双变量线性回归分析
计量经济学第三章 双变量线性回归模型

双变量线性回归模型的统计假设
(1). E(ut) = 0, t= 1, 2, ...,n 即各期扰动项的均值(期望值)为0.
(5) (6)
其中:Y Yt , X X t
n
n
xt X t X ,
yt Yt Y
样本均值 离差
(5)式和(6)式给出了OLS法计算ˆ 和 ˆ 的 公式,ˆ 和 ˆ称为线性回归模型 Yt = + Xt + ut
的参数 和 的普通最小二乘估计量 (OLS estimators)。
一. 双变量线性回归模型的概念
设 Y = 消费, X = 收入, 我们根据数据画出散点图
Y
*
*
*
*
*
图1
这意味着
Y = + X
(1)
写出计量经济模型
Y = + X + u
(2)
其中 u = 扰动项或 误差项
Y为因变量或被解释变量
X
X为自变量或解释变量
和 为未知参数
设我们有Y和X的n对观测值数据,则根据(2)式, 变量Y的每个观测值应由下式决定:
=β
——假设(4) ——假设(1)
这表明,ˆ 是β的无偏估计量。
在证明 ˆ 无偏性的过程中, 我们仅用到(1)和(4)两
条假设条件。
由 ˆ Y ˆ X ,我们有:
E(ˆ ) E(Y ˆ X ) E( X u ˆ X ) X E(u) X E(ˆ)
双变量线性回归分析结果的报告以及案例

数据清洗
处理缺失值、异常值和重复数据,确保数据质 量。
数据探索
初步分析数据,了解变量之间的关系和分布情况。
模型建立
确定变量
选择与响应变量相关的预测变量,并考虑变量的 多重共线性。
建立模型
使用最小二乘法或其他优化算法拟合线性回归模 型。
模型诊断
检查模型的残差图、散点图等,确保模型满足线 性回归的前提假设。
卧室数量与房价之间存 在正相关关系,但影响 较小。
地理位置对房价有显著 影响,靠近市中心的房 屋价格更高。
周边设施对房价有积极 影响,特别是学校和公 园等设施。
05 双变量线性回归分析的未 来研究方向
深度学习与线性回归的结合
01
深度学习技术可以用于特征提 取,将原始数据转化为更高级 别的特征表示,然后利用线性 回归模型进行预测。
双变量线性回归分析结果的报告以 及案例
目录
• 双变量线性回归分析概述 • 线性回归分析的步骤 • 双变量线性回归分析的案例 • 线性回归分析的局限性 • 双变量线性回归分析的未来研究方向
01 双变量线性回归分析概述
定义与原理
双变量线性回归分析是一种统计学方法,用于研究两个变量之间的线性关系。通 过最小二乘法等数学手段,找到一条最佳拟合直线,使得因变量能够根据自变量 进行预测。
线性回归分析假设因变量和自变 量之间存在线性关系,但在实际 应用中,非线性关系可能更为常 见。
独立性假设
自变量之间应相互独立,但在实 际数据中,自变量之间可能存在 多重共线性,影响回归结果的准 确性。
无异常值和缺失值
假设
数据集中不应含有异常值和缺失 值,否则会影响回归模型的稳定 性和准确性。
模型泛化能力
双变量线性回归

描出散点图发现:随着收入的增加,消费“平 均地说”也在增加,且 Y 的条件均值均落在一 条正斜率的直线上。这条直线称为总体回归线。
中央财经大学统计学院 边雅静
12
3500
每 3000
月 2500 消
2000
费
1500
支 出 1000
Y(元) 500
0
但由于调查的完备性,给定收入水平 X 的消费支 出 Y 的分布是确定的,即以 X 的给定值为条件的 Y 的条件分布(Conditional distribution)是已知 的,例如:P(Y=561|X=800)=1/4。
中央财经大学统计学院 边雅静
11
因此,给定收入 X 的值 Xi ,可以得到消费支出 Y的条件均值(conditional mean)或条件期望 (conditional expectation):E( Y | X = Xi )。
问题:是否能从一次抽样中获得总体的近似的信息?如果 可以,如何从抽样中获得总体的近似信息? 例:在上例的总体中有如下一个样本,能否从该样本估计 总体回归函数PRF?
表 2.1.3 家庭消费支出与可支配收入的一个随机样本 Y 800 1100 1400 1700 2000 2300 2600 2900 3200 3500 X 594 638 1122 1155 1408 1595 1969 2078 2585 2530
28
一、 对变量和模型的假定
1)重复抽样中,解释变量
X
是一组固定的值或
i
虽然是随机的,但与干扰项 ui独立;
中央财经大学统计学院 边雅静
3
一、变量间的关系及回归分析的基本概念
双变量问题处理技巧

