计算⼀些statistical functional(统计泛函)。
假设要计算的statistical functional为T(F),那么,可以利⽤经验分布函数,代替未知的分布函数,计算出θ=T(F)的plug-in estimator(嵌⼊式估计量):ˆθ=T(ˆFn)。
如果存在某个r(x)使得T(F)=∫r(x)dF(x),那么T就称为linear functional(线性泛函),这是因为这样的T必定满⾜T(aF+bG)=aT(F)+bT(G)。
经验分布函数_概述说明以及解释

经验分布函数概述说明以及解释1. 引言1.1 概述经验分布函数是一种统计工具,用于描述和分析随机变量的分布情况。
它是一种非参数的方法,不需要对概率分布进行假设,因此被广泛应用于各个领域的数据分析中。
通过经验分布函数,我们可以了解到样本数据的累积概率分布,并将其与理论概率分布进行比较。
1.2 文章结构本文将以以下方式呈现关于经验分布函数的研究内容:首先,在第二部分中,我们将对经验分布函数的定义进行详细解释,包括相关的理论介绍、数学表达式以及直观解释。
然后,在第三部分中,我们将探讨经验分布函数在不同领域中的应用场景,例如数据分析与可视化、生物统计学和工程领域等。
接着,在第四部分中,我们将介绍经验分布函数的计算方法和算法实现。
这包括基本思想与步骤、常见的计算方法和公式推导以及算法实现和代码示例。
最后,在第五部分中,我们将给出总结主要观点和研究结果,并对经验分布函数未来发展提出展望和建议。
1.3 目的本文的目的是为读者提供对经验分布函数的全面理解。
通过详细介绍经验分布函数的定义、应用场景以及计算方法,希望能够帮助读者更好地应用经验分布函数进行数据分析,并为未来经验分布函数在各个领域中的发展提供一些启示和建议。
2. 经验分布函数的定义:2.1 理论介绍:经验分布函数是统计学中常用的一种非参数估计方法,用于描述一个随机变量的累积分布函数(CDF)。
该函数基于观测数据样本,通过对每个观测值的累计概率进行排序和求和得到。
它能够直观地展示数据集中数值的分布情况。
2.2 数学表达式:假设我们有一个由n个独立随机观测值组成的样本集合X={x₁, x₂,..., xn},其中每个xi代表一个随机变量。
经验分布函数F(x)在某个特定点x处的取值表示小于或等于x的样本比例。
数学上,经验分布函数可以表示为:F(x) = (1/n) * Σ(i=1 to n) [I(xi ≤x)]其中[ ]表示指示函数,当括号内条件满足时取值为1,否则为0;Σ表示求和运算;i代表索引变量。
样本分布函数

4. 总体分布函数为
Fx P{X x}.
而样本分布函数为 Fn x f {X x}.
由Bernoulli 大数定律,当n充分大时,有 Fn (x) P F (x).
即,对 0,有 lim P n
Fn (x) F (x)
1.
而格里汶科(Glivenko)定理:P{lim sup n
(1) 0 Fn x 1;
(2) Fn x是非减函数;
(3) Fn 1, Fn 0;
(4) Fn x在每个观测值x(i)处右连续,点x(i)是Fn (x)的跳
跃间断点,Fn (x)在该点的跃度就等于fi .
2. 样本分布函数
Fn x的图形如右所示:
3. 样本分布函数不是样本 的联合分布 函数.
样本分布函数
样本分布函数(经验分布函数)
设总体X的分布函数为:Fx P{X x}.
从总体中抽取容量为n的样本,得到n个样本观测值. 若样 本容量n较大,则相同的观测值可能重复出现若干次,整理 后写出下面的样本频率分布表:
其中
x1 x2 xl
fi
ni n
i 1,2,,l,
l n,
l
ni n,
i 1
l
fi 1.
i 1
Def. 设函数
0,
Fn x
fi ,
xi x
1,
x x1 xi x xi1
x xl
(i 1, 2,, l 1)
x 其中和式 xi x 是对所有不超过
的一切 xi 的频率 fi
求和,则称 Fn x 为样本分布函数或经验分布函数.
样本分布函数的性质:
Fn (x) F (x)
0} 1,
这表明当n充分大时,Fn (x)与F (x)存在着更密切的近似关系.
