上下文无关文法及其语法树
前后文无关文法和语言

第2章 前后文无关文法和语言 文法开始符号是一个特殊的非终结符,它代表文法所定义的 语言中我们最终感兴趣的语法实体,即语言的目标,而其它语 法实体只是构造语言目标的中间变量;如表达式文法的语言目 标是表达式,而程序语言的目标通常为程序。 产生式(也称产生规则或规则)是定义语法实体的一种书写规 则。一个语法实体的相关规则可能不止一个。例如,有: P→α1 P→α2 P→αn 为书写方便,可将这些有相同左部的产生式合并为一个,即 缩写成 P→α1∣α2∣„∣αn 其中,每个αi(i=1,2,„,n)称为P的一个候选式,直竖“∣” 读为“或”,它与“→”一样是用来描述文法的元语言符号 (即不属于Σ的字符)。
第2章 前后文无关文法和语言
研究程序设计语言 语法:每个程序构成的规律 语义:每个程序的含义 1、语法 -- 表示构成语言句子的各个记号之间的组合规律。 语法包括:词法规则和语法规则 例如:C语法规定了构成条件语句的各个记号的组合规律为: 第一个单词(记号)必须是”if”,然后是单词”(”、表 达式,„.。 2、语义 -- 表示各个记号的特定含义。(各个记号和记号所 表示的对象之间的关系) 对一个语言来说,不仅要给出它的词法、语法规则,而且要 定义它的单词符号和语法单位的意义。离开语义,语言只 不过是一堆符号的集合。 所谓一个语言的语义是这样的一组规则,使用它可以定义 一个程序的意义。这些规则称为语义规则。 阐明语义要比阐明语法难的多,现在还没有一种形式系统 描述语义。
有关定义和记号
符号:可以相互区别的记号(元素)。 字母表:符号(元素)的非空有穷集合。 符号串:由字母表中的符号组成的任何有穷序列 称为该字母表上的符号串。1.空符号串ε(没有 符号的符号串)是上的符号串 2.若x是上的符 号串,a是的元素,则xa是上的符号串 3. y是 上的符号串,当且仅当它可以由1和2导出。 例如: Σ={a,b} ε,a,b,aa,ab,aabba…都是上的符号串
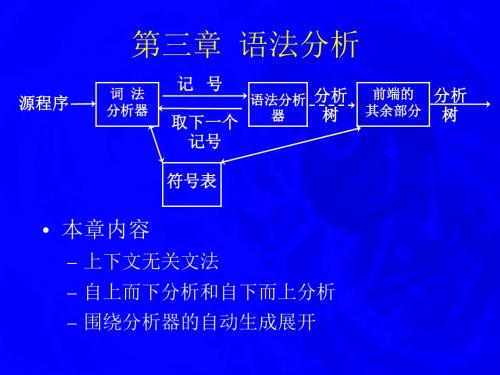
第四章语法分析

最右推导
E rm E rm (E) rm (E + E) rm (E + id) rm (id + id)
4.1 上下文无关文法
4.1.3 分析树 例 E E + E | E E | (E ) | E | id
E
E
( E ) E + E id
id
4.1 上下文无关文法
4.2 语言和文法
4.2.7 提左因子
有左因子的文法 A b1 | b2 提左因子 A A A b 1 | b 2
4.2 语言和文法
例 悬空else的文法 stmt if expr then stmt else stmt | if expr then stmt | other 提左因子
无二义的文法
stmt matched _stmt | unmatched_stmt matched_stmt if expr then matched_stmt else matched_stmt | other unmatched_stmt if expr then stmt | if expr then matched_stmt else unmatched_stmt
句型 文法G的开始符为S,S *, 可能含有非终结符, 则叫做文法G的句型。
4.1 上下文无关文法
例 E E + E | E E | (E ) | E | id 最左推导
E lm E lm (E) lm (E + E) lm (id + E) lm (id + id)
按串长进行归纳:配对括号串可由S推出
深入剖析编程语言的语法解析和词法分析技术

