Compiler-Directed Scratch Pad Memory Hierarchy Design and Management
Memory Compiler

SEC ASIC
5-1
STDL80
MEMORY COMPILERS SELECTION GUIDE
MEMORY COMPILERS
In 0.5µm CMOS standard cell memory compilers, the y-mux type selecting option was added to give the customers freedom selecting aspect ratio of the memory layout. Many of the characteristics of a memory cell are depend on its y-mux type. So, when you change the y-mux type from one to the other to change the aspect ratio, you have to know that it will change many major characteristics, such as access time, area and power consumption, of the memory. < Figure 1. Example of Y-mux Types and Aspect Ratio >
y-mux ቤተ መጻሕፍቲ ባይዱ 4
y-mux = 8
y-mux = 16
Dual Banks
In some of 0.5µm CMOS standard cell memory compilers is a generator option which defines the number of bit array banks. This dual bank scheme doubles the maximum capacity of the memory compilers.
计算机编程英语

page replacement algorithm 页替换算法
paged segments 段页式管理
PCB(process control block) 进程控制块
peer entities 对等实体
period 时期 周期
phase 阶段 局面 状态
multiple - term formula 多项式
multiplexing 多路复用技术
multiplication 乘法
mutual exclusion 互相 排斥
non - key attributes 非码属性
Nyquist 奈奎斯特
object oriented 对象 趋向的 使适应的
process 过程 加工 处理
program debugging 程序排错
projection selection join 投影 选择 连接
protocol 协议
prototype 原型 样板
prototyping method(model) 原型化周期(模型)
pseudo - code 伪码(程序设计语言PDL)
IPC 工业过程控制
ISAM VSAM 索引顺序存取方法 虚拟存储存取方法
join/natural join/semi join 连接/自然连接/半连接
kernel executive supervisor user 核心 执行 管理 用户
kernels 核心程序
key comparison 键(码)值比较
Manchester 曼彻斯特
map 地图 映射图
matrix 矩阵 点阵
XDAIS标准

现代软件开发,已从上世纪的面向过程编程发展到当前的面向框架编程。
软件开发经验已证明:框架话、模块化的开发方式可以极大的提高软件开发效率,提高代码质量及代码重用率。
然而,在嵌入式编程中,由于长期缺乏完善的开发框架和可用的API,开发人员依旧利用C或汇编语言和底层硬件打交道,凡是亲力亲为,这必然会增加嵌入式开发的入门门槛,降低代码的重用性,甚至增加代码易集时的复制度(不过这些缺点,对于程序员来说确是好事,入门门槛高、开发复制意味着高付出高回报,不像现在桌面电脑端的开发,已经被人研究烂了,如果你不是超超超超级大牛,根本找不到一份满意的薪水)。
基于这点,TI公司发布了一套DSP算法标准——TMS320 DSP Algorithm Standard,规范了DSP算法软件的开发,并提供了类似C++语言类的封装方式的算法接口,使得算法集成变得简单统一。
XDAIS标准如果你对TMS320 DSP Algorithm Standard还陌生的话,那么如果提起另一个名字:xdais,那么就顺眼地多了。
没错,我们在Codec Engine文档中经常看到的xdais,实际上就是TMS320 DSP Algorithm Standard的另一个名字。
根据TI官方白皮书,xdais标准一共提供了39条规则,15条指南。
这些规则和指南一共分为4个部分:只要你的算法满足xdais标准,你也可以像笔记本上打上的“Vista Capable”那样,在算法上面打上TI的认证图标:IALG接口前面说了,xdais标准里含有39条标准,15个指南。
这些标准、指南几乎涵盖了整个DSP开发的生命周期,例如使用TI的C语言啊,所有C6x算法必须支持低位优先啊。
具体的规则可以参考《TMS320 DSP Algorithm Standard Rules and Guidelines User’s Guide》,本文不再讨论。
xdais作为一个DSP的开发框架,定义了一些接口:•IALG –为算法实例对象的创建定义了独立于框架的算法接口。
Memory-Compiler使用入门介绍

Memory Compiler使用介绍在使用Memory Compiler时,请务必确保你的RAM从头到尾的规格与设定都相同,否则会造成一些不可避免的错误。
首先在RTL代码阶段,要用到RAM就要用Artisan公司提供的Memory Compile产生的verilog代码,此时不需要着急产生其他后阶段的必要数据,因为RTL代码阶段,只需要行为级模型即可。
当进入门级代码后,RAM compiler就要产生其他的相关数据了,同时要考虑RAM版图的位置与方向。
由于一个大的设计不会设计一次就会完成,所以有两个重点,第一个是每次使用RAM compiler时都一定要让它产生特性设置文档,避免忘记自己做过的设定。
第二件事是对应的文件名要定义好,否则RAM的方向不同但是又用到了相同的文件名,就会把原始数据覆盖掉。
下图为SRAM在流程中需要产生的文档RTL阶段在RTL阶段主要只是产生verilog行为级和设置文件。
因为在RTL阶段不需要考虑RAM 的位置信息。
Memory Compiler提供4种选择,分别为ra1sh,ra2sh,rf1sh,rf2sh。
前面的ra与rf分别指的是SRAM与register file,其中rf在同样的情况下比ra占的面积小,但是rf的大小有限制,其限制大小位4096bits。
而后面1sh与2sh表示位单端口还是双端口,如果SRAM 的容量比较大的话,相同设置下,1sh比2sh面积要小,速度也要快,功耗要低。
Memory Compiler运行界面如下图所示instance name:该设置是对RAM的命名,由于ram的特性有地址和位数,所以在命名的时候尽量包含这些信息。
number of words:该设置用来确定RAM的深度,即寻址空间大小。
number of bits:该设置用来确定RAM的宽度。
frequency:该设置用来确定RAM的工作频率,该设置确定后就可以基本确定RAM的功耗,估计的结果位平均电流,通过该数据来设定电源环的宽度。
计算机专业常用英语

2.RISCReducedInstructionsetComputing 精简指令集计算技术
比较CISCcomplexInstructionsetComputing复杂指 令集计算技术
3.assignmentstatement赋值语句
4.optimizev.优化
optimizer优化器[程序]
4. package 软件包;( 封装 )外壳
packaged software 套装软件
比较 packet n. ( 信息 )包;( 报文 )分组 pack v. 压缩
5. descending sort 降序排序
比较 ascending sort 升序排序
7
2021/10/10
6. superscalar 超标量结构
8
2021/10/10
7. complex number 复数
比较 real number 实数
8. Multimedia Extensions 多媒体扩展(技术)
multimedia 多媒体 extension 扩展名
9. benckmark n. 基准(测试)程序
v. 测量性能
A test used to measure hardware or software performance. 一种用于测量硬件或软件性能的测试程序。
To change a program in order to be able to run it on a different computer.改变一个程序,使之能在不同的计算 机上运行。
24
2021/10/10
3.1 Boolean Algebra
1. Boolean algebra 布尔代数
编译原理术语中英文对照表
General left recursion
通常左递归
General LR(1) parsing algorithm 通用 LR(1)语法分析算法
Global data
全局数据
Global declaration Global optimization
全局声明 全局优化
Global variable GNU Bison parser generator
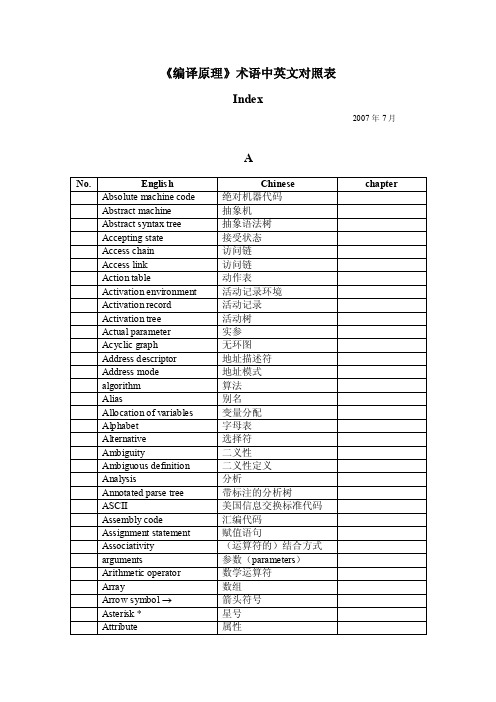
《编译原理》术语中英文对照表
Index
2007 年 7 月
No.
Englis h
Absolute machine code
Abstract machine
Abstract syntax tree
Accepting state
Access chain
Access link
Action table
Activation environment
F
Chinese 阶乘函数 有限自动机 First 集 一个词法分析器的自动 生成器 浮点除法 浮点数 浮点值类型 流图 Follow 集 形式定义 For 语句 编译器的前端 函数声明 函数定义
chapter
G
No.
Englis h
Chinese
Garbage collection
垃圾收集
General immediate left recursion 通常直接左递归
chapter
Attribute grammar Automata Automatic code generator Auxiliary routine Available expression
属性文法 自动机 代码自动生成 附属函数 有效表达式
sdcc 语法-概述说明以及解释

sdcc 语法-概述说明以及解释1.引言1.1 概述SDCC(Small Device C Compiler)是一款开源的C语言编译器,主要针对嵌入式系统和小型设备进行编译优化。
它具有高度的可移植性和灵活性,可在各种硬件平台上进行交叉编译,包括8位和16位微控制器和其他嵌入式设备。
与传统的C语言编译器相比,SDCC在资源受限的环境下表现出色。
它使用了许多优化技术,如占用内存的最小化、代码紧凑化、速度优化等,以最大程度地减小生成的机器码的大小和执行时间。
这将有助于提高嵌入式系统的性能和效率,适用于各种小型项目和嵌入式应用。
此外,SDCC还支持多种目标平台的编译,包括各种常用的嵌入式处理器和微控制器。
它提供了广泛的功能和库支持,可以方便地与其他外部设备和传感器进行交互。
这使得开发人员能够灵活地构建各种嵌入式应用,从简单的小型项目到复杂的嵌入式系统。
尽管SDCC是一款开源的编译器,但它的功能和性能丝毫不逊色于商业化的C编译器。
它经过多年的发展和改进,已经成为嵌入式系统开发中的重要工具之一。
在开发嵌入式软件时,选择SDCC作为编译器可以帮助开发人员提高代码质量、加快开发速度,并且兼顾项目的可维护性和可移植性。
总之,SDCC是一款优秀的C语言编译器,特别适用于嵌入式系统和小型设备。
它的高度可移植性、灵活性和优化技术使得开发人员能够高效地构建各种嵌入式应用。
无论是初学者还是有经验的开发人员,都可以通过学习和使用SDCC来掌握嵌入式系统开发的核心技能,为各种小型项目和嵌入式应用提供高效、可靠的解决方案。
1.2文章结构文章结构是指文章的整体组织框架,它有助于读者更好地理解文章的内容和思路。
本文的结构由引言、正文和结论三个部分组成。
引言部分介绍了整篇文章的背景和内容概要。
在引言的基础上,文章的结构被进一步展示出来。
因此,引言可被看作是整个文章结构的一个入口。
正文部分是论述文章的重点内容。
它由多个要点组成,每个要点以二级标题的形式呈现。
introduction Compiler

LLi
15
G di Policies Grading P li i
LLi 4
Course Objectives
Programming Language Design
– Strengthens the understanding of the key concepts of f programming i languages l – Provides the theoretical foundation and implementation skills for designing and implementing programming languages.
#include <stdio.h> int main ( ) { int i, j; i = 1; i 1; j = i++ + ++i; printf("%d\n", j); }
LLi 8
•
“ The world of compiler design has changed significantly. Programming languages have evolved to present new compilation problems. Computer architectures offer a variety of resources of which hi h th the compiler il d designer i must tt take k advantage. d t P Perhaps h most t interestingly, the venerable technology of code optimization has found use outside compilers. It is now used in tools that find bugs in software and most importantly software, importantly, find security holes in existing code code. And much of the "front-end" technology - grammars, regular expressions, parsers, and syntax-directed translators – are still in wide use.” use. “ We recognize g that few readers will build, or even maintain, a compiler for a major programming language. Yet the models, theory, and algorithms associated with a compiler can be applied to a wide range of problems in software design and software development . W therefore We th f emphasize h i problems bl th that t are most t commonly l encountered in designing a language processor, regardless of the source language or target machine. ”
自然语言处理中英文术语对照

