Hive基础演示文档.ppt
合集下载
Hive培训ppt课件
目录实例: /hive/data/http_temp/pt_data=1/pt_hour=2014040323
3*
HIVE基本操作实例
1、登录生产环境,ssh 。 [hadoop@hm-nn-ser-01 ~]$ hive
2、查看表 hive (default)> show tables;
4*
HIVE基本操作实例
3、建表 create EXTERNAL table IF NOT EXISTS test( sid bigint, ipsid string, reqteid string, respteid string, imsi string, imei int, apn string, msisdn string, rattype string, lac string, cellci string, area string, city string) partitioned by (pt_date bigint) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; 查看表结构 hive (default)> desc test;
8*
Hive RCFile数据加载方案
2、Hive中数据文件TEXTFILE格式加载、转换为RCFILE格式
由于RCFILE格式的表不能直接从文件中导入数据,数据要先导入到TEXTFILE格式的表 中,然后再从TEXTFILE表中用导入到RCFILE表中。
SQL实例如下: hive -e "set mapred.job.priority=VERY_HIGH; set press.output=true; set press=true; set pression.codec=press.GzipCodec; set pression.codecs=press.GzipCodec; INSERT OVERWRITE table ip_rc PARTITION (pt_date = ${DATE}, pt_hour = ${HOUR}) select sid, pid, reqteid, respteid, imsi, imei, apn, msisdn, rattype, lac, ci, area, ...... sys_reported_time, pt_data from ip_temp where pt_hour = ${HOUR};" 这个加载、转换、压缩过程对集群资源消耗较大,需要较长时间。
3*
HIVE基本操作实例
1、登录生产环境,ssh 。 [hadoop@hm-nn-ser-01 ~]$ hive
2、查看表 hive (default)> show tables;
4*
HIVE基本操作实例
3、建表 create EXTERNAL table IF NOT EXISTS test( sid bigint, ipsid string, reqteid string, respteid string, imsi string, imei int, apn string, msisdn string, rattype string, lac string, cellci string, area string, city string) partitioned by (pt_date bigint) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ; 查看表结构 hive (default)> desc test;
8*
Hive RCFile数据加载方案
2、Hive中数据文件TEXTFILE格式加载、转换为RCFILE格式
由于RCFILE格式的表不能直接从文件中导入数据,数据要先导入到TEXTFILE格式的表 中,然后再从TEXTFILE表中用导入到RCFILE表中。
SQL实例如下: hive -e "set mapred.job.priority=VERY_HIGH; set press.output=true; set press=true; set pression.codec=press.GzipCodec; set pression.codecs=press.GzipCodec; INSERT OVERWRITE table ip_rc PARTITION (pt_date = ${DATE}, pt_hour = ${HOUR}) select sid, pid, reqteid, respteid, imsi, imei, apn, msisdn, rattype, lac, ci, area, ...... sys_reported_time, pt_data from ip_temp where pt_hour = ${HOUR};" 这个加载、转换、压缩过程对集群资源消耗较大,需要较长时间。
Hive优化培训ppt课件

2)有数据倾斜时使用负载均衡
set hive.groupby.skewindata = true; -- 有数据倾斜的时候进行负载均衡(默认是false) 当选项设定为 true 时,生成的查询计划有两个 MapReduce 任务。在第一个 MapReduce 任务中,map 的输出结果会随机分布 到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的group by key有可能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处理的数据结果按照group by key分布到各个 reduce 中,最 后完成最终的聚合操作。
