Power-aware RAM mapping for FPGA embedded memory blocks
Conformal_Verification_Guide_8.1

I N VE N TI V ECONFIDENTIALFormal Verification GuidePrototype | Implement | VerifyAgenda• Equivalence Checking Refresh • Verification Guide– RTL Design – Verifiable Synthesis Flow – Abort Resolution• ECO Automation • Best Practice Recommendation2August 6, 2009Cadence ConfidentialEncounter Conformal Product FamilyVerifies 100% of design functionality without requiring test vectors Provides independent verification for lowest risk silicon Validates CPF LP Equivalence Checking Verifies Low Power design implementation Performs structural and functional checksEquivalence CheckingRTL or Gate RTL or GateDigital Custom Verification including Memories, Data Paths, and IO Orders of magnitude faster than simulationLow Power VerificationFunctional Checksv1v2ISOABFinds bugs earlier in the design cycle Verifies proper CDC synchronization to avoid clock related re-spins Creates safer EC environmentValidation, generation and analysis of constraints Uses industry proven formal engines Shorter design cycle with improved timing constraintsConstraint DesignECO Implementationo1 o2Provides automated RTL2GDS ECO solution Identifies and generates fix to implement ECO Interfaces with physical implementation tool flow3August 6, 2009Cadence ConfidentialEncounter Conformal & FED Product FamilyEquivalence CheckingRTL or Gate RTL or GateConstraint DesignLow Power VerificationFunctional ChecksAValidation, generation & analysis of constraints Shorter design cycles with improved timing constraintsv 1v2ISOB100% Independent vector-less verification of implementation RTL Gate Transistor CDC & Ext ChecksStructural and functional LP checks LP design implementation Verification LP Equivalence CheckingNew Products ECO Implementation RC-Physical Synthesis Chip Planning Systemso 1 o 2Automated RTL2GDS ECO solution Identifies and generates ECO fix Physical Correlation & Predictability with final backend Congestion Analysis & Opto (Congestion Relief) Architectural & Economic Forecasting Lower IC Cost & Expedite TTM4August 6, 2009Cadence ConfidentialI N VE N TI V ECONFIDENTIALCrash Course on Equivalency CheckingPrototype | Implement | VerifyEquivalence Checking FlowGolden Design Standard Library Revised DesignSpecify Constraints and Design ModelingSetup Mode LEC ModeSpecify Compare ParametersCompare DesignsMiscompare?yesDiagnosenoEquivalence Checking Complete6August 6, 2009Cadence ConfidentialMapping! What is that?Pairing corresponding golden and revised key points:G RPI PO DFF DLAT BBOX CUT Z EPI PO DFF DLAT BBOX CUT Z E Key points Combinatorial logicGolden RevisedE UExtra Points Unreachable Points Unmapped Points7August 6, 2009Cadence ConfidentialComparison– Only mapped points can be compared. – Comparison is an iterative process.• Conformal remembers points already compared. • Comparison can be interrupted with Control-c. • Enter compare to continue comparing.set log file logfile.$LEC_VERSION -replace add notranslate module *sram* -library -both read design cpu_rtl.v -verilog -golden read design -file verilog.vc -verilog -revised // Command:pin constraint 0 scan_en -revised add compare ================================================================================ set flatten model -latch_fold Compared points PO DFF DLAT BBOX Total add renaming rule rule0 "abc" "xyz" -map -revised -------------------------------------------------------------------------------Equivalent renaming rule rule1 "xyz" "C" -map -golden 2 146 2 1 151 add -------------------------------------------------------------------------------set system mode lec Non-equivalent 0 2 0 0 2 add compare points -all ================================================================================ compare ...8August 6, 2009Cadence ConfidentialUsing the Mapping Manager to Debug NEQsMain windowUnmapped pointsMapped pointsCompared points9August 6, 2009Cadence ConfidentialCategories of Comparison ResultsEquivalent: Key points proven to be equivalent (green-filledcircle)Inverted-Equivalent: Key points proven to be complementary (divided green-filled circle) Nonequivalent: Key points proven to be different (red-filled circle) Abort: Key points not yet proven equivalent or nonequivalent due to timeout or other system parameters (yellow-filled circle) Not-Compared: Key points not yet compared?10LEC> report compare data -class [...]August 6, 2009Cadence ConfidentialI NVENTIVE CONFIDENTIAL RTL DesignFor Ease of VerificationRTL Design For Ease of Verification•To highlight the impact of RTL design on verification –Useful for RTL designers to understand their impact of coding styles on verification–Useful guidelines for machine/script generated RTL codes •Factors in RTL designs that can affect the ease of verifications are–Don’t care conditions in RTL description–Structuring of logics–Partitioning of designsRTL Design For Ease of VerificationDon’t-Cares Conditions in RTL•Don’t-care conditions are created in RTL by–X assignments–Incomplete case–Out-of-range indexing–Range constraint (VHDL)• A don’t-care condition can be synthesized to– a constant (zero or one)–or any Boolean function•Designs with extensive don’t-care conditions can be difficult to verify •Use LEC “report design data”to report don’t cares•Use LEC “report rule checks”to report out-of-range indexingRTL Rule Checkers•LEC’s RTL rule checker provides an fast and easy way to detect RTL coding styles that can impact verification •For example, index out of range is reported as –// Warning: (RTL7.3) Array index in RHS might be out of range (occurrence:1)•Running LEC RTL rule checker early in the RTL design process can reduce many potential synthesis andverification issues later onRTL Rule CheckersSETUP> read design –golden rtl.vSETUP> read design –revised rtl.vSETUP> set system mode lecSETUP> report rule check –golden –design –verbose > lint.rptSETUP> report message –golden –model –verbose > model.rpt•Consider Synthesis and EC ramifications of design –Multiply-driven and floating nets–Combinational cycles–Assignment size mismatch–Ambiguities leading to simulation mismatches–EtcRTL Design For Ease of VerificationDon’t-Cares Due to Index Out of Range•Don’t care is created when index is out of range –When the index can address more locations thanwhat an array can hold•For examplereg[4:0] q; // q has 5 locationsReg[2:0] A; // A can index 8 locationsBAD -q[A];// (1) out-of-range conditionGOOD -q[(A> 4) ? 0: A)];// (2) No out-of-rangeLogic Structuring•Structural Similarity–How closely does RTL structure match the netlist •Designs with higher structural similarity between RTL and netlist are easier to verify•Synthesis can restructure code. For examples:–Resource sharing–Map unsigned operators to signed operators•Minimize structural differences between RTL and netlist by:–Using Verilog 2K to code signed arithmetics–Using explicit grouping (such as in additions) with parenthesis –Manually code resource sharingDesign Partitioning•Partitioning a complex block breaks it into smaller pieces for ease of verification•Guidelines–Keep high complexity design modules small in size–Avoid excessive logic cone depth–Separate datapath block (especially those requiring retiming) from control block–Partitioning may impact QOR so the tradeoffs should be explored early in the design cycle•Smaller blocks are easier to verify. Well partitioned designs can also make use of more techniques to ease verificationsI NVENTIVE CONFIDENTIAL Verifiable Synthesis FlowModule Data PathArchitecture & Advanced Synthesis Optimizations Create Verification Challenges DatapathArchitectureBoundary OptimizationPhase Inversion Resource Sharing• A synthesis flow with verification considerations can significantly reduce verification challenges–Enable the identification of synthesis bugs more easily–Allow use of more LEC features (e.g., module-based datapath analysis, hierarchical comparisons) to streamline the verification processL E CSynthesis Optimization on Datapath Modules•Synthesis tools like RC and DC can group several datapath operators into asingle datapath unit which called datapath module. These modules can be synthetic or they can be instantiated components such as DW modules•For Design Compiler, these modules are reported in the resource report with string DP_OP as naming convention•These modules boundary are not preserved if ungrouping and boundary optimization are applied, making them difficult to prove Synthesis Flow Needs To Be Verification-Friendly R T L D a t a p a t h D e si g n ungroup/boundary optimizationMulti-Stage Synthesis•The basic principle of ensuring ease of verification is to break difficult to verify synthesis optimizations intostages in the synthesis flow•Recommend synthesis stages–RTL to first mapped netlist•Enable: datapath synthesis•Disable: ungrouping, boundary optimizations, phase inversions –Mapped netlist to optimized mapped•Enable: Ungrouping, Incremental optimizations, boundaryoptimizationsEmbed Verification Requirements in Synthesis •To deploy an easy to verify synthesis flow, embed the verificationsinto the synthesis scripts–Instead of resynthesizing after running into verification challenges •Control synthesis options that impact verification, e.g.,–Range constraint–Datapath synthesis, resource sharing–Ungrouping, boundary optimizations•Allow for a range of verification requirements to allow for trade-offs in verifiability•This is default behavior for Encounter RTL Compiler (RC)LEC Feature Module Based Datapath (MDP) Analysis (DC Synthesis)•Datapath synthesis may cause aborts because of operator optimization.•This is handled in RTL Compiler with Netlist Verification (more later). DC netlists require MDP.•Module-Based Datapath (MDP) Analysis performs datapath abstraction at a module level•This analysis is performed in addition to and prior to the regular operator level analysis•The result goal is to improve the quality of the operator-level analysis•Requires the preservation of synthetic datapath modules during synthesisRTLRTLFinal GateDC Script LE C DC Script Original Flow New Flow RTL FinalGate DC + MDP Script Intermediate Gate L E C LE C •Include MDP Script •Output Intermediate &Final Netlist•Perform RTL2Gate•Perform Gate2Gate Improve Synthesis Script to Ensure Verification Success (MDP) Analysis (DC Synthesis)DC Synthesis Script to Enable MDP Analysis•To enable the successful verification of datapath design using Design Compiler synthesis, LEC provides a script to ensure that LEC’s Module-Based Datapath (MDP) Analysis can be effectively applied•The script can be embedded into the overall synthesis script as followssource <lec_release_path>/share/cfm/lec/scripts/mdp.tcl…compile_ultra_mdp<level> <design_module>compile_ultra……<continue original DC synthesis script commands>…•compile_ultra_mdp command is placed before the first compile_ultra command in the DC script•Design module is the name of the top module that is synthesizedDC Synthesis Script for Datapath Verification •MDP level can be 1, 2, 3, or 4, and affects the synthesis as followsMDP Level Preserve Hierarchy ofBoundaryOptimizationSequentialOutputInversion DP/DW Design1YES NO ALLOW ALLOW 2YES NO DISABLE ALLOW 3YES NO DISABLE DISABLE 4YES YES DISABLE DISABLECollecting DC Synthesis Data•During the synthesis process, the following information should be collected for verification–Datapath Resource File: This is required to ensure that datapath intensive design can be easily verified–Change Name File: This is required to ensure name-based mapping for ease of verification–VSDC File: This file contains information that can help to guide the setup of the verification–Synthesis log file: This can contain information to help guide the setup of the verificationLEC Feature Qualifying Your DC Synthesis Environments •New versions of synthesis tools may introduce new verificationrequirements–New optimization techniques (e.g., sequential constant groups)–New datapath structures (e.g., new multiplier architectures)–New technology mapping techniques (e.g., using multi-bit library cells)–Changes in naming conventions (e.g., in generate statements)–Changes in default synthesis option settings (e.g., having sequential merge optimizations ON by default)•LEC ships with IP-free designs that can be used as testcases in a new synthesis environment or tool–Enable users to provide early feedbacks to the Conformal team to ensure success of verifications in the latest synthesis environment –At $conformal_dir/share/cfm/lec/demo/*How to Determine QoR ImpactRTL RTLFinalGate DC ScriptL E CDCScriptOriginal FlowNew FlowRTLRTLFinalGateDC ScriptDC + MDPScriptIntermediateGate L ECL E CQoR ImpactRC Netlist Verification Flow• RC verification flow– Only one intermediate netlist between RTL code and the final netlist – Two LEC comparisons: RTL-to-Intermediate & Intermediate-toFinal – Better support of advanced (datapath) optimizations – LEC-friendly netlist by 'write_hdl –lec’• additional datapath info (as comments) about architecture changes31August 6, 2009Cadence ConfidentialRC Netlist Verification Flow•Synthesize with no ungrouping •Output Intermediate & Final Netlist •Perform RTL2Gate •Perform Gate2GateNew Flowwrite_hdl -lecRTLFinal GateEC LIntermediate GateEC LIntermediate netlist to Ensure Verification Success32August 6, 2009Cadence ConfidentialRC Netlist Verification Flow for Datapathread_hdl elaborate read_sdcFirst netlist generated with “-lec” optionsynthesize -to_mapped write_hdl -lec > intermediate.v write_do_lec -revised intermediate.v > rtl2map.do [ungroup in any way] <no more datapath architecture change> Do not ungroup before first netlistsynthesize -incr as many times as wished without “-lec” option; write_hdl > final.v write_do_lec -golden intermediate.v -revised final.v > map2final.do exit Every “write_hdl” followed by “write_do_lec”33August 6, 2009Cadence ConfidentialRC Netlist Verification Flow for Datapath• First LEC run (RTL-gate):read design <RTL_code> -golden read design intermediate.v -revised compare – write_do_lec generates a hierarchical dofile script (rtl2map.do) – Conformal dofile script will contain the following commands: analyze datapath –module –verbose analyze datapath -verbose• Second LEC run (gate-gate):read design intermediate.v -golden read design final.v -revised compare – write_do_lec generates a flat dofile script (map2final.do)34August 6, 2009Cadence ConfidentialSummary• When a design is complex and contains many datapath operators, with today’s advance synthesis optimizations, the datapath become structurally different between RTL and netlist, creating challenge to all verification tools • To effectively help Conformal datapath analysis quality and improve verification result, an integrated synthesis & verification flow is needed • DC MDP Analysis and the recommended synthesis script will help close the gap between datapath synthesis and verification • RC Netlist Verification flow reduces the chance of aborts for a more complete verification35August 6, 2009Cadence ConfidentialI N VE N TI V ECONFIDENTIALAbort ResolutionResolving Aborts• Abort is reported when formal (exhaustive) analysis cannot provide a complete proof of equivalence within a resource limit– The design has been partially verified since no input vector resulting in non-equivalence has been found either• Resource limit is adjusted by compare effort– SET COMPARE EFFORT <LOW|MED|HIGH|COMPLETE>• This section describes– Techniques to resolve aborts – Methods to isolate abort to better understand the aborted region and options for further verifications37August 6, 2009Cadence ConfidentialResolving AbortsReview Synthesis Flow• Abort can be avoided by following the guidelines given earlier • For datapath intensive design– Check that MDP level 4 has been used for DC synthesis – Use Netlist Verification Flow for RC synthesis• RTL design for ease of verification– Check for excessive don’t care conditions with LEC’s rule checker and design report• Partition the design well and use LEC’s hierarchical comparison– Check that all complex modules can be hierarchically compared38August 6, 2009Cadence ConfidentialResolving AbortsReview LEC Dofiles• Hierarchical Comparison– Check that hierarchical comparison is used – For module containing abort, check that it has no submodules that can be further hierarchically compared• For datapath intensive design– Check that MDP has been used (Analyze datapath –module) – Check that datapath analysis are successful• Abort Analysis– Check that LEC’s abort analysis has been used (analyze abort)• Multithreading– Check that multithreading is used for abort analysis39August 6, 2009Cadence ConfidentialResolving AbortsAdvanced LEC Techniques• Several advanced techniques are available to resolve aborts • Advanced options for ‘analyze datapath’– – – – -wordlevel -share -effort high -addertree• Advanced commands and techniques– run partition_compare (help run partition_compare –verbose) – add partition points – read design –norangeconstraint –vhdl40August 6, 2009Cadence ConfidentialRe-synthesis and RTL Recoding•Re-synthesis of problem blocks–Adjust effort level–Disable range constraints–Preserve key signals and boundaries •Pros–Makes verification easy for all future runs •Cons–Requires additional efforts, may impact qualityAbort Isolation•When aborts cannot be completely resolved, it is useful to identify the region where aborts occurred–Allow for a more targeted re-synthesis–Allow for a better understanding on the netlist that leads to abort –Allow for additional verification to these smaller regions •Techniques to isolate abort–Ensure that the modules are hierarchically compared•Easier if RTL is partitioned well–In MDP analysis flow, abstracted datapath cluster can be automatically isolatedAbort Isolation for Datapath Module •When using MDP analysis, LEC can isolate the datapathmodule that causes the abort so that the remaining non-aborting netlist can be verified–That is, if the remaining netlist is equivalent and the datapath module is also equivalent, then the entire netlist is equivalent •Provides more visibility into the region of abort –Instead of reporting all fanout keypoints from the datapath module as abort, only the datapath module is reported as abort(See next slide)•The is invoked as–ANALYZE DATAPATH –isolate_abort_module…Abort Isolation for Datapath Module •Results with abort:==============================================================Compared points PO Total--------------------------------------------------------------Abort 67 67==============================================================•Results with abort isolation:==============================================================Compared points PO Total--------------------------------------------------------------Equivalent 67 67==============================================================Compared results of isolated instances in Revised design (top)==============================================================Status Instance (Module)--------------------------------------------------------------Abort i5/add_123_S1_DP_OP_123_456(NV_GR_PE_STRI_core_add_123_S1_DP_OP_123_456) ==============================================================Multi-Threading•For machines with multi-core CPUs–No need to set up the parallel processing environment–Takes advantage of multi-core, multi-CPU machines •Parallel ComparisonLEC> compare –threads #•Best for large gate-to-gate comparisons, where the comparison canbe distributed to multiple comparison threadsLEC> analyze abort –compare –threads #•Best for RTL-to-gate comparison aborts, where a few keypoints canconsume a large portion of the runtime*Obsoletes the previous method of parallel comparisons using the command Run Parallel Compare•Support two new multiplier architectures •Improve divider architecture analysis•Support higher effort analysis for better datapath learning quality.Results from sample testcasesRadix-8Unsigned DividerHigh Effort AnalysisDatapath AnalysisI NVENTIVE CONFIDENTIAL ECO AutomationPrototype | Implement | VerifyECO ChallengesNomenclature•Engineering Change Order (ECO) is the process of making local changes to the design netlist without re-running the entire synthesis and P&R flow•ECO Types–Functional ECO•Changes the functionality of the design–Non-functional ECO•Fix timing, cross talk, DRV, routing violations with minimal effort•ECO Stages–Pre-Mask ( Pre tape-out) ECO•Uses normal logic gates to implement change–Post-Mask (Metal-only ECO)•Uses spare gates only to implement changeECO ChallengesManual Task•Current ECO flows are manual–Process is very time and resource consuming–Error Prone–Limited by ECO size•Very difficult to identify location of needed fix–Easy to modify RTL, yet difficult to transfer fix to gate netlist•Manual ECO changes do not easily incorporate use of –Spare gates, location, timing, routing access–Freed cells (used originally but not used in ECO patch)•Hard to manually optimize the eco patchECO ChallengesManual Flow Targeting Post Mask ECOSynthesisNew RTL (R2)Old RTL (R1)Old Netlist (G1)Final Netlist (New DEF)ECO Route/DRV/SIOld DEFP&RManual EditingTest InsertionNew Netlist(G2)ECECDelete/add connections Map to spare gatesDifficult to identify where to fix!Which logic cones are affected?P&RWhat type/many spare cells are available and how can I optimally map new gates to them?Use limited Metal Layers!How can I get the smallest possible change?Create ECO CmdWill this ECO meet timing, is it DRC clean?ORB a c k -e n d EC Or o n t -e n d E C ORepeat process for each ECO。
PM5461-KIT PSX PFX PFX-I PFX-L 96 80 64×G3 PCIe Sw

PM5461-KITPSX/PFX/PFX-I/PFX-L 96/80/64×G3PCIe® Switch HD Evaluation KitHighlightsPCIe Interface• 1 ×16 edge connector for connection to a host• 1 ×16 slot connector for add-in cardsMini-SAS HD• 8 SFF-8644 external mini-SAS HD connectors• 8 SFF-8643 internal mini-SAS HD connectorsPCIe Clock Interface• Common reference clock with or without spread spectrumclocking (SSC)• Separate reference clock no SSC (SRNS)• Separate reference clock with independent SSC (SRIS)Serial Peripheral Interfaces (SPI)• 2 quad SPI buses• 128 Mb on-board SPI Flash for bootup and initializationThe Microchip name and logo and the Microchip logo are registered trademarks of Microchip Technology Incorporated in the U.S.A. and other countries. All other trademarks mentioned herein are property of their respective companies. © 2020, Microchip Technology Incorporated. All Rights Reserved. 12/20 DS00002850BPeripheral I/O Interfaces• 11 two-wire (TWI)/SMBus interfaces• 128 Kbps SEEPROM for storage and PCIe switch configuration • TWI bus access and connectivity to the temperature sen-sor, fan controller, voltage monitor, GPIO and TWI expand-ers, PCIe connectors, iPass Sideband and FPGA• 109 GPIOs with 3 dedicated as GPIOs and 106 GPIOs are multiplexed to provide TWI, SPI, SGPIO, Ethernet and UART interfaces• UART access using USB Type B and 3-pin connector header • 14-pin EJTAG connector header for Green Hills Software probe connectivity•10/100 Mbps Ethernet supporting MII and RMIIFPGA and CPLD Functionality • Drive board status LEDs• Monitor interrupts from I/O expanders and PCIe SFF cables• Provide Adaptive Voltage Scaling (AVS) control signal to device and regulators• Control and monitor power regulator output •Manage board and switch resetLocal Bus Interface (LBI)—PSX Only• 4 chip selects mapping to a unique 16 MB memory interface• 128 Mb of on-board NOR flash memory for storage of firmware image•16 Mb of on-board SRAM for extended command/data RAMPower Supply• 0.925 V and 1.8 V power rails supplied by on-board regulators • PCIe switch sense points for monitoring and measuring power rail voltages•12V power provided through 8-pin CPU power connector or 6-pin PCIe connector or PCIe edge connector (add-in card)PSX Software Development Kit• The PSX software development kit allows development and test of custom PCIe switch functionality• The PSX SDK relies on the Green Hills MULTI ® develop-ment environment available directly from Green Hills Software•The EJTAG debugger supports test and debug of custom PSX firmwareChipLink Diagnostic ToolsThe ChipLink diagnostic tools software provides the following:• Access to registers in the PCIe switch• Configuration of high-speed analog settings for signal integrity evaluation• Monitoring of status and mode indicatorsNote: For PFX-I, only functional evaluation is possible because commercial temperature parts are populated on the evalua-tion board.Kit ContentsThe following contents are included with the PM5461-KIT:• PSX/PFX/PFX-I/PFX-L Gen3 PCIe Switch HD Eval Board • SFF-8644 (×4) external to SFF-8639 multi-link 1 m cable • SFF-8643 (×4) internal to SFF-8639 multi-link 1 m cable • SFF-8644 (×4) external to SFF-8644 (×4) external 1 m cable • SFF-8643 (×4) internal to SFF-8644 (×4) external 1 m cable • iPass internal-to-internal 1 m cable and SATA-to-SATA cable • 3-wire to serial 1 m UART cable• Evaluation kit software installation files and user's guide • Power supply and USB-RS232 cableKit Requirements (Supplied Separately)Required for operation of the kit and must be supplied separately:• Personal computer running Windows, Linux, or Mac OS • ATX 750 W power supply, 1 × 6-pin PCIe connect and one 8-pin CPU power connector (Microchip recommends a Corsair CX750M ATX power supply)Optional (Supplied Separately)The following optional items must be supplied separately:• NVMe/PCIe SSD• High-speed oscilloscope for performing eye-diagram measurements• Jitter analyzer for analyzing jitter components• For PSX only: Green Hills MULTI development environ-ment and EJTAG debugger for firmware developmentOptional Evaluation Kit Adapter CardsNot included with the kit but available as separate purchases:• ADP_1×16SLOT_4×4HD: PCIe Gen3 1×16 slot to 4×4 HD • ADP_EDGEG4: PCIe Gen3/Gen4 1x16 Edge to 4x4 OcuLink Adapter Board Converts a x16 Edge PCIe Interface to an OCuLink PCIe interface or vice-versa• ADP_SLOTG4: PCIe Gen3/Gen4 1x16 Slot to 4x4 OcuLink Adapter Board Converts a x16 Slot PCIe Interface to an OCuLink PCIe Interface or vice-versa。
Himax HM01B0 UPduino 芯片说明书

