多元统计分析基于R上机实验(6)
R-多元统计分析上机讲义

应用多元统计分析R实验上机讲义应用多元统计分析 (4)Applied Multivariate Statistical Analysis (4)第一章绪论 (4)第二章矩阵 (4)2.1矩阵的建立 (4)2.2矩阵的下标(index)与子集(元素)的提取 (6)2.3 矩阵四则运算 (7)2.3.1 矩阵的加减运算 (7)2.3.2 矩阵的相乘 (8)2.3.3 矩阵的求逆 (8)2.4矩阵的其他一些代数运算 (8)2.4.1 求转置矩阵 (8)2.4.2 提取对角元素 (8)2.4.3矩阵的合并与拉直 (8)2.4.4方阵的行列式 (9)2.4.5 矩阵的特征根和特征向量 (9)2.4.6 其它函数 (9)2.5 矩阵的统计运算 (11)2.5.1 求均值 (11)2.5.2 标准化 (11)2.5.3 减去中位数 (11)第三章多元正态分布及参数的估计 (12)3.1 绘制二元正态密度函数及其相应等高线图 (12)3.2 多元正态分布的参数估计 (14)3.2.1 多元正态总体的相关量 (14)3.2.2 极大似然估计 (14)第四章多元正态总体参数的假设检验 (15)4.1 几个重要统计量的分布 (15)4.2 单总体均值向量的检验及置信域 (16)4.2.1均值向量的检验 (16)4.2.2样本协方差阵的特征值和特征向量 (17)4.3多总体均值向量的检验 (17)4.3.1 两正态总体均值向量的检验 (17)4.3.2 多个正态总体均值向量的检验-多元方差分析 (19)4.4协方差阵的检验 (20)4.4.2 多总体协方差阵的检验 (20)4.5独立性检验 (20)4.6正态性检验 (21)第五章判别分析 (22)5.1距离判别 (22)5.1.1 马氏距离 (22)5.1.2 两总体的距离判别 (22)5.1.3 多个总体的距离判别 (26)5.2贝叶斯判别法及广义平方距离判别法 (26)5.2.1 先验概率(先知知识) (26)5.2.2 广义平方距离 (26)5.2.3 后验概率(条件概率) (27)5.2.4 贝叶斯判别准则 (27)5.3费希尔(Fisher)判别 (29)第六章聚类分析 (30)6.2距离和相似系数 (30)6.2.1距离 (31)6.2.2数据中心化与标准化变换 (31)6.2.3相似系数 (31)6.3 系统聚类法 (31)6.4类个数的确定 (34)6.5动态聚类法 (36)6.7变量聚类方法 (36)第七章主成分分析 (37)7.2 样本的主成分 (38)7.3 主成分分析的应用 (39)第八章因子分析 (42)8.3 参数估计方法 (42)8.4 方差最大的正交旋转 (45)8.5 因子得分 (45)第九章对应分析方法 (46)第十章典型相关分析 (48)应用多元统计分析Applied Multivariate Statistical Analysis第一章绪论在实际问题中,很多随机现象涉及到的变量不是一个,而是经常是多个变量,并且这些变量间又存在一定的联系。
多元统计分析基于R课程设计

多元统计分析基于R课程设计引言多元统计分析是现代统计学的重要组成部分,具有广泛的应用背景。
在数据科学领域,R语言是一种非常受欢迎的统计计算工具,能够方便地进行多元统计分析和可视化。
本课程设计旨在通过R语言进行多元统计分析的基础学习,提高学生对多元统计分析方法和应用的理解。
课程内容第一章:多元统计分析基础本章主要介绍多元统计分析的基本概念、理论与应用背景,包括多元正态分布、协方差矩阵、多元线性回归、主成分分析等内容。
通过使用R语言的数据分析工具和可视化包,学生将学习多元统计分析的基本方法、数据处理和可视化等方面的技能。
第二章:多元方差分析该章节主要介绍多元方差分析的理论和方法,包括单因素设计和多因素设计的多元方差分析。
本章还将介绍如何使用R语言进行多元方差分析,包括如何构建模型、计算方差分析表、进行置信区间分析和产生可视化图形等方面的技能。
第三章:判别分析本章将介绍判别分析的基本原理、方法和应用。
特别是线性判别分析和二次判别分析的主要方法和算法。
还将介绍R语言中的相关包,包括MASS和caret等,以进行判别分析的学习。
第四章:聚类分析本章将介绍聚类分析的基本理论和方法、层次聚类和分类聚类的原理和方法。
包括k均值算法、K中心点算法和高斯混合模型等的算法和应用。
还将介绍R语言中的相关包,包括stats和cluster等,以进行聚类分析的学习。
课程安排本课程设计分为7个星期,每周授课3个小时左右。
每个星期的课程安排如下:第一周•介绍课程内容和教学目标•多元统计分析基础概念:多元正态分布、协方差矩阵、多元线性回归、主成分分析等。
第二周•多元方差分析介绍•单因素设计的多元方差分析第三周•多因素设计的多元方差分析•使用R语言进行多元方差分析第四周•判别分析概述和应用•线性判别分析和二次判别分析第五周•介绍聚类分析•基于类簇的分析方法:K均值算法、K中心点算法第六周•分层聚类分析和分类聚类分析•高斯混合模型第七周•课程总结和讨论•提高阅读和写作技能的方法课程评估课程评估主要包括三个方面:作业、期末项目和参与度。
多元统计分析课程多元统计分析实验指导书

