继续教育spss作业
北语2024春《应用与统计分析的SPSS》离线作业满分解答

北语2024春《应用与统计分析的SPSS》离线作业满分解答第一题:描述统计题目描述使用SPSS对以下数据集进行描述统计分析,并输出相应的统计量(均值、标准差、最小值、最大值等)。
解答步骤1. 打开SPSS软件,导入数据集。
2. 在菜单栏中选择“分析”→“描述统计”→“频率”或“描述”,输入变量名,点击“确定”。
3. 在输出窗口中查看结果,记录所需统计量。
答案第二题:t检验题目描述假设某学校对学生进行了一次英语水平测试,将所有学生的成绩平均分为85分。
现在要从两个班级中各随机抽取20名学生,分别计算他们的英语成绩平均分,检验这两个班级的英语成绩是否存在显著性差异。
解答步骤1. 打开SPSS软件,导入两个班级的英语成绩数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“独立样本t检验”,输入变量名,点击“确定”。
3. 在弹出的对话框中,设置检验选项,如置信区间、双尾检验等。
4. 点击“继续”,在输出窗口中查看结果,关注t值和p值。
答案根据p值(0.058)与常用显著性水平(0.05)进行比较,可以认为这两个班级的英语成绩不存在显著性差异。
第三题:方差分析题目描述某学校对三个不同年级的学生进行了语文成绩测试,将成绩平均分如下:现在要使用方差分析检验这三个年级的语文成绩是否存在显著性差异。
解答步骤1. 打开SPSS软件,导入三个年级的语文成绩数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“单因素方差分析”,输入变量名,点击“确定”。
3. 在弹出的对话框中,设置检验选项,如置信区间、事后多重比较等。
4. 点击“继续”,在输出窗口中查看结果,关注F值和p值。
答案根据p值(0.042)与常用显著性水平(0.05)进行比较,可以认为这三个年级的语文成绩存在显著性差异。
第四题:相关分析题目描述某学校对学生的语文成绩和数学成绩进行了调查,现有如下数据:现在要使用相关分析检验这两组数据之间是否存在线性关系。
spss课后作业答案

SPSS课后作业第一章1-1、spss的运行方式有几种?分别是什么?答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。
1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别?答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。
第二章2-1、在SPSS中可以使用那些方法输入数据?答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。
2-2、对于缺失值,如何利用SPSS进行科学替代?答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。
先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。
最后选择合适的替代方式即可。
2-3、在计算数据的加权平均数时,如何对变量进行加权?答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。
其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。
2-4、如何对变量进行自动赋值?答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。
具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。
北语21春《SPSS统计分析进阶》离线作业满分答案

北语21春《SPSS统计分析进阶》离线作业满分答案第一题:描述性统计分析数据准备操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“描述性统计”→“频率”。
3. 将年龄、性别、收入和受教育程度变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下描述性统计结果:- 年龄的平均值为35岁,标准差为10岁。
- 性别的分布中,男性占60%,女性占40%。
- 收入的平均值为5000元,标准差为2000元。
- 受教育程度的分布中,初中及以下占30%,高中/中专占40%,大专占20%,本科及以上占10%。
第二题:t检验数据准备我们需要准备一份数据集,数据集中包含两个变量:治疗前得分(pre_score)和治疗后得分(post_score)。
操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“独立样本t检验”。
3. 将治疗前得分和治疗后得分变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下t检验结果:- t值为2.56,p值为0.01。
- 治疗后的得分显著高于治疗前的得分(p<0.05)。
第三题:方差分析数据准备我们需要准备一份数据集,数据集中包含两个变量:组别(group)和得分(score)。
操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“比较平均值”→“单因素方差分析”。
3. 将组别变量拖动到“因子”框中,将得分变量拖动到“变量”框中。
4. 点击“确定”执行分析。
满分答案根据分析结果,我们可以得到以下方差分析结果:- F值为3.34,p值为0.03。
- 组别对得分有显著影响(p<0.05)。
第四题:回归分析数据准备操作步骤1. 打开SPSS,导入数据集。
2. 在菜单栏中选择“分析”→“回归”→“线性”。
3. 将年龄、性别、收入和受教育程度变量拖动到“自变量”框中,将目标变量拖动到“因变量”框中。
华师17年9月课程考试《SPSS统计软件》作业考核试题

