数据模型与决策.ppt
合集下载
数据、模型与决策(课件PPT)

7ຫໍສະໝຸດ 案例1 有兄弟姐妹的人得病少
有兄弟姐妹一起成长,不仅增添亲情, 而且有预防疾病的好处
一项来自澳大利亚的研究表明:兄弟 姐妹在6岁之前的相互传染病毒可以增 强免疫功能,并预防多发性硬化症。
塔斯马尼亚州研究者观察了136名多发 性硬化症患者,并与272名健康者进行 了对比。
8
科学家发现:在幼儿时期与兄弟姐妹 有五年以上密切生活的人患多发性硬 化症的几率下降了88%,而与兄弟姐 妹接触1-3年的人可降低43%。
9
案例2
“坐立不安”让人苗条
科学家最近发现了保持苗条身材的奥 妙。如果一个人平时闲不住,小动作 很多,日常消耗的热量就多,就能保 持苗条的身材。
美国梅欧医院请来了20位志愿者,进
行了为期一年的研究。志愿者分为两 组,一组较瘦,另一组轻度微胖。所 有志愿者都穿上一种带有传感器的特 制内衣,内衣里的装置每隔半秒钟记 录一次人体的姿态与活动
3.1 类别数据的表格表示
例3.1 交通事故的驾驶因素分析 造成交通事故的驾驶因素有判断失误、察
觉得晚、驾驶错误、偏离规定的行驶路线 和酒后或疲劳驾驶等。某地区交通管理部 门对某段时间中的50起交通事故进行驾驶因 素分析,得到的原始数据如下:
16
驾驶错误 察觉得晚 判断失误 驾驶错误 酒后或疲劳 驾驶 察觉得晚
驾驶错误
察觉得晚 察觉得晚 判断失误 察觉得晚
驾驶错误 察觉得晚 察觉得晚 判断失误 察觉得晚
察觉得晚
驾驶错误 判断失误 驾驶错误 察觉得晚
17
从例3.1的数据,你能看出些什么? 也许你看出了“察觉得晚”、“判断
失误”等因素比较多,“偏离规定的 行驶路线”、“酒后或疲劳驾驶”等 因素比较少。很好! 其实,只要借助一些简单的图表,就 能对数据加以整理并进行初步的定量 分析。 一些常用的软件如Excel,几乎能完美 地为你完成这些图表!
有兄弟姐妹一起成长,不仅增添亲情, 而且有预防疾病的好处
一项来自澳大利亚的研究表明:兄弟 姐妹在6岁之前的相互传染病毒可以增 强免疫功能,并预防多发性硬化症。
塔斯马尼亚州研究者观察了136名多发 性硬化症患者,并与272名健康者进行 了对比。
8
科学家发现:在幼儿时期与兄弟姐妹 有五年以上密切生活的人患多发性硬 化症的几率下降了88%,而与兄弟姐 妹接触1-3年的人可降低43%。
9
案例2
“坐立不安”让人苗条
科学家最近发现了保持苗条身材的奥 妙。如果一个人平时闲不住,小动作 很多,日常消耗的热量就多,就能保 持苗条的身材。
美国梅欧医院请来了20位志愿者,进
行了为期一年的研究。志愿者分为两 组,一组较瘦,另一组轻度微胖。所 有志愿者都穿上一种带有传感器的特 制内衣,内衣里的装置每隔半秒钟记 录一次人体的姿态与活动
3.1 类别数据的表格表示
例3.1 交通事故的驾驶因素分析 造成交通事故的驾驶因素有判断失误、察
觉得晚、驾驶错误、偏离规定的行驶路线 和酒后或疲劳驾驶等。某地区交通管理部 门对某段时间中的50起交通事故进行驾驶因 素分析,得到的原始数据如下:
16
驾驶错误 察觉得晚 判断失误 驾驶错误 酒后或疲劳 驾驶 察觉得晚
驾驶错误
察觉得晚 察觉得晚 判断失误 察觉得晚
驾驶错误 察觉得晚 察觉得晚 判断失误 察觉得晚
察觉得晚
驾驶错误 判断失误 驾驶错误 察觉得晚
17
从例3.1的数据,你能看出些什么? 也许你看出了“察觉得晚”、“判断
失误”等因素比较多,“偏离规定的 行驶路线”、“酒后或疲劳驾驶”等 因素比较少。很好! 其实,只要借助一些简单的图表,就 能对数据加以整理并进行初步的定量 分析。 一些常用的软件如Excel,几乎能完美 地为你完成这些图表!