双变量问题处理技巧双变量问题处理技巧双变量问题是指涉及两个变量之间的关系或相互影响的问题。
在许多领域中,如统计学、经济学和社会科学等,研究人员经常遇到需要处理双变量问题的情况。
下面将介绍一些处理双变量问题的技巧。
1. 散点图分析:散点图是一种常用的数据可视化方法,可以用来展示两个变量之间的关系。
通过绘制散点图,可以观察到变量之间的相关性,包括线性关系、非线性关系或者无关系。
根据散点图的形状和趋势,可以判断变量之间的关系类型,并进一步分析相关性的强度。
2. 相关性分析:相关性分析用于度量两个变量之间的相关性程度。
常用的相关性系数包括皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数适用于线性关系的变量,而斯皮尔曼相关系数适用于非线性关系的变量。
相关性分析可以帮助我们了解两个变量之间的关系强度和方向。
3. 线性回归分析:线性回归分析是一种用于建立两个变量之间线性关系的模型。
通过拟合数据点到一条直线或曲线上,可以建立一个数学模型来预测或解释一个变量对另一个变量的影响。
线性回归分析可以帮助我们确定两个变量之间的因果关系,并进行预测和解释。
4. 多元回归分析:多元回归分析是一种用于处理多个自变量和一个因变量之间关系的方法。
当我们需要控制其他变量的影响,以及确定多个自变量对因变量的独立贡献时,可以使用多元回归分析。
通过多元回归分析,我们可以建立一个多变量的模型,更全面地理解变量之间的关系。
5. 因果推断:在处理双变量问题时,我们常常需要确定两个变量之间的因果关系。
因果推断是一种从相关性到因果关系的推断方法,可以帮助我们确定一个变量对另一个变量的影响。
在进行因果推断时,需要注意排除混淆变量的干扰,并使用实验证据或因果分析方法来支持因果关系的存在。
总之,处理双变量问题需要运用适当的技巧和方法来分析和解释两个变量之间的关系。
通过散点图分析、相关性分析、线性回归分析、多元回归分析和因果推断等方法,我们可以更好地理解和解释双变量问题,并得出有意义的结论。
线性回归分析——双变量模型

线性回归分析双变量模型回归分析的含义回归分析是研究一个叫做因变量的变量对另一个或多个叫做解释变量的变量的统计依赖关系。
其用意在于,通过解释变量的已知值或给定值去估计或预测因变量的总体均值。
双变量回归分析:只考虑一个解释变量。
(一元回归分析,简单回归分析)复回归分析:考虑两个以上解释变量。
(多元回归分析)统计关系与确定性关系统计(依赖)关系:非确定性的关系。
在统计依赖关系中,主要处理的是随机变量,也就是有着概率分布的变量。
特别地,因变量的内在随机性是注定存在的。
例如:农作物收成对气温、降雨、阳光以及施肥的依赖关系便是统计性质的。
这些解释变量固然重要,但是并不能使我们准确地预测农作物的收成。
确定性关系:函数关系。
例如物理学中的各种定律。
)/(221r m m k F回归与因果关系❑回归分析研究因变量对于解释变量的统计依赖关系,但并不一定意味着因果关系。
一个统计关系式,不管多强和多么具有启发性,都永远不能确立因果联系。
❑因果关系的确立必须来自于统计关系以外,最终来自于这种或那种理论(先验的或是理论上的)。
回归分析与相关分析(一)❑相关分析:用相关系数测度变量之间的线性关联程度。
例如:测度统计学成绩和高等数学成绩的的相关系数。
假设测得0.90,说明两者存在较强的线性相关。
❑回归分析:感兴趣的是,如何从给定的解释变量去预测因变量的平均取值。
例如:给定一个学生的高数成绩为80分,他的统计学成绩平均来说应该是多少分。
回归分析与相关分析(二)❑在相关分析中,对称地对待任何两个变量,没有因变量和解释变量的区分。
而且,两个变量都被当作随机变量来处理。
❑在回归分析中,因变量和解释变量的处理方法是不对称的。
因变量被当作是统计的,随机的。
而解释变量被当作是(在重复抽样中)取固定的数值,是非随机的。
(把解释变量假定为非随机,主要是为了研究的便利,在高级计量经济学中,一般不需要这个假定。
)双变量回归模型(一元线性回归模型)双变量回归模型(最简单的回归模型)模型特点因变量(Y)仅依赖于唯一的一个解释变量(X)。
双变量回归模型分析案例及模型形式的探讨