统计学专业《多元统计分析》课程实验指导书主撰人:李燕辉主审人:潘文荣刖言《多元统计分析》是统计学专业的一门重要的专业主干课。
它主要用于研究多维随机变量之间相互关系及内在统计规律,是认识和探索社会经济现象数量方面关系的重要方法和工具,在实际工作中具有广泛的应用前景。
由于其理论涉及的数学知识多而深,是本科生中最难学的一门课。
传统的教学方法主要是从理论上讲授,由于计算复杂、工作量大、分析过程长、计算工具和硬件条件等原因,讲授过程中举例比较困难,脱离实践,教学效果不理想。
由于统计专业学习多元统计分析,主要是掌握每个方法的基本原理,能够运用多元统计分析方法分析社会经济现象,该课程的教学更应强调方法的应用、学生实际操作能力和解决实际问题能力的培养。
为此,我们对该课程的教学进行多方面改革,以培养学生应用能力为主线,将多媒体技术、统计分析软件、案例教学、实践教学等有机结合起来,达到提高课堂教学效率和教学质量的目的,使学生真正掌握多元统计分析方法,培养了学生动手能力、数据分析能力、使用统计分析软件能力以及对实际经济问题的综合统计分析能力。
在我们的教学实践中,将《多元统计分析》总课时分解为课堂教学和实验教学两个部分。
该实验指导书就是为《多元统计分析》实验课设计的。
目录第一部份绪论(2)第二部份基本实验指导(3)实验一均值检验、多元方差分析(3)实验二聚类分析、判别分析(3)实验三因子分析、主成分分析(4)实验四联合分析(5)实验五对应分析(6)实验六多元数据综合分析(7)第一部份绪论本指导书是根据《多元统计分析》课程实验教学大纲编写的,适用于统计学专业。
一、本课程实验的作用与任务本课程为统计学专业必修的技术课程。
通过实验教学,使学生能够更好地了解多元统计分析的基本概念和基本原理,对一些常用的多元统计思想和统计方法有更深的认识,提高学生处理常见的多元统计问题的实际操作能力。
要求学生密切关注社会经济中的热点问题,独立进行思考,查找自己感兴趣的研究资料,自己动手设计多元变量,以提高学生解决实际问题的能力。
多元统计方法的R语言实现

多元统计方法的R语言实现一、主成分分析主成分分析是一种降维技术,用于从原始数据中提取出最重要的特征,以减少变量的数量。
R语言中有多个包可以进行主成分分析的实现,比如FactoMineR、psych等。
以下是使用FactoMineR包进行主成分分析的示例代码:```R# 安装并加载FactoMineR包install.packages("FactoMineR")library(FactoMineR)#读取数据data <- read.csv("data.csv")#主成分分析result <- PCA(data)#结果展示summary(result) # 查看主成分分析的结果plot(result) # 绘制主成分分析的结果```二、聚类分析聚类分析是一种将相似的对象分组为簇的分析方法。
R语言中有多个包可以进行聚类分析的实现,比如cluster、kmeans等。
以下是使用cluster包进行聚类分析的示例代码:```R# 安装并加载cluster包install.packages("cluster")library(cluster)#读取数据data <- read.csv("data.csv")#聚类分析result <- kmeans(data, 3) # 将数据分为3个簇#结果展示summary(result) # 查看聚类分析的结果plot(result, data) # 绘制聚类分析的结果```三、判别分析判别分析是一种用于确定变量与分类之间关系的分析方法。
R语言中有多个包可以进行判别分析的实现,比如MASS、caret等。
以下是使用MASS包进行判别分析的示例代码:```R#安装并加载MASS包install.packages("MASS")library(MASS)#读取数据data <- read.csv("data.csv")#判别分析result <- lda(class ~ ., data) # 将class变量与其他变量进行判别分析#结果展示summary(result) # 查看判别分析的结果plot(result) # 绘制判别分析的结果```四、因子分析因子分析是一种用于确定变量的共同因素的分析方法。
多元统计课程实验报告

