随机化算法实验(Sherwood型线性时间选择)
舍伍德(Sherwood)算法学习笔记

舍伍德(Sherwood)算法学习笔记⼀.概念引⼊设A是⼀个确定性算法,当它的输⼊实例为x时所需的计算时间记为tA(x)。
设Xn 是算法A的输⼊规模为n的实例的全体,则当问题的输⼊规模为n时,算法A所需的平均时间为。
这显然不能排除存在x∈Xn使得的可能性。
希望获得⼀个随机化算法B,使得对问题的输⼊规模为n的每⼀个实例均有。
这就是舍伍德算法设计的基本思想。
当s(n)与tA(n)相⽐可忽略时,舍伍德算法可获得很好的平均性能。
概率算法的⼀个特点是对同⼀实例多次运⽤同⼀概率算法结果可能同。
舍伍德算法(O(sqrt(n)),综合了线性表和线性链表的优点)总能求的问题的⼀个正确解,当⼀个确定性算法在最坏情况和平均情况下差别较⼤时可在这个确定性算法中引⼊随机性将之改造成⼀个舍伍德算法;引⼊随机性不是为了消除最坏,⽽是为了减少最坏和特定实例的关联性。
⽐如线性表a的查找若是找10(独⼀⽆⼆),如果在a[0]则为O(1),若是最后⼀个则O(n),可见时间与输⼊实例有关,此时可引⼊随机性将之改造成⼀个舍伍德算法。
有时候⽆法直接把确定性算法改造为舍伍德算法,这时候对输⼊洗牌。
下⾯是洗牌算法源代码:import java.util.Random;public class Shuffle {public static void main(String[] args) {int a[] = new int[]{1,2,4,5,8};/** Collections.shuffle(list)参数只能是list*/myShuffle(a);for(int i:a) {//犯了个低级错误,输出了a[i],结果数组下标越界异常System.out.print(i+" ");}System.out.println();}private static void myShuffle(int[] a) {int len = a.length;for(int i=0; i<len; i++) {Random r = new Random();//直接Random.nextInt(len)提⽰静态⽅法⾥⽆法引⽤int j = r.nextInt(len);//Collections.swap(list,i,j)必须是list类型if(i!=j) {//原来没加这个条件int temp = a[i];a[i] = a[j];a[j] = temp;}}}}⼆.舍伍德思想解决迅雷2010年校招--发牌问题描述:52张扑克牌分发给4⼈,每⼈13张,要求保证随机性。
随机算法 通俗滴介绍随机算法思维

1. 2.
p(x):对输入实例成功地运行las_vegas的概率 若存在常数δ>0,使得对的所有实例p,都有p(x)>= δ ,则 失败的概率小于1- δ 。 3. 连续运行k次,失败的概率降低为(1- δ )k。 4. k充分大, (1- δ )k趋于0。
2 拉斯维加斯算法
二、实例
例:识别重复元素 考虑一个有n个数字的数组a[],其中有n/2个不同的元素,其余元素 是另一个元素的拷贝,即数组中共有(n/2)+1个不同的元素。 问题是要识别重复的元素。 答: 1)确定性算法: 至少需要(n/2)+2个时间步。
Las Vegas
1.2 什么是随机化
对拉斯维加斯算法而言,虽然使用了随机策略,但这个策略为的是 保证公平,因而计算结果仍然是正确的。而为了保证公平,就不免要费 点时间。因此,拉斯维加斯算法保障计算结果的正确性,但不保证算法 的时间效率。
1.2 什么是随机化
为第二种目的设计的随机化算法称为蒙特卡罗算法(Monte Carlo Algorithms)。 不过,这里的蒙特卡罗与摩洛哥的赌场蒙特卡罗并无关系,发明算法的人是为了 纪念抚养过他的叔叔而命名的。(也许,他的叔叔名字含有蒙特卡罗。 ) 蒙特卡罗算法的主要目的是用来解决难解即复杂性很高的问题,其主要追 求的是算法的时间效率。为了这个效率,不得不牺牲准确性甚至是正确性。 因此,蒙特卡罗算法保证算法的运行时间,但不保证算法结果的正确性。
1.1 为什么随机化
面对考试,部分不知道如何解答的问题时,胡乱地写一通货任意选 择一个答案就是随机策略。随机策略是我们不知所措的时候所采取的 一种策略。 古人在面对疑难问题时的会采取占卜, 而占卜本身不会启示将 来发生的问题,它起的作用就是帮助占卜者作出决定。 因此,这里随机化有有了它的另一个用途:解答我们解答不了的问 题,虽然这个解答不一定正确。
理解临床试验随机化

我们以区组长度4为例:
1. 2.
3. 4.
一个区组内的4个研究对象可以有6种排列方式:1. AABB, 2. ABAB, 3. ABBA, 4. BAAB, 5. BABA, 6. BBAA 确定好所有的排列形式后,接下来需要将6个区组随机排列。我们可以用 各种方式(如SPSS、Excel、SAS等)产生一串随机数字,比如: 92591264823981721367278057575098834352688429029…… 因为只有6种排列方式,因此可以只选择1-6之间的数字, 25126423121362555343526422…… 按照上述随机数字排列区组。当然,也可以采用其它方法随机排列区 组。 至此,区组随机化就完成了,两组人数完全相等。
对照
对照药的选择 对照药物的选择分为阳性对照药(即有活性的药物)和阴 性对照药(即安慰剂)。新药为注册申请进行临床试验, 阳性对照药原则上应选同一药物家族中公认较好的品种。 新药上市后为了证实对某种疾病或某种病症具有优于其 他药物的优势,可选择特定的适应症和选择对这种适应 症公认最有效的药物(可以和试验药不同结构类型、不同 家族但具有类似作用的药物)作为对照。 对照分组的英文术语为Arm。
分层随机化例子
随机化实施手段
信封法
随机方案编写好后,我们最常用的一种方法是使用信封进 行方案隐藏。以前使用的普通信封是“按顺序编码、不透 光、密封的信封”,即将每个分组方案装入一个不透光的 信封,信封外面写上编码,密封后交给研究者,待有研究 对象进入研究时,如果符合入选标准和排除标准,给病人 编号,再打开相应编号的信封,按信封内的分组方案进行 干预。每个研究对象所接受的治疗方案由生成的随机序列 决定。
随机号管理
第6章 随机化算法

第6章 随机化算法
使用拉斯维加斯算法不会得到不正确的解。即一 旦使用拉斯维加斯算法找到一个解,那么这个解 就一定是正确解。但是有时,在使用拉斯维加斯 算法时会找不到解。与蒙特卡罗算法相类似,拉 斯维加斯算法找到正确解的概率随着其所耗费的 计算时间的增加而提高。对于所求解问题的任一 实例,采用同一个拉斯维加斯算法反复对于该实 例求解足够多的次数,可以使得求解失效的概率 尽可能地变小。
第6章 随机化算法 随机化选择算法
在第二章中所叙述的选择算法,是从n个元素 中选择第k小的元素,它的运行时间是20cn, 因此,它的计算时间复杂度为(n) 如果加入随 机性的选择因素,就可以不断提高算法的性能。 假定输入的数据规模为n,可以证明,这个算 法的计算时间复杂度小于4n。以下就是这个算 法的一个具体描述:
第6章 随机化算法
算法6.2 随机化选择算法
输入:从数组A的第一个元素下标为low,最后 一个元素下标为high中,选择第k小的元素
输出:所选择的元素
• template<class Type>
• Type select_random(Type A[],int low,int high,int k)
第6章 随机化算法
6.2 谢伍德(Sherwood)算法
6.2.1 随机化快速排序算法
在第二章中所叙述的快速排序算法中,我们采用 的是将数组的第一个元素作为划分元素进行排 序,在平均情况下的计算时间复杂度为
(n*log n) 在最坏情况下,也就是说,数组中的 元素已经按照递增顺序或者递减顺序进行排列
数值随机化算法常用于数值问题到的求解。这类算法所 得到的解往往是近似解。并且近似解的精度随着计算时 间的增加并且近似解的精度随着计算时间的增加会不断 地提高。在许多情况下,由于要计算出问题的精确解是 不可能的或者是没有必要的,因此用数值随机化算法可 以获得相当满意的解。
算法实验报告——线性时间选择问题