数据模型与决策PPT课件

07.12.2020
若按这3个维度对研究总体分类,那么共有18个类,它们可以 用一个立方体来表示,如图4.1所示,其中每个“格子”代表 一类。譬如,正前方标有“1”的格子表示属于大都市区域且 人口少于5000人的城市中的所有食品超市。 从例3.5,我们不难理解分层抽样的定义:将总体分成若干个 互不重叠的子总体,从每个子总体中独立地进行抽样。每个 子总体,也即例4.5中的“格子”,被成为层(stratum)。
07.12.2020
例2.2 美国政府研究如下一个问题:是否需要为中低收入家 庭提供日间托儿服务? 如果这项服务能使得这些儿童在日后收到更多更好的教育, 则政府可以少付出福利金、增加税收而很有效益。 卡罗来那州的一项启蒙计划从1972年开始对一群儿童进行跟 踪观测,结果显示,良好的日间照护对儿童以后的就学和就业 有很大影响。 启蒙计划中受试对象是111个人,他们在1972年还是名婴儿, 出生在低收入家庭,身体健康,所有这些婴儿都得到社会工作 者的帮助,其中随机选出一半的人给予密集学前教育。 这里进行了对比,解释变量是是否接受学期教育,而反应变 量则很复杂,包括是否上大学以及就业情况。
07.12.2020
例1.3 权威人物的意见 有两个内容相同的问题: 问题A:陆军部和海军部应当合并为统一的作战部,您同意 么? 问题B:艾森豪威尔将军说,陆军部和海军部应当合并为统 一的作战部,您同意么? 结果对问题A表示同意的比例为29%,而对问题B表示同意 的比例为49%,两者相距甚远。无疑,权威人物艾森豪威尔 将军的意见影响了被调查者的意见。
数据、模型与决策
数据的产生与图表描述
一、 调查面面观 二、 实验面面观 三、 数据的图表描述
07.12.2020
一、 调查面面观
若按这3个维度对研究总体分类,那么共有18个类,它们可以 用一个立方体来表示,如图4.1所示,其中每个“格子”代表 一类。譬如,正前方标有“1”的格子表示属于大都市区域且 人口少于5000人的城市中的所有食品超市。 从例3.5,我们不难理解分层抽样的定义:将总体分成若干个 互不重叠的子总体,从每个子总体中独立地进行抽样。每个 子总体,也即例4.5中的“格子”,被成为层(stratum)。
07.12.2020
例2.2 美国政府研究如下一个问题:是否需要为中低收入家 庭提供日间托儿服务? 如果这项服务能使得这些儿童在日后收到更多更好的教育, 则政府可以少付出福利金、增加税收而很有效益。 卡罗来那州的一项启蒙计划从1972年开始对一群儿童进行跟 踪观测,结果显示,良好的日间照护对儿童以后的就学和就业 有很大影响。 启蒙计划中受试对象是111个人,他们在1972年还是名婴儿, 出生在低收入家庭,身体健康,所有这些婴儿都得到社会工作 者的帮助,其中随机选出一半的人给予密集学前教育。 这里进行了对比,解释变量是是否接受学期教育,而反应变 量则很复杂,包括是否上大学以及就业情况。
07.12.2020
例1.3 权威人物的意见 有两个内容相同的问题: 问题A:陆军部和海军部应当合并为统一的作战部,您同意 么? 问题B:艾森豪威尔将军说,陆军部和海军部应当合并为统 一的作战部,您同意么? 结果对问题A表示同意的比例为29%,而对问题B表示同意 的比例为49%,两者相距甚远。无疑,权威人物艾森豪威尔 将军的意见影响了被调查者的意见。
数据、模型与决策
数据的产生与图表描述
一、 调查面面观 二、 实验面面观 三、 数据的图表描述
07.12.2020
一、 调查面面观
数据、模型与决策(第10版)PPT taylor_introms10_ppt_10

10-3
Optimal Value of a Single Nonlinear Function Basic Model
Profit function, Z, with volume independent of price: Z = vp - cf - vcv
where v = sales volume p = price cf = unit fixed cost cv = unit variable cost
Copyright © 2010 Pearson Education, Inc. Publishing as Prentice Hall
10-2
Overview
■ Problems that fit the general linear programming format but contain nonlinear functions are termed nonlinear programming
(NLP) problems.
■ Solution methods are more complex than linear programming
methods.
■ Determining an optimal solution is often difficult, if not
impossible.
Copyright © 2010 Pearson Education, Inc. Publishing as Prentice Hall
Figure 10.4
10-7
Constrained Optimization in Nonlinear Problems Definition
■ A nonlinear problem containing one or more constraints becomes a
数据模型与决策-管理科学导论ppt课件

城市交通规划
通过模拟城市交通流量和交通拥堵情况,优 化城市交通规划和道路设计。
金融风险管理
通过模拟金融市场波动和风险情况,评估和 管理金融风险。
能源管理
通过模拟能源生产和消耗情况,优化能源规 划和调度,降低能源成本和碳排放。
06
CATALOGUE
数据模型与决策的未来发展