一、实验背景随着社会经济的发展和科学技术的进步,数据量日益庞大,如何从大量数据中提取有价值的信息,成为统计学研究的热点问题。
多元统计分析作为统计学的一个重要分支,通过对多个变量之间的关系进行分析,为决策者提供有力的数据支持。
本实验旨在通过实际操作,让学生熟练掌握多元统计分析方法,提高数据分析能力。
二、实验目的1. 掌握多元统计分析的基本概念和方法;2. 学会运用多元统计分析方法解决实际问题;3. 提高数据分析能力,为后续课程打下坚实基础。
三、实验内容本次实验以某城市居民消费数据为例,运用多元统计分析方法对其进行分析。
四、实验步骤1. 数据导入首先,将实验数据导入统计软件(如SPSS、R等)。
本实验采用SPSS软件,数据集包含以下变量:(1)收入(y):居民年收入;(2)教育程度(x1):居民最高学历;(3)年龄(x2):居民年龄;(4)家庭人口(x3):家庭人口数量;(5)住房面积(x4):家庭住房面积。
2. 描述性统计分析对数据集进行描述性统计分析,包括各变量的均值、标准差、最大值、最小值等。
3. 相关性分析运用皮尔逊相关系数、斯皮尔曼等级相关系数等方法,分析变量之间的相关关系。
4. 主成分分析运用主成分分析方法,提取主要成分,降低数据维度。
5. 聚类分析运用K-means聚类分析方法,将居民划分为不同的消费群体。
6. 随机森林回归分析运用随机森林回归分析方法,预测居民收入。
五、实验结果与分析1. 描述性统计分析根据描述性统计分析结果,可知居民年收入、教育程度、年龄、家庭人口、住房面积的平均值、标准差、最大值、最小值等。
2. 相关性分析通过相关性分析,发现收入与教育程度、年龄、家庭人口、住房面积之间存在显著的正相关关系。
3. 主成分分析根据主成分分析结果,提取出两个主成分,累计方差贡献率为84.95%,可以解释大部分的变量信息。
4. 聚类分析通过K-means聚类分析,将居民划分为3个消费群体。
多元统计分析及R语言建模(第五版)课件第六七章

7 聚类分析及R使用
关于变量变换
平移变换 极差变换 标准差变换 主成分变换 对数变换
7 聚类分析及R使用
系
(1)计算n个样品
统
两两间的距离
聚
类
法
过
(5)确定类的
程
个数和样品名称
(2)构造n个类, 每类包含1个样品
(4)绘制 系统聚类图
(3)合并距离 最近两类为新类
(4)计算新类与各 类距离,若类个数为 1,转到第5步,否则
回到第3步
例7-1数据的系统聚类 最短距离法(采用欧氏距离)
例7-1数据的系统聚类
概 念 和 原 理
7 聚类分析及R使用
【例7.3】kmeans算法的R语言实现及模拟分析:模拟正态随机变量
7 聚类分析及R使用
7 聚类分析及R使用
模拟10个变量2000个样品的正态随机矩阵
7 聚类分析及R使用
系统聚类分析的特点 综合性 形象性 客观性
关于kmeans算法 kmeans算法只有在类的均值被定义的情况下才能使用
功能评分为7.5, 销售价格为65百元, 问该厂产品的销售前景如何?
6 判别分析及R使用
6 判别分析及R使用
1. 线性判别(等方差)
[1] 0.9
6 判别分析及R使用
6 判别分析及R使用
2. 二次判别(异方差)
[1] 0.95
6 判别分析及R使用
6.4.1 Bayes判别准则 Fisher判别缺点 一是判别方法与各总体出现的概率无关 二是判别方法与错判后造成的损失无关 Bayes判别准则
多元统计分析及R语言建模
第6章 判别分析及R使用
多元统计分析及R语言建模

y
X 连续变量
连续变量 线性回归方程
0-1变量
有序变量
多分类变量
分类变量
实验设计模型(方 差分析模型)
logistic回归模型
累积比数模型 对数线性模型
对数线性模型 多分类logistic回归模型
连续伴有删失 cox比例风险模型
连续变量 分类变量
协方差分析模型
5广义与一般线性模型及R使用
5.2 广义线性模型
程 序 与 结 果
得到初步的logistic回归模型:
5广义与一般线性模型及R使用
5.2 广义线性模型
(2)逐步筛选变量logistic回归模型:
logit.step<-step(logit.glm,direction="both") summary(logit.step)
#逐步筛选法变量选择
#逐步筛选法变量选择结果
序
pre2<-predict(logit.step,data.frame(x1=0)) #预测视力有问题的司机Logistic回归结果
与
p2<-exp(pre2)/(1+exp(pre2)) #预测视力有问题的司机发生事故概率
结
c(p1,p2) #结果显示
果
5广义与一般线性模型及R使用
5.2 广义线性模型
程 序 与 结 果
PA>0.05,说明各种燃料A对火箭射程有无显著影响,
PB>0.05,说明各种推进器B对火箭射程也无显著影响。
5广义与一般线性模型及R使用
案例分析 广义线性模型及其应用
关于40个不同年龄(age,定量变量)和性别(sex,定性变量,用0和1代表 女和男)的人对某项服务产品的观点(y,二水平定性变量,用1和0代表认可
多元统计分析:R与Python的实现 (6)

