NHANES项目介绍及数据提取流程
nhanes采集数据的流程

nhanes采集数据的流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!NHANES(美国国家健康与营养调查)是一项旨在评估美国成年人和儿童健康和营养状况的研究计划。
NHANES数据检索工具说明书

Package‘nhanesA’July16,2023Version0.7.4Date2023-07-16Title NHANES Data RetrievalBugReports https:///cjendres1/nhanes/issuesDepends R(>=3.0.0)Imports stringr,foreign,rvest,magrittr,xml2,plyrDescription Utility to retrieve data from the National Health and NutritionExamination Survey(NHANES)website<https:///nchs/nhanes/index.htm>. License GPL(>=2)Encoding UTF-8URL https:///package=nhanesASuggests knitr,rmarkdownVignetteBuilder knitrRoxygenNote7.2.3NeedsCompilation noAuthor Christopher Endres[aut,cre]Maintainer Christopher Endres<*******************>Repository CRANDate/Publication2023-07-1616:00:03UTCR topics documented:browseNHANES (2)nhanes (3)nhanesAttr (3)nhanesCodebook (4)nhanesDXA (5)nhanesSearch (6)nhanesSearchTableNames (7)12browseNHANES nhanesSearchVarName (8)nhanesTables (9)nhanesTableVars (10)nhanesTranslate (11)Index13 browseNHANES Open a browser to NHANES.DescriptionThe browser may be directed to a specific year,survey,or table.UsagebrowseNHANES(year=NULL,data_group=NULL,nh_table=NULL)Argumentsyear The year in yyyy format where1999<=yyyy.data_group The type of survey(DEMOGRAPHICS,DIETARY,EXAMINATION,LABO-RATORY,QUESTIONNAIRE).Abbreviated terms may also be used:(DEMO,DIET,EXAM,LAB,Q).nh_table The name of an NHANES table.DetailsbrowseNHANES will open a web browser to the specified NHANES site.ValueNo return valueExamplesbrowseNHANES()#Defaults to the main data sets pagebrowseNHANES(2005)#The main page for the specified survey yearbrowseNHANES(2009, EXAM )#Page for the specified year and survey groupbrowseNHANES(nh_table= VIX_D )#Page for a specific tablebrowseNHANES(nh_table= DXA )#DXA main pagenhanes3 nhanes Download an NHANES table and return as a data frame.DescriptionUse to download NHANES data tables that are in SAS format.Usagenhanes(nh_table,includelabels=FALSE)Argumentsnh_table The name of the specific table to retrieve.includelabels If TRUE,then include SAS labels as variable attribute(default=FALSE). DetailsDownloads a table from the NHANES website as is,i.e.in its entirety with no modification or cleansing.NHANES tables are stored in SAS’.XPT’format but are imported as a data frame.Function nhanes cannot be used to import limited access data.ValueThe table is returned as a data frame.Examplesnhanes( BPX_E )nhanes( FOLATE_F ,includelabels=TRUE)nhanesAttr Returns the attributes of an NHANES data table.DescriptionReturns attributes such as number of rows,columns,and memory size,but does not return the table itself.UsagenhanesAttr(nh_table)Argumentsnh_table The name of the specific table to retrieve4nhanesCodebookDetailsnhanesAttr allows one to check the size and other charactersistics of a data table before import-ing into R.To retrieve these characteristics,the specified table is downloaded,characteristics are determined,then the table is deleted.ValueThe following attributes are returned as a listnrow=number of rowsncol=number of columnsnames=name of each columnunique=true if all SEQN values are uniquena=number of’NA’cells in the tablesize=total size of table in bytestypes=data types of each columnExamplesnhanesAttr( BPX_E )nhanesAttr( FOLATE_F )nhanesCodebook Display codebook for selected variable.DescriptionReturns full NHANES codebook including Variable Name,SAS Label,English Text,Target,and Value distribution.UsagenhanesCodebook(nh_table,colname,dxa=FALSE)Argumentsnh_table The name of the NHANES table that contains the desired variable.colname The name of the table column(variable).dxa If TRUE then the2005-2006DXA codebook will be used(default=FALSE).DetailsEach NHANES variable has a codebook that provides a basic description as well as the distribution or range of values.This function returns the full codebook information for the selected variable.ValueThe codebook is returned as a list object.Returns NULL upon error.nhanesDXA5 ExamplesnhanesCodebook( AUX_D , AUQ020D )nhanesCodebook( BPX_J , BPACSZ )nhanesDXA Import Dual Energy X-ray Absorptiometry(DXA)data.DescriptionDXA data were acquired from1999-2006.UsagenhanesDXA(year,suppl=FALSE,destfile=NULL)Argumentsyear The year of the data to import,where1999<=year<=2006.suppl If TRUE then retrieve the supplemental data(default=FALSE).destfile The name of a destinationfile.If NULL then the data are imported into the R environment but nofile is created.DetailsProvide destfile in order to write the data tofile.If destfile is not provided then the data will be imported into the R environment.ValueBy default the table is returned as a data frame.When downloading tofile,the return argument is the integer code from download.file where0means success and non-zero indicates failure to download.Examplesdxa_b<-nhanesDXA(2001)dxa_c_s<-nhanesDXA(2003,suppl=TRUE)##Not run:nhanesDXA(1999,destfile="dxx.xpt")6nhanesSearch nhanesSearch Perform a search over the comprehensive NHANES variable list.DescriptionThe descriptions in the master variable list will befiltered by the provided search terms to retrievea list of relevant variables.The search can be restricted to specific survey years by specifying ystartand/or ystop.UsagenhanesSearch(search_terms=NULL,exclude_terms=NULL,data_group=NULL,ignore.case=FALSE,ystart=NULL,ystop=NULL,includerdc=FALSE,nchar=128,namesonly=FALSE)Argumentssearch_terms List of terms or keywords.exclude_terms List of exclusive terms or keywords.data_group Which data groups(e.g.DIET,EXAM,LAB)to search.Default is to search all groups.ignore.case Ignore case if TRUE.(Default=FALSE).ystart Four digit year offirst survey included in search,where ystart>=1999.ystop Four digit year offinal survey included in search,where ystop>=ystart.includerdc If TRUE then RDC only tables are included in list(default=FALSE).nchar Truncates the variable description to a max length of nchar.namesonly If TRUE then only the table names are returned(default=FALSE).DetailsnhanesSearch is useful to obtain a comprehensive list of relevant tables.Search terms will be matched against the variable descriptions in the NHANES Comprehensive Variable Lists.Match-ing variables must have at least one of the search_terms and not have any exclude_terms.The search may be restricted to specific surveys using ystart and ystop.If no arguments are given,then nhanesSearch returns the complete variable list.nhanesSearchTableNames7ValueReturns a data frame that describes variables that matched the search terms.If namesonly=TRUE,then a character vector of table names that contain matched variables is returned.ExamplesnhanesSearch("bladder",ystart=2001,ystop=2008,nchar=50)nhanesSearch("urin",exclude_terms="During",ystart=2009)nhanesSearch(c("urine","urinary"),ignore.case=TRUE,ystop=2006,namesonly=TRUE)nhanesSearchTableNamesSearch for matching table namesDescriptionReturns a list of table names that match a specified pattern.UsagenhanesSearchTableNames(pattern=NULL,ystart=NULL,ystop=NULL,includerdc=FALSE,includewithdrawn=FALSE,nchar=128,details=FALSE)Argumentspattern Pattern of table names to matchystart Four digit year offirst survey included in search,where ystart>=1999.ystop Four digit year offinal survey included in search,where ystop>=ystart.includerdc If TRUE then RDC only tables are included(default=FALSE).includewithdrawnIF TRUE then withdrawn tables are included(default=FALSE).nchar Truncates the variable description to a max length of nchar.details If TRUE then complete table information from the comprehensive data list isreturned(default=FALSE).DetailsSearches the Doc Filefield in the NHANES Comprehensive Data List(see https:///nchs/nhanes/search/DataPag for tables that match a given name pattern.Only a single pattern may be entered.8nhanesSearchVarNameValueReturns a character vector of table names that match the given pattern.If details=TRUE,then a data frame of table attributes is returned.NULL is returned when an HTML read error is encountered. ExamplesnhanesSearchTableNames( BMX )nhanesSearchTableNames( HPVS ,includerdc=TRUE,details=TRUE) nhanesSearchVarName Search for tables that contain a specified variable.DescriptionReturns a list of table names that contain the variableUsagenhanesSearchVarName(varname=NULL,ystart=NULL,ystop=NULL,includerdc=FALSE,nchar=128,namesonly=TRUE)Argumentsvarname Name of variable to match.ystart Four digit year offirst survey included in search,where ystart>=1999.ystop Four digit year offinal survey included in search,where ystop>=ystart.includerdc If TRUE then RDC only tables are included in list(default=FALSE).nchar Truncates the variable description to a max length of nchar.namesonly If TRUE then only the table names are returned(default=TRUE).DetailsThe NHANES Comprehensive Variable List is scanned tofind all data tables that contain the given variable name.Only a single variable name may be entered,and only exact matches will be found.ValueBy default,a character vector of table names that include the specified variable is returned.If namesonly=FALSE,then a data frame of table attributes is returned.ExamplesnhanesSearchVarName( BMXLEG )nhanesSearchVarName( BMXHEAD ,ystart=2003)nhanesTables Returns a list of table names for the specified survey group.DescriptionEnables quick display of all available tables in the survey group.UsagenhanesTables(data_group,year,nchar=128,details=FALSE,namesonly=FALSE,includerdc=FALSE)Argumentsdata_group The type of survey(DEMOGRAPHICS,DIETARY,EXAMINATION,LABO-RATORY,QUESTIONNAIRE).Abbreviated terms may also be used:(DEMO,DIET,EXAM,LAB,Q).year The year in yyyy format where1999<=yyyy.nchar Truncates the table description to a max length of nchar.details If TRUE then a more detailed description of the tables is returned(default=FALSE).namesonly If TRUE then only the table names are returned(default=FALSE).includerdc If TRUE then RDC only tables are included in list(default=FALSE).DetailsFunction nhanesTables retrieves a list of tables and a description of their contents from the NHANES website.This provides a convenient way to browse the available tables.NULL is returned when an HTML read error is encountered.ValueReturns a data frame that contains table attributes.If namesonly=TRUE,then a character vector of table names is returned.ExamplesnhanesTables( EXAM ,2007)nhanesTables( LAB ,2009,details=TRUE,includerdc=TRUE)nhanesTables( Q ,2005,namesonly=TRUE)nhanesTables( DIET , P )nhanesTables( EXAM , Y )nhanesTableVars Displays a list of variables in the specified NHANES table.DescriptionEnables quick display of table variables and their definitions.UsagenhanesTableVars(data_group,nh_table,details=FALSE,nchar=128,namesonly=FALSE)Argumentsdata_group The type of survey(DEMOGRAPHICS,DIETARY,EXAMINATION,LABO-RATORY,QUESTIONNAIRE).Abbreviated terms may also be used:(DEMO,DIET,EXAM,LAB,Q).nh_table The name of the specific table to retrieve.details If TRUE then all columns in the variable description are returned(default=FALSE).nchar The number of characters in the Variable Description to print.Default length is128,which is set to enhance readability cause variable descriptions can be verylong.namesonly If TRUE then only the variable names are returned(default=FALSE).DetailsNHANES tables may contain more than100variables.Function nhanesTableVars provides a con-cise display of variables for a specified table,which helps to ascertain quickly if the table is of interest.NULL is returned when an HTML read error is encountered.ValueReturns a data frame that describes variable attributes for the specified table.If namesonly=TRUE, then a character vector of the variable names is returned.ExamplesnhanesTableVars( LAB , CBC_E )nhanesTableVars( EXAM , OHX_E ,details=TRUE,nchar=50)nhanesTableVars( DEMO , DEMO_F ,namesonly=TRUE)nhanesTranslate Display code translation information.DescriptionReturns code translations for categorical variables,which appear in most NHANES tables.UsagenhanesTranslate(nh_table,colnames=NULL,data=NULL,nchar=32,mincategories=2,details=FALSE,dxa=FALSE)Argumentsnh_table The name of the NHANES table to retrieve.colnames The names of the columns to translate.data If a data frame is passed,then code translation will be applied directly to thedata frame.In that case the return argument is the code-translated data frame.nchar Applies only when data is defined.Code translations can be very long.Truncate the length by setting nchar(default=32).mincategories The minimum number of categories needed for code translations to be appliedto the data(default=2).details If TRUE then all available table translation information is displayed(default=FALSE).dxa If TRUE then the2005-2006DXA translation table will be used(default=FALSE). DetailsMost NHANES data tables have encoded values.E.g.1=’Male’,2=’Female’.Thus it is often helpful to view the code translations and perhaps insert the translated values in a data frame.Onlya single table may be specified,but multiple variables within that table can be selected.Codetranslations are retrieved for each variable.ValueThe code translation table(or translated data frame when data is defined).Returns NULL upon error.ExamplesnhanesTranslate( DEMO_B ,c( DMDBORN , DMDCITZN ))nhanesTranslate( BPX_F , BPACSZ ,details=TRUE)nhanesTranslate( BPX_F , BPACSZ ,data=nhanes( BPX_F ))IndexbrowseNHANES,2nhanes,3nhanesAttr,3nhanesCodebook,4nhanesDXA,5nhanesSearch,6 nhanesSearchTableNames,7 nhanesSearchVarName,8nhanesTables,9nhanesTableVars,10nhanesTranslate,1113。
nhanes血脂的测量方法

