统计学第八章课件
合集下载
经济统计学第八章PPT资料(正式版)

1.由样本的已知资料去估计未知的总体数量特征。 2.选取样本必须遵循随机原则。 3.抽样推断中产生的误差可以事先控制。
二、抽样推断的作用 1. 对不可能进行全面调查的现象总体进行推断。 2. 对于某些不必要进行全面调查的总体进行推
断。 3. 可以对全面调查的数据进行补充或修正。 4. 可以用于大批量生产过程中产品的质量检验
成数是是非标志的平均数。所谓是非标志就 是指只能取两种标志表现的标志。假定具有某种 相同标志表现的变量值记为1,不具备该种标志表 现的变量值记为0,那么成数 可以看作是这两个 变量的加权算术平均数,即 是是非标志的平均数:
X P
X f1N 10N 0N 1P
f
N 1N 0 N
(3)总体数量标志标准差。总体数量标志标准差 是指全及总体中根据各单位标志值计算的标准差。
1.抽样框
抽样之前,必须根据预定的要求将总体划分 成一个个抽样单位,这些单位互不重叠,原来的 总体单位只能属于某一个抽样单位。抽样单位可 以是原来的总体单位,也可以不是原来的总体单 位。
全部抽样单位所构成的名单称为抽样框。
抽样框的作用是:
(1)易于贯彻随机原则和进行抽选工作,提高抽 样效率。
(2)确定了调查对象即全及总体的范围。
X X (未分组资) 料 N
X Xf (分组资料 ) f
(2)全及成数:全及总体中具有某一相同 标志表现的单位数占全及总体单位数的比 重,用P或者Q表示。
若以N1代表具有某种相同标志表现的单位数, N0代表不具有某种相同标志表现的单位数,
N=N1+N0,则总体成数为:
P N1 N
QN0NN11P NN
经济统计学第八章
本章重点
第一节 抽样推断概述 第二节 抽样误差和抽样估计 第三节 抽样的组织方式 第四节 样本容量的确定和总量指标的推算
二、抽样推断的作用 1. 对不可能进行全面调查的现象总体进行推断。 2. 对于某些不必要进行全面调查的总体进行推
断。 3. 可以对全面调查的数据进行补充或修正。 4. 可以用于大批量生产过程中产品的质量检验
成数是是非标志的平均数。所谓是非标志就 是指只能取两种标志表现的标志。假定具有某种 相同标志表现的变量值记为1,不具备该种标志表 现的变量值记为0,那么成数 可以看作是这两个 变量的加权算术平均数,即 是是非标志的平均数:
X P
X f1N 10N 0N 1P
f
N 1N 0 N
(3)总体数量标志标准差。总体数量标志标准差 是指全及总体中根据各单位标志值计算的标准差。
1.抽样框
抽样之前,必须根据预定的要求将总体划分 成一个个抽样单位,这些单位互不重叠,原来的 总体单位只能属于某一个抽样单位。抽样单位可 以是原来的总体单位,也可以不是原来的总体单 位。
全部抽样单位所构成的名单称为抽样框。
抽样框的作用是:
(1)易于贯彻随机原则和进行抽选工作,提高抽 样效率。
(2)确定了调查对象即全及总体的范围。
X X (未分组资) 料 N
X Xf (分组资料 ) f
(2)全及成数:全及总体中具有某一相同 标志表现的单位数占全及总体单位数的比 重,用P或者Q表示。
若以N1代表具有某种相同标志表现的单位数, N0代表不具有某种相同标志表现的单位数,
N=N1+N0,则总体成数为:
P N1 N
QN0NN11P NN
经济统计学第八章
本章重点
第一节 抽样推断概述 第二节 抽样误差和抽样估计 第三节 抽样的组织方式 第四节 样本容量的确定和总量指标的推算
管理统计学第8章PPT课件

km
k
km
• (2)如果各水平下抽(Y取ij 样 Y本)数2 不等m,分(别Yi为nYi个)2
(Yij Y i )2
i1 j1
i1
i1 j1
•令
k ni
k
k ni
(Yij Y )2 ni (Yi Y )2
(Yij Y i )2
i1 j1
i1
i1 j1
km
ST
( Yij Y )2
Ti2
1406.25 475.24 998.56 470.89 888.04 1246.09
m
Yij2
j 1
358.49
131.82
252.34
124.95
244.36 316.03
T Ti 177.7
Ti2 5485.07
Yij2 1427.99
第26页/共70页
• 再将计算结果分别代入SA与SE两式
• 方差分析在理论上应满足3个基本的前 提条件。
• 条件1:K个总体都服从正态分布; • 条件2:K个总体的方差相等; • 条件3:K个样本之间是独立的。
第11页/共70页
8.1.2 方差分析的基本假定
• 需要说明的是: • 这些条件在一定程度上是可以放宽的,如果总体服从正态分布的条件不1 方差分析的基本原理
• 显然,组内误差只包含随机误差;而组间误差包含随机误差和系统误差。如果 不同水平对结果没有影响,那么组间误差只包含随机误差,这时,组间误差与 组内误差经过平均后的比值会很接近1;反之,如果不同水平对结果有明显的 影响,这时,组间误差要比组内误差要大,两者经过平均后的比值会大于1, 当这个比值大到一定程度时,就有理由相信,不同水平对结果是有显著影响的。
统计学基础(第六版)教学课件第8章

2009
呈现出一定的抛物
2008
趋势;管理成本则
2007
现一定的指数变化
2005
净利润呈现一定的
2006
2005
线性趋势;产量呈
净利润
《统计学基础》(第六版)
管理成本
第8章
8.3 时间序列预测的程序和方法
确定时间序列的成分
4000
年份
8 - 13
第8章
《统计学基础》(第六版)
8.3 时间序列预测的程序和方法
84
60
233