HM01B0-UPD-EVNHimax HM01B0 UPduino Shield User GuideFPGA-UG-02081 Version 1.0November 2018Himax HM01B0 UPduino ShieldUser GuideContentsAcronyms in This Document (3)1.Introduction (4)1.1.Further Information (4)2.Power Supply (5)3.Board Overview (5)4.iCE40 UltraPlus Pin Summary (7)5.Software Requirements (9)6.Board Configuration and Programming (9)6.1.Board Configuration (9)6.2.Programming the SPI Flash (10)6.3.Programming the CRAM Directly (11)7.Storage and Handling (13)8.Ordering Information (13)References (14)Technical Support Assistance (14)Appendix A. Himax HM01B0 UPduino Shield Board Schematics (15)Revision History (19)FiguresFigure 1.1. Himax HM01B0 UPduino Shield (4)Figure 3.1. UPduino v2.0 – Front View (5)Figure 3.2. UPduino v2.0 – Back View (5)Figure 3.3. Himax HM01B0 Adapter Board – Front View (6)Figure 3.4. Himax HM01B0 Adapter Board – Back View (6)Figure 6.1. Programming Settings (9)Figure 6.2. Device Family and Device Setting (10)Figure 6.3. Onboard SPI Flash Device Properties Settings (11)Figure 6.4. Device Family and Device Settings (12)Figure 6.5. Device Properties for iCE40 Device Configuration Memory (12)Figure A.1. UPduino 2.0 FPGA Schematic (15)Figure A.2. UPduino 2.0 SPI Flash/I/O Pins/Regulator Connections (16)Figure A.3. UPduino 2.0 FTDI Chip Connection (17)Figure A.4. Himax HM01B0 Adapter Board Schematic (18)TablesTable 4.1. Upstream Connector Mapping (7)Table 8.1. Reference Part Number (13)© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.2 FPGA-UG-02081-1.0Himax HM01B0 UPduino ShieldUser Guide Acronyms in This DocumentA list of acronyms used in this document.Acronym DefinitionFPGA Field-Programmable Gate ArrayFTDI Future Technology Devices InternationalI²S Inter-IC SoundLED Light-Emitting DiodeSOIC Small Outline Integrated CircuitSPI Serial Peripheral InterfaceUSB Universal Serial Bus© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice. FPGA-UG-02081-1.0 3Himax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.4 FPGA-UG-02081-1.01. IntroductionThe Himax HM01B0 UPduino Shield is an evaluation and development platform based on the iCE40™ UltraPlus FPGA (Field-Programmable Gate Array). It consists of two boards – the UPduino v2.0 and the Himax HM01B0 Aapter Board. The UPduino v2.0 is an efficient, low-cost base platform designed by Gnarly Grey, including the iCE40UP5K FPGA, and basic power and programming control. The Himax HM01B0 Adapter Board adds a camera with a low-power Himax image sensor, two microphones, and multiple LEDs for quick visual feedback.This flexible and powerful platform enables designers to investigate and experiment with key features of the iCE40 UltraPlus FPGA and assists with rapid prototyping and testing of specific designs.Key features of the Himax HM01B0 UPduino Shield include: ∙ UPduino v2.0∙ iCE40 FPGA - iCE40UP5K-SG48I (5K LUTs, 39 I/Os, 120 Kbits Embedded Block RAM, 1 PLL and more in a 7 mm x7 mm 48-pin QFN package.)∙ USB connection for UART and device programming ∙ On-board Boot Flash ∙ RGB LED∙ Himax HM01B0 Adapter Board∙ Camera module with Himax HM01B0 image sensor ∙ Two I 2S microphones ∙ Six green LEDs∙ Also included with the kit∙ 3 ft Micro USB cable for programming and power ∙ QuickStart GuideFigure 1.1. Himax HM01B0 UPduino Shield1.1. Further InformationThis board features an iCE40UP5K-SG48I FPGA. More information about this FPGA can be found on the Lattice web site at: /iCE40UltraPlus . A complete description of this device can be found in iCE40 UltraPlus Family Data Sheet (FPGA-DS-02008).Himax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.FPGA-UG-02081-1.0 52. Power SupplyExternal 5 V Power from the USB Connector (J7) provides power to the entire two board set. Alternately, power can be applied to headers on the UPduino v2.0 board: ∙ J6 - 5.0 V ∙ J9 – Ground3. Board OverviewThe following diagrams show key features of the Himax HM01B0 Adapter and UPduino v2.0 boards.RGB LED iCE40 UltraPlus FPGAMicro USB ConnectorFigure 3.1. UPduino v2.0 –Front ViewUSB uCFigure 3.2. UPduino v2.0 – Back ViewHimax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.6FPGA-UG-02081-1.0Camera Module with Himax HM01B0 Sensor Holes for MicrophoneAudio InputLEDsFigure 3.3. Himax HM01B0 Adapter Board –Front ViewDual I2S MicrophonesFigure 3.4. Himax HM01B0 Adapter Board – Back ViewHimax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.FPGA-UG-02081-1.0 74. iCE40 UltraPlus Pin SummaryThe following is a reference to indicate the connection of the iCE40 UltraPlus FPGA I/O pins on each board. SG48 Function Pin Type Bank Differential Pair UPduino v2.0 Himax HM01B0Adapter 1 VCCIO_2 VCCIO 2 – – – 2 IO B_6a PIO 2 –JP6-16 I2S data 3 IO B_9b DPIO 2 COMP_of_IOB_8a JP6-11 Molex1 – 8: SDA 4 IO B_8a DPIO 2 TRUE_of_IOB_9bJP6-10 Molex1 – 7: SCL5 VCC VCC VCC –– –6 IO B_13b DPIO 1 COMP_of_IOB_12aJP6-8 Molex1 – 5: FVLD7 CDONE CONFIG 1 – LED – D2– 8 creset_b CONFIG 1 – – –9 IO B_16a PIO 1 – JP6-7 Molex1 – 4: TRIG 10 IO B_18a PIO 1 – TP3 – 11 IO B_20a PIO 1 –JP6-6 MCLK12 IO B_22a DPIO 1 TRUE_of_IOB_23b JP6-1 Molex1 – 18: D1 13 IO B_24a DPIO1 TRUE_of_IOB_25bJP6-3RESET_CAM (NC)14 IO B_32a_SPI_SO DPIO/CONFIG_SPI 1 – SPI Flash – SDO – 15 IO B_34a_SPI_SCK DPIO/CONFIG_SPI 1 – SPI Flash – SCK – 16 IO B_35b_SPI_SS DPIO/CONFIG_SPI 1 – SPI Flash – CS – 17 IO B_33b_SPI_SI DPIO/CONFIG_SPI1 – SPI Flash – SDI–18 IO B_31b PIO 1 – JP6- 5 PWDN (NC) 19 IO B_29b PIO 1 – JP6- 4 Molex1 – 16: PCLK 20 IO B_25b_G3 DPIO/GBIN 1 COMP_of_IOB_24a TP4 –21 IO B_23b DPIO 1 COMP_of_IOB_22aJP6- 2 Molex1 – 17: D022 SPI_V CCIO1 VCCIO 1 –– – 23 IOT_37a DPIO/I3C 0 TRUE_of_IOT_36bJP5- 3 D9 24 VPP_2V5 VPP VPP –– – 25 IOT_36b DPIO/I3C 0 COMP_of_IOT_37a JP5- 4 D826 IOT_39a DPIO 0 TRUE_of_IOT_38b JP5- 5 Molex1 – 24: D7 27 IOT_38b DPIO 0 COMP_of_IOT_39aJP5- 6 Molex1 – 23: D628 IOT_41a PIO 0 – JP5- 16 LED5 29 VCCPLL VCCPLL – – – 30 VCC VCC VCC –– –31 IOT_42b DPIO 0 COMP_of_IOT_43a JP5- 9 Molex1 – 20: D3 32 IOT_43a DPIO 0 TRUE_of_IOT_42bJP5- 7 Molex1 – 22: D533 VCCIO_0 VCCIO 0 –– – 34 IOT_44b DPIO 0 COMP_of_IOT_45aJP5- 11 LEDO35 IOT_46b_G0 DPIO/GBIN 0 –JP5- 8 Mole x1 – 21: D436 IOT_48b DPIO 0 COMP_of_IOT_49a JP5- 13 LED237 IOT_45a_G1 DPIO/GBIN 0 TRUE_of_IOT_44b JP5- 10 Molex1 – 19: D238 IOT_50b DPIO 0 COMP_of_IOT_51aJP5- 15 LED4 39 RGB0 LED 0 – RGB LED – Red –40 RGB1 LED 0 – RGB LED – Green – 41 RGB2 LED 0 –RGB LED – Blue– 42 IOT_51a DPIO 0 TRUE_of_IOT_50b JP5- 14 LED3 43IOT_49aDPIOTRUE_of_IOT_48bJP5- 12LED1Himax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.8 FPGA-UG-02081-1.0SG48 Function Pin Type Bank Differential Pair UPduino v2.0 Himax HM01B0Adapter 44 IO B_3b_G6 DPIO/GBIN 2 COMP_of_IOB_2a JP6- 9 Molex1 – 6: LVLD 45 IO B_5b DPIO 2 COMP_of_IOB_4a JP6- 13 U2 – 2: STBY 46 IO B_0a PIO 2 –JP6- 15 I25 Clk 47 IO B_2a DPIO 2 TRUE_of_IOB_3b JP6- 14 I25 WS 48 IO B_4a DPIO 2 TRUE_of_IOB_5bJP6- 12 –Paddle GNDGNDGND––Molex1 – 9: INTHimax HM01B0 UPduino ShieldUser Guide 5.Software RequirementsInstall the following software before you begin developing designs for the board:∙Lattice Radiant 1.0 (or higher)∙Used for developing your own custom designs for the iCE40 UltraPlus FPGA∙Download at: /radiant∙Radiant Programmer 1.0 (or higher)∙Used to program the iCE40 UltraPlus FPGA∙This is included with Radiant software installation, or as a stand-alone tool.∙Download at: /radiant6.Board Configuration and Programming6.1.Board ConfigurationThe iCE40 UltraPlus on Himax HM01B0 UPduino Shield can be programmed via the included micro-USB cable using a PC running Lattice Radiant Programmer software. After the software is installed and launched, and the USB cable is connected to the board, see below for programming procedures.There are two modes to program the iCE40 UltraPlus FPGA on the UPduino v2.0 board.∙SPI Flash Programming (default): In this mode, the on-board SPI Flash is programmed, which in-turn programs the iCE40 UltraPlus FPGA at power-up or reset. This allows the user program to be stored in non-volatile memory when the board is powered-off or reset. This is the default programming mode.∙Direct CRAM Programming: In this mode, the iCE40 UltraPlus FPGA CRAM memory is programmed directly. This may allow for more rapid reconfiguration (if you need to regularly re-program the iCE40 UltraPlus whiledebugging), but the program is not be retained when the board is powered-off. To use this mode, a modification to the board is required.The default programming mode is SPI Flash programming. To change the programming mode, resistor R4 and R3 must be removed and replaced in the orientation shown in Figure 6.1.Figure 6.1. Programming Settings© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice. FPGA-UG-02081-1.0 9Himax HM01B0 UPduino ShieldUser Guide6.2.Programming the SPI FlashTo program the SPI Flash:1.Set board resistors to horizontal for SPI Flash programming.Note: This is the default mode.2.Connect the Himax HM01B0 UPduino Shield via USB cable to PC with Radiant Programmer installed.3.Start Radiant Programmer.4.Set Device Family to iCE40 UltraPlu s and Device to iCE40UP5K as shown in Figure 6.2.Figure 6.2. Device Family and Device Setting5.Click the iCE40 UltraPlus row, and select Edit > Device Properties.6.In the Device Properties dialog box, apply the settings below that are common to the three files to program (seeFigure 6.3).a.Under Device Operation, select the options below:∙Target Memory —External SPI Flash Memory (SPI FLASH)∙Port Interface—SPI∙Access Mode— Direct Programming∙Operation—Erase, Program, Verifyb.Under Programming Options, select the option below:∙Programming File —<Select desired file to program>c.Under SPI Flash Options, select the options below:∙Family —SPI Serial Flash∙Vendor —Winbond∙Device —W25P32∙Package —16-pin SOIC© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.10 FPGA-UG-02081-1.0Himax HM01B0 UPduino ShieldUser GuideFigure 6.3. Onboard SPI Flash Device Properties Settings7.Click OK to close the Device Properties window.8.Click the Program button in Radiant Programmer to program the Onboard SPI Flash.6.3.Programming the CRAM DirectlyTo program the CRAM directly:1.Set board resistors to vertical for CRAM Programming.2.Connect the Himax HM01B0 UPduino Shield via USB cable to PC with Radiant Programmer installed.3.Start Radiant Programmer.4.Set Device Family to iCE40 UltraPlus and Device to iCE40UP5K as shown in Figure 6.4.5.Click the iCE40 UltraPlus row, and select Edit > Device Properties.© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice. FPGA-UG-02081-1.0 11Himax HM01B0 UPduino ShieldUser GuideFigure 6.4. Device Family and Device Settings6.In the Device Properties dialog box, apply the as shown in Figure 6.5.∙Target Memory —Compressed Random Access Memory (CRAM)∙Port Interface —Slave SPI∙Access Mode — Direct Programming∙Operation —Fast Configuration7.Click OK to close the Device Properties window.8.Click the Program button in Radiant Programmer to begin programming.Figure 6.5. Device Properties for iCE40 Device Configuration Memory© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.12 FPGA-UG-02081-1.0Himax HM01B0 UPduino ShieldUser Guide© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal .All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.FPGA-UG-02081-1.0 137. Storage and HandlingStatic electricity can shorten the life span of electronic components. Observe these tips to prevent damage that can occur from electrostatic discharge:∙ Use antistatic precautions such as operating on an antistatic mat and wearing an antistatic wristband. ∙ Store the development board in the provided packaging.∙ Touch a metal USB housing to equalize voltage potential between you and the board.8. Ordering InformationDescriptionOrdering Part Number China RoHS Environment-Friendly Use Period (EFUP)Himax HM01B0 UPduino ShieldHM01B0-UPD-EVNHimax HM01B0 UPduino ShieldUser GuideReferencesFor more information, refer to∙iCE40 Ultra Plus Family Data Sheet (FPGA-DS-02008)∙/iCE40UltraPlusTechnical Support AssistanceSubmit a technical support case through /techsupport.© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal.All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.14 FPGA-UG-02081-1.0Himax HM01B0 UPduino ShieldUser Guide Revision HistoryRevision 1.0, November 2018Section Change SummaryAll Initial release.© 2018 Lattice Semiconductor Corp. All Lattice trademarks, registered trademarks, patents, and disclaimers are as listed at /legal. All other brand or product names are trademarks or registered trademarks of their respective holders. The specifications and information herein are subject to change without notice.FPGA-UG-02081-1.0 197th Floor, 111 SW 5th Avenue Portland, OR 97204, USAT 503.268.8000 HM01B0-UPD-EVN。
DLP Design DDLLPP-FFPPG USB-FPGA Module User Manua
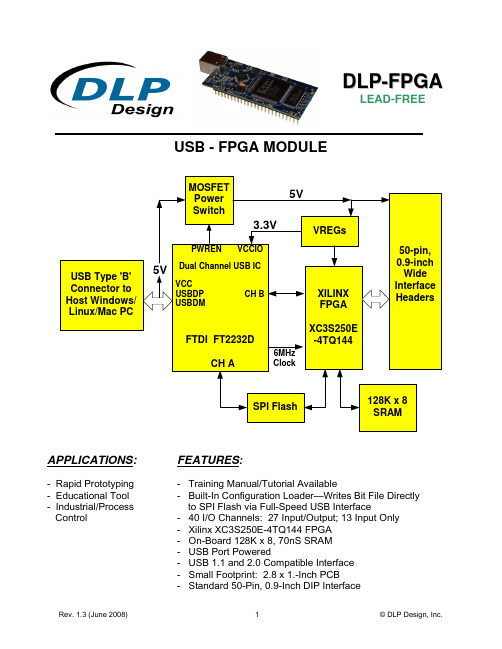
D L P-F P G ALEAD-FREEUSB - FPGA MODULEAPPLICATIONS:- Rapid Prototyping- Educational Tool- Industrial/ProcessControlFEATURES:- Training Manual/Tutorial Available- Built-In Configuration Loader—Writes Bit File Directlyto SPI Flash via Full-Speed USB Interface- 40 I/O Channels: 27 Input/Output; 13 Input Only- Xilinx XC3S250E-4TQ144 FPGA- On-Board 128K x 8, 70nS SRAM- USB Port Powered- USB 1.1 and 2.0 Compatible Interface- Small Footprint: 2.8 x 1.-Inch PCB- Standard 50-Pin, 0.9-Inch DIP Interface1.0 INTRODUCTIONThe DLP-FPGA Module is a low-cost, compact prototyping module that can be used for rapid proof of concept or for educational environments. The module is based on the Xilinx Spartan 3E and Future Technology Devices International’s FT2232D Dual-Channel USB IC. Used by itself or with the optional 200-page training manual, the DLP-FPGA provides both the beginner as well as the experienced engineer with a rapid path to developing FPGA-based designs. When combined with the free WebPACK™ Tools from Xilinx, this module is more than sufficient for creating anything from basic logical functions to a highly complex system controller.As a bonus feature, one channel of the dual-channel USB interface is used to load user bit files directly to the SPI Flash—no external programmer is required. This represents a savings of as much as $200 in that no additional programming cable is required for configuring the FPGA. All that is needed to load bit files to the DLP-FPGA is a Windows software utility (free with purchase), a Windows PC and a USB cable. The module can also be programmed from within the Xilinx ISE tool environment using a Xilinx programming cable (purchased separately).The DLP-FPGA is fully compatible with the free ISE™ WebPACK™ tools from Xilinx. ISE WebPACK offers the ideal development environment for FPGA designs with HDL synthesis and simulation, implementation, device fitting and JTAG programming.The DLP-FPGA has on-board voltage regulators that generate all required power supply voltages from a single 5-volt source. Power for the module can be taken from either the host USB port or from a user-supplied, external 5-volt power supply.Connection to user electronics is made via a 50-pin, 0.9-inch wide, industry-standard 0.025 square inch post DIP header. Other on-board features include a 128K x 8 static RAM IC for user projects, and both JTAG and SPI Flash interface ports for connection to Xilinx programming tools.2.0 TRAINING MANUALA 200+ page training manual for the DLP-FPGA is also available. While this manual is designed to provide entry-level instruction for those new to designing with FPGAs, it is recommended for developers who have some experience with FPGA products and associated development tools. An ISE™ WebPACK™Software installation DVD is included with the manual.The manual is comprised of 5 Chapters and 4 Labs as outlined below:Chapter 1: Installing the Xilinx ISE WebPACK tools and Understanding the Design FlowChapter 2: Lab 1: Implementing a Simple AND Gate: Create a New Project, Implement the Design, View the Synthesized Design, View the Placed and Routed DesignChapter 3: Lab 2: Heartbeat: Understanding the Digital Clock Manager (DCM), Methods of Starting ISE Project Navigator, VHDL Module Structure, Utilizing Hierarchy, Adding the DCM Component, Adding the Heartbeat Component, Connecting the Components, Synthesizing the Design Using XST, Simulating the Design Using the ISE Simulator, Adding the User Constraint File, Implementing the Design, Download the Design to the FPGAChapter 4: Lab 3: Memory Test: Block Diagram, DCM Design, SRAM State Machine, Bi-Directional Buffers, Test Failed Indicator, User Constraint File, Synthesize the Memory Test Design, Simulate the Memory Test Design, Implementing the Design, Download the Design to the FPGAChapter 5: Lab 4: USB Loopback: Initial Design, USB State Machine Module, Language Template, Bi-Directional Buffers, Synthesize, Simulate, Pin Constraints, Implement, Download the Design to the FPGA(The completed design files for each lab are available for download from the DLP Design website upon purchase of the DLP-FPGA and Lab Manual.)3.0 FPGA SPECIFICATIONSThe FPGA device used on the DLP-FPGA is the Xilinx Spartan 3E: XC3S250E-4VQ100.•Part Number: XC3S250E•System Gates: 250K•Equivalent Logic Cells: 5,508• CLB Arrayo Rows: 34o Columns: 26o Total CLB’s: 612o Total Slices: 2,448•Distributed RAM Bits: 38K•Block RAM Bits: 216K•Dedicated Multipliers: 12•DCM’s: 44.0 BITLOADAPP SOFTWAREWindows software is provided for use with the DLP-FPGA that will load an FPGA configuration (.bit) file directly to the SPI Flash device via the USB interface. This app (shown below) will allow the user to erase the flash, verify the erasure and then program and verify the flash:5.0 JTAG INTERFACEThe easiest way to load an FPGA configuration (bit file) to the FPGA is to run the BitLoadApp software, then select and program a file from the local hard drive directly to the SPI flash. Once written to the SPI flash, the configuration will load to the FPGA and execute. Alternatively, a traditional JTAG header location is provided on the DLP-FPGA giving the user access to the pins on the FPGA required by the development tools. (Refer to the schematic at the end of this datasheet for details.)6.0 EEPROM SETUP / MPROGThe DLP-FPGA has a dual-channel USB interface to the host PC. Channel A is used exclusively to load an FPGA configuration (bit file) to the SPI flash. This configuration data is automatically transferred to the FPGA when power is applied to the module. Channel B is used for communication between the FPGA and host PC at run time. A 93C56B EEPROM connected to the USB interface IC is used to store the setup for the two channels. The parameters stored in the EEPROM include the Vendor ID (VID), Product ID (PID), Serial Number, Description String, driver selection (VCP or D2XX) and port type (UART serial or FIFO parallel).As mentioned above, Channel A is used exclusively for loading the FPGA’s configuration to the SPI flash, and Channel B is used for communication between the host PC and the DLP-FPGA. As such, the D2XX drivers and FIFO mode must be selected in the EEPROM for Channel A. Channel B must use the FIFO mode, but can use either the VCP or D2XX drivers. The VCP drivers make the DLP-FPGA appear as an RS232 port to the host app. The D2XX drivers provide faster throughput, but require working with a .lib or .dll library in the host app.The operational modes and other EEPROM selections are written to the EEPROM using the MPROG utility. This utility and its manual are available for download from the bottom of the page at.7.0 TEST BIT FILEA test file is provided as a download from the DLP Design website that provides rudimentary access to the I/O features of the DLP-FPGA.The following features are provided:• Ping•Read the High/Low State of the Input-Only Pins•Drive I/O Pins High/Low or Read their High/Low State•Simple Loopback on Channel B•Simple Read/Write of Each Address in the SRAMThis bit file is available from the DLP-FPGA’s download page.8.0 USB DRIVERSUSB drivers for the following operating systems are available for download from the DLP Design website at :W i n d o w s X P x 64 M a c O S X W i n d o w s S e r v e r 2003M a c O S 9 W i n d o w s 2000 M a c O S 8 W i n d o ws 98, M EL i n u xNotes:1. The bit file load utility only runs on the Windows platforms.2. The bit file load utility requires the use of USB channel A, and channel A is dedicated to this function.3. If you are using the dual-mode drivers from FTDI (CDM2.02.04) and wish to use the VirtualCOM Port (VCP) drivers for Channel B communications, then it may be necessary to disable the D2XX drivers first via Device Manager. To do so, right click on the Channel B entry under USB Controllers that appears when the DLP-FPGA is connected, select Properties, select the Advanced tab, check the option for “Load VCP” and click OK. Once you unplug and then replug the DLP-FPGA, a COM port should appear in Device Manager under Ports (COM & LPT).9.0 USING THE DLP-FPGASelect a power source via Header Pins 23 and 24, and connect the DLP-FPGA to the PC to initiate the loading of USB drivers. The easiest way to do this is to connect Pins 23 and 24 to each other. This will result in operational power being taken from the host PC. Once the drivers are loaded, the DLP-FPGA is ready for use.Pin 25Top View (Interface Headers on bottom of PCB)Pin 50T A B L E1NN (dec)* NN (hex)* Name FPGA Pin JP2 Pin0 0 user_io(0) U5 Pin 58 JP2 Pin 21 1 user_io(1) U5 Pin 59 JP2 Pin 42 2 user_io(2) U5 Pin 93 JP2 Pin 53 3 user_io(3) U5 Pin 94 JP2 Pin 64 4 user_io(4) U5 Pin 96 JP2 Pin 75 5 user_io(5) U5 Pin 97 JP2 Pin 86 6 user_io(6) U5 Pin 103 JP2 Pin 97 7 user_io(7) U5 Pin 104 JP2 Pin 108 8 user_io(8) U5 Pin 105 JP2 Pin 129 9 user_io(9) U5 Pin 106 JP2 Pin 1310 A user_io(10) U5 Pin 112 JP2 Pin 1411 B user_io(11) U5 Pin 113 JP2 Pin 1512 C user_io(12) U5 Pin 116 JP2 Pin 1613 D user_io(13) U5 Pin 117 JP2 Pin 1714 E user_in(14) [INPUT ONLY!] U5 Pin 119 JP2 Pin 1815 F user_in(15) [INPUT ONLY!] U5 Pin 120 JP2 Pin 1916 10 user_io(16) U5 Pin 122 JP2 Pin 2017 11 user_io(17) U5 Pin 123 JP2 Pin 2118 12 user_io(18) U5 Pin 124 JP2 Pin 2219 13 user_io(19) U5 Pin 125 JP2 Pin 2720 14 user_io(20) U5 Pin 126 JP2 Pin 2921 15 user_io(21) U5 Pin 130 JP2 Pin 3022 16 user_io(22) U5 Pin 131 JP2 Pin 3123 17 user_io(23) U5 Pin 132 JP2 Pin 3224 18 user_io(24) U5 Pin 134 JP2 Pin 3325 19 user_io(25) U5 Pin 135 JP2 Pin 3426 1A user_io(26) U5 Pin 139 JP2 Pin 3527 1B user_io(27) U5 Pin 140 JP2 Pin 3628 1C user_io(28) U5 Pin 142 JP2 Pin 3730 1E user_in(0) U5 Pin 10 JP2 Pin 4931 1F user_in(1) U5 Pin 12 JP2 Pin 4832 20 user_in(2) U5 Pin 29 JP2 Pin 4733 21 user_in(3) U5 Pin 31 JP2 Pin 4634 22 user_in(4) U5 Pin 36 JP2 Pin 4535 23 user_in(5) U5 Pin 38 JP2 Pin 4436 24 user_in(6) U5 Pin 41 JP2 Pin 4337 25 user_in(7) U5 Pin 47 JP2 Pin 4238 26 user_in(8) U5 Pin 48 JP2 Pin 4139 27 user_in(9) U5 Pin 66 JP2 Pin 3940 28 user_in(10) U5 Pin 69 JP2 Pin 38Read: 29,>40 Read:1D,>29Returns Read Pin Error E4 n/a n/aWrite: 14, 15, >30 Write: E, F,>1EReturns Write Pin Error E2 for PinClear (low), or E3 for Pin Set(high)n/a n/aGround 1,11,25,26,40,50FPGA_RESET 1283 5VIN – Module power source 23PORTVCC – Power from Host PC 24VCCSW – 5V power after hostenumerates the USB port28*N o t e:This is the I/O number for use with the Test Bit File described in Section 7.10.0 MECHANICAL DIMENSIONS IN INCHES (MM) (PRELIMINARY)11.0 DISCLAIMER© DLP Design, Inc., 2007Neither the whole nor any part of the information contained herein nor the product described in this manual may be adapted or reproduced in any material or electronic form without the prior written consent of the copyright holder.This product and its documentation are supplied on an as-is basis, and no warranty as to their suitability for any particular purpose is either made or implied. DLP Design, Inc. will not accept any claim for damages whatsoever arising as a result of the use or failure of this product. Your statutory rights are not affected. This product or any variant of it is not intended for use in any medical appliance, device, or system in which the failure of the product might reasonably be expected to result in personal injury.This document provides preliminary information that may be subject to change without notice.12.0 CONTACT INFORMATIONDLP Design, Inc.1605 Roma LaneAllen, TX 75013Phone: 469-964-8027Fax: 415-901-4859Email Sales: *******************EmailSupport:*********************Website URL: 。
FPGA可编程逻辑器件芯片XCZU9EG-2FFVB1156I中文规格书