abbreviation 缩写 [省略语]ablative 夺格(的)abrupt 突发音accent 口音/{Phonetics}重音accusative 受格(的)acoustic phonetics 声学语音学acquisition 习得action verb 动作动词active 主动语态active chart parser 活动图句法剖析程序active knowledge 主动知识active verb 主动动词actor-action-goal 施事(者)-动作-目标actualization 实现(化)acute 锐音address 地址{信息科学}/称呼(语){语言学} adequacy 妥善性adjacency pair 邻对adjective 形容词adjunct 附加语 [附加修饰语]adjunction 加接adverb 副词adverbial idiom 副词词组affective 影响的affirmative 肯定(的;式)affix 词缀affixation 加缀affricate 塞擦音agent 施事agentive-action verb 施事动作动词agglutinative 胶着(性)agreement 对谐AI (artificial intelligence) 人工智能 [人工智能] AI language 人工智能语言 [人工智能语言]Algebraic Linguistics 代数语言学algorithm 算法 [算法]alienable 可分割的alignment 对照 [多国语言文章词;词组;句子翻译的] allo- 同位-allomorph 同位语素allophone 同位音位alpha notation alpha 标记alphabetic writing 拼音文字alternation 交替alveolar 齿龈音ambiguity 歧义ambiguity resolution 歧义消解ambiguous 歧义American structuralism 美国结构主义analogy 类推analyzable 可分析的anaphor 照应语 [前方照应词]animate 有生的A-not-A question 正反问句antecedent 先行词anterior 舌前音anticipation 预期 (音变)antonym 反义词antonymy 反义A-over-A A-上-A 原则apposition 同位语appositive construction 同位结构appropriate 恰当的approximant 无擦通音approximate match 近似匹配arbitrariness 任意性archiphoneme 大音位argument 论元 [变元]argument structure 论元结构 [变元结构] arrangement 配列array 数组articulatory configuration 发音结构articulatory phonetics 发音语音学artificial intelligence (AI) 人工智能 [人工智能] artificial language 人工语言ASCII 美国标准信息交换码aspect 态 [体]aspirant 气音aspiration 送气assign 指派assimilation 同化association 关联associative phrase 联想词组asterisk 标星号ATN (augmented transition network) 扩充转移网络attested 经证实的attribute 属性attributive 属性auditory phonetics 听觉语音学augmented transition network 扩充转移网络automatic document classification 自动文件分类automatic indexing 自动索引automatic segmentation 自动切分automatic training 自动训练automatic word segmentation 自动分词automaton 自动机autonomous 自主的auxiliary 助动词axiom 公理baby-talk 儿语back-formation 逆生构词(法)backtrack 回溯Backus-Naur Form 巴科斯诺尔形式 [巴科斯诺尔范式] backward deletion 逆向删略ba-construction 把─字句balanced corpus 平衡语料库base 词基Bayesian learning 贝式学习Bayesian statistics 贝式统计behaviorism 行为主义belief system 信念系统benefactive 受益(格;的)best first parser 最佳优先句法剖析器bidirectional linked list 双向串行bigram 双连词bilabial 双唇音bilateral 双边的bilingual concordancer 双语关键词前后文排序程序binary feature 双向特征[二分征性]binding 约束bit 位 [二进制制;比特]biuniqueness 双向唯一性blade 舌叶blend 省并词block 封阻[封杀]Bloomfieldian 布隆菲尔德(学派)的body language 肢体语言Boolean lattice 布尔网格 [布尔网格]borrow 借移Bottom-up 由下而上bottom-up parsing 由下而上剖析bound 附着(的)bound morpheme 附着语素 [黏着语素]boundary marker 界线标记boundary symbol 界线符号bracketing 方括号法branching 分枝法breadth-first search 广度优先搜寻 [宽度优先搜索]breath group 换气单位breathy 气息音的buffer 缓冲区byte 字节CAI (Computer Assisted Instruction) 计算机辅助教学CALL (computer assisted language learning) 计算机辅助语言学习canonical 典范的capacity 能力cardinal 基数的cardinal vowels 基本元音case 格位case frame 格位框架Case Grammar 格位语法case marking 格位标志CAT (computer assisted translation) 计算机辅助翻译cataphora 下指Categorial Grammar 范畴语法Categorial Unification Grammar 范畴连并语法 [范畴合一语法] causative 使动causative verb 使役动词causativity 使役性centralization 央元音化chain 炼chart parsing 表式剖析 [图表句法分析]checked 受阻的checking 验证Chinese character code 中文编码 [汉字代码]Chinese character code for information interchange 中文信息交换码[汉字交换码]Chinese character coding input method 中文输入法 [汉字编码输入] choice 选择Chomsky hierarchy 杭士基阶层 [Chomsky 层次结构]citation form 基本形式CKY algorithm (Cocke-Kasami-Younger) CKY 算法classifier 类别词cleft sentence 分裂句click 啧音clitic 附着词closed world assumption 封闭世界假说cluster 音群Cocke-Kasami-Younger algorithm CKY 算法coda 音节尾code conversion 代码变换cognate 同源(的;词)Cognitive Linguistics 认知语言学coherence 一致性cohesion 凝结性 [黏着性;结合力]collapse 合并collective 集合的collocation 连用语 [同现;搭配]combinatorial construction 合并结构combinatorial insertion 合并中插combinatorial word 合并词Combinatory Categorial Grammar 组合范畴语法comment 评论commissive 许诺[语行]common sense semantics 常识语意学Communication Theory 通讯理论 [通讯论;信息论]Comparative Linguistics 比较语言学comparison 比较competence 语言知能compiler 编译器complement 补语complementary 互补complementary distribution 互补分布complementizer 补语标记complex predicate 复杂谓语complex stative construction 复杂状态结构complex symbol 复杂符号complexity 复杂度component 成分compositionality 语意合成性 [合成性]compound word 复合词Computational Lexical Semantics 计算词汇语意学Computational Lexicography 计算词典编纂学Computational Linguistics 计算语言学Computational Phonetics 计算语音学Computational Phonology 计算声韵学Computational Pragmatics 计算语用学Computational Semantics 计算语意学Computational Syntax 计算句法学computer language 计算器语言computer-aided translation 计算机辅助翻译 [计算器辅助翻译]computer-assisted instruction (CAI) 计算机辅助教学computer-assisted language learning 计算机辅助语言学习[计算器辅助语言学习] concatenation 串联concept classification 概念分类concept dependency 概念依存conceptual hierarchy 概念阶层concord 谐和concordance 关键词 (前后文) 排序concordancer 关键词 (前后文) 排序的程序concurrent parsing 并行句法剖析conditional decision 条件决定 [条件决策]conjoin 连接conjunction 连接词 (合取;逻辑积;"与";连词)conjunctive 连接的connected speech 连续语言Connectionist model 类神经网络模型Connectionist model for natural language 自然语言类神经网络模型[自然语言连接模型]connotation 隐涵意义consonant 子音 [辅音]constituent 成分constituent structure tree 词组结构树constraint 限制constraint propagation 限制条件的传递 [限定因素增殖]constraint-based grammar formalism 限制为本的语法形式Construct Grammar 句构语法content word 实词context 语境context-free language 语境自由语言 [上下文无关语言]context-sensitive language 语境限定语言 [上下文有关语言;上下文敏感语言] continuant 连续音continuous speech recognition 连续语音识别contraction 缩约control agreement principle 控制一致原理control structure 控制结构control theory 控制论convention 约定俗成[规约]convergence 收敛[趋同现象]conversational implicature 会话含义converse 相反(词;的)cooccurrence relation 共现关系 [同现关系]co-operative principle 合作原则coordination 对称连接词 [同等;并列连接]copula 系词co-reference 同指涉 [互指]co-referential 同指涉coronal 前舌音corpora 语料库corpus 语料库Corpus Linguistics 语料库语言学corpus-based learning 语料库为本的学习correlation 相关性counter-intuitive 违反语感的courseware 课程软件 [课件]coverb 动介词C-structure 成分结构data compression 数据压缩 [数据压缩]data driven analysis 资料驱动型分析 [数据驱动型分析]data structure 数据结构 [数据结构]database 数据库 [数据库]database knowledge representation 数据库知识表示 [数据库知识表示]data-driven 资料驱动 [数据驱动]dative 与格declarative knowledge 陈述性知识decomposition 分解deductive database 演译数据库 [演译数据库]default 默认值 [默认;缺省]definite 定指Definite Clause Grammar 确定子句语法definite state automaton 有限状态自动机Definite State Grammar 有限状态语法definiteness 定指degree adverb 程度副词degree of freedom 自由度deixis 指示delimiter 定界符号 [定界符]denotation 外延denotic logic 符号逻辑dependency 依存关系Dependency Grammar 依存关系语法dependency relation 依存关系depth-first search 深度优先搜寻derivation 派生derivational bound morpheme 派生性附着语素Descriptive Grammar 描述型语法 [描写语法]Descriptive Linguistics 描述语言学 [描写语言学] desiderative 意愿的determiner 限定词deterministic algorithm 决定型算法 [确定性算法] deterministic finite state automaton 决定型有限状态机deterministic parser 决定型语法剖析器 [确定性句法剖析程序] developmental psychology 发展心理学Diachronic Linguistics 历时语言学diacritic 附加符号dialectology 方言学dictionary database 辞典数据库 [词点数据库]dictionary entry 辞典条目digital processing 数字处理 [数值处理]diglossia 双言digraph 二合字母diminutive 指小词diphone 双连音directed acyclic graph 有向非循环图disambiguation 消除歧义 [歧义消除]discourse 篇章discourse analysis 篇章分析 [言谈分析]discourse planning 篇章规划Discourse Representation Theory 篇章表征理论 [言谈表示理论] discourse strategy 言谈策略discourse structure 言谈结构discrete 离散的disjunction 选言dissimilation 异化distributed 分布式的distributed cooperative reasoning 分布协调型推理distributed text parsing 分布式文本剖析disyllabic 双音节的ditransitive verb 双宾动词 [双宾语动词;双及物动词] divergence 扩散[分化]D-M (Determiner-Measure) construction 定量结构D-N (determiner-noun) construction 定名结构document retrieval system 文件检索系统 [文献检索系统] domain dependency 领域依存性 [领域依存关系]double insertion 交互中插double-base 双基downgrading 降级dummy 虚位duration 音长{语音学}/时段{语法学/语意学}dynamic programming 动态规划Earley algorithm Earley 算法echo 回声句egressive 呼气音ejective 紧喉音electronic dictionary 电子词典elementary string 基本字符串 [基本单词串]ellipsis 省略EM algorithm EM算法embedding 崁入emic 功能关系的empiricism 经验论Empty Category Principle 虚范畴原则 [空范畴原理]empty word 虚词enclitics 后接成份end user 终端用户 [最终用户]endocentric 同心的endophora 语境照应entailment 蕴涵entity 实体entropy 熵entry 条目episodic memory 情节性记忆epistemological network 认识论网络ergative verb 作格动词ergativity 作格性Esperando 世界语etic 无功能关系etymology 词源学event 事件event driven control 事件驱动型控制example-based machine translation 以例句为本的机器翻译exclamation 感叹exclusive disjunction 排它性逻辑 “或”experiencer case 经验者格expert system 专家系统extension 外延external argument 域外论元extraposition 移外变形 [外置转换]facility value 易度值feature 特征feature bundle 特征束feature co-occurrence restriction 特征同现限制 [特性同现限制] feature instantiation 特征体现feature structure 特征结构 [特性结构]feature unification 特征连并 [特性合一]feedback 回馈felicity condition 妥适条件file structure 档案结构finite automaton 有限状态机 [有限自动机]finite state 有限状态Finite State Morphology 有限状态构词法 [有限状态词法]finite-state automata 有限状态自动机finite-state language 有限状态语言finite-state machine 有限状态机finite-state transducer 有限状态置换器flap 闪音flat 降音foreground information 前景讯息 [前景信息]Formal Language Theory 形式语言理论Formal Linguistics 形式语言学Formal Semantics 形式语意学forward inference 前向推理 [向前推理]forward-backward algorithm 前前后后算法frame 框架frame based knowledge representation 框架型知识表示Frame Theory 框架理论free morpheme 自由语素Fregean principle Fregean 原则fricative 擦音F-structure 功能结构full text searching 全文检索function word 功能词Functional Grammar 功能语法functional programming 函数型程序设计 [函数型程序设计]functional sentence perspective 功能句子观functional structure 功能结构functional unification 功能连并 [功能合一]functor 功能符fundamental frequency 基频garden path sentence 花园路径句GB (Government and Binding) 管辖约束geminate 重叠音gender 性Generalized Phrase Structure Grammar 概化词组结构语法 [广义短语结构语法] Generative Grammar 衍生语法Generative Linguistics 衍生语言学 [生成语言学]generic 泛指genetic epistemology 发生认识论genetive marker 属格标记genitive 属格gerund 动名词Government and Binding Theory 管辖约束理论GPSG (Generalized Phrase Structure Grammar) 概化词组结构语法[广义短语结构语法]gradability 可分级性grammar checker 文法检查器grammatical affix 语法词缀grammatical category 语法范畴grammatical function 语法功能grammatical inference 文法推论grammatical relation 语法关系grapheme 字素haplology 类音删略head 中心语head driven phrase structure 中心语驱动词组结构 [中心词驱动词组结构] head feature convention 中心语特征继承原理 [中心词特性继承原理] Head-Driven Phrase Structure Grammar 中心语驱动词组结构律heteronym 同形heuristic parsing 经验式句法剖析Heuristics 经验知识hidden Markov model 隐式马可夫模型hierarchical structure 阶层结构 [层次结构]holophrase 单词句homograph 同形异义词homonym 同音异义词homophone 同音词homophony 同音异义homorganic 同部位音的Horn clause Horn 子句HPSG (Head-Driven Phrase Structure Grammar) 中心语驱动词组结构语法human-machine interface 人机界面hypernym 上位词hypertext 超文件 [超文本]hyponym 下位词hypotactic 主从结构的IC (immediate constituent) 直接成份ICG (Information-based Case Grammar) 讯息为本的格位语法idiom 成语 [熟语]idiosyncrasy 特异性illocutionary 施为性immediate constituent 直接成份imperative 祈使句implicative predicate 蕴含谓词implicature 含意indexical 标引的indirect object 间接宾语indirect speech act 间接言谈行动 [间接言语行为]Indo-European language 印欧语言inductional inference 归纳推理inference machine 推理机器infinitive 不定词 [to 不定式]infix 中缀inflection/inflexion 屈折变化inflectional affix 屈折词缀information extraction 信息撷取information processing 信息处理 [信息处理]information retrieval 信息检索Information Science 信息科学 [信息科学; 情报科学] Information Theory 信息论 [信息论]inherent feature 固有特征inherit 继承inheritance 继承inheritance hierarchy 继承阶层 [继承层次]inheritance of attribute 属性继承innateness position 语法天生假说insertion 中插inside-outside algorithm 里里外外算法instantiation 体现instrumental (case) 工具格integrated parser 集成句法剖析程序integrated theory of discourse analysis 篇章分析综合理论[言谈分析综合理论]intelligence intensive production 知识密集型生产intensifier 加强成分intensional logic 内含逻辑Intensional Semantics 内涵语意学intensional type 内含类型interjection/exclamation 感叹词inter-level 中间成分interlingua 中介语言interlingual 中介语(的)interlocutor 对话者internalise 内化International Phonetic Association (IPA) 国际语音学会internet 网际网络Interpretive Semantics 诠释性语意学intonation 语调intonation unit (IU) 语调单位IPA (International Phonetic Association) 国际语音学会IR (information retrieval) 信息检索IS-A relation IS-A 关系isomorphism 同形现象IU (intonation unit) 语调单位junction 连接keyword in context 上下文中关键词[上下文内关键词] kinesics 体势学knowledge acquisition 知识习得knowledge base 知识库knowledge based machine translation 知识为本之机器翻译knowledge extraction 知识撷取 [知识题取]knowledge representation 知识表示KWIC (keyword in context) 关键词前后文 [上下文内关键词] label 卷标labial 唇音labio-dental 唇齿音labio-velar 软颚唇音LAD (language acquisition device) 语言习得装置lag 发声延迟language acquisition 语言习得language acquisition device 语言习得装置language engineering 语言工程language generation 语言生成language intuition 语感language model 语言模型language technology 语言科技left-corner parsing 左角落剖析 [左角句法剖析]lemma 词元lenis 弱辅音letter-to-phone 字转音lexeme 词汇单位lexical ambiguity 词汇歧义lexical category 词类lexical conceptual structure 词汇概念结构lexical entry 词项lexical entry selection standard 选词标准lexical integrity 词语完整性Lexical Semantics 词汇语意学Lexical-Functional Grammar 词汇功能语法Lexicography 词典学Lexicology 词汇学lexicon 词汇库 [词典;词库]lexis 词汇层LF (logical form) 逻辑形式LFG (Lexical-Functional Grammar) 词汇功能语法liaison 连音linear bounded automaton 线性有限自主机linear precedence 线性次序lingua franca 共通语linguistic decoding 语言译码linguistic unit 语言单位linked list 串行loan 外来语local 局部的localism 方位主义localizer 方位词locus model 轨迹模型locution 惯用语logic 逻辑logic array network 逻辑数组网络logic programming 逻辑程序设计 [逻辑程序设计] logical form 逻辑形式logical operator 逻辑算子 [逻辑算符]Logic-Based Grammar 逻辑为本语法 [基于逻辑的语法] long term memory 长期记忆longest match principle 最长匹配原则 [最长一致法] LR (left-right) parsing LR 剖析machine dictionary 机器词典machine language 机器语言machine learning 机器学习machine translation 机器翻译machine-readable dictionary (MRD) 机读辞典Macrolinguistics 宏观语言学Markov chart 马可夫图Mathematical Linguistics 数理语言学maximum entropy 最大熵M-D (modifier-head) construction 偏正结构mean length of utterance (MLU) 语句平均长度measure of information 讯习测度 [信息测度] memory based 根据记忆的mental lexicon 心理词汇库mental model 心理模型mental process 心理过程 [智力过程;智力处理] metalanguage 超语言metaphor 隐喻metaphorical extension 隐喻扩展metarule 律上律 [元规则]metathesis 语音易位Microlinguistics 微观语言学middle structure 中间式结构minimal pair 最小对Minimalist Program 微言主义MLU (mean length of utterance) 语句平均长度modal 情态词modal auxiliary 情态助动词modal logic 情态逻辑modifier 修饰语Modular Logic Grammar 模块化逻辑语法modular parsing system 模块化句法剖析系统modularity 模块性(理论)module 模块monophthong 单元音monotonic 单调monotonicity 单调性Montague Grammar 蒙泰究语法 [蒙塔格语法]mood 语气morpheme 词素morphological affix 构词词缀morphological decomposition 语素分解morphological pattern 词型morphological processing 词素处理morphological rule 构词律 [词法规则] morphological segmentation 语素切分Morphology 构词学Morphophonemics 词音学 [形态音位学;语素音位学] morphophonological rule 形态音位规则Morphosyntax 词句法Motor Theory 肌动理论movement 移位MRD (machine-readable dictionary) 机读辞典MT (machine translation) 机器翻译multilingual processing system 多语讯息处理系统multilingual translation 多语翻译multimedia 多媒体multi-media communication 多媒体通讯multiple inheritance 多重继承multistate logic 多态逻辑mutation 语音转换mutual exclusion 互斥mutual information 相互讯息nativist position 语法天生假说natural language 自然语言natural language processing (NLP) 自然语言处理natural language understanding 自然语言理解negation 否定negative sentence 否定句neologism 新词语nested structure 套结构network 网络neural network 类神经网络Neurolinguistics 神经语言学neutralization 中立化n-gram n-连词n-gram modeling n-连词模型NLP (natural language processing) 自然语言处理node 节点nominalization 名物化nonce 暂用的non-finite 非限定non-finite clause 非限定式子句non-monotonic reasoning 非单调推理normal distribution 常态分布noun 名词noun phrase 名词组NP (noun phrase) completeness 名词组完全性object 宾语{语言学}/对象{信息科学}object oriented programming 对象导向程序设计 [面向对向的程序设计] official language 官方语言one-place predicate 一元述语on-line dictionary 线上查询词典 [联机词点]onomatopoeia 拟声词onset 节首音ontogeny 个体发生Ontology 本体论open set 开放集operand 操作数 [操作对象]optimization 最佳化 [最优化]overgeneralization 过度概化overgeneration 过度衍生paradigmatic relation 聚合关系paralanguage 附语言parallel construction 并列结构Parallel Corpus 平行语料库parallel distributed processing (PDP) 平行分布处理paraphrase 转述 [释意;意译;同意互训]parole 言语parser 剖析器 [句法剖析程序]parsing 剖析part of speech (POS) 词类particle 语助词PART-OF relation PART-OF 关系part-of-speech tagging 词类标注pattern recognition 型样识别P-C (predicate-complement) insertion 述补中插PDP (parallel distributed processing) 平行分布处理perception 知觉perceptron 感觉器 [感知器]perceptual strategy 感知策略performative 行为句periphrasis 用独立词表达perlocutionary 语效性的permutation 移位Petri Net Grammar Petri 网语法philology 语文学phone 语音phoneme 音素phonemic analysis 因素分析phonemic stratum 音素层Phonetics 语音学phonogram 音标Phonology 声韵学 [音位学;广义语音学]Phonotactics 音位排列理论phrasal verb 词组动词 [短语动词]phrase 词组 [短语]phrase marker 词组标记 [短语标记]pitch 音调pitch contour 调形变化Pivot Grammar 枢轴语法pivotal construction 承轴结构plausibility function 可能性函数PM (phrase marker) 词组标记 [短语标记]polysemy 多义性POS-tagging 词类标记postposition 方位词PP (preposition phrase) attachment 介词依附Pragmatics 语用学Precedence Grammar 优先级语法precision 精确度predicate 述词predicate calculus 述词计算predicate logic 述词逻辑 [谓词逻辑]predicate-argument structure 述词论元结构prefix 前缀premodification 前置修饰preposition 介词Prescriptive Linguistics 规定语言学 [规范语言学]presentative sentence 引介句presupposition 前提Principle of Compositionality 语意合成性原理privative 二元对立的probabilistic parser 概率句法剖析程序problem solving 解决问题program 程序programming language 程序设计语言 [程序设计语言]proofreading system 校对系统proper name 专有名词prosody 节律prototype 原型pseudo-cleft sentence 准分裂句Psycholinguistics 心理语言学punctuation 标点符号pushdown automata 下推自动机pushdown transducer 下推转换器qualification 后置修饰quantification 量化quantifier 范域词Quantitative Linguistics 计量语言学question answering system 问答系统queue 队列radical 字根 [词干;词根;部首;偏旁]radix of tuple 元组数基random access 随机存取rationalism 理性论rationalist (position) 理性论立场 [唯理论观点]reading laboratory 阅读实验室real time 实时real time control 实时控制 [实时控制]recursive transition network 递归转移网络reduplication 重叠词 [重复]reference 指涉referent 指称对象referential indices 指针referring expression 指涉词 [指示短语]register 缓存器 [寄存器]{信息科学}/调高{语音学}/语言的场合层级{社会语言学} regular language 正规语言 [正则语言]relational database 关系型数据库 [关系数据库]relative clause 关系子句relaxation method 松弛法relevance 相关性Restricted Logic Grammar 受限逻辑语法resumptive pronouns 复指代词retroactive inhibition 逆抑制rewriting rule 重写规则rheme 述位rhetorical structure 修辞结构rhetorics 修辞学robust 强健性robust processing 强健性处理robustness 强健性schema 基朴school grammar 教学语法scope 范域 [作用域;范围]script 脚本search mechanism 检索机制search space 检索空间searching route 检索路径 [搜索路径]second order predicate 二阶述词segmentation 分词segmentation marker 分段标志selectional restriction 选择限制semantic field 语意场semantic frame 语意架构semantic network 语意网络semantic representation 语意表征 [语义表示]semantic representation language 语意表征语言semantic restriction 语意限制semantic structure 语意结构Semantics 语意学sememe 意素Semiotics 符号学sender 发送者sensorimotor stage 感觉运动期sensory information 感官讯息 [感觉信息]sentence 句子sentence generator 句子产生器 [句子生成程序]sentence pattern 句型separation of homonyms 同音词区分sequence 序列serial order learning 顺序学习serial verb construction 连动结构set oriented semantic network 集合导向型语意网络 [面向集合型语意网络] SGML (Standard Generalized Markup Language) 结构化通用标记语言shift-reduce parsing 替换简化式剖析short term memory 短程记忆sign 信号signal processing technology 信号处理技术simple word 单纯词situation 情境Situation Semantics 情境语意学situational type 情境类型social context 社会环境sociolinguistics 社会语言学software engineering 软件工程 [软件工程]sort 排序speaker-independent speech recognition 非特定语者语音识别spectrum 频谱speech 口语speech act assignment 言语行为指定speech continuum 言语连续体speech disorder 语言失序 [言语缺失]speech recognition 语音辨识speech retrieval 语音检索speech situation 言谈情境 [言语情境]speech synthesis 语音合成speech translation system 语音翻译系统speech understanding system 语音理解系统spreading activation model 扩散激发模型standard deviation 标准差Standard Generalized Markup Language 标准通用标示语言start-bound complement 接头词state of affairs algebra 事态代数state transition diagram 状态转移图statement kernel 句核static attribute list 静态属性表statistical analysis 统计分析Statistical Linguistics 统计语言学statistical significance 统计意义stem 词干stimulus-response theory 刺激反应理论stochastic approach to parsing 概率式句法剖析 [句法剖析的随机方法] stop 爆破音Stratificational Grammar 阶层语法 [层级语法]string 字符串[串;字符串]string manipulation language 字符串操作语言string matching 字符串匹配 [字符串]structural ambiguity 结构歧义Structural Linguistics 结构语言学structural relation 结构关系structural transfer 结构转换structuralism 结构主义structure 结构structure sharing representation 结构共享表征subcategorization 次类划分 [下位范畴化]subjunctive 假设的sublanguage 子语言subordinate 从属关系subordinate clause 从属子句 [从句;子句]subordination 从属substitution rule 代换规则 [置换规则]substrate 底层语言suffix 后缀superordinate 上位的superstratum 上层语言suppletion 异型[不规则词型变化] suprasegmental 超音段的syllabification 音节划分syllable 音节syllable structure constraint 音节结构限制symbolization and verbalization 符号化与字句化synchronic 同步的synonym 同义词syntactic category 句法类别syntactic constituent 句法成分syntactic rule 语法规律 [句法规则]Syntactic Semantics 句法语意学syntagm 句段syntagmatic 组合关系 [结构段的;组合的]Syntax 句法Systemic Grammar 系统语法tag 标记target language 目标语言 [目标语言]task sharing 课题分享 [任务共享]tautology 套套逻辑 [恒真式;重言式;同义反复] taxonomical hierarchy 分类阶层 [分类层次] telescopic compound 套装合并template 模板temporal inference 循序推理 [时序推理] temporal logic 时间逻辑 [时序逻辑]temporal marker 时貌标记tense 时态terminology 术语text 文本text analyzing 文本分析text coherence 文本一致性text generation 文本生成 [篇章生成]Text Linguistics 文本语言学text planning 文本规划text proofreading 文本校对text retrieval 文本检索text structure 文本结构 [篇章结构]text summarization 文本自动摘要 [篇章摘要]text understanding 文本理解text-to-speech 文本转语音thematic role 题旨角色thematic structure 题旨结构theorem 定理thesaurus 同义词辞典theta role 题旨角色theta-grid 题旨网格token 实类 [标记项]tone 音调tone language 音调语言tone sandhi 连调变换top-down 由上而下 [自顶向下]topic 主题topicalization 主题化 [话题化]trace 痕迹Trace Theory 痕迹理论training 训练transaction 异动 [处理单位]transcription 转写 [抄写;速记翻译]transducer 转换器transfer 转移transfer approach 转换方法transfer framework 转换框架transformation 变形 [转换]Transformational Grammar 变形语法 [转换语法]transitional state term set 转移状态项集合transitivity 及物性translation 翻译translation equivalence 翻译等值性translation memory 翻译记忆transparency 透明性tree 树状结构 [树]Tree Adjoining Grammar 树形加接语法 [树连接语法]treebank 树图数据库[语法关系树库]trigram 三连词t-score t-数turing machine 杜林机 [图灵机]turing test 杜林测试 [图灵试验]type 类型type/token node 标记类型/实类节点type-feature structure 类型特征结构typology 类型学ultimate constituent 终端成分unbounded dependency 无界限依存underlying form 基底型式underlying structure 基底结构unification 连并 [合一]Unification-based Grammar 连并为本的语法 [基于合一的语法] Universal Grammar 普遍性语法universal instantiation 普遍例式universal quantifier 全称范域词unknown word 未知词 [未定义词]unrestricted grammar 非限制型语法usage flag 使用旗标user interface 使用者界面 [用户界面]Valence Grammar 结合价语法Valence Theory 结合价理论valency 结合价variance 变异数 [方差]verb 动词verb phrase 动词组 [动词短语]verb resultative compound 动补复合词verbal association 词语联想verbal phrase 动词组verbal production 言语生成vernacular 本地话V-O construction (verb-object) 动宾结构vocabulary 字汇vocabulary entry 词条vocal track 声道vocative 呼格voice recognition 声音辨识 [语音识别]vowel 元音vowel harmony 元音和谐 [元音和谐]waveform 波形weak verb 弱化动词Whorfian hypothesis Whorfian 假说word 词word frequency 词频word frequency distribution 词频分布word order 词序word segmentation 分词word segmentation standard for Chinese 中文分词规范word segmentation unit 分词单位 [切词单位]word set 词集working memory 工作记忆 [工作存储区]world knowledge 世界知识writing system 书写系统X-Bar Theory X标杠理论 ["x"阶理论]Zipf's Law 利夫规律 [齐普夫定律]阅读。
智能融合2软件FAQs July 2014说明书

