人声后期精细效果处理方法
基本的人声后期处理步骤

基本的人声后期处理步骤进行每一步效果处理时都要用鼠标选中要处理的小节,选中后波形背景是变成白色.(1)降噪.人声之前会有一段噪音,那就是环境噪音,选中那段环境噪音,然后在菜单栏上选择“效果”,接着选择“刷新效果列表”,出现对话框,选择“是”刷新完后,接着选择菜单栏上“效果”里的“噪音消除”选项,然后选择“降噪器”,进去后选择“噪音采样”,然后按“关闭”.再重新选择菜单栏的“效果”里的“噪音消除”的“降噪器”,最后按确定,这样录音过程中的环境噪音就消除了.这只是环境噪音的消除,人声末尾的尾音这也要消除,否则会影响整首歌曲的效果消除这个噪音有专门的插件“waves”的“Rvox”效果器,这个效果器能剪除人声末尾的尾音,建议设置不要过,否则在每句话的首尾处会有明显的突然消失声音的感觉.(2)激励人声.双击人声音轨切换到波形编辑界面,选定全部波形,然后在“效果”里选择“DerectX”里的“BBESonicmaximizer”插件,然后大家会看到三个旋钮,第一个调的是低音,第二个调的是高音,第三个调的是总输出音量.大家可以根据人声来调整高低音还要总音量,开始录进去的人声不是很有力度,这就需要加高音激励起来,这样听起来就好听些,不信大家可以试试看咯.(3)压限.安装waves 4.0后,在“DerectX”选择“wavesC4”,出现调整窗口.这时候要根据自己的声音对高低频进行调节,开始使用软件的时候也许还不知道怎么调整相关数据,大家可以这样,在调整窗口选择“load”,进去后会看到很多种效果,大家可以选择倒数第四个“pop vocal”,然后按确定.压限的作用就是人声的高频不要“噪”,低频不要“浑”。
开始不知道怎么用上面的方法,以后熟练以后要根据自己的人声调整正确数据.(4)增强人声的力度和表现力.安装“Ultrafunk fx”效果器后会有名称叫“Compressor R3”的效果器,这效果器的作用就是增强人声的力度和表现力打开后会看到上面有四个小方框,不同的数据会有不同的效果,开始不知道怎么用的时候可以把这四个数据输进去,第一个输入:-20 第二个输入:4.0第三个输入:16 第四个输入:7.0 除了顶上这四个,底下还有2个,第一个输入:40 第二个输入:200 然后按确定就可以增强人声的力度和表现力了.上面提供的只是大概的数据,具体数据还要*大家去感觉,最后确定.(5)混响.安装“Ultrafunk fx”效果器后有会叫“Reverb R3”的效果器.此工作需要很细心,不同的录音环境,不同的曲风混响效果都不一样的.这需要大家不断的积累经验,容积较大、吸声不足的房间,效果器的人工混响时间要短.男声演唱时混响时间应短些;女声演唱时混响时间可长些.专业歌手混响时间应短些,否则会破坏原有音色的特征,业余歌手可用较长的混响时间,以掩盖声音的不足之处等等……开始使用这个软件的朋友可以具体我提供的数据输进去,一共有13个小方框,第一:0.0 第二:75 第三:7.1 第四:0 第五:50 第六:100 第七:1.0 第八:500 第九:2.2第十:7.8 第十一:0.0 第十二:-14.3 第十三:-12.3 .再次声明,上面提供的不是标准数据,这只是给刚开始用此软件朋友提供的,具体的数据要*自己的耳朵去感觉.(6)均衡人声.安装“Ultrafunk fx”效果器后有会叫“Equalizer”的效果器.主要作用就是均衡人声,让高频在保持不噪的前提下调整到清晰通透;低频保证不浑浊的前提下调整到清晰、自然.同样开始使用此软件朋友可以先使用我提供的这些数据,不是标准数据,具体数据还要*大家以后自己去摸索。
Samplitude Pro X 12人声后期制作的步骤

人声后期制作教程之--混音的步骤及效果器的选择主讲:Sunday总引:第一步降噪第二步音量的平衡第三步美化人声1、高频激励效果器2、电子管模拟器第四步重中之重EQ均衡器第五步模拟效果的添加1、延迟2、混响第六步母带处理第七步导出第一步降噪在录音开始前呢,我们一般情况下,在歌手进入录音室是第一遍让歌手听音乐什么都不要做,也不要唱歌,听一段伴奏在歌手听伴奏的时候,录音师要做的就是录个5~10秒的录音室环境噪音一集软件设备连接造成的噪音,以便我们降噪时作为采样。
点击保存保存采样后点击右下角确定。
之后选中所有波形打开降噪器载入保存的采样试试调节处理程度切记不要降噪太多只要不要把人声原有的东西给降了就OK,重复确定第二步音量的平衡1.压缩器compressor压限器这个就是我们所说的压缩器了,作用呢,就是均衡人声的大小,现在仔细说一下每个的作用按照图文里的标记来说滤波器:指压限过后的声音圆滑度,也就是指穿透力度,数越大,就越圆滑阀值:压限作用阀值指的是控制人声大小的数值,简单来说就是把大小不一的声音放在一个点上,比率:这个是压缩的比率,这是和前面的阀值相互作用的,就像水龙头的开关一样,一点一点的开启,如果将这个开到6:1的时候,就好像一个水库,有6米高,只存着1米的水这样是极其不协调的,但是如果小于1的时候,就变成了水位超过储存量,这样就变成了扩散器了,所以调的时候一般就大于1的数值入:输入的电平信号出:压限过后人声的大小启奏:这里是指起始缓冲,就是声音超过压限作用阀值的时候在多长的时间开始发挥压释放:结束缓冲,声音低于压限作用阀值在多长的时间里取消压限功能现在我将通常用到的参数说出来:男声:阀值-23比率6:1③30启奏0.1释放70女声:阀值-26比率6:1③20启奏3.0释放300这个只是个参考值,所有完美的效果都是靠大家的双耳所以加油喽经过这一道的压限再听一下声音,会明显感觉到舒服了很多,像先前那样声音大小不一的感觉也好了许多,2音量平衡的精细的加工通过调节快速编辑点处理字词间的音量平衡第三步美化人声降噪讲完,平衡讲完,接下来,对之后美化人声有一定效果的效果器说明一下,不过请大家不要误解后期能把声音做得多么好听,后期只是将人的声音适当美化而已,如果干声部分不好的话,做出来的效果完全不像自己的了,那样也就没有意思了,1。
audacity人声消除参数

