极限压缩文件方法
游戏极限压缩常见命令

游戏极限压缩常见命令游戏极限压缩常见命令2010年11月14日星期日 0:19文章只是写给自己看的,文中所有的out为输出文件名,in为输入文件名至于这些软件,我就不提供地址了,google一下吧,不算很难找~老外用的比较多(国内相对很少,主要因为都是控制台程序,没有图形界面)btw:文中所有程序都省略了后缀(.exe)1分钟后关机:shutdown -s -f -t 60---------------------------压缩部分-----------------------------预压缩(解压)precomp -slow [-oOUT.pcf] inFile无压缩量打包7za a -tzip -mx0 out.zip 压缩的文件(或列表,空格分开)简单压缩srep inFile out.reparc最高压缩量压缩arc a -mx out.arc 压缩的文件(或列表,空格分开)7z最高量压缩7za a -t7z -mx9 out.7z 压缩的文件(或列表,空格分开)---------------------------解压部分----------------------------- 解压arc(-y代表不管什么错误都有确定)arc x -y in.arc解压7z7za x -y in.7z(zip)srep解压(-d:解压;-delete:操作完成后删除源文件)srep -d -delete in.rep outFile还原原始文件precomp -r in.pcf--------------------------音频转换------------------------------ wav转MP3(-h 高品质MP3)lame -h in.wav out.mp3MP3转wavlame --decode in.mp3 out.wavwav转ogg(-q4 中低品质 q2较低)oggenc2 -q4 in.wav out.oggogg转wavoggdec -w out.wav in.oggwav编码转换(-q:安静模式 -i:ima-adpcm格式)sox -q in.wav -i out.wav首先准备的软件1:Precomp (只需要这两个文件precomp.exe,packjpg_dll.dll) 2:FreeArc(其实也就是只需要个arc.exe) 打包步骤: 1:使用一个压缩格式对需要压缩的文件(通常就是game啦)进行打包,注意这里的打包指的是无压缩打包就是说使用压缩软件把分散的游戏文件打包成一个单个的文件,你可以7za,winzip,winrar,freearc都可以常见的集中于7za打包和freearc打包,个人倾向于freearc打包, 命令行指令: arc a -m0 [打包后的文件名].arc [需要打包的文件夹完整|相对路径] -m0:指的是无压缩量打包,详见freearc的文档例如:arc a -m0 k1.arc "e:\game" 即将e盘的game文件夹打包成一个单独的文件k1.arc 打完后的文件大小应该和源文件夹大小一致! 2:使用precomp对打包文件进行预压缩(啥叫预压缩呢,简单的说就是分析文件,将已经压缩的数据流,解压出来,便于真正压缩时能获得更高的压缩量,所以预压缩后文件会变大,甚至会变成原来的2倍大) 命令行指令: precomp.exe -slow -v k1.arc -slow:尽量分析数据流多释放些数据-v:显示执行信息(不想看就省略) k1.arc:当然就是刚才打包的文件咯执行后生成k1.pcf文件(这就是预压缩后的实际文件) 3:使用freearc对与压缩文件进行压缩,当然尽量压小些的话,压缩参数就要高些,同时压缩时间也越长命令行指令: arc a -mx "game.arc" "k1.pcf" a:添加压缩包 -mx:和前面的-m0是同一种参数,mx指最大压缩量,压缩和解压时使用的内存最大(经过反复的测试,发现机器的内存值越大,压缩量越高,所以在支持4G以上内存的64位OS上压缩量可以达到最大,当然在2g内存下使用一些特殊的参数也能提高一些压缩量,我的参数arc a -mlzma:767m -di -lc- --cache10m -i2 "game.arc" "k1.pcf" -di:显示压缩信息,-i2:di的辅助参数,显示更多信息,-lc-最大压缩内存使用量, -mlzma=767m 使用lzma算法的最大内存占用值,767是我在2g内存下测试的极限值,再大内存就不够用了,大家可以根据自己机器的实际情况自行测试这个值的大小) 好了经过漫长的等待后文件就压缩好了,通常游戏中的过场动画是没什么压缩量的,所以大家经常看到游戏主程序和动画分开下载的情况这样的压缩结果可能比一般winrar压缩,7z压缩小的多,但是由于多层压缩,压缩时间上并没有什么优势... 所以再次向制作高压游戏的大大们致敬~辛苦了~ 简单说一下解压,解压很简单了一般写个批处理啥的,执行相关的命令即可arc.exe x -y game.arc x:解压-y确认选项全选y 解出k1.pcf precomp.exe -r k1.pcf -r:还原预解压的文件还原出k1.arc arc.exe x -y k1.arc 解压完成了LZ要首先熟悉品处理才行,压缩解压工具要全部用批处理调用的.....关于游戏的极限压缩(就是常见的高压版)2010年10月07日星期四 14:32其实游戏压缩已经经历了很长时间的技术变革了....记得01~02年那会,那些藏金阁中的高压版游戏,都是要经过无数遍的解压(当然还包括了文件格式转换,比如图片格式转换(jpg->bmp),声音格式转换(ogg->mp3,ogg->wav))....随着游戏加密技术的发展,现在的游戏可没以前那么容易解开了,资源也没那么容易搞定,不过压缩技术也在进步目前市面上主流的高压版游戏都是经过多层压缩的(当然以前也是)..经过几日的反复研究,终于摸索出一些门道首先准备的软件1:Precomp (只需要这两个文件precomp.exe,packjpg_dll.dll) 2:FreeArc(其实也就是只需要个arc.exe)打包步骤:1:使用一个压缩格式对需要压缩的文件(通常就是game啦)进行打包,注意这里的打包指的是无压缩打包就是说使用压缩软件把分散的游戏文件打包成一个单个的文件,你可以7za,winzip,winrar,freearc都可以常见的集中于7za打包和freearc打包,个人倾向于freearc打包, 命令行指令:arc a -m0 [打包后的文件名].arc [需要打包的文件夹完整|相对路径]-m0:指的是无压缩量打包,详见freearc的文档例如:arc a -m0 k1.arc "e:\game" 即将e盘的game文件夹打包成一个单独的文件k1.arc打完后的文件大小应该和源文件夹大小一致!2:使用precomp对打包文件进行预压缩(啥叫预压缩呢,简单的说就是分析文件,将已经压缩的数据流,解压出来,便于真正压缩时能获得更高的压缩量,所以预压缩后文件会变大,甚至会变成原来的2倍大)命令行指令:precomp.exe -slow -v k1.arc-slow:尽量分析数据流多释放些数据-v:显示执行信息(不想看就省略)k1.arc:当然就是刚才打包的文件咯执行后生成k1.pcf文件(这就是预压缩后的实际文件)3:使用freearc对与压缩文件进行压缩,当然尽量压小些的话,压缩参数就要高些,同时压缩时间也越长命令行指令:arc a -mx "game.arc" "k1.pcf"a:添加压缩包-mx:和前面的-m0是同一种参数,mx指最大压缩量,压缩和解压时使用的内存最大(经过反复的测试,发现机器的内存值越大,压缩量越高,所以在支持4G以上内存的64位OS上压缩量可以达到最大,当然在2g内存下使用一些特殊的参数也能提高一些压缩量,我的参数arc a -mlzma:767m -di -lc---cache10m -i2 "game.arc" "k1.pcf" -di:显示压缩信息,-i2:di 的辅助参数,显示更多信息,-lc-最大压缩内存使用量, -mlzma=767m 使用lzma算法的最大内存占用值,767是我在2g内存下测试的极限值,再大内存就不够用了,大家可以根据自己机器的实际情况自行测试这个值的大小)好了经过漫长的等待后文件就压缩好了,通常游戏中的过场动画是没什么压缩量的,所以大家经常看到游戏主程序和动画分开下载的情况这样的压缩结果可能比一般winrar压缩,7z压缩小的多,但是由于多层压缩,压缩时间上并没有什么优势...所以再次向制作高压游戏的大大们致敬~辛苦了~简单说一下解压,解压很简单了一般写个批处理啥的,执行相关的命令即可arc.exe x -y game.arcx:解压-y确认选项全选y解出k1.pcfprecomp.exe -r k1.pcf-r:还原预解压的文件还原出k1.arcarc.exe x -y k1.arc解压完成了在玩一些硬盘游戏的时候,会常常看到弹出命令提示符,然后进行漫长的解压缩。
几种压缩算法

