线性时间选择
作文写作中的时间顺序安排技巧

作文写作中的时间顺序安排技巧时间顺序是作文写作中非常重要的一种组织结构。
合理的时间顺序安排可以使文章结构清晰,逻辑严密,使读者更容易理解和接受作者的观点。
本文将探讨一些在作文写作中使用时间顺序安排的技巧,帮助读者提升写作水平。
一、线性时间顺序线性时间顺序是最常见的一种安排方式,即按照事件发生的先后顺序进行叙述。
这种方式适用于叙事性作文,如记叙文和故事。
作者可以通过描述事件的发生顺序,使读者跟随故事情节的展开,产生一种身临其境的感觉。
例如,当写一篇关于自己夏日旅行的作文时,可以按照旅行的时间顺序来叙述。
首先描述旅行的准备工作,如收拾行李、购买车票等;然后描述旅行的开始,如乘坐火车或飞机到达目的地;接着叙述旅行中的各个景点和活动,如游览名胜古迹、品尝当地美食等;最后描述旅行的结束和回家的过程。
二、逆序时间顺序逆序时间顺序是指按照事件发生的相反顺序进行叙述。
这种方式适用于写作议论文或说明文中,当作者希望先给出结论或观点,然后再逐步分析和解释原因或依据时,可以使用逆序时间顺序。
例如,当写一篇关于环境污染的作文时,可以先给出结论,即环境污染对人类健康和自然生态造成了严重的影响;然后逐步分析和解释导致环境污染的原因,如工业排放、交通尾气等;最后可以提出解决环境污染的方法和建议。
三、并列时间顺序并列时间顺序是指将多个事件或观点按照时间顺序并列在一起,没有明确的先后关系。
这种方式适用于写作说明文或议论文中,当作者希望列举多个相关的事件或观点时,可以使用并列时间顺序。
例如,当写一篇关于健康生活方式的作文时,可以列举多个有助于保持健康的习惯和行为,如均衡饮食、适量运动、保持良好的睡眠等。
这些习惯和行为之间没有明确的先后关系,但它们都对健康有着重要的影响。
四、时间跳跃时间跳跃是指在作文中不按照严格的时间顺序叙述,而是在不同时间段之间进行跳跃。
这种方式适用于写作议论文或说明文中,当作者希望突出某个事件或观点的重要性,或者进行对比分析时,可以使用时间跳跃。
计算机算法与设计复习题(含答案)

1、一个算法的优劣可以用(时间复杂度)与(空间复杂度)与来衡量。
2、回溯法在问题的解空间中,按(深度优先方式)从根结点出发搜索解空间树。
3、直接或间接地调用自身的算法称为(递归算法)。
4、 记号在算法复杂性的表示法中表示(渐进确界或紧致界)。
5、在分治法中,使子问题规模大致相等的做法是出自一种(平衡(banlancing)子问题)的思想。
6、动态规划算法适用于解(具有某种最优性质)问题。
7、贪心算法做出的选择只是(在某种意义上的局部)最优选择。
8、最优子结构性质的含义是(问题的最优解包含其子问题的最优解)。
9、回溯法按(深度优先)策略从根结点出发搜索解空间树。
10、拉斯维加斯算法找到的解一定是(正确解)。
11、按照符号O的定义O(f)+O(g)等于O(max{f(n),g(n)})。
12、二分搜索技术是运用(分治)策略的典型例子。
13、动态规划算法中,通常不同子问题的个数随问题规模呈(多项式)级增长。
14、(最优子结构性质)和(子问题重叠性质)是采用动态规划算法的两个基本要素。
15、(最优子结构性质)和(贪心选择性质)是贪心算法的基本要素。
16、(选择能产生最优解的贪心准则)是设计贪心算法的核心问题。
17、分支限界法常以(广度优先)或(以最小耗费(最大效益)优先)的方式搜索问题的解空间树。
18、贪心选择性质是指所求问题的整体最优解可以通过一系列(局部最优)的选择,即贪心选择达到。
19、按照活结点表的组织方式的不同,分支限界法包括(队列式(FIFO)分支限界法)和(优先队列式分支限界法)两种形式。
20、如果对于同一实例,蒙特卡洛算法不会给出两个不同的正确解答,则称该蒙特卡洛算法是(一致的)。
21、哈夫曼编码可利用(贪心法)算法实现。
22概率算法有数值概率算法,蒙特卡罗(Monte Carlo)算法,拉斯维加斯(Las Vegas)算法和舍伍德(Sherwood)算法23以自顶向下的方式求解最优解的有(贪心算法)24、下列算法中通常以自顶向下的方式求解最优解的是(C)。
线性时间选择中位数

湖南涉外经济学院计算机科学与技术专业《算法设计与分析》课程线性时间选择(中位数)实验报告班级:学号:姓名:教师:成绩:2012年5月【实验目的】1 掌握线性时间选择的基本算法及其应用2 利用线性时间选择算法找出数组的第k小的数3 分析实验结果,总结算法的时间和空间复杂度【系统环境】Windows7 旗舰版平台【实验工具】VC++6.0英文企业版【问题描述】描述:随机生成一个长度为n的数组。
数组为随机生成,k由用户输入。
在随机生成的自然数数组元素找出这n个数的第k小的元素。
例:A[5]={3,20,50,10,21} k=3,则在数组A中第3小的元素为20【实验原理】原理:将所有的数(n个),以每5个划分为一组,共[n/5]组(将不足五个的那组忽略);然后用任意一种排序算法(因为只对五个数进行排序,所以任取一种排序法就可以了,这里我选用冒泡排序),将每组中的元素排好序再分别取每组的中位数,得到[n/5]个中位数;再取这[n/5]个中位数的中位数(如果n/5是偶数,就找它的2个中位数中较大的一个)作为划分基准,将全部的数划分为两个部分,小于基准的在左边,大于等于基准的放右边。
在这种情况下,找出的基准x至少比3(n-5)/10个元素大,因为在每一组中有2个元素小于本组的中位数,中位数处于1/2*[n/5-1],即n/5 个中位数中又有(n-5)/10个小于基准x。
同理,基准x也至少比3(n-5)/10个元素小。
而当n≥75时,3(n-5)/10≥n/4所以按此基准划分所得的2个子数组的长度都至少缩短1/4。
思路:如果能在线性时间内找到一个划分基准,使得按这个基准所划分出的2个子数组的长度都至少为原数组长度的ε倍(0<ε<1是某个正常数),那么就可以在最坏情况下用O(n)时间完成选择任务。
例如:若ε=9/10,算法递归调用所产生的子数组的长度至少缩短1/10。
所以,在最坏情况下,算法所需的计算时间T(n)满足递归式T(n)≤T(9n/10)+O(n) 。
算法设计与分析课件--分治法-线性时间选择

