灰库图
灰度图象亮度变换

实验报告院(系):数学与计算机科学学院专业班级:计算机1602班1了解灰度图像亮度变换的意义和手段;2熟悉灰度变换的基本性质;3通过本实验掌握利用MA TLAB编程实现数字图像的灰度变换。
二、实验原理1算法见教材P51,4.1.1灰度线性变换2利用MA TLAB软件实现数字图像灰度变换的程序:I=imread('lena.bmp'); %读入原图像文件subplot(1,2,1);imshow(I); %显示原图像a=0;b=255;c=50;d=205;m=uint8(zeros(255,255));for j=1:size(I,1)for k=1:size(I,2)if(I(j,k)>=a&&I(j,k)<b)m(j,k)=(d-c)/(b-a)*(I(j,k)-a)+c;elsem(j,k)=I(j,k);endendendsubplot(1,2,2);imshow(m);I=imread('lena.bmp'); %读入原图像文件subplot(1,2,1);imshow(I); %显示原图像a=0;b=255;c=50;d=205;m=uint8(zeros(255,255));for j=1:size(I,1)for k=1:size(I,2)if(I(j,k)>=0&&I(j,k)<a)m(j,k)=c/a*I(j,k);elsem(j,k)=I(j,k);endendendsubplot(1,2,1);imshow(m);三、实验步骤1打开计算机,安装和启动MA TLAB程序;程序组中“work”文件夹中应有待处理的图像文件;2利用MatLab工具箱中的函数编制灰度变换文件FG;3 运行FG文件;4记录和整理实验报告。
四、实验仪器1计算机;2 MA TLAB程序;3移动式存储器(U盘等)。
4记录用的笔、纸。
Labview中数组转化为灰度图

Labview中将数组显示为灰度图在matlab中将数组转化为灰度图像非常简单,比如A是数组,那么显示为灰度图像的程序两步可以完成:A=(A-min(A(:)))./(max(A(:))-min(A(:))); %归一化imshow(A); %显示灰度图在labview中显示灰度图相对困难一些,包括用到视觉与运动模块中的一些函数,基本都是32位的彩色数据。
那么在未安装视觉与运动模块的情况下,其实可以用强度图来显示灰度图。
首先在前面板上放置一个强度图,位置在,控件/图形/强度图:注意此时需要改变一些属性,将鼠标移动在强度图上,右键,打开属性首先改外观中的大小参数,比如显示为640*480大小的,那么高度和宽度设置为相应的数,然后是改动标尺,标尺里用X轴,Y轴,Z轴,将名称都删掉,X轴,Y轴的显示标尺标签和显示标尺前的√都去掉,将自动调整标尺的√也去掉,最大值按实际大小填写。
然后Z轴的显示标尺前的√保留,最小值为0,最大值为255.再回到显示格式中,X,Y,Z轴都选择浮点,位数都选0,精度类型都选择精度位数。
然后点击确定。
然后回到前面板,在标尺上右键,(注意将鼠标移动在数字上然后右键,不然刻度颜色为灰色禁用),选择刻度颜色,然后选择最上边的色度。
完成后前面板将是下面的效果。
下面ctrl+E前往程序框图,然后构建数组,然后连线,然后就是灰度显示了。
我们构建一个480*640的数组,显示为白色(255),然后在绘制大小为100*100的全黑方块(0),然后在(200,300),(200,300)区间绘制灰阶为150的方块。
连线如下:效果图如下:当然,如果是从黑白相机采集的图像,直接就可以用强度图显示了。
2016/5/10,14:45 于光电研究所212。
数字图像处理领域的二十四个典型算法

数字图像处理领域的⼆⼗四个典型算法数字图像处理领域的⼆⼗四个典型算法及vc实现、第⼀章⼀、256⾊转灰度图⼆、Walsh变换三、⼆值化变换四、阈值变换五、傅⽴叶变换六、离散余弦变换七、⾼斯平滑⼋、图像平移九、图像缩放⼗、图像旋转数字图像处理领域的⼆⼗四个典型算法及vc实现、第三章图像处理,是对图像进⾏分析、加⼯、和处理,使其满⾜视觉、⼼理以及其他要求的技术。
图像处理是信号处理在图像域上的⼀个应⽤。
⽬前⼤多数的图像是以数字形式存储,因⽽图像处理很多情况下指数字图像处理。
本⽂接下来,简单粗略介绍下数字图像处理领域中的24个经典算法,然后全部算法⽤vc实现。
由于篇幅所限,只给出某⼀算法的主体代码。
ok,请细看。
⼀、256⾊转灰度图算法介绍(百度百科):什么叫灰度图?任何颜⾊都有红、绿、蓝三原⾊组成,假如原来某点的颜⾊为RGB(R,G,B),那么,我们可以通过下⾯⼏种⽅法,将其转换为灰度: 1.浮点算法:Gray=R*0.3+G*0.59+B*0.11 2.整数⽅法:Gray=(R*30+G*59+B*11)/100 3.移位⽅法:Gray =(R*28+G*151+B*77)>>8; 4.平均值法:Gray=(R+G+B)/3; 5.仅取绿⾊:Gray=G; 通过上述任⼀种⽅法求得Gray后,将原来的RGB(R,G,B)中的R,G,B统⼀⽤Gray替换,形成新的颜⾊RGB(Gray,Gray,Gray),⽤它替换原来的RGB(R,G,B)就是灰度图了。
灰度分为256阶。
所以,⽤灰度表⽰的图像称作灰度图。
程序实现: ok,知道了什么叫灰度图,下⾯,咱们就来实现此256⾊灰度图。
这个Convert256toGray(),即是将256⾊位图转化为灰度图:void Convert256toGray(HDIB hDIB) { LPSTR lpDIB; // 由DIB句柄得到DIB指针并锁定DIB lpDIB = (LPSTR) ::GlobalLock((HGLOBAL)hDIB); // 指向DIB象素数据区的指针 LPSTR lpDIBBits; // 指向DIB象素的指针 BYTE * lpSrc; // 图像宽度 LONG lWidth; // 图像⾼度 LONG lHeight; // 图像每⾏的字节数 LONG lLineBytes; // 指向BITMAPINFO结构的指针(Win3.0) LPBITMAPINFO lpbmi; // 指向BITMAPCOREINFO结构的指针 LPBITMAPCOREINFO lpbmc; // 获取指向BITMAPINFO结构的指针(Win3.0) lpbmi = (LPBITMAPINFO)lpDIB; // 获取指向BITMAPCOREINFO结构的指针 lpbmc = (LPBITMAPCOREINFO)lpDIB; // 灰度映射表 BYTE bMap[256]; // 计算灰度映射表(保存各个颜⾊的灰度值),并更新DIB调⾊板 int i,j; for (i = 0; i < 256;i ++) { // 计算该颜⾊对应的灰度值 bMap[i] = (BYTE)(0.299 * lpbmi->bmiColors[i].rgbRed + 0.587 * lpbmi->bmiColors[i].rgbGreen + 0.114 * lpbmi->bmiColors[i].rgbBlue + 0.5); // 更新DIB调⾊板红⾊分量 lpbmi->bmiColors[i].rgbRed = i; // 更新DIB调⾊板绿⾊分量 lpbmi->bmiColors[i].rgbGreen = i; // 更新DIB调⾊板蓝⾊分量 lpbmi->bmiColors[i].rgbBlue = i; // 更新DIB调⾊板保留位 lpbmi->bmiColors[i].rgbReserved = 0; } // 找到DIB图像象素起始位置 lpDIBBits = ::FindDIBBits(lpDIB); // 获取图像宽度 lWidth = ::DIBWidth(lpDIB); // 获取图像⾼度 lHeight = ::DIBHeight(lpDIB); // 计算图像每⾏的字节数 lLineBytes = WIDTHBYTES(lWidth * 8); // 更换每个象素的颜⾊索引(即按照灰度映射表换成灰度值) //逐⾏扫描 for(i = 0; i < lHeight; i++) { //逐列扫描 for(j = 0; j < lWidth; j++) { // 指向DIB第i⾏,第j个象素的指针 lpSrc = (unsigned char*)lpDIBBits + lLineBytes * (lHeight - 1 - i) + j; // 变换 *lpSrc = bMap[*lpSrc]; } } //解除锁定 ::GlobalUnlock ((HGLOBAL)hDIB); }变换效果(以下若⽆特别说明,图⽰的右边部分都是为某⼀算法变换之后的效果):程序实现:函数名称:WALSH()参数:double * f - 指向时域值的指针double * F - 指向频域值的指针r -2的幂数返回值:⽆。
灰度图转浮雕