1110010101110110111100010 - DABBDCEAAB
下一个问题是:象上面这样的前缀编码只能表示整数位的符号,对几点几位的符号只能用近似的整数位输出,那么怎样输出小数位数呢?科学家们用算术编码解决了这个问题,我们将在第四章对算术编码作详细的讨论。
总结一下
不同的模型使用不同的方法计算字符的出现概率,由此概率可以得出字符的熵;然后使用不同的编码方法,尽量接近我们期望得到的熵值。所以,压缩效果的好坏一方面取决于模型能否准确地得到字符概率,另一方面也取决于编码方法能否准确地用期望的位数输出字符代码。换句话说,压缩 = 模型 + 编码。如下图所示:
资源
我们已经知道,编写压缩程序往往不能对数据的整个字节进行处理,而是要按照二进制位来读写和处理数据,操作二进制位的函数也就成为了压缩程序中使用最为普遍的工具函数。
奇妙的二叉树:Huffman的贡献
提起 Huffman 这个名字,程序员们至少会联想到二叉树和二进制编码。的确,我们总以 Huffman 编码来概括 D.A.Huffman 个人对计算机领域特别是数据压缩领域的杰出贡献。我们知道,压缩 = 模型 + 编码,作为一种压缩方法,我们必须全面考虑其模型和编码两个模块的功效;但同时,模型和编码两个模块又相互具有独立性。举例来说,一个使用 Huffman 编码方法的程序,完全可以采用不同的模型来统计字符在信息中出现的概率。因此,我们这一章将首先围绕 Huffman 先生最为重要的贡献 —— Huffman 编码展开讨论,随后,我们再具体介绍可以和 Huffman 联合使用的概率模型。
a | d e
0 | 1
+-----+-----+
| |
pdf压缩极限

pdf压缩极限pdf压缩极限涉及到数字数据压缩技术的最前沿。
它的核心目标在于寻找一个平衡点:在尽可能减小PDF文件大小的同时,保持文件内容的完整性和可读性。
PDF,作为一种常用的文档格式,广泛应用于各种场景,其压缩极限的研究对于提升存储效率与网络传输速度具有重大意义。
要理解pdf压缩极限,首先需要对"压缩"这一概念有一个清晰的认识。
简单来说,压缩就是通过特定的算法和技术,将文件中的冗余信息去除,从而减小文件大小的过程。
然而,这个过程并非无损的,过度的压缩可能会导致文件质量的损失。
那么,什么是pdf压缩极限呢?要回答这个问题,我们首先要明白影响压缩极限的几个关键因素。
首先是原始文件的大小和内容。
例如,一个包含大量高清图片和复杂排版的PDF文件,其压缩极限自然会比一个简单的文字档要低。
其次是使用的压缩算法和技术。
不同的算法和技术对文件内容的处理方式和效率各有不同,这也会影响压缩极限。
在理论层面,当PDF文件被压缩到无法恢复到原始状态时,我们可以认为达到了压缩极限。
但在实际应用中,为了确保文件的可读性和完整性,我们通常会设置一个合理的压缩率限制。
例如,一些先进的压缩技术可以在保证文件质量的同时,实现高达90%的压缩率。
然而,我们必须警惕过度压缩可能带来的问题。
过度的压缩不仅可能导致文件质量的损失,如文字模糊、图片失真等,还可能影响文件的打开和阅读。
因此,在压缩PDF文件时,我们需要根据实际情况进行权衡,选择合适的压缩算法和参数设置。
pdf压缩极限是一个复杂且多变的概念,它涉及到数字数据压缩技术的方方面面。
为了在减小文件大小的同时保持文件质量,我们需要深入研究各种压缩算法和技术,以寻找最佳的平衡点。
同时,我们也需要认识到过度压缩的危害,避免因追求压缩率而牺牲文件质量。
在未来,随着技术的不断进步,我们有理由相信pdf 压缩极限会不断被突破,为我们的工作和生活带来更多的便利。
图片格式及如何压缩图片的字节大小(kb)