双变量回归模型分析案例及模型形式的探讨双变量回归模型是一种用于分析两个变量之间关系的统计模型。
它可以用来预测一个变量(因变量)受另一个变量(自变量)的影响程度,或者研究两个变量之间的相关性。
本文将探讨一个双变量回归模型的分析案例,并探讨该模型的形式。
假设我们想要分析一个人的身高和体重之间的关系。
我们收集了一组数据,包括100个人的身高和体重数据。
我们想要建立一个双变量回归模型,来预测一个人的体重受其身高的影响程度。
首先,我们需要将收集到的数据进行整理和描述性统计分析。
我们可以计算身高和体重的平均值、方差和相关系数等指标。
这些指标可以提供有关数据的整体特征和两个变量之间的关系强度的信息。
接下来,我们可以使用散点图来可视化身高和体重之间的关系。
散点图可以显示每个人的身高和体重,并观察它们之间的模式和趋势。
基于散点图的观察,我们可以大致判断两个变量之间是否存在线性关系。
然后,我们可以使用最小二乘法来估计回归方程的系数。
回归方程的形式可以表示为:Y=β0+β1X,其中Y代表体重,X代表身高,β0和β1分别是回归方程的截距和斜率。
最小二乘法的目标是最小化实际观测值和回归方程预测值之间的误差平方和。
在估计回归系数之后,我们可以对回归方程进行模型拟合和评估。
拟合优度指标,如R平方和调整后的R平方,可以用来评估模型的拟合程度。
R平方的取值范围在0到1之间,越接近1说明模型对数据的解释能力越强。
最后,我们可以使用回归模型进行预测和推断。
通过将新的身高值代入回归方程,我们可以预测对应的体重。
此外,我们还可以进行假设检验和置信区间估计,以评估回归系数的显著性和区间估计。
总之,双变量回归模型可以用于分析两个变量之间的关系,并进行预测和推断。
在实际应用中,我们需要注意模型的前提假设、数据的合理性和模型的解释力。
另外,还可以通过添加交互项、多项式项或考虑其他模型形式来扩展双变量回归模型。
3.1双变量线性回归分析的基本概念

