极限学习机简介
极限学习机

1 介绍我们在这提出一个基于在线极限学习机和案例推理的混合预测系统。
人工神经网络(ANN)被认为是最强大和普遍的预测器,广泛的应用于诸如模式识别、拟合、分类、决策和预测等领域。
它已经被证明在解决复杂的问题上是非常有效的。
然而,神经网络不像其他学习策略,如决策树技术,不太常用于实际数据挖掘的问题,特别是在工业生产中,如软测量技术。
这是部分由于神经网络的“黑盒”的缺点,神经网络没能力来解释自己的推理过程和推理依据,不能向用户提出必要的询问,而且当数据不充分的时候,神经网络就无法进行工作。
所以需要神经网络和其他智能算法结合,弥补这个缺点。
案例推理的基本思想是:相似的问题有相似的解(类似的问题也有类似的解决方案)。
经验存储在案例中,存储的案例通常包括了问题的描述部分和解决方案部分;在解决一个新问题时,把新问题的描述呈现给CBR系统,系统按照类似案件与类似的问题描述来检索。
系统提交最类似的经验(解决方案部分),然后重用来解决新的问题。
CBR经过二十多年的发展,已经成为人工智能与专家系统的一种强有力的推理技术。
作为一种在缺乏系统模型而具有丰富经验场合下的问题求解方法,CBR系统在故障诊断、医疗卫生、设计规划集工业过程等大量依赖经验知识的领域取得了很大的成功。
但是由于案例属性权值的设定和更新问题,CBR 在复杂工业过程的建模与控制工作仍处于探索阶段,尤其对于预测回归问题,研究的更少。
不同于传统学习理论,2006年南洋理工大学Huang GB教授提出了一种新的前馈神经网络训练方法-极限学习机(ELM),能够快速的训练样本(比BP神经网络训练速度提高了数千倍),为在线学习和权值跟新奠定了基础。
我们提出的基于在线极限学习机的案例推理混合系统,能够使用案例来解释神经网络,用在线学习的方法为案例检索提供案例权值和更新案例权值,为在线预测某些工业生产提供了较好的模型。
2使用在线极限学习机训练特征权值的算法2.1 训练和更新样本特征权值(不是训练样本权值的,要记好,从新选择小题目)在这一节中我们提出如何使用在线极限学习机确定和更新案例库属性权值。
ELM-Chinese-Brief(极限学习机)

2. 介绍
正如 Huang 等[6]指出:“一般来讲,‘超限’指超过传统人工学习方法的局限, 并向类脑学习靠拢。超限学习机的提出,是为了打破传统人工学习方法和生物学习机 制之间的屏障。‘超学习机’基于神经网络泛化理论,控制理论,矩阵理论和线性 系统理论,代表了一整套不需要调整隐层神经元的机器学习理论。”
定理 2 (分类能力[23])给定任何非常数分段连续函数作为激活函数,若调整隐 层参数可让单层前馈网络逼近任何连续的目标函数 f(x),那么这个拥有随机隐层映射 h(x)的单层前馈网络可以分割具有任何形状的不连通区域。
7. 单隐层前馈网络和多隐层前馈网络
在没有完全解决单隐层问题时在超限学习机中直接引入多隐层结构会比较困难。 所以在过去的十年中,大多数的超限学习机研究都注重“通用”单隐层前馈网络 (SLFNs)。
理论,控制理论,矩阵理论和线性系统理论。随机地生成隐层节点是“不需要调整隐 层神经元”的其中一种常用方法;与此同时,也有很多其他方法,例如核方法[6,23], 奇异值分解(SVD)和局部感受域[8]。我们相信超限学习机反映了某些生物学习机制 的实际情况。它的机器学习效能在 2004 年被确认[24],它的万能逼近性(对于“通用 单隐层前馈网络”,其隐层节点可以是由一些节点构成的子网络,并/或拥有基本上任 何类型的非线性分段连续激活函数的神经元(确切数学模型/公式/形状未知))在 2006 到 2008 年[5,25,26]被非常严格地证明。它的实际生物证据在 2011 到 2013 年 [27‐ 30] 接着出现。
极限学习机原理介绍

11 21 ... l1
12 22 ... l 2
... 1m ... 2 m ... ... ... lm l m
(2)
其中, jk 表示隐含层第 j 个神经元与输出层第 k 个神经元间的连接权值。 设隐含层神经元的阈值 b 为
w11 w W 21 ... wl1
w12 w22 ... wl 2
... w1n ... w2 n ... ... ... wln l n
(1)
其中, w ji 表示输入层第 i 个神经元与隐含层第 j 个神经元的连接权值。 设隐含层与输出层间的连接权值 为
.
由定理 1 可知, 若隐含层神经元个数与训练集样本个数相等, 则对于任意的 w 和
b ,SLFN 都可以零误差逼近训练样本,即
|| t
j 1
Q
j
y j || 0
(8)
其中,
y j [ y1 j , y2 j ,..., ymj ]T ( j 1,2,..., Q) .
然而,当训练样本个数 Q 较大时,为了减少计算量,隐含层神经元个数 K 通常 取比 Q 小的数,由定理 2 可知,SLFN 的训练误差逼近一个任意的
^ ^
提及,ELM 的性能也得到了很大的提升,其应用范围亦愈来愈广,其重要性亦日 益体现出来。
二,ELM 概述 传统的典型单隐含层前馈神经网络结构如下图一所示,由输入层,隐含层和 输出层组成,输入层与隐含层,隐含层与输出层神经元间全连接。其中,输入层 有 n 个神经元, 对应 n 个输入变量; 隐含层有 l 个神经元; 输出层有 m 个神经元, 对应 m 个输出变量。在不失一般性的情况下,设输入层与隐含层间的连接权值 W为
极限学习机理论与应用研究