()是微软公司为了弥补使用地不足而开发地一种位扩展图元文件格式,也属于矢量文件格式,其目地是欲使图元文件更加容易接受个人收集整理勿做商业用途
、()格式
格式由公司研制而成,是和地统称:是最初地基于×分辨率地动画文件格式,而则采用了更高效地数据压缩技术,所以具有比更高地压缩比,其分辨率也有了不少提高.个人收集整理勿做商业用途
二、格式
是英文(图形交换格式)地缩写.顾名思义,这种格式是用来交换图片地.事实上也是如此,上世纪年代,美国一家著名地在线信息服务机构针对当时网络传输带宽地限制,开发出了这种图像格式.个人收集整理勿做商业用途
格式地特点是压缩比高,磁盘空间占用较少,所以这种图像格式迅速得到了广泛地应用.最初地只是简单地用来存储单幅静止图像(称为),后来随着技术发展,可以同时存储若干幅静止图象进而形成连续地动画,使之成为当时支持动画为数不多地格式之一(称为),而在图像中可指定透明区域,使图像具有非同一般地显示效果,这更使风光十足.目前上大量采用地彩色动画文件多为这种格式地文件,也称为格式文件.个人收集整理勿做商业用途
同时还是一种很灵活地格式,具有调节图像质量地功能,允许你用不同地压缩比例对这种文件压缩,比如我们最高可以把地位图文件压缩至.当然我们完全可以在图像质量和文件尺寸之间找到平衡点.个人收集整理勿做商业用途
由于优异地品质和杰出地表现,它地应用也非常广泛,特别是在网络和光盘读物上,肯定都能找到它地影子.目前各类浏览器均支持这种图像格式,因为格式地文件尺寸较小,下载速度快,使得页有可能以较短地下载时间提供大量美观地图像,同时也就顺理成章地成为网络上最受欢迎地图像格式.个人收集整理勿做商业用途
七、格式
()是一种新兴地网络图像格式.在年底,由于公司宣布拥有专利地压缩方法,要求开发软件地作者须缴交一定费用,由此促使免费地图像格式地诞生.一开始便结合及两家之长,打算一举取代这两种格式.年月日由向国际网络联盟提出并得到推荐认可标准,并且大部分绘图软件和浏览器开始支持图像浏览,从此图像格式生机焕发.个人收集整理勿做商业用途
7-zip的极限压缩算法

7-zip的极限压缩算法
7-Zip 使用了一种名为LZMA 的压缩算法,这是一种非常高效的压缩算法,特别适合处理大型文件和数据流。
LZMA 算法具有极高的压缩比,尤其是在处理大量数据时。
以下是LZMA 算法的一些关键特性:
1.字典编码:LZMA 使用字典编码,这意味着它查找并存储重复的数
据块,而不是简单地存储每个字节。
这种方法能够显著减少重复数据的大小。
2.范围编码:与传统的熵编码方法不同,LZMA 使用范围编码来进一
步提高压缩效率。
范围编码能够更有效地表示数据中的概率分布,从而在压缩过程中实现更高的效率。
3.多线程支持:7-Zip 支持多线程压缩,这使得在多核处理器系统上能
够更快地完成压缩任务。
通过并行处理,可以显著提高压缩大型文件的性能。
4.高压缩比:LZMA 算法提供了非常高的压缩比,尤其是在处理大量
数据时。
这使得7-Zip 在许多场景下成为了一个非常有效的压缩工具。
5.解压缩速度:虽然LZMA 压缩算法相对较慢,但解压缩速度相对较
快。
这意味着当你需要快速访问压缩文件时,解压缩操作不会成为瓶颈。
6.可配置的压缩级别:7-Zip 允许用户选择不同的压缩级别,可以根据
需要平衡压缩时间和压缩比。
这为用户提供了更大的灵活性,可以根据需求选择最适合的压缩设置。
总的来说,7-Zip 的LZMA 算法是一种非常强大且高效的压缩算法,特别适用于处理大型文件和数据流。
其高效的字典编码、范围编码和多线程支持等特性使得它在许多场景下成为了首选的压缩工具。
gzip压缩算法

下面我们就来介绍gzip如何实现寻找当前strstart开始的串的最长匹配串。
如果每次为当前串寻找匹配串时,都要和之前的每个串的至少3个字节进行比较的话,那么比较量将是非常非常大的。为了提高比较速度,gzip使用了哈希表。这是gzip实现LZ77的关键。这个哈希表是一个叫head的数组(后面我们将看到为什么这个缓冲区叫head)。gzip对windows中的每个串,使用串的头三个字节,也就是strstart,strstart 1,strstart 2,用一个设计好的哈希函数来进行计算,得到一个插入位置ins_h。也就是用串的头三个字节来确定一个插入位置。然后把串的位置,也就是 strstart的值,保存在head数组的第ins_h项中。我们马上就可以看到为什么要这样做。head数组在没有插入任何值时,全部为0。
首先,gzip 从要压缩的文件中读入64KB的内容到一个叫window的缓冲区中。为了简单起见,我们以32KB以下文件的压缩为例做说明。对于我们这里使用32KB以下文件,gzip将整个文件读入到window缓冲区中。然后使用一个叫strstart的变量在window数组中,从0开始一直向后移动。strstart在每一个位置上,都在它之前的区域中,寻找和当前strstart开始的串的头3个字节匹配的串,并试图从这些匹配串中找到最长的匹配串。
现在我们也就知道了,三个字节通过哈希函数计算得到同一ins_h的所有的串被链在了一起,head[ins_h]为链头,prev数组中放着的更早的串。这也就是head和prev名称的由
来。
gzip寻找匹配串的另外一个值得注意的实现是,延迟匹配。会进行两次尝试。比如当前串为str,那么str发生匹配以后,并不发生压缩,还会对str 1串进行匹配,然后看哪种
webscarab使用方法