audacity人声消除参数使用Audacity进行人声消除是一种常见的音频处理方法。
通过调整Audacity的参数,可以有效地去除背景噪音,使人声更加清晰。
本文将介绍一些常用的Audacity人声消除参数,帮助读者在处理音频时获得更好的效果。
我们需要了解Audacity的一些基本操作。
打开音频文件后,我们可以看到波形图和控制面板。
在控制面板中,有一些参数可以调整,以达到人声消除的效果。
1. 静音区域分析(Silence Finder)在Audacity中,可以使用静音区域分析工具来自动检测音频中的静音区域。
静音区域通常是指没有人声的部分,通过分析这些区域,我们可以更好地了解背景噪音的特点。
在Audacity中,选择“效果”-“静音区域分析”可以进行静音区域分析。
2. 消除噪音(Noise Reduction)消除噪音是人声消除的核心步骤之一。
在Audacity中,可以使用噪音消除效果来处理音频文件。
选择要处理的音频段落,然后选择“效果”-“噪音消除”,在对话框中点击“获取噪音样本”,然后点击“OK”进行处理。
3. 声音增强(Amplify)在消除噪音后,有时人声可能会变得过于柔弱,这时可以使用声音增强工具来提高人声的音量。
在Audacity中,选择要处理的音频段落,然后选择“效果”-“放大”,在对话框中可以调整增益的大小。
4. 频谱编辑器(Spectral Editing)频谱编辑器是Audacity中一个非常强大的工具,它可以直接编辑音频的频谱图。
通过调整频谱图中的参数,可以对音频进行更精细的处理。
在Audacity中,选择“效果”-“频谱编辑器”,然后调整参数进行编辑。
5. 去除杂音(De-essing)有时,音频中可能存在过多的“s”音(也称为“嘶音”),这会影响人声的清晰度。
在Audacity中,可以使用去除杂音工具来处理这个问题。
选择要处理的音频段落,然后选择“效果”-“去除杂音”,在对话框中可以调整去除杂音的强度。
人声处理五步骤

人声处理五步骤标准化降燥压缩 eq 声场人声激励均衡混响后期人声处理基础步骤降噪,压缩,均衡,混响首先是先听有没有喷麦什么的监督发音喷麦有无念错接下来就是调EQ就是把干音处理好最后一个做音效拼接EQ是调声音的就是有些人声音闷那就要调亮有些声音远就要拉近来还有些声音很厚实这个就是把大家的声音都弄的差不多不然就不像在同一个空间说话了呀那就穿越了闷的声音调降低频增高频远的声音增中频高频还有加混响比较大的时候干音后面的静音剪的不要太短否则就是一段话没说完就掐段了广播剧后期制作的一般步骤(2009-02-23 16:05:32)标签:频段混响散射度阈值 hz 分类:音频制作技术广播剧后期制作的一般步骤1、降噪2、压缩主要掌握压缩器中的几个概念,然后根据自己的听力去压缩首先要设定压缩的阈值(threshould),他设定当电平值打到多少的时候,限制器开始工作,比如说,你输入-20dbfs,那么-20dbfs以下不被压缩,-20dbfs以上被压缩压缩比例(ratio),压缩比例只针对阈值以上的电平进行处理,而对阈值以下的电平不工作,接上例子,阈值是-20dbfs,压缩比例是2:1,那么就是说-20dbfs以上的电平以2:1的比例被压缩比如,如果是-50dbfs<-20dbfs,那么它不被压缩,但是-10dbfs>-20dbfs,那么就要被压缩,但压缩的只是大于阈值的那一部分,在这个例子中,-10dbfs-(-20dbfs)=10dbfs,那么对10dbfs进行2:1压缩,就是所,如果是2就变成1,那么现在是10dbfs 就变成5dbfs,在加上阀值-20dbfs就是,-20dbfs+5dbfs=-15dbfs,也就是原来是-10dbfs的被压缩到-15dbfs再说平滑系数(我自己翻译的,英文是knee),当你没有对它进行设定的时候,限制器做的是线性变化,但当你社定时候折线将会变成曲线,那么限制期的门限会下移动变成压缩器的门限,这样避免压缩出来的声音生硬接着是acctak time和release time分别是压缩开始和结束的缓冲时间,比如你设定的是15MS,那么在达到-20dbfs的时候,回过15MS才开始压缩.增益(gain),不多做解释了,就是放大或减少音量,同样在增大或减少音量时也受ratio 影响,比如对阈值以下的值是按1:1放大缩小,但是对阈值以上的按ratio放大或缩小.压缩的作用不仅仅是让电平的声音更平均一些,可以压出很多声音的特点来.而且有时候结合其他的声音可能会有一些特有的压缩效果,单独听可能会有点问题,但是放到剧里效果还是不错的.当压缩不够的时候,会觉得人声台词有很坚硬的感觉,很刺耳.压缩过量的时候,就觉得声音软塌塌的,而且有点闷.不够和过量都是RATIO决定.ATTACK TIME和RELEASE TIME也是很重要的.两者小,则声音的压缩快,很快进入和离开工作状态.前小后大,则声音的回复慢,声音过度更加柔和一些.一些特殊的声音利用ATTACK 和release可以起到一些避让的作用.untrafunk的压缩器只是压缩器,当你用的过分的时候,最好配个gate(噪声门)一起用.ratio大于10的时候压缩器可以近似做限制器了.3、EQ----黄金定律除非有特殊需要,否则尽量不要去调整EQ用动圈话筒的朋友可能高频要多提升1. 如果声音浑浊,请衰减250hz附近的频段。
音乐消人声后期处理方法
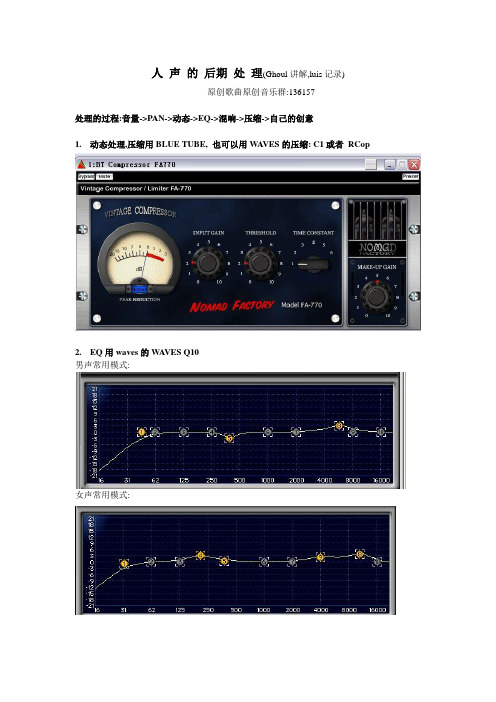
人声的后期处理(Ghoul讲解,luis记录)
原创歌曲原创音乐群:136157
处理的过程:音量->PAN->动态->EQ->混响->压缩->自己的创意
1.动态处理,压缩用BLUE TUBE, 也可以用W A VES的压缩: C1或者RCop
2.EQ用waves的W A VES Q10
男声常用模式:
女声常用模式:
3.混响: 用W A VES的RVER
PREDELAY,这个设置为3MS到5MS一般就是一个小型到重型的录音室了,如果是10ms就大点了,
TIME一般不用那么长的,一般1S前后就可以了;
SIZE这个以耳朵为准. DIFFUSION 建议50到86,其他的要自己听了,DECAY,可以不动了. TIME包含了DEcay,DECAY是TIME的一部分;
EARL Y REF是早反射;REVEB是混响中的音量
4.最后再加一次压缩,BLUE TUBE,最后的压缩是用来限制加入混响以后的声音不置于过大
一般情况下,我有的时候会这样做:
两个压缩,一个是PEAK压缩,一个是RMS压缩;
如果是PEAK压缩的话,只是针对一些比较大的声音,来压缩,流出更多空间做其他的东西RMS压缩是对整个人声,真正做到声音均匀的压缩
Tc的混响
shape 是环境;DIFFUSE是密度,COLOR是频率截至;FACTOR是两段均衡;MIX是干湿比;LEVELS是输入输出量, PERDELAYS是早反射,第二个是预反射,第三个是混响的时间。
歌曲人声后期精细效果处理的方法与