算法实验报告——线性时间选择问题实验五线性时间选择问题年级16 学号飞宇成绩专业信息安全实验地点C1-413 指导教师丽萍实验⽇期⼀、实验⽬的1、理解分治法的基本思想2、掌握分治法解决问题的基本步骤,并能进⾏分治算法时间空间复杂度分析。
⼆、实验容线性时间选择问题:给定线性序集中n个元素和⼀个整数k(k>=1⽽且k<=n),要求在线性时间找出这n个元素中第k⼩的元素。
1.随机快速排序2.利⽤中位数线性时间选择三、算法描述1.随机快速排序在算法Randomized_Select中执⾏Randomized_Partition,将数组分成两个⼦数组,在Randomized_Partition中调⽤Partition 函数确定⼀个基准元素,对数组进⾏划分。
由于划分是随机产⽣的,由此导致算法Randomized_Select也是⼀个随机化算法。
2.利⽤中位数线性时间选择四、程序1.随机快速排序#include#include#includeint Randomized_Select(int a[],int p,int r,int i);int Randomized_Partition(int a[],int p,int r);int Partition(int a[],int p,int r);void swap(int *a,int *b);int Random(int p,int q);int main(){int a[] = {10,9,8,7,6,5,4,3,2,1};int i = 3;printf("第%d⼩的数是:\n%d",i,Randomized_Select(a,0,9,i));return 0;}{int temp;temp = *a;*a = *b;*b = temp;}int Random(int p,int q)//产⽣p和q之间的⼀个随机整数{int i,number;srand((unsigned)time(NULL));number = rand()%(q-p+1)+p;return number;}int Partition(int a[],int p,int r)//快排的部分{int x = a[r];int i = p- 1;int j;for(j = p;j<=r-1;j++){if(a[j] <= x){i = i + 1;swap(&a[j],&a[i]);}}swap(&a[i+1],&a[r]);return i+1;}int Randomized_Partition(int a[],int p,int r)//随机交换数字{int i = Random(p,r);swap(&a[r],&a[i]);return Partition(a,p,r);int Randomized_Select(int a[],int p,int r,int i)//选择算法核⼼{if(p == r) return a[p];int q = Randomized_Partition(a,p,r);int k = q - p + 1;if(i == k)//如果刚好等于i,输出return a[q];else if(i < k)//如果i⽐k⼩,证明要找的元素在低区return Randomized_Select(a,p,q-1,i);else //找的元素在⾼区return Randomized_Select(a,q+1,r,i-k); //因为a[q]已经是前⾯第k个⼩的,所以在后⾯就是i-k⼩}2. 利⽤中位数线性时间选择#include#include#include#includeusing namespace std;templatevoid Swap(Type &x,Type &y);inline int Random(int x, int y);templatevoid BubbleSort(Type a[],int p,int r);templateint Partition(Type a[],int p,int r,Type x);templateType Select(Type a[],int p,int r,int k);int main(){//初始化数组int a[10];//必须放在循环体外⾯srand((unsigned)time(0));for(int i=0; i<10; i++)a[i] = Random(0,50);cout<<"a["<}cout<cout<<"第3⼩元素是"<//重新排序,对⽐结果BubbleSort(a,0,9);for(int i=0; i<10; i++){cout<<"a["<}cout<}templatevoid Swap(Type &x,Type &y){Type temp = x;x = y;y = temp;}inline int Random(int x, int y){int ran_num = rand() % (y - x) + x; return ran_num;}//冒泡排序templatevoid BubbleSort(Type a[],int p,int r) {//记录⼀次遍历中是否有元素的交换bool exchange;for(int i=p; i<=r-1;i++){exchange = false ;{if(a[j]{Swap(a[j],a[j-1]);exchange = true;}}//如果这次遍历没有元素的交换,那么排序结束if(false == exchange){break ;}}}templateint Partition(Type a[],int p,int r,Type x){int i = p-1,j = r + 1;while(true){while(a[++i]while(a[--j]>x);if(i>=j){break;}Swap(a[i],a[j]);}return j;}templateType Select(Type a[],int p,int r,int k){if(r-p<75)BubbleSort(a,p,r);return a[p+k-1];}//(r-p-4)/5相当于n-5for(int i=0; i<=(r-p-4)/5; i++){//将元素每5个分成⼀组,分别排序,并将该组中位数与a[p+i]交换位置//使所有中位数都排列在数组最左侧,以便进⼀步查找中位数的中位数BubbleSort(a,p+5*i,p+5*i+4);Swap(a[p+5*i+2],a[p+i]);}//找中位数的中位数Type x = Select(a,p,p+(r-p-4)/5,(r-p-4)/10);int i = Partition(a,p,r,x);int j = i-p+1;if(k<=j){return Select(a,p,i,k);}else{return Select(a,i+1,r,k-j);}}五、测试与分析1.随机快速排序O(n)2.利⽤中位数线性时间选择O(n)。
算法设计与分析-线性时间选择
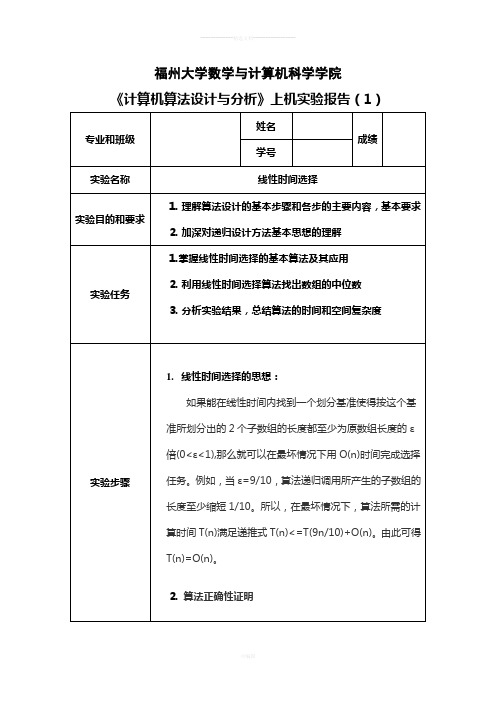
福州大学数学与计算机科学学院《计算机算法设计与分析》上机实验报告(1)(1)将所有的数n个以每5个划分为一组共组,将不足5个的那组忽略,然后用任意一种排序算法,因为只对5个数进行排序,所以任取一种排序法就可以了。
将每组中的元素排好序再分别取每组的中位数,得到个中位数。
(2)取这个中位数的中位数,如果是偶数,就找它的2个中位数中较大的一个作为划分基准。
(3)将全部的数划分为两个部分,小于基准的在左边,大于等于基准的放右边。
在这种情况下找出的基准x至少比个元素大。
因为在每一组中有2个元素小于本组的中位数,有个小于基准,中位数处于,即个中位数中又有个小于基准x。
因此至少有个元素小于基准x。
同理基准x也至少比个元素小。
而当n≥75时≥n/4所以按此基准划分所得的2个子数组的长度都至少缩短1/4。
通过上述说明可以证明将原问题分解为两个子问题进行求解能够更加节省求解时间。
3.查找中位数程序代码1.#include "stdafx.h"2.#include <ctime>3.#include <iostream>ing namespace std;5.6.template <class Type>7.void Swap(Type &x,Type &y);8.9.inline int Random(int x, int y);10.11.template <class Type>12.void BubbleSort(Type a[],int p,int r);13.14.template <class Type>15.int Partition(Type a[],int p,int r,Type x);16.17.template <class Type>18.Type Select(Type a[],int p,int r,int k);19.20.int main()21.{22.//初始化数组23.int a[200];24.25.//必须放在循环体外面26. srand((unsigned)time(0));27.28.for(int i=0; i<200; i++)29. {30. a[i] = Random(0,500);31. cout<<"a["<<i<<"]:"<<a[i]<<" ";32. }33. cout<<endl;34.35. cout<<"第100小的元素是"<<Select(a,0,199,100)<<endl;36.37.//重新排序,对比结果38. BubbleSort(a,0,199);39.40.for(int i=0; i<200; i++)41. {42. cout<<"a["<<i<<"]:"<<a[i]<<" ";43. }44. cout<<endl;45.}46.47.template <class Type>48.void Swap(Type &x,Type &y)49.{50. Type temp = x;51. x = y;52. y = temp;53.}54.55.inline int Random(int x, int y)56.{57.int ran_num = rand() % (y - x) + x;58.return ran_num;59.}60.61.//冒泡排序62.template <class Type>63.void BubbleSort(Type a[],int p,int r)64.{65.//记录一次遍历中是否有元素的交换66.bool exchange;67.for(int i=p; i<=r-1;i++)68. {69. exchange = false ;70.for(int j=i+1; j<=r; j++)71. {72.if(a[j]<a[j-1])73. {74. Swap(a[j],a[j-1]);75. exchange = true;76. }77. }78.//如果这次遍历没有元素的交换,那么排序结束79.if(false == exchange)80. {81.break ;82. }83. }84.}85.86.template <class Type>87.int Partition(Type a[],int p,int r,Type x)88.{89.int i = p-1,j = r + 1;90.91.while(true)92. {93.while(a[++i]<x && i<r);94.while(a[--j]>x);95.if(i>=j)96. {97.break;98. }99. Swap(a[i],a[j]);100. }101.return j;102.}103.104.105.template <class Type>106.Type Select(Type a[],int p,int r,int k)107.{108.if(r-p<75)109. {110. BubbleSort(a,p,r);111.return a[p+k-1];112. }113.//(r-p-4)/5相当于n-5114.for(int i=0; i<=(r-p-4)/5; i++)115. {116.//将元素每5个分成一组,分别排序,并将该组中位数与a[p+i]交换位置117.//使所有中位数都排列在数组最左侧,以便进一步查找中位数的中位数118. BubbleSort(a,p+5*i,p+5*i+4);119. Swap(a[p+5*i+2],a[p+i]);120. }121.//找中位数的中位数122. Type x = Select(a,p,p+(r-p-4)/5,(r-p-4)/10);123.int i = Partition(a,p,r,x);124.int j = i-p+1;125.if(k<=j)126. {127.return Select(a,p,i,k);128. }129.else130. {1.实验结果说明(找中位数结果截图)实验结果2.实验结果分析通过上面的结果图可以看出程序能够快速生成一个无序数组并找到第K小的元素。
随机化算法——精选推荐

