第九章_文件
计算机二级C语言文件习题答案

(4)fseek(fp,-2L,SEEK_END);文件定位于文件末尾的倒数第二个字符型字节处,即定位于整数‘c’的前面。
(5)fread(&t,1,1,fp);从文件中读取一个1字节的数字,并且赋值给变量t .即t变量得到的值为‘c’.
(6)关闭文件。
(7)输出变量t的值,即c.
2) i=2,i<6为真,执行循环体fprintf(fp,”%d”,i);给fp指针打开的文件out.dat中写入数据2。判断i%3==0为假,因此不执行fprintf(fp,”\n”)。
3) i=3,i<6为真,执行循环体fprintf(fp,”%d”,i);给fp指针打开的文件out.dat中写入数据3。判断i%3==0为真,执行fprintf(fp,”\n”),写入回车符。
(5)从文件 中读取一个数字赋值给变量n ,则变量n得到的值为123.
(6)关闭文件,输出变量n得到的值,即输出的结果为123.
20.答案选择:D
解析:
(1) fopen(“d2.dat”,”w”);打开的是一个文本文件,以写的方式打开该文件。
(2) fprintf(fp,“%d%d\n”,a[0],a[1],a[2]);将a[0],a[1]的值写到文件中,文件中的内容为:12换行,
18.答案选择:C
解析:fread函数的格式为:fread(buffer,size,count,fp);其中的buffer代表的是从文件中读取出来的数据存放的首地址。size 代表的是每一个数据所占有的字节数,count代表的是读入数据的个数。所以选择答案C。
19.答案选择:B
解析:
(1)fopen(“d1.dat”,”w”);打开的是一个文本文件,以写的方式打开该文件。
C语言程序设计 第9章 文件

9.3 文件的顺序读写
❖ 【例9.4】fputs函数和fgets函数的使用。
9.3 文件的顺序读写
❖ 9.3.3 fprintf函数和fscanf函数 ❖ fprintf与fscanf函数为格式读写函数,与printf、scanf类似,fprintf与
fscanf用于从文件中读取指定格式的数据和把指定格式的数据写入文件,这 是按数据格式要求进行文件的输入/输出。其一般形式为: ❖ fscanf(fp,format,args); ❖ fprintf(fp,format,args); ❖ 其中,fp为文件指针,format为格式控制字符串,args为输入或输出的地 址列表。 ❖ 例如,若文件指针fp已指向一个已打开的文件文本,a、b分别为整型变量 ,则以下语句从fp所指向的文件中读入两个整数放入变量a和b中。 ❖ fscanf(fp,”%d%d”,&a,&b); ❖ 又如,若文件指针fp已指向一个已打开的文件文本,x、y分别为整型变量 ,则以下语句将x、y中的数据按%d的格式输出到fp所指向的文件中。 ❖ fprintf(fp,"%d%d",&a,&b);
本章小结
❖ 本章主要介绍了以下内容。 ❖ (1)文件的概念 ❖ 介绍了文件及文件指针的基本概念,以及文件的打开与关闭
函数fopen、fclose等。 ❖ (2)文件的顺序读写 ❖ 主要介绍了从文件中输出字符、字符串,以及将字符、字符
串写入文件的函数。 ❖ (3)随机文件的读写及错误检测 ❖ 主要介绍了随机文件读写的应用,以及文件的出错检测。
❖ 在实际读写文件中,人们常常希望能直接读到某一数据 项而不是按物理位置顺序逐个读下来。这种可以任意指 定读写位置的操作称为文件的随机读写。可以想象,只 要能移动位置指针到所需要的地方,实现文件的定位, 就能实现随机读写。
第九章 招标投标文书