2.5 线性时间选择
这样找到的m*划分是否能达到O(n)的时间复杂度? |A| = |D| = 2r, |B| = |C| = 3r +2,n = 10r +5. |A| + |D| + |C| = 7r + 2 = 7(n-5)/10 +2 = 7n/10 -1.5 < 7n/10 表明子问题的规模不超过原问题的7/10(d)。
T(n) = T(cn) + T(dn) + tn
6
2.5 线性时间选择
Select(S, k) Input: n个数的数组S,正整数k
T(n) = T(cn) + T(dn) + tn
Output: S中的第k个小元素
1. 将S划分成5个元素一组,共[n/5]个组;
2. 每组寻找一个中位数,把这些中位数放到集合M中;
寻找一个分割点m*, 使得左边子表S1中的元素都小于m*, 右子表 S2中的元素都大于m*。 如果寻找m*的时间复杂度达到O(nlogn), 那就不如直接使用排序 算法了。 如果直接寻找m*, 时间复杂度是O(n). 假设选择算法的时间复杂度为T(n), 递归调用这个算法在S的一 个真子集M上寻找m*,应该使用T(cn)时间,这里c是小于1的常数, 反映了M的规模与S相比缩小许多。
✓ 不妨假设n是5的倍数,且n/5是奇数,即n/5 = 2r+1. 于是: |A| = |D| = 2r, |B| = |C| = 3r +2,n = 10r +5.
✓ 如果A和D中的元素都小于m*,那么把它们的元素都加入到S1, S1对应规约后子问题的上限。 类似的,若A和D中的元素都 大于m*, 则把他们的元素都加 入到S2,S2对应规约后子问题 的上限。
快速选择算法线性时间选择第k小的元素

快速选择算法线性时间选择第k小的元素快速选择算法:线性时间选择第k小的元素快速选择算法是一种高效的算法,用于在未排序的数组中选择第k 小的元素。
该算法的时间复杂度为O(n),在大规模数据处理和排序任务中具有广泛的应用。
1. 算法原理快速选择算法基于快速排序算法的分治思想,通过每次选择一个枢纽元素,并将数组中的元素分为左右两部分,来实现快速查找排序后的第k小元素。
具体步骤如下:- 选择枢纽元素:从未排序数组中选择一个元素作为枢纽元素,可以随机选择或选择固定位置的元素,比如选取数组的第一个元素。
- 划分数组:将数组分为两部分,左边的元素小于枢纽元素,右边的元素大于等于枢纽元素。
- 判断位置:比较枢纽元素的位置与k的大小关系,如果位置小于k,则递归在右半部分查找第k小元素;如果位置大于k,则递归在左半部分查找第k小元素;否则,返回该位置的元素即为第k小元素。
2. 算法步骤下面给出一种实现快速选择算法的伪代码:```function quickSelect(A, k, left, right):if left == right:return A[left]pivotIndex = partition(A, left, right)if k == pivotIndex:return A[k]else if k < pivotIndex:return quickSelect(A, k, left, pivotIndex - 1) else:return quickSelect(A, k, pivotIndex + 1, right) function partition(A, left, right):pivot = A[left]i = left + 1j = rightwhile i <= j:if A[i] < pivot and A[j] > pivot:swap A[i] and A[j]i = i + 1j = j - 1if A[i] >= pivot:i = i + 1if A[j] <= pivot:j = j - 1swap A[left] and A[j]return j```3. 算法性能分析快速选择算法通过每次划分数组来减小搜索范围,因此平均时间复杂度为O(n),其中n为数组的长度。
线性时间的排序算法

线性时间的排序算法前⾯已经介绍了⼏种排序算法,像插⼊排序(直接插⼊排序,折半插⼊排序,希尔排序)、交换排序(冒泡排序,快速排序)、选择排序(简单选择排序,堆排序)、2-路归并排序(见我的另⼀篇⽂章:)等,这些排序算法都有⼀个共同的特点,就是基于⽐较。
本⽂将介绍三种⾮⽐较的排序算法:计数排序,基数排序,桶排序。
它们将突破⽐较排序的Ω(nlgn)下界,以线性时间运⾏。
⼀、⽐较排序算法的时间下界所谓的⽐较排序是指通过⽐较来决定元素间的相对次序。
“定理:对于含n个元素的⼀个输⼊序列,任何⽐较排序算法在最坏情况下,都需要做Ω(nlgn)次⽐较。
”也就是说,⽐较排序算法的运⾏速度不会快于nlgn,这就是基于⽐较的排序算法的时间下界。
通过决策树(Decision-Tree)可以证明这个定理,关于决策树的定义以及证明过程在这⾥就不赘述了。
你可以⾃⼰去查找资料,推荐观看《》。
根据上⾯的定理,我们知道任何⽐较排序算法的运⾏时间不会快于nlgn。
那么我们是否可以突破这个限制呢?当然可以,接下来我们将介绍三种线性时间的排序算法,它们都不是通过⽐较来排序的,因此,下界Ω(nlgn)对它们不适⽤。
⼆、计数排序(Counting Sort)计数排序的基本思想就是对每⼀个输⼊元素x,确定⼩于x的元素的个数,这样就可以把x直接放在它在最终输出数组的位置上,例如:算法的步骤⼤致如下:找出待排序的数组中最⼤和最⼩的元素统计数组中每个值为i的元素出现的次数,存⼊数组C的第i项对所有的计数累加(从C中的第⼀个元素开始,每⼀项和前⼀项相加)反向填充⽬标数组:将每个元素i放在新数组的第C(i)项,每放⼀个元素就将C(i)减去1C++代码:/*************************************************************************> File Name: CountingSort.cpp> Author: SongLee> E-mail: lisong.shine@> Created Time: 2014年06⽉11⽇星期三 00时08分55秒> Personal Blog: http://songlee24.github.io************************************************************************/#include<iostream>using namespace std;/**计数排序:A和B为待排和⽬标数组,k为数组中最⼤值,len为数组长度*/void CountingSort(int A[], int B[], int k, int len){int C[k+1];for(int i=0; i<k+1; ++i)C[i] = 0;for(int i=0; i<len; ++i)C[A[i]] += 1;for(int i=1; i<k+1; ++i)C[i] = C[i] + C[i-1];for(int i=len-1; i>=0; --i){B[C[A[i]]-1] = A[i];C[A[i]] -= 1;}}/* 输出数组 */void print(int arr[], int len){for(int i=0; i<len; ++i)cout << arr[i] << " ";cout << endl;}/* 测试 */int main(){int origin[8] = {4,5,3,0,2,1,15,6};int result[8];print(origin, 8);CountingSort(origin, result, 15, 8);print(result, 8);return 0;}当输⼊的元素是0到k之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k)。
时间的线性与循环特性