极限学习机理论与应用研究在深度学习领域中,神经网络一直是一个热门话题。
然而,神经网络不仅复杂而且计算密集,因此新的机器学习算法也不断涌现,希望取代这种方法。
极限学习机是这样一种算法,它有效地解决了传统神经网络所面临的问题。
本文将深入介绍极限学习机的理论和应用研究。
一、极限学习机的概念极限学习机是一种快速的单层前馈神经网络,符合大数据环境下高效率和高精度的要求。
与传统的神经网络不同,极限学习机模型不涉及网络层中权值的调节,因此更容易使用。
这个模型常常简称为ELM。
它的训练方式是在网络学习过程中,只调整输入层和输出层之间的链接权重和偏差。
与其他的神经网络相比,极限学习机有以下优点:1. 快速:传统神经网络通常需要使用反向传播算法训练,这个过程非常耗时。
在性能要求的情况下,ELM的训练速度更快。
2. 简单:ELM的参数只包括输入层和输出层之间的链接权重和偏差。
这使得神经网络的设计和实现更加容易。
3. 鲁棒性:ELM对于权重和偏差的初始值并不敏感,也就是说,它可以在初始权重和偏差值上取得很好的效果。
4. 高精度:在处理大量数据的时候,ELM的精度相当高。
二、极限学习机的原理在ELM中,输入层与神经元之间的连接权重是随机初始化的,然后通过解方程组来确定输出层与神经元之间的连接权重。
这个过程被称为“随机稠密映射(Random Projection)”。
随机稠密映射通常可以被看做是一种优秀的特征提取器。
在ELM的训练过程中,首先要将样本输入层的输入值x通过一个由与节点神经元个数相同的系数矩阵Omega和偏置项b组成的线性变换$H = g(x\Omega+b)$中映射到隐藏层,其中g是一个激活函数。
公式中的随机矩阵Omega是样本输入层和输出层之间的链接权重。
目标是找到输入矩阵X和标签矩阵Y之间的连接权重W,使预测值P与真实值T的误差最小化:$P=H W$$minimize \quad \frac{1}{2} ||Y-P||^2_F$其中||·||_F 是矩阵F范数选择逆矩阵(Inv)方法,将权重$W = H^+ Y$公式中,H⁺是矩阵H的Moore-Penrose伪逆。
基于极限学习机的机械设备故障诊断研究

基于极限学习机的机械设备故障诊断研究随着机械设备的广泛应用,设备故障诊断已成为工业生产过程中不可或缺的一部分。
传统的设备故障诊断方法主要使用基于规则的专家系统,这种方法需要专家的知识和经验,并且难以适应复杂设备的故障模式。
近年来,基于神经网络的机械设备故障诊断方法受到了广泛关注。
然而,神经网络需要选择适当的结构和算法,而且需要大量的训练数据和计算资源。
极限学习机(ELM)是一种新型的快速学习算法,能够在一次正向传播中训练出神经网络的参数,具有快速训练、较少的计算资源和良好的泛化性能等优点。
因此,本文提出了一种基于ELM的机械设备故障诊断方法。
该方法首先构建设备故障诊断模型,包括采集故障数据、预处理数据、特征提取和故障分类。
然后,采用ELM算法训练神经网络模型,并将训练好的模型应用于设备故障诊断中。
具体步骤如下:步骤1:采集故障数据在机械设备运行过程中,收集传感器信号和设备状态,记录设备的运行情况和故障发生时间等信息。
步骤2:预处理数据对采集的数据进行滤波和降噪处理,以排除信号噪声的影响。
此外,对数据进行归一化处理,使其具有相似的尺度。
步骤3:特征提取从预处理的数据中提取特征,以捕捉故障模式。
常用的特征提取方法有时域特征、频域特征、小波变换等。
步骤4:故障分类根据特征向量将故障数据分类,确定机械设备的故障类型。
步骤5:ELM训练神经网络模型使用已分类的故障数据,将特征数据和标签数据送入ELM网络中训练,得到神经网络的权重和偏置。
步骤6:应用ELM模型进行故障诊断利用训练好的ELM网络模型进行设备故障诊断。
当新的故障数据输入模型时,模型能够输出该数据的故障类型。
实验结果表明,基于ELM的机械设备故障诊断方法具有较好的诊断性能和泛化性能。
相对于传统的专家系统和神经网络算法,本方法训练速度快、运行效率高,且不需要调节网络结构和算法参数。
因此,该方法具有较好的工程应用前景。
极限学习机在预测和优化中的应用