SmartFusion2 SoftwareFAQsJuly 2014Table of Contents2SmartFusion2 Software FAQs1.Where can I find information about the DSP flow? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.Can I use the SmartFusion2 drivers provided by Microsemi together with my own application codeeventually in production? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43.Why is Cortex-M3 processor not running at 166 MHz in my design as published? . . . . . . . . . . 44.What is the speed of a mathblock? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45.Does the MATLAB/Simulink front-end tool have a blockset that uses mathblocks? . . . . . . . . . 46.Can the internal 25 MHz/ 50 MHz SmartFusion2 oscillator be used as the clock source for PCIe?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47.Can the internal 25 MHz/50 MHz SmartFusion2 oscillator be used as the clock source for USB?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48.What is maximum payload size for PCIe? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49.How should the JTAGSEL pin of the SmartFusion2 device be connected? . . . . . . . . . . . . . . . 410.What is the purpose of CoreConfigP core? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 511.For which memories can SECDED protection be enabled? . . . . . . . . . . . . . . . . . . . . . . . . . . . 512.What is the state of SmartFusion2 I/Os during JTAG programming? . . . . . . . . . . . . . . . . . . . . 513.Where can I get the SmartFusion2 peripheral firmware drivers? . . . . . . . . . . . . . . . . . . . . . . . . 714.What is the purpose of POWER_ON_RESET_N signal and what scenarios will assert this? . . 715.What does a mirrored master or mirrored slave port mean? . . . . . . . . . . . . . . . . . . . . . . . . . . . 816.Why is SPLL used for in PCIe? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 817.What is the source for the SPLL clock in SERDES? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 818.Which clock is used for the AHB buses in PCIe? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 819.Can fabric clock be used as reference clock in EPCS mode (In SERDES IP)? . . . . . . . . . . . . 820.Is the "Repair minimum delay violation" option for the router supported for SmartFusion2 device?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 821.Is it possible to get SmartFusion2 symbol and footprint files for Altium? . . . . . . . . . . . . . . . . . . 822.Does the SERDES simulation model have a feature to reduce simulation run times? . . . . . . . 823.Can the SERDES IP simulation model be used for simulating a PCIe system? . . . . . . . . . . . . 824.Is simulation of serial behavior of SERDES IP supported? . . . . . . . . . . . . . . . . . . . . . . . . . . . . 825.How are SmartFusion2 hardware blocks initialized? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 826.How does cache controller improve the execution time? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 827.What is Zeroization and is it supported by SmartFusion2 device? . . . . . . . . . . . . . . . . . . . . . . 828.How to use MSS clock conditioning circuit (CCC)? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 929.Does Microsemi have plans to support lower core voltage parts? . . . . . . . . . . . . . . . . . . . . . . . 930.Can SmartFusion2 support USB OTG and what type of USB is supported? . . . . . . . . . . . . . . 931.How should unused SERDES pins/power supplies on SmartFusion2 device be connected on theboard? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 932.Do blank devices have ramp rate? What is the default ramp rate? . . . . . . . . . . . . . . . . . . . . . . 933.What is the percentage deviation from power calculator values with the actual silicon results? 934.What is the default toggling rate used by power calculator to calculate the power? . . . . . . . . . 935.How to configure PCIe address parameter of SERDES configurator? . . . . . . . . . . . . . . . . . . 1036.Are IBIS models different for SmartFusion2 and IGLOO2? . . . . . . . . . . . . . . . . . . . . . . . . . . . 1037.How to set seed value for SmartFusion2/IGLOO2 place and route? . . . . . . . . . . . . . . . . . . . . 1138.What does the below RGB error message mean, which is observed during place and route? 1139.Are basic blocks available for SmartFusion2 and IGLOO2? . . . . . . . . . . . . . . . . . . . . . . . . . . 11SmartFusion2 Software FAQs340.How to enable system timers or MSS timers? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114SmartFusion2 Software FAQs1.Where can I find information about the DSP flow?DSP Quickstart and Design Tutorial document demonstrates the essential flow for directly generating RTL files from the design/higher-level algorithm created in the MathWorks' MATLAB ®/ Simulink ® software.Refer to the DSP Flow For SmartFusion2 SoC FPGA Quickstart and Design Tutorial for more information.To use the DSP flow, you should have the MathWorks MATLAB /Simulink software and license already installed. In addition, you need to install the Synopsys ® Synphony Model Compiler AE. The Synphony Model Compiler AE can only be launched from the MATLAB/Simulink tools.For more information about Synphony Model Compiler AE and the recommended, supported, and compatible MathWorks' tools versions, refer to the Design Software page.2.Can I use the SmartFusion2 drivers provided by Microsemi together with my own application code eventually in production?Yes, you can use SmartFusion2 devices firmware drivers, such as USB and MAC along with your application code for production purpose.3.Why is Cortex-M3 processor not running at 166 MHz in my design as published?When any peripheral is connected to Cortex-M3 processor, the frequency decreases. It might not run at the maximum speed of 166 MHz. The frequency depends on interconnected peripherals.4.What is the speed of a mathblock?A mathblock runs up to 350MHz depending on the application.Refer to Implementation of 9x9 Multiplications, Wide-Multiplier, and Extended Addition Using IGLOO2/SmartFusion2 Mathblock application note for further details.Note:This is applicable only for SmartFusion2/IGLOO2 devices.5.Does the MATLAB/Simulink front-end tool have a blockset that uses mathblocks?A mathblock is available in an IP catalog. Apart from this, you can use mathblocks by using Synphony Model Compiler integrated with the Matlab tool.Refer to the DSP Flow For SmartFusion2 SoC FPGA Quickstart and Design Tutorial for more information.For more information on how to integrate and download Symphony model compiler, refer to the Design Software page.6.Can the internal 25 MHz/ 50 MHz SmartFusion2 oscillator be used as the clock source for PCIe?Yes, refer to SmartFusion2 SoC FPGA Clocking Resources User Guide for more information.7.Can the internal 25 MHz/50 MHz SmartFusion2 oscillator be used as the clock source for USB?Yes, refer to SmartFusion2 SoC FPGA Clocking Resources User Guide for more information.8.What is maximum payload size for PCIe?The maximum payload size for PCIe is 512 bytes.9.How should the JTAGSEL pin of the SmartFusion2 device be connected?JTAGSEL pin of SmartFusion2 device should be pulled high for use with SoftConsole and should be pulled low for use with IAR and Keil products.SmartFusion2 Software FAQs510.What is the purpose of CoreConfigP core?CoreConfigP facilitates the configuration of peripheral blocks (MDDR, FDDR, and SERDESIF) in a SmartFusion2 device.It has a mirrored master APB port and several mirrored slave APB ports. The mirrored master port should be connected to the FIC_2_APB_MASTER master port of the microcontroller subsystem (MSS).For example,The MDDR controller must be configured to match the external DDR memory specifications. The configuration of the MDDR is defined in a file and is imported using the MDDR GUI configurator. The configuration is done through the CoreConfigP soft IP core which is the master of theconfiguration data initialization process. Upon reset, the soft IP core CoreConfigP will copy the data from embedded nonvolatile memory (eNVM) to the configuration registers of the MDDR controller through the FIC_2 advanced peripheral bus (APB) Interface.11.For which memories can SECDED protection be enabled?The single error correct double error detect (SECDED) protection is available for following memories:•Ethernet buffers •CAN message buffers •Cortex-M3 embedded scratch pad memory (eSRAMs)•USB buffers •PCIe buffer •DDR memory controllersRefer to the SmartFusion2 SoC FPGA Reliability and Security User Guide for more information on SECDED.12.What is the state of SmartFusion2 I/Os during JTAG programming?While programming in JTAG mode, the Cortex-M3 processor is in reset. All I/Os (MSIO, MSIOD, and DDRIO) are controlled by boundary scan registers according to IEEE1149.1 and IEEE1532 standards. I/O state can also be configured before programming, in Libero SoC software using the "Specify I/O states during programming window" as shown in Figure 1 on page 6.6SmartFusion2 Software FAQsRefer to the Libero SoC v11.0 User Guide for more information.Figure 1:Specify I/O States During Programming WindowSmartFusion2 Software FAQs713.Where can I get the SmartFusion2 peripheral firmware drivers?The firmware drivers are accessible from the SoftConsole firmware catalog. See Figure 2.14.What is the purpose of POWER_ON_RESET_N signal and what scenarios will assert this?It is a power-on reset from system controller to the FPGA fabric. The system controller initiates reset due to power-on reset, assertion of DEVRST_N input, completion of programming, or completion of Zeroization. POWER_ON_RESET_N signal can be used in the user design as a system power-on-reset for the FPGA fabric. It is an active Low-output signal.The POWER_ON_RESET_N signal is available by instantiating the SYSRESET macro (see Figure 3), from the Libero SoC IP catalog into SmartDesign or by instantiating it directly inside HDL file. Figure 2:Firmware Catalog Figure 3:SYSRESET Macro8SmartFusion2 Software FAQs15.What does a mirrored master or mirrored slave port mean?The mirrored interfaces are complementary interfaces located in the CoreAHB/APB that allow AHB/APB bus masters to connect to AHB/APB slaves through the CoreAHB/APB. The AHB/APB master port gets connected to the mirrored master port on the CoreAHB/APB, and the slave ports get connected to the mirrored slave ports on the CoreAHB/APB. In short, the mirrored ports are same ports as the normal interfaces but the directions of these ports are reversed.16.Why is SPLL used for in PCIe?The SPLL is used to re-time the bridge interface between the fabric and the hardened blocks of the SERDESIF.17.What is the source for the SPLL clock in SERDES?CLK_BASE is the input reference clock (source) of the SPLL.18.Which clock is used for the AHB buses in PCIe?The SPLL output is used as the AXI/AHB bridge clock.19.Can fabric clock be used as reference clock in EPCS mode (In SERDES IP)? Yes, fabric clock can be used as reference clock in the EPCS mode.20.Is the "Repair minimum delay violation" option for the router supported for SmartFusion2 device?This option is currently not supported for the SmartFusion2 device.21.Is it possible to get SmartFusion2 symbol and footprint files for Altium?Altium tool foot print and symbols are currently not available for Smartfusion2 device.22.Does the SERDES simulation model have a feature to reduce simulation run times?Presently, there is no option to bypass the clock and data recovery logic to reduce the simulation run time.23.Can the SERDES IP simulation model be used for simulating a PCIe system? Yes. BFM model can be used where SERDES acts as AXI/AHB bus master and slave. However, serial protocol is not implemented in this case.24.Is simulation of serial behavior of SERDES IP supported?Yes, it is supported. For all SERDES modes, full RTL model is used to simulate the SERDES serial behavior.25.How are SmartFusion2 hardware blocks initialized?SmartFusion2 hardware blocks are initialized through a combination of flash bits and Libero generated logic (CoreConfigP).26.How does cache controller improve the execution time?For details on improving the execution time using Cache Controller, refer to the SmartFusion2 SoC FPGA - Cache Controller Configuration application note.27.What is Zeroization and is it supported by SmartFusion2 device?Zeroization is a system service that destroys the sensitive data in the device and then verifies that the data is gone before allowing any further operations to take place. Yes, SmartFusion2 SoC FPGAs support Zeroization.SmartFusion2 Software FAQs928.How to use MSS clock conditioning circuit (CCC)?Run the following steps:•Instantiate the SmartFusion2 MSS component into your Libero SoC project.•Configure (enable/disable) the MSS components appropriately for the application needs using MSS configurator.•Configure the MSS CCC input and output clock frequencies using the MSS_CCC configurator.•Set the MPLL analog supply voltage to 2.5 V or 3.3 V to match the supply on the board.29.Does Microsemi have plans to support lower core voltage parts?Currently, SmartFusion2 works on 1.2 V core voltage. We are planning for 1.0 V core voltage support in future.30.Can SmartFusion2 support USB OTG and what type of USB is supported?Yes, SmartFusion2 device supports USB OTG. The following USB flash drives are currently supported:•Sandisk Cruzer BladeTM - 16 GB/8 GB/4 GB/1 GB •Kingston DataTraveler ® - 4 GB/2 GB •Kingston ® DataTraveler ®109 - 8 GB •Transcend JetFlash ® - 4 GB31.How should unused SERDES pins/power supplies on SmartFusion2 device be connected on the board?Refer to the Knowledge Base Article to know about handling unused SERDES pins.32.Do blank devices have ramp rate? What is the default ramp rate?No, the blank devices do not have default ramp rate values.Note:The 50 us, 1 ms, 10 ms, and 100 ms ramp rates are not applicable for blank devices, and they are valid only forthe programmed devices.33.What is the percentage deviation from power calculator values with the actual silicon results?The deviation percentage from power calculator with the actual silicon results is less than 10%.34.What is the default toggling rate used by power calculator to calculate the power?The power calculator engine uses inputs at 12.5% toggle rate and provides the power estimation.10SmartFusion2 Software FAQs 35.How to configure PCIe address parameter of SERDES configurator?PCIe address is mapped to bits [31:12] (LSB of Base address AXI Master WindowsX_2) and bits [31:0] (MSB of Base address AXI Master WindowsX_3).The zeros in these fields indicate the offset. For example, If the PCIe address value is set to be 0x1000 in the GUI, then the BAR0 address + 0x1000_000 is mapped to 0x0 of AXI window.36.Are IBIS models different for SmartFusion2 and IGLOO2?IBIS models are identical for SmartFusion2 and IGLOO2 given package.Figure 4: PCIe ConfiguratorTable 1: AXI_MASTER_WINDOW Registers Bit Numbers Name Description[31:12]AXI_MASTER_WINDOWx[0]Base address AXI3 master window x [11:0]Reserved [31:12]AXI_MASTER_WINDOWx[1]Size of AXI3 master window x [11:1]Reserved 0Enable bit of AXI3master window x [31:12]AXI_MASTER_WINDOWx[2]LSB of base address PCIe window x [11:6]Reserved [5:0]Theses bits set the BAR. To select a BAR, set thefollowing values:0*01: BAR0 (32-bit BAR) or BAR0/1 (64-bit BAR)0*02: BAR1 (32-bit BAR) only0*04: BAR2 (32-bit BAR) or BAR2/3 (64-bit BAR)0*08: BAR3 (32-bit BAR) only0*10: BAR4 (32-bit BAR) or BAR4/5 (64-bit BAR)0*20: BAR5 (32-bit BAR) only[31:0]AXI_MASTER_WINDOWx[3]MSB of base address PCIe window xSmartFusion2 Software FAQs1137.How to set seed value for SmartFusion2/IGLOO2 place and route?For example, set a seed value of 6 for place and route.The 'extended_run_lib' Tcl script enables you to set the starting seed value in batch mode from a command line prompt.To set a seed value of 6,<prompt>C:/Microsemi/Libero_v11.3/Designer/bin/libero.exe script:C:/Microsemi/Libero_v11.3/Designer/scripts/extended_run_lib.tcl logfile:extended_run.log "script_args:-root F:/SF2_seed/seed_check/designer/top -n 3 -starting_seed_index 6 -slack_criteria tns -stop_on_success"Refer to the Libero Tcl Commands Reference Guide for more information.Here,•C:/Microsemi/Libero_v11.3/Designer/bin/libero.exe = Libero installation directory •C:/Microsemi/Libero_v11.3/Designer/scripts/extended_run_lib.tcl = Scripts file location in the Libero installation directory •F:/SF2_seed/seed_check/designer/top = Root module location under designer directory in Libero project38.What does the below RGB error message mean, which is observed during place and route?Error: RGB: Cannot place all RGB’s in row 60.RGB stands for row global buffer.The error message indicates that the particular row of FPGA runs out of global resources. Change or edit the placement constraints provided in the PDC file. Refer to the SmartFusion2 Clocking Resources User Guide for more information.39.Are basic blocks available for SmartFusion2 and IGLOO2?Basic blocks are not available for SmartFusion2 and IGLOO2.40.How to enable system timers or MSS timers?System timers or MSS timers are enabled by default, refer to Chapter 18 in MSS User Guide for more information.55800028-1/7.14© 2014 Microsemi Corporation. All rights reserved. Microsemi and the Microsemi logo are trademarks of Microsemi Corporation. All other trademarks and service marks are the property of their respective owners.Microsemi Corporate HeadquartersOne Enterprise, Aliso Viejo CA 92656 USA Within the USA: +1 (800) 713-4113 Outside the USA: +1 (949) 380-6100Sales: +1 (949) 380-6136Fax: +1 (949) 215-4996E-mail:***************************Microsemi Corporation (Nasdaq: MSCC) offers a comprehensive portfolio of semiconductor and system solutions for communications, defense and security, aerospace, and industrial markets. Products include high-performance and radiation-hardened analog mixed-signal integrated circuits, FPGAs, SoCs, and ASICs; power management products; timing and synchronization devices and precise time solutions, setting the world's standard for time; voice processing devices; RF solutions; discrete components; security technologies and scalable anti-tamper products; Power-over-Ethernet ICs and midspans; as well as custom design capabilities and services. Microsemi is headquartered in Aliso Viejo, Calif. and has approximately 3,400 employees globally. Learn more at .。
psp硬件规格说明书开发级

