第3章参数估计
计量经济学 第三章:违背假设问题及参数估计方法

2.D-W检验 D-W检验适合于一阶自相关检验,构造统计量
d
2 e e t t 1 t 2 n
et
t 1
n
2
n et et 1 2(1 ˆ) 则:d 21 t 2n 2 et t 1 0d 4
e 0 1 f ( X ) 2 f ( K )
四、存在异方差模型的估计方法(Eviews权重法) 1.解释变量的某种(函数)形式作为权数
Eviews6.0权数为: 1 f ( x)
1 f ( x) 标准差的倒数 2 方差的倒数 1 f ( x) Eviews7.2权数: 标准差 f ( x) 2 f 方差 ( x)
采用时间序列数据的模型往往存在序列相关
三、序列相关检验
检验方法主要有: 图示法 D-W检验 LM检验 例3-3(表3-3),进出口对于国内生产总值的影响 1.图示法 ①估计原模型,得到残差; ②构造残差与残差滞后期之间的散点图; ③若存在线性关系,则存在序列相关。 另外,也可以构造残差与时间序列t的散点图,通过 分析随时间序列的规律性判断是否存在序列相关。
2.加权最小二乘法的权数为: 1 ei ◇消除异方差的经验做法: 指数模型能够有效地减弱异方差现象; 多个解释变量优先考虑用残差序列作为权数。
例3-1(表3-1),能源消费问题 ◇原模型为: ECt 0 1GDPt t ◇原模型参数估计结果为: ˆ 87307.06 0.6 t
t t t 1 2 t 2 s t s
s 0
E ( t ) s E ( t s ) 0
s 0
2 2s Var ( t ) Var ( t s ) 2 1 s 0 2 s Cov( t , t s ) 1 2
参数估计的一般步骤

参数估计的一般步骤引言:参数估计是统计学中一项重要的任务,它用于根据样本数据来推断总体参数的值。
参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
本文将详细介绍参数估计的一般步骤,并以人类的视角进行描述,使读者更好地理解和应用这些步骤。
一、确定估计方法在参数估计中,首先需要确定合适的估计方法。
估计方法可以分为点估计和区间估计两种。
点估计方法通过单个数值来估计参数的值,例如最大似然估计和矩估计。
区间估计方法则通过一个区间来估计参数的范围,例如置信区间估计。
选择合适的估计方法是参数估计的第一步。
二、选择样本在确定了估计方法后,接下来需要选择合适的样本进行参数估计。
样本应当具有代表性,能够反映总体的特征。
为了保证样本的代表性,可以使用随机抽样方法来选择样本。
通过合理选择样本,可以减小估计误差,提高参数估计的准确性。
三、计算估计值在选择好样本后,需要计算参数的估计值。
对于点估计方法,可以使用最大似然估计或矩估计等方法来计算参数的估计值。
对于区间估计方法,可以使用置信区间估计来计算参数的范围。
计算估计值时,需要根据样本数据和估计方法进行相应的计算,确保估计结果的准确性。
四、进行推断在计算得到估计值后,需要进行推断,即根据估计值对总体参数进行推断。
对于点估计方法,可以直接使用估计值作为总体参数的估计值。
对于区间估计方法,可以使用置信区间来表示总体参数的范围。
通过推断可以了解总体参数的可能取值范围,帮助做出正确的决策和预测。
总结:参数估计的一般步骤包括确定估计方法、选择样本、计算估计值和进行推断。
在进行参数估计时,需要选择合适的估计方法和样本,计算出估计值,并进行相应的推断。
参数估计在统计学中扮演着重要的角色,它帮助我们根据样本数据来推断总体参数的值,从而更好地了解和应用统计学。
通过本文的介绍,希望读者能够更好地理解和应用参数估计的一般步骤。
参数估计假设检验练习题

第三章 假设检验例子例1:某糖厂用自动打包机装糖。
已知每袋糖的重量(单位:千克)服从正态分布()2~,X N μσ。
今随机抽查9袋,称出它们的重量并计算得到*48.5, 2.5x s ==。
取显著性水平0.05α=。
在下列两种情形下分别检验()01:50 :50H H μμ=≠22(1) 4 (2)σσ=未知解:()()2*01220.97512~,48.5, 2.5,9,0.05:50 :50(1) 4 (2)(1) 2.251.962.25 1.96X N x s n H H u uu αμσαμμσσ-=====≠======>糖的重量,现在已知显著性水平,在两种情形下检验:未知解:计算检验统计量的观测值 临界值,因为,所以拒绝原假设即不能认为糖的重量50的平均值是千克,即打包机工作不正常。
()()()()2*0120.97512~,48.5, 2.5,9,0.05:50 :50(2) 1.818 2.306 1.8 2.306X N x s n H H t t n t αμσαμμσ-=====≠===-==<糖的重量,现在已知显著性水平,在两种情形下检验:未知解:计算检验统计量的观测值 临界值,因为,所以不能拒绝原假设,即不能认为打包机工作不正常。
例2:在上题中,试在显著性水平0.1α=下检验()2201: 4 :4H H σσ=>()()()()*2201*22202210.948.5, 2.5,9,0.1: 4 :4112.51813.36212.513.362.x s n H H n s n αασσχσχχ-=====>-==-==<显著性水平,解:计算检验统计量的观测值 临界值,因为,所以不能拒绝原假设,即不能认为打包机工作不正常例3:监测站对某条河流每日的溶解氧(DO )质量浓度记录了30个数据,并由此算得 2.52, 2.05x s ==。
已知这条河流的每日DO 质量浓度服从()2,N μσ,试在显著性水平0.05α=下检验()01: 2.7 : 2.7H H μμ=≠。
概率论与数理参数估计