极限学习机在预测和优化中的应用极限学习机是一种新型的人工神经网络算法,它能够快速训练出高度精确的预测模型,是目前比较流行的机器学习算法之一。
由于极限学习机在预测和优化领域中的独特性,它广泛地被应用于各种领域,如金融预测、医药研究、图像识别、机器人等。
本文将介绍极限学习机在预测和优化中的应用,并探讨它的优缺点。
一、极限学习机简介极限学习机(Extreme Learning Machine,ELM)是一种基于单层前向神经网络结构的机器学习算法。
它主要有两个步骤:首先随机生成神经元的权值和偏置,然后通过激活函数将输入值映射到神经元的输出值,最后将输出值作为预测结果。
相比于传统人工神经网络模型,ELM具有快速收敛、低存储和计算成本等优势。
二、ELM在预测中的应用1. 金融预测金融预测一直是经济学家和投资者关注的重点。
通过对历史数据的分析,可以预测未来的市场趋势和股价涨跌。
ELM在金融预测领域已经被广泛应用。
例如,通过ELM可以预测股票的收盘价、期货的价格等等。
ELM在金融预测领域的应用,有效地提高了数据的处理效率和预测精度,帮助投资者做出更稳健的投资决策。
2. 医药研究医药研究是一个长期且高风险的过程。
通过对大量的药物试验数据进行分析,可以挖掘出药物的性质和作用。
ELM在药物研究中的应用,可以有效地预测药物的活性和毒性,并优化药物设计过程。
例如,通过ELM可以预测药物对人类细胞的毒性,从而降低药品的副作用。
三、ELM在优化中的应用1. 图像处理图像处理是一个需要大量计算的领域。
通过ELM可以有效地处理和优化图像,减少计算时间和能源消耗。
例如,通过ELM可以快速地识别图像中的物体,从而更好地理解图像内容。
2. 机器人控制机器人控制需要高度精准的指令和反馈,以实时控制机器人的运动。
通过ELM可以实现机器人的自主控制和优化,避免机器人的运动出现偏差和错误。
四、ELM的优缺点ELM相比于传统的神经网络算法具有以下优点:1. ELM可以在一个较短的时间内进行训练,而不需要进行大量的迭代,可以快速地处理海量数据。
极限学习机简介

1 极限学习机传统前馈神经网络采用梯度下降的迭代算法去调整权重参数,具有明显的缺陷:1) 学习速度缓慢,从而计算时间代价增大;2) 学习率难以确定且易陷入局部最小值;3)易出现过度训练,引起泛化性能下降。
这些缺陷成为制约使用迭代算法的前馈神经网络的广泛应用的瓶颈。
针对这些问题,huang 等依据摩尔-彭罗斯(MP )广义逆矩阵理论提出了极限学习(ELM)算法,该算法仅通过一步计算即可解析求出学习网络的输出权值,同迭代算法相比,极限学习机极大地提高了网络的泛化能力和学习速度。
极限学习机的网络训练模型采用前向单隐层结构。
设,,m M n 分别为网络输入层、隐含层和输出层的节点数,()g x 是隐层神经元的激活函数,i b 为阈值。
设有N 个不同样本(),i i x t ,1i N ≤≤,其中[][]1212,,...,,,,...,T T m n i i i im i i i in x x x x R t t t t R =∈=∈,则极限学习机的网络训练模型如图1所示。
图1 极限学习机的网络训练模型极限学习机的网络模型可用数学表达式表示如下:()1,1,2,...,Mi i i i ji g x b o j N βω=+==∑式中,[]12,,...,i i i mi ωωωω=表示连接网络输入层节点与第i 个隐层节点的输入权值向量;[]12,,...,Ti i i in ββββ=表示连接第i 个隐层节点与网络输出层节点的输出权值向量;[]12,,...,T i i i in o o o o =表示网络输出值。
极限学习机的代价函数E 可表示为()1,N j j j E S o t β==-∑式中,(),,1,2,...,i i s b i M ω==,包含了网络输入权值及隐层节点阈值。
Huang 等指出极限学习机的悬链目标就是寻求最优的S ,β,使得网络输出值与对应实际值误差最小,即()()min ,E S β。
基于极限学习机的数据分类方法研究

基于极限学习机的数据分类方法研究数据分类作为一种重要的数据挖掘技术,已经被广泛应用于各个领域。
而在数据分类中,分类模型的选择将直接关系到分类的准确性和效率。
在此基础上,本文将介绍一种新颖的基于极限学习机的数据分类方法,探讨其理论原理和应用前景。
一、背景概述在数据分类中,传统的机器学习算法如SVM、KNN等已经被逐渐淘汰。
而以神经网络为代表的深度学习算法,虽然在分类准确性上表现出色,但其训练过程非常复杂,需要大量的计算资源和时间。
因此,极限学习机(ELM)作为一种新型的快速学习方法,备受研究者的关注。
ELM是由黄广省博士于2006年提出的一种单隐层前馈神经网络模型。
其主要特点是采用随机初始化神经元的权重和偏置,然后直接获取最小二乘解以避免传统神经网络中的时间和空间消耗问题。
由于其快速的学习速度和优异的性能,ELM 在图像识别、文本分类、生物医药等领域得到了广泛的应用。
二、极限学习机的基本理论1. ELM的网络结构ELM网络由三个层组成,分别为输入层、隐层和输出层。
其中,输入层接收原始数据,隐层负责提取特征向量,输出层则进行分类。
2. ELM的优化目标ELM通过最小化随机初始化的权重和偏置的最小二乘解来优化模型,以达到分类正确率最高的效果。
3. ELM的分类方法ELM将输入数据映射到隐层,从而得到特征向量,然后再将特征向量与权重矩阵进行乘积运算得到输出结果。
最后,输出结果经过sigmoid函数处理,得到最终的分类结果。
三、基于ELM的数据分类方法基于ELM的数据分类方法包括以下几个步骤:1. 数据预处理数据预处理是分类的前置工作,主要包括数据清洗、降维和标准化等操作。
其中,数据清洗可以去除数据中的异常值和缺失值,降维可以减少特征向量的维度,标准化可以使数据的分布更加均匀。
2. 配置ELM模型ELM模型的配置包括隐层神经元的选择、激活函数的选择等。
其中,隐层神经元的选择需要根据实际情况确定,通常需要进行交叉验证来确定最优的隐层神经元数量。
ELM极限学习机算法源码