2007
2938
124
73
213
➢
第2步,找出适合该时间序列的预测方法。
2008
3125
214
121
230
2009
3250
216
126
223
第3步,对可能的预测方法进行评估,以确定最
2010
3813
354
172
240
➢
2011
4616
420
218
208
佳预测方案。
2012
4125
514
110.94
110.61
109.60
110.29
110.50
110.00
108.61
—
119.87
133.41
148.01
163.71
179.42
197.89
218.63)根据式(8.5)得:
ҧ =
− 1 × 100 =
0
9
27563
− 1 × 100 = 11.26%
2021/11/5
贾俊平版统计学课件 第8章

▽与原假设对立的假设称备择假设,记为 H1 ,用 、 或 表示。 对于新生儿体重的例子,可以表示为
H 0 : 3190
H1 : 3190
(2)确定检验统计量及其分布
▽用于检验假设的统计量称为检验统计量
▽根据 H 0 及相应条件选择适当的统计量,并确定统计量
的分布 对于新生儿体重的例子,可利用 x 0 构造检验统计量. 若新生儿体重为正态分布 N ( , 2 ) ,且 已知,则在 H 0 为真 时,用 z 作为检验统计量,并且
H 0 : 3190 H1 : 3190
并已知 x 3210, 80, n 100 ,则
z0 x 0
n
3210 3190 80 100
2.5
于是
p 2Pz z0 2 0.00621 0.01242
双侧检验的P值
/ 2
/ 2 拒绝
▽犯第二类错误的概率为 。
表8-1 假设检验中各种可能结果的概率
实际情况
H 0 为真 H 0 不真
决策
接受 H 0
1
拒绝 H 0
1
假设检验中的两类错误(决策结果)
H0: 无罪
假设检验就好像一场审判过程 统计检验过程
陪审团审判
实际情况 裁决 无罪 无罪 有罪 正确 错误 有罪 错误 正确 接受H0 拒绝H0 决策
若p-值 /2, 不能拒绝 H0 若p-值 < /2, 拒绝 H0
8.1.6 假设检验的形式
研究的问题 假设
双侧检验
H0 H1
左侧检验
右侧检验
= 0 ≠0
第八章 假设检验 (《统计学》PPT课件)

与其,为选取“适当的”的而苦恼,不如干脆 把真正的(P值)算出来。
第二节 一个正态总体的假设检验
一、正态总体
设总体X ~ N(m, 2),抽取容量为n的样本 x1, x2, xn
样本均值 X 与方差S2 计算公式分别为:
2
1 n 1
n i1
(xi
X)
我们将利用上述信息,来检验关于未知参数均值 和方差的假设。
总体参数
均值
方差
总体方差已知
z 检验
(单尾和双尾)
总体方差已知
t 检验
(单尾和双尾)
2 检验
(单尾和双尾)
第二节 一个正态总体的假设检验
二、均值m的假设检验
1.H0:m=m0
2.选择检验统计量:
2已知: Z X m0 ~ N(0,1)
/ n
2未知:
小样本: t X m0 ~ t(n 1)
这个值不像我 们应该得到的 样本均值 ...
...因此我们拒绝 原假设μ=50
... 如果这是总 体的假设均值
60
μ=80
H0
样本均值
第一节 假设检验概述
三、假设检验的程序
一个完整的假设检验过程,通常包括以下几个步骤:
首先,设立原假设H0与备选假设H1; 第二步,构造检验统计量,并根据样本观察数据
小样本:当 t t
2
,则拒绝原假设,反之则接受H0;
5.得出结论。
二、均值m的假设检验
6.例题分析
[例8.3] 某广告公司在广播电台做流行歌曲磁带广告 ,它的插播广告是针对平均年龄为21岁的年轻人的,标 准差为16。这家广告公司经理想了解其节目是否为目标 听众所接受。假定听众的年龄服从正态分布,现随机抽 取400多位听众进行调查,得出的样本结果为x 25 岁S2,18 。以0.05的显著水平判断广告公司的广告策划是否符合 实际?
第二节 一个正态总体的假设检验
一、正态总体
设总体X ~ N(m, 2),抽取容量为n的样本 x1, x2, xn
样本均值 X 与方差S2 计算公式分别为:
2
1 n 1
n i1
(xi
X)
我们将利用上述信息,来检验关于未知参数均值 和方差的假设。
总体参数
均值
方差
总体方差已知
z 检验
(单尾和双尾)
总体方差已知
t 检验
(单尾和双尾)
2 检验
(单尾和双尾)
第二节 一个正态总体的假设检验
二、均值m的假设检验
1.H0:m=m0
2.选择检验统计量:
2已知: Z X m0 ~ N(0,1)
/ n
2未知:
小样本: t X m0 ~ t(n 1)
这个值不像我 们应该得到的 样本均值 ...
...因此我们拒绝 原假设μ=50
... 如果这是总 体的假设均值
60
μ=80
H0
样本均值
第一节 假设检验概述
三、假设检验的程序
一个完整的假设检验过程,通常包括以下几个步骤:
首先,设立原假设H0与备选假设H1; 第二步,构造检验统计量,并根据样本观察数据
小样本:当 t t
2
,则拒绝原假设,反之则接受H0;
5.得出结论。
二、均值m的假设检验
6.例题分析
[例8.3] 某广告公司在广播电台做流行歌曲磁带广告 ,它的插播广告是针对平均年龄为21岁的年轻人的,标 准差为16。这家广告公司经理想了解其节目是否为目标 听众所接受。假定听众的年龄服从正态分布,现随机抽 取400多位听众进行调查,得出的样本结果为x 25 岁S2,18 。以0.05的显著水平判断广告公司的广告策划是否符合 实际?
