数据库所有操作总结1
第3章 数据库的基本操作(1)

■若在文件名前指定了驱动器标识符,则文件建立在指定的 驱动器上,否则建立在当前驱动器上。 ■不指定文件扩展名时,缺省扩展名为.DBF。 ■若磁盘上存在这个文件或文件重名,系统显示一个警告对 话框,提示是否要改写表。如果需要改写,则选择【是】, 否则选择【否】。 ■不要用A-J单个字母作为表文件名,因为它们是专门用于工 作区别名的。
记录的总字节数=各个字段的宽度+ 1
LIST STRU和DISP STRU命令的区别:
DISP STRU:在每显示一屏信息后暂停,等待用户按任 意一键后继续显示; LIST STRU:显示信息时没有周期性暂停,而是连续 向下显示,直到显示完毕。
二. 显示表中的记录
格式:LIST ︱ DISPLAY
• 逻辑型字段:只允许输入下列字母中的一个: y, Y, t, T, n, N, f, F
• 日期型字段:mm-dd-yy mm取值范围01~12 dd取值范围01~31
• 备注型字段的输入:
Ctrl+PgDn: 弹出字段编辑窗口
Ctrl+W: 保存该字段内容到备注文件中。 输入数据后,该字段栏显示为Memo
指针定位就是将记录指针移到指定的记录上,记录指针指向的记 录称为当前记录。VFP提供了绝对定位和相对定位两类命令。
(1)记录指针的绝对定位
格式: GOTO [RECORD <数值表达式> ]∣TOP∣BOTTOM 功能:将记录指针直接定位到指定的记录上。
钮,所改变的设置仅在本次系统运行期间有效,退出系统 后,所做的修改将丢失。
二. 建立表前的准备
在建立表结构以前,首先应该根据用户的需求,明确所要创建 的表中应该包含哪些字段,每个字段的名称、类型和宽度。
数据库实训报告1

管理信息系统实训报告班级 10电子信息01班学号 101202060133 姓名赵发剑实训地点:机房2楼7号指导教师:张慧娥一、实训目的在当今的信息社会里,信息技术一日千里飞速发展,数据库技术已经广泛地渗透到各个领域,数据库应用技术也已经成为计算机工作人员的必修课程。
在目前比较流行的数据库开发系统中,Access2003是应用比较广的一种。
本系统正是基于Access2003开发环境下开发的学生管理系统,开发该系统是为了掌握数据库、数据表及表间关系的创建与修改方法,理解参照完整性概念。
了解查询基本功能,能熟练创建各种类型的查询。
了解窗体的作用,能利用各种方法创建、编辑出界面美观的窗体。
了解报表的作用,能按需制作格式正确的报表。
掌握系统集成技术,能将各分散对象组装成一个的完整系统。
二、实习内容及要求1 能够利用一个项目管理器,集中进行数据库和数据表的管理。
2能够在一个项目管理器的管理下,利用“向导”集中进行表单的设计和管理并在建立的表单界面的基础上,运行他们,并合理输入数据。
3 能够在一个项目管理器的管理下,进行自主表单的设计和管理。
4 能够在一个项目管理器的管理下,进行报表的设计和管理,进行菜单和主程序的设计和管理。
5能够在一个项目管理器的管理下,进行应用程序的打包和安装,使之生成WEB 可执行文件。
三、实训地点:2楼7号机房四、实训过程与步骤实训一数据表及关系的创建1、创建数据库:启动ACCESS,创建以学生学号命名的数据库。
2、创建数据表:经过对收集到的数据表经过规范化处理,在数据表设计视图中创建三个数据表:学生档案表、课程名表、学生选课成绩表,各表结构如下:学生档案表字段名学号姓名性别出生日期政治面貌班级编号入学成绩毕业学校文本文本数字文本字段类型文本文本文本日期/时间字段大小8 4 2 短日期 4 6 3 20备注主键学生选课情况字段名姓名班级编号课程编号课程名课程类别学分成绩字段类型文本文本文本文本文本数字数字字段大小8 6 3 8 6 字节单精度备注主键课程名表字段名课程编号课程名课程类别学分学时字段类型文本文本文本数字数字字段大小 3 8 3 字节字节备注主键学生成绩表字段名ID 学号课程编号学年学期成绩字段类型自动编号文本文本文本文本数字字段大小8 3 10 1 单精度备注主键3、创建表间关系,如下图1-1所示。
数据库学习总结_1

数据库学习总结(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如工作总结、实习报告、活动方案、规章制度、心得体会、合同协议、条据文书、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays, such as work summaries, internship reports, activity plans, rules and regulations, personal experiences, contract agreements, documentary evidence, teaching materials, complete essays, and other sample essays. If you would like to learn about different sample formats and writing methods, please pay attention!数据库学习总结数据库学习总结(精品5篇)数据库学习总结要怎么写,才更标准规范?根据多年的文秘写作经验,参考优秀的数据库学习总结样本能让你事半功倍,下面分享【数据库学习总结(精品5篇)】相关方法经验,供你参考借鉴。
数据库实验一实验报告总结