TyRaNiD
August 4, 2006
TyRaNiD ()
The Naked PSP
August 4, 2006
1 / 61
What This Presentation Covers
What I am going to talk about: Coding on the PSP using C PSP Internals Development tools What I am not going to talk about: Games Piracy Modchips
TyRaNiD ()
The Naked PSP
August 4, 2006
7 / 61
History of PSP Home brew
Revisions of the PSP
Running Your Own Code
How you run code depends on the firmware revision of the PSP For versions 1.0 and 1.5 build a special EBOOT.PBP file and run directly on the PSP For version 2.0 use eLoader in libTIFF mode For version 2.01+ use Grand Theft Auto UMD plus eLoader For version 2.7+ no known way of developing
TyRaNiD ()
The Naked PSP
August 4, 2006
8 / 61
Alleviation [FWW91]. analyses [TRM91].
![Alleviation [FWW91]. analyses [TRM91].](https://img.taocdn.com/s3/m/c0a45e4ef7ec4afe04a1df66.png)
A Bibliography of Supercomputing’91Nelson H.F.BeebeCenter for Scientific ComputingUniversity of UtahDepartment of Mathematics,322INSCC155S1400E RM233Salt Lake City,UT84112-0090USATel:+18015815254FAX:+18015814148E-mail:beebe@(Internet) WWW URL:/~beebe/25October1998Version1.02AbstractThis bibliography records articles presented at the Supercomputing’91conference.Title word cross-reference 15[MS91].1990[STVS91].2600[SWL+91].3[SWL+91].4[KSY91].’91[IEE91].access[BC91,BS91].accesses[GV91]. across[MMF+91,NGHG+91].adaptive[FGPS91].Albuquerque[IEE91]. algebra[KS91].algorithm[Pug91,TG91,YG91,de91]. algorithms[FGPS91,Nar91].alias[Chi91]. Alleviation[FWW91].analyses[TRM91]. Analysis[Nar91,CV91,Pug91,WL91]. animation[UHP91].aperture[PMG91]. Application[RJCC91].applications[DKMS91,MK91].applied[Chr91].approach[KS91]. approaches[TMB91].Architecture[HQA+91,AFH+91,BP91a, Kar91,KSS+91,Tze91].Architecture-independent[HQA+91]. architectures[BL91,Nar91,TRM91]. array[BL91,GV91,Nar91].arrays[QM91]. arrhythmias[Sad91].auditorialization[HW91].automatic[CP91,KS91].12balance[VN91].balancing[AGM91,KSY91].bank[BU91]. based[BDG+91,Kar91,KSS+91].behavior[FLK+91,MK91].Bell[DKMS91,STVS91].benchmarks[BBB+91,BF91]. benchmarks-summary[BBB+91].block[Chr91,KS91].Boltzmann[Elt91]. bounded[Aln91].bounded-degree[Aln91].Burgers[Elt91]. C[HQA+91,Smi91].cardiac[Sad91].case[HQA+91].CG[Chr91].challenge[CFK+91].Chaotic[Sad91]. Characterizing[GPCJ91].checkpoint[BP91b].chip[BC91].class[Chr91].Climate[Che91,MMF+91]. code[EOS91,HKM91].coherence[CV91]. communicating[IAS+91]. communication[VN91].communications[Koe91,QM91]. community[MW91].Comparison[CV91,NGHG+91,SWL+91]. Compiler[HKT91,Koe91,STVS91,AFH+91].Compiler-time[Koe91]. compilers[Smi91].complex[SBGM91]. computation[Kar91].computational[Elt91].computations[KS91].computer[TRM91]. computers[JH91,RJCC91].Computing[Dan91,SBGM91,IAS+91,TV91,Wil91].concurrent[BDG+91,KWFN91]. conditioned[PF91].conflict[SN91].conflict-free[SN91].connected[Tze91]. Connection[MS91,SDM91].conquer[GK91].consistency[DWB+91]. constant[Aln91].contention[BU91]. contentions[BS91].costs[PBH91].course[TV91].Cray[SWL+91].cube[Tze91].cube-connected[Tze91]. cycles[Tze91].DAGs[YG91].data[BC91,GV91,Kan91,MC91,Nar91]. dataparallel[HQA+91].debate[Can91]. debugging[GH91].decoupled[BU91]. degree[Aln91].Delayed[DWB+91]. dense[Mal91].dependence[Pug91]. Design[Tze91,WL91,CM91,SN91]. Detecting[GV91].detection[MC91]. development[BDG+91].differential[HIS91].dimensional[Elt91,TRM91].directed[BP91a].directory[CV91]. distributed[AGM91,AFH+91,HKT91, IAS+91,Mal91,SY91].distributed-memory[HKT91]. Distributing[NGHG+91].Distribution[MMF+91,KSY91].divide[GK91].divide-and-conquer[GK91].division[QM91,de91].DNA[NGHG+91]. DOACROSS[CY91,SY91].dynamic[Chi91].dynamics[TMB91].effective[BC91].Effects[VN91,DWB+91]. Efficient[SY91,Chr91,TG91,WL91]. element[BL91,TRM91].elliptic[STVS91]. EM-4[KSY91].emerging[KSS+91]. empirical[CY91,LMSS91].environment[Dan91].equation[Elt91,HIS91].Euclidean[de91]. evaluation[CP91].examination[TG91]. execution[SY91].experiments[LG91]. explicit[PBH91].Exploration[Wil91]. Factoring[HSF91].factorization[Mal91,VN91].fast[Pug91,YG91,de91].FFTs[lWR91].finite[Kar91,TRM91].finite-element[TRM91].floating[MMNP91].floating-point[MMNP91].flow[EOS91,SBGM91].fluid[HIS91].fly[MC91].fork[MC91].fork-join[MC91]. format[MMNP91].FORTRAN[Can91,UHP91].3FortranD[HKT91].framework[CM91]. free[SN91].Fujitsu[SWL+91].Fully[FGPS91].Fully-adaptive[FGPS91]. function[KSY91].functions[HIS91]. generation[BL91,HKM91,Koe91]. generator[STVS91].geometries[Kar91,SBGM91].geophysics[Wil91].Gigaflops[MS91]. Gigascale[Mei91].good[Smi91].Gordon[STVS91,DKMS91].GPFP[BL91].Graphical[BDG+91,UHP91].grid[STVS91].GSI[Mei91]. heterogeneous[NGHG+91].hierarchical[WL91].High[GK91,YZ91, CFK+91,CM91,MMF+91].high-performance[CM91].high-speed[MMF+91].highly[Tze91].hot[GPCJ91].hypercubes[lWR91].ill[PF91].ill-conditioned[PF91].image[PMG91].implementation[Chr91,EOS91]. implications[TRM91].independent[HQA+91].information[HW91].Input[MK91].Input/output[MK91].integer[Pug91]. integrated[Chi91].integration[Mei91]. intelligence[MW91].Intelligent[IAS+91]. interactive[CP91].interconnection[FWW91,WL91]. Interprocedural[HKM91].issues[RJCC91].iteration[RS91]. iterative[PF91].join[MC91].K2[AFH+91].language[HIS91].Large[KWFN91,PBH91,RJCC91].lattice[Elt91].lectures[DKMS91].level[GK91].libraries[MMNP91].linear[Chr91,FJ91,KS91,PF91].Load[KSY91,AGM91,VN91].localization[PBH91].lookahead[BU91]. loops[CY91,HSF91].LU[Mal91]. machine[GPCJ91,MS91,SDM91]. machines[HKT91,RS91].management[Chi91].mapping[IAS+91]. Mass[MW91].Massively[TV91,BL91, FLK+91,RJCC91,SBGM91].math[MMNP91].matrix[Kar91,VN91]. Measurement[BS91].mechanism[BP91b].media[EOS91]. memory[AFH+91,BU91,BP91b,BS91, Chi91,GPCJ91,GH91,HKT91,Mal91, PBH91,RS91,SN91,SY91,de91].method[Chr91,Elt91,HSF91,Kan91]. Mexico[IEE91].mid[TV91].mid-course[TV91].milieu[KWFN91]. MIMD[Dan91,GPCJ91,HKT91].miss[DWB+91].model[MMF+91]. modeling[Che91,Dan91,MS91,SDM91]. molecular[TMB91].MOVE[CM91].MP[SWL+91].MTOOL[GH91]. multicomputer[AGM91]. multicomputers[KSS+91]. multidimensional[RS91].multiple[BS91].multiplexed[JH91]. multiprocessor[GH91,Mal91,PBH91, QM91].multiprocessors[SN91,SY91,ZB91]. multistage[FWW91,FJ91].NAS[BBB+91,BF91].NEC[SWL+91]. nested[MC91].Network[KSS+91,BDG+91].Network-based[KSS+91,BDG+91]. networks[Aln91,FWW91,FJ91,MMF+91, WL91].next[BL91].non[CWW91].non-uniform[CWW91].nonshared[RS91].November[IEE91]. number[Aln91,YG91].4Object[LG91].Ocean[SDM91].Omega[Pug91].on-chip[BC91].On-the-fly[MC91].operand[BU91]. operating[AFH+91].optical[JH91,QM91].Optimal[Aln91]. optimizations[HKT91].oriented[LG91]. output[MK91].package[PF91].packet[FGPS91].pairs[TG91].Parallel[TMB91,lWR91, AFH+91,BBB+91,BF91,BL91,CWW91, CP91,Che91,Chr91,DWB+91,EOS91,FLK+91,HKM91,HSF91,Kar91,KSS+91, LG91,PMG91,RJCC91,SBGM91,TG91, TV91,UHP91,Wil91].parallelism[CWW91,GK91,MC91]. parallelization[KS91,STVS91].partial[HIS91].partitioning[BP91a,VN91].patterns[Koe91].PDEQSOL[HIS91]. penalty[BC91].Performance[AGM91,BF91,GH91,CM91, FGPS91,SWL+91,YZ91].permutations[FJ91].PILS[PF91]. pivoting[Mal91].point[MMNP91]. Pointer[LMSS91].porous[EOS91].power[lWR91].power-of-two[lWR91]. practical[HSF91,Pug91].prediction[AGM91].preliminary[BBB+91].preloading[BC91].prime[de91].Prize[DKMS91,STVS91].problem[TV91].problems[HIS91]. Proceedings[IEE91].processes[IAS+91]. processing[BL91,Kan91,KWFN91,PMG91,YZ91].processor[AFH+91,BP91a,BS91,CM91,Nar91,SBGM91]. processors[YG91].profiles[CWW91]. Programming[PBH91,CP91,HQA+91, LG91,Pug91].programs[CWW91,DWB+91,FLK+91,GH91,MC91,UHP91]. projective[Kar91].protein[NGHG+91]. prototype[KSY91].races[MC91].radar[PMG91].Radix[ZB91].range[TMB91].rate[DWB+91].reality[Wil91].recovery[BP91b].reduce[BC91,BU91]. redundant[GV91].references[BU91]. regular[Koe91].rekindled[Can91]. reliable[Tze91].replicated[Nar91]. requirements[MW91].reservoir[KWFN91,RJCC91,YZ91]. resolution[Chi91].results[BBB+91,BF91,Elt91,LG91]. Retire[Can91].robust[HSF91].rollback[BP91b].rounds[Aln91].routing[FGPS91].saturation[FWW91].scale[KWFN91,PBH91,RJCC91]. Scheduling[CWW91,HSF91,VN91,YG91]. scheme[BC91,Chi91].schemes[CV91]. school[CFK+91].scientific[HQA+91,HW91].Seismic[MS91].semantics[BP91a]. semantics-directed[BP91a].sequences[NGHG+91].shared[GPCJ91, GH91,Kan91,PBH91,SY91].shared-memory[SY91].short[TMB91]. simulation[KWFN91,RJCC91,YZ91]. simulations[TMB91].software[CV91]. Solution[HIS91].solver[HIS91,PF91]. sort[ZB91].sorting[Aln91].spaces[RS91].sparse[Kar91,VN91]. speed[MMF+91].spots[GPCJ91].static[YG91].storage[MW91].studies[HQA+91].study[CY91,LMSS91]. summary[BBB+91].supercomputer[BL91,DKMS91]. supercomputers[Che91,NGHG+91,PMG91,SWL+91].Supercomputing[IEE91,BDG+91,CFK+91,MK91].support[BP91b,GK91]. switching[FGPS91].SX[SWL+91].SX-3[SWL+91].symbolic[Kan91]. Synthetic[PMG91].system[AFH+91]. systems[AGM91,BS91,Chr91,IAS+91,REFERENCES5PF91,de91].target[LMSS91].technology[Mei91].test[Pug91].Three[TRM91,HQA+91,SWL+91].Three-dimensional[TRM91].Threshold[Mal91].Tiling[RS91].Time[JH91,QM91,Koe91].Time-division[QM91].tools[BDG+91,CP91].tracking[LMSS91,TV91].tracking-an[LMSS91].transformations[HKM91].translation[BP91b].tree[FWW91]. tridiagonal[Chr91].turbulent[SBGM91]. two[BF91,Elt91,lWR91].two-dimensional[Elt91].ultra[de91].unbounded[YG91].uniform[CWW91].Universal[FJ91]. Using[BU91].Vector[EOS91,BS91,Che91,Kan91,YZ91, ZB91].Vector/parallel[EOS91]. Vectorizing[Smi91].via[FJ91].virtual[BP91b].viscous[Elt91]. Visualizing[FLK+91].VLSI[Aln91].VP[SWL+91].VP-2600[SWL+91].Wide[MMNP91].wormhole[FGPS91].Y-MP[SWL+91].ReferencesAnnaratone:1991:KDM [AFH+91]M.Annaratone,M.Fillo,M.Halbherr,R.Ruhl,Steiner,P.,and M.Viredaz.The K2distributed memory parallel pro-cessor:architecture,compilerand operating system.In IEEE[IEE91],pages900–909.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Ahmad:1991:PPD [AGM91]I.Ahmad, A.Ghafor,andK.Mehrotra.Performance pre-diction of distributed load bal-ancing on multicomputer sys-tems.In IEEE[IEE91],pages830–839.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Alnuweiri:1991:OBV [Aln91]H.M.Alnuweiri.Optimalbounded-degree VLSI networksfor sorting in a constant num-ber of rounds.In IEEE[IEE91],pages732–739.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Bailey:1991:NPB [BBB+91] D.H.Bailey,E.Barszcz,J.T.REFERENCES6Barton, D.S.Browning,R.L.Carter,L.Dagum,R. A.Fa-toohi,P.O.Frederickson,T.A.Lasinski,R.S.Schreiber,H.D.Simon,V.Venkatakrishnan,andS.K.Weeratunga.The NAS par-allel benchmarks-summary andpreliminary results.In IEEE[IEE91],pages158–165.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Baer:1991:EOP [BC91]J.-L.Baer and T.-F.Chen.An effective on-chip preloadingscheme to reduce data accesspenalty.In IEEE[IEE91],pages176–186.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Beguelin:1991:GDT [BDG+91] A.Beguelin,J.J.Dongarra,G.A.Geist,R.Manchek,andV.S.Sunderam.Graphicaldevelopment tools for network-based concurrent supercomput-ing.In IEEE[IEE91],pages435–444.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Bailey:1991:PRT [BF91] D.H.Bailey and P.O.Freder-ickson.Performance results fortwo of the NAS parallel bench-marks.In IEEE[IEE91],pages166–173.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Beal:1991:GAP [BL91] D.Beal and mbrinoudakis.GPFP:an array processing el-ement for the next generationof massively parallel supercom-puter architectures.In IEEE[IEE91],pages348–357.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Bird:1991:SPP [BP91a]P.L.Bird and U. F.Ple-ban.A semantics-directed par-titioning of a processor architec-ture.In IEEE[IEE91],pagesREFERENCES7702–709.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Bowen:1991:VMT [BP91b]N.S.Bowen and D.K.Prad-han.A virtual memory trans-lation mechanism to supportcheckpoint and rollback recov-ery.In IEEE[IEE91],pages890–899.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Bucher:1991:MMA [BS91]I.Y.Bucher and M.L.Simmons.Measurement of memory accesscontentions in multiple vectorprocessor systems.In IEEE[IEE91],pages806–817.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Bird:1991:ULR [BU91]P.L.Bird and -ing lookahead to reduce mem-ory bank contention for decou-pled operand references.In IEEE[IEE91],pages187–196.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Cann:1991:RFD [Can91] D.Cann.Retire FORTRAN?A debate rekindled.In IEEE[IEE91],pages264–272.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Cohen:1991:HSS [CFK+91]M.Cohen,M.Foster,D.Kratzer,P.Malone,and A.Solem.A high school supercomputingchallenge.In IEEE[IEE91],pages68–75.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.REFERENCES8Chervin:1991:CMP [Che91]R.Chervin.Climate model-ing with parallel vector super-computers.In IEEE[IEE91],pages677–??ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Chiueh:1991:IMM [Chi91]T.-C.Chiueh.An integratedmemory management schemefor dynamic alias resolution.In IEEE[IEE91],pages682–691.ISBN0-8186-9158-1(IEEEcase),0-8186-2158-3(IEEE pa-per),0-8186-6158-5(IEEE mi-crofiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACMorder number415913.IEEEComputer Society Press ordernumber2158.IEEE catalognumber91CH3058-5.Chronopoulos:1991:TEP [Chr91] A.T.Chronopoulos.Towardsefficient parallel implementationof the CG method applied to aclass of block tridiagonal linearsystems.In IEEE[IEE91],pages578–587.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Corporal:1991:MFH [CM91]Corporal,H.and H.Mulder.MOVE:a framework for high-performance processor design.In IEEE[IEE91],pages692–701.ISBN0-8186-9158-1(IEEEcase),0-8186-2158-3(IEEE pa-per),0-8186-6158-5(IEEE mi-crofiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACMorder number415913.IEEEComputer Society Press ordernumber2158.IEEE catalognumber91CH3058-5.Cheng:1991:EAI [CP91] D.Y.Cheng and D.M.Pase.An evaluation of automatic andinteractive parallel programmingtools.In IEEE[IEE91],pages412–423.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Chen:1991:CAS [CV91]Y.-C.Chen and A.V.Veiden-parison and anal-ysis of software and directorycoherence schemes.In IEEE[IEE91],pages818–829.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNREFERENCES9QA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Chang:1991:SPP [CWW91]Yao-Jen Chang,J.-L.C.Wu,andJingshown Wu.Scheduling par-allel programs with non-uniformparallelism profiles.In IEEE[IEE91],pages502–511.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Chen:1991:ESD [CY91] D.-K.Chen and P.-C.Yew.Anempirical study on DOACROSSloops.In IEEE[IEE91],pages620–632.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Dannevik:1991:CMM [Dan91]puting mod-eling in a MIMD environment.In IEEE[IEE91],pages678–??ISBN0-8186-9158-1(IEEEcase),0-8186-2158-3(IEEE pa-per),0-8186-6158-5(IEEE mi-crofiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACMorder number415913.IEEEComputer Society Press ordernumber2158.IEEE catalognumber91CH3058-5.deDinechin:1991:UFE [de91] B.D.de Dinechin.A ultra fastEuclidean division algorithm forprime memory systems.In IEEE[IEE91],pages56–65.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Dongarra:1991:GBP [DKMS91]J.J.Dongarra, A.Karp,K.Miura,and H.D.Simon.Gor-don Bell Prize lectures(super-computer applications).In IEEE[IEE91],pages328–337.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Dubois:1991:DCE [DWB+91]M.Dubois,J.-C.Wang,L.A.Barroso,K.Lee,and Y.-S.Chen.Delayed consistency andits effects on the miss rate ofparallel programs.In IEEE[IEE91],pages197–206.ISBNREFERENCES100-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Elton:1991:LBM [Elt91] B.H.Elton.A lattice Boltzmannmethod for a two-dimensionalviscous Burgers equation:com-putational results.In IEEE[IEE91],pages242–252.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Ewing:1991:VPI [EOS91]R.Ewing,P.O’Leary,andJ.Sochacki.Vector/parallel im-plementation of a porous mediaflow code.In IEEE[IEE91],pages294–303.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Felperin:1991:FRP [FGPS91]S.A.Felperin,L.Gravano,G.D.Pifarre,and J.C.L.Sanz.Fully-adaptive routing:packet switch-ing performance and wormholealgorithms.In IEEE[IEE91],pages654–663.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Fiduccia:1991:UMN [FJ91] C.M.Fiduccia and E.M.Ja-cobson.Universal multistagenetworks via linear permuta-tions.In IEEE[IEE91],pages380–389.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Friedell:1991:VBM [FLK+91]M.Friedell,Polla,S.Kochhar,S.Sistare,Juda,and J.Visual-izing the behavior of massivelyparallel programs.In IEEE[IEE91],pages472–480.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-REFERENCES11ber2158.IEEE catalog number91CH3058-5.Farrens:1991:ATS [FWW91]M.Farrens, B.Wetmore,andA.Woodruff.Alleviation of treesaturation in multistage inter-connection networks.In IEEE[IEE91],pages400–409.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Goldberg:1991:PDS [GH91] A.J.Goldberg and J.L.Hen-nessy.Performance debug-ging shared memory multipro-cessor programs with MTOOL.In IEEE[IEE91],pages481–490.ISBN0-8186-9158-1(IEEEcase),0-8186-2158-3(IEEE pa-per),0-8186-6158-5(IEEE mi-crofiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACMorder number415913.IEEEComputer Society Press ordernumber2158.IEEE catalognumber91CH3058-5.Gursoy:1991:HLS [GK91] A.Gursoy and L.V.Kale.Highlevel support for divide-and-conquer parallelism.In IEEE[IEE91],pages283–292.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Glen:1991:CMH [GPCJ91]R.R.Glen,D.V.Pryor,J.M.Conroy,and T.Johnson.Char-acterizing memory hot spots ina shared memory MIMD ma-chine.In IEEE[IEE91],pages554–566.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Granston:1991:DRA [GV91] E.D.Granston and A.V.Vei-denbaum.Detecting redundantaccesses to array data.In IEEE[IEE91],pages854–865.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Hirayama:1991:SFP [HIS91]H.Hirayama,M.Ikeda,andN.Sagawa.Solution functionsof PDEQSOL(partial differen-tial equation solver language)forfluid problems.In IEEE[IEE91],pages218–227.ISBNREFERENCES120-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Hall:1991:ITP [HKM91]M.W.Hall,K.Kennedy,andK.S.McKinley.Interproce-dural transformations for paral-lel code generation.In IEEE[IEE91],pages424–434.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Hiranandani:1991:COF [HKT91]S.Hiranandani,K.Kennedy,and pileroptimizations for FortranD onMIMD distributed-memory ma-chines.In IEEE[IEE91],pages86–100.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Hatcher:1991:ASP [HQA+91]P.J.Hatcher,M.J.Quinn,R.J.Anderso,padula,B.K.Seevers,and A.F.Bennett.Architecture-independent scien-tific programming in dataparallelC:three case studies.In IEEE[IEE91],pages208–217.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Hummel:1991:FPR [HSF91]S. F.Hummel, E.Schonberg,and L. E.Flynn.Factor-ing:a practical and robustmethod for scheduling parallelloops.In IEEE[IEE91],pages610–619.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Hotchkiss:1991:ASI [HW91]R.S.Hotchkiss and C.L.Wampler.The auditorializationof scientific information.In IEEE[IEE91],pages453–461.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-REFERENCES13ber2158.IEEE catalog number91CH3058-5.Ieumwananonthachai:1991:IMC [IAS+91] A.Ieumwananonthachai, A.N.Aizawa,S.R.Schwartz,Wah,B.W.,and J.C.Yan.In-telligent mapping of communi-cating processes in distributedcomputing systems.In IEEE[IEE91],pages512–521.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.IEEE:1991:PSA [IEE91]IEEE,editor.Proceedings,Su-percomputing’91:Albuquerque,New Mexico,November18–22,1991.IEEE Computer SocietyPress,1109Spring Street,Suite300,Silver Spring,MD20910,USA,1991.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Jordan:1991:TMO [JH91]H.F.Jordan and V.P.Heuring.Time multiplexed optical com-puters.In IEEE[IEE91],pages370–378.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Kanada:1991:MVP [Kan91]Y.Kanada.A method of vectorprocessing for shared symbolicdata.In IEEE[IEE91],pages722–731.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCN QA76.5.S8941991.ACM order number415913.IEEE Computer SocietyPress order number2158.IEEEcatalog number91CH3058-5.Karmarkar:1991:NPA [Kar91]N.Karmarkar.A new paral-lel architecture for sparse ma-trix computation based onfiniteprojective geometries.In IEEE[IEE91],pages358–369.ISBN0-8186-9158-1(IEEE case),0-8186-2158-3(IEEE paper),0-8186-6158-5(IEEE microfiche),0-89791-459-7(ACM).LCCNQA76.5.S8941991.ACM or-der number415913.IEEE Com-puter Society Press order num-ber2158.IEEE catalog number91CH3058-5.Koelbel:1991:CGR [Koe91] piler-timegeneration of regular commu-nications patterns.In IEEE[IEE91],pages101–110.ISBN。
计算机英语词汇

