管理统计学经典计算题
管理统计学试题(1)

A卷一、单项选择1、在企业统计中,下列标志中属于数量标志的是( C )A、文化程度 B. 职业 C. 月工资 D. 行业2、下列属于相对数的综合指标有( B )A、国民收入 B. 人均国民收入C、国内生产净值 D. 设备台数3、下列各项中,属于时点指标的是( A )A、库存额 B. 总收入 C. 平均收入 D. 人均收入4、无偏估计是指( B )A、样本统计量的值恰好等于待估的总体参数B、所有可能样本估计值的数学期望等于待估总体参数C、样本估计值围绕待估总体参数时期误差最小D、样本量扩大到和总体单元相等时与总体参数一致5、时间数列的构成要素(B )A、变量和次数 B. 时间和指标数值C、时间和次数 D. 几何平均数6、把样本总体中全部单位数的集合称为( C )A、样本B、小总体C、样本容量D、总体容量7、下列属于时期指标的是(A )A、工业总产值B、学生人数C、设备台数D、土地面积8、狭义指数是反映(A )数量综合变动的方法A、有限总体B、无限总体C、复杂总体D、简单总体9、一组数据中出现频率最多的变量值称为(A )A、众数B、中位数C、四分位数D、平均数10、一个由500人组成的随机样本表明,乘坐公共交通工具上班的工作人员,平均每月的交通费支出是20元,离散系数为0.4,则标准差为( D )A、80B、0.02C、4D、811、在用样本统计量估计总体参数时,估计量的评价标准之一就是使它与总体参数的离差越小越好。
这种评价标准称为( B )A、无偏性B、有效性C、一致性D、充分性12、对某单位200名职工的工资收入情况进行调查,则总体单位是( B )A、200名职工B、200名职工的工资总额C、每名职工D、每名职工的工资13、以下属于品质标志的有(B )A、产品产量B、老王是男性C、劳动生产率D、会计班50人14、根据你的判断,下面的相关系数取值错误的是( C )A、-0.86B、0.87C、1.25D、015、统计总体的基本特征是( A )A、同质性,数量性B、具体性,数量性C、大量性,同质性D、总体性,社会性二、多项选择题1、下列属于数量指标的是(ABCDE )A 、平均年龄B 、人均国民收入C 、产品质量D 、资金利润率E 、上缴税利额2、全面调查包括( CE )A 、重点调查B 、抽样调查C 、普查D 、典型调查E 、统计年报3、在全国人口普查中,( ACDE )A 、全国人口是统计总体B 、每个人是总体单位C 、性别是品质标志D 、年龄是变量E 、人口平均寿命是统计指标4、下列指标中,属于时点指标的有( ABE )A 、企业个数B 、机器台数C 、产品质量D 、利润总额E 、学生人数5、在编制指数时,商品销售量指数和商品价格指数中的同度量因素应该是( AC )A 、商品销售单位B 、 平均工资水平C 、商品销售量D 、职工人数E 、商品销售额三、判断题1、统计一词包含统计工作、统计资料、统计学三种含义 ( √ )2、调查单位和填报单位在任何情况下都不可能一致 ( × )3、随机性是抽样调查的特点之一4、对全国各大型钢铁生产基地的生产情况进行调查,以掌握全国钢铁生产的基本情况。
管理统计学练习题及答案资料
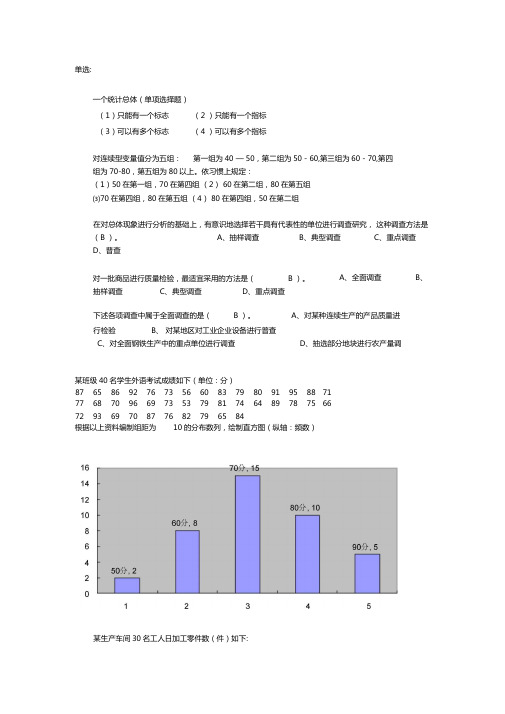
单选:一个统计总体(单项选择题)(1)只能有一个标志(2 )只能有一个指标(3)可以有多个标志(4 )可以有多个指标对连续型变量值分为五组:第一组为40 — 50,第二组为50 - 60,第三组为60 - 70,第四组为70-80,第五组为80以上。
依习惯上规定:(1)50在第一组,70在第四组(2) 60在第二组,80在第五组⑶70在第四组,80在第五组(4) 80在第四组,50在第二组在对总体现象进行分析的基础上,有意识地选择若干具有代表性的单位进行调查研究,这种调查方法是(B )。
A、抽样调查B、典型调查C、重点调查D、普查对一批商品进行质量检验,最适宜采用的方法是( B )。
下述各项调查中属于全面调查的是( B )。
A、对某种连续生产的产品质量进行检验B、对某地区对工业企业设备进行普查某班级40名学生外语考试成绩如下(单位:分)87 65 86 92 76 73 56 60 83 79 80 91 95 88 71 77 68 70 96 69 73 53 79 81 74 64 89 78 75 66 72 93 69 70 87 76 82 79 65 84根据以上资料编制组距为10的分布数列,绘制直方图(纵轴:频数)某生产车间30名工人日加工零件数(件)如下:A、全面调查B、抽样调查C、典型调查D、重点调查C、对全面钢铁生产中的重点单位进行调查D、抽选部分地块进行农产量调30 26 42 41 36 44 40 37 37 25 45 29 43 31 36 36 49 34 47 33 43 38 42 32 34 38 46 43 39 35要求:根据以上资料分成如下几组:25- 30, 30- 35, 35- 40, 40- 45 , 45- 50,计算出各组的频数和频率,整理编制次数分布表。
30名二人日加工零件滋次数分布表为:某工厂12名工人完成同一工件所需的时间(分钟)为:31 34 29 32 35 38 34 30 29 32 31 26 32试计算这些数据的众数,极值,极差,平均数,中位数,下四分位数,上四分位数。
管理统计学计算题复习

