自相关的检验与修正
实验四--自相关性的检验及修正

实验四 -- 自相关性的检验及修正实验四自相关性的检验及修正一、实验目的掌握自相关性的检验与处理方法。
二、实验学时: 2三、实验内容及操作步骤建立我国城乡居民储蓄存款模型,并检验模型的自相关性。
1.回归模型的筛选2.自相关的检验3.自相关的调整四、实验要求利用表 5-1 资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。
我国城乡居民储蓄存款与GDP统计资料( 1978 年= 100)存款GDP 年份存款余额Y GDP指数X年份余额指数Y X19919241.6 199211759.4 199315203.5 199421518.8 199529662.3 199638520.8 199746279.8 199853407.5 199959621.8 200064332.4308.2200286910.6888.5 351.52003103617.7981.6 399.62004119555.41084.5 452.020051410511201.7 494.22006161587.31361.2 544.520071725341560.5 596.920082178851717.8 640.620092607721861.1 691.520103033022050.0 750.62011343635.92228.9 811.12410.3200173762.43995512012【实验步骤】(一)回归模型的筛选⒈相关图分析SCAT X Y相关图表明, GDP指数与居民储蓄存款二者的曲线相关关系较为明显。
现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。
⒉估计模型,利用LS命令分别建立以下模型⑴线性模型: LS Y C Xy?62251.79175.4516 xt (-9.5629) (33.3308)R2= 0.9823 F=1110.940S.E=15601.32⑵双对数模型: GENR LNY=LOG(Y)GENR LNX=LOG(X)LS LNY C LNX?0.59996 1.7452 ln xln yt(-1.6069) (31.8572)R2= 0.9807 F= 1014.878 S.E=0.1567⑶对数模型: LS YCLNX?y1035947170915.4 ln xt(-10.2355)(11.5094)R2=0.8688 F =132.4672 S.E =42490.60⑷指数模型: LS LNY C Xln y? 9.5657 0.001581xt (55.0657) (11.2557)2R = 0.8637 F=126.6908 S.E=0.4163LS Y CXX2?16271.5477.8476x0.0378x2yt(-2.4325)(6.1317) (7.8569)R2= 0.9958F=2274.040 S.E= 7765.275⒊选择模型比较以上模型,可见各模型回归系数的符号及数值较为合理。
实验四--自相关性的检验及修正

实验四--自相关性的检验及修正
自相关性的检验是研究经济数据中自身序列的行为特征,它可用于识别趋势、判断虚
假反应、探究影响力以及衡量规律的发展变化,以及有助于指导未来政策的制定。
因此,自相关性检验是一项重要的经济学技术,它可以为序列分析获取相关信息,让研究者对特
定事件影响有更深刻的认识。
自相关性检验大概分为两个步骤:也就是统计学检验和模型修正。
统计学检验流程大
致包括参数估计、假设检验和结论。
其中,假设检验可以让研究者判断序列是否有自相关性,而参数估计则可以得到自相关性的大小和方向。
从模型修正的角度来说,研究的目的
是建立一个能够自相关数据的特性并形式化处理的模型,这个模型必须注意记录自相关数
据的自身行为特征。
研究者也可以尝试采用其他方法进行模型修正,比如添加外生变量、增加时间序列滞后期、建立自回归模型和分析突变点等。
自相关性检验和模型修正在实践中都带有一定的挑战,例如原始数据的质量,可能存
在噪声;外生变量的准确性和凝聚力;记录的常数和参数的可靠性;动态变化趋势的准确
性等。
因此,研究者在进行自相关性检验和模型修正时要注意仔细进行检测和修正,以确
保研究结果的可靠性和有效性。
自相关(序列相关)