•General purpose computer 通用计算机•Control unit 控制单元•Integrated circuit: IC 集成电路•Microprocessor 微处理器•Component 组件•Instruction 指令•Encode/decode 编码•Program counter 程序计数器•Concurrent 同时•Register 寄存器•Loop 循环•Floating point 浮点数•Conditional statement 条件语句•Vector 矢量•Matrix 矩阵•Binary 二进制的•bit/byte 字节•Hard disk 硬盘•Floppy disk 软盘•Optical disk 光盘•Firmware 固件•Flash memory 闪存•Peripheral 外围设备•Cache 高速缓存2、•monitor/display 显示器、监视器•connector 连接器•Pixel 像素•Flat panel 平板•Host 主机•High resolution 高分辨率•HD: high definition 高清•Slot 插槽•Upgrade/update 更新•Analog/digital 模拟量/数字•Communicate 交流•Switch/router/hub/bridge 交换机/路由器/集线器/网桥•Expansion card 扩展卡•Wireless 无线的•Motherboard 主板•Multimedia 多媒体•Application 应用•User interface 用户接口•Middleware 中间件•Distributed system 分布式系统•Machine language/ programming language/natural language…•Assembly Language 汇编语言•Source code/Object code 源代码/目标代码•Executable file 可执行文件•Compile/compiler 编译/编译程序•Driver 驱动程序•Debug/Breakpoint 调试/断点•Database 数据库•Library 库•DLL: Dynamic Link Library 动态链接库•Call a function 调用函数•Script 脚本•Package 包•Pointer 指针•Sequential/conditional/iterative 顺序/条件/循环•Software engineer 软件工程师•Software engineering 软件工程•Software developer 软件开发人员•Stand-alone program 独立程序•Instruction set 指令集4、•Core 核心•Kernel 内核•Interface 接口•Video card/video adapter 视频卡/视频适配器•Sound card 声卡•Command 命令•Maintain 维护•Version/edition 版本/版本(书)•Transparent 透明的•Release 释放•System crash 系统崩溃•System failure 系统失效•Stable-> stability->instability 稳定,稳固,不稳定•Reboot 重新启动•Unauthorized intruder 未经授权的入侵者•malfunction 故障、功能失常Data structure 数据结构Array/matrix 数组/矩阵Record 记录Algorithm 算法3D:Three-dimensional 三维Subscript 下标Consistent 一致的Mainframe 大型机•Directory 目录•Entity 实体•Suffix 后缀•Column 列•Decision table 决策表•Truth table 真值表•HTML 超文本标签语言•Binary tree 二叉树•Linked list 链表•Stack 栈•Queue 队列•Buffer 缓冲区•Capacity 容量•Singly-linked list 单向链表•Doubly-linked list 双向链表•Circularly-linked list 循环链表•Node 结点•Directed graph 有向图•Undirected graph 无向图6、•Efficiency 效率•Run a program 运行程序•Command line 命令行•Text editor 文本编辑器•Automatic 自动化•Invoke 调用•Declare 声明•Statement 语句•Symbol 符号•Main function 主函数• A block of code 代码片段•Variable 变量•Calculate 计算•Space 空间•Integer 整数•Quit 退出•Object oriented 面向对象•Compatible 兼容的•Open source code 开源代码•Scripting language 脚本语言7、•Structured 结构化•Retrieve 检索•Model/modeling 模型/建模•Relational model 关系模型•Hierarchical model 层级模型•Network model 网络模型•Administrator 管理员•Data integrity 数据完整性•Concurrency 并发性•Recovery 恢复•Logical model 逻辑模型•Attribute 属性、特征•Domain 域•Tuple 元祖•Integrity constraint 完整性约束•Unique constraint 唯一性约束•Index 索引•Primary key/ foreign key 主键/外键•Normal forms 范式•Transaction 事务•Replication/replica 复制/复制品8、•Procedural programming 程序的设计•Class 类•Inheritance 继承•be derived from 来自、源自•Reuse 重新使用•Instance 实例•Subclass 子类•Prototype 原型,模型•Template 模板•Characteristic 特征•Superclass 超类(父类)•Hierarchy 层次,层级•Concept 概念•Namespace 命名空间•Specification 规格说明书•Polymorphism 多态性9、•Telecommunication 电信•Scalability 可伸缩性•Protocol 协议•Communication medium 通信媒体•Connect/Connection/Connectivity/Interconnect 连接v/连接n/连通性/互连•Ethernet 以太•microwave 微波•Network layer 网络层•Reference model 参考模型•Wireless 无线•Architecture 结构•Peer-to-peer 对等•Topology 拓扑学•Hierarchical 分级的•Value-added network 增值网络•Bluetooth 蓝牙•Data transfer rate 数据传输效率•Carrier 载体•Access 存取,访问•Cable 缆绳•Optical cable 光缆•Addressing system 寻址系统•Network segment 网段•Traffic 通信量,流量•Broadcast 广播•Packet 小包•Circuit-switched network 电路转换网络•Virtual circuit 虚拟电路•Uplink 向上传输•Destination node 目标结点•Forwarding table 转发表•Server Farm 服务器群•Internet/Intranet/Extranet 互联网/内联网/外联网11、•Third party 第三方•Non-core business 非核心业务•Service provider 服务提供商•HRO: human resource outsourcing 人力资源外包•Software publisher 软件发行商•Localization 本地化•Offshore/Onshore/ Nearshoring 离岸/在岸/近岸•Subset 子集•Labor cost 人工成本•Multinational corporation 跨国公司•Service delivery model 服务交付模式•IP: intellectual Property 知识产权•Data mining 数据挖掘12、•project management 项目管理•delivery of IT services 提供IT服务•fundamental 基本•core competence/competency 核心能力/能力,资格•Criteria 标准•Academic literature 学术文献•transaction cost theory 交易成本理论•organizational hierarchy 组织层级•agency /agent 代理/代理人•case studies 案例研究。
摩卡电子V2401 2402系列独立计算机商品介绍说明书