General DescriptionThe Zynq® UltraScale+™ MPSoC family is based on the Xilinx® UltraScale™ MPSoC architecture. This family of products integrates a feature-rich 64-bit quad-core or dual-core Arm® Cortex™-A53 and dual-core Arm Cortex-R5 based processing system (PS) and Xilinx programmable logic (PL) UltraScale architecture in a single device. Also included are on-chip memory, multiport external memory interfaces, and a rich set of peripheral connectivity interfaces.Processing System (PS)Arm Cortex-A53 Based Application Processing Unit (APU)•Quad-core or dual-core•CPU frequency: Up to 1.5GHz•Extendable cache coherency•Armv8-A Architectureo64-bit or 32-bit operating modeso TrustZone securityo A64 instruction set in 64-bit mode,A32/T32 instruction set in 32-bit mode •NEON Advanced SIMD media-processing engine •Single/double precision Floating Point Unit (FPU)•CoreSight™and Embedded Trace Macrocell(ETM)•Accelerator Coherency Port (ACP)•AXI Coherency Extension (ACE)•Power island gating for each processor core •Timer and Interruptso Arm Generic timers supporto Two system level triple-timer counterso One watchdog timero One global system timer•Cacheso32KB Level1, 2-way set-associativeinstruction cache with parity (independent foreach CPU)o32KB Level1, 4-way set-associative data cache with ECC (independent for each CPU) o1MB 16-way set-associative Level2 cache with ECC (shared between the CPUs)Dual-core Arm Cortex-R5 Based Real-Time Processing Unit (RPU)•CPU frequency: Up to 600MHz•Armv7-R Architectureo A32/T32 instruction set•Single/double precision Floating Point Unit (FPU)•CoreSight™ and Embedded Trace Macrocell (ETM)•Lock-step or independent operation•Timer and Interrupts:o One watchdog timero Two triple-timer counters•Caches and Tightly Coupled Memories (TCMs) o32KB Level1, 4-way set-associativeinstruction and data cache with ECC(independent for each CPU)o128KB TCM with ECC (independent for each CPU) that can be combined to become 256KBin lockstep modeOn-Chip Memory•256KB on-chip RAM (OCM) in PS with ECC •Up to 36Mb on-chip RAM (UltraRAM) with ECC in PL•Up to 35Mb on-chip RAM (block RAM) with ECC in PL•Up to 11Mb on-chip RAM (distributed RAM) in PL 找FPGA和CPLD可编程逻辑器件,上深圳宇航军工半导体有限公司Programmable Logic (PL)Configurable Logic Blocks (CLB)•Look-up tables (LUT)•Flip-flops•Cascadable adders36Kb Block RAM•True dual-port•Up to 72 bits wide•Configurable as dual 18Kb UltraRAM•288Kb dual-port•72 bits wide•Error checking and correctionDSP Blocks•27x18 signed multiply•48-bit adder/accumulator•27-bit pre-adder Programmable I/O Blocks •Supports LVCMOS, LVDS, and SSTL• 1.0V to 3.3V I/O•Programmable I/O delay and SerDes JTAG Boundary-Scan•IEEE Std 1149.1 Compatible Test Interface PCI Express•Supports Root complex and End Pointconfigurations•Supports up to Gen3 speeds•Up to five integrated blocks in select devices 100G Ethernet MAC/PCS•IEEE Std 802.3 compliant•CAUI-10 (10x 10.3125Gb/s) orCAUI-4 (4x 25.78125Gb/s)•RSFEC (IEEE Std 802.3bj) in CAUI-4 configuration •Up to four integrated blocks in select devices Interlaken•Interlaken spec 1.2 compliant•64/67 encoding•12 x 12.5Gb/s or 6 x 25Gb/s•Up to four integrated blocks in select devices Video Encoder/Decoder (VCU)•Available in EV devices•Accessible from either PS or PL •Simultaneous encode and decode•H.264 and H.265 supportSystem Monitor in PL•On-chip voltage and temperature sensing•10-bit 200KSPS ADC with up to 17 external inputsZynq UltraScale+ MPSoCsA comprehensive device family, Zynq UltraScale+ MPSoCs offer single-chip, all programmable,heterogeneous multiprocessors that provide designers with software, hardware, interconnect, power, security, and I/O programmability. The range of devices in the Zynq UltraScale+MPSoC family allows designers to target cost-sensitive as well as high-performance applications from a single platform using industry-standard tools. While each Zynq UltraScale+MPSoC contains the same PS, the PL, Video hard blocks, and I/O resources vary between the devices.The Zynq UltraScale+ MPSoCs are able to serve a wide range of applications including:•Automotive: Driver assistance, driver information, and infotainment•Wireless Communications: Support for multiple spectral bands and smart antennas•Wired Communications: Multiple wired communications standards and context-aware network services •Data Centers: Software Defined Networks (SDN), data pre-processing, and analytics •Smarter Vision: Evolving video-processing algorithms, object detection, and analytics•Connected Control/M2M: Flexible/adaptable manufacturing, factory throughput, quality, and safetyThe UltraScale MPSoC architecture provides processor scalability from 32 to 64 bits with support for virtualization, the combination of soft and hard engines for real-time control, graphics/video processing, waveform and packet processing, next-generation interconnect and memory, advanced powermanagement, and technology enhancements that deliver multi-level security, safety, and reliability. Xilinx offers a large number of soft IP for the Zynq UltraScale+MPSoC family. Stand-alone and Linux device drivers are available for the peripherals in the PS and the PL. Xilinx’s Vivado® Design Suite, SDK™, and PetaLinux development environments enable rapid product development for software, hardware, and systems engineers. The Arm-based PS also brings a broad range of third-party tools and IP providers in combination with Xilinx's existing PL ecosystem.The Zynq UltraScale+MPSoC family delivers unprecedented processing, I/O, and memory bandwidth in the form of an optimized mix of heterogeneous processing engines embedded in a next-generation, high-performance, on-chip interconnect with appropriate on-chip memory subsystems. Theheterogeneous processing and programmable engines, which are optimized for different application tasks, enable the Zynq UltraScale+ MPSoCs to deliver the extensive performance and efficiency required to address next-generation smarter systems while retaining backwards compatibility with the original Zynq-7000 All Programmable SoC family. The UltraScale MPSoC architecture also incorporates multiple levels of security, increased safety, and advanced power management, which are critical requirements of next-generation smarter systems. Xilinx’s embedded UltraFast™ design methodology fully exploits theTable 7:Zynq UltraScale+ MPSoC Device FeaturesCG DevicesEG DevicesEV DevicesAPU Dual-core Arm Cortex-A53Quad-core Arm Cortex-A53Quad-core Arm Cortex-A53RPU Dual-core Arm Cortex-R5Dual-core Arm Cortex-R5Dual-core Arm Cortex-R5GPU –Mali-400MP2Mali-400MP2VCU––H.264/H.265ASIC-class capabilities afforded by the UltraScale MPSoC architecture while supporting rapid system development.The inclusion of an application processor enables high-level operating system support, e.g., Linux. Other standard operating systems used with the Cortex-A53 processor are also available for theZynq UltraScale+MPSoC family. The PS and the PL are on separate power domains, enabling users to power down the PL for power management if required. The processors in the PS always boot first, allowing a software centric approach for PL configuration. PL configuration is managed by software running on the CPU, so it boots similar to an ASSP.。
FPGA可编程逻辑器件芯片XCZU5EV-2SFVC784I中文规格书

Programmable Logic DesignMay 8, 2008Military and AerospaceTable 2-9:Virtex-5 FamilyMilitary and AerospaceXilinx is the leading supplier of high-reliability PLDs to the aerospace and defensemarkets. These devices are used in a wide range of applications such as electronic warfare, missile guidance and targeting, RADAR, SONAR communications, signal processing, avionics, and satellites. The Xilinx QPro family of ceramic and plastic QML products provides you with advanced programmable logic solutions for next-generation designs. The QPro family also includes select products that are radiation hardened for use insatellite and other space applications. Our quality management system is fully compliant with all ISO9001 requirements. In 1997, Xilinx became fully qualified as a QML supplier by meeting all of the requirements for MIL Standard 38535.Automotive and IndustrialXilinx XA Solutions – Architecting Automotive IntelligenceIn-car electronic content is increasing at a phenomenal rate. It includes such applications as navigation systems, entertainment systems, instrument clusters, advanced driverinformation systems, and communications devices. To address the needs of automotive electronics designers, Xilinx has created a new family of devices with an extended industrial temperature range option. This new “XA” family consists of existing Xilinx industrial grade (I) FPGAs and CPLDs, with the addition of a new extended temperature grade (Q) for selected devices. The new Q product grade (-40°C to +125°C ambient for CPLDs and junction for FPGAs) is ideal for automotive and industrial applications. The wide range of device density and package combinations enables you to deliver high- performance, cost-effective, flexible solutions that meet your application needs.Design-In FlexibilityWith Xilinx XA devices, you can design-in flexibility and get your product to market faster than ever before. Because many new standards continue to evolve (such as the LIN, MOST, Logic Logic/Serial DSP/Serial Emb./SerialOct ‘06Feb ‘07NowMay ‘06LX LXT SXT FXTProgrammable Logic Design May 8, 2008HDL Design Process architecture BEHAVE of MULT isbeginY <= A * B;end BEHAVE;After (32 x 32 multiplier):entity MULT isport(A,B:in std_logic_vector (31 downto 0);Y:out std_logic_vector (63 downto 0));end MULT;architecture BEHAVE of MULT isbeginY <= A * B;end BEHAVE;HDL is also ideal for design re-use. You can share your “library” of parts with otherdesigners at your company, therefore saving and avoiding duplication of effort.HDL SynthesisOnce we have specified the design in a behavioral description we can convert it into gatesusing the process of synthesis. The synthesis tool does the intensive work of figuring outwhat gates to use, based on the high-level description file you provide (using schematiccapture, you would have to do this manually.) Because the resulting netlist is vendor anddevice family-specific, you must use the appropriate vendor library. Most synthesis toolssupport a large range of gate array, FPGA, and CPLD device vendors.In addition, you can specify optimization criteria that the synthesis tool will take intoaccount when making the gate-level selections, also called mapping. Some of these optionsinclude: optimizing the complete design for the least number of gates, optimizing a certainsection of the design for fastest speed, using the best gate configuration to minimize power,and using the FPGA-friendly, register-rich configuration for state machines.You can easily experiment with different vendors, device families, and optimizationconstraints, thus exploring many different solutions instead of just one with the schematicapproach.To recap, the advantages of high level design and synthesis are many. It is much simplerand faster to specify your design using HDL, and much easier to make changes to thedesign because of the self-documenting nature of the language. You are relieved from thetedium of selecting and interconnecting at the gate level. You merely select the library andoptimization criteria (e.g., speed, area) and the synthesis tool will determine the results.You can also try different design alternatives and select the best one for your application. Infact, there is no real practical alternative for designs exceeding 10,000 gates.ISE SoftwareISE advanced HDL synthesis engines produce optimized results for PLD synthesis, one ofthe most essential steps in your design methodology. It takes your conceptual HDL designdefinition and generates a logical or physical representation for the targeted silicon device.A state-of-the-art synthesis engine is required to produce highly optimized results with afast compile and turnaround time. To meet this requirement, the synthesis engine must betightly integrated with the physical implementation tool and proactively meet design。
FPGA可编程逻辑器件芯片XC7K325T-2FFG900I中文规格书

Chapter1 Packaging OverviewAbout this GuideXilinx® 7series FPGAs include four FPGA families that are all designed for lowest power to enable a common design to scale across families for optimal power, performance, and cost.The Spartan®-7 family is the lowest density with the lowest cost entry point into the7series portfolio. The Artix®-7 family is optimized for highest performance-per-watt and bandwidth-per-watt for cost-sensitive, high-volume applications. The Kintex®-7 family is an innovative class of FPGAs optimized for the best price-performance. The Virtex®-7family is optimized for highest system performance and capacity.This 7series packaging and pinout product specification, part of an overall set ofdocumentation on the 7series FPGAs, is available on the Xilinx website .IntroductionThis section describes the pinouts for the 7series FPGAs in various fine pitch and flip-chip1.0mm pitch BGA packages, 0.8mm and 0.5mm pitch chip-scale packages, and 0.5mmpitch wire-bond lead frame packages.Spartan-7, Artix-7, and Kintex-7 devices are offered in low-cost, space-saving packages that are optimally designed for the maximum number of user I/Os.Virtex-7T and Virtex-7XT devices are offered exclusively in high performance flip-chip BGA packages that are optimally designed for improved signal integrity and jitter.For pinout and packaging information on the Virtex-7HT devices.Package inductance is minimized as a result of optimal placement and even distributionas well as an increased number of Power and GND pins.The FFG, FLG, FHG, FBG, SBG, and RFG flip-chip packages marked with the Pb-free Character on the upper right of the device are RoHS 6 of 6 compliant. The FFG, FLG, FHG, FBG, SBG, and RFG flip-chip packages not marked with the Pb-free character are RoHS 6 of 6 compliant,Pin DefinitionsTable1-12 lists the pin definitions used in 7series FPGAs packages.Note:There are dedicated general purpose user I/O pins listed separately in Table1-12. There are also multi-function pins where the pin names start with either IO_LXXY_ZZZ_# or IO_XX_ZZZ_#, where ZZZ represents one or more functions in addition to being general purpose user I/O. If not used for their special function, these pins can be user I/O.user I/O after stage 2 configuration is complete.Power/Ground PinsGND Dedicated N/A GroundRSVDGND Dedicated N/A Reserved pins, tie to GNDVCCAUX Dedicated N/A 1.8V power-supply pins for auxiliary circuits VCCAUX_IO_G#(2)Dedicated N/A 1.8V/2.0V power-supply pins for auxiliary I/O circuits VCCINT Dedicated N/A0.9V/1.0V power-supply pins for the internal core logic VCCO_#(3)Dedicated N/A Power-supply pins for the output drivers (per bank) VCCBRAM Dedicated N/A 1.0V power-supply pins for the FPGA logic block RAMVCCBATT_0Dedicated N/A Decryptor key memory backup supply; this pin should be tied to the appropriate V CC or GND when not used(4). Specific Spartan-7 devices (XC7S6 and XC7S15) do not support AES encryption. In these devices, connect VCCBATT_0 to VCCAUX or GND.VREF Multi-function N/A These are input threshold voltage pins. They become user I/Os when an external threshold voltage is not needed (per bank).Analog to Digital Converter (XADC) PinsFor more information, see the XADC Package Pins table in UG480, 7Series FPGAs and Zynq-7000 All Programmable SoC XADC Dual 12-Bit 1 MSPS Analog-to-Digital Converter User GuideVCCADC_0(5)(6)Dedicated N/A XADC analog positive supply voltageThe XC7S6 and XC7S15 Spartan-7 devices do not support the XADC. In these devices, connect the VCCADC_0 pin to VCCAUX.GNDADC_0(5)(6)Dedicated N/A XADC analog ground referenceThe XC7S6 and XC7S15 Spartan-7 devices do not support the XADC. In these devices, connect the GNDADC_0 pin to GND.VP_0(5)Dedicated Input XADC dedicated differential analog input (positive side) VN_0(5)Dedicated Input XADC dedicated differential analog input (negative side) VREFP_0(5)Dedicated N/A 1.25V reference inputVREFN_ 0(5)Dedicated N/A 1.25V reference GND referenceAD0P through AD15PAD0N through AD15N Multi-function Input XADC (analog-to-digital converter) differential auxiliary analog inputs 0–15.Auxiliary channels 6, 7, 13, 14, and 15 are not supported on Kintex-7 devices.Table 1-12:7Series FPGAs Pin Definitions (Cont’d)Pin Name Type Direction DescriptionChapter 2:7Series FPGAs Package Files。
FPGA现状及发展趋势