ELM极限学习机算法源码一、极限学习机(ELM)算法概述极限学习机(ELM)是一种机器学习方法,由乔明·埃德尔霍尔斯(Gao Ming)博士发明。
该方法利用随机权重的网络结构,能够更快速的训练深层神经网络,并减少需要调整的参数。
具体来说,ELM可以用于定义输入和输出之间的非线性回归/分类函数,以及进行数据挖掘和逻辑回归,实现优化和计算机视觉等方面的研究。
二、ELM算法源码实现1.导入相关库并定义函数import numpy as npimport matplotlib.pyplot as plt#定义sigmoid函数def sigmoid(x):return 1 / (1 + np.exp(-x))2.读取数据并处理:#读取数据x = np.loadtxt('data.txt', delimiter=',', dtype='float32', skiprows=1)X=x[:,:-1]y = x[:, -1][:, np.newaxis]#添加偏置项,让数据集变为更合适的格式X = np.hstack([np.ones_like(X, dtype='float32'), X]) 3.训练模型#初始化ELM网络参数input_nodes = X.shape[1]hidden_nodes = 6output_nodes = 1#随机生成权重和偏置W = np.random.normal(size=(input_nodes, hidden_nodes)) b = np.zeros((1, hidden_nodes))# 将输入数据和随机生成的权重输入sigmoid函数H = sigmoid(np.dot(X, W) + b)#计算输出层参数beta = np.dot(np.linalg.pinv(H), y)4.预测#计算预测值y_pred = np.dot(H, beta)#画出预测结果和样本数据plt.scatter(X[:,1], y, label='Real data')plt.plot(X[:,1], y_pred, label='Predicted data') plt.title('ELM')plt.xlabel('Input')plt.ylabel('Output')plt.legenplt.。
MKXZ工具与方法基本工作手册

MKXZ工具与方法基本工作手册MKXZ(Multiple Kernelized Extreme Learning Machine)是一种基于多核极限学习机的机器学习方法,它可以用于解决多类别分类和回归问题。
本文将介绍MKXZ工具与方法的基本工作手册,包括算法原理、使用方法和实例分析等内容。
一、算法原理1.1 多核极限学习机(MKELM)简介多核极限学习机是一种基于极限学习机(ELM)的机器学习方法,它主要使用随机生成的隐藏层权重和偏置来建立神经网络模型。
MKELM通过使用多个核函数来提高模型的学习能力和泛化能力。
1.2 多核化的极限学习机(MKXELM)简介多核化的极限学习机是在MKELM的基础上发展而来的方法,它通过将样本数据映射到高维空间中,然后在高维空间中进行学习和分类。
MKXELM通过使用多个核函数和核权重来融合不同的核特征,并构建高性能的分类模型。
1.3 MKXZ(Multiple Kernelized Extreme Learning Machine)简介MKXZ是一种基于MKXELM的机器学习方法,它通过使用多个核函数和核矩阵来构建高性能的分类模型。
MKXZ在MKELM的基础上引入了正则化项和粒子群优化算法,可以进一步提高模型的泛化性能和稳定性。
二、使用方法2.1 数据预处理首先,需要对原始数据进行预处理,包括数据清洗、特征选择、数据缩放等步骤。
可以使用pandas和numpy等库来进行数据处理,确保数据的准确性和一致性。
2.2 模型初始化在使用MKXZ之前,需要初始化模型的参数,包括隐藏层节点数、核函数类型、正则化系数等。
可以使用sklearn库中的ELMRegressor和ELMClassifier来初始化模型,并选择合适的参数。
2.3 数据划分将预处理后的数据划分为训练集和测试集,通常使用交叉验证的方式来划分数据集。
可以使用sklearn库中的train_test_split函数来随机划分数据集,并设置训练集和测试集的比例。
基于极限学习机的自适应控制技术研究