时间的线性与循环特性时间是我们生活中最基本、最普遍的概念之一。
我们按照时间来安排工作、学习、娱乐和休息。
我们按照时间来记录历史事件和个人经历。
然而,时间的本质及其特性并不总是那么容易理解。
本文将探讨时间的线性与循环特性,从哲学、科学和文化的角度展开讨论。
一、时间的线性特性在日常生活中,时间以线性的方式被感知和使用。
我们习惯于用钟表来衡量时间的流逝,将时间分割为一秒、一分钟、一小时、一天、一周、一个月、一年等等。
这种线性传统是在工业革命时期开始的,人们根据机械时钟和铁路时刻表来规划日常生活。
时间的线性特性为人们提供了一种方便的工具,让人们能够更好地管理时间。
然而,时间线性特性的存在并不意味着时间本质上就是线性的。
一些哲学家和科学家认为,时间可能是流动的、持续不断的。
爱因斯坦的相对论揭示了时间与空间的相互关系,提出了时空曲率的概念。
这种曲率意味着时间可以被引力场或运动速度所影响。
相对论的理论告诉我们,时间并不是简单的线性过程,而是由多个因素相互作用所构成的复杂网络。
二、时间的循环特性除了线性特性外,时间还具有循环性。
我们生活在由季节、月相、日出和日落等周期性现象组成的自然循环中。
很多文化都有以岁月为单位的周期,例如中国的十二生肖和西方的十二星座。
这些循环性的概念让我们可以将时间分割为更小的部分,以更好地理解和适应生活中的变化。
在宗教和哲学领域,时间的循环特性也得到了广泛探讨。
古代印度哲学家提出了轮回转生的概念,认为时间是一种永恒地重复的封闭循环。
佛教也强调生死轮回的思想,通过解脱来打破这种循环。
这些观点揭示了人类对时间的认识和探索的深度。
三、科学与文化的交织科学研究和文化传承中,线性和循环特性常常交织在一起。
物理学家研究宇宙的演化过程,探索时间在空间中的展开方式。
历史学家研究人类文明的发展,记录时间中的事件和演变。
艺术家以线性或循环方式创作作品,通过表达他们对时间的理解和感受。
同时,文化也为人们提供了不同的时间观念和解读。
线性规划时间管理

线性规划时间管理简介在当今高效快节奏的生活中,时间管理变得至关重要。
许多人往往发现自己在不断忙碌的同时却没有充分利用他们的时间。
线性规划在时间管理中起到了关键作用。
本文将介绍什么是线性规划,以及如何将其应用于时间管理中,提高时间利用率。
什么是线性规划线性规划是一种数学建模技术,通过确定一组线性方程和不等式的最优解,来寻找最佳决策方案。
线性规划在工程、经济学和管理学等领域有着广泛的应用。
在时间管理中,线性规划可以帮助我们合理规划和分配时间,以实现最高的效率。
如何使用线性规划进行时间管理要使用线性规划进行时间管理,以下是一些具体的步骤和指导:1. 确定目标和约束条件首先,要明确自己的目标和约束条件。
例如,你可能希望在一天内完成尽可能多的任务,但你可能有一些约束条件,如工作时间、休息时间和个人生活等。
明确这些目标和约束条件,将有助于后续的规划过程。
2. 列出任务清单接下来,列出你需要完成的任务清单。
这可以是一天、一周或一个月的任务清单。
将任务按重要性和紧急性进行分类,有助于你更好地了解哪些任务对于实现目标是关键的。
3. 分配时间和优先级根据任务的重要性和紧急性,为每个任务分配适当的时间和优先级。
线性规划的关键是找到最佳的决策方案,以最大化时间利用率。
这可能意味着放弃一些不必要或不重要的任务,或通过优化时间利用方式来提高效率。
4. 设置时间段和时间段的权重将时间段分解为较小的时间段,并为每个时间段设置权重。
例如,你可能会发现一天中的早晨比下午更容易集中精力,因此可以将较重要的任务安排在早晨完成。
5. 构建线性规划模型根据上述步骤,将问题转化为线性规划的模型。
使用线性规划软件或工具,输入目标、约束条件、任务清单和时间段权重,以生成最优的时间管理方案。
6. 优化和调整根据生成的时间管理方案,进一步优化和调整。
根据实际情况,你可能需要对任务的优先级、时间段权重或约束条件进行微调。
持续的优化和调整将帮助你找到最适合自己的时间管理方案。
算法:线性时间选择(CC++)