随机误差项的意义(引入原因) (1)理论的含糊性; (2)数据的欠缺; (3)众多细小因素对因变量的综合影响; (4)变量的观测误差的影响; (5)模型设定误差的影响; (6)变量内在随机性的影响; (7) 省略原则。
回归模型存在两个特点:
建立在某些假定条件不变前提下抽象出来 的回归函数不能百分之百地再现所研究的 经济过程。 也正是由于这些假定与抽象,才使我们能 够透过复杂的经济现象,深刻认识到该经 济过程的本质。
由上图发现:随着收入的增加,消费支出Y“平 均地说”也在增加,且Y的条件均值均落在一根 正斜率的直线上。这条直线称为总体回归直线。
概念(二)
当解释变量Xi取给定值时因变量Yi的条件期望 值或条件均值的轨迹称为总体回归曲线 (population regression curve)。 总体回归直线(Population regression line, PRL )
二、线性的含义
线性回归模型有两种解释: (1)对变量为线性 (2)对参数为线性
三、 PRF的随机设定以及随机误差项的性质 和意义
PRF说明了在给定的收入水平下,该社区家庭的 平均消费支出随收入变化的规律。 但对某一个别的家庭,其消费支出可能与该平均 水平有偏差。 ui Yi E(Y | X i )
总体回归函数PRF的随机设定形式 含义:它表明因变量除了受解释变量的系统 性影响外,还受其他因素的随机性影响。 由于函数中引入了随机项,成为计量经济学 模型,因此也称为总体回归模型。
随机误差项的性质
随机误差项是所有可能影响因变量,但又 未能包括到回归模型中来的被忽略变量的 替代(surrogate)或代理(proxy)变量。 E(ui| Xi)=0
线性回归分析——双变量模型

线性回归分析——双变量模型在进行线性回归分析之前,我们首先需要明确我们要解决的问题,确定自变量和因变量。
比如,我们可以研究体重和身高之间的关系,其中体重是因变量,身高是自变量。
收集到数据后,我们可以进行描述性统计分析来对数据进行初步的了解。
我们可以计算出体重和身高的平均值、方差、最大值和最小值等统计指标。
此外,我们还可以绘制散点图来观察变量之间的关系。
在进行线性回归分析之前,我们需要满足一些假设条件。
首先,我们假设自变量和因变量之间存在线性关系。
其次,我们假设观测误差服从正态分布。
最后,我们假设观测误差的方差是常数。
接下来,我们可以通过最小二乘法来估计线性回归模型的参数。
最小二乘法的目标是最小化观测值与预测值之间的残差的平方和。
我们可以使用统计软件或者编程语言来进行计算。
线性回归模型可以表示为:Y=β0+β1X+ε其中,Y表示因变量,X表示自变量,β0表示截距,β1表示斜率,ε表示观测误差。
在进行参数估计后,我们可以对模型进行拟合优度的评估。
拟合优度指标可以帮助我们判断模型的拟合程度。
常见的拟合优度指标有R方值、调整R方值和残差分析。
R方值表示因变量的变异程度可以由自变量解释的比例。
R方值的取值范围是0到1,越接近1表示模型的拟合效果越好。
调整R方值是在R方值的基础上考虑模型中自变量的个数进行修正。
残差分析可以用来评估模型中未解释的部分。
在进行结果解释时,我们需要注意解释截距和斜率的意义。
截距表示当自变量为0时,因变量的值。
斜率表示自变量的单位变化对因变量的影响。
最后,我们还可以对模型的统计显著性进行检验。
常见的方法有t检验和F检验。
t检验可以用来判断截距和斜率的显著性,F检验可以用来判断模型整体的显著性。
总结:线性回归分析是一种常用的数据分析方法,可以用于研究两个变量之间的线性关系。
通过收集数据,建立模型,估计参数和进行拟合优度评估,我们可以获得对变量之间关系的深入认识。
同时,我们还可以通过检验模型的显著性来判断模型的可靠性。
chapter02经典线性回归模型:双变量线性回归模型

每 月 家 庭 消 费 支 出 Y
1489 1538
1600 1702
1712 1778
1841 1886
2078 2179
2298 2316
2289 2313
2398 2423
2487 2513
2538 2567
2853 2934
3110
3142 3274
1900
2012
2387
2498 2589
例:100个家庭构成的总体
(单位:元)
每 月 家 庭 可 支 配 收 入 X
1000 820 888 932 960 1500 962 1024 1121 1210 1259 1324 2000 1108 1201 1264 1310 1340 1400 1448 2500 1329 1365 1410 1432 1520 1615 1650 3000 1632 1726 1786 1835 1885 1943 2037 3500 1842 1874 1906 1068 2066 2185 2210 4000 2037 2110 2225 2319 2321 2365 2398 4500 2275 2388 2426 2488 2587 2650 2789 5000 2464 2589 2790 2856 2900 3021 3064 5500 2824 3038 3150 3201 3288 3399
E(Y X i ) = f ( X i )
这个函数称为总体回归函数(PRF)
例:100个家庭构成的总体
(单位:元)
每 月 家 庭 可 支 配 收 入 X
1000 820 888 932 960 1500 962 1024 1121 1210 1259 1324 2000 1108 1201 1264 1310 1340 1400 1448 2500 1329 1365 1410 1432 1520 1615 1650 3000 1632 1726 1786 1835 1885 1943 2037 3500 1842 1874 1906 1068 2066 2185 2210 4000 2037 2110 2225 2319 2321 2365 2398 4500 2275 2388 2426 2488 2587 2650 2789 5000 2464 2589 2790 2856 2900 3021 3064 5500 2824 3038 3150 3201 3288 3399
第二章 双变量线性回归模型(计量经济学-北京大学,岳昌君)