统计学第八章 时间序列分析

季节指数
乘法模型中的季节成分通过季节指数来反映。 季节指数(季节比率):反映季节变动的相
对数。 1、月(或季)的指数之和等于1200%(或
400%) 。 2、季节指数离100%越远,季节变动程度
越大,数据越远离其趋势值。
用移动平均趋势剔除法计算季节指数
1、计算移动平均值(TC),移动期数为4或 12,注意需要进行移正操作。
移动平均的结果 4000 3500 3000 2500 2000 1500 1000 500 0
Example 2
移动平均法可以作为测定长期趋势的一种 较为简单的方法,在股市技术分析中有广 泛的应用。比如对某只股票的日收盘价格 序列分别求一次5日、10日、一个月的移动 平均就可以得到其5日、10日、一个月的移 动平均股价序列,进而得到5日线、10日线、 月线,用以反映股价变动的长期趋势。
1987 1800 1992 1980 1997 2880
1988 1620 1993 2520 1998 3060
1989 1440 1994 2559 1999 2700
4000
3500
销售收入
3000
2500
2000
1500
1000
500
0
年份
2000 2001 2002 2003 2004
销售 收入 3240 3420 3240 3060 3600
部分数据
销售 收入
t
1985 1080
1
1986 1260
2
1987 1800
3
1988 1620
4
1989 1440
5
……
…
2003 3060
19
统计学第八章时间数列
2020/1/19
增长速度growth rate 表明现象的增长程度
某现 基象 期报 水 告 平 报期 告 基的 期 期 基 增 水 水 期 长 平 平 发 水 量 展 平 1速
环比增长速度=环比发展速度-1 定基增长速度=定基发展速度-1
2020/1/19
增 1长 的 % 绝 环 对 逐 比 期 增 1 值 增 0 长 0上 长 1速 0 期 量 0度 水平
n 1
n 1
(5)间隔不相等不连续时点的时点数列
2020/1/19
aa1 2a2t1a2 2a3t2an12 antn1 t1t2tn1
增长量和平均增长量 •增长量growth amount
总量指标报告期水平与基期水平之差,表明 该指标在一定时期内增加或减少的绝对数量。
社会经济现象以若干年为周期的 涨落起伏相同或基本相同的一种 波浪式的变动
随机变动(I)
客观社会经济现象由于天灾、人 祸、战乱等突发事件或偶然因素 引起是无周期性波动
2020/1/19
一般模型 加法模型
Y=T+S+C+I
乘法模型 Y=T×S×C×I
分解方法
加法模型 T=Y-(S+C+I)
乘法模型
2020/1/19
✓水平法(几何平均法)
n
X
n
Xi
i1
n
an a0
适用:水平指标的平均发展速度计算
2020/1/19
✓方程法(累计法)
a 0 x a 0 x 2 a 0 x 3 a 0 x n a i
xx2x3xnai a0
适用:侧重于考察中长期间的累计总量
平均增长速度 = 平均发展速度-100% 表明现象在一个较长时期中逐期平均增长变化的程度
统计学第八章

19
8.1.3 两类错误
项目
没有拒绝H0
拒绝H0
H0为真
1-α(正确)
α(弃真错误)
H0为假
β(取伪错误)
1-β(正确)
假设检验中各种可能结果的概率
20
8.1.3 两类错误
α和β的关系: 1、 α和β的关系就像跷跷板, α小β就大, α大β就小。因为, 要减少弃真错误α,就要扩大接受域。而扩大接受域,就必然导致取 伪错误的可能性增加。因此,不能同时做到犯两种错误的概率都很 小。要使α和β同时变小,唯一的办法就是增大样本量。 α和β两者的 关系就像是区间估计当中可靠性和精确性的关系一样。 2、在假设检验中,大家都在执行这样一个原则,即首先控制犯α错 误原则。
一般来说,在研究问题的过程中,我们想要予以反对的那个结论, 我们就把它作为原假设。
比如,一家研究机构估计,某城市当中家庭拥有汽车的比例超过 30%。为了验证这种估计是否正确,该研究机构随机的抽取了一个样本 进行检验。试陈述用于检验的原假设和备择假设。
解:研究者想要收集证据予以支持的假设是:“该城市中家庭拥有 汽车的比例超过30%”。因此,原假设是总体比例小于等于30%,备择 假设是总体比例大于30%。可见,通常我们应该先确定备择假设,再确 定原假设。
6
8.1.2 假设的表达式
在假设检验中,一般要先设立一个假设(比如从来没做过坏事),然 后从现实世界的数据中找出假设与现实的矛盾,从而否定该假设。所以, 在多数统计教材当中,假设检验都是以否定事先设定的那个假设为目标的。
如果搜集到的数据分析结构不能否定该假设,只能说明我们掌握的现 实不足以否定该假设,但不能说明该假设一定成立。这是假设检验做结论 的时候尤其要注意的一点。比如一个人在数次的观察中都没有干坏事,但 并不说明他从来都没干过坏事。
8.1.3 两类错误
项目
没有拒绝H0
拒绝H0
H0为真
1-α(正确)
α(弃真错误)
H0为假
β(取伪错误)
1-β(正确)
假设检验中各种可能结果的概率
20
8.1.3 两类错误
α和β的关系: 1、 α和β的关系就像跷跷板, α小β就大, α大β就小。因为, 要减少弃真错误α,就要扩大接受域。而扩大接受域,就必然导致取 伪错误的可能性增加。因此,不能同时做到犯两种错误的概率都很 小。要使α和β同时变小,唯一的办法就是增大样本量。 α和β两者的 关系就像是区间估计当中可靠性和精确性的关系一样。 2、在假设检验中,大家都在执行这样一个原则,即首先控制犯α错 误原则。
一般来说,在研究问题的过程中,我们想要予以反对的那个结论, 我们就把它作为原假设。
比如,一家研究机构估计,某城市当中家庭拥有汽车的比例超过 30%。为了验证这种估计是否正确,该研究机构随机的抽取了一个样本 进行检验。试陈述用于检验的原假设和备择假设。
解:研究者想要收集证据予以支持的假设是:“该城市中家庭拥有 汽车的比例超过30%”。因此,原假设是总体比例小于等于30%,备择 假设是总体比例大于30%。可见,通常我们应该先确定备择假设,再确 定原假设。
6
8.1.2 假设的表达式
在假设检验中,一般要先设立一个假设(比如从来没做过坏事),然 后从现实世界的数据中找出假设与现实的矛盾,从而否定该假设。所以, 在多数统计教材当中,假设检验都是以否定事先设定的那个假设为目标的。
如果搜集到的数据分析结构不能否定该假设,只能说明我们掌握的现 实不足以否定该假设,但不能说明该假设一定成立。这是假设检验做结论 的时候尤其要注意的一点。比如一个人在数次的观察中都没有干坏事,但 并不说明他从来都没干过坏事。