人声后期精细效果处理的方法与要点在人声效果的精细处理上,大多数人都是使用反复试探性调节的方法,以寻找音感效果最好的处理效果。
此种调音方式的不足十分明显:(1) 寻找一个理想的调音效果,需经多次猜测,所以需要较长的时间。
(2) 较好的调音效果常常是偶然遇到的,这对于调音规律的归纳总结没什么帮助,并且以后也不易再现。
(3) 不同设备的各项固定参数和可调参数都不尽相同,因而使用某一设备的经验,通常都无法用于另一设备。
发展到目前的效果处理设备,用于改变音源音色的技术手段并不太多,其中比较常用的只有频率均衡、延时反馈、限幅失真等3种基本方法,然而这些效果处理设备的不同参数组合所产生的音色则大相径庭。
效果处理器的参数设置可以有很多项,尤其是延时反馈,这种模拟混响效果参数的设置理论上可达几十项之多。
当然这些专业性极强的参数,大多数人都难以理解,也不知道如何理解。
因此,大部分效果处理设备都只设置一、二个可调参数,并且其可调范围也比较狭窄。
这种调整简单的效果处理设备容许人们在上面进行尝试性调整,而不会出现太大的问题。
但对于效果处理要求更为精细的调音场合,例如在多轨录音系统当中,则必须使用更为专业的效果处理设备,用以做出更为精细的效果处理。
频率均衡很明显,频率均衡的分段越多,效果处理的精细程度也就越高。
除了图示均衡,一般调音的均衡单元通常只有三四个频段,这显然满足不了精确处理音源的要求。
为了能足够灵活的对人声进行任意的均衡处理,我们建议使用增益、频点和宽度都可调整的四段频率均衡。
多数频率均衡的可调参数只有增益一项,然而这并不意味着其他两项参数不存在,而且这两项参数为不可调的固定参数。
当然这两项参数设置为可调也并非难事,但这些会增加设备的成本,并使其调整变得复杂化。
所以增益、频点和宽度都可调整的参量均衡电路,通常只有在高档设备上才能见到。
实际上,增益、频点和宽度都是可调整的频率均衡,几乎不可能使用胡猜乱试的方法找出一个理想的音色。
人声处理步骤

人声处理步骤制作清唱的后期效果这个过程的所有步骤都必须在清唱音轨的单轨状态下完成。
选中“音轨2”,点击窗口左上方的绿色尖头按钮进入“音轨2”的单轨状态。
此时,可能AUDITION的3个插件安装完毕后还未被激活(这样插件的功能就无法使用),点击“效果”菜单——“刷新效果列表”,3个插件就会被激活了。
以下是对清唱加工的几个步骤,所有步骤执行后都可以返回,只要在单轨状态下,点击窗口上方的工具栏中“撤消上次*作”按钮即可。
1、去噪(作用是消除录音时录入的环境噪声)点击“效果”菜单——“噪音消除”——“降噪器”,降噪是要先噪音采样的,就是选中你清唱最前面那段没有人声的空白的部分(一、两秒种就够了),进入“降噪器”,然后选“噪音采样”,再点“关闭”,然后取消你之前选的那段空白部分(此时就等于选中了整首歌),再进入“降噪器”,设置“降噪级别”的高低,(一般不宜超过50,视具体情况而定),然后就点“确定”,完工!2、激励(作用是对人声的高音做润色,使之听起来更清脆明亮)点击“效果”菜单—“DirectX”—“BBESonicMaximizer”,出现的对话框里有三个带有刻度的圆盘,最左边的圆盘是用来对低音的调节、中间的用来调节高音,右边的用来调节总体音频。
一般情况下,对清唱的人声只作高音激励,所以,在这里我们只需要调节那个圆盘。
即拖动圆盘上的杠杆转动,刻度越大对高音的激励就越明显(一般刻度不宜超过4,视具体情况而定),然后“确定”,完成。
3、加混响(卡拉OK常用效果,作用是使人声听起来不那么干)点击“效果”菜单—“DirectX”—“Ultrafunkfx”—“Reverb”,我认为在出现的对话框里只有一点比较有实际作用,就是“Decay Time”的数值,数值越大,混响效果就越厉害。
软件默认数值是1.5,我觉得很合适,没什么必要更改了,直接“确定”即可。
4、压限(作用是把整首歌的音频均衡压缩,尽量避免显出突兀之处)点击“效果”菜单—“DirectX”—“WavesC4”,出现的对话框里有个“软件设置”的下拉框,选择“Pop vocal”,然后“确定”,这个步骤就完成了。
13个人声处理技巧,让声音具有唱片般的品质