数据模型与决策的新趋势和挑战
数据模型的基本元素
实体
数据模型中的基本单元,可以是具体或抽象的 事物。
属性
描述实体的特征或参数,例如人的姓名、年龄 等。
关系
实体之间的连接或交互方式,例如父子关系、同事关系等。
数据模型的分类
概念数据模型
用于描述现实世界中的事物和关系,如ER图 。
逻辑数据模型
描述数据之间的结构和规则,如关系模型。
• 模拟模型的定义:模拟模型是一 种通过数学、计算机或物理手段 对现实世界进行抽象和模拟的工 具。它通过建立数学模型或计算 机模型来模拟系统的行为和过程 ,以便更好地理解和预测系统的 性能和结果。
模拟模型的定义和特点
01
模拟模型的特点
02
模拟模型能够模拟真实世界的复杂系统,包括物理系统、工程系统、 经济系统和社会系统等。
物理数据模型
描述数据在计算机中的存储和访问方式,如 文件系统或数据库管理系统。
02
CATALOGUE
决策制定过程
决策的定义和重要性
总结词
决策是管理活动中最重要的环节之一,它决定了组织未来的发展方向和目标。
详细描述
决策是指组织或个人为了实现某种目标,根据现有信息和经验,对未来行动方案进行选择和决定的过 程。决策的正确与否直接影响到组织的发展和成败,因此决策在管理活动中具有至关重要的地位。
《数据模型与决策》课件

04
实际案例分析
案例一:基于数据模型的营销决策
总结词
通过数据模型分析市场趋势,制定有效的营销策略。
详细描述
利用大数据和统计模型分析消费者行为和市场趋势,预 测未来市场需求,制定个性化的营销策略,提高销售业 绩和市场占有率。
总结词
优化营销预算分配。
详细描述
通过数据分析确定各营销渠道的投资回报率,合理分配 营销预算,提高营销效果和投资回报率。
03
未来还需要加强数据安全和隐 私保护等方面的研究,以保障 数据的安全性和可靠性。
数据模型与决策的实际应用价值
数据模型与决策在企业管理 中具有重要的应用价值,可 以帮助企业进行科学决策和
优化资源配置。
数据模型与决策还可以帮助 企业提高市场竞争力,如通 过数据分析发现市场趋势和 消费者需求,制定更加精准
总结词
提升客户满意度和忠诚度。
详细描述
通过数据模型分析客户反馈和行为数据,了解客户需求 和期望,优化产品和服务,提高客户满意度和忠诚度。
案例二:基于数据模型的金融风险评估
总结词
利用数据模型评估贷款违约风险。
01
02
详细描述
通过分析历史数据和信贷信息,利用统计模 型和机器学习算法评估贷款违约风险,为金 融机构提供风险预警和决策支持。
数据模型在决策中的作用
数据模型为决策提供数据支持
通过建立数据模型,将原始数据转化为有价值的信息,帮助决策者 更好地理解数据,从而做出更准确的决策。
数据模型提高决策效率
数据模型可以对大量数据进行处理和分析,快速得出结果,提高决 策效率。
数据模型降低决策风险
通过数据模型的预测和模拟功能,可以预测未来趋势,帮助决策者 提前做好准备,降低决策风险。
《数据模型与决策》案例分析报告生产策略.ppt

贝贝加100
85%
贝贝加200
15%
16
数据模型与决策分析—生产战略
案例问题解答
• 定义约束条件—有贝贝加200的产量占25%的约束
约束
制型和焊接 喷漆和成型 装配、调试和包装 产量约束(贝贝加200占 25%)
耗用时间
≤ ≤ ≤
可用时间
600 450 140
S-0.75*S-0.75*D
≤
0
17
8
数据模型与决策分析—生产战略
线性规划解决问题步骤
步骤
1 描述目标 2 描述约束条件 3 定义决策变量
主要内容
本题的目标就是使产品的利润贡献最大
对于生产时间来说,一共有3个约束条件,它们制约着贝贝 加100和贝贝加200的生产数量 贝贝加100的产量S,贝贝加200的产量D
4
用决策变 量写出目标
总利润函数 Max
Contents
1. 案例背景资料
2. 案例分析思路
3. 案例问题解答
4. Excel运算过程
2
数据模型与决策分析—生产战略
案例背景资料
3
数据模型与决策分析—生产战略
案例背景资料
比特健身公司在长岛自由港设有生产厂。最近公司设计了两种适合种种体形 的家庭健身器材。这两种器材都使用了BETTER塑形专利技术,大大增加了健 身者的活动范围,可以满足各种运动动作的需要。现在这种功能只有昂贵笨重 的物理理疗器才有。 在最近的贸易展览会上。由于这种机器的参与,使得公司的收效显著。事实 上,订单要求的生产数量已经大大超过了公司现阶段的生产能力。于是,公司 的管理层决定生产这两种器材。这两种器材分别叫作贝贝加100和贝贝加200, 是由不同的原材料生产出来的。 贝贝加100由一个柜架单元、压力源和PEC源组成。制造每个柜架需要用4 个小时进行制型和焊接,2个小时进行喷漆和成型。每个压力源都需要用2个小 时进行制型和焊接,1个小时进行喷漆和成型。每个PEC源都需要用2个小时进 行制型和焊接,2个小时进行喷漆和成型。此外对于每个贝贝加100型的器材还 需要用2个小时进行装配、调试和包装。柜架单元的原材料的价格是450美元, 压力源的材料价格是300美元,PEC源的材料价格是250美元,包装的成本预计 是每台50美元。
工商管理硕士(MBA)系列教材《数据、模型与决策》课件集(共19章)

第一章 决策过程 数据、模型与决策 (第二版)
首先,依据VCD的销售曲线,1998年的增长加速度已 下降,可以判断为进入高速成长的后期。虽然电子产品没有 成熟期也是可能的,但当时的替代产品DCD对VCD的替代却受 到较大的配套消费制约,对VCD在音响效果、图像方面的缺陷 是人所共知的。然而,DVD在声像方面的优越性能却需要有高 品质彩电、5.1声道的音响、功放及高价格碟片的配套才能实 现。按当时的市价,享受高品质的DVD的投入需7000元,配套 投入需2万元。而一台VCD的价格只有千元,这一强烈的差异 可以得出结论,对大多数以看故事为主的消费者,DVD不会是 首选。即VCD进入成熟期后,DVD成为主流的消费品之前,存 在着一个新的市场空间“在不需要庞大配套投入的基础上改 进VCD”,这意味着可以形成一个新的产品概念:“与普遍家 庭视像设备相匹配的能改善视像效果的产品”。在这一概念 指导下,产生了曾是一度流行的SVCD,CVD等产品。