FPGA核心单元-CLB LUT作为函数发生器:
FPGA核心单元-CLB
LUT作为移位寄存器:
FPGA核心单元-DCM
3、数字时钟管理模块(DCM)
大多数FPGA均提供数字时钟管理。通过该模 块提供数字时钟管理和相位环路锁定。相位环路 锁定能够提供精确的时钟综合,且能够降低抖动 ,并实现过滤功能。
Device,CPLD)
现场可编程门阵列(Field Programmable Gate Array,
FPGA)
可编程逻辑器件简介
• PROM、EPROM和EEPROM, 第一阶段 • 由于结构的限制,只能完成简单的数字逻辑功能。
• PAL和GAL,正式被称为PLD,能够完成各种逻辑运算功能。 第二阶段 • 由“与”、“非”阵列组成,以乘积和形式完成大量的逻辑组合。
PLD的发展史
FPGA的发展史(1)
1985年 Xilinx 1991年 Xilinx 1995年 Altera 1998年 Xilinx
• 推出全球第一款FPGA产品——XC2064,采用2μm工艺, 包含64个逻辑模块和85,000个晶体管,门数量不超过1,000 门。
• 推出XC4000系列FPGA,这是第一款被广泛使用的FPGA, 包含44万个晶体管。采用0.7μm工艺。
• 7系列FPGA统计架构 • 利用高-K金属栅、高性能、低功耗28nm工艺技术,为您实现低
功耗、最高性能和生产力最大化。
Xilinx公司简介
Xilinx公司成立于1984年,首创了现场可编
程逻辑阵列(FPGA)这一创新性的技术,并 于1985年首次推出商业化产品。目前Xilinx 占有全世界FPGA产品一半以上的市场份额 。Xilinx公司的FPGA器件基于SRAM架构, 可“无限次”编程;LUT可配置为分布式 RAM;块RAM可配置为多种模式;全数字 式的时钟管理系统,可提供灵活精确的时 钟信号;VersaRing提供了IOB与CLB的连接 ,可以更便利的实现PIN锁定。
FPGA可编程逻辑器件芯片XC7A100T-2CSG324I中文规格书

Chapter1 Packaging OverviewAbout this GuideXilinx® 7series FPGAs include four FPGA families that are all designed for lowest power to enable a common design to scale across families for optimal power, performance, and cost.The Spartan®-7 family is the lowest density with the lowest cost entry point into the7series portfolio. The Artix®-7 family is optimized for highest performance-per-watt and bandwidth-per-watt for cost-sensitive, high-volume applications. The Kintex®-7 family is an innovative class of FPGAs optimized for the best price-performance. The Virtex®-7family is optimized for highest system performance and capacity.This 7series packaging and pinout product specification, part of an overall set ofdocumentation on the 7series FPGAs, is available on the Xilinx.IntroductionThis section describes the pinouts for the 7series FPGAs in various fine pitch and flip-chip1.0mm pitch BGA packages, 0.8mm and 0.5mm pitch chip-scale packages, and 0.5mmpitch wire-bond lead frame packages.Spartan-7, Artix-7, and Kintex-7 devices are offered in low-cost, space-saving packages that are optimally designed for the maximum number of user I/Os.Virtex-7T and Virtex-7XT devices are offered exclusively in high performance flip-chip BGA packages that are optimally designed for improved signal integrity and jitter.For pinout and packaging information on the Virtex-7HT devices.Package inductance is minimized as a result of optimal placement and even distributionas well as an increased number of Power and GND pins.The FFG, FLG, FHG, FBG, SBG, and RFG flip-chip packages marked with the Pb-free Character on the upper right of the device are RoHS 6 of 6 compliant. The FFG, FLG, FHG, FBG, SBG, and RFG flip-chip packages not marked with the Pb-free character are RoHS 6 of 6 compliant,Table 1-6 lists the quantity of GTX and GTH serial transceiver channels for the Virtex-7XT FPGAs. In all devices, a serial transceiver channel is one set of MGTRXP, MGTRXN, MGTTXP, and MGTTXN pins.Table 1-6:Serial Transceiver Channels (GTX/GTH) by Device/Package (Virtex-7XT FPGAs)DeviceFFG1157FFV1157RF1157FFG1158FFV1158RF1158FFG1761FFV1761RF1761FFG1926FFG1927FFV1927FFG1928FFG1930RF1930FLG1926FLG1928FLG1930GTX GTH GTX GTH GTX GTH GTX GTH GTX GTH GTX GTH GTX GTH GTX GTH GTX GTH GTX GTHXC7VX330T 020–028–––––––XC7VX415T 020048––048–––––XC7VX485T 200480280–560–240–––XC7VX550T –048––080–––––XC7VX690T 0204836064080–024–––XC7VX980T –––064–07224–––XC7VX1140T –––––––06496024XQ7VX330T 020–028–––––––XQ7VX485T ––280–––240–––XQ7VX690T 0204836–––024–––XQ7VX980T––––––24–––Spartan-7 Devices User I/OPinsSpartan-7 FPGA Packages: HR I/O Banks OnlyCPGA196CSGA225CSGA324FTGB196FGGA484FGGA676XC7S6 XA7S6User I/O100100–100––Differential9696–96––XC7S15 XA7S15User I/O100100–100––Differential9696–96––XC7S25 XA7S25User I/O–150150100––Differential–14414496––XC7S50 XA7S50User I/O––210100250–Differential––20296240–XC7S75 XA7S75User I/O––––338400 Differential––––324384XC7S100 XA7S100User I/O––––338400 Differential––––324384Power/Ground PinsGND Dedicated N/A GroundRSVDGND Dedicated N/A Reserved pins, tie to GNDVCCAUX Dedicated N/A 1.8V power-supply pins for auxiliary circuits VCCAUX_IO_G#(2)Dedicated N/A 1.8V/2.0V power-supply pins for auxiliary I/O circuits VCCINT Dedicated N/A0.9V/1.0V power-supply pins for the internal core logic VCCO_#(3)Dedicated N/A Power-supply pins for the output drivers (per bank) VCCBRAM Dedicated N/A 1.0V power-supply pins for the FPGA logic block RAMVCCBATT_0Dedicated N/A Decryptor key memory backup supply; this pin should be tied to the appropriate V CC or GND when not used(4). Specific Spartan-7 devices (XC7S6 and XC7S15) do not support AES encryption. In these devices, connect VCCBATT_0 to VCCAUX or GND.VREF Multi-function N/A These are input threshold voltage pins. They become user I/Os when an external threshold voltage is not needed (per bank).Analog to Digital Converter (XADC) PinsFor more information, see the XADC Package Pins table in UG480, 7Series FPGAs and Zynq-7000 All Programmable SoC XADC Dual 12-Bit 1 MSPS Analog-to-Digital Converter User GuideVCCADC_0(5)(6)Dedicated N/A XADC analog positive supply voltageThe XC7S6 and XC7S15 Spartan-7 devices do not support the XADC. In these devices, connect the VCCADC_0 pin to VCCAUX.GNDADC_0(5)(6)Dedicated N/A XADC analog ground referenceThe XC7S6 and XC7S15 Spartan-7 devices do not support the XADC. In these devices, connect the GNDADC_0 pin to GND.VP_0(5)Dedicated Input XADC dedicated differential analog input (positive side) VN_0(5)Dedicated Input XADC dedicated differential analog input (negative side) VREFP_0(5)Dedicated N/A 1.25V reference inputVREFN_ 0(5)Dedicated N/A 1.25V reference GND referenceAD0P through AD15PAD0N through AD15N Multi-function Input XADC (analog-to-digital converter) differential auxiliary analog inputs 0–15.Auxiliary channels 6, 7, 13, 14, and 15 are not supported on Kintex-7 devices.Table 1-12:7Series FPGAs Pin Definitions (Cont’d)Pin Name Type Direction Description。
基于存储器映射的Flash高速低功耗驱动实现

基于FPGA双RAM乒乓操作的数据存储系统的研究-图文(精)

科技信息。
机械与电子o2021年第2l期基于FPGA双RAM乒乓操作的数据存储系统的研究钱黄生1夏忠珍z11。
中国电子科技集团公司第四十一研究所山东青岛266555;2.南京立汉化学有限公.-3江苏南京211102l【搐要】本文阐速了在对实时性要求较高,而对数据存储深度要求不高的数据采集系统中,用FPGA构建双RAM来乒乓存储数据的方法,重点介绍了乒乓操作的控制方法。
本方法在XILINX9.1软件中通过时序仿真。
并且通过XC2VP20验证了本方法完全能够满足设计的要求。
【关键词】FPGA;KAM;乒乓操作0引言经过70年的不断开展,FPGA已由当初的1200门开展成为今天的百万门级。
通过不断更新优化产品架构和生产工艺,实现了更多的逻辑单元、更高的性能、更低的单位本钱和功耗【11。
本文用到的FPGA是xilinx公司Virtex-Il Pro家族的xc2vp20芯片,它包含2个POWER PC处理器.20880个cell.多达290KB的分布式RAM以及88个18KB的Block RAM嘲。
由于本系统的存储深度不大,所以采用FPGA片内资源来构建RAM。
这样效率更高.且使用方便,而且还可以防止板级信号干扰。
既节省了印制板空间又节约了成本。
1乒乓操作原理乒乓操作口棚是种经常应用于数据流控制的处理方法。
图l是它的典型操作示意图。
乒乓操作的处理流程为:输人数据流通过“输入数据选择单元〞将数据流等时分配到两个数据缓冲区.数据缓冲模块选择双口RAM (DPRAM或单r】RAM,FIFO等。
在第一个周期,将输入的数据流缓存到。
数据暂存单元1〞:在第2个周期,通过“输人数据选择单元〞的切换,将输入的数据流缓存到“数据暂存单元2〞,同时将“数据暂存单元1〞缓存的第1个周期数据通过“输出数据选择单元〞的选择。
输送到“数据处理单元〞即上位机凄走进行处理;在第3个缓冲周期通过“输人数据选择单元〞的再次切换,将输入的数据流缓存到“数据暂存单元1〞,同时将“数据暂存单元2〞缓存的第2个周期的数据通过“输出数据选择单元〞切换,输送到“数据处理单元〞进行运算处理。
XilinxFPGA 的power-up配置和 start-up过程

Xilinx FPGA的power-up配置和 start-up过程FPGA的配置分为3步,1.清除配置SRAM2.下载配置数据3. Start-up过程激活逻辑Power-up配置从上图可见,配置在FPGA上电时自动进行。
上电后,FPGA自动开始清楚RAM的内容(此时,外围电路应使/program=1),清除RAM后,FPGA使/INIT变为无效,开始装载配置bit(如果保持/INIT信号有效,则可以延迟装载bit,INIT是双向端口)。
装载bit的过程中,FPGA会做CRC检查,发现错误则把/INIT信号拉低。
配置完成后done变高。
配置时序如下图所示。
也可以通过把/program置低开始(在不重新上电的情况下开始配置FPGA)对Xilinx FPGA的配置有四个主要步骤(不重新上电的情况下开始配置FPGA):(1)配置存储器清空(Clearing Configuration Memory)将PROGRAM管脚拉低300ns以上。
当PROGRAM拉低后,开始配置存储器,将存储器清空。
此时INIT将被拉低,当PROGRAM置高后,FPGA将继续将INIT置低直到完全清除完所有的配置存储器。
当INIT变高时,配置便可以开始了。
(2)加载配置数据(Loading Configuration Data)当INIT变高时,便可以配置FPGA了。
配置时,先将CCLK置低,再将数据发送到DIN上,延时45ns以上,再将CCLK置高,该位数据便写入到了FPGA中(数据是低位在前),然后再准备下一次的输入。
如此反复,将所有数据输入完毕为止。
(3)CRC错误校验(CRC Error Checking)在加载数据过程中,嵌入到配置文件中的CRC值同FPGA计算出来的值比较,若有CRC 校验错误产生,则INIT置低,且FPGA停止加载。
Start-up过程默认的start-up过程在DONE信号变高并延迟一个CCLK后进行,此时global tri-state signal(GTS)信号释放,这样允许器件output打开。
PolarFire SoC FPGA:工程样本(ES)设备 55900219 版本1.0 7 20

ER0219Errata PolarFire SoC FPGA: Engineering Samples (ES)DevicesMicrosemi HeadquartersOne Enterprise, Aliso Viejo,CA 92656 USAWithin the USA: +1 (800) 713-4113 Outside the USA: +1 (949) 380-6100 Sales: +1 (949) 380-6136Fax: +1 (949) 215-4996Email: *************************** ©2020 Microsemi, a wholly owned subsidiary of Microchip Technology Inc. All rights reserved. Microsemi and the Microsemi logo are registered trademarks of Microsemi Corporation. All other trademarks and service marks are the property of their respective owners. Microsemi makes no warranty, representation, or guarantee regarding the information contained herein or the suitability of its products and services for any particular purpose, nor does Microsemi assume any liability whatsoever arising out of the application or use of any product or circuit. The products sold hereunder and any other products sold by Microsemi have been subject to limited testing and should not be used in conjunction with mission-critical equipment or applications. Any performance specifications are believed to be reliable but are not verified, and Buyer must conduct and complete all performance and other testing of the products, alone and together with, or installed in, any end-products. Buyer shall not rely on any data and performance specifications or parameters provided by Microsemi. It is the Buyer’s responsibility to independently determine suitability of any products and to test and verify the same. The information provided by Microsemi hereunder is provided “as is, where is” and with all faults, and the entire risk associated with such information is entirely with the Buyer. Microsemi does not grant, explicitly or implicitly, to any party any patent rights, licenses, or any other IP rights, whether with regard to such information itself or anything described by such information. Information provided in this document is proprietary to Microsemi, and Microsemi reserves the right to make any changes to the information in this document or to any products and services at any time without notice.About MicrosemiMicrosemi, a wholly owned subsidiary of Microchip T echnology Inc. (Nasdaq: MCHP), offers a comprehensive portfolio of semiconductor and system solutions for aerospace & defense, communications, data center and industrial markets. Products include high-performance and radiation-hardened analog mixed-signal integrated circuits, FPGAs, SoCs and ASICs; power management products; timing and synchronization devices and precise time solutions, setting the world's standard for time; voice processing devices; RF solutions; discrete components; enterprise storage and communication solutions, security technologies and scalable anti-tamper products; Ethernet solutions; Power-over-Ethernet ICs andmidspans; as well as custom design capabilities and services. Learn more at .Contents1Revision History . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11.1Revision 1.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2Errata for PolarFire SoC Engineering Samples . . . . . . . . . . . . . . . . . . . . . . . . . . . . .22.1Sample Revisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.2PCB Designs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22.3ES Device Identification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 3Errata Descriptions and Workarounds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .43.1Microprocessor Subsystem (MSS) cannot Access System Controller SPI Flash . . . . . . . . . . . . . . . . . . 43.2AXI Switch Memory Protection Unit (MPU) is not Operational . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53.3MSS I2C peripheral will Work only with MSS Core Version 2.0.108 and above . . . . . . . . . . . . . . . . . . . 53.4In Worst-case Scenario, MSS CPU's Frequency is Limited to 600 MHz . . . . . . . . . . . . . . . . . . . . . . . . . 53.5When MSS Works as a Master, DRI Interrupt Line should not be Used . . . . . . . . . . . . . . . . . . . . . . . . . 63.6DRI Error and DRI Fault Interrupts are not Connected to the Maintenance Interrupt . . . . . . . . . . . . . . . 63.7MSS GPIO Configuration Registers should only be Reset by the CPU's . . . . . . . . . . . . . . . . . . . . . . . . 63.8Fabric APB DRI's Slow Writes Corrupt the SmartDebug JTAG/SPI Read Data . . . . . . . . . . . . . . . . . . . 63.9System Controller Suspend Mode is not Supported . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63.10PolarFire SoC MSS GEM (Gigabit Ethernet MAC) has Issue with 'Undersize Frame Counter' in EthernetStatistics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63.11Auto-program or Auto-Update of eNVM should not be Used . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.12Auto-update System Service will Allow SPI Master Mode to be Used Incorrectly Configured for SPI SlaveMode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4Fabric Transceiver Protocols and DDR Memory Interfaces . . . . . . . . . . . . . . . . . . .7 5Libero SoC Software Errata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7 6Embedded Software Errata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7Figure 1ES Identification Markings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3TablesTable 1Sample Revisions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Table 2PolarFire SoC ES Operating Conditions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Table 3Summary of PolarFire SoC ES FPGA Errata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4Revision History1Revision HistoryThe revision history describes the changes that were implemented in the document. The changes arelisted by revision, starting with the current publication.1.1Revision 1.0The first publication of this document.2Errata for PolarFire SoC Engineering SamplesThe PolarFire ® SoC FPGA family engineering samples (ES) are subject to the limitations described inthis errata document. This document contains updated information about any known engineeringsample-specific issues and provides the available limitations and workarounds. Engineering sampleissues identified in this document will be corrected in subsequent production revision of the devices listedin the following table. Contact Microchip Technical Support for more information.2.1Sample RevisionsThe following table lists the sample revisions released. If not specified, the errata items impact all ESrevisions listed in the table.The following table lists the operating conditions for the PolarFire-SoC engineering samples. Theoperating conditions for production devices follow datasheet specifications. These operating conditionsare for engineering samples only. See DS0147: PolarFire SoC Advanced Datasheet for productionspecifications.2.2PCB DesignsFor information about how to determine proper signal pinout, see UG0901: PolarFire SoC FPGA BoardDesign Guidelines User Guide . The proper signal pinout is required for all clocking, transceiver, andFPGA pin recommendations.Table 1 •Sample Revisions Device PackagesRevisionMPFS250T FCVG484EES1FCG1152EES FCSG536EESFCVG784EESTable 2 • PolarFire SoC ES Operating ConditionsOperation Temperature Range VDD Core Voltage (Programming Voltage Only)Program / Erase 20 °C to 50 °C 11.T J = Junction Temperature1.0 ± 0.03 V 22.VDD = 1.05 V ± 0.03 V is not supported on PolarFire SoC ES silicon but will be supported for Production silicon. However, VDDA is supported at both 1.0 V and 1.05 V ± 0.03 V on ES silicon.20 °C to 50 °C2.3ES Device IdentificationPolarFire SoC FPGA engineering samples can be identified by the temperature grade field in the lowerleft-hand corner. As the following illustration shows, an ES annotation will appear in the temperaturegrade field indicating device is engineering sample and revision marking is shown along right side ofcode mark.Figure 1 • ES Identification Markings3Errata Descriptions and WorkaroundsThe following sections describe device errata and the workarounds wherever applicable.The following table lists the ES specific device errata and the affected PolarFire SoC ES device revision. For die revision part marking specification, see ES Identification Markings, page 3.3.1Microprocessor Subsystem (MSS) cannot Access System Controller SPI FlashPolarFire SoC ES silicon has an issue in system controller between the analog dynamic reconfiguration interface (DRI) register block and SPI block that results in incorrect data during reads from the RXFIFO. Writes and reads to other SPI registers (for example, control, frame count, Tx data and direct access) work correctly.Due to this issue, the MSS cannot directly access the PolarFire SOC external flash device via the SPI controller attached to the system controller using DRI bus.This limitation will be fixed in production silicon.Table 3 •Summary of PolarFire SoC ES FPGA Errata Description Silicon Revisions DetailsMicroprocessor Subsystem (MSS) cannot Access SystemController SPI Flash, page 41Applicable to all PolarFire SoC ES versions.AXI Switch Memory Protection Unit (MPU) is not Operational,page 5.MSS I2C peripheral will Work only with MSS Core Version2.0.108 and above, page 5.In Worst-case Scenario, MSS CPU's Frequency is Limited to600 MHz, page 5When MSS Works as a Master, DRI Interrupt Line should notbe Used, page 6DRI Error and DRI Fault Interrupts are not Connected to theMaintenance Interrupt, page 6MSS GPIO Configuration Registers should only be Reset bythe CPU's, page 6Fabric APB DRI's Slow Writes Corrupt the SmartDebugJTAG/SPI Read Data, page 6System Controller Suspend Mode is not Supported, page 6PolarFire SoC MSS GEM (Gigabit Ethernet MAC) has Issuewith 'Undersize Frame Counter' in Ethernet Statistics, page 6Auto-program or Auto-Update of eNVM should not be Used,page 7Only Applicable to PolarFire SoC ES Revision 1 silicon.Auto-update System Service will Allow SPI Master Mode to beUsed Incorrectly Configured for SPI Slave Mode, page 73.2AXI Switch Memory Protection Unit (MPU) is notOperationalPolarFire SoC ES parts have silicon bug that may cause AXI bus issues when illegal messages arerejected by PolarFire SoC memory protection unit (MPU). For this reason, MPU is currently disabled aspart of system start-up firmware. This means that the MPU's are inactive and will not generate accesswarnings or interrupts.This limitation will be fixed in production silicon.3.3MSS I2C peripheral will Work only with MSS CoreVersion 2.0.108 and aboveIn PolarFire SoC ES parts, MSS I2C clock and data signals are pulled low after MSS initialization. MSScore in Libero 12.4 has the required workaround for this MSS I2C issue in ES device. Use MSS coreversion 2.0.108 or above for Libero 12.4 or use Libero 12.5 and above where workaround will beautomatically applied when the user selects an ES part. Note that the workaround fix in Libero is usingthe fabric in all cases and the user will need to program the FPGA portion to have the MSS I2C working.This limitation will be fixed in production silicon. User designs using MSS I2C in ES silicon can not beported to production silicon. Users need to regenerate the MSS configurator and bitstream when portingdesign to production silicon and make sure to target the correct device.3.4In Worst-case Scenario, MSS CPU's Frequency isLimited to 600 MHzIn PolarFire SoC ES, maximum achievable MSS CPU frequency is 625 MHz for both STD and -1 speedgrades. The eMMC/SD controller requires a fixed 200 MHz clock, fed from the same PLL as the CPU.The CAN controller requires a clock, which is a multiple of 8 MHz, also fed from the same PLL as theCPU. However, in engineering samples, the following limitations applies for these clock frequencies:1.If the eMMC/SD controller is being used in the system, the maximum MSS CPU clock frequency is600 MHz.2.If the CAN controller is being used in the system (but not the eMMC/SD controller), the maximumMSS CPU clock frequency is either 624 MHz (with 100 MHz reference clock) or 620 MHz (with125 MHz reference clock). There is a general restriction in the available MSS CPU frequency:•If using 100 MHz reference clock for MSS PLL:When no eMMC/SD or CAN is being used, the MSS CPU frequencies are—all integer values from 2through 625•When eMMC/SD being used (with or without CAN), the MSS CPU frequencies are:2, 4, 5, 6, 8, 10, 12, 15, 16, 20, 24, 25, 30, 32, 40, 48, 50, 60, 75, 80, 100, 120, 125, 150, 160,200, 240, 250, 300, 400, 500, 600.•When CAN being used (without eMMC/SD), the MSS CPU frequencies are:All integer values from 2 through 156,Every 2nd value from 158 through 312Every 4th value from 316 through 624•If using 125 MHz reference clock for MSS PLL:•When no eMMC/SD or CAN is being used, the MSS CPU frequencies are—all integer values from 2 through 250 and every 5th value from 255 through 625.•When eMMC/SD being used (with or without CAN), the MSS CPU frequencies are:2, 4, 5, 6, 8, 10, 12, 15, 16, 20, 24, 25, 30, 32, 40, 48, 50, 60, 75, 80, 100, 120, 125, 150, 160,200, 240, 250, 300, 400, 500, 600•When CAN being used (without eMMC/SD), the MSS CPU frequencies are:2 – 32, 34, 35, 36, 38, 40, 42, 44, 45, 46, 48, 50, 52, 54, 55, 56, 58, 60, 62, 64, 65, 68, 70, 72,75, 76, 80, 84, 85, 88, 90, 92, 95, 96, 100, 104, 105, 108, 110, 112, 115, 116, 120, 124, 125,128, 130, 135, 136, 140, 144, 145, 150, 152, 155, 160, 168, 170, 176, 180, 184, 190, 192, 200,208, 210, 216, 220, 224, 230, 232, 240, 248, 250, 260, 270, 280, 290, 300, 310, 320, 340, 360,380, 400, 420, 440, 460, 480, 500, 520, 540, 560, 580, 600, 620.Errata Descriptions and WorkaroundsNote:The User Crypto may also get its clock from the MSS PLL but has the option of getting its clock from the FPGA fabric. This does not place the same limitations on MSS CPU frequency.This limitation will be fixed in production silicon.3.5When MSS Works as a Master, DRI Interrupt Line shouldnot be UsedThe DRI interrupt system should not be used with the PolarFire SOC ES silicon device. If enabled, theinterrupt input to the fabric and MSS from the DRI system cannot be cleared without a device reset. As aworkaround, few events that DRI interrupts may have been used for are also available as status signalsto the fabric.This limitation will be fixed in production silicon.3.6DRI Error and DRI Fault Interrupts are not Connected tothe Maintenance InterruptDRI Error and DRI Fault interrupt bits in the Maintenance Register function as expected but will notcause a CPU interrupt—the interrupt enable is effectively disabled in ES silicon.This limitation will be fixed in production silicon.3.7MSS GPIO Configuration Registers should only be Resetby the CPU'sThe three MSS GPIO blocks do not support the fabric reset functionality in PolarFire SoC ES silicon. TheGPIO blocks should be configured so that the byte resets use the internal MSS reset, that is, theGPIO_CR configuration register 'soft_reset_select' bits should not be set to 0.This limitation will be fixed in production silicon.3.8Fabric APB DRI's Slow Writes Corrupt the SmartDebugJTAG/SPI Read DataA fabric DRI write operation to one of the PCIe subsystem (PCIESS) controllers APB configurationblocks may corrupt a SmartDebug JTAG/SPI read operation; the read will return zero. If this issuspected, the SmartDebug operation should be carried out again until the expected data is received.This limitation will be fixed in production silicon.3.9System Controller Suspend Mode is not SupportedSystem controller suspend mode is not supported in PolarFire SoC ES silicon parts. This limitation will befixed in production silicon.3.10PolarFire SoC MSS GEM (Gigabit Ethernet MAC) hasIssue with 'Undersize Frame Counter' in EthernetStatisticsIn the Polarfire SoC, for 1Gbps half-duplex mode, Ethernet statistics "undersize_frames" counter withinthe GEM increments for received frame sizes less than 512 bytes instead of incrementing for less than64 bytes. Subsequent transition to 1Gbps full-duplex mode does not resolve the issue. User should notethat 'Undersize Frame counter' reports correctly for all other speeds and duplex modes, including 1Gbpsfull-duplex if not transitioning from half-duplex.Fabric Transceiver Protocols and DDR Memory Interfaces3.11Auto-program or Auto-Update of eNVM should not beUsedBoot initiated auto-program/auto-update of eNVM will fail. Auto-program/update of eNVM should not beused on PolarFire SoC ES silicon. This limitation will be fixed in production silicon.3.12Auto-update System Service will Allow SPI Master Modeto be Used Incorrectly Configured for SPI Slave ModeIn PolarFire SoC ES silicon, auto-update system service will allow SPI master mode to be used on aPolarFire SoC ES silicon device configured in SPI slave mode. Ideally, it should throw an error. If thisservice is used on device configured in slave mode, there is a possibility of contention on the SPI flashpins. Fix for this issue is that auto-update system service should not be used if the PolarFire SoC ESsilicon device is configured for slave mode.This limitation will be fixed in production silicon.4Fabric Transceiver Protocols and DDR Memory InterfacesSupported transceiver protocols and DDR memory interfaces are reused features from PolarFire FPGA.These are currently in plan for validation and these features are in the process of being validated. Thesefeatures are expected to work with similar robustness as in PolarFire FPGAs.5Libero SoC Software ErrataFor more Libero SoC related "known Issues and limitations", see Libero SoC Release Notes document. 6Embedded Software ErrataSee the "Known Issues and useful tips" section in SoftConsole Release Notes document.These SoftConsole known issues are under active investigation to ascertain the root cause and toresolve the underlying problems with the intention that these are resolved in a future release.。
一种基于FPGA的低功耗、容错状态机设计方法