灰度图转浮雕简易处理步骤灰度图转浮雕简易处理过程(入门)发这个贴,算是给新人和自己上个小课吧。
当是无脑输出。
刚好给客户完成一张抽屉面的图,规格为61*395.就以此为例吧。
原图如下:第一步:打开精雕软件,文件-输入-点阵图像-选择指定图像(注意文件类型)〈图1〉第二步:绘制所需尺寸图形,绘制-矩形(随意画个)-选中矩形-变换-放缩(输入395*61);编辑-单线等距-选中矩形向内偏移4MM(起外框线条)-'绘制,矩形'以内框左上角为起点按住SHIFT拉伸差不多8MM左右放手〈图21〉-'编辑修剪'点选内框和小矩形-右键确认,左键修剪掉内框左上角线条-'编辑,倒圆角'-输入半径5右键(注意左右下角)-右键确认上圆角<图22>;给外框上中心线修剪掉内框除左上角部分的其它三部分〈图23〉-点选左上角部分‘变换镜像’以为中心线为轴对称(注意右上角选复制图形)-‘编辑,连接’内框-‘单线等距’向外偏移4MM;点选灰度图按住SHIFT移动图像到方框内并放缩至合适位置(尽量别去让图像变形;小技巧:拉伸时按住CTRL同时两边拉伸)〈图24〉。
第三步:灰度转浮雕,艺术曲面-图像处理-位图转网格(注意左下角出现:点选一位图)-点击图像-弹出窗口输入需要的曲面高度(我这里为3.5MM);右向左框选曲面按6进入‘虚拟雕塑环境’F6‘全局观察’-‘雕塑,冲压’去掉外框线条〈图32〉。
第四步(重要部分,个人技巧):完善灰度图转浮雕,去掉中心线-‘颜色,等高填色’(注意右上角,如图41设置)-点击浮雕(如图42效果)-再次在龙头外线点击(龙头明显还有水纹,直到把多余水纹填色掉,如图43)-‘颜色,颜色区域矢量化’生成外框线(小技巧:这个还有另外一个快捷键是/)-‘效果,磨光’多磨几次直到表面光滑,当然图像不能模糊了;接下来这个步骤很重要雕出来好不好看就看这了,‘冲压’右边选颜色内,SHIFT+左键拾取填充的颜色-左键冲压闭合区域(图中有三个位置注意了)-如是正版5.5支持‘特征,削除锯齿’加以应用下,定更接近美感。
【646】灰度图array转为RGB三通道array

【646】灰度图array转为RGB三通道array 两种⽅法可以实现:通过 numpy ⾃⼰实现通过 cv2.cvtColor 函数实现,灰度图转 RGB 所谓的灰度图转为三通道,就是三个通道都是⼀样的信息,相当于相同维度信息的重复,主要是通过 numpy.array 来实现,其实是可以通过类似⼴播的形式来实现。
1. 每⼀⾏赋值相同的内容>>> a = np.zeros((3,3))>>> aarray([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])>>> b = np.arange(3)>>> barray([0, 1, 2])>>> a[:, :] = b # 等价于 a[...] = b>>> aarray([[0., 1., 2.],[0., 1., 2.],[0., 1., 2.]])2. 每⼀列赋值相同的内容>>> a = np.zeros((3,3))>>> aarray([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])>>> b = np.arange(3)>>> barray([0, 1, 2])>>> c = b.reshape((3,1))>>> carray([[0],[1],[2]])>>> a[...] = c>>> aarray([[0., 0., 0.],[1., 1., 1.],[2., 2., 2.]])3. 灰度图转为RGB三通道灰度图是⼆维数据,⾸先通过 np.expand_dims() 增加⼀个维度然后直接通过赋值即可以填充其他三个通道为相同的信息 原图的 RGB 显⽰import cv2from PIL import Imageimg = cv2.imread("yingmu.jpg")img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)display(Image.fromarray(img)) RGB 转为灰度图gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)display(Image.fromarray(gray)) 灰度图转为 RGB# 通过 cv2 函数img = cv2.cvtColor(gray, cv2.COLOR_GRAY2RGB)# 通过 numpy 实现img_arr = np.zeros_like(img)img_arr[...] = np.expand_dims(gray, axis=-1)# ⽤来判断两者是否相同,结果是 True(img == img_arr).all() 关于判断两个 numpy.array 是否相同参考博⽂:。
精雕灰度图转浮雕的做法