高阶序列相关的广义差分法
如果原模型存在:
i 1 i 1 2 i 2 l i l i
(2.5.11)
可以将原模型变换为:
Yi 1Yi 1 l Yi l 0 (1 1 l ) 1 ( X i 1 X i 1 l X i l ) i
yt 0 1x1t 2 x2t k xkt yt 1 ut
(4)回归含有截距项; (5)没有缺落数据。
一阶自相关的Dubin-watson检验
自相关存在时,有 ut ut 1 v,vt无自相关。 t Covut , ut 1 相关系数: ,
三、序列相关性的后果
1、参数估计量无偏但非有效 ; 2、变量的显著性检验失去意义 ; 3、模型的预测失效 ;
1、参数估计量无偏但非有效
OLS参数估计量仍具无偏性
OLS估计量不具有有效性
在大样本情况下,参数估计量仍然不具有渐近有效 性,这就是说参数估计量不具有一致性
2、变量的显著性检验失去意义
i 1 l ,2 l , , n
(2.5.12) 模型(2.5.12)为广义差分模型,该模型不存在序列相 关问题。采用OLS法估计可以得到原模型参数的无偏、 有效的估计量。 广义差分法可以克服所有类型的序列相关带来的问题, 一阶差分法是它的一个特例。
随机误差项相关系数的估计
应用广义差分法,必须已知不同样本点之间随机误差 项的相关系数1, 2,…, l 。实际上,人们并不知道它 们的具体数值,所以必须首先对它们进行估计。
Euiu j 0, i j
i
如果仅是Eut ut 1 0 ,称有一阶自相关 二、实际经济问题中的序列相关性
计量经济学第六章自相关

计量经济学第六章自相关自相关是计量经济学中一种重要的现象,它指的是一个变量与其自己在过去时间点上的相关性。
自相关在实证研究中十分常见,对经济学家来说,了解和掌握自相关性质是至关重要的。
1. 引言自相关作为计量经济学的一项基础概念,是经济学研究中不可或缺的一个重要方法。
自相关性的存在通常会引起回归结果的偏误,而忽略自相关性可能导致估计不准确的结果。
因此,探讨自相关性的性质和应对方法是计量经济学的重点之一。
2. 自相关的定义和表示自相关是指一个变量与其自身在过去时间点上的相关性。
假设我们有一个时间序列数据集,其中变量yt表示一个时间点上的观测值,t表示时间索引。
自相关系数可以通过计算观测值yt与其在过去某一时间点上的观测值yt-k(k为时间滞后期数)的相关性来得到。
数学上,自相关系数可以用公式表示为:ρ(k) = Cov(yt, yt-k) / (σ(yt) * σ(yt-k))其中,ρ(k)表示第k期的自相关系数,Cov表示协方差,σ表示标准差。
3. 自相关性的性质自相关性具有以下几个性质:3.1 一阶自相关性一阶自相关性是指变量值yt与前一期的观测值yt-1之间的相关性。
一阶自相关系数ρ(1)通常用来检验时间序列数据是否存在自相关性。
若ρ(1)大于零且显著,则表明存在正的一阶自相关性;若ρ(1)小于零且显著,则表明存在负的一阶自相关性。
3.2 高阶自相关性除了一阶自相关性,时间序列数据还可能存在高阶自相关性。
高阶自相关性是指变量值yt与过去第k期的观测值yt-k之间的相关性。
通过计算不同滞后期的自相关系数ρ(k),可以了解数据在不同时间跨度上的自相关性情况。
3.3 异方差自相关性异方差自相关性是指时间序列数据中的方差不仅与自身相关,还与过去观测值的相关性有关。
异方差自相关性可能导致在回归分析中的标准误差失效,从而产生无效的回归结果。
因此,在处理存在异方差自相关性的数据时要采取合适的修正方法。
4. 自相关性的检验方法在实证研究中,经济学家通常使用多种方法来检验数据中的自相关性,常用的方法包括:4.1 Durbin-Watson检验Durbin-Watson检验是一种常用的检验自相关性的方法,其基本思想是通过检验误差项的相关性来判断自相关是否存在。
第六章自相关性详解