随机化算法随机化算法特征:对于所求问题的同⼀实例⽤同⼀随机化算法求解两次可能得到完全不同的结果,这两次求解的时间甚⾄得到的结果可能会有相当⼤的差别。
分类:1.数值随机化算法这类算法常⽤于数值问题的求解,所得到的解往往都是近似解,⽽且近似解的精度随计算时间的增加不断提⾼。
使⽤该算法的理由是:在许多情况下,待求解的问题在原理上可能就不存在精确解,或者说精确解存在但⽆法在可⾏时间内求得,因此⽤数值随机化算法可以得到相当满意的解。
⽰例:计算圆周率Π的值将n个点随机投向⼀个正⽅形,设落⼈此正⽅形内切圆(半径为r)中的点的数⽬为k。
假设所投⼊的点落⼊正⽅形的任⼀点的概率相等,则所投⼊的点落⼊圆内的概率为Π*r2/4*r2=Π/4。
当n→∞时,k/n→Π/4,从⽽Π约等于4*k/n。
#include <bits/stdc++.h>using namespace std;typedef long long ll;const int maxn = 1e2 + 10;const int INF = 0x3f3f3f3f;#define m 65536L#define b 1194211693L#define c 12345Lclass RandomNumber{private:unsigned long d; //d为当前种⼦public:RandomNumber(unsigned long s=0); //默认值0表⽰由系统⾃动给种⼦unsigned short random(unsigned long n); //产⽣0:n-1之间的随机整数double fRandom(void); //产⽣[0,1)之间的随机实数};//函数RandomNumber⽤来产⽣随机数种⼦RandomNumber::RandomNumber(unsigned long s){if(s==0) d=time(0); //由系统提供随机种⼦else d=s; //由⽤户提供随机种⼦}unsigned short RandomNumber::random(unsigned long n){d=b*d+c; //⽤线性同余式计算新的种⼦dreturn (unsigned short)((d>>16)%n); //把d的⾼16位映射到0~(n-1)范围内}double RandomNumber::fRandom(void){return random(m)/double(m);}double Darts(int n){static RandomNumber darts;int k=0,i;double x,y;for(int i=1;i<=n;++i){x=darts.fRandom();y=darts.fRandom();if((x*x+y*y)<=1)k++;}return4.0*k/double(n);}int main(){srand(time(NULL));//指定运⾏次数,次数越⾼精度越⾼printf("%.8lf\n",Darts(10000));return0;}2.蒙特卡罗算法家特卡罗算法是计算数学中的⼀种计算⽅法,它的基本特点是以概率与统计学中的理论和⽅法为基础,以是否适合于在计算机上使⽤为重要标志。
随机算法