概率论与数理参数估计参数估计是概率论与数理统计中的一个重要问题,其目标是根据样本数据推断总体的未知参数。
参数估计分为点估计和区间估计两种方法。
点估计是通过样本计算得到总体未知参数的一个估计值。
常见的点估计方法有最大似然估计和矩估计。
最大似然估计是通过观察到的样本数据,选择使得观察到的样本数据出现的概率最大的未知参数值作为估计值。
矩估计是通过样本的矩(均值、方差等统计量),与总体矩进行对应,建立样本矩与总体矩之间的方程组,并求解未知参数。
这两种方法都可以给出参数的点估计值,但是其性质和效果不尽相同。
最大似然估计具有渐近正态性和不变性,但是可能存在偏差较大的问题;矩估计简单且易于计算,但是可能存在方程组无解的情况。
区间估计是给出参数估计结果的一个范围,表示对未知参数值的不确定性。
常见的区间估计方法有置信区间和预测区间。
置信区间是指给定的置信水平下,总体参数的真值落在一些区间内的概率。
置信区间的计算依赖于样本的分布和样本量。
预测区间是对一个新的观察值进行预测的区间,它比置信区间要宽一些,以充分考虑不确定性。
在参数估计过程中,需要注意样本的选取和样本量的确定。
样本是总体的一个子集,必须能够代表总体的特征才能得到准确的估计结果。
样本量的确定是通过统计方法和实际需求来确定的,要保证估计结果的可靠性。
参数估计在实际应用中有着广泛的应用。
例如,在医学领域中,通过对病人的样本数据进行统计分析,可以推断患者患其中一种疾病的概率,进而进行治疗和预防措施的制定。
在金融领域中,可以通过对股票的历史价格进行统计分析,推断未来股价的变动趋势,从而进行投资决策和风险评估。
在市场调研中,可以通过对消费者的问卷调查数据进行统计分析,推断消费者的偏好和需求,为企业的市场开发和产品设计提供依据。
综上所述,概率论与数理统计中的参数估计是一门重要的学科,通过对样本数据的统计分析,可以推断总体的未知参数,并对不确定性进行评估。
参数估计在实际应用中有着广泛的应用,对于科学研究和决策制定具有重要的意义。
SPSS第三章参数估计

利利利利
t 21.192
Mean df Sig. (2-tailed) Difference 32 .000 8.86364
结论: 结论
1:33家平均受益量为 8.8636万元 万元, 表1:33家平均受益量为 8.8636万元,标准 差为2.4027万元. 2.4027万元 差为2.4027万元.
新电池 ):18.2\10.4\12.6\18.0\11.7\15.0\24.0\17.6\ (日):18.2\10.4\12.6\18.0\11.7\15.0\24.0\17.6\23 .6\24.8\19.3\20.5\19.8\17.1\ .6\24.8\19.3\20.5\19.8\17.1\16.3 旧电池 ):12.1\17.5\8.6\13.9\7.8\15.1\17.9\10.6\ (日):12.1\17.5\8.6\13.9\7.8\15.1\17.9\10.6\13.8 14.2\15.3\ \14.2\15.3\11.6
挂牌上课态度反映得分(X) 挂牌上课态度反映得分( 10—20 10 20 20—30 20 30 30—40 30 40 40—50 40 50 50—60 50 60 60—70 60 70 合计 人数(f ) 人数( 2 6 10 12 20 10 60
案例1 案例1
(1分表示"很不同意" (1分表示"很不同意",7分表示"很同 分表示 分表示" 10项态度分累加后得一总态度分 项态度分累加后得一总态度分, 意",将10项态度分累加后得一总态度分,这种 量叫7级李克累加量表): 量叫7级李克累加量表): 试计算: 试计算: 学生态度得分的平均值和标准差; (1)学生态度得分的平均值和标准差; 构造学生态度得分平均值的98%置信区间. 98%置信区间 (2)构造学生态度得分平均值的98%置信区间.
第3章 ML估计和Bayesian参数估计