y A bx vt
* t * t
其中,A=a(1- ρ )。
ˆ /(1 利用OLS法估计A、b,进而得到: a ˆA
若ρ =1,则可得到一阶差分模型 yt-yt-1=b(xt-xt-1) +υ 如果为高阶自回归形式: ε t=ρ 1ε t-1+ρ 2ε t-2+…+ρ pε
(2)构造检验统计量:
DW
(e
2
n
t
et 1 )
2
2 e t 1
n
DW统计量与ρ 之间的关系: 因为对于大样本,
2 2 e e t et 1 2 t 1 2 2 n n n
所以:
DW
2
2 2 ( e 2 e e e t t t 1 t 1 )
e
2 t
2 2 e 2 e e e t t t 1 t 1 ) 2 e t
2( e t et et 1 )
2 e t
et et 1 21 2 2 1 et
Байду номын сангаас
e
et et 1
2 t
ˆ) S (b
2
( xt x )
2
ˆ2 ( xt x ) 2
三、t检验失效。 四、模型的预测精度降低。
第三节 自相关性的检验
一、残差图检验 二、德宾-沃森(Durbin-Watson,DW)检验 适用条件:随机项一阶自相关性;解释变量 与随机项不相关;不含有滞后的被解释变量, 截距项不为零;样本容量较大。 基本原理和步骤: (1) 提出假设 H0: ρ =0一
③在大样本情况下,有 nR2~χ 2(p) 给定α ,若nR2大于临界值,拒绝H0。 EViews软件操作:在方程窗口中点击View\ Residual Test \Serial Correlation LM Test。
6.3自相关的检验

三、LM检验(BG检验) LM检验既可以检验一阶自相关,也可以检 验高阶自相关。 对于k元线性回归模型
Y X X X t 01 1 t 2 2 t k k tu t
设自相关形式为: u u u v t 1 t 1 p tp t 原假设为:
图 示 法 有 两 种 绘 制 方 式 , 一 种 是 绘 制 ee 与 的 t t 1 散 点 图 。
et
e t1
图 6 . 1e 与 e 的 关 系 t t 1
如果大部分点落在第Ⅰ、Ⅲ象限,表明随机误差 项ut存在着正自相关。
et et
e t1 e t1
图 6 . 2e 与 e 的 关 系 t t 1
然后,通过分析这些“近似估计量”之间的相 关性,以判断随机误差项是否具有自相关性。
一、图示法
由 于 残 差是 e 随 机 误 差 项的 u 计 , 因 此 , 如 t t 估 果存 u 在 自 相 关 性 , 必 然 会 由 残 差 项反 e 映 出 来 。 t t 因 此 , 可 以 利 用 残 差的 e 化 来 判 断 随 机 误 差 项 t 变 的 自 相 关 性 。
L
不 能 确 定
d
U
无 自 相 关
2
4 dU
不 能 确 定
4 dL
负 自 相 关
4
DW
DW检验的缺点和局限性 • DW检验有两个不能确的区域,一旦DW值落在这 两个区域,就无法判断。这时,只有增大样本容 量或选取其他方法
• DW统计量的上、下界表要求 n>15 ,这是因为 样本如果再小,利用残差就很难对自相关的存在 性做出比较正确的诊断 • DW检验不适应随机误差项具有高阶序列相关的检验
回归检验法检验自相关

回归检验法检验自相关自相关是指时间序列中自身过去值与当前值之间的相关关系。
在时间序列分析中,自相关的存在可能会影响建模和预测的准确性。
为了验证时间序列数据中是否存在自相关,常常使用回归检验法进行检验。
回归检验法是一种常用的统计方法,用于检验时间序列数据中的自相关性。
它可以帮助我们判断时间序列数据是否存在自相关,并进一步确定是否需要进行自相关修正。
具体步骤如下:1. 收集并整理时间序列数据。
首先,我们需要收集所需的时间序列数据,并按照时间顺序进行整理。
确保数据的准确性和完整性是非常重要的,因为数据的质量直接影响到后续的分析和检验结果。
2. 统计学描述。
在进行回归检验之前,我们需要对数据进行统计学描述,包括均值、方差、偏度和峰度等指标。
这些指标可以帮助我们对数据的分布情况和特征进行初步了解。
3. 绘制自相关图。
自相关图是判断数据自相关性的一种常用图形方法。
通过绘制自相关图,我们可以观察不同滞后阶数下的自相关系数,并判断是否存在显著的自相关。
4. 设置假设。
在进行回归检验之前,我们需要设置相应的假设。
通常,我们假设时间序列数据不存在自相关(原假设),然后根据样本数据进行统计检验,以判断是否拒绝原假设。
5. 进行回归检验。
在进行回归检验时,我们可以使用多种方法,如Durbin-Watson检验、Ljung-Box检验和皮尔逊相关系数检验等。
这些检验方法基于不同的统计指标和算法,旨在判断自相关是否显著,并对其进行修正。
6. 解读结果。
根据回归检验的结果,我们可以得出结论,判断时间序列数据中的自相关性程度。
如果结果显示存在自相关,我们可以进一步进行自相关修正,以提高建模和预测的准确性。
回归检验法可以帮助我们判断时间序列数据中是否存在自相关,并进一步确定是否需要进行自相关修正。
通过合理使用回归检验方法,我们可以更好地分析和预测时间序列数据,提高决策的准确性和可靠性。
在使用回归检验法进行自相关检验时,我们需要注意数据的质量和准确性,选择合适的检验方法,并根据结果进行解读和处理。
多重共线性和自相关的检验和解决