Randomized Algorithms (随机算法)Probabilistic Algorithms (概率算法)起源可以追溯到20世纪40年代中叶。
当时Monte Carlo在进行数值计算时,提出通过统计模拟或抽样得到问题的近似解,而且出现错误的概率随着实验次数的增多而显著地减少,即可以用时间来换取求解正确性的提高。
但Monte Carlo方法很长时间没有引入到非数值算法中来。
74年,Michael Rabin(76年Turing奖获得者, 哈佛教授, 以色列人) 在瑞典讲演时指出:有些问题,如果不用随机化的方法,而用确定性的算法,在可以忍受的时间内得不到所需要的结果。
e.g. Presburge算术系统(其中只有加法)中的计算程序,即使只有100个符号,用每秒1万亿次运算的机器1万亿台、进行并行计算也需做1万亿年。
但如果使用随机性的概念,可以很快得出结果,而出错率则微乎其微。
74年Rabin关于随机化算法的思想还不太成熟,到76年,Rabin设计了一个判定素数的随机算法,该算法至今仍是一个典范。
随机算法在分布式计算、通信、信息检索、计算几何、密码学等许多领域都有着广泛的应用。
最著名的是在公开密钥体系、RSA算法方面的应用。
用随机化方法解决问题之例:设有一函数表达式f(x1,x2,…x n),要判断f在某一区域D中是否恒为0。
如果f不能用数学方法进行形式上的化简(这在工程中是经常出现的),如何判断就很麻烦。
如果我们随机地产生一个n维的坐标(r1,r2,…r n) D,代入f得f(r1,r2,…r n)≠0,则可断定在区域D内f≢0。
如果f(r1,r2,…r n)=0,则有两种可能:1. 在区域D内f≡0;2. 在区域D内f≢0,得到上述结果只是巧合。
如果我们对很多个随机产生的坐标进行测试,结果次次均为0,我们就可以断言f≢0的概率是非常之小的。
如上例所示,在随机算法中,我们不要求算法对所有可能的输入均正确计算,只要求出现错误的可能性小到可以忽略的程度;另外我们也不要求对同一输入算法每次执行时给出相同的结果。
舍伍德算法

舍伍德算法1. 简介舍伍德算法(Sherwood Algorithm)是一种用于高效训练随机森林的算法。
随机森林是一种集成学习的方法,通过构建多个决策树进行分类或回归。
舍伍德算法的目标是在保持模型准确性的同时,尽可能地减少训练时间。
2. 随机森林在介绍舍伍德算法之前,我们先来了解一下随机森林。
2.1 决策树决策树是一种常用的分类和回归方法。
它通过对数据集进行划分,构建一个树状结构来进行预测。
每个内部节点表示一个特征或属性,每个叶子节点表示一个类别或数值。
2.2 集成学习随机森林是一种集成学习的方法,它通过构建多个决策树来进行分类或回归,并将它们的结果进行组合来得到最终结果。
这种集成学习的方式可以提高模型的准确性和鲁棒性。
2.3 随机性随机森林中引入了两种随机性:样本随机性和特征随机性。
•样本随机性:从训练集中有放回地抽取样本,构建不同的决策树。
这样可以使得每个决策树的训练集都有一定的差异,增加模型的多样性。
•特征随机性:对于每个决策树的节点,在候选特征中随机选择一部分特征进行划分。
这样可以使得每个决策树都只考虑了部分特征,减少了特征之间的相关性。
3. 舍伍德算法舍伍德算法是一种用于高效训练随机森林的算法。
它通过并行计算和数据分布来加速训练过程,并在保持模型准确性的同时减少了计算资源的消耗。
3.1 并行计算舍伍德算法利用多线程和多核计算来并行计算决策树的构建过程。
在每个线程中,舍伍德算法使用不同的训练集子集来构建决策树,然后将它们组合成一个随机森林。
3.2 数据分布为了进一步提高训练速度,舍伍德算法将数据分布到不同的计算节点上进行并行计算。
在每个计算节点上,舍伍德算法只使用部分数据来构建决策树。
这样可以减少每个决策树的训练时间,并充分利用计算资源。
3.3 特征选择舍伍德算法使用一种基于随机投影的方法来选择特征。
它通过随机选择一部分特征,并对它们进行投影,然后选择投影后具有最大方差的特征作为划分特征。
算法设计与分析课件--随机化算法-舍伍德算法

5
7.5 舍伍德算法 – 线性时间选择
线性时间选择:
给定线性序集中n个元素和一个整数k (1≤k≤n),要求找出 这n个元素中第k小的元素。
如将这n个元素依其线性序排列,排在第k个位置的元素 即为要找的元素。
线性选择的分治算法对基准元素的选择比较复杂:
先分组,然后取每一组的中位数,接下来再取中位数的 中位数,最后以该中位数为基准元素对n个元素进行划分。
如要消除上述的差异性,必须在基准元素的选择上多做 考虑。如在基准元素选择时引入随机性,即随机地选择 基准元素。
引入随机性的快速排序算法便为舍伍德算法,可以较高 概率地获得算法的平均性能。
4
7.5 舍伍德算法 – 随机快速排序
基于舍伍德方法的随机快速排序算法:
QUICK-SORT(A, low, high) if low < high
then pivotpos = RAND-PARTITION(A,low,high) //划分序列 QUICK-SORT(A,low,pivotpos-1) //对左区间递归排序 QUICK-SORT(A,pivotpos+1,high) //对右区间递归排序
RAND-PARTITION(A, low, high) RandomNumber rnd i = RandomNumber.random(high-low+1) + low SWAP(a[low], a[i]) j = PARTITION(A, low, high) return j
{
RandomNumber rnd;
for(int i=1;i<n;i++)
{
int j=rnd.Random(n-i)+i;
数据分析知识:数据分析中的实验随机化设计

数据分析知识:数据分析中的实验随机化设计随机化设计在数据分析的实验中扮演着非常重要的角色。
在研究一个因果关系时,我们需要确保任何产生影响的因素都要被随机且均匀地分配到实验组和对照组中。
这是因为如果我们的实验组和对照组在任何方面都不同,那么我们无法得出清晰且可靠的结论。
因此,在实验设计及数据收集的过程中,随机化是必不可少的一步。
随机化设计的过程包括两个主要的步骤:随机分组和随机分派。
在随机分组中,我们将实验参与者随机分配到实验组和对照组;在随机分派中,我们随机地将实验条件/操作分配给实验组和对照组。
随机化的设计能够消除不同因素的干扰,保证每组实验参与者的学习能力、生理和心理状况等各方面因素的均衡,并且能够在一定程度上避免不确定影响因素的干扰,确保实验的真实性和可靠性。
以一种常见的实验为例,如何在实验设计中使用随机化来消除因素的干扰。
假设我们正在进行一项关于某种新药物的实验,我们的目的是了解这种新药物是否能够治愈某种病。
我们需要在实验设计中避免一些因素的干扰,这些因素可能会影响实验结果的可靠性和真实性。
为了达到这个目的,我们需要进行随机化。
步骤一:分组首先,我们需要将实验参与者随机分配到实验组和对照组。
使用计算机程序可以很轻松地实现这一步骤。
通过随机分组,我们可以让两个组之间的参与者具有相似的特征、生理状况和心理状况等各方面因素的均衡,从而更好地控制因素的影响。
我们可以通过以下方案进行随机分组:-将参与者的基本信息(如年龄、性别、体重、过敏史等)输入到电脑程序中,并用随机函数分配到实验组和对照组中。
-通过满足特定需求的软件,根据一定的算法,将参与者均匀且随机地分配到实验组和对照组中。
步骤二:随机分派接下来,我们需要随机地将实验条件/操作分配给实验组和对照组。
这一步骤通常由实验者来执行,确保每组实验参与者在遵循实验方案的情况下获得同样的待遇。
通过随机分派,我们可以消除实验条件/操作自身对实验结果的影响,比如:-在实验组和对照组中分别给予药物(诱发因素)和安慰剂(对照组),确保实验者和实验者之间得到同样的待遇,并消除诱发因素(药物)本身对实验结果的影响;-在实验组和对照组中分别进行同样类型的治疗(如手术),确保实验者和实验者之间得到同样的待遇,并消除不同手术对实验结果的影响。
随机化算法实验(Sherwood型线性时间选择)