精雕灰度图转浮雕的做法:首先打开精雕作图软件如图,打开之后点击屏幕左上方的“文件”如图,找到目录下的“输入”然后找到“点阵图像”单击文件类型选择(*.bmp),找到所需要加工的图打开,如:打开之后看一下图的尺寸是否是你需要加工的尺寸,如果不是那就需要修改一下图的加工尺寸首先选中图片,单击屏幕左上方的“变换”,找到目录下的“放缩”(快捷键Alt+4),如图假如雕刻尺寸是200X200(MM)只要修改横向尺寸为200,点一下“保持比例”就可以了,纵向尺寸就自动变到200,如果你雕刻的尺寸是不规则的,比如是200X100(mm)那就横向尺寸改到200,纵向尺寸改成100,这次不需要点击“保持比例”,尺寸修改完之后,点击屏幕中心上方的“艺术曲面”,找到目录下的“图像纹理”——单击“位图转网格”,这是把鼠标放到图片上点击一下会出现如图:需要修改一下你的加工工件的雕刻深度如图:如果雕刻是3毫米,输入3就可以了,然后点击“确定”,出现如图出现一个网格,这个网格就是我们用灰度图转出来的浮雕图,然后我们把灰度图移开或是删除,现在我们开始绘制一个矩形,单击屏幕左上方的“绘制”,找到目录下的“矩形”(Ctrl+T)点击,找到空白处单击鼠标左键,移动鼠标出现矩形再次点击鼠标左键,就绘制出一个矩形,然后单击鼠标右键退出,选中矩形单击“变换”目录下的——“尺寸等同”,这是用鼠标左键单击以下网格出现如图:选择双向尺寸等同之后点击确定,此时矩形和网格一样大,然后再单击屏幕右侧工具栏的“对齐”,找到目录下的如图:点击,现在用鼠标左键单击网格出现如下图:现在单击“确定”,矩形和网格上下左右全部对齐,现在单击一下网格进入屏幕左侧工具栏里的“虚拟雕塑工具”如下图:下一步会出现如图:假如看不到这种图片说明你前一步没有选择网格,下一步单击屏幕上方的“模型”找到目录下的——“Z向变换”如下图:单击Z向变换,屏幕右侧会出现如图:点击一下——“高点移至X0Y”如图:现在低点是-3了,(为什么高点是0低点是-3呢?就比如你雕刻的深度是3,你是要在物体的表面往下雕刻3毫米,所以说高点0就是加工物体的表面,低点-3就是你所加工浮雕的深度,这样应该明白这一步是怎么回事了)。
【国家自然科学基金】_灰度图_基金支持热词逐年推荐_【万方软件创新助手】_20140802
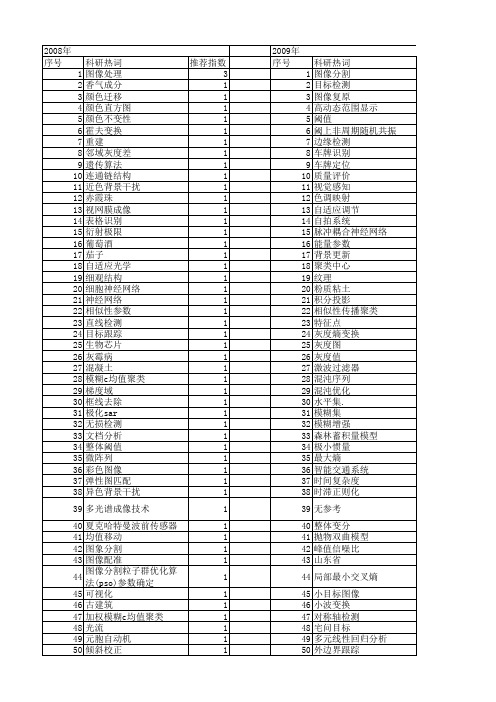
科研热词 推荐指数 图像处理 3 香气成分 1 颜色迁移 1 颜色直方图 1 颜色不变性 1 霍夫变换 1 重建 1 邻域灰度差 1 遗传算法 1 连通链结构 1 近色背景干扰 1 赤霞珠 1 视网膜成像 1 表格识别 1 衍射极限 1 葡萄酒 1 茄子 1 自适应光学 1 细观结构 1 细胞神经网络 1 神经网络 1 相似性参数 1 直线检测 1 目标跟踪 1 生物芯片 1 灰霉病 1 混凝土 1 模糊c均值聚类 1 梯度域 1 框线去除 1 极化sar 1 无损检测 1 文档分析 1 整体阈值 1 微阵列 1 彩色图像 1 弹性图匹配 1 异色背景干扰 1 多光谱成像技术 1 夏克哈特曼波前传感器 1 均值移动 1 图象分割 1 图像配准 1 图像分割粒子群优化算法(pso)参数确定 1 可视化 1 古建筑 1 加权模糊c均值聚类 1 光流 1 元胞自动机 1 倾斜校正 1 伪彩色合成 1 二值化 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
1 1 1 1 1 1 1 1 1 1 1 1 1 1
推荐指数 3 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 8 59 60
三种不同灰度图像增强算法对比