第一章 决策过程
数据、模型与决策 (第二版)
1.2.2 明确目标
• 目标的基本含义:希望得到的结果或希 望达到的标准。
• 这一步骤是把上一步骤的问题定义进一 步具体地展开。
第一章 决策过程
数据、模型与决策 (第二版)
1.2.3 提出方案
• 提出方案是拟定实现目标的方案 • 存在多个方案均能实现目标是普遍现象
第一章 决策过程
数据、模型与决策 (第二版)
1.3.2 产品开发的明确问题
回想1998年中期,人们可能记 忆起当时的视频产品VCD的市场相当火红, 然而的替代产品DVD在技术上已经成熟, 一些人士认为DVD取代VCD是很快的事。 事实上1999年以后却是SVCD,CVD等产品 主打市场,DVD并没有在一夜间走红。这 里可以看到一个开发新产品决策中的明 确问题的分析。
首先,依据VCD的销售曲线,1998年的增长加速度已 下降,可以判断为进入高速成长的后期。虽然电子产品没有 成熟期也是可能的,但当时的替代产品DCD对VCD的替代却受 到较大的配套消费制约,对VCD在音响效果、图像方面的缺陷 是人所共知的。然而,DVD在声像方面的优越性能却需要有高 品质彩电、5.1声道的音响、功放及高价格碟片的配套才能实 现。按当时的市价,享受高品质的DVD的投入需7000元,配套 投入需2万元。而一台VCD的价格只有千元,这一强烈的差异 可以得出结论,对大多数以看故事为主的消费者,DVD不会是 首选。即VCD进入成熟期后,DVD成为主流的消费品之前,存 在着一个新的市场空间“在不需要庞大配套投入的基础上改 进VCD”,这意味着可以形成一个新的产品概念:“与普遍家 庭视像设备相匹配的能改善视像效果的产品”。在这一概念 指导下,产生了曾是一度流行的SVCD,CVD等产品。
第一章 决策过程
数据、模型与决策 (第二版)
1.2.2 明确目标
• 目标的基本含义:希望得到的结果或希 望达到的标准。
• 这一步骤是把上一步骤的问题定义进一 步具体地展开。
第一章 决策过程
数据、模型与决策 (第二版)
1.2.3 提出方案
• 提出方案是拟定实现目标的方案 • 存在多个方案均能实现目标是普遍现象
第一章 决策过程
数据、模型与决策 (第二版)
1.3.2 产品开发的明确问题
回想1998年中期,人们可能记 忆起当时的视频产品VCD的市场相当火红, 然而的替代产品DVD在技术上已经成熟, 一些人士认为DVD取代VCD是很快的事。 事实上1999年以后却是SVCD,CVD等产品 主打市场,DVD并没有在一夜间走红。这 里可以看到一个开发新产品决策中的明 确问题的分析。
数据模型与决策5PPT课件

啡。用总体参数表示就是:Ha :p0.5
假设及p值
显著性检验会找对原假设不利但对备择假设有利的证据。如果 观测到的结果,在原假设为真的情况下是出人意料的,而在备 择假设为真时却较易发生,这个证据就很强。比如说,当事实 上总体只有一半喜欢现煮咖啡时,发现50位受试对象中有36位 喜欢,就会出人意料。有多么出人意料呢?显著性检验用概率 来回答这个问题:这个概率指的就是,在 H 0 正确时得到的结果 跟预期结果的差距。怎么样算是“跟预期结果的差距很大”?
这既和 H 0 有关,也和 H a 有关。在口味测试中,我们希望得到
4)概率 我们可以用概率来度量对断言不利的证据到底有多 强。当总体的真正比例是0.5时,一个样本的值会这么大或更大 的概率是多少?
若 pˆ 0.5,6 这个概率就是图13.2中正态曲线之下的阴影区面积。 这个面积是0.20.
我们的样本比例值事实上是 pˆ 0.72,只有0.001的机率会得到 这样大的样本结果,它对应的区域小到在图13.2里根本看不到。
假设检验的基本概念
例 咖啡是现煮的吗?
注重口味的人,想来应该是喜欢现煮咖啡超过即溶咖啡的。 但从另一方面来看,有些喝咖啡的人也可能只是对咖啡因有 瘾。一位持怀疑态度的人断言:喝咖啡的人里,只有一半偏 好现煮咖啡。让我们做个实验来检定这个断言。
让50个受试对象都品尝两杯没有做记号的咖啡,并且要说出 喜欢哪一杯。两杯中有一杯是即溶咖啡,另一杯是现煮咖啡。 实验结果得到的统计量是样本中说比较喜欢现煮咖啡的人的 比例。
(2)事实上,偏好现煮咖啡的总体比例大于0.5,所以 样本结果差不多就是预期的结果。
我们不能确定(1)一定不对,因为我们的口味测试结果 有可能真的就只是机遇造成的。但是,这样的一个结果完全 是由机遇造成的概率非常小(0.001),所以我们相当有信心 的认为(2)才是对的。
假设及p值
显著性检验会找对原假设不利但对备择假设有利的证据。如果 观测到的结果,在原假设为真的情况下是出人意料的,而在备 择假设为真时却较易发生,这个证据就很强。比如说,当事实 上总体只有一半喜欢现煮咖啡时,发现50位受试对象中有36位 喜欢,就会出人意料。有多么出人意料呢?显著性检验用概率 来回答这个问题:这个概率指的就是,在 H 0 正确时得到的结果 跟预期结果的差距。怎么样算是“跟预期结果的差距很大”?
这既和 H 0 有关,也和 H a 有关。在口味测试中,我们希望得到
4)概率 我们可以用概率来度量对断言不利的证据到底有多 强。当总体的真正比例是0.5时,一个样本的值会这么大或更大 的概率是多少?
若 pˆ 0.5,6 这个概率就是图13.2中正态曲线之下的阴影区面积。 这个面积是0.20.
我们的样本比例值事实上是 pˆ 0.72,只有0.001的机率会得到 这样大的样本结果,它对应的区域小到在图13.2里根本看不到。
假设检验的基本概念
例 咖啡是现煮的吗?