吴喜之
主成分分析
. . . .... .... .... . . . . .... .... .... . .
June 28, 2019
. .. . . ..
3 / 39
从例子中产生的问题
Example
教师数据 (full.aaup.csv) 该数据来自美国大学教授协会 (AAUP) 年度普查, 包括分别按 照正教授和副教授的平均工资和补贴 (1994 年) 统计的数据.a一共有 17 个变量, 其中有 4 个定性变量: FICE (联邦 ID 代码)、College (学校名称)、State (州)、Type (类型: I、IIA, 或 IIB). 还有 13 个数量变量: ASF (正教授平均工资)、ASA1 (副教授平均工资)、ASA2 (助理 教授平均工资)、ASALL (所有级别平均工资)、ACF (正教授平均补贴)、ACA1 (副教授平 均补贴)、ACA2 (助理教授平均补贴)、ACALL (所有级别平均补贴)、NF (正教授人数)、 NA1 (副教授人数)、NA2 (助理教授人数)、NIN (助教人数)、NALL (所有级别教授数目). 该数据涉及 1161 个学校. 其中只有 13 个是定量变量, 而经典主成分分析只能处理定量变 量. 因此, 虽然数据为 1161 × 17 矩阵的形式, 但我们只使用其中的 13 列数据, 即 1161 × 13 矩阵的形式. 这里的数据是对原始数据通过程序包 missForestb的函数 missForest() 弥补缺失值后的数据.
吴喜之
主成分分析
. . . .... .... .... . . . . .... .... .... . .
June 28, 2019
. .. . . ..
《多元统计分析分析》实验报告

《多元统计分析分析》实验报告2012 年月日学院经贸学院姓名学号实验实验成绩名称一、实验目的(一)利用SPSS对主成分回归进行计算机实现.(二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释.二、实验内容以教材例题7.2为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用三、实验步骤(以文字列出软件操作过程并附上操作截图)1、数据文件的输入或建立:(文件名以学号或姓名命名)将表7.2数据输入spss:点击“文件”下“新建”——“数据”见图1:图1点击左下角“变量视图”首先定义变量名称及类型:见图2:图2:然后点击“数据视图”进行数据输入(图3):图3完成数据输入2、具体操作分析过程:(1)首先做因变量Y与自变量X1-X3的普通线性回归:在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4):图4将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5):然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“D.W”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。
选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9)其他选项按软件默认。
最后点击“确定”,运行线性回归,输出相关结果(见表1-3)图5 图6图7图8图9回归分析输出结果:的协差阵也就是相关阵进行分解做因子分析或主成分分析),如果不需要对变量做标准化处理就选“协方差矩阵”;“输出”中的两项都选,要求输出没有旋转的因子解(主成分分析必选项)和碎石图(用图形决定提取的主成分或因子的个数);“抽取“下,默认的是基于特征值(大于1表示提取的因子或主成分至少代表1个单位标准差的变量信息,因为标准化后的变量方差为1,因子或者主成分作为提取的综合变量应该至少代表1个变量的信息),也可以自选提取的因子个数(即第二项),本例中做主成分回归,选择提取全部可能的3个主成分,所以自选个数填3。
统计分析中利用R语言进行多元回归分析

统计分析中利用R语言进行多元回归分析统计分析是一种数据分析方法,它通过收集、整理和分析数据,推断出数据之间的关系,并对未来趋势作出预测,以支撑决策。
多元回归分析是其中的一种方法,它通过多个自变量对一个因变量的影响进行分析。
在实践中,R语言成为了一种非常流行的工具,帮助研究人员进行多元回归分析。
本文将介绍如何使用R语言进行多元回归分析。
一、R语言介绍R语言是一种自由软件,被广泛应用于统计学、数据挖掘和机器学习等领域。
R语言具有开放源代码、跨平台、多维数据结构和强大的统计分析功能等特点。
二、多元回归分析介绍在多元回归分析中,研究人员通常需要了解多个因素对一个变量的影响。
例如,许多研究都会使用多元回归分析来了解教育、经济和人口统计学因素对收入的影响。
在多元回归分析中,有一个因变量和多个自变量。
因变量是需要预测或理解的变量,而自变量是用来解释因变量的变量。
通过分析不同自变量与因变量之间的关系,可以更好地理解它们之间的相互作用。
多元回归分析常用的公式为:Y = b0 + b1X1 + b2X2 + b3X3 + … + bnXn其中,Y为因变量,X1、X2、X3、…、Xn为自变量,b0、b1、b2、b3、…、bn为回归系数。
三、使用R语言进行多元回归分析R语言提供了多种函数用于执行回归分析。
其中,通常使用的是 lm 函数。
lm函数是 R 语言中最基本的回归函数之一,它用于创建一个线性回归模型。
下面我们以一个案例来介绍如何使用 R 语言进行多元回归分析。
在这个案例中,我们使用的数据集是 mtcars。
该数据集包含了32辆不同的车型,其中每个车型有11个变量,其中 mpg 是其燃油效率,其他变量包括马力、排量、车重、加速度等等。
首先,我们需要加载数据集,代码如下:```library(datasets)data(mtcars)head(mtcars)```然后,我们选择自变量和因变量。
在这个案例中,我们选择mpg 作为因变量,选择所有其他变量作为自变量。
多元统计分析 实验报告