nhanes血脂的测量方法
NHANES(National Health and Nutrition Examination Survey)是美国国家健康和营养调查的一部分,用于收集有关美国人口健康和营养状况的数据。
在NHANES中,血脂的测量方法主要包括以下步骤:
1. 采集血液样本:在NHANES中,受试者在空腹状态下抽取静脉血液样本。
2. 分离血脂:将血液样本放置在离心机中,以分离出血浆和血清。
3. 测量血脂水平:使用自动生化分析仪测量血脂水平,包括总胆固醇、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇和甘油三酯等。
4. 记录数据:测量结果被记录在NHANES数据库中,并用于分析美国人口的血脂水平和相关健康问题。
需要注意的是,血脂的测量方法可能因实验室和仪器不同而有所差异。
同时,血脂水平受到多种因素的影响,如饮食、生活习惯和遗传因素等。
因此,为了准确地评估个人的血脂水平和风险,建议咨询医生或专业医疗机构进行检测和评估。
nhanes 回归方法

nhanes 回归方法NHANES(National Health and Nutrition Examination Survey,国家健康和营养调查)是美国国家卫生统计中心(NCHS)进行的一项重要调查,旨在评估美国人民的健康状况和营养摄入情况。
NHANES数据通常用于进行流行病学研究和健康政策制定。
在NHANES数据分析中,回归方法经常被用于探究不同变量之间的关系,下面我将从多个角度来讨论NHANES数据中回归方法的应用。
首先,NHANES数据通常涉及大量的变量,包括个人特征、生活方式、健康状况、营养摄入等多个方面,因此在回归分析中,需要考虑到多重共线性、样本偏差等问题。
在应用回归方法时,研究人员需要仔细选择合适的自变量和控制变量,以及考虑到样本的代表性和权重,以确保结果的准确性和可靠性。
其次,NHANES数据集通常是复杂的横断面调查数据,因此在回归分析中需要考虑到数据的复杂性和相关性。
研究人员可能需要使用多元回归、逻辑回归、多层线性模型等多种回归方法,以探究不同变量对健康和营养状况的影响,或者预测特定健康结果的概率。
另外,NHANES数据集还包括了时间序列数据,因此在回归分析中需要考虑到时间趋势和季节性变化等因素。
研究人员可能需要使用时间序列回归方法,如ARIMA模型、趋势回归等,以探究健康和营养状况随时间的变化趋势,或者预测未来的发展趋势。
此外,NHANES数据集还可以用于探究因果关系,比如探究特定营养摄入与健康指标之间的因果关系。
在这种情况下,研究人员可能需要使用因果推断方法,如倾向得分匹配、双重差分等,以控制潜在的混杂因素,从而得出更可靠的因果关系结论。
综上所述,NHANES数据集在回归分析中的应用涉及到多重共线性、样本偏差、复杂性、时间序列等多个方面的考量,研究人员需要结合实际问题选择合适的回归方法,并在分析过程中注意数据的特点和限制,以得出科学可靠的结论。
nhanes 加权公式