• 3.内容要明确、具体。招标、投标多是 一次性的经济活动,没有反复磋商与协商 的过程。因此,凡属应当向投标人说明的 事项,包括招标的基本内容及其条件、要 求,都应写得清楚、具体、明确,避免产 生歧义误解,严禁错别字出现。
• 4.必须突出重点。招标公告只需把招标 目的、项目、步骤、时间、地点等内容写 出来即可,一些宣传鼓动性文字不宜多写, 保证重点突出,避免喧宾夺主。
• 6.中标后需履行的手续。要让中标人知 道中标后应履行的手续。
(三)投标须知的格式
• 投标须知一般由三部分构成。 • 1.标题。投标须知属招标文件系列中的
补充性文件,因此它的标题一般较简单, 只需写明文书种类即可,即“投标须知”。 • 2.正文。正文一般以条文式结构出现, 将所述内容分项归类,并用序号标示。 • 3.落款。落款主要署明招标单位的全称 和文件拟制的时间。
• 2.告知性。招标公告旨在通过新闻传媒 把有关指标的标的、条件、要求等信息及 时告知于众,使投标人能够做到有的放矢, 提供最佳方案,以实现招标人的目的。
(二)招标公告的种类及内容
• 1.项目名称、招标编号。项目名称一般 放置在公告开头,起醒目作用,如“×× 大学新教学楼项目”、“内蒙古河套灌溉 区配套工程”等。设置招标编号是为了便 于归档和查对,如“ITCG-8520 3”。若是国际性招标公告,一般还要注 明信贷机构及贷款协定号,如“国际开发 协会开发信贷协定第1885-CHA 号”。
第九章 招标投标文书
一、招标公告
• (一)招标公告的概念及特点 • 招标公告,又称招标广告、招标通告或招
标启事。它是由招标人通过新闻媒介公开 发布的,以招标内容及其相应条件、数据、 要求等事项为主要内容的一种文书。
• 招标公告是一种比较有效的招揽宣传工具, 通过它,有关招标的标的、条件、要求等 就能及时告知于众,众多的投标人就能根 据特定条件、资格及要求,努力准备投标 方案。招标公告对推动招标活动的有效开 展,具有十分重要的作用。
第九章 文件压缩与解压缩

第九章文件压缩与解压缩在Linux系统下,它有.gz、.tar.gz、tgz、bz2、.Z、.tar等众多的压缩文件名,此外windows下的.zip和.rar也可以在Linux下使用,需要不同的程序命令来进行压缩和解压缩。
一、以zip和unzip处理.zip文件1>以zip创建.zip文件“zip”是广泛使用的压缩程序,文件经过它压缩后会产生扩展名为.zip的压缩文件。
Zip是功能强大的程序,同时也包含了很多参数,可以直接输入“zip”参数,可以相应的参考:[root@localhost root]# zip使用方法就是先指定压缩后的文件,然后接着输入所有要一起压缩的文件名称即可。
[root@localhost root]# ls file*[root@localhost root]# zip file.zip file*一起要压缩的文件类型并没有限制,如下范例:[root@localhost root]# zip file.zip anaconda-ks.cfg sys.log 123.txta)为了节省硬盘的空间,可以在创建压缩文件后,要求系统会自动删除源文件,需要参数“m”:[root@localhost root]# zip –m file.zip file*在压缩整个目录内容时,经常出现目录中存在其他子目录的情形,此时有两个选择。
b)若选择一并压缩子目录中的内容,可以使用参数“-r”(Recursive); [root@localhost root]# zip –r file.zip *c)若不需要压缩子目录中的文件,则使用参数“-j”(Junk)[root@localhost root]# zip –j file.zip *d)若是压缩后的文件可能会在其他的平台上解压缩,例如MS-DOS或WINDOWS系统,最好使用兼容的命名格式即8.3的命名方式,变更文件名称,然后再进行压缩,需要加参数“k ”来执行压缩。
VB第九章 文件

设计界面:在窗体中添加驱动器列表框Drive1、目录列表框 Dir1和文件列表框File1以及框架Frame1、图象框Image1;
将File1的Pattern属性改为“*.bmp;*.exe”
将Image1的Stretch属性设置为True
Private Sub Form_Load()
File1.Pattern = "*.bmp;*.exe" End Sub
在2号缓冲区读取C盘根目录下名为Student.dat的文件的语句为: Open “C:\Student.dat” For Input As #2
2、写操作 要将数据写入顺序文件,应以Output或Append方式打开 该文件,然后使用Print #或Write # 语句将数据写入文件中。 1)Print # 文件号,[数据项列表] 其中:数据项列表和前面讲过的对象的Print方法中的格式基 本相同,只是在每行多了回车换行符。
文件的分类及访问模式: 顺序文件:是按记录号的顺序进行存储的文件。见下图:
记录1 记录2 记录3 …… 记录N
记录分隔符
顺序文件中每条记录的长度可不相同,记录与记录之间 的分隔符为回车换行符(Chr(13)和Chr(10)),而记录中各 数据项之间还有特定的分界符(如逗号等)。 显然,顺序文件是将记录按行进行存储。如文本文件就是 典型的顺序文件,其中的每一行字符串都是一条记录。 顺序文件在机器中是以ASCII形式进行存储的。 顺序访问模式:查找某个记录是从第一条记录开始,直到找 到需要的记录为止。修改某个记录,则将整个文件读出来, 修改后再将整个文件写回外存。此模式专门处理文本文件。
如果要在文件列表框中双击某个可执行文件就能执行该文件,则必须 要有如下的过程: Private Sub File1_DblClick( )
VB复习答案_第九章文件