数据库实验一实验报告总结【实验目的】该实验的主要目的是让学生通过实际的操作和实践,了解并掌握数据库的基本操作,熟悉数据库的设计原理和方法,学会使用SQL语言进行数据查询和管理,并能够根据实际需求对数据库进行优化和改进。
本次实验主要分为三个部分:1. 熟悉SQL语言通过实验的学习,大家学习了SQL语言的基础操作,如SELECT、FROM、WHERE、GROUP BY、ORDER BY等关键字,了解了SQL语言的执行顺序和语法结构,掌握了数据的添加、删除、修改和查询操作。
2. 数据库设计与应用在本次实验中,我们使用MySQL数据库,并通过实际操作学习了数据库的设计与应用,掌握了数据库的设计过程,包括数据结构的设计、表的分类和关系的建立等。
通过数据的导入和导出,我们能够实现数据的备份和恢复,确保数据的安全和完整性。
3. 数据库优化与管理在实验的最后一部分,我们学习了数据库的优化与管理,了解了索引的作用和创建方法,以及优化查询语句的技巧,提升了数据库的性能和效率。
1. 掌握了SQL语言的基本语法和常见操作,能够熟练使用SQL语言进行数据查询、添加、修改和删除等操作。
2. 学习了数据库的设计原理和方法,了解了数据结构的设计和表的关系建立,能够根据实际需求设计出适合的数据库。
4. 加深了对数据库的理解,提高了数据管理和处理的能力,为以后的学习和工作打下了坚实的基础。
1. 建议增加实验的复杂度,让学生面对更加综合的应用场景,更好地锻炼他们的独立思考和实际操作能力。
2. 建议增加操作的实践环节,引导学生自己动手操作,更好地理解和掌握知识点。
3. 建议加强实验的理论讲解,让学生更好地理解和掌握理论知识,为以后的工作和研究打下坚实的基础。
【总结】本次实验内容丰富,实践性强,让我深刻地体会到了数据库的重要性和实用性。
通过实际操作,我掌握了SQL语言的基本语法和常用操作,并了解了数据库的设计原理和方法,能够根据实际需求设计和维护数据库。
数据库类型枚举(Enum)使用总结

数据库类型枚举(Enum)使⽤总结1、定义枚举定义枚举很简单,直接使⽤enum关键字声明即可,例如定义性别的枚举,性别只有男和⼥public enum Sex{⼥ = 0,//’0‘是’⼥‘对应的内部表⽰,也可以说是⼥的Value,’⼥‘是外部表⽰,也可以说是Name男 = 1,}2.使⽤枚举代码3.通常我们在数据库中,很多的⼀些状态、类型、性别等等字段保存的是数字,但我们在开发时需要判断这些状态时,直接使⽤if(UserInfo.Sex==0)这种⽅式来判断,显然不太好,如果状态多时,⾃⼰都难分辨哪个数字代表什么状态。
并且代码也不可观,我们在写代码时应该尽量少写硬代码。
如果使⽤枚举定义,数据库存储的枚举对应的值,⽽在写代码时使⽤枚举的名称,这样⼀看代码就知道数据库储值的是什么状态。
⾮常清楚明了。
4.UI层显⽰枚举的名称。
如果数据库存储的是枚举的值(为数字),⽽在UI上当然不能已数字的⽅式显⽰,应该显⽰对应的枚举名称。
例如在⼀个⽤户信息列表中需要绑定⽤户性别(枚举为上述的Sex),那该如何显⽰枚举的名称呢?⼀下提供多种⽅式 3.1:GridView控件绑定数据源为例,可以添加⼀列模板项,通过值获取枚举名称代码1 <asp:TemplateField HeaderText="性别">2 <ItemTemplate>3 <%#(枚举所在命名空间.Sex)Convert.ToInt32(Eval("Sex"))%>4 </ItemTemplate>5</asp:TemplateField> 3.2: 通过Enum对象获取名称代码1 <asp:TemplateField HeaderText="性别">2 <ItemTemplate>3 <%#Enum.GetName(typeof(枚举所在命名空间.Sex), Convert.ToInt32(Eval("Sex")))%>4 </ItemTemplate>5 </asp:TemplateField>还有很多⽅式来处理这个问题,⼤家可以⾃由选择。
SQL实验报告总结

《数据库系统概论(第四版)》体会学号:姓名:班级:教师:学期实验总结与心得【实验名称】数据库的创建【实验内容】 1、新建sql注册表。
2、新建数据库。
主数据文件:逻辑文件名为student_data,物理文件名为student.mdf,初始大小为10mb,最大尺寸为无限大,增长速度为10%;数据库的日志文件:逻辑名称为student_log,物理文件名为student.ldf,初始大小为1mb,最大尺寸为5mb,增长速度为1mb 3、修改已注册的sql server属性为使用sql server身份验证。
【实验名称】数据库的附加、分离、导入导出及分离【实验内容】1. 数据库文件的附加与分离 (转载于:sql实验报告总结)2. 数据库文件的导入和导出3..数据库的删除4.修改数据库【实验名称】数据库的创建(书中作业)【实验内容】1. 在数据库student中创建一个学生基本信息表1.用企业管理其创建表2.用查询分析器创建表2.sql server 2005的系统数据类型分为哪几类?常用的数据类型有哪些?答:字符串类型、整型、长整型、短整型、浮点数类型、定点数类型、日期、时间。
常用的数据类型有:字符串类型、整型、长整型、短整型、浮点数类型、定点数类型、日期、时间3.在数据库student中创建一个名为t_couse(课程信息表) 1.用企业管理其创建t_course表2.用查询分析器创建t_course4.在数据库student中创建一个名为t_score(学生成绩)的表5.sql server 2005 中有多少种约束?其作用分别是什么答:非空约束,作用指定某一列不允许空值有助于维护数据的完整性,因为这样可以确保行中的列永远保护数据。
主键约束,作用可以保证实体的完整性,是最重要的一种约束。
唯一约束,作用指定一个或多个列的组合值具有唯一性,以防止在列中输入重复的值。
检查约束,作用对输入列或者整个表中的值设置检查条件,以限制输入值,保证数据库数据的完整性。
数据库系统概论总结(一)