nhanes 加权公式NHANES(全称为National Health and Nutrition Examination Survey)是美国一个重要的国家级民生统计调查项目,旨在评估和监测全美人口的健康状况和营养摄入情况。
在NHANES中,加权公式用于调整样本数据以代表整个美国人口。
NHANES的加权公式基于样本选择和抽样过程,以及样本个体代表性的统计权重。
这些权重将用于为采集到的样本数据进行加权,以评估样本数据在代表整个美国人口时的相对比例。
在NHANES中,有两个常用的加权公式:抽样权重(Sampling Weight)和就诊权重(Examination Weight)。
抽样权重是根据样本选择和抽样设计的结果分配给样本个体的权重。
该权重用于调整样本数据,以反映不同地区、民族、年龄和性别等因素在样本选择中的不同概率,并校正可能的非响应率。
就诊权重是根据样本个体的就诊情况和响应率分配的权重。
就诊权重用于调整样本数据,以反映不同人群就诊率的差异。
加权的目的是确保NHANES样本能够在统计分析中准确地代表整个美国人口。
通过使用加权公式,研究人员可以根据NHANES样本得出关于整个人口的估计值,并进行有效的比较和分析。
值得注意的是,NHANES加权公式只能保证样本代表性,而不能确保准确性。
因此,在使用NHANES数据时,研究人员需要考虑样本的限制,并结合其他可靠的数据源进行综合分析。
此外,NHANES调查还提供了一些其他的加权公式,以应对不同的统计需求,如碰撞权重(Collision Weight)和医疗健康统计权重(Medical Health Statistics Weight)等。
总之,NHANES加权公式是一种用于调整样本数据以代表整个美国人口的统计方法。
它能够在一定程度上保证样本的代表性,为研究人员提供基于NHANES数据的准确估计和分析。
nhanes项目介绍及数据提取流程

nhanes项目介绍及数据提取流程NHANES项目简介NHANES(National Health and Nutrition Examination Survey)是美国国家卫生与营养调查项目,旨在评估全美国人口的健康状况和营养状况,以促进公共卫生政策的制定和实施。
该项目自1960年开始,每年抽取一定数量的美国民众并经过体检和问卷调查,收集各种健康和营养信息。
截至目前,NHANES已成为全球公认的最大规模、最全面、最有代表性的健康和营养调查项目之一。
NHANES项目的数据是由美国国家卫生和营养调查中心(NCHS)负责管理和提供。
数据提取流程主要包括以下步骤:1.访问NHANES官方网站NHANES官方网站为https:///nchs/nhanes/index.htm。
用户需要在网站上注册账号,并完成相关的授权手续,方可下载NHANES数据。
2.确定所需数据类型和时间范围NHANES数据分为多个类型,包括人口学、体格测量、营养、健康问题、实验室等数据。
用户需根据自己的研究需要选择所需的数据类型和时间范围。
3.通过NCHS Research Data Center(RDC)下载数据用户需通过RDC下载NHANES数据。
RDC是NCHS提供的一种数据使用形式,用于保护NHANES数据的隐私和保密性。
用户需要通过在线预约的方式,在指定地点进行数据的下载和使用。
下载的数据格式为SAS、SPSS、Stata等。
4.数据处理和分析用户下载的NHANES数据是经过整理和编码的,需要进行数据处理和分析。
数据处理主要包括数据清理、变量选取、数据转换等。
数据分析则是将数据进行统计分析、描述分析、因素分析等,得出研究结论。
总结NHANES数据是健康和营养领域研究的重要数据来源,为解决公共卫生问题和制定卫生政策提供了有力支撑。
数据提取流程较为复杂,需要用户了解和掌握相关技能和知识。
在数据处理和分析过程中,用户需严格遵守NHANES数据使用规则,保护数据的隐私和机密。
nhanes数据库使用手册

nhanes数据库使用手册一、概述NHANES(National Health and Nutrition Examination Survey)数据库是一个大型的美国国家级的健康和营养调查数据集,由美国国家健康统计中心(National Center for Health Statistics, NCHS)进行管理和发布。
该数据库包含了大量关于人口健康和营养状况的信息,对于医学研究、公共卫生研究和流行病学研究具有重要的价值。
二、数据集特点NHANES数据库的数据集具有以下几个特点:1. 全国代表性:该数据集包含了来自全国各地的受访者,使得研究人员能够根据全国情况进行分析。
2. 综合性:该数据集包含了健康和营养状况的多种指标,包括生物学指标、生活方式、饮食、体格测量等。
3. 长期稳定性:NHANES数据集已经存在多年,并且每年进行更新,使得研究人员可以进行长期的趋势分析和研究。
4. 可靠性:该数据集经过了严格的质量控制和校验,保证了数据的准确性和可靠性。
三、数据集使用说明使用NHANES数据库需要遵守一定的规定和流程,下面是一些基本的使用说明:1. 获取许可:在使用NHANES数据集之前,需要先从NCHS获取许可。
NCHS会要求提供研究目的、研究背景等信息,以便评估是否批准使用申请。
2. 数据下载:获得使用许可后,可以通过NCHS的官方网站下载NHANES数据集。
数据集以电子表格的形式提供,包含了所需的各项指标和变量。
3. 数据处理:下载数据后需要进行数据处理和分析。
可以使用各种统计分析软件(如SPSS、SAS、Stata等)进行数据处理和分析。
在处理过程中需要注意数据的缺失值、异常值等问题。
4. 结果发布:在使用NHANES数据库进行研究成果发布时,必须注明数据来源和出处,遵守相关的知识产权和隐私保护规定。
5. 数据共享:为了保证数据的共享和利用,研究人员需要遵守NCHS的数据共享政策,在研究完成后将数据集共享给其他研究人员使用。
nhanesR:数据文件查找
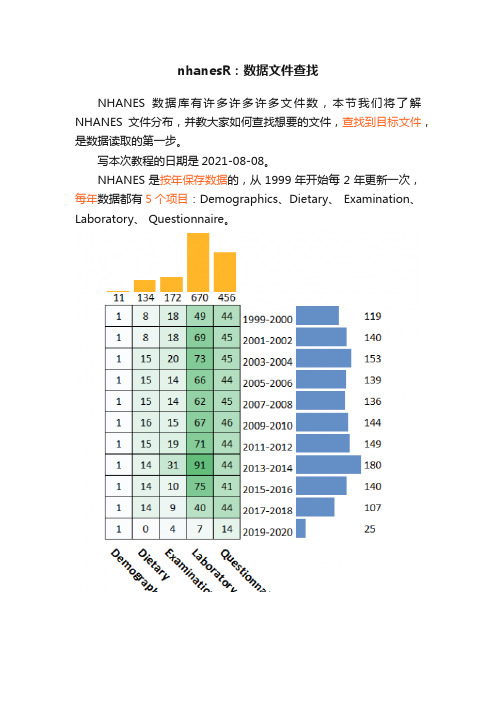
nhanesR:数据文件查找NHANES数据库有许多许多许多文件数,本节我们将了解NHANES文件分布,并教大家如何查找想要的文件,查找到目标文件,是数据读取的第一步。
写本次教程的日期是2021-08-08。
NHANES是按年保存数据的,从1999年开始每2年更新一次,每年数据都有5个项目:Demographics、Dietary、 Examination、Laboratory、 Questionnaire。
在年度方面,1999-2000年有119个数据文件,最少的是2017-2018年,只有107个数据,最多的是2013-2014年,有180个数据。
目前2019-2020年还在更新中,只有25个数据。
平均每年有大约140个数据左右。
在5大项目方面,Demographics数据量最少,Laboratory数据量最多。
Demographics每年只有1个数据,Dietary在1999-2000和2001-2002这两年都有8个文件,而后面基本都有15个文件,因为自2003年开始,表格的设计发生了变化。
在读取数据之前,需要先查询到我们需要的数据,在nhanesR包中,我们提供了nhs_files_pc()命令来查询本地数据库的文件,在nhs_files_pc()命令中,有以下几个重要参数。
·years:年份,默认所有所有年份·items:5大项目,忽略大小、左匹配、默认所有项目·pattern:文件名中包含的字符·file_ext:文件扩展名,默认是所有类型文件,用于后续的数据读取。
现在,我们要找到所有年份的人口学数据demo·没有赋值years和items表示在所有年和项目文件中查询·将demo赋值给pattern,表示在所有文件名中查询包含demo 的文件名·将tsv赋值给file_ext表示文件扩展名为tsv查询结果共有11个,是自1999年到2020年的全部11个人口学数据文件。
nhanes数据库选题设计

nhanes数据库选题设计研究设计:使用NHANES数据库进行健康与膳食习惯的相关性分析背景:NHANES(美国国家健康和营养调查)是美国一项广泛调查,旨在了解美国民众的健康情况和膳食习惯。
该数据库收集了大量关于人口特征、健康状况、膳食摄入、生物标志物以及其他健康相关因素的数据。
在这个任务中,我们将利用这些数据来探索健康与膳食习惯之间的关联。
方法:1. 数据采集:我们将使用NHANES数据库中的最新可用数据。
这些数据包括人口特征(如年龄、性别、种族)、体重指数、血压、健康状况、膳食信息(如摄入量、食物种类、饮食习惯等)等。
2. 数据清洗:我们将对原始数据进行清理和整理,排除缺失值和异常值,并确保数据的准确性和一致性。
3. 数据分析:我们将使用适当的统计方法对清洗后的数据进行分析。
可能的分析方法包括描述性统计、相关性分析、多元回归分析等,以探索健康与膳食习惯之间的关联情况。
4. 结果解释:根据分析结果,我们将解释健康与膳食习惯之间的关联,并讨论可能的解释和机制。
我们还将提供对于公共卫生和营养方面的启示,以及任何可能的干预措施。
意义:这项调研将有助于揭示人们的膳食习惯如何与健康状况相关联。
通过分析NHANES数据库中的大规模数据,我们可以获得对美国人口整体健康和膳食情况的全面了解。
这些研究结果可以为制定公共卫生政策、改善人们的膳食习惯以及预防疾病提供重要的依据。
总结:在本研究中,我们将使用NHANES数据库,以健康与膳食习惯之间的关联为研究主题,通过数据采集、清洗、分析和结果解释等步骤,揭示两者之间的关系,并探讨其中的意义和启示。
这项研究对于促进人们的健康、营养管理以及制定相关政策具有重要意义。
nhanes课题设计套路