【例】某投资银行25年的年利率分别是:1年 3%,4年5%,8年8%,10年10%,2年 15%,求平均年本利率。
f fn f1 f2 XG x1 x2 xn
xf
500 800 300 1600
m x
f
m 平均价格H m 87000 54 . 38 ( 元 ) x 1600
总体标志总量 总体单位总量
课堂练习
[资料]甲乙企业职工的工资如下表:
月工资(元) 800 元以下 800-1000 1000-1200 1200-1500 1500 以上 合 计 甲企业每组 乙企业每组职 工资总额(元) 工人数(人) 7000 12 13500 18 22000 30 24300 16 11550 4
批次 第一批 第二批 第三批 合计 价格(元/千克) 采购金额 (元)
x
m
50 55 60 —
25000 44000 18000 87000
解:该厂原材料采购价格和采购金额
批次 第一批 第二批 第三批 合计 价格(元/千克) 采购金额 (元) 采购量(千克)
x
m
50 55 60 —
25000 44000 18000 87000
合计
3000
—
—
某乡农民家庭人均纯收入及分组资料表所示, 分别用向上累计和向下累计求中位数。
家庭平均年 农民家庭 纯收入(元) 数(户) 800-1000 1000-1200 1200-1400 1400-1600 1600-1800 1800-2000 2000-2200 2200-2400 240 480 1050 600 270 210 120 30 农户数累计(户) 向上累计 240 720 1770 2370 2640 2850 2970 3000 向下累计 3000 2760 2280 1230 630 360 150 30
管理统计学考试题及答案

管理统计学考试题及答案A)三种;(B)五种;(C)七种;(D)九种。
4.矩估计法是用什么来估计总体矩?(A)A)样本矩;(B)样本均值;(C)样本方差;(D)样本标准差。
5.判断估计优劣的标准有哪些?(D)A)无偏性;(B)最小方差性;(C)一致估计性;(D)以上都是。
6.什么是测量的信度?(A)A)多次测量的结果的稳定性或一致性;(B)测量结果的准确性;(C)测量结果的可靠性;(D)测量结果的精度。
7.什么叫做总体?(A)A)所研究对象的全体;(B)样本中的元素;(C)数据的类别;(D)数据测度的方法。
8.什么叫做个体?(B)A)数据的类别;(B)总体中的元素;(C)所研究对象的全体;(D)样本中的元素。
9.什么叫做简单随机样本?(C)A)所有个体被抽到的机会不均等;(B)随机抽样中产生的一组随机变量X;(C)每个个体被抽到的机会均等;(D)抽样时需要考虑样本的分层结构。
10.什么是统计量?(D)A)未知参数的随机变量;(B)总体的元素;(C)样本的元素;(D)不含未知参数的随机变量的函数。
14.从某厂生产的彩电中任取9台测得平均寿命为15万小时,样本标准差为0.05小时。
现在要检验这批彩电的寿命均值是否为16万小时。
假设H0为寿命均值为16万小时,H1为寿命均值大于16万小时。
根据样本数据,计算得到t值为-60,查表得到在显著性水平为0.05时,t分布的临界值为1.833.因为t值小于临界值,所以接受H0,即这批彩电的寿命均值为16万小时。
15.设某因素有S个水平,它们均服从正态分布,即N(μ,σ)。
其中,Xij表示第i个水平的第j个个体。
现在要检验假设H0:μ1=μ2=…=μs,即不同水平的总体均值相同,H1为至少有两个水平的总体均值不同。
根据题意,我们可以计算出SST、SSA和SSE,然后代入公式F=(SSA/(s-1))/(SSE/(n-s))中计算F值。
根据F分布表,查找在显著性水平为0.05时的临界值Fα。
管理统计学考试题及答案