统计学第八章

P值是通过计算得到的。P值的大小取决于三 个因素,一是样本数据与原假设之间的差异; 另一个是样本量;再一个是被假设参数的总 体分布。
第八章 假设检验
例子中计算出来的P=0.01242,这就是说, 如果原假设成立,样本均值等于和大于3210 克的概率只有0.01242,这是很小的,由此 我们可以拒绝原假设,得到与前面z值检验相 同的结论。
第八章 假设检验
但什么样的概率才算小呢?著名的英国统计 学家费希尔把小概率的标准定为0.05,虽然 费希尔没有对为什么选择0.05给出充分的解 释,但人们还是沿用了这个标准,把0.05或 者比0.05更小的概率看成小概率。
如果原假设成立,那么在一次试验中z统计量 落入图8-3两侧拒绝域的概率只有0.05,这个 概率是很小的。如果这个情况真的出现,我 们有理由认为总体的真值不是3190克,也即 拒绝原假设,接受备择假设。
第八章 假设检验
8.1.3 两类错误 对于原假设提出的命题,我们需要做出判断, 这种判断可以用“原假设正确”或“原假设 错误”来表述。当然,这是依据样本提供的 信息进行判断的,也就是由部分来推断总体, 因而判断有可能正确,也有可能不正确,也 就是说,我们面临着犯错误的可能性。
第八章 假设检验
所犯的错误有两种类型: 第1类错误是原假设Ho为真却被我们拒绝了, 犯这种错误的概率用α表示,所以也称为α错 误或弃真错误。 第2类错误是原假设为伪我们却没有拒绝,犯 这种错误的概率用β表示,所以也称β错误或 取伪错误。
第八章 假设检验
u是我们要检验的参数,即1990年新生儿综 体体重的均值。该表达式提出的命题是, 1990年新生儿与1989年的新生儿在体重上没 有什么差异。 显然,3190克是1989年新生儿总体的均值, 是我们感兴趣的数值。如果用u0表示感兴趣 的数值,原假设更一般的表达式为: H0:u=u0 或H0:u-u0=0
第八章 假设检验
例子中计算出来的P=0.01242,这就是说, 如果原假设成立,样本均值等于和大于3210 克的概率只有0.01242,这是很小的,由此 我们可以拒绝原假设,得到与前面z值检验相 同的结论。
第八章 假设检验
但什么样的概率才算小呢?著名的英国统计 学家费希尔把小概率的标准定为0.05,虽然 费希尔没有对为什么选择0.05给出充分的解 释,但人们还是沿用了这个标准,把0.05或 者比0.05更小的概率看成小概率。
如果原假设成立,那么在一次试验中z统计量 落入图8-3两侧拒绝域的概率只有0.05,这个 概率是很小的。如果这个情况真的出现,我 们有理由认为总体的真值不是3190克,也即 拒绝原假设,接受备择假设。
第八章 假设检验
8.1.3 两类错误 对于原假设提出的命题,我们需要做出判断, 这种判断可以用“原假设正确”或“原假设 错误”来表述。当然,这是依据样本提供的 信息进行判断的,也就是由部分来推断总体, 因而判断有可能正确,也有可能不正确,也 就是说,我们面临着犯错误的可能性。
第八章 假设检验
所犯的错误有两种类型: 第1类错误是原假设Ho为真却被我们拒绝了, 犯这种错误的概率用α表示,所以也称为α错 误或弃真错误。 第2类错误是原假设为伪我们却没有拒绝,犯 这种错误的概率用β表示,所以也称β错误或 取伪错误。
第八章 假设检验
u是我们要检验的参数,即1990年新生儿综 体体重的均值。该表达式提出的命题是, 1990年新生儿与1989年的新生儿在体重上没 有什么差异。 显然,3190克是1989年新生儿总体的均值, 是我们感兴趣的数值。如果用u0表示感兴趣 的数值,原假设更一般的表达式为: H0:u=u0 或H0:u-u0=0
统计学_第八章__时间序列分析
第八章 时间序列分析
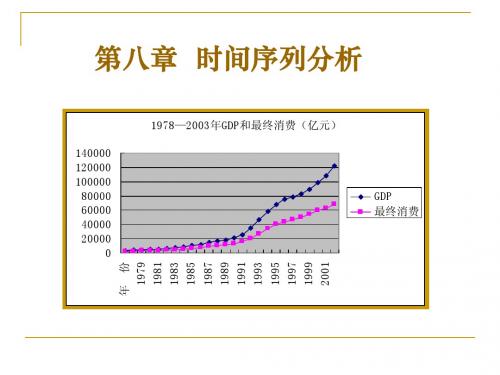
1978—2003年GDP和最终消费(亿元) 140000 120000 100000 80000 60000 40000 20000 0
年 份 1979 1981 1983 1985 1987 1989 1991 1993 1995 1997 1999 2001
GDP 最终消费
4、二者关系 (1)各逐期增长量之和等于相应的累计增长量
an a0 (a1 a0 ) (a2 a1 ) (a3 a2 ) (an an1 )
(2)相邻两期的逐期增长量之和等于相应的 累计增长量;相邻两期的累计增长量之差等于 相应的逐期增长量
(二)平均增长量 1、概念 一段时期内平均每期增加或者减少的绝 对数量。或者说是逐期增长量的序时平均数。 2、计算公式
a0 a1 a 2 a n 或 a n 1
af a f
B、如果是间断时点数列,计算方法为: 『两个假设条件: 一是假设上期期末水平等于本期期初水平; 二是假设现象在间隔期内数量变化是均匀的。』 Ⅰ、间隔期相等的时点数列,采用“首尾(首末)折半 法”计算。 先计算各间隔期的平均数;然后再将这些平均数进行 简单算术平均。例如:
第一节
时间序列分析概述
一、时间序列的概念和作用
(一)、概念: 1、时间序列:将不同时间的某一统计指标数据按照 时间的先后顺序排列起来而形成的统计序列,也称时间 数列或动态数列。 2、基本构成要素(从形式上看): 一是时间顺序(现象所属的时间)。可以是年份、季 度、月份或其他任何时间,称时间要素(常用t表示); 二是不同时间的统计数据(现象在不同时间上的观察 值)。可以是绝对数、相对数、平均数,称数据要素 (常用小写的英文字母a、b、c表示)。
1978—2003年GDP和最终消费(亿元) 140000 120000 100000 80000 60000 40000 20000 0
年 份 1979 1981 1983 1985 1987 1989 1991 1993 1995 1997 1999 2001
GDP 最终消费
4、二者关系 (1)各逐期增长量之和等于相应的累计增长量
an a0 (a1 a0 ) (a2 a1 ) (a3 a2 ) (an an1 )
(2)相邻两期的逐期增长量之和等于相应的 累计增长量;相邻两期的累计增长量之差等于 相应的逐期增长量
(二)平均增长量 1、概念 一段时期内平均每期增加或者减少的绝 对数量。或者说是逐期增长量的序时平均数。 2、计算公式
a0 a1 a 2 a n 或 a n 1
af a f
B、如果是间断时点数列,计算方法为: 『两个假设条件: 一是假设上期期末水平等于本期期初水平; 二是假设现象在间隔期内数量变化是均匀的。』 Ⅰ、间隔期相等的时点数列,采用“首尾(首末)折半 法”计算。 先计算各间隔期的平均数;然后再将这些平均数进行 简单算术平均。例如:
第一节
时间序列分析概述
一、时间序列的概念和作用
(一)、概念: 1、时间序列:将不同时间的某一统计指标数据按照 时间的先后顺序排列起来而形成的统计序列,也称时间 数列或动态数列。 2、基本构成要素(从形式上看): 一是时间顺序(现象所属的时间)。可以是年份、季 度、月份或其他任何时间,称时间要素(常用t表示); 二是不同时间的统计数据(现象在不同时间上的观察 值)。可以是绝对数、相对数、平均数,称数据要素 (常用小写的英文字母a、b、c表示)。
《统计学》第八章国民经济核算体系

中国传统国民经济核算体系
❖ 中国传统国民经济核算体系是适应国家高度集中计划管 理的需要,在前苏联、东欧国家的MPS的基础上建立起 来的。
❖ 1951年,有关部门建立了农产品平衡表、工业生产资料 和消费品平衡表,后来,又扩大了这些平衡表的种类。
❖ 1952年国家统计局、各大行政区和各省市统计部门在全 国范围内进行了工农业总产值和劳动就业调查。后来, 在此基础上形成了工农业总产值核算,又逐步从工农业 总产值核算扩大到工业、农业、建筑业、交通运输业和 商业五大物质部门总产值核算。
价 值 运 动
流通 实现产品在 空间的转移
分配 包括初次分 配和再分配
社会总供给 销 售
使用
投资与 消费
购 买 社会总需求
社会再生产
如果总 供给与 总需求 实现平 衡,社 会再生 产就能 顺利实 现。
三、国民经济统计学
(一)、国民经济统计学的研究对象: 是以国民经济为整体,研究其数量
表现和数量关系的方法论的科学。
SNA:
第一时期:1665——1920年 初创阶段 第二时期:1920——1939年 发展较快,核算方法有了 较大的改进。
第三时期:1939——1953年 国民收入统计大有发展, 一是计算国民收入的国家大为增加,二是受到国际组织 的重视。
第四时期:1953——1968年 对原有的旧SNA加以补充 和拓展,建立五大核算和七大帐户的国民经济帐户体系。
MPS
采用限制性生产的概念,只 对五大物质生产部门的产品 进行核算,而把非物质生产 部门排除在外。
主要反映物质产品 的生产、交换和使 用的实物运动。
主要采用平衡 表法,侧重每 个平衡表内部 的平衡,但平 衡表之间的联 系不够严谨。
统计学原理第8章相关与回归分析[精]
![统计学原理第8章相关与回归分析[精]](https://img.taocdn.com/s3/m/3898d2394a7302768e9939a6.png)
估计标准误差就是因变量的估计值yc与实际值y之间差异 公 的平均程度。记为Syx,它的基本公式为:
式
或
式中,Syx表示估计标准误差;下标yx表示y依x的回归方程; y是因变量的实际值;yc是因变量的估计值。
例8.4以例8.1的资料计算估计标准误差。
步骤: 1.设计一张计算表,将已知x的值代入回归方程求出对应的yc的值 2.计算离差y-yc并加以平方求和 3.求出估计标准误差Syx。
数关系。
当r=0时,表示x与y完全没有线性相关。
当0<|r|<1时,表示x与y存在着一定的线性相关。一般分四个
等级,判断标准如下:
若0<|r|<0.3,则称x与y为微弱相关;
若0.3<|r|<0.5, 则称x与y为低度相关;
若0.5<|r|<0.8, 则称x与y为显著相关;
若0.8<|r|<1, 则称x与y为高度相关。
8.3.2简单直线回归方程
a, b是待定参数 利用最小二乘法 得到a,b求值,再反解得到方程式
建立回归直线的过程:列计算表,求出∑xy,∑x2,∑y2,x,y; 计算Lxy,Lxx和Lyy的值;求出b和a的值并写出方程
例 8.2某工厂某产品的产量与单位成本资料见表8.2,试 求单位成本依产量的回归直线方程。
★ 填空题 (1) 现象之间的相关关系,从相关因素的个数看,可分为()和();从相关的形式
的两个回归方程。() (9) 估计标准误差指的就是因变量的估计值yc与实际值y之间的平均误差程度。() (10) 在任何相关条件下,都可以用相关系数r说明变量之间相关的密切程度。() (11) 若变量x与y的相关系数r1=-0.8,变量p与q的相关系数r2=-0.92,由于r1>r2,
统计学第8章 时间序列分析

a n 1
a0
(二)增长速度(增减速度)
增长速度=
增减量 基期水平
报告期水平 基期水平 基期水平
报告期水平 基期水平 1
发展速度1
环比增长速度= an an1 an 1
an1
an1
=环比发展速度 - 100%
定基增长速度= an a0 an 1
a0
a0
=定基发展速度 - 100%
例题:
时间序列的构成要素与模型
(构成要素与测定方法)
时间序列的构成要素
长期趋势
季节变动
循环波动 不规则波动
线性趋势 非线性趋势
按月(季)平均法
移动平均法
二次曲线 指数曲线
趋势剔出法
半数平均法
修正指数曲线
最小平方法
Gompertz曲线 Logistic曲线
剩余法
线性趋势
一、移动平均法
(Moving Average Method)
移动平均法(趋势图)
200
汽 150
车
产 100
量
(万辆)50
产量 五项移动平均趋势值 五项移动中位数
0
1981
1985
1989
1993
1997
(年份)
图11-1 汽车产量移动平均趋势图
移动平均法特点
1、对原数列有修匀作用,移动项数越大,修匀 作用越强。
2、移动平均时,项数为奇数时,只需一次移动 平均,其平均值作为移动平均项中间一期; 当为偶数时,需再进行一次相邻两平均值的 移动平均。
年份
销售额 逐 期 增 减 量 环比发展速度 定基增长速
(万元) (万元)
(%)
度(%)
统计学第八章时间数列

环比增长速度=逐期增长量/前一期水平
=(报告期水平-前一期水平)/前一期水平 =环比发展速度-1(或100%)
发展速度与增长速度
2、定基增长速度。 定基增长速度是报告期的累计增长量与 某一固定基期水平之比,说明现象在较 长时间内总的增长速度。公式如下:
定基增长速度=累计增长量/某一固定期水平 =报告期水平-某一固定期水平)/某一固定期 水平 =定基发展速度-1(或100%)
1、移动平均法。 移动平均法是对原时间数列逐项求 序时平均数,平均项数固定,并逐 项移动得出由这些平均数构成的新 数列,它可以消除某些因素及随机 因素的影响,显示出现象的长期趋 势。
测定长期趋势的方法
设时间数列的水平顺次为: a1,a2,a3, an 若取三项平均移动平均形成的新数 列为:
a1 a 2 a 3 a 2 a3 a 4 a2 , a3 , 3 3
第八章 时间数列