算法分析与设计实验报告第八次实验姓名学号班级时间12.26上午地点工训楼309实验名称随机化算法实验(Sherwood型线性时间选择)实验目的1.通过上机实验,要求掌握Sherwood 型线性时间选择算法的问题描述、算法设计思想、程序设计。
2.使用舍伍德型选择算法,根据不同的输入用例,能准确的输出用例中的中值,并计算出程序运行所需要的时间。
实验原理问题描述:给定任意几组数据,利用舍伍德型选择算法,找出数组中的中值并输出(若数组为奇数个则输出中值,若数组为偶数个则输出第n/2 小元素)。
基本思想:设A是一个确定性算法,当它的输入实例为x时所需的计算时间记为tA(x)。
设Xn是算法A的输入规模为n的实例的全体,则当问题的输入规模为n时,算法A所需的平均时间为。
这显然不能排除存在x∈Xn使得的可能性。
希望获得一个随机化算法B,使得对问题的输入规模为n的每一个实例均有。
这就是舍伍德算法设计的基本思想。
当s(n)与tA(n)相比可忽略时,舍伍德算法可获得很好的平均性能。
实验步骤(1)先判断是否需要进行随机划分即(k∈(1,n)?n>1?);(2)产生随机数j,选择划分基准,将a[j]与a[l]交换;(3)以划分基准为轴做元素交换,使得一侧数组小于基准值,另一侧数组值大于基准值;(4)判断基准值是否就是所需选择的数,若是,则输出;若不是对子数组重复步骤(2)(3)(4)。
else//第k小在pivot的左边部分 {r = j - 1;}}}测试结果输入较小的序列数:输入较大的序列数:不输出数组数只输出结果比较:附录:完整代码(随机化算法)Sherwood.cpp//随机化算法线性时间选择输入预处理洗牌#include"RandomNumber.h"#include<iostream>#include<time.h>#include<iomanip>using namespace std;template<class Type>Type select(Type a[],int l,int r,int k); //声明选出要选择的元素的函数template<class Type> //声明判断是否越界的函数Type select(Type a[],int n,int k);template<class Type> //声明洗牌算法函数Shufflevoid Shuffle(Type a[],int n);template <class Type> //声明交换函数inline void Swap(Type &a,Type &b);void ran(int *input,int n) //随机生成数组元素函数{int i;srand(time(0));for(i=0;i<n;i++)input[i]=rand()%100; //生成的数据在0~100之间input[i]='\0';}int main(){int n;cout<<"输入元素个数:";cin>>n;int *a=new int[n+1];cout<<"原数组为:"<<endl;ran(a,n); //随机生成数组for(int i=0; i<n; i++){cout<<a[i]<<" ";}cout<<endl;Shuffle(a,n);//洗牌,将原有的输入进行随机洗牌cout<<"洗牌后数组为:"<<endl;for(int i=0; i<n; i++){cout<<a[i]<<" ";}cout<<endl;clock_t start,end,over; //计算程序运行时间的算法start=clock();end=clock();over=end-start;start=clock();//选出序列中的最大值元素cout<<"所给数组的最大值为:"<<select(a,n,n)<<endl;//选出序列中的最小值元素cout<<"所给数组的最小值为:"<<select(a,n,1)<<endl;end=clock();printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK); //显示运行时间cout<<endl;system("pause");return 0;}//计算a[0:n-1]中第k小元素//假设a[n]是一个键值无穷大的元素template<class Type>Type select(Type a[],int n,int k){if(k<1 || k>n){cout<<"请输入正确的k!"<<endl;return 0;}return select(a,0,n-1,k); //如果输入合法则进行选择,找出要求的解}//计算a[l:r]中第k小元素template<class Type>Type select(Type a[],int l,int r,int k){while(true){if(l>=r) //此种情况表示只有一个元素{return a[l];}int i = l;int j = r+1;Type pivot = a[l]; //轴值每次都选择最左边的元素//以划分基准为轴做元素交换while(true){ //将<pivot的元素换到轴值左边//将>pivot的元素换到轴值右边while(a[++i]<pivot);while(a[--j]>pivot);if(i>=j){break;}Swap(a[i],a[j]);}if(j-l+1 == k) //如果轴值是要选的元素即第k小{return pivot;}//如果轴值不是要选的元素//a[j]必然小于等于pivot,做最后一次交换,满足左侧比pivot小,右侧比pivot大a[l] = a[j];a[j] = pivot;//对子数组重复划分过程if(j-l+1<k) //第k小在pivot的右边部分{k = k-j+l-1;//右侧:k-(j-l+1)=k-j+l-1l = j + 1;}else//第k小在pivot的左边部分{r = j - 1;}}}template <class Type>inline void Swap(Type &a,Type &b){Type temp = a;a = b;b = temp;}//随机洗牌算法template<class Type>void Shuffle(Type a[],int n){static RandomNumber rnd; //随机数类for(int i=0; i<n; i++){int j = rnd.Random(n-i)+i; //随机生成i~n之间的整数Swap(a[i],a[j]); //随机选取的数作为基准值}}RandomNumber.h#include"time.h"const unsigned long maxshort=65536L;const unsigned long multiplier=1194211693L;const unsigned long adder=12345L;class RandomNumber //定义一个随机数类{private://当前种子unsigned long randSeed;public://构造函数,默认值表示由系统自动生产种子RandomNumber(unsigned long s=0);unsigned short Random(unsigned long n);//产生0~n-1之间的随机整数double fRandom(void);//产生[0,1)之间的随机实数};RandomNumber::RandomNumber(unsigned long s)//产生种子{if(s==0){randSeed=time(0);//用系统时间产生种子}else{randSeed=s;//由用户提供种子}}//产生0~n-1之间的随机整数unsigned short RandomNumber::Random(unsigned long n){randSeed=multiplier*randSeed+adder; //线性同余式return (unsigned short)((randSeed>>16)%n);。
线性时间选择实验报告

线性时间选择一.实验目的:1.理解算法设计的基本步骤和各步的主要内容、基本要求;2.加深对递归设计方法基本思想的理解,并利用其解决现实生活中的问题;3.通过本次试验初步掌握将算法转化为计算机上机程序的方法。
二.实验内容:1.编写实现算法:给定n个元素,在这n个元素中找到第key小的元素;2.将输入的数据存储到指定的文本文件中,而输出数据存放到另一个文本文件中,包括结果和具体的运行时间;3.对实验结果进行分析。
三.实验操作:1.线性时间选择的思想:首先将这n个元素分成5组,利用排序算法找到其中的中位数,再将这些中位数排序找到整个数组的中位数median,以这个中位数median为界限,将整个数组划分为三部分,小于median,等于median和大于median三部分,判断key在哪部分中,对那部分进行递归调用,直到找到等于key的元素为止。
综上判断,其时间复杂度为:T(n)<=cn(n为实验数据的个数),故为线性时间。
2.快速排序:本次排序使用的是快速排序,快速排序是一种相对较快的排序方式,能够减少一定的时间开销。
代码实现:void quickSort(int List[],int low,int high){if(low>=high) return;int first=low;int last=high;int key=List[first];while(first<last){while(first<last&&List[last]>=key) --last;List[first]=List[last];while(first<last&&List[first]<=key) ++first;List[last]=List[first];}List[first]=key;quickSort(List,low,first-1);quickSort(List,last+1,high);}3.实验数据的输入:为了保证实验数据的随机性,本实验采用随机生成的方式提供数据,并将输入输出数据存储到指定的文本文件中,需要采用C++文件流操作,对于数据的输入,由于cin对数据的读取会忽略空格和换行操作,故使用cin流来控制数据的输入。
随机算法(数值概率舍伍德)