一种基于FPGA的低功耗、容错状态机设计方法李列文;桂卫华;胡小龙【摘要】针对FPGA(Field Programmable Gate Array)在航空航天领域应用面临的可靠性和功耗问题,提出了一种适于FPGA实现的低功耗、容错有限状态机设计方法.该方法与传统FPGA中实现状态机占用布线资源、查找表、寄存器等资源的思想不同,它将状态机映射到FPGA内嵌块RAM,同时采用两块RAM构成双模冗余结构,通过比较两块RAM输出数据的一致性确定RAM中数据出错的情况,并结合奇偶校验进行检错与纠错.实验结果表明:与经典的三模冗余方法相比,该方法有更低的功耗和更高的可靠性,并能对一位错误实现在线纠错.【期刊名称】《湖南大学学报(自然科学版)》【年(卷),期】2010(037)006【总页数】6页(P77-82)【关键词】低功耗;有限状态机;容错;现场可编程门阵列【作者】李列文;桂卫华;胡小龙【作者单位】中南大学,信息科学与工程学院,湖南,长沙,410075;长沙师范学校,电子信息工程系,湖南,长沙,410100;中南大学,信息科学与工程学院,湖南,长沙,410075;中南大学,信息科学与工程学院,湖南,长沙,410075【正文语种】中文【中图分类】TP368;TN873现场可编程门阵列(FPGA)以其高性能、可重构、设计周期短等优势,被认为是在航空航天领域的重要器件.由于空间辐射,基于SRAM 的FPGA在空间环境工作时,极易受到单粒子翻转(Single E-vent Upset,SEU)的影响.SEU是由于带电重粒子轰击集成电路时造成瞬时充放电而导致存储单元的逻辑状态翻转[1],它能改变FPGA内部寄存器、块RAM、查找表(Look-Up-Table,LUT)、配制存储块的内容,可能引起计算结果错误、程序执行序列错误,甚至使系统崩溃.此外,在宇宙空间的高真空环境,由于没有空气来散发电子系统产生的热量,整个环境对系统的散热非常不利,电子系统散热只能用其它方式来解决,这就势必对系统功耗指标提出严格的要求.因此,可靠性和功耗问题已经成为FPGA在航空航天领域应用首要考虑和解决的问题.有限状态机(Finite State Machine,FSM)是数字系统设计中的重要组成部分,是FPGA中实现高效率高可靠性逻辑控制的重要途径.有限状态机可靠性直接关系到整个系统的稳定,国内外许多研究机构针对FPGA中有限状态机的容错能力展开了研究.目前,FPGA中实现有限状态机主要有两种方法.第一种是传统方法,该方法用寄存器存储状态信息,用组合逻辑产生下一状态和输出值,实现时主要占用FPGA的布线资源、查找表、寄存器等资源.基于这种实现方法,国内外提出了许多容错方法.如系统级N模冗余、选择性冗余结构等.在众多容错方法中三模冗余(T riple Module Redundancy,TMR)是最典型的方法之一,该方法在增加系统可靠性的同时,大大增加了系统的资源开销,使系统功耗也随之增大,而且三模冗余结构不具备在线纠错能力[2].第二种方法是利用FPGA中存储资源,将有限状态机映射到FPGA内嵌的块RAM[3-4].新一代的FPGA器件中除了有触发器、查找表、布线资源等可编程逻辑资源外,还有一些存储资源,如Xilinx公司的Virtex系列FPGA内部有成块的RAM 资源.Altera公司的Stratix系列FPGA包含 Tri Matrix存储器[5].该方法充分利用了新一代的FPGA器件存储资源,大大减少了FPGA的布线压力和功耗.此外,还可以通过修改块RAM 的内容的方式来改变有限状态机的功能而不必重新综合、布局、布线.在此方法基础上,文献[4]提出了一种容错状态机实现方法,该方法用块RAM执行状态机,采用汉明码用于检错与纠错.该方法特点是对一位错误能在线检测并纠正,缺点是实现较复杂,容易产生误校验(在发生二位错误时,编码以一位错误来处理并加以“纠正”,结果将引起更大的错误).本文针对三模冗余容错方法具有占用资源多、功耗大等缺点,结合高性能FPGA结构特点,充分利用FPGA内嵌块RAM资源,提出了一种新的低功耗、容错状态机设计方法.首先,文章分析了FSM映射到块RAM思想并给出了相应算法,在此基础上提出了基于块RAM的双模冗余结构状态机设计方法,该方法通过比较两块RAM的输出值,结合奇偶校验进行检错与纠错,几乎能检验出所有错误,并能对一位错误实现在线纠错.1 容错状态机设计基于双RAM冗余结构容错状态机设计主要思想:整个设计采用两块块RAM构成双模比较冗余结构,同时将状态机映射到块 RAM,映射到块RAM的状态机每个字增加一位用于奇偶校验,系统工作时通过比较两个模块的输出,并结合奇偶校验结果对系统进行查错和纠错.实现过程主要包括两步:1)FSM映射到块 RAM.2)双模冗余结构设计.1.1 FSM映射到块RAM使用FPGA中块RAM执行状态机时,存储器每个存储单元内容包括状态编码(由它和状态机的输入位一起形成下一状态的存储位置的地址)和状态机的输出位.一个有限状态机映射到FPGA块RAM的实例如图1所示.其中图1(a)为有限状态机的状态转换图(state transition graph,STG),图1(b)为状态机在存储块中执行示意图. 图1 有限状态机映射到块RAM示意图Fig.1 Mapping an FSM into the blockRAM图中RAM的数据宽度为4比特,高3位是状态机当前状态的编码,低1位是状态机向下一状态转换时的输出值.例如,“0000“存储单元中高3位存放S1的状态编码“001”,低1位则存放态转换时的输出值“0”状态机转换时下一状态的地址由当前状态编码和当前输入决定.例如,从状态S1到状态S2跳转时由于当前状态S1的编码为“001”,而且状态S1到状态S2跳转时输入为“1”,因此由S1的状态编码“001”和“1”组合在一起构成S2状态编码的存储单元地址“0011”.该存储单元高三位存放S2的状态编码“010”,第 4位存放输出值“0”.同样,状态转换图的其它状态也按这种方式存储.如果用I表示状态机输入的位数,O表示状态机输出位数.S为状态编码的位数,则执行该状态机所需存储器的大小可表示为:式中:i+S为所需的地址线数目,O+S为每个存储单元的位数.地址线和所需存储单元的数目随状态机输入数增加而增加.实现FSM映射到块RAM的映射算法如图2所示.图2 有限状态机映射到块RAM实现算法Fig.2 Algorithms mapping an FSM into the block RAM算法中的第1行对状态转换图中所有状态进行编码.第2行~第4行比较每片RAM 的地址线数目与状态机编码位数和输入位数之和.如果单片RAM的地址线数目大于状态机编码位数和输入位数之和,则进一步确定此片 RAM的每个存储单元位数是否小于编码位数与输出位数之和.第5行~第10行用于处理单片存储单元位数不能满足存储编码位数与输出位数情况,此时多片 RAM串行连接,进行位扩展.第13行~第 16行则处理单片RAM地址线不能满足要求的情况.第18行~第20行完成多片RAM并行连接,进行字扩展,在保证有足够的地址线后,跳转到第3行确保每个存储单元有足够的存储位.在完成所有FSM映射后算法终止.1.2 基于块RAM的双模冗余结构1)双模冗余结构基于块RAM的双模冗余结构如图3所示.图中两块RAM构成双冗余结构,每块RAM具有两个端口,分别称为端口A和端口B,每个端口都有独立地址线、数据线、时钟信号线、复位信号线和使能端.此外,存储在两块RAM的数据每个字增加一位奇偶校验位,奇偶校验器用于对输出数据进行奇偶校验,可以检测出RAM中每个存储单元出现的寄数个错误.图3 基于块RAM的双模冗余结构Fig.3 The duple-redundancy structure based on block RAM图中多路选择器可用FPGA自带的多路选择器单元实现,这样可以避免SEU的影响.奇偶校验器和比较器采用三模冗余结构,它们的输出通过一个表决器,表决器符合下列等式:式中:a,b,c为表决器的输入.表决器也可能受到SEU影响,因而表决器也采用三模冗余结构.2)双模冗余结构工作分析基于块 RAM的双模冗余结构运行状态机时,两块RAM接受相同的输入,运行相同的任务,每个时钟周期,两块RAM输出的数据通过比较器进行比较,根据输出数据是否一致来判断两块RAM中是否出现错误,同时结合寄偶校验码进行查错与纠错.双模冗余结构工作时可能出现的错误分为3类.第1类指两块RAM输出相同字的对应位只有一处错误;第2类指两块RAM 输出相同字的对应位有两处以上错误,包括一个字中有多个错误,或两个字中分别有错误,不包括两块RAM输出相同字的对应位置发生偶数个的错误;第 3类指两块RAM输出相同字的对应位置发生偶数个错误.第1类错误发生时,比较器显示结果是两块RAM输出相同字的对应位不一致的数目为一位.对于这种情况,由奇偶校验位确定出错的块RAM,并通过多路选择器从没有出错的块RAM中选取正确的数据输出,同时用正确RAM数据对出错RAM的内容进行修正,从而实现了对一位错误的在线纠正.实现系统一位错误的在线纠正的结构如图 4所示.图4 一位错误在线纠正结构图Fig.4 The structure of an error's on-line error correction对于第2类错误,即图3中的比较器比较两块RAM输出数据时,比较结果是两块RAM输出的两个字中不同的位数超过一位,此时可以确定系统出现了错误,但不能确定错误来源于那一块RAM,因此必须调用外部正确的数据对两块RAM内部数据擦洗校正.当第3类错误发生时,由于两块RAM 输出相同字的对应位置发生偶数个错误.此时比较器和奇偶校验都将失去作用,但实验证明,出现这种错误的概率极小,在系统可靠性分析时将对这种错误出现的概率进行分析.2 系统可靠性分析2.1 双模冗余结构的可靠性建模要验证双模冗余结构的可靠性,首先建立瞬时错误估计模型.当前已有不少文献对存储器的可靠性进行了研究[6-8].本文对双模冗余结构可靠性是在这些研究的基础上进行的.2.1.1 双模冗余结构的可靠性基于双模冗余结构系统工作时,当系统出现一位错误时,系统能在线检测并在线纠正,当出现两个或两个以上错误时,则中断现行操作,启用外部擦洗,因此双模冗余结构的可靠性是指能检测出多个错误情况下的可靠性.下面推断计算双模冗余结构可靠性计算公式,依照泊松分布,有N个字且每个字为W位的存储器可靠性满足下面公式[9].式中:λ为瞬时出错的概率.w为每个字的位数,N为存储器的总字数.在基于双模冗余结构系统中,两块R AM输出的两个字中必须包含一个正确的字用于纠正出错的输出字,同时一个字中最多不超过一位错误,有一位错误出现并能在线纠错情况下的稳定性计算公式为:式中:第1项为两块RAM输出字都是正确的情况;第2项为一个SEU错误能使用冗余块RAM在线修正的情况.2.1.2 两块RAM输出相同字的对应位置发生偶数个错误概率对于前面提到的第3类错误,即双模冗余结构中来自两块不同RAM的两个输出字相同的位上出现偶数个错误的概率推导过程如下:1)假设两块RAM各自的一个输出字都发生两个错误,则错误出现在两个输出字相同位上的概率为:2)两个错误在一个字上发生的概率为:3)用式(5)和式(6)二式可计算RAM冗余结构两块RAM的输出字相同的位上同时出现两个错误的概率为:4)同理,可计出一个字上发生的所有偶数个错误的概率,从而可以出自两块不同RAM 的两个输出字相同的位上出现偶数个错误的概率为:本文在计算两块不同RAM的两个输出字相同的位上出现偶数个错误概率时的一些实验用数据来源于文献[10],其中t=10 d/λ=48×10-6次翻转/每位/d.根据式(8)得出P偶数 =10-9,从这个数值可看出:两块不同RAM的两个输出字相同的位上出现偶数个错误的概率极小,在系统实际工作时可不加以考虑.2.2 三模冗余结构的可靠性建模为了进行比较,对三模冗余结构的可靠性建模.对于传统的基于查找表和触发器的状态机的实现方式采用和双模冗余结构相同的错误评估模型,Xilinx Virtex-Ⅱ中每个查找表包含16个存储单元.因此设计存储单元可以表示为L×16,其中L为设计中使用的查找表数目,状态机组合部分的可靠性可用式(9)计算:式中:RLUT为所有查找表组合的可靠性,L为设计中查找表数目[11],整个三模冗余结构的可靠性计算见式(10).式(10)计算有两个假设:1)三模冗余系统中应有两个或两个以模块正常工作;2)实现状态机使用的触发器也采用三模冗余结构,不会受SEU影响而发生错误.3 实验及结果分析实验采用6个MCNC基准电路对基于块RAM双模冗余结构和三模冗余结构进行可靠性、功耗两个方面比较.3.1 可靠性实验在计算有限状态在基于三模冗余结构上执行的可靠性时,假设四输入的查找表中的16位任意一位有错误将导致设计失败.在计算三模冗余结构稳定时,设计了出错位占查找表总位数不同百分比的情况,即分别对一个查找表中出错位占25%,50%,75%和100%4种情况进行了可靠性计算.基于三模冗余和基于双模冗余的可靠性比较的实验结果见表1.表1 三模冗余结构与双模冗余结构稳定性比较Tab.1 Reliability comparison between TMR and duple-redundancy structure三模冗余结构稳定性测试电路出错位占100%出错位占75%出错位占50%出错位占25%双模冗余稳定性Keyb 0.384 0660.534 9870.384 066 0.384 066 0.999 998 planet 0.025 0270.066 5250.204 712 0.556 679 0.999 995 Dk16 0.374 6700.526 0110.709 9360.897 428 0.999 999 Exl 0.254 9760.404 9250.611 972 0.853 104 0.999 996 sty r 0.065 8080.154 6520.344 582 0.686 622 0.999 996 sand 0.047 7000.122 6520.298 954 0.648 920 0.999 996从表1中可以看出:双模冗余结构的可靠性要高于传统三模冗余结构.其主要原因是:双模冗余结构能对系统出现的一位错误实现在线纠正,而三模冗余结构只能在系统的三个模块比较后才能发现系统错误,而且不具有在线纠错能力,构成三模冗余结构的3个模块中只有两个或两个以上模块无错时系统才能正常工作.因此,当系统有高充足的块RAM资源时,双模冗余结构是一种实现高稳定性有限状态机很好的方法.3.2 功耗实验为了对两种设计方法的功耗进行分析比较,设计了仿真实验.整个实验在Xilinx公司的FPGA Virtex-ⅡI系列器件XC2V1500上进行,仿真工具采用 Modelsim6.1,综合工具采用Xilinx公司的ISE8.1[12],用XPower进行功耗分析.用 XPower进行功耗分析流程如图5所示.图5 使用XPower进行功耗分析流程图Fig.5 XPower analyzing the power consumptionXPower是Xilinx公司开发的专门用来进行功耗分析的工具.XPower直接集成在ISE软件中,XPower从布局和布线(.ncd)文档获得FPGA设计信息,从Vcd文档中获得网络设计中所需的时钟频率、开关活动等信息,该文件可在布局和布线时由Xilinx工具产生,功耗报告在Pwr文档中给出.三模冗余与双模冗余的节约功耗比较如表2所示,实验时钟频率为100 MHz,功耗单位为mW.表2 三模冗余结构与双模冗余节约功耗比较Tab.2 The power comparison between TMR and duple-redundancy structure测试电路三模冗余功耗双模冗余功耗节约功耗/%Keyb 190.85 144.27 32.28 planet 324.35 232.92 39.46 Dk16 191.24 144.02 32.79 Exl 244.87 225.41 8.63 styr 270.61 184.96 46.30 sand 274.27 181.48 51.13从表2中看出:双模冗余结构的功耗明显低于传统三模冗余结构,其主要原因是:采用查找表和触发器资源实现的三模冗余结构时,除了查找表和触发器消耗大量的能量之外,负责联通查找表和触发器等FPGA内部单元的布线资源也要消耗较多的能量[13],而用双模冗余结构实现有限状态机时,主要占用块RAM资源几乎不需要消耗布线资源,因而具有较低的功耗.4 结论1)提出了一种适于FPGA实现的低功耗、容错有限状态机设计方法.该方法在基于将FSM映射到RAM的基础上,充分利用FPGA所带存储资源,采用双RAM冗余结构,并结合奇偶校验进行检错与纠错.实验结果表明,较传统的TMR方法,该方法具有低功耗、高稳定性等优势,非常适合于提高FPGA在高空工作环境下的容错能力.2)提出了冗余方法和编码容错相结合的思想.在传统冗余容错思想的基础上结合编码容错不但能提高系统的可靠性,还能提高系统在线纠错能力.今后将编码压缩、编码容错、冗余容错相结合以节约存储资源、降低功耗是一个值得研究的方向.3)提出了同时考FPGA功耗和容错的思路.在以往有关FPGA的研究中,往往只注重FPGA功耗或系统容错能力单个方面,但随着FPGA在航空航天、军工领域广泛应用,同时考虑基于FPGA的系统功耗和容错能力将成为一个新的研究方向.参考文献[1] BOLCHINI C,QUA RTA D.SEU mitigation for sram-based fpgas through dynamic partial reconfiguration[C]//P roceedings of the 17th great lakes symposium on Great lakes symposium on VLSI.Italy:ACM Press,2007:55-60.[2] STERPONE L.Analy sis of the robustness of the TMR architecture in SRAM-based FPGAs[J].IEEE Transaction on NuclearScience,2005,52(5):1545-1549.[3] TESSIER R,BETZ V.Power-efficient RAM mapping algorithms for FPGA Embedded memory blocks[J].IEEE T rans.of Computer-AidedDesign,2007,26(2):278-289.[4] FRIGERIO L,SALICE F.Ram-based fault tolerant state machines for FPGA[C]//Proceedings of IEEE Design and Fault TolerantSymposium,Rome,Italy:IEEE Press,2007,312-320.[5] GYO RFI T,CRE O.High performance true random number generator based on FPGA block RAMs[C]//Proceeding s of the 2009 IEEE International Symposium on Parallel and Distributed ProcessingRome,Italy:IEEE Press,2009:1-8.[6] MAESTROo J A,REVIRIEGO P.Study of the effects of MBUs on the reliability of a 150 nm SRAM device[C]//Proceedings of the 45th annual Design Automation Conference.New York:ACM Press,2008:930-935. [7] MAEST RO J A,REVIRIEGO P.Reliability of single-error correction protected memories[J].IEEE Transactions on Reliability,2009,58(1):193-201.[8] ARGYRIDES C,VARGAS F.Embedding current monito ring in h-tree RAM architecture for multiple SEU tolerance and reliability improvement[C]// Proceedings of the 2008 14th IEEE International On-Line T estingSymposium,Washington:IEEE Press,2008,155-160.[9] REVIRIEGO P,MAEST RO J A.Reliability analysis of memories suffering multiple bit upsets[J].IEEE Trans on Device and MaterialsReliability,2007,7(4):592-601.[10] ASADI G,T AHOORI M B.Soft error rate estimation and mitigation for SRAM-based FPGAs[C]//Proceedings of the 2005 ACM/SIGDA 13th international symposium on Field-programmable gate arrays.New York:ACM Press,2005,149-160.[11] 徐拾义.可信计算系统设计和分析[M].北京:清华大学出版社,2006:74-97.XU Shi-yi.Analysis and design of trusted computer system[M].Beijing:Tsinghua University Press,2006:74-97.(In Chinese)[12] 张红南,刘晓巍.IC卡的优化设计及FPGA仿真[J].湖南大学学报:自然科学版,2006,33(2):66-69.ZHANG Hong-nan,LIU Xiao-wei.Optimized design and simulation based on FPGA of IC card[J].Journal of Hunan University:Natural Sciences 2006,33(2):66-69.(In Chinese)[13] T UAN T,RAHMAN A.A 90-nm low-power FPGA for battery-powered applications[J].IEEE T rans on Computer-Aided Design,2007,26(2):296-300.。
FPGA可编程逻辑器件芯片XCVU13P-L2FLGA2577E中文规格书