三种不同灰度图像增强算法对比一、摘要本文主要是运用直方图均衡化、平滑、锐化三种常见的图像增强算法对图像进行处理,并在此基础上分别用这 3 种算法处理的灰度图像进行比较,比对它们对图像的处理效果, 分析 3 种方法在图像增强处理能力的优劣之处。
结果发现,直方图均衡化可以均衡图像的灰度等级, 经过直方图的均衡化,图像的细节更加清楚了,但是由于直方图均衡化没有考虑图像的内容,只是简单的将图像进行直方图均衡,提高图像的对比度,使图像看起来亮度过高,使图像细节受到损失;图像平滑的目的是减少或消除图像的噪声, 图像平滑可以使图像突兀的地方变得不明显, 但是会使图像模糊,这也是图像平滑后不可避免的后果,只能尽量减轻,尽量的平滑掉图像的噪声又尽量保持图像细节,这也是图像平滑研究的主要问题;图像锐化使图像的边缘、轮廓变得清晰,并使其细节清晰,常对图像进行微分处理,但是图像的信噪比有所下降。
关键词: 图像增强 灰度图 直方图 平滑 锐化二、三种图像增强算法图像预处理是相对图像识别、图像理解而言的一种前期处理,主要是指按需要进行适当的变换突出某些有用的信息,去除或削弱无用的信息,在对图像进行分析之前, 通常要对图像质量进行改善,改善的目的就是要使处理后的图像比原始图像更适合特定的应用。
影响图像清晰度的因素很多,主要有光照不足、线路传输收到干扰等。
现存的图像增强技术主要分为空间域法和频率域法两类,其中的增强方法主要有直方图的修正、灰度变换、图像平滑、图像锐化、伪彩色和假彩色处理等。
下面主要采用直方图均衡化、图像平滑、图像线性锐化对图像进行增强处理, 对比他们的处理效果,分析 3 种方法的在图像增强处理方面的优劣。
1、直方图均衡化直方图均衡化也称为直方图均匀化,是一种常见的灰度增强算法,是将原图像的直方图经过变换函数修整为均匀直方图,然后按均衡后的直方图修整原图像。
为方便研究,先将直方图归一化,然后图像增强变换函数需要满足2个条件。
Artcam利用灰度图做浮雕文件教程

Artcam用灰度图做浮雕刀路的方法1、双击Artcam打开软件,导入灰度图文件—新的—通过图像文件2、打开图片—设置尺寸、原点、浮雕高度—确认原图很大,我们根据自己的需要调整尺寸,浮雕高度暂时定为2(即Z方向高度)调整尺寸:选择图像尺寸,然后可以对图像宽度和高度进行调整(调整一个尺寸另一个尺寸自动调整,按比例缩放)注意:点的设置,一般情况下矩形的雕刻区域我们都把左下角定为原点,圆形的区域把圆心定为原点,不管我们把哪里设置成原点,在雕刻之前都要设置机器的原点和我们的设计原点一致。
在窗口我们看见灰度图,可以放大观看灰度图细节点击3D模式可以查看立体效果3、调整浮雕高度、光顺浮雕我们可以通过浮雕操作选框对浮雕进行调整光顺浮雕和缩放浮雕高度功能比较常用光顺浮雕:如果通过放大观察发现原图不够光顺,可以通过光顺浮雕调整,建议光顺次数不要太多,避免失去细节(一般3次左右即可)浮雕高度:根据需要调整即可,太浅雕刻效果差,太深雕刻时间长。
4、点击刀具路径—加工浮雕弹出刀具路径设置界面在弹出的刀具路径设置界面中,选择螺旋加工如果是方形的工件,我们一般选择平行加工“加工安全高度”是指抬刀空走时的高度,一般太高了浪费时间,太低了不安全,一定要注意固定夹具等的影响,以免撞断刀。
5、选择刀具刀具选项是重要的选项,点击“选取”进入,原软件中有很多刀具,都是英文的,参数也不一定适合,建议全部删除,我们定义自己的刀具以后方便使用。
点击“增加刀具”在这个示例中我们用到的是平底尖刀,请按照上图设置。
带角度的刀有两个重要的参数,一个是角度一个是刀尖的直径,正确设置才能生成合理的刀路。
下切步距:是指一次允许的最大深度,我们可以根据雕刻材料的强度等多设置几种刀具方便以后选择,超出步距的深度将分成几刀输出;行距:是指平行或螺旋雕刻时两行刀路的距离,一般要小于刀尖的直径,这里我们用的0.1 的刀尖行距设置成0.07;主轴转速:设置成8000 就行了,我们的主轴电机最高转速7500;给进率:是指刀头移动的速度,要根据不同的材料而定,这里我们设置成400,意思是每分钟400mm;下切速率:就是刀向下走的速度,有些铣刀是侧刃工作的下切速度一定要小,这里我们用的尖刀可以用100。
图像灰度直方图
灰度级数反映了一幅数字图像的亮度层次多少。 图像数据的层次越多视觉效果就越好。
一般来说,G 2g ,g就是表示存储图像像素灰度 值所需的比特位数。
若 一 幅 数 字 图 像 的 量 化 灰 度 级 数 G=256=28 级 , 灰 度取值范围一般是0~255的整数,由于用8bit就能表示灰 度图像像素的灰度值,因此常称8 bit 量化。
B1 G1 R1 B2 G2 R2
: Bn Gn Rn
对于真彩色图,3个字节才能表示1个像素.
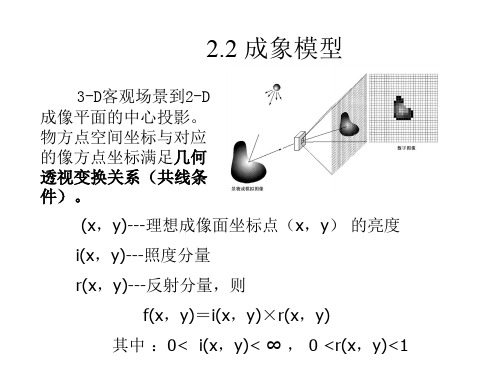
2.4图像灰度直方图
2.4.1 概念 一、定义
灰度直方图反映的是一幅图像中各灰度级像素出现 的频率。以灰度级为横坐标,纵坐标为灰度级的频率, 绘制频率同灰度级的关系图就是灰度直方图。它是图像 的一个重要特征,反映了图像灰度分布的情况。
2.3图像数字化
图像数字化是将一幅画面转化成计算机能处理的形式—— 数字图像的过程。
模拟图像
数字图像
正方形点阵
2.3.1采样
将连续的图像空间上变换成离散点的操作称为采样。 采样孔b)
(a) 正方形网格; (b) 正六角形网格
采样间隔和采样孔径的大小是两个很重要的参 数。
采样间隔越小, 所得图像像素数越 多,空间分辨率高, 图像质量好,但数
据量大。
量化等级越多,所 得图像层次越丰富,灰 度分辨率高,图像质量 好,但数据量大;
量化等级越少,图 像层次欠丰富,灰度分 辨率低,会出现假轮廓 现象,图像质量变差, 但数据量小。
但在极少数情况下 对固定图像大小时,减 少灰度级能改善质量, 产生这种情况的最可能 原因是减少灰度级一般 会增加图像的对比度。 例如对细节比较丰富的 图像数字化。
下图是一幅图像的灰度直方图。
BMP图像由彩图变成灰度图