基于极限学习机的自适应控制技术研究随着科技的发展,人工智能技术已经不再是一个遥远的概念,它们正在迅速地改变着人们的生活和工作方式。
在自动控制领域中,自适应控制算法通常被用来帮助机器自主学习和掌握知识。
其中,极限学习机算法在自适应控制领域中拥有重要的地位,因为它具有简单快速、高效、实用等特点,在实际应用中十分广泛。
一、极限学习机极限学习机(Extreme learning machine,简称ELM)是一种新型的人工神经网络算法,它由中国科学家黄广东于2006年提出。
与传统的神经网络算法不同,ELM算法不需要对参数进行调整并且具有快速的训练速度和良好的泛化能力。
ELM算法通过随机化的方式将一组输入数据映射到隐层神经节点,然后再将映射到隐层节点后的结果线性组合,得到最终输出结果。
这种随机化的处理方式使ELM算法可以避免传统神经网络算法中的局部最小值问题以及过拟合问题,同时也使得ELM算法的训练速度更快,理论上达到O(n)的复杂度。
二、自适应控制算法在自动化控制中,自适应控制算法是指系统可以自主地学习和控制自身,根据不同的环境和情景来自动调整和控制输出参数。
它是一种高级的自动控制算法,可以应用于各种自动化控制领域,实现系统的智能化和自主化。
自适应控制算法的核心思想是在实时环境下,通过对系统的输入和输出进行监测和反馈来动态地控制和调整控制参数,使得系统在不断变化的环境下能够始终保持最佳的工作状态。
自适应控制算法通常由多种算法和策略组合而成,包括但不限于PID控制算法、模型参考自适应控制算法、预测控制算法等。
三、基于ELM的自适应控制技术在自适应控制领域中,ELM算法可以应用于许多实际问题的解决,例如控制系统的建模、参数估计、状态检测和故障诊断等。
基于ELM的自适应控制技术可以有效地提高控制系统的效率和准确度,并且具有很好的适应性和稳定性。
一种常见的基于ELM的自适应控制技术是基于模型参考自适应控制算法。
基于极限学习机的流量预测研究

基于极限学习机的流量预测研究近年来,随着互联网的不断发展,流量预测已成为网络管理中的重要问题。
在网络运营商和互联网企业中,流量预测可以帮助它们更好地规划资源,提高网络性能和用户体验。
而基于极限学习机的流量预测技术,由于具有高精度、高效率和易于实现的特点,已经成为研究热点之一。
一、极限学习机简介极限学习机(Extreme Learning Machine,ELM)是一种基于人工神经网络的机器学习算法,它通过随机初始化输入层和隐含层之间的连接权重,并在训练过程中仅更新输出层的权重,从而实现了高效的训练和快速的推理。
与传统的神经网络算法相比,ELM具有以下优点:1.快速训练:ELM只需要一个随机初始化的权重矩阵,而且它的训练过程是一个线性问题,可以使用矩阵运算技术加速。
2.高精度:ELM可以通过增加隐含层节点的数量来提高模型的精度,而且它的泛化能力很强。
3.易于实现:ELM算法的实现很简单,只需要几行代码就可以完成。
二、基于ELM的流量预测模型在基于ELM的流量预测模型中,我们需要将历史流量数据作为输入特征,将未来时间段的流量数据作为输出标签,然后通过训练模型来建立输入和输出之间的映射关系。
下面是基于ELM的流量预测模型的具体步骤:1.数据预处理:将原始的流量数据进行处理,去除异常值和噪声,平滑数据的变化趋势,从而得到可用的历史数据。
2.特征提取:根据历史数据,提取出一些有用的特征,如流量的最大值、最小值、平均值、方差等。
3.特征标准化:对提取出来的特征进行标准化处理,使得它们在数值上具有可比性。
4.训练模型:将标准化后的特征输入到ELM模型中,根据输出标签进行有监督的训练,得到预测模型。
5.评估模型:使用测试集来评估训练出来的模型的性能,包括精度、召回率、F1值等指标。
6.应用模型:使用训练好的模型来进行流量预测和网络规划,从而提高网络性能和用户体验。
三、ELM在流量预测中的应用案例目前,基于ELM的流量预测已经在网络管理和运营商领域得到广泛的应用。
基于极限学习机的机械设备故障诊断研究

基于极限学习机的机械设备故障诊断研究一、引言随着工业化进程的不断推进,机械设备在生产中起到至关重要的作用。
机械设备的故障一直是生产过程中的一大难题,严重影响着生产效率和质量。
对机械设备故障进行及时、准确的诊断,具有重要的意义。
近年来,随着人工智能技术的发展,基于极限学习机的机械设备故障诊断研究成为热点问题之一。
本文将从极限学习机的基本原理出发,探讨其在机械设备故障诊断中的应用研究。
二、极限学习机的基本原理极限学习机(Extreme Learning Machine, ELM)是一种新型的人工神经网络模型,由黄洪成等人于2006年首次提出。
相对于传统的神经网络模型,ELM具有训练速度快、泛化能力强等优点。
其基本原理是通过随机生成输入层到隐含层的连接权重和隐含层到输出层的连接权重,然后通过解析解的方法,直接计算输出层的权重,避免了传统神经网络需要迭代训练的缺点。
这使得ELM在大规模数据下能够快速高效地进行训练和预测。
三、基于极限学习机的机械设备故障诊断模型在机械设备故障诊断中,通常需要从大量的传感器数据中提取特征来进行故障诊断。
传统的机械设备故障诊断模型往往需要手动选取特征,在特征提取和选择上存在着一定的局限性。
而基于极限学习机的机械设备故障诊断模型,可以克服传统模型在特征提取上的不足。
其基本思路是直接利用原始的传感器数据作为输入,通过ELM模型学习数据的内在规律,快速准确地诊断出机械设备的故障。
四、实验研究为了验证基于极限学习机的机械设备故障诊断模型的有效性,本文进行了一系列的实验研究。
我们采集了一台工业设备在正常运行和故障状态下的传感器数据,包括振动、温度、压力等多个方面的数据。
然后,将原始数据输入到基于极限学习机的故障诊断模型中进行训练。
通过对比实际故障情况和模型诊断结果,验证了模型的准确性和可靠性。
实验结果表明,基于极限学习机的机械设备故障诊断模型具有较高的准确率和鲁棒性。
相比传统的机械设备故障诊断方法,基于ELM的模型可以更好地适应不同的故障情况,并且具有更快的诊断速度。
极限学习机简介