算法:线性时间选择(CC++)Description给定线性序集中n个元素和⼀个整数k,n<=2000000,1<=k<=n,要求找出这n个元素中第k⼩的数。
Input第⼀⾏有两个正整数n,k. 接下来是n个整数(0<=ai<=1e9)。
Output输出第k⼩的数Sample Input6 31 3 52 4 6Sample Output3利⽤快速排序可以找出第k⼩的,加上随机函数改进⼀下:#include <cstdio>#include <cstdlib>#include <ctime>#include <iostream>int num[2000001];void quictSort(int, int, int);int partition(int, int);int main(){int n, m, i;srand(unsigned(time(NULL))); // 随机函数种⼦while (~scanf("%d%d", &n, &m)){for (i = 0; i < n; i++)scanf("%d", &num[i]);quictSort(0, n - 1, m - 1);printf("%d\n", num[m - 1]);}return 0;}// 快速排序void quictSort(int left, int right, int mTop){if (left < right){int p = partition(left, right); // 分为两段if (p == mTop) // 如果随机找到第mTop⼩就直接返回return;if (p < mTop)quictSort(p + 1, right, mTop); // 找到的位置⽐mTop⼩就在[p + 1, right]区间找if (p > mTop)quictSort(left, p - 1, mTop); // 找到的位置⽐mTop⼤就在[left, p - 1]区间找}}// 从⼩到⼤排int partition(int left, int right){int r = rand() % (right - left + 1) + left; // 随机选择⼀个数int key = num[r];std::swap(num[r], num[left]); // 交换到数组⾸位while (left < right){// 从数组后⾯开始, 找⽐随机选择的数⼩的, 然后从前找⽐随机选择的数⼤的while (left < right && num[right] >= key)right--;if (left < right)num[left] = num[right];while (left < right && num[left] <= key)left++;if (left < right)num[right] = num[left];}num[left] = key; // 将随机选择的数存回return left; // 返回随机选择的数分割数组的下标, 左边都是⽐它⼩的, 右边都是⽐它⼤的}中位数法线性时间选择划分:AC代码:#include <cstdio>#include <cstdlib>int num[2000001];int select(int low, int high, int top);int partition(int low, int high, int median); void selectSort(int low, int high);void swap(int &a, int &b);int main(){int n, m, i;while (~scanf("%d%d", &n, &m)){for (i = 0; i < n; i++)scanf("%d", &num[i]);printf("%d\n", select(0, n - 1, m - 1));/*for (i = 0; i < n; i++)printf("%d%c", num[i], i < n - 1 ? ' ' : '\n'); */}return 0;}// 中位数法线性时间选择int select(int low, int high, int top){// ⼩于75个数据随便⽤⼀个排序⽅法if (high - low < 74){selectSort(low, high); // 选择排序return num[low + top]; // 排完序直接返回第low + top的数}int groupNum = (high - low - 4) / 5; // 每组5个数, 计算多少个组, 从0开始计数for (int i = 0; i <= groupNum; i++){int start = low + 5 * i; // 每组的起始位置int end = start + 4; // 每组的结束位置for (int j = 0; j < 3; j++) // 从⼩到⼤冒3个泡for (int k = start; k < end - j; k++)if (num[k] > num[k + 1])swap(num[k], num[k+1]);swap(num[low + i], num[start + 2]); // 每组的中位数交换到前⾯第low + i的位置}// 上⾯排完后, 数组low + 0 到 low + groupNum都是每⼀组的中位数int median = select(low, low + groupNum, (groupNum + 1) / 2); // 找中位数的中位数int p = partition(low, high, median); // 将数组分为两段, 左边的⼩于中位数的中位数, 右边的⼤于中位数的中位数 int n = p - low; // 计算p到low之间有多少个数, 后⾯得减掉if (n == top)return num[p]; // 如果运⽓好, 刚好要找的就是中位数if (n > top)return select(low, p - 1, top); // n⽐top⼤就在左边找if (n < top)return select(p + 1, high, top - n - 1); // n⽐top⼩就在右边找, 并且top要减去已经⼤的个数}// 以中位数进⾏分割, 分成两半int partition(int low, int high, int median){int p;for (int i = low; i <= high; i++)if (num[i] == median){p = i;break;}// 将中位数交换到最前⾯swap(num[p], num[low]);// 记下最前⾯的数int key = num[low];// 把⼩于key的放前⾯, ⼤于key的放后⾯while (low < high){while (num[high] >= key && low < high)high--;if (low < high)num[low] = num[high];while (num[low] <= key && low < high)low++;if (low < high)num[high] = num[low];}// 分别从两头开始, 找到中间时, 把key存回num[low] = key;return low;}// 选择排序void selectSort(int low, int high){for (int i = low; i <= high; i++){int MIN = i;for (int j = i + 1; j <= high; j++)if (num[MIN] > num[j])MIN = j;swap(num[i], num[MIN]);}}// 交换两个元素void swap(int &a, int &b){int temp = a;a = b;b = temp;}。
算法设计与分析-线性时间选择
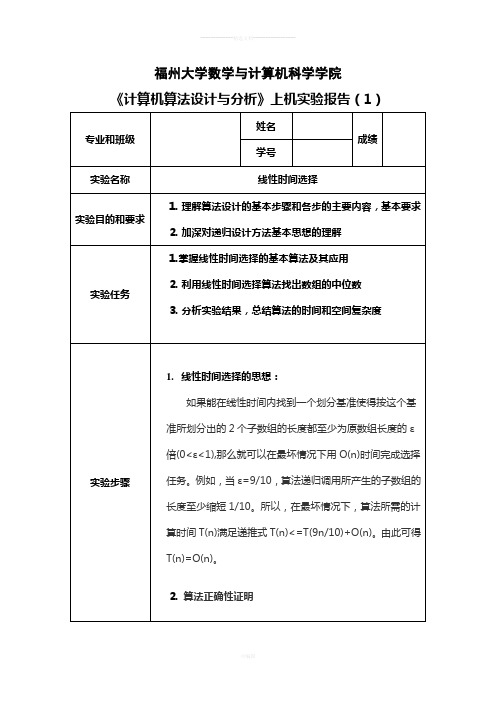
福州大学数学与计算机科学学院《计算机算法设计与分析》上机实验报告(1)(1)将所有的数n个以每5个划分为一组共组,将不足5个的那组忽略,然后用任意一种排序算法,因为只对5个数进行排序,所以任取一种排序法就可以了。
将每组中的元素排好序再分别取每组的中位数,得到个中位数。
(2)取这个中位数的中位数,如果是偶数,就找它的2个中位数中较大的一个作为划分基准。
(3)将全部的数划分为两个部分,小于基准的在左边,大于等于基准的放右边。
在这种情况下找出的基准x至少比个元素大。
因为在每一组中有2个元素小于本组的中位数,有个小于基准,中位数处于,即个中位数中又有个小于基准x。
因此至少有个元素小于基准x。
同理基准x也至少比个元素小。
而当n≥75时≥n/4所以按此基准划分所得的2个子数组的长度都至少缩短1/4。
通过上述说明可以证明将原问题分解为两个子问题进行求解能够更加节省求解时间。
3.查找中位数程序代码1.#include "stdafx.h"2.#include <ctime>3.#include <iostream>ing namespace std;5.6.template <class Type>7.void Swap(Type &x,Type &y);8.9.inline int Random(int x, int y);10.11.template <class Type>12.void BubbleSort(Type a[],int p,int r);13.14.template <class Type>15.int Partition(Type a[],int p,int r,Type x);16.17.template <class Type>18.Type Select(Type a[],int p,int r,int k);19.20.int main()21.{22.//初始化数组23.int a[200];24.25.//必须放在循环体外面26. srand((unsigned)time(0));27.28.for(int i=0; i<200; i++)29. {30. a[i] = Random(0,500);31. cout<<"a["<<i<<"]:"<<a[i]<<" ";32. }33. cout<<endl;34.35. cout<<"第100小的元素是"<<Select(a,0,199,100)<<endl;36.37.//重新排序,对比结果38. BubbleSort(a,0,199);39.40.for(int i=0; i<200; i++)41. {42. cout<<"a["<<i<<"]:"<<a[i]<<" ";43. }44. cout<<endl;45.}46.47.template <class Type>48.void Swap(Type &x,Type &y)49.{50. Type temp = x;51. x = y;52. y = temp;53.}54.55.inline int Random(int x, int y)56.{57.int ran_num = rand() % (y - x) + x;58.return ran_num;59.}60.61.//冒泡排序62.template <class Type>63.void BubbleSort(Type a[],int p,int r)64.{65.//记录一次遍历中是否有元素的交换66.bool exchange;67.for(int i=p; i<=r-1;i++)68. {69. exchange = false ;70.for(int j=i+1; j<=r; j++)71. {72.if(a[j]<a[j-1])73. {74. Swap(a[j],a[j-1]);75. exchange = true;76. }77. }78.//如果这次遍历没有元素的交换,那么排序结束79.if(false == exchange)80. {81.break ;82. }83. }84.}85.86.template <class Type>87.int Partition(Type a[],int p,int r,Type x)88.{89.int i = p-1,j = r + 1;90.91.while(true)92. {93.while(a[++i]<x && i<r);94.while(a[--j]>x);95.if(i>=j)96. {97.break;98. }99. Swap(a[i],a[j]);100. }101.return j;102.}103.104.105.template <class Type>106.Type Select(Type a[],int p,int r,int k)107.{108.if(r-p<75)109. {110. BubbleSort(a,p,r);111.return a[p+k-1];112. }113.//(r-p-4)/5相当于n-5114.for(int i=0; i<=(r-p-4)/5; i++)115. {116.//将元素每5个分成一组,分别排序,并将该组中位数与a[p+i]交换位置117.//使所有中位数都排列在数组最左侧,以便进一步查找中位数的中位数118. BubbleSort(a,p+5*i,p+5*i+4);119. Swap(a[p+5*i+2],a[p+i]);120. }121.//找中位数的中位数122. Type x = Select(a,p,p+(r-p-4)/5,(r-p-4)/10);123.int i = Partition(a,p,r,x);124.int j = i-p+1;125.if(k<=j)126. {127.return Select(a,p,i,k);128. }129.else130. {1.实验结果说明(找中位数结果截图)实验结果2.实验结果分析通过上面的结果图可以看出程序能够快速生成一个无序数组并找到第K小的元素。
选择中位数-线性时间算法