13个人声处理技巧,让声音具有唱片般的品质如果你已经知道怎么进行EQ处理、怎么选择话筒、怎么让歌手的声音变得更加平滑…可是还想知道更多、更好、更厉害的知识。
那么,这篇文章就是你提升人声处理技术的机会。
用一轨人声做Double(叠合)你想要叠合人声部分,于是就在多条轨道上重复录制了人声,想要从里面选出较好的部分来建立两条人声。
不幸的是,某一乐句只有一次录音是出色的——另一个可能有瑕疵,或歌手在录音时爆音了。
这时候不要着急:把出色的部分拷贝到另一轨上,对音调进行微调,然后设置20到25ms的延迟就可以了。
细调混响的扩散(Diffusion)好的人声当然需要好的混响,那么试试低扩散(“密度”)的参数。
这样做的原因是:扩散控制着回声的“厚度”。
高扩散把回声放置得很近,而低扩散把它们摆得很远。
对于节奏性的声音,低扩散会制造很多密集空间的声音,像石头撞在钢铁上一样。
但是对于人声,低扩散能给你足够的混响效果,但不会引起太多反射。
细调混响衰减时间很多混响都提供了频率的交叉点,高频和低频各自带有单独的衰减时间。
为了防止与中频乐器过多的竞争,可以在低频的地方使用低的衰减时间,在高频的地方使用高的衰减时间,这样可以给人声增加“空气感”,同时也能加强唇齿音,让人声更加生动。
最后调整交叉点的位置,让人声达到较好的效果。
声像自动化(Automation)对于Double的人声,你可以把两者都放在中间,或者一个靠左,一个靠右,然后添加不同的效果。
比如,在声场里有背景人声,我通常会把它放在中间。
如果不想人声比乐器突出,我会把两个轨道放得开一点,不使之成为焦点。
简单来说:用自动化来控制声像,对于不同的部分使用不同的声像。
令人竖起汗毛的人声记得Pink Floyd曾经用的那种轻声的,令人竖起汗毛的人声吗?试着让人声尽量多一些语气,像说话,而不是唱歌,然后插入一个声码器(软件或硬件),以人声作为调制器,粉噪作为载体。
你可能不需要太多粉噪的高频。
我的后期人声处理

我的后期人声处理我在这里写的对相对录音条件较差的同胞们或许会帮助打一下首先我们要改善我们的录音环境,使其尽可能的完美。
双击屏幕右下的小喇叭图标,选择选项→属性把这些没打勾的全部都给勾上,除了前两个其他全部选择静音!然后选择录音,勾上麦克风,确定下面开始正式介绍一下后期处理1 降噪先选取音轨较为平整的部分(如果噪音大小不一,选择郊小的部分,这样不会损失原声)然后选择降噪器选择噪音采样→保存采样,保存后关闭降噪器CTRL+A全选音轨,再次打开降噪器,加载采样,然后选取刚刚保存的采样,确定降噪完成2 修补录音(精华部分)先找出降噪未干净的部分,静音掉(如图)对于不太会换气的朋友,肯定有很多唤起的部分很明显,可以找出来,静音掉然后仔细听一遍找出卡塔声和噗声选中(尽可能小的范围)后点效果→噪音清除→卡塔声/噗声清除点自动查找所有电平然后确定(由于声音不同,驱除方法也不同,但是大家可以先掌握这种普通简单的方法)然后再仔细听一遍找出声音忽然变大的部分,特别是唱高音部分好多朋友会忽然声音变大,就象小宇宙突然爆发了一样(呵呵,开个玩笑),然后选中,选择混响处理参数可以选择默认就行,这个无所谓,主要调整DRY和E.R.这两个选项,向左调节可以使声音变小,调节量需要自己来试,reverb可以拉到最左边(可以先轻微调节,然后确定再听一下这一段,如果不满意,撤消后再打开混象调节)总之就是一遍一遍的听,找出自己不满意的地方,尽量的修饰,需要注意的是,不要做太大的调节,以免在后面的处理中失真.3 EQ(也就是大家平常说的均衡器)这个图片在最后放上去,连接错无了,不好意思啊。
4 压限(可以避免干声出现忽大忽小)使用插件:DirectX->Ultafunkfx->Compressor不会用的朋友只要对应图上参数填写就可以5 动态低频处理(使声线更加浑厚,)使用插件:DirectX->WavesMaxxBass 对应参数如下图混响处理使用插件:DirectX->Ultafunkfx->Reverb 参数如图完美混响(主要弥补上一步的不足)至此,干声处理完毕加一步呵呵有朋友提到音量的问题处理完毕后可能发现干声与伴奏的的音量不一样大这个问题很好解决你可以调整干声或者伴奏的音量,双击进入单音轨编辑,选择效果→波形\振幅→音量标准化,输入百分比就行了最后和伴奏一起混缩混缩后还有一个非常重要的步骤,就是同步混响处理(使人声与伴奏的混响尽量达到一致)使用插件:DirectX->WavesRVerb参数如下图低语调型:轻声细语、感情细腻,可采取近距离拾音,话筒与口型很近,这样可增加亲切感,可拾取纤细、微弱的声调。
声音的后期处理

声音的后期处理音色的调节在对人声的美化、修饰上,可以通过调音台上面的输入通道中的四段均衡器,对音色进行频率处理,来提高音色的艺术表现力。
调音台中的四段均衡器分为的4个频段,根据德车柏林音乐研究所资料介绍,它们是:HF:6-16 kHz,影响音色的表现力、解析力。
MID HF:600Hz~6 kHz,影响音色的明亮度、清晰度。
MID HF:200~600Hz,影响音色和力茺和结实度。
LF:20~200Hz,影响音色的混厚度和丰满度。
如果高频段频率过弱,其音色就变得色彩、韵味、个性的失落;如果高频段频率过强,音色就会变得尖噪、嘶哑、刺耳。
如果中高频段的频率过弱,音色就变得暗淡、朦胧;如果中高频段的频率过强,其音色就会变得呆板。
如果中低频段的频率过弱,音色会变得空虚、无力、软绵绵的;如果中低频段的频率过强,音色会变得生硬、失去活力。
如果低频段的频率过弱,音色将会变得单薄、苍白;如果低频段的频率过强,音色会变得浑浊不清。
要使音色有美感,就要泛音丰富、有层次,使歌声有音响美,听众听起来悦耳动听,提升量不易过强。
LF(低音)过量,声音混浊不清;HF (高音)过量,声音尖噪刺耳。
提升某一频段后,还工考虑对其他频段的影响,要总体地考虑歌声的清晰度和丰满度。
1、对普通人的调音有一些歌唱爱好者和业余歌手,也有一些人仅是娱乐消遗,他们多为自己演唱。
其中有的人没有受过基本专业训练,缺乏演唱技巧,甚至有噪音不好和不会使用话筒的人,其中,男声易出现喉音和沙哑,女声易出现气息噪音和声带噪声。
为消除以上现象采用如下具体处理手段。
(1)在100Hz以下要切除,消除低频噪声,使音色更加纯净。
(2)在500-800Hz要小量衰减,使音色不要太生硬。
(3)在MID频段提升3-6dB,以增强明亮度,使声音清晰、明亮;(4)一般人声音都较低,而且缺乏响度,所以音量要开得大一些;亦可把200-300Hz范围频率加以提升,以增加声音的响度,业余歌手动态范围不大,勿用自动音量控制。
人声后期精细效果处理方法

