FromBinaryOppositiont_省略_IdentityinEvery
Quantum Computers and Dissipation

1
Introduction
Quantum computers can accept input states which represent a coherent superposition of many different possible inputs and subsequently evolve them into a corresponding superposition of outputs. Computation, i.e. a sequence of unitary transformations, affects simultaneously each element of the superposition generating a massive parallel data processing albeit within one piece of quantum hardware. As the result quantum computers can efficiently solve some problems which are believed to be intractable on any classical computer (Deutsch 1985, Deutsch and Jozsa 1992, Bernstein and Vazirani 1993, Simon 1994, Shor 1994). The most striking example is the factoring problem: to factor a number N of L digits on any classical computer requires an execution time that grows exponentially with L (approximately exp L1/3 for the best known algorithms such as the Number Field Sieve (Lenstra et al. 1990)). In contrast Shor (1994) has shown that quantum
编译原理教程课后习题答案第二章
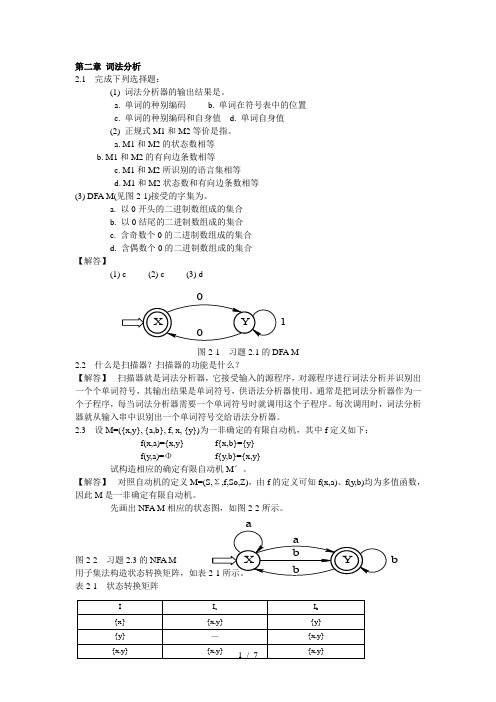
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
Java编码规则