Date:6月21日任务:BMP真彩图像转为灰度图一,算法及公式:1,什么叫灰度图?任何都有红、绿、蓝三原色组成,假设原先某点的颜色为(R,G,B),那么,咱们能够通过下面几种方式,将其转换为灰度:浮点算法:Gray=R*0.3+G*0.59+B*0.11整数方式:Gray=(R*30+G*59+B*11)/100移位方式:Gray =(R*28+G*151+B*77)>>8;平均值法:Gray=(R+G+B)/3;仅取绿色:Gray=G;通过上述任一种方式求得Gray后,将原先的RGB(R,G,B)中的R,G,B统一用Gray替换,形成新的颜色RGB(Gray,Gray,Gray),用它替换原先的RGB(R,G,B)确实是灰度图了。
2,改变象素矩阵的RGB值,来达到彩色图转变为灰度图加权平均值算法:依照光的亮度特性,其实正确的灰度公式应当是为了提高速度咱们做一个完全能够同意的近似,公式变形如下:R=G=B=(R*3+G*6+B)/103,真正的24位真彩图与8位的灰度图的区别就在于,真彩图文件中没有调色板,灰度图有调色板,真彩图中的象素矩阵是RGB值,灰度图中的象素矩阵是调色板索引值。
源代码1只简单的改变象素矩阵的RGB值,来达到彩色图转为灰度图,并无添加调色板。
源代码2添加了调色板。
二,源代码1,//能够输入文件名的源代码,有些变量概念进行了完善#include "stdio.h"#include "stdlib.h"#include "string.h"#include "windows.h"#include "conio.h"typedef struct{unsigned char b;unsigned char r;unsigned char g;}pixel;pixel a[640][480];unsigned char aa[640][480];void main(){BITMAPFILEHEADER FILEH;BITMAPINFOHEADER INFOH;RGBQUAD RGBH[256];char name[11];char *fname[11];printf("输入需要转换的图片名:");scanf("%s",&name);*fname=name;strcat(*fname,".bmp");printf("%s",*fname);FILE *fp;if((fp=fopen(*fname,"rb"))==NULL){//if((fp=fopen(*fname,"wb"))==NULL)//避免第一次进入时初始化失败//{printf("打开文件%s失败!按任意键返回主菜单!",fname);getch();exit(1);//}}printf("%s",*fname);int LEN1=sizeof(BITMAPFILEHEADER);int LEN2=sizeof(BITMAPINFOHEADER);int X,Y;printf("\nlen=%d,%d\n",LEN1,LEN2);fread(&FILEH,sizeof(BITMAPFILEHEADER),1,fp);fread(&INFOH,sizeof(BITMAPINFOHEADER),1,fp);X=INFOH.biWidth;Y=INFOH.biHeight;//printf("%d*%d",X,Y);if(FILEH.bfType!=0x4d42){fclose(fp);printf("文件头不正确,不是bmp!");exit(1);}if(INFOH.biBitCount!=24&&INFOH.biBitCount!=8) {fclose(fp);printf("信息头不正确,不是bmp!");exit(1);}//*RGBH=A;unsigned char blue,green,red,color;int j,k;if(INFOH.biBitCount==8){fread(&RGBH,sizeof(RGBQUAD),256,fp);for(j=0;j<Y;j++)for(k=0;k<X;k++){fread(&color,1,1,fp);red=RGBH[color].rgbRed;green=RGBH[color].rgbGreen;blue=RGBH[color].rgbBlue;aa[j][k]=(unsignedchar)(0.299*(float)red+0.574*(float)green+0.114*(float)blue );}}if(INFOH.biBitCount==24){for(j=0;j<Y;j++)for(k=0;k<X;k++){fread(&blue,1,1,fp);fread(&green,1,1,fp);fread(&red,1,1,fp);a[j][k].b=blue;a[j][k].g=green;a[j][k].r=red;aa[j][k]=(unsignedchar)(0.299*(float)red+0.574*(float)green+0.114*(float)blue );}}//printf("ok");fclose(fp);printf("输入输出的灰度图片名:");scanf("%s",&name);strcat(*fname,".bmp");if((fp=fopen(*fname,"wb"))==NULL){fclose(fp);printf("打开图片124.bmp失败");exit(1);}INFOH.biBitCount=8;fwrite(&FILEH,LEN1,1,fp);fwrite(&INFOH,LEN2,1,fp);int m=0;for(int i=0;i<256;i++){fwrite(&i,1,1,fp);fwrite(&i,1,1,fp);fwrite(&i,1,1,fp);fwrite(&m,1,1,fp);}for(j=0;j<Y;j++)for(k=0;k<X;k++){fwrite(&aa[j][k],1,1,fp);}fclose(fp);printf("生成灰度图%s成功!\n",*fname);}2,--------------------------------------------#ifndef _BMPTEST_H_#define _BMPTEST_H_#include <stdio.h>typedef unsigned char BYTE;typedef unsigned short WORD;typedef struct {long imageSize;long blank;long startPostition;}BmpHead;typedef struct {long length;long width;long height;WORD colorPlane;WORD bitColor;long zipFormat;long readSize;long xPels;long yPels;long colorUse;long colorImportant;}InfoHead;typedef struct {BYTE rgbBlue;BYTE rgbGreen;BYTE rgbRed;BYTE rgbReserved;}RGBMixPlate;#endif----------------------------------------------------------------------------------------#include "bmpFormat.h"#include <tiffio.h>#include <stdlib.h>int main(int argc, char *argv[]){//tiff文件涉及变量TIFF *image; //tiff文件指针uint32 width, height; //图片的宽度和高度char *buffer; //保存tiff文件中的图像灰度信息缓存tsize_t stripSize; //tiff中图像的条大小unsigned long bufferSize; //缓存大小int stripMax, stripCount; //图像总共的条数和读条信息时的控制变量unsigned long imageOffset, result; //读文件信息时的控制变量和每次读的结果//循环操纵变量unsigned int i;unsigned int j;//bmp文件涉及变量BmpHead bmphead; //bmp文件头(不包括固定信息) InfoHead infohead; //bmp信息头RGBMixPlate *color; //调色板BYTE *index; //图像数据在调色板中的索引值FILE *bmp; //bmp文件指针char bm[2]={'B','M'}; //bmp文件头中的一块固定信息,表示这是一张BMP图片‘// 打开tiff图片if((image = TIFFOpen(argv[1], "r")) == NULL){fprintf(stderr, "Could not open incoming image\n");return -1;}//获取图片的宽度和高度TIFFGetField(image, TIFFTAG_IMAGEWIDTH, &width);TIFFGetField(image, TIFFTAG_IMAGELENGTH, &height);stripSize = TIFFStripSize (image); //每条的大小stripMax = TIFFNumberOfStrips (image); //一共有多少条imageOffset = 0; //后面读取文件信息时使用的偏移量//根据文件信息申请相应的数据空间bufferSize = TIFFNumberOfStrips (image) * stripSize;if((buffer = (char *) malloc(bufferSize)) == NULL){fprintf(stderr, "Could not allocate enough memory for the uncompressed image\n");return -1;}//读取文件中的灰度信息for (stripCount = 0; stripCount < stripMax; stripCount++) {if((result = TIFFReadEncodedStrip (image, stripCount,buffer + imageOffset,stripSize)) == -1){fprintf(stderr, "Read error on inputstrip number %d\n", stripCount);return -1;}imageOffset += result;}//bmp文件头成员赋值bmphead.blank=0; //保留字,为0bmphead.imageSize=14+40+4*256+width*height; //图片的大小=文件头大小+信息头大小+调色板大小+实际图片大小bmphead.startPostition=14+40+4*256;//图片实际数据相对于文件头的偏移量//bmp信息头成员赋值(可参见BMP文件解析每一个成员的概念)infohead.length=40;infohead.width=width;infohead.height=height;infohead.colorPlane=1;infohead.bitColor=8;infohead.zipFormat=0;infohead.readSize=width*height;infohead.xPels=400;infohead.yPels=300;infohead.colorUse=0;infohead.colorImportant=0;//申请调色板和数据域空间color=(RGBMixPlate *)malloc(sizeof(RGBMixPlate)*256); index=(BYTE *)malloc(sizeof(BYTE)*infohead.readSize); //生成256色灰度调色板for(i=0;i<256;i++){color[i].rgbBlue=i;color[i].rgbGreen=i;color[i].rgbRed=i;color[i].rgbReserved=0;}//256色灰度bmp的数据信息实际确实是该灰度在相应灰度值的调色板中的颜色for(i=0;i<height;i++)for(j=0;j<width;j++)index[i*width+j]=buffer[(height-1-i)*width+j]; //tiff图片是从左上到右下,bmp图片是从左下到右上//创建bmp图片bmp=fopen(argv[2],"wb");if(bmp==NULL){printf("open new file error\n");return -1;}//写入相应的数据fwrite(bm,1,2,bmp);fwrite(&bmphead,1,12,bmp);fwrite(&infohead,1,40,bmp);fwrite(color,1,256*sizeof(color),bmp);fwrite(index,1,infohead.readSize,bmp);fclose(bmp);//释放有关资源free(buffer);free(color);free(index);TIFFClose(image); fclose(bmp);return 0;}。
8位灰度图像BMP的保存