《计量经济学》课程实训项目报告项目名称多重共线性和自相关的检验及解决方法实训日期2012.11.23 实训人53 班级统计1005 学号1004100508 指导教师张维群应用软件SPSS 实训地点实验楼314实训目的1.多重共线性和自相关的检验及解决方法的软件操作能力训练2.验证多重共线性和自相关的检验及解决方法的理论,并加深理解。
实训内容1.根据自己在网上寻找到的感兴趣的数据,用膨胀因子法和相关系数法对其进行是否存在多重共线性的检验;运用图示法和D-W法对数据是否存在自相关进行检验。
2.若检验出有多重共线性,则用逐步回归法剔除对因变量影响不大的解释变量;若检验出存在自相关,则用广义差分法建立新的模型进行解决。
实训数据资料说明1.问题:我国GDP的增长率与第一产业增长率、第二产业增长率、第三产业增长率用最小二乘法回归时的模型是否存在多重共线性和自相关。
若存在,先解决多重共线性再解决自相关并重新估计。
2.指标有哪些?自变量有x1:第一产业增长率,x2:第二产业增长率,x3:第三产业增长率。
因变量是y:GDP的增长率。
3.数据来源什么地方?数据是从网上查找的,数据包括从1981—2010年我国的GDP增长率、第一产业增长率、第二产业增长率和第三产业增长率,为时间序列数据,样本量为30。
实训结果与简要分析首先对原始数据进行用普通最小二乘法进行大致的拟合,并选择Linear Regression-Statistics-Collinearity diagnostics,即用膨胀因子法对原模型进行多重共线性检验,结果如下:Model SummaryModel R R Square Adjusted R Square Std. Error of the Estimate1 .982a.965 .961 .55883表1A N OVA bModel Sum of Squares df Mean Square F Sig.1 Regression 224.079 3 74.693 239.176 .000aResidual 8.120 26 .312T otal 232.199 29表2Coefficients aModel1(Constant) 第一产业增长率第二产业增长率第三产业增长率Unstandardized Coeff icients B .690 .187 .456 .287Std. Error .400 .047 .030 .042 Standardized Coeff icients Beta .169 .742 .344t 1.727 3.971 15.045 6.837 Sig. .096 .001 .000 .000 Collinearity Statistics T olerance .740 .553 .531VIF 1.351 1.809 1.883表3由表1可知模型的可决系数R^=0.965>0.8,可见其拟合程度较好。
eviews异方差、自相关检验与解决办法

eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。
自相关(序列相关)