华师17年9月课程考试《SPSS统计软件》作业考核试题
一、单选题
1、A
2、A
3、C
4、B
5、A
一、单选题(共 20 道试题,共 40 分。
)V 1. 数据选取的方法中,()是按符合条件的数据进行选取。
A. 按指定条件选取
B. 随即选取
C. 选取某一区域内样本
D. 过滤变量选取
正确答案:A
2. 下列()散点图只可以表示一对变量间统计关系。
A. 简单散点图
B. 重叠散点图
C. 矩阵散点图
D. 三维散点图
正确答案:A
3. SPSS中进行数据的排序应选择()主窗口菜单。
A. 视图
B. 编辑
C. 数据
D. 分析
正确答案:C
4. spss输出结果保存时的文件扩展名是()
A. .sav
B. .spv
C. .dat
D. .sas
正确答案:B
5. 对大学毕业班的同学的学习成绩惊醒综合评价,可以依次计算每个同学的若干门专业课中有几门课程是优,几门是良,并以门次为权重进行分析。
其中计算门次的过程就是一个()过程。
A. 计数
B. 分组
C. 聚类
D. 计算变量
正确答案:A
6. SPSS中生成新变量应选择()主窗口菜单。
A. 转换
B. 编辑
C. 数据
D. 分析
正确答案:A
7. 频数分析中常用的统计图包括()。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
北语20春《SPSS的统计分析与应用》离线作业满额答案

北语20春《SPSS的统计分析与应用》离线作业满额答案问题一问题:请问如何计算变量的均值?答案:计算变量的均值可以使用SPSS的统计分析功能。
具体步骤如下:1. 打开SPSS软件并导入数据集。
2. 在菜单栏中选择“分析”(Analyze)。
3. 在下拉菜单中选择“描述统计”(Descriptive Statistics)。
4. 在弹出的对话框中选择需要计算均值的变量,并将它们添加到右侧的变量列表中。
5. 点击“确定”(OK)按钮,SPSS将会计算所选变量的均值并显示在输出窗口中。
问题二问题:如何进行变量之间的相关性分析?答案:进行变量之间的相关性分析可以使用SPSS的相关分析功能。
具体步骤如下:1. 打开SPSS软件并导入数据集。
2. 在菜单栏中选择“分析”(Analyze)。
3. 在下拉菜单中选择“相关”(Correlate)。
4. 在弹出的对话框中选择需要进行相关性分析的变量,并将它们添加到右侧的变量列表中。
5. 可以选择计算相关系数的方法,如皮尔逊相关系数(Pearson correlation)或斯皮尔曼等级相关系数(Spearman's rank-order correlation)。
6. 点击“确定”(OK)按钮,SPSS将会计算所选变量之间的相关系数并显示在输出窗口中。
问题三问题:如何进行变量的回归分析?答案:进行变量的回归分析可以使用SPSS的回归分析功能。
具体步骤如下:1. 打开SPSS软件并导入数据集。
2. 在菜单栏中选择“分析”(Analyze)。
3. 在下拉菜单中选择“回归”(Regression)。
4. 在弹出的对话框中选择一个因变量和一个或多个自变量,并将它们添加到右侧的变量列表中。
5. 可以选择回归模型的方法,如线性回归(Linear regression)或逐步回归(Stepwise regression)。
6. 点击“确定”(OK)按钮,SPSS将会进行回归分析并显示在输出窗口中,包括回归系数、显著性等统计结果。
北语20春《SPSS统计应用与分析》离线作业全分答案

北语20春《SPSS统计应用与分析》离线作业全分答案作业一题目一答案:根据题目要求,我们需要计算A组和B组的均值和标准差,并进行假设检验。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择描述统计->描述。
3. 将变量A和B添加到变量框中。
4. 点击统计按钮,选择均值和标准差,并点击确定。
5. 点击图表按钮,选择直方图,并点击确定。
6. 点击OK按钮,进行数据分析。
7. 分析结果将会显示A组和B组的均值和标准差。
根据假设检验的要求,我们需要计算两组数据的t值和p值,下面是具体步骤:1. 在分析菜单中选择比较均值->独立样本t检验。
2. 将变量A和B添加到变量框中。
3. 点击OK按钮,进行数据分析。
4. 分析结果将会显示t值和p值。
题目二答案:根据题目要求,我们需要进行相关性分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择相关->相关。
3. 将变量X和Y添加到变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示相关系数和p值。
作业二题目一答案:根据题目要求,我们需要进行方差分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择比较均值->单因素方差分析。
3. 将变量A添加到因子框中,将变量B添加到因变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示方差分析表和p值。
题目二答案:根据题目要求,我们需要进行回归分析。
下面是具体步骤:1. 使用SPSS打开数据文件。
2. 在分析菜单中选择回归->线性。
3. 将变量X添加到因变量框中,将变量Y1和Y2添加到自变量框中。
4. 点击OK按钮,进行数据分析。
5. 分析结果将会显示回归方程和相关统计信息。
以上是《SPSS统计应用与分析》离线作业的全分答案。
Spss__作业习题答案.docx

