SPSS上机实验(一)
SPSS实验一

SPSS上机实验(1)实验要求:1、掌握SPSS软件的窗口界面和基本操作。
2、掌握数据文件、输出文件的建立、保存、打开操作。
3、掌握常用的数据预处理操作。
实验内容:1、某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同?患者group1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11健康人group2 : 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 1)建立数据文件,以a1.sav 文件名保存。
2)进行总体样本数据预分析,总体样本的血磷值分布情况。
3)进行分组样本数据预分析,查看克山病患者和正常人样本的血磷值分布情况。
4)取消样本的分组。
建立全体样本的血磷值分布直方图(Histogram)5)进行两组样本血磷值的独立样本t检验,并理解输出结果的含义。
6)保存结果文件a1.spo。
并以HTML格式导出结果文件到a1.htm。
2、对a1.sav分别完成以下操作,并将数据文件保存为a2.sav。
(1) 在a1.sav中建立新变量temp,令其值当血磷值大于1时为2,否则为1。
(2) 在a1.sav中生成新变量temp3,当血磷值小于1时取值为0,1~2时取值为10,大于2时取值为20。
(3) 对数据集a1.sav按group升序,x降序的次序排列。
3、根据以下数据建立数据文件a3.sav,并完成以下各项操作。
1)定义变量:(变量值无特别要求,采用表中实际参数)变量名变量标签变量值ID 编号Name 姓名Sex 性别1=男、2=女Height 身高(厘米)Weight 体重(公斤)2)进行总体样本数据预分析,总体样本的年龄、身高、体重分布情况。
3)根据年龄和性别进行分组样本数据预分析,查看各年龄段相同性别样本的体重情况。
SPSS上机实验报告一
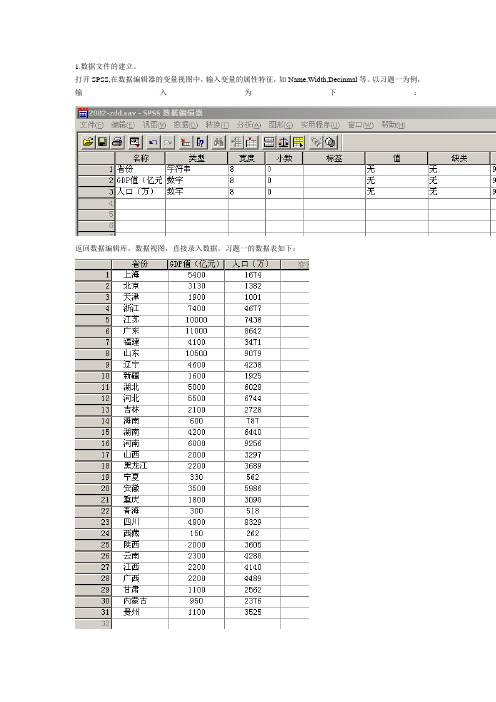
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
spss 上机实验报告

spss 上机实验报告
《SPSS上机实验报告》
在当今社会,数据分析已经成为了各行各业中不可或缺的一部分。
而SPSS作为一款功能强大的统计分析软件,被广泛应用于科研、商业、教育等领域。
本次
实验旨在通过SPSS软件进行数据分析,以探讨数据的规律性和相关性,为进一步的研究和决策提供科学依据。
实验一:描述性统计分析
首先,我们对所收集到的数据进行了描述性统计分析。
通过SPSS软件,我们得出了数据的平均值、标准差、最大值、最小值等指标,从而对数据的分布情况
有了更清晰的了解。
这些统计指标为我们提供了数据的基本特征,为后续的分
析奠定了基础。
实验二:相关性分析
接下来,我们利用SPSS软件进行了相关性分析。