nhanes课题设计套路NHANES(National Health and Nutrition Examination Survey)是美国国家卫生和营养检查调查的缩写,是一项定期进行的全国性调查,旨在评估美国人口的健康和营养状况。
NHANES的课题设计套路通常包括以下几个方面:1. 目标确定,NHANES的课题设计首先需要明确研究的目标和研究问题。
例如,研究者可能想了解特定人群的健康状况、营养摄入情况,或者探索某些因素与健康指标之间的关系。
2. 样本选择,NHANES采用多阶段分层抽样的方法,以确保样本的代表性。
研究者需要根据研究目标确定所需的样本规模和特征,并根据NHANES提供的样本选择方法进行抽样。
3. 数据收集,NHANES通过面访、体检和实验室检测等方式收集数据。
研究者需要确定所需的变量和指标,并根据NHANES的数据收集流程进行数据采集。
4. 数据分析,NHANES提供了丰富的数据,研究者可以利用这些数据进行统计分析和建模。
根据研究问题,研究者可以选择适当的统计方法和模型,对数据进行分析并得出结论。
5. 结果解释,研究者需要将分析结果进行解释,并结合相关文献和理论进行讨论。
他们应该考虑研究的局限性,并提出可能的解释和推论。
6. 结果应用,NHANES的研究结果可以用于制定公共卫生政策、改善健康服务和教育,以及指导个体的健康行为。
研究者可以将研究结果应用于实际问题,并提出相关建议和措施。
总之,NHANES的课题设计套路包括目标确定、样本选择、数据收集、数据分析、结果解释和结果应用等环节。
研究者需要严谨地进行每个环节的工作,确保研究的科学性和可靠性。
nhanes 平滑曲线拟合

nhanes 平滑曲线拟合(最新版)目录1.NHANES 简介2.平滑曲线拟合的概念和原理3.NHANES 平滑曲线拟合的具体方法4.NHANES 平滑曲线拟合的应用案例5.NHANES 平滑曲线拟合的优点和局限性正文1.NHANES 简介HANES(National Health and Nutrition Examination Survey)是美国国家卫生和营养调查的一项重要研究,旨在收集关于美国人健康和营养状况的数据。
NHANES 的研究人员会对参与者进行详细的身体检查和问卷调查,以了解他们的健康状况、生活方式和饮食习惯等方面的信息。
这些数据对于了解美国人的健康状况和制定相关政策具有重要意义。
2.平滑曲线拟合的概念和原理平滑曲线拟合是一种数据分析方法,通过对数据点进行加权平均,得到一条平滑的曲线,以揭示数据背后的规律。
在实际应用中,平滑曲线拟合可以用于预测趋势、发现异常值和消除数据噪声等。
3.NHANES 平滑曲线拟合的具体方法HANES 平滑曲线拟合的具体方法主要包括以下几个步骤:(1)数据预处理:将 NHANES 收集的原始数据进行清洗和整理,剔除异常值和缺失值,确保数据质量。
(2)选择合适的拟合模型:根据数据特点和研究目的,选择合适的平滑曲线拟合模型,如线性拟合、多项式拟合、指数拟合等。
(3)拟合参数估计:利用最小二乘法或其他优化算法,求解拟合模型的参数,得到平滑曲线。
(4)拟合效果评估:通过比较拟合曲线与实际数据点的吻合程度,评估拟合效果,以便进一步调整拟合模型和参数。
4.NHANES 平滑曲线拟合的应用案例HANES 平滑曲线拟合在健康和营养领域的应用案例众多,以下是两个具体的例子:(1)分析美国人身高和体重的关系:通过对 NHANES 收集的身高和体重数据进行平滑曲线拟合,可以揭示美国人身高和体重之间的关系,为制定相关政策提供依据。
(2)研究不同年龄段人群的营养摄入状况:通过对 NHANES 收集的不同年龄段人群的营养摄入数据进行平滑曲线拟合,可以了解不同年龄段人群的营养摄入状况,为制定针对性的营养干预措施提供参考。
CDC NHANES数据分析工具包 RNHANES版本1.1.0说明书