经验分布函数及其应用
经验分布函数及其应用经验分布函数定义定义:设12n x x x ⋯,,,是总体(离散型、或连续型,分布函数F(x)未知)的n 个独立观测值,按大小顺序可排成12***n x x x ≤≤⋯≤ 。
若1**k k x x x +<< ,则不超过x 的观测值的频率为函数,就等于在n 次重复独立试验中事件{}x ξ≤的频率。
()110,=,,1,2,,11,k k nn x x k x x x k n nx x x F ***+*⎧≤⎪⎪<≤=-⎨⎪>⎩*⎪…… 我们称此函数()n F x 为总体的经验分布函数或样本分布函数。
简单性质:1.对于每一组观测值1,2,i i x i ξ*=*=,……,n ,()n F x *单调,非降,左连续且在1,2,i x x i =*=,……,n 点有间断点,在每个点的跳跃值都是1n 。
2.显然()01n F x ≤≤,具有分布函数的其他性质。
3.()n F x *为样本12n x x x ⋯,,,的函数,是一统计量,即为一随机变量,由于12n x x x ⋯,,,相互独立且有相同的分布函数()F x ,因而它等价于n 次独立重复试验的伯努利概型中事件{}x ξ≤发生k 次其余n k - 次不发生的额概率,即有:{}{}()()1()k n k k k n n k P F x C F x F x n -⎧⎫==-⎨⎬⎩⎭4.格列汶科定理设总体ξ 的分布函数为()F x ,经验分布函数为()n F x *,对于任何实数x ,记 ()()sup n x n F x F x D -∞<<*+∞=-则有lim 01n n P D →∞⎧⎫⎪⎪==⎨⎬⎪⎪⎩⎭ 其中n D 也为一统计量用来衡量()n F x *与()F x 之间在所有的x 的值上的最大差异程度,格列汶科定理证明了统计量n D 以概率为1地收敛于0,也就是如下所要说的经验分布函数的收敛性问题。
经验分布函数

经验分布函数在数理统计中,有时需要用到经验分布函数。
我们可以把它理解为,利用部分样本的信息所得到的分布函数。
由于我们没有必要获得全部样本,因此这里就暂且不讨论完整的经验分布函数了。
经验分布函数是对经验的一种近似描述。
这种方法既简单又直观,还能够给予我们清晰、形象的印象。
通过查阅资料发现,经验分布函数主要应用在几何分析领域,也即一个已知结果,求未知结果或者多组结果进行比较。
我们可以很轻易地从经验分布函数得到最优化模型的参数值,再将该参数值代入相关方程式,便能得到其他更加复杂的结果。
虽然这些结果非常复杂,但是我们却往往会忽略它们的含义。
因此,建立正确、准确的经验分布函数,有助于我们更好地理解各种结果之间的联系与差异,并且能够促使我们找到解决方案。
经验分布函数和统计分布函数的区别如下:1.分布函数通常取自变量,而经验分布函数通常取自然变量;2.概率密度分布函数总是连续的(例外情况除外),而经验分布函数是离散的。
经验分布函数通常表示数学期望和标准差的线性组合,而统计分布函数则通常表示一条曲线的斜率。
3.经验分布函数通常包括分位点、四分位点等经典特征,而统计分布函数仅包括两个独立随机变量的和等概率事件的概率分布。
4.当两个或多个分布有共同的基础数据集时,经验分布函数和统计分布函数可以互相转换。
5.经验分布函数与概率密度函数的重要区别在于前者是用样本数据估计参数,后者是用参数反映样本数据的分布。
6.经验分布函数只考虑实测数据的统计规律,而不考虑由于试验误差引起的数据分布的不规则性。
7.统计分布函数与经验分布函数都受到参数估计方法及样本大小的限制。
8.利用经验分布函数预测未知参数的方法称作回归分析法,此方法是统计推断中的主要方法之一。
9.在进行线性回归分析时,当可决系数是1/2时,其回归方程可写成经验分布函数公式。
10.经验分布函数是估计未知参数的先决条件,但是它不能保证得到精确无偏的估计。