θ μ 未知
x ~N , 2
给定样本集
~N 0 , 02
,已知随机变量
均值未知而方差已知。均值变量的先验分布 求μ 的后验概率 p D
p D pD p p D
吸收所有与μ 无关的项
p D p
p D p D p 1 xi 2 1 1 0 2 1 exp exp 2 2 2 2 0 2 0 2 i 1
ˆ 2 但当n->∞时: 2
——渐近无偏估计
最大似然估计(ML)
ML估计总结
简单性 收敛性:无偏或者渐近无偏 如果假设的类条件概率模型 p x i , θi
正确,
则通常能获得较好的结果。但果假设模型出现偏 差,将导致非常差的估计结果。
参数估计
参数估计(parametric
的解。而只有θ点使得 似然函数最大。
方程组没有唯一解的情况
最大似然估计(ML)
1 ,1 x 2 p x 2 1 0, 其他
H N ln 2 1
H 1 N 0 1 2 1
均匀分布的情况
H 1 N 0 2 2 1
0 xi 2 i 1 0
N
由两式指数项中对应的系数相等得:
N 1 1 2 2 2 N 0 N N N ˆN 2 2 N 02
1 ˆ 其中: N N
x
i 1
N
i
2 p D ~N N , N 求解方程组得:
N p D p
3 第三章 参数估计与非参数估计
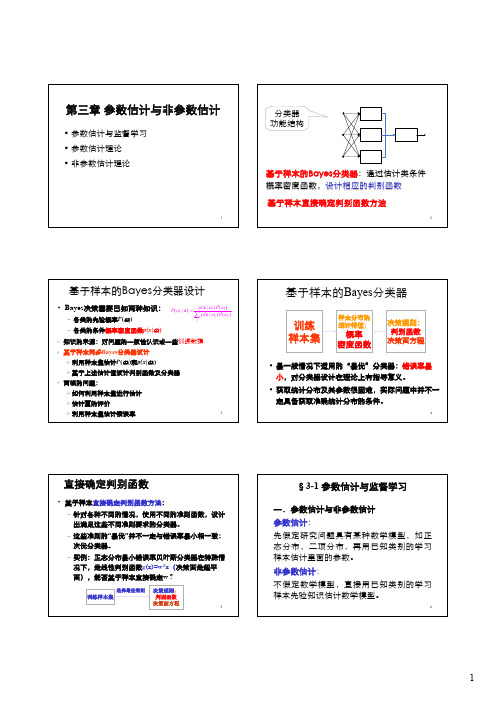
1第三章参数估计与非参数估计•参数估计与监督学习•参数估计理论•非参数估计理论2基于样本的Bayes分类器:通过估计类条件概率密度函数,设计相应的判别函数分类器功能结构基于样本直接确定判别函数方法3基于样本的Bayes 分类器设计•Bayes 决策需要已知两种知识:–各类的先验概率P (ωi )–各类的条件概率密度函数p(x |ωi )(|)()(|)(|)()i i i j j jp P P p P ωωωωω=∑x x x 知识的来源:对问题的一般性认识或一些训练数据基于样本两步Bayes 分类器设计¾利用样本集估计P (ωi )和p(x |ωi )¾基于上述估计值设计判别函数及分类器面临的问题:¾如何利用样本集进行估计¾估计量的评价¾利用样本集估计错误率4基于样本的Bayes 分类器训练样本集样本分布的统计特征:概率密度函数决策规则:判别函数决策面方程•最一般情况下适用的“最优”分类器:错误率最小,对分类器设计在理论上有指导意义。
•获取统计分布及其参数很困难,实际问题中并不一定具备获取准确统计分布的条件。
5直接确定判别函数•基于样本直接确定判别函数方法:–针对各种不同的情况,使用不同的准则函数,设计出满足这些不同准则要求的分类器。
–这些准则的“最优”并不一定与错误率最小相一致:次优分类器。
–实例:正态分布最小错误率贝叶斯分类器在特殊情况下,是线性判别函数g (x)=w T x (决策面是超平面),能否基于样本直接确定w ?训练样本集决策规则:判别函数决策面方程选择最佳准则6一.参数估计与非参数估计参数估计:先假定研究问题具有某种数学模型,如正态分布,二项分布,再用已知类别的学习样本估计里面的参数。
非参数估计:不假定数学模型,直接用已知类别的学习样本先验知识估计数学模型。
§3-1 参数估计与监督学习13¾估计量:样本集的某种函数f (X),X ={X 1, X 2 ,…, X N }¾参数空间:总体分布未知参数θ所有可能取值组成的集合(Θ)12ˆ(,,...,)N d θθ=x x x 的()是样本集的函数,它对样本集的一次实现估计称计量点估为估计值¾点估计的估计量和估计值§3-2 参数估计理论14¾估计量评价标准: 无偏性,有效性,一致性–无偏性:E ( )=θ–有效性:D ( )小,估计更有效–一致性:样本数趋于无穷时,依概率趋于θ:ˆθˆlim ()0N P θθε→∞−>=ˆθˆθ15最大似然估计计算方法•Maximum Likelihood (ML)估计–估计参数θ是确定而未知的,Bayes 估计方法则视θ为随机变量。
参数估计方法