深入剖析编程语言的语法解析和词法分析技术编程语言的语法解析和词法分析技术是编程语言的重要组成部分,它们决定了程序的正确性和执行效率。
本文将深入剖析这两种技术,重点讨论它们的原理和应用。
一、词法分析技术词法分析是将程序的输入流(源代码)划分为一个个词法单元(Token)的过程。
词法单元是程序中的最小单元,它可以是关键字、标识符、运算符、分隔符等。
词法分析器(Lexer)根据一定的规则(正则表达式或有限自动机)将源代码分割成一系列的词法单元,并将其分类。
词法分析器的主要任务是通过有限自动机来实现对源代码的识别和切分。
有限自动机是一种状态机,它具有有限个状态和规定状态之间的转移条件。
词法分析器会对每个字符进行扫描,根据当前状态和扫描到的字符决定下一个状态,直到识别出一个完整的词法单元。
词法分析技术的主要应用是在编译器中进行关键字、标识符和常量的识别。
通过词法分析,编译器可以将源代码转换为一个个具有特定含义的词法单元,以便后续的语法分析和语义分析。
二、语法解析技术语法解析是将词法单元序列组织成一个语法树的过程。
语法树是以分层结构表示程序语句的树形模型,其中每个节点表示一个语法单元。
语法解析器(Parser)通过指定的文法规则(通常是上下文无关文法)来识别和解析语法单元,并将其组织成语法树。
语法解析器的主要任务是根据文法规则,将词法单元序列转换成一个抽象语法树(AST)。
抽象语法树是一个以语法单元为节点、以关系为边的有向无环图。
它将程序的结构和语法关系清晰地表示出来,方便后续的语义分析和代码生成。
常见的语法解析技术有自顶向下的递归下降分析和自底向上的LR 分析。
递归下降分析是一种自顶向下的分析方法,它从文法的最高层级开始,通过递归调用子程序来解析语法单元。
而LR分析是一种自底向上的分析方法,它从词法单元序列底部开始,通过移入-规约的操作来逐步构建语法树。
语法解析技术的主要应用是在编程语言中进行语法错误检查和语法树构建。
编译原理第三章语法分析
3.2 语言和文法
• 文法的优点
–文法给出了精确的,易于理解的语法说明 –自动产生高效的分析器
–可以给语言定义出层次结构
3.2 语言和文法
• 文法的优点
–文法给出了精确的,易于理解的语法说明 –自动产生高效的分析器
–可以给语言定义出层次结构
–以文法为基础的语言实现便于语言的修改
3.2 语言和文法
F id | (E)
3.2 语言和文法
E E+T|T TT* F|F F id | (E)
E T T T * F id F id
E E
T F
+
T F
T * F
id
*
F
id
id id * id * id 和 id + id * id 的分析树
id
3.2 语言和文法
3.2.5 消除二义性 stmt if expr then stmt | if expr then stmt else stmt | other • 句型:if expr then if expr then stmt else stmt
3.2 语言和文法
3.2.5 消除二义性 stmt if expr then stmt | if expr then stmt else stmt | other • 句型:if expr then if expr then stmt else stmt • 两个最左推导: stmt if expr then stmt if expr then if expr then stmt else stmt stmt if expr then stmt else stmt if expr then if expr then stmt else stmt