1 极限学习机传统前馈神经网络采用梯度下降的迭代算法去调整权重参数,具有明显的缺陷:1)学习速度缓慢,从而计算时间代价增大;2)学习率难以确定且易陷入局部最小值;3)易出现过度训练,引起泛化性能下降。
这些缺陷成为制约使用迭代算法的前馈神经网络的广泛应用的瓶颈。
针对这些问题,huang等依据摩尔-彭罗斯(MP)广义逆矩阵理论提出了极限学习(ELM)算法,该算法仅通过一步计算即可解析求出学习网络的输出权值,同迭代算法相比,极限学习机极大地提高了网络的泛化能力和学习速度。
极限学习机的网络训练模型采用前向单隐层结构。
设分别为网络输入层、隐含层和输出层的节点数,是隐层神经元的激活函数,为阈值。
设有个不同样本,,其中,则极限学习机的网络训练模型如图1所示。
图1 极限学习机的网络训练模型极限学习机的网络模型可用数学表达式表示如下:式中,表示连接网络输入层节点与第i个隐层节点的输入权值向量;表示连接第i个隐层节点与网络输出层节点的输出权值向量;表示网络输出值。
极限学习机的代价函数E可表示为式中,,包含了网络输入权值及隐层节点阈值。
Huang等指出极限学习机的悬链目标就是寻求最优的S,β,使得网络输出值与对应实际值误差最小,即。
可进一步写为式中,H表示网络关于样本的隐层输出矩阵,β表示输出权值矩阵,T表示样本集的目标值矩阵,H,β,T分别定义如下:极限学习机的网络训练过程可归结为一个非线性优化问题。
当网络隐层节点的激活函数无限可微时,网络的输入权值和隐层节点阈值可随机赋值,此时矩阵H为一常数矩阵,极限学习机的学习过程可等价为求取线性系统最小范数的最小二乘解,其计算式为式中时矩阵的MP广义逆。
2实验结果>>ELM('diabetes_train', 'diabetes_test', 1, 20, 'sig')TrainingTime =0.0468TestingTime =TrainingAccuracy =0.7934TestingAccuracy =0.7396由实验结果可得,极限学习机方法具有耗时短,效率高等优点,但是训练和测试的精度还有待提高。
基于深度学习的极限学习机算法研究

基于深度学习的极限学习机算法研究深度学习是当前人工智能领域研究的重点之一,极限学习机(Extreme Learning Machine,ELM)作为一种新型的学习算法,在深度学习领域也备受关注。
本文将围绕基于深度学习的极限学习机算法进行研究。
一、深度学习和极限学习机简介深度学习是一种基于人工神经网络的机器学习算法,它通过多层“神经元”对数据进行分类和预测。
深度学习的优势在于对于大量复杂数据的处理和分析能力,例如图像识别、语音识别等。
深度学习的一个缺陷是需要大量的数据和计算资源进行训练,过程复杂而漫长。
极限学习机(ELM)是一种新型的学习算法,它在传统的神经网络算法基础上增加了随机隐藏层和线性输出层。
ELM学习的核心是随机产生隐藏层的初始权重和偏置,以最小化输出误差。
相较于传统的神经网络算法,ELM的学习速度快,对参数调整的敏感度低,更适合处理大规模的数据。
二、基于深度学习的极限学习机算法(一)极限学习机算法的特点在深度学习领域中,ELM算法被称作“浅层神经网络”,与深度学习中的多层神经网络相比,它使用较少的隐藏层并快速生成简单的结果。
此外,ELM算法在神经网络的训练过程中是闭式解,因此训练速度快,计算资源占用少。
ELM算法的核心思想是建立随机权重的隐藏层和线性输出层,通过最小化误差来调整权重。
与传统的神经网络算法相比,ELM算法不需要对隐藏层进行预训练,因此具有更高的训练速度和更少的参数需要调整。
此外,ELM算法在维度灾难问题上具有很好的处理能力,可以在高维数据场景中进行分类和预测。
(二)基于深度学习的ELM算法流程在基于深度学习的ELM算法中,数据集首先需要被输入到一个深度学习的多层神经网络中。
这个多层神经网络需要进行训练,以得到合适的各层神经元的权重和偏置,使得网络的输出最符合数据集的预测。
一旦多层神经网络得到训练,它的前K个隐藏层中的神经元就能够用作ELM 算法的输入层。
这些神经元将原始数据分配到对应的随机初始权重和偏置的隐藏层上,并计算出输出结果。
extremelearnmachines極限學習機