8位灰度图像BMP的保存[zz]2012-04-07 21:01在图像处理中,我们经常需要将真彩色图像转换为黑白图像。
严格的讲应该是灰度图,因为真正的黑白图像是二色,即只有纯黑,纯白二色。
开始之前,我们先简单补充一下计算机中图像的表示原理。
计算机中的图像大致可以分成两类:位图(Bitmap)和矢量图(Metafile)。
位图可以视为一个二维的网格,整个图像就是由很多个点组成的,点的个数等于位图的宽乘以高。
每个点被称为一个像素点,每个像素点有确定的颜色,当很多个像素合在一起时就形成了一幅完整的图像。
我们通常使用的图像大部分都是位图,如数码相机拍摄的照片,都是位图。
因为位图可以完美的表示图像的细节,能较好的还原图像的原景。
但位图也有缺点:第一是体积比较大,所以人们开发了很多压缩图像格式来储存位图图像,目前应用最广的是JPEG格式,在WEB上得到了广泛应用,另外还有GIF,PNG等等。
第二是位图在放大时,不可避免的会出现“锯齿”现象,这也由位图的本质特点决定的。
所以在现实中,我们还需要使用到另一种图像格式:矢量图。
同位图不同,矢量图同位图的原理不同,矢量图是利用数学公式通过圆,线段等绘制出来的,所以不管如何放大都不会出现变形,但矢量图不能描述非常复杂的图像。
所以矢量图都是用来描述图形图案,各种CAD软件等等都是使用矢量格式来保存文件的。
在讲解颜色转换之前,我们要先对位图的颜色表示方式做一了解。
位图中通常是用RGB 三色方式来表示颜色的(位数很少时要使用调色板)。
所以每个像素采用不同的位数,就可以表示出不同数量的颜色。
如下图所示:每像素的位数一个像素可分配到的颜色数量12^1 = 222^2 = 442^4 = 1682^8 = 256162^16 = 65,536242^24 = 16,777,216从中我们可以看出,当使用24位色(3个字节)时,我们可以得到1600多万种颜色,这已经非常丰富了,应该已接近人眼所能分辨的颜色了。
基于地貌特征的灰度图在地形建模中的应用