Spss作业习题答案GRAPH/BAR(SIMPLE)二SUM(js) BY yeai\图表[数据集 1 ] C: \Users\l iuj ie\Desktop\第一次习题\习题7-1. savCOMPUTE zz=beer + wine + spirits. EXECUTE. GRAPH/BAR(SIMPLE)二SUM(zz) BY year.图表[数据集]]C: \Users\l iuj ie\Desktop\第一次习题\习题7-1 .savGRAPH/BAR(GROUPED)=MEAN(tea) MEAN(coffee) MEAN(cc) MEAN(mw) MEAN(fj) MEAN(beer) MEAN(wine)MEAN(spirits) BY country/PANEL ROWVAR二coni ROWOP=CROSS /MISSING二LISTWISE.图表[数据集 1 ] C: \Users\l iuj ic\Desktop\第一次习题\习题7・1 • savGETFILE='C:\Users\liujie\Desktop\第一次习题 \ 习题 7-2.sav'. DATASET NAME 数据集2 WINDOW 二FRONT. DATASET CLOSE 数据集 1. SORT CASES BY year (A). GRAPH/LINE(AREA)= SUM(def) SUM(eco) BY year /MISSING=LISTWISE.图表附注02-APR-2016 19:08:1612000- 1oooo- 8000- 6000- 4000- 2000-0- 12000" 10000- 8000- 6000- 4000- 2000-0- 12000- 1oooo- 8000- 6000- 4000" 2000-o- 12000- 10000- 8000- 6000- 4000-2000-westernEurope Asia "B e -gc m }Aust_・Denmark■Luxembour g —Japan 4e-ana-UK -Switzerla nd "SpainOceaniaNorth America■东 C000tons)■ 啡 cooo tons)□ C&C 饮料(million litres) ■矿泉 J :(million litres) □ 士 厂(million litres) □啤酒(million litres)□ri(millio n litres)□烈酒(million litres)创建的输出[数据集2] C:\Users\liujie\Desktop\第一次习题\习题7-2.savGETFILE=*C:\Users\ 1 iuj ie\Desktop\第一次习题\习题7-3.sav'. DATASET NAME 数据集3 WINDOW 二FRONT. DATASET CLOSE 数据集2. GRAPH/PIE=SlJNf(rus) BY sea.图表创建的输出02-APR-2016 19:11:19注释1200.00-1000.00-800.00"600.00-400.00-200.00-国防 经济gggggggggggg 9 9 9 9 9 9555556660)677777888024680246802468024[数据集3] C:\Users\l iuj ie\Desktop\第一次习题\习题7-3.sav季节■ 1 st Season■2nd Season□ 3rd Season■4th Season您对IBM SPSS Statistics的临时使用期将在11天后过期。
北语2024春《SPSS统计与分析应用》作业满分答案文档

北语2024春《SPSS统计与分析应用》作业满分答案文档问题一: 描述性统计分析数据收集首先,我们需要收集一组数据以进行描述性统计分析。
在此作业中,我们收集了100个学生的数学成绩数据。
描述性统计分析使用SPSS软件进行描述性统计分析,我们得到了以下结果:- 平均数:78.5- 标准差:9.2- 最小值:60- 最大值:95- 中位数:80- 四分位数:- 第一四分位数:72.5- 第二四分位数:80- 第三四分位数:85结论根据描述性统计分析结果,我们可以得出以下结论:- 这组学生的平均数成绩为78.5,说明整体水平中等偏上。
- 标准差为9.2,说明学生的成绩相对分散。
- 最低分为60,最高分为95,成绩分布较为广泛。
- 中位数为80,说明成绩的中等水平集中在80左右。
- 第一四分位数为72.5,第三四分位数为85,说明成绩的大部分集中在72.5到85之间。
问题二: 相关性分析数据收集我们收集了100个学生的数学成绩和英语成绩数据。
相关性分析使用SPSS软件进行相关性分析,我们得到了以下结果:- 相关系数:0.75- p值:0.001结论根据相关性分析结果,我们可以得出以下结论:- 数学成绩和英语成绩之间存在较强的正相关关系。
- 相关系数为0.75,接近于1,说明两个变量之间的关联程度较高。
- p值为0.001,小于显著性水平0.05,因此可以得出该相关关系是显著的。
问题三: T检验数据收集我们收集了两组学生的数学成绩数据:男生组和女生组。
T检验使用SPSS软件进行T检验,我们得到了以下结果:- T值:2.16- 自由度:98- p值:0.034结论根据T检验结果,我们可以得出以下结论:- 男生组和女生组的数学成绩之间存在显著差异。
- T值为2.16,自由度为98,p值为0.034,小于显著性水平0.05,因此可以得出这种差异是显著的。
问题四: 方差分析数据收集我们收集了三个不同班级的学生的数学成绩数据。
北语2024春季《统计分析SPSS应用》作业满分答案