注重口味的人,想来应该是喜欢现煮咖啡超过即溶咖啡的。 但从另一方面来看,有些喝咖啡的人也可能只是对咖啡因有 瘾。一位持怀疑态度的人断言:喝咖啡的人里,只有一半偏 好现煮咖啡。让我们做个实验来检定这个断言。
让50个受试对象都品尝两杯没有做记号的咖啡,并且要说出 喜欢哪一杯。两杯中有一杯是即溶咖啡,另一杯是现煮咖啡。 实验结果得到的统计量是样本中说比较喜欢现煮咖啡的人的 比例。
(2)事实上,偏好现煮咖啡的总体比例大于0.5,所以 样本结果差不多就是预期的结果。
我们不能确定(1)一定不对,因为我们的口味测试结果 有可能真的就只是机遇造成的。但是,这样的一个结果完全 是由机遇造成的概率非常小(0.001),所以我们相当有信心 的认为(2)才是对的。
《数据模型与决策》课件

通过分析交易数据和用户行为, 识别和预防潜在的欺诈行为,保 护金融机构的资产安全。
基于市场数据和风险评估,为投 资者提供最佳的投资组合配置建 议。
推荐系统领域
协同过滤模型
通过分析用户的历史行为和偏好,为用户推荐与其兴趣相似的物品 或服务。
内容过滤模型
根据物品的内容特征和用户的历史行为,为用户推荐与其兴趣相关 的物品或服务。
特征工程
根据业务需求和数据特点,选择和构造对模型预测性 能有利的特征。
特征筛选
去除冗余、无关或低质量的特征,提高模型效率和准 确性。
特征转换
对特征进行转换,如归一化、标准化、离散化等,以 适应模型需求。
模型训练与优化
模型评估
使用测试数据集对模型进行评估,分析模型 的性能和误差。
模型训练
使用训练数据集对模型进行训练,得到初步 模型。
决策树模型
分类决策树
通过递归地将数据集划分为更小的子集来预测 分类结果。
回归决策树
用于预测连续目标变量的值,而不是分类结果 。
集成学习决策树
通过结合多个决策树模型来提高预测精度和稳定性。
神经网络模型
前馈神经网络
将输入数据传递给隐藏层,然后输出 结果。
循环神经网络
能够处理序列数据,并记忆先前状态 的信息。
ERA
数据模型定义
总结词
数据模型是用于描述数据、数据关系以及数据操作的抽象表示。
详细描述
数据模型是通过对现实世界的数据和数据关系的抽象,建立一个结构化的模型,以便更好地组织、管理和处理数 据。它提供了一种通用的语言和框架,用于描述数据的属性、关系和操作。
数据模型分类
总结词
数据模型可以根据不同的分类标准进行划分。
数据、模型与决策(第10版)PPT taylor_introms10_ppt_11

about the events in an experiment.
■ A list of corresponding probabilities for each event is referred to as a probability distribution.
■ If two or more events cannot occur at the same time they are termed mutually exclusive.
■ A set of events is collectively exhaustive when it includes all the events that can occur in an experiment.
Copyright © 2010 Pearson Education, Inc. Publishing as Prentice Hall
■ It is often the only means available for making probabilistic
estimates. ■ Frequently used in making business decisions. ■ Different people often arrive at different subjective probabilities.
objective probability that can be stated prior to the occurrence of the event. It is based on the logic of the process producing the outcomes.
■ Objective probabilities that are stated after the outcomes of an event have been observed are relative frequencies, based on
■ A list of corresponding probabilities for each event is referred to as a probability distribution.
■ If two or more events cannot occur at the same time they are termed mutually exclusive.
■ A set of events is collectively exhaustive when it includes all the events that can occur in an experiment.
Copyright © 2010 Pearson Education, Inc. Publishing as Prentice Hall
■ It is often the only means available for making probabilistic
estimates. ■ Frequently used in making business decisions. ■ Different people often arrive at different subjective probabilities.
objective probability that can be stated prior to the occurrence of the event. It is based on the logic of the process producing the outcomes.
■ Objective probabilities that are stated after the outcomes of an event have been observed are relative frequencies, based on
数据、模型与决策-管理科学导论PPT课件

02
03
预测市场趋势
个性化营销
通过大数据分析,企业可以预测 市场趋势,提前做好战略规划和 布局。