≤管理统计学≥练习题一、填空题1. 什么叫做总体: 所研究对象的全体 。
什么叫做个体: 总体中的元素 。
2. 试述简单随机样本: 随机抽样中产生的一组随机变量n X X X ,,21每个个体被抽到的机会均等。
3. 常用的综合抽样方法有:分层抽样,整群抽样,系统抽样4. 统计量: 不含未知参数的随机变量12,,n X X X 的函数。
5. 总体未知参数的估计有 点估计 和 区间估计 两种估计方法。
6. 数据测度的类别有 比率级,间距级,序次级,名义级,数据。
7. 当n 充分大时 近似地服从均值为 μ标准差为的正态分布。
(中心极限定理)8. 测量的信度: 多次测量的结果的稳定性或一致性 ;9. 设12n x x x ⋅⋅⋅是正态分布2(,)N μσ的样本观察值,则2,μσ的极大似然估计值为:1ˆˆi x x n μ==∑,221ˆ()ix x nσ=-∑。
10. 设n X X X ,,21是正态分布),(2σμN 的样本,则2,σμ的极大不显然估计量为:1ˆi X X n μ==∑,221ˆ()i X X nσ=-∑ 11. 设n X X X ,,21是正态分布),(2σμN 的样本,1ˆi X X nμ==∑是参数μ的 无偏估计 ,但221ˆ()i X X n σ=-∑不是2σ的 无偏估计 。
12. 普查: 收集有限总体中每个个体的有关指标值 。
抽样调查: 在总体中选择一部分个体进行调查,从所了解的局部信息来推断总体的信息 。
13. 常用的调查方法有:(1)电话访谈 (2)邮件访谈 (3)人员访谈 (4)电子邮件访谈 (5)网络问卷和BBS 等其他电子方式的访谈 。
14. 矩估计法: 用样本矩来估计总体矩 。
15. 判断估计优劣的标准 无偏性,最小方差性,一致估计性 。
16. 设X 为测量变量,T 为变量X 的真值,S 为系统偏误,R 为随机偏误,则=X T S R ++。
若0=R ,多次测量一个结果都是不变的,则这个测量结果是 完全可信的 ;反之,R 越大,这个变量的测量越不可信。
管理统计学期末复习典型例题

统计学是一门收集、整理和分析数据的方法科学,其目的是探索数据的内在数量规律性,以达到对客观事物的科学认识。
包括:1.数据搜集:例如,调查与试验;2.数据整理:例如,分组;3.数据展示:例如,图和表;4.数据分析:例如,回归分析。
统计学的分科:按内容分为描述统计学(描述数据特征;找出数据的基本规律)和推断统计学(对总体特征作出推断);按性质分为理论统计学(统计学的一般理论和数学原理)和应用统计学(在各领域的具体应用)。
一、描述统计学的典型例题【例3.3】某生产车间50名工人日加工零件数如下(单位:个)117 122 124 129 139 107 117 130 122 125108 131 125 117 122 133 126 122 118 108110 118 123 126 133 134 127 123 118 112112 134 127 123 119 113 120 123 127 135137 114 120 128 124 115 139 128 124 121要求:请对上述数据进行分组,编制频数分布表;绘制直方图,并对该情况进行简要的分析说明可以按Sturges 提出的经验公式来确定组数K=1+lgn/lg2确定各组的组距:组距=( 最大值- 最小值)÷组数等距分组表(上下组限重叠——不重不漏:左闭右开)(上下组限间断)面积来表示各组的频数分布;在直角坐标中,用横轴表示数据分组,纵轴表示频数或频率,各组与相应的频数就形成了一个矩形,即直方图(Histogram);直方图下的总面积等于1。
分组数据—直方图(直方图的绘制)对该情况进行简要的分析说明(略)【例3.4】在某地区调查120名刚毕业参加工作的研究生月工资收入,进行分组求该120名刚毕业参加工作的研究生月工资收入的平均数、中位数和标准差。
计算过程(略)1)如果资料已经分组,组数为k ,用x1,x2 ,…,xk 表示各组中点,f1,f2…,fk=(19×2500+30×3500+42×4500+18×5500+11×6500)/120=4266.7 2)一组n 个观测值按数值大小排列,处于中央位置的值称为中位数以 表示 3)样本标准差:对于已分组的频数分布(组数为k )【例4.4】[P49习题6]一图书馆每天平均登记 μ =320本,标准差为 σ =75本。
(完整word版)《管理统计学》复习资料(计算部分).doc

(完整word版)《管理统计学》复习资料(计算部分).doc《管理统计学》复习资料(计算部分)一、算术平均数和调和平均数的计算加权算术平均数公式xxf xxf(常用)ff( x 代表各组标志值,f 代表各组单位数,f 代表各组的比重)f加权调和平均数公式xmm 代表各组标志总量)( x 代表各组标志值, mx1.某企业 2003 年某月份生产资料如下:按工人劳动生产率分组(件 / 人)生产班组实际产量(件)50-60 3 8250 60-70 5 6500 70-80 8 5250 80-902 2550 90- 10024750计算该企业的工人平均劳动生产率。
分析:工人平均劳动生产率 x总产量 m(结合题目)总工人人数mx组中值 x按工人劳动生产率分组(件 / 人) x生产班组实际产量(件) m工人数mx55 50- 60 3 8250 65 60- 70 5 6500 75 70- 80 8 5250 8580- 90 2 2550 9590-10024750从公式可以看出,“生产班组”这列资料不参与计算,是多余条件,将其删去。
其余两列资料,根据问题“求平均××”可知“劳动生产率”为标志值 x ,而剩余一列资料“实际产量”在公式中做分子,因此用调和平均数公式计算,并将该资料记作m 。
每一组工人数每一组实际产量劳动生产率,即m。
x同上例,资料是组距式分组,应以各组的组中值来代替各组的标志值。
m 8250 6500 5250 2550 4750 27300 (件 /人)解: x8250 6500 5250 2550 475068.25m 400x55 65 75 85952.若把上题改成:按工人劳动生产率分组(件/ 人)生产班组生产工人数(人)50-60 3 15060-70 5 10070-80 8 7080-90 2 3090 以上 2 50计算该企业的工人平均劳动生产率。
统计管理试题及答案