11.用回归分析预测未知参数时,回归系数 K 的选择原则是:在所研究的经济范围内,用当前人均收入水平计算出的 K 值尽可能小。
数理统计14:什么是假设检验,拟合优度检验(1),经验分布函数

数理统计14:什么是假设检验,拟合优度检验(1),经验分布函数在之前的内容中,我们完成了参数估计的步骤,今天起我们将进⼊假设检验部分,这部分内容可参照《数理统计学教程》(陈希孺、倪国熙)。
由于本系列为我独⾃完成的,缺少审阅,如果有任何错误,欢迎在评论区中指出,谢谢!⽬录Part 1:什么是假设检验假设检验是⼀种统计推断⽅法,⽤来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的。
其步骤,其实就是提出⼀个假设,然后⽤抽样作为证据,判断这个假设是正确的或是错误的,这⾥判断的依据就称为该假设的⼀个检验。
假设检验在数理统计中有重要的⽤途,⽐如:橙⼦的平均重量是80⽄,这就是⼀个假设。
我们怎么才能知道它是对的还是错的?这需要我们对橙⼦总体进⾏抽样,然后对样本进⾏⼀定的处理,⽐如计算总体均值的区间估计,如果区间估计不包含80⽄,就认为原假设不成⽴,便拒绝原假设。
当然,由于样本具有随机性,因此我们只是对该假设进⾏检验⽽不是证明,也就是说不论假设检验的结果是接受假设还是拒绝假设,都不能认为假设本⾝是正确的或是错误的。
同时,假设的检验也不是唯⼀确定的,对任何假设都可以有⽆数种⽅案进⾏检验,⽐如上⾯的例⼦,95%的区间估计是⼀种检验,99%的区间估计也可以作为检验,90%的当然也可以,只要事先确定了即可。
总之,要将实⽤问题转化为统计假设检验问题处理,⼀般需要经历以下⼏个步骤:明确所要处理的问题,将其转化为⼆元问题,只能⽤“是”和“否”来回答。
设计适当的检验,规定假设的拒绝域,即拒绝假设时样本X 会落⼊的区域范围(当然也可以是统计量会落⼊的范围,这两个意思是⼀致的)。
抽取样本X 进⾏观测,计算需要的统计量的值。
根据样本的具体值作出接受假设或者否定假设的决定。
以下是假设检验问题的⼀些常⽤概念:零假设即原假设,指的是进⾏统计检验时预先建⽴的假设,⼀般是希望证明其错误的假设,⽤字母H 0表⽰。
这种区分⽅式⽐较⽞乎。
经验分布函数定义

经验分布函数定义经验分布函数(empirical distribution function,简称EDF)是描述一组随机变量的累积分布函数的一种估计方法。
它通过从这组随机变量中取样得到的观测值的经验累计频率来估计真实的分布函数。
假设我们有一组独立同分布的随机变量X₁,X₂,...,Xn,我们可以将这些随机变量按照大小排列,得到观测值的有序序列:X(1)≤X(2)≤...≤X(n)然后,我们定义经验分布函数F_n(x)为:F_n(x)=(1/n)*Σ(i=1,n)I(X(i)≤x)其中,I(·)是指示函数,当其参数为真时取值为1,否则取值为0。
经验分布函数F_n(x)的值表示小于等于x的观测值所占的比例。
1.F_n(x)是递增函数。
随着x的增加,F_n(x)的值也增加。
2.F_n(x)在每个观测值X(i)处发生跳跃。
当x趋近于一些观测值时,F_n(x)的值在该观测值处跃升。
3.当x趋近于负无穷时,F_n(x)趋近于0;当x趋近于正无穷时,F_n(x)趋近于14.当存在多个相同的观测值时,F_n(x)在这些观测值处的跳跃幅度等于相同观测值的个数除以总观测值的个数。
经验分布函数在统计学中有广泛的应用,特别对于描述数据分布情况和做出推断。
通过经验分布函数,我们可以估计随机变量的各种统计量,比如均值、方差、分位数等。
此外,经验分布函数还可以与其他分布函数进行比较,用来检验数据是否符合一些特定的分布。
在实际应用中,经验分布函数通常会被可视化成经验分布函数图或经验分布函数曲线,用于直观地展示数据的分布情况。
经验分布函数图的横轴表示观测值,纵轴表示累积频率。