The V2401/2402 Series embedded computers are based on the Intel Atom N270 x86 processor, and feature 4 RS-232/422/485 serial ports, 8 RS-232 serial ports, dual Gigabit LAN ports, 6 USB 2.0 hosts, and a CompactFlash socket. The V2401 computer provides VGA, DVI, and LVDS outputs, and the V2402 computer provides both VGA and DVI outputs, making them particularly well-suited for industrial applications such as SCADA and factory automation.The V2401 and V2402 come with 4 RS-232/422/485 serial ports, and the V2401 has an additional 8 RS-232 ports, making them ideal for connecting a wide range of serial devices, and the dual 10/100/1000 Mbps Ethernet ports offer a reliable solution for network redundancy, Front View promising continuous operation for data communication and management. As an added convenience, the V2401/2402 computers have 4 DIs, and 4 DOs for connecting digital input/output devices. In addition, the CompactFlash and USB sockets provide the V2401/2402 computers with the reliability needed for industrial applications that require data buffering and storage expansion.Pre-installed with Linux, Windows CE 6.0, or Windows Embedded Standard 2009, the V2401/2402 Series provides programmers with a friendly environment for developing sophisticated, bug-free application software at a low cost.In addition, the V2402 series also offers -40 to 70°C wide temperature models for harsh environments.V2401/2402 SeriesOverviewAppearancePower/Storage 10/100/1000 Mbps(V2401)Rear ViewHardware SpecificationsComputerCPU: Intel Atom N270 1.6 GHz processorOS (pre-installed): Linux, Windows CE 6.0 or Windows Embedded Standard 2009System Chipset: Intel 945GSE + ICH7-MBIOS: 8 Mbit Flash BIOS, SPI type, ACPI function supportedFSB: 400/533 MHzSystem Memory: 2 GB capacity, 1 GB pre-installed: 1 x 2 GBDDR2-533 200 pin SO-DIMM SDRAM slotUSB: USB 2.0 compliant hosts x 6, type A connector, supports system boot upStorageBuilt-in: 2 GB onboard industrial DOM to store OSStorage Expansion: CompactFlash socket for CF card expansion, supporting CF Type-I/II socket with DMA modeHDD Support: 1 SATA-II connector for HDD expansionOther PeripheralsKB/MS: 1 PS/2 interface supporting standard PS/2 keyboard and mouse through Y-type cableAudio: HD audio, with line-in and line-out interfaceDisplayGraphics Controller: Intel Gen 2.5 Integrated Graphics Engine, 250 MHz core render clock and 200 MHz core display clock at 1.05-V core voltage VGA Interface: DB15 female connectorLVDS Interface: Onboard HIROSE DF13-40DP-1.25 V connector (V2401 only)DVI Interface: DVI-connector (chrontel CH7307 SDVO to DVI transmitter)Ethernet InterfaceLAN: 2 auto-sensing 10/100/1000 Mbps ports (RJ45)Serial InterfaceSerial Standards:• V2401/2402: 4 RS-232/422/485 ports*, software selectable (DB9 male connector)• V2401 only: 8 RS-232 ports (68-pin VHDC connector)*COM1’s pin 9 signal can be set by jumper as N/C (default), +5 V, or +12 V ESD Protection: 4 kV for all signalsSerial Communication ParametersData Bits: 5, 6, 7, 8Stop Bits: 1, 1.5, 2Parity: None, Even, Odd, Space, MarkFlow Control: RTS/CTS, XON/XOFF, ADDC® (automatic data direction control) for RS-485Baudrate: 50 bps to 921.6 kbps (non-standard baudrates supported; see user’s manual for details)Serial LEDs RS-232/422/485RS-232 Serial Port x 8 DI x 4Software SpecificationsSerial SignalsRS-232: TxD, RxD, DTR, DSR, RTS, CTS, DCD, GND RS-422: TxD+, TxD-, RxD+, RxD-, GND RS-485-4w: TxD+, TxD-, RxD+, RxD-, GND RS-485-2w: Data+, Data-, GNDDigital InputInput Channels: 4, source type Input Voltage: 0 to 30 VDC at 25 Hz Digital Input Levels for Dry Contacts: • Logic level 0: Close to GND • Logic level 1: OpenDigital Input Levels for Wet Contacts: • Logic level 0: +3 V max.• Logic level 1: +10 V to +30 V (Source to DI)Isolation: 3 kV opticalDigital OutputOutput Channels: 4, sink typeOutput Current: Max. 200 mA per channelOn-state Voltage: 24 VDC nominal, open collector to 30 VDC Connector Type: 10-pin screw terminal block (4 DI points, 4 DO points, DI Source, GND)Isolation: 3 kV optical isolationLEDsSystem: Power, StorageLAN: 100M/Link x 2, 1000M/Link x 2 (on connector)Switches and ButtonsPower Switch: on/off (front panel)Reset Button: For warm reboot (rear panel)Physical CharacteristicsHousing: Aluminum Weight:• V2401: 2.1 kg • V2402: 2 kg Dimensions:Without ears: 250 x 57 x 152 mm (9.84 x 2.24 x 5.98 in)With ears: 275 x 63 x 152 mm (10.83 x 2.48 x 5.98 in)Mounting: DIN rail, wall, VESAEnvironmental LimitsOperating Temperature:• Standard models: -10 to 60°C (14 to 140°F) • Wide temp. models : -40 to 70°C (-40 to 158°F)Storage Temperature: -40 to 85°C (-40 to 185°F)Ambient Relative Humidity: 5 to 95% (non-condensing)Anti-vibration: 5 g rms @ IEC-68-2-34, random wave, 5-500 Hz, 1 hr/axisAnti-shock: 50 g @ IEC-68-2-27, half sine wave, 11 msPower RequirementsInput Voltage: 9 to 36 VDC (3-pin terminal block for V+, V-, SG)Power Consumption: 26 W (without LVDS output) 2.9 A @ 9 VDC 1.08 A @ 24 VDC 720 mA @ 36 VDCStandards and CertificationsSafety: UL 508, UL 60950-1, CSA C22.2 No. 60950-1-07, EN 60950-1, CCC (GB9254, GB17625.1)EMC: EN 55022 Class A, EN 61000-3-2 Class D, EN 61000-3-3, EN 55024, FCC Part 15 Subpart B Class A Wheeled Vehicles: e-Mark (e4)Green Product: RoHS, CRoHS, WEEEReliabilityAutomatic Reboot Trigger: Built-in WDT (watchdog timer) supporting 1-255 level time interval system reset, software programmable MTBF (mean time between failures): V2401: 238,762 hrs V2402: 228,172 hrsWarrantyWarranty Period: 3 yearsDetails: See /warrantyLinuxOS: Linux 2.6.26, Debian Lenny 5.0File System: EXT2Internet Protocol Suite: TCP, UDP, IPv4, SNMPv1/v2c/v3, ICMP, ARP, HTTP, CHAP, PAP, SSH 1.0/2.0, SSL, DHCP, NTP, NFS, Telnet, FTP, TFTP, PPP, PPPoEInternet Security: OpenVPN, iptables firewallWeb Server (Apache): Allows you to create and manage web sites; supports PHP and XMLTerminal Server (SSH): Provides secure encrypted communications between two un-trusted hosts over an insecure networkDial-up Networking: PPP Daemon for Linux that allows Unix machines to connect to the Internet through dialup lines, using the PPP protocol, as a PPP server or client. Works with ‘chat’, ‘dip’, and ‘diald’, among (many) others. Supports IP, TCP, UDP, and (for Linux) IPX (Novell).File Server: Enables remote clients to access files and other resources over the networkWatchdog: Features a hardware function to trigger system reset in a user specified time interval (Moxa API provided)Application Development Software:• Moxa API Library (Watchdog timer, Moxa serial I/O control, Moxa DI/DO API)• GNU C/C++ compiler • GNU C library • PerlWindows XP EmbeddedOS: Windows Embedded Standard 2009 SP3File System: NTFSInternet Protocol Suite: DHCP, DNS, FTP, HTTP, SNTP, NTP, Telnet, SMTP, SNMPv2, TCP, UDP, IPv4, ICMP, IGMP, IPsec, TAPI, ICS, PPP, CHAP, EAP, PPPoE, PPTP, NetBIOSWeb Server (IIS): Allows users to create and manage websitesSilverlight 2.0: A free runtime that powers rich application experiences and delivers high quality, interactive video across multiple platforms and browsers, using the .NET frameworkRemote Registry Service: Enables remote users to modify registry settings on this computerRemote Desktop: The Terminal Server Remote Desktop component provides remote access for the desktop of a computer running Terminal ServicesWatchdog: Features a hardware function to trigger system reset in a user specified time interval (Moxa API provided)Enhanced Writer Filter: Redirect disk write operations to volatile (RAM) or non-volatile (disk) storageFile Based Write Filter: The File Based Write Filter (FBWF) component redirects all write requests directed at protected volumes to the overlay cache, which records and displays the changes while preserving the protected status of the target volume.Application Development Software: • Moxa API Library• Microsoft .Net Framework 3.5 with SP1• Active Directory Service Interface (ADSI) Core • Active Template Library (ATL), 2.0 • Common Control Libraries • Common File Dialogs• Direct3D, DirectPlay, DirectShow, and Direct show filtersOrdering InformationAvailable ModelsV2401-CE: x86 ready-to-run embedded computer with Intel Atom N270, VGA, LVDS, DVI, Audio, 2 LANs, 12 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, WinCE 6.0V2401-XPE: x86 ready-to-run embedded computer with Intel Atom N270, VGA, LVDS, DVI, Audio, 2 LANs, 12 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, Windows Embedded Standard 2009V2401-LX: x86 ready-to-run embedded computer with Intel Atom N270, VGA, LVDS, DVI, Audio, 2 LANs, 12 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, Linux 2.6V2402-CE: x86 ready-to-run embedded computer with Intel Atom N270, VGA, DVI, Audio, 2 LANs, 4 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, WinCE 6.0V2402-XPE: x86 ready-to-run embedded computer with Intel Atom N270, VGA, DVI, Audio, 2 LANs, 4 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, Windows Embedded Standard 2009, -10 to 60°C operating temperatureV2402-LX: x86 ready-to-run embedded computer with Intel Atom N270, VGA, DVI, Audio, 2 LANs, 4 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, Linux 2.6, -10 to 60°C operating temperatureV2402-T-XPE: x86 ready-to-run embedded computer with Intel Atom N270, VGA, DVI, Audio, 2 LANs, 4 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF, Windows Embedded Standard 2009, -40 to 70°C operating temperatureV2402-T-LX: x86 ready-to-run embedded computer with Intel Atom N270, VGA, DVI, Audio, 2 LANs, 4 serial ports, 4 DIs, 4 DOs, 6 USB 2.0 ports, CF,Linux 2.6, -40 to 70°C operating temperatureOptional Accessories (can be purchased separately) CBL-M68M9x8-100: 8-port RS-232 cable with VHDC connector PWR-24250-DT-S1: Power adaptorPWC-C7US-2B-183: Power cord with 2-pin connector, USA plug PWC-C7EU-2B-183: Power cord with 2-pin connector, Euro plug PWC-C7UK-2B-183: Power cord with 2-pin connector, British plug PWC-C7AU-2B-183: Power cord with 2-pin connector, Australia plug PWC-C7CN-2B-183: Power cord with 2-pin connector, China plug FK-75125-01: Hard disk installation package (for SSD)DK-DC50131-01: DIN-Rail mounting kit Package Checklist• V2401 or V2402 embedded computer • Terminal block to power jack converter • PS2 to KB/MS Y-type cable• Wall mounting kit• Documentation and software CD or DVD • Quick installation guide (printed)• Warranty card• Mapi32 Libraries• Message Queuing (MSMQ) Core• Microsoft Visual C++ Run Time Libraries• Power Management dynamic-link library• RPC• Windows API, Script Engines, and WMIWindows Embedded CE 6.0OS: Windows Embedded CE 6.0 R3File System: FAT (for on-board flash)Internet Protocol Suite: TCP, UDP, IPv4, SNMPv2, ICMP, IGMP, ARP, HTTP, CHAP, PAP, SSL, DHCP, SNTP, SMTP, Telnet, FTP, PPPWeb Server (WinCE IIS): Supports ASP, ISAPI Secure Socket Layer (SSL 2/3) and Transport Layer Security (TLS/SSL 3.1) publickey-based protocols, and Web Administration ISAPI ExtensionsDial-up Networking: Supports RAS client API and PPP, Extensible Authentication Protocol (EAP), and RAS scriptingFile Server: Enables remote clients to access files and other resources over the networkWatchdog: Features a hardware function to trigger system reset in a user specified time interval. (Moxa API provided)Application Development Software:• Moxa WinCE 6.0 SDK• Moxa API Library• C Libraries and Run-times• Component Services (COM and DCOM)• Microsoft® .NET Compact Framework 2.0• XML, including DOM, XQL, XPATH, XSLT, SAX, SAX2• SOAP Toolkit Client• Winsock 2.2。
Memory-Compiler使用入门介绍