i i 2 i
其中 X和Y是X和Y的样本均值 定义离差:xi X i X;yi Yi Y 。 ˆ 代入正规方程( 1)得 用小写字母表示对均值 的离差。将 2 1 1 ˆ ˆ ˆ X 1 Yi 2 X i Y 2 n n
已知给定X=80,Y取5个不同的值:55、60、65、
70、75。问:Y取每个值的概率有多大? 古典概率模型:取每个值的概率相等。因此有:
P(Y=55|X=80)=1/5; P(Y=60|X=80)=1/5; P(Y=65|X=80)=1/5; P(Y=70|X=80)=1/5; P(Y=75|X=80)=1/5;
假定4:ui和Xi的协方差为零。即,Cov(ui,Xi)=E(uiXi)=0 假定5:在重复抽样中X的值是固定的(非随机) 假定6:随机干扰项服从0均值、同方差的正态分布。 即: ui ~N(0, 2 ) 注:在实际建模时,除了假定6以外,对模型是否满足假定都要进行检 验。对于假定6,由中心极限定理,当样本趋于无穷大时,对于任何 实际模型都是满足的。
16
4 PRF的随机设定
事实:给定收入Xi,个别家庭的支出Yi围绕在条 件均值E(Y|Xi)附近。 将个别的Yi围绕其期望值的离差(Deviation)表述 如下: ui=Yi-E(Y|Xi) 或Yi=E(Y|Xi)+ui E(Y|Xi)是系统性成分或确定性成分; ui随机或非确定性成分 随机扰动项:离差ui是一个不可观测的可正可负 的随机变量。
14
3 “线性”的含义
Y= 1+2X+u 是线性的! lnY= 1+2lnX+u 也是线性的! Y= 1ln(2X+u)不是线性的!
3.1双变量线性回归分析的基本概念【精】

在引例中,条件期望值E(Y|Xi)是Xi的一个线 性函数,可以记为: E(Y|Xi)=1+2Xi
线性总体回归函 数
1和2为未知而固定的参数,称为回归系数 (regression coefficients)。1和2也分别称 为截距(intercept)和斜率系数(slope coefficient)。
ad
2
§3.1 双变量线性回归分析的 基本概念
一、总体回归直线与总体回归函数(PRF) 二、线性的含义 三、PRF的随机设定以及随机误差项的性质和意义 四、样本回归直线与样本回归函数(SRF)
ad
3
一、总体回归直线与总体回归函数(PRF)
ad
4
概念(一) 1、条件分布(Conditional 的分布。 2、条件概率(Conditional probability):给 定X的Y的概率,记为P(Y|Xi) 。 3、条件期望(Conditional Expectation ) 给定X的Y的期望值,记为E(Y|X=Xi)
ad 5
数据相对应的条件概率P(Y|Xi)
800 1100 1/6 1/6 1/6 1/6 1/6 1/6 1400 1/11 1/11 1/11 1/11 1/11 1/11 1/11 1/11 1/11 1/11 1/11 1700 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 2000 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 2300 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1/14 1705 2600 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 1/13 2900 1/10 1/10 1/10 1/10 1/10 1/10 1/10 1/10 1/10 1/10 3200 1/9 1/9 1/9 1/9 1/9 1/9 1/9 1/9 1/9 3500 1/6 1/6 1/6 1/6 1/6 1/6
第2章_线性回归的基本思想:双变量模型 (2)