通过观察经验分布函数图,我们可以对数据的集中程度、集群情况、异常值等进行初步分析和判断。
总结起来,经验分布函数是一种非参数方法,通过观测值的经验累计频率来估计真实的分布函数。
它在统计数据分析中具有重要的作用,通常用于描述数据分布、做出推断和进行数据分析。
经验分布函数和分布函数的关系

经验分布函数和分布函数的关系1.什么是经验分布函数?经验分布函数是统计学中常用的一种描述数据分布的方法。
简单说,就是已知一组数据的情况下,对于任意一个数,该数在这组数据中的排名除以数据总量所得的一个数值。
例如,一组数据为[1,2,3,4,5],经验分布函数可以表示为:当x<=1时,F(x)=0;当1<x<=2时,F(x)=0.2;当2<x<=3时,F(x)=0.4;当3<x<=4时,F(x)=0.6;当4<x<=5时,F(x)=0.8;当x>5时,F(x)=1。
2.什么是分布函数?分布函数是概率论中的一个重要概念,用来描述一个随机变量的概率分布。
分布函数的定义是指,对于一个实数x,在实数集R上,函数F(x)表示随机变量X小于等于x的概率。
通俗地说,就是一个数x 在整体数据中所占的比例。
3.经验分布函数和分布函数的关系经验分布函数是对样本数据的经验归纳,而分布函数是对一个总体的推断。
因此,在统计学中它们之间是有联系的。
具体而言,当样本数量足够大时,根据极限定理,经验分布函数趋近于总体分布函数,也就是说,样本中观测到的数据分布趋向于总体数据的分布。
在实际应用中,可以通过经验分布函数来推断总体的分布函数,从而对总体的性质和规律进行分析和预测。
例如,在风险评估中,可以通过对历史数据的分析,得出某个风险事件出现的概率,并能及时采取措施进行风险管理。
4.应用场景经验分布函数和分布函数在数据分析中的应用非常广泛,具体包括以下几个方面:4.1数据预处理在大数据分析的场景中,经常需要对数据进行处理,识别异常数据,去除噪声。
这就需要通过经验分布函数来进行分类,确定每个数据点在整体数据分布中所占的位置,从而实现数据的分类和筛选。
4.2风险评估在风险评估中,可以通过经验分布函数来分析历史数据,了解某个风险事件出现的概率,并及时采用措施进行风险管理。
比如,对于股票交易,可以通过经验分布函数来推断股票涨跌的概率,从而预测未来的股票市场变化,为投资决策提供参考。
经验分布函数定义

经验分布函数定义经验分布函数是概率论和数理统计中常用的一个概念,它用来描述一个随机变量的累积分布函数。
在统计学中,经验分布函数被广泛应用于数据分析和模型拟合,它能够提供对数据集的整体分布情况进行可视化和定量的描述。
经验分布函数的定义很简单,它是一个非参数的统计量,可以用来估计随机变量的分布函数。
对于一个给定的样本集,经验分布函数给出了小于或等于某个特定值的观察值的比例。
在数学上,经验分布函数可以用以下形式表示:F(x) = (1/n) * Σ[从i=1到n] I(Xi ≤ x)其中,n是样本数量,Xi是第i个观察值,I( )是指示函数,当括号中的条件为真时取值为1,否则取值为0。
通过经验分布函数,我们可以直观地了解数据集的分布情况。
经验分布函数的图像呈现了数据集中小于等于某个特定值的观测值的累积百分比。
通常,我们可以通过画经验分布函数的图像来观察数据的分布形态,进而进行数据的分析和判断。
经验分布函数在统计学中有着广泛的应用。
首先,它可以用来检验数据是否服从某个特定的理论分布。
如果经验分布函数的图像与理论分布函数的图像相吻合,那么我们可以认为数据集服从该理论分布。
其次,经验分布函数可以用来进行数据的拟合和模型的选择。
通过与不同的理论分布进行比较,我们可以选择适合数据集的最佳模型。
此外,经验分布函数还可以用来进行置信区间的估计和假设检验等统计推断。
除了在统计学中的应用,经验分布函数在实际问题中也有着重要的意义。