计算语言学Part2高级语言及其语法描述

文法的直观概念
关于文法的定义
定义3.1
文法G定义为四元组(VN, VT, P, S)。 其中VN为非终结符号(或语法实体,或变量)集;VT为终结符 号集;P为产生式(也称规则)的集合;VN, VT和P是非空有穷 集。S称做识别符号或开始符号,是一个非终结符(S∈ VN), 至少要在一条规则中作为左部出现。 VN和VT不含公共元素,即VN∩VT=Φ。通常V表示VN∪VT,V称 为文法G的字母表或字汇表。
Part2 高级语言及其语法描述
授课:胡静
内容提要
预备知识——形式语言基础 程序语言的定义(语法定义、语义定义) 高级语言的一般特性(程序结构、数据类型和操作、 语句与控制结构) 程序语言的文法
文法的类型 上下文无关文法及其语法树 有关文法实用中的一些说明
预备知识
更多的概念和一些约定
A, B, C, … 用来表示非终结符 a, b, c, … 表示终结符 …, X, Y, Z 可以用来表示终结符或者非终结符 …, w, x, y, z 表示终结符号串 α, β, γ, δ, … 表示由终结符或非终结符构成的符号串 在产生式A→α中,
语句与控制结构
表达式:一个表达式是由运算量(操作数,即数据引 用或函数调用)和算符组成的。 语句:不同程序语言含有不同形式和功能的各种语句
执行语句:描述程序的动作,分为赋值语句、控制语 句、输入/输出语句; 说明性语句:定义各种不同数据类型的变量或运算 从形式上分,语句可以分为简单句、复合句和分程序 等。
程序语言的定义
程序语言的语法定义
所谓一个语言的语法是指这样一组规则,用它可以形 成和产生一个合式的程序。这些规则一部分称为词法 规则则,另一部分称为语法规则(或产生规则)
编译原理(清华)第三章文法和语言

例 文法G: S→0S1,S→01 有直接推导: 0S1 00S11 ( S→0S1 ) 00S11 000S111 ( S→0S1 ) 000S111 00001111 ( S→01 ) S 0S1 ( S→0S1 )
推导和归约 若存在v=w0 w1 ... wn=w ,(n>0) 则称v推导出w,或w归约到v,记为v=+>w 若有v =+>w,或v=w,则记作v=*>w
2. 符号串 – 定义:由字母表中的符号组成的任何有穷序列 – 例: 0,00,10是字母表∑={0‚1}上的符号串 a,ab,aaca是Α={a‚b,c}上的符号串 – 在符号串中,符号是有顺序的,顺序不同,代 表不同的符号串,如:ab和ba不同 – 不含任何符号的符号串称为空串,用ε表示 注意:{ε}并不等于空集合{ } – 符号串长度: 符号串中含有符号的个数 如: |abc|=3 | ε|=0
3.3 文法和语言的形式定义
1.文法的定义 2.文法的简化表示法 3.推导与归约 4.句型、句子、语言的定义 5.文法的等价
1.文法的定义
产生式(规则) 产生式是一个有序对(α,β),通常写作 α→β(或α::=β ) 文法定义: 文法G(Grammar)定义为四元组(VN,VT,P,S) VN (Nonternimal):非终结符集 VT (Terminal):终结符集 P (Production): 产生式(规则)集合 S: 开始符号或识别符号
第三章
文法和语言
学习目标: 掌握:自上而下与自下而上的分析方法 理解:文法的形式定义,推导,归约,句 型,句子,语言,上下文无关文法,规范 句型,语法树,短语,直接短语,句柄 了解:文法的类型,文法使用中的限制, 文法的二义性
编译原理(第二版)第3章 文法和语法

〈动词〉::= 是 | 学习
〈直接宾语〉::=〈代词〉|〈名词〉
“我是大学生”是否是该语言的句子?