参数估计方法参数估计是统计学中的一个重要概念,它是指根据样本数据推断总体参数的过程。
在实际应用中,我们往往需要利用已知数据来估计总体的各种参数,比如均值、方差、比例等。
参数估计方法有很多种,其中最常用的包括最大似然估计和贝叶斯估计。
本文将对这两种参数估计方法进行详细介绍,并分析它们的优缺点。
最大似然估计是一种常用的参数估计方法,它是建立在似然函数的基础上的。
似然函数是关于总体参数的函数,它衡量了在给定参数下观察到样本数据的概率。
最大似然估计的思想是寻找一个参数值,使得观察到的样本数据出现的概率最大。
换句话说,就是要找到一个参数值,使得观察到的样本数据出现的可能性最大化。
最大似然估计的优点是计算简单,且在大样本情况下具有较好的渐近性质。
但是,最大似然估计也有一些局限性,比如对于小样本情况下可能会出现估计不准确的问题。
另一种常用的参数估计方法是贝叶斯估计。
贝叶斯估计是建立在贝叶斯定理的基础上的,它将参数看作是一个随机变量,而不是一个固定但未知的常数。
在贝叶斯估计中,我们需要先假设参数的先验分布,然后根据观察到的样本数据,利用贝叶斯定理来计算参数的后验分布。
贝叶斯估计的优点是能够充分利用先验信息,尤其在小样本情况下具有较好的稳定性。
但是,贝叶斯估计也存在一些问题,比如对于先验分布的选择比较敏感,且计算复杂度较高。
在实际应用中,我们需要根据具体的问题和数据特点来选择合适的参数估计方法。
对于大样本情况,最大似然估计可能是一个不错的选择,因为它具有较好的渐近性质。
而对于小样本情况,贝叶斯估计可能更适合,因为它能够充分利用先验信息,提高估计的稳定性。
当然,除了最大似然估计和贝叶斯估计之外,还有很多其他的参数估计方法,比如矩估计、区间估计等,每种方法都有其特点和适用范围。
总之,参数估计是统计学中的一个重要概念,它涉及到如何根据已知数据来推断总体的各种参数。
最大似然估计和贝叶斯估计是两种常用的参数估计方法,它们各有优缺点,适用于不同的情况。
参数点估计

例 1 设总体 X 服从参数为λ 的指数分布,其中参
数λ 未知, (X1, X2,, Xn) 是来自总体的一个样本,
求参数λ 的矩估计量.
解: 其概率密度函数为
f
(x,
)
e x
,
x0
0, x 0
总体X的期望为 E( X ) xexdx 1
0
从而得到方程
设 (x1, x2,, xn ) 为总体 X 的一个样本观察值,若似然函数
n
L(1 ,2 ,,k ) L( x1 , x2 ,, xk ;1 ,2 ,,k ) f ( xi ;1 ,2 ,,k ) i 1
将其取对数,然后对1,2 ,,k 求偏导数,得
ˆ1 X;
ˆ 2
1 2
X1
1 3
X2
1 6
X3;
ˆ3 X1
且ˆ1较ˆ2 , ˆ3都有效.
证明 显然有 E(ˆ1 ) E(ˆ2 ) E(ˆ3 ) 且 D(ˆ1 ) D( X ) D( X ) / 3
D(ˆ2 ) D( X1 / 2 X 2 / 3 X 3 / 6) 14D( X ) / 36
设总体的分布类型已知,但含有未知参数θ .设 (x1, x2 ,, xn ) 为总体 X 的一个样本观察值,若似然函数 L( ) 关于θ 可导. 令 d L( ) 0
d
解此方程得θ的极大似然估计值ˆ(x1, x2,, xn ) , 从而得到θ的极大似然估计量ˆ(X1, X2,, Xn) .
又由于 X1, X 2 ,, X n 相互独立且都服从泊松分布
于是有
E(ˆ1)
E(
X
参数估计的一般步骤

参数估计的一般步骤
参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的值。
它是一个重要的统计推断技术,可以帮助我们了解和描述总体的特征。
参数估计的一般步骤如下:
1. 确定研究对象和目标参数:首先,我们需要明确研究对象是什么,需要估计的是哪个参数。
例如,我们可能希望估计某个产品的平均寿命,那么研究对象是产品,目标参数是平均寿命。
2. 收集样本数据:为了进行参数估计,我们需要收集一定数量的样本数据。
样本应该能够代表总体,并且必须是随机选择的,以避免抽样偏差。
3. 选择合适的估计方法:根据研究对象和目标参数的不同,我们可以选择不同的估计方法。
常见的估计方法包括点估计和区间估计。
点估计给出一个单一的数值作为参数的估计值,而区间估计给出一个范围,以表明参数估计值的不确定性。
4. 计算估计值:根据选择的估计方法,我们可以使用样本数据计算出参数的估计值。
例如,对于平均寿命的估计,我们可以计算样本的平均值作为总体平均寿命的估计值。
5. 评估估计的准确性:估计值的准确性可以通过计算估计的标准误
差或置信区间来评估。
标准误差反映了估计值与真实参数值之间的差异,而置信区间提供了参数估计值的不确定性范围。
6. 解释和应用估计结果:最后,我们需要解释估计结果并应用于实际问题中。
根据估计结果,我们可以得出结论,做出决策或提出建议。
参数估计是一种重要的统计推断方法,可以帮助我们了解总体特征并做出准确的推断。
通过正确的步骤和方法,我们可以获得可靠的参数估计结果,并将其应用于实际问题中。
参数估计的基本理论