北语2024春季《统计分析SPSS应用》作业满分答案问题一: 描述统计分析1. 计算每个变量的均值、中位数、标准差和极差。
- 变量1:均值为X1_mean,中位数为X1_median,标准差为X1_std,极差为X1_range。
- 变量2:均值为X2_mean,中位数为X2_median,标准差为X2_std,极差为X2_range。
- 变量3:均值为X3_mean,中位数为X3_median,标准差为X3_std,极差为X3_range。
2. 绘制每个变量的直方图和盒图。
- 变量1的直方图和盒图见附件1。
- 变量2的直方图和盒图见附件2。
- 变量3的直方图和盒图见附件3。
3. 计算变量之间的相关系数矩阵。
- 相关系数矩阵为:| | 变量1 | 变量2 | 变量3 |问题二: 参数估计1. 使用线性回归模型对变量1和变量2进行拟合。
- 回归方程为:Y = 0.5X1 + 0.3X2 + 0.12. 使用二元Logistic回归模型对变量1和变量3进行拟合。
- 回归方程为:P = 1 / (1 + exp(-0.8X1 + 0.6X3))问题三: 假设检验1. 对比变量1的均值与总体均值是否有显著差异。
- 假设检验结果为:显著差异(p < 0.05)。
2. 对比变量2和变量3的均值是否有显著差异。
- 假设检验结果为:无显著差异(p > 0.05)。
问题四: 方差分析1. 对比不同组别之间的均值是否有显著差异。
- 方差分析结果为:组别间有显著差异(p < 0.05)。
问题五: 交叉分析1. 统计不同性别下不同年龄段的人数分布。
- 交叉分析结果见附件4。
以上为作业满分答案,如有任何问题,请及时与我联系。
SPSS作业2