webscarab使用方法(原创实用版1篇)篇1 目录1.WebP 格式概述2.WebP 极限压缩方法的原理3.WebP 极限压缩方法的实现4.WebP 极限压缩方法的优缺点5.WebP 极限压缩方法的应用前景篇1正文1.WebP 格式概述WebP 是一种由 Google 开发的图像格式,主要用于网络图像的传输和显示。
相较于传统的 JPEG 格式,WebP 具有更高的压缩率和更快的加载速度,因此在网络应用中具有广泛的应用前景。
2.WebP 极限压缩方法的原理WebP 极限压缩方法是一种基于 WebP 图像格式的高效图像压缩技术。
其主要原理是将图像中的颜色信息进行量化和编码,以减少图像的数据量。
同时,WebP 极限压缩方法还可以根据图像的特征,对图像进行有损压缩,从而在保证图像质量的前提下,进一步提高压缩率。
3.WebP 极限压缩方法的实现WebP 极限压缩方法的实现主要包括以下几个步骤:(1)颜色量化:通过对图像中的颜色进行量化,将原本连续的颜色值映射到离散的颜色值,从而减少图像的数据量。
(2)编码:将量化后的颜色值进行编码,以便在存储和传输过程中能够被有效还原。
(3)有损压缩:通过对图像的特征进行分析,采用有损压缩算法对图像进行压缩,以进一步提高压缩率。
4.WebP 极限压缩方法的优缺点WebP 极限压缩方法具有以下优缺点:优点:(1)压缩率高:相较于传统的 JPEG 格式,WebP 极限压缩方法具有更高的压缩率,能够有效减少图像的数据量。
(2)加载速度快:由于 WebP 极限压缩方法的压缩率较高,因此图像的加载速度较快,能够提高用户的浏览体验。
缺点:(1)兼容性问题:由于 WebP 格式相较于 JPEG 格式较新,因此在一些较老的设备或浏览器上,可能存在兼容性问题。
(2)存储空间需求:由于 WebP 极限压缩方法需要存储量化和编码后的颜色值,因此相对于 JPEG 格式,WebP 格式的存储空间需求较大。
ZIP压缩算法详细分析及解压实例解释

ZIP压缩算法详细分析及解压实例解释最近自己实现了一个ZIP压缩数据的解压程序,觉得有必要把ZIP压缩格式进行一下详细总结,数据压缩是一门通信原理和计算机科学都会涉及到的学科,在通信原理中,一般称为信源编码,在计算机科学里,一般称为数据压缩,两者本质上没啥区别,在数学家看来,都是映射。
一方面在进行通信的时候,有必要将待传输的数据进行压缩,以减少带宽需求;另一方面,计算机存储数据的时候,为了减少磁盘容量需求,也会将文件进行压缩,尽管现在的网络带宽越来越高,压缩已经不像90年代初那个时候那么迫切,但在很多场合下仍然需要,其中一个原因是压缩后的数据容量减小后,磁盘访问IO的时间也缩短,尽管压缩和解压缩过程会消耗CPU资源,但是CPU计算资源增长得很快,但是磁盘IO资源却变化得很慢,比如目前主流的SATA硬盘仍然是7200转,如果把磁盘的IO压力转化到CPU上,总体上能够提升系统运行速度。
压缩作为一种非常典型的技术,会应用到很多很多场合下,比如文件系统、数据库、消息传输、网页传输等等各类场合。
尽管压缩里面会涉及到很多术语和技术,但无需担心,博主尽量将其描述得通俗易懂。
另外,本文涉及的压缩算法非常主流并且十分精巧,理解了ZIP的压缩过程,对理解其它相关的压缩算法应该就比较容易了。
1、引子压缩可以分为无损压缩和有损压缩,有损,指的是压缩之后就无法完整还原原始信息,但是压缩率可以很高,主要应用于视频、话音等数据的压缩,因为损失了一点信息,人是很难察觉的,或者说,也没必要那么清晰照样可以看可以听;无损压缩则用于文件等等必须完整还原信息的场合,ZIP自然就是一种无损压缩,在通信原理中介绍数据压缩的时候,往往是从信息论的角度出发,引出香农所定义的熵的概念,这方面的介绍实在太多,这里换一种思路,从最原始的思想出发,为了达到压缩的目的,需要怎么去设计算法。
而ZIP为我们提供了相当好的案例。
尽管我们不去探讨信息论里面那些复杂的概念,不过我们首先还是要从两位信息论大牛谈起。
linux 压缩 极限 -回复

linux 压缩极限-回复Linux 压缩极限- 减小文件体积,提高存储与传输效率引言:在日常使用中,我们时常需要将文件打包并压缩以减小文件的体积,并提高文件的存储和传输效率。
Linux系统提供了多种压缩工具和算法,能够满足我们的需求。
本文将介绍Linux下常用的压缩工具以及它们的优势和不足,同时分享一些压缩的技巧和策略,帮助我们在压缩文件时达到更高的极限效果。
一、常用的Linux压缩工具1. Gzip:Gzip是Linux下最常用的压缩工具之一。
它使用DEFLATE算法来进行无损压缩,并且只能压缩单个文件。
使用Gzip压缩文件时,我们只需要在终端运行"gzip 文件名"即可。
它能够将文件压缩成.gz的扩展名,并同时保留原文件。
优点:压缩速度快,压缩比高,适用于大多数文件类型。
缺点:不能压缩目录,只适用于单个文件。
2. Bzip2:Bzip2是一种更高级的压缩工具,使用Burrows-Wheeler变换和Huffman编码进行数据压缩。
与Gzip相比,Bzip2的压缩比更高,但压缩速度较慢。
优点:压缩比高。
缺点:压缩速度慢。
3. Xz:Xz是一种压缩工具,使用LZMA2算法,并采用多线程来加速压缩过程。
它的压缩比比Gzip和Bzip2更高,但也相应地导致了更慢的压缩速度。
优点:高压缩比。
缺点:压缩速度较慢。
4. Zip:Zip是一种常见的压缩格式,它可以将多个文件和目录压缩到一个文件中。
Zip格式在Windows和Linux系统中都有良好的兼容性。
优点:兼容性强,可以压缩多个文件和目录。
缺点:压缩比相对较低。
二、压缩的技巧和策略1. 使用压缩级别:大多数压缩工具提供多个压缩级别,从1到9不等。
一般情况下,默认的压缩级别为6或者7,这个级别在压缩速度和压缩比之间提供了一个平衡点。
如果我们追求更高的压缩比,可以尝试使用较高的压缩级别,但要注意这会导致较长的压缩时间。
2. 去除冗余信息:在压缩文件之前,我们可以采取一些策略来去除冗余信息,从而减小文件的体积。
LZ算法