第九章文件第一题:是非题(共10分,每项1分)1. 在VB中,可通过函数Shell调用DOS或Windows下的可执行程序。
A.对√B.错第二题、单选题(共45分,每项1.5分)1. 下面关于随机文件的描述,不正确的是______。
10A.每条记录的长度必须相同B.一个文件中记录号不必惟一√C.文件的组织结构比顺序文件复杂D.可通过编程对文件中的某条记录方便地修改2. 要使用FSO对象模型,必须通过【工程】菜单中的______命令将FSO对象模型引入到当前工程中。
7A.部件B.工程属性C.添加属性D.引用√3. 下面关于顺序文件的描述,正确的是______。
12A.每条记录的长度必须相同B.可通过编程对文件中的某条记录方便地修改C.数据以ASCII码形式存放在文件中,所有可通过文本编辑软件显示√D.文件的组织结构复杂4. 在顺序文件中______。
11A.文件中按每条记录的记录号从小到大排序B.文件中按每条记录的长度从小到大排序C.文件中按记录的某关键数据项的从小到大的顺序D.记录是按写入的先后顺序存放的,读出也是按写入的先后顺序读出√5. 按文件的组织方式分为______。
6A.顺序文件和随机文件√B.文本文件和二进制文件C.程序文件和数据文件D.只读文件和读写文件6. 在随机文件中______。
12A.文件中的内容是通过随机数产生的B.文件中的记录号是通过随机数产生的C.可对文件中的记录根据记录号随机地读写√D.文件的每条记录的长度是随机的7. 使用驱动器列表框的______属性可以返回或设置磁盘驱动器的名称。
8A.ChDriveB.Drive√C.ListD.ListIndex8. 下列控件中,不属于文件系统控件的是______。
6A.驱动器列表框B.文件列表框C.目录列表框D.图象列表框√9. 文件列表框中用于设置或返回所选文件的文件名的属性是______。
7A.FilePathB.FileC.PathD.FileName√10. 为了建立一个随机文件,其中每一条记录有多个不同数据类型的数据项组成,应使用______。
第九章投标文件格式

第九章投标文件格式一、本工程的投标授权委托书(附件一)、资格标格式(附件四)、商务标格式(附件五)由招标人统一提供。
投标授权委托书本授权委托书声明:我(姓名)系(投标人名称)的法定代表人,现授权委托(姓名)为我公司的合法代理人,全权代表我公司参加招标投标活动,以本公司名义签署投标文件、参加开标、询标以及处理与之有关的一切事宜。
我承认代理人在上述活动中所签署的所有内容。
代理人无转委托权,特此委托。
投标人(盖章):法定代表人(签字或盖章):授权委托日期:年月日资格标格式资格标(封面)项目名称:投标人:(盖章)法定代表人:(签字或盖章)地址:年月日目录1、资格后审申请书(附件四-1)2、法定代表人资格证明书(附件四-2)3、项目管理班子配备表(附件四-3)4、拟用于本招标工程项目的主要施工机械设备一览表(附件四-4)5、温岭市建设工程诚信投标承诺书(附件四-5)6、证书及相关资料复印件附件四-1资格后审申请书致: (招标人全称)1、经授权作为代表,并以 (投标人企业全称) (以下简称“投标人”)的名义,在充分理解《投标人资格后审申请书》的基础上,本申请书签字人在此以 (项目名称全称) 投标人的身份,向你方提出资格后审申请。
2、按资格后审文件的要求,你方授权代表可调查、审核我方提交的与本申请书相关的声明、文件和资料,并通过我方的开户银行和客户,澄清本申请书中有关财务和技术方面的问题。
本申请书还将授权给有关的任何个人或机构及其授权代表,按你方的要求,提供必要的相关资料,以核实本申请书中提交的或与本投标人的资金来源、经验和能力有关的声明和资料。
3、本申请充分理解下列情况:3.1资格后审合格的投标人的投标,须以资格后审申请提供的内容为准;3.2你方保留如下权利:(1)更改本招标项目的规模和金额的权利。
前述情况发生时,投标仅面向资格后审合格且能满足变更后要求的投标人。
(2)接受符合资格后审合格条件的申请;拒绝不符合资格后审合格条件的申请。
第9章 JSP中的文件操作-JSP实用教程(第4版)-耿祥义-清华大学出版社