200 35 31 30 28 26 22 20
225 36 34 31 29 27 26 23
250 38 36 33 30 28 25 23
275 40 37 32 30 29 27 25
300 42 39 34 31 30 29 26
325 43 35 31 30 29 33 32
350 375 45 39 33 30 27 30 28 46 40 34 31 28 32 30
2019/2/21
R 2 0.99
2
回归分析可以用来:
1、找到被解释变量(Y)与解释变 量(X)运动的相互关系,并检验 某些假设 如:固定其它条件不变,施肥 量每增加一单位, 收成变化多 少?是增收还是减产? 2、在已知解释变量(X)的基础上, 估计或预测被解释变量(Y)的均 值 如:估计身高170的父亲,其 儿子的平均身高 3、综合分析、指导决策
随机干扰项的性质和意义 Yi B1 B2 X i ui
它是从模型中省略下来,但又集体地影
响着Y的全部变量的替代物。
博 彩 支 出
系统成分/定性:可支配收入(X) 其它变量的影响 如性格、年龄、 性别
B1+B2 X i
非系统/随机成分:
ui
另外一些说不清的随机事件: 如某几天心情好,多买点
slope
Regression coefficients
12
2019/2/21
度量了X每变动一单位,Y(条件) 均值的变化率
2、总体回归函数(PRF)
(Population Regression Function)
条件回归分析
E(Y Xi )=B1+B2 X i
E( Y )
B1
3.6 双变量线性回归分析结果的报告以及案例