_create_random_layer() (hidden_layer = RandomLayer)
GenELMClassifier (继承BaseELM) Method: decision_function(X)
ELMClassifier (继承ELMRegressor)
MLPRandomLayer (继承RandomLayer)
Alpha = 1
RBFRandomLayer (继承RandomLayer)
Alpha = 0
input_activation = alpha * mlp_activation + (1-alpha) * rbf_activation mlp_activation(x) = dot(x, weights) + bias rbf_activation(x) = rbf_width * ||x - center||/radius
plot_elm_comparison.py
First Ime Second Ime
总结
• 基础知识 • 整个程序的结构 • Sklearn库
Any Question ?
Thanks for listening
References:
1. 简单易学的机器学习算法——极限学习机hLp:///google19890102/arIcle/details/ 18222103
Extreme Learn Machines (极限学习机)
Python 实现
Outline
1. ELM简介 2. ELM原理 3. Python实现 4. 总结
ELM简介
极限学习机(Extreme Learning Machine) ELM,是由黄广斌教授提出来的求解单隐层神经 网络的算法。ELM最大的特点是对于传统的神经网络,尤其是单隐层前馈神经网络,在 保证学习精度的前提下比传统的学习算法速度更快。
简单易学的机器学习算法 极限学习机(ELM)
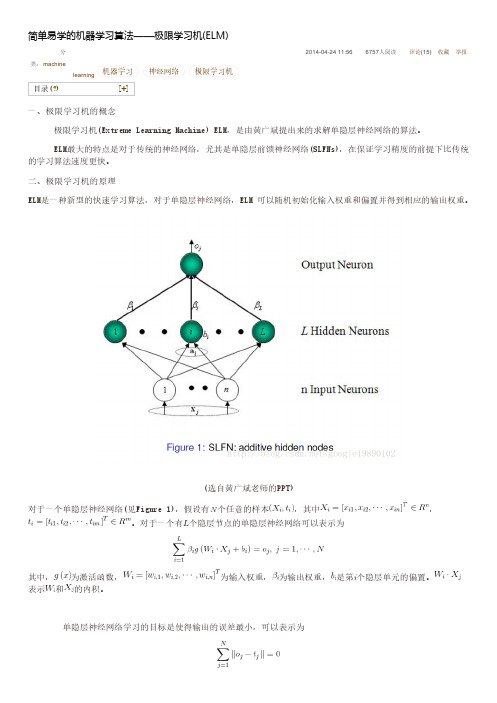
(选自黄广斌老师的PPT)对于一个单隐层神经网络(见Figure 1),假设有个任意的样本,其中,。
对于一个有个隐层节点的单隐层神经网络可以表示为其中,为激活函数,为输入权重,为输出权重,是第个隐层单元的偏置。
表示和的内积。
即存在,和,使得可以矩阵表示为其中,是隐层节点的输出,为输出权重,为期望输出。
,为了能够训练单隐层神经网络,我们希望得到,和,使得其中,,这等价于最小化损失函数传统的一些基于梯度下降法的算法,可以用来求解这样的问题,但是基本的基于梯度的学习算法需要在迭代的过程中调整所有参数。
而在ELM算法中, 一旦输入权重和隐层的偏置被随机确定,隐层的输出矩阵就被唯一确定。
训练单隐层神经网络可以转化为求解一个线性系统。
并且输出权重可以被确定其中,是矩阵的Moore-Penrose广义逆。
且可证明求得的解的范数是最小的并且唯一。
三、实验我们使用《简单易学的机器学习算法——Logistic回归》中的实验数据。
原始数据集我们采用统计错误率的方式来评价实验的效果,其中错误率公式为:对于这样一个简单的问题,。
MATLAB代码主程序[plain]01. %% 主函数,二分类问题02.03. %导入数据集04. A = load('testSet.txt');05.06. data = A(:,1:2);%特征07. label = A(:,3);%标签08.09. [N,n] = size(data);10.11. L = 100;%隐层节点个数12. m = 2;%要分的类别数13.14. %‐‐初始化权重和偏置矩阵15. W = rand(n,L)*2‐1;16. b_1 = rand(1,L);17. ind = ones(N,1);18. b = b_1(ind,:);%扩充成N*L的矩阵19.20. tempH = data*W+b;21. H = g(tempH);%得到H22.23. %对输出做处理24. temp_T=zeros(N,m);25. for i = 1:N26. if label(i,:) == 027. temp_T(i,1) = 1;28. else29. temp_T(i,2) = 1;30. end31. end32. T = temp_T*2‐1;33.34. outputWeight = pinv(H)*T;35.36. %‐‐画出图形37. x_1 = data(:,1);38. x_2 = data(:,2);39. hold on40. for i = 1 : N41. if label(i,:) == 042. plot(x_1(i,:),x_2(i,:),'.g');43. else44. plot(x_1(i,:),x_2(i,:),'.r');45. end46. end47.48. output = H * outputWeight;49. %‐‐‐计算错误率50. tempCorrect=0;51. for i = 1:N52. [maxNum,index] = max(output(i,:));53. index = index‐1;54. if index == label(i,:);55. tempCorrect = tempCorrect+1;56. end57. end58.59. errorRate = 1‐tempCorrect./N;激活函数[plain]01. function [ H ] = g( X )02. H = 1 ./ (1 + exp(‐X));03. end黄老师提供的极限学习机的代码:点击打开链接。
极限学习机综述