数据模型(续)(p12)
数据模型分成两个不同的层次
(1) 概念模型 也称信息模型,它是按用户的观点来 也称信息模型, 对数据和信息建模。 对数据和信息建模。 它是按计算机系统的观点对数据建模。 (2) 结构模型 它是按计算机系统的观点对数据建模 概念模型最终要转换成结构模型。
实体型间联系 ---三种类型
1.两个实体型 两个实体型 2.三个实体型 三个实体型 3.一个实体型 一个实体型 一对一联系( 一对一联系(1:1) ) 一对多联系( 一对多联系(1:n) ) 多对多联系( 多对多联系(m:n) )
关系模型的基本概念
关系(Relation)
一个关系对应通常说的一张表。
数据管理的发展阶段
人工管理阶段 文件系统阶段 数据库系统阶段
数据独立性分两种
物理独立性—用户的应用程序与磁盘上 存储数据的相互独立。指数据的物理存 储改变了,应用程序不用改变。 逻辑独立性—用户的应用程序与数据库 的逻辑结构的相互独立,逻辑结构发生 改变,应用程序不用改变。
数据模型
在数据库中用数据模型这个工具来抽象、表 抽象、 抽象 示和处理现实世界中的数据和信息。通俗地 示和处理 讲数据模型就是现实世界的模拟—“抽象” 数据模型应满足三方面要求
(2) 属性(Attribute)
实体所具有的某一特性称为属性。 实体所具有的某一特性称为属性。一个实体可以由若干个 属性来刻画。 属性来刻画。
(3) 码(Key)--任何一个实体都应有一个或多个码
唯一标识实体的属性集称为码。 唯一标识实体的属性集称为码。
信息世界中的基本概念(续)
最新第一次数据库实验报告

最新第一次数据库实验报告实验目的:本次实验旨在通过实际操作,加深对数据库管理系统(DBMS)的理解和应用。
通过创建数据库、表、以及进行数据的插入、查询、更新和删除等基本操作,掌握数据库的基本工作原理和SQL语言的使用。
实验环境:- 操作系统:Windows 10- 数据库管理系统:MySQL 8.0- 开发工具:MySQL Workbench实验步骤:1. 打开MySQL Workbench,连接到本地MySQL服务器。
2. 创建名为“StudentDB”的数据库。
3. 在“StudentDB”数据库中创建一个学生表(Students),包含学号(ID)、姓名(Name)、年龄(Age)、专业(Major)四个字段。
4. 向学生表中插入至少五条学生记录。
5. 实施查询操作,包括:- 查询所有学生信息。
- 查询年龄大于20岁的学生信息。
- 查询姓“张”的学生信息。
6. 对学生表进行更新操作,修改某个学生的专业信息。
7. 删除一条学生记录,并提交更改。
8. 创建一个视图(View),用于查询特定格式的学生信息。
9. 实施数据的备份与恢复操作。
实验结果:1. 成功创建“StudentDB”数据库。
2. 学生表(Students)创建完成,包含必要字段。
3. 插入五条学生记录,操作成功。
4. 查询操作均执行成功,得到预期结果。
5. 更新操作成功,学生专业的更改被正确反映。
6. 删除操作执行成功,目标记录已被移除。
7. 视图创建成功,能够查询到特定格式的学生信息。
8. 数据备份与恢复操作顺利完成,验证了数据的完整性。
实验分析:通过本次实验,我深入理解了数据库的创建、表的构建、数据的增删改查等操作。
在实践中,我学会了如何使用SQL语言来管理数据库,并且认识到了数据完整性和安全性的重要性。
此外,通过视图的创建,我了解到了如何有效地组织和呈现数据。
实验总结:本次数据库实验是一个很好的学习机会,让我将理论知识与实践操作相结合。
DB2学习总结(1)——DB2数据库基础入门