第一节 第二节 第三节 第四节 时间数列概述 时间数列的水平指标 时间数列的速度指标 动态数列的因素分析
第八章 时间数列
第一节 时间数列概述 一、时间数列的概念及作用 二、时间数列的种类 三、编制时间数列的原则
时间数列的概念及作用
一)时间数列的概念
时间数列亦称动态数列,是将反映某现象的 统计指标在不同时间上的数值,按时间先后 顺序排列而形成的一种数列;如:
动态数列影响因素及其分解 模型
3、循环变动(以C表示) 循环变动是指现象以若干年为一周 期,近乎规律性的盛衰交替变动。 如经济危机就是循环变动,每一循 环周期都要经历危机、萧条、复苏 和高涨四个阶段。
动态数列影响因素及其分解 模型
4、随机变动(以I表示) 随机变动亦称不规则变动或剩余变 动,是动态数列除了上述三种变动 之外剩余的一种变动,是偶然因素 引起的一种随机波动。如自然灾害、 战争等无法预见的因素引起的波动。
=(报告期水平-前一期水平)/前一期水平 =环比发展速度-1(或100%)
发展速度与增长速度
2、定基增长速度。 定基增长速度是报告期的累计增长量与 某一固定基期水平之比,说明现象在较 长时间内总的增长速度。公式如下:
定基增长速度=累计增长量/某一固定期水平 =报告期水平-某一固定期水平)/某一固定期 水平 =定基发展速度-1(或100%)
1、移动平均法。 移动平均法是对原时间数列逐项求 序时平均数,平均项数固定,并逐 项移动得出由这些平均数构成的新 数列,它可以消除某些因素及随机 因素的影响,显示出现象的长期趋 势。
测定长期趋势的方法
设时间数列的水平顺次为: a1,a2,a3, an 若取三项平均移动平均形成的新数 列为:
a1 a 2 a 3 a 2 a3 a 4 a2 , a3 , 3 3
第八章 时间数列
第一节 第二节 第三节 第四节 时间数列概述 时间数列的水平指标 时间数列的速度指标 动态数列的因素分析
第八章 时间数列
第一节 时间数列概述 一、时间数列的概念及作用 二、时间数列的种类 三、编制时间数列的原则
时间数列的概念及作用
一)时间数列的概念
时间数列亦称动态数列,是将反映某现象的 统计指标在不同时间上的数值,按时间先后 顺序排列而形成的一种数列;如:
动态数列影响因素及其分解 模型
3、循环变动(以C表示) 循环变动是指现象以若干年为一周 期,近乎规律性的盛衰交替变动。 如经济危机就是循环变动,每一循 环周期都要经历危机、萧条、复苏 和高涨四个阶段。
动态数列影响因素及其分解 模型
4、随机变动(以I表示) 随机变动亦称不规则变动或剩余变 动,是动态数列除了上述三种变动 之外剩余的一种变动,是偶然因素 引起的一种随机波动。如自然灾害、 战争等无法预见的因素引起的波动。
经济统计学第8章PPT课件

上呈直线趋势,可以用直线模型来表示。 y=a0+a1X1+…+apXp+ε 曲线相关:两个变量之间的变动关系在散点图
上呈曲线趋势,可以用曲线模型来表示。相关:两种变量的相对应数值同时扩大
或缩小,其变动方向一致。 2、负相关:两种变量相对应的数值,此增彼
精选ppt课件2021
10
(二)相关系数的使用:
1、取值范围:|r|≤1, r < 0,负相关;r > 0,正相关。 2、密切程度判断: |r|=0,不相关(或非直线相关); |r|=1完全相关。 |r| < 0.3,弱相关; 0.3 ≤|r| < 0.5,低相关; 0.5≤|r|<0.8,显著相关; 0.8 ≤|r|<1, 高度相关 。
YX
样本一元线 性模型
YabX e
精选ppt课件2021
19
最小二乘法
用最小二乘法得到的a、b称为、的最 小二乘估计,他们所确定的直线 称为Y对X的线性回归方程。
Yˆi abXi
求a、b的方法(原理):
(YYˆ)2 Qmin (YabX2)Qmin
Q a 2(YabX)(1)0
Q b 2(YabX)(X)0
30
6
7
36
7
8
37
8
9
42
9
9
40
10
10
精选ppt课件2021
45
24
销售额 50
相关图
40
30
20
10
客流量
2 4 6 8 10 12
计算相关系数r=0.9918
精选ppt课件2021
25
利用最小二乘法求解参数a,b
a Y bX 4.081
上呈曲线趋势,可以用曲线模型来表示。相关:两种变量的相对应数值同时扩大
或缩小,其变动方向一致。 2、负相关:两种变量相对应的数值,此增彼
精选ppt课件2021
10
(二)相关系数的使用:
1、取值范围:|r|≤1, r < 0,负相关;r > 0,正相关。 2、密切程度判断: |r|=0,不相关(或非直线相关); |r|=1完全相关。 |r| < 0.3,弱相关; 0.3 ≤|r| < 0.5,低相关; 0.5≤|r|<0.8,显著相关; 0.8 ≤|r|<1, 高度相关 。
YX
样本一元线 性模型
YabX e
精选ppt课件2021
19
最小二乘法
用最小二乘法得到的a、b称为、的最 小二乘估计,他们所确定的直线 称为Y对X的线性回归方程。
Yˆi abXi
求a、b的方法(原理):
(YYˆ)2 Qmin (YabX2)Qmin
Q a 2(YabX)(1)0
Q b 2(YabX)(X)0
30
6
7
36
7
8
37
8
9
42
9
9
40
10
10
精选ppt课件2021
45
24
销售额 50
相关图
40
30
20
10
客流量
2 4 6 8 10 12
计算相关系数r=0.9918
精选ppt课件2021
25
利用最小二乘法求解参数a,b
a Y bX 4.081
统计学原理第8章相关与回归分析

两个回归方程。() (9) 估计标准误差指的就是因变量的估计值yc与实际值y之间的平均误差程度。() (10) 在任何相关条件下,都可以用相关系数r说明变量之间相关的密切程度。() (11) 若变量x与y的相关系数r1=-0.8,变量p与q的相关系数r2=-0.92,由于r1>r2,因
此x与y间相关的程度比较高。()
27
同步练习
★ 判断题 (1) 根据结果标志对因素标志的不同反映,可以把现象间数量上的依存关系划分为
函数关系和相关关系。() (2) 正相关指的就是因素标志和结果标志的数量变动方向都是上升的。() (3) 相关系数是测定变量间相关密切程度的唯一方法。() (4) 只有当相关系数接近于1时,才能说明两变量之间存在高度相关系数。() (5) 若变量x的值减少,y的值也减少,说明变量x与y之间存在相关关系。() (6) 回归系数b和相关系数r都可以来判断现象之间相关的密切程度。() (7) 若回归直线方程为:yc=160-2.3x,则变量x与y之间存在负的相关关系。() (8) 回归分析中,对于没有明显因果关系的两个变量x与y,可以建立y依x和x依y的