人声后期精细效果处理方法在人声效果的精细处理上,大多数人都是使用反复试探性调节的方法,以寻找音感效果最好的处理效果。
此种调音方式的不足十分明显:(1) 寻找一个理想的调音效果,需经多次猜测,所以需要较长的时间。
(2) 较好的调音效果常常是偶然遇到的,这对于调音规律的归纳总结没什么帮助,并且以后也不易再现。
(3) 不同设备的各项固定参数和可调参数都不尽相同,因而使用某一设备的经验,通常都无法用于另一设备。
发展到目前的效果处理设备,用于改变音源音色的技术手段并不太多,其中比较常用的只有频率均衡、延时反馈、限幅失真等3种基本方法,然而这些效果处理设备的不同参数组合所产生的音色则大相径庭。
效果处理器的参数设置可以有很多项,尤其是延时反馈,这种模拟混响效果参数的设置理论上可达几十项之多。
当然这些专业性极强的参数,大多数人都难以理解,也不知道如何理解。
因此,大部分效果处理设备都只设置一、二个可调参数,并且其可调范围也比较狭窄。
这种调整简单的效果处理设备容许人们在上面进行尝试性调整,而不会出现太大的问题。
但对于效果处理要求更为精细的调音场合,例如在多轨录音系统当中,则必须使用更为专业的效果处理设备,用以做出更为精细的效果处理。
频率均衡很明显,频率均衡的分段越多,效果处理的精细程度也就越高。
除了图示均衡,一般调音的均衡单元通常只有三四个频段,这显然满足不了精确处理音源的要求。
为了能足够灵活的对人声进行任意的均衡处理,我们建议使用增益、频点和宽度都可调整的四段频率均衡。
多数频率均衡的可调参数只有增益一项,然而这并不意味着其他两项参数不存在,而且这两项参数为不可调的固定参数。
当然这两项参数设置为可调也并非难事,但这些会增加设备的成本,并使其调整变得复杂化。
所以增益、频点和宽度都可调整的参量均衡电路,通常只有在高档设备上才能见到。
实际上,增益、频点和宽度都是可调整的频率均衡,几乎不可能使用胡猜乱试的方法找出一个理想的音色。
SamplitudeProX人声后期制作的步骤

SamplitudeProX人声后期制作的步骤————————————————————————————————作者:————————————————————————————————日期:人声后期制作教程之--混音的步骤及效果器的选择主讲:Sunday总引:第一步降噪第二步音量的平衡第三步美化人声1、高频激励效果器2、电子管模拟器第四步重中之重EQ均衡器第五步模拟效果的添加1、延迟2、混响第六步母带处理第七步导出第一步降噪在录音开始前呢,我们一般情况下,在歌手进入录音室是第一遍让歌手听音乐什么都不要做,也不要唱歌,听一段伴奏在歌手听伴奏的时候,录音师要做的就是录个5~10秒的录音室环境噪音一集软件设备连接造成的噪音,以便我们降噪时作为采样。
点击保存保存采样后点击右下角确定。
之后选中所有波形打开降噪器载入保存的采样试试调节处理程度切记不要降噪太多只要不要把人声原有的东西给降了就OK,重复确定第二步音量的平衡1.压缩器compressor压限器这个就是我们所说的压缩器了,作用呢,就是均衡人声的大小,现在仔细说一下每个的作用按照图文里的标记来说滤波器:指压限过后的声音圆滑度,也就是指穿透力度,数越大,就越圆滑阀值:压限作用阀值指的是控制人声大小的数值,简单来说就是把大小不一的声音放在一个点上,比率:这个是压缩的比率,这是和前面的阀值相互作用的,就像水龙头的开关一样,一点一点的开启,如果将这个开到6:1的时候,就好像一个水库,有6米高,只存着1米的水这样是极其不协调的,但是如果小于1的时候,就变成了水位超过储存量,这样就变成了扩散器了,所以调的时候一般就大于1的数值入:输入的电平信号出:压限过后人声的大小启奏:这里是指起始缓冲,就是声音超过压限作用阀值的时候在多长的时间开始发挥压释放:结束缓冲,声音低于压限作用阀值在多长的时间里取消压限功能现在我将通常用到的参数说出来:男声:阀值-23比率6:1③30启奏0.1释放70女声:阀值-26比率6:1③20启奏3.0释放300这个只是个参考值,所有完美的效果都是靠大家的双耳所以加油喽经过这一道的压限再听一下声音,会明显感觉到舒服了很多,像先前那样声音大小不一的感觉也好了许多,2音量平衡的精细的加工通过调节快速编辑点处理字词间的音量平衡第三步美化人声降噪讲完,平衡讲完,接下来,对之后美化人声有一定效果的效果器说明一下,不过请大家不要误解后期能把声音做得多么好听,后期只是将人的声音适当美化而已,如果干声部分不好的话,做出来的效果完全不像自己的了,那样也就没有意思了,1。
中后期人声处理解释及常见效果器插件应用

1。
均衡(EQ)均衡器是人声处理中最常用最重要的效果器,主要的用途是弥补人声录制时的一些频率,从而对音色有所调整和修饰。
比如对中频的适当提升,可以增加人声的亲切感;对高频的适当提升,可以增加泛音,使得听起来穿透力和清晰度更强等等。
另外,我们还经常通过均衡效果器,对人声进行滤波。
值得注意的是:均衡器的使用要顾及到歌手的音色特点、录音环境条件、伴奏音乐的频率特性来调整,不能一味的盲目调节。
比如某个歌手的嗓音穿透力超强,高频泛音很足,那么后期就没必要在泛音频点上再作提升,否则会显得声音很“炸”,让听者觉得刺耳;有时候你的录音话筒受频响范围所限(尤其是一些非专业的动圈麦克风),拾取的人声会有频率缺失,这时候后期调整均衡,就要根据这个录音条件的特点来进行适当的补偿;有时候伴奏音乐的低频很强,如果人声的低频部分与其重叠,很容易造成歌曲整体的低音过多而产生混浊的感觉,也起不到突出人声的效果,这时候则需要对人声的低频部分进行一些电平衰减。
通过均衡,还可以去除一些演唱中的杂音,比如女歌手的音频通常在7--10KHZ衰减大约3个dB,可消除咝音。
另外,对于鼻音,齿音过重,曝麦声等等,都可以通过均衡器进行修饰和润化。
要说明的一点:提升或衰减某个频段的电平,肯定会对其他频段产生或多或少的影响。
所以做均衡的时候一定要整体的去考虑,不能头疼医头,脚疼治脚。
软件推荐:Waves出品的Q-10插件,Ultrafunk的equalizer插件等,它们都属于参数均衡器。
2。
激励(Exciter)激励器是在音频信号中加入特定的泛音成分,也就是我们常说的“谐波”,增加声音回放时的细腻度及清晰度,让声音更清晰好听,更温暖有力,也更有层次感。
有时候我们给一个比较差的歌手录音的时候,可以给他(她)的话筒后接一个激励器,能让歌声泛音丰富,改善一定的音色,同时能让歌手增加自信心;而在录制乐队现场演出的时候,使用激励器,可以增加现场感和各声部的清晰度,更好的还原真实的环境;另外在合理的运用下,激励器还可以起到扩宽声场的作用。
教你如何调节人声音色的调试技巧30