Writing Robust Java Code The AmbySoft Inc. Coding Standards for Javav17.01dScott W. AmblerSoftware Process Mentor This Version: January 15, 2000This page left unintentionally blank.(yuk yuk yuk)Purpose of this White PaperThis white paper describes a collection of standards, conventions, and guidelines for writing solid Java code. They are based on sound, proven software engineering principles that lead to code that is easy to understand, to maintain, and to enhance. Furthermore, by following these coding standards your productivity as a Java developer should increase remarkably – Experience shows that by taking the time to write high-quality code right from the start you will have a much easier time modifying it during the development process. Finally, following a common set of coding standards leads to greater consistency, making teams of developers significantly more productive.Important Features of This White Paper•Existing standards from the industry are used wherever possible – You can reuse more than just code.•The reasoning behind each standard is explained so that you understand why you should follow it.•Viable alternatives, where available, are also presented along with their advantages and disadvantages so that you understand the tradeoffs that have been made.•The standards presented in this white paper are based on real-world experience from numerous object-oriented development projects. This stuff works in practice, not just theory.•These standards are based on proven software-engineering principles that lead to improved development productivity, greater maintainability, and greater enhancability.T arget AudienceP rofessional software developers who are interested in:•Writing Java code that is easy to maintain and to enhance•Increasing their productivity•Working as productive members of a Java development teamHelp Me Improve These StandardsBecause I welcome your input and feedback, please feel free to email me at scott@ with your comments and suggestions. Let’s work together and learn from one another.AcknowledgmentsThe following people have provided valuable input into the development and improvement of these standards, and I would like to recognize them for it.Stephan Marceau Lyle Thompson David Pinn Larry VirdenEva Greff Wayne Conrad Michael Appelmans William GilbertGraham Wright Alex Santos Kiran Addepalli Brian SmithLarry Allen Dick Salisbury Bruce Conrad Michael FinneyJohn Pinto Vijay Eluri Carl Zimmerman Hakan SoderstromBill Siggelkow Camille Bell Fredrik Nystrom Cory RadcliffKathy Eckman Guy Sharf Scott HarperKyle Larson Robert Marshall Peter C.M. HaightMark Brouwer Gerard Broeksteeg Helen GilmoreScott W. AmblerJanuary 2000This page also left unintentionally blank. (although now it isn’t quite as funny)Table of Contents1.GENERAL CONCEPTS (1)1.1W HY C ODING S TANDARDS ARE I MPORTANT (1)1.2T HE P RIME D IRECTIVE (1)1.3W HAT M AKES U P A G OOD N AME (2)1.4G OOD D OCUMENTATION (3)1.4.1The Three Types of Java Comments (4)1.4.2 A Quick Overview of javadoc (5)1.5A MBLER’S L AW OF S TANDARDS (6)2.STANDARDS FOR MEMBER FUNCTIONS (7)2.1N AMING M EMBER F UNCTIONS (7)2.1.1Naming Accessor Member Functions (7)2.1.1.1Getters (7)2.1.1.1.1Alternative Naming Convention for Getters – Has and Can (8)2.1.1.2Setters (8)2.1.1.3Constructors (8)2.2M EMBER F UNCTION V ISIBILITY (9)2.3D OCUMENTING M EMBER F UNCTIONS (9)2.3.1The Member Function Header (9)2.3.2Internal Documentation (11)2.4T ECHNIQUES FOR W RITING C LEAN C ODE (12)2.4.1Document Your Code (12)2.4.2Paragraph/Indent Your Code (13)2.4.3Paragraph and Punctuate Multi-Line Statements (13)2.4.4Use Whitespace in Your Code (14)2.4.5Follow The Thirty-Second Rule (14)2.4.6Write Short, Single Command Lines (14)2.4.7Specify the Order of Operations (14)2.5J AVA C ODING T IPS (15)2.5.1Organize Your Code Sensibly (15)2.5.2Place Constants on the Left Side of Comparisons (15)3.STANDARDS FOR FIELDS (ATTRIBUTES/PROPERTIES) (16)3.1N AMING F IELDS (16)3.1.1Use a Full English Descriptor for Field Names (16)3.1.1.1Alternative – Hungarian Notation (16)3.1.1.2Alternative – Leading or Trailing Underscores (17)3.1.2Naming Components (Widgets) (17)3.1.2.1Alternative for Naming Components – Hungarian Notation (17)3.1.2.2Alternative for Naming Components – Postfix-Hungarian Notation (17)3.1.3Naming Constants (18)3.1.4Naming Collections (19)3.1.4.1Alternative for Naming Collections – The ‘Some’ Approach (19)3.1.5Do Not “Hide” Names (19)3.2F IELD V ISIBILITY (20)3.3D OCUMENTING A F IELD (21)3.4T HE U SE OF A CCESSOR M EMBER F UNCTIONS (21)3.4.1Naming Accessors (22)3.4.2Advanced Techniques for Accessors (23)3.4.2.1Lazy Initialization (23)3.4.2.2Getters for Constants (24)3.4.2.3Accessors for Collections (26)3.4.2.4Accessing Several Fields Simultaneously (26)3.4.3Visibility of Accessors (27)3.4.4Why Use Accessors? (28)3.4.5Why Shouldn’t You Use Accessors? (28)3.5A LWAYS I NITIALIZE S TATIC F IELDS (29)4.STANDARDS FOR LOCAL VARIABLES (30)4.1N AMING L OCAL V ARIABLES (30)4.1.1Naming Streams (30)4.1.2Naming Loop Counters (30)4.1.3Naming Exception Objects (31)4.1.4Bad Ideas for Naming Local Variables (31)4.2D ECLARING AND D OCUMENTING L OCAL V ARIABLES (32)4.2.1General Comments About Declaration (32)5.STANDARDS FOR PARAMETERS (ARGUMENTS) TO MEMBER FUNCTIONS (33)5.1N AMING P ARAMETERS (33)5.1.1Alternative – Prefix Parameter Names with ‘a’ or ‘an’ (33)5.1.2Alternative – Name Parameters Based on Their Type (33)5.1.3Alternative – Name Parameters The Same as Their Corresponding Fields (if any) (34)5.2D OCUMENTING P ARAMETERS (34)6.STANDARDS FOR CLASSES, INTERFACES, PACKAGES, AND COMPILATION UNITS (35)6.1S TANDARDS FOR C LASSES (35)6.1.1Class Visibility (35)6.1.2Naming Classes (35)6.1.3Documenting a Class (36)6.1.4Class Declarations (37)6.1.4.1Apply The “final” Keyword Sensibly (37)6.1.4.2Ordering Member Functions and Fields (37)6.1.5Minimize the Public and Protected Interface (38)6.2S TANDARDS FOR I NTERFACES (39)6.2.1Naming Interfaces (39)6.2.2Documenting Interfaces (39)6.3S TANDARDS FOR P ACKAGES (40)6.3.1Naming Packages (40)6.3.2Documenting a Package (40)6.4S TANDARDS FOR C OMPILATION U NITS (41)6.4.1Naming a Compilation Unit (41)6.4.2Documenting a Compilation Unit (41)7.MISCELLANEOUS STANDARDS/ISSUES (42)7.1R EUSE (42)7.2U SE W ILD C ARDS W HEN I MPORTING C LASSES (42)7.2.1Alternative – Explicitly Specify Each Imported Class (42)7.3O PTIMIZING J AVA C ODE (43)7.4W RITING J AVA T EST H ARNESSES (46)8.THE SECRETS OF SUCCESS (47)8.1U SING T HESE S TANDARDS E FFECTIVELY (47)8.2O THER F ACTORS T HAT L EAD TO S UCCESSFUL C ODE (48)9.PROPOSED JAVADOC TAGS FOR MEMBER FUNCTIONS (50)10.WHERE TO GO FROM HERE (51)10.1C REATING Y OUR O WN I NTERNAL C ORPORATE G UIDELINES? (51)10.1.1Using This PDF File (51)10.1.2Obtaining the Source Document for This File (51)11.SUMMARY (52)11.1J AVA N AMING C ONVENTIONS (53)11.2J AVA D OCUMENTATION C ONVENTIONS (55)11.2.1Java Comment Types (55)11.2.2What To Document (56)11.3J AVA C ODING C ONVENTIONS (G ENERAL) (57)GLOSSARY (58)REFERENCES AND SUGGESTED READING (62)12.ABOUT THE AUTHOR (64)13.INDEX (65)1. General ConceptsI’d like to start this white paper with a discussion of some general concepts that I feel are important for coding standards. I begin with the importance of coding standards, propose the “Prime Directive” for standards, and then follow with the factors that lead to good names and good documentation. This section will set the stage for the rest of this white paper, which covers standards and guidelines for Java coding.1.1 Why Coding Standards are ImportantCoding standards for Java are important because they lead to greater consistency within your code and the code of your teammates. Greater consistency leads to code that is easier to understand, which in turn means it is easier to develop and to maintain. This reduces the overall cost of the applications that you create.You have to remember that your Java code will exist for a long time, long after you have moved on to other projects. An important goal during development is to ensure that you can transition your work to another developer, or to another team of developers, so that they can continue to maintain and enhance your work without having to invest an unreasonable effort to understand your code. Code that is difficult to understand runs the risk of being scrapped and rewritten – I wouldn’t be proud of the fact that my code needed to be rewritten, would you? If everyone is doing their own thing then it makes it very difficult to share code between developers, raising the cost of development and maintenance.Inexperienced developers, and cowboys who do not know any better, will often fight having to follow standards. They claim they can code faster if they do it their own way. Pure hogwash. They MIGHT be able to get code out the door faster, but I doubt it. Cowboy programmers get hung up during testing when several difficult-to-find bugs crop up, and when their code needs to be enhanced it often leads to a major rewrite by them because they’re the only ones who understand their code. Is this the way that you want to operate? I certainly do not.1.2 The Prime DirectiveNo standard is perfect and no standard is applicable to all situations: sometimes you find yourself in a situation where one or more standards do not apply. This leads me to introduce what I consider to be the prime directive of standards:When you go against a standard, document it. All standards, except for this one, can be broken. If you do so, you must document why you broke the standard, the potential implications of breaking the standard, and any conditions that may/must occur before the standard can be applied to thissituation.The bottom line is that you need to understand each standard, understand when to apply them, and just as importantly when not to apply them.1.3 What Makes Up a Good NameWe will be discussing naming conventions throughout the standards, so let’s set the stage with a few basics:e full English descriptors1 that accurately describe the variable/field/class/… For example, usenames like firstName, grandTotal, or CorporateCustomer. Although names like x1, y1, or fn are easy to type because they’re short, they do not provide any indication of what they represent and result in code that is difficult to understand, maintain, and enhance (Nagler, 1995; Ambler, 1998a).e terminology applicable to the domain. If your users refer to their clients as customers, then use theterm Customer for the class, not Client. Many developers will make the mistake of creating generic terms for concepts when perfectly good terms already exist in the industry/domain.e mixed case to make names readable. You should use lower case letters in general, but capitalizethe first letter of class names and interface names, as well as the first letter of any non-initial word(Kanerva, 1997).e abbreviations sparingly, but if you do so then use them intelligently. This means you shouldmaintain a list of standard short forms (abbreviations), you should choose them wisely, and you should use them consistently. For example, if you want to use a short form for the word “number,” thenchoose one of nbr, no, or num, document which one you chose (it doesn’t really matter which one), and use only that one.5.Avoid long names (< 15 characters is a good idea). Although the class namePhysicalOrVirtualProductOrService might seem to be a good class name at the time (OK, I’mstretching it on this example) this name is simply too long and you should consider renaming it tosomething shorter, perhaps something like Offering (NPS, 1996).6.Avoid names that are similar or differ only in case. For example, the variable names persistentObjectand persistentObjects should not be used together, nor should anSqlDatabase and anSQLDatabase (NPS, 1996).7.Capitalize the first letter of standard acronyms. Names will often contain standard abbreviations, suchas SQL for Standard Query Language. Names such as sqlDatabase for an attribute, or SqlDatabase for a class, are easier to read than sQLDatabase and SQLDatabase.1 I use the term “full English descriptor” throughout this document, but what I really mean is “full [insert your language here] descriptor”, so if the spoken language of your team is French then use full French descriptors everywhere.1.4 Good DocumentationWe will also be discussing documentation conventions, so let’s discuss some of the basics first:ments should add to the clarity of your code. The reason why you document your code is to makeit more understandable to you, your coworkers, and to any other developer who comes after you(Nagler, 1995).2.If your program isn’t worth documenting, it probably isn’t worth running (Nagler, 1995). What can Isay, Nagler hit the nail on the head with this one.3.Avoid decoration, i.e. do not use banner-like comments. In the 1960s and 1970s COBOL programmersgot into the habit of drawing boxes, typically with asterisks, around their internal comments (NPS, 1996).Sure, it gave them an outlet for their artistic urges, but frankly it was a major waste of time that added little value to the end product. You want to write clean code, not pretty code. Furthermore, because many of the fonts used to display and print your code are proportional, and many aren’t, you can’t line up your boxes properly anyway.4.Keep comments simple. Some of the best comments I have ever seen are simple, point-form notes. Youdo not have to write a book, you just have to provide enough information so that others canunderstand your code.5.Write the documentation before you write the code. The best way to document code is to write thecomments before you write the code. This gives you an opportunity to think about how the code will work before you write it and will ensure that the documentation gets written. Alternatively, you should at least document your code as you write it. Because documentation makes your code easier tounderstand you are able to take advantage of this fact while you are developing it. The way I look at it, if you are going to invest the time writing documentation you should at least get something out of it (Ambler, 1998a).6.Document why something is being done, not just what. Fundamentally, I can always look at a piece ofcode and figure out what it does. For example, I can look at the code in Example 1 below and figure out that a 5% discount is being given on orders of $1,000 dollars or more. Why is this being done? Is therea business rule that says that large orders get a discount? Is there a limited-time special on large ordersor is it a permanent program? Was the original programmer just being generous? I do not know unless it is documented somewhere, either in the source code itself or in an external document (Ambler, 1998a).if ( grandTotal >= 1000.00){grandTotal = grandTotal * 0.95;}Example 1.11.4.1 The Three Types of Java CommentsJava has three styles of comments: Documentation comments start with /** and end with */, C-style comments which start with /* and end with */, and single-line comments that start with // and go until the end of the source-code line. In the chart below is a summary of my suggested use for each type of comment, as well as several examples.Comment Type Usage ExampleDocumentation Use documentation commentsimmediately before declarations ofinterfaces, classes, member functions,and fields to document them.Documentation comments are processedby javadoc, see below, to create externaldocumentation for a class./**Customer – A customer is any person or organization that we sell services and products to. @author S.W. Ambler*/C style Use C-style comments to document outlines of code that are no longerapplicable, but that you want to keep justin case your users change their minds, orbecause you want to temporarily turn itoff while debugging./*This code was commented outby J.T. Kirk on Dec 9, 1997because it was replaced by thepreceding code. Delete it after two years if it is still not applicable.. . . (the source code )*/Single line Use single line comments internallywithin member functions to documentbusiness logic, sections of code, anddeclarations of temporary variables.// Apply a 5% discount to all invoices // over $1000 as defined by the Sarek // generosity campaign started in// Feb. of 1995.The important thing is that your organization should set a standard as to how C-style comments and single-line comments are to be used, and then to follow that standard consistently. Use one type to document business logic and use the other to document out old code. I prefer using single-line comments for business logic because I can put the documentation on the same line as the code (this is called endlining and sometimes inlining). I then use C-style comments for documenting out old code because I can comment out several lines at once and because C-style looks very similar to documentation comments I rarely use them so as to avoid confusion.Tip – Beware Endline CommentsMcConnell (1993) argues strongly against the use of endline comments, also known as inline comments or end of line comments. He points out that the comments have to be aligned to the right of the code so that they do not interfere with the visual structure of the code. As a result they tend to be hard to format, and that “if you use many of them, it takes time to align them. Such time is not spent learning more about the code; it is dedicated solely to the tedious task of pressing the spacebar or the tab key.” He also points out that endline comments are also hard to maintain because when the code on the line grows it bumps the endline comment out, and that if you are aligning them you have to do the same for the rest of them. My advice, however, is to not waste your time aligning endline comments.1.4.2 A Quick Overview of javadocIncluded in Sun’s Java Development Kit (JDK) is a program called javadoc that processes Java code files and produces external documentation, in the form of HTML files, for your Java programs. I think that javadoc is a great utility, but at the time of this writing it does have its limitations. First, it supports a limited number of tags, reserved words that mark the beginning of a documentation section. The existing tags are a very good start but I feel are not sufficient for adequately documenting your code. I’ll expand upon this statement later. For now, I present a brief overview of the current javadoc tags in the chart below, and will refer you to the JDK javadoc documentation for further details.Tag Used for Purpose@author name Interfaces,Classes,Interfaces Indicates the author(s) of a given piece of code. One tag per author should be used.@deprecated Interfaces,Classes,MemberFunctions Indicates that the API for the class… has been deprecated and therefore should not be used any more.@exception name description MemberFunctions Describes the exceptions that a member function throws. You should use one tag per exception and give the full class name for the exception.@param name description MemberFunctions Used to describe a parameter passed to a member function, including its type/class and its usage. Use one tag per parameter.@return description MemberFunctions Describes the return value, if any, of a member function. You should indicate the type/class and the potential use(s) of the return value.@since Interfaces,Classes, MemberFunctions Indicates how long the item has existed, i.e. since JDK 1.1@see ClassName Classes,Interfaces,MemberFunctions, Fields Generates a hypertext link in the documentation to the specified class. You can, and probably should, use a fully qualified class name.@see ClassName#member functionName Classes,Interfaces,MemberFunctions, FieldsGenerates a hypertext link in the documentation tothe specified member function. You can, andprobably should, use a fully qualified class name.@version text Classes,Interfaces Indicates the version information for a given piece of code.The way that you document your code has a huge impact both on your own productivity and on the productivity of everyone else who later maintains and enhances it. By documenting your code early in the development process you become more productive because it forces you to think through your logic before you commit it to code. Furthermore, when you revisit code that you wrote days or weeks earlier you can easily determine what you were thinking when you wrote it – it is documented for you already.1.5 Ambler’s Law of StandardsWhenever possible, reuse standards and guidelines, don’t reinvent them. The greater the scope of the standards and guidelines the more desirable they are, industry standards are more desirable than organizational standards which in turn are more desirable than project standards. Projects aren’t developed in a vacuum and organizations do not operate in a vacuum either, therefore the greater the scope of the standard the greater the chance that somebody else is also following it, making it that much easier for you to work together with them.Ambler’s Law of StandardsIndustry standards > organizational standards > project standards >personal standards > no standardsBlatant Advertising – Purchase The Elements of Java Style today!This book (Vermeulen et. al., 2000) presents a collection of strategies forwriting superior Java source code. This book presents a wider range ofguidelines than what is presented here in this paper, and more importantlypresents excellent source code examples. It covers many topics that are notcovered in this paper, such as type safety issues, exception handling,assertions, and concurrency issues such as synchronization. This paper wascombined with Rogue Wave’s internal coding standards and then togetherwere evolved to become The Elements of Java Style, so you should find thebook to be an excellent next step in your Java learning process. Visit/elementsJavaStyle.html for more details.2. Standards For Member FunctionsI’m a firm believer in maximizing the productivity of systems professionals. Because I also recognize that an application spends the majority of its existence being maintained, not developed, I am very interested in anything that can help to make my code easier to maintain and to enhance, as well as to develop. Never forget that the code that you write today may still be in use many years from now and will likely be maintained and enhanced by somebody other than you. You must strive to make your code as “clean” and understandable as possible, because these factors make it easier to maintain and to enhance.In this section we will concentrate on four topics:•Naming conventions•Visibility•Documentation conventions•Techniques for writing clean Java code2.1 Naming Member FunctionsMember Functions should be named using a full English description, using mixed case with the first letter of any non-initial word capitalized. It is also common practice for the first word of a member function name to be a strong, active verb.Examples:openAccount()printMailingLabel()save()delete()This convention results in member functions whose purpose can often be determined just by looking at its name. Although this convention results in a little extra typing by the developer, because it often results in longer names, this is more than made up for by the increased understandability of your code.2.1.1 Naming Accessor Member FunctionsWe will discuss accessors, member functions that get and set the values of fields (fields/properties) in greater detail in chapter 3. The naming conventions for accessors, however, are summarized below.2.1.1.1 GettersGetters are member functions that return the value of a field. You should prefix the word ‘get’ to the name of the field, unless it is a boolean field and then you prefix ‘is’ to the name of the field instead of ‘get.’Examples:getFirstName()getAccountNumber()getLostEh()isPersistent()isAtEnd()By following this naming convention you make it obvious that a member function returns a field of an object, and for boolean getters you make it obvious that it returns true or false. Another advantage of this standard is that it follows the naming conventions used by the beans development kit (BDK) for getter member functions (DeSoto, 1997). The main disadvantage is that ‘get’ is superfluous, requiring extra typing.2.1.1.1.1 Alternative Naming Convention for Getters – Has and CanA viable alternative, based on proper English conventions, is to use the prefix ‘has’ or ‘can’ instead of ‘is’for boolean getters. For example, getter names such as hasDependents() and canPrint() make a lot of sense when you are reading the code. The problem with this approach is that the BDK will not pick up on this naming strategy (yet). You could rename these member functions isBurdenedWithDependents() and isPrintable(). J2.1.1.2 SettersSetters, also known as mutators, are member functions that modify the values of a field. You should prefix the word ‘set’ to the name of the field, regardless of the field type.Examples:setFirstName(String aName)setAccountNumber(int anAccountNumber)setReasonableGoals(Vector newGoals)setPersistent(boolean isPersistent)setAtEnd(boolean isAtEnd)Following this naming convention you make it obvious that a member function sets the value of a field of an object. Another advantage of this standard is that it follows the naming conventions used by the beans development kit (BDK) for setter member functions (DeSoto, 1997). The main disadvantage is that ‘set’ is superfluous, requiring extra typing.2.1.1.3 ConstructorsConstructors are member functions that perform any necessary initialization when an object is first created. Constructors are always given the same name as their class. For example, a constructor for the class Customer would be Customer(). Note that the same case is used.Examples:Customer()SavingsAccount()PersistenceBroker()This naming convention is set by Sun and must be strictly adhered to.2.2 Member Function VisibilityFor a good design where you minimize the coupling between classes, the general rule of thumb is to be as restrictive as possible when setting the visibility of a member function. If member function doesn’t have to be public then make it protected, and if it doesn’t have to be protected then make it private.Visibility Description Proper Usagepublic A public member function can be invoked byany other member function in any otherobject or class.When the member function must be accessible by objects and classes outside of the class hierarchy in which the member function is defined.protected A protected member function can beinvoked by any member function in the classin which it is defined or any subclasses ofthat class.When the member function provides behavior that is needed internally within the class hierarchy but not externally.private A private member function can only beinvoked by other member functions in theclass in which it is defined, but not in thesubclasses.When the member function provides behavior that is specific to the class. Private member functions are often the result of refactoring, also known as reorganizing, the behavior of other member functions within the class to encapsulate one specific behavior.No visibility is indicated. This is called default or package visibility, and is sometimes referred to as friendly visibility. The member function is effectively public to all other classes within the same package, but private to classes external to the package.This is an interesting feature, but be careful with its use. I use it when I’m building domain components (Ambler, 1998b), collections of classes that implement a cohesive business concept such as “Customer”, to restrict access to only the classes within the component/package.2.3 Documenting Member FunctionsThe manner in which you document a member function will often be the deciding factor as to whether or not it is understandable, and therefore maintainable and extensible.2.3.1 The Member Function HeaderEvery Java member function should include some sort of header, called member function documentation, at the top of the source code that documents all of the information that is critical to understanding it. This information includes, but is not limited to the following:1.What and why the member function does what it does. By documenting what a member function doesyou make it easier for others to determine if they can reuse your code. Documenting why it doessomething makes it easier for others to put your code into context. You also make it easier for others to determine whether or not a new change should actually be made to a piece of code (perhaps the reason for the new change conflicts with the reason why the code was written in the first place).2.What a member function must be passed as parameters. You also need to indicate what parameters, ifany, must be passed to a member function and how they will be used. This information is needed so。
人工智能基础_青岛大学中国大学mooc课后章节答案期末考试题库2023年