Package‘RNHANES’October12,2022Type PackageTitle Facilitates Analysis of CDC NHANES DataVersion1.1.0Date2016-11-28URL /silentspringinstitute/RNHANESBugReports https:///silentspringinstitute/RNHANES/issuesDescription Tools for downloading and analyzing CDC NHANES data,with a focus on analytical laboratory data.License Apache License2.0|file LICENSELazyData TRUEDepends R(>=2.10)Imports foreign,survey,rvest,xml2,methods,dplyrSuggests testthat,knitr,rmarkdownVignetteBuilder knitrRoxygenNote5.0.1NeedsCompilation noAuthor Herb Susmann[cre,aut],Silent Spring Institute[cph]Maintainer Herb Susmann<************************>Repository CRANDate/Publication2016-11-2902:45:46R topics documented:RNHANES-package (2)demography_filename (2)download_nhanes_file (3)file_suffix (3)load_nhanes_description (4)12demography_filename nhanes_analyze (4)nhanes_cycle_years (5)nhanes_data_files (5)nhanes_detection_frequency (6)nhanes_hist (7)nhanes_load_data (8)nhanes_load_demography_data (9)nhanes_quantile (10)nhanes_sample_size (11)nhanes_search (11)nhanes_survey (12)nhanes_survey_design (14)nhanes_variables (14)nhanes_vcov (15)process_file_name (16)validate_year (16)Index17 RNHANES-package RNHANES simplifies downloading and analyzing NHANES data.DescriptionRNHANES simplifies downloading and analyzing NHANES data.demography_filename Translates cycle years into the correct demographyfilename suffix,e.g.’2001-2002’returns’B’DescriptionTranslates cycle years into the correct demographyfilename suffix,e.g.’2001-2002’returns’B’Usagedemography_filename(year)Argumentsyear NHANES cycle,e.g."2001-2002"Valuesuffix character e.g."B"download_nhanes_file3 download_nhanes_file Download an NHANES datafile from a given cycleDescriptionDownload an NHANES datafile from a given cycleUsagedownload_nhanes_file(file_name,year,destination=tempdir(),cache=TRUE)Argumentsfile_namefile nameyear NHANES cycledestination directory to download thefile intocache whether to cache thefileValuepath to the downloadedfilefile_suffix Returns the NHANESfile suffix for the given yearDescriptionReturns the NHANESfile suffix for the given yearUsagefile_suffix(year)Argumentsyear NHANES cycle year(e.g."2001-2002")Valuesuffix character(e.g."B"or"C")4nhanes_analyzeload_nhanes_descriptionDownload an NHANES descriptionfileDescriptionDownload an NHANES descriptionfileUsageload_nhanes_description(file_name,year,destination=tempdir(),cache=FALSE)Argumentsfile_namefile nameyear NHANES cycledestination directory to download thefile intocache whether to cache thefileValuedata frame containing thefile descriptionnhanes_analyze Compute quantiles from NHANES weighted survey dataDescriptionCompute quantiles from NHANES weighted survey dataUsagenhanes_analyze(analysis_fun,nhanes_data,column,comment_column="",weights_column="",filter=NULL)Argumentsanalysis_fun function to use to analyze each variablenhanes_data data frame containing NHANES datacolumn column name of the variable to compute quantiles forcomment_column comment column name of the variableweights_column name of the weights columnfilter logical expression used to subset the datanhanes_cycle_years5 Valuea data framenhanes_cycle_years List the valid NHANES cycle yearsDescriptionList the valid NHANES cycle yearsUsagenhanes_cycle_years()Valuevector of NHANES cycle yearsnhanes_data_files List the NHANES datafilesDescriptionList the NHANES datafilesUsagenhanes_data_files(components="all",destination=tempfile(),cache=TRUE)Argumentscomponents one of"all","demographics","dietary","examination","laboratory","question-naire"destination destinatino to save thefile listscache whether to cache the downloadedfile lists so they don’t have to be re-downloaded every timeValuedata frame of NHANES datafiles available to download6nhanes_detection_frequencyExamples##Not run:#Download a data frame of all the NHANES data filesfiles<-nhanes_data_files()#Download a data frame of just the laboratory fileslab_files<-nhanes_data_files(component="laboratory")##End(Not run)nhanes_detection_frequencyCompute detection frequencies of NHANES dataDescriptionCompute detection frequencies of NHANES dataUsagenhanes_detection_frequency(nhanes_data,column,comment_column,weights_column="",filter=NULL)Argumentsnhanes_data data frame containing NHANES datacolumn column names of the variables to compute detection frequencies forcomment_column comment column names of the variables to compute detection frequencies for weights_column sample weight columnfilter logical expression used to subset the dataValuenamed vector of detection frequenciesExamples##Not run:dat<-nhanes_load_data("UHG_G","2011-2012",demographics=TRUE)#Compute detection frequencynhanes_detection_frequency(dat,c("URXUHG"),c("URDUHGLC"))##End(Not run)nhanes_hist7 nhanes_hist Plot a weighted histogram of an NHANES variableDescriptionPlot a weighted histogram of an NHANES variableUsagenhanes_hist(nhanes_data,column,comment_column,weights_column="",filter="",transform="",...)Argumentsnhanes_data data frame containing NHANES datacolumn column name of the variable to plotcomment_column comment column of the variable to plotweights_column name of the weights columnfilter logical expression used to subset the datatransform transformation to apply to the column.Accepts any function name,for example: "log"...parameters passed through to svyhist functionValuea data frameExamples##Not run:dat<-nhanes_load_data("PFC_G","2011-2012",demographics=TRUE)nhanes_hist(dat,"LBXPFOA")##End(Not run)8nhanes_load_data nhanes_load_data Download NHANES datafiles.DescriptionDownload NHANES datafiles.Usagenhanes_load_data(file_name,year,destination=tempdir(),demographics=FALSE,cache=TRUE,recode=FALSE,recode_data=FALSE,recode_demographics=FALSE,allow_duplicate_files=FALSE)Argumentsfile_name NHANESfile name(e.g."EPH")or a vector offilenames(e.g c("EPH","GHB")) year NHANES cycle year(e.g."2007-2008")or a vector of cycle yearsdestination directory to download thefiles todemographics include demographics data into the datasetcache whether to cache thefile to diskrecode whether to recode the data and demographics(overrides other parameters)recode_data whether to recode just the datarecode_demographicswhether to recode just the demographicsallow_duplicate_fileshow to handle a request that has duplicatefile names/cycle years.By defaultduplicates will be removed.DetailsIf you supply vectors for bothfile_name and year,then the vectors are paired and eachfile_name/year pair is downloaded.For example,file_name=c("EPH,GHB"),year=c("2009-2010","2011-2012")will download"EPH_F.XPT"and"EPH_G.XPT".In other words,the function does not download every possible combination offile_name and year.You can specifyfile names in several formats.In order of specificity:You can supply the complete filename:"EPH_F.XPT"You can supply thefilename without an extension:"EPH_F"You can supply thefilename without a suffix:"EPH",year="2009-2010"If you are loading the samefile across multiple years,you must supply thefilename without a suffix so that the correct suffix for each year can be used.This function returns either a list or a data frame.If you load multiplefiles,the return value will always be a list.This is because the columns may not match in betweenfiles.If you load onefile, the result will be a data frame.nhanes_load_demography_data9Valueiffile_name or year is a vector,returns a list containing a data frame for eachfile_name.Iffile_name and year are both singletons,then a data frame is returned.Examples##Not run:nhanes_load_data("UHG","2011-2012")#Load data with demographicsnhanes_load_data("UHG","2011-2012",demographics=TRUE)#Download to/tmp directory and overwrite the file if it already existsnhanes_load_data("HDL_E","2007-2008",destination="/tmp",cache=FALSE)##End(Not run)nhanes_load_demography_dataDownload NHANES demographyfiles for a specific cycle.DescriptionDownload NHANES demographyfiles for a specific cycle.Usagenhanes_load_demography_data(year,destination=tempdir(),cache=FALSE)Argumentsyear NHANES cycle year(e.g."2011-2012")destination directory to download thefile tocache whether load thefile if it already exists on diskExamples##Not run:nhanes_load_demography_data("2011-2012")##End(Not run)10nhanes_quantile nhanes_quantile Compute quantiles from NHANES weighted survey dataDescriptionCompute quantiles from NHANES weighted survey dataUsagenhanes_quantile(nhanes_data,column,comment_column="",weights_column="",quantiles=seq(0,1,0.25),filter=NULL)Argumentsnhanes_data data frame containing NHANES datacolumn column name of the variable to compute quantiles forcomment_column comment column name of the variable for checking if computed quantiles are below the LODweights_column name of the weights columnquantiles numeric or vector numeric of quantiles to computefilter logical expression used to subset the dataValuea data frameExamples##Not run:dat<-nhanes_load_data("UHG_G","2011-2012",demographics=TRUE)#Compute50th,95th,and99th quantilesnhanes_quantile(dat,"URXUHG","URDUHGLC","WTSA2YR",c(0.5,0.95,0.99))##End(Not run)nhanes_sample_size11 nhanes_sample_size Compute the sample size of NHANES dataDescriptionCompute the sample size of NHANES dataUsagenhanes_sample_size(nhanes_data,column,comment_column="",weights_column="",filter=NULL)Argumentsnhanes_data data frame containing NHANES datacolumn column name of the variable to compute quantiles forcomment_column comment column name of the variable for checking if computed quantiles are below the LODweights_column name of the weights columnfilter logical expression used to subset the dataValuea data frameExamples##Not run:dat<-nhanes_load_data("UHG_G","2011-2012",demographics=TRUE)nhanes_sample_size(dat,"URXUHG","URDUHGLC")##End(Not run)nhanes_search Search the results from nhanes_variables or nhanes_data_filesDescriptionSearch the results from nhanes_variables or nhanes_data_filesUsagenhanes_search(nhanes_data,query,...,fuzzy=FALSE,ignore_case=TRUE,max_distance=0.2)Argumentsnhanes_data nhanes variable list,from nhanes_variables function,or datafile list,from nhanes_data_files query regular expression search query...additional arguments to pass to dplyr::filterfuzzy whether to use fuzzy string matching for search(based on edit distances)ignore_case whether search query is case-sensitivemax_distance parameter for tuning fuzzy string matching,0-1Valuedata framefiltered by search queryExamples##Not run:nhanes_files<-nhanes_data_files()#Search for data files about pesticidesnhanes_search(nhanes_files,"pesticides")##End(Not run)nhanes_survey Apply a function from the survey package to NHANES dataDescriptionApply a function from the survey package to NHANES dataUsagenhanes_survey(survey_fun,nhanes_data,column,comment_column="",weights_column="",filter=NULL,analyze="values",callback=NULL,...)Argumentssurvey_fun the survey package function(e.g.svyquantile or svymean)nhanes_data data frame containing NHANES datacolumn column name of the variable to compute quantiles forcomment_column comment column name of the variableweights_column name of the weights columnfilter logical expression used to subset the dataanalyze one of"values"or"comments",whether to apply the survey function to the value or comment column.callback optional function to execute on each row of the dataframe...other arguments to pass to the survey functionDetailsThis function provides a generic way to apply any function from the survey package to NHANES data.RNHANES provides specific wrappers for computing quantiles(nhanes_quantile)and detec-tion frequencies(nhanes_detection_frequency),and this function provides a general way to use any survey function.Valuea data frameExamples##Not run:library(survey)nhanes_data<-nhanes_load_data("EPH","2011-2012",demographics=TRUE)#Compute the mean of triclosan using the svymean functionnhanes_survey(svymean,nhanes_data,"URXTRS","URDTRSLC",na.rm=TRUE)#Compute the variance using svyvarnhanes_survey(svyvar,nhanes_data,"URXTRS","URDTRSLC",na.rm=TRUE)##End(Not run)14nhanes_variables nhanes_survey_design Build survey objects for NHANES dataDescriptionBuild survey objects for NHANES dataUsagenhanes_survey_design(nhanes_data,weights_column="")Argumentsnhanes_data data frame containing NHANES dataweights_column name of the weights columnValuea survey design objectExamples##Not run:dat<-nhanes_load_data("UHG_G","2011-2012",demographics=TRUE)design<-nhanes_survey_design(dat,"WTSA2YR")svymean(~RIDAGEYR,design)svyglm(URXUHG~RIDAGEYR+RIAGENDR,design)##End(Not run)nhanes_variables Load the NHANES comprehensive variable listDescriptionLoad the NHANES comprehensive variable listUsagenhanes_variables(components="all",destination=tempfile(),cache=TRUE)nhanes_vcov15Argumentscomponents one of"all","demographics","dietary","examination","laboratory","question-naire"destination where to save the variable listcache whether to cache the downloaded variable list so it doesn’t have to be re-downloaded every timeHelper function for nhanes_variables functionValuedatExamples##Not run:#Download the comprehensive NHANES variable listvariables<-nhanes_variables()#Download the variable list and cache it in a specific filevariables<-nhanes_variables(destination="./nhanes_data")##End(Not run)nhanes_vcov Extract variance/covariance matrix from parameters of svymeanDescriptionExtract variance/covariance matrix from parameters of svymeanUsagenhanes_vcov(nhanes_data,columns,weights_column="",filter="")Argumentsnhanes_data data frame containing NHANES datacolumns columns to include in svymean forweights_column name of the weights columnfilter logical expression used to subset the dataValuea data frame16validate_year Examples##Not run:dat<-nhanes_load_data("PFC_G","2011-2012",demographics=TRUE)nhanes_vcov(dat,c("LBXPFOA","LBXPFOS"))##End(Not run)process_file_name Processes afile name to make sure it is valid and has the correct suf-fix and extension File names with an extension(e.g.".XPT")are notalteredDescriptionProcesses afile name to make sure it is valid and has the correct suffix and extension File names with an extension(e.g.".XPT")are not alteredUsageprocess_file_name(file_name,year,extension=".XPT")Argumentsfile_name name of thefileyear NHANES cycle yearextensionfile extensionvalidate_year Check that the year is in the correct format e.g.’2001-2002’is correctand returns TRUE,’2001’is not correct and returns FALSEDescriptionCheck that the year is in the correct format e.g.’2001-2002’is correct and returns TRUE,’2001’is not correct and returns FALSEUsagevalidate_year(year,throw_error=TRUE)Argumentsyear the year or years to validatethrow_error whether to throw an error if the year is invalidIndexdemography_filename,2download_nhanes_file,3file_suffix,3load_nhanes_description,4nhanes_analyze,4nhanes_cycle_years,5nhanes_data_files,5nhanes_detection_frequency,6nhanes_hist,7nhanes_load_data,8nhanes_load_demography_data,9nhanes_quantile,10nhanes_sample_size,11nhanes_search,11nhanes_survey,12nhanes_survey_design,14nhanes_variables,14nhanes_vcov,15process_file_name,16RNHANES(RNHANES-package),2rnhanes(RNHANES-package),2RNHANES-package,2rnhanes-package(RNHANES-package),2validate_year,1617。
nhanes检验结果单位解读