大数据分析能够深入了解消费者 需求和行为,为企业提供个性化 营销策略,提高销售效果。
人工智能在管理中的应用
自动化流程
01
人工智能技术可以自动化处理大量重复性工作,提高工作效率。
智能决策支持
02
人工智能可以通过数据分析和模式识别,为管理者提供智能化
课程目标
1
掌握数据、模型与决策的基本概念和原理。
2
学会运用数据和模型进行决策的方法和技巧。
3
培养分析和解决实际问题的能力,提高管理效率。
02
数据在决策中的作用
数据收集与整理
数据收集
确定数据来源,设计数据收集方案, 确保数据的全面性和准确性。
数据整理
对收集到的数据进行清洗、分类、编 码和整合,使其满足分析需求。
• 总结词:风险决策分析方法包括风险偏好分析、敏感性分析、决策树等,这些 方法可以帮助决策者更好地理解和评估风险,从而做出更明智的决策。
• 详细描述:风险偏好分析用于确定决策者的风险偏好程度,敏感性分析用于评 估方案对不确定性的敏感程度,决策树则用于表示和分析多阶段决策问题。
多属性决策分析
• 总结词:多属性决策分析是一种基于多个属性或准则的决策方法,通过综合评 估不同方案在不同属性下的表现,选择最优方案。
详细描述
投票法是最简单也是最常用的群 决策方法,一致矩阵法则通过将 问题分解为多个子问题,逐一解 决,最终达成共识;德尔菲法则 通过匿名反馈的方式反复征询专 家管理科学中的前沿话题
大数据分析在管理中的应用
01
数据分析驱动决策
数据模型与决策-管理科学导论课件
数据库设计
数据库设计是指根据需求分析和数据模型的原理, 设计数据库结构、定义关系和属性,并制定数据存 取的规则。
实体-关系模型(ER模型)
1 实体
2 关系
实体是现实世界中具有独立存在和可区分性 质的事物,通过实体间的关系来描述和表达。
关系是实体之间的联系,可以是一对一、一 对多或多对多的关系。它用于表示实体之间 的关联和依赖。
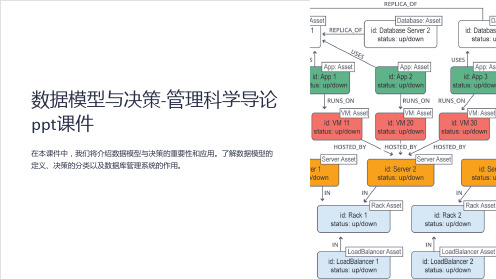
数据模型与决策-管理科学导论 ppt课件
在本课件中,我们将介绍数据模型与决策的重要性和应用。了解数据模型的 定义、决策的分类以及数据库管理系统的作用。
数据模型的定义及特点
数据模型定义
数据模型是描述现实世界中各种实体及其属性和关系的工具,通过表达方式来帮助我们理解 和处理数据。
数据模型特点
数据模型具有抽象性、简洁性和可扩展性的特点,可以有效地组织和管理各种类型的数据。
数据库规范化(Normalization)
1
第一范式
Hale Waihona Puke 确保每个属性都是原子的,数据库中的每个字段都存储一个值。
2
第二范式
消除非主属性对主键部分的依赖,确保每个非主属性完全依赖于主键。
3
第三范式
消除传递依赖,确保所有非主属性只依赖于主键,而不依赖于其他非主属性。
数据挖掘和数据挖掘应用
数据挖掘过程
数据挖掘是从大量数据中发现有价值的模式和关联 的过程,包括数据预处理、模型选择和模式评估。
数据挖掘应用
数据挖掘在市场分析、客户关系管理、风险评估等 领域具有重要的应用价值。
决策的概念和决策分类
1 决策的概念
决策是根据一定的信息和目标,做出选择和 行动的过程。它是管理科学中的关键环节。
数据模型与决策-31(连续分布)-PPT文档资料

80%
1%
9% 1%
153.31 159.68 80%
175.28 181.65 9% 成年女子身高的分布
1%
143.85 149.57
163.59 169.31
正态分布性质
➢ 若随机变量X有正态分布N(,2),则 X c有正态分布N( c,2) cX有正态分布 N(c,c22 )
➢ 若随机变量X1有正态分布N(1,12),X2有 正态分布 N(2 ,22 ) ,X1和X 2 相互独立,则 X1 X2有正态分布N(1 2,12 22) X1 X2有正态分布N(1 2,12 22)
数据模型与决策-31(连续分布)
第三讲 连续分布
连续概率分布及其应用
盐在水中是均匀分布的, 盐的密度是常数
概率密度函数 累积分布函数
这里涉及到累积的概念
均匀分布
正态分布
例:将1克盐放入茶杯,加水搅拌后,盐在水中是均匀分布的, 如果从杯子里倒出半杯盐水,那么这半杯盐水中含有多少盐? (0.5克)
正态分布应用
例 某个学校想新建一个阅览室供900个学生自修,但 规模有待确定(当然最大是900个座位),经过调研, 每一个学生每天去阅览室的可能性为1/3,为了保证 去的学生以95%的把握都有座位,试估计阅览室规模 的大小。
解: 设座位数为n,去阅览室的人数为X, 则有X=X1+X2+...+X900 其中X1=0或1, 0表示不去阅览室,1表示去阅览室
正态分布
成年男子身高的分布N(167.48, 6.092),身 高 175 厘米的成年男子高不高?输入
“=1-normdist(175,167.48,6.09,1)”, 身高超过 175 厘米的成年男子有 10.845% 成年女子身高的分布N(156.58, 5.472),175
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
%都是死掉的那个人先动手。真是这样吗? 如果你跟人打架把对方给揍死了,警察问你谁先动
手的时候你怎么回答?
11.12.2020
例1.2 美国的种族效应 1989年,纽约市选出第一位黑人市长,维吉尼亚选出第一位黑 人州长。这两个事件,在投票所访问投完票的选民后所预测到 的胜负差距,都比实际开票的差距大。 因此,调查机构相当确定,有些受访选民因为不愿承认没投票 给黑人候选人而说了谎。
11.12.2020
例1.4 总统选举预测 1936年民主党人罗斯福任美国总统第一任满,共和党人兰登 与他竞选总统。
《文学摘要》杂志根据有约二百四十万人参加的民意测验, 预测兰登会以57%对43%的优势获胜。自1916年以来的五届 总统选举中,《文学摘要》杂志都正确地预测出获胜的一方, 其影响力很大。
11.12.2020
例1.3 权威人物的意见 有两个内容相同的问题: 问题A:陆军部和海军部应当合并为统一的作战部,您同意 么? 问题B:艾森豪威尔将军说,陆部和海军部应当合并为统 一的作战部,您同意么? 结果对问题A表示同意的比例为29%,而对问题B表示同意 的比例为49%,两者相距甚远。无疑,权威人物艾森豪威尔 将军的意见影响了被调查者的意见。
那时盖洛普刚刚设立起他的调查机构,他根据一个约五万人 的样本,预测罗斯福会以56%对44%的优势获胜。
实际结果是,罗斯福以62%对38%的优势胜出。当时有人说, 这次选举的最大赢家不是罗斯福,而是盖洛普。自这之后, 盖洛普的调查机构得到迅速的发展,国内外闻名,而《文学 摘要》杂志不久就垮了。 《文学摘要》杂志的调查方法有什么问题?