通过相关系数的计算,我们发现了数据之间的相关程度,并得出了相关性显著性检验的结果。
这些分析为我
们揭示了数据之间的内在联系,为我们理解数据背后的规律性提供了重要线索。
实验三:多元回归分析
最后,我们进行了多元回归分析,以探讨不同自变量对因变量的影响程度。
通
过SPSS软件的模型拟合和显著性检验,我们得出了各个自变量的回归系数,并对模型的拟合程度进行了评估。
这些结果为我们提供了对因变量影响因素的深
入理解,为我们在实际应用中进行预测和决策提供了重要参考。
通过以上实验,我们不仅掌握了SPSS软件的基本操作技能,还深入了解了数据分析的方法和原理。
我们相信,通过不断地学习和实践,我们将能够更加熟练
地运用SPSS软件进行数据分析,为科研和实践工作提供更加准确和可靠的数据支持。
SPSS上机实验报告就此结束。
Spss上机报告1讲解
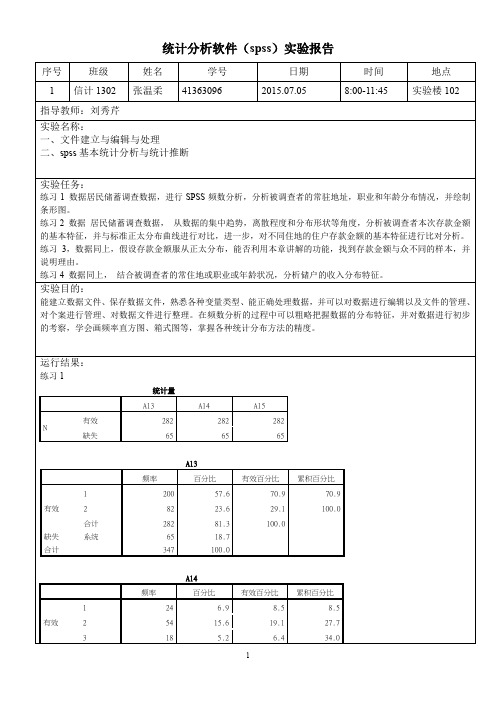
统计分析软件(spss)实验报告
练习2
统计量
A5
有效282
N
缺失65
均值4738.09
均值的标准误651.799
中值1032.43a
众数1000
标准差10945.569
方差119805486.302
偏度 5.234
偏度的标准误.145
峰度33.656
峰度的标准误.289
全距100000
极小值 1
极大值100001
和1336141
a. 利用分组数据进行计算。
居民收入较集中在2000元以下,高收入人群较少,收入在2000元以上的数据离散程度较大,分布形状与标准正态分布差距较大。
根据表格分析,不同地区的人群居民收入差距不是特别大啊,但2地区的居民收入离散程度较1地区收入人群大,在置信水平为95%的情况下可以说两地区的收入平均值是相等的。
统计量
A5
N 有效282
缺失65 平均值4738.09 标准平均值误差651.799 中位数1000.00 方式1000 标准偏差10945.569 方差119805486.302 偏度 5.234 标准偏度误差.145 峰度33.656 标准峰度误差.289 范围100000 最小值 1 最大值100001
运用spss对数据进行标准化分析,得到的标准值大于3时数据即为异常。
交叉表
A4
11。
SPSS上机完整版 (1)
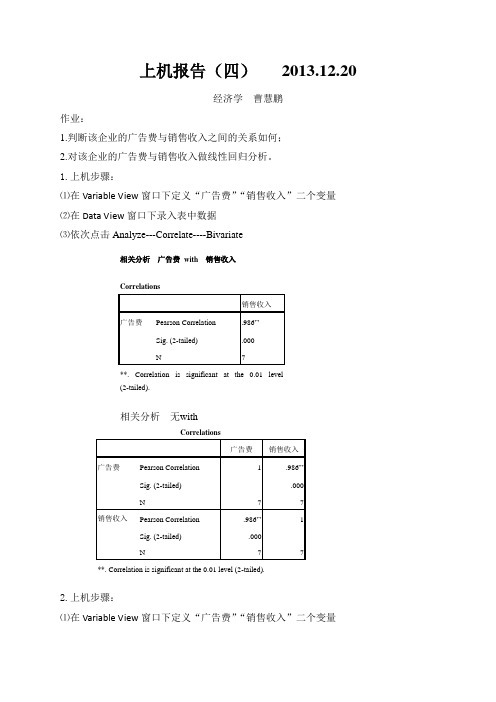
.986a
.973
.967
.60444
a. PrediAb
Model
Sum of Squares
df
Mean Square
F
Sig.
1
Regression
65.602
1
65.602
179.558
.000a
Residual
1.827
5
.365
Total
67.429
6
a. Predictors: (Constant),广告费
b. Dependent Variable:销售收入
回归系数
Coefficientsa
Model
Unstandardized Coefficients
Standardized Coefficients
t
Sig.