Join优化
1)优先过滤数据,最大限度减少参与join的数据量
2)小表join大表原则 join 操作的reduce阶段,位于join左边的表内容会被加载进内存
3)多表join使用相同多连接键
4)启用mapjoin mapjoin是将join双方比较小的表直接分发到各个map进程的内存中,在map进程中进行join操作,这样就 不用进行reduce步骤,从而提高了速度
启用压缩
1)Map输出压缩
set press=true; set press.codec=press.SnappyCodec;
2)中间数据压缩
set press.intermediate=true; set pression.codec=press.SnappyCodec; set pression.type=BLOCK;
-- 是否根据输入小表的大小,自动将reduce端的common join 转化为map join,将小表刷入内存中。 set hive.auto.convert.join = true; -- 刷入内存表的大小(字节) set hive.mapjoin.smalltable.filesize = 2500000; -- Map Join所处理的最大的行数。超过此行数,Map Join进程会异常退出 set hive.mapjoin.maxsize=1000000;
set hive.groupby.skewindata = true; -- 有数据倾斜的时候进行负载均衡(默认是false) 当选项设定为 true 时,生成的查询计划有两个 MapReduce 任务。在第一个 MapReduce 任务中,map 的输出结果会随机分布 到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的group by key有可能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处理的数据结果按照group by key分布到各个 reduce 中,最 后完成最终的聚合操作。
Join优化
1)优先过滤数据,最大限度减少参与join的数据量
2)小表join大表原则 join 操作的reduce阶段,位于join左边的表内容会被加载进内存
3)多表join使用相同多连接键
4)启用mapjoin mapjoin是将join双方比较小的表直接分发到各个map进程的内存中,在map进程中进行join操作,这样就 不用进行reduce步骤,从而提高了速度
启用压缩
1)Map输出压缩
set press=true; set press.codec=press.SnappyCodec;
2)中间数据压缩
set press.intermediate=true; set pression.codec=press.SnappyCodec; set pression.type=BLOCK;
-- 是否根据输入小表的大小,自动将reduce端的common join 转化为map join,将小表刷入内存中。 set hive.auto.convert.join = true; -- 刷入内存表的大小(字节) set hive.mapjoin.smalltable.filesize = 2500000; -- Map Join所处理的最大的行数。超过此行数,Map Join进程会异常退出 set hive.mapjoin.maxsize=1000000;
04-2 Hive入门与实战[27页]
![04-2 Hive入门与实战[27页]](https://img.taocdn.com/s3/m/e58abb56ec3a87c24128c45e.png)
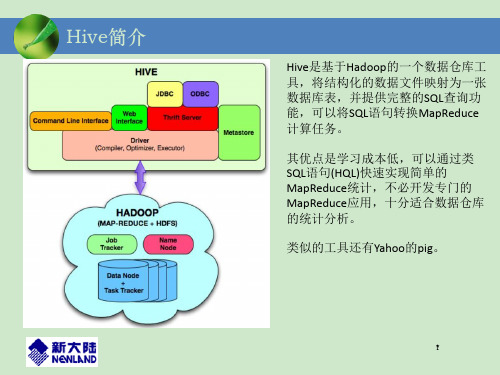
Hive简介-Hive的历史由来
5
Hadoop和Hive组建成为Facebook数据仓库的发展史
随着数据量增加某些查询需要几个小时甚至几天才能完成。 当数据达到1T时,MySql进程跨掉。
可以支撑几个T的数据,但每天收集用户点击流数据(每天 约400G)时,Oracle开始撑不住。
有效解决了大规模数据的存储与统计分析的问题,但是 MapReduce程序对于普通分析人员的使用过于复杂和繁琐。
MapReduce
数据仓库 HDFS
Hadoop
Hive体系结构
解析器
编译器:完成 HQL 语句从词法分析、语法 分析、编译、优化以及执行计划的生成。 优化器是一个演化组件,当前它的规则是 :列修剪,谓词下压。 执行器会顺序执行所有的Job。如果Task 链不存在依赖关系,可以采用并发执行的 方式执行Job。
10
CLI接口
用户接口 JDBC/ODBC客户端
WEB接口
Thrift服务器
解析器 编译器 优化器 执行器
元数据库
Hive
MapReduce
数据仓库 HDFS
Hadoop
11
目录
一、 Hive简介 二、 Hive体系结构 三、 Hive工作机制 四、 Hive应用场景 五、 Hive安装部署 六、 Hive例子 七、 SparkSQL简介
Hive体系结构
用户接口
CLI:Cli 启动的时候,会同时启动一个 Hive 副本。 JDBC客户端:封装了Thrift,java应用 程序,可以通过指定的主机和端口连 接到在另一个进程中运行的hive服务器 ODBC客户端:ODBC驱动允许支持 ODBC协议的应用程序连接到Hive。 WUI 接口:是通过浏览器访问 Hive
Hive基础ppt课件

Resets the configuration to the default values (as of Hive 0.10: see HIVE-3202).