多元统计分析实验报告多元统计分析实验报告一、引言多元统计分析是一种研究多个变量之间关系的统计方法,可以帮助我们更全面地了解数据集中的信息。
本实验旨在通过多元统计分析方法,探索不同变量之间的关系,并分析其对研究结果的影响。
二、数据收集与处理在本实验中,我们收集了一份关于学生学业成绩的数据集。
数据集包括学生的性别、年龄、家庭背景、学习时间、考试成绩等多个变量。
为了方便分析,我们对数据进行了清洗和预处理,包括删除缺失值、标准化处理等。
三、描述性统计分析在进行多元统计分析之前,我们首先对数据进行了描述性统计分析。
通过计算各变量的均值、标准差、最小值、最大值等统计量,我们对数据的整体情况有了初步的了解。
例如,我们发现男生和女生的平均成绩存在差异,家庭背景与学习时间之间存在一定的相关性等。
四、相关性分析为了探索不同变量之间的关系,我们进行了相关性分析。
通过计算各个变量之间的相关系数,我们可以了解它们之间的线性关系强弱。
通过绘制相关系数矩阵的热力图,我们可以直观地观察到各个变量之间的相关性。
例如,我们发现学习时间与考试成绩之间存在较强的正相关关系,而年龄与考试成绩之间的相关性较弱。
五、主成分分析主成分分析是一种常用的降维方法,可以将多个相关变量转化为少数几个无关的主成分。
在本实验中,我们应用主成分分析方法对数据进行了降维处理。
通过计算各个主成分的解释方差比例,我们可以确定保留的主成分个数。
通过绘制主成分得分图,我们可以观察到不同变量在主成分上的贡献程度。
例如,我们发现第一主成分主要与学习时间和考试成绩相关,而第二主成分主要与家庭背景和性别相关。
六、聚类分析聚类分析是一种将样本按照相似性进行分类的方法,可以帮助我们发现数据集中的潜在模式和群体。
在本实验中,我们应用聚类分析方法对学生进行了分类。
通过选择适当的聚类算法和距离度量,我们可以将学生分为不同的群体。
通过绘制聚类结果的散点图,我们可以观察到不同群体之间的差异。
R语言版应用多元统计分析主成分分析

z* n2
z* np
z* (n
)
'
该主成分得分矩阵地第1列为第一主成分在n个样品上地得分,第2
列为第二主成分在n个样品上地得分,如此类推。利用第一主成分得分
或前m个主成分地综合得分,可以对样品进行排序或评估。
6.2 样本主成分
主成分地含义: 主成分地含义与所分析问题地实际背景有关,根据主成分载荷对主
p
分
定义6.1
主成分
z
k
地方差在总方差中所占比例 m
zk 地贡献率,而前m个主成分地贡献率之与 k
k p
i
i 称为主成
i称1 为 z1,, zm
地累计贡献率。
k 1
i 1
6.1 总体主成分
通常取尽可能较小地m,使 z1,, zm地累计贡献率达到一个比较高地
百分比,比如75%以上。
定义6.2 原始变量 xi 与主成分 z1,, zm地相关系数地平方与称为前m
其中 x* (x1*,, x*p )' 为原始变量 x (x1,, xp )' 经标准化后地向量。
6.2 样本主成分
令
z*
(z1* ,,
z
* p
)'
U
*'
x*,
其中 U *
(u1*
,
,
u
* p
)
(ui*j ) p p
。对照总体主成分地性质可知,样本主成分
有以下性质。
(1) (2)
Var (zk* )
时对应称设地z1特1 是a征1'x向为量地第。最一称大主特z成2征分值a。2 ',x类则为似相第地应二,地主设单成位a分是2特。征地向第量二大a即1特为征所值求。2此
(整理)多元统计分析上机实验.

多元统计分析上机实验指导第一部分 SPSS软件基本操作当用户安装SPSS软件后,点击快捷图标,将会出现以下界面:图1.1 启动SPSS后出现的对话框对话框包括一个六选一单选对话框和一个复选对话框,其内容为:●Run the tutorial 运行操作指南;●Type in data 输入数据选项,建立新的数据集时可选择此项;●Run an existing query 运行一个已经存在的数据文件选项;●Create new query using Database Wizard 用数据库处理工具建立新文件;●Open an existing date source 打开一个已经存在的数据文件;●Open another type of file 打开其他类型的文件。
●Don’t show this dialog in the future 是一复选对话框,选中该复选项后,下次启动SPSS时将不会显示对话框,直接显示数据编辑窗口。
如果只是利用该软件做一般性的统计分析,不做高级开发工作,可以在“Don’t show this dialog in the future”左方的小方块里打钩,以后启动SPSS时将不会显示对话框,直接显示数据编辑窗口。
§1.1 数据文件的建立SPSS 软件包的数据编辑主窗口类似于EXCEL ,数据文件的建立就是在数据编辑窗口中完成的。
数据编辑窗口可以显示两张表,分别是Data View (见图1.2)和Variable View (见图1.3),通过点击下端的2个同名窗口标签按钮实现相互切换。
数据编辑区是SPSS 的主要操作窗口,是一个二维平面表格,用于对数据进行各种编辑;标尺栏由纵向标尺栏和横向标尺栏,横向标尺栏显示数据变量,纵向标尺栏显示数据顺序(如时间顺序)。
Data View 表可以直接输入观测数据值或存放数据,表的左端列边框显示观测个体的序号,最上端行边框显示变量名。
多元统计与r语言建模