常用的方法有: (1)科克伦-奥科特(Cochrane-Orcutt)迭代法。 (2)杜宾(durbin)两步法
附:杜宾(durbin)两步法
该方法仍是先估计1,2,,L,再对差分 模型进行估计。
第一步,变换差分模型为下列形式:
Yi 1Yi 1 l Yi l 0 (1 1 l ) 1 ( X i 1 X i 1 l X i l ) i
利用
ut ut 1 vt
有
ut 1 ut 2 vt 1,, ut m1 ut m vt m1
ut mut m m1vt ( m1) m2vt ( m2) vt 1 vt
1 2 Cov N , N u n 1
i 1 l ,2 l , , n
(2.5.13)
采用 OLS 法估计该方程,得各Y j ( j i 1, i 2, i l ) 前的
ˆ1 , ˆ 2 , , ˆl 。 系数 1 , 2 , , l 的估计值
ˆ1 , ˆ 2 ,, ˆ l 代入差分模型 第二步,将估计的
i
对各方程估计并进行显著性检验,如果存在某 一种函数形式,使得方程显著成立,则说明原模 型存在序列相关性。
具体应用时需要反复试算。 回归检验法的优点是:
一旦确定了模型存在序列相关性,也就同时知 道了相关的形式;
它适用于任何类型的序列相关性问题的检验。
(2)杜宾-瓦森(Durbin-Watson)检验法
三、序列相关性的后果
1、参数估计量无偏但非有效 ; 2、变量的显著性检验失去意义 ; 3、模型的预测失效 ;
自相关的检验与修正
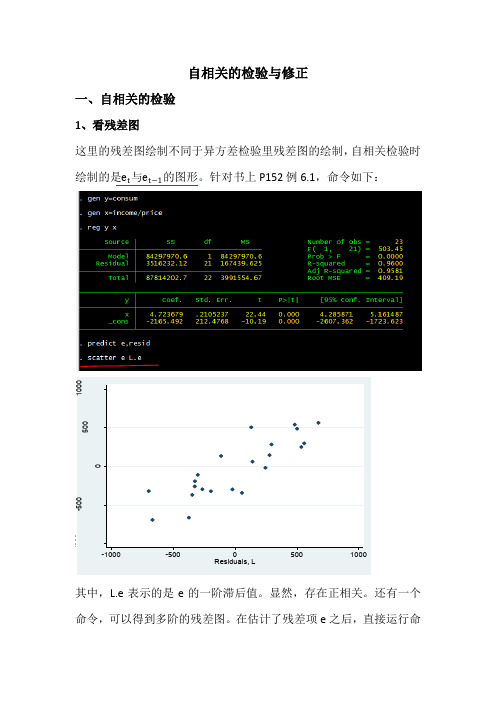
自相关的检验与修正一、自相关的检验1、看残差图这里的残差图绘制不同于异方差检验里残差图的绘制,自相关检验时绘制的是e t 与e t −1的图形。
针对书上P152例6.1,命令如下:其中,L.e 表示的是e 的一阶滞后值。
显然,存在正相关。
还有一个命令,可以得到多阶的残差图。
在估计了残差项e之后,直接运行命R e s i d u a l s令ac e 就可得到下图(ac 为autocorrelation 的缩写):横轴表示的是滞后阶数,阴影部分表示的是相应的置信区间,在上图中,显然一阶滞后是自相关的。
补充:滞后算子L 。
L.x 表示x 的一阶滞后值,L2.x 表示二阶滞后值。
差分算子D 。
D.x 表示x 的一阶差分,D2.x 表示二阶差分。
LD.x 表示一阶差分的一阶滞后值。
需要注意的是,在使用之后算子和差分算子时,一定要事先设定时间变量。
2、DW 检验该方法出现较早,现在已经过时,主要是因为该方法只能检验一阶自相关。
命令:estat dwatson 。
经验上DW 值在1.8---2.2之间接受原假设,不存在一阶自相关。
DW 值接近于0或者接近于4,拒绝原假设,存在一阶自相关。
3、LM检验(BG检验)命令:estat bgodfrey 一阶滞后自相关检验estat bgodfrey,lags(p) P阶滞后自相关检验滞后阶数P的选取最简单的方法就是看自相关图,阴影部分以外的自相关阶数为显著。
二、自相关的处理—广义最小二乘法FGLS命令:prais y x1 x2 x3 该命令对应的是书上P147的(6.33)方法prais y x1 x2 x3,corc 该命令对应的是书上P147的(6.32)方法在自相关检验及处理上,还有比较常用的稳健标准差命令newey以及Q-Test命令,感兴趣的同学可以去查阅相关书籍。
实验六自相关模型的检验和处理-学生实验报告