9.2 RandomAccessFile类
需要对一个文件进行读写操作时,可以创建一个RandomAccessFile对象, RandomAccessFile对象可以读取文件的数据,也可以向文件写入数据。
RandomAccessFile类的两个构造方法:
• RandomAccessFile(String name,String mode) 参数name用来确定一个文件名, 参数mode取“r”(只读)或“rw”(可读写),决定对文件的访问权利。
example9_2.jsp
2.servlet Example9_2_Servlet.java
3.配置文件web.xml web.xml
9.3 文件上传
用户通过一个JSP页面上传文件给服务器时,form表单必须将ENCTYPE的属性值设成 multipart/form-data,并含有File类型的GUI组件。含有File类型GUI组件的form表单如 下所示:
例子9_3中,用户通过example9_3.jsp页面上传文本文件A.txt。
9.3 文件上传
例子9_3中,用户通过example9_3.jsp页面上传文本文件A.txt。 例子9_3 example9_3.jsp
example9_3_accept.jsp
例子9_4
例子9_4中,通过输入、输出流技术获取文件的内容,即去掉表单的信息。 根据不同用户的session对象互不相同这一特点,将用户提交的全部信息首 先保存成一个临时文件,该临时文件的名字是用户的session对象的id,然 后读取该临时文件的第2行,因为这一行中含有用户上传的文件的名字, 再获取第4行结束的位置,以及倒数第6行结束的位置,因为这两个位置之 间的内容是上传文件的内容,然后将这部分内容存入文件,该文件的名字 和用户上传的文件的名字保持一致,最后删除临时文件。 例子9_4的Web应用程序使用MVC模式(MVC的知识见第7章)。
C语言文件

void main()
XUAN SHANLI
打 { FILE *in,*out;
开 char ch;
源 if((in=fopen("aa.c","r"))==NULL)
文 件
{ printf("cannot open the infile\n");
打
exit(0); }
开 if((out=fopen("ttt.c","w"))==NULL)
大
学
1、文件的分类: 例:短整型数 123: ASCII码: 00110001 00110010 00110011
存储形式:二进制文件:按数据在1 (内49存) 存储2 (形50式) 。 3 (51) 文本 (AS二C进II)制文码件::0一00个00字000符0占11一110个11字节。123
XUAN SHANLI
fp文件指针
format ,格式说明字符串,取%d、%x、%f、%c等;
说明输入转化的格式。
&arg1…&argn,接收输入变量的地址列表。
合
肥 功能:从fp对应的文件的当前位置,顺序读入一个字符序
工 列,按format说明的格式和类型进行转换并存放到对应变
量单元。
p273表9-1 二进制文件
控制符
读/写方式
控制符
读/写方式
“r” 打开文件(已存在)只读 “rb” 打开文件(已存在)只读
XUAN SHANLI
“w”
建立文件(新)只写
“wb”
打开文件(新)只写
“a”
打开文件在尾部追加 “ab” 打开文件在尾部追加
第9章 文件(答案)