多元统计与r语言建模多元统计与R语言建模引言:多元统计分析是统计学中的一种重要方法,用于研究多个变量之间的关系和相互影响。
而R语言作为一种开源的统计计算和绘图软件,具有强大的数据分析和建模能力。
本文将介绍多元统计分析的基本概念和常用方法,并结合R语言进行建模实例。
一、多元统计分析的基本概念1. 多元统计分析的目的:多元统计分析旨在探索和解释多个变量之间的关系,以及变量与其他因素之间的关联。
2. 变量类型:在多元统计分析中,变量可以分为两大类:定性变量和定量变量。
定性变量是指具有类别或标签的变量,如性别、学历等;定量变量是指具有数值意义的变量,如年龄、收入等。
3. 多元统计方法:常用的多元统计方法包括:主成分分析、因子分析、聚类分析、判别分析、回归分析等。
二、R语言在多元统计分析中的应用1. R语言简介:R语言是一种功能强大的统计计算和绘图软件,具有丰富的数据分析函数和扩展包,可以进行各种统计分析和建模。
2. R语言的优势:R语言具有开源免费、社区活跃、生态丰富、可扩展性强等优势,使其成为统计学家和数据分析师的首选工具。
3. R语言的应用:R语言可以应用于数据预处理、描述性统计分析、假设检验、回归建模、分类与聚类分析等多元统计分析任务。
三、基于R语言的多元统计建模实例为了更好地理解多元统计分析方法和R语言的应用,我们将以一个实际案例展示如何使用R语言进行多元统计建模。
案例背景:某电商平台想要了解用户购买行为与用户特征之间的关系,以便制定个性化的推荐策略。
为此,我们收集了一份包含用户购买行为和用户特征的数据集。
数据准备:我们需要导入数据集并进行数据预处理。
这包括数据清洗、数据变换和缺失值处理等步骤。
在R语言中,可以使用各种函数和包来完成这些任务。
数据探索:在进行多元统计建模之前,我们需要对数据进行探索和描述性统计分析。
这可以帮助我们了解数据的分布、关联性和异常值等信息。
R 语言提供了丰富的可视化函数和统计函数,如直方图、散点图、相关系数等。
多元统计分析实验报告
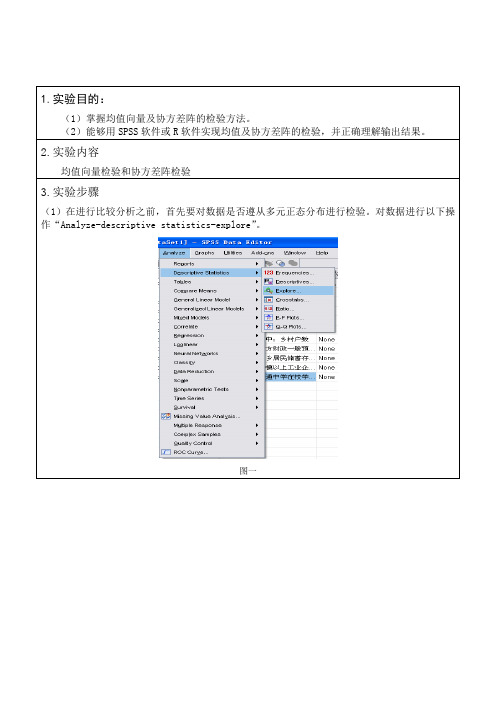
1.实验目的:(1)掌握均值向量及协方差阵的检验方法。
(2)能够用SPSS软件或R软件实现均值及协方差阵的检验,并正确理解输出结果。
2.实验内容均值向量检验和协方差阵检验3.实验步骤(1)在进行比较分析之前,首先要对数据是否遵从多元正态分布进行检验。
对数据进行以下操作“Analyze-descriptive statistics-explore”。
图一图二单击plots,选择正态分布检验,单击continue,ok 得出结果。
图三(2)多元正态分布有关均值与方差的检验,单击“Analyze-general linear model-multivariate”,得到下图。
图4Options打开,将省份导入display means for中,如图5,continue继续,ok运行。
图54.实验结果(或心得体会)Tests of NormalityKolmogorov-Smirnov a Shapiro-WilkStatistic df Sig. Statistic df Sig.年末总户数(户).116 94 .003 .942 94 .000 年末总人口(万人).406 94 .000 .659 94 .000 地方财政一般预算收入(万元).174 94 .000 .842 94 .000 行政区域土地面积.177 94 .000 .837 94 .000 其中:乡村户数.141 94 .000 .924 94 .000 地方财政一般预算支出.258 94 .000 .777 94 .000 城乡居民储蓄存款余额.230 94 .000 .603 94 .000 规模以上工业企业个数.167 94 .000 .854 94 .000 普通中学在校学生数.336 94 .000 .588 94 .000。
多元统计分析程序r代码-6