数据压缩与LZ系列算法及其改进LZ77字典压缩算法简介字典压缩的原理是构建一个字典,用索引来代替重复出现的字符或字符串。
如果字符串相对长,那么对整个字符串构建字典,这个字典将会很大,并且随着字典的增大,匹配速度也会快速下降。
原始的LZ77算法是利用了字符串中上下文的相关性特点,通过一个滑动窗口(一个查找缓冲区)来作为字典,对要压缩的字符串保留一个look-aheadbuffer。
压缩后的字符串采用三元组来表示:<位移,长度,下一个字符>,在滑动窗口中从后往前找,如果在窗口中有曾经出现过的相同字符,看最多可以匹配多少字节,完了继续往前查找,查找完了取窗口中最长的匹配串(如果有多个相同长度的串可以匹配,取最后一个),将这个匹配串距当前位置的位移,长度,及下一个字符构成的三元组写出。
如果在滑动窗口找不到匹配串,那么位移=长度=0,加上不能压缩的字符一起输出。
滑动窗口可以通过循环队列实现。
解压缩是一个比较简单而且快速的过程,在需要解压缩时通过位移和长度拷贝之前出现过的字符串就可以完成。
LZ77字典压缩的改进LZ77压缩算法的大部分时间都会花在字符串匹配上,针对这一点有多种改进:∙构建查找树,该思路也有多种实现方法,如LZSS。
∙构建链表法实现的哈希表,通过对一个字符串的头三个字节做哈希,快速找到匹配字符串的位置之后再沿链表做顺序搜索,如LZRW。
Deflate算法,其在ZIP和GZIP,以及许多软件中使用到,是使用LZ77的变种和huffman编码结合的一种压缩算法。
在ZLib的源码中可以找到详细的算法说明。
类似的还有鼎鼎有名的7-ZIP所使用的LZMA算法,也是LZ77算法和算术编码结合的算法,对LZ77的三元组都根据概率再次进行编码,压缩比很高,但是压缩速度相对较慢。
LZ78/LZW系列算法LZ77算法针对过去的数据进行处理,而LZ78 算法却是针对后来的数据进行处理。
LZ78通过对输入缓存数据进行预先扫描与它维护的字典中的数据进行匹配来实现这个功能,在找到字典中不能匹配的数据之前它扫描进所有的数据,这时它将输出数据在字典中的位置、匹配的长度以及找不到匹配的数据,并且将结果数据添加到字典中。
图像压缩的几种常见算法介绍
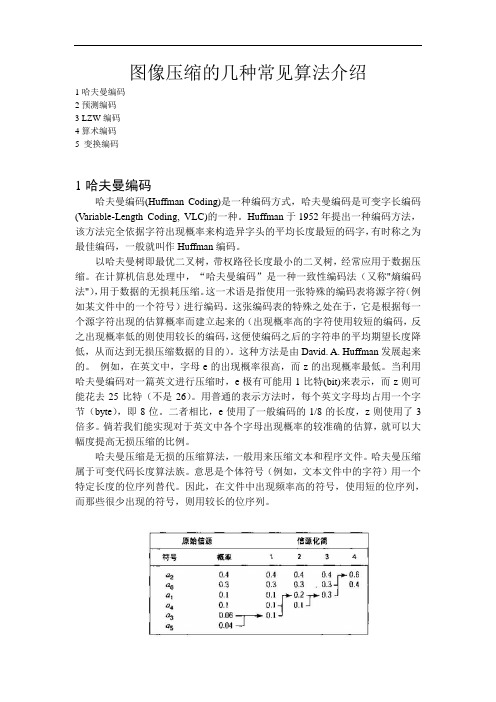
图像压缩的几种常见算法介绍1哈夫曼编码2预测编码3 LZW编码4算术编码5 变换编码1哈夫曼编码哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(Variable-Length Coding, VLC)的一种。
Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。
以哈夫曼树即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。
在计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称"熵编码法"),用于数据的无损耗压缩。
这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。
这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。
这种方法是由David. A. Huffman发展起来的。
例如,在英文中,字母e的出现概率很高,而z的出现概率最低。
当利用哈夫曼编码对一篇英文进行压缩时,e极有可能用1比特(bit)来表示,而z则可能花去25比特(不是26)。
用普通的表示方法时,每个英文字母均占用一个字节(byte),即8位。
二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。
倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
哈夫曼压缩是无损的压缩算法,一般用来压缩文本和程序文件。
哈夫曼压缩属于可变代码长度算法族。
意思是个体符号(例如,文本文件中的字符)用一个特定长度的位序列替代。
因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。
图1 霍夫曼信源化简图2 霍夫曼编码分配过程2预测编码预测编码是根据离散信号之间存在着一定关联性的特点,利用前面一个或多个信号预测下一个信号,然后对实际值和预测值的差(预测误差)进行编码。
压缩映像原理数列极限

压缩映像原理数列极限
压缩映像原理:又称为巴拉赫不动点定理,是度量空间理论的一
个非常重要的工具,
压缩映像原理的定义:设函数f(x)在(-∞,+∞)内L
ipschitz连续,即L >0,s1t,x1,x2∈(-∞,+∞)有∣f(x1)-
f(x2)∣≤L∣x1-x2∣
若0<L<1,则称f(x)是压缩的。
利用压缩映像原理求极限的本质是通过数列的递推公式得到一个
可微函数f(x),然后通过证明f(x)是压缩的即满足Lipschitz条件,就可以间接证明数列是收敛的,进而通过f(x)的不动点求的数列的
极限,极限值恰好为不动点值。
接下来通过几道例题来体会利用压
缩映像原理求极限的魅力。
这些例子很重要,所以大家务必要明确,尤其是关于f(x)的选取,以及如何证明是压缩的。
快速法压缩实验报告(3篇)