DB2学习总结(1)——DB2数据库基础⼊门DB2的特性完全Web使能的:可以利⽤HTTP来发送询问给服务器。
⾼度可缩放和可靠:⾼负荷时可利⽤多处理器和⼤内存,可以跨服务器地分布数据库和数据负荷;能够以最⼩的数据丢失快速地恢复,提供多种备份策略。
DB2数据库启停启动数据库:db2start停⽌数据库:db2stop检查存在的数据库LIST DATABASE DIRECTORY数据库连接、断开CONNECT TO databasenameCONNECT RESET创建、删除数据库CREATE DB databasename注:如果已经连着⼀个数据库的话,就创建不了数据库,会报“应⽤程序已经与⼀个数据库相连”的错DROP DB databasename第⼆节表数据类型可分为数值型(numeric)、字符串型(character string)、图形字符串(graphic string)、⼆进制字符串型(binary string)或⽇期时间型(datetime)。
还有⼀种叫做DATALINK的特殊数据类型。
DATALINK值包含了对存储在数据库以外的⽂件的逻辑引⽤。
数值型数据类型包括:⼩整型,SMALLINT:两字节整数,精度为5位。
范围从-32,768到32,767。
⼤整型,INTEGER或INT:四字节整数,精度为10位。
范围从-2,147,483,648到2,147,483,647。
巨整型,BIGINT:⼋字节整数,精度为19位。
范围从-9,223,372,036,854,775,808到9,223,372,036,854,775,807。
⼩数型,DECIMAL(p,s)、DEC(p,s)、NUMBERIC(p,s)或NUM(p,s):⼩数型的值是⼀种压缩⼗进制数,它有⼀个隐含的⼩数点。
压缩⼗进制数将以⼆-⼗进制编码(binary-coded decimal,BCD)记数法的变体来存储。
⼩数点的位置取决于数字的精度(p)和⼩数位(s)。
数据库系统工程师知识点总结

数据库系统工程师知识点总结一、数据库基础概念。
1. 数据与数据库。
- 数据(Data):是描述事物的符号记录。
例如学生的姓名、年龄、成绩等都是数据。
- 数据库(Database,DB):是长期储存在计算机内、有组织的、可共享的数据集合。
它具有数据结构化、数据共享性高、冗余度低且易扩充、数据独立性高等特点。
2. 数据库管理系统(DBMS)- 功能:数据定义(定义数据库中的数据对象,如创建表、视图等)、数据操纵(对数据库中的数据进行查询、插入、删除、修改等操作)、数据库的运行管理(保证数据库的正常运行,如并发控制、安全性检查等)、数据库的建立和维护(数据库的初始建立、数据的转储和恢复等)。
- 常见的DBMS:Oracle(大型商业数据库,功能强大,适用于企业级应用)、MySQL(开源数据库,广泛应用于Web开发等多种场景)、SQL Server(微软的数据库产品,与Windows环境集成度高)等。
3. 数据库系统(DBS)- 由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员(DBA)和用户构成。
二、数据模型。
1. 概念模型。
- 用于信息世界的建模,是现实世界到机器世界的一个中间层次。
- 常用的概念模型是E - R模型(Entity - Relationship Model)。
- E - R模型的基本元素:实体(Entity,如学生、课程等客观存在并可相互区分的事物)、属性(Attribute,实体所具有的某一特性,如学生的姓名是学生实体的一个属性)、联系(Relationship,实体之间的联系,如学生与课程之间存在选课联系)。
2. 逻辑模型。
- 层次模型:用树形结构表示实体及其之间的联系,有且只有一个根节点,根节点以外的节点有且只有一个父节点。
例如,一个公司的部门组织架构可以用层次模型表示。
- 网状模型:用网状结构表示实体及其之间的联系,允许一个以上的节点无双亲,一个节点可以有多于一个的双亲。
数据库技术三级考试知识点总结

数据库技术三级考试知识点总结一、数据库基础。
1. 数据库系统概述。
- 数据库(DB)、数据库管理系统(DBMS)和数据库系统(DBS)的概念。
数据库是长期存储在计算机内、有组织、可共享的数据集合;DBMS是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据;数据库系统是由数据库、数据库管理系统、应用程序、数据库管理员(DBA)等组成的人机系统。
- 数据库系统的特点,如数据结构化(整体结构化,数据不再针对某一应用,而是面向全组织)、数据的共享性高、冗余度低且易扩充、数据独立性高(包括物理独立性和逻辑独立性)等。
2. 数据模型。
- 概念模型:用于信息世界的建模,是现实世界到机器世界的一个中间层次。
常用的概念模型是实体 - 联系模型(E - R模型),其中包括实体(客观存在并可相互区别的事物)、属性(实体所具有的某一特性)和联系(实体之间的联系有一对一、一对多和多对多等类型)。
- 数据模型的组成要素:数据结构(描述数据库的组成对象以及对象之间的联系)、数据操作(对数据库中各种对象的实例允许执行的操作的集合,包括操作及有关的操作规则)和数据的完整性约束条件(一组完整性规则,用以限定符合数据模型的数据库状态以及状态的变化,以保证数据的正确、有效和相容)。
- 常见的逻辑数据模型:- 层次模型:用树形结构表示实体及其之间的联系,有且只有一个根结点,根结点以外的其他结点有且只有一个父结点。
- 网状模型:用网状结构表示实体及其之间的联系,允许一个以上的结点无双亲,一个结点可以有多于一个的双亲。
- 关系模型:以二维表的形式组织数据,关系模型中的数据结构是关系(二维表),关系操作包括查询(选择、投影、连接等)和更新(插入、删除、修改)操作,关系的完整性约束包括实体完整性(主关键字不能取空值)、参照完整性(外键要么取空值,要么取对应主键的值)和用户定义的完整性。
3. 数据库系统结构。
《数据库原理与应用》实验报告一(1)