基于地貌特征的灰度图在地形建模中的应用摘要:三维立体地形模型的构建可以进行数字化模拟陆地战场环境,尤其是战略重要地位置,其中数字高程模型成为了三维地形模型优劣的关键所在。
由于实际情况的复杂性,绝大多数的三维重建都无法真实的将地形的复杂性和不规则性完全表示出来。
为了在一定程度上减少模型建模的误差,本文介绍了利用灰度图对数字高程模型进行纠正,然后利用山脊山谷线进行模型校正,从而能够更好地、更精确的反应地形信息,得到更为准确、实用的地形模型,更加真实地虚拟战场环境,与此同时为地形分析教学带来新的技术手段。
关键词:三维地形模型;数字高程模型;灰度图;山脊线;山谷线一、引言虚拟战场环境主要是利用测绘数字化成果为基础,利用计算机的数学原理将测绘成果进行分析、处理,从而得到现实地形的模拟,并且模型相比传统沙盘等模型,具有可交互性以及可量算性。
通过对现实战场环境的模拟,有利于指挥员对现场环境的评估、部署,更大程度上提高了效率和精度。
也有利于军事演习以及兵棋对抗演练,可以通过模拟的方式提高军事训练的水平和我军实战化的能力。
如现在可以利用虚拟方式展示当年为何上甘岭战役那么重要,如下图可以一目了然:三维地形建模是构建虚拟战场的必经之路,模型质量的优劣直接影响整个虚拟战场的质量。
在这样的背景下,对于提高地形模型的精度就成为了整个课题的关键。
目前三维地形的基础数据主要是等高线和点的高程数据,对于这两种数据的生产技术已经非常成熟,但是实际测绘中不可能完全根据计算机的分辨率去采集数据,这样不仅成本高而且数据量会变得非常大造成数据难以处理。
这就要求我们根据已有的数据提出算法来实现更高效、更准确的可视化模型。
目前从基础数据模拟三维地形的曲面建模方法主要有:曲面生成法,不规则三角网法,规则格网法等。
曲面生成法:这是一种非常原始的方式。
它主要是利用参数曲面如:有理样条曲面、Conns曲面等,通过插值、拟合等方式生成所需的曲面三维地形模型。
一种基于灰度图的地震变面积波形绘制方法

一种基于灰度图的地震变面积波形绘制方法发表时间:2014-12-09T13:08:27.920Z 来源:《价值工程》2014年第10月中旬供稿作者:陶春峰[导读] 在地球物理勘探中,地震资料计算机显示方法主要有:变密度彩色显示、波形显示、变面积黑白(填充波形)显示等。
陶春峰TAO Chun-feng曰詹仕凡ZHAN Shi-fan曰冉贤华RAN Xian-hua曰李磊LI Lei曰赵佳瑜ZHAO Jia-yu(中国石油集团东方地球物理勘探有限责任公司,涿州072751)(BGP,CNPC,Zhuozhou 072751,China)摘要:在地球物理勘探中,地震资料计算机显示方法主要有:变密度彩色显示、波形显示、变面积黑白(填充波形)显示等,其中变面积显示方式在数据采集和资料处理阶段使用最为广泛。
现有变面积显示技术在查看小范围数据时波形填充显示效果比较好,当扩大显示范围时由于屏幕分辨率限制,只能对波形进行抽希显示,这种现实方法精度不高,显示效果不美观。
本文提出一种基于灰度的变面积绘制方法,将像素位置看成一个单元,首先统计要填充的波形落在单元内部的强弱权值,最后根据每个单元内的波形权值设置像素的颜色深浅,即使用颜色的深浅表示波形的强弱。
实验表明,本文提出方法绘制的地震剖面显示精度更高,效果更加美观。
Abstract院Currently in geophysical exploration, there are some kinds of methods for seismic waveform display with computer: variabledensity color display, waveform display, variable area filled waveform display, etc. The variable area filled waveform display effect is goodwhen displaying small range data. However, when the display range expands, due to the limit of screen resolution, the only way is toresample data. This method's accuracy is not high, showing unsightly. This article describes one method for display waveform which is basedon gray variable area. Take every pixel as a unit, add up the power of wave in the unit, then use the power to calculate the blackness, whichmeans using the blackness to show the waveform. Experiment shows that the seismic profile displayed with this method has higher accuracy,and the effect is more beautiful.关键词:地震剖面;波形显示;变面积剖面;灰度Key words院seismic profile;waveform display;variable area profile;gray 中图分类号院TP317.4 文献标识码院A 文章编号院1006-4311(2014)29-0208-03 0 引言在地球物理勘探[1]中,地震资料在计算机上的显示方法主要有:变密度彩色剖面、波形显示、变面积波形填充三种。
将一幅图像转换为灰度图