D=scale(DA[,1:300])
R=cov(D)
eigen(R)$values
#计算残差平方和
x=as.matrix(DA[,1:300])
y=DA[,301]
coef<- coef(lm.reg)[2:301]
coef
r<- y-491.4-as.vector(coef%*%t(x))
#例6.2
rm(list=ls())
DA=read.csv("hs300.csv",header=T)
lm.reg=lm(Y~X1+X2+X3+X4+X5+X6+X7+X8+X9+X10+X11+X12+X13+X14+X15+X16+X17+X18+X19+X20+X21+X22+X23+X24+X25+X26+X27+X28+X29+X30+X31+X32+X33+X34+X35+X36+X37+X38+X39+X40+X41+X42+X43+X44+X45+X46+X47+X48+X49+X50+X51+X52+X53+X54+X55+X56+X57+X58+X59+X60+X61+X62+X63+X64+X65+X66+X67+X68+X69+X70+X71+X72+X73+X74+X75+X76+X77+X78+X79+X80+X81+X82+X83+X84+X85+X86+X87+X88+X89+X90+X91+X92+X93+X94+X95+X96+X97+X98+X99+X100+X101+X102+X103+X104+X105+X106+X107+X108+X109+X110+X111+X112+X113+X114+X115+X116+X117+X118+X119+X120+X121+X122+X123+X124+X125+X126+X127+X128+X129+X130+X131+X132+X133+X134+X135+X136+X137+X138+X139+X140+X141+X142+X143+X144+X145+X146+X147+X148+X149+X150+X151+X152+X153+X154+X155+X156+X157+X158+X159+X160+X161+X162+X163+X164+X165+X166+X167+X168+X169+X170+X171+X172+X173+X174+X175+X176+X177+X178+X179+X180+X181+X182+X183+X184+X185+X186+X187+X188+X189+X190+X191+X192+X193+X194+X195+X196+X197+X198+X199+X200+X201+X202+X203+X204+X205+X206+X207+X208+X209+X210+X211+X212+X213+X214+X215+X216+X217+X218+X219+X220+X221+X222+X223+X224+X225+X226+X227+X228+X229+X230+X231+X232+X233+X234+X235+X236+X237+X238+X239+X240+X241+X242+X243+X244+X245+X246+X247+X248+X249+X250+X251+X252+X253+X254+X255+X256+X257+X258+X259+X260+X261+X262+X263+X264+X265+X266+X267+X268+X269+X270+X271+X272+X273+X274+X275+X276+X277+X278+X279+X280+X281+X282+X283+X284+X285+X286+X287+X288+X289+X290+X291+X292+X293+X294+X295+X296+X297+X298+X299+X300,data=DA)
原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码

原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码R语言作为一种功能强大的数据分析工具,在数据挖掘领域得到了广泛的应用。
本文将介绍使用R语言进行多元统计分析的方法,并结合实际数据分析案例进行详细分析。
同时,为了便于读者学习和复现,也附上了相关的R代码。
一、多元统计分析简介多元统计分析是指同时考虑多个变量之间关系的统计方法。
在现实生活和研究中,往往会遇到多个变量相互关联的情况,通过多元统计分析可以揭示这些变量之间的联系和规律。
R语言提供了丰富的统计分析函数和包,可以方便地进行多元统计分析。
二、数据分析案例介绍我们选取了一份关于房屋销售数据的案例,来演示如何使用R语言进行多元统计分析。
该数据集包含了房屋的各种属性信息,如房屋面积、卧室数量、卫生间数量等,以及最终的销售价格。
我们的目标是分析这些属性与销售价格之间的关系。
首先,我们需要导入数据集到R中,并进行数据预处理。
预处理包括数据清洗、缺失值处理、异常值检测等。
R语言提供了丰富的数据处理函数和包,可以帮助我们高效地完成这些任务。
接下来,我们可以使用R语言的统计分析函数进行多元统计分析。
常用的多元统计分析方法包括主成分分析(PCA)、因子分析、聚类分析等。
这些方法可以帮助我们从众多的变量中找到重要的变量,对数据集进行降维和聚类,以便更好地理解数据和进行预测。
在本案例中,我们选择主成分分析作为多元统计分析的方法。
主成分分析是一种常用的降维技术,通过线性变换将原始变量转化为一组新的互相无关的变量,称为主成分。
主成分分析可以帮助我们发现数据中的主要模式和结构,从而更好地解释数据。
最后,我们可以通过可视化方法展示多元统计分析的结果。
R语言提供了丰富多样的数据可视化函数和包,可以生成各种图表和图形,帮助我们更直观地理解和传达数据分析的结果。
三、附录:R语言代码下面是进行多元统计分析的R语言代码。
需要注意的是,代码的具体实现可能会因数据集的不同而有所差异,请根据实际情况进行调整和修改。
多元统计方法的R语言实现