课程名称:数据库原理与应用
实验编号 及实验名称 姓 名
新电 402 实验一 SQL Server 数据库基本操作
系 班
别 级
计科系
学
号
2 年 11 月 2 日 无
实验地点 指导教师Fra bibliotek实验日期 同组其他成员
实验时数 成 绩
6
一、实验目的及要求
1、 掌握 SQL Server 系统的数据库创建方式。 2、 掌握 SQL Server 系统的数据表的创建方式。 3、 掌握 SQL Server 系统的数据编辑的基本方式。
2、至少完成主要的实验内容,实验步骤和实验结果基本正确。 3、仅完成部分的实验内容,实验步骤和结果基本正确。 4、虽然完成了主要实验内容,但是实验步骤和结果存在多处重大错误。 5、未能很好地完成规定的实验内容,且实验步骤和结果基本不正确。 6、其它: 评定等级:优秀 良好 中等 及格 不及格 教师签名: 2012 年 11 月 日
教师信息表:teacher 字段名称 tNO tName tSex tBirth tRank 含义 教师号 姓名 性别 出生年月 职称 数据类型 Char(6) Varchar(20) char(4) datetime Varchar(20) 否 是否允许空 否 否 主键 Yes
3、表中数据的 SQL 方式编辑
) create table teacher (tNO tName tSex tBirth tRank ) Char(6) Varchar(20) char(4) datetime Varchar(20) not null PRIMARY KEY, not null, not null, not null, not null
Visual FoxPro VF 第5章 数据库及其操作(1)

例:16、在Visual FoxPro中,下面描述正确的 是______。(09-3) A、数据库表允许对字段设置默认值 B、自由表允许对字段设置默认值 C、自由表或数据库表都允许对字段设置默 认值 D、自由表或数据库表都不允许对字段设置 默认值
例:20、以下关于空值(NULL值)叙述正确 的是______。(09-3) A、空值等于空字符串 B、空值等同于数值0 C、空值表示字段或变量还没有确定的值 D、Visual FoxPro不支持空值
例:21、在Visual FoxPro中,有关参照完整性的删除规 则正确的描述是______。(09-3) A、如果删除规则选择的是"限制",则当用户删除父 表中的记录时,系统将自动删除子表中的所有相关记录 B、如果删除规则选择的是"级联",则当用户删除父 表中的记录时,系统将禁止删除与子表相关的父表中的 记录 C、如果删除规则选择的是"忽略",则当用户删除父 表中的记录时,系统不负责检查子表中是否有相关记录 D、上面三种说法都不对
例:11、不带条件的DELETE命令(非SQL命 令)将删除指定表的___当前___记录。(069) 试比较: 不带条件的DELETE命令(是SQL命令)将删 除指定表的__所有___记录。
例:22、在Visual FoxPro中以下叙述错误的 是______。(06-4) A、关系也被称作表 B、数据库文件不存储用户数据 C、表文件的扩展名是.dbf D、多个表存储在一个物理文件中
6、索引 主索引 在指定字段或表达式中不允许出现重复值的索引。建立主索引的字 段是主关键字,一个表只能有一个主关键字,即一个表只能创建一 个主索引。 注:只能为数据库中的每一个表建立一个主索引。 候选索引 候选索引象主索引一样要求字段值的唯一性并决定处理记录的顺序。 在数据库和自由表中可以建立多个候选索引。 惟一索引 索引项的唯一。 普通索引 普通索引可以决定记录的处理顺序,它不仅允许字段中出现重复值, 并且索引项中也允许出现重复值。在一个表中可以建立多个普通索 引。
数据库管理工具DataGrip使用总结(一)
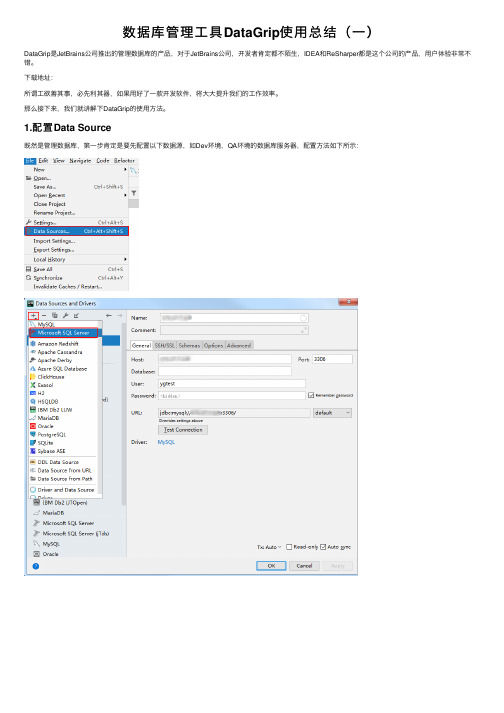
数据库管理⼯具DataGrip使⽤总结(⼀)
DataGrip是JetBrains公司推出的管理数据库的产品,对于JetBrains公司,开发者肯定都不陌⽣,IDEA和ReSharper都是这个公司的产品,⽤户体验⾮常不错。
下载地址:
所谓⼯欲善其事,必先利其器,如果⽤好了⼀款开发软件,将⼤⼤提升我们的⼯作效率。
那么接下来,我们就讲解下DataGrip的使⽤⽅法。
1.配置Data Source
既然是管理数据库,第⼀步肯定是要先配置以下数据源,如Dev环境,QA环境的数据库服务器,配置⽅法如下所⽰:
以上是以Microsoft SQL Server为例,如果是连接MySQL数据库,⽅法类似。
2.新建表
在要添加表的数据库上右键,然后按如下图操作:
假如我们在Dev环境创建了⼀张表,提测到QA环境时,测试要求提供脚本,但是你⼜没有保存,此时可以使⽤SQL Generator⾃动⽣成创建表的脚本:
4.新建查询窗⼝(console)
操作数据库时,平时最常⽤的肯定就是查询窗⼝了,我们会查询数据分析问题,会写⼀些SQL脚本,那么在DataGrip中如何新建console呢?
⼩技巧:如果希望⽣成的关键字都是SELECT,FROM这种全⼤写的,输⼊第⼀个字母时,输⼊⼤写的,这样选择完智能提⽰的关键字,就是全⼤写的。
5.设置长SQL语句⾃动换⾏
在查询窗⼝中,有时SQL语句会很长,拖动⽔平滚动条查看会很不⽅便,此时就可以设置SQL语句⾃动换⾏:
注意:该设置不是全局的,只是针对当前活动的console。
数据库备份策略与实施步骤详解(一)