〈句子〉::=〈主语〉〈谓语〉 〈主语〉::=〈代词〉|〈名词〉 〈代词〉::= 你 | 我 | 他 〈名词〉::= 王明 | 大学生 | 工人 | 英语 〈谓语〉::=〈动词〉〈直接宾语〉 〈动词〉::= 是 | 学习 〈直接宾语〉::=〈代词〉|〈名词〉 〈句子〉
}的文法。
分析:n≧1,所以必须用递归规则。a和b的 个数 一样多,但c的个数不同,所以将生成 含 a,b的部分与生成含e的部分分开,A生成 ab,B生成e. G[Z]:Z→AB
A→aAb|ab
B→eB|ε
4)文法的等价
• 若L(G1)=L(G2),则称文法G1和G2是等价的。
如文法G1[A]:A→0R 与 G2[S]:S→0S1 等价
设 z = abc, 那么 z 的头是: ε ,a ,ab , abc(除 abc 外都是固有头) z 的尾是: ε ,c ,bc , abc(除 abc 外都是固有尾)
4、符号串的运算
符号串的长度:符号串中符号的个数.符号串s的长度 记为|s|。 ε的长度为0 符号串的连接:符号串x、y的连接,是把y的符号写在 x的符号之后得到的符号串xy 例 x=ST,y=abu 则 xy=STabu
|x|=2,|y|=3,|xy|=5
εx = xε= x
方幂:符号串x自身连接n次得到的符号串 xx…xx(n个x)定义为 xn x0=ε , x1=x, x2=xx, x3=xxx x=AB, 则 x0=ε , x1=AB, x2=ABAB, x3=ABABAB 对于 n>0, xn = xxn-1 = xn-1x
例如: 汉语的字母表中包括汉字、数字及标点符号等。 C语言的字母表是由字母、数字、若干专用符号及IF、 FOR之类的保留字组成。
编译原理课程设计之第三章上下文无关文法及分析

14
无关文法及分析
1. 上下文无关文法(即2型文法)的形式定义:
上下文无关文法是一个四元组(VT , VN , P , S):
① ②
终非结终符 结集 符合 集合VTVN(与VT产的不生左相式部交)
产生式 的右部
③ 产生式或文法规则A→α形成的集合P,
其中A∈VN,α∈(VT∪VN)* 4) 开始符号S,其中S∈VN
25
无关文法及分析
3.2 上下文无关文法的形式定义
1. 上下文无关文法(即2型文法)的形式定义 2. chomsky文法的分类 3. 推导和规约的定义 4. 句型和句子的定义 5. 最左和最右推导 6. 文法定义的语言 7. 递归产生式和递归文法 8. 文法和语言
mcy
编译原理课程设计之第三章上下文
mcy
编译原理课程设计之第三章上下文
1
无关文法及分析
第三章 上下文无关文法及分析
本章的目的是为语言的语法 描述寻求形式工具,要求该 工具对程序设计语言给出精 确无二义的语法描述。
mcy
编译原理课程设计之第三章上下文
2
无关文法及分析
第三章 上下文无关文法及分析
✓3.1 语法分析过程 ▪ 3.2 上下文无关文法的形式定义
下面的2型文法描述了包含加法、减法和乘法的简 单整型算术表达式的语法结构。
文法G[exp]:
exp → exp op exp exp →(exp) exp → number
34-3 是符合该 语法结构的简单 整型算术表达式 (句子)吗?
op → + | - | *
mcy
编译原理课程设计之第三章上下文
令G是一个如上所定义的文法,则G=(VT,VN,P,S)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
S
x A
y
11
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
* (3)
)
E + E
它所对应的语法树件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
二、二义性(1/2)
1. 定义:
一个文法的某个句子对应两棵不同的语法树,则这个文法是二义 的。 或 一个文法的某个句子有两个不同的最左(右)推导,则这个文法 是二义的。 2. 区别
G’: E→ T | E+T T→ F | T*F
F→ (E) | i
9
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
3.6 句型的分析
句型分析的任务就是按文法的产生式,识别输入的符号是否是 该文法的句型。语法树——是句型推导过程的几何表示,可以十分 直观的显示某句型的结构。因此在句型时,对输入符号串构造语法 树,以此识别它是否是该文法的一个句型(或句子)。因此,语法 树又可称为语法分析树或分析树。我们把完成句型分析的程序称为 分析程序或识别程序,分析算法又称识别算法。
分析算法又分为:
从左到右分析算法;
从右到左分析算法;
自上而下的分析法
自下而上的分析法
10
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
自上而下的分析法
基本思想:从文法的开始符号出发,反复使用各种产生式,寻 找“匹配”输入符号串的推导。即对任何输入符号串,从文法的开 始符号(根结)出发,自上而下地为输入串建立一棵语法树,直到 语法树结果正好是输入的符号串为止。 例如:文法G[S]: S→ xAy 文法的一个句子。 解: S x (1) A y (2) A→ ** | *,识别输入串x*y是否是该 S
最左推导是指:任何一步α=> β都是对α中的最左非终结符进行替换。
同样,可定义最右推导(又称规范推导):任何一步α=>β都是对α中的最 右非终结符进行替换。 由规范推导所得到的句型称为规范句型。
5
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
语法树的特点
一棵语法树是这些不同推导过程的共性抽象,是它们 的代表。一棵语法树完全等价于一个最左(右)推导, 这种等价性包括树的步步生长和推导的步步展开是完 全一致的。
例1 文法G= ( {E}, {+, *, i , (, )}, P, E),其中P为:
E→ E+E | E*E | (E) | i
对该文法关于(i*i+i)的推导的语法树如下所示:
2
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
接语法树构造举例
代次
E(根) 1
文法和语言
一个句型是否只对应唯一的一棵语法树?