B
Std. Error
广告费
销售收入
广告费
Pearson Correlation
1
.986**
Sig. (2-tailed)
.000
N
7
7
销售收入
Pearson Correlation
.986**
1
Sig. (2-tailed)
.000
N
7
7
**. Correlation is significant at the 0.01 level (2-tailed).
2.上机步骤:
⑴在Variable View窗口下定义“广告费”“销售收入”二个变量
⑵在Data View窗口下录入表中数据
⑶依次点击Analyze---Regression----Linear
统计学spss上机实验报告
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)。
对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)。
操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示的选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为“我的文件”并保存在桌面。
如图1-4所示。
图1-4数据的输入步骤4:调用Graphs菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
步骤5:数据准备。
步骤6:选Graphs菜单的Bar过程,弹出Bar Chart定义选项。
在定义选项框的下方有一数据类型栏,系统提供3种数据类型:Summaries for groups of cases:以组为单位体现数据;Summaries of separate variables:以变量为单位体现数据;Values of individual cases:以观察样例为单位体现数据。
实验一 SPSS基本操作

实验一 SPSS基本操作
一、实验目的
通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,对SPSS有一个浅层次的综合认识。
二、实验性质
必修,基础层次
三、主要仪器及试材
计算机及SPSS软件
四、实验内容
1.操作SPSS的基本方法
2.打开文件、保存文件
3.认识各种窗口类型
4.练习系统参数设置
五、实验学时
2学时
六、实验方法与步骤
1.开机
2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS
3.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语
句编辑窗
4.练习系统参数设置
5.关闭SPSS,关机
七、实验注意事项
1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。
2.遇到各种难以处理的问题,请询问指导教师。
3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员
同意,禁止使用移动存储器。
4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换,应报指导教师或实验室管理人员同意。
5.上机时间,禁止使用计算机从事与课程无关的工作。
八、上机作业
1.学习掌握spss打开与关闭的各种方法以及各种spss文件类型的打开与保存方法。
2.打开spss5种类型的窗口,认识窗口特征及其功能。
3.熟悉spss系统参数设置的影响,了解spss系统参数设置的基本方法。
4.任选一个菜单中的命令,试用Help获得英文帮助,熟悉获得帮助的操作。
SPSS实验上机题

SPSS实验上机题实验1 数据文件建立与管理某航空公司38名职员性别和工资情况的调查数据,如下表所示,试在SPSS中进行如下操作:(1)定义变量,将gender定义为字符型变量,salary定义为数值型变量,在数据窗口录入数据,并保存数据文件,将其命名为“data1_1.sav”。
(2)打开文件data1_1.sav,练习增加一个个案,删除一个个案,增加一个变量、删除一个变量,以及个案和变量的复制、粘贴操作。
(3)将数据文件按性别分组;将数据文件按工资进行组距分组。
(4)查找工资大于40000美元的职工。
(5)按工资进行升序和降序排列,比较升序和降序排列结果有什么不同。
(6)练习数据的分类汇总操作,要求按照性别分类汇总样本的总数。
(7)练习数据选取操作,要求随机选取70%的数据。
(8)当工资大于40000美元时,职工的奖金是工资的20%;当工资小于40000美元时,职工的奖金是工资的10%,假设实际收入=工资+奖金,计算所有职工的实际收入,并将结果添加到income变量中。