Nhanes检验结果单位解读1. 介绍美国国家健康和营养调查(NHANES)是由美国国家卫生和营养中心(NCHS)开展的一项重要健康调查项目,其旨在为研究人员、政策制定者和公众提供全国范围内关于健康和营养状况的详细信息。
NHANES调查的内容广泛,包括人口统计学信息、身体测量数据、实验室检测结果等。
其中,实验室检测结果是了解个体健康状况的重要指标之一。
2. Nhanes检验结果单位解读的重要性NHANES调查的实验室检验结果涵盖了许多身体指标,如血糖、血脂、肝功能等,这些结果对于了解个体的身体健康状况至关重要。
然而,对于大部分普通人来说,这些实验室检验结果的单位和具体含义并不是很清楚。
对于NHANES检验结果单位的解读十分重要,它能够帮助人们更好地理解自己的检测结果,进而采取相应的健康管理措施。
3. 血糖检测在NHANES的实验室检验结果中,血糖是一个重要的指标。
血糖的单位通常是以毫摩尔/升(mmol/L)或毫克/分升(mg/dL)来表示。
在国际上,毫摩尔/升是更为常见的单位,而在美国,毫克/分升则是常用的单位。
在实际生活中,了解这两种单位之间的换算关系对于理解自己的血糖水平十分重要。
4. 血脂检测另一个在NHANES实验室检验结果中常见的指标是血脂,包括胆固醇、甘油三酯等。
这些指标的单位通常以毫摩尔/升(mmol/L)或毫克/分升(mg/dL)来表示。
对于国际单位和美国单位之间的换算关系,也需要进行了解和解读。
5. 肝功能检测肝功能检测也是NHANES实验室检验结果中的重要指标之一,包括丙氨酸氨基转移酶(ALT)、天冬氨酸氨基转移酶(AST)等。
这些指标的单位通常是以国际单位/升(IU/L)来表示,需要对其具体含义和健康标准进行理解和解读。
6. 结语NHANES实验室检验结果单位的解读对于个体健康管理和疾病预防具有重要意义。
通过了解不同指标的单位和具体含义,人们可以更好地理解自己的健康状况,及时采取健康管理措施。
如何利用临床数据快速发表SCI?

如何利用临床数据快速发表SCI?临床科研分很多种,Clinical trial(临床试验), Retrospective study(回顾性观察研究), Prospective observational study(前瞻性观察研究)等,而开展临床实验时病例的分配与随访、数据的收集与处理等都需要花费巨大的人力物力,耗时较长,前瞻性观察研究也离不开方案设计、撰写、数据收集等,耗时耗力。
那有没有什么简单的方法可以发表回顾性的观察研究呢?为什么我们推荐大家使用NHANES,构建自己的临床数据挖掘系统能力?与自己收集医院HIS 系统病例数据不同,NHANES 不需要你再自行收集数据,数据均已收集完成,你只需要掌握临床科研挖掘系统能力,就能在自己感兴趣的领域成为专家。
我们选择 NHANES 的原因是,就像我在丁香科研课程上介绍:NHANES 数据库是一座金矿,也是发表第1篇临床 SCI 的最优选择,目前已经收集了20年、10w人、超大变量信息等可以分析的数据,且后续会持续 2 年不断更新,选择 NHANES 就是选择以最低的成本获取高质量的临床科研数据。
不断更新的临床数据库+最前沿临床科研挖掘系统,数据和技术均不断迭代,才能持续转换为巨大的临床科研价值,发文章的速度会远超一般人想象,同时,'临床科研挖掘系统’的也不是每个团队都具备的能力,这些原因造成很多数据库的价值在沉寂。
我们在过去帮助多个数据库实现进行价值挖掘,现在将在这个领域积累的最前沿临床科研挖掘系统能力在 NHANES 数据库上进行开放。
如果你在思考自己的临床科研的战略,或者想要从0-1发表1篇临床科研文章,我们都建议大家选择 NHANES 入手,先掌握发表临床科研的方法,然后不断深入,发文章多发同一个专题的文章,引起这个领域其他研究者的关注,同时主动做汇报、与更厉害的专家交流请教,不断积累自己的影响力和人脉,再调动产业的资源做更大型的研究。
海水中铵态氮的测定原理

海水中铵态氮的测定原理海水中铵态氮的测定原理主要有两种方法:温度蒸馏法和Nessler法。
温度蒸馏法是一种将海水中的铵态氮转化为氨氮后通过蒸馏来测定含量的方法。
具体步骤如下:1. 取一定量的海水样品,并加入强碱溶液,将所有铵态氮转化为氨氮。
2. 通过加热将样品中的氨氮蒸发出来,并通过冷凝器冷却成液态。
3. 收集冷凝的液体,并使用强碱溶液中和其中的氨氮。
4. 将中和液中的氨氮通过酸溶液置换为氨气,通过蒸馏冷凝器将氨气连续轮流抽剩。
5. 计量收集到的氨气,并使用特定的仪器,如分光光度计等,测量氨气的吸光度。
6. 根据氨气的吸光度,使用标准曲线或公式计算出样品中的铵态氮含量。
Nessler法是一种使用Nessler试剂与铵态氮发生反应,并形成深黄色络合物来测定铵态氮的方法。
具体步骤如下:1. 取一定量的海水样品,并加入Nessler试剂。
2. Nessler试剂与溶液中的铵态氮发生反应,生成深黄色的络合物。
3. 使用分光光度计等仪器测量络合物的吸光度。
4. 根据吸光度值,使用标准曲线或公式计算出样品中的铵态氮含量。
这两种方法虽然原理不同,但都属于测量海水中铵态氮含量的常用方法。
它们的优缺点如下:温度蒸馏法的优点:1. 可以将海水中的铵态氮转化为氨氮,提高测量的灵敏度和准确性。
2. 尽量避免了其他质量干扰物质的干扰。
3. 测量结果稳定可靠,适用于不同浓度的样品。
温度蒸馏法的缺点:1. 需要一系列繁琐的实验操作步骤,耗时较长。
2. 对实验操作人员的技术要求较高。
Nessler法的优点:1. 操作简单,易于掌握。
2. 测量结果稳定准确,可用于大样品量的分析。
Nessler法的缺点:1. 对其他物质的干扰较敏感,可能产生较大的误差。
2. Nessler试剂有毒,需要严格控制操作条件和试剂的使用量。
3. 与温度蒸馏法相比,Nessler法的测量灵敏度较低。
综上所述,温度蒸馏法和Nessler法都是常用的海水中铵态氮测定方法。
nhanesR:NHANES数据库简介