Sets the value of a particular configuration variable (key). Note: If you misspell the variable name, the CLI will not show an error.
Page 3
Hive 和普通关系数据库的异同
Hive 是建立在 Hadoop 之上数据存储
的,所有 Hive 的数据都是存 储在 HDFS 中的。 数据库则可以将数据保存在块 设备或者本地文件系统中
Hive 中没有定义专门的数据格
数据格式 式,由用户指定,需要指定三
个属性:列分隔符,行分隔符 ,以及读取文件数据的方法 数据库中,存储引擎定义了自 己的数据格式。所有数据都会 按照一定的组织存储
Page 4
目录
1 Hive结构 2 Hive基础操作 33 Hive的MAP/RED 4 山东现场实际应用
Page 5
Hive客户端
CLI
usage: hive -d,--define <key=value> -e <quoted-query-string> -f <filename> -h <hostname> --hiveconf <property=value>
delete FILE[S] <filepath>* delete JAR[S] <filepath>*
! <command>
dfs <dfs command>
Sets the value of a particular configuration variable (key). Note: If you misspell the variable name, the CLI will not show an error.
Page 3
Hive 和普通关系数据库的异同
Hive 是建立在 Hadoop 之上数据存储
的,所有 Hive 的数据都是存 储在 HDFS 中的。 数据库则可以将数据保存在块 设备或者本地文件系统中
Hive 中没有定义专门的数据格
数据格式 式,由用户指定,需要指定三
个属性:列分隔符,行分隔符 ,以及读取文件数据的方法 数据库中,存储引擎定义了自 己的数据格式。所有数据都会 按照一定的组织存储
Page 4
目录
1 Hive结构 2 Hive基础操作 33 Hive的MAP/RED 4 山东现场实际应用
Page 5
Hive客户端
CLI
usage: hive -d,--define <key=value> -e <quoted-query-string> -f <filename> -h <hostname> --hiveconf <property=value>
delete FILE[S] <filepath>* delete JAR[S] <filepath>*
! <command>
dfs <dfs command>
Hive概述

10 Hive的数据类型
• 基本数据类型
11 Hive的数据类型
• 复合类型
类型 ARRAY
MAP
ST相同
一组无序的键/值对。键的类型必须是 原子 的,值可以是任何类型,同一个映射 的键 的类型必须相同,值得类型也必须相 同
示例 Array(1,2)
Map(‘a’,1,’b’,2)
Hive概述及其应用
2 Hive数据仓库
3 Hive是什么
• Hive是基于Hadoop之上的数据仓库 • 一种可以存储、查询和分析存储在 Hadoop 中的大规模数据 • Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉SQL 的用户查询数据 • 允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer来处理内建的 mapper 和
13
案例
• 1)内部表 create table test_table ( id int, name string, no int) row format delimited fields terminated by ',‘ stored as textfile ; 2)外部表 create external table test_table ( id int, name string, no int) row format delimited fields terminated by ',‘ stored as textfile ;
14 加载数据
• 本地加载 load data local inpath ‘路径’ [overwrite] into table 表名
• HDFS加载数据 load data inpath ‘路径’ [overwrite] into table 表名
第一章hive概述

结构化数据: 关系数据 半结构化数据:XML数据 非结构化数据:Word,PDF, 文本,媒体日志
2. Hadoop 大数据存储 大数据分析