比如,在风险管理中,我们可以利用经验分布函数来评估不同投资组合的风险水平;在医学研究中,经验分布函数可以用来分析疾病发病率的变化趋势;在市场营销中,经验分布函数可以用来研究产品销售情况的分布规律。
经验分布函数是统计学中重要的工具之一,它能够提供对数据集的整体分布情况进行可视化和定量的描述。
通过经验分布函数,我们可以更好地理解和分析数据,并进行统计推断和决策。
在实际应用中,经验分布函数有着广泛的应用领域,对于了解数据的分布规律和进行风险评估具有重要意义。
经验分布

2.估计参考值范围的两种方法: (1)百分位数法
百分位数法是根据样本观察值编制频率分布表,按累计频率求出 x1- a 2
和 xa 2 的估计值。
具体做法如下:
在给定 a 后,与各组段累计频率比较,有
a
Fn (ai- 1) <
? 2
Fn (ai )
Fn (a j- 1) < 1-
a? 2
Fn (a j )
ห้องสมุดไป่ตู้
区间的长度应略大于极差除以小区间数,各小区间端点值比观察值多一
位小数。
3)列表求频数。
(2)求概率密度的近似值---频率密度。
2.作直方图
以每个小区间 D xi
为底,以相应的频率密度
vi n
/ D xi
为高作出一系
列矩形。
经验分布函数
若总体 X 的 n 个独立观察值 x1 #x2 L ? xn 的累积频率为
P{a #X b}= 1- a
(0 < a < 1)
则称区间[a,b]为具有水平1- a 的 X 的参考值范围。
(2)参考值的范围根据背景分为两种。
一种是双侧的,需要确定其下限 a = x1- a 2 和上限 b = xa 2 。另一种是单
侧的,只需确定下限 a = x1- a (b = + ? ) 或上限 b = xa (a = - ? ).
经验分布函数定义

经验分布函数定义经验分布函数是统计学中常用的一种分布函数,用于描述随机变量的概率分布。
它通常用来分析和描述随机事件发生的概率,并通过对样本数据的观察来估计总体分布的特征。
下面我们将从统计学的角度来介绍经验分布函数。
在统计学中,我们经常需要研究一些未知的总体分布。
由于无法获得总体的全部观测数据,我们只能通过样本数据来对总体进行推断。
而经验分布函数就是一种通过样本数据来估计总体分布的方法。
经验分布函数的定义如下:对于给定的样本数据,我们将数据中小于等于某个值的观测值的比例作为对总体分布中小于等于该值的概率的估计。
形式化地说,对于一个样本数据集{x1, x2, ..., xn},经验分布函数 F(x) 的定义如下:F(x) = (1/n) * Σ(i=1 to n) I(xi ≤ x)其中,I(·) 是指示函数,当括号内的条件成立时,I(·) 的值为1,否则为0。
该函数的取值范围为[0, 1],表示小于等于某个值的观测值的比例。
经验分布函数的特点是能够根据样本数据的观测值来估计总体分布的概率。
当样本数据足够大时,经验分布函数能够较好地逼近总体分布函数。
这使得经验分布函数成为一种常用的非参数统计方法,无需对总体分布做任何假设。
经验分布函数在统计学中有着广泛的应用。
它可以用来描述和比较不同数据集的分布特征,例如用来比较两个样本数据集的分布是否相似,或者用来检验某个样本数据是否服从某个特定的分布。
此外,经验分布函数还可以用于构建置信区间和假设检验等统计推断。
举个例子来说明经验分布函数的应用。
假设我们想要研究某个地区的年降水量分布。
我们可以收集一系列年降水量的观测数据,然后计算得到经验分布函数。
通过观察经验分布函数的形状,我们可以对该地区的年降水量分布进行描述和比较,从而了解该地区的降水情况。
在实际应用中,经验分布函数常常与其他统计方法结合使用。
例如,我们可以利用经验分布函数来估计总体的分位数,进而计算出总体的中位数、均值等统计量。
经验分布函数例题

例4随机观察总体X ,得到一个容量为10的样本值:
3.2, 2.5, -2, 2.5, 0, 3, 2, 2.5, 2, 4 求X 经验分布函数.