一、双变量线性回归分析结果的报告
ˆ ˆ X ˆ Y i 1 2 i
r2
df n 2
F1,n2
ˆ ˆ X ˆ Y i 1 2 i
df n 2
r2
二、双变量线性回归分析结果的评价 回归系数的估计值的符号是否与理论或事先 预期相一致?
案例2: 教材P81 习题3.23
回归系数是不是统计上显著的?
回归模型在多大程度上解释了因变量Y的变 异?
补充:正态性检验
残差直方图 正态概率图 雅克-贝拉(JB)检验
S 2 ( K 3) 2 JB n[ ] 6 24
案例分析
案例1:
伊春林区位于黑龙江省东北部,森林覆盖率 为62.5%,是我国主要的木材工业基地之一。 1999年伊春林区木材采伐量为532万m3。按 此速度44年之后,1999年的蓄积量将被采伐 一空。所以目前亟待调整木材采伐规划与方 式,保护森林生态环境。为缓解森林资源危 机,并解决部分职工就业问题,除了做好木 材的深加工外,还要充分利用木材剩余物生 产林业产品,如纸浆、纸袋、纸板等。因此 预测林区的年木材剩余物是安排木材剩余物 加工生产的一个关键环节。
计量经济学方法论
陈述经济学理论或感兴趣的经济现象; 设定数理经济学模型; 设定相应的计量经济学模型; 采集数据; 估计计量经济模型的参数; 基于所估计பைடு நூலகம்模型进行假设检验; 模型的应用。
建立工作文件,完成数据输入 散点图 OLS估计 模型的统计检验 1)拟合优度检验 2)变量的显著性检验 3)区间估计 4)正态性检验 报告估计结果 预测
第二章:双变量线性回归分析
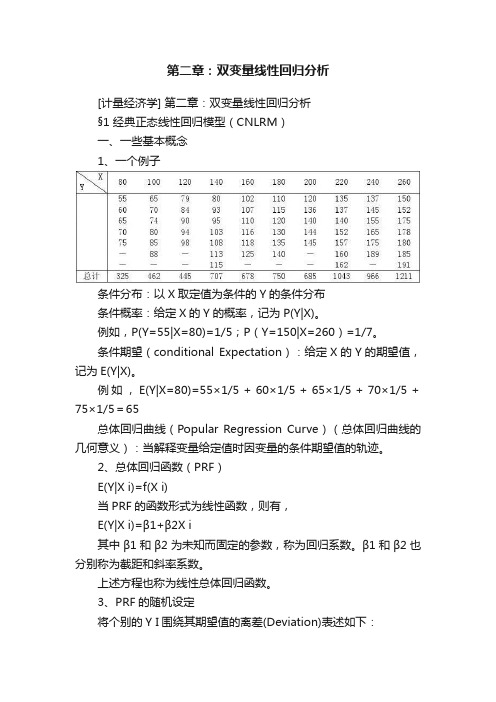
第二章:双变量线性回归分析[计量经济学] 第二章:双变量线性回归分析§1 经典正态线性回归模型(CNLRM)一、一些基本概念1、一个例子条件分布:以X取定值为条件的Y的条件分布条件概率:给定X的Y的概率,记为P(Y|X)。
例如,P(Y=55|X=80)=1/5;P(Y=150|X=260)=1/7。
条件期望(conditional Expectation):给定X的Y的期望值,记为E(Y|X)。
例如,E(Y|X=80)=55×1/5+60×1/5+65×1/5+70×1/5+75×1/5=65总体回归曲线(Popular Regression Curve)(总体回归曲线的几何意义):当解释变量给定值时因变量的条件期望值的轨迹。
2、总体回归函数(PRF)E(Y|X i)=f(X i)当PRF的函数形式为线性函数,则有,E(Y|X i)=β1+β2X i其中β1和β2为未知而固定的参数,称为回归系数。
β1和β2也分别称为截距和斜率系数。
上述方程也称为线性总体回归函数。
3、PRF的随机设定将个别的Y I围绕其期望值的离差(Deviation)表述如下:u i=Y i-E(Y|X i)或Y i=E(Y|X i)+u i其中u i是一个不可观测的可正可负的随机变量,称为随机扰动项或随机误差项。
4、“线性”的含义“线性”可作两种解释:对变量为线性,对参数为线性。
本课“线性”回归一词总是指对参数β为线性的一种回归(即参数只以它的1次方出现)。
模型对参数为线性?模型对变量为线性?是不是是LRM LRM不是NLRM NLRM注:LRM=线性回归模型;NLRM=非线性回归模型。
5、随机干扰项的意义随机扰动项是从模型中省略下来的而又集体地影响着Y 的全部变量的替代物。
显然的问题是:为什么不把这些变量明显地引进到模型中来?换句话说,为什么不构造一个含有尽可能多个变量的复回归模型呢?理由是多方面的:(1)理论的含糊性(2)数据的欠缺(3)核心变量与周边变量(4)内在随机性(5)替代变量(6)省略原则(7)错误的函数形式6、样本回归函数(SRF )(1)样本回归函数iY ?=1?β+2?βi X 其中Y ?=E(Y|X i )的估计量;1?β=1β的估计量;2β=2β的估计量。
计量经济学 两变量线性回归

消费性支出 y 585 576
1983
1984
686
834 1075 1293 1437
615
726 992 1170 1282
例3-1 上海市人均居民收 入和人均消费支出数据 (1981-2002)
1985 1986 1987
1988
1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002
i i i
最小。
23
1.最小二乘估计(OLS)(续)
核心:残差平方和 ei 2 最小。
min V ei Yi (a bX i )
2 i i
i
2
一阶条件为: V 0 a V 0 b
24
1.最小二乘估计(OLS)(续)
V 2 (Yi a bX i ) 0 a V 2 (Yi a bX i ) X i 0 b
(Y a bX ) 0
i i
(Yi a bX i ) X i 0
正规方程组
ei 0 利用残差记号ei可以 i 把正规方程组写为: e X 0 i i i
25
参数α和β的最小二乘估计量a和b
由正规方程 组得到:
Yi na b X i X iYi a X i b X i 2
3
1.模型建立
建立两变量线性回归模型必须有理论和现实 根据 一个例子: 凯恩斯绝对收入假设消费理论:消费(Y) 是由收入(X )唯一决定的,是收入的线性 函数: Y=+X 要利用经验和数据分布情况来判断变量 间的关系是否是线性关系。