Hive 编程
分布式系统基础架构
利用集群的威 力进行高速运
算和存储
Hive 编程
Hadoop的核心
分布式文件系统HDFS(Hadoop Distributed File System) 分布式计算MapReduce
不支持 支持 支持
高 好
传统数据库 支持单条和批量导入
支持 支持 支持
低 有限
1.4 Hive的架构
Hive 编程
Hive 编程
1. 用户接口模块
包括 CLI、HWI、JDBC、ODBC、Thrift Server 等,用 来实现外部应用对 Hive 的访问。
2. 驱动模块
把 HiveSQL 语句转换成一系列 MapReduce 作业。包 括编译器、优化器、执行器等。
Hive 编程
3.元数据存储模块Metastore
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。 Hive 中的元数据通常包括:表的名字,表的列和分区及其属 性,表的属性(内部表和外部表),表的数据所在目录等。元 数据存储模块描述存储表的信息。
元数据默认存在Hive自带的 Derby 数据库中; 但是,通常把元数据存在MySQL数据库中。
Hadoop :Hdfs+MapRedcue
Hive 编程
Hive 编程
(2)MapReduce编程的不便性
大量数据存储在HDFS上,如何快速对HDFS上的数据进行 统计分析?
MapReduce
Mapper
DBA
Reducer Driver
2. Hadoop 大数据存储 大数据分析
Hive 编程
分布式系统基础架构
利用集群的威 力进行高速运
算和存储
Hive 编程
Hadoop的核心
分布式文件系统HDFS(Hadoop Distributed File System) 分布式计算MapReduce
不支持 支持 支持
高 好
传统数据库 支持单条和批量导入
支持 支持 支持
低 有限
1.4 Hive的架构
Hive 编程
Hive 编程
1. 用户接口模块
包括 CLI、HWI、JDBC、ODBC、Thrift Server 等,用 来实现外部应用对 Hive 的访问。
2. 驱动模块
把 HiveSQL 语句转换成一系列 MapReduce 作业。包 括编译器、优化器、执行器等。
Hive 编程
3.元数据存储模块Metastore
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。 Hive 中的元数据通常包括:表的名字,表的列和分区及其属 性,表的属性(内部表和外部表),表的数据所在目录等。元 数据存储模块描述存储表的信息。
元数据默认存在Hive自带的 Derby 数据库中; 但是,通常把元数据存在MySQL数据库中。
Hadoop :Hdfs+MapRedcue
Hive 编程
Hive 编程
(2)MapReduce编程的不便性
大量数据存储在HDFS上,如何快速对HDFS上的数据进行 统计分析?
MapReduce
Mapper
DBA
Reducer Driver
大数据系列-Hive入门与实战(ppt 69张)

13
将查询字符串转换成解析树表达式。
语义解析器
将解析树转换成基于语句块的内部查询表达式。
语法解析器
逻辑计划 生成器 查询计划 生成器
将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组 成,操作符是Hive的最小处理单元,每个操作符处理代表一道 HDFS操作或者是MR作业。 将逻辑计划转化成物理计划(MR Job)。
Hive (SQL)
程序语言
计算 表存储 对象存储
HCatalog (元数据)
Hbase (列存储)
HDFS (Hadoop分布式文件系统)
Hive体系结构-Hive设计特征
8
Hive 做为Hadoop 的数据仓库处理工具,它所有的数据都存储在Hadoop 兼容的文件系统中。Hive 在加载数据过程中不会对数据进行任何的修改,只 是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改 写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。 支持索引,加快数据查询。
CLI接口
用户接口 JDBC/ODBC客户端 WEB接口
Thrift服务器 解析器 编译器 优化器 元apReduce
数据仓库 HDFS
•
•
Hadoop
Hive 的数据文件存储在 HDFS 中,大部 分的查询由 MapReduce 完成。(对于包 含 * 的查询,比如 select * from tbl 不会 生成 MapRedcue 作业)
CLI接口
用户接口 JDBC/ODBC客户端 WEB接口
Thrift服务器 解析器 编译器 优化器 元数据库
• • •
• Thrift服务器
执行器