【模型4】财政收入的对数log(cs)对时间T的回归模型
【模型5】收入法GDPS的对数log(GDPS)对时间T的回归模型
数据见“附表:省宏观经济数据(部分)-第六章”
(一)自相关的检验
1.图形法检验
使用图形检验法分别检验上述【模型1-4】是否存在自相关问题。分别作这四个模型的残差散点图(即残差后一项对前一项的散点图: 对 )和残差趋势图(即残差 对时间 的线图),并判断模型是否存在自相关以及是正的自相关还是负的自相关。
S.E. of regression
0.058174
Akaike info criterion
-2.710105
Sum squared resid
0.074454
Schwarz criterion
实验室:普通配置的计算机,Eviews软件及常用办公软件。
实验训练容(包括实验原理和操作步骤):
【实验原理】
自相关的检验:图形法检验、D-W检验
自相关的处理:广义差分变换、迭代法
【实验步骤】
本实验中考虑以下模型:
【模型1】财政收入CS对收入法GDPS的回归模型
【模型2】财政支出CZ对财政收入CS的回归模型
(请对得到的图表进行处理,以上在一页)
2.D-W检验
分别计算上述【模型1-3】和【模型5】的D-W统计量的值,判断模型是否存在自相关问题。
【模型1】
CS=12.50360 +0.080296GDPS
(15.58605) (0.001891)
(0.802615) (42.45297)
R^2=0.985232 SE=61.92234 DW=0.942712 F=1802.255
第七节自相关检验与修正

et (1)et1 (1)
e2 t-1
(1)
3.利用(ˆ 1)进行广义差分变换:
y
* t
yt
ˆ (1)yt1
x*t xt ˆ (1)xt1
4.用OLS法估计广义差分模型:y
* t
A
b2x*t
v
,
t
得到b1和b2的估计值,代入(1)中的一元线性回归模型,
求出残差et (2)和(ˆ 2)
et (2)et1 (2) et2 (2)
此法也适用于多元线性回归模型。
(三)迭代估计或Cochranc-Orcutt
(科克伦-奥克特)估计
依据的近似估计公式, 进行一系列迭代,
逐步提高的近似估计精度.步骤如下:
1.利用OLS法估计模型yt b1 b2xt ut , 求出残差et (1);
2.根据残差计算的(第一轮)估计值:
(ˆ 1)
其中,
var(bˆ2
)是y
t
系数估计方差。
1
杜宾证明:当一阶自相关系数 时0 ,h统计量近 似服从标准正态分布,所以利用正态分布可以对 一阶自相关性进行检验。
显然,当 n var(bˆ时2) ,1h统计量无法算出,于是, 杜宾建议采用渐进等价检验,即采用OLS估计的 残差et,建立如下线性回归模型
,即存在自相关
0
。
二、 自相关模型的修正方法
针对自相关产生的原因,可给出不同的处理方法。 如果是模型中省略了重要的解释变量,使随机项产生了 自相关,则应重新建立模型; 如果是模型建立不当,应重新建立模型; 如果是由于数据加工的原因,可增加样本容量、变换数 据处理形式等。 除了上述原因外还存在自相关,这就是真正的自相关。 如果模型存在真正自相关,其他假定都满足,则可采用广 义差分法、迭代法等估计参数。
计量经济学实验报告(自相关性)

实验6.美国股票价格指数与经济增长的关系——自相关性的判定和修正一、实验内容:研究美国股票价格指数与经济增长的关系。
1、实验目的:练习并熟练线性回归方程的建立和基本的经济检验和统计检验;学会判别自相关的存在,并能够熟练使用学过的方法对模型进行修正。
2、实验要求:(1)分析数据,建立适当的计量经济学模型(2)对所建立的模型进行自相关分析(3)对存在自相关性的模型进行调整与修正二、实验报告1、问题提出通过对全球经济形势的观察,我们发现在经济发达的国家,其证券市场通常也发展的较好,因此我们会自然地产生以下问题,即股票价格指数与经济增长是否具有相关关系?GDP是一国经济成就的根本反映。
从长期看,在上市公司的行业结构与国家产业结构基本一致的情况下,股票平均价格的变动跟GDP的变化趋势是吻合的,但不能简单地认为GDP 增长,股票价格就随之上涨,实际走势有时恰恰相反。
必须将GDP与经济形势结合起来考虑。
在持续、稳定、高速的GDP增长下,社会总需求与总供给协调增长,上市公司利润持续上升,股息不断增加,老百姓收入增加,投资需求膨胀,闲散资金得到充分利用,股票的内在含金量增加,促使股票价格上涨,股市走牛。
本次试验研究的1970-1987年的美国正处在经济持续高速发展的状态下,据此笔者利用这一时期美国SPI与GDP的数据建立计量经济学模型,并对其进行分析。
2、指标选择:指标数据为美国1970—1987年美国股票价格指数与美国GDP数据。
3、数据来源:实验数据来自《总统经济报告》(1989年),如表1所示:表1 4、数据处理将两组数据利用Eviews绘图,如图1、2所示:图1 GDP数据简图图2 SPI数据简图经过直观的图形检验,在1970-1987年间,美国的GDP保持持续平稳上升,SPI虽然有些波动,但波动程度不大,和现实经济相符,从图形上我们并没有发现有异常数据的存在。
所以可以保证数据的质量是可以满足此次实验的要求。
异方差、自相关检验及修正