D产量每增加1000件时,单位成本下降78元
E产品的产量随生产用固定资产价值的减少而减少
(4) 测定现象间有无相关关系的方法是()。
A编制相关表 B绘制相关图 C对客观现象作定性分析
D计算估计标准误系数时,()。
A相关的两个变量都是随机的
B相关的两个变量是对等的关系
C相关的两个变量一个是随机的,一个是可以控制的量
特点 在进行回归分析时,必须根据研究目的确定相关的变量中谁为自变 量,谁为因变量。 回归方程的作用在于由自变量的数值来估计因变量的值。一个回 归方程只能作一种推算或估计。 在回归分析中,因变量是随机的,自变量是可以控制的量。
此x与y间相关的程度比较高。()
27
同步练习
★ 判断题 (1) 根据结果标志对因素标志的不同反映,可以把现象间数量上的依存关系划分为
函数关系和相关关系。() (2) 正相关指的就是因素标志和结果标志的数量变动方向都是上升的。() (3) 相关系数是测定变量间相关密切程度的唯一方法。() (4) 只有当相关系数接近于1时,才能说明两变量之间存在高度相关系数。() (5) 若变量x的值减少,y的值也减少,说明变量x与y之间存在相关关系。() (6) 回归系数b和相关系数r都可以来判断现象之间相关的密切程度。() (7) 若回归直线方程为:yc=160-2.3x,则变量x与y之间存在负的相关关系。() (8) 回归分析中,对于没有明显因果关系的两个变量x与y,可以建立y依x和x依y的
D产量每增加1000件时,单位成本下降78元
E产品的产量随生产用固定资产价值的减少而减少
(4) 测定现象间有无相关关系的方法是()。
A编制相关表 B绘制相关图 C对客观现象作定性分析
D计算估计标准误系数时,()。
A相关的两个变量都是随机的
B相关的两个变量是对等的关系
C相关的两个变量一个是随机的,一个是可以控制的量
特点 在进行回归分析时,必须根据研究目的确定相关的变量中谁为自变 量,谁为因变量。 回归方程的作用在于由自变量的数值来估计因变量的值。一个回 归方程只能作一种推算或估计。 在回归分析中,因变量是随机的,自变量是可以控制的量。
统计学第八章 单因素方差分析(1)

称为处理平方 处理平方 和,记为 SSA
总平方和SST=处理平方和SSA+误差平方和SSe
即, ( y ij − y •• ) = n∑ ( y i • − y •• ) + ∑∑ ( y ij − y i• ) 2 ∑∑
2 i =1 j =1 i =1 i =1 j =1 a n 2 a a n
i =1 j =1
a
n
= n∑ ( y i• − y •• ) + 2∑ [( y i• − y •• )∑ ( y ij − y i• )] + ∑∑ ( y ij − y i • )
2 i =1 i =1 j =1 i =1 j =1
a
a
n
a
n
j =1
∑ ( y ij − y i • ) = 0
换句话说,采用两两t检验法,要进行45次t检验,程序太繁琐。
原因(2):检验的I 型错误增大,从而检验的 可靠性低
a = 2 时, H 0 只有一个,即
µ 1= µ 2
a = 3 时, H 0 有 3 个,即 µ 1= µ 2, µ 2= µ 3, µ 1= µ 3
a = 5时,H 0 有10个,即µ1=µ 2,µ 2=µ3, , µ 4=µ5 L
二、方差分析的几个概念
1、方差分析(analysis of variance):将试验数据的总变异分 解成不同来源的变异,从而评定不同来源的变异相对重要性 的一种统计方法。 2、试验指标(experiment index):为衡量试验结果的好坏或 处理效应的高低,在试验中具体测定的性状或观测的项目。 3、试验因素(experiment factor):试验中所研究的影响试验 指标的因素:单因素、双因素或多因素试验。 4、因素水平(level of factor):因素的具体表现或数量等级。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3
第一节 假设检验的基本思想
一、假设检验的概念
二、假设检验的基本原理
三、假设检验的类型
4
一、假设检验的概念
假设检验是抽样推断中的重要内容。所谓假设检 验,就是事先对总体参数或总体分布形式作出某 种假设,然后利用抽样研究的样本信息来判断这 一假设是否合理,即判断样本信息与原假设是否 有显著差异,从而决定应接受或否定原假设的统 计推断方法。
H 0 : 0
H 0 : 0
备择假设
H1 : 0
H1 : 0
H1 : 0
返回ቤተ መጻሕፍቲ ባይዱ
13
第二节 假设检验的一般步骤
一、假设检验的步骤 一个完整的假设检验过程,通常包括以下五个步骤: 第一步,根据问题要求提出原假设和备选假设; 第二步,确定适当的检验统计量及相应的抽样分布; 第三步,选取显著性水平,确定原假设的接受域和拒绝域 第四步,计算检验统计量的值; 第五步,做出统计决策。 上述五个步骤中,选择合适的假设是前提,而确定合适统 计量是关键。注意的是,做假设检验用的统计量与参数估 计用的随机变量在形式上是一致的,每一个区间估计法都 对应一个假设检验法。
14
二、 假设检验确定原假设和备选假设的原则和注意事项 (1)原假设和备择假设都是关于总体参数的。 (2)原假设与备选假设互斥。 (3)假设检验是概率意义下的反证法,一般情况下把“不能轻 易否定的命题”作为原假设。 (4)原假设和备选假设是一个完备事件组,二者相互对立。 (5)在假设检验中,等号“=”总是放在原假设上。 (6)假设检验只提供不利于原假设的证据,并不提供原假设“ 正确”的证据。如果不能拒绝原假设,并不等于“证明” 原假设是真的。它仅仅意味着我们没有足够的证据拒绝原 假设。此时我们只说“不拒绝原假设”,而不说“接受原 假设”。
21
Z
x / n
解
产品的标准重量是500毫升,过轻或者过重都不符合产品 质量标准。检验过程如下:
(1)提出假设: H 0 : 500, H1 : 500
(2)总体标准差 未知,但是由于大样本抽样,故仍选 用 Z 统计量;
(3)显著性水平 0.05 ,由双侧检验,查表可以得出 临界值: Z = ±1.96; (4)计算统计量 Z 的值:Z ,式中用 代替 S ;
1.9 6
n
s
n
8
三、假设检验的类型
(一)双侧检验
在假设检验中,研究者感兴趣的备择假设的内容, 可以是原假设在某一特定方向的变化,也可以是一 种没有特定方向的变化。 在实际工作中,当所关心的问题是要检验样本统计 量与总体参数有没有显著性差异,而不问差异的方 向是正差还是负差,如检验“某机器设备的运转是 否正常?”、“某零件的尺寸是否符合质量标准要 求?”等问题,即没有特定方向的变化,就称为双 侧检验或双尾检验。如图所示,双侧检验的拒绝域 位于统计量分布曲线的两侧。