选择中位数-线性时间算法 本章继续讲⼀些关于奇淫技巧(算法啦)的做法,对于⼀个⽆序数组,我们如何找到其中位数呢? ⾸先回顾⼀下中位数的概念:是按顺序排列的⼀组数据中居于中间位置的数。
1,当前的先决条件是⽆序数组,那根据原理可以很快想到⼀种解法,对数组进⾏遍历,每次找出其最⼤值、最⼩值,最终残留的⼀位或两位即为中位数(两位则取平均值),时间复杂度 O(N) * N;当然,⼀次遍历中我们可以同时获取到最⼤值和最⼩值,将遍历的次数降低⼀半到 O(N)*N/2,但同样难以改变其时间复杂度为O(N2)的事实(这⾥有想法的同学先不要着急否定,后⾯⼀步步迭代)。
2,很明显,上述的⽅法⽆法达到我们的想要的⼀种状态,那反观概念,如果是排好序的数组,我们完全可以在⼀次计算中得到其中位数,那就可以对数组先进⾏⼀次快排,使其达到有序的状态再返回中位数,时间复杂度就是快排的复杂度O(N * log N) 3,换⼀种思路,我们知道数组的个数,那中位数⽆⾮就是整个数组中第 (n)/2(偶数则包含 n/2-1)⼤的数,所以我们也可以采⽤堆排的⽅案,找出第 i 位⼤的值即中位数,时间复杂度就是堆排的复杂度O(N * log N) 4,本章重点解法,我们假设每次可以将数组分成两个部分,时刻保证前半部分 A 的任何元素⼤于后半部分 B 的任何元素,那只需要知道数组的中位数是在前半部分还是后半部分既可递归查找,另⼀半便可以抛弃不需要再次遍历排序。
⼤致思路便是这样,具体流程如下: 1,按快速排序的第⼀部分流程,将第⼀个数据进⾏遍历,找出其最终位置 p,这是左边 A 均⼩于当前数值,后⾯ B 均⼤于当前数值2,如果 p - start + 1 == i,则即可返回当前数值3,如果 p - start + 1 < i,则中位数在 B 部分,递归修改 start, i;反之中位数在 A 部分,递归修改 end,i 上述的⽅法其实最坏情况下(⽐如完全倒序或完全正序)的时间复杂度也会达到最差的 O(N2),所以这种⽅法的仅期望情况下(数次切割即可找到中位数),才可以线性时间内找到中位数,⽽且这种⽅法也会⽐传统的快排快⼀部分(因为丢弃了⼀部分)。
概率算法汇总