实验2 数据特征的描述统计分析1.下表是一电脑公司某年连续120天的销售量数据(单位:台)。
试对其进行频数分析,计算均值、中位数、众数、四分位数,标准差、最大值、最小值、全距,偏度、峰度系数;画出直方图、茎叶图、箱线图;解释结果并说明其分布特征。
234159187155158172163183182177156165 143198141167203194196225177189203165 187160214168188173176178184209175210161152149211206196196234185189196172 150161178168171174160153186190172207 228162223170208165197179186175213176 153163218180192175197144178191201181 166196179171210233174179187173202182 154164215233168175198188237194205195 1742261801722111902001721871891881952.下表是某班同学月生活费资料,试对其进行描述分析,并对结果作出说明。
spss实验一、实验步骤
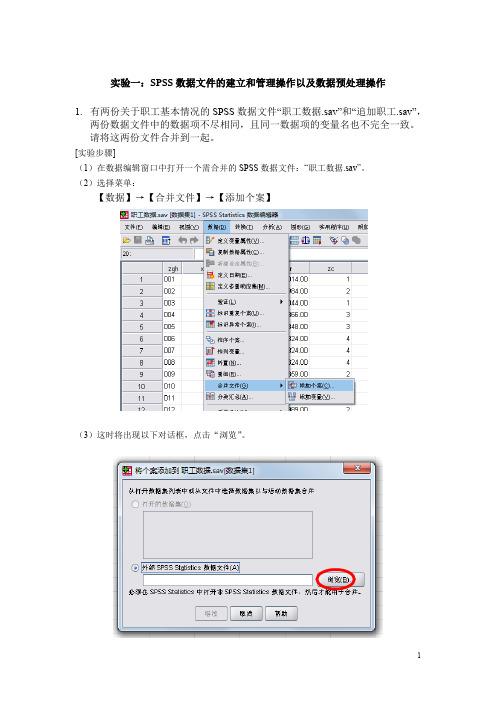
实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.sav”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。
SPSS上机实验(一)

SPSS上机实验(一)
实验要求:
1、上网查找较大样本数据,样本数不少于50个;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小值、最大值、
全距(P35);
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指标,离
散趋势指标(P59-63),结果反映到实验报告中;
4、对数据进行分组整理,列出分组频数分布表(P64-65),结果反映到实验
报告中;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表示P(68-70),
结果放映到实验报告中;
实验报告
1、实验目的
学习如何将收集到的统计数据输入计算机,建成一个正确得SPSS数据文件,以及掌握如何对原始数据文件进行整理和变换。
利用SPSS软件对样本总体的数量特征和分布特征进行描述统计分析。
2、实验要求
1、上网查找较大样本数据,建立SPSS数据文件;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小值、最大值、
全距、中位数、众数;
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指标,离
散趋势指标;
4、对数据进行分组整理,列出分组频数分布表;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表示;
3、实验步骤
查找数据——建立数据文件——数据分析——说明分析结果的实际含义
4、实验内容
5、实验问题
6、实验体会
实验评分(三)。
Spss上机实习内容

Spss上机实习内容实验一熟悉spss系统运行管理方式一、上机要求1、学习掌握spss打开与关闭的各种方法以及各种spss文件类型的打开与保存方法。
2.打开spss5种类型的窗口,认识窗口特征及其功能。
3.熟悉spss系统参数设置的影响,了解spss系统参数设置的基本方法。
4.任选一个菜单中的命令,试用Help获得英文帮助,熟悉获得帮助的操作。
5.熟悉SPSS 10个主菜单下面的基本命令。
实验二掌握SPSS数据文件的建立方法一、上机要求1、能独立完成在SPSS中建库、录入数据等基本操作。
(1)定义变量(2)输入数据(3)保存数据文件(注意:spss文件类型为后缀名为.sav的文件)(4)读入其他类型的数据文件2、数据文件的编辑(1)变量的插入与删除(2)观察量的插入与删除(3)根据已存在的变量建立新变量二、上机操作三十名学生的身高与体重数据录入spss。
表1 三十名学生的身高与体重数据进行以下操作:(1)在Variable view 中定义变量 (2)在data view 中输入数据 (3)保存数据文件实验三 掌握SPSS 数据文件的管理方法一、上机要求1、数据预处理方法2、对数据进行整理、分组,生成统计表和统计图二、上机内容1、以表一的内容练习数据排序、筛选。