解 :把样本值按从小到大的顺序排列为
5.25.22202=<=<<-4
2.335.2<<<=
于是得经验分布函数为
,
4,14
2.3,10/92.33,10/835.2,10/75
.22,
10/420,10/202,10/12,0)(10⎪⎪⎪
⎪⎪⎩
⎪⎪
⎪⎪
⎪⎨
⎧≤<≤<≤<≤<≤<≤<≤--<=x
x x x x x x x x F
其中如5.22<≤x 时, 因事件
}{x X ≤包含的样本值个数
,
4=k 故
事件
}
X≤发生的频率为,10/4从而.10/4)(10=x F
{x
是一个阶梯注: 经验分布函数)(x F
n
形函数, 当样本容量增大时, 相邻两阶梯的跃度变低, 阶梯宽度变窄, 容易想像, 这样的阶梯形折线几乎就是一条曲线, 如果设总体X的分布
函数为),(x F那么)(x F
n非常接近于).(x F
本文档局部内容来源于网络,如有内容侵权请告知删除,感谢您的配合!。
经验累积分布函数图
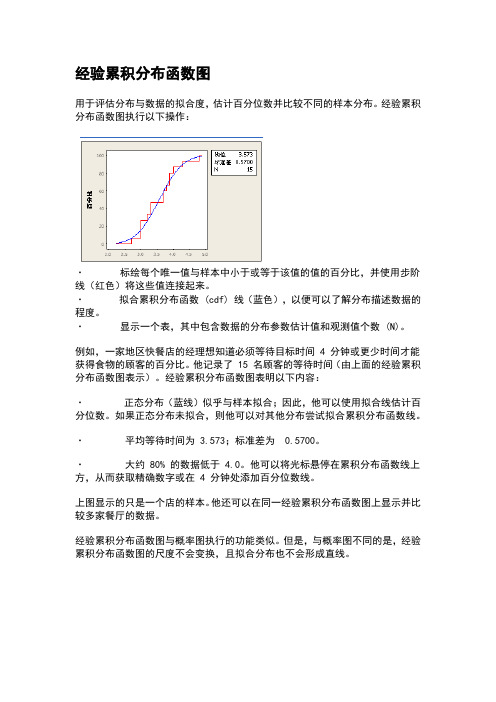
经验累积分布函数图
用于评估分布与数据的拟合度,估计百分位数并比较不同的样本分布。
经验累积分布函数图执行以下操作:
·标绘每个唯一值与样本中小于或等于该值的值的百分比,并使用步阶线(红色)将这些值连接起来。
·拟合累积分布函数 (cdf) 线(蓝色),以便可以了解分布描述数据的程度。
·显示一个表,其中包含数据的分布参数估计值和观测值个数 (N)。
例如,一家地区快餐店的经理想知道必须等待目标时间 4 分钟或更少时间才能获得食物的顾客的百分比。
他记录了 15 名顾客的等待时间(由上面的经验累积分布函数图表示)。
经验累积分布函数图表明以下内容:
·正态分布(蓝线)似乎与样本拟合;因此,他可以使用拟合线估计百分位数。
如果正态分布未拟合,则他可以对其他分布尝试拟合累积分布函数线。
·平均等待时间为 3.573;标准差为0.5700。
·大约 80% 的数据低于 4.0。
他可以将光标悬停在累积分布函数线上方,从而获取精确数字或在 4 分钟处添加百分位数线。
上图显示的只是一个店的样本。
他还可以在同一经验累积分布函数图上显示并比较多家餐厅的数据。
经验累积分布函数图与概率图执行的功能类似。
但是,与概率图不同的是,经验累积分布函数图的尺度不会变换,且拟合分布也不会形成直线。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(1)均匀分布U(a,b) 1)unifrnd (a,b)产生一个[a,b] 均匀分布的随机数
2)unifrnd (a,b,m, n)产生m行n列的均匀分布随机数矩阵 当只知道一个随机变量取值在(a,b)内,但不 知道(也没理由假设)它在何处取值的概率大,在 何处取值的概率小,就只好用U(a,b)来模拟它。
f分布的逆累积分布函数 伽玛分布的逆累积分布函数 几何分布的逆累积分布函数 超几何分布的逆累积分布函数 正态分布的逆累积分布函数 泊松分布的逆累积分布函数
X=tinv(p,v) X=Unidnv(p,N) X=unifinv(p,A,B)
学生氏t分布的逆累积分布函数 离散均匀分布的逆累积分布函数 连续均匀分布的逆累积分布函数
(2)方差未知(检验法)
方差未知时,采用检验法,MATLAB函数为 h=ttest(x,m ,alpha,tail) 各参数意义同上,同样ttest函数也有几个常见 用法: [h,p]=ttest(参数) [h,p,ci]=ttest(参数)
(3)泊松分布 参数估计命令为 [lambdahat,lambdaci]=poissfit(x,alpha) 返回参数的估计值和置信区间. (4)均匀分布(已知,未知) 参数估计命令为 [ahat,bhat,aci,bci]=unifit(x,alpha) 返回值分别为参数的估计值和置信区间. (5)指数分布 参数估计命令为 [lambdahat, lambdaci]=expfit(x,alpha)
解:输入a1=a';b=a1(:); %将矩阵变成数列 [p1,p2,p1ci,p2ci]= normfit (b) 或者: a1=a';b=a1(:); 均值、标准差的极 [p,pci]=mle('norm',b) 输出:[p1,p2,p1ci,p2ci]= normfit (b) 大似然估计分别 为:600和195.6436 p1 =600 p2 =196.6292 均值95%的置信区 p1ci = 560.9845 间为:(561.6536, 639.0155 638.3464); p2ci =172.6418 标准差95%的置信 228.4192 区间为:(170.6834, 或phat =600.0000 195.6436 220.6038); pic = 561.6536 170.6834 638.3464 220.6038
X=0.6567的密度函数值.