教你如何调节人声音色的调试技巧30调节人声音色是音频工程中非常重要的一项技术,可以通过调整音色使人声听起来更加自然、明亮或者柔和。
下面是30种调节人声音色的调试技巧。
1.使用均衡器调整声音频率,增强或削弱特定频段,例如,增加高频可以让声音更明亮,增加低频可以让声音更加厚实。
2.减小低频干扰噪音,可以通过使用高通滤波器来实现,并通过调整截止频率来控制频段。
3.增加高频细节,可以使用融合型均衡器来提高声音的透明度和清晰度。
4.提高声音的明亮度,可以通过使用合成器或扩频来实现。
5.减小高频嘶嘶声或者尖锐感,可以通过使用压缩器或去噪器来控制。
6.处理S音、爆音等问题,可以使用降噪、消短或去爆音处理。
7.提高声音的厚度,可以通过增加低频共振来实现。
8.提高声音的亮度和清晰度,可以使用光谱调频合成器。
9.减小呼吸声或噪音间隙,可以使用自动静音或降噪器处理。
10.在串联信号处理器时,确保合适的顺序,例如,均衡器在压缩器之前使用。
11.处理呼吸,可以使用音量自动化,调整音量或使用动态处理器。
12.通过混响器添加混响效果,使声音听起来更加自然。
13.使用压缩器来增加声音的稳定性和一致性。
14.使用滤波器削弱或增强声音的尖锐部分。
15.在录音过程中使用合适的麦克风类型,不同的麦克风对声音的影响也是不同的。
16.使用固定均衡器或图形均衡器来调整频率响应。
17.使用合适的固定增益滤波器来增强或削弱特定频段。
18.使用多段均衡器调整不同的频率带,以改变整体声音。
19.使用动态均衡器调整频率响应,以实现更自然的音色。
20.使用宽频带均衡器调整整体声音。
22.使用多声道录音和混音技术,以增强声音效果。
23.使用声音合成器和合成音色调整声音。
24.使用合适的音量增益,以确保声音不会过于尖锐或模糊。
25.调整音色时,要注意不要过度处理或造成声音失真。
27.注意声音的动态范围,以避免过度声音压缩或失真。
28.将声音与背景音乐或其他音轨进行混合,以融合声音效果。
人声后期处理的步骤,声卡效果,可以参照添加插件

人声后期处理的步骤,声卡效果,可以参照添加插件/s/blog_4ddc30040102v31a.html总引:第一步降噪第二步音量的平衡第三步美化人声1、高频激励效果器2、电子管模拟器第四步重中之重 EQ均衡器第五步模拟效果的添加 1、延迟2、混响第六步母带处理第七步导出第一步降噪在录音开始前呢,我们一般情况下,在歌手进入录音室是第一遍让歌手听音乐什么都不要做,也不要唱歌,听一段伴奏在歌手听伴奏的时候,录音师要做的就是录个5~10秒的录音室环境噪音一集软件设备连接造成的噪音,以便我们降噪时作为采样。
点击保存保存采样后点击右下角确定。
之后选中所有波形打开降噪器载入保存的采样试试调节处理程度切记不要降噪太多只要不要把人声原有的东西给降就OK了第二步音量的平衡 1.压缩器compressor压限器这个就是我们所说的压缩器了,作用呢,就是均衡人声的大小,现在仔细说一下每个的作用按照图文里的标记来说滤波器:指压限过后的声音圆滑度,也就是指穿透力度,数越大,就越圆滑阀值:压限作用阀值指的是控制人声大小的数值,简单来说就是把大小不一的声音放在一个点上,比率:这个是压缩的比率,这是和前面的阀值相互作用的,就像水龙头的开关一样,一点一点的开启,如果将这个开到6:1的时候,就好像一个水库,有6米高,只存着1米的水这样是极其不协调的,但是如果小于1的时候,就变成了水位超过储存量,这样就变成了扩散器了,所以调的时候一般就大于1的数值入:输入的电平信号出:压限过后人声的大小启奏:这里是指起始缓冲,就是声音超过压限作用阀值的时候在多长的时间开始发挥压限功能释放:结束缓冲,声音低于压限作用阀值在多长的时间里取消压限功能现在我将通常用到的参数说出来:男声:阀值-23 比率6:1 ③30启奏0.1 释放70 女声:阀值-26 比率6:1 ③20启奏3.0 释放300 这个只是个参考值,所有完美的效果都是靠大家的双耳所以加油喽经过这一道的压限再听一下声音,会明显感觉到舒服了很多,像先前那样声音大小不一的感觉也好了许多, 2音量平衡的精细的加工通过调节快速编辑点处理字词间的音量平衡第三步美化人声降噪讲完,平衡讲完,接下来,对之后美化人声有一定效果的效果器说明一下,不过请大家不要误解后期能把声音做得多么好听,后期只是将人的声音适当美化而已,如果干声部分不好的话,做出来的效果完全不像自己的了,那样也就没有意思了,1。
人声后期制作教程之美化人声