由抽样推断那章介绍的抽样分布定理可知:当正态总体 方差已知时,无论样本容量大小,样本均值都服从正态 分布;若非正态总体的方差已知,当大样本抽样时,样 本均值仍然服从正态分布,即样本均值 x ~ N ( , 2 n) 设总体 X 1 , X 2 ,, X n 值。 是样本 X ~ N ( , 2 ) 的观察
s/ n 4.48/ 10
由于 t =0.94< t =2.262,落在接受域,故不能拒绝 2 25 原假设 H 0 ,即不能说明这批产品不符合质量标准。
9
接受域
拒绝域
2
1
拒绝域
2
Z
2
0 图8-1 双侧检验
Z
2
10
(二)单侧检验 在实际工作中,当所关心的问题是产品的某个性能指标与 原先相比是否有显著的提高或降低,如试验采用某种新工 艺是否降低成本? 试验采用某种新工艺是否能提高产品质 量等问题,显然感兴趣的是在某一特定方向的变化,这种 具有方向性的假设检验就称为单侧检验(One-side Test) 或单尾检验。根据实际工作的关注点不同,单侧假设检验 问题可以有不同的方向。一般地,如“试验采用某种新工 艺是否降低成本”的检验为左侧检验;“试验采用某种新 工艺是否提高产品质量”的检验为右侧检验。左侧检验的 拒绝域位于统计量分布曲线的左侧,右侧检验的拒绝域位 于统计量分布曲线的右侧。见图8-2、图8-3。
17
(一)总体方差已知、大样本的情况下总体均值的假设检验 当总体服从均值为 ,方差 2 n 为的正态分布,即样本 均值 x ~ N (, 2 n)。
若 x 进行标准化,对应的统计量为
Z x 0
~N(0,1)
n
18
例:2009年某农贸市场商品平均销售额为32808元, 标准差为3820元。现在随机抽取200个摊位进行调查, 测定2010年平均销售额为33400元。按照5%的显著性 水平,判断该农贸市场2010年商品平均销售额与 2009年有无明显差异。 解 :在本例中,我们关心的是前后两年该农贸市场 商品平均销售额有没有显著的差异,不涉及差异的 方向,因此,本例题属于双侧检验。检验过程如下:
t x 0 ~ t (n 1) s n
(8-2)
23
t检验的决策规则如下:
t 若采用双侧检验, H0 : 0 , H1 : 0;临界值为— 2 t 和 2 。当— t ≤t≤ t 时,不能拒绝原假设;反 ta 2 2 之,则拒绝原假设。
H 0 : 0 , H1 : 0 ;临界值为 t a 若采用左侧检验, 当 t t a 时,拒绝原假设;反之,则不能拒绝原假 设。
第八章教学课件
第八章 假设检验
第一节 假设检验的基本思想
第二节 假设检验的一般步骤 第三节 总体参数检验
第四节
第五节
假设检验的两类错误
Excel在假设检验中的应用
2
第一节 假设检验的基本思想
【引例】 某公司的销售总部准备制定 2011年招聘推销 人员的营销策略。根据往年的情况,主管经理估计推 销人员的平均年龄是35岁,其中20-35岁的推销人员占 总人数的70%,研究人员从2010年的推销人员中随机抽 取40人,调查得知他们的平均年龄是32岁,其中25-35 岁的推销人员占74%。根据这份调查结果,问:主管经 理 的 对 推 销 人 员 年 龄 的 估 计 是 否 准 确 ?
2
x s/ n
498 500 11 / 100
1.81
(5)检验判断:由于 Z =1.81< Z =1.96,落在接受 2 域,故不能拒绝原假设,即不能说明这批产品不符合质量 标准。
22
(三)总体方差未知、小样本的情况 下总体均值的假设检验
设总体服从正态分布 X ~ (, 2 ) ,但总体标准差 未 知,此时的检验统计量中包含了未知参数 ,因此不能 用上述检验对总体均值进行检验。在小样本抽样情况 下,要利用 Z 检验法进行总体均值的检验,其检验统 计量及分布为
H 0 : 0 , H1 : 0 ;临界值为 t 。 若采用右侧检验, a 当 t t 时,拒绝原假设;反之,则不能拒绝原假 a 设。
24
【例8-7】 沿用例8-6,对饮料厂功能型饮料产品进行抽样 检查,随机抽取10瓶产品,测得每瓶重量数据如下(单位 :ml ):496、499、504、493、503、492、502、501、 494、502。试以5%的显著性水平判断这批产品的质量是否 合格。 解:根据前面的分析,本例为双侧检验问题,其检验过程如 下: H 0 : 500, H1 : 500 正态总体的标准差 未知,小样本抽样( n 10 ),故选用 t 统计量; n 1 9时,查表可以得出临界值: 当 a 0.05 ,自由度 t 2 (9)=2.262; 根据样本数据计算得到: x 498.6, s 4.48, n 10 样本统计量 t x 498.6 500 0.94
5
二、假设检验的基本原理
一个假设的提出总是以一定的理由为基础的, 对总体做出的统计假设进行检验的方法依据是 概率论中的“小概率事件实际不可能发生”的 原理,即概率很小的事件在一次实验中可以把 它看成是不可能发生的。下面通过引例来说明 假设检验的基本原理。
6
【例8-1】 以引例某公司的销售总部为例,该主 管经理估计招聘推销人员的平均年龄是35岁,研 究人员从2010年加入的推销人员中随机抽取40人, 调查得到他们的年龄数据如下: 33 30 32 28 38 35 31 32 33 30 35 29 39 34 36 37 34 36 31 29 29 26 19 21 36 38 42 39 36 38 27 22 29 34 36 32 39 37 28 39 试根据调查结果判断主管经理的估计是否准确。
x s
x 1.96
也可以说 的概率只有5%,通常认为这 n 是一个很小的概率,据此可以将视为小概率事件。本例中 x 33, s 5.25, ,已知 ,经过计算得 n 40, 35 x 33 35 计算统计量: 2.41 1.96
s/ n 5.25 / 40
11
接受域
拒绝域
1
Z
0
图8-2 左侧检验
接受域
拒绝域
1
0 图8-3 右侧检验
Z
12
设为总体参数(这里代表总体均值),仍为假设的参数的 具体数值,我们可将假设检验的基本形式总结如表8-1所。
表8-1 假设检验的基本形式
假设 双侧检验 单侧检验
左侧检验
右侧检验
原假设
H 0: 0
第五步:检验判断:由于 Z 2.19 Z =1.96,落在拒绝 2 域,故拒绝原假设 H 0 。
x 33400 32808 2.19 n 3820 200