第1篇一、实验目的1. 掌握快速法压缩实验的基本原理和操作方法。
2. 了解不同材料的压缩特性,分析材料在压缩过程中的力学行为。
3. 培养实验操作技能和数据分析能力。
二、实验原理快速法压缩实验是一种研究材料力学性能的常用方法。
实验过程中,将试样置于压缩试验机上,通过施加轴向压力,使试样发生压缩变形,直至试样破坏。
通过测量试样在不同压力下的变形量,可以计算出材料的弹性模量、屈服强度、抗压强度等力学性能指标。
三、实验设备及仪器1. 快速压缩试验机:用于施加轴向压力,测量试样的变形和破坏。
2. 试样:实验选用不同材料的试样,如低碳钢、铸铁等。
3. 游标卡尺:用于测量试样尺寸。
4. 数据采集系统:用于记录实验数据。
四、实验步骤1. 准备实验试样:根据实验要求,选取合适的试样,并测量试样尺寸。
2. 安装试样:将试样放置在试验机上,调整试样位置,确保试样与试验机压板接触良好。
3. 设置实验参数:设置试验机加载速度、加载方式等参数。
4. 开始实验:启动试验机,施加轴向压力,记录试样在不同压力下的变形量。
5. 实验结束:当试样发生破坏时,停止加载,记录试样破坏时的压力值。
6. 数据处理:将实验数据进行分析,计算材料的力学性能指标。
五、实验结果与分析1. 低碳钢压缩实验结果(1)弹性模量:根据实验数据,计算低碳钢的弹性模量为E1。
(2)屈服强度:根据实验数据,确定低碳钢的屈服强度为S1。
(3)抗压强度:由于低碳钢在压缩过程中不会发生断裂,因此不测抗压强度。
2. 铸铁压缩实验结果(1)弹性模量:根据实验数据,计算铸铁的弹性模量为E2。
(2)屈服强度:根据实验数据,确定铸铁的屈服强度为S2。
(3)抗压强度:根据实验数据,计算铸铁的抗压强度为b2。
六、实验总结1. 通过快速法压缩实验,掌握了不同材料的压缩特性,分析了材料在压缩过程中的力学行为。
2. 培养了实验操作技能和数据分析能力,为今后从事相关研究奠定了基础。
七、实验注意事项1. 实验过程中,确保试样与试验机压板接触良好,避免因接触不良导致实验数据误差。
LZ算法

数据压缩与LZ系列算法及其改进LZ77字典压缩算法简介字典压缩的原理是构建一个字典,用索引来代替重复出现的字符或字符串。
如果字符串相对长,那么对整个字符串构建字典,这个字典将会很大,并且随着字典的增大,匹配速度也会快速下降。
原始的LZ77算法是利用了字符串中上下文的相关性特点,通过一个滑动窗口(一个查找缓冲区)来作为字典,对要压缩的字符串保留一个look-aheadbuffer。
压缩后的字符串采用三元组来表示:<位移,长度,下一个字符>,在滑动窗口中从后往前找,如果在窗口中有曾经出现过的相同字符,看最多可以匹配多少字节,完了继续往前查找,查找完了取窗口中最长的匹配串(如果有多个相同长度的串可以匹配,取最后一个),将这个匹配串距当前位置的位移,长度,及下一个字符构成的三元组写出。
如果在滑动窗口找不到匹配串,那么位移=长度=0,加上不能压缩的字符一起输出。
滑动窗口可以通过循环队列实现。
解压缩是一个比较简单而且快速的过程,在需要解压缩时通过位移和长度拷贝之前出现过的字符串就可以完成。
LZ77字典压缩的改进LZ77压缩算法的大部分时间都会花在字符串匹配上,针对这一点有多种改进:∙构建查找树,该思路也有多种实现方法,如LZSS。
∙构建链表法实现的哈希表,通过对一个字符串的头三个字节做哈希,快速找到匹配字符串的位置之后再沿链表做顺序搜索,如LZRW。
Deflate算法,其在ZIP和GZIP,以及许多软件中使用到,是使用LZ77的变种和huffman 编码结合的一种压缩算法。
在ZLib的源码中可以找到详细的算法说明。
类似的还有鼎鼎有名的7-ZIP所使用的LZMA算法,也是LZ77算法和算术编码结合的算法,对LZ77的三元组都根据概率再次进行编码,压缩比很高,但是压缩速度相对较慢。
LZ78/LZW系列算法LZ77算法针对过去的数据进行处理,而LZ78 算法却是针对后来的数据进行处理。
LZ78通过对输入缓存数据进行预先扫描与它维护的字典中的数据进行匹配来实现这个功能,在找到字典中不能匹配的数据之前它扫描进所有的数据,这时它将输出数据在字典中的位置、匹配的长度以及找不到匹配的数据,并且将结果数据添加到字典中。
webp极限压缩方法

webp极限压缩方法(原创版6篇)目录(篇1)1.引言2.WebP 格式概述3.极限压缩方法的原理4.极限压缩方法的实现5.极限压缩方法的优缺点6.结论正文(篇1)【引言】WebP 是一种由 Google 开发的图像格式,目的是在保证图像质量的同时,实现更高的压缩率,从而减小文件大小和加快网络传输速度。
在WebP 格式中,有一种被称为极限压缩的方法,可以在保证图像质量的前提下,实现更高的压缩率。
本文将对 WebP 极限压缩方法进行介绍和分析。
【WebP 格式概述】WebP 是一种基于 VP8 编码的图像格式,它可以将图像压缩到更小的文件大小,同时保持较高的图像质量。
WebP 格式支持有损压缩和无损压缩两种方式,其中有损压缩可以进一步细分为普通压缩和极限压缩两种。
【极限压缩方法的原理】极限压缩方法是一种基于深度学习的图像压缩方法,它利用神经网络来学习图像的特征,从而实现更高效的压缩。
极限压缩方法通过对图像进行多次编码和解码,以及对编码结果进行熵编码,来实现更高的压缩率。
【极限压缩方法的实现】在实现极限压缩方法时,需要先对图像进行预处理,包括降噪、锐化等操作,以提高图像的质量。
然后,使用神经网络对图像进行特征提取和编码,得到压缩后的图像。
最后,通过熵编码对压缩后的图像进行进一步的压缩。
【极限压缩方法的优缺点】极限压缩方法的优点在于它可以在保证图像质量的前提下,实现更高的压缩率,从而减小文件大小和加快网络传输速度。
然而,极限压缩方法的缺点在于它的实现复杂度较高,需要大量的计算资源和时间。
【结论】总的来说,WebP 极限压缩方法是一种有效的图像压缩方法,它可以在保证图像质量的前提下,实现更高的压缩率。
目录(篇2)1.引言2.WebP 格式概述3.极限压缩方法的原理4.极限压缩方法的实现5.极限压缩方法的优缺点6.结论正文(篇2)【引言】WebP 是一种由 Google 开发的图像格式,旨在提供一种更加高效的图像压缩方法。
webp极限压缩方法