int j, p{ o//s随itio机n;抛硬币
// Random (2) = 1 表示正面
/f/o初r (始j=0化s;j数<taN组tiCchOeRaINda+sn1;djo++m) Number
coinTtoosssse;s +=
return tosses;
coinToss.Random
(2);
• 包括 – 数值概率算法 – 蒙特卡罗(Monte Carlo)算法 – 拉斯维加斯(Las Vegas)算法 – 舍伍德(Sherwood)算法
整理ppt
4
随机算法的分类
• 数值概率算法常用于数值问题的求解。将一个问题的计算与 某个概率分布已经确定的事件联系起来,求问题的近似解。 这类算法所得到的往往是近似解,且近似解的精度随计算时 间的增加而不断提高。在许多情况下,要计算出问题的精确 解是不可能或没有必要的,因此可以用数值随机化算法得到 相当满意的解。
E (g * (i) )a b g * (x )f(x )d x a b g (x )d x I
由强大数定律:
n
Pr(ln i m1n i1g*(i)I)1
若选
I
1 n
n
g*(i )
,则 I依概率1收敛于I,平均值法就是
i1
用 I作为I的近似值。
整理ppt
22
b
假设设要计算的积分形式为:I g ( x)dx ,可以任选一个有简便
0
a x b x a, x b
此时所求积分变为:
b
I (ba) g(x)
• 其中b0,c0,dm。d称为该随机序列的种子。如何选取该 方法中的常数b、c和m直接关系到所产生的随机序列的随机性 能。这是随机性理论研究的内容,已超出本书讨论的范围。从 直观上看,m应取得充分大,因此可取m为机器大数。
随机化算法(4)—拉斯维加斯(LasVegas)算法

随机化算法(4)—拉斯维加斯(LasVegas)算法已出连载:正⽂:悟性不够,这⼀章看代码看了快⼀个上午,才理解。
上⼀章讲过《》,但是他的有点是计算时间复杂性对所有实例⽽⾔相对均匀,⽽其平均时间复杂性没有改变。
⽽拉斯维加斯算法怎么显著改进了算法的有效性。
的⼀个显著特征是它所作的随机性决策有可能导致算法找不到所需的解。
因此通常⽤⼀个bool型函数表⽰拉斯维加斯算法。
void Obstinate(InputType x, OutputType &y){// 反复调⽤拉斯维加斯算法LV(x, y),直到找到问题的⼀个解bool success= false;while (!success)success = LV(x,y);}考虑⽤拉斯维加斯算法解决:对于n后问题的任何⼀个解⽽⾔,每⼀个皇后在棋盘上的位置⽆任何规律,不具有系统性,⽽更象是随机放置的。
由此容易想到下⾯的拉斯维加斯算法。
在棋盘上相继的各⾏中随机地放置皇后,并注意使新放置的皇后与已放置的皇后互不攻击,直⾄n个皇后已相容地放置好,或已没有下⼀个皇后的可放置位置时为⽌。
注意这⾥解决的是找到其中⼀个⽅法,求不是求出N皇后的全部解。
这⾥提前说明⼀下,否则不好理解。
接下来的这个⽤Las Vegas算法解决N皇后问题,我们采⽤的是随机放置位置策略和回溯法相结合,具体就是⽐如⼋皇后中,前⼏⾏选择⽤随机法放置皇后,剩下的选择⽤回溯法解决。
这个程序不是很好理解,有的地⽅我特别说明了是理解程序的关键,⼤家看时⼀定要认真了,另外,王晓东的书上先是⽤单纯的随机法解决,⼤家可以先去理解书上这个例⼦。
然后再来分析我这个程序。
不过那本书上关于这⼀块错误⽐较多,⼤家看时要注意哪些地⽅他写错了。
拉斯维加斯算法解决N皇后代码:依然⽤到了RandomNumber.h头⽂件,⼤家可以去看下,我就不贴出来了。
剩下部分的代码:注意QueensLV()函数是这个程序的精髓所在。
0045算法笔记——【随机化算法】舍伍德随机化思想搜索有序表