第3章 参数估计的基本理论信号检测:通过准则来判断信号有无;参数估计:由观测量来估计出信号的参数;解决1)用什么方法求取参数,2)如何评价估计质量或者效果严格来讲,这一章研究的是参数的统计估计方法,它是数理统计的一个分支。
推荐两本参考书高等教育出版社《数理统计导论》,《Nonlinear Parameter Estimation 》。
我们首先从一个估计问题入手,来了解参数估计的基本概念。
3.1 估计的基本概念3.1.1 估计问题对于观察值x 是信号s 和噪声n 叠加的情况:()x s n θ=+其中θ是信号s 的参数,或θ就是信号本身。
若能找到一个函数()f x ,利用()12,,N f x x x 可以得到参数θ的估计值 θ,相对估计值 θ,θ称为参数的真值。
则称()12,,N f x x x 为参数θ的一个估计量。
记作 ()12,,Nf x x x θ= 。
在上面的方程中,去掉n 实际上是一个多元方程求解问题。
这时,如果把n 看作是一种干扰或摄动,那么就可以用解确定性方程的方法来得出()f x 。
但是我们要研究的是参数的统计估计方法,所以上面的描述并不适合我们的讨论。
下面给出估计的统计问题描述。
(点估计)设随机变量x 具有某一已知函数形式的概率密度函数,但是该函数依赖于未知参数θ,Ω∈θ ,Ω称为参数空间。
因此可以把x 的概率密度函数表示为一个函数族);(θx p 。
N x x x ,,,21 表示随机样本,其分布取自函数族);(θx p 的某一成员,问题是求统计量 ()12,,Nf x x x θ= ,作为参数θ的一个估计量。
以上就是用统计的语言给出的参数估计问题的描述。
数。
统计量的两个特征:1,随机变量的函数,因此也是随机变量;2,不依赖于未知参数,因此当我们得到随机变量的一组抽样,就可以计算得到统计量的值。
例3-1:考虑由(1,2,,)i ix s n i N =+= ,给定的观测样本。
参数估计理论与应用(第三章 )

那么它仍然有可能是一个好的估计。
考虑实随机过程{xk}的相关函数的两种估计量:
Rˆ1( )
1
N
N
xk xk ,
k 1
Rˆ2 ( )
1 N
N k 1
xk
xk
假定数据{xk}是独立观测的,容易验证
E[
Rˆ1
(
)]
E[
N
1
N
xk xk ]
k 1
1
N
N
E[ xk xk ]
k 1
Fisher 信息 Fisher 信息用J(θ)表示,定义为
J ( )
E{[
ln
p(x
| ]2}
E[
2
2
ln
p(x
| )]
(3.1.1)
2020/4/9
第三章 参数估计理论与应用
当考虑 N 个观测样本 X={ x1,…,xN }, 此时,联合条件分 布密度函数可表示为
p(x | ) p(x1, , xN | )
0
lim P{|
N
1 N
N
xi2 x 2 (E[ x2 ] E2[x]) | }
i 1
lim
N
P{|
ˆ
2 N
2
|
}
0,
0
2020/4/9
第三章 参数估计理论与应用
于是
lim
N
P{ | ˆ1
1
|
}
3
lim
N
P{|ˆ N
|
}
0
lim
N
P{ | ˆ2
2
|
}
2
3
参数估计的一般步骤

参数估计的一般步骤参数估计是统计学中的一种方法,用于根据样本数据估计总体参数的取值。
它在各个领域都有广泛的应用,例如经济学、医学、社会学等。
本文将介绍参数估计的一般步骤,帮助读者了解如何进行参数估计。
一、确定参数类型在进行参数估计之前,首先需要确定要估计的参数类型。
参数可以是总体均值、总体比例、总体方差等,根据具体问题来确定。
二、选择抽样方法接下来,需要选择合适的抽样方法来获取样本数据。
常用的抽样方法有简单随机抽样、系统抽样、分层抽样等。
选择合适的抽样方法可以保证样本的代表性,从而提高参数估计的准确性。
三、收集样本数据在进行参数估计之前,需要收集样本数据。
收集样本数据时要注意数据的准确性和完整性,避免数据采集过程中的偏差。
四、计算点估计量得到样本数据后,可以计算点估计量来估计总体参数的取值。
点估计量是根据样本数据计算得出的一个具体数值,用来估计总体参数的未知值。
常见的点估计量有样本均值、样本比例等。
五、构建置信区间除了点估计量,还可以构建置信区间来估计总体参数的取值范围。
置信区间是一个区间估计,表示总体参数的真值有一定的概率落在该区间内。
置信区间的计算方法与具体的参数类型有关,可以利用统计学中的分布理论或抽样分布来计算。
六、进行假设检验除了估计总体参数的取值,参数估计还可以用于假设检验。
假设检验是根据样本数据来判断总体参数是否符合某个特定的假设。
在假设检验中,需要先提出原假设和备择假设,然后计算检验统计量,最后根据统计显著性水平来判断是否拒绝原假设。
七、解释结果需要对参数估计的结果进行解释和说明。
解释结果时要清楚、简洁,避免使用过于专业的术语,以便读者能够理解和接受。
参数估计是统计学中重要的内容之一,它可以帮助我们从有限的样本数据中推断总体的特征。
通过合理选择抽样方法、收集准确的样本数据,并运用适当的统计方法,我们可以得到准确可靠的参数估计结果,为实际问题的决策提供科学依据。
第3章统计推断基础1_3节