统计管理试题及答案一、单项选择题(每题2分,共10分)1. 统计数据的收集方法不包括以下哪一项?A. 观察法B. 实验法C. 调查法D. 推断法答案:D2. 以下哪个不是统计学的主要研究对象?A. 数据B. 信息C. 现象D. 规律答案:B3. 描述统计数据集中趋势的指标不包括以下哪一项?A. 平均数B. 中位数C. 众数D. 方差答案:D4. 以下哪个不是统计分析的主要步骤?A. 数据收集B. 数据整理C. 数据分析D. 数据解释答案:D5. 以下哪个是描述统计数据离散程度的指标?A. 标准差B. 均值C. 众数D. 频数答案:A二、多项选择题(每题3分,共15分)1. 统计数据的类型包括以下哪些?A. 定量数据B. 定性数据C. 离散数据D. 连续数据答案:A、B2. 统计分析中常用的图表包括以下哪些?A. 条形图B. 折线图C. 饼图D. 散点图答案:A、B、C、D3. 以下哪些是统计分析中常用的描述性统计方法?A. 均值B. 方差C. 标准差D. 相关系数答案:A、B、C4. 统计学中,以下哪些是概率分布?A. 正态分布B. 二项分布C. 泊松分布D. 均匀分布答案:A、B、C、D5. 以下哪些是统计分析中常用的假设检验方法?A. t检验B. 卡方检验C. F检验D. 非参数检验答案:A、B、C、D三、简答题(每题5分,共20分)1. 简述统计学的定义及其在现代社会中的重要性。
答案:统计学是一门应用数学科学,主要通过收集、分析、解释和展示数据来帮助人们做出决策。
在现代社会中,统计学在商业、医学、社会科学、政府决策等领域都有着广泛的应用,它帮助人们理解数据背后的模式和趋势,从而做出更加科学和合理的决策。
2. 描述统计学中“总体”和“样本”的概念。
答案:在统计学中,“总体”指的是研究对象的全部个体,而“样本”则是从总体中抽取的一部分个体。
样本用于代表总体,通过对样本的研究来推断总体的特征。
3. 解释统计学中的“置信区间”和“置信水平”。
管理统计学练习题答案

管理统计学练习题作案1.用简单随机重复抽样方法选取样本时,如果要使抽样平均误差降低50%,则样本容量需要扩大到原来的:A 2倍;B 3倍;C 4倍;D 5倍正确答案:C单选题2.任一随机事件出现的概率为:A 大于0;B 小于0;C 不小于1;D 在0与1之间正确答案:D单选题3.为调查某学校学生的上网时间,从一年级学生中抽取80名,从二年级学生中抽取60名,三年级学生中抽取50名进行调查。
这种调查方法是:A 简单随机抽样;B 整群抽样;C 系统调查;D 分层调查正确答案:D单选题4.以下属于数量综合指数的是:A 产量综合指数;B 价格综合指数;C 销售额综合指数;D 成本综合指数正确答案:A单选题5.对一个假设检验问题而言的检验统计量,和对一组特定的样本观察值而言的检验统计量分别是:A 确定的量和随机变量;B 随机变量和确定的量;C 确定的量和确定的量;D 随机变量和随机变量正确答案:B单选题6.对两变量的散点图拟合最好的回归线必须满足一个基本条件是:A 因变量的各个观察值与拟合值差的和为最大;B 因变量的各个观察值与拟合值差的和为最小;C 因变量的各个观察值与拟合值差的平方和为最大;D 因变量的各个观察值与拟合值差的平方和为最小。
正确答案:D单选题7.在计算指数的公式中,同度量因素的选择时期是:A 报告期;B 基期;C 分母为基期,分子为报告期;D 分子分母为同一时期正确答案:D单选题8.对于总体单位在被研究的标志上有明显差异的情形,适宜于:A 等距抽样;B 分层抽样;C 简单随机抽样;D 多阶段抽样正确答案:B单选题9.定基发展速度与环比发展速度之间的关系表现为定基发展速度等于相应各环比发展速度:A 的连乘积;B 的连乘积再减去100%;C 之和;D 之和再减去100%正确答案:A单选题10.在方差分析中,反映样本数据与其组平均值差异的是:A 总体离差平方和;B 组间误差;C 抽样误差;D 组内误差正确答案:D单选题11.在建立与评价了一个回归模型以后,我们可以:A 估计未来所需要样本的容量;B 计算相关系数与判定系数;C 以给定因变量的值估计自变量的值;D 以给定自变量的值估计因变量的值。
《管理统计学》——期末考试参考答案