问题描述用两个数组来表示所给的含有n个元素的有序集S。
用value[0:n]存储有序集中的元素,link[0:n]存储有序集中元素在数组value中位置的指针(实际上使用数组模拟链表)。
link[0]指向有序集中的第一个元素,集value[link[0]]是集合中的最小元素。
一般地,如果value[i]是所给有序集S中的第k个元素,则value[link[i]]是S中第k+1个元素。
S中元素的有序性表现为,对于任意1<=i<=n有value[i]<=value[link[i]]。
对于集合S中的最大元素value[k]有,link[k]=0且value[0]是一个大数。
例:有序集S={1,2,3,5,8,13,21}的一种表现方式如图所示:搜索思想对于有序链表,可采用顺序搜索的方式在所给的有序集S中搜索值为x的元素。
如果有序集S中含有n个元素,则在最坏的情况下,顺序搜索算法所需的计算时间为O(n)。
利用数组下标的索引性质,可以设计一个随机化搜索算法,一改进算法的搜索时间复杂性。
算法的基本思想是,随机抽取数组元素若干次,从较接近搜索元素x的位置开始做顺序搜索。
如果随机搜索数组元素k次,则其后顺序搜索所需的平均比较次数为O(n/k+1)。
因此,如果去k=|sqrt(n)|,则算法所需的平均计算时间为(Osqrt(n))。
随机化思想下的有序表实现具体代码如下:1、RandomNumber.h[cpp]view plain copy1.#include"time.h"2.//随机数类3.const unsigned long maxshort = 65536L;4.const unsigned long multiplier = 1194211693L;5.const unsigned long adder = 12345L;6.7.class RandomNumber8.{9.private:10.//当前种子11. unsigned long randSeed;12.public:13. RandomNumber(unsigned long s = 0);//构造函数,默认值0表示由系统自动产生种子14. unsigned short Random(unsigned long n);//产生0:n-1之间的随机整数15.double fRandom(void);//产生[0,1)之间的随机实数16.};17.18.RandomNumber::RandomNumber(unsigned long s)//产生种子19.{20.if(s == 0)21. {22. randSeed = time(0);//用系统时间产生种子23. }24.else25. {26. randSeed = s;//由用户提供种子27. }28.}29.30.unsigned short RandomNumber::Random(unsigned long n)//产生0:n-1之间的随机整数31.{32. randSeed = multiplier * randSeed + adder;//线性同余式33.return (unsigned short)((randSeed>>16)%n);34.}35.36.double RandomNumber::fRandom(void)//产生[0,1)之间的随机实数37.{38.return Random(maxshort)/double(maxshort);39.}2、7d3d2.cpp[cpp]view plain copy1.//随机化算法搜素有序表2.#include "stdafx.h"3.#include "RandomNumber.h"4.#include "math.h"5.#include <iostream>ing namespace std;7.8.template<class Type>9.class OrderedList10.{11.friend int main();12.public:13. OrderedList(Type Small,Type Large,int MaxL);14. ~OrderedList();15.bool Search(Type x,int& index); //搜索指定元素16.int SearchLast(void); //搜索最大元素17.void Insert(Type k); //插入指定元素18.void Delete(Type k); //删除指定元素19.void Output(); //输出集合中元素20.private:21.int n; //当前集合中元素的个数22.int MaxLength; //集合中最大元素的个数23. Type *value; //存储集合中元素的数组24.int *link; //指针数组25. RandomNumber rnd; //随机数产生器26. Type Small; //集合中元素的下界27. Type TailKey; //集合中元素的上界28.};29.30.//构造函数31.template<class Type>32.OrderedList<Type>::OrderedList(Type small,Type Large,int MaxL)33.{34. MaxLength = MaxL;35. value = new Type[MaxLength+1];36. link = new int[MaxLength+1];37. TailKey = Large;38. n = 0;39. link[0] = 0;40. value[0] = TailKey;41. Small = small;42.}43.44.//析构函数45.template<class Type>46.OrderedList<Type>::~OrderedList()47.{48.delete value;49.delete link;50.}51.52.//搜索集合中指定元素k53.template<class Type>54.bool OrderedList<Type>::Search(Type x,int& index)55.{56. index = 0;57. Type max = Small;58.int m = floor(sqrt(double(n)));//随机抽取数组元素次数59.60.for(int i=1; i<=m; i++)61. {62.int j = rnd.Random(n)+1;//随机产生数组元素位置63. Type y = value[j];64.65.if((max<y)&& (y<x))66. {67. max = y;68. index = j;69. }70. }71.72.//顺序搜索73.while(value[link[index]]<x)74. {75. index = link[index];76. }77.78.return (value[link[index]] == x);79.}80.81.//插入指定元素82.template<class Type>83.void OrderedList<Type>::Insert(Type k)84.{85.if((n == MaxLength)||(k>=TailKey))86. {87.return;88. }89.int index;90.91.if(!Search(k,index))92. {93. value[++n] = k;94. link[n] = link[index];95. link[index] = n;96. }97.}98.99.//搜索集合中最大元素100.template<class Type>101.int OrderedList<Type>::SearchLast(void)102.{103.int index = 0;104. Type x = value[n];105. Type max = Small;106.int m = floor(sqrt(double(n)));//随机抽取数组元素次数107.108.for(int i=1; i<=m; i++)109. {110.int j = rnd.Random(n)+1;//随机产生数组元素位置111. Type y = value[j];112.113.if((max<y)&&(y<x))114. {115. max = y;116. index = j;117. }118. }119.120.//顺序搜索121.while(link[index]!=n)122. {123. index = link[index];124. }125.return index;126.}127.128.//删除集合中指定元素129.template<class Type>130.void OrderedList<Type>::Delete(Type k)131.{132.if((n==0)&&(k>=TailKey))133. {134.return;135. }136.137.int index;138.if(Search(k,index))139. {140.int p = link[index];141.if(p == n)142. {143. link[index] = link[p];144. }145.else146. {147.if(link[p]!=n)148. {149.int q = SearchLast();150. link[q] = p;151. link[index] = link[p];152. }153. value[p] = value[n];//删除元素由最大元素来填补154. link[p] = link[n];155. }156. n--;157. }158.}159.160.//输出集合中所有元素161.template<class Type>162.void OrderedList<Type>::Output()163.{164.int index = 0,i = 0;165.while(i<n)166. {167. index = link[index];168. cout<<value[index]<<" ";169. i++;170. }171. cout<<endl;172. cout<<"value:";173.for(i=0; i<=n; i++)174. {175. cout.width(4);176. cout<<value[i];177. }178. cout<<endl;179. cout<<"link:";180.for(i=0; i<=n; i++)181. {182. cout.width(4);183. cout<<link[i];184. }185. cout<<endl;186.}187.188.int main()189.{190.static RandomNumber rnd;191. OrderedList<int> *ol = new OrderedList<int>(0,100,100); 192.193.//创建194. cout<<"=========创建==========="<<endl;195.while(ol->n<10)196. {197.int e = rnd.Random(99);198. ol->Insert(e);199. }200. ol->Output();201. cout<<endl;202.203.//搜索204. cout<<"=========搜索==========="<<endl;205.int index;206. cout<<"搜索有序表value数组中第5个元素如下:"<<endl; 207. cout<<"value[5]="<<ol->value[5]<<endl;208. ol->Search(ol->value[5],index);209. cout<<"位置搜索结果为:"<<ol->link[index]<<endl;210. cout<<endl;211.212.//删除213. cout<<"=========删除==========="<<endl;214. cout<<"删除有序表value数组中第5个元素如下:"<<endl; 215. cout<<"value[5]="<<ol->value[5]<<endl;216. ol->Delete(ol->value[5]);217. ol->Output(); 218.219.delete ol; 220.return 0; 221.}程序运行结果如图:。
0046算法笔记——【随机化算法】舍伍德随机化思想解决跳跃表问题

问题描述如果用有序链表来表示一个含有n个元素的有序集S,则在最坏情况下,搜索S中一个元素需要O(n)计算时间。
提高有序链表效率的一个技巧是在有序链表的部分结点处增设附加指针以提高其搜索性能。
在增设附加指针的有序链表中搜索一个元素时,可借助于附加指针跳过链表中若干结点,加快搜索速度。
这种增加了向前附加指针的有序链表称为跳跃表。
应在跳跃表的哪些结点增加附加指针以及在该结点处应增加多少指针完全采用随机化方法来确定。
这使得跳跃表可在O(logn)平均时间内支持关于有序集的搜索、插入和删除等运算。
例如:如图,(a)是一个没有附加指针的有序表,而图(b)在图(a)的基础上增加了跳跃一个节点的附加指针。
图(c)在图(b)的基础上又增加了跳跃3个节点的附加指针。
在跳跃表中,如果一个节点有k+1个指针,则称此节点为一个k级节点。
以图(c)中跳跃表为例,看如何在改跳跃表中搜索元素8。
从该跳跃表的最高级,即第2级开始搜索。
利用2级指针发现元素8位于节点7和19之间。
此时在节点7处降至1级指针进行搜索,发现元素8位于节点7和13之间。
最后,在节点7降至0级指针进行搜索,发现元素8位于节点7和11之间,从而知道元素8不在搜索的集合S中。
相关原理在一般情况下,给定一个含有n个元素的有序链表,可以将它改造成一个完全跳跃表,使得每一个k级结点含有k+1个指针,分别跳过2^k-1,2^(k-1)-1,…,2^0-1个中间结点。
第i个k级结点安排在跳跃表的位置i2^k处,i>=0。
这样就可以在时间O(logn)内完成集合成员的搜索运算。
在一个完全跳跃表中,最高级的结点是级结点。
完全跳跃表与完全二叉搜索树的情形非常类似。
它虽然可以有效地支持成员搜索运算,但不适应于集合动态变化的情况。
集合元素的插入和删除运算会破坏完全跳跃表原有的平衡状态,影响后继元素搜索的效率。
为了在动态变化中维持跳跃表中附加指针的平衡性,必须使跳跃表中k级结点数维持在总结点数的一定比例范围内。
算法分析与复杂性理论