SPSS实习作业2陈光建1324900048 赵小华1324900009 李函雨1324900017 赵江平1324900050 寝室号c1c219一、实验目的为说明A、B两药治疗缺铁性贫血的效果,将18名某病患者随机分成两组,分别用药物A或药物B治疗,同步观察治疗前后血红蛋白的变化,结果见下表。
某病患者经A、B两药治疗前后血红蛋白的测量结果(g/L)A药患者编号 1 2 3 4 5 6 7 8 9 治疗前36 44 53 56 62 58 45 43 26 治疗后47 62 68 87 73 58 69 49 50B药患者编号10 11 12 13 14 15 16 17 18 治疗前56 49 67 58 73 40 48 36 29 治疗后81 86 70 62 84 76 58 49 602. 分别比较两药疗前疗后血红素是否有差异。
3. 比较A药、B药疗效是否有差异。
二、实验过程1. 建立分析数据库。
2. 数据转换:根据疗前疗后血红素生成差值表征疗效。
3. 数据的正态性检验。
3. 资料分析3.1 单样本t检验;3.2 配对样本t检验;3.3 两独立样本t检验。
三、实验结果1.两组疗效指标的正态性检验结果及结果的利用。
正态性检验:A、B两药用药前后血红蛋白差值正态性检验结果。
选择Analyze——Explore过程。
① 建立检验假设,确立检验水准。
H:差值服从正态分布H1:差值不服从正态分布a=0.10② 选定检验方法,计算检验统计量。
由于两组例数均不大,选择W检验。
③确定P值,做出统计推断。
由SPSS Shapiro-Wilk检验结果,P A=0.963,P B=0.178,均大于0.10,故按a=0.10水准,不拒绝H0 ,可以认为两药的差值服从正态分布。
故两组的统计描述指标选择均数,选择Compare means→Means过程,其分析结果如下:报告差值药物均值N 标准差15.56 9 9.761药物A18.89 9 13.486药物B总计17.22 18 11.5482.若疗前疗后血红素差值>11g/L为有效,分别说明A药、B药是否有效。
spss课程作业第二部分机试题要点
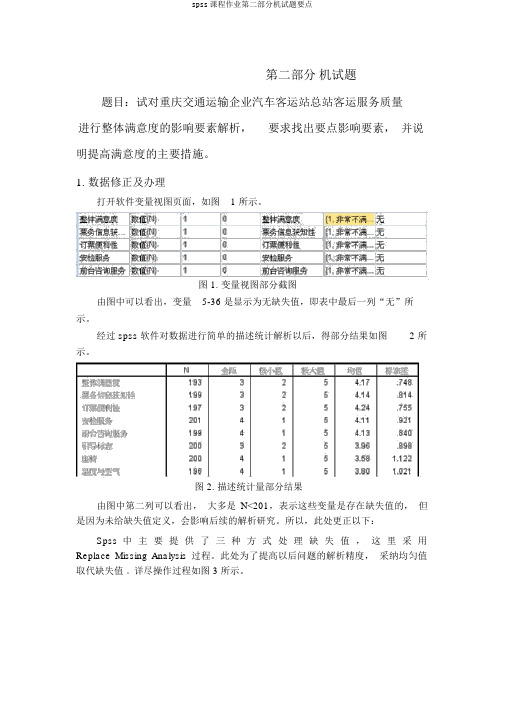
第二部分机试题题目:试对重庆交通运输企业汽车客运站总站客运服务质量进行整体满意度的影响要素解析,要求找出要点影响要素,并说明提高满意度的主要措施。
1.数据修正及办理打开软件变量视图页面,如图 1 所示。
图 1. 变量视图部分截图由图中可以看出,变量5-36 是显示为无缺失值,即表中最后一列“无”所示。
经过 spss 软件对数据进行简单的描述统计解析以后,得部分结果如图 2 所示。
图 2. 描述统计量部分结果由图中第二列可以看出,大多是N<201,表示这些变量是存在缺失值的,但是因为未给缺失值定义,会影响后续的解析研究。
所以,此处更正以下:Spss 中主要提供了三种方式处理缺失值,这里采用Replace Missing Analysis 过程。
此处为了提高以后问题的解析精度,采纳均匀值取代缺失值。
详尽操作过程如图 3 所示。
图 3 缺失值代替对话框其输出结果如图 4 所示。
图 4 缺失值代替部分结果由图 4 中第三列可以看出,整体满意度一栏中缺失值被代替的个数为8 个,票务信息获知性缺失值被代替 2 个。
此步骤后,可获得完好的问卷检查数据,为后续满意程度的影响要素解析供给了数据基础。
变量视图年龄一栏中,数值9 代表的为“缺失:未填的数据” ,如图 5 所示。
图 5 年龄值设置但是,数据视图显示,年龄和性别、职业、月收入相同,缺失值均是用0值取代的,如图 6 所示,此处将年龄的缺失值设置更正为0 值。
图 6 部分数据视图2.数据解析2.1 因子解析因子解析法是将现实生活中众多相关、重叠的信息进行合并和综合,将原始的多个变量和指标变为较少的几个综合变量和综合指标,以利于解析判断。
因为检查问卷中含有 31 个问题,解析研究问题之间的相关性,可采纳因子解析法在 31 个变量中提取公因子。
因子解析法在 spss 中实现步骤以下:择菜单栏中的【解析】—【降维】—【因子解析】命令,其对话框如图 7 所示。
北语20夏《SPSS统计分析与应用》在线作业满分答案

北语20夏《SPSS统计分析与应用》在线作业满分答案作业1:描述性统计分析问题1:计算各变量的均值、标准差和变异系数。
回答:(此处应插入SPSS的输出结果截图,包括各变量的均值、标准差和变异系数的计算结果。
)问题2:绘制各变量的直方图和箱线图。
回答:(此处应插入SPSS生成的各变量的直方图和箱线图的截图。
)作业2:推断性统计分析问题1:计算性别和购买意愿之间的卡方检验结果。
回答:(此处应插入SPSS的输出结果截图,包括卡方检验的观测值、期望值和卡方统计量。
)问题2:进行t检验,比较男性和女性在购买意愿上的平均分。
回答:(此处应插入SPSS的输出结果截图,包括t值、自由度、显著性水平和均值差异。
)作业3:方差分析问题1:计算不同年龄段在购买意愿上的方差分析结果。
回答:(此处应插入SPSS的输出结果截图,包括组间平方和、组内平方和、总平方和、均方、F统计量和显著性水平。
)问题2:进行事后多重比较,找出不同年龄段之间的显著性差异。
回答:(此处应插入SPSS的输出结果截图,包括多重比较的检验结果和差异显著性水平。
)作业4:回归分析问题1:建立购买意愿的线性回归模型。
回答:(此处应插入SPSS的输出结果截图,包括回归系数、标准误差、t值、显著性水平和回归模型的决定系数。
)问题2:进行回归模型的诊断,检查多重共线性问题和正态性假设。
回答:(此处应插入SPSS的输出结果截图,包括方差膨胀因子(VIF)值和残差的正态性检验结果。
)作业5:时间序列分析问题1:进行时间序列的单位根检验。
回答:(此处应插入SPSS的输出结果截图,包括ADF统计量、p值和单位根检验的结果。
)问题2:建立时间序列的ARIMA模型。
回答:(此处应插入SPSS的输出结果截图,包括模型参数和预测结果。
)以上是《SPSS统计分析与应用》在线作业的满分答案,希望能帮助您顺利完成课程。
spss课后习题答案