>> y = pdf (‘norm’, 0.6578, 0, 1 ) y = 0.3213
4.常用分布的累积分布函数的命令:
函数名 X=Binocdf(k,n,p) X=Chi2cdf(x,n) X=expcdf(p,mu) X=fcdf(x,v1,v2) X=Gamcdf(x,A,B) X=Geocdf(k,p) X=hygecdf(p,M,K,N) 对应的累积分布函数 二项分布的累积分布函数 卡方分布的累积分布函数 指数分布的累积分布函数 f分布的累积分布函数 伽玛分布的累积分布函数 几何分布的累积分布函数 超几何分布的累积分布函数
调用格式: 按照上表中的格式直接调用, 如:X=norminv(p,mu,sgm)
6.随机数的产生 定义:设随机变量X~F(x),则称随机变量X的 抽样序列{Xi}为分布F(x)的随机数 1.常用分布随机数的产生
在Matlab软件中,可以直接产生满足各种常用 分布的随机数,命令如下:
函数名 binornd chi2rnd exprnd
例1 已知二项分布:一次实验,事件A发生的
概率p=0.1,在30次独立重复实验中,计算事件
A恰好发生10次的概率P=P{X=10}. >>p = pdf ('bino',10,30,0.1)
p = 3.6528e-004
p 3.6528 10 4 即
例2 计算正态分布N(0,1)的随机变量在
X=Normcdf(x,mu,sgm)
X=poisscdf(k,lambda) X=tcdf(xຫໍສະໝຸດ v)正态分布的累积分布函数
泊松分布的累积分布函数 学生氏t分布的累积分布函数
5.常用分布的逆累计分布函数的命令:
函数名 X=Binoinv(y,n,p) X=Chi2inv(p,v) X=expinv(p,mu)
对应分布的随机数
frnd gamrnd geornd hygernd normrnd poissrnd trnd unidrnd unifrnd
二项分布的随机数 卡方分布的随机数 指数分布的随机数 f分布的随机数 伽玛分布的随机数 几何分布的随机数 超几何分布的随机数 正态分布的随机数 泊松分布的随机数 学生氏t分布的随机数 离散均匀分布的随机数 连续均匀分布的随机数
9.假设检验的MATLAB实现
1 单个正态总体均值的检验 (1)方差已知(检验法或检验法) 检验函数为ztest,其基本用法为 h=ztest(x,m,sigma,alpha,tail) 函数的功能是在显著性水平alpha下检验标 准差为sigma的正态分布的样本x是否具有均 值m,返回值h是一个布尔值,h=0表示在显著 性水平为alpha时不拒绝原假设,h=1则表示拒 绝.参数tail是一个可选值,意义如下:
例5、产生N(10,4)上的一个随机数,10个随机数, 2行5列的随机数.
命令 (1) y1=normrnd(10,2) (2) y2=normrnd(10,2,1,10) (3) y3=normrnd(10,2,2,5)
7.求随机变量的期望和方差
在MATLAB的统计工具箱中,可以使用命令 [M,V]=NAMEstat(参数) 来计算某种分布NAME的期望和方差.其中 NAME指常见函数分布名.在命令中,不同的 分布,输入的参数意义不同,反回的M和V分别 代表期望和方差.