第9章文件一、选择题1、若fp是指向某文件的指针,且已读到此文件末尾,则库函数feof(fp)的返回值是(C )A)EOF B)0 C)非零值D)NULL2、若fp已正确定义并指向某个文件,当未遇到该文件结束标志时函数feof(fp)的值为(A )A)0 B)1 C)-1 D)一个非0值3、当调用函数fopen发生错误时,函数的返回值是(B )。
A)2 B)0 C)1 D)EOF4、下列关于C语言数据文件的叙述中正确的是(D )A)文件由ASCII码字符序列组成,C语言只能读写文本文件B)文件由二进制数据序列组成,C语言只能读写二进制文件C)文件由记录序列组成,可按数据的存放形式分为二进制和文本文件D)文件由数据流形式组成,可按数据的存放形式分为二进制和文本文件5、以下叙述中不正确的是(D )A) C语言中的文本文件以ASCII码形式存储数据B) C语言中对二进制位的访问速度比文本文件快C) C语言中,随机读写方式不使用于文本文件D) C语言中,顺序读写方式不使用于二进制文件6、以下叙述中错误的是(D )。
A) 二进制文件打开后可以先读文件的末尾,而顺序文件不可以B) 在程序结束时,应当用fclose函数关闭已打开的文件C) 利用fread函数从二进制文件中读数据,可以用数组名给数组中所有元素读入数据D) 不可以用FILE定义指向二进制文件的文件指针7、以下程序企图把从终端输入的字符输出到名为abc.txt的文件中,直到从终端读入字符#号时结束输入和输出操作,但程序有错。
main(){FILE *fout; char ch;fout=fopen(“abc.txt”,”w”);ch=fgetc(stdin);while(ch!='#'){ fputc(ch,fout);ch =fgetc(stdin);}fclose(fout);}出错的原因是(D )A) 函数fopen调用形式有误B) 输入文件没有关闭C) 函数fgetc调用形式有误D) 文件指针stdin没有定义8、在C程序中,可把整型数以二进制形式存放到文件中的函数是(C )A)fprintf B)fread C)fwrite D)fputc9、C语言中系统的标准输出文件是指( B)A)打印机B)显示器C)键盘D)硬盘10、以下程序完成的功能是(C )main(int argc,char *argv[]){FILE *in,*out;in=fopen(argv[1],"r");out=fopen(argv[2],"w");while(!feof(in))fputc(fgetc(in),out);fclose(in);fclose(out);}A)全盘复制B)文件输入C)文件复制D)文件输出11、有以下程序,程序运行后,文件t1.dat中的内容是(B )void WriteStr(char *fn,char *str){FILE *fp;fp=fopen(fn,"w");fputs(str,fp);fclose(fp);}main(){WriteStr("t1.dat","start");WriteStr("t1.dat","end");}A)start B)end C)startend D)endrt12、有以下程序main(){FILE *fp; int i=20,j=30,k,n;fp=fopen("d1.dat","w");fprintf(fp,"%d\n",i);fprintf(fp,"%d\n",j);fclose(fp);fp=fopen("d1.dat","r");fscanf(fp,"%d%d",&k,&n);printf("%d%d\n",k,n);fclose(fp);}程序运行后的输出结果是(A )。
第九章压缩和存储【文件存储类型、压缩方式的选择】