人工智能基础_青岛大学中国大学mooc课后章节答案期末考试题库2023年1.AlphoGo在落子选择时用的搜索技术是答案:蒙特卡洛树搜索2.下面关于搜索过程描述错误的是答案:对CLOSED表上的节点进行排序的准则,以便选出一个“最好”的节点作为扩展使用3.以下关于与或树说法错误的是答案:或树中各子节点间用弧链接4.以下关于博弈理论说法错误的是答案:博弈双方均力图选取对自己最为不利的方案5.以下关于说法错误的是答案:剪枝就是在搜索深度不变的情况下,利用已有的搜索信息增加生成的节点数6.关于鲁滨逊归结原理叙述错误的是答案:若子句集S不包含空子句,则称子句集S是可满足的7.下面关于概率分配函数说法错误的是答案:样本空间的概率分配函数值为08.以下关于模糊集合的运算说法错误的是答案:A交B的隶属度等于对应元素隶属度的大者9.以下不是常用的模糊推理模式的是答案:模糊因果推理10.以下哪一项不属于专家系统知识库的建立环节答案:知识排序11.下列属于人工智能的知识表示方法的有答案:状态空间表示法逻辑表示法本体表示法产生式表示法12.状态空间表示法用()和()来表示问题算符状态13.以下情况首选广度优先搜索的有答案:问题的解出现在相对较浅的水平分支因子不是太大没有一条路径是特别深的14.下面关于爬山法叙述正确的是答案:随机选择一个登山的起点每次拿相邻点与当前点进行比对,取两者中较优者,作为爬坡的下一步选择最大点作为本次爬山的顶点,即为该算法获得的最优解重复直至该点的邻近点中不再有比其大的点15.爬山法中可能遇到的问题有山篱问题高原问题山脊问题16.下面关于最佳优先搜索叙述正确的是答案:open表中节点按照节点接近目标状态的启发式估值实现需要open表和closed表不保留重复状态是一种智能搜索算法17.动态规划算法的特点包括答案:使用最优化原理无后效性有重叠子问题18.搜索算法的评价指标包括答案:完备性最优性单调性可接受性19.关于知识表示叙述正确的有答案:知识表示就是把知识形式化或者模型化好的知识表示形式应便于理解知识表示是一种计算机可以接受的数据结构知识表示具有一定的针对性和局限性20.常用的连接词有答案:蕴含析取否定合取21.推理过程中常用的等价性包括答案:德摩根律结合律分配律交换律22.一个良好的规则库应该具有以下哪些特性答案:知识一致表达灵活知识完整组织合理23.模糊集可用的描述方式有答案:图示表示法扎德表示法函数表示法向量表示法24.专家系统中的知识包括答案:知识库级知识数据级知识控制级知识25.专家系统包括答案:推理机综合数据库知识库26.以下哪些情况适合开发为专家系统答案:问题需要使用启发式知识、经验规则才能得到答案问题有一定的实用价值问题可以通过符号操作和符号结构进行求解问题相对较为复杂27.模仿还原就是一个从当前混乱状态寻找路径到达期望即目标状态的过程答案:正确28.如果所求序列可以使得总代价最低,则问题称为最优搜索问题。
A method for obtaining digital signatures and public-key cryptosystems

Key Words and Phrases: digital signatures, public-key cryptosystems, pri-
I Introduction
The era of \electronic mail" 10] may soon be upon us; we must ensure that two important properties of the current \paper mail" system are preserved: (a) messages are private , and (b) messages can be signed . We demonstrate in this paper how to build these capabilities into an electronic mail system. At the heart of our proposal is a new encryption method. This method provides an implementation of a \public-key cryptosystem," an elegant concept invented by Di e and Hellman 1]. Their article motivated our research, since they presented the concept but not any practical implementation of such a system. Readers familiar with 1] may wish to skip directly to Section V for a description of our method.
五种lsat逻辑推理错误解析

五种lsat逻辑推理错误解析我们都知道逻辑错误,一般指思维过程中违反形式逻辑规律的要求和逻辑规则而产生的错误。
如“偷换概念”、“偷换论题”、“自相矛盾”等。
但是你们知道五种lsat逻辑推理错误吗?我们一定明白:逻辑推理:主要是指遵循逻辑规律来分析推理的思路,把不同排列顺序的意识进行相关性的推导就是逻辑推理。
在同一思维过程中,同一个概念或同一个思想对象,必须保持前后一致性,亦即保持确定性,这是逻辑推理的一条重要思维规律。
以下五种典型的逻辑错误,在LSAT逻辑部分最为常见:1. % vs.absolute no.2. representative sample3. necessity vs. sufficency4. correlation vs. causation5. alternative possibility这几种错误是对偶的关系:比如,当看到出现百分比/比例/单位含量等时,首先要想的是绝对数量上的变化,反之亦然,当看到出现绝对数量时,考虑比例上的变化;又如,当人举一个例子,想推而广之,得出一种带有普遍性的结论时(与类比不同,类比是from case to case),就要考虑他举的这个例子具有代表性与否,如果是出现在逻辑错误类型的试题中时,问题往往就出在这里;必要条件与充分条件不用多讲,是到底谁推出谁的问题,充分条件时能合理地推出结论,而必要条件时就不行,题目往往是把两者加以混淆;一般关系与因果关系题,常见的是A after B, therefore B casues A. 其实,两者的关系也许是A cause B,也许是C causes both A and B,或者AB根本没什么关系。
涉及其他可能性的题目,太多了。
其实也与因果有关。
当结论说A causes B,或者隐含了A 就是B的原因时,其假设就是没有其他原因同时起作用。
如果有可能是其他原因在发生作用,说A导致了B就不能保证了。
这种错误往往是忽视了其他某个可能的其他原因。
山东工商学院2022秋季考试_编译原理复习资料_普通用卷

山东工商学院2020学年第一学期编译原理课程试题 A卷(考试时间:120分钟,满分100分)特别提醒:1、所有答案均须填写在答题纸上,写在试题纸上无效。
2、每份答卷上均须准确填写函授站、专业、年级、学号、姓名、课程名称。
一单选题 (共43题,总分值43分 )1. 基本块内的优化为()。
(1 分)A. 代码外提,删除归纳变量B. 删除多余运算,删除无用赋值C. 强度削弱,代码外提D. 循环展开,循环合并2. 若a为终结符,则A->α·a β为()项目。
(1 分)A. 移进B. 归约C. 接受D. 待约3. 优化可生成()的目标代码。
(1 分)A. 运行时间较短B. 运行时间短但占用内存空间大C. 占用存储空间较小D. 运行时间短且占用存储空间小4. 下面哪种不是中间代码?()(1 分)A. 三元式B. 四元式C. 二元式D. 后缀式5. 一个上下文无关文法 G 包括四个组成部分,它们是:一组非终结符号,一组终结符号,一个开始符号,以及一组()。
(1 分)A. 句子B. 句型C. 单词D. 产生式6. 下列()优化方法不是针对循环优化进行的。
(1 分)A. 强度削弱B. 删除归纳变量C. 删除多余运算D. 代码外提7. 文法G[A]:A→ε A→aB B→Ab B→a是()。
(1 分)A. 0型文法B. 1型文法C. 2型文法D. 3型文法8. 在LR分析法中,分析栈中存放的状态是识别规范句型()的 DFA 状态。
(1 分)A. 句柄B. 前缀C. 活前缀D. LR(0) 项目9. 四元式之间的联系是通过()来实现的。
(1 分)A. 指示器B. 临时变量C. 符号表D. 程序变量10. 下面哪种不是中间代码?()(1 分)A. 三元式B. 四元式C. 二元式D. 后缀式11. 若一个文法是递归的,则它所产生的语言的句子是()。
(1 分)A. 无穷多个B. 有穷多个C. 可枚举的D. 个数是常量12. 将编译程序分成若干个“遍”是为了(1 分)A. 提高程序的执行效率B. 使程序的结构更加清晰C. 利用有限的机器内存并提高机器的执行效率D. 利用有限的机器内存但降低了机器的执行效率13. 下列哪种不是代码生成技术?()(1 分)A. 基于多元式B. 基于树结构C. 基于LR(0)D. 基于DAG14. 四元式之间的联系是通过()来实现的。
二分法的英文解释

二分法的英文解释The binary search algorithm is a fundamental concept in computer science and mathematics. It is a powerful and efficient technique used to locate a specific item within a sorted collection of data. In this article, we will delve into the details of the binary search algorithm, exploring its mechanics, applications, and complexities.At its core, the binary search algorithm operates by repeatedly dividing the search interval in half. It begins by comparing the target value with the middle element of the array. If the target value matches the middle element, the search is complete, and the index of the element is returned. If the target value is less than the middle element, the search continues in the lower half of the array. Conversely, if the target value is greater than the middle element, the search proceeds in the upper half of the array. This process is repeated until the target value is found or until the search interval is empty.One of the key requirements for the binary search algorithm to work is that the data collection must be sorted in ascending order. This prerequisite enables the algorithm to exploit the properties of the sorted array, significantly reducing the search space with each iteration. By systematically eliminating half of the remaining elements at each step, binary search achieves a logarithmic time complexity of O(log n), where n is the number of elements in the array. This efficiency makes binary search particularly suitable for large datasets where linear search algorithms would be impractical.The binary search algorithm finds its applications in various domains, including but not limited to:1. Searching: Binary search is commonly used to quickly locate elements in sorted arrays or lists. Its efficiency makes it indispensable for tasks such as searching phone directories, dictionaries, or databases.2. Sorting: While binary search itself is not a sorting algorithm, it can be combined with sorting algorithms like merge sort or quicksort to efficiently search for elements in sorted arrays.3. Computer Science: Binary search serves as a foundational concept in computer science education, providing students with a fundamental understanding of algorithm design and analysis.4. Game Development: Binary search is utilized in game development for tasks such as collision detection, pathfinding, and AI decision-making.Despite its efficiency and versatility, binary search does have certain limitations. One significant constraint is that the data collection must be sorted beforehand, which can incur additional preprocessing overhead. Additionally, binary search is not well-suited for dynamic datasets that frequently change, as maintaining the sorted order becomes non-trivial.In conclusion, the binary search algorithm is a powerful tool for efficiently locating elements within sorted arrays. Its logarithmic time complexity and widespread applications make it a fundamental concept in computer science and mathematics. By dividing the search space in half with each iteration, binary search demonstrates the elegance and efficiency of algorithmic design. Whether used in searching, sorting, or other computational tasks, the binary search algorithm remains a cornerstone of algorithmic problem-solving.。
编译原理第3章课后习题答案

Dtran[I,b] =ε-closure(move(I,b))= ε-closure({5, 16})=G DFA D 的转换表 Dtran NFA 状态 {0,1,2,4,7} {1,2,3,4,6,7,8} {1,2,4,5,6,7} {1,2,4,5,6,7,9} {1,2,4,5,6,7,10,11,12,13,15} {1,2,3,4,6,7,8,12,13,14,15,17,18} {1,2,4,5,6,7, 12,13,15,16,17,18} {1,2,4,5,6,7, 9,12,13,15,16,17,18} {1,2,4,5,6,7, 10,11,12,13,15,16,17,18} 可得 DFA 的如下状态转换图: DFA 状态 A B C D E F G H I a B B B B F F F F F b C D C E G H G I G
3.3.1 给出 3.2.2 中正则表达式所描述的语言的状态转换图。
(1)a( a|b )*a 的状态转换图如下:
(2)
ε
ε a
b
(3)
a
start 0
a a a
1 2
4
b a b
5
b b
3
6
7
(4)a*ba*ba*ba*
a b
a b
a b
a
3.6.3 使用算法 3.25 和 3.20 将下列正则表达式转换成 DFA: (1)
注:consonant 为除五元音外的小写字母,记号 ctnvowels 对应的定义即为题目要求的正则
定义。
(2) 所有由按字典顺序递增序排列的小写字组成的串。 a*b*……z* (3)注释,即/*和*/之间的串,且串中没有不在双引号( “)中的*/。 head——>/* tail ——>*/ * * incomment->(~(*/)|“. ”) comment->head incomment tail (9)所有由 a 和 b 组成且不含有子串 abb 的串。 * * A->b (a︱ab)
Problems marked with a ’ ’ are for CSc 211 students only. ALGORITHM DESIGN AND ANALYSIS

P ROBLEM S ET5CSc136/211,Winter2004Aaron G.Cass Assigned:9February2004Department of Computer Science Due:16February2004Union College Problems marked with a’*’are for CSc211students only.A LGORITHM D ESIGN AND A NALYSIS1.Consider the problem of calculating a n,given a and n.(a)Design a brute-force algorithm for solving this problem,and determine its worst-case runningtime.(b)Design a divide-and-conquer algorithm for solving this problem,and determine its worst-caserunning time.(c)Design a decrease-by-one-and-conquer algorithm for solving this problem,and determine itsworst-case running time.(d)Design a decrease-by-half-and-conquer algorithm for solving this problem,and determine itsworst-case running time.(e)Which of these is better?2.[From[1]§5.5,#1]Design a decrease-by-half algorithm for computing log2n and determine itsworst-case time efficiency.3.*[From[1]§5.1,#9]Binary insertion sort is standard insertion sort except that it uses binary search tofind an appropriate position to insert A[i]among the previously sorted A[0]≤...≤A[i−1].Determine the worst-case efficiency class of this algorithm.4.[From[2]pg.177,#6.19]Given an array of integers A[1..n],such that,for all i,1≤i<n,we have|A[i]−A[i+1]|≤1.Let A[1]=x and A[n]=y,such that x<y.Design an efficient search algorithm to find j such that A[j]=z for a given value z,x≤z≤y.What is the maximal number of comparisons to z that your algorithm makes?5.[From[2]pg.177,#6.22]Given a real number x and a list S of n real numbers,the problem is todetermine whether there are two elements of S whose sum is exactly x.(a)Assuming the list is already sorted,the problem can be solved inΘ(n log n)worst-case time usingbinary search.Give the algorithm for this solution approach.(b)Assuming the list S is already sorted,design an algorithm to solve this problem inΘ(n)worst-case time.(c)Prove that any algorithm solving this problem must have worst-case running time inΩ(n).R EFERENCES[1]Anany Levitin.Introduction to the Design and Analysis of Algorithms.Addison-Wesley,2003.[2]Udi Manber.Introduction to Algorithms:A Creative Approach.Addison-Wesley,1989.19February20041。
《算法导论》习题答案