Hive
将查询字符串转换成解析树表达式。
语义解析器
将解析树转换成基于语句块的内部查询表达式。
语法解析器
逻辑计划 生成器 查询计划 生成器
将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组 成,操作符是Hive的最小处理单元,每个操作符处理代表一道 HDFS操作或者是MR作业。 将逻辑计划转化成物理计划(MR Job)。
Hive (SQL)
程序语言
计算 表存储 对象存储
HCatalog (元数据)
Hbase (列存储)
HDFS (Hadoop分布式文件系统)
Hive体系结构-Hive设计特征
8
Hive 做为Hadoop 的数据仓库处理工具,它所有的数据都存储在Hadoop 兼容的文件系统中。Hive 在加载数据过程中不会对数据进行任何的修改,只 是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改 写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。 支持索引,加快数据查询。
CLI接口
用户接口 JDBC/ODBC客户端 WEB接口
Thrift服务器 解析器 编译器 优化器 元apReduce
数据仓库 HDFS
•
•
Hadoop
Hive 的数据文件存储在 HDFS 中,大部 分的查询由 MapReduce 完成。(对于包 含 * 的查询,比如 select * from tbl 不会 生成 MapRedcue 作业)
CLI接口
用户接口 JDBC/ODBC客户端 WEB接口
Thrift服务器 解析器 编译器 优化器 元数据库
• • •
• Thrift服务器
执行器
Hive
大数据系列-Hive入门与实战(ppt 69页)

元数据库中 查询数据表 列表:
HDFS下对 应存储目 录:
Hive开发使用-Hive的数据模型
28
外部表
外部表指向已经在HDFS中存在的数据,可以创建Partition。它和内 部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。 内部表的创建过程和数据加载过程这两个过程可以分别独立完成,也可 以在同一个语句中完成,在加载数据的过程中,实际数据会被移动到数 据仓库目录中;之后对数据访问将会直接在数据仓库目录中完成。删除 表时,表中的数据和元数据将会被同时删除。而外部表只有一个过程, 加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路 径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅 删除该链接。
大数据系列- Hive入门与实战
2
目录
一、 Hive简介 二、 Hive体系结构 三、 Hive工作机制 四、 Hive应用场景 五、 Hive安装部署 六、 Hive开发使用 七、 SparkSQL简介
Hive简介-Hive是什么?
3
Hive是构建在Hadoop之上的数据仓库平台
Hive是一个SQL解析引擎,它将SQL语句转译成 MapReduce作业并在Hadoop上执行。
Hive的优势-上百行MR程序与一条HQL的对比
16
Hive的应用场景-Hive的缺点
17
Hive的HQL表达能力有限:有些复杂运算用HQL不易表 达。 Hive效率低:Hive自动生成MR作业,通常不够智能; HQL调优困难,粒度较粗;可控性差。 针对Hive运行效率低下的问题,促使人们去寻找一种更快, 更具交互性的分析框架。 SparkSQL 的出现则有效的提高 了Sql在Hadoop 上的分析运行效率。
HDFS下对 应存储目 录:
Hive开发使用-Hive的数据模型
28
外部表
外部表指向已经在HDFS中存在的数据,可以创建Partition。它和内 部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。 内部表的创建过程和数据加载过程这两个过程可以分别独立完成,也可 以在同一个语句中完成,在加载数据的过程中,实际数据会被移动到数 据仓库目录中;之后对数据访问将会直接在数据仓库目录中完成。删除 表时,表中的数据和元数据将会被同时删除。而外部表只有一个过程, 加载数据和创建表同时完成(CREATE EXTERNAL TABLE ……LOCATION),实际数据是存储在LOCATION后面指定的 HDFS 路 径中,并不会移动到数据仓库目录中。当删除一个External Table时,仅 删除该链接。
大数据系列- Hive入门与实战
2
目录
一、 Hive简介 二、 Hive体系结构 三、 Hive工作机制 四、 Hive应用场景 五、 Hive安装部署 六、 Hive开发使用 七、 SparkSQL简介
Hive简介-Hive是什么?