异方差、自相关的检验与修正实验目的:通过对模型的检验掌握异方差性问题和自相关问题的检验方法及修正的原理,以及相关的Eviews 操作方法。
模型设定:εβββ+++=23121i i i X X YYi----人均消费支出X1--从事农业经营的纯收入X2--其他来源的纯收入 中国内地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 北京 5724.5 958.3 7317.2 湖北 2732.5 1934.6 1484.8 天津 3341.1 1738.9 4489 湖南 3013.3 1342.6 2047 河北 2495.3 1607.1 2194.7 广东 3886 1313.9 3765.9 山西 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 内蒙古 2772 2560.8 781.1 海南 2232.2 2213.2 1042.3 辽宁 3066.9 2026.1 2064.3 重庆 2205.2 1234.1 1639.7 吉林 2700.7 2623.2 1017.9 四川 2395 1405 1597.4 黑龙江 2618.2 2622.9 929.5 贵州 1627.1 961.4 1023.2 上海 8006 532 8606.7 云南 2195.6 1570.3 680.2 江苏 4135.2 1497.9 4315.3 西藏 2002.2 1399.1 1035.9 浙江 6057.2 1403.1 5931.7 陕西 2181 1070.4 1189.8 安徽 2420.9 1472.8 1496.3 甘肃 1855.5 1167.9 966.2 福建 3591.4 1691.4 3143.4 青海 2179 1274.3 1084.1 江西 2676.6 1609.2 1850.3 宁夏 2247 1535.7 1224.4 山东 3143.8 1948.2 2420.1 新疆 2032.4 2267.4 469.9 河南 2229.3 1844.6 1416.4 数据来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》参数估计:估计结果如下:2709030.01402097.01402.728X X Y ++=Λ(2.218) (2.438) (16.999) 922173.02=R D.W.=1.4289 F=165.8853 SE=395.2538实验步骤:一、检查模型是否存在异方差1.图形分析检验(1)散点相关图分析分别做出X1和Y 、X2和Y 的散点相关图,观察相关图可以看出,随着X1、X2的增加,Y 也增加,但离散程度逐步扩大,尤其表现在X1和Y .这说明变量之间可能存在递增的异方差性。
检验自相关的方法

d t2
n
2 t
t2
t2
t2
n
2 t
t 1
t 1
对于大样本(即n很大)来说,可以认为
n
n
n
2 t 1
2 t
2 t
t2
t2
t 1
于是(6.3.2)式可以改写成
n
n
2
2 t 1
2
t
t
1
n
t t 1
d t2
t2
n
2 t 1
2(1
t
2 n
)
2 t 1
t2
t2
(6.3.2) (6.3.3)
注意εt是随机项ut的估计量,根据(6.1.3)便有
图6.3.5
由图6.3.5知,相关系数和偏相关系数都具有一阶自相关。
(1 d ) ( k 1 )2
ˆ 2
n
1 (k 1 )2
n
(6.3.6)
来计算 ˆ ,式中k是模型中自变量的个数。此公
式可以使的偏倚程度减少。
三、回归检验法 它的具体步骤如下: (1)对样本观测值用OLS法建立线性回归模型, 然后计算残差εt。
(2)由于事先不知道u自相关的类型,可以对不同形
(4)根据样本容量n,自变量个数和显著水平0.05 (或0.01)从D-W检验临界值表中查出dL和du。 (5)将d 的现实值与临界值进行比较: ①若d < dL,则否定H0,即u存在一阶线性正自相关; ②若d > 4- dL,则否定H0,即u存在一阶线性负自相关; ③若du< d < 4- du,则不否定 H0,即u不存在(一阶)线 性自相关;
§6.3 检验自相关的方法
一、图解法 (一)
固定效应模型修正组内自相关