《算法导论》习题答案Chapter2 Getting Start2.1 Insertion sort2.1.2 将Insertion-Sort重写为按非递减顺序排序2.1.3 计算两个n位的二进制数组之和2.2 Analyzing algorithms2.2.1将函数用符号表示2.2.2写出选择排序算法selection-sort 当前n-1个元素排好序后,第n个元素已经是最大的元素了.最好时间和最坏时间均为2.3 Designing algorithms计算递归方程的解(1) 当时,,显然有T((2) 假设当时公式成立,即,则当,即时,2.3.4 给出insertion sort的递归版本的递归式2.3-6 使用二分查找来替代insertion-sort中while循环j?n;if A[i]+A[j]<xi?i+1elsej?j-1if A[i]+A[j]=xreturn trueelsereturn false时间复杂度为。
或者也可以先固定一个元素然后去二分查找x减去元素的差,复杂度为。
Chapter3 Growth of functions3.1Asymptotic notation3.1.2证明对于b时,对于,时,存在,当时,对于,3.1-4 判断与22n是否等于O(2n)3.1.6 证明如果算法的运行时间为,如果其最坏运行时间为O(g(n)),最佳运行时间为。
最坏时间O(g(n)),即;最佳时间,即3.1.7:证明定义3.2 Standard notation and common functions 3.2.2 证明证明当n>4时,,是否多项式有界~与设lgn=m,则?lgn~不是多项式有界的。
mememmmm2设,,是多项式有界的3.2.5比较lg(lg*n)与lg*(lgn)lg*(lgn)= lg*n-1设lg*n=x,lgx<x-1较大。
THE CACHE INFERENCE PROBLEM and its Application to Content and Request Routing

T HE C ACHE I NFERENCE P ROBLEMand its Application to Content and Request Routing N IKOLAOS L AOUTARIS G EORGIOS Z ERVAS A ZER B ESTAVROS G EORGE K OLLIOS nlaout@ zg@ best@ gkollios@Abstract—In many networked applications,independent caching agents cooperate by servicing each other’s miss streams, without revealing the operational details of the caching mecha-nisms they employ.Inference of such details could be instru-mental for many other processes.For example,it could be used for optimized forwarding(or routing)of one’s own miss stream(or content)to available proxy caches,or for making cache-aware resource management decisions.In this paper,we introduce the Cache Inference Problem(CIP)as that of inferring the characteristics of a caching agent,given the miss stream of that agent.While CIP is insolvable in its most general form,there are special cases of practical importance in which it is,including when the request stream follows an Independent Reference Model (IRM)with generalized power-law(GPL)demand distribution. To that end,we design two basic“litmus”tests that are able to detect LFU and LRU replacement policies,the effective size of the cache and of the object universe,and the skewness of the GPL demand for ing extensive experiments under synthetic as well as real traces,we show that our methods infer such characteristics accurately and quite efficiently,and that they remain robust even when the IRM/GPL assumptions do not hold,and even when the underlying replacement policies are not“pure”LFU or LRU.We exemplify the value of our inference framework by considering example applications.I.I NTRODUCTIONMotivation:Caching is a fundamental building block of computing and networking systems and subsystems.In a given system,multiple caching agents may co-exist to provide a single service or functionality.A canonical example is the use of caching in multiple levels of a memory system to implement the abstraction of a“memory hierarchy”.For distributed systems,the use of caching is paramount: route caches are used to store recently-used IP routing entries and is consulted before routing tables are accessed;route caches are also used in peer-to-peer overlays to cache hub and hub cluster information as well as Globally Unique IDentifiers (GUIDs)to IP translations for content and query routing purposes[1];DNS lookups are cached by DNS resolvers to reduce the load on upper-level DNS servers[2];distributed host caching systems are used in support of P2P networks to allow peers tofind and connect to one another[3];web proxy and reverse proxy caches are used for efficient content distribution and delivery[4],[5],and the list goes on.When multiple caching agents are used to support a single operation,be it a single end-host or a large CDN overlay network,the“design”of such agents is carefully coordinated Computer Science Dept,Boston University,Boston,Massachusetts,USA. Dept of Informatics and Telecommunications,University of Athens,Greece. outaris is supported by a Marie Curie Outgoing International Fellowship of the EU MOIF-CT-2005-007230.A.Bestavros and G.Kollios are supported in part by NSF CNS Cybertrust Award#0524477,CNS NeTS Award #0520166,CNS ITR Award#0205294,and EIA RI Award0202067.to ensure efficient operation.For instance,the size and replace-ment strategies of the caching mechanisms used to implement traditional memory hierarchies are matched up carefully to maximize overall performance under a given workload(typi-cally characterized by reference models or benchmarks).Sim-ilarily,the placement,sizing,and cache replacement schemes used for various proxies in a CDN are carefully coordinated to optimize the content delivery process subject to typically-skewed demand profile from various client populations. Increasingly,however,a system may be forced to rely on one or more caching agents that are not necessarily part of its autonomous domain and as such may benefit from infering the characteristics of such agents.Next,we give a concrete example to motivate the work presented in this paper. Application to Informed Caching Proxy Selection:Consider a web server(or a proxy thereof),which must decide which one of potentially many candidate reverse caching proxies (possibly belonging to competing ISPs)it should use to“front end”its popular content.Clearly,in such a setting,it cannot be assumed that details of the design or policies of such caching agents would be known to(let alone controlled or tuned by) the entity that wishes to use such agents.Yet,it is clear that such knowledge could be quite valuable.For example,given a choice,a web server would be better off selecting a reverse proxy cache with a larger cache size.Alternatively,if the web server needs to partition its content across multiple reverse proxies,it would be better off delegating content that exhibits popularity over long time scales to proxies employing an LFU-like replacement policy,while delegating content that exhibits popularity over shorter time scales to proxies employing an LRU-like replacement policy.Even if the web server has no choice in terms of the reverse caching proxy to use,it may be useful for the web server to ascertain the characteristics of the reference stream served by the caching proxy.The above are examples of how knowledge of the charac-teristics of remote caching agents could empower a server to make judicious ter,in Section VIII,we show how the same information could also empower a client-side caching proxy to make judicious decisions regarding which other caching proxies to use to service its own miss stream.Both of these are examples of Informed Caching Proxy Selection, which has applications in any system that allows autonomous entities theflexibility of selecting from among(or routing content or requests across)multiple remote caching agents. The Cache Inference Problem:In many of the distributed ap-plications and networking systems(to which we have alluded above),a caching agent that receives a request which it cannot service from its local storage redirects(or routes)such requeststo other subsystems–e.g.,another caching agent,or an origin server.Such redirected requests constitute the“miss stream”of the caching agent.Clearly,such a miss stream carries in it information about the caching mechanisms employed by the caching agent.While the subsystems at the receiving end of such miss streams may not be privy to the“design”of the caching agent producing such a miss stream,it is natural to ask whether“Is it possible to use the information contained in a miss stream to infer some of the characteristics of the remote cache that produced that stream?”Accordingly,the most general Cache Inference Problem (CIP)could be stated as follows:“Given the miss stream of a caching agent,infer the replacement policy,the capacity, and the characteristics of the input request stream”.The above question is too unconstrained to be solvable,as it allows arbitrary reference streams as inputs to the cache. Thus,we argue that a more realistic problem statement would be one in which assumptions about common characteristics of the cache reference stream(i.e.,the access pattern)are made.We single out two such assumptions,both of which are empirically justified,commonly made in the literature, and indeed leveraged in many existing systems.Thefirst is that the reference stream follows the Independent Reference Model(IRM)[6],whereas the second is that the demand for objects follows a Generalized Power Law(GPL).As we show in Section II,CIP when subjected to the IRM and GPL assumptions is solvable.As we hinted above,we underscore that the GPL and IRM assumptions on the request stream have substantial empirical justification,making the solution of the CIP problem of significant practical value to many systems.Moreover,as will be evident later in this paper,the solutions we devise for the CIP problem subject to GPL and IRM work well even when the request stream does not satisfy the GPL and IRM assumptions. Beyond Inference of Caching Characteristics:So far,we have framed the scope of our work as that of“infering”the characteristics of an underlying caching agent.While that is the main technical challenge we consider in this paper(with many direct applications),we note that the techniques we develop have much wider applicability and value.In particular, we note that our techniques could be seen as“modeling”as opposed to“inference”tools.For instance,in this paper we provide analytical and numerical approaches that allow us to discern whether an underlying cache uses LFU or LRU replacement.In many instances,however,the underlying cache may be using one of many other more elaborate replace-ment strategies(e.g.,GreedyDual,LRFU,LRU(k),etc.)or replacement strategies that use specific domain knowledge (e.g.,incorporating variable miss penalties,or variable object sizes,or expiration times,etc.).The fact that an underlying cache may be using a replacement strategy other than LFU and LRU does not mean that our techniques cannot be used effectively to build a robust model of the underlying cache. By its nature,a model is a simplifcation or an abstraction of an underlying complex reality,which is useful as long as it exhibits verifiable predictive powers that could assist/inform the processes using such models–e.g.,to inform resource schedulers or resource allocation processes.The inherent value of the techniques we devise in this paper for modeling purposes is an important point that we would like to emphasize at the outset.To drive this point home,we discuss below an example in which modeling an underlying cache could be used for informed resource management. Application to Caching-Aware Resource Management: Consider the operation of a hosting service.Typically,such a service would employ a variety of mechanisms to improve performance and to provide proper allocation of resources across all hosted web sites.For instance,the hosting service may be employing traffic shapers to apportion its out-bound bandwidth across the various web sites to ensure fairness, while at the same time,it may be using a third-party caching network to front-end popular content.For simplicity,consider the case in which two web sites A and B are hosted under equal Service Level Agreements(SLAs).As such,a natural setting for the traffic shaper might be to assign equal out-bound bandwidth to both A and B.Now,assume that web site A features content with a highly-skewed popularity profile and which is accessed with high intensity,whereas web site B features content with a more uniform popularity and which is accessed with equally high ing the techniques we devise in this paper,by observing the miss streams of A and B,the hosting service would be able to construct a“model”of the effective caches for A and B.We emphasize“effective”because in reality,there is no physical separate caches for A and for B,but rather,the caching network is shared by A and B(and possibly many other web sites).In other words, using the techniques we devise in this paper would allow us to construct models of the“virtual”caches for A and ing such models,we may be able to estimate(say)the hit rates and that the caching network delivers for A and B.For instance,given the different cacheability of the workloads for A and B,we may get.Given such knoweldge,the hosting service may opt to alter its traffic shaping decision so as to allocate a larger chunk of the out-bound bandwidth to B to compensate it for its inability to reap the benefits from the caching network.This is an example of caching-aware resource management which benefits from the ability to build effective models of underlying caching processes.1Paper Overview and Contributions:In addition to concisely formulating the cache inference problem in Section II,this paper presents a general framework that allows us to solve these problems in Section III.In Sections IV and V,we develop analytical and numerical approaches that allow us to obtain quite efficient instantiations of our inference procedure for LFU and LRU.In Section VI,we generalize our instanti-ations to allow for the inference of the size of the underlying cache and that of the object universe.In Section VII,we present evidence of the robustness of our inference techniques, using extensive simulations,driven with both synthetic and real traces.In Section VIII,we present experimental results that illustrate the use of our inference techniques for informed request routing.We conclude the paper in Sections IX and X with a summary of related work and on-going research.1The ability to infer the relative benefits from a shared cache in order to inform resource management decisions has been contemplated quite recently for CPU scheduling in emerging multi-core architectures[7],[8].II.P ROBLEM S TATEMENT AND A SSUMPTIONS Consider an object set,where denotes the th unit-sized object.2Now,assume that there exists a client that generates requests for the objects in.Let denote the th request and let indicate that the th request refers to object.The requests constitute the input of a cache memory with space that accommodates up to objects,operating under an unknown replacement policy ALG.3If the requested object is currently cached,then leads to a cache hit,meaning that the requested object can be sent back to the client immediately.If is not currently cached,then leads to a cache miss,meaning that the object has to be fetchedfirst before it can be forwarded to the client,and potentially cached for future use.Let denote the th miss that appears on the“output”of the cache,where by output we mean the communication channel that connects the cache to a subsystem that is able to produce a copy of all requested objects,e.g.,an“origin server”that maintains permanent copies of all objects:if the th miss is due to the th request,.In both cases(hit or miss), a request affects the information maintained for the operation of ALG,and in the case of a miss,it also triggers the eviction of the object currently specified by ALG.Definition1:(CIP)Given:(i1)the miss-stream,,and(i2)the cache size and the object universe size,find:(o1)the input request stream,, and(o2)the replacement policy ALG.If one thinks of ALG as being a function ALG,then CIP amounts to inverting the output and obtaining the input and the function ALG itself.Can the above general CIP be solved?The answer is no.To see that,it suffices to note that even if we were are also given ALG,we still could not infer the’s from the’s and,in fact,we cannot even determine.For instance,consider the case in which some very popular objects appear on the miss-stream only when they are requested for thefirst time and never again as all subsequent requests for them lead to hits.These objects are in effect“invisible”as they can affect and in arbitrary ways that leave no sign in the miss-stream and thus cannot be infered.4Since the general CIP is too unconstrained to be solvable, we lower our ambition,and target more constrained versions that are indeed solvable.Afirst step in this direction is to impose the following assumption(constraint).Assumption1:Requests occur under the Independent Ref-erence Model(IRM):requests are generated independently and follow identical stationary distributions,i.e.,,whereis a Probability Mass Function(PMF)over the object set.2The unit-sized object assumption is a standard one in analytic studies of replacement algorithms[6],[9]to avoid adding0/1-knapsack-type complex-ities to a problem that is already combinatorial.Practically,it is justified on the basis that in many caching systems the objects are much smaller than the available cache size,and that for many applications the objects are indeed of the same size(e.g.,entries in a routing table).3We refer interested readers to[10]for a fairly recent survey of cache replacement strategies.4Similar examples illustrating the insolvability of CIP can be given without having to resort to such pathological cases.The IRM assumption[6]has long being used to characterize cache access patterns[11],[12]by abstracting out the impact of temporal correlations,which was shown in[13]to be minuscule,especially under typical,Zipf-like object popularity profiles.Another justification for making the IRM assumption is that prior work[14]has showed that temporal correlations decrease rapidly with the distance between any two references. Thus,as long as the cache size is not minuscule,temporal correlations do not impact fundamentally the i.i.d.assumption in IRM.Regarding the stationarity assumption of IRM,we note that previous cache modeling and analysis works have assumed that the request distribution is stationary over some long-enough time scale.Moreover,for many application do-mains,this assumption is well supported by measurement and characterization studies.5The IRM assumption makes CIP simpler since rather than identifying the input stream,it suffices to characterize statistically by infering the of the’s.Still,it is easy to see that CIP remains insolvable even in this form(see[15] for details).We,therefore,make one more assumption that makes CIP solvable.Assumption2:The PMF of the requests is a Generalized Power Law(GPL),i.e.,the th most popular object,hereafter (without loss of generality)assumed to be object is re-quested with probability,where is the skewness of the GPL and is a normalization constant.The GPL assumption allows for an exact specification of the input using only a single unknown—the skewness parameter .6Combining the IRM and GPL assumptions leads to the following simpler version of CIP,which we call CIP2.Definition2:(CIP2)Given:(i1)the miss-stream,,and(i2)the cache size and the object universe size,find:(o1)the skewness parameter of the IRM/GPL input,and(o2)the replacement policy ALG.Before concluding this section,we should emphasize that the IRM/GPL assumptions were made to obtain a framework within which the CIP problem becomes solvable using sound analysis and/or numerical methods.However,as we will show in later sections of this paper,the inference techniques we devise are quite robust even when one or both of the IRM and GPL assumptions do not hold.This is an important point that we want to make sure is quite understood at this stage.III.A G ENERAL I NFERENCE F RAMEWORKLet denote the appearance probability of the th most popular object in the miss stream of CIP2—let this be object.For a cache of size,under LFU replacement ,whereas under LRU replacement may assume any value between and,depending on demand skewness and cache size(more details in Section V).In both cases,,where is the indicator function.Below,we present our general inference framework for solving CIP2.It consists of the following three steps:5Obviously,if the demand is non-stationary and radically changing over shorter small time scales,then no analysis can be carried out.6Without the GPL assumption the input introduces unknowns,whereas without the IRM assumption it introduces unknowns,that can be arbitrary many,and even exceed.1.Hypothesis:In this step we hypothesize that a knownreplacement policy ALG operates in the cache.2.Prediction:Subject to the hypothesis above,we want to predict the PMF of the miss stream obtained when ALGoperates on an IRM GPL input request stream.This requires the following:(i)obtain an estimate of the exact skewness of the unknown GPL()input PMF,and(ii)derive the steady-state hit probabilities for different objects under thehypothesized ALG and,i.e.,,.The’s and the’s(corresponding to a GPL())lead to our predicted miss-stream as follows:(1)3.Validation:In this step we compare our predicted PMF to the PMF of the actual(observed)miss stream,and decide whether our hypothesis about ALG was correct.In order to define a similarity measure between and,we view each PMF as a(high-dimensional)vector,and define the distance between them to be the-norm distance between their corre-sponding vectors.Thus,the error between the predicted PMF and the observed one is given by. In this work,unless otherwise stated,we use the-norm.A positive validation implies a solution to CIP2as we would have inferred both the unknown replacement algorithm and the PMF of the input stream,using only the observed miss stream.In the above procedure,the prediction step must be cus-tomized for different ALG s assumed in the hypothesis step. In Sections IV and V,we do so for LFU and LRU,using a combination of analytical and fast numerical methods.The above inference procedure has important advantages over an alternative naive“simulation-based”approach that assumes an and an ALG,performs the corresponding sim-ulation,and then validates the assumptions by comparing the actual and the predicted PMFs.While the overall approach is similar,we take special care to employ analytic or fast numeric techniques where possible and thus avoid time-consuming simulations(mainly for the prediction step).Such advantages will be evident when we present our analytical method for de-riving under LFU,and the corresponding analytical and fast numerical methods for obtaining the predicted miss streams for both LFU and LRU.Needless to say,fast inference is important if it is to be performed in an on-line fashion.IV.T HE P REDICTION S TEP FOR LFUThe main challenge here is to obtain an estimate of by using the observed miss stream of an LFU cache.We start with some known techniques from the literature and then present our own SPAI analytical method.Having obtained the estimate and the corresponding,it is straightforward to construct the predicted PMF of the actual miss stream PMF .This is so because LFU acts as a cut-offfilter on the most-popular objects in the request stream,leading to the following relationship for.(2)A.Existing Methods:MLE,OLS,and RATThere are several methods for estimating the skewness of a power-law distribution through samples of its tail.In this section we will briefly present three popular ones:the Maxi-mum Likelihood Estimator(MLE),the Linear Least Squares (OLS)estimator,and the RAT estimator.MLS and OLS are numeric methods of significant computational complexity, whereas RAT is analytic.The Maximum Likelihood Estimator(MLE):Given a vector of miss stream observations we would like to determine the value of the exponent which maximizes the probability (likelihood)of the sampled data[16].Using the power law input demand,we can derive an equation that can be solved using standard iterative numerical methods and provide an unbiased estimate of[15].An Alternative Analytical Estimator(RAT):MLE is asymptot-ically optimal.In practice we may be interested in obtaining an estimate with a limited number of observations.A(poorer) estimator uses and to get.Equating towe get(3)(4)(5)A Linear Least-Squares Estimator(OLS):Yet another method to estimate is to use linear least-squares estimation on the plot of,i.e.,the PDF of the miss stream.Thisgraphical method is well documented and perhaps one of the most commonly used(e.g.,in[17]).B.SPAI:Our Single Point Analytic Inversion MethodAs its name suggests,SPAI considers a single(measurement)“point”–the appearance frequency of the most popular object in the miss stream of an LFU cache,which is subject to GPL demand with skewness parameter–and uses it to derive an estimate of.A brief overview of SPAI goes as follows:We start with an equation that associates the measured frequency at the miss-stream with the request frequency of the unknown input stream.We use our assumption(that the input is GPL)to substitute all’s by analytic expressions of and.We employ a number of algebraic approximations to transform our initial non-algebraic equation into a polynomial equation of our single unknown .We then obtain a closed-form expression for by solving a corresponding cubic equation obtained by an appropriate truncation of our original polynomial equation.The details are presented next.Number of miss stream observationsαNumber of miss stream observationsαNumber of miss stream observationsαNumber of miss stream observationsαFig.1.SPAI vs MLE,OLS,and RAT on inferring the exponent of a GPL from samples of its tail (objects with rank and higher)shown withconfidence intervals.Using the integral approximationfor the th generalized Harmonic number of order ,,we can write:For large we have ,leading to the followingapproximation.After term re-arrangement,we re-write the last equation as(6)or equivalently aswhere:(7)Expanding the exponential formon around point we get .By substituting in Eq.(7),we get the following master equation :(8)Equation (8)can be approximated through “truncation”,i.e.,by limiting to instead of .For we get a quadraticequation which has one non-zero real solution.Forwe get a cubic equation with two real solutions and we can choose the positive one.Finally,for we get:7(9)At least one of the roots of the cubic equation in the paren-theses of Eq.(9)is real —we select the one in and useit to obtain the skewness parameter through.7Notice that for we actually have a cubic equation of (insidethe parentheses)after factoring out the common term .We can therefore use the cubic formula [18]to obtain a closed-form solution for the unknown .Theoretically we could go even further and consider ,which would put a quartic equation in the parentheses.The solution of the general quartic equation,however,involves very cumbersome formulas for the roots and is marginally valuable since the cubic equation already provides a close approximation as will be demonstrated later on.and the quarticequation is actually as far as we can go because forwe would have a quintic equation in the parentheses for which there does not exist a general solution over the rationals in terms of radicals (the “Abel-Ruffini”theorem).C.SPAI Versus Existing ApproachesWe perform the following experiment in order to compare the performance of SPAI to existing approaches that could be used for the prediction step.We simulate an LFU cache of size ,driven by a input request stream.In Figure 1we plot the estimated skewness obtained from SPAI and the other methods (on the y-axis)for different numbers of miss-stream samples (on the x-axis).We use low ()and high ()skewness,and low and high()relative cache sizes.These results indicate that SPAI performs as well as (and most of the time better than)MLE and OLS,over which it has the additional advantage of being an analytical method ,thus incurring no computational complexity.SPAI’s rival analytical method,RAT,performs much worse.V.T HE P REDICTION S TEP FOR LRUThe steady-state hit probabilities of LRU bear no simple characterization,and this has several consequences on the prediction step of our cache inference framework presented in Section III.First,even if we had ,it is not trivial to derive the ’s (and therefore get the ’s through Eq.(1)).Computing exact steady-state hit probabilities for LRU under IRM is a hard combinatorial problem,for which there exist mostly numerical approximation techniques [19],[20],[21].Second,and most importantly,the steady-state hit probabilities depend on the skewness of the input through a function.Since we do not have a simple analytic expressionfor,it is impossible to invert Eq.(1)and obtain a closed-form expression for ,as with our SPAI method for LFU.Unfortunately,our analytical derivation of [22]cannot be used for this purpose as it involves a complex non-algebraic function 8that leads to a final equation for (through Eq.(1))that admits no simple closed-form solution.In light of the discussion above,our approach for the prediction step for LRU replacement is the following.We resort to a numeric search technique for obtaining ,i.e.,we start with an arbitrary initial value ,computethe corresponding steady-state hit probabilitiesusing either the numeric technique of Dan and Towsley [19],or our own analytical one from [22],and compute the miss probability for each object of the input.Next,we sort these in decreasing popularity to obtain the predicted miss streamand,finally,the error .We then use a local search approach to find the that minimizes the error .8The unknown appearing in complex polynomial and exponential formsover multiple different bases.。
Tikhonov吉洪诺夫正则化