3
Hive是构建在Hadoop之上的数据仓库平台
Hive是一个SQL解析引擎,它将SQL语句转译成 MapReduce作业并在Hadoop上执行。
Hive的优势-上百行MR程序与一条HQL的对比
16
Hive的应用场景-Hive的缺点
17
Hive的HQL表达能力有限:有些复杂运算用HQL不易表 达。 Hive效率低:Hive自动生成MR作业,通常不够智能; HQL调优困难,粒度较粗;可控性差。 针对Hive运行效率低下的问题,促使人们去寻找一种更快, 更具交互性的分析框架。 SparkSQL 的出现则有效的提高 了Sql在Hadoop 上的分析运行效率。
数据仓库工具Hive教程PPT模板

a
2101.hiv eserver 2服务器
b
2202.hiv e压缩控
制
c
2303.hiv e本地模
式控制
d
2404.hiv e高级聚
合
e
2505.hiv e分析函 数-开窗
f
2606.hiv e分析函
数
day02
2 hive
第
开 发
章 数 据
仓
库
01 2 - 7 07. hi ve 索 引表 02 2 - 8 08. hi ve 合 并小
1回顾
04
1404.hive
桶表
02
1202.hive02 复杂类型-函
数
05
1505.hive 文件格式
03
1303.hive
分区表
06
1-606.hive 复杂类型函
数
第1章数据仓库 hive开发day01
1-707.hive排序处理
第2章数据仓库hive开发
02 day02
第2章数据仓库hive开发day02
文件
03 2 - 9 09. hi ve 合 并小 04 2 - 1 010 .处 理大量小
文件2
文件问题
05 2 - 1 111 .h adoop 解 06 2 - 1 212 .h ive 自 动
决大量小文件的方式
map端转换控制
第2章数据仓库 hive开发day02
2-1313.hive倾斜连接控制
202x
数据仓库工具hive教程
演讲人
2 0 2 x - 11 - 11
目录
01. 第1章数据仓库hive开发day01 02. 第2章数据仓库hive开发day02
hive大数据利器课件

二、数据分桶的作用
2.1 数据抽样 在处理大规模数据集时,尤其载数据挖掘的阶段,可以用一份数据验证一下,代码是否可以运行成 功,进行局部测试,也可以抽样进行一些代表性统计分析。 2.2 map-side join 可以获得更高的查询处理效率。桶为表加上了额外的结构,(利用原有字段进行分桶),Hive 在处 理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表, 可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相 同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大 大较少JOIN的数据量。 查看sampling数据:select * from student tablesample(bucket 1 out of 32 on id);
group by和order by 同时使用,不会按组进行排序where,group by,having,order by同时使用,执行顺序为 (1)where过滤数据 (2)对筛选结果集group by分组,group by 执行顺序是在select 之前的。因此group by中不能使用select 后面字段的别名的。 (3)对每个分组进行select查询,提取对应的列,有几组就执行几次 (4)再进行having筛选每组数据 (5)最后整体进行order by排序
•查询建表法: create table movies_select as select * from movies;
•like建表法 create table movies_like like movies_select ;
Hive表的执行顺序
在hive的执行语句当中的执行查询的顺序:这是一条sql:select … from … where … group by … having … order by … 执行顺序: from … where … select … group by … having … order by … 其实总结hive的执行顺序也是总结mapreduce的执行顺序:MR程序的执行顺序: map阶段: 1.执行from加载,进行表的查找与加载 2.执行where过滤,进行条件过滤与筛选 3.执行select查询:进行输出项的筛选 4.map端文件合并:reduceReduce阶段:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按 列映射到对应的 Reduce阶段: 1.group by:对map端发送过来的数据进行分组并进行计算。 2.having:最后过滤列用于输出结果 3.order by排序后进行结果输出到HDFS文件 所以通过上面的例子我们可以看到,在进行select之后我们会形成一张表,在这张表当中做分组排序这些操作。