2、频数统计(男生女生记录)3、作条形图、饼图、茎叶图、盒形图、直方图、散点图排序操作步骤:点击“data”菜单→点击子菜单“ sort case”打开 sort case 对话框→点击变量进行右侧框内→选定ascending(升序) →ok 。
筛选操作步骤:点击“data”菜单→点击子菜单“select case” →根据要求选项→ok 。
频数统计操作步骤:.依次点击Analyze-—>descriptive statistics-—>frequencies ,弹出对话框; .选Display frequency tables . 单击主菜单OK 键条形图、饼图和直方图的操作步骤:.依次点击Analyze-—>descriptive statistics-—>frequencies ,弹出对话框; . 箭头送入所分析变量,点击下端Charts ,弹出对话框14 14 14 14 14 15 15 15 15 15 15 15 15 15 15年龄 164.7 160.5 147.0 153.2 157.9 166.0 169.0 170.0 165.1 172.0 159.4 161.3 158.0158.6 169.0身高 13 13 13 13 13 13 13 13 13 13 13 14 14 14 14年龄 男 男 男 男 男 女 女 女 女 女 男 男 男 男 男性别44.1 53.0 36.4 30.1 40.4 57.0 58.5 51.0 58.0 55.0 44.7 45.4 44.3 42.8 51.1体重 女 女 女 女 女 男 男 男 男 男 女 女 女 女 女性别 1617 18 19 20 21 22 23 24 25 26 27 28 29 30序号 47.5 37.8 38.6 41.6 43.3 47.3 47.1 47.0 33.8 33.8 49.2 54.5 50.0 44.058.0体重 156.0 155.0 144.6 161.5 161.3 158.0 161.0 162.0 164.3 144.0 157.9 176.1 168.0 164.5 153.01 2 3 4 5 6 7 8 9 10 11 12 13 14 15身高 序号.选中. Bar Charts——条形图或者. Pie Charts——饼图或者. Histograms——直方图.单击主菜单OK键,茎叶图与箱线图的操作步骤:.依次点击Analyze->descriptive statistics->explore, 弹出对话框;. 箭头送入所分析变量,系统自动生成茎叶图与箱线图.单击主菜单OK键实验四掌握用SPSS作统计量描述一、上机要求:掌握SPSS进行作统计量描述的常用命令、操作过程以及分析结果的判读。
spss实验一、实验步骤

实验一:SPSS数据文件的建立和管理操作以及数据预处理操作1.有两份关于职工基本情况的SPSS数据文件“职工数据.sav”和“追加职工.sav”,两份数据文件中的数据项不尽相同,且同一数据项的变量名也不完全一致。
请将这两份文件合并到一起。
[实验步骤](1)在数据编辑窗口中打开一个需合并的SPSS数据文件:“职工数据.sav”。
(2)选择菜单:【数据】→【合并文件】→【添加个案】(3)这时将出现以下对话框,点击“浏览”。
(4)打开需进行纵向合并处理的SPSS数据文件“追加职工.s av”。
按“继续”后,显示纵向合并数据文件窗口。
(如下图)(5)对话框右边【新的活动数据集中的变量】框中显示的变量名是两个数据文件中的同名变量,对话框左边【非成对变量】框中显示的变量名是两个文件中的不同名变量。
其中,变量名后面的【*】表示该变量是当前数据编辑窗口中(“职工数据.sav”)的变量,【+】表示该变量是(2)“追加职工.sav”中指定的磁盘文件中的变量。
SPSS默认这些变量的含义不同,且不放入合并后的新文件中。
如果不接受这种默认,可选择其中的两个变量名并按【对】按钮指定配对,表示虽然它们的名称不同但数据含义是相同的,可进入合并后的数据文件中。
本题中,显然职称zc(*)和职称zc1(+)两个变量名需要按【对】按钮指定配对。
方法是:按住“Ctrl键”,同时鼠标点zc(*)和zc1(+),然后按【对】按钮,这时【新的活动数据集中的变量】框中出现“zc&zc1”变量名。
(6)把【非成对变量】框中显示的其他变量名全部标记,按右向箭头。
(7)按【确定】,完成操作。
2.根据“住房状况调查.sav”数据,通过数据排序功能分析本市户口和外地户口家庭的住房面积情况。
(按升序排列)[实验步骤](1)在数据编辑窗口中打开SPSS数据文件:“住房状况调查.sav”。