95%可信区间 99%可信区间
公区间式范围 窄 宽 X t S , X t S 0.05/ 2, X
0.05 / 2,
X
X
t0.01/ 2,
S X
,
X t0.01/ 2, SX
估计错误的概率 大(0.05) 小(0.01)
均数的 标准差 0.2212 0.1580 0.0920
n
0.2236 0.1581 0.0913
3个抽样实验结果图示
频数
450
400 350
n 5; SX 0.2212
300
250
200
150
100
50
0 3.71 3.92 4.12 4.33 4.54 4.74 4.95 5.15 5.36 5.57 5.77 5.98 6.19
均数
频数
频数
450
400 350 300
n 10; SX
0.1580
250
200
150
100
50
0 3.71 3.92 4.12 4.33 4.54 4.74 4.95 5.15 5.36 5.57 5.77 5.98 6.19
均数
450
400 350
n 30; SX
0.0920
300
250
统计推断基础
统计推断
statistical inference
内容:
总体
抽样研究
样本
1. 参数估计 (estimation of
参 数 统计推断 统计量
如:总体均数
如:样本均数 X
第三章 参数估计

第三章 参数估计重点:1.总体参数与统计量2.样本均值与样本比例及其标准误差难点:1.区间估计2.样本量的确定知识点一:总体分布与总体参数统计分析数据的方法包括:描述统计和推断统计(第一章)推断统计是研究如何利用样本数据来推 断总体特征的统计学方法,包括参数估计和假设检验两大类。
总体分布是总体中所有观测值所形成的分布。
总体参数是对总体特征的某个概括性的度量。
通常有总体平均数( μ)总体方差(σ2 )总体比例( π)知识点二:统计量和抽样分布总体参数是未知的,但可以利用样本信息来推断。
统计量是根据样本数据计算的用于推断总体的某些量,是对样本特征的某个概括性度量。
统计量是样本的函数,如样本均值()、样本方差( s2)、样本比例(p)等。
构成统计量的函数中不能包括未知因素。
由于样本是从总体中随机抽取的,样本具有随机性,由样本数据计算出的统计量也就是随机的。
统计量的取值是依据样本而变化的,不同的样本可以计算出不同的统计量值。
[例题·单选题]以下为总体参数的是( )a.样本均值b.样本方差c.样本比例d.总体均值答案:d解析:总体参数是对总体特征的某个概括性的度量。
通常有总体平均数、总体方差、总体比例题·判断题:统计量是样本的函数。
答案:正确解析:统计量是样本的函数,如样本均值()、样本方差()、样本比例(p)等。
构成统计量的函数中不能包括未知因素。
[例题·判断题]在抽样推断中,作为推断对象的总体和作为观察对象的样本都是确定的、唯一的。
答案:错误解析:作为推断对象的总体是唯一的,但作为观察对象的样本不是唯一的,不同的样本可以计算出不同的统计量值。
(一)样本均值的抽样分布设总体共有n个元素,从中随机抽取一个容量为n的样本,在重置抽样时,共有n n种抽法,即可以组成n n不同的样本,在不重复抽样时,共有个可能的样本。
每一个样本都可以计算出一个均值,这些所有可能的抽样均值形成的分布就是样本均值的分布。
参数估计的一般步骤

参数估计的一般步骤
参数估计是通过从总体中抽取一个样本,利用样本数据对总体未知参数进行估计的过程。
参数估计的一般步骤如下:
1. 确定总体参数:首先需要明确要估计的总体参数,例如总体均值、总体比例、总体方差等。
2. 选择样本:从总体中抽取一个合适的样本。
样本的选择应该具有代表性,能够反映总体的特征。
3. 收集样本数据:对选择的样本进行观测或测量,收集样本数据。
4. 选择估计方法:根据所收集的样本数据和要估计的总体参数,选择合适的估计方法。
常见的估计方法包括点估计和区间估计。
5. 计算估计量:使用所选择的估计方法,根据样本数据计算出估计量。
估计量是用于估计总体参数的统计量。
6. 评估估计量的性质:评估所计算出的估计量的性质,如无偏性、有效性、一致性等。
这些性质可以帮助判断估计量的优劣。
7. 计算置信区间或置信水平:如果进行的是区间估计,根据估计量和置信水平,计算出总体参数的置信区间。
8. 解释估计结果:根据估计量或置信区间,对总体参数进行推断和解释。
同时,需要考虑估计结果的统计显著性和实际意义。
9. 分析误差和不确定性:考虑样本大小、抽样方法等因素对估计结果的影响,分析可能存在的误差和不确定性。
10. 结论和应用:根据参数估计的结果,得出结论并将其应用于实际问题中,例如进行决策、预测或进一步的研究。
需要注意的是,参数估计的具体步骤和方法会根据不同的统计问题和数据类型而有所差异。
在进行参数估计时,应根据实际情况选择合适的方法,并结合统计学原理和专业知识进行分析和解释。
第三章(多元线性回归模型)3-2答案