人声后期制作教程之美化人声---小林在前一章节里,已经将降燥的基本原理告诉大家了,接下来,对之后美化人声有一定效果的效果器说明一下,不过请大家不要误解后期能把声音做得多么好听,后期只是将人的声音适当美化而已,如果干声部分不好的话,做出来的效果完全不像自己的了,那样也就没有意思了,1)麦克风模拟器这是一个可以模拟出各类品牌麦克风的插件,这个就是我所说的麦克风模拟器了,图文中我做了几个标识,为了方便大家的理解,①这个位子是我们实际中所用的麦克风,如果没有找到你用的麦克风牌子请向下拉选择bypass mic②模拟的麦克风选项,在这里可以选择一下你喜欢的麦克型号,每一种都有自己的特点③-④preserve source---bass--Treble:保留麦克风的原信号,如果你录出来的声音觉得麦的低频可以而高频不足,点亮了BASS上面的灯就可以只对高频进行处理,Treble上面的灯点亮的话,那么就只对低频进行处理了,⑤这个容易理解,就是音量的调节了Tube Saturation:这个选项可以调节人声的温暖度,其实呢,所谓的温暖,也是一种人声失真的表现,只不过大多数人接受了而已,不过不宜调节过多,推荐2.0以前适当调节,调节过头人声感觉很噪2。
高频激励效果器这个是BBE效果器,相信大家应该很熟悉了,这个效果器主要是针对每个人声的高音,低音部分进行一定的美化,大家看到三个旋钮,第一个调的是低音,第二个调的是高音,第三个调的是总输出音量.在我的理解里,男声与女声分别蛮大的男声,高音通常不足,女声呢,刚好相反,当然了每个人的声音都不同,这就要靠各位的听觉了调节时注意:低频过多会让人声变得模糊不清,高频过高刚让人声变得尖锐刺耳我的建议是高音和低音的调整量都为2DB--4DB,如果过了这个点,人声不像自己的了,听着很怪最佳:低音饱满不浑浊,高音明亮不尖锐3。
电子管模拟器这个图为电子管模拟器,可以让人声较之前听着更加舒服,接下来说明一下如何应用图中①这个位子是我们最经常用到的,点亮了这个灯,然后适当调节,可以让人声变得好听,和伴奏更加贴切而②这个位子,我个人不推荐点亮这个灯,如果一定要点的话,请先听一下伴奏的节奏是否很强烈,如果伴奏的节奏感很强,那么你可以点这个灯,接下来说一下具体的参数男声:③+0.5④+0.4-0.5⑤-0.1女声:③+0.5④+06⑤-1.54。
对人声的调音技巧