6期大数据之数据仓库工具Hive教程(讲理论还讲实操)课件PPT模板

行流程
03 1 - 3 03. 配置h i ve
04 1 - 4 04. hi ve 初 始化-
建库-建表
05
1-505.hive-
06
1-606.hive-使用win7
hiveserver2-beelin
测试hiveserver
第1章hive第 1天
0 1 1-707.hive-使用explode表生成 函数实现wo
0 2 1-808.创建表完整语法 0 3 1-909.cast类型转换函数-concat
连接函数
0 4 1-1010.内部表-外部表-hdfs数据 加载
0 5 1-1111.分区表-加载分区-删除-查 看
0 6 1-1查询-jmap命令行 方式查看jvm堆使用 1-1414.map端连接处理(优化手 段) 1-1515.union-distinct
02
第2章HIVE第2天
第2章hive第2天
2-101.hive回顾 2-202.orderby全排序-mr严格模 式 2-303.sortby-单个reduce的输出 结果排序方 2-404.distributeby-sortby 2-505.排序总结-orderbysortby-dis
logo
logo
202x
6期大数据之数据仓库工具hive教 程(讲理论还讲实操)
演讲人 202x-11-11
目录
01. 第1章hive第1天 02. 第2章hive第2天
01
第1章HIVE第1天
第1章hive 第1天
01 1 - 1 01. hi ve 介 绍-执 02 1 - 2 02. hi ve 安 装
感谢聆听
03 1 - 3 03. 配置h i ve
04 1 - 4 04. hi ve 初 始化-
建库-建表
05
1-505.hive-
06
1-606.hive-使用win7
hiveserver2-beelin
测试hiveserver
第1章hive第 1天
0 1 1-707.hive-使用explode表生成 函数实现wo
0 2 1-808.创建表完整语法 0 3 1-909.cast类型转换函数-concat
连接函数
0 4 1-1010.内部表-外部表-hdfs数据 加载
0 5 1-1111.分区表-加载分区-删除-查 看
0 6 1-1查询-jmap命令行 方式查看jvm堆使用 1-1414.map端连接处理(优化手 段) 1-1515.union-distinct
02
第2章HIVE第2天
第2章hive第2天
2-101.hive回顾 2-202.orderby全排序-mr严格模 式 2-303.sortby-单个reduce的输出 结果排序方 2-404.distributeby-sortby 2-505.排序总结-orderbysortby-dis
logo
logo
202x
6期大数据之数据仓库工具hive教 程(讲理论还讲实操)
演讲人 202x-11-11
目录
01. 第1章hive第1天 02. 第2章hive第2天
01
第1章HIVE第1天
第1章hive 第1天
01 1 - 1 01. hi ve 介 绍-执 02 1 - 2 02. hi ve 安 装
感谢聆听
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
表名
BUCKETING_COLS COLUMNS_V2 DBS PARTITION_KEYS SDSSD_PARAMS Nhomakorabea说明
Hive表CLUSTERED BY字段信息(字段名,字段序号)
Hive表字段信息(字段注释,字段名,字段类型,字段序 号)
关联键
SD_ID , INTEGER_IDX
CD_ID
元数据库信息,保存HDFS中存放hive表的路径
语句 转换
解析器:生成抽象语法树 语法分析器:验证查询语句 逻辑计划生成器(包括优化器):生成操作符树 查询计划生成器:转换为map-reduce任务
数据 存储
Hive数据以文件形式存储在HDFS的指定目录下 Hive语句生成查询计划,由MapReduce调用执行
Page 2
Hive元数据
✓ 数据库在处理小数据时执行延 迟较低
Page 4
目录
1 Hive结构 2 Hive基础操作 33 Hive的MAP/RED 4 山东现场实际应用
Page 5
Hive客户端
CLI
usage: hive -d,--define <key=value> -e <quoted-query-string> -f <filename> -h <hostname> --hiveconf <property=value>
Page 3
Hive 和普通关系数据库的异同
Hive 是建立在 Hadoop 之上数据存储
的,所有 Hive 的数据都是存 储在 HDFS 中的。 数据库则可以将数据保存在块 设备或者本地文件系统中
Hive 中没有定义专门的数据格
数据格式 式,由用户指定,需要指定三
个属性:列分隔符,行分隔符 ,以及读取文件数据的方法
Checks whether the given resources are already added to the distributed cache or not.