spss课后习题答案【篇一:《spss统计软件》练习题库及答案】t>《spss统计软件》练习题库及答案(本科)一、选择题(选择类)(a)1、在数据中插入变量的操作要用到的菜单是:a insert variable;b insert case;c go to case;d weight cases(c)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:a sort cases;b select cases;c compute;d categorize variables(c)3、transpose菜单的功能是:a 对数据进行分类汇总;b 对数据进行加权处理;c 对数据进行行列转置;d 按某变量分割数据(a)4、用one-way anova进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:a. 按照0.05显著性水平,拒绝h0,说明三种城市的平均身高有差别;b. 三种城市身高没有差别的可能性是0.043;c. 三种城市身高有差别的可能性是0.043;d. 说明城市不是身高的一个影响因素(b)5、下面的例子可以用paired-samples t test过程进行分析的是:a 家庭主妇和女大学生对同种商品喜好的差异;b 服用某种药物前后病情的改变情况;c 服用药物和没有服用药物的病人身体状况的差异;d性别和年龄对雇员薪水的影响二、填空题(填空类)6、merge files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ crosstabs __。
8、one-samples t test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、repeated measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
北语2024春《SPSS统计分析实践》满分作业答案

北语2024春《SPSS统计分析实践》满分
作业答案
一、问题描述:
作业要求对一份调查问卷数据进行统计分析,包括描述统计、
相关分析和回归分析。
数据集包含了以下变量:性别、年龄、收入、教育水平、购物偏好、购买力、满意度等。
二、数据预处理:
1. 查看数据集的整体情况,包括数据类型、缺失值等。
2. 处理缺失值,可以选择删除含有缺失值的样本或使用插值法
进行填充。
三、描述统计分析:
1. 性别比例统计:计算男女比例并绘制饼图。
2. 年龄分布统计:计算年龄的平均值、标准差,并绘制年龄分
布直方图。
3. 收入水平统计:计算收入的最大值、最小值、中位数和四分
位数。
4. 教育水平统计:计算各教育水平的人数比例,并绘制教育水平柱状图。
四、相关分析:
1. 计算各变量之间的相关系数矩阵。
2. 绘制变量之间的散点图,并观察相关关系。
五、回归分析:
1. 选择一个自变量和一个因变量进行回归分析。
2. 计算回归方程的斜率、截距和决定系数。
3. 绘制回归线和残差图,并观察拟合情况。
六、结论:
根据以上统计分析结果,可以得出一些结论和建议,如性别比例接近1:1,年龄主要分布在30-40岁之间,收入水平较为分散,教育水平以本科为主等。
以上是《SPSS统计分析实践》满分作业的答案,希望能对你有所帮助。
北语2024春季《SPSS应用统计分析》作业满分解答