固定效应模型修正组内自相关
固定效应模型是一种广泛应用于面板数据分析的统计模型,用于控制个体特征和时间特征对因变量的影响。
然而,当面板数据中存在组内自相关时,固定效应模型的估计结果可能会出现偏误。
组内自相关是指同一组或个体的观测值之间存在相关性,这可能违反了固定效应模型的基本假设。
修正组内自相关的方法之一是使用异方差-自相关一致(HAC)估计。
HAC 估计可以通过修正固定效应模型的标准误来解决组内自相关的问题,从而得到更准确的参数估计。
另一种方法是使用广义矩估计(GMM)来处理面板数据中的自相关性,GMM 方法可以在控制组内自相关的同时,有效地处理异方差和其他潜在的内生性问题。
此外,还可以考虑使用时间序列分析中常见的自相关和异方差模型,如ARIMA 模型或GARCH 模型,来对面板数据中的自相关和异方差进行建模和控制。
这些方法可以帮助我们更准确地理解面板数据的特征和规律。
除了上述方法,还可以考虑使用空间计量模型来处理面板数据中存在的空间自相关性,这种方法可以捕捉到不同地理区域之间的
相互影响和相关性,从而更全面地分析面板数据的特征。
总之,修正固定效应模型中的组内自相关是一个重要且复杂的问题,需要综合运用统计学、计量经济学和空间统计学等多个领域的方法来全面处理。
在实际应用中,需要根据具体数据的特点和研究问题的需求来选择合适的方法进行修正。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验2 自相关的检验与修正
一、实验目的:
掌握自相关模型的检验方法与处理方法.。
二、实验内容及要求:
表1列出了1985-2007年中国农村居民人均纯收入与人均消费性支出的统计数据。
(1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。
(2)检验模型是否存在自相关。
(3)如果存在自相关,试采用适当的方法加以消除。
表1 1985-2007年中国农村居民人均纯收入与人均消费性支出(单位:元)
实验如下:
首先对数据进行调整,将全年人均纯收入和全年人均消费性支出相应调整为全年实际人均纯收入和全年实际人均消费性支出。
图1
1、用OLS估计法估计参数
图2
图3
图4
从图4中可以看出,中国农村居民人均消费性支出与人均纯收入存在着显著的正相关关系。
估计回归方程:
从图3中可以得出,估计回归方程为:
Y=56.21878+0.698928X
t=(3.864210)(31.99973)
R2=0.979904 F=1023.983 D.W.=0.409903
(1)图示法
图5
从图5中,可以看出残差的变化有系统模式,连续为正或连续为负,表示残差项存在一阶正自相关。
(2)DW检验
从图3中可以得到D.W.=0.409903,在显著水平去5%,n=23,k=2,d L=1.26, d U=1.44。
此时0<D.W.< d L,表明存在正自相关。
(3)B-G检验
图6
从图6中可得到,nR2=14.90587,临界概率 P=0.0006,因此辅助回归模型是显著的,即存在自相关性。
又因为, e t-1,e t-2的回归系数均显著地不为 0
3.自相关的修正
使用广义差分法对自相关进行修正:
图7
对原模型进行广义差分,得到广义差分方程:
Y t-0.815024Y t-1=β1(1-0.815024)+β2(X t -0.815024X t-1)+u t
对广义差分方程进行回归:
图8
从图8中可以得出此时的D.W.=1.324681,在取显著水平为5%,n=23,k=2,d L=1.26, d U=1.44,模型中d L<DW<d U,此时不能确定是否存在自相关。
在广义差分法无法完成修正的情况下,现建立对对数模型:
图9
对双对数模型进行调整:
图10
图11
从图11中可以得出此时的D.W.=1.985950,在取显著水平为5%,n=23,k=2,d L=1.26, d U=1.44,模型中d U<DW<4-d U,此时不存在自相关。
由此完成对自相关的修正。
(注:可编辑下载,若有不当之处,请指正,谢谢!)。