多元统计方法的R语言实现2. 因子分析(Factor Analysis)因子分析是一种用来探索多个变量背后的潜在因子结构的方法。
在R语言中,可以使用`factanal(`函数进行因子分析。
该函数可以指定因子的个数,并返回因子载荷矩阵和公共因子方差等信息。
3. 聚类分析(Cluster Analysis)聚类分析是一种将观测对象按照其中一种相似性度量进行分组的方法。
在R语言中,可以使用`hclust(`函数进行层次聚类分析。
该函数可以根据不同的距离度量方法(如欧氏距离、曼哈顿距离等)和聚类算法(如单链接、完全链接等)进行聚类分析。
4. 判别分析(Discriminant Analysis)判别分析是一种通过建立分类函数来将样本分配到已知类别的方法。
在R语言中,可以使用`lda(`函数进行线性判别分析。
该函数会返回判别分析的结果,包括线性判别函数的系数和判别准确率等。
5. 集群分析(Canonical Correlation Analysis,CCA)集群分析是一种用于研究两个集群之间关系的方法。
在R语言中,可以使用`cca(`函数进行典型相关分析。
该函数会返回典型相关系数、典型相关向量和典型相关变量等信息。
6. 结构方程模型(Structural Equation Modeling,SEM)结构方程模型是一种同时考虑模型的测量模型和结构模型的方法。
在R语言中,可以使用`lavaan`包进行结构方程模型的分析。
该包提供了一系列函数用于指定模型、估计参数和进行统计检验。
以上只是介绍了一些常用的多元统计方法及其在R语言中的实现。
R 语言作为一种功能强大的统计分析工具,还提供了许多其他扩展包用于不同的多元统计方法,如主成分回归、多维尺度分析等。
通过在R语言中实现多元统计方法,可以更方便地进行数据分析和统计推断。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2
3
4
5
pc6.1
Variances
0.5
Comp.1
1.0
1.5
2.0
2.5
3.0
3.5
Comp.2
Comp.3
.4
Comp.5
Comp.6
6
Comp.2
-0.2
0.0
0.2
0.4
0.6
4
-0.4
12
6 5
3
-0.6
-0.6
-0.4
-0.2
0.0 Comp.1
0.2
0.4
0.6
四、收获或心得体会
y1 a11 x1 a12 x2 a1 p x p a1T X T y2 a21 x1 a22 x2 a2 p x p a2 X y p a p1 x1 a p 2 x2 a pp x p a pT X
7
《多元统计分析--基于 R》实 验 报 告 (6)
学号: 140940137 姓名: 刘思 班级: 1409401 成绩:
实验名称:主成分分析与 R 实现 所使用的工具软件及环境: R 软件 一、实验目的:
实验地点:化工楼 317
理解主成分分析的统计思想和实际意义; 掌握与主成分分析有关的函数。 理解主成分分析的数学模型和在二维空间上的几何解释; 能够利用计算机软件以及主成分分析有关的函数,自己编程解决实际问题并给出分析报 告 二、实验步骤: 1、主成分分析的统计思想、主成分分析的数学模型 2、与主成分分析有关的函数 3、主成分分析的应用及 R 程序 4、实证分析 三、实验内容 1、 主成分分析的统计思想、数学模型 统计思想:主成分分析的本质就是“降维” ,将高维数据有效的转化为低维数据来处 理,揭示变量之间的内在联系,进而分析解决实际问题。 数学模型:设总体 X ( x1 , x2 ,, x p )T 的期望为 ,协方差矩阵为 , X 的 p 个主 成分记为 y1 , y2 ,, y p 二者的关系为:
式中, y i 的方差为:
Var( yi ) aiT ai , i 1,2,, p
p 个主成分一定是互不相关的。
1
2、与主成分分析有关的R函数 1. princomp函数 princomp(x,cor=F,scores=T,„) x是用于主成分分析的数据矩阵或数据框,cor=T表示用样本相关系数矩阵R作主 成分分析,cor=F(默认值)表示用样本协方差矩阵S作主成分分析;scores为是 否输出主成分得分 2. summary函数 summary(object,loadings=T,„) 用于提取主成分的信息,object是由princomp()得到的对象;loadings=T表示显 示载荷loadings的内容,默认不显示 3. loadings函数 loadings(object) 用于显示主成分分析中载荷loadings的内容,在主成份分析中实际是给出主成份 的载荷,也就是正交矩阵Q的各列。其中,object是由princomp()得到的对象。 实际上,在summary函数中输入选项loadings=TURE,就可得到loadings函数的这 些显示内容。 4. predict函数 Predict(obect,newdata,...) 该函数用于预测主成份分析的值,其中,object是由princomp()得到的对象, newdata是要由其进行预测的数据框。 3、案例分析与R实现 结合数据文件 eg6.1