webp极限压缩方法(原创实用版3篇)目录(篇1)I.引言A.介绍webp格式B.为什么需要webp压缩II.WebP压缩技术原理A.压缩算法介绍B.压缩比与图像质量的关系C.WebP算法的优化之处III.WebP压缩的优点与限制A.优点1.高压缩比2.图像质量较好3.支持透明度4.支持多帧B.限制1.对压缩比要求极高的场景可能不适用2.压缩后的图像质量可能受到影响IV.WebP压缩的应用场景A.图片分享平台B.视频网站C.移动应用D.广告行业V.结论A.WebP是一种高效的图片压缩格式B.在保证图像质量的前提下,可以大大减小文件大小,提高传输效率C.需要根据具体应用场景选择合适的压缩比,以达到最佳效果正文(篇1)WebP是一种基于无损压缩的图片格式,它是由Google开发的一种新的图片格式。
WebP格式的图像文件可以大大减小文件大小,提高图片传输效率,同时保持较高的图像质量。
目录(篇2)I.引言A.介绍webp格式B.为什么需要webp压缩II.WebP压缩技术原理A.压缩算法介绍B.压缩比与质量的关系C.压缩算法的优缺点III.WebP压缩实践方法A.使用浏览器自带的图片压缩功能B.使用图片编辑软件进行压缩C.调整图片格式参数进行压缩IV.WebP压缩应用场景A.网络传输B.社交媒体平台C.电子设备存储V.结论A.WebP格式的应用前景B.总结全文正文(篇2)随着互联网的普及,网络传输的数据量越来越大,如何在保证图片质量的前提下,尽可能地减小图片文件的大小成为了大家关注的焦点。
WebP 是一种基于VP8视频编码技术的图片格式,具有高压缩比的特点,可以有效减小图片文件的大小,因此受到了广泛关注。
接下来,我们将从WebP 压缩技术原理、实践方法、应用场景三个方面来介绍WebP压缩方法。
一、WebP压缩技术原理WebP格式采用了先进的VP8视频编码技术,通过采用高效的压缩算法,可以将图片文件的大小压缩到传统JPEG格式的几分之一。
极限压缩格式

极限压缩格式1. 引言在数字化时代,数据的存储和传输变得越来越重要。
为了更高效地利用存储空间和加快数据传输速度,人们一直在寻找更好的压缩算法。
极限压缩格式是一种新兴的压缩技术,它能够将文件大小大大减小而不丢失任何信息。
本文将详细介绍极限压缩格式的原理、应用以及未来发展方向。
2. 原理极限压缩格式的原理基于信息熵和无损压缩算法。
信息熵是一个度量信息量的指标,可以理解为一个信源产生信息的平均不确定性。
无损压缩算法则是指在压缩过程中不丢失任何信息。
极限压缩格式通过对文件进行分析,找到其中的规律和重复模式,并利用这些规律和模式来减小文件大小。
具体而言,它使用以下几种方法:2.1 字典编码字典编码是极限压缩格式中最基本也是最重要的方法之一。
它通过建立一个字典,将输入文件中出现的字符串映射到较短的编码。
在压缩过程中,将输入文件中的字符串替换为对应的编码,从而减小文件大小。
字典编码算法有很多种,其中最著名的是Lempel-Ziv-Welch(LZW)算法。
LZW算法通过动态构建字典来实现压缩,能够有效地处理各种类型的文件。
2.2 预测编码预测编码是另一种常用的压缩方法。
它利用已有的数据来预测下一个数据的值,并将预测误差进行编码。
在解压缩时,利用预测值和编码来还原原始数据。
预测编码算法有很多种,其中最著名的是Arithmetic Coding算法。
Arithmetic Coding通过将输入文件映射到一个区间上,并根据概率分布对区间进行划分,从而实现高效的压缩。
2.3 混合编码混合编码是将字典编码和预测编码结合起来使用的一种方法。
它首先利用字典编码对文件进行初步压缩,然后再使用预测编码对剩余部分进行进一步压缩。
混合编码能够充分利用字典编码和预测编码各自的优势,从而提高压缩效率。
3. 应用极限压缩格式在许多领域都有广泛的应用。
以下是一些常见的应用场景:3.1 文件压缩极限压缩格式可以用于对各种类型的文件进行压缩,包括文本文件、图像文件、音频文件等。
极限压缩格式

极限压缩格式
(最新版)
目录
1.极限压缩格式的定义
2.极限压缩格式的优点
3.极限压缩格式的缺点
4.极限压缩格式的应用领域
5.我国在极限压缩格式领域的发展
正文
极限压缩格式是一种将数据进行高压缩比的编码方式,其目的是在保证数据完整性的同时,尽可能地减少数据量,便于存储和传输。
首先,极限压缩格式的优点是显而易见的。
在存储和传输大量数据时,它可以大大节省空间和带宽。
例如,一部高清电影未经压缩可能需要几十GB 的存储空间,而通过极限压缩格式,可能只需要几 GB 甚至更小的空间。
在传输方面,压缩后的数据传输速度更快,可以减少等待时间。
然而,极限压缩格式并非完美无缺。
首先,它的压缩过程需要复杂的算法和大量的计算资源,这可能导致计算速度慢和能耗增加。
其次,解压缩过程也需要相应的算法和资源,可能会对终端设备造成压力。
最后,极限压缩格式可能会损失部分数据质量,特别是对于需要高保真度的数据,如音频和视频。
尽管有这些缺点,极限压缩格式在实际应用中仍然具有广泛的应用领域。
例如,在云计算和大数据领域,极限压缩格式可以大大降低存储和计算成本。
在物联网和智能家居领域,极限压缩格式可以帮助设备更有效地传输和处理数据。
我国在极限压缩格式领域也取得了显著的发展。
我国的科研团队在压
缩算法和硬件设备上不断创新,提高了压缩效率和降低了能耗。
同时,我国也在积极推动极限压缩格式在各行各业的应用,以提高我国的数据处理和存储效率。
总的来说,极限压缩格式是一种具有巨大潜力的数据编码方式。
极限压缩格式