例如 对于文法G[E]: E→ E+E | E*E | (E) | i,关于(i*i+i)存在一个 与前面不同的最左推导: E(根) E (E)
(E*E) (i*E) (i*E+E) (i*i+E) (i*i+i)
( E i
E * E
• 文法的二义性:存在两个不同文法G(二义)、G’(无二义),却有 L(G)=L(G’),即产生语言相同。
• 语言的二义性
8
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
二义性其它问题
人们已证明,二义性问题是不可判定的,即不存在一个算法, 它能在有限步骤内,确切地判断一个文法是否是二义的。我们所能 做的就是为无二义性寻找一些充分条件,例如对文法G[E]: E→ E+E | E*E | (E) | i 修改,规定运算符“+”与“*”的优先关系和结合 规则,设“*”的优先性高于“+”,且服从左结合。
(
E E i *
E
+ E i
)
E i
2 3
4
5
3
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
语法树的问题分析
(1)允许产生同名结点(反映递归性);
(2)没有后代的结点为端末结; (3)语法树不能反映生养后代的先后;
(4)一棵语法树表示了一个句型种种可能的(但未必是所有 的)不同推导过程。
文法和语言
上下文无关文法及其语法树
一、语法树(推导树)
1. 直观定义:用图表示上下文无关文法句型的推导的直观方法。 语法树有助于理解一个句子的语法层结构的层次,语法树通常表示
成一棵倒立的树,根在上,枝叶在下。
2. 形式定义
对文法G=( VN, VT, P, S)相关联的语法树满足以下4个条件:
(1)根结点由开始符号S所标记;
4
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
文法和语言
最左推导/最右推导/规范句型
注意:从一个句型到另一个句型的推导过程往往是不唯一的。
例如 E+E (i+i):
(a)E+E => E+i => i+i ——最右推导
(b)E+E => i+E => i+i
——最左推导
例:推导(i*i+i) 最左推导:E =>(E) =>(E+E)=>(E*E+E)=>(i*E+E)=>(i*i+E)=> (i*i+i) 最右推导:E=>(E)=>(E+E)=>(E+i)=>(E*E+i)=>(E*i+i)=>(i*i+i) 但两种推导的语法树相同。
6
软件教研室 徐慧英 吕振洪来自 中国最大的资料库下载
中国最大的资料库下载
文法和语言
语法树构造的过程
从根结点S开始推导,当非终结符被它的某个候选式所替 换时,这个非终结符的相应结就产生出下一代新结,候选式 中自左向右的每个符号对应一个新结,并用这些符号标记其 相应的新结。每个新结与其父结点间都有一条连线。在一棵 语法树生长过程中的任何时刻,所有那些没有后代的端末结 自左向右排列起来就是一个句型。
(2)每个结点都有一个标记,此标记是V(即VN∪ VT)的一个符号; (3) 非终结符VN中的结点至少有一个除它自己以外的子孙结点;
1
(4)对产生式A→ A1 A2… Ak,结点A1 , A2 ,… , Ak是结点A的直接子孙, 软件教研室 徐慧英 吕振洪来自 顺序与产生式相同。