nhanesR:NHANES数据库简介NHANES简介国家健康和营养检查调查(NHANES) 是一项旨在评估美国成人和儿童健康和营养状况的研究计划。
该调查的独特之处在于它结合了访谈和体检。
NHANES 是国家卫生统计中心 (NCHS) 的一项重大计划。
NCHS 是疾病控制和预防中心 (CDC) 的一部分,负责为国家提供重要和健康统计数据。
NHANES 计划始于 1960 年代初,并作为一系列针对不同人群或健康主题的调查进行。
1999 年,该调查成为一项持续性计划,其重点不断变化,关注各种健康和营养测量,以满足新出现的需求。
该调查每年对大约5,000 人的全国代表性样本进行检查。
这些人分布在全国各县,每年有 15 个县被访问。
NHANES 采访包括人口统计、社会经济、饮食和健康相关问题。
检查部分包括医学、牙科和生理测量,以及由训练有素的医务人员进行的实验室测试。
调查的结果将用于确定主要疾病的流行情况和疾病的危险因素。
信息将用于评估营养状况及其与健康促进和疾病预防的关联。
NHANES 的发现也是身高、体重和血压等测量的国家标准的基础。
这项调查的数据将用于流行病学研究和健康科学研究,这有助于制定健全的公共卫生政策、指导和设计健康计划和服务,并为国家扩展健康知识。
调查内容与以往的健康检查调查一样,将收集有关人群慢性病患病率的数据。
对先前未确诊疾病以及受访者已知和报告的疾病的估计是通过调查得出的。
此类信息是 NHANES 计划的一个特殊优势。
将检查风险因素,即一个人的生活方式、体质、遗传或环境中可能增加患某种疾病或病症的机会的那些方面。
将研究吸烟、饮酒、性行为、吸毒、身体健康和活动、体重和饮食摄入量。
还将收集有关生殖健康某些方面的数据,例如口服避孕药的使用和母乳喂养的做法。
要研究的疾病、医疗条件和健康指标包括:1.贫血(Anemia)2.身体成分(Body composition)3.心血管疾病(Cardiovascular disease)4.糖尿病(Diabetes)5.环境暴露(Environmental exposures)6.眼疾(Eye diseases)7.听力损失(Hearing loss)8.传染性疾病(Infectious diseases)9.肾脏疾病(Kidney disease)10.营养(Nutrition)11.肥胖(Obesity)12.口腔健康(Oral health)13.骨质疏松症(Osteoporosis)14.身体素质和身体机能(Physical fitness and physical functioning)15.生殖史和性行为(Reproductive history and sexual behavior)16.呼吸系统疾病(哮喘、慢性支气管炎、肺气肿)(Respiratory disease (asthma, chronic bronchitis, emphysema))17.性传播疾病(Sexually transmitted diseases)18.想象(Vision)19.味觉和嗅觉(Taste and smell)选择调查样本以代表所有年龄段的美国人口。
NHANES数据结构

NHANES数据结构自1999年起,NHANES的数据每2年发布1次,并持续更新。
NHANES数据主要由以下4个部分组成:1.按照时间:年周期(Years Cycle)2.按照收集方法:5大项目(Items)3.按照数据类型:数据文件(Data Files)4.每次数据文件都有多个字段(Variable)下面来详细介绍一下各自的特点。
1、年周期(Year Cycle)当前的NHANES,也称为连续性NHANES(Continuous NHANES),是指自1999 年以来产生的数据的两年周期,目前已有11个年周期。
2、5大项目(Items)每个周期按收集方法分为五个部分:1.人口统计(Demographics)2.饮食(Dietary)3.检查(Examination)4.实验室(Laboratory)5.问卷(Questionnaire)•人口统计文件:包含调查设计变量,例如权重、分层和初级抽样单位,以及人口统计变量。
•饮食文件:包含从参与者那里收集的有关其饮食摄入量的数据,其中包括食物、饮料和膳食补充剂。
•检查文件:包含通过体检和牙科检查收集的信息。
•实验室文件:包含对血液、尿液、头发、空气、结核病皮肤测试以及家庭灰尘和水样本的分析结果。
•问卷文件:包含通过家庭和移动考试中心访谈收集的数据。
3、数据文件每个项目中都有许多单独的数据文件。
要查找文件想要的文件,调查内容手册可以帮助你,并且会告诉你某些文件是否随着时间发生了改变。
•/nchs/data/nhanes/survey-contents-508.pdf下面列出了这些数据文件的示例。
•人口数据:包含人口统计变量以及调查权重和其他调查设计变量•饮食数据:用于饮食访谈、补充剂使用等的个人文件。
•检查数据:关于听力、血压、身体测量、肌肉力量、口腔健康、视力检查等的个人文件。
•实验室数据:关于尿液收集、甲型肝炎病毒、HIV、重金属、血浆葡萄糖、总胆固醇、甘油三酯等的个人文件。
nhanes饮食数据计算方法

nhanes饮食数据计算方法嘿,朋友们!咱今儿来聊聊 NHANES 饮食数据计算方法。
这可真是个有意思的事儿呢!你知道吗,NHANES 就像是一个超级大的美食宝库,里面藏着各种各样关于我们吃吃喝喝的数据。
那怎么从这个大宝藏里算出有用的信息呢?咱先来说说数据收集吧。
就好像你去菜市场买菜,得一样一样挑选,把各种食材都弄清楚。
NHANES 也是这样,得把每个人吃的每一口食物都详细记录下来。
这可不是个简单活儿呀!然后呢,就得对这些数据进行整理啦。
这就好比你把买回家的菜分类放好,肉放一堆,菜放一堆,水果放一堆。
把这些饮食数据按照不同的类别、不同的时间等等进行归类整理。
接下来就是关键的计算啦!比如说,要算一个人一天摄入了多少蛋白质,那就要把吃的所有含有蛋白质的食物的量都加起来。
这就像是搭积木,一块一块往上加,最后看看堆起来有多高。
再比如,算某种营养素的摄入量占总摄入量的比例,这就好像分蛋糕呀,看看这块蛋糕里某种口味占了多大一块儿。
这可不是随便算算就行的,得特别仔细,不然就会出错哟!你想想,如果算错了,那不就像做饭放错了调料,味道全变啦!而且呀,这计算过程中还得考虑很多因素呢。
比如说不同食物的营养成分含量不一样,烹饪方法也会影响营养成分呢。
那怎么才能保证算得准确呢?这就需要专业的知识和技能啦!就像一个好厨师,得知道各种食材怎么搭配,怎么做才好吃。
咱普通人可能觉得这挺复杂的,但对于那些研究饮食和健康的专家们来说,这可是他们的拿手好戏呢!他们能从这些数据里发现很多有趣的东西,比如哪种饮食习惯更健康,哪些地区的人饮食有什么特点。
哎呀,这 NHANES 饮食数据计算方法可真是不简单呀!但它却能让我们更好地了解自己的饮食,知道该怎么吃得更健康。
所以呀,别小看了这些数据和计算方法,它们就像是我们健康的小卫士呢!通过它们,我们能找到更好的饮食之道,让自己更有活力,更健康。
总之呢,NHANES 饮食数据计算方法虽然有点复杂,但它真的很重要呀!它能帮助我们更好地照顾自己的身体,让我们吃得明白,吃得健康。
nhanes 的命名规则