General DescriptionXilinx® UltraScale™ architecture comprises high-performance FPGA, MPSoC, and RFSoC families that address a vast spectrum of system requirements with a focus on lowering total power consumption through numerous innovative technological advancements.Kintex® UltraScale FPGAs: High-performance FPGAs with a focus on price/performance, using both monolithic andnext-generation stacked silicon interconnect (SSI) technology. High DSP and block RAM-to-logic ratios and next-generation transceivers, combined with low-cost packaging, enable an optimum blend of capability and cost.Kintex UltraScale+™ FPGAs: Increased performance and on-chip UltraRAM memory to reduce BOM cost. The ideal mix of high-performance peripherals and cost-effective system implementation. Kintex UltraScale+ FPGAs have numerous power options that deliver the optimal balance between the required system performance and the smallest power envelope.Virtex® UltraScale FPGAs: High-capacity, high-performance FPGAs enabled using both monolithic and next-generation SSI technology. Virtex UltraScale devices achieve the highest system capacity, bandwidth, and performance to address key market and application requirements through integration of various system-level functions.Virtex UltraScale+ FPGAs: The highest transceiver bandwidth, highest DSP count, and highest on-chip and in-package memory available in the UltraScale architecture. Virtex UltraScale+ FPGAs also provide numerous power options that deliver the optimal balance between the required system performance and the smallest power envelope.Zynq® UltraScale+ MPSoCs: Combine the Arm® v8-based Cortex®-A53 high-performance energy-efficient 64-bit application processor with the Arm Cortex-R5F real-time processor and the UltraScale architecture to create the industry's first programmable MPSoCs. Provide unprecedented power savings, heterogeneous processing, and programmable acceleration. Zynq® UltraScale+ RFSoCs: Combine RF data converter subsystem and forward error correction with industry-leading programmable logic and heterogeneous processing capability. Integrated RF-ADCs, RF-DACs, and soft-decision FECs (SD-FEC) provide the key subsystems for multiband, multi-mode cellular radios and cable infrastructure.Family ComparisonsDS890 (v3.13) July 21, 2020Product Specification Table 1:Device ResourcesKintex UltraScale FPGAKintexUltraScale+FPGAVirtexUltraScaleFPGAVirtexUltraScale+FPGAZynqUltraScale+MPSoCZynqUltraScale+RFSoCMPSoC Processing System✓✓RF-ADC/DAC✓SD-FEC✓System Logic Cells (K)318–1,451356–1,843783–5,541862–8,938103–1,143678–930 Block Memory (Mb)12.7–75.912.7–60.844.3–132.923.6–94.5 4.5–34.627.8–38.0 UltraRAM (Mb)0–8190–3600–3613.5–22.5 HBM DRAM (GB)0–16DSP (Slices)768–5,5201,368–3,528600–2,8801,320–12,288240–3,5283,145–4,272 DSP Performance (GMAC/s)8,1806,2874,26821,8976,2877,613 Transceivers12–6416–7636–12032–1280–728–16 Max. Transceiver Speed (Gb/s)16.332.7530.558.032.7532.75 Max. Serial Bandwidth (full duplex) (Gb/s)2,0863,2685,6168,3843,2681,048 Memory Interface Performance (Mb/s)2,4002,6662,4002,6662,6662,666I/O Pins312–832280–668338–1,456208–2,07282–668280–408RF Data Converter SubsystemZynq UltraScale+ RFSoCs contain an RF data converter subsystem consisting of multiple RF-ADCs and RF-DACs.RF-ADCsThe RF-ADCs can be configured individually for real input signals. RF-ADCs in all devices other than the XCZU43DR can also be configured as a pair for I/Q input signals. The RF-ADC tile has one PLL and a clocking instance. Decimation filters in the RF-ADCs can operate in varying decimation modes at 80% of Nyquist bandwidth with 89dB stop-band attenuation. Each RF-ADC contains a 48-bit numerically controlled oscillator (NCO) and a dedicated high-speed, high-performance, differential input buffer with on-chip calibrated 100Ω termination.RF-DACsThe RF-DACs can be configured individually for real outputs. RF-DACs in all devices other than the XCZU43DR can also be configured as a pair for I/Q output signal generation. The RF-DAC tile has one PLL and a clocking instance. Interpolation filters in the RF-DACs can operate in varying interpolation modes at 80% of Nyquist bandwidth with 89dB stop-band attenuation. Each RF-DAC contains a 48-bit NCO.Soft-Decision Forward Error Correction (SD-FEC)Some members of the Zynq UltraScale+ RFSoC family contain integrated SD-FEC blocks capable of encoding and decoding using LDPC codes and decoding using Turbo codes.LDPC Decoding/EncodingA range of quasi-cyclic codes can be configured over an AXI4-Lite interface. Code parameter memory can be shared across up to 128 codes. Codes can be selected on a block-by-block basis with the encoder able to reuse suitable decoder codes. The SD-FEC uses a normalized min-sum decoding algorithm with a normalization factor programmable from 0.0625 to 1 in increments of 0.0625. There can be between 1 and 63 iterations for each codeword. Early termination is specified for each codeword to be none, one, or both of the following:∙Parity check passes∙No change in hard information or parity bits since last operationSoft or hard outputs are specified for each codeword to include information and optional parity with 6-bit soft log-likelihood ratio (LLR) on inputs and 8-bit LLR on outputs.Clock DistributionClocks are distributed throughout UltraScale devices via buffers that drive a number of vertical and horizontal tracks. There are 24 horizontal clock routes per clock region and 24 vertical clock routes per clock region with 24 additional vertical clock routes adjacent to the MMCM and PLL. Within a clock region, clock signals are routed to the device logic (CLBs, etc.) via 16 gateable leaf clocks.Several types of clock buffers are available. The BUFGCE and BUFCE_LEAF buffers provide clock gating at the global and leaf levels, respectively. BUFGCTRL provides glitchless clock muxing and gating capability. BUFGCE_DIV has clock gating capability and can divide a clock by 1 to 8. BUFG_GT performs clock division from 1 to 8 for the transceiver clocks. In MPSoCs and RFSoCs, clocks can be transferred from the PS to the PL using dedicated buffers.Memory InterfacesMemory interface data rates continue to increase, driving the need for dedicated circuitry that enables high performance, reliable interfacing to current and next-generation memory technologies. Every UltraScale device includes dedicated physical interfaces (PHY) blocks located between the CMT and I/O columns that support implementation of high-performance PHY blocks to external memories such as DDR4, DDR3, QDRII+, and RLDRAM3. The PHY blocks in each I/O bank generate the address/control and data bus signaling protocols as well as the precision clock/data alignment required to reliably communicate with a variety of high-performance memory standards. Multiple I/O banks can be used to create wider memory interfaces.As well as external parallel memory interfaces, UltraScale architecture-based devices can communicate to external serial memories, such as Hybrid Memory Cube (HMC), via the high-speed serial transceivers. All transceivers in the UltraScale architecture support the HMC protocol, up to 15Gb/s line rates. UltraScale devices support the highest bandwidth HMC configuration of 64lanes with a single FPGA.Block RAMEvery UltraScale architecture-based device contains a number of 36Kb block RAMs, each with two completely independent ports that share only the stored data. Each block RAM can be configured as one 36Kb RAM or two independent 18Kb RAMs. Each memory access, read or write, is controlled by the clock. Connections in every block RAM column enable signals to be cascaded between vertically adjacent block RAMs, providing an easy method to create large, fast memory arrays, and FIFOs with greatly reduced power consumption.All inputs, data, address, clock enables, and write enables are registered. The input address is always clocked (unless address latching is turned off), retaining data until the next operation. An optional output data pipeline register allows higher clock rates at the cost of an extra cycle of latency. During a write operation, the data output can reflect either the previously stored data or the newly written data, or it can remain unchanged. Block RAM sites that remain unused in the user design are automatically poweredPackagingThe UltraScale devices are available in a variety of organic flip-chip and lidless flip-chip packages supporting different quantities of I/Os and transceivers. Maximum supported performance can depend on the style of package and its material. Always refer to the specific device data sheet for performance specifications by package type.In flip-chip packages, the silicon device is attached to the package substrate using a high-performance flip-chip process. Decoupling capacitors are mounted on the package substrate to optimize signal integrity under simultaneous switching of outputs (SSO) conditions.。
特殊英语词汇

ASIC: Applicatio n Specific In tegrated Circuit (特殊应用积体电路)ASC( Auto-Sizi ng and Ce nteri ng ,自动调效屏幕尺寸和中心位置)ASC( Anti Static Coat in gs ,防静电涂层)AGAS( Anti Glare Anti Static Coati ngs ,防强光、防静电涂层)BLA: Bearn Lan di ng Area (电子束落区)BMC( Black Matrix Screen ,超黑矩阵屏幕)CRC: Cyclical Redu nda ncy Check (循环冗余检查)CRT (Cathode Ray Tube,阴极射线管)DDC Display Data Channel ,显示数据通道DEC( Direct Etching Coatings ,表面蚀刻涂层)DFL (Dynamic Focus Lens,动态聚焦)DFS( Digital Flex Scan ,数字伸缩扫描)DIC: Digital Image Co ntrol (数字图像控制)Digital Multisca n II (数字式智能多频追踪)DLP (digital Light Processing ,数字光处理)DOSD: Digital On Scree n Display (同屏数字化显示)DPMS( Display Power Ma nageme nt Sig nalli ng ,显示能源管理信号)Dot Pitch (点距)DQL(Dynamic Quadrapole Lens ,动态四极镜)DSP( Digital Signal Processing ,数字信号处理)EFEAL (Extended Field Elliptical Aperture Lens ,可扩展扫描椭圆孔镜头)FRC: Frame Rate Con trol (帧比率控制)HVD( High Voltage Differential ,高分差动)LCD (liquid crystal display ,液晶显示屏)LCOS: Liquid Crystal On Silico n (硅上液晶)LED (light emitting diode ,光学二级管)L-SAGIC( Low Power-Small Aperture G1 wiht Impregnated Cathode,低电压光圈阴极管)LVD (Low Voltage Differential ,低分差动)LVDS: Low Voltage Differe ntial Sig nal (低电压差动信号)MALS( Multi Astigmatism Lens System ,多重散光聚焦系统)MDA( Monochrome Adapter,单色设备)MS: Mag netic Sen sors (磁场感应器)Porous Tun gste n (活性钨)RSDS: Reduced Swi ng Differe ntial Sig nal (小幅度摆动差动信号)SC (Screen Coatings ,屏幕涂层)Sin gle Ended (单终结)Shadow Mask (阴罩式)TDT (Timeing Detection Table ,数据测定表)TICRG: Tu ngsten Impreg nated Cathode Ray Gun (钨传输阴级射线枪)TFT (thin film transistor ,薄膜晶体管)UCC( Ultra Clear Coatings ,超清晰涂层)VAGP: Variable Aperature Grille Pitch (可变间距光栅)VBI: Vertical Bla nki ng In terval (垂直空白间隙)VDT (Video Display Termi nals ,视频显示终端)VRR: Vertical Refresh Rate (垂直扫描频率)4、视频3D:(Three Dimensional ,三维)3DS (3D SubSystem,三维子系统)AE (Atmospheric Effects ,雾化效果)AFR( Alternate Frame Re nderi ng ,交替渲染技术)Ani sotropic Filteri ng (各向异性过滤)APPE( Advanced Packet Parsing Engine ,增强形帧解析引擎)AV (Analog Video ,模拟视频)Back Buffer,后置缓冲Backface culling (隐面消除)Battle for Eyeballs (眼球大战,各3D图形芯片公司为了争夺用户而作的竞争)Bil in ear Filteri ng (双线性过滤)CEM( cube en vir onment mapp ing ,立方环境映射)CG( Computer Graphics,计算机生成图像)Clipp ing (剪贴纹理)Clock Syn thesizer ,时钟合成器compressed textures (压缩纹理)Con curre nt Comma nd Engine ,协作命令引擎Cen ter Process ingUn it Utilizati on 处理器,中央占用率DAC (Digital to An alog Co nverter ,数模传换器)Decal (印花法,用于生成一些半透明效果,如:鲜血飞溅的场面)DFP( Digital Flat Pan el ,数字式平面显示器)DFS (Dynamic Flat Shading 动态平面描影,可用作加速Dithering 抖动)Directional Light ,方向性光源DME (Direct Memory Execute 直接内存执行)DOF( Depth of Field ,多重境深)dot texture ble ndi ng (点型纹理混和)Double Bufferi ng (双缓冲区)DIR (Direct Rendering Infrastructure ,基层直接渲染)DVI (Digital Video In terface ,数字视频接口)DxR (DynamicXTended Resolution 动态可扩展分辨率)DXTC( Direct X Texture Compress ,DirectX 纹理压缩,以S3TC为基础)Dyn amic Z-bufferi ng (动态Z轴缓冲区),显示物体远近,可用作远景E-DDC (En ha need Display Data Cha nnel ,增强形视频数据通道协议,定义了显示输出与主系统之间的通讯通道,能提高显示输出的画面质量)Edge Anti —aliasing ,边缘抗锯齿失真E-EDID( Enhanced Extended Identification Data ,增强形扩充身份辨识数据,定义了电脑通讯视频主系统的数据格式)Execute Buffers ,执行缓冲区environment mapped bump mapp ing (环境凹凸映射)Extended Burst Transactions ,增强式突发处理Front Buffer ,前置缓冲Flat (平面描影)Frames rate is King (帧数为王)FSAA (Full Scene Anti —aliasi ng ,全景抗锯齿)Fog (雾化效果)flip double buffered (反转双缓存)fog table quality (雾化表画质)GART (Graphic Address Remapp ng Table ,图形地址重绘表)Gouraud Shad ing,高洛德描影,也称为内插法均匀涂色GP(Graphics Processi ng Un it ,图形处理器)GTF (Generalized Timing Formula ,一般程序时间,定义了产生画面所需要的时间,包括了诸如画面刷新率等)HAL (Hardware Abstraction Layer ,硬件抽像化层)hardware moti on compe nsati on (硬件运动补偿)HDTV( high defini tion televisi on ,高清晰度电视)HEL Hardware Emulatio n Layer (硬件模拟层)high tria ngle cou nt (复杂三角形计数)ICD(Installable Client Driver ,可安装客户端驱动程序)IDCT(Inverse Discrete Cosine Transform ,非连续反余弦变换,GeForce 的DVD硬件强化技术)Immediate Mode,直接模式IPPR:(Image Processing and Pattern Recognition 图像处理和模式识别)large textures (大型纹理)LF (Lin ear Filteri ng ,线性过滤,即双线性过滤)lighti ng (光源)lightm ap (光线映射)Local Peripheral Bus (局域边缘总线)mip map pi ng (MIP 映射)Modulate (调制混合)Motion Compensation ,动态补偿motion blur (模糊移动)MPPS (Million Pixels Per Second ,百万个像素/ 秒)Multi-Resolution Mesh ,多重分辨率组合Multi Threaded Bus Master ,多重主控Multitexture (多重纹理)nerest Mipmap (邻近MIP映射,又叫点采样技术)Overdraw (透支,全景渲染造成的浪费)partial texture down loads (并行纹理传输)Parallel Processi ng Perspective Engine (平行透视处理器)PC ( Perspective Correction,透视纠正)PGC ( Parallel Graphics Configuration ,并行图像设置)pixel (Picture eleme nt ,图像元素,又称 P 像素,屏幕上的像素点)poi nt light (一般点光源)point sampling(点采样技术,又叫邻近 MIP 映射)Precise Pixel In terpolation ,精确像素插值 Procedural textures(可编程纹理)RAMD ((Random Access Memory Digital to Analog Converter ,随机存储器数 / 模转换器)Reflection mappi ng (反射贴图)ender (着色或渲染) S 端子(Seperate )S3 ( Sight 、Sou nd 、Speed ,视频、音频、速度)S3TC (S3 Texture Compress , S3纹理压缩,仅支持 S3显卡) S3TL (S3 Transformation & Lighting Scree n Buffer(屏幕缓冲)SDTV ( Sta ndard Defin iti on Television SEM ( spherical environment mapp ingShadi ng ,描影 Si ngle Pass Multi-Texturi ng,单通道多纹理 SLI (Scan li ne In terleave扫描线间插,3Dfx 的双Voodoo 2配合技术)Smart Filter (智能过滤)soft shadows (柔和阴影) soft reflectio ns (柔和反射),S3多边形转换和光源处理),标准清晰度电视),球形环境映射)spot light (小型点光源)SRA( Symmetric Ren deri ng Architecture ,对称渲染架构)Ste ncil Buffers (模板缓冲)Stream Processor (流线处理)SuperScaler Rendering ,超标量渲染TBFB(Tile Based Frame Buffer ,碎片纹理帧缓存)texel (T像素,纹理上的像素点)Texture Fidelity (纹理真实性)texture swapp ing (纹理交换)T&L (Transform and Lighting ,多边形转换与光源处理)T-Buffer (T 缓冲,3dfx Voodoo4 的特效,包括全景反锯齿Full-scene Anti-Aliasing 、动态模糊Motion Blur 、焦点模糊Depth of Field Blur 、柔和阴影Soft Shadows、柔和反射Soft Reflections )TCA (Twin Cache Architecture ,双缓存结构)Tran spare ncy (透明状效果)Tran sformati on (三角形转换)Trili near Filteri ng (三线性过滤)Texture Modes,材质模式TMIPM (Trilinear MIP Mapping 三次线性MIP材质贴图)UMA( Unified Memory Architecture ,统一内存架构)Visualize Geometry Engine ,可视化几何引擎Vertex Lighti ng (顶点光源)Vertical In terpolatio n (垂直调变)VIP (Video In terface Port ,视频接口)ViRGE (Video and Ren deri ng Graphics Engine 视频描写图形引擎)Voxel (Volume pixels ,立体像素,Novalogic 的技术)VQTC( Vector-Qua ntizati on Texture Compressi on,向量纹理压缩)VSIS (Video Signal Standard ,视频信号标准)v-sy nc (同步刷新)Z Buffer (Z 缓存)Data Structures 基本数据结构Diction aries 字典Priority Queues 堆Graph Data Structures 图Set Data Structures 集合Kd-Trees线段树Numerical Problems 数值问题Solvi ng Lin ear Equatio ns 线性方程组Ban dwidth Reduction 带宽压缩Matrix Multiplicatio n 矩阵乘法Determi nants and Perma nents 行歹U式Con stra ined and Uncon stra ined Optimizati on 最值问题Lin ear Programmi ng 线性规戈URa ndom Number Gen eratio n 随机数生成Factoring and Primality Testing 因子分解/ 质数判定Arbitrary Precisi on Arithmetic 高精度计算Knapsack Problem 背包问题Discrete Fourier Transform 离散Fourier 变换Combi natorial Problems 组合问题Sorti ng 排序Search ing 查找Media n and Selectio n 中位数Gen erati ng Permutati ons 排歹U生成Gen erati ng Subsets 子集生成Gen erat ing Partitio ns 划分生成Gen erat ing Graphs 图的生成Cale ndrical Calculati ons 日期Job Scheduli ng 工程安排Satisfiability 可满足性Graph Problems --------- p olynomial 图论-多项式算法Conn ected Comp onents 连通分支Topological Sorting 拓扌卜排序Mi nimum Spa nning Tree 最小生成树Shortest Path 最短路径Tran sitive Closure and Reduct ion 传递闭包Matchi ng 匹配Eulerian Cycle / Chinese Postman Euler 回路/ 中国邮路Edge and Vertex Connectivity 害9边/ 害9点Network Flow 网络流Drawi ng Graphs Nicely 图的描绘Drawi ng Trees 树的描绘Pla narity Detection and Embeddi ng 平面性检测和嵌入Graph Problems -------- hard 图论-NP 问题Clique最大团In depe ndent Set 独立集Vertex Cover 点覆盖Traveli ng Salesma n旅行商问题ProblemHamilt onian Cycle Hamilt on 回路Graph Partiti on 图的划分Vertex Colori ng 点染色Edge Colori ng 边染色Graph Isomorphism 同构Steiner Tree Steiner 树Feedback Edge/Vertex Set 最大无环子图Computati onal Geometry 计算几何Convex Hull 凸包Trian gulati on 三角剖分Voronoi Diagrams Voronoi 图Nearest Neighbor Search 最近点对查询Range Search范围查询Poi nt Locati on 位置查询In tersect ion Detect ion 碰撞测试Bin Packi ng 装箱问题Medial-Axis Tran sformatio n 中轴变换Polygon Partitio ning 多边形分割Simplifyi ng Polygo ns 多边形化简Shape Similarity 相似多边形Motion Pla nning 运动规划Mai ntai ning Li ne Arra ngeme nts 平面分害9Min kowski Sum Min kowski 和Set and Stri ng Problems 集合与串的问题Set Cover 集合覆盖Set Pack ing 集合配置Stri ng Matchi ng 模式匹配Approximate Stri ng Matchi ng 模糊匹配Text Compressi on 压缩Cryptography 密码Fi nite State Machi ne Mi nimizatio n 有穷自动机简化Lon gest Common Substri ng 最长公共子串Shortest Com mon Superstri ng 最短公共父串DP ---- Dyn amic Programmi ng ----- 动态规戈U。
fpga电源监控芯片原理

fpga电源监控芯片原理FPGA power monitoring is a critical aspect of FPGA design and implementation. The power supply monitoring chip plays a crucial role in ensuring the stability and reliability of the power supply to the FPGA. FPGA电源监控是FPGA设计和实施中的关键方面。
电源监控芯片在确保向FPGA稳定可靠的电源供应中发挥着至关重要的作用。
One of the key principles behind FPGA power supply monitoring chips is to continuously monitor the voltage, current, and temperature of the power supply to the FPGA. This allows for real-time monitoring and adjustment of the power supply to ensure that the FPGA operates within safe and optimal power parameters. FPGA 电源监控芯片的关键原理之一是持续监测FPGA电源的电压、电流和温度。
这可以实现对电源的实时监控和调整,以确保FPGA在安全和最佳的电源参数范围内运行。
The power supply monitoring chip utilizes various sensing mechanisms such as voltage sensors, current sensors, and temperature sensors to accurately measure and monitor the power supply to the FPGA. These sensors provide real-time feedback to themonitoring chip, which in turn regulates the power supply to ensure the FPGA operates within safe operational limits. 电源监控芯片利用各种传感机制(如电压传感器、电流传感器和温度传感器)精确测量和监控FPGA的电源供应。
具功耗意识的FPGA设计技巧