方法一:对于彩色转灰度,有一个很著名的心理学公式:Gray = R*0.299 + G*0.587 + B*0.114方法二:而实际应用时,希望避免低速的浮点运算,所以需要整数算法。
注意到系数都是3位精度的没有,我们可以将它们缩放1000倍来实现整数运算算法:Gray = (R*299 + G*587 + B*114 + 500) / 1000RGB一般是8位精度,现在缩放1000倍,所以上面的运算是32位整型的运算。
注意后面那个除法是整数除法,所以需要加上500来实现四舍五入。
就是由于该算法需要32位运算,所以该公式的另一个变种很流行:Gray = (R*30 + G*59 + B*11 + 50) / 100方法三:上面的整数算法已经很快了,但是有一点仍制约速度,就是最后的那个除法。
移位比除法快多了,所以可以将系数缩放成2的整数幂。
习惯上使用16位精度,2的16次幂是65536,所以这样计算系数:0.299 * 65536 = 19595.264 ≈ 195950.587 * 65536 + (0.264) = 38469.632 + 0.264 = 38469.896 ≈ 384690.114 * 65536 + (0.896) = 7471.104 + 0.896 = 7472可能很多人看见了,我所使用的舍入方式不是四舍五入。
四舍五入会有较大的误差,应该将以前的计算结果的误差一起计算进去,舍入方式是去尾法:写成表达式是:Gray = (R*19595 + G*38469 + B*7472) >> 162至20位精度的系数:Gray = (R*1 + G*2 + B*1) >> 2Gray = (R*2 + G*5 + B*1) >> 3Gray = (R*4 + G*10 + B*2) >> 4Gray = (R*9 + G*19 + B*4) >> 5Gray = (R*19 + G*37 + B*8) >> 6Gray = (R*38 + G*75 + B*15) >> 7Gray = (R*76 + G*150 + B*30) >> 8Gray = (R*153 + G*300 + B*59) >> 9Gray = (R*306 + G*601 + B*117) >> 10Gray = (R*612 + G*1202 + B*234) >> 11Gray = (R*1224 + G*2405 + B*467) >> 12Gray = (R*2449 + G*4809 + B*934) >> 13Gray = (R*4898 + G*9618 + B*1868) >> 14Gray = (R*9797 + G*19235 + B*3736) >> 15Gray = (R*19595 + G*38469 + B*7472) >> 16Gray = (R*39190 + G*76939 + B*14943) >> 17Gray = (R*78381 + G*153878 + B*29885) >> 18Gray = (R*156762 + G*307757 + B*59769) >> 19Gray = (R*313524 + G*615514 + B*119538) >> 20仔细观察上面的表格,这些精度实际上是一样的:3与4、7与8、10与11、13与14、19与20所以16位运算下最好的计算公式是使用7位精度,比先前那个系数缩放100倍的精度高,而且速度快:Gray = (R*38 + G*75 + B*15) >> 7其实最有意思的还是那个2位精度的,完全可以移位优化:Gray = (R + (WORD)G<<1 + B) >> 2将一幅图像转换为灰度图灰度图是指用灰度表示的图像,灰度是在白色和黑色之间分的若干个等级,其中最常用的是256级,也就是256级灰度图。
灰度图象,像素反转,对比度及亮度调值,以及两张相同大小图片的混合

灰度图象,像素反转,对⽐度及亮度调值,以及两张相同⼤⼩图⽚的混合⼀、图像的像素变换:1.灰度图像⽣成:灰度图像的⽣成办法是由彩⾊图像的三个通道的像素值取均值后赋给单通道的灰度图像值:C++代码实现(1)opencv的API代码如下:1.输⼊图像(彩⾊)2.⾃定义的输出图像3.⽅法,BGR —GRAY(2)不⽤opencvAPI代码实现:⽣成⼀个灰度⼤⼩的矩阵:核⼼步骤:RGB到灰度图转换公式:Y' = 0.299 R + 0.587 G + 0.114 B 也可以⽤ Y=(R+G+B)/3代码如下:#include <opencv2/core/core.hpp>#include <opencv2/imgcodecs.hpp>#include <opencv2/opencv.hpp>#include <opencv2/highgui/highgui.hpp>#include <iostream>using namespace cv;using namespace std;int main(int argc, char** args) {Mat image = imread("L:/4.jpg", IMREAD_COLOR);if (image.empty()) {cout << "could not find the image resource..." << std::endl;return -1;}namedWindow("input", CV_WINDOW_AUTOSIZE);imshow("input", image);Mat gray_image;gray_image.create(image.size(),IMREAD_GRAYSCALE);int height = image.rows;int width = image.cols;for (int row = 0; row < height; row++){for (int col = 0; col < width; col++){int b = image.at<Vec3b>(row, col)[0];int g = image.at<Vec3b>(row, col)[1];int r = image.at<Vec3b>(row, col)[2];int gray =0.114*b +0.587*g + 0.299*r ;// int gray =(b +g + r)/3 ;gray_image.at<uchar>(row, col) = gray;}}namedWindow("output", CV_WINDOW_AUTOSIZE);imshow("output", gray_image);waitKey(0);return0;}效果图:⼆、图像灰度值反转:图像的反转原理很简单,每个像素的⾊度的范围为(0-255)彩⾊为r,g,b,三个通道。
彩色图转灰度图--matlab-实现代码

(一):彩色图像转灰度图1、设计任务1) 读入彩色和灰度图像并显示;2) 对彩色图像转化为灰度图像并显示;3) 比较两种方法的效果。
2、设计目的1) 掌握彩色图转灰度图的基本原理与方法;2) 初步掌握MATLAB的使用方法;3) 了解MATLAB在数字信号处理,尤其是图像处理中显现出来的优势。
3、源代码% 把RGB格式的图片转换为YUV格式。
clear; clc;x=imread('lena512.BMP');[line,row,dim]=size(x);x1=double(x); % 数据类型转换subplot(1,3,1) % 分割当前绘图窗口为(1,3)的区域,显示此图片与1号区域imshow(uint8(x)) % 数据类型转换,并且显示当前图片title('原图');% 矩阵乘,根据【RGB】转【YUV】关系转灰度图Y1=0.299*x(:,:,1)+0.587*x(:,:,2)+0.114*x(:,:,3);y1=[round(Y1)]; % 取整subplot(1,3,2)imshow(uint8(y1))title('根据各分量转换关系转换后图片');% 求RGB各个分量均值转灰度图Y2=(x(:,:,1)+x(:,:,2)+x(:,:,3))/3;y2=[round(Y2)];subplot(1,3,3)imshow(uint8(y2))title('求均值转换后图片');图(1)彩色转灰度图程序运行结果4、结果分析由运行结果可以看出,根据RGB到YUV各个分量关系转换得到的灰度图比较真实,而用简单的求RGB各个分量的均值转弧度图,其结果很不理想,图片基本看不清楚原来的轮廓。
(二):对灰度图像实现按比例缩小和放大1、设计任务1) 对灰度图实现在行上k1=0.6,列上k2=0.75的按比例缩小;2) 对灰度图实现在行上k1=1.2,列上k2=1.5的按比例放大;2、设计目的1) 掌握图像的放大和缩小原理;2) 用MATLAB实现图像的按比例放大和缩小;3) 明白图像的放大和缩小并不是简单的互为逆过程。