Memory Compiler使用介绍在使用Memory Compiler时,请务必确保你的RAM从头到尾的规格与设定都相同,否则会造成一些不可避免的错误。
首先在RTL代码阶段,要用到RAM就要用Artisan公司提供的Memory Compile产生的verilog代码,此时不需要着急产生其他后阶段的必要数据,因为RTL代码阶段,只需要行为级模型即可。
当进入门级代码后,RAM compiler就要产生其他的相关数据了,同时要考虑RAM版图的位置与方向。
由于一个大的设计不会设计一次就会完成,所以有两个重点,第一个是每次使用RAM compiler时都一定要让它产生特性设置文档,避免忘记自己做过的设定。
第二件事是对应的文件名要定义好,否则RAM的方向不同但是又用到了相同的文件名,就会把原始数据覆盖掉。
下图为SRAM在流程中需要产生的文档RTL阶段在RTL阶段主要只是产生verilog行为级和设置文件。
因为在RTL阶段不需要考虑RAM 的位置信息。
Memory Compiler提供4种选择,分别为ra1sh,ra2sh,rf1sh,rf2sh。
前面的ra与rf分别指的是SRAM与register file,其中rf在同样的情况下比ra占的面积小,但是rf的大小有限制,其限制大小位4096bits。
而后面1sh与2sh表示位单端口还是双端口,如果SRAM 的容量比较大的话,相同设置下,1sh比2sh面积要小,速度也要快,功耗要低。
Memory Compiler运行界面如下图所示instance name:该设置是对RAM的命名,由于ram的特性有地址和位数,所以在命名的时候尽量包含这些信息。
number of words:该设置用来确定RAM的深度,即寻址空间大小。
number of bits:该设置用来确定RAM的宽度。
frequency:该设置用来确定RAM的工作频率,该设置确定后就可以基本确定RAM的功耗,估计的结果位平均电流,通过该数据来设定电源环的宽度。
Memory Compiler使用介绍

Memory Compiler使用介绍在使用Memory Compiler时,请务必确保你的RAM从头到位的规格与设定都相同,否则会造成一些不可避免的错误。
首先在RTL代码阶段,要用到RAM就要用Artisan公司提供的Memory Compile产生的verilog代码,此时不需要着急产生其他后阶段的必要数据,因为RTL代码阶段只需要行为级模型即可。
当进入门级代码后,RAM compiler就要产生其他的相关数据了,同时要考虑RAM版图的位置与方向。
由于一个大的设计不会设计一次就会完成,所以有两个重点,第一个是每次使用RAM compiler时都一定要让它产生特性设置文档,避免忘记自己做过的设定。
第二件事是对应的文件名要定义好,否则RAM的方向不同但是又用到了相同的文件名,就会把原始数据覆盖掉。
下图为SRAM在流程中需要产生的文档RTL阶段在RTL阶段主要只是产生verilog行为级和设置文件。
因为在RTL阶段不需要考虑RAM的位置信息。
Memory Compiler提供4种选择,分别为ra1sh,ra2sh,rf1sh,rf2sh。
前面的ra与rf分别指的是SRAM与registerfile,其中rf在同样的情况下比ra占的面积小,但是rf的大小有限制,其限制大小位4096bits。
而后面1sh与2sh表示位单端口还是双端口,如果SRAM的容量比较大的话,相同设置下,1sh比2sh面积要小,速度也要快,功耗要低。
Memory Compiler运行界面如下图所示instance name:该设置是对RAM的命名,由于ram的特性有地址和位数,所以在命名的时候尽量包含这些信息。
number of words:该设置用来确定RAM的深度,即寻址空间大小。
number of bits:该设置用来确定RAM的宽度。
frequency:该设置用来确定RAM的工作频率,该设置确定后就可以基本确定RAM的功耗,估计的结果位平均电流,通过该数据来设定电源环的宽度。
英语_陌生单词H

第8关
blackout n.断电,停电 blatancy n. 喧骚 blighted adj. 毁灭的 blissful a. 充满喜悦的 blizzard n. blocking 分块 blow off 吹掉,将(热水等)放出 blow out 吹熄(灯火等) boast of 吹牛,自夸,夸耀 bobwhite n. 鹑的一种
第18关
commuter n.(尤指市郊之间)乘公交车辆上下班者 compiler 编译器 concerto n. conflate v. confused a. 困惑的,烦恼的 consomme n. 清汤 construe v. consular a.领事的 conveyor n.传送机 convulse v.
第10关
braggart braiding brattish
貌的 breeding bridging brighten brimming brindled bring in bring on
n. n. 编组 adj. (指小孩) 讨厌的; 宠坏的; 不听话的; 不礼
n.繁殖 桥接 v.使更为光明
第14关
careworn carnival carousel car-park cashmere casually cataract catch on catch up cavalier
adj. 疲倦的,饱经忧患的 n. n.圆盘传送带 停车场
n. 产于咯什米尔和西藏的一种羊毛 ad.1.偶然地,碰巧地;2.漫不经心地,随便地 n. 大瀑布,奔流,洪水,白内障 理解,明白,变得流行 赶上;打断…的话 n.骑士, 武士, 对女人献殷勤, 有礼貌的绅士
第20关
credence criteria crockery crowding crusader crushing cry down cryotron cuspidor cut into
Windows Open JDK1.7 配置方法