概率算法概率算法的一个基本特征是对所求解问题的同一实例用同一概率算法求解两次可能得到完全不同的效果。
这两次求解问题所需的时间甚至所得到的结果可能会有相当大的差别。
一般情况下,可将概率算法大致分为四类:数值概率算法,蒙特卡罗算法,拉斯维加斯算法和舍伍德算法。
一、数值概率算法常用于数值问题的求解。
这类算法所得到的往往是近似解。
而且近似解的精度随计算时间的增加不断提高。
在许多情况下,要计算出问题的精确解是不可能或没有必要的,因此用数值概率算法可得到相当满意的解。
1、用随机投点法计算π值设有一半径为r 的圆及其外切四边形。
向该正方形随机地投掷n 个点。
设落入圆内的点数为k 。
由于所投入的点在正方形上均匀分布,因而所投入的点落入圆内的概率为4422ππ=r r 。
所以当n 足够大n k 4≈π(n k≈4π)2、计算定积分设f(x)是[0,1]上的连续函数,且0≤f(x) ≤ 1。
需要计算的积分为⎰=1)(dx x f I , 积分I 等于图中的面积G在图所示单位正方形内均匀地作投点试验,则随机点落在曲线下面的概率为⎰⎰⎰==≤10)(01)()}({x f r dx x f dydx x f y P 假设向单位正方形内随机地投入 n 个点(xi,yi)。
如果有m 个点落入G 内,则随机点落入G 内的概率nm ≈I 3、解非线性方程组求解下面的非线性方程组⎪⎪⎩⎪⎪⎨⎧===0),,,(0),,,(0),,,(21212211n n n n x x x f x x x f x x x f 其中,x 1, x 2, …, x n 是实变量,fi 是未知量x1,x2,…,xn 的非线性实函数。
要求确定上述方程组在指定求根范围内的一组解x 1*, x 2*, …, x n * 。
在指定求根区域D 内,选定一个随机点x0作为随机搜索的出发点。
在算法的搜索过程中,假设第j 步随机搜索得到的随机搜索点为xj 。
在第j+1步,计算出下一步的随机搜索增量∆xj 。
五大常用算法

五大常用算法之一:分治算法分治算法一、基本概念在计算机科学中,分治法是一种很重要的算法。
字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)……任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。
问题的规模越小,越容易直接求解,解题所需的计算时间也越少。
例如,对于n个元素的排序问题,当n=1时,不需任何计算。
n=2时,只要作一次比较即可排好序。
n=3时只要作3次比较即可,…。
而当n较大时,问题就不那么容易处理了。
要想直接解决一个规模较大的问题,有时是相当困难的。
二、基本思想及策略分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
这种算法设计策略叫做分治法。
如果原问题可分割成k个子问题,1<k≤n,且这些子问题都可解并可利用这些子问题的解求出原问题的解,那么这种分治法就是可行的。
由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。
在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。
这自然导致递归过程的产生。
分治与递归像一对孪生兄弟,经常同时应用在算法设计之中,并由此产生许多高效算法。
三、分治法适用的情况分治法所能解决的问题一般具有以下几个特征:1) 该问题的规模缩小到一定的程度就可以容易地解决2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
智慧树知到《算法分析与设计》章节测试答案

智慧树知到《算法分析与设计》章节测试答案第一章1、给定一个实例,如果一个算法能得到正确解答,称这个算法解答了该问题。
A:对B:错答案: 错2、一个问题的同一实例可以有不同的表示形式A:对B:错答案: 对3、同一数学模型使用不同的数据结构会有不同的算法,有效性有很大差别。
A:对B:错答案: 对4、问题的两个要素是输入和实例。
A:对B:错答案: 错5、算法与程序的区别是()A:输入B:输出C:确定性D:有穷性答案: 有穷性6、解决问题的基本步骤是()。
(1)算法设计(2)算法实现(3)数学建模(4)算法分析(5)正确性证明A:(3)(1)(4)(5)(2)B:(3)(4)(1)(5)(2)C:(3)(1)(5)(4)(2)D:(1)(2)(3)(4)(5)答案: (3)(1)(5)(4)(2)7、下面说法关于算法与问题的说法错误的是()。
A:如果一个算法能应用于问题的任意实例,并保证得到正确解答,称这个算法解答了该问题。
B:算法是一种计算方法,对问题的每个实例计算都能得到正确答案。
C:同一问题可能有几种不同的算法,解题思路和解题速度也会显著不同。
D:证明算法不正确,需要证明对任意实例算法都不能正确处理。
答案: 证明算法不正确,需要证明对任意实例算法都不能正确处理。
8、下面关于程序和算法的说法正确的是()。
A:算法的每一步骤必须要有确切的含义,必须是清楚的、无二义的。
B:程序是算法用某种程序设计语言的具体实现。
C:程序总是在有穷步的运算后终止。
D:算法是一个过程,计算机每次求解是针对问题的一个实例求解。
答案: 算法的每一步骤必须要有确切的含义,必须是清楚的、无二义的。
,程序是算法用某种程序设计语言的具体实现。
,算法是一个过程,计算机每次求解是针对问题的一个实例求解。
9、最大独立集问题和()问题等价。
A: 最大团B:最小顶点覆盖C:区间调度问题D:稳定匹配问题答案:最大团,最小顶点覆盖10、给定两张喜欢列表,稳定匹配问题的输出是()。
线性时间选择算法

福州大学数学与计算机科学学院《计算机算法设计与分析》上机实验报告(1)图中箭头指向表示大的数值指向小的数值,所以根据图可以看出,在x的右边,每一个包含5个元素的组中至少有3个元素大于x,在x的左边,每一组中至少有3个元素小于x (保证x分割一边必定有元素存在)。
图中显示的中位数的中位数x的位置,每次选取x作为划分的好处是能够保证必定有一部分在x的一边。
所以算法最坏情况的递归公式可以写成:,使用替换法可以得出)(。
Tncn4、算法代码:#include <iostream>#include <ctime>using namespace std;template <class Type>void Swap(Type &x,Type &y);inline int Random(int x, int y);template <class Type>int Partition(Type a[],int p,int r);template<class Type>int RandomizedPartition(Type a[],int p,int r);template <class Type>Type RandomizedSelect(Type a[],int p,int r,int k);int main(){void SelectionSort(int a[]);int s;int a[2000];int b[2000];for(int i=0; i<2000; i++){a[i]=b[i]=rand()%10000;cout<<a[i]<<" ";}cout<<endl;SelectionSort(b);for(int j=0;j<2000;j++){printf("a[%d]:%d ",j+1,b[j]);}cout<<endl;printf("请输入要求的第几最小数:");scanf("%d",&s);cout<<RandomizedSelect(a,0,1999,s)<<endl; }template <class Type>void Swap(Type &x,Type &y){Type temp = x;x = y;y = temp;}inline int Random(int x, int y){srand((unsigned)time(0));int ran_num = rand() % (y - x) + x;return ran_num;}template <class Type>int Partition(Type a[],int p,int r){int i = p,j = r + 1;Type x = a[p];while(true){while(a[++i]<x && i<r);while(a[--j]>x);if(i>=j){break;}Swap(a[i],a[j]);}a[p] = a[j];a[j] = x;return j;}template<class Type>int RandomizedPartition(Type a[],int p,int r){int i = Random(p,r);Swap(a[i],a[p]);return Partition(a,p,r);}template <class Type>Type RandomizedSelect(Type a[],int p,int r,int k) {if(p == r){return a[p];}int i = RandomizedPartition(a,p,r);int j = i - p + 1;if(k <= j){return RandomizedSelect(a,p,i,k);}else{//由于已知道子数组a[p:i]中的元素均小于要找的第k小元素//因此,要找的a[p:r]中第k小元素是a[i+1:r]中第k-j小元素。
线性时间选择