Tikhonov regularizationFrom Wikipedia, the free encyclopediaTikhonov regularization is the most commonly used method of of named for . In , the method is also known as ridge regression . It is related to the for problems.The standard approach to solve an of given as,b Ax =is known as and seeks to minimize the2bAx -where •is the . However, the matrix A may be or yielding a non-unique solution. In order to give preference to a particular solution with desirable properties, the regularization term is included in this minimization:22xb Ax Γ+-for some suitably chosen Tikhonov matrix , Γ. In many cases, this matrix is chosen as the Γ= I , giving preference to solutions with smaller norms. In other cases, operators ., a or a weighted ) may be used to enforce smoothness if the underlying vector is believed to be mostly continuous. This regularizationimproves the conditioning of the problem, thus enabling a numerical solution. An explicit solution, denoted by , is given by:()b A A A xTTT 1ˆ-ΓΓ+=The effect of regularization may be varied via the scale of matrix Γ. For Γ=αI , when α = 0 this reduces to the unregularized least squares solution providedthat (A T A)−1 exists.Contents••••••••Bayesian interpretationAlthough at first the choice of the solution to this regularized problem may look artificial, and indeed the matrix Γseems rather arbitrary, the process can be justified from a . Note that for an ill-posed problem one must necessarily introduce some additional assumptions in order to get a stable solution.Statistically we might assume that we know that x is a random variable with a . For simplicity we take the mean to be zero and assume that each component isindependent with σx. Our data is also subject to errors, and we take the errorsin b to be also with zero mean and standard deviation σb. Under these assumptions the Tikhonov-regularized solution is the solution given the dataand the a priori distribution of x, according to . The Tikhonov matrix is then Γ=αI for Tikhonov factor α = σb/ σx.If the assumption of is replaced by assumptions of and uncorrelatedness of , and still assume zero mean, then the entails that the solution is minimal . Generalized Tikhonov regularizationFor general multivariate normal distributions for x and the data error, one can apply a transformation of the variables to reduce to the case above. Equivalently,one can seek an x to minimize22Q P x x b Ax -+-where we have used 2P x to stand for the weighted norm x T Px (cf. the ). In the Bayesian interpretation P is the inverse of b , x 0 is the of x , and Q is the inverse covariance matrix of x . The Tikhonov matrix is then given as a factorization of the matrix Q = ΓT Γ. the ), and is considered a . This generalized problem can be solved explicitly using the formula()()010Ax b P A QPA A x T T-++-[] Regularization in Hilbert spaceTypically discrete linear ill-conditioned problems result as discretization of , and one can formulate Tikhonov regularization in the original infinite dimensional context. In the above we can interpret A as a on , and x and b as elements in the domain and range of A . The operator ΓΓ+T A A *is then a bounded invertible operator.Relation to singular value decomposition and Wiener filterWith Γ= αI , this least squares solution can be analyzed in a special way viathe . Given the singular value decomposition of AT V U A ∑=with singular values σi , the Tikhonov regularized solution can be expressed asb VDU xT =ˆ where D has diagonal values22ασσ+=i i ii Dand is zero elsewhere. This demonstrates the effect of the Tikhonov parameteron the of the regularized problem. For the generalized case a similar representation can be derived using a . Finally, it is related to the :∑==qi iiT i i v bu f x1ˆσwhere the Wiener weights are 222ασσ+=i i i f and q is the of A .Determination of the Tikhonov factorThe optimal regularization parameter α is usually unknown and often in practical problems is determined by an ad hoc method. A possible approach relies on the Bayesian interpretation described above. Other approaches include the , , , and . proved that the optimal parameter, in the sense of minimizes:()()[]21222ˆTTXIX XX I Tr y X RSSG -+--==αβτwhereis the and τ is the effective number .Using the previous SVD decomposition, we can simplify the above expression:()()21'22221'∑∑==++-=qi iiiqi iiub u ub u y RSS ασα()21'2220∑=++=qi iiiub u RSS RSS ασαand∑∑==++-=+-=qi iqi i i q m m 12221222ασαασστRelation to probabilistic formulationThe probabilistic formulation of an introduces (when all uncertainties are Gaussian) a covariance matrix C M representing the a priori uncertainties on the model parameters, and a covariance matrix C D representing the uncertainties on the observed parameters (see, for instance, Tarantola, 2004 ). In the special case when these two matrices are diagonal and isotropic,and, and, in this case, the equations of inverse theory reduce to theequations above, with α = σD / σM .HistoryTikhonov regularization has been invented independently in many differentcontexts. It became widely known from its application to integral equations from the work of and D. L. Phillips. Some authors use the term Tikhonov-Phillips regularization . The finite dimensional case was expounded by A. E. Hoerl, who took a statistical approach, and by M. Foster, who interpreted this method as a - filter. Following Hoerl, it is known in the statistical literature as ridge regression .[] References•(1943). "Об устойчивости обратных задач [On the stability of inverse problems]". 39 (5): 195–198.•Tychonoff, A. N. (1963). "О решении некорректно поставленных задач и методе регуляризации [Solution of incorrectly formulated problems and the regularization method]". Doklady Akademii Nauk SSSR151:501–504.. Translated in Soviet Mathematics4: 1035–1038. •Tychonoff, A. N.; V. Y. Arsenin (1977). Solution of Ill-posed Problems.Washington: Winston & Sons. .•Hansen, ., 1998, Rank-deficient and Discrete ill-posed problems, SIAM •Hoerl AE, 1962, Application of ridge analysis to regression problems, Chemical Engineering Progress, 58, 54-59.•Foster M, 1961, An application of the Wiener-Kolmogorov smoothing theory to matrix inversion, J. SIAM, 9, 387-392•Phillips DL, 1962, A technique for the numerical solution of certain integral equations of the first kind, J Assoc Comput Mach, 9, 84-97•Tarantola A, 2004, Inverse Problem Theory (), Society for Industrial and Applied Mathematics,•Wahba, G, 1990, Spline Models for Observational Data, Society for Industrial and Applied Mathematics。
编译原理 第二版 第三章课后答案