数据库备份策略与实施步骤详解一、导言在信息时代,数据被广泛应用于各个行业和领域。
然而,随着数据量的不断增长,数据库备份变得尤为重要。
数据库备份是指将数据从一个存储器(如硬盘)复制到另一个存储器的过程。
本文将详细介绍数据库备份的策略和实施步骤。
二、数据库备份策略1. 定期备份定期备份是数据库备份的基本策略。
通过定期备份,可以确保数据的安全性和可靠性。
一般来说,可以按照每天、每周或每月的频率进行备份。
此外,为了减少备份对系统性能的影响,可以选择在业务低峰期进行备份。
2. 多地备份多地备份是为了应对意外情况,如自然灾害、设备故障等。
通过将备份数据存储在不同的地方,可以避免单一点的风险。
可以选择将备份数据存储在本地和远程的数据中心,或者使用云存储服务。
3. 增量备份与全量备份增量备份与全量备份是备份时常用的两种方式。
全量备份是指备份数据库中所有数据的过程,而增量备份则只备份自上次全量备份以来的变化数据。
全量备份需要更多的时间和存储空间,但恢复数据更加简单和快速;增量备份则能够节省时间和存储空间,但在恢复数据时需要进行多个增量备份的逐一恢复。
三、数据库备份实施步骤1. 确定备份周期首先,需要根据业务需求和数据变化情况来确定备份周期。
一般来说,可以根据数据库的活动度和重要性来设置备份周期。
2. 选择备份工具在进行数据库备份时,需要选择合适的备份工具。
有些数据库系统自带备份工具,如MySQL的mysqldump工具;还有一些第三方工具,如Oracle的RMAN工具。
选择备份工具时,要考虑其稳定性、可靠性和可扩展性等因素。
3. 确定备份存储方式备份存储方式是指将备份数据存储在何种介质上。
可以选择硬盘、磁带或者云存储等方式。
硬盘备份速度快,但存储空间有限;磁带备份存储容量大,但备份速度较慢;云存储备份无需额外的硬件投入,并提供灵活的存储空间。
4. 定时自动备份为了确保备份的及时性和准确性,可以设置定时自动备份任务。
数据库outer用法(一)

数据库outer用法(一)数据库outer用法详解什么是数据库outer?数据库outer是一种结构化数据存储的工具,可以用来存储和管理各种类型的数据。
它是一种常用的数据操作工具,被广泛应用于软件开发、数据分析和数据管理等领域。
数据库outer的几种常见用法:以下是一些常见的数据库outer用法,供参考:1.连接(Join)操作:outer可以用来连接多个表,通过匹配表中的共同字段,将相关数据合并到一个结果集中。
常见的outer连接包括左连接、右连接和全外连接。
例如:SELECT *FROM table1LEFT OUTER JOIN table2ON = ;这个查询语句将从table1中选择所有的记录,并将与table2中具有相同id的记录连接起来。
2.过滤(Filter)操作:outer可以用来过滤掉不需要的数据,只返回符合指定条件的数据。
可以使用WHERE子句来指定过滤条件。
例如:SELECT *FROM tableWHERE column = 'value';这个查询语句将从table中选择所有column等于’value’的记录。
3.排序(Sort)操作:outer可以用来按照指定的字段对数据进行排序。
可以使用ORDER BY子句来指定排序字段和排序方式。
例如:SELECT *FROM tableORDER BY column ASC;这个查询语句将从table中选择所有记录,并按照column字段的升序进行排序。
4.聚合(Aggregate)操作:outer可以用来对数据进行聚合计算,如计算平均值、总和、最大值、最小值等。
可以使用聚合函数(例如SUM、COUNT、AVG等)来实现。
例如:SELECT SUM(column)FROM table;这个查询语句将从table中选择column字段的所有记录,并计算其总和。
5.分组(Group)操作:outer可以用来按照指定的字段对数据进行分组,然后对每个分组进行聚合计算。
FastAPI数据库系列(一)MySQL数据库操作