对人声的调音技巧调音技巧是指对人声进行音频处理的一系列技术。
在音频制作中,人声调音是非常重要的一环,它能够帮助改善人声的质量和逼真度,使其更好地融入音频作品中。
本文将介绍一些常用的人声调音技巧。
1.去除噪音和杂音:在录制人声时,常常会存在一些噪音和杂音,如电流噪声、电脑风扇声等。
使用去噪工具或者进行各种滤波处理可以有效地去除这些噪音和杂音。
2.噪音门限:通过设置恰当的噪音门限,可以使人声在停止的情况下不被录制到,从而避免无意义的背景噪音被录入。
3.去除嘶嘶声:有些人的口腔中含有过多的唾液,容易产生嘶嘶声。
通过使用均衡器或者去除滤波器等工具,可以一定程度上去除这一问题。
4.喷射气流音的平滑:录制人声时,如果离麦克风过近或者喷射气流导致爆音,可以采用限幅器等工具进行处理。
5.EQ处理:通过使用均衡器,可以调整人声的频率响应。
一般来说,男性声音的频率范围较低,女性声音的频率范围较高。
因此,可以根据人声的性别和音色调整均衡器来改善人声的质量。
6.压缩和限制:通过使用压缩器和限制器等工具,可以调整人声的动态范围,使其更加平滑和一致。
这有助于确保人声在整个录音中的可听性和舒适度。
7.延迟和混响:通过添加一些延迟和混响效果,可以改善人声的宽度和深度。
这使得人声在音频中更加立体感,更具吸引力。
8.唇齿音的控制:一些人在说话时会产生强烈的唇齿音,这会影响人声的质量。
使用均衡器和压缩器等工具,可以控制唇齿音的强度,从而改善人声的品质。
10.分离和制作双声道:根据需要,可以使用立体声技术将人声从伴奏音乐中分离出来,或者制作出一些立体声效果,以增加音频的吸引力。
总之,人声调音技巧对于音频制作来说非常重要。
通过使用合适的工具和技术,可以使人声更加清晰、自然,融入到音频作品中,提升整体质量。
不同的音频素材和需求可能需要不同的处理方法,因此在操作中灵活运用各种调音技巧是很重要的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
人声后期精细效果处理方法在人声效果的精细处理上,大多数人都是使用反复试探性调节的方法,以寻找音感效果最好的处理效果。
此种调音方式的不足十分明显:(1) 寻找一个理想的调音效果,需经多次猜测,所以需要较长的时间。
(2) 较好的调音效果常常是偶然遇到的,这对于调音规律的归纳总结没什么帮助,并且以后也不易再现。
(3) 不同设备的各项固定参数和可调参数都不尽相同,因而使用某一设备的经验,通常都无法用于另一设备。
发展到目前的效果处理设备,用于改变音源音色的技术手段并不太多,其中比较常用的只有频率均衡、延时反馈、限幅失真等3种基本方法,然而这些效果处理设备的不同参数组合所产生的音色则大相径庭。
效果处理器的参数设置可以有很多项,尤其是延时反馈,这种模拟混响效果参数的设置理论上可达几十项之多。
当然这些专业性极强的参数,大多数人都难以理解, 也不知道如何理解。
因此,大部分效果处理设备都只设置一、二个可调参数,并且其可调范围也比较狭窄。
这种调整简单的效果处理设备容许人们在上面进行尝试性调整,而不会出现太大的问题。
但对于效果处理要求更为精细的调音场合,例如在多轨录音系统当中,则必须使用更为专业的效果处理设备,用以做出更为精细的效果处理。
频率均衡很明显,频率均衡的分段越多,效果处理的精细程度也就越高。
除了图示均衡,一般调音的均衡单元通常只有三四个频段,这显然满足不了精确处理音源的要求。
为了能足够灵活的对人声进行任意的均衡处理,我们建议使用增益、频点和宽度都可调整的四段频率均衡。
多数频率均衡的可调参数只有增益一项,然而这并不意味着其他两项参数不存在,而且这两项参数为不可调的固定参数。
当然这两项参数设置为可调也并非难事,但这些会增加设备的成本,并使其调整变得复杂化。
所以增益、频点和宽度都可调整的参量均衡电路,通常只有在高档设备上才能见到。
实际上,增益、频点和宽度都是可调整的频率均衡,几乎不可能使用胡猜乱试的方法找出一个理想的音色。
在这里我们必须研究音频信号的物理特性、技术参数以及他在人耳听感上的对应关系。
人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用语调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
从理论上讲,应使人声在发任何音时,其响度都保持恒定。
为了在不破坏人生自然感的基础上对其进行特定效果的处理可以使用1/5倍频程的均衡处理,具体有以下几种情形:(1) 音感狭窄,缺乏厚度,可在800Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-3dB。
(2) 卷舌齿音的音感尖啸,”嘘"音缺乏清澈感,可在2500Hz处使用1/5倍频程的衰减处理,衰减的最大值可以在-6Db。
对音源的均衡处理,最好是使用能显示均衡曲线的均衡器。
一般数字调音台均衡器上的均衡增益调节钮用"G"来标识,均衡频率调节钮用"F"来标识,均衡带宽调节钮用"F"或"Q"来标识。
延时反馈延时反馈是效果处理当中应用最为广泛,但也是最为复杂的方式。
其中,混响、合唱、镶边、回声等效果,其基本处理方式都是延时反馈。
1、混响混响效果主要是用于增加音源的融合感。
自然音源的延时声阵列非常密集、复杂,所以模拟混响效果的程序也复杂多变。
常见参数有以下几种:混响时间:能逼真的模拟自然混响的数码混响器上都有一套复杂的程序,其上虽然有很多技术参数可调,然而对这些技术参数的调整都不会比原有的效果更为自然,尤其是混响时间。
高频滚降:此项参数用于模拟自然混响当中,空气对高频的吸收效应,以产生较为自然的混响效果。
一般高频混降的可调范围为0.1~1.0。
此值较高时,混响效果也较接近自然混响;此值较低时,混响效果则较清澈。
扩散度:此项参数可调整混响声阵密度的增长速度,其可调范围为0~10,其值较高时,混响效果比较丰厚、温暖;其值较低时,混响效果则较空旷、冷僻。
预延时:自然混响声阵的建立都会延迟一段时间,预延时即为模拟次效应而设置。
声阵密度:此项参数可调整声阵的密度,其值较高时,混响效果较为温暖,但有明显的声染色;其值较低时,混响效果较深邃,切声染色也较弱。
频率调制:这是一项技术性的参数,因为电子混响的声阵密度比自然混响稀疏,为了使混响的声音比较平滑、连贯,需要对混响声阵列的延时时间进行调制。
此项技术可以有效的消除延时声阵列的段裂声,可以增加混响声的柔和感。
调治深度:指上述调频电路的调治深度。
混响类型:不同房间的自然混响声阵列差别也较大,而这种差别也不是一两项参数就能表现的。
在数码混响器当中,不同的自然混响需要不同的程序。
其可选项一般有小厅(S-Hall)、大厅(L-Hall)、房间(Room)、随机(Random)、反混响(Reverse)钢板(Plate)、弹簧(Sprirg)等。
其中小厅、大厅房间混响属自然混响效果;钢板、弹簧混响则可以模拟早期机械式混响的处理效果。
房间尺寸:这是为了配合自然混响效果而设置的,很容易理解。
房间活跃度:活跃度,就是一个房间的混响强度,他与房间墙面吸声特性有关,此项参数即用于调节此特性。
早期反射声与混响声的平衡:混响的早期反射声与其处理效果特性关系密切,而混响声阵的音感则不那么变化多端,所以数码混响器的这两部分的生成是分开的,本参数就是用于调整早期反射声与混响声阵之间响度平衡。
早期反射声与混响声的延时时间:即早期反射声与混响声阵之间的延时时间控制。
此时间较长,混响效果的前段就较清澈;此时间较短,早期反射声与混响声就会重叠在一起,混响效果的前段就较浑浊。
除以上可调参数之外,混响效果还有一些其他附属参数,例如低通滤波、高通滤波、直达/混响声的响度平衡控制等。
2、延时延时就是将音源延迟一段时间后,再欲播放的效果处理。
依其延迟时间的不同,可分别产生合唱、镶边、回音等效果。
当延迟时间在3~35ms之间时人耳感觉不到滞后音的存在,并且他与原音源叠加后,会因其相位干涉而产生”梳状滤波”效应,这就是镶边效果。
如果延迟时间在50ms 以上时,其延迟音就清晰可辨,此时的处理效果才是回音。
回音处理一般都是用于产生简单的混响效果。
延时、合唱、镶边、回音等效果的可调参数都差不多,具体有以下几项:延时时间(Dly),即主延时电路的延时时间调整。
反馈增益(FB Gain),即延时反馈的增益控制。
反馈高频比(Hi Ratio),即反馈回路上的高频衰减控制。
调制频率(Freq),指主延时的调频周期。
调制深度(Depth),指上述调频电路的调制深度。
高频增益(HF),指高频均衡控制。
预延时(Ini Dly),指主延时电路预延时时间调整。
均衡频率(EQ F),这里的频率均衡用于音色调整,此为均衡的中点频率选择。
由于延时产生的效果都比较复杂多变,如果不是效果处理专家,建议使用设备提供的预置参数,因为这些预置参数给出的处理效果一般都比较好。
声激励对音源信号进行浅度的限幅处理,音响便会产生一种类似”饱和”的音感效果从而使其发音在不提高其实际响度的基础上有响度增大的效果。
一些数码效果器上也配有非线性饱和效果,他就是对信号的振幅处理,模拟大电瓶信号在三极管上的饱和所引起的非线性,从而产生出”发硬”的音感效果。
由于限幅失真所引起的主要是产生额外的高次谐波成分,因而新设计的激励器,为了使其处理效果柔和一些,都是通过在音源中家置高次载波成分来模拟限幅失真,营造不那么”嘶哑”的声激励效果。
另外,通过一个用于加强高次谐波的高通滤波器对原信号进行处理,然后再叠加在经延时的原信号上,可以营造出音头清澈的声效果。
显然、这种处理方式可以产生出不那么嘈杂的激励处理。
激励处理类似于音响设备的过载失真,因而对音源的过量激励,会产生令人不悦的嘈杂感。
由于早期音响设备的保真度都不高,人们已经习惯了那种稍显嘈杂的音响,而对于音感清洁的高保真度音响,反而不太习惯,感觉其发音过分柔弱。
在人声音源当中,除了一少部分经过专门训练的人之外,大部分的发言都缺乏劲度,因而这里的激励处理是十分必要的。
对人声的激励处理有下面几种情形:(1) 对人声乐音的激励处理,其频谱分布以2500Hz为中点。
此种激励的效果比较自然舒适、对增加音源突出感的作用也比较明显。
(2) 对人声鼻音的激励处理,其频谱分布以500Hz为中点。
此种激励可以有效地增大人声的劲度感。
(3) 对人声800Hz附近进行激励,可以增加音源的喧嚣感,当然此处理方式的使用应十分谨慎,最好是只用于摇滚乐的演唱。
⑷对人声3500-6800HZ范围内的频谱,不宜使用激励处理,因为它容易使音源产生令人不悦的嘈杂声响。
(5) 对人声的齿音一般应避免使用激励处理,因为此频段的失真很容易被人察觉。
当然如果是使用激励效果比较柔和的数字式激励器,也可以对齿音做轻微的激励处理,以用于加重齿音的清析感。
其处理的频谱应在7200Hz以上。
歌唱发音的激励处理通常要保守一些。
在实际的调音当中,激励处理的音感效果有可能随长时间的听音而逐渐弱化,所以在调节激励效果时,时间不要超过10分钟。