第三章作业第三章作业答案P47 练习1、文法G=({A,B,S},{a,b,c},P,S),其中P为:S->Ac|aB A->ab B->bc写出L(G [S])的全部元素。
S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2、文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?【解】N=>ND=>NDD.... =>NDDDD...D=>D......DG[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}或:解: N ND n-1D n{0,1,3,4,5,6,7,8,9}+∴L(G[N])= {0,1,3,4,5,6,7,8,9}+5.写一文法,使其语言是偶正数的集合。
要求:(1)允许0打头(2)不允许0打头【解】(1)允许0开头的偶正整数集合的文法E->NT|G|SFMT->NT|GN->D|1|3|5|7|9D->0|GG->2|4|6|8S->NS|εF->1|3|5|7|9|GM->M0|0(2)不允许0开头的偶正整数集合的文法E->NT|DT->FT|GN->D|1|3|5|7|9D->2|4|6|8F->N|0G->D|09.考虑下面上下文无关文法:S→SS*|SS+|a(1) 表明通过此文法如何生成串aa+a*,并为该串构造推导树。
(2) 该文法生成的语言是什么?【解】(1) S=>SS*=>SS+S*aa+a*该串的推导树如下:(2) 该文法生成的语言是只含+、*的算术表达式的逆波兰表示。
11.令文法G[E]为:E→T|E+T|E-TT→F|T*F|T/FF→(E)|i证明E+T*F是它的一个句型,指出这个句型的所有短语、直接短语和句柄。
ACM-GIS%202006-A%20Peer-to-Peer%20Spatial%20Cloaking%20Algorithm%20for%20Anonymous%20Location-based%