《管理统计学》——期末考试参考答案一、单选题1.两个总体平均数不等,但标准差相等,则( )。
A.平均数小,代表性大B.平均数大,代表性大C.两个平均数代表性相同D.无法判断正确答案:B2.统计指标按所反映总体现象的内容不同可以分为数量指标和质量指标,其中数量指标的表现形式是( )。
A.绝对数B.相对数C.平均数D.百分数正确答案:A3.下列各项中,应采用加权算术平均法计算的是( )。
A.已知各企业劳动生产率和各企业产值,求平均劳动生产率B.已知计划完成百分比和计划产值,求平均计划完成百分比C.已知计划完成百分比和实际产值,求平均计划完成百分比D.已知生产同种产品各企业的产品单位成本和总成本,求平均单位成本正确答案:B4.总量指标数值大小( )。
A.随总体范围扩大而增加B.随总体范围扩大而减少C.随总体范围缩小而增大D.与总体范围大小无关正确答案:A5.在分组数列中,各组变量值都增加2倍,每组次数都减少二分之一,算数平均数( )。
A.不变B.增加2倍C.减少二分之一D.无法确定正确答案:B6.调查几个大型钢铁企业,就可以了解我国钢铁生产的基本情况,这种调查属于( )。
A.普查B.典型调查C.重点调查D.抽样调查正确答案:C7.相关分析和回归分析相辅相成,又各有特点,下面正确的描述有( )。
A.在相关分析中,相关的两变量都不是随机的B.在回归分析中,自变量是随机的,因变量不是随机的C.在回归分析中,因变量和自变量都是随机的D.在相关分析中,相关的两变量都是随机的正确答案:D8.比较相对指标可用于( )的比较。
A.实际水平与计划水平B.先进单位与落后单位C.总体某一部分数值与另一部分数值D.同类现象不同时期正确答案:B9.组距式变量数列的组中值是( )。
A.组限变动范围内的一个变量值B.上限与下限的中点C.在组内的一个变量值D.总体单位的一个变量正确答案:B10.“统计”一词的三种含义是( )。
A.统计工作、统计资料和统计学B.统计调查、统计整理和统计分析C.统计设计、统计分析和统计预测D.统计方法、统计分析和统计预测正确答案:A11.规定普查的标准时点旨在保证调查资料的( )。
《管理统计学》习题参考答案

《管理统计学》作业参考答案统计推断(P147—148)5.解:设7.6:7.6:10>↔≤μμH H11.3200/5.27.625.7/0=-=-=nS x U μ当α=0.01时,33.201.0=>u U ,所以拒绝原假设,即当α=0.01时,现今每个家庭每天看电视的平均时间较10年前显著增大。
6.解:设211210::μμμμ>↔≤H H233.250140165.278224823801121=+-=+-=n n S y x t T当α=0.05时,)88(05.0t t >,拒绝0H ,故在置信水平为95%时可以认为第一分店的营业额高于第二分店的营业额。
当α=0.01时,)88(05.0t t <,接受0H ,故在置信水平为99%时还没有充分的把握说明第一分店的营业额高于第二分店的营业额。
9.解:这是一个成对比较问题设0:0:10>↔≤d d H H μμ且3486.0,375.0==d d s x ,()83311.19t 0.05=402.310/3486.0375.0/*===dd d n S x t当α=0.05时,)9(05.0*t t >,拒绝原假设,即显著性水平为5%时可以判断人的情感更显著地表现在左脸上。
非参数检验1.(P 168)解:设:0H 消费额与分店位置无关,:1H 消费额与分店位置有关根据题意可以计算理论频数得列联表如下:由于()()84146.3)1(,111,2,2205.0==--==χb a b a ,而接受0H ,即有95%的把握说明消费额与分店位置无关。
84146.3)1(07788.2)(205.022=<=-=∑χχEE O回归分析和相关分析(P136)1.解:图中数据如下:x y nx bnyx b y a S S b y x n y x y y x x S y n y y y S x n x x x S n y x y x y xiixxxy ii i i i n i i xy i i ni i yy i i ni i xx i i i i i i0535.49491.243因此9491.243103270535.4103765,0535.41.4505.1824故5.182437653271011249401))((5.900237651011426525)(1)(1.45032710111143)(1)(10,1426525,11143,124940,3765,327122*********2+==⨯-=-=-=====⨯⨯-=-=--==⨯-=-=-==⨯-=-=-=======∧∧∧∧∧===∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑直线回归方程为:(1)相关系数906375.05.90021.4505.1824 =⨯==yyxx xy S S S r(2)当广告费为30万元时,该周销售额的区间估计为:()()()()()()0817.400,0265.3311.4507.32301011306.21722.14300535.49491.243)(11)2(1722.148/81.1606210/7.32,81.16065.9002906375.011,306.22102202/0222/05.0=-++⨯⨯±⨯+=⎪⎪⎭⎫ ⎝⎛-++-±+∈==-===⨯-=-==-∧∧xx yy S x x n n st x b a y RSS s x S r RSS t α(3)当广告费为42万时周平均销售额的95%置信区间为:()()8607.431,5315.3961.4507.3242101306.21722.14420535.49491.243)(1)2(2202/0=-+⨯⨯±⨯+= ⎝⎛⎪⎪⎭⎫-+-±+∈+∧∧xx S x x n n st x b a bx a α时间序列(P219)解:题中数据可整理如下:(1)、因此有:ty n t b n y t b y a t t n y t ty n S Sb n t ty y t tttttty tt835.0595.94趋势故595.9414105835.0141412835.01102510151414121051078014)(14,1015,10780,1412,105222+==⨯-=-=-==-⨯⨯-⨯=--=======∧∧∧∧∧∑∑∑∑∑∑∑∑∑∑∑方程为:直线(2)、对于加法模型,有S=y-T ,根据实际数据和直线趋势方程,得下表:把同一季节的因子作一平均,得季度平均值,如下表所示:因5.310+(-6.025)+(-9.440)+10.392=0.237,故修正因子05925.04237.0==L ,每个季节因子减去L 得修正后季节因子为:5.251,-6.084,-9.499,10.333。
《管理统计学》综合练习题