FastAPI数据库系列(⼀)MySQL数据库操作⼀、简介FastAPI中你可以使⽤任何关系型数据库,可以通过SQLAlchemy将其轻松的适应于任何的数据库,⽐如:PostgreSQLMySQLSQLiteOracleMicrosoft SQL Server... SQLAlchemy是⼀个ORM(object-relational mapping)的框架。
在ORM中,你创建⼀个类就会通过SQLAlchemy将其⾃动转成⼀张表,在类中的每⼀个属性就会将其转成表中的字段。
这⾥有⼀些实例,假如有⼀个⼤的项⽬,⾥⾯包含⼀个⼦包叫做sql_app:.└── sql_app├──__init__.py├── crud.py├── database.py├── main.py├── models.py└── schemas.py__init__.py 是⼀个空⽂件,但是说明sql_app是⼀个packagedatabase.py 数据库配置相关models.py 数据库模型表schemas.py 模型验证crud.py 数据库操作相关main.py 主⽂件⼆、简单实例该实例以MySQL为例,SQLAlchemy需要借助于pymysql连接数据库,所以需要进⾏安装这两个⼯具包:pip install sqlalchemypip install pymysql1、database.pyfrom sqlalchemy import create_enginefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy.orm import sessionmakerSQLALCHEMY_DATABASE_URL = "mysql+pymysql://root:123456@127.0.0.1:3306/test"# echo=True表⽰引擎将⽤repr()函数记录所有语句及其参数列表到⽇志engine = create_engine(SQLALCHEMY_DATABASE_URL, encoding='utf8', echo=True)# SQLAlchemy中,CRUD是通过会话进⾏管理的,所以需要先创建会话,# 每⼀个SessionLocal实例就是⼀个数据库session# flush指发送到数据库语句到数据库,但数据库不⼀定执⾏写⼊磁盘# commit是指提交事务,将变更保存到数据库⽂件中SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)# 创建基本映射类Base = declarative_base()在数据库相关的配置⽂件中,⾸先创建⼀个SQLAlchemy的"engine",然后创建SessionLocal实例进⾏会话,最后创建模型类的基类。
oracle数据库group by用法(一)