程序设计报告我保证没有抄袭别人作业!1.题目内容题名为线性时间选择。
题目要求:给定无序序列集中n个元素和一个整数k,1<=k<=n。
要找到这n个元素中第k小的元素。
2.算法分析(1)分治法思想将n个输入元素划分成n/5个组,每组5个元素,只可能有一个组不是5个元素。
用任意一种排序算法,将每组中的元素排好序,并取出每组的中位数,共n/5个。
递归调用select来找出这n/5个元素的中位数。
如果n/5是偶数,就找它的2个中位数中较大的一个。
以这个元素作为划分基准。
在此处选用的排序算法为快速排序。
算法框架:Type Select(Type a[], int p, int r, int k){if (r-p<75) {//用快速排序算法对数组a[p:r]排序;return a[p+k-1];};for ( int i = 0; i<=(r-p-4)/5; i++ )将a[p+5*i]至a[p+5*i+4]的第3小元素与a[p+i]交换位置;//找中位数的中位数,r-p-4即上面所说的n-5Type x = Select(a, p, p+(r-p-4)/5, (r-p-4)/10);int i=Partition(a,p,r, x),j=i-p+1;if (k<=j) return Select(a,p,i,k);else return Select(a,i+1,r,k-j);}快速排序的算法int i=p,j=r+1;int x=a[p];while(1){ while(a[int qsort(int *a,int p,int r) { if(p<r){ int q;q=partition(a,p,r);qsort(a,p,q-1);qsort(a,q+1,r);}}int partition(int a[],int p,int r){++i]<x);while(a[--j]>x);if(i>=j)break;else swap(i,j);}a[p]=a[j];a[j]=x;return j;}3.算法的优化一般我们选择无序序列的某个元素作为划分元素,每次调用Partition(A,p,r),所需的元素比较次数是Ο(r-p+1)。
常用的几种时间线类型

常用的几种时间线类型
在数据分析和可视化中,常用的几种时间线类型包括:
线性时间线(Linear Timeline):
线性时间线是最常见的时间线类型,时间的间隔是均匀分布的,每个时间点之间的间隔是相等的。
适用于大多数时间序列数据的分析和可视化。
对数时间线(Logarithmic Timeline):
对数时间线将时间轴上的间隔以对数形式呈现,用于显示数据随时间指数级增长或减少的情况。
适用于处理数据增长或衰减速率不均匀的情况。
日期时间线(Datetime Timeline):
日期时间线用于显示日期和时间的时间线,适用于需要按照精确的日期和时间进行数据分析和可视化的场景,如股票市场分析、天气预报等。
相对时间线(Relative Timeline):
相对时间线通常以某个事件或基准时间点为参考,显示相对于该事件或时间点的时间间隔。
例如,相对于某次交易的时间线、相对于某个事件发生的时间线等。
周末/工作日时间线(Weekend/Business Day Timeline):
这种时间线将时间轴分成周末和工作日两个部分,通常用于分析和可视化与工作日相关的数据,如工作日的交通流量、周末的销售额等。
季节性时间线(Seasonal Timeline):
季节性时间线将时间轴按照季节进行分割,适用于分析和可视化与季节相关的数据变化,如季节性销售变化、气温季节性变化等。
这些时间线类型可以根据数据的特点和分析的需求选择合适的类型,以便更好地理解数据的变化趋势和模式。
时间的线性与循环