1 、如图所示,是一个正态曲线。
试根据图象写出其正态分布的概率密度函数的解析式,并求出总体随机变量的期望和方差。
解:从正态曲线的图象可知,该正态曲线关于直线x=20对称,最大值为错误!,所以μ=20,错误!=错误!,于是概率密度函数的解析式为φμ,σ(x)=错误!e-错误!,x∈(-∞,+∞)。
总体随机变量的期望是μ=20,方差是σ2=(2)2=2。
2、已知随机变量ξ服从正态分布N(2,σ2),且P(ξ〈4)=0.8,求P(0<ξ〈2)解:∵P(ξ〈4)=0.8,∴P(ξ〉4)=0.2,由题意知图象的对称轴为直线x=2,P (ξ<0)=P(ξ>4)=0。
2,∴P(0〈ξ〈4)=1-P(ξ<0)-P(ξ〉4)=0.6.∴P(0<ξ〈2)=错误!P(0〈ξ<4)=0.3。
3、在一次测试中,测量结果X服从正态分布N(2,σ2)(σ>0),若X在(0,2)内取值的概率为0。
2,求:(1)X在(0,4)内取值的概率;(2)P(X>4).解:(1)由于X~N(2,σ2),对称轴x=2,画出示意图,∵P(0<X<2)=P(2<X<4),∴P(0<X<4)=2P(0<X<2)=2×0.2=0.4。
(2)P(X>4)=错误![1-P(0<X<4)]=错误!(1-0。
4)=0。
3。
4、某年级的一次信息技术测验成绩近似服从正态分布N(70,102),如果此年级共有1 000名学生,求:(1)成绩低于60分的约有多少人?(2)成绩在80~90内的约有多少人?解:(1)设学生的得分情况为随机变量X,X~N(70,102),则μ=70,σ=10。
分析在60~80之间的学生的比为P(70-10<X≤70+10)=0.682 6 所以成绩低于60分的学生的比为错误!(1-0。
682 6)=0.158 7,即成绩低于60分的学生约有1 000×0。
158 7≈159(人)。
管理统计学试卷(含答案)

管理统计学试卷(含答案)统计学试卷C(含答案及评分标准)一、单项选择题每小题1分共10分。
(请将唯一正确答案序号写在括号内)A)13%,C.总体各单位标志值的变异D.组内方差的平均值5.在其他条件相同的前提下:重复抽样误差(A)A.大于不重复抽样误差;B.小于不重复抽样误差C.等于不重复抽样误差;D.何者更大无法判定;6.所谓显着水平是指(A)A.原假设为真时将其接受的概率;B.原假设不真时将其舍弃的概率;C.原假设为真时将其舍弃的概率;D.原假设不真时将其接受的概率;)。
Array 8.(C)二、多项选择题每小题2分共10分(正确答案包含1至5项,请将正确答案的序号写在括号内,错选、漏选、多选均不得分)ADE)。
A.国内生产总值;B.商品库存额;C.人口数;D.出生人数;E.投资额;2..四分位差和标准差的计量单位是(CE)。
A.与总体单位本身的计量单位相同;B.通常以百分数作为三、判断题每小题1分共10分(请在各小题的号内标明,正确打√,错误打х)2.当原假设为假时接受原假设,称为假设检验的第一类错误(X)。
3.产品的单位成本随产量增加而下降,称两者存在负相关。
(√))(X)字,1.众数众数是统计总体或分布数列中出现的频数最多、频率最高的标志值。
在分布曲线图上,它就是曲线最高峰所对应的标志值。
2.调和平均数调和平均数是各标志值倒数平均数的倒数。
3.整群抽样整群抽样就是将总体各单位分成若干群,然后从其中随机抽取部分群,对中选的群进行全面调查的抽样组织方式。
字,1.答:统计研究的全过程包括:(答出各个环节给4分,完整性1分)(一)统计设计。
根据所要研究问题的性质,在有关学科理论的指导下,制定统计指标、指标体系和统计分类,给出统一的定义、标准。
提出收集、整理和分析数据的方案和工作进度等。
(二)收集数据。
统计数据的收集有两种基本方法:实验法和统计调查。
(三)整理与分析。
包括描述统计和推断统计。
(四)统计资料的积累、开发与应用2.为什么人们明知彩票中奖的概率很低仍然去购买彩票。
统计专题训练经典练习题(含答案)