oracle数据库group by用法(一)Oracle数据库Group By用法详解在Oracle数据库中,GROUP BY是一种常用的查询语句,用于按照指定的列对查询结果进行分组。
通过GROUP BY语句,可以对分组后的数据进行聚合运算,如计算总和、平均值等。
本文将介绍一些常见的GROUP BY用法,并对其进行详细解释。
1. 基本用法下面是GROUP BY的基本语法:SELECT column_name(s)FROM table_nameWHERE conditionGROUP BY column_name(s)•column_name(s):指定要分组的列名,可以是一个或多个列名。
•table_name:指定要操作的表名。
•condition:查询条件,可选。
2. 分组查询通过GROUP BY可以实现对指定列的分组查询,例如:SELECT department, COUNT(*)FROM employeesGROUP BY department;上述示例中,我们通过GROUP BY将employees表中的数据按照department列进行分组,并计算每个部门的员工数量。
3. 加入聚合函数GROUP BY常常和聚合函数一起使用,以进行进一步的统计和计算。
下面是一个示例:SELECT department, AVG(salary)FROM employeesGROUP BY department;上述示例中,我们按照department列进行分组,并计算每个部门的平均工资。
4. 多个分组列GROUP BY语句支持多个分组列的定义,即可以按照多个列对查询结果进行分组。
示例如下:SELECT department, gender, AVG(salary)FROM employeesGROUP BY department, gender;上述示例中,我们按照department和gender两列进行分组,并计算每个部门和性别的平均工资。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<ANY : 只要小于子查询中的任何一个值即可 SELECT * FROM emp WHERE sal< ANY(SELECT MIN(sal) FROM emp GROUP BY deptno); <ALL:比最小的值小 SELECT * FROM emp WHERE sal<ALL(SELECT MIN(sal) FROM emp GROUP BY deptno);
插入语句
intsert into 表名 values(值 1 值 2 值 3…..) 插入的数值的字段类型要与定义的时候一样 intsert into 表名 values(值 1,值 2,null,值 3………) 有不想写的可以用 null 来标示 intsert into 表名(字段 1.字段 2,字段 3………) values(值 1 值 2 值 3……) 类型对应 注意:数值的 类型 个数 顺序 不能超过最大值
新增加一条记录到 MYEMP 中,但日期格式按'1988-09-09'的方式指定 � TO_DATE 函数的使用 INSERT INTO myemp(empno,ename,job,hiredate,sal,deptno) VALUES(7896,'赵六','清洁工',TO_DATE('1984-09-09','yyyy-mm-dd'),9000,40);
新增加一条记录到 MYEMP 中,但是该员工没有奖金也没有上级领导 第一种写法: INSERT INTO myemp (empno,ename,job,hiredate,sal,deptno) VALUES(7899,'张三','清洁工','14-2 月 -1995',9000,40) 第二种写法:(用 null 来指定没有值的列) INSERT INTO myemp VALUES(7898,'王五','清洁工',null,'14-2 月 1995',9000,null,40)
限定查询----LIKE 匹配日期 查询 1982 年入职的所有雇员的信息 SELECT *FROM empWHERE hiredateLIKE '%82%' 限定查询----LIKE 匹配数字 查询工资中包含 5 的雇员信息 SELECT *FROM empWHERE salLIKE '%5%' 对结果排序----ORDER BY 带有 ORDER BY 子句的 SQL 语句基本格式 SELECT 列... FROM 表 WHERE 条件 ORDER BY 列 查询员工资大于 1500 的信息,按工资排序 SELECT * FROM emp WHERE sal>1500 ORDER BY sal 查询工资大于 1500 员工的信息,按工资降序,按雇佣日期升序排序 SELECT * FROM emp WHERE sal>1500ORDER BY salDESC,hiredate ASC 说明: ASC 排序,DESC 降序,默认 ASC 左、右外连接 查询员工编号,姓名,所在部门号,部门名称,将没有员工的部门也显示出来 SELECT e.ename,d.deptno,d.dnameFROM emp e,dept dWHERE e.deptno(+)=d.deptno; 注: (+)在左边,表示右连接,会列出右表中出现但是没有在左表中出现的行 交叉连接(CROSS JOIN) :用来产生笛卡尔积的 SELECT * FROM emp CROSS JOIN dept; 自然连接(NATURAL JOIN) :自动进行关联字段的匹配 SELECT * FROM emp NATURAL JOIN dept; USING 子句:直接指定操作关联列 SELECT * FROM emp JOIN dept USING(deptno); ON 子句:用户自己编写连接条件 SELECT * FROM empJOIN deptON emp.deptno=dept.deptno; RIGHT JOIN:右外连接 SELECT e.empno,e.ename,d.deptno,d.dname FROM emp e RIGHT JOIN dept d ON e.deptno=d.deptno; 子查询---IN 的使用 查询和 SMITH 或 JONES 在同一部门,同一职位工作的员工 SELECT * FROM emp WHERE (deptno,job) IN(SELECT deptno,job FROM emp WHERE enameIN('SMITH','JONES'));
子查询---ANY 的使用 =ANY : 与 IN 操作符的效果一致 查询和 SMITH 或 JONES 在同一部门,同一职位工作的员工 SELECT * FROM emp WHERE (deptno,job) =ANY (SELECT deptno,jopFROM emp WHERE ename IN('SMITH','JONES')); >ANY : 只要大于子查询中的任何一个值即可 SELECT * FROM emp WHERE sal > ANY(SELECT MIN(sal) FROM EMP GROUP BY deptno); >ALL:比最大的值大 SELECT * FROM emp WHERE sal>ALL(SELECT MIN(sal) FROM emp GROUP BY deptno);
修改记录
update 表名 set 字段= 值,字段 =值 ,字段= 值……. where 条件; 注意:条件必须写
删除记录
delete from 表名 where 条件; 注意:条件必须写 ROLLBACK (回滚) 在 sqlplus 中如果使用 ROLLBACK 的话那么将 撤销操作直到 上次执行 commit 的时候的 状态
限定查询----NOT IN 的使用 查询出雇员编号不是 7369,7499,7521 的雇员的具体信息 SELECT *FROM empWHERE empno NOT IN(7369,7499,7521); 限定查询----LIKE 的使用 查询中雇员的名字第二个字符是 M 的雇员信息 SELECT empno,ename,comm,salFROM empWHERE ename LIKE '_M%'; 说明: _ 匹配一个字符,% 匹配 0 个或多个字符
标量函数的使用
转化大小写 select upper(‘sddfa’) from dual select lower(‘sddfa’) from dual 将首字母大写 其余小写 select initcap (ename)from emp; 连接字符串:
select count(deptno)from dept; select contact (‘hello’,’woeld’) from dual; select ‘abc’|| ‘jkh’|| ‘sdf’ from dual; 求子串: select substr (字符串,起始位,结束位) from dual; 起始位写 0 或者 1 都可以代表第一位 select substr (字符串,起始位) from dual; 从起始位开始往后截取 求字符串长度: select length(ename )from emp; 字符串替换 select replace (原始字符串,想要被替换的字符串,替换字符串 )from dual; 输出字符串的后三位 select ename ,substr(ename,length(ename)-2) from dual ; select ename substr(ename,-3)from dual ; 四舍五入 select round(132.78454)from dual; 四舍五入取整 select round(132.7834round (1323.7858416, -2) from dual; 小数不要 并且 整数位两位取整 本代码得 1300 截断小数位 select trunc (546541.151) from dual 不管四舍五入 直接截断小数 5465541 select trunc(789.536,2) from dual 截断小数 指定小数的数位 789.53 select trunc(789.536,-2) from dual 截断小数 并且对整数进行截断 700 取余 select mod(10,3)from dual ; 运算规律: 日期+ 数字=日期 日期--数字=日期 日期—日期 = 数字 显示系统时间 select sysdate from dual; select to_char(sysdate,'yyyy-mm-dd,hh24:mi:ss') from dual; 显示某本门员工进入公司星期数: select empno,ename ,round( (sysdate-hiredate)/7)from emp where deptno=10;
插入记录到表中 INSERT 的语法 INSERT INTO 表名(字段名 1,字段名 2,......)VALUES(值 1,值 2......); 为 MYEMP 中增加一条记录 INSERT INTO myemp(empno,ename,job,mgr,hiredate,sal,comm,deptno)VALUES(7899,' 张 三 ',' 清洁工','7369','14-2 月 -1995',9000,300,40) 注:给定的值要和指定的字段数一致 当为表中的所有列都插入数据数,可以采用如下简单写法 INSERT INTO 表名 VALUES(值 1,值 2......); INSERT INTO myemp VALUES(7991,'李四','清洁工','7369','14-2 月 1995',9000,300,40) 注:要求给定值的数目和表中列的数目一致,并且值的顺序和表中列的顺序一致。