极限压缩格式极限压缩格式是一种针对数据的压缩技术,其目标是在尽可能减小文件大小的同时,保持文件内容的完整性和可读性。
这种压缩格式通常被广泛应用于各种数据存储和传输场景,例如网络传输、数据备份和存储空间优化等。
一、极限压缩格式的特点1.高压缩比:极限压缩格式通常采用先进的压缩算法和技术,能够在保证文件完整性和可读性的前提下,实现更高的压缩比。
这意味着可以将文件大小压缩到更小的程度,从而节省存储空间和网络带宽。
2.保持文件完整性:与一些简单的文件压缩工具不同,极限压缩格式不会损害文件的完整性。
在解压缩时,文件内容将保持不变,不会出现数据丢失或损坏的情况。
3.优化的存储和传输:由于极限压缩格式能够将文件大小最小化,因此在存储和传输时可以更高效地利用存储空间和网络带宽。
这有助于降低存储成本和加快数据传输速度。
4.强大的适应性:极限压缩格式通常能够适应不同的数据类型和文件大小。
无论是文本文件、图像文件还是视频文件,都可以通过极限压缩格式进行高效率的压缩。
二、极限压缩格式的实现原理极限压缩格式的实现原理主要基于字典编码和算术编码等核心算法。
这些算法通过分析文件内容的重复模式和冗余信息,生成一个字典,然后利用字典进行编码,从而减小文件的大小。
1.字典编码:字典编码的基本思想是将文件中出现频率较高的字符串存储在一个字典中,然后将文件中出现的每个字符串替换为字典中的索引。
这样就可以用较短的索引代替较长的字符串,从而实现压缩。
2.算术编码:算术编码是一种概率模型编码方法。
它根据文件内容的概率分布情况,将文件中的信息转换为一系列二进制数。
在解码时,再根据这个二进制数序列还原出原始文件内容。
由于二进制数的长度通常比原始数据短,因此可以实现更高的压缩比。
三、极限压缩格式的应用场景1.网络传输:极限压缩格式可以减小文件大小,从而加快网络传输速度,并节省带宽成本。
2.数据备份:通过使用极限压缩格式,可以将大量数据备份到较小的存储空间中,从而降低存储成本并提高备份效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
极限压缩文件方法
介绍如何使1G的文件压缩到1M的文件。
1.常见文件压缩
首先我们用WinRAR的最高压缩率对常见的文本文件、程序文件和多媒体文件进行压缩,其压缩结果如下(见图1):
压缩后分别还是挺大的
从上图可以看出,多媒体文件压缩比最低,与原文件相差无几,而文本文件和程序文件压缩比要高一些,最高达到3:1,从实际经验来看,我们平时常见的文件压缩比都在10倍以下。
那么,再来看看这个RAR压缩包(见图2),注意其中的原文件大小和压缩后的包裹大小分别为16777215和18407,这是多大的比例?笔者用计算器算了一下,约等于911:1,接近1000倍的压缩比!这是怎么回事?真的假的?跟我一起继续做下面的试验就明白了。
这个简直是不可思议
2.把大象装进瓶子里
这里笔者从自己的电脑里随便找了个文件“数字图像噪声和去除.htm”,这是笔者在浏览网页时使用另存为功能从网上下载的文章,大小为125KB。
第一步:压缩为ZIP文件。
右键单击“数字图像噪声和去除.htm”文件,选择
“WinRAR→添加到档案文件”,在压缩选项对话框中选择“档案文件类型”为“ZIP”,“压缩方式”为“最好”(见图3),单击“确定”开始压缩。
可以看到压缩后的“数字图像噪声和去除.zip”文件只有19KB,压缩率还不错,不过仍离我们的目标相去甚远。
第二步:用WinRAR打开“数字图像噪声和去除.zip”,记下“大小”列中显示的原文件大小数值“127594”,打开计算器程序,单击“查看”菜单选择“科学型”,输入数字“127594”,再点击“十六进制”选项将其转换为16进制值,结果是“1F26A”(见图4)。
用科学型计算器认真算一下
第三步:用UltraEdit编辑器打开“数字图像噪声和去除.zip”文件,我们要在文件中找到“1F26A”的数据,不过由于文件中的十六进制数是高低位倒置表示的,所
以我们要查找的数据就变成了“6AF201”,单击“搜索”菜单中的“替换”,将文件中的“6AF201”替换为“FFFFFF”(见图5),共替换两处,文件开头和结尾各一处,替换后保存文件修改。
替换数值
小提示
我们前面之所以要选择ZIP压缩格式,而不是直接使用RAR压缩格式,是因为WinRAR对RAR格式的CRC检验非常严格,对文件进行任何修改都会提示压缩错误,而使用ZIP格式压缩,修改后再用WinRAR打开时不会进行严格的CRC检验,没有任何错误提示。
第四步:现在再用WinRAR打开“数字图像噪声和去除.zip”文件,你会惊奇地发现,压缩包中显示的原文件体积达到了16777KB(见图6),也就是16MB!现在你明白我们第三步中所做修改的目的了吧,我们就是要把原文件从“蟋蟀”变成“大象”!而且,现在你把压缩包中的“数字图像噪声和去除.htm”文件解压出来,其文件体积仍然是16MB,而且可以正常打开浏览。
谜底揭晓了
第五步:接下来就很简单了,把这个修改后的ZIP格式变成RAR格式即可,如果用WinRAR“工具”菜单中的“转换档案文件格式”功能转换后的压缩比会稍微缩小,这里我们直接将“数字图像噪声和去除.zip”改名为“数字图像噪声和去除.rar”,就做成了最开始看到的那个超级压缩包。
3.文件压缩原理
文件压缩分为有损压缩和无损压缩两种,我们常用的WinRAR、WinZip都是属于无损压缩,其基本原理都是一样的,简单地说也就是把文件中的重复数据用更简洁的方法表示,例如一个文件中有1000个字母A,那么这将占用1KB的数据空间,如果用压缩算法就可以用1000A来表示,那么它只需要5个字节的数据空间,压缩比达到了200倍。
那么由此看来,1000倍甚至更高倍的压缩比是可以实现的,但要求源文件必须有足够多的重复数据。
不过,我们平时使用的文件都不可能是这样的,所以通常文件压缩比都在10倍以下,如果某个软件声称对任何文件都能够产生这种超高压缩比的话,那它肯定就是具有欺骗性质的了。
小编有话说:很多网上下载的文件只有300MB或400MB,但是解压后,居然可以达到2GB甚至更多,也许你会奇怪,为什么你用WinRAR压缩同样的文件,就没有这样的压缩效果呢?其实这是因为这些文件是用多款不同的压缩软件进行压缩的,用压缩音频最好的压缩软件压缩音频文件,用压缩动画最好的压缩软件压缩动画文件。
而且在压缩时所选的参数也是最佳的,这样也就保证了最后生成的压缩文件是最小的。