统计专题训练经典练习题(含答案)统计专题训练经典练题(含答案)以下是一些统计学的经典练题,附带答案供参考。
1. 对于一个班级的学生成绩,已知平均分为75分,标准差为5分。
如果班级总人数为100人,问有多少学生的成绩在65分以上?答案:根据正态分布的性质,我们可以应用标准正态分布表,计算得到 z 值为 (65-75)/5 = -2,查表得到对应的累积概率为 0.0228,因此在65分以上的学生人数约为0.0228 * 100 ≈ 2.28,即约有 2 名学生的成绩在65分以上。
2. 一家工厂生产的产品长度服从正态分布,平均长度为10cm,标准差为0.5cm。
若从该工厂中随机抽取50个产品,问有多少产品的长度在9.5cm至10cm之间?答案:由于从该工厂中抽取的产品长度服从正态分布,我们可以计算出抽样分布的均值和标准差为 10cm 和0.5cm/sqrt(50) ≈0.0707cm。
然后,我们可以将区间 [9.5cm, 10cm] 转化为 z 值计算区间内的概率。
计算得到 z 值为 (10-9.5)/0.0707 ≈ 7.07,查表得到对应的累积概率为 0.9999。
因此,在9.5cm至10cm之间的产品数量约为0.9999 * 50 ≈ 49.995,即约有 50 个产品的长度在9.5cm至10cm之间。
3. 某次调查发现,两种不同品牌的汽车在某一地区的市场占有率的估计值分别为 0.60 和 0.40,并且总样本量为 5000。
现在需要对这一地区汽车市场占有率的差异进行检验。
问如何构建零假设和备择假设?并说明该检验的类型。
答案:对于差异检验,我们可以构建如下的零假设和备择假设:零假设(H0):两个品牌的汽车市场占有率没有差异,即 p1= p2。
备择假设(H1):两个品牌的汽车市场占有率存在差异,即p1 ≠ p2。
该检验属于双侧检验,因为备择假设是双向的,即可能两个品牌的市场占有率存在大于和小于的差异。
管理统计学习题参考答案第三章

第三章1. 解:反映集中趋势的指标有众数、中位数、均值;反映离中趋势的指标有极差、四分位差、标准差、变异系数。
2. 解:正态分布下,众数=中位数=均值; 正偏态下,众数<中位数<均值; 负偏态下,众数>中位数>均值。
3. 解:将数据从小到大依次排序为12,17,19,21,22,23,25,26,27,28,30,32,34,36,38,39,39,41,42,56。
众数0M =39,中位数e M =(28+30)/2=29,均值x =607/20=30.354. 解:由于标准差受计量单位大小的影响,还受到数据均值水平的影响,于是,计算变异系数反映相对离散程度的指标来消除这些影响。
5. 解:将数据从小到大依次排序为12,17,19,21,22,23,25,26,27,28,30,32,34,36,38,39,39,41,42,56。
极差R =56-12=44四分位差()[]()[]51538397502222232503813...Q Q RQ =-⨯+--⨯+=-= 标准差σ = 10.20变异系数V =10.20/30.35=0.346. 解:工龄的均值、标准差、变异系数如下:均值x = 7 标准差 σ = 2.05 变异系数V = 2.16/7=0.29年工资的均值、标准差和变异系数如下: 均值 x = 280 标准差 σ =96.75变异系数V = 96.75/280=0.35由于工龄的变异系数 < 年工资的变异系数,年工资的离散程度更大。
7. 解:相关系数是指协方差与两个标准差之比,记为r ,则有r = 6xy /(6x 6y )其中协方差的大小会受到计量单位和数据均值水平的影响,从而使不同相关总体之间的相关程度缺乏可比性。
为了使不同相关总体之间的相关程度具有广泛的可比性,需要计算相关系数。
公司10名员工的工龄(X)与工资(Y)相关计表协方差184σ1840/10==xy相关系数r =184/(2.05×96.75)=0.938. 解:平均指标反映的是统计数据的集中趋势,变异系数反映的是统计数据的离中趋势,偏度则是测定统计数据的非对称程度。
管理统计学复习题及答案

(2) 对该企业所生产的产品的说明,你的结论是什么? (3) 计算统计量的 P-值。
14、某厂计划购进一台机器用来生产铝合金薄板,现有三种型号的机器均可用来生 产规格相同的铝合金薄板。为了引入一台优良的机器,现对三种型号的机器分别做实验, 测量薄板的厚度精确到千分之一厘米。作实验的结果以及用 SPSS 对结果进行分析的部分 信息如下述两个表:
11、一图书馆平均每天登记 320 本书,标准差为 80 ,考虑营业的 36 天为一 个样本, x 为每天登记书的数量的样本平均值。
(1) 说明 x 的抽样分布? (2) 这 36 天里样本均值为 305 350 的概率为多少? (3) 这 36 天里样本均值大于等于 326 的概率为多少?
12、检验某一食品灌装生产线时,对其充入食品重量的精度做出如下假设。
----------- ------
(2) 判断可否认为三台机器生产得到的铝合金板厚度没有差异? ( 0.05 ,
F0.05 (2,12) 3.89 )
15、现要研究某公司的广告支出费用(X)和该公司的销售额(Y)之间关系,已知该公司
广告支出费用和销售额的统计数据以及相关数据的处理结果如下表(不考虑单位)。
8
2
X ) i1 i
0.995 8 2 Y i1 i
(
8 i1
X
i
)2
8
(
8
i1Yi
)2
8
则在 x0=16 处, Ŷ0 = 2.09+1.931×16=32.986 (2)由
| t || b1 || S (b1 )
b1
MSE
| 35.542 t0.025(6) 0.7176
天津大学管理统计学试题汇总