时间的线性与循环时间是我们生活中一件无法回避的事实。
无论我们喜欢与否,时间始终在不断地流逝。
有人说时间如流水般奔逝,追溯不可得;有人说时间如细沙般流逝,握持不住。
然而,我们是否可以从不同的角度来思考时间呢?是不是时间只有线性的一种存在方式呢?有人会说,时间是线性的,因为它总是朝着未来前进,不会回转。
我们的人生也是如此,从出生到死亡,经历了各种各样的事情,积累了各种各样的经验。
从这个角度来看,时间确实是线性的。
然而,我们是否可以从更宏观的角度来看待时间呢?宇宙学家们告诉我们,宇宙的起源可以追溯到大爆炸,即宇宙大爆炸理论。
在这个理论中,宇宙的起源并不是线性的,而是一个循环的过程。
宇宙会经历无数个周期,每一个周期都有一个大爆炸和一个大崩溃。
换句话说,宇宙是一个无限循环的系统,它以一种无比复杂而又美妙的方式存在着。
如果我们将这种循环的观念应用到时间中,又会有怎样的效果呢?我们能否抛开我们对时间线性性的限制,去探索时间的另一个维度呢?在古代文明中,人们相信时间是循环的。
他们通过观察自然现象,如季节的更替、日夜的交替等,得出了时间循环的观念。
他们以此为基础,创造了农历和太阳历等时间体系。
在这些时间体系中,时间被划分为不同的阶段,而这些阶段又是循环的。
比如,农历中的月份是按照月亮的运行周期来划分的,每个月份都是一个循环周期。
而太阳历中的一年则是按照地球绕太阳运行的周期来划分的,每一年都是一个循环周期。
在现代社会中,我们对时间的认知更多地倾向于线性。
我们用钟表来测量时间,将一天划分为24个小时,每个小时又划分为60分钟,每分钟又划分为60秒钟。
我们的生活日程也是按照线性的方式进行安排的,我们在特定的时间进行工作、学习和休息。
我们似乎忘记了时间也可以是循环的,我们也可以按照自然的规律去生活,而不是完全受制于钟表。
当然,时间的循环性并不意味着我们可以随心所欲地改变时间的流动。
然而,我们可以通过改变对时间的认知方式,去更好地适应时间的变化。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用7:线性时间选择(续)
设所有元素互不相同。在这种情况下, 找出的基准x至少比 3(n-5)/10个元 素大,因为在每一组中有2个元素小 于本组的中位数,而n/5个中位数 中又有(n-5)/10个小于基准x。
同理,基准x也至少比3 (n-5)/10个 元素小。而当n≥75时, 3(n-5)/10 ≥n/4,所以按此基准划分所得的2个 子数组的长度都至少缩短1/4。
T
(n)
C2
n
T
(n
C1 / 5)
T
(3n
/
4)
n 75 n 75
根据定理有:
f (n)
பைடு நூலகம்
c2n 1 1
3
20c2n
(n)
54
因此,T(n)=O(n)。
补充:定理
• 定理:令b, d和c1,c2是大于0的常数,则如下递归
方程
• 的解是:
f
(n
)
b f (floor
(c1n))
f
n 1 (floor(c2n))
for ( int i = 0; i<=(r-p-4)/5; i++ ) 将a[p+5*i]至a[p+5*i+4]的第3小元素 与a[p+i]交换位置;
//找中位数的中位数,r-p-4即上面所说的n-5 Type x = Select(a, p, p+(r-p-4)/5, (r-p-4)/10); int i=Partition(a,p,r, x), j=i-p+1; if (k<=j) return Select(a,p,i,k); else return Select(a,i+1,r,k-j); }
复杂度分析
• 设对n个元素的数组调用Select需要T(n)时 间,那么找中位数的中位数x至多用了T(n/5) 时间。
• 我们已经证明:按照算法所选的基准x进行 划分所得到的两个子数组分别至多有3n/4个 元素。所以无论对哪一个子数组调用Select 都至多用了T(3n/4)的时间。
• 因此,
复杂度分析(续)
• (12) 因为k=4,而第一、第二个子数组的 元素个数为4,所以33即为所求取的第18 个小元素。
应用7:线性时间选择(续)
Type Select(Type a[], int p, int r, int k) {
if (r-p<75) { 用某个简单排序算法对数组a[p:r]排序; return a[p+k-1]; };
应用7:线性时间选择
应用7:线性时间选择
问题:给定线性序集中n个元素和一个整数k,1≤k≤n,要求 找出这n个元素中第k小的元素
第1种算法 template<class Type> Type RandomizedSelect(Type a[],int p,int r,int k) {
if (p==r) return a[p]; int i=RandomizedPartition(a,p,r), j=i-p+1; if (k<=j) return RandomizedSelect(a,p,i,k); else return RandomizedSelect(a,i+1,r,k-j); }
例子(续)
• (9) 因为k=4,第一个子数组的元素个数大于k, 所以放弃后面两个子数组,以k=4对第一个子 数组递归调用本算法;
• (10) 将这个子数组分成5个元素的一组: {31,33,35,37,32},取其中值元素为33;
• (11) 根据33,把第一个子数组划分成 {31,32,29},{33},{35,37,41};
– P={8,4,11, 3,13,6,19,16,5,7,23,22} – Q={25} – R={31,60,33,51,57,49,35,43,37,52,32,54,41,46,29}
例子(续)
• (5) 由于|P|=13,|Q|=1,k=18,所以放弃P,Q, 使k=18-13-1=4,对R递归地执行本算法;
• (6) 将R划分成3(floor(18/5))组:
{31,60,33,51,57},{49,35,43,37,52},{32,54,41,46, 29} • (7) 求取这3组元素的中值元素分别为:{51,43,41}, 这个集合的中值元素是43; • (8) 根据43将R划分成3组:
– {31, 33, 35,37,32, 41, 29},{43},{60, 51,57, 49, 52,54, 46}
• (1) 把前面25个元素分为5(=floor(29/5))组; (8,31,60,33,17),(4,51,57,49,35),(11,43,37,3,13),(52,6,19,25 ,32),(54,16,5,41,7).
• (2) 提取每一组的中值元素,构成集合{31,49,13,25,16}; • (3) 递归地使用算法求取该集合的中值,得到m=25; • (4) 根据m=25, 把29个元素划分为3个子数组:
应用7:线性时间选择(续)
将n个输入元素划分成n/5个组,每组5 个元素,只可能有一个组不是5个元素。用 任意一种排序算法,将每组中的元素排好 序,并取出每组的中位数,共n/5个。
递归调用select来找出这n/5个元素的 中位数。如果n/5是偶数,就找它的2个 中位数中较大的一个。以这个元素作为划 分基准。
bn
n2
f
(n)
(n log (n)
n)
c1 c2 1 c1 c2 1
• 特别地,当c1+c2<1时,有
f (n) bn O(n) 1 c1 c2
郑宗汉.算法设计与分析.清华大学出版社.2005.pp.91.
返回
应用7:线性时间选择(续)
上述算法将每一组的大小定为5,并选 取75作为是否作递归调用的分界点。 这2点保证了T(n)的递归式中2个自 变量之和n/5+3n/4=19n/20=εn, 0<ε<1。这是使T(n)=O(n)的关键之 处。当然,除了5和75之外,还有其 他选择。
应用7:线性时间选择(续)
在最坏情况下,算法randomizedSelect 需要O(n2)计算时间。
但可以证明,算法randomizedSelect可 以在O(n)平均时间内找出n个输入元素中 的第k小元素。
第2种算法:例子
• 按递增顺序,找出下面29个元素的第18个元素: 8,31,60,33,17,4,51,57,49,35,11,43,37,3,13,52,6,19,25,32,5 4,16,5,41,7,23,22,46,29.
应用7:线性时间选择(续)
如果能在线性时间内找到一个划分基准,使 得按这个基准所划分出的2个子数组的长度 都至少为原数组长度的ε倍(0<ε<1是某个正 常数),那么就可以在最坏情况下用O(n)时 间完成选择任务。
应用7:线性时间选择(续)
例如,若ε=9/10,算法递归调用所产生 的子数组的长度至少缩短1/10。所以, 在最坏情况下,算法所需的计算时间 T(n)满足递归式T(n)≤T(9n/10)+O(n) 。 由此可得T(n)=O(n)。