(2)选择菜单:【数据】→【排序个案】(3)指定主排序变量“户口状况”到【排序依据】框中,并选择【排序顺序】框中的选项指出该变量按升序还是降序排序。
SPSS实验一:基本操作

一、数据文件的建立
变量名:学号、姓名、性别、籍贯、民族、数学、语文、英语、综合
【备注】性别:男=1,女=2;籍贯:西部=1,非西部=0;民族:汉族=1,少数民族=2
录入15个记录,信息自定。
二、根据以上文件,完成下列操作
1、按数学成绩降序排序
2、计算不同性别学生的英语平均成绩
3、计算文化课成绩(文化课成绩=数学+语文+英语+综合),升序排序
4、建立新的变量集:(1)基本信息(2)各科成绩
5、用分数段将综合成绩重新赋值,保持其他原有记录
6、选取文化课成绩≥400,籍贯为西部的少数民族学生的记录
实验报告的填写
课程名称、专业班级、学号、实验地点、指导教师
1、实验名称:SPSS软件的基本操作
2、实验目的:掌握相关软件的基本操作,了解软件自带的排序、分类汇总、变量重新赋值、筛选等功能
3、实验内容
4、实验步骤:2+3+6。
Spss实验操作步骤
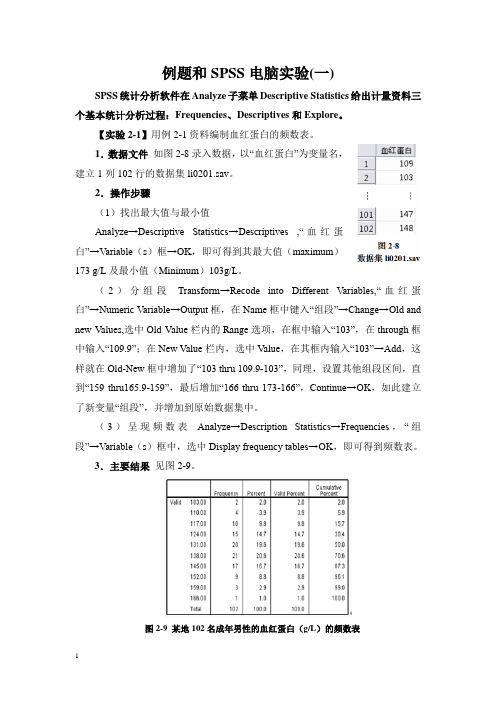
例题和SPSS电脑实验(一)SPSS统计分析软件在Analyze子菜单Descriptive Statistics给出计量资料三个基本统计分析过程:Frequencies、Descriptives和Explore。
【实验2-1】用例2-1资料编制血红蛋白的频数表。
建立1列102行的数据集li0201.sav。
2.操作步骤(1)找出最大值与最小值Analyze→Descriptive Statistics→Descriptives ,“血红蛋白”→Variable(s)框→OK,即可得到其最大值(maximum)173 g/L及最小值(Minimum)103g/L。
(2)分组段Transform→Recode into Different Variables,“血红蛋白”→Numeric Variable→Output框,在Name框中键入“组段”→Change→Old andnew Values,选中Old Value栏内的Range选项,在框中输入“103”,在through框中输入“109.9”;在New Value栏内,选中Value,在其框内输入“103”→Add,这样就在Old-New框中增加了“103 thru 109.9-103”,同理,设置其他组段区间,直到“159 thru165.9-159”,最后增加“166 thru 173-166”,Continue→OK,如此建立了新变量“组段”,并增加到原始数据集中。
(3)呈现频数表Analyze→Description Statistics→Frequencies,“组段”→Variable(s)框中,选中Display frequency tables→OK,即可得到频数表。
3.主要结果见图2-9。
图2-9 某地102名成年男性的血红蛋白(g/L)的频数表【实验2-2】用例2-1的资料求其均数。
操作步骤同实验2-1中(1),得均数(mean )为136.87 g/L 。
spss 上机
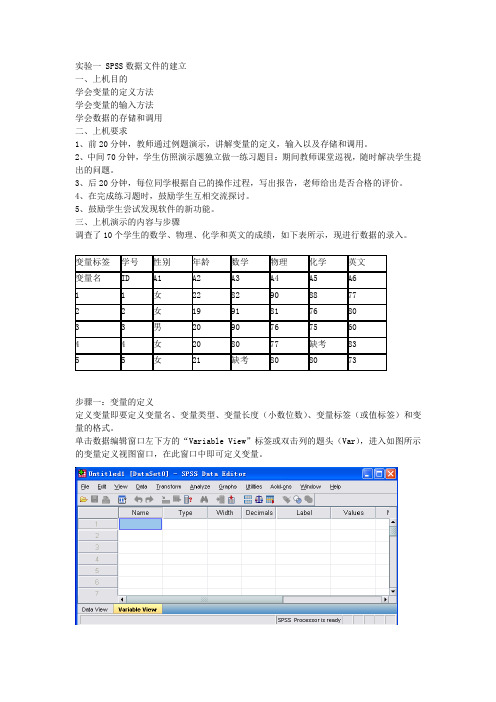
实验一 SPSS数据文件的建立一、上机目的学会变量的定义方法学会变量的输入方法学会数据的存储和调用二、上机要求1、前20分钟,教师通过例题演示,讲解变量的定义,输入以及存储和调用。
2、中间70分钟,学生仿照演示题独立做一练习题目:期间教师课堂巡视,随时解决学生提出的问题。
3、后20分钟,每位同学根据自己的操作过程,写出报告,老师给出是否合格的评价。
4、在完成练习题时,鼓励学生互相交流探讨。
5、鼓励学生尝试发现软件的新功能。
三、上机演示的内容与步骤调查了10个学生的数学、物理、化学和英文的成绩,如下表所示,现进行数据的录入。
步骤一:变量的定义定义变量即要定义变量名、变量类型、变量长度(小数位数)、变量标签(或值标签)和变量的格式。
单击数据编辑窗口左下方的“Variable View”标签或双击列的题头(Var),进入如图所示的变量定义视图窗口,在此窗口中即可定义变量。
1、Name:框内输入变量名SPSS默认的变量为Var00001、Var00002等,用户也可以根据自己的需要来命名变量。
SPSS 变量的命名和一般的编程语言一样,有一定的命名规则,具体内容如下。
变量名必须以字母、汉字或字符@开头,其他字符可以是任何字母、数字或_、@、#、$等符号。
∙变量最后一个字符不能是句号。
∙变量名总长度不能超过8个字符(即4个汉字)。
∙不能使用空白字符或其他特殊字符(如“!”、“?”等)。
变量命名必须惟一,不能有两个相同的变量名。
∙在SPSS中不区分大小写。