stopvegas = 3
③回溯算法与lv算法 混合使用 1 先在棋盘的前若 2 干行中随机地放臵皇 3 后,(即设定 stopvegas的值)然 4 后在后继行中用回溯 5 法继续搜索,直至找 到一个解或宣告失败.6 随机放臵的皇后 7 越多,后继回溯搜索 所需的时间就越少, 8 但失败的概率就越大. 1
完全回溯法
LV和回溯混合效 率最高的情况
完全LV算法ห้องสมุดไป่ตู้
8
分析:
①完全回溯法比LV算法在解八皇后问题时效率 低得多; ②LV算法和回溯的混合使用有利于提高解八皇 后的效率。
9
LV算法具体应用分析
2、N皇后问题 下面是n取不同值时效率对比情况:
随着n值的增加,与回溯法相比,使用LV算法的 高效率性逐渐明显。
10
LV算法的现状与展望
缺点:时间复杂度不确定,有时候得不到解, 而要多次运行算法。 LV算法还可以来解决排序问题,分班问题, 考试系统安排问题,aD-Hoc网络中基于距离的动 态概率广播协议问题,航天器与短期空间碎云碰 撞问题等等。 如今,人们在实验中发现基于重启优化方法可 以提高LV算法的性能和稳定性,可以很直观的解 决一些NP难解问题,如TSP问题。
e
0.000000 0.000000 39.852940 15.784404 8.884438 7.165462 6.662811 6.315917 6.017177
t
113.000000 38.165001 28.320000 29.720001 38.134998 52.995003 45.480000 47.285000 48.285000
拉斯维加斯算法利用随机来指导解的搜索即使做了个不宜的选择也可以保证正确的解因为这样会导致算法进入绝境这样就会报告在这一次运行中无法得到解然后重新启动算法直到得到正确的结果
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
算法分析与设计实验报告第八次实验姓名学号班级时间12.26上午地点工训楼309实验名称随机化算法实验(Sherwood型线性时间选择)实验目的1.通过上机实验,要求掌握Sherwood 型线性时间选择算法的问题描述、算法设计思想、程序设计。
2.使用舍伍德型选择算法,根据不同的输入用例,能准确的输出用例中的中值,并计算出程序运行所需要的时间。
实验原理问题描述:给定任意几组数据,利用舍伍德型选择算法,找出数组中的中值并输出(若数组为奇数个则输出中值,若数组为偶数个则输出第n/2 小元素)。
基本思想:设A是一个确定性算法,当它的输入实例为x时所需的计算时间记为tA(x)。
设Xn是算法A的输入规模为n的实例的全体,则当问题的输入规模为n时,算法A所需的平均时间为。
这显然不能排除存在x∈Xn使得的可能性。
希望获得一个随机化算法B,使得对问题的输入规模为n的每一个实例均有。
这就是舍伍德算法设计的基本思想。
当s(n)与tA(n)相比可忽略时,舍伍德算法可获得很好的平均性能。
实验步骤(1)先判断是否需要进行随机划分即(k∈(1,n)?n>1?);(2)产生随机数j,选择划分基准,将a[j]与a[l]交换;(3)以划分基准为轴做元素交换,使得一侧数组小于基准值,另一侧数组值大于基准值;(4)判断基准值是否就是所需选择的数,若是,则输出;若不是对子数组重复步骤(2)(3)(4)。
else//第k小在pivot的左边部分 {r = j - 1;}}}测试结果输入较小的序列数:输入较大的序列数:不输出数组数只输出结果比较:附录:完整代码(随机化算法)Sherwood.cpp//随机化算法线性时间选择输入预处理洗牌#include"RandomNumber.h"#include<iostream>#include<time.h>#include<iomanip>using namespace std;template<class Type>Type select(Type a[],int l,int r,int k); //声明选出要选择的元素的函数template<class Type> //声明判断是否越界的函数Type select(Type a[],int n,int k);template<class Type> //声明洗牌算法函数Shufflevoid Shuffle(Type a[],int n);template <class Type> //声明交换函数inline void Swap(Type &a,Type &b);void ran(int *input,int n) //随机生成数组元素函数{int i;srand(time(0));for(i=0;i<n;i++)input[i]=rand()%100; //生成的数据在0~100之间input[i]='\0';}int main(){int n;cout<<"输入元素个数:";cin>>n;int *a=new int[n+1];cout<<"原数组为:"<<endl;ran(a,n); //随机生成数组for(int i=0; i<n; i++){cout<<a[i]<<" ";}cout<<endl;Shuffle(a,n);//洗牌,将原有的输入进行随机洗牌cout<<"洗牌后数组为:"<<endl;for(int i=0; i<n; i++){cout<<a[i]<<" ";}cout<<endl;clock_t start,end,over; //计算程序运行时间的算法start=clock();end=clock();over=end-start;start=clock();//选出序列中的最大值元素cout<<"所给数组的最大值为:"<<select(a,n,n)<<endl;//选出序列中的最小值元素cout<<"所给数组的最小值为:"<<select(a,n,1)<<endl;end=clock();printf("The time is %6.3f",(double)(end-start-over)/CLK_TCK); //显示运行时间cout<<endl;system("pause");return 0;}//计算a[0:n-1]中第k小元素//假设a[n]是一个键值无穷大的元素template<class Type>Type select(Type a[],int n,int k){if(k<1 || k>n){cout<<"请输入正确的k!"<<endl;return 0;}return select(a,0,n-1,k); //如果输入合法则进行选择,找出要求的解}//计算a[l:r]中第k小元素template<class Type>Type select(Type a[],int l,int r,int k){while(true){if(l>=r) //此种情况表示只有一个元素{return a[l];}int i = l;int j = r+1;Type pivot = a[l]; //轴值每次都选择最左边的元素//以划分基准为轴做元素交换while(true){ //将<pivot的元素换到轴值左边//将>pivot的元素换到轴值右边while(a[++i]<pivot);while(a[--j]>pivot);if(i>=j){break;}Swap(a[i],a[j]);}if(j-l+1 == k) //如果轴值是要选的元素即第k小{return pivot;}//如果轴值不是要选的元素//a[j]必然小于等于pivot,做最后一次交换,满足左侧比pivot小,右侧比pivot大a[l] = a[j];a[j] = pivot;//对子数组重复划分过程if(j-l+1<k) //第k小在pivot的右边部分{k = k-j+l-1;//右侧:k-(j-l+1)=k-j+l-1l = j + 1;}else//第k小在pivot的左边部分{r = j - 1;}}}template <class Type>inline void Swap(Type &a,Type &b){Type temp = a;a = b;b = temp;}//随机洗牌算法template<class Type>void Shuffle(Type a[],int n){static RandomNumber rnd; //随机数类for(int i=0; i<n; i++){int j = rnd.Random(n-i)+i; //随机生成i~n之间的整数Swap(a[i],a[j]); //随机选取的数作为基准值}}RandomNumber.h#include"time.h"const unsigned long maxshort=65536L;const unsigned long multiplier=1194211693L;const unsigned long adder=12345L;class RandomNumber //定义一个随机数类{private://当前种子unsigned long randSeed;public://构造函数,默认值表示由系统自动生产种子RandomNumber(unsigned long s=0);unsigned short Random(unsigned long n);//产生0~n-1之间的随机整数double fRandom(void);//产生[0,1)之间的随机实数};RandomNumber::RandomNumber(unsigned long s)//产生种子{if(s==0){randSeed=time(0);//用系统时间产生种子}else{randSeed=s;//由用户提供种子}}//产生0~n-1之间的随机整数unsigned short RandomNumber::Random(unsigned long n){randSeed=multiplier*randSeed+adder; //线性同余式return (unsigned short)((randSeed>>16)%n);。