3.2 多元线性回归模型的估计一、判断题1.满足基本假设条件下,样本容量略大于解释变量个数时,可以得到各参数的唯一确定的 估计值,但参数估计结果的可靠性得不到保证 ( T )二 、单项选择题1、线性回归模型的参数估计量ˆβ是随机向量Y 的函数,即1ˆ()X X X Y β-''=。
ˆβ是 (A )A 、随机向量B 、非随机向量C 、确定性向量D 、常量2.已知含有截距项的四元线性回归模型估计的残差平方和为∑=800e 2i ,样本容量为25,则其随机误差项i u 的方差的普通最小二乘估计为 (A )。
A 、40B 、32C 、38.095D 、36.364 三 、多项选择题1、对于二元样本回归模型12233ˆˆˆˆi i i iY X X e βββ=+++,下列各式成立的有(ABC ) A 、0e i =∑ B 、0X e i 2i =∑C 、0X e i 3i =∑D 、0Y e i i =∑E 、0X X i3i 2=∑四、计算题1、某地区通过一个样本容量为722的调查数据得到劳动力受教育年数的一个回归方程为10.360.0940.1310.210i i i i edu sibs medu fedu =-++ R 2=0.214式中,edu 为劳动力受教育年数,sibs 为劳动力家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与父亲受到教育的年数。
问(1)sibs 是否具有预期的影响?为什么?若medu 与fedu 保持不变,为了使预测的受教育水平减少一年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数均为12年,另一个的父母受教育的年数均为16年,则两人受教育的年数预期相差多少年?解:(1)预期sibs 对劳动者受教育的年数有影响。
因此在收入及支出预算约束一定的条件下,子女越多的家庭,每个孩子接受教育的时间会越短。
第3章 概率密度函数的参数估计