A Peer-to-Peer Spatial Cloaking Algorithm for AnonymousLocation-based Services∗Chi-Yin Chow Department of Computer Science and Engineering University of Minnesota Minneapolis,MN cchow@ Mohamed F.MokbelDepartment of ComputerScience and EngineeringUniversity of MinnesotaMinneapolis,MNmokbel@Xuan LiuIBM Thomas J.WatsonResearch CenterHawthorne,NYxuanliu@ABSTRACTThis paper tackles a major privacy threat in current location-based services where users have to report their ex-act locations to the database server in order to obtain their desired services.For example,a mobile user asking about her nearest restaurant has to report her exact location.With untrusted service providers,reporting private location in-formation may lead to several privacy threats.In this pa-per,we present a peer-to-peer(P2P)spatial cloaking algo-rithm in which mobile and stationary users can entertain location-based services without revealing their exact loca-tion information.The main idea is that before requesting any location-based service,the mobile user will form a group from her peers via single-hop communication and/or multi-hop routing.Then,the spatial cloaked area is computed as the region that covers the entire group of peers.Two modes of operations are supported within the proposed P2P spa-tial cloaking algorithm,namely,the on-demand mode and the proactive mode.Experimental results show that the P2P spatial cloaking algorithm operated in the on-demand mode has lower communication cost and better quality of services than the proactive mode,but the on-demand incurs longer response time.Categories and Subject Descriptors:H.2.8[Database Applications]:Spatial databases and GISGeneral Terms:Algorithms and Experimentation. Keywords:Mobile computing,location-based services,lo-cation privacy and spatial cloaking.1.INTRODUCTIONThe emergence of state-of-the-art location-detection de-vices,e.g.,cellular phones,global positioning system(GPS) devices,and radio-frequency identification(RFID)chips re-sults in a location-dependent information access paradigm,∗This work is supported in part by the Grants-in-Aid of Re-search,Artistry,and Scholarship,University of Minnesota. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on thefirst page.To copy otherwise,to republish,to post on servers or to redistribute to lists,requires prior specific permission and/or a fee.ACM-GIS’06,November10-11,2006,Arlington,Virginia,USA. Copyright2006ACM1-59593-529-0/06/0011...$5.00.known as location-based services(LBS)[30].In LBS,mobile users have the ability to issue location-based queries to the location-based database server.Examples of such queries include“where is my nearest gas station”,“what are the restaurants within one mile of my location”,and“what is the traffic condition within ten minutes of my route”.To get the precise answer of these queries,the user has to pro-vide her exact location information to the database server. With untrustworthy servers,adversaries may access sensi-tive information about specific individuals based on their location information and issued queries.For example,an adversary may check a user’s habit and interest by knowing the places she visits and the time of each visit,or someone can track the locations of his ex-friends.In fact,in many cases,GPS devices have been used in stalking personal lo-cations[12,39].To tackle this major privacy concern,three centralized privacy-preserving frameworks are proposed for LBS[13,14,31],in which a trusted third party is used as a middleware to blur user locations into spatial regions to achieve k-anonymity,i.e.,a user is indistinguishable among other k−1users.The centralized privacy-preserving frame-work possesses the following shortcomings:1)The central-ized trusted third party could be the system bottleneck or single point of failure.2)Since the centralized third party has the complete knowledge of the location information and queries of all users,it may pose a serious privacy threat when the third party is attacked by adversaries.In this paper,we propose a peer-to-peer(P2P)spatial cloaking algorithm.Mobile users adopting the P2P spatial cloaking algorithm can protect their privacy without seeking help from any centralized third party.Other than the short-comings of the centralized approach,our work is also moti-vated by the following facts:1)The computation power and storage capacity of most mobile devices have been improv-ing at a fast pace.2)P2P communication technologies,such as IEEE802.11and Bluetooth,have been widely deployed.3)Many new applications based on P2P information shar-ing have rapidly taken shape,e.g.,cooperative information access[9,32]and P2P spatio-temporal query processing[20, 24].Figure1gives an illustrative example of P2P spatial cloak-ing.The mobile user A wants tofind her nearest gas station while beingfive anonymous,i.e.,the user is indistinguish-able amongfive users.Thus,the mobile user A has to look around andfind other four peers to collaborate as a group. In this example,the four peers are B,C,D,and E.Then, the mobile user A cloaks her exact location into a spatialA B CDEBase Stationregion that covers the entire group of mobile users A ,B ,C ,D ,and E .The mobile user A randomly selects one of the mobile users within the group as an agent .In the ex-ample given in Figure 1,the mobile user D is selected as an agent.Then,the mobile user A sends her query (i.e.,what is the nearest gas station)along with her cloaked spa-tial region to the agent.The agent forwards the query to the location-based database server through a base station.Since the location-based database server processes the query based on the cloaked spatial region,it can only give a list of candidate answers that includes the actual answers and some false positives.After the agent receives the candidate answers,it forwards the candidate answers to the mobile user A .Finally,the mobile user A gets the actual answer by filtering out all the false positives.The proposed P2P spatial cloaking algorithm can operate in two modes:on-demand and proactive .In the on-demand mode,mobile clients execute the cloaking algorithm when they need to access information from the location-based database server.On the other side,in the proactive mode,mobile clients periodically look around to find the desired number of peers.Thus,they can cloak their exact locations into spatial regions whenever they want to retrieve informa-tion from the location-based database server.In general,the contributions of this paper can be summarized as follows:1.We introduce a distributed system architecture for pro-viding anonymous location-based services (LBS)for mobile users.2.We propose the first P2P spatial cloaking algorithm for mobile users to entertain high quality location-based services without compromising their privacy.3.We provide experimental evidence that our proposed algorithm is efficient in terms of the response time,is scalable to large numbers of mobile clients,and is effective as it provides high-quality services for mobile clients without the need of exact location information.The rest of this paper is organized as follows.Section 2highlights the related work.The system model of the P2P spatial cloaking algorithm is presented in Section 3.The P2P spatial cloaking algorithm is described in Section 4.Section 5discusses the integration of the P2P spatial cloak-ing algorithm with privacy-aware location-based database servers.Section 6depicts the experimental evaluation of the P2P spatial cloaking algorithm.Finally,Section 7con-cludes this paper.2.RELATED WORKThe k -anonymity model [37,38]has been widely used in maintaining privacy in databases [5,26,27,28].The main idea is to have each tuple in the table as k -anonymous,i.e.,indistinguishable among other k −1tuples.Although we aim for the similar k -anonymity model for the P2P spatial cloaking algorithm,none of these techniques can be applied to protect user privacy for LBS,mainly for the following four reasons:1)These techniques preserve the privacy of the stored data.In our model,we aim not to store the data at all.Instead,we store perturbed versions of the data.Thus,data privacy is managed before storing the data.2)These approaches protect the data not the queries.In anonymous LBS,we aim to protect the user who issues the query to the location-based database server.For example,a mobile user who wants to ask about her nearest gas station needs to pro-tect her location while the location information of the gas station is not protected.3)These approaches guarantee the k -anonymity for a snapshot of the database.In LBS,the user location is continuously changing.Such dynamic be-havior calls for continuous maintenance of the k -anonymity model.(4)These approaches assume a unified k -anonymity requirement for all the stored records.In our P2P spatial cloaking algorithm,k -anonymity is a user-specified privacy requirement which may have a different value for each user.Motivated by the privacy threats of location-detection de-vices [1,4,6,40],several research efforts are dedicated to protect the locations of mobile users (e.g.,false dummies [23],landmark objects [18],and location perturbation [10,13,14]).The most closed approaches to ours are two centralized spatial cloaking algorithms,namely,the spatio-temporal cloaking [14]and the CliqueCloak algorithm [13],and one decentralized privacy-preserving algorithm [23].The spatio-temporal cloaking algorithm [14]assumes that all users have the same k -anonymity requirements.Furthermore,it lacks the scalability because it deals with each single request of each user individually.The CliqueCloak algorithm [13]as-sumes a different k -anonymity requirement for each user.However,since it has large computation overhead,it is lim-ited to a small k -anonymity requirement,i.e.,k is from 5to 10.A decentralized privacy-preserving algorithm is proposed for LBS [23].The main idea is that the mobile client sends a set of false locations,called dummies ,along with its true location to the location-based database server.However,the disadvantages of using dummies are threefold.First,the user has to generate realistic dummies to pre-vent the adversary from guessing its true location.Second,the location-based database server wastes a lot of resources to process the dummies.Finally,the adversary may esti-mate the user location by using cellular positioning tech-niques [34],e.g.,the time-of-arrival (TOA),the time differ-ence of arrival (TDOA)and the direction of arrival (DOA).Although several existing distributed group formation al-gorithms can be used to find peers in a mobile environment,they are not designed for privacy preserving in LBS.Some algorithms are limited to only finding the neighboring peers,e.g.,lowest-ID [11],largest-connectivity (degree)[33]and mobility-based clustering algorithms [2,25].When a mo-bile user with a strict privacy requirement,i.e.,the value of k −1is larger than the number of neighboring peers,it has to enlist other peers for help via multi-hop routing.Other algorithms do not have this limitation,but they are designed for grouping stable mobile clients together to facil-Location-based Database ServerDatabase ServerDatabase ServerFigure 2:The system architectureitate efficient data replica allocation,e.g.,dynamic connec-tivity based group algorithm [16]and mobility-based clus-tering algorithm,called DRAM [19].Our work is different from these approaches in that we propose a P2P spatial cloaking algorithm that is dedicated for mobile users to dis-cover other k −1peers via single-hop communication and/or via multi-hop routing,in order to preserve user privacy in LBS.3.SYSTEM MODELFigure 2depicts the system architecture for the pro-posed P2P spatial cloaking algorithm which contains two main components:mobile clients and location-based data-base server .Each mobile client has its own privacy profile that specifies its desired level of privacy.A privacy profile includes two parameters,k and A min ,k indicates that the user wants to be k -anonymous,i.e.,indistinguishable among k users,while A min specifies the minimum resolution of the cloaked spatial region.The larger the value of k and A min ,the more strict privacy requirements a user needs.Mobile users have the ability to change their privacy profile at any time.Our employed privacy profile matches the privacy re-quirements of mobiles users as depicted by several social science studies (e.g.,see [4,15,17,22,29]).In this architecture,each mobile user is equipped with two wireless network interface cards;one of them is dedicated to communicate with the location-based database server through the base station,while the other one is devoted to the communication with other peers.A similar multi-interface technique has been used to implement IP multi-homing for stream control transmission protocol (SCTP),in which a machine is installed with multiple network in-terface cards,and each assigned a different IP address [36].Similarly,in mobile P2P cooperation environment,mobile users have a network connection to access information from the server,e.g.,through a wireless modem or a base station,and the mobile users also have the ability to communicate with other peers via a wireless LAN,e.g.,IEEE 802.11or Bluetooth [9,24,32].Furthermore,each mobile client is equipped with a positioning device, e.g.,GPS or sensor-based local positioning systems,to determine its current lo-cation information.4.P2P SPATIAL CLOAKINGIn this section,we present the data structure and the P2P spatial cloaking algorithm.Then,we describe two operation modes of the algorithm:on-demand and proactive .4.1Data StructureThe entire system area is divided into grid.The mobile client communicates with each other to discover other k −1peers,in order to achieve the k -anonymity requirement.TheAlgorithm 1P2P Spatial Cloaking:Request Originator m 1:Function P2PCloaking-Originator (h ,k )2://Phase 1:Peer searching phase 3:The hop distance h is set to h4:The set of discovered peers T is set to {∅},and the number ofdiscovered peers k =|T |=05:while k <k −1do6:Broadcast a FORM GROUP request with the parameter h (Al-gorithm 2gives the response of each peer p that receives this request)7:T is the set of peers that respond back to m by executingAlgorithm 28:k =|T |;9:if k <k −1then 10:if T =T then 11:Suspend the request 12:end if 13:h ←h +1;14:T ←T ;15:end if 16:end while17://Phase 2:Location adjustment phase 18:for all T i ∈T do19:|mT i .p |←the greatest possible distance between m and T i .pby considering the timestamp of T i .p ’s reply and maximum speed20:end for21://Phase 3:Spatial cloaking phase22:Form a group with k −1peers having the smallest |mp |23:h ←the largest hop distance h p of the selected k −1peers 24:Determine a grid area A that covers the entire group 25:if A <A min then26:Extend the area of A till it covers A min 27:end if28:Randomly select a mobile client of the group as an agent 29:Forward the query and A to the agentmobile client can thus blur its exact location into a cloaked spatial region that is the minimum grid area covering the k −1peers and itself,and satisfies A min as well.The grid area is represented by the ID of the left-bottom and right-top cells,i.e.,(l,b )and (r,t ).In addition,each mobile client maintains a parameter h that is the required hop distance of the last peer searching.The initial value of h is equal to one.4.2AlgorithmFigure 3gives a running example for the P2P spatial cloaking algorithm.There are 15mobile clients,m 1to m 15,represented as solid circles.m 8is the request originator,other black circles represent the mobile clients received the request from m 8.The dotted circles represent the commu-nication range of the mobile client,and the arrow represents the movement direction.Algorithms 1and 2give the pseudo code for the request originator (denoted as m )and the re-quest receivers (denoted as p ),respectively.In general,the algorithm consists of the following three phases:Phase 1:Peer searching phase .The request origina-tor m wants to retrieve information from the location-based database server.m first sets h to h ,a set of discovered peers T to {∅}and the number of discovered peers k to zero,i.e.,|T |.(Lines 3to 4in Algorithm 1).Then,m broadcasts a FORM GROUP request along with a message sequence ID and the hop distance h to its neighboring peers (Line 6in Algorithm 1).m listens to the network and waits for the reply from its neighboring peers.Algorithm 2describes how a peer p responds to the FORM GROUP request along with a hop distance h and aFigure3:P2P spatial cloaking algorithm.Algorithm2P2P Spatial Cloaking:Request Receiver p1:Function P2PCloaking-Receiver(h)2://Let r be the request forwarder3:if the request is duplicate then4:Reply r with an ACK message5:return;6:end if7:h p←1;8:if h=1then9:Send the tuple T=<p,(x p,y p),v maxp ,t p,h p>to r10:else11:h←h−1;12:Broadcast a FORM GROUP request with the parameter h 13:T p is the set of peers that respond back to p14:for all T i∈T p do15:T i.h p←T i.h p+1;16:end for17:T p←T p∪{<p,(x p,y p),v maxp ,t p,h p>};18:Send T p back to r19:end ifmessage sequence ID from another peer(denoted as r)that is either the request originator or the forwarder of the re-quest.First,p checks if it is a duplicate request based on the message sequence ID.If it is a duplicate request,it sim-ply replies r with an ACK message without processing the request.Otherwise,p processes the request based on the value of h:Case1:h= 1.p turns in a tuple that contains its ID,current location,maximum movement speed,a timestamp and a hop distance(it is set to one),i.e.,< p,(x p,y p),v max p,t p,h p>,to r(Line9in Algorithm2). Case2:h> 1.p decrements h and broadcasts the FORM GROUP request with the updated h and the origi-nal message sequence ID to its neighboring peers.p keeps listening to the network,until it collects the replies from all its neighboring peers.After that,p increments the h p of each collected tuple,and then it appends its own tuple to the collected tuples T p.Finally,it sends T p back to r (Lines11to18in Algorithm2).After m collects the tuples T from its neighboring peers, if m cannotfind other k−1peers with a hop distance of h,it increments h and re-broadcasts the FORM GROUP request along with a new message sequence ID and h.m repeatedly increments h till itfinds other k−1peers(Lines6to14in Algorithm1).However,if mfinds the same set of peers in two consecutive broadcasts,i.e.,with hop distances h and h+1,there are not enough connected peers for m.Thus, m has to relax its privacy profile,i.e.,use a smaller value of k,or to be suspended for a period of time(Line11in Algorithm1).Figures3(a)and3(b)depict single-hop and multi-hop peer searching in our running example,respectively.In Fig-ure3(a),the request originator,m8,(e.g.,k=5)canfind k−1peers via single-hop communication,so m8sets h=1. Since h=1,its neighboring peers,m5,m6,m7,m9,m10, and m11,will not further broadcast the FORM GROUP re-quest.On the other hand,in Figure3(b),m8does not connect to k−1peers directly,so it has to set h>1.Thus, its neighboring peers,m7,m10,and m11,will broadcast the FORM GROUP request along with a decremented hop dis-tance,i.e.,h=h−1,and the original message sequence ID to their neighboring peers.Phase2:Location adjustment phase.Since the peer keeps moving,we have to capture the movement between the time when the peer sends its tuple and the current time. For each received tuple from a peer p,the request originator, m,determines the greatest possible distance between them by an equation,|mp |=|mp|+(t c−t p)×v max p,where |mp|is the Euclidean distance between m and p at time t p,i.e.,|mp|=(x m−x p)2+(y m−y p)2,t c is the currenttime,t p is the timestamp of the tuple and v maxpis the maximum speed of p(Lines18to20in Algorithm1).In this paper,a conservative approach is used to determine the distance,because we assume that the peer will move with the maximum speed in any direction.If p gives its movement direction,m has the ability to determine a more precise distance between them.Figure3(c)illustrates that,for each discovered peer,the circle represents the largest region where the peer can lo-cate at time t c.The greatest possible distance between the request originator m8and its discovered peer,m5,m6,m7, m9,m10,or m11is represented by a dotted line.For exam-ple,the distance of the line m8m 11is the greatest possible distance between m8and m11at time t c,i.e.,|m8m 11|. Phase3:Spatial cloaking phase.In this phase,the request originator,m,forms a virtual group with the k−1 nearest peers,based on the greatest possible distance be-tween them(Line22in Algorithm1).To adapt to the dynamic network topology and k-anonymity requirement, m sets h to the largest value of h p of the selected k−1 peers(Line15in Algorithm1).Then,m determines the minimum grid area A covering the entire group(Line24in Algorithm1).If the area of A is less than A min,m extends A,until it satisfies A min(Lines25to27in Algorithm1). Figure3(c)gives the k−1nearest peers,m6,m7,m10,and m11to the request originator,m8.For example,the privacy profile of m8is(k=5,A min=20cells),and the required cloaked spatial region of m8is represented by a bold rectan-gle,as depicted in Figure3(d).To issue the query to the location-based database server anonymously,m randomly selects a mobile client in the group as an agent(Line28in Algorithm1).Then,m sendsthe query along with the cloaked spatial region,i.e.,A,to the agent(Line29in Algorithm1).The agent forwards thequery to the location-based database server.After the serverprocesses the query with respect to the cloaked spatial re-gion,it sends a list of candidate answers back to the agent.The agent forwards the candidate answer to m,and then mfilters out the false positives from the candidate answers. 4.3Modes of OperationsThe P2P spatial cloaking algorithm can operate in twomodes,on-demand and proactive.The on-demand mode:The mobile client only executesthe algorithm when it needs to retrieve information from the location-based database server.The algorithm operatedin the on-demand mode generally incurs less communica-tion overhead than the proactive mode,because the mobileclient only executes the algorithm when necessary.However,it suffers from a longer response time than the algorithm op-erated in the proactive mode.The proactive mode:The mobile client adopting theproactive mode periodically executes the algorithm in back-ground.The mobile client can cloak its location into a spa-tial region immediately,once it wants to communicate withthe location-based database server.The proactive mode pro-vides a better response time than the on-demand mode,but it generally incurs higher communication overhead and giveslower quality of service than the on-demand mode.5.ANONYMOUS LOCATION-BASEDSERVICESHaving the spatial cloaked region as an output form Algo-rithm1,the mobile user m sends her request to the location-based server through an agent p that is randomly selected.Existing location-based database servers can support onlyexact point locations rather than cloaked regions.In or-der to be able to work with a spatial region,location-basedservers need to be equipped with a privacy-aware queryprocessor(e.g.,see[29,31]).The main idea of the privacy-aware query processor is to return a list of candidate answerrather than the exact query answer.Then,the mobile user m willfilter the candidate list to eliminate its false positives andfind its exact answer.The tighter the spatial cloaked re-gion,the lower is the size of the candidate answer,and hencethe better is the performance of the privacy-aware query processor.However,tight cloaked regions may represent re-laxed privacy constrained.Thus,a trade-offbetween the user privacy and the quality of service can be achieved[31]. Figure4(a)depicts such scenario by showing the data stored at the server side.There are32target objects,i.e., gas stations,T1to T32represented as black circles,the shaded area represents the spatial cloaked area of the mo-bile client who issued the query.For clarification,the actual mobile client location is plotted in Figure4(a)as a black square inside the cloaked area.However,such information is neither stored at the server side nor revealed to the server. The privacy-aware query processor determines a range that includes all target objects that are possibly contributing to the answer given that the actual location of the mobile client could be anywhere within the shaded area.The range is rep-resented as a bold rectangle,as depicted in Figure4(b).The server sends a list of candidate answers,i.e.,T8,T12,T13, T16,T17,T21,and T22,back to the agent.The agent next for-(a)Server Side(b)Client SideFigure4:Anonymous location-based services wards the candidate answers to the requesting mobile client either through single-hop communication or through multi-hop routing.Finally,the mobile client can get the actualanswer,i.e.,T13,byfiltering out the false positives from thecandidate answers.The algorithmic details of the privacy-aware query proces-sor is beyond the scope of this paper.Interested readers are referred to[31]for more details.6.EXPERIMENTAL RESULTSIn this section,we evaluate and compare the scalabilityand efficiency of the P2P spatial cloaking algorithm in boththe on-demand and proactive modes with respect to the av-erage response time per query,the average number of mes-sages per query,and the size of the returned candidate an-swers from the location-based database server.The queryresponse time in the on-demand mode is defined as the timeelapsed between a mobile client starting to search k−1peersand receiving the candidate answers from the agent.On theother hand,the query response time in the proactive mode is defined as the time elapsed between a mobile client startingto forward its query along with the cloaked spatial regionto the agent and receiving the candidate answers from theagent.The simulation model is implemented in C++usingCSIM[35].In all the experiments in this section,we consider an in-dividual random walk model that is based on“random way-point”model[7,8].At the beginning,the mobile clientsare randomly distributed in a spatial space of1,000×1,000square meters,in which a uniform grid structure of100×100cells is constructed.Each mobile client randomly chooses itsown destination in the space with a randomly determined speed s from a uniform distribution U(v min,v max).When the mobile client reaches the destination,it comes to a stand-still for one second to determine its next destination.Afterthat,the mobile client moves towards its new destinationwith another speed.All the mobile clients repeat this move-ment behavior during the simulation.The time interval be-tween two consecutive queries generated by a mobile client follows an exponential distribution with a mean of ten sec-onds.All the experiments consider one half-duplex wirelesschannel for a mobile client to communicate with its peers with a total bandwidth of2Mbps and a transmission range of250meters.When a mobile client wants to communicate with other peers or the location-based database server,it has to wait if the requested channel is busy.In the simulated mobile environment,there is a centralized location-based database server,and one wireless communication channel between the location-based database server and the mobile。
lvq算法基本原理