例如,HXH、hxh或Hxh对SPSS而言,均为同一变量名称。
∙ SPSS的保留字(Reserved Keywords)不能作为变量的名称,如ALL、AND、WITH、OR等。
2、Type:用户可根据具体资料的属性对数据进行格式化。
1)Numeric:数值型,同时定义数值的宽度(Width),即整数部分+小数点+小数部分的位数,默认为8位;定义小数位数(Decimal Places),默认为2位。
spss实验报告一,二
实验报告
实验目的: 通过上机操作, 熟练掌握spss相关知识。
实验内容:
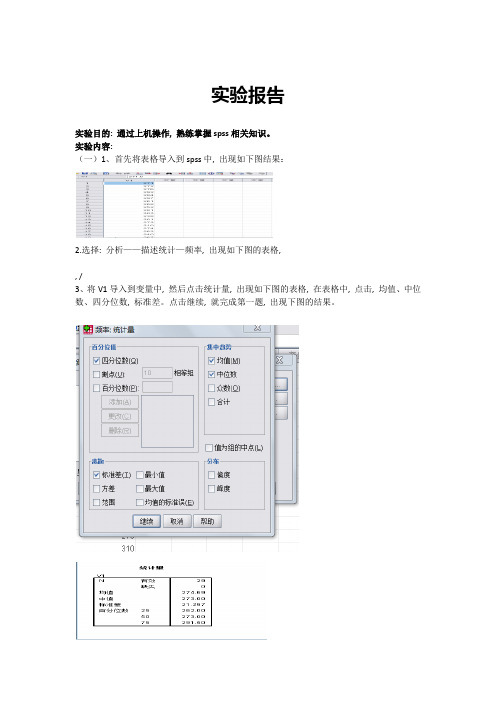
(一)1、首先将表格导入到spss中, 出现如下图结果:
2.选择: 分析——描述统计—频率, 出现如下图的表格,
, /
3、将V1导入到变量中, 然后点击统计量, 出现如下图的表格, 在表格中, 点击, 均值、中位数、四分位数, 标准差。
点击继续, 就完成第一题, 出现下图的结果。
以上就是第一题的结果。
(二)
1.首先将表格导入到spss中, 如下图:
2.从上表中, 可知, 方法A要比B.C的只都要高, 可见平均值要高于B.C, 就应该对这三组进行平均值, 方差的计算进行比较。
选择: 分析——描述统计——描述, 出现如下图的表格:
将方法A.B.C分别导入到变量中, 然后点击选项这个按钮, 出现如下图的表格进行选择:
可以选择标准差, 最大值, 最小值, 均值, 然后点击继续, 则会出现结果, 通过对结果进行对比, 选择方案。
由图可知, 方法A的平均值高于B、C, 而且最小值也都大于B、C的最大值, 可知A的组装优越于B、C, 即使标准差大于B, 稳定性稍微差于B, 但总体上组装的结果要比B好, 所以要选择方案A。
spss上机实验

实验一spss基本操作实验目的1.建立数据文件。
完成如下操作:定义变量,输入数据.将spss test 1.1及spss test 1.1文件中数据分别输入.2.保存数据。
完成如下操作:将第一步文件保存为:spss test 1.1.sav, spss test 1.1a.sav3.打开数据文件。
完成如下操作:(1)打开SPSS数据文件.。
(2)调用AS CⅡ数据,打开spss test 1.2和spss test 1.3。
(3)打开EXCEL文件, spss test 1.44.数据编辑。
完成如下操作:定义时间变量,插入变量,插入记录,观察值排序,数据转置,合并数据,拆分数据,选择记录,常用编辑操作。
5.数据整理。
完成如下操作.计算产生变量,自动重赋值实验指导SPSS的文件类型:数据文件:扩展名为“.sav”结果文件:扩展名为“.spo”图形文件:扩展名为“.cht”语句命令文件:扩展名为“.sps”SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件.一.建立数据文件将附后1.1的内容录入,1.在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
(1)数据编辑(SPSS Data Editor)界面介绍(2) 数据文件格式数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。
(3) 定义变量建立数据文件的第一步是定义变量。
在数据编辑窗口左下角激活(Variable View)变量定义窗口,如下图在数据窗口中,用户定义数据变量的名称、数据类型、宽度、小数位和标记等信息。
变量的数据类型当鼠标指针移至单元格,单击后该单元格的右边就会显示一个“…”按钮,单击该按钮就会显示一个数据类型设置窗口,如下图所示。
武汉理工大学实验报告:spss上机实验

SPSS上机考试姓名:班级:学号:实验一:聚类分析一、实验问题某校从高中二年级女生中随机抽取16名,测得身高和体重数据如下表:试分别利用最短距离法、最长距离法、重心法、类平均法、中间距离法将它们聚类(分类统计量采用绝对距离),并画出聚类图。
二、实验步骤1、1.数据处理:在SPSS中的Data View中导入数据,并在Variable View中定义变量。
2、点击“Analyze-Classify-Hierarchical Cluster,打开Hierarchical Cluster的对话框,从左侧将2个聚类指标选入Variables栏中,将表示序号(字符串)选入Lable Cases By栏中按“Plots”按钮,在弹出的窗口中选中Dendrogram(谱系图)选项,按“Continue”返回主对话框。
再按“Method”按钮,在Cluster Method,下面就各种方法进行结果输出。