E步: 步
Q ( θ θ i 1 ) = E Y l ( θ X, Y ) X , θ i 1
模式识别 – 概率密度函数的参数估计
训练样本: 训练样本: 来自子类: 来自子类:
x y
1 1
x y
2 2
x y
n n
已知y的条件下,参数的估计: 已知 的条件下,参数的估计: 的条件下
1 n ai = ∑ I ( yt = i ) n t =1 i = ∑ I ( yt = i ) xt
t =1 n n
非参数估计方法。 非参数估计方法。
模式识别 – 概率密度函数的参数估计
3.1 最大似然估计
独立同分布假设:样本集D中包含 个样本:x1, 独立同分布假设:样本集 中包含 个样本: 中包含n个样本 x2, …, xn,样本都是独立同分布的随机变量 (i.i.d,independent identically distributed)。 , 。
模式识别 – 概率密度函数的参数估计
3.2 期望最大化算法 期望最大化算法(EM算法 算法) 算法
EM算法的应用可以分为两个方面: 算法的应用可以分为两个方面: 算法的应用可以分为两个方面
1. 训练样本中某些特征丢失情况下,分布参数 训练样本中某些特征丢失情况下, 特征丢失情况下 的最大似然估计; 的最大似然估计; 2. 对某些复杂分布模型假设,最大似然估计很 对某些复杂分布模型假设, 复杂分布模型假设 难得到解析解时的迭代算法。 难得到解析解时的迭代算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Lower Bound Upper Bound
5 - 35
5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range Interquartile Range Skewness Kurtosis
25袋食品的重量
112.5
101.0
103.0
102.0
100.5
102.6
107.5
95.0
108.8
115.6
100.0
123.5
102.0
101.6
102.2
116.6
95.4
97.8
108.6
105.0
136.8
5 - 23
102.8
101.5
98.4
93.3
x 105.36
x z 2
n
希望根据所给的样本确定一个随机区间, 使其
包含参数真值的概率达到指定的要求。
2.区间估计
重复抽样 不重复抽样
5-5
区间估计 (Interval Estimate)
1. 在点估计的基础上,给出总体参数估计的一个估计 区间,该区间由样本统计量加减估计误差而得到
2. 根据样本统计量的抽样分布能够对样本统计量与总 体参数的接近程度给出一个概率度量
问卷调查由调查员直接到宿舍发放并当场回收。对四 个年级中每年级各发60份问卷,其中男、女生各 30份。共收回有效问卷共200份。其中有关上网时 间方面的数据经整理如下表所示
5-3
大学生每周上网花多少时间?
回答类别 3小时以下 3~6小时 6~9小时 9~12小时 12小时以上
合计
人数(人) 32 35 33 29 71 200
1450
1480
1510
1520
1480
1490
1530
1510
1460
1460
1470
1470
5 - 25
x 1490
s 24.77
x t 2
s 1490 2.131 24.77
n
16
149013.2
1476.8,1503.2
5 - 26
总体均值的区间估计
【例3】一家保险公司收集到由66个投保人组成的随 机样本,得到每个投保人的年龄(单位:周岁)数据如 下表。试建立投保人年龄90%的置信区间
区间估计 Analyze Descriptive Statistics Explore
5 - 30
Spread vs.Level with Levene Test:输出散布——层 次图,包括回归直线斜率及方差齐次性的Levene 检验。若无分组变量,此选项无效。
None:不生成散布——层次图; Power estimation:转换幂值估计,表示对每一组 数据产生一个中位数范围的自然对数与四分位数 范围的自然对数的散点图; Transformed:对原始数据进行转换,有:三次 方(Cube)、平方(Square)、平方根(1/Square root) 取对数(Logarithm)。
5 - 11
置信区间与置信水平的关系
均值的抽样分布
x
/2
1 –
/2
x x
(1 - ) % 区间包含了 % 的区间未包含
5 - 12
区间估计的种类
均值 方差已知
方差未知
一个总体 方差
区间 估计
比率
均值差 两个总体
方差比
5 - 13
一个总体参数的区间估计
总体参数 均值 比例 方差
5 - 14
第3章 参数估计
参数估计在统计方法中的地位
• 统计方法
描述统计
推断统计
参数估计 假设检验
5-2
大学生每周上网花多少时间?
为了解学生每周上网花费的时间,中国人民大学公共 管理学院的4名本科生对全校部分本科生做了问卷 调查。调查的对象为中国人民大学在校本科生,调 查内容包括上网时间、途径、支出、目的、关心的 校园网内容,以及学生对收费的态度,包括收费方 式、价格等
105.36 1.96
10 25
105.36 3.92
101.44,109.28
5 - 24
【例2】已知某种灯泡的寿命服从正态分布,现从一 批灯泡中随机抽取16只,测得其使用寿命(单位:h) 如下。建立该批灯泡平均使用寿命95%的置信区间
16灯泡使用寿命的数据
1510
1520
1480
1500
符号表示
2
样本统计量
x p s2
一个总体方差已知时均值的区间估计
• 需要的定义: 若 X 服从标准正态分布,则满足下式:
P( X < -za)﹦或 P( X ﹥za)﹦ 的z或-z叫标准正态分布的单侧上分位点。
z
5 - 15
z
• 若 X 服从标准正态分布,则满足体参数在一定置信水平下的 估计区间
2. 统计学家在某种程度上确信这个区间会包含真正的总 体参数,所以给它取名为置信区间
3. 总体参数的真值是固定的,而用样本构造的区间则是 不固定的,因此置信区间是一个随机区间,它会因样 本的不同而变化,而且不是所有的区间都包含总体参 数。我们只能希望这个区间是大量包含总体参数真值 的区间中的一个,但它也可能是少数几个不包含参数 真值的区间中的一个。
Sn
5 - 21
自由度小于45时重复抽样条件下均值的两个
(1 )% 的单侧置信区间为:
x t (n 1)
s n
x t (n 1)
s n
自由度大于45时重复抽样条件下均值的两个
(1 )% 的单侧置信区间为:
x z
s n
x z
s n
5 - 22
【例1】一家食品生产企业以生产袋装食品为主,为 对产量质量进行监测,企业质检部门经常要进行抽 检,以分析每袋重量是否符合要求。现从某天生产 的一批食品中随机抽取了25袋,测得每袋重量如下 表所示。已知产品重量的分布服从正态分布,且总 体标准差为10克。试估计该批产品平均重量的置信 区间,置信水平为95%
176.2316
173.4236
174.0000
61.410
7.83647
158.00
190.00
32.00
9.00
-.081
.414
-.201
.809
5 - 34
gender 身高(厘米) 女生
De sc rip tiv es
Mean
95% Confidence Interval for Mean
频率(%) 16 17.5 16.5 14.5 35.5 100
平均上网时间为8.58小时,标准差为0.69小时。全 校学生每周的平均上网时间是多少?每周上网 时间在12小时以上的学生比例是多少?
5-4
大致判断出总体分布的类型后,用样本参数
推断总体分布的相应参数。
均值 方差
1.点估计
不同样本算得的 的估计值不同,因此 还
Lower Bound Upper Bound
男生
5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range Interquartile Range Skewness Kurtosis Mean 95% Confidence Interval for Mean
均值的标准误差(抽样平均误差)
重复抽样(放回) X
n
不重复抽样
Nn
X n N 1
均值的标准误差又称为抽样平均误差或均值 标准误差、标准误差。
5 - 20
一个总体方差未知时均值的区间估计
• 需要的定义:
t (n)
t (n)
• 需要的定理:
若随机变量 X~ N (, 2 )则有如下定理成立: T X ~ t(n 1)
的z/2叫标准正态分布
的双侧上分位点。
z
z
2
2
5 - 16
• 需要的定理:
若随机变量 X ~ N(, 2)则有如下定理成立:
重复抽样条件下:
Z X n
~
N (0,1)
不重复抽样条件下:
Z X ~ N(0,1) n Nn N 1
5 - 17
重复抽样条件下均值的单侧区间估计:
• 因为 X 服从标准正态分布,所以:
2 n
P(
X
2
n﹥z)﹦或
P(
X 2 n
﹤﹣z)﹦
重复抽样条件下均值的双侧区间估计: • 因为 X 服从标准正态分布,所以:
2 n
P(
X 2 n
﹥z/2)﹦
5 - 18
重复抽样条件下均值的置信区间:
单侧置信区间
x z
n
x z
n
双侧置信区间:
x z 2
n
x z 2
n
5 - 19
5-9
点估计值
置信区间的表述
(95%的置信区间)
☺ 我没有抓住参数!
从均值为185的总体中抽出n=10的20个样本构造出的20个置信区间
5 - 10
置信区间的表述
(Confidence Interval)
1. 使用一个较大的置信水平会得到一个比较宽的置信区间, 而使用一个较大的样本则会得到一个较准确(较窄)的区间。 直观地说,较宽的区间会有更大的可能性包含参数
1. 将构造置信区间的步骤重复很多次,置 信区间包含总体参数真值的次数所占的 比例,也称置信度
2. 表示为 (1 -
为是总体参数未在区间内的比例
3. 常用的置信水平值有 99%, 95%, 90%