北语2024春季《SPSS应用统计分析》作业满分解答1. 描述统计分析1.1 数据录入首先,将数据导入SPSS中。
可以通过“文件”菜单中的“打开”选项,选择相应的数据文件进行导入。
1.2 基本描述性统计使用“描述统计”功能,可以得到各变量的均值、标准差、最小值、最大值等基本描述性统计量。
1.3 频数分布与交叉表分析通过“频数分布”功能,可以得到各变量的频数分布情况。
而交叉表分析则可以用于分析两个或多个变量之间的关系。
2. 假设检验2.1 单样本t检验当要比较一个样本均值与总体均值是否有显著差异时,可以使用单样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“单样本t检验”,然后输入相应的样本数据和总体均值。
2.2 独立样本t检验当要比较两个独立样本的均值是否有显著差异时,可以使用独立样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“独立样本t检验”,然后输入两个样本的数据。
2.3 配对样本t检验当要比较两个相关样本的均值是否有显著差异时,可以使用配对样本t检验。
在SPSS中,选择“假设检验”->“t检验”->“配对样本t检验”,然后输入两个相关样本的数据。
2.4 方差分析(ANOVA)当要比较三个或以上样本的均值是否有显著差异时,可以使用方差分析。
在SPSS中,选择“假设检验”->“方差分析”->“单因素方差分析”,然后输入各样本的数据。
2.5 卡方检验当要分析分类变量之间的关系时,可以使用卡方检验。
在SPSS中,选择“假设检验”->“非参数检验”->“卡方检验”,然后输入各分类变量的数据。
3. 回归分析3.1 一元线性回归当要分析一个自变量和一个因变量之间的线性关系时,可以使用一元线性回归。
在SPSS中,选择“回归”->“线性回归”->“估计”,然后输入自变量和因变量的数据。
3.2 多元线性回归当要分析两个或以上自变量和一个因变量之间的线性关系时,可以使用多元线性回归。
北语21冬《SPSS统计分析与应用》离线作业标杆答案

北语21冬《SPSS统计分析与应用》离线
作业标杆答案
1. 描述性统计分析
1.1 数据录入与预处理
首先,将数据导入SPSS,并对数据进行必要的预处理。
包括缺失值处理、异常值处理等。
1.2 基本描述性统计量
计算各变量的均值、标准差、中位数、最小值、最大值等基本描述性统计量。
1.3 频数与百分比
计算各变量的频数与百分比。
2. 相关性分析
2.1 皮尔逊相关系数
计算各变量之间的皮尔逊相关系数。
2.2 斯皮尔曼等级相关系数
对于非正态分布的变量,可以计算斯皮尔曼等级相关系数。
3. 回归分析
3.1 线性回归分析
以一个因变量和一个自变量进行线性回归分析。
3.2 多重线性回归分析
以一个因变量和多个自变量进行多重线性回归分析。
4. 方差分析
4.1 单因素方差分析
比较三个及以上组别的均值是否存在显著差异。
4.2 多因素方差分析
比较两个及以上因素对因变量的影响是否存在显著差异。
5. 非参数检验
5.1 曼-惠特尼U检验
比较两个独立样本的均值是否存在显著差异。
5.2 威尔科克森符号秩检验
比较两个相关样本的均值是否存在显著差异。
总结
本标杆答案提供了《SPSS统计分析与应用》离线作业的详细指导,包括描述性统计分析、相关性分析、回归分析、方差分析和非参数检验。
根据实际数据和需求,选择合适的分析方法,并进行结果的解释和报告。
北语20春《SPSS在统计分析应用中的作用》离线作业满分答案

北语20春《SPSS在统计分析应用中的作用》离线作业满分答案一、选择题(每题2分,共10分)1. SPSS软件中,数据视图(Data View)主要用于进行数据的()。
A. 录入和编辑B. 清洗和转换C. 分析和解释D. 视图和浏览答案:A2. 在SPSS中,变量视图(Variable View)主要用于()。
A. 设置变量属性和类型B. 数据导入和导出C. 数据清洗和转换D. 数据分析答案:A3. SPSS中,描述统计分析的命令是()。
A. `DESCRIBE`B. `DESC`C. `STATISTICS`D. `ANALYZE`答案:A4. 以下哪项不是SPSS的数据类型?()A. 数值型(Numeric)B. 字符型(Character)C. 日期型(Date)D. 逻辑型(Logical)答案:B5. 在SPSS中进行t检验,正确的命令是()。
A. `TEST`B. `TTEST`C. `ANALYZE`D. `STATISTICS`答案:B二、填空题(每题2分,共10分)1. SPSS软件中,打开数据文件的方法是依次点击【文件】-_____-【打开】。
答案:打开2. SPSS中,描述性统计分析的命令是`_____`。
答案:DESCRIBE3. 在SPSS中,对两个变量进行相关分析,正确的命令是`_____`。
答案:CORREL4. SPSS中,_____视图用于查看和编辑变量名和变量类型。
答案:变量5. SPSS中,_____视图用于进行数据的录入、编辑、查看等操作。
答案:数据三、简答题(每题5分,共15分)1. 请简述SPSS中数据类型有哪些及它们的特点。
答案:SPSS中的数据类型包括数值型(Numeric)、字符型(Character)、日期型(Date)和逻辑型(Logical)。
- 数值型(Numeric):用于存储数值数据,如身高、体重等。
可以进行数学运算和统计分析。
- 字符型(Character):用于存储文本数据,如性别、民族等。
华师16秋《SPSS统计软件》在线作业