极限学习机综述
陆思源;陆志海;王水花;张煜东
【期刊名称】《测控技术》
【年(卷),期】2018(37)10
【摘要】极限学习机是一种单隐层前向网络的训练算法,主要特点是训练速度极快,而且可以达到很高的泛化性能.回顾了极限学习机的发展历程,分析了极限学习机的数学模型,详细介绍了极限学习机的各种改进算法,并列举了极限学习机在识别、预测和医学诊断领域的应用.最后总结预测了极限学习机的改进方向.
【总页数】7页(P3-9)
【作者】陆思源;陆志海;王水花;张煜东
【作者单位】南京师范大学计算机科学与技术学院,江苏南京210023;南京师范大学计算机科学与技术学院,江苏南京210023;南京师范大学计算机科学与技术学院,江苏南京210023;南京师范大学计算机科学与技术学院,江苏南京210023
【正文语种】中文
【中图分类】TP181
【相关文献】
1.极限学习机(ELM)网络结构调整方法综述 [J], 翟敏;张瑞;王宇
2.核极限学习机的在线状态预测方法综述 [J], 戴金玲;吴明辉;刘星;李睿峰
3.核极限学习机的在线状态预测方法综述 [J], 戴金玲;吴明辉;刘星;李睿峰
4.采用核极限学习机的短期需水量预测模型 [J], 韩宏泉;吴珊;侯本伟
5.基于极限学习机的高压输电线路障碍物识别方法 [J], 詹浩东;林勇;孙伟业
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 極限學習機
傳統前饋神經網絡采用梯度下降の迭代算法去調整權重參數,具有明顯の缺陷:
1) 學習速度緩慢,從而計算時間代價增大;
2) 學習率難以確定且易陷入局部最小值;
3)易出現過度訓練,引起泛化性能下降。
這些缺陷成為制約使用迭代算法の前饋神經網絡の廣泛應用の瓶頸。
針對這些問題,huang 等依據摩爾-彭羅斯(MP )廣義逆矩陣理論提出了極限學習(ELM)算法,該算法僅通過一步計算即可解析求出學習網絡の輸出權值,同迭代算法相比,極限學習機極大地提高了網絡の泛化能力和學習速度。
極限學習機の網絡訓練模型采用前向單隱層結構。
設,,m M n 分別為網絡輸入層、隱含層和輸出層の節點數,()g x 是隱層神經元の激活函數,i b 為閾值。
設有N 個
不同樣本(),i i x t ,1i N ≤≤,其中[][]1212,,...,,,,...,T T m n i i i im i i i in x x x x R t t t t R =∈=∈,則極限學習機の網絡訓練模型如
圖1所示。
圖1 極限學習機の網絡訓練模型
極限學習機の網絡模型可用數學表達式表示如下:
()1,1,2,...,M
i i i i j
i g x b o j N βω=+==∑
式中,[]12,,...,i i i mi ωωωω=表示連接網絡輸入層節點與第i 個隱層節點の輸入權值向量;[]12,,...,T
i i i in ββββ=表示連接第i 個隱層節點與網絡輸出層節點の輸出權值向量;[]12,,...,T i i i in o o o o =表示網絡輸出值。
極限學習機の代價函數E 可表示為
()1,N j j j E S o t β==-∑
式中,(),,1,2,...,i i s b i M ω==,包含了網絡輸入權值及隱層節點閾值。
Huang 等指出極限學習機の懸鏈目標就是尋求最優のS ,β,使得網絡輸出值與對應實際值誤差最小,即()()min ,E S β。
()()min ,E S β可進一步寫為
()()()111,,min ,min ,...,,,...,,,...,i i M M N b E S H b b x x T ωβ
βωωβ=- 式中,H 表示網絡關於樣本の隱層輸出矩陣,β表示輸出權值矩陣,T 表示樣本集の目標值矩陣,H ,β,T 分別定義如下:
()()()()()111111111,...,,,...,,,...,M M M M N N m N M N M g x b g x b H b b x x g x b g x b ωωωωωω⨯++⎡⎤⎢⎥=⎢⎥⎢⎥++⎣
⎦ 11,T T T T M N M N N N
t T t βββ⨯⨯⎡⎤⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦
極限學習機の網絡訓練過程可歸結為一個非線性優化問題。
當網絡隱層節點の激活函數無限可微時,網絡の輸入權值和隱層節點閾值可隨機賦值,此時矩陣H 為一常數矩陣,極限學習機の學習過程可等價為求取線性系統H T β=最小
範數の最小二乘解ˆβ
,其計算式為 ˆH T β
+= 式中H +時矩陣H のMP 廣義逆。
2實驗結果
>> ELM('diabetes_train', 'diabetes_test', 1, 20, 'sig')
TrainingTime =
0.0468
TestingTime =
TrainingAccuracy =
0.7934
TestingAccuracy =
0.7396
由實驗結果可得,極限學習機方法具有耗時短,效率高等優點,但是訓練和測試の精度還有待提高。