具功耗意识的FPGA设计技巧动态电源主要是由RAM、I/O、频率树、规律电源等因素所造成,接下来将分离介绍降低不同类型动态电源的技巧。
RAM电源消耗RAM模块在读/写操作时会消耗电源。
主要造成影响的信号包括地址线(address line)、Read Enable(RE)、以及Write Enable(WE)。
通常,读取的电源消耗会比写入高一点,而RAM读/写的电源会随延续地址的汉明距离(Hamming distance)增强而变大。
因此,应当尽量在启用读取信号前,先尽可能执行最多的写入操作,然后,在切换回写入操作前,尽可能读取内存以取得所需的数据,这样才干有效降低 RAM 电源消耗。
在降低峰值 RAM电源方面,可以考虑采纳将读取和写入操作置于频率边沿(clock edge)的反侧,或是对RAM读/写埠上的频率予以门控(gate)。
I/O电源消耗FPGA I/O电压通常比核心电压大,而且通常I/O 组(bank)会消耗不少的电源,因此设计人员在打算选用I/O标准、接口频率需求、接脚限制等设计时,都需要十分谨慎。
差动式 (differential) I/O,如LVDS、LVPECL和阻抗终端式I/O,如HSTL、SSTL等,通常其静态电源较高,但动态电源较低。
因此,对有较高切换(toggle)频率的设计来说,可以选用这些I/O。
降低 I/O 数量是重要关键,设计人员应重新考虑整体的设计/功能区隔(partitioning)是否恰当?以及是否可能用时光多任务(time- multiplexed)的方式削减I/O数量。
此外,因为高切换频率会导致动态电源增高,为了降低 I/O的活动或切换率,设计人员必需消退 I/O 驱动器输出端的非预期突发信号(glitch)。
另一个常用技巧是,挑选可降低切换位的编码(bus encoding),并将总线上的延续数值关联在一起。
第1页共3页。
基于FPGA的SPI Flash配置存储器复用的实现