nhanes 的命名规则NHANES是National Health and Nutrition Examination Survey的缩写,意为国家健康与营养调查。
该项目由美国国家卫生与营养调查中心(National Center for Health Statistics)主导,并得到美国疾病控制与预防中心(Centers for Disease Control and Prevention)的支持。
NHANES是美国健康和营养状况的重要数据来源,自20世纪60年代开始进行,至今已经进行了多个周期的调查。
NHANES的主要目的是评估美国民众的健康状况和营养摄入情况,以及各种疾病和健康问题的发生率。
通过对样本人群进行面对面的问卷调查、体格测量、实验室检测和营养评估,NHANES收集了大量的健康和营养数据。
这些数据对于制定公共健康政策、评估公共卫生干预措施的效果、研究疾病的风险因素等方面都具有重要意义。
NHANES的命名规则遵循一定的标准,以确保数据的准确性和可比性。
每个周期的调查都被分为两个阶段:家庭调查和医疗检查。
在家庭调查阶段,调查员将访问家庭并收集一系列的健康和营养信息,包括个人健康史、生活方式、饮食习惯等。
在医疗检查阶段,被调查者将前往指定的检查中心接受身体检查和实验室检测,以提供更详细的健康数据。
NHANES数据的命名规则采用了一种特定的编码方式,以确保数据的唯一性和一致性。
例如,每个被调查者都有一个唯一的标识号码,称为“SEQN”,用于跟踪该人在不同调查周期的数据。
此外,NHANES还使用了其他的变量命名规则,如“BMX”表示体格测量数据,“BPX”表示血压数据,“DRXTOT”表示饮食调查数据等。
NHANES的命名规则不仅仅是为了方便数据管理和分析,更重要的是确保数据的一致性和可比性。
通过统一的命名规则,不同调查周期的数据可以进行比较和整合,从而更好地了解美国民众的健康和营养状况的变化趋势。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
•循证研究与临床转化·方法学 •NHANES项目介绍及数据提取流程郭晓娟1,2,田国祥3,潘振宇2,杨津2,柳青青2,吕军2,4基金项目:国家社会科学基金一般项目(16BGL183)作者单位:1 710061 西安,西安交通大学第一附属医院神经内科;2 710061 西安,西安交通大学医学部公共卫生学院;3 100700 北京,中国人民解放军总医院第七医学中心;4 710061 西安,西安交通大学第一附属医院临床研究中心通讯作者:吕军,E-mail:lujun2006@ doi:10.3969/j.issn.1674-4055.2019.06.03【摘要】美国国家健康与营养调查(NHANES,National Health and Nutrition Examination Survey)是一项旨在评估美国成人和儿童健康和营养状况的研究计划,该调查的独特之处在于它结合了访谈和体检。
NHANES是国家卫生统计中心(NCHS,National center for Health Statistics)的主要计划,是国家营养监测的基石,为营养和健康政策的制定提供了大量数据。
NHANES项目信息及调查数据会在网站上及时更新且向公众免费开放。
本文通过介绍NHANES项目相关内容及数据提取方法,方便需要的研究者快速高效地获取自己需要地数据。
【关键词】国家健康与营养;NHANES;数据提取【中图分类号】R4【文献标志码】A 开放科学(源服务)标识码(OSID)NHANES Project Introduction AndData Extraction Process Guo Xiaojuan *, Tian Guoxiang, Pan Zhenyu, Yang Jin, Liu Qingqing, Lyu Jun. *Department of Neurology, the First Affiliated Hospital of Xi'an Jiao tong University, Xi'an, 710061.Correspondingauthor: Lyu Jun, E-mail: lujun2006@[Abstract ] The National Health and Nutrition Examination Survey (NHANES) is a research program designed to assess the health and nutritional status of adults and children in the United States. The survey is unique in that it combines interviews and medical examinations. NHANES is the main program of the National Center for Health Statistics (NCHS) and is the cornerstone of national nutrition monitoring, providing a large amount of data for the development of nutrition and health policies. NHANES project information and survey data will be updated on the website and free to the public. This paper introduces the relevant content and data extraction methods of NHANES project, which is convenient for researchers who need to quickly and efficiently obtain the data they need.[Key words ] National Health AndNutrition;NHANES;Data Extraction美国国家健康与营养调查(N H A N E S ,National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息[1]。
项目内容包括家庭访谈和健康体检两部分。
调查在参与者的家中进行。
NHANES协议由国家卫生统计研究伦理中心审查委员会批准。
所有成年参与者都提供书面通知同意,18岁以下参与者需在父母或监护人同意下进行[2-4]。
NHANES采用分层多阶段抽样设计,以获得美国居民的代表性样本[5]。
抽样计划由四个阶段组成:选择初级抽样单位(PSU),县或邻近的群体县;选择县内部的单位;选择住宅单位和选择住宅单位内的样本人[4]。
1 NHANES项目介绍NHANES计划始于20世纪60年代初期,是一项针对不同人群或健康主题的调查,由国家营养监测系统与国家健康调查系统相结合,形成了国家健康与营养调查(NHANES)。
自20世纪80年代以来,NHANES收集了参与者的生物样本,包括血清、血浆和尿液等。
存储的生物样本可供研究人员随时使用。
使用NHANES生物样本产生的数据被添加到NHANES数据库并提供给公众,旨在解决未来的医疗,环境和公共卫生问题。
1999年该调查成为一项持续计划,重点关注各种健康和营养测量,以满足新出现的需求。
项目每年调查一个全国代表性的样本,约5000人,这些人群位于全国各县。
研究小组由医生、医疗技术人员及健康调查员组成。
参与调查遵循自愿原则,选定的参与者将接受标准化的个人访谈。
NHANES 访谈部分包括人口统计学、社会经济学、饮食和健康相关问题。
体检部分包括生理测量、实验室检查等内容。
调查结果将用于确定主要疾病的患病率和疾病的风险因素,也是衡量身高、体重和血压等国家标准的基础。
2 NHANES网站介绍2.1 登陆网站 打开网站首页:https:///nchs/nhanes/index.htm,该网站是属于CDC (Centers For Disease Control and Prevention),也就是美国疾病控制与预防中心(图1)。
2.2 选择数据集在左侧的导航栏中,选择我们感兴趣的Questionnaires,Datasets,and Related Documentation,也就是调查问卷,数据集和相关文档一项(图2)。
2.3 选择数据年份 在这里我们看到虽然2017~2018年份已经存在,但在本文撰写时该数据还未整理完成,因此这里我们选择最近的日期,点击NHANES 2015-2016(图3)。
3 数据下载介绍3.1 下载数据 返回上一页,点击“DEMO_I Data [XPT - 3.6 MB]”,下载数据,该数据为XPT格式,也就是SAS软件的数据格式,可以使用SAS Universal Viewer来查看,可以导入到R语言中,使用R Studio查看(图6)。
3.2 下载并安装R语言及R Studio3.2.1 安装R语言 R Studio必须在安装R语言的条件下才能使用,打开R语言网址,https:///,选择适合自己电脑操作系统的版本安装(图7)。
图1NHANES网站页面图2数据集选择页面图3 选择数据年份页面2.4 选择需要的数据集 在“Data,Documentation,Codebooks,SAS Code”一项中,有6项不同的数据,分别是“Demographics Data”(人口数据)、“Dietary Data”(饮食数据)、“Examination Data”(检查数据)、“Laboratory Data”(化验数据)、“Questionnaire Data”(问卷数据)、“Limited Access Data”(限制访问数据)。
这里我们以“Demographics Data”为例,明确如何应用(图4)。
2.5 理解数据变量 在上表中有几个重要内容,“NHANES 2015-2016 Demographics Variable List”:人口数据的所有变量列表;“DEMO_I Doc”:关于所有变量如何采集和数据类型的详细说明;“DEMO_I Data [XPT -3.6 MB]”:真实数据的下载链接。
点击NHANES 2015-2016 Demographics Variable List 进入下一页,可以看到变量类型比如患者访谈时使用的语言,出生国家,是否为美国公民,学历,家庭人数等信息(图5)。
图4选择需要数据集页面图5变量说明页面图6下载数据页面图7 安装R语言页面3.2.2 安装R Studio 进入R Studio网站,找到以下链接,点击进入:https:///products/rstudio/download/#download,选择适合的版本。
这里我们选择最基本的免费版,选择适用自己电脑操作系统的版本,点击下载。
下载完成后点击按照,此处无需特别设置(图8)。
3.2.3 启动R Studio 安装完R语言之后启动,成功进入R Studio(图9)。
3.3 编写R语言脚本 点击左上角的绿色+,选择”R Script”,来创建一个新的R脚本(图10)。
3.4 编写代码导入数据 输入以下代码来导入我们刚才下载的人口数据(图11)。
然后导入到R Studio,导入之后发现有9544个样本,21个变量,说明不是所有人都采集了血压信息(图14)。
将两个数据集合并成一个,取名为merge_data,下面是完整的加载两个数据集并合并的代码(图15)。
3.7 综合分析 在合并后的数据中,我们可根据自己的研究领域进行查询,如在140~190的人群分布。
在合并后的数据中,点击Filter,在弹出的下拉菜单中可根据变量做各种条件过滤,比如选择BPXCHR中140-190的人群,可看到共有166个样本符合该条件(图16)。
4 讨论国家健康与营养调查是由美国疾病预防控制中心国家卫生统计中心连续开展的横断面调查,图8 R Studio安装页面图9R Studio启动页面图10R脚本创建页面图11 编写代码页面3.5 导入数据 数据导入成功后,会以表格形式展示,可以看到,人口数据中总共有9971个样本,47个变量。
SEQN是样本编号,以83 736为例,可以看到RIDSTATR=2,表示进行了面试和检查,RIAGENDER=2,表示女性,RIDAGEYR=42,表示42岁(图12)。