第四章统计抽样与抽样分布1. 某工厂生产钢板,据统计,其长度服从正态分布,且平均数u=30.5厘米,标准擦σ=0.2厘米。
试问:从这一总体随即取出一块钢板,长度在30.25厘米和30.75厘米之间的概率是多大?2. 某小组五个工人的周工资分别为140元,160元,180元,200元,220元,现在用重复抽样的方法从中抽出2个工人的工资构成样本。
要求:(1)计算总体工人平均工资和和标准差(2)列出样本平均工资的抽样分布3. 某保险公司的老年人寿保险共有10000人参加,每人每年交200元。
若老人在该年内死亡,公司付给家属1万元。
设老年人死亡率为0.017,试求保险公司在一年的这项保险中亏本的概率。
第五章参数估计1. 设总体X服从泊松分布:P{ X=k} = ,λ>0,k=0,1,2,……样本为(X1,,X2,……, Xn),求参数λ的极大似然估计值2. 设样本(X1,,X2,……, Xn)来自(0-1)分布总体,即概率函数f(x;p)= , x=0,1 (0<p<1)求p的极大似然估计3. 设总体X的概率密度函数为f( x,θ)= ,0<x<θ0, 其他则θ=2是θ的无偏估计量,其中=而X1,X2,……,Xn是取自X的样本4. 设总体X的数学期望E(X)存在,(X1,X2,X3)为一个样本,试证统计量ψ1(X1,X2,X3)=1/4X1+2/4X2+1/4X3ψ2(X1,X2,X3)=1/3X1+1/3X2+1/3X3ψ3(X1,X2,X3)=1/5X1+2/5X2+2/5X3都是总体期望E(X)的无偏估计量,并判别哪一个最有效5. 某车间生产的螺杆直径服从正态分布N(μ,σ2),今随机的从中抽取5只测得直径值(单位:mm)为22.3,21.5,22.0,21.8,21.4(1)已知σ=0.3,求均值μ的0.95置信区间(2)如果σ未知,求均值μ的0.95置信区间6.测量铅的密度16次,计算出=2.795,s=0.029,设这16次测量结果可以看作一正态总体X的样本观察值,试求出铅的密度X的均值的95%的置信区间7. 对某种型号飞机的飞行速度进行15次独立实验,测得最大飞行速度(单位m/s)为422.2 418.7 425.6 420.3 425.8 423.1 431.5428.2 438.3 434.0 412.3 417.2 413.5 441.3 423.7根据长期的经验,可以认为最大飞行速度服从正态分布,试求最大飞行速度的期望与标准差的置信区间8. 为了估计灯泡寿命,测试10个灯泡,得=1500h,S=20h,如果灯泡寿命服从正态分布N(μ,σ2),求μ,σ的置信区间(置信度为0.95)9. 岩石密度的测量误差X服从正态分布N(μ,σ2),先抽取容量为12的样本,计算的样本均方差S=0.2,求总体X均方差σ的90%的置信区间10. 在一批货物的容量为100的样本中,经检验,发现16个次品,试求这批货物的次品率p的95%的置信区间11. 某高教研究机构想了解一大型企业内具有大专以上文化程度的职工所占的比例,他们随机抽选了500名职工,从中发现有76人具有大专以上文化程度,是给出该企业大专以上文化程度的职工比例的0.95置信区间12. 随机地从A批导线中抽取4根,并从B批导线中抽取5根,测得其电阻为A批导线:0.143 0.142 0.143 0.137B批导线:0.140 0.142 0.136 0.138 0.140设测试数据分别取自正态总体N(μ1,σ2)和N(μ2,σ2),并且它们相互独立,又μ1,μ2以及σ2均为未知数,试求μ1-μ2的95%的置信区间13. 设二正态总体N(μ1,σ12)和N(μ2,σ22)的参数都未知,现依次取容量为25和15的两个样本,测得样本方差分别为=6.38,上=5.15,试求二总体方差比的90%的置信区间14. 某商业研究所想了解某省百货商店的平均规模,研究人员从全省随机抽选了50个百货商店作样本,测得样本均值和标准差分别为10000和4800,试求该省百货商店平均规模的0.95置信区间15. 在某城市组织职工家庭生活抽样调查,已知职工贾平平均每人每月生活费收入的标准差为10.5元,问需抽选多少户进行调查,才能以95%的把握保证对职工人均神火飞的估计误差不超过1元16. 在一所大学某次统计学科期末考试后,有36分试卷被选为样本。