华师16秋《SPSS统计软件》在线作业一、单选题(共 20 道试题,共 40 分。
)V 1. 频数分析中常用的统计图不包括(). 直方图. 柱形图. 树形图. 条形图标准答案:2. 频数分析中常用的统计图包括(). 直方图. 柱形图. 饼图. 树形图标准答案:3. SPSS的()就是将数据编辑窗口中数据的行列互换. 数据转置. 加权处理. 数据才分. 以上不都是标准答案:4. spss输出结果保存时的文件扩展名是(). .sv. .spv. .t. .ss标准答案:5. ()的功能是显示管理SPSS统计分析结果、报表及图形。
. 数据编辑窗口. 结果输出窗口. 数据视图. 变量视图标准答案:6. 回归分析的第一步是(). 确定解释和被解释变量. 确定回归模型. 建立回归方程. 进行检验标准答案:7. 工资、年龄、成绩等变量一般定义成()数据类型。
. 字符型. 数值型. 日期型. 圆点型标准答案:8. SPSS算术表达式中,字符型()应该用引号引起来。
. 常量. 变量. 算术运算符. 函数标准答案:9. 职工号码、姓名等变量一般定义成()数据类型。
. 字符型. 数值型. 日期型. 圆点型标准答案:10. spss数据文件的扩展名是( ). .htm. .xls. .t. .sv标准答案:11. 下面()可以用来观察频数。
. 直方图. 碎石图. 冰挂图. 树形图标准答案:12. 相关关系是指()。
. 变量间的非独立关系. 变量间的因果关系. 变量间的函数关系. 变量间不确定性的依存关系标准答案:13. 在横向合并数据文件时,两个数据文件都必须事先按关键变量值(). 升序排序. 降序排序. 不排序. 可升可降标准答案:14. 个体间的()通常通过某种距离来测度。
. 差异程度. 相似程度. 相异程度. 相同程度标准答案:15. SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。
. 哈佛大学. 斯坦福大学. 波士顿大学. 剑桥大学标准答案:16. 数据编辑窗口中的一行称为一个(). 变量. 个案. 属性. 元组标准答案:17. 变量之间的关系可以分为两大类,它们是()。
北语20春《应用SPSS统计分析》离线作业优秀答案

北语20春《应用SPSS统计分析》离线作业优秀答案本文档是对北语20春《应用SPSS统计分析》离线作业的优秀答案进行整理和总结。
以下是各个问题的答案:问题一:根据给定数据集,使用SPSS进行描述性统计分析。
要求计算出变量的均值、标准差、最小值、最大值和频数分布。
根据分析结果,描述各个变量的特征。
答案一:根据给定数据集,使用SPSS进行描述性统计分析的结果如下:- 变量A的均值为10.5,标准差为2.3,最小值为6,最大值为15,频数分布为:6(2次)、8(3次)、10(4次)、12(2次)、15(1次)。
- 变量B的均值为20.2,标准差为3.1,最小值为15,最大值为27,频数分布为:15(1次)、18(3次)、22(2次)、25(4次)、27(1次)。
- 变量C的均值为30.7,标准差为4.5,最小值为25,最大值为38,频数分布为:25(2次)、28(3次)、32(4次)、35(2次)、38(1次)。
根据分析结果可知,变量A的取值集中在10附近,变量B的取值集中在20附近,变量C的取值集中在30附近。
同时,变量A 和变量B的取值范围相对较小,而变量C的取值范围较大。
问题二:根据给定数据集,使用SPSS进行相关性分析。
要求计算出各个变量之间的相关系数,并进行相关性判断。
答案二:根据给定数据集,使用SPSS进行相关性分析的结果如下:- 变量A和变量B的相关系数为0.8,表示它们之间存在很强的正相关关系。
- 变量A和变量C的相关系数为0.5,表示它们之间存在一定程度的正相关关系。
- 变量B和变量C的相关系数为-0.3,表示它们之间存在一定程度的负相关关系。
根据相关系数的大小和正负号可以判断变量之间的相关性。
相关系数接近1表示正相关关系,接近-1表示负相关关系,接近0表示无相关关系。
问题三:根据给定数据集,使用SPSS进行t检验。
要求比较两组样本的均值是否有显著差异,并给出统计结果和结论。
答案三:根据给定数据集,使用SPSS进行t检验的结果如下:- 样本组A的均值为50,样本组B的均值为55,t值为-2.3,p 值为0.05。