11.12.2020
继续例1.4 从常理来看,应该调查数据越多,结论越可靠。 罗斯福的实际得票率为62%,《文学摘要》杂志的预测为
43%,误差达到19%。误差之大令人惊异。这样大的误差是怎 么得来的呢?
经过研究发现,原因在于《文学摘要》杂志选取样本有 偏性。杂志是根据电话簿和俱乐部会员的名册,将问卷邮寄 给一千万人。当时美国四个家庭中仅有一家装电话。他选取 的样本有排斥穷人的选择偏性。这样的民意测验非常不利于 民主党人罗斯福。
11.12.2020
问题的措辞也可能造成误差 问题的措辞造成的误差是计量误差的一种。例3.3显示了由 于问题的措辞不同而造成的不同的调查结果。研究表明,问 卷的不同用词会造成被调查者不同的反应,从而造成调查误 差。我们来看几个措辞不当的问题。
11.12.2020
问:您住的地方到这里是多少时间的路程? 1、不超过10分钟 2、10~20分钟 3、20~30分钟 4、30分钟以上 用什么方式呢?步行?骑自行车?乘汽车?还是坐飞碟?
心理研究表明,低收入和高收入的人倾向于不回答问卷, 因此中等收入的人在回答者中的比例过高。为此现代调查机构 更喜欢采用亲自询问来代替邮寄问卷
11.12.2020
即使亲自询问,也有不回答偏性的问题。 访问员来访时,不在家的人与在家接受访问的人可能在 工作时间、家庭关系和社会背景等方面有比较大的差异,从 而看法也不一样。 例如有一项关于快餐的市场调查。抽取500户家庭进行 调查。白天访问时,有150户家庭没人。能不能仅用白天有人 的350户家庭的数据?不能。这里有不回答偏性。白天不在家 的150户可能是吃快餐比较多的家庭。
11.12.2020
此外,《文学摘要》杂志调查的一千万人中只有二百四 十万人回答了问卷,不回答者可能非常有别于回答者,这二百 四十万人代表不了被邮寄问卷的一千万人。
譬如,1936年《文学摘要》杂志的一次专门的调查,给 在芝加哥的选民每三人寄去一张问卷。约20%的被调查者作了 回答,其中支持兰登的超过半数。但是在选举中,兰登在芝加 哥的得票率只有三分之一。所以当出现高不回答率时,谨防不 回答偏性。
问: 您全家的月收入是多少? 1、低于2000元 2、2000~5000元 3、5000~8000元 4、8000~11000元 5、11000元以上 “全家”的定义是什么?“月收入”包括哪些?而且各 月收入不同怎么办?
11.12.2020
问:您是否赞成禁止私人拥有枪械以降低犯罪率? 1、很赞成 2、比较赞成 3、说不清 4、比较不赞成
数据、模型与决策
数据的产生与图表描述
一、 调查面面观 二、 实验面面观 三、 数据的图表描述
11.12.2020
一、 调查面面观
1.1 调查如何出错 1.2 抽样误差与非抽样误差 1.3 抽样设计 1.4 解读调查结论
11.12.2020
1.1 调查如何出错 例1.1 谁先动手? 有人调查研究酒吧里的打架致死事件,发现其中90
11.12.2020
实际的抽样调查是很复杂的,即使采用了好的随机抽样 方法、准确地计算了误差界限,调查结果也不一定可靠。 就拿例3.1来说,本来应该是对打架双方都进行调查,但 已经死去的被调查者无法回答,而剩下的被调查者又可 能为保全自己而不如实地回答。那么,这样的调查结果 会可靠吗?
下面,我们来看看抽样调查有些什么样的误差来源,以 及抽样调查者应如何与之奋斗。
11.12.2020
1.2 抽样误差与非抽样误差
统计调查的目的是取得能准确反映客观状况的统计数据。 在许多时候,调查结果并不能准确地表现事实,总会有误差 出现。在调查的各个阶段,误差都有可能出现。 如果其中一个阶段出现了较大误差,可能会把其他阶段都进 行得很好的一次调查毁掉,因此必须认真细致地实施调查的 每一个阶段、严格控制误差。 为了保证统计数据的质量,了解误差的来源与减小误差的措 施很有必要。
11.12.2020
误差按其性质可以分为两类,一类是抽样误差,它是由于抽 选样本的随机性而产生的误差。只有采用概率抽样的方式才 可能估计抽样误差。另一类是非抽样误差,它是指除抽样误 差以外的、由于各种原因而引起的误差。 在概率抽样、非概率抽样和全面调查中,非抽样误差都有可 能存在。 若采用了概率抽样方法,那么我们可以估计出抽样误差的大 小,还可以通过选择样本量的大小来控制抽样误差。在谨慎 执行的抽样调查中,抽样误差通常不大。而非抽样误差相对 比较难以估计和控制。
手的时候你怎么回答?