基于FPGA的SPI Flash配置存储器复用的实现陈燕文;韩焱;徐磊;莫璧铭【摘要】FPGA是一种基于SRAM技术制造的可编程器件,内部数据具有掉电即失的特点.因此,配置电路是FPGA系统中必不可少的部分.本文提出一种复用FPGA配置存储器的方法:配置存储器既能满足FP-GA系统的配置需要,又可以作为通用存储器满足用户存储数据的需求,提高了配置存储器的利用率,使得采集存储系统小型化、集成化成为可能.制定了SPI Flash复用的方案,分析了复用配置存储器的可行性.并且编写基于FPGA的SPI接口控制程序,实现对配置存储器的擦除、读写等操作.利用Modelsim,Chips-cope等调试工具验证了控制程序的可靠性.%FPGA is a programmable device based on SRAM technology,and the internal data in FPGA will be lost when the power fails.Therefore,the configuration circuit is an essential part of the FPGA system.This paper puts forward a method of multiplexing FPGA configuration memory:memory allo-cation can not only meet the needs of FPGA system configuration,but also be used as a universal memo-ry data storage to meet needs of user.This method improves the utilization rate of the memory alloca-tion,and makes it possible to make the acquisition storage system miniaturization and integration.First-ly,the scheme of SPI Flash reuse is worked out,and the feasibility of reusing configuration memory is analyzed.And the SPI interface control program based on FPGA is written to realize the erasure,read-ing and writing of configuration memory.The reliability of the control program is verified by using Mod-elsim,Chipscope and other debugging tools.【期刊名称】《测试技术学报》【年(卷),期】2017(031)006【总页数】7页(P491-497)【关键词】FPGA;配置存储器复用;SPI接口控制;Chipscope【作者】陈燕文;韩焱;徐磊;莫璧铭【作者单位】中北大学信息探测与处理技术山西省重点实验室,山西太原 030051;中北大学信息探测与处理技术山西省重点实验室,山西太原 030051;中北大学信息探测与处理技术山西省重点实验室,山西太原 030051;中北大学信息探测与处理技术山西省重点实验室,山西太原 030051【正文语种】中文【中图分类】TN98FPGA(现场可编程门阵列)是在PAL, GAL, CPLD等可编程器件的基础上进一步发展的产物[1]. 目前主流的FPGA制造工艺均是基于SRAM技术,这种技术使得FPGA能够实现较高的工作频率,但是也决定了FPGA中数据掉电即失的特点[2-3]. 因此,配置电路是FPGA系统中必不可少的一部分. 随着存储技术的快速发展,存储颗粒密度越来越高,储存器向大容量、小体积方向发展[4-7]. FPGA的配置存储器往往在满足存储自身配置程序的同时,仍富余较大的存储空间. 本文提出一种复用FPGA配置存储器的方案,提高了存储器的利用率.本系统采用Xilinx公司的Spartan6-LX16作为主控芯片、华邦公司的W25Q128BV作为数据存储和配置芯片、 MAX1308作为数据转换模块,设计构建了存储采集系统. 制定了SPI Flash配置芯片的复用方案,编写了存储器控制程序,并且对程序功能和复用方案进行了验证,最终实现了对配置芯片的复用.系统组成如图 1 所示,本系统中使用的MAX1308模数转换芯片拥有8个采样通道、最高采样率为1 MPS. MAX1308为并行数据传输,采集一次产生的12 bit数据被同时输出至数据端口. FIFO1与FIFO2是位宽为8、深度为1 024的数据缓冲器. 在采集完成之后,数据的低8 b被写入数据FIFO1,通道标识号(4 bit)和数据的高4 b被写入数据FIFO2. 在SPI读写控制器的协调下,数据被有序地从FIFO中读出并写入SPI FLASH. 系统中的SPI FLASH为复用存储器,既能满足FPGA系统的配置需要,又可以作为通用存储器满足用户存储数据的需求.按照主从关系划分, FPGA中常用的配置方式有主动配置、被动配置和JTAG配置[8],按照数据总线的位宽又可分为串行配置和并行配置[9-10]. 本文中使用SPI Flash作为程序存储器的配置方案是主动串行配置方式的一种. Xilinx公司Spartan6系列芯片程序加载过程如图 2 所示.Spartan 6系列FPGA程序加载方式可以通过模式控制引脚M[1∶0]进行选择. 在采用SPI主动串行配置方式时,M[1∶0]应被设置为10. 在FPGA系统上电之后,外部向FPGA的PROGRAM_B引脚送入一个宽度不小于500ns的低脉冲,清除配置空间,重启配置过程[11]. 接下来初始化标志位INT_B拉低并对模式控制引脚进行采样,当初始化完成之后INT_B拉高. 随后FPGA通过CCLK引脚将时钟送入存储控制器,并且向FLASH发送读命令及数据起始地址[12]. 在接受到读命令和地址信息之后, FLASH将配置信息有序地放入DOUT引脚供FPGA读取[13].在完成配置程序的加载之后, CCLK, DIN, DOUT, CSO等引脚恢复成为普通的用户引脚,这使得在不改变硬件连接的前提下,利用配置FLASH余下的存储空间成为可能.对于确定型号的FPGA来讲,配置文件所需要的储存空间是一定的. 厂家会在芯片手册中对配置文件的大小进行说明. 以Spartan 6 系列中LX16型芯片为例,配置的bit文件的大小为3 731 264 bit,约为456 KB. 为了满足第三方存储器对数据格式的要求,开发工具还需要将bit文件转换为MCS文件. 在转换过程中,加入了校验及地址信息,因此转换之后文件所占的空间变大,转换之后的文件大小为2 MB. 本课题中用到的W25Q128BV配置存储器容量为16 MB,按照配置程序在存储器中的存放规则,将前2 MB的空间作为程序的配置空间,后14 MB作为用户的通用存储空间. 配置空间与通用存储空间对应地址关系如图 3 所示.设计中使用的W25Q128BV型SPI FLASH存储空间为128 Mbit, 由65 536页组成. 页是该Flash最基本的组成单元,一页的容量为256 Byte. 16页组成一个扇区sector(4 KB), 8个扇区组成一块block(32 KB). 该芯片具有先进的写保护机制,并且具有整体擦除和扇区擦除、灵活的页编程指令和写保护功能.本节重点介绍页编程操作、数据读取操作、扇区擦除操作的过程. 本设计中供用户存放数据的地址区间为200 000H-FFFFFFH,因此存储器的读写及擦除操作均是以200 000h为起始地址.在片选信号CS拉低之后,外部向FLASH写入页编程令码02H,随后写入所要目标区域的地址. 地址的一般格式为一个标准的页地址,即数据位的低8 b全为‘0’. 当写入地址的低8 b不为‘0’时,若数据写入时钟周期数多于剩余的字节位数,则在完成从当前位置写到结束位置之后重新回到开始位置进行数据写入,若数据写入时钟周期数小于或者等于剩余的字节位数,则在时钟结束之后就停止数据的写入.在写入地址之后,向FLASH发送256B的数据. 在数据编程期间BUSY信号为1. 在FLASH完成数据编程后,状态寄存器WEL位转换为‘0’. 若要进行下一页数据的编程,需要在BUSY信号拉低之后向FLASH写入写使能命令将WEL位置至1. 图5是读操作程序的仿真图形. 对比图 4 与图 5 可以发现,二者时序操作一致. 该FLASH支持数据单字节读出和多字节读出. 在片选信号CS拉低之后,向FLASH写入数据读取命令码03H,然后写入所要读取区域的地址. 在地址写入之后, FLASH在下一个时钟下降沿时将目标地址的数据加载到数据输出端口. 若片选信号和时钟信号一直有效, FLASH的地址会自动递加并且将数据加载到数据输出总线,直到将FLASH中所有数据读出. 设计中使用此种模式对SPI FLASH进行读操作. 图 7 是Verilog程序仿真图.擦除操作可以将存储器中的存储字节由‘0’置为‘1’,而写数操作只能将‘1’置为‘0’. 因此,擦除操作是数据写入FLASH之前必须要进行的步骤.W25Q128BV型FLASH支持3种擦除方式:扇区擦除、块擦除和双块擦除. 本设计中使用扇区擦除方式对FLASH进行格式化.由图 8 可以看出,在片选信号有效之后向FLASH中写入擦除命令码20 H. 随后写入所要擦除区域的地址即可. 数据擦除期间BUSY为1. 在擦除命令执行之后,状态寄存器WEL位转换为‘0’. 若要进行下一地址的擦除,需要在BUSY信号拉低之后向FLASH写入写使能命令将状态寄存器的WEL标志位至1. 图 9 是程序仿真图.该型FLASH支持3种SPI模式,本设计中使用标准SPI模式. SPI的时钟为25 MHz,使用的是模式3,即在不工作时时钟线是低电平,在时钟下降沿时将数据锁存进设备. 为了便于程序的编写,现对命令码进行分类编码,如表 1 所示.根据SPI的基本控制时序及FLASH对于时序的要求,编写控制程序. 控制状态机如图 10 所示.当前状态为IDLE时,不断查询外部是否有命令码写入. 若有命令码写入跳转至cmd_send状态. cmd_send状态时,首先让spi的片选及时钟使能信号有效,并且完成命令码的接收. 然后根据接收命令码的类型判断状态机下一步的转向. 如果接收到命令码为写使能或写无效命令则直接转到完成状态fini_done;如果是读状态命令跳转则到读等待状态,并且把所要读的数据个数置为1(读一个字节)、位数置为7(8 b);若是为其它命令码,则转至地址发送状态addr_send. 在地址发送完成之后,再次对命令码类型cmd_type进行判断. 处于写状态writ_data时,FIFO控制器将数据从FIFO1和FIFO2中读出并完成并串转换,在时钟时加载至数据输入总线. 在完成读写数之后,转向完成状态fini_done. 处于完成状态fini_done时, spi的片选及时钟使能信号均转成无效.程序是在ISE14.2环境下编写的,结合自带的嵌入式逻辑分析仪Chipscope进行在线调试分析. 调试时对系统输入的模拟信号为峰值为5 V、直流偏置为+2.5 V、频率为1 kHz的正弦波,将AD的采样率设置为400 KPS. 通过设置触发条件抓取不同采集通道上的数据. 图 11,图 12 给出的是采集通道为1时的板级信号.在写入读命令和地址(200000H),测试时采集线连接flash_addr的高16 b,因此显示的是2000H)之后, SPI Flash在时钟下降沿时将目标地址的数据加载至数据输出端口. FPGA在上升沿时把数据锁存进读寄存器(mydata_o)并完成移位操作. 图12是以波形形式显示的读寄存器中数据. 对比模拟输入与的数据输出,二者数据一致. 关闭系统电源之后,重新给系统上电, FPGA将SPI Flash中的配置程序加载至片内. 此时程序同样能够实现预设的功能,说明用户写入的数据并未对配置程序产生影响,验证了复用方案的正确性.本文设计了一种复用FPGA配置存储器方案,并且经过仿真与在线调试验证了复用方案的可行性. 此种方案使得FPGA的配置存储器的存储空间得到充分利用,并且节省采集卡板的空间,使得采集存储系统小型化、集成化成为可能. 此外,本设计中采用的是模块化设计, SPI控制程序可以作为一个模块被例化进其他工程中,因此具有很高的兼容性.【相关文献】[1] 黄耀兴. 现场可编程门阵列性能初探[J]. 硅谷, 2011(5): 193.Huang Yaoxing. Preliminary performance of field programmable gate array [J]. SiliconValley, 2011(5): 193. (in Chinese)[2] 李骞, 汪学刚, 李汉钊. 基于3-DES算法的FPGA加密应用[J]. 电子技术应用, 2008, 34(1):132-134.Li Qian, Wang Xuegang, Li Hanzhao. Application of FPGA encryption based on 3-DES algorithm[J]. Application of Electronic Technology, 2008, 34(1): 132-134.(in Chinese) [3] 李艳, 张东晓, 于芳. RTL综合中FPGA片上RAM工艺映射[J]. 电子学报, 2016, 44(11): 2660-2667.Li Yan, Zhang Dongxiao, Yu Fang. RTL synthesis, FPGA on chip RAM process mapping, Acta[J]. Acta Electronical Sinica, 2016, 44(11): 2660-2667.(in Chinese)[4] 郑文静, 李明强, 舒继武. Flash存储技术[J]. 计算机研究与发展, 2010, 47(4): 716-726. Zheng Wenjing, Li Mingqiang, Shu Jiwu. Flash storage technology[J]. Computer Research and Development, 2010, 47(4): 716-726. (in Chinese)[5] Grupp L M, Caulfield A M, Coburn J, et al. Characterizing flash memory: anomalies, observations, and applications[C]. Ieee/acm International Symposium on Microarchitecture. IEEE, 2010: 24-33.[6] 高剑, 郭士瑞, 蒋常斌. FLASH存储器的测试方法[J]. 电子测量技术, 2008, 31(7): 117-120. Gao Jian, Guo Shirui, Jiang Changbin. Test methods for FLASH memory[J]. Electronic Measurement Technology, 2008, 31(7): 117-120. (in Chinese)[7] Kang D, Jeong W, Kim C, et al. 256 Gb 3 b/Cell V-nand Flash Memory With 48 Stacked WL Layers[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 210-217.[8] 张立哲, 刘丽静. 适应远程升级的FPGA配置方法[J]. 计算机与网络, 2011(14): 56-59. Zhang Lizhe, Liu Lijing. FPGA configuration method for remote upgrade[J]. Computer and Network, 2011(14): 56-59. (in Chinese)[9] Wirthlin M, Johnson E, Rollins N, et al. The reliability of FPGA circuit designs in the presence of radiation induced configuration upsets[C]. IEEE Symposium on Field-Programmable Custom Computing Machines. IEEE Computer Society, 2003: 133. [10] 宁李谱, 杨宾峰, 苗青林. FPGA器件的配置方式研究[J]. 河南科技学院学报(自然科学版), 2008, 36(3): 109-110.Ning Lipu, Yang Binfeng, Miao Qinglin. Study of configuration schemes of FPGAs[J]. Journal of Henan Institute of Science and Technology (Natural Science Edition), 2008,36(3): 109-110. (in Chinese)[11] 李飞飞, 苏延川, 王鹏. 基于DSP的FPGA配置方法研究与实现[J]. 现代电子技术, 2011,34(24): 60-62.Li Feifei,Su Yanchuan,Wang Peng. Research and implementation of FPGA configuration with DSP[J]. Modern Electronics Technique, 2011, 34(24): 60-62. (in Chinese)[12] Xie T T. A FPGA Configuration Method for Improving System Initial Efficiency[J]. Computer & Modernization, 2012, 203(7): 215-217.[13] Gomez-Cornejo J, Zuloaga A, Villalta I, et al. A novel BRAM content accessing and processing method based on FPGA configuration bitstream[J]. Microprocessors & Microsystems, 2017, 49: 64-76.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Power-aware RAM Mapping for FPGA EmbeddedMemory BlocksRussell Tessier Department of Electrical and Computer Engineering University of Massachusetts Amherst, MA, USA tessier@Vaughn Betz, David NetoAltera Toronto Technology Centre151 Bloor St, Suite 200Toronto, ON, CANADAThiagaraja GopalsamyAltera Corporation101 Innovation DriveSan Jose, CA, USAABSTRACTEmbedded memory blocks are important resources in contemporary FPGA devices. When targeting FPGAs, application designers often specify high-level memory functions which exhibit a range of sizes and control structures. These logical memories must be mapped to FPGA embedded memory resources such that physical design objectives are met. In this work a set of power-aware logical-to-physical RAM mapping algorithms are described which convert user-defined memory specifications to on-chip FPGA memory block resources. These algorithms minimize RAM dynamic power by evaluating a range of possible embedded memory block mappings and selecting the most power-efficient choice. Our automated approach has been integrated into a commercial FPGA compiler and tested with 40 large FPGA benchmarks. Through experimentation, we show that, on average, embedded memory dynamic power can be reduced by 21% and overall core dynamic power can be reduced by 7% with a minimal loss (1%) in design performance. Categories and Subject DescriptorsB.7.2 [Integrated Circuits]: Design AidsGeneral TermsAlgorithmsKeywordsFPGA, Embedded memory block, Dynamic power1.INTRODUCTIONOn-chip memory is an essential component of programmable logic devices. Most on-chip data storage is implemented in large RAM blocks integrated into the FPGA architecture. These storage blocks allow for the implementation of a variety of memory structures, including FIFOs, scratch pad memories, and shift registers, within close physical proximity of logic resources. Due to their extensive use, embedded memory blocks have been found to consume between 10-20% of core dynamic power in typical FPGA designs [1]. As the amount of FPGA logic and on-chip memory grows rapidly over the next few years, the power-efficient use of memory blocks will become increasingly important.Embedded memory blocks in contemporary FPGAs are typically implemented with synchronous SRAM [2][17] to improve design performance. Like other synchronous SRAM architectures, FPGA embedded memory accesses are performed in concert with a design clock and a series of interface signals including read/write (R/W) enables, clock enables, address, and data signals. During application development, designers may directly specify the source of control signals that are used to manipulate design RAMs. More typically, a higher-level RAM representation is specified and automatically converted to physical RAMs and associated control circuitry. Control signals, such as R/W enable and clock enables are generated by this control circuitry.Synchronous FPGA embedded memories primarily consume dynamic power as a result of internal RAM clocking. To save power, RAM control signals can be configured to suppress internal clocking when RAM access is unnecessary on a specific clock cycle. Although user-defined or generated control signals provide for valid functional embedded memory behaviour, their configuration may not efficiently suppress unnecessary clocked memory accesses, leading to wasted RAM dynamic power. These limitations motivate a need for RAM mapping algorithms that take power objectives into account while maintaining valid functional behavior.In this paper we describe a series of algorithms to automatically map user-specified logical memories to available physical embedded memory block resources with the goal of reducing overall FPGA dynamic power consumption. In considering feasible RAM mappings, our approach estimates the relative dynamic power consumption of each potential implementation and selects the most power-efficient implementation subject to on-chip RAM availability constraints. When necessary, user-specified RAM control signals (R/W enable, clock enables) are remapped to achieve a logically-equivalent RAM implementation with reduced dynamic power consumption. If an FPGA contains embedded memory blocks of different sizes, a mapping using each block type is considered.Our mapping techniques have been integrated into the Altera Quartus II synthesis system [1] and targeted to a variety of Altera FPGA families which contain embedded memories. Through experimentation with 40 RAM-based Stratix II designs, we showPermission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.FPGA’06, February 22-24, 2006, Monterey, California, USA.Copyright 2006 ACM 1-59593-292-5/06/0002…$5.00.an average embedded memory dynamic power reduction of 21% and overall core dynamic power reduction of 7%.In the next section we discuss related power-aware memory mapping techniques. In Section 3 the basic operation of FPGA embedded memories are described along with details of the basic mapping flow used to translate user-specified logical memory to physical embedded memory blocks. Section 4 provides the details of our power-aware RAM mapping techniques and supporting algorithms. Experimental results are presented in Section 5. Section 6 concludes the paper and offers directions for future work.2.Related WorkWe are unaware of any prior CAD tools that produce a power-efficient mapping of design RAM to FPGA or structured ASIC embedded memory. Previous research efforts that map design logic to embedded memory blocks in ASICs [4][14] and FPGAs [9] do not consider power optimization as a mapping goal. Although FPGA logic and routing dynamic power reduction has been studied [10], these techniques were not applied to embedded memory blocks.RAM dynamic power-reduction techniques for ASICs and microprocessor systems have been considered at the application-mapping, compiler, and circuit levels. Although these approaches provide insight into reducing FPGA embedded memory power, none are directly applicable. Several synthesis techniques for application-specific embedded systems create power-optimized memory structures based on application address traces. In Benini et al. [5], the memory trace of an embedded application is analyzed by an algorithm to determine the portion of program and data memory that is most frequently accessed. These addresses are then grouped into memory banks which are implemented with scratch pad memories. Infrequently accessed addresses are grouped into larger physical memory blocks. Later work by Cao et al. [6] extends this optimization to consider data width scaling. Wuytack et al. [16] have developed techniques to optimize the entire memory hierarchy of an application for power consumption based on application information. These previous approaches rely on application trace information to perform memory partitioning.A number of compiler techniques have been developed for processor-based systems which optimize power while mapping data to fixed system memory resources. For example, in Unsal et al. [15], a series of memory locations for multimedia applications are remapped to a small, local scratch pad memory to save dynamic power. In Petrov and Orailoglu [13], the organization and power consumption of a translation look-aside buffer are adjusted on a per-application basis. In Gebotys [8], memory energy is managed through memory and register allocation using a network flow algorithm. In Ferrahi et al. [7], a compiler technique to optimize sleep mode operation for memories is described. Memory reactivations are minimized via scheduling to save dynamic power.Numerous circuit-level techniques for power reduction have been explored [11] including reduced swing pre-decode lines, multi-stage address decoding, and divided word and bit lines, amongothers. These techniques may be used in the future by FPGA designers to reduce FPGA embedded memory block power and are additive to the approaches described in this paper.3.BackgroundThe development of a power-efficient embedded RAM mapping strategy requires insight into the internal behaviour of synchronous SRAM. Typically, each port of an embedded memory block is controlled by one or more read/write (R/W) enable signals, clock (Clk) enable signals, and clock signals. As shown in Figure 1, these signals directly or indirectly control data movement in different parts of the embedded memory port.During a typical memory read operation the following events occur in sequence, in response to a rising clock edge:•The memory port clock (MClk) is strobed causing the BIT lines to be precharged to Vcc.•The read address is decoded and one word line is activated.•The BIT line difference is identified by sense amps causing the read data to be strobed into a columnmultiplexer.•Read data passes through the column multiplexer and a latch conditioned by Read Enable to the RAM externalRead Data lines.Memory write operations require a similar sequence of operations which occur in the following order:•The memory port clock (MClk) is strobed causing the BIT lines to be precharged to Vcc.•The Write Enable signal, conditioned by MClk, createsa write pulse which transfers write data to the writebuffers and a word line is activated following writeaddress decode.•Write buffer data is stored in the RAM cellsMClkClkClkFigure 1: Internal view of embedded memory read/write portFor both synchronous read and write RAM operations, most dynamic power is consumed via BIT line precharging [12]. To control clocking, embedded memory ports often have a clock enable signal which can eliminate internal precharging, word-line decoding, and RAM cell access. The disabling of the clock enable signal when memory port access is not required provides the best technique to eliminate embedded memory dynamic power consumption for a memory port. If a RAM port is inactive on a given clock cycle and its clock can be suppressed via an inactive clock enable, the RAM port will not consume significant dynamic power.A number of contemporary FPGAs support embedded memory blocks with R/W enable and clock enable signals. Altera Stratix [3] and Stratix II [2] devices support both R/W enables and clock enables on each port of TriMatrix embedded memory block dual-port memory. Each Xilinx Virtex-II [18] and Virtex-4 [17] embedded SelectRAM block contains write enable and clock enable control signals on each port, but no separate read enable. The goal of power-aware RAM mapping is to implement the functionality of a user-defined RAM module (logical memory) in one or more FPGA embedded memory blocks so that memory precharges are limited. This optimization goal attempts to minimize RAM dynamic activity through the use of RAM port clock enables whenever possible. The effective use of clock enable signals ensures that the bulk of embedded memory block dynamic power is consumed when a required access to data within a RAM is performed. In some cases this goal may require the synthesis of one of more clock enable signals during the mapping process. This mapping must achieve the samefunctional behaviour for the RAM as specified by the designer while allowing for possible tradeoffs regarding design power consumption and design area and performance.3.1 Typical FPGA RAM Mapping FlowFPGA embedded memory blocks are used to implement a variety of RAM components including FIFOs, shift registers, and single and dual-port memories. Logical RAMs are specified by the designer in RTL or schematic form, created by the FPGA compiler and mapped [1], as shown in Figure 2:1. Logical memory creation – User-defined RAM descriptionsare processed by the FPGA compilation software to create logical memories with desired characteristics.2. Logical-to-physical RAM processing - Logical RAMs are converted into one or more RAM blocks which match the external interface and size constraints of available embedded memory blocks.3. Embedded memory block placement – RAM blocks andassociated control logic are assigned to available on-chip embedded memory block and logic resources. The power-aware algorithms developed in this work are applied in the logical-to-physical RAM processing step. Traditionally, RAM mapping has targeted logical RAM performance and FPGA area minimization [9] rather than power consumption. To conserve dynamic power it is desirable to map memory functions specified by designers to available physical memories so that power consumption is optimized within area and delay constraints. As shown in Section 4.2, an area-optimal embedded memory implementation does not always consume the least amount of dynamic power.The size of both logical and physical (embedded) memory blocks can be defined in terms of the number of addressable locations (depth ) and output bits per memory (width ). The number of address bits required for both logical and physical memories is directly related to memory block depth. The number of data in and data out bits is related to memory block width. To promote flexibility, an FPGA embedded memory block may typically be programmed to support a range of depth versus width configurations [2][17].Until the relatively recent adoption of synchronous SRAMs, most user-defined RAM designs targeted asynchronous memories (both external and internal to FPGAs) which use read and write enable for data access control. Although embedded memory blocks now allow for the use of either operation-specific enable or clock enable signals to provide access control, many designers continue to use the operation-specific enable approach, ignoring the clock enable. Contemporary RAM mapping flows (e.g. Figure 2) automatically map these user-defined enable signals to the R/W enable signals located on the embedded memory block ports. Unspecified clock enables are set to be continuously active. The use of read and write enable signals for data access control instead of associated clock enable signals leads to sub-optimal power consumption in many cases.A second impediment to reduced RAM power dissipation is related to logical RAM size. In most cases the size of a user-FIFO, Shift Register, RAMMemoryFigure 2: Typical Logical RAM to Embedded Memory Block Mapping FlowLogical memoryand 1 bit memory blockData[0:3Physical memoriesFigure 3: Area-efficient mapping of a 4Kx4 logical RAM to 4 Kbit memory blocksspecified logical memory will not exactly match the width and depth dimensions of an embedded memory block. Since existing RAM mapping flows focus on optimizing delay and resource usage, rather than power, logical memories are typically mapped using a minimum of external logic. As an example, Figure 3 illustrates the mapping of a 4Kx4 logical memory to four 4Kx1 embedded memory blocks. In this case, each memory block is configured as 4Kx1 so that a single bit of each addressable location is located in each block. This configuration requires no external logic. However, all four memory blocks must be active during each logical memory access, so this is a high-power implementation.4. Power-Aware RAM MappingOur RAM mapping approach consists of two algorithms that obtain a power-efficient mapping of logical memories to FPGA embedded memory blocks. Two specific cases are targeted: 1. Since most embedded memory block dynamic power is aresult of clock-induced precharging, we identify cases where user-specified logical RAM read and write enable signals can be automatically converted to or combined withcorresponding read and write clock enable signals while maintaining correct functional behaviour.2. For cases where more than one embedded memory block isrequired to implement a logical RAM, we implement a multi-banked RAM mapping. As a result of this banked mapping, only one embedded memory block is clocked per access. In some cases the banked structure may require the inclusion of supporting logic.4.1 Conversion of read and write enable to read and write clock enableIn general, synchronous embedded memory blocks exhibit the same functional RAM behaviour if either an enable or a clock enable is used to control a read (or write) access and the alternate signal is set to an active state. To illustrate this observation, all four configurations of active-high enable and clock enable signals are considered for read and write accesses. For a successful read (or write) access both enable and clock enable signals must be set to active-high.The functional equivalence of embedded memory read enable and read clock enable can be observed in Figure 4 based on the discussion of RAM read steps in Section 3. Using the figure, the behaviour of the following four read cases can be considered: 1. Read Clk Enable = 0, Read Enable = 0 – New data will notbe transferred to the column multiplexer since the BIT lines are not precharged.2. Read Clk Enable = 1, Read Enable = 0 – New data isobtained from the RAM cell following BIT line precharge but will not be transferred to the Read Data lines since the latch conditioned by Read Enable is closed.3. Read Clk Enable = 0, Read Enable = 1 – New data will notbe transferred to the column multiplexer since the BIT lines are not precharged. Indeterminate data passes through the latch and is driven onto the Read Data lines.4. Read Clk Enable = 1, Read Enable = 1 – New data isobtained from the RAM cell following bit line precharge and passed through the latch to the Read Data lines.Consider a scenario where Read Enable is attached to a control signal and Read Clk Enable is always tied to active logic 1. From the enumeration it can be seen that since the AND of Read Enable and Read Clk Enable is needed for a successful read, the signals are functionally equivalent for reads, the Read Clk Enable signal can be driven by the signal previously tied to Read Enable, and Read Enable can be tied to logic 1.Similarly, the functional equivalence of embedded memory write enable and write clock enable can be observed in Figure 5 based on the discussion of RAM write steps in Section 3.Using the figure, the behaviour of the following four write cases can be considered:1. Write Clk Enable = 0, Write Enable = 0 – A writeenable pulse will not be generated by the pulsegenerator preventing write data from being loaded onto the BIT lines. The BIT lines are not precharged. 2. Write Clk Enable = 1, Write Enable = 0 – A writeenable pulse will not be generated by the pulsegenerator preventing write data from being loaded onto the BIT lines. The BIT lines are precharged.MClk Write EnableIf write enable = 0, operations in unshaded boxes are suppressedFigure 5: Functional equivalence of embedded memory write enable and write clock enableRead DataColumn Mux Sense AmpsColumn DecodeRAM cellBITBITBit Line Pre-chargeLatchIf read clk enable = 0, operations in shaded boxes are suppressed If read enable = 0, operation in unshaded box is suppressedFigure 4: Functional equivalence of embedded memory read enable and read clock enable3.Write Clk Enable = 0, Write Enable = 1 – A writeenable pulse will not be generated by the pulsegenerator preventing write data from being loaded ontothe BIT lines. The BIT lines are not precharged.4.Write Clk Enable = 1, Write Enable = 1 – A writeenable pulse is generated, the BIT lines are precharged,write data is loaded onto the BIT lines and into RAMcellsConsider a scenario where Write Enable is attached to a control signal and Write Clk Enable is always tied to active logic 1. From the enumeration it can be seen that since the AND of Write Enable and Write Clk Enable is needed for a successful write operation, the signals are functionally equivalent for writes, the Write Clk Enable signal can be driven by the signal previously labelled Write Enable, and Write Enable can be tied to logic 1. The conversion of user-defined read and write enable signals to respective clock enables primarily reduces power by eliminating BIT line precharging when embedded memory block data accessis not required. The same functional RAM behaviour is maintained.For some logical memories, a designer may specify both an enable and a clock enable signal for an embedded memory port. In these cases, additional logic (an AND gate) must be added to the user design to allow the user-defined enable signal to condition the associated memory port clock. The combining of the enable and clock enable signal forms a new combined clock enable signal which can be attached to the memory port clock enable input. Depending on designer timing constraints, the addition of logic delay to the clock enable path may negatively impact mapped design performance. As a result, this approach may only be appropriate if design power reduction is considered more important than design performance or preliminary timing information is available to determine if performance is not likely to be affected.The mapping steps in Figure 6 are performed on each logical RAM. These steps perform enable-to-clock enable conversion and combining for embedded memory block inputs Clken and Enable and designer signals User Clken and User Enable. 4.2Power-aware RAM PartitioningAs shown in Figure 3, a logical memory which exceeds the size of an embedded memory block must be mapped to multiple blocks. Although the mapping shown in Figure 3 does not require any supporting logic, each memory block is active during each memory access, requiring substantial power consumption. In this case, the depth of each physical memory block matches the depth of the logical memory and the width of each physical memory block is smaller than its logical memory counterpart. This mapping is an example of vertical memory slicing.In general, an FPGA embedded memory block can be structured to have a variety of depth and width configurations, each with the same bit storage capacity. For example, an Altera M4K 4608 bit embedded memory block can be organized into configurations ranging from 4096x1 to 256x18 [2]. This allows a range of choices in mapping a logical RAM to physical memory blocks. For example, Figures 3 and 7 provide two example mapping alternatives. In the mapping in Figure 7, the width of each physical memory block matches the width of the logical memory while the depth of each physical memory block is reduced compared to its logical memory counterpart. This mapping can be considered an example of horizontal memory slicing. This second mapping requires the inclusion of address decoding circuitry to determine which memory block contains the requested data. Additionally, a multiplexer is required on the read port to select the requested word during read requests. Although dynamic power is consumed by the added address decoder and multiplexer, all but one of the embedded memory blocks is disabled during RAM accesses, saving considerable dynamic power. Unused memory blocks are disabled by connecting the outputs of the address decoder to memory block clock enable signals.The vertical and horizontal RAM slicing implementations shown in Figures 3 and 7 represent the end points of a spectrum of feasible logical-to-physical RAM mappings (e.g. 2Kx2 RAM block configurations are also possible). If, as a result of a mapping change, an embedded memory block is converted from a given depth to one that is half as deep, the following additional mapping changes are required:block4Addr[0:9] LogicalmemoryFigure 7: Alternate mapping of a 4Kx4 logical RAM to 4 Kbit memory blocks1. Each write port data line must be tied to twice the number ofsource/destination embedded memory blocks. 2. The size of the address decoder increases by a factor of 2. 3. The bit input size of each multiplexer on the embeddedmemory read port increases by a factor of 2. 4. One address line is removed from each of the embeddedmemory blocks. The relative power consumed by each logical-to-physical mapping can be evaluated by assessing the power consumed by the memory blocks during a data access, the address decoder, the output multiplexer, and associated routing. As mappings approach the vertical slicing implementation (maximum physical block depth), memory block power is increased and multiplexer and address decoder power is decreased. As mappings approach the horizontal slicing implementation, multiplexer and address decoder power is increased and memory block power is decreased. Figure 8 shows the dynamic power consumed by various mappings of a 4Kx32 logical RAM in a Stratix II device for a selection of embedded memory block depths as reported by the Quartus II PowerPlay power analyzer. The plot shows that the power optimal mapping for this logical RAM falls between the horizontal slicing on the left and vertical slicing on the right. All mappings achieve the same functional behaviour.4.3 Logical RAM Partitioning AlgorithmA power-aware RAM partitioning algorithm has been developed to evaluate the relative power consumption of a series of logical-to-physical RAM mappings. Each mapping is evaluated based on the number of active embedded memory blocks per port, the amount of associated address decoder and multiplexer circuitry required, and associated routing. Since contemporary FPGAs contain a set of different embedded memory block sizes, mapping evaluation is performed for each block type to determine the most power-efficient choice. The relative cost for each mapping is determined based on the estimated dynamic power consumption of the mapping. This cost can be expressed for each port of each logical RAM as:Cost = W * P mux + N * P ram + P addr_decode (1)Where Cost is the relative power cost for the mapping, W is the width of the logical RAM, P mux is the per-bit dynamic power of a read port multiplexer, N is the number of required embedded memory blocks, P ram is the per-block dynamic power, and P addr_decode is the dynamic power consumption of the address decoder. Specific algorithm steps for a logical memory are shown in Figure 9.Our approach is effective for both single- and dual-port logical RAMs. The key power savings aspect of the approach is the connection of address decoder outputs to embedded memory block clock enables. Only the addressed memory block is precharged on a given clock cycle saving considerable RAM dynamic power.The inclusion of a memory block read port multiplexer can negatively impact design performance for designs which include the RAM block output on the design critical path. Design performance is not explicitly considered by the partitioning algorithm. However, to minimize performance impact, only configurations which require a 4-to-1 or smaller multiplexer on each read port output bit are considered.In addition to possibly affecting performance, the inclusion of multiplexers consumes device logic. This added logic may result in an overflow of required design logic elements for a target device.Figure 8: Dynamic power consumption of a 4Kx32 logical RAM at 100 MHz in different slicing configurationsFigure 9: Power-aware memory partitioning algorithm applied to each logical RAM4.4Parameter EvaluationThe algorithms described in Sections 4.1 and 4.3 have been integrated into Quartus II version 5.1 and applied to Stratix II FPGAs [2]. Experimental results were determined in two phases. First, the technology parameters noted in Equation (1) were determined via parameter evaluation experiments with a representative set of logical RAMs. After parameter evaluation, the algorithms were tested with 40 commercial benchmark designs containing logical RAMs.The logical RAMs used for parameter evaluation included ROMs and single and dual port RAMs of sizes ranging from 512x2 to 8Kx132. Parameter evaluation was performed for the Altera Stratix II architecture, which contains three types of embedded memory blocks, each of a different size: 576-bit (M512), 4,608 bit (M4K), 589,824 bit (M-RAM) [2]. Each memory block allows for implementation of both single and dual-port synchronous RAMs.Each logical RAM used for parameter evaluation was mapped to each of the three Stratix II memory block types using multi-block partitioning ranging from horizontal slicing to vertical slicing. Following synthesis with Quartus II, the memory designs were placed and routed using Quartus II. All synthesis, place, and route steps used an unattainable 1 GHz timing constraint to ensure maximum fitting effort by the CAD software. Designs were simulated at 100 MHz with random input vectors and dynamic power analysis was performed using the Quartus II PowerPlay power analyzer. All compiled designs were able to satisfy a minimum clock frequency of 100 MHz.Statistical averaging was then used to determine the following values based on measured values for all RAM implementations: •Power consumed by single bit of an n-to-1 multiplexer, P mux, Values for only 2-to-1 and 4-to-1 multiplexers were determined since shallower embedded memory blocks depth slicings are not performed by our system due to performance concerns.•Per-port design power consumed by an active physical memory block, P ram, for an M512, M4K, and M-RAM embedded memory block.•Power consumed by a k-to-n address decoder, P addr_decode, for a 2-to-4 and 1-to-2 decoder.Because the power analyzer takes detailed placement and routing into account when producing a power estimate, the averaged values for P mux and P addr_decode take the effects of control signal, address, and data fanout into account.Although the calculated parameters measure dynamic power values averaged across the RAM parameter evaluation design set, the access patterns of user logical RAMs may differ. Since our algorithm considers relative rather than absolute dynamic power values in making tradeoffs, we consider the subsequent use of these parameters across a range of user benchmarks to be acceptable and representative of most RAM access patterns.Table 1: Benchmark Design StatisticsDesign LUTs MemorybitsFlipflopsTarget Device1 8005 254680 6247 EP2S15F6722 9106 47264 6971 EP2S15F6723 15988 548 12948 EP2S60F10204 9802 292608 5363 EP2S15F6725 8853 63744 7349 EP2S60F10206 5751 168 1750 EP2S60F10207 5743 168 1030 EP2S60F10208 13121 426512 10394 EP2S60F10209 23464 327680 3215 EP2S60F102010 215 331776 27EP2S15F48411 243 331776 47EP2S15F48412 26154 327680 3215 EP2S90F150813 5295 1134 3587 EP2S15F48414 5488 512 4915 EP2S60F102015 7409 6432 5944 EP2S60F102016 23550 128452 22063 EP2S60F102017 8071 43008 3863 EP2S30F67218 17857 66336 12199 EP2S90F150819 17857 66336 12199 EP2S90F150820 35849 89600 19745 EP2S90F150821 12039 1206785 8542 EP2S60F102022 11785 65536 8131 EP2S30F67223 11149 36096 5297 EP2S30F67224 13714 51456 6415 EP2S60F102025 5881 111872 4673 EP2S15F67226 4816 98684 3875 EP2S15F67227 10066 227010 7384 EP2S15F67228 18987 184320 14940 EP2S60F102029 3082 124290 2702 EP2S15F67230 30352 88048 25489 EP2S60F102031 8458 168416 6966 EP2S15F67232 23283 337501 18868 EP2S30F67233 13112 293856 9149 EP2S30F67234 36741 1402661 16492 EP2S90F150835 16731 524288 15547 EP2S30F48436 12560 1057428 9181 EP2S60F67237 2136 171098 1618 EP2S15F48438 4183 286956 3913 EP2S15F48439 5384 153864 2809 EP2S60F102040 28199 1009920 12148 EP2S60F10205.ResultsFollowing the determination of the tuning parameters and the integration of our algorithms with Quartus II, experimentation was performed on 40 commercial designs provided by Altera. This benchmark set includes designs which contain RAM from encryption, signal processing, and communications processing domains. LUT, memory bit and flip flop counts for each design are shown in Table 1. As seen in Figure 2, optimization occurs after complex memory functions (e.g. FIFOs, shift registers) are converted to logical RAMs, but before structures are assigned to specific embedded memories. The 40 designs were targeted to the smallest Stratix II device which would hold them. The specific device used for each design is listed in Table 1.。