3.结果输出(1)最短距离法分类统计量采用绝对距离Block,采用最短距离法Nearest neighbor返回主对话框后点击“OK”即可得到聚类结果的树形图如下:(2)最长距离法分类统计量采用绝对距离Block,采用最短距离法Furthest neighbor返回主对话框后点击“OK”即可得到聚类结果的树形图如下:(3)重心法分类统计量采用绝对距离Block,采用最短距离法Centroid clustering返回主对话框后点击“OK”即可得到聚类结果的树形图如下:(4)类平均法-组间平均法分类统计量采用绝对距离Block,采用最短距离法Between-groups linkage返回主对话框后点击“OK”即可得到聚类结果的树形图如下:(5)中间距离法分类统计量采用绝对距离Block,采用最短距离法Median clustering返回主对话框后点击“OK”即可得到聚类结果的树形图如下:分析:就以中间聚类法为例,当采用绝对距离时,分为3类的时候分别为:①5 12 13 15 16 1 6 7②4 ③8 11 9 10 2 14基于上述各种聚类方法的分析可知,分为3类的时候各个方法相似度最高,所以将其分为3类最为合适。
《SPSS》实验报告实验一

广东金融学院实验报告课程名称:社会科学统计软件SPSS应用
附四
4.1分析某班级学生的高考数学成绩和全国的平均成绩70之间是否存在显著性差异。
4.1.1 实验过程:
输入数据:
图4-1-1 输入数据
图4-1-2 选择变量
4.1.2实验结果:
下面为
从结果输出表中可以看出,在置信区间95%,其0.584>0.5,拒绝原假设,说明学生的高考数学成绩和全国的平均成绩70之间存在显著性差异。
4.2分析A、B两所高校大一学生的高考数学成绩之间是否存在显著性差异
4.2.1实验过程
图4-2-1 输入数据
图4-2-2 选择独立样本T检验
4.2.2
从上表可以看出,在95%的置信区间上,0.423>0.05,可以认为拒绝原假设。
两所高校大一学生的高考数学成绩之间存在显著性差异。
4.3 研究一个班同学在参加了暑期数学、化学培训班后,学习成绩是否有显著变化。
4.3.1实验过程
图4-3-1 选择配对样本T检验
4.3.2实验结果
从上表可以看出,培训前后的均值变化情况,数学1=72.944<数学2=84.7778;化学1=82.3333<化学2=89.9444;明显提高了。
从上表可以看出,在95%的置信区间上,概率分别为0.046<0.05,0.032<0.05,可以认为接受原假设,一个班同学在参加了暑期数学、化学培训班后,学习成绩不存在显著变化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS上机实验(一)
实验要求:
1、上网查找较大样本数据,样本数不少于50个;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小
值、最大值、全距(P35);
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指
标,离散趋势指标(P59-63),结果反映到实验报告中;
4、对数据进行分组整理,列出分组频数分布表(P64-65),结果
反映到实验报告中;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表
示P(68-70),结果放映到实验报告中;
实验报告
1、实验目的
学习如何将收集到的统计数据输入计算机,建成一个正确得SPSS数据文件,以及掌握如何对原始数据文件进行整理和变换。
利用SPSS软件对样本总体的数量特征和分布特征进行描述统计分析。
2、实验要求
1、上网查找较大样本数据,建立SPSS数据文件;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小值、
最大值、全距、中位数、众数;
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指
标,离散趋势指标;
4、对数据进行分组整理,列出分组频数分布表;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表
示;
3、实验步骤
项目要求分值实验内容实验内容齐全,完成实验要
求,达到实验目的。
50%
实验方法实验方法正确,能够在不同的
环境下选择最好的方法。
10%
实验问题能够深入实验,发现问题,并
提出解决办法
10%
实验体会总计实验中的心得,为以后的
实验指引方向。
10%
实验态度态度积极、认真,克服实验中
的困难20%
查找数据——建立数据文件——数据分析——说明分析结果的实际含义
4、实验内容
5、实验问题
6、实验体会
实验评分(三)。