明:1.本文来自于《深入理解Java虚拟机:JVM高级特性与最佳实践》第一章,转载请注明出处。
2.作者推荐大家对本文“看过就算”,真正要编译JDK的话,请不要选择在Windows平台编译,难度……嗯,应该说是“麻烦程度”比Linux平台编译高几个数量级。
在Linux 平台的JDK编译攻略,请参考撒迦这篇文章。
相信我,哪怕你没有Linux环境,临时装一个ubuntu,加上安装操作系统的时间都比直接在Windows下编译来得快。
3.如果要在Windows平台编译的话,看看是否需要把整个JDK(HotSpot、Library、Utils(如VisualVM等)、JAXWS、etc)都编译出来,相信大部分人只想要一个虚拟机,那可以关闭掉其他部分的编译,省事不少。
但本文是按照“全部编译”来写的攻略。
-------------------------- 上面是唠叨,下面是攻略,我是分割线 -------------------------- 1.5 实战:自己编译JDK想要一探JDK内部的实现机制,最便捷的路径之一就是自己编译一套JDK,通过阅读和跟踪调试JDK源码去了解Java技术体系的原理,虽然门槛会高一点,当肯定会比阅读各种文章、书籍来得更加贴近本质些。
另外JDK中的很多底层方法都是Native的,需要跟踪这些方法的运作或对JDK进行Hack的时候,都需要自己编译一套JDK。
现在网络上有不少开源的JDK实现可以供我们选择,如Apache Harmony、OpenJDK等。
考虑到Sun系列的JDK是现在使用得最广泛的JDK版本,笔者选择了OpenJDK进行这次编译实战。
1.5.1 获取JDK源码首先确定要使用的JDK版本,OpenJDK 6和OpenJDK 7都是开源的,源码都可以在它们的主页(/)上找到,OpenJDK 6的源码其实是从OpenJDK 7的某个基线中引出的,然后剥离掉JDK 1.7相关的代码,从而得到一份可以通过TCK 6的JDK 1.6实现,因此直接编译OpenJDK 7会更加“原汁原味”一些,其实这两个版本的编译过程差异并不大。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Compiler-Directed Scratch Pad Memory Hierarchy Design and ManagementM.KandemirMicrosystems Design Lab Pennsylvania State University University Park,PA16802,USA kandemir@A.ChoudharyECE DepartmentNorthwestern University Evanston,IL60208,USA choudhar@ABSTRACTOne of the primary challenges in embedded system design is design-ing the memory hierarchy and restructuring the application to take ad-vantage of it.This task is particularly important for embedded image and video processing applications that make heavy use of large multi-dimensional arrays of signals and nested loops.In this paper,we show that a simple reuse vector/matrix abstraction can provide compiler with useful information in a concise ing this information,com-piler can either adapt application to an existing memory hierarchy or can come up with a memory hierarchy.Our initial results indicate that the compiler is very successful in both optimizing code for a given memory hierarchy and designing a hierarchy with reasonable perfor-mance/size ratio.Categories and Subject DescriptorsB.3[Hardware]:Memory Structures;D.3.4[Programming Lan-guages]:Processors—Compilers;OptimizationGeneral TermsDesign,Experimentation,PerformanceKeywordsData Reuse,Scratch Pad Memory,Memory Hierarchy1.INTRODUCTIONEmbedded system design has undergone a major renaissance in the lastfive years.An important characteristic of this change is that soft-ware is playing an ever increasing role in system design.Consequently, automatic compiler support for optimizing embedded software is of critical importance.Classical compiler methods alone,however,may not be sufficient for attaining the highest levels of performance from an embedded platform.Instead,embedded system-specific issues should2.OUR APPROACH2.1BackgroundThe iteration space of a loop nest contains one point for each iteration.An iteration vector can be used to label each such point in. We use to represent the iteration vector for a loop nest of depth,where each corresponds to a loop index(or its value at a specific point in time),starting with for the outermost loop index. In fact,an iteration space can be viewed as a polyhedron bounded by the loop limits.The subscript function for a reference to an array is a mapping from the iteration space to the data space.The data space can also be viewed as a polyhedron bounded by array bounds.A subscript function defined this way maps an iteration vector to an array element. In this paper,we assume that subscript mappings are affine functions of the enclosing loop indices and symbolic constants.Many array ref-erences found in embedded image and video processing codes fall into this category.Under this assumption,a reference to an array can be represented as where is a linear transformation matrix called the access(reference)matrix,is the offset vector,and is the iteration vector[12].If the loop is-deep and the array is-dimensional,is and has elements.For example,the reference in Figure1(a)can be written as:According to Li[8],if and are two iteration vectors that access the same memory location,is called a reuse vector(assum-ing that is lexicographically greater than).For a loop of depth, the reuse vector is dimensional.The loop corresponding to thefirst non-zero element from top is the one that carries the corresponding reuse.If there are more than one reuse vector in a given direction, they are represented by the lexicographically smallest one.The reuse vector gives us useful information about how array elements are used by different loops in a given nest.In this paper,we mainly focus on self reuses(that is,the reuses originating from individual references) as in very rare circumstances group reuse(that is,the reuse between different references to the same array)brings additional benefits that cannot be exploited by self reuse[8].There is a temporal reuse due to reference if and only if there exist two different iterations and such that;that is,. This last expression indicates that the temporal reuse vector belongs to the kernel set(null set)of[12].As an example,let us focus on the matrix multiply nest shown in Figure1(a).The reuse vector due to rmally, what this means is that,forfixed values of loops and,the successive iterations of the loop access the same element from this array.That is,the loop carries(exhibits)temporal reuse for this reference.The reuse vectors coming from individual references make up a reuse matrix,.In considering the matrix multiply code again,we find that:Thefirst,second,and third columns in this matrix correspond to the reuse vectors for,and,respectively.As will be discussed shortly,each column indicates which array sections should be brought into(and discarded from)the SPM at what time.A linear one-to-one mapping between two iteration spaces can be represented by a square,non-singular ing such a transfor-mation,each element of the original iteration space is mapped to on the transformed iteration space.Converting the original loop nest to the transformed nest is a two-step process[12].First,each array reference is transformed to.Second, the loop bounds are transformed accordingly.Finding the new loop bounds can necessitate the use of Fourier-Motzkin elimination,details of which can be found in[12].It can be shown that if is a linear transformation matrix,is a reuse vector,and is a reuse matrix, and are the transformed reuse vector and the transformed reuse matrix,respectively[8].In Sections2.2through2.5,we assume the existence of an SPM hi-erarchy and focus on how to manage dataflow through this hierarchy. In Section2.6,we show how to design a memory hierarchy based on data reuse.Till Section2.4,we exclusively focus on a two-level mem-ory hierarchy which contains a large(slow and energy-consuming) memory and a small(fast and less energy-consuming)memory.The problem is then to decide what data to bring to the fast memory at what time and how to decide when data in the fast memory are not useful anymore.We use the terms(software-controlled)memory hierarchy and SPM hierarchy interchangeably.2.2Reuse Based Data TransfersRecall that in Figure1(a)leads to a reuse vector of. Suppose that we have a section of array in Figure1(a),(the th row),residing in the fast memory.Since all loop iterationsaccess this same array section,this section can be kept in the fast mem-ory(in the fast SPM)during the entire execution of these iterations; and,following the execution of the iteration,it can be dis-carded from the fast memory.It should also be noted that this section can be brought into the fast memory just before the iteration starts execution(i.e.,just before the loop is entered).For clarity, we represent these iterations collectively using,where de-notes all iterations in the corresponding loop level;we also represent this array section using,where indicates all elements in the corresponding dimension.To sum up,by just considering the value of 1in this reuse vector(the second entry),we can decide the point in the code at which an array section(in our case,this is the th row of )should be brought into the fast memory and the point at which it should be removed from the fast memory.This brings us to the follow-ing conclusion:An array section should remain in the fast memory fromthe start of the loop that carries reuse for the correspond-ing array reference to the termination of the same loop.Let us consider the following generic-deep loop nest that accesses an-dimensional array:...In this nest,each is an affine function correspond-ing to a subscript expression.and are the lower and upper bounds for loop.Assume that is the corre-sponding reuse vector.Assume further(for now)that there is only a single non-zero element(say)in;all other elements are assumed to be zero.In other words,the loop is the one that carries the reuse. In this case,the compiler can make use of the fast memory as fol-lows.Let us use to denote all indices enu-merated in a dimension byfixing thefirst loops at specific val-ues()and considering all values(within the loop bound ranges)for all other loop index positions.Just before executing the loop,the compiler brings the array section containing all elements represented by...into the fast memory,and keeps them there while executing all iterations in. When the last iteration in this set has been executed,the section can be removed from the fast memory.If this is done,the said set of elements would reside in the fast memory as long as they are reused,and as soon as the last iteration that reuses the elements is completed,the set can be removed from the fast memory.It should be emphasized that if any element in this set is updated while it is in the fast memory,it should be written back to slow memory.If there are multiple references to the same array,the reuse vectors are considered together and the corresponding data transfers are com-bined as much as possible.Consider the nested loop in Figure1(b). We have two reuse vectors:(due to reference)and (due to reference).We note that the data transfer in-dicated by is subsumed by the transfer indicated by; that is,once the transfer of the th row to the fast memory is complete (just before entering the loop),there is no need for performing an extra transfer for the element.Let us now focus on the code given in Figure1(c).In this case,the reuse vectors are and .Consequently,both data transfers should be performed be-fore the loop is entered.However,one data transfer contains the th row of the array whereas the other contains the th column.Except for one element,these two transfers do not overlap;so,they should be per-formed separately.Our current implementation uses the following rule to decide whether the transformations required by different references to the same array can be combined.Let andbe two references to array.If,there is a good chance that there exists significant amount of data reuse between these two references(even if).Consequently,in this case,the data transfers due to these references can be combined and performed to-gether.On the other hand,if,these two references are treated as if they belong to different arrays.If a nest contains ref-erences to multiple arrays,each array is treated independently and a separate data transfer is performed for each array.2.3TransformationsIn some cases,it may not be clear which loop carries the reuse.To make the loop carrying the reuse explicit,it may be necessary to apply loop transformations.As an example,consider the loop nest shown in Figure1(d).When considered alone,none of the references in this nest has temporal reuse.However,there is a group reuse in this nest with a reuse vector of.Consequently,it is not trivial to find the point in the code to perform memory transfers so that we can exploit the fast memory.However,if we transform this nest using the loop transformation matrixwe obtain the nest in Figure1(e).We now see that the reuse vector for this transformed nest is.This means that only the innermost loop carries reuse,and we can make use of the fast memory.To see how the reuse is exploited in this case,let us list the array elements accessed by a few initial iterations:andandandandandandWe observe that(for a specific)the iterations in cause the reuse of elements,where.Therefore,just before entering the loop(in the transformed nest),these elements can be brought into the fast memory. As compared to the matrix multiply case,this example illustrates two interesting points.First,in some cases,loop transformations might be necessary for identifying where(in the code)to perform data transfers. Second,the data transfers for different values of the outer loop are of different sizes.So,if we are to design a memory hierarchy,in deter-mining the size of the fast memory,we should consider the maximum number of reused elements over all values.Another question in this example is how to determine the transfor-mation matrix to use.We can determine the transformation matrix using the default and desired reuse vectors.For our current example, the default reuse vector is.Since we have only two loops in the nest,if want to make sure that the reuse will be carried by one of them,the desired reuse vector should.Then, from,we can determine the entries of.Note that we used loop transformations in this section to modify the group temporal reuse vector so as to exploit a two-level memory hierarchy.As will be discussed shortly,loop transformations can also be used for modifying the temporal reuse vectors.2.4Multi-Level HierarchyWhen there are multiple non-zero elements in a given reuse vector, we can use this fact for exploiting a multi-level memory hierarchy.In the most general case,we can exploit a memory level for each non-zero entry in the reuse vector.To illustrate this,let us consider the four-deep nest in Figure1(f).For,the reuse vector is which indicates that there are reuses in and loops(although the reuse itself is carried by the loop).We can exploit these reuses as follows.Before entering the loop,the row of this array can be transferred from the slow memory(called Level1)to the fast memory(called Level2).In addition to that,if we have an even faster memory(called Level3), the element can be transferred to this memory(just before the loop)and can be used from there throughout the execution of the loop.In other words,at a given time,one row of array can be in Level2SPM and one element from this row can be in Level1SPM (the fastest level).This is depicted in Figure2.A similar data transfer scheme is valid for reference as well.Before entering the loop,the entire array can be transferred to Level2(if we have that much space in Level2),and a row the array can be transferred to Level 1before the loop.It is important to note that just the fact that there are two non-zero entries in the temporal reuse vector does not mean that we can use the nest in question only with a three-level memory hierarchy.In fact,we can still use it with a two-level memory hierarchy and the fact that there are two non-zero entries in the reuse vector gives the compiler flexibility in scheduling data transfers.For example,focusing on ref-erence in Figure1(f),we have two options assuming a two-level memory:(i)we can perform data transfer before the loop,or (ii)we can perform data transfer before the loop.Note that transfer before the loop requires a larger fast memory space,but it is also expected to give better results.It is also important to emphasize that loop transformations can make a nested loop written for a two-level of memory hierarchy suitable for a three-level of memory hierarchy,and vice versa.For example,the loop transformation matrixcan transform a reuse vector to.Note that while is suitable for a two-level of memory hierarchy,is suitable for a three-level of memory hierarchy.2.5Imperfectly Nested LoopsWhile all examples given so far have focused on perfect nests only, our reuse vector/matrix based strategy can work with imperfectly-nested loops as well.An imperfect nest is the one that contains assignment statements between loops,whereas in a perfect nest all assignment statements are nested within the innermost loop.In our framework, imperfectly-nested loop nests in general present opportunities for min-(a)(b)(c)(d)(e)(f)(g)(h)Figure1:Different code fragments.i thLevel 3(fastest) Figure2:Exploiting three-level pute reuse matrixlevel=1;for i=1,k=number of non-zeros in;if(k level)then level=k;endif endfor;for l=2,levelcapacity[level]=0;endfor;for i=1,currentlevel]=capacity[currentlevel=currentvector,,we decide that the hierarchy should be at least twolevels and that the smaller(and faster)memory should be able to hold .Considering the second reuse vector,,we can see that the number of levels does not need to be increased(as this reuse vector has the same number of non-zero elements as the previous one). However,it should be large enough to hold an entire row of.Finally, the last reuse vector implies that the fast memory should be able to hold the entire array.Based on these,our algorithm decides that we need a two-level SPM hierarchy and that the faster level should have a capacity of at least elements.By default,we assume that the slower level has a capacity to hold the entire working set( elements).In the algorithm in Figure3,wefirst compute the number of levels in the hierarchy and thenfind the capacity of each level.The function‘reference(.)’gives the array reference corresponding to the reuse vector under consideration,and the‘’function computes the SPM space demanded by that reference(see Section2.2).We next discuss how to modify this strategy if the underlying system has some memory space constraints.For example,in case we may not be able to store the entire array(in our current example)in the fast memory,we need to modify the code slightly.We note that strip-mining,a loop transformation that divides the iteration space of a given loop into stripes[12],can be useful in this context.In our example,we can strip-mine the loop as shown in Figure1(h).In this code,is the stripe size.Now,the total space requirement for the fast memory (considering only,,and loops)is.By choosing a suitable value for,the space demand(put on the fast memory)can be kept under control.2.6.2Enforcing a HierarchyThe algorithm presented in the previous subsection does not try to modify the code to enforce it to adopt a pre-specified memory hierar-chy;that is,it does not modify the reuse matrix;it just builds a hierar-chy considering the current reuse matrix.In many cases,however,we might want to modify the reuse matrix to control the number of levels in the hierarchy.A reuse matrix can be changed using two types of transformations:The transformations that change the number of zeroes and non-zeroes in the reuse vectors.The transformations that re-order zeroes and non-zeroes in the reuse vectors(without changing their numbers).Since in general the second type of transformation can be reduced to thefirst type,we focus only on thefirst types of transformations here.Our approach can take a reuse matrix and transform it to an-other reuse matrix such that in the resulting matrix most reuse vectors demand a-level memory hierarchy,where being a value between2 and(the number of loops in the nest).For the clarity of presenta-tion,however,we present the algorithm for only the case when (see Figure4);that is,for each reuse vector in,we would like to make all the entries in the vector zero,except two entries(these two entries will represent the loops that exhibit reuse).Note that in gen-eral the order in which the reuse vectors in a given reuse matrix are processed might also be important.Our current approach orders reuse vectors from left to right considering the number of times each reuse vector occurs in the code.The most frequently used reuse vector oc-cupies the leftmost column whereas the least frequently used one sits in the rightmost column.Then,for the most frequent reuse vector,the algorithm makes sure that only two non-zero elements are obtained (after the transformation).It achieves this by selecting suitable vectors for thefirst rows of.In doing so,data dependences are also checked using the approach in[8](this is not shown in the code for clarity).It then processes the remaining reuse vectors and selects suit-able vectors for the remaining two rows.As soon as all rows of have been determined,the algorithm returns the transformed reuse matrix ()and terminates.3.EXPERIMENTSWe used array-based versions of four embedded image processing applications to evaluate the effectiveness of our strategy.wood is a compute reuse matrixlet be the transformation matrix and be the rows of;finished=false;select such that,...,; j=2;while(notfinished)bool=();bool=();....bool=();k=number of trues in bool,bool,...,bool;if(k(-4))thenset to vector in;set to vector in;finished=true;elseif(k=(-3))thenif(is not set)thenset to vector in;elseif(is not set)thenset to vector in;finished=true;endif;endif;endif;j=j+1;endwhile;return(TR);Figure4:Memory hierarchy transformationalgorithm.color-based visual surface inspection method for wood properties.It builds the color histogram percentile features of the image to recog-nize wood surface defects with relatively low complexity.wavelet is a wavelet-based noise reduction and restoration application.mpc is a medical pattern classification application.It is used mainly for choosing therapy for peptic ulcers.Finally,usonic is a feature-based estimation algorithm for ultrasonic image sequences.The total input sizes used for wood,wavelet,mpc,and usonic are271KB, 306KB,586KB,and410KB,respectively.For each benchmark code, we experimented with four different versions.ver1is a static SPMoptimization strategy.It profiles the code and selects a set of array el-ements that has the highest reuse.It then puts these elements in the fast memory(at the beginning of the program)and keeps them there throughout the execution.ver2is a nest-based dynamic SPM man-agement strategy.It changes the contents of SPM depending on the current access pattern;its details can be found elsewhere[7].ver3 is the reuse vector/matrix based SPM management strategy discussed in this paper.ver4is a version that uses a cache memory(instead of SPM)in conjunction with the locality-optimized version of each appli-cation.All versions tested here have been implemented in a source-to-source translator using the SUIF infrastructure[1].Our compiler takes a C code as input and optimizes it taking into account the memory hi-erarchy.The compiler output(which is also a C code)is then fed into a custom simulator.The simulator models a memory hierarchy(which is constructed using SPMs)and assumes a simple,single-issue embed-ded core(running on200MHz).For cache experiments,the simulator directly calls Dinero[4].We performed two sets of evaluations.In thefirst set,wefixed the SPM hierarchy and evaluated the performance and energy consump-tion of each version.In the second set,for each version,we determined the total fast level memory size and energy consumption under a given performance bound.We calculated the access latencies for different sizes of SPMs and data caches using the CACTI tool[6].To compute the per access energy costs for different sizes of memories,we em-ployed a slightly modified form of the model proposed by Shiue and Chakrabarti[11].While our simulator also gives the energy spent in interconnect,we found this value very small for all benchmarks used. Figure5gives the performance(execution cycles)and energy re-sults for two-level(top)and three-level(bottom)memory hierarchies. All values presented are normalized with respect to the correspond-ing value of ver4(the cache version).In the two-level memory,the simulated faster memory(SPM)size is4KB;the cache used in the ver4version is also4KB(two-way associative with a block size of 32bytes).In the three-level memory hierarchy,the fastest SPM size is 2KB and the middle level memory is6KB.In all cases,thefirst level memory(the slowest memory)is1MB.These results show that our strategy outperforms both ver1and ver2in both energy and per-formance.We also note that the gains are larger with the three-level memory(as our reuse vector based strategy utilizes all the fast levels fully).The average performance improvements due to ver1,ver2, and ver3are9.4%,18.3%,and26.5%,respectively,for the two-level memory.The corresponding values for the three-level memory are 10.0%,19.2%,and32.3%.Figure6shows the percentage increase in memory capacity and energy consumption(with respect to our ap-proach)when all version generate the same performance results.Our experimentation methodology is as follows.First,we ran the algo-rithm in Figure3and determined a memory hierarchy for our version (ver3).We then recorded the total memory size(excluding the slow-est memory,the size of which is alwaysfixed at1MB)used by our ver-sion and its execution time.Then,we ran other versions using several different levels and capacities,and found(for each version)the con-figuration that gave the same execution time as ver3(within an error margin of2%).We observe from these results that in order to catch the performance of ver3,the other versions demand much larger memory space and(because of this)significantly larger energy consumption. Even ver2(which is the best among the remaining ones)increases the memory capacity(omitting the slowest one)by35.4%and energy consumption by16.5%on theaverage.Figure6:Percentage increase in memory size and energy over ver3under constant performance.4.CONCLUSIONSWe presented and discussed a scratch-pad memory(SPM)hierarchy design and optimization framework.In this framework,the compiler has a central role in the sense that it manages theflow of data across a given hierarchy(by staging computation and data).Given an access pattern,the compiler can also come up with a memory hierarchy which might be used as a starting point for further analysis and synthesis. The effectiveness of this strategy was measured using four complete applications from the embedded image processing domain.Our results reveal that this optimization framework is very successful in reducing both energy and execution cycles and that it outperforms two previous approaches to SPM management.5.REFERENCES[1]S.P.Amarasinghe,J.M.Anderson,m,and C.W.Tseng.TheSUIF compiler for scalable parallel machines.In Proc.the Seventh SIAM Conference on Parallel Processing for Scientific Computing,February,1995.[2]L.Benini,A.Macii,E.Macii,and M.Poncino.Increasing energyefficiency of embedded systems by application-specific memoryhierarchy generation.IEEE Design&Test of Computers,pages74–85,April-June,2000.[3] F.Catthoor,S.Wuytack,E.D.Greef,F.Balasa,L.Nachtergaele,and A.Vandecappelle.Custom memory management methodology–exploration of memory organization for embedded multimedia systemdesign.Kluwer Academic Publishers,June,1998.[4]Dinero IV Trace-Driven Uniprocessor Cache Simulator.URL:/markhill/DineroIV/[5]J.Eyre and J.Bier.DSP processors hit the mainstream.IEEE ComputerMagazine,pp.51–59,August1998.[6]N.P.Jouppi and S.J.E.Wilton.An enhanced access and cycle timemodel for on-chip caches.Research Report93/5,Compaq WRL,PaloAlto,CA,July1994.[7]M.Kandemir,J.Ramanujam,M.Irwin,N.Vijaykrishnan,I.Kadayif,and A.Parikh.Dynamic management of scratch-pad memory space.In Proc.the38th Design Automation Conference,Las Vegas,NV,June2001.[8]piling for NUMA Parallel Machines.Ph.D.Thesis,Computer Science Department,Cornell University,Ithaca,NY,1993. [9]P.R.Panda,N.D.Dutt,and A.Nicolau.Efficient utilization ofscratch-pad-memory in embedded processor applications.In Proc.European Design and Test Conference,Paris,March1997.[10]P.R.Panda,N.D.Dutt,and A.Nicolau.Architectural exploration andoptimization of local memory in embedded systems.In Proc.ISSS’97,Antwerp,September1997.[11]W-T.Shiue and C.Chakrabarti.Memory exploration for low power,embedded systems.In Proc.Design Automation Conference,NewOrleans,Louisiana,1999.[12]M.Wolfe.High Performance Compilers for Parallel Computing,Addison-Wesley Publishing Company,1996.。