对原假设, tail=0,备择假设为双边检验:,(参数缺省时的默认情 况) tail=1,备择假设为右边检验:, tail=-1,备择假设为左边检验:. 根据需求的不同,ztest函数还有以下用法: [h,p,]=ztest(参数) [h,p,ci]=ztest(参数) [h,p,ci,zval]=ztest(参数) 返回值中,p给出假设成立的概率值,p值非常小时对 假设质疑,ci给出均值的置信区间,而zval给出统计量 的值.
调用格式: 1、y=random(‘name’, A1, A2, A3, m, n) 其中:’name’为相应分布的名称,A1, A2, A3为分布 参数,m为产生随机数的行数,n为列数。 2、直接调用。 如: y=binornd(n, p, 1,10) 产生参数位n,p的1行10 列的二项分布随机数
例4、产生U(2, 8)上的一个随机数,10个随机数, 2行5列的随机数。 命令:(1) y1=unifrnd(2,8) (2) y2=unifrnd(2,8,1,10) (3) y3=unifrnd(2,8,2,5) y1=7.7008 y2=3.3868 5.6411 4.9159 7.3478 6.5726 4.7388 2.1110 6.9284 4.6682 5.6926
1.经验分布函数
经验分布函数图像的Matlab绘图命令是 cdfplot,其输入参数为样本数据量,有两个 可选输出参数:第一个是图形句柄;第二 个是关于样本数据的几个重要统计量,包 括样本最小值、最大值、均值、中值和标 准差。
2.频率直方图
Matlab中提供了直方图的计算和作图函数 hist. hist函数的调用格式如下: [r,xout]=hist(Y,t) [r,xout]=hist(Y,mbins) 其中Y为样本向量;t是分割区间向量;r是统 计输出的频数;xout是分割区间向量,等于 t.
8.参数估计的MATLAB实现 参数估计,就是从样本出发去构造一个统计量作为 总体中某未知参数的一个估计量。 一般,求待估参数通常用极大似然估计 给定样本的观测值算出参数 的估计值,它是未 知参数的近似值。 在理论与实际应用中,不仅需要知道参数 的近 似值,还需要知道这种估计的精度。对于给定的 (0< < 1),求样本以1- 的概率包含真实参 数的一个范围或区间,这种区间称为置信区间。 1- 称为置信度也称为置信水平。
2.利用mle函数进行参数估计的命令: [phat,pci]=mle(‘dist’,data,alpha) 其中,phat 参数的极大似然估计; Pci 置信区间;alpha置信水平;缺省为0.05 dist 表示分布类型; data 为已知数据 例1. 计算下面服从正态分布数据的极大似然估计 和置信区间
3.常用分布的分布密度函数的命令:
Name(概率密度函数名) ‘bino’ ‘chi2’ ‘norm’ ‘poiss’ ‘t’ ‘unif’ ‘unid’ 函数说明 二项分布 卡方分布 正态分布 泊松分布 T分布 均匀分布 离散均匀分布
计算随机变量在X= K处,参数为A,B的概率密度 函数值的一般命令格式为: Y= pdf (name, K, A ) Y= pdf (name, K, A, B )
1 常见分布的参数估计 命令 Normfit expfit Poissfit 功能 正态分布参数估计 指数分布参数估计 泊松分布参数估计 各函数返回已给 数据向量参数的 最大似然估计值 和 (1 ) 的置信 区间, 的默认 值为0.05,即置 信度为95%。
unifit
binofit betafit
均匀分布参数估计
二项分布参数估计 Beta 分布参数估计
从表格可以看出:所有命令都是 分布函数名加上fit的后缀.
设x为样本数据,1-alpha为给定的置信水平,当缺省 时,alpha默认取值为0.05,下面列举了几种常见 分布的参数估计的MATLAB命令. (1)正态分布 参数估计命令为 [muhat,sigmahat,muci,sigmaci]=normfit(x,alpha) 返回值muhat为样本均值的点估计值,sigmahat为标 准差的点估计值,muci为均值的区间估计,sigmaci为 标准差的区间估计.当x是一个矩阵时,则是针对列 进行计算的,下同. (2)二项分布(已知,未知) 参数估计命令为 [phat,pci]=binofit(x,n,alpha) 返回值为参数的估计值和区间估计.