Prints a list of configuration variables that are overridden by the user or Hive.
Prints all Hadoop and Hive configuration variables.
add FILE[S] <filepath> <filepath>* add JAR[S] <filepath> <filepath>*
Resets the configuration to the default values (as of Hive 0.10: see HIVE-3202).
Sets the value of a particular configuration variable (key). Note: If you misspell the variable name, the CLI will not show an error.
delete FILE[S] <filepath>* delete JAR[S] <filepath>*
! <command>
dfs <dfs command>
<query string> source FILE <filepath>
Lists the resources already added to the distributed cache.
DB_ID
Hive分区表分区键
TBL_ID
所有hive表、表分区所对应的hdfs数据目录和数据格式。 SD_ID,CD_ID
序列化反序列化信息,如行分隔符、列分隔符、NULL的 表示字符等
SD_ID
SEQUENCE_TABLE
保存了hive对象的下一个可用ID
元数据存储在关系数据库如 mysql, derby ,oracle中
Hive基础
目录
1 Hive结构 2 Hive基础操作 33 Hive的MAP/RED 4 山东现场实际应用
Page 1
Hive结构图
用户 接口
CLI:启动的时候,会同时启动一个 Hive 副本 Client:Hive 的客户端,用户连接至 Hive Server WUI:通过浏览器访问 Hive
Adds one or more files, jars to the list of resources in the distributed cache.
list FILE[S] list JAR[S]
list FILE[S] <filepath>* list JAR[S] <filepath>*
数据库中,存储引擎定义了自 己的数据格式。所有数据都会 按照一定的组织存储
Hive VS RDBMS
Hive 的内容是读多写少的因此 ,不支持对数据的改写和删除
,数据都是在加载的时候中确
定好的
数据库中的数据通常是需要经数据更新
常进行修改
执行延迟
✓ Hive 在查询数据的时候,需要 扫描整个表(或分区),因此延 迟较高,因此hive只有在处理 大数据时才有优势
--hivevar <key=value> -i <filename> -S,--silent -v,--verbose
Command quit exit reset
set <key>=<value>
set set -v
Load,InDessceriprtiotn
Use quit or exit to leave the interactive shell.
SERDES SERDE_PARAMS TABLE_PARAMS TBLS
指定ROW FORMAT SERDE的类型,即序列化时的一些参数
序列化反序列化信息,如行分隔符、列分隔符、NULL的表示 字符等
SERDE_ID
表级属性,如是否外部表,表注释等
TBL_ID
所有hive表的基本信息
TBL_ID,SD_ID
解析用户提交hive语句,对其进行 解析,分解为表、字段、分区等 hive对象
根据解析到的信息构建对应的表、 字段、分区等对象,从 SEQUENCE_TABLE中获取构建对 象的最新ID,与构建对象信息(名称, 类型等)一同写入到元数据表中去, 成功后将SEQUENCE_TABLE中对 应的最新ID+5。