lvq算法基本原理
LVQ(Learning Vector Quantization)算法是一种监督学习算法,用于模式识别和分类任务。
其基本原理是通过学习一组原型向
量(也称为参考向量)来表示不同类别的数据,从而实现模式分类。
LVQ算法的基本原理可以分为以下几个步骤:
1. 初始化,首先,需要初始化一组原型向量,这些向量通常是
从训练数据中随机选择的。
每个原型向量代表一个类别。
2. 训练过程,在训练过程中,LVQ算法会遍历训练数据集中的
每个样本,并计算每个样本与原型向量的相似度。
相似度通常使用
欧氏距离或者余弦相似度来衡量。
然后,算法会找到与样本最相似
的原型向量,并根据样本的类别标签和原型向量的类别标签来更新
最相似的原型向量。
如果样本被错误分类,那么最相似的原型向量
会向样本移动,从而更好地代表该类别。
如果样本被正确分类,那
么最相似的原型向量会远离样本,以确保不会过拟合。
3. 调整学习率,在训练过程中,通常会使用学习率来控制原型
向量的移动步长。
学习率可以随着训练的进行而逐渐减小,以确保
收敛到最优解。
4. 分类,一旦完成训练,LVQ算法就可以用于对新样本进行分类。
对于新样本,算法会计算其与每个原型向量的相似度,并将其分类为与之最相似的原型向量所代表的类别。
总的来说,LVQ算法通过不断调整原型向量来逼近训练数据,从而实现对新样本的准确分类。
它是一种简单而有效的分类算法,特别适用于小型数据集和低维特征空间。
朴素贝叶斯推导

朴素贝叶斯推导引言朴素贝叶斯(Naive Bayes)是一种常用的机器学习算法,特别适用于文本分类、垃圾邮件过滤等任务。
本文将对朴素贝叶斯算法进行推导,从数学原理到具体应用进行详细介绍。
贝叶斯定理贝叶斯定理是朴素贝叶斯算法的基础,它描述了在已知后验概率的条件下,如何计算前验概率。
贝叶斯定理的数学公式如下:P(A|B)=P(B|A)P(A)P(B)其中: - P(A|B)是在事件 B 发生的条件下事件 A 发生的概率,也称为后验概率; - P(B|A)是在事件 A 发生的条件下事件 B 发生的概率; - P(A)是事件A 发生的前验概率; - P(B)是事件B 发生的概率。
朴素贝叶斯分类器朴素贝叶斯分类器是基于贝叶斯定理的一种分类算法。
它假设所有特征之间相互独立,即给定类别的情况下,特征之间是条件独立的。
这个假设在实际应用中可能并不成立,但由于其简单性和高效性,朴素贝叶斯分类器仍然是一种常用的分类算法。
朴素贝叶斯分类器的基本思想是给定一个待分类的样本,在已知各个特征的条件下,计算样本属于每个类别的概率,然后选择具有最大概率的类别作为样本的分类结果。
朴素贝叶斯推导以下将对朴素贝叶斯分类器进行推导,从条件概率到最终的分类结果。
条件概率首先,假设我们有一个待分类的样本x,它有n个特征x1,x2,...,x n。
我们要计算样本属于类别C k的概率P(C k|x)。
根据贝叶斯定理,我们有:P(C k|x)=P(x|C k)P(C k)P(x)其中, - P(x|C k)是样本x在类别C k下的概率密度函数; - P(C k)是类别C k的先验概率; - P(x)是样本x在所有类别下的概率。
朴素贝叶斯假设朴素贝叶斯分类器对特征之间的条件概率做出了一个假设:假设所有特征之间相互独立。
也就是说,给定类别的情况下,特征之间是条件独立的。
根据该假设,我们可以将条件概率P(x|C k)重写为:P(x|C k)=P(x1,x2,...,x n|C k)=P(x1|C k)P(x2|C k)...P(x n|C k)最大后验概率根据朴素贝叶斯分类器的思想,我们要选择具有最大后验概率P(C k|x)的类别作为样本的分类结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中外文学文化研究本栏目责任编辑:梁书收稿日期:2010-08-14修回日期:2010-09-18基金项目:天津市2008年度哲学社会科学规划课题“美国文学中的左派激进主义传统”的阶段性成果(项目编码为TJYW08-2-027)作者简介:师卓(1980-),女,天津人,硕士,讲师,研究方向为美国文学。
Everyday Use is the best of essays written by Alice Walker,a very famous African American woman novelist.In this novel,two sisters from Africa -American family give us a deep impres -sion.So,from the angle of "Binary Opposition"and "Identity",this paper discusses the two sisters'natures,appearances and the most important matter —the different views about the quilt.Owing to their binary opposition natures and appearances,Dee,the old -er sister and Maggie,the younger sister has different opinions to the quilt,their family's heritage.However,in fact,their two opin -ions for the quilt are identical.1What is "Binary Opposition"and "Identity"?1.1Binary oppositionA binary opposition is a pair of opposites,thought by the Structuralisms to powerfully form and organize human thought and culture.Some are commonsense,such as raw vs.cooked;however,many such oppositions imply or are used in such a way that privileges one of the terms of the opposition,creating a hier -archy.This can be seen in English with white and black,where black is used as a sign of darkness,danger,evil,etc.,and white as purity,goodness,and so on.Another example of a contested binary opposition is rational vs.emotional,in which the rational term is usually privileged and associated with men,while emo -tional is inferior and associated with women.1.2IdentityIdentity comes from Deconstruction.It sometimes involves i -dentifying the oppositions working in a text and then demonstrat -ing how the text itself undermines the hierarchy implied or as -serted by the opposition.2The Reason of the Opposite Opinions for the QuiltWhen two children are brought up by the same parent in the same environment,one might logically conclude that these chil -dren will be very similar,or at least have comparable qualities.In Alice Walker's Everyday Use,however,this is not the case.The only thing Maggie and Dee share in common is the fact that they were both raised by the same woman in the same home.They differ in appearance,personality,and ideas that concern thefamily artifacts.Maggie is not as attractive as Dee.She is a thin and awk -ward girl.Her mother notes,"good looks passed her by".Fur -thermore,she carries herself like someone with low self -esteem,"chin on chest and eyes on ground".On the other hand,Dee is an attractive woman.Her mother describes Dee as having,"nice hair,and a full figure".Dee takes pride in her appearance.She dresses in fashionable clothes.When Dee arrives for her visit,her mother says,"Even her feet were always neat -looking".Besides their appearances,Maggie and Dee have their own unique personalities.When Maggie is first introduced in the sto -ry,she is nervous about her sister's visit.In fact,Dee's arrival makes Maggie so uncomfortable that she tries to flee to the safety of the house.Maggie is also intimidated by Dee,as shown when Maggie is unable to confront Dee about the quilts.Maggie gives in and says that Dee may have the quilts because she is not used to "winning".Unlike Maggie,Dee is a bold young woman.As a young girl,Dee has never been afraid to express herself.Her mother remembers,"She would always look anyone in the eye.Hesitation was no part of her nature".Dee also shows herself to be selfish when she sets her sights on the butter churn.Dee does not seem to care that her family is still using the churn.She states that she will "display part of it in her alcove,and do something artistic with the rest of it".The family artifacts are important to both Maggie and Dee,but for different reasons.Maggie values the family quilts for their sentiment and usefulness.She learned how to quilt from her grandmother and aunt who made the quilts.Her mother has been saving the quilts for Maggie to use after she is married.The quilts are meant to be used and appreciated everyday.However,Maggie hints that she regards the quilts as a reminder of her grandmother and aunt when she says,"I can 'member them with -out the quilts".Dee also values the family quilts.She sees the quilts as priceless objects to own and display.Going off to col -lege has brought Dee a new awareness of her heritage.She re -turns wearing ethnic clothing and has changed her name to "Wangero."She explains to her mother and Maggie that changing her name is the way to disassociate herself from "the people who(下转第214页)From Binary Opposition to Identity in Everyday Use师卓(天津农学院人文社会科学系,天津300384)Abstract:Everyday Use is the best of essays written by Alice Walker,a very famous African American woman novelist.In this essay,two sisters from Africa -American family give us a deep impression.Although they are sisters,Maggie and Dee are different.With a concept of structuralism:binary opposition,this article shows the two sisters:Maggie and Dee have different natures,appearances and the views for the quilt.However,with their attitudes to the quilt analyzed by deconstructionism:breaking the binary opposition,the two sisters are identical:both of them regard the quilt as the rare material.Finally,this thesis points out an insufficiency of the essay.Key words:alice walker;everyday use;binary opposition;identity中图分类号:I06文献标识码:A文章编号:1009-5039(2010)10-0187-01187Overseas English 海外英语本栏目责任编辑:梁书中外文学文化研究2010年10月(上接第187页)oppress [her]'?Before she went away to college,the quilts were not good enough for her.Her mother had offered her one of the quilts,but she stated,"They were old -fashioned and out of style".Now she is determined to have the quilts to display in her home.Dee believes that she can appreciate the value of the quilts more than Maggie,who will "be backward enough to put them to ev -eryday use".Dee wants the quilts for more materialistic reasons.She considers the quilts "priceless".Indeed,although Maggie and Dee are two sisters,they are different.Maggie is awkward and unattractive,while Dee is con -fident and beautiful.Maggie is content with her simple life,while Dee wants to have an extravagant lifestyle.Maggie is nervous and intimidated by Dee,who,in turn,is bold and selfish.Maggie val -ues the sentiment of the family quilts,while Dee wants to display them as a symbol of her heritage.Beyond any question,with bi -nary opposition characters and appearances result in the opposite opinions for the quilt.3From Binary Opposition to IdentitySuperficially,Alice Walker shows that the two sisters raised in the same environment can and many times are unique individ -uals and they have the opposite standpoints for the quilt.Maggie uses the objects of their heritage in obeisance to the heritage.The quilt,as an heirloom should be everyday use in the family.Therefore,the quilt not only represents the family,but also is an integral part of the family.On the contrary,Dee accuses her fam -ily of no understanding their heritage.The quilt,as an artifact should be put up on a wall or even sent to the Museum.Thus,the quilt,as an African culture,not only represents its culture,but also is an inseparable part of that culture.But,as a matter of fact,the two viewpoints are identical.Whether the quilt,as the art,it can be valued for personal and emotional reasons,or for fi -nancial and aesthetic reasons,both of the two sisters regard the quilt as the rare material,in my point of view,which is absolute from the "Binary Opposition"to the "Identity".That the two sis -ters regard the quilt as the treasure does be identity.4ConclusionIn general,the quilt in this novel symbolizes the art.To be certain,the art should be a living,breathing part of the culture it arose from,rather than a frozen timepiece to be observed from a distance.So,as far as I'm concerned,the two points for the quilt is not complete proper.On the one hand,if the quilt is put on the wall or even sends to the museum,it becomes an impassive historical relic and cannot be kept alive.On the other hand,the quilt is snatched from Dee and given to Maggie.At the same time,Alice Walker is saying that the second set of values is the correct one and the quilt should be really everyday use,—liter -ally in the case of the quilts,figuratively in the case of conven -tional art.But,Alice Walker cannot ask Maggie to learn how to do the second,the third,even more quilts and teach another people do the quilts,that's to say,pass the quilts every one,ev -ery generation,and every country.For the above reason,my pa -per argues that if Alice Walker can add this point —the expan -sion of the quilt -making,to her article,Everyday Use,this essay,is the acme of the perfection.References:[1]Danielle,Chris.Living by Grace:The Life and Times of AliceWalker[EB/OL].[2001-05-06]./.[2]Hoel,Helga.Personal Names and Heritage:AliceWalker's "Ev -eryday Use"[EB/OL].[2002-07-03].http://home.online.no/hel -hoel/walker.htm.[3]Raman Selden.A Reader's Guide to Contemporary Literary Th -eory [M].Beijing:Foreign Language Teaching and Research Pr -ess,2005.[4]White,David."Everyday Use",Defining African2American Her -itage [EB/OL].[2002-09-19]/contem -porary/alice.[5]Whitsitt,Sam.In Spite of It All:A Reading of Alice Walker's "Everyday Use"[EB/OL].[2000-08-12]./p/articles.[6]Zhang hanxi.Advanced English [M].Beijing:Foreign Language Teaching and Research Press,1995.花。