11.12.2020
例1.2 美国的种族效应 1989年,纽约市选出第一位黑人市长,维吉尼亚选出第一位黑 人州长。这两个事件,在投票所访问投完票的选民后所预测到 的胜负差距,都比实际开票的差距大。 因此,调查机构相当确定,有些受访选民因为不愿承认没投票 给黑人候选人而说了谎。
11.12.2020
例1.4 总统选举预测 1936年民主党人罗斯福任美国总统第一任满,共和党人兰登 与他竞选总统。
《文学摘要》杂志根据有约二百四十万人参加的民意测验, 预测兰登会以57%对43%的优势获胜。自1916年以来的五届 总统选举中,《文学摘要》杂志都正确地预测出获胜的一方, 其影响力很大。
11.12.2020
例1.3 权威人物的意见 有两个内容相同的问题: 问题A:陆军部和海军部应当合并为统一的作战部,您同意 么? 问题B:艾森豪威尔将军说,陆部和海军部应当合并为统 一的作战部,您同意么? 结果对问题A表示同意的比例为29%,而对问题B表示同意 的比例为49%,两者相距甚远。无疑,权威人物艾森豪威尔 将军的意见影响了被调查者的意见。
那时盖洛普刚刚设立起他的调查机构,他根据一个约五万人 的样本,预测罗斯福会以56%对44%的优势获胜。
实际结果是,罗斯福以62%对38%的优势胜出。当时有人说, 这次选举的最大赢家不是罗斯福,而是盖洛普。自这之后, 盖洛普的调查机构得到迅速的发展,国内外闻名,而《文学 摘要》杂志不久就垮了。 《文学摘要》杂志的调查方法有什么问题?
11.12.2020
继续例1.4 从常理来看,应该调查数据越多,结论越可靠。 罗斯福的实际得票率为62%,《文学摘要》杂志的预测为
43%,误差达到19%。误差之大令人惊异。这样大的误差是怎 么得来的呢?
经过研究发现,原因在于《文学摘要》杂志选取样本有 偏性。杂志是根据电话簿和俱乐部会员的名册,将问卷邮寄 给一千万人。当时美国四个家庭中仅有一家装电话。他选取 的样本有排斥穷人的选择偏性。这样的民意测验非常不利于 民主党人罗斯福。
11.12.2020
问题的措辞也可能造成误差 问题的措辞造成的误差是计量误差的一种。例3.3显示了由 于问题的措辞不同而造成的不同的调查结果。研究表明,问 卷的不同用词会造成被调查者不同的反应,从而造成调查误 差。我们来看几个措辞不当的问题。
11.12.2020
问:您住的地方到这里是多少时间的路程? 1、不超过10分钟 2、10~20分钟 3、20~30分钟 4、30分钟以上 用什么方式呢?步行?骑自行车?乘汽车?还是坐飞碟?
心理研究表明,低收入和高收入的人倾向于不回答问卷, 因此中等收入的人在回答者中的比例过高。为此现代调查机构 更喜欢采用亲自询问来代替邮寄问卷
11.12.2020
即使亲自询问,也有不回答偏性的问题。 访问员来访时,不在家的人与在家接受访问的人可能在 工作时间、家庭关系和社会背景等方面有比较大的差异,从 而看法也不一样。 例如有一项关于快餐的市场调查。抽取500户家庭进行 调查。白天访问时,有150户家庭没人。能不能仅用白天有人 的350户家庭的数据?不能。这里有不回答偏性。白天不在家 的150户可能是吃快餐比较多的家庭。
11.12.2020
此外,《文学摘要》杂志调查的一千万人中只有二百四 十万人回答了问卷,不回答者可能非常有别于回答者,这二百 四十万人代表不了被邮寄问卷的一千万人。
譬如,1936年《文学摘要》杂志的一次专门的调查,给 在芝加哥的选民每三人寄去一张问卷。约20%的被调查者作了 回答,其中支持兰登的超过半数。但是在选举中,兰登在芝加 哥的得票率只有三分之一。所以当出现高不回答率时,谨防不 回答偏性。
问: 您全家的月收入是多少? 1、低于2000元 2、2000~5000元 3、5000~8000元 4、8000~11000元 5、11000元以上 “全家”的定义是什么?“月收入”包括哪些?而且各 月收入不同怎么办?
11.12.2020
问:您是否赞成禁止私人拥有枪械以降低犯罪率? 1、很赞成 2、比较赞成 3、说不清 4、比较不赞成
数据、模型与决策
数据的产生与图表描述
一、 调查面面观 二、 实验面面观 三、 数据的图表描述
11.12.2020
一、 调查面面观
1.1 调查如何出错 1.2 抽样误差与非抽样误差 1.3 抽样设计 1.4 解读调查结论
11.12.2020
1.1 调查如何出错 例1.1 谁先动手? 有人调查研究酒吧里的打架致死事件,发现其中90
11.12.2020
实际的抽样调查是很复杂的,即使采用了好的随机抽样 方法、准确地计算了误差界限,调查结果也不一定可靠。 就拿例3.1来说,本来应该是对打架双方都进行调查,但 已经死去的被调查者无法回答,而剩下的被调查者又可 能为保全自己而不如实地回答。那么,这样的调查结果 会可靠吗?
下面,我们来看看抽样调查有些什么样的误差来源,以 及抽样调查者应如何与之奋斗。
11.12.2020
1.2 抽样误差与非抽样误差
统计调查的目的是取得能准确反映客观状况的统计数据。 在许多时候,调查结果并不能准确地表现事实,总会有误差 出现。在调查的各个阶段,误差都有可能出现。 如果其中一个阶段出现了较大误差,可能会把其他阶段都进 行得很好的一次调查毁掉,因此必须认真细致地实施调查的 每一个阶段、严格控制误差。 为了保证统计数据的质量,了解误差的来源与减小误差的措 施很有必要。
11.12.2020
误差按其性质可以分为两类,一类是抽样误差,它是由于抽 选样本的随机性而产生的误差。只有采用概率抽样的方式才 可能估计抽样误差。另一类是非抽样误差,它是指除抽样误 差以外的、由于各种原因而引起的误差。 在概率抽样、非概率抽样和全面调查中,非抽样误差都有可 能存在。 若采用了概率抽样方法,那么我们可以估计出抽样误差的大 小,还可以通过选择样本量的大小来控制抽样误差。在谨慎 执行的抽样调查中,抽样误差通常不大。而非抽样误差相对 比较难以估计和控制。