第九章压缩和存储【⽂件存储类型、压缩⽅式的选择】1. 结论 存储格式⼀般选择 : orc 和 parquet 压缩⽅式⼀般选择 : snappy(不可切⽚)、lzo(可切⽚) 注意: 当读取单个⼤⽂件时,要选择lzo⽅式2. hive ⽀持的⽂件存储格式⾏式存储 : textfile、sequencefile列式存储 : orc、parquet3. ⾏式存储、列式存储说明-- 数据表channel credit_date scorehuawei 2021-08-01 5huawei 2021-08-01 5huawei 2021-08-03 12huawei 2021-08-04 25huawei 2021-08-02 1huawei 2021-08-07 7huawei 2021-08-08 10huawei 2021-08-06 33vivo 2021-09-01 1vivo 2021-09-02 2vivo 2021-09-04 5vivo 2021-09-09 9vivo 2021-09-07 77vivo 2021-09-08 10vivo 2021-09-11 3-- ⾏式存储huawei,2021-08-01,5,huawei,2021-08-01,5...vivo,2021-09-01,1-- 列式存储huawei,huawei,huawei,vivo,vivo,2021-08-01,2021-08-01,...5,5,12View Code4. ⾏式存储、列式存储原理https:///m0_37657725/article/details/98354168?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_ 5. ⾏式存储优缺点优点:1. 快速加载数据2. 快速定位数据根据某个字段查找某⾏数据时只需要定位字段的位置,其与字段的位置都在⽬标字段的相邻位置列式存储则需要每个位置去聚合所有字段缺点:1. ⽆法快速查询数据,特别是只查询表中的少数列时2. 压缩不充分,⼀⾏数据中,字段数据类型不⼀致,压缩时⽆法统⼀压缩算法6. 列式存储优缺点优点:1. 减少数据读取量(只读取需要的列)2. 压缩⽐更⾼(同列数据类型必相同)缺点:1.查询多个字段时,⽆法快速定位到记录,需要跨block扫描数据(⽆法保证同⼀⾏数据存储在同⼀个block上)7. 测试textfile、orc、Parquet 对⽐磁盘开销(不使⽤压缩)1. textfile ⽰例-- 建表create table home.log_text (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string)row format delimited fields terminated by '\t'stored as textfile;-- load 数据load data local inpath '/root/log.data' into table home.log_text ;-- 查看⽂件⼤⼩(HDFS)dfs -du -h /user/hive/warehouse/home.db/log_text;18.1 M 54.4 M /user/hive/warehouse/home.db/log_text/log.data-- 源⽂件⼤⼩[root@gaocun ~]# du -h log.data18.1 log.data-- 说明只是将⽂件拷贝到hdfs,并未压缩2.orc ⽰例-- 建表create table home.log_orc (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string)row format delimited fields terminated by '\t'stored as orctblproperties("press"="NONE"); -- 设置 orc 存储不使⽤压缩;-- insert 数据到 log_orcinsert into table home.log_orc select * from home.log_text ;-- 查看⽂件⼤⼩(HDFS)dfs -du -h /user/hive/warehouse/home.db/log_orc;7.7 M 23.1 M /user/hive/warehouse/home.db/log_orc/000000_0-- 源⽂件⼤⼩[root@gaocun ~]# du -h log.data18.1 log.data3.parquet ⽰例-- 建表create table home.log_parquet (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string)row format delimited fields terminated by '\t'stored as parquet;-- insert 数据到 log_parquetinsert into table home.log_parquet select * from home.log_text ;-- 查看⽂件⼤⼩(HDFS)dfs -du -h /user/hive/warehouse/home.db/log_parquet;13.1 M 39.3 M /user/hive/warehouse/home.db/log_parquet/000000_0-- 源⽂件⼤⼩[root@gaocun ~]# du -h log.data18.1 log.dataView Code8. 测试textfile、orc、Parquet 对⽐压缩算法-- 测试textfile、orc、Parquet 对⽐压缩算法结论:源⽂件 log.data 18.1Morc-none : 7.7 Morc-zlib : 2.8 Morc-snappy : 3.7 Mparquet-zlib : (不⽀持)parquet-snappy : 6.4 M压缩⽐ : zlib > snappy说明 : 项⽬中 hive表中数据存储格式⼀般选择为: orc 和 parquet压缩⽅式 : snappy、lzoorc ⽀持压缩⽅式 : None、Zlib(默认使⽤)、Snappyparquet ⽀持压缩⽅式 : Uncompress(默认使⽤,不压缩)、Snappy、Gzip、Lzo当读取单个⼤⽂件时,要使⽤ Lzo⽅式(⽂件可切分)1.orc-zlib ⽰例-- 建表create table home.log_orc_zlib (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string)row format delimited fields terminated by '\t'stored as orctblproperties("press"="zlib"); -- 设置 orc 存储使⽤zlib压缩;-- insert 数据到 log_orc_zlibinsert into table home.log_orc_zlib select * from home.log_text ;-- orc 使⽤压缩dfs -du -h /user/hive/warehouse/home.db/log_orc_zlib;2.8 M 8.3 M /user/hive/warehouse/home.db/log_orc_zlib/000000_0-- orc 不使⽤压缩dfs -du -h /user/hive/warehouse/home.db/log_orc;7.7 M 23.1 M /user/hive/warehouse/home.db/log_orc/000000_0-- 源⽂件⼤⼩[root@gaocun ~]# du -h log.data18.1 log.data2.orc-snappy ⽰例-- 建表create table home.log_orc_snappy (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string)row format delimited fields terminated by '\t'stored as orctblproperties("press"="snappy"); -- 设置 orc 存储使⽤ snappy 压缩;-- insert 数据到 log_orc_snappyinsert into table home.log_orc_snappy select * from home.log_text ;-- orc 使⽤压缩dfs -du -h /user/hive/warehouse/home.db/log_orc_snappy;3.7 M 11.2 M /user/hive/warehouse/home.db/log_orc_snappy/000000_0-- orc 不使⽤压缩dfs -du -h /user/hive/warehouse/home.db/log_orc;7.7 M 23.1 M /user/hive/warehouse/home.db/log_orc/000000_0-- 源⽂件⼤⼩[root@gaocun ~]# du -h log.data18.1 log.dataZLIB ⽐ Snappy 压缩的还⼩。
第九章电子产品的文件及管理12页

第九章电子产品的文件及管理9.1 文件的定义与类别9.1.1 文件定义与类型文件是指信息及其承载媒体,其中媒体可以是纸张、磁盘、光盘或其他电子媒体、样件或他们的组合。
文件的类型可以是多种多样的,有纸面文件,有电子化文件,也可以是标准样品、程序软件、照片、底片、胶片等。
文件是指导生产和管理活动的依据和证实材料,文件一建立就要受控,文件管理的失控将对生产和质量产生重大影响,为保证文件的适用性、系统性、协调性和完整性,每一个组织都要对质量管理体系要求有关的所有文件和资料,制定和执行文件控制程序。
9.1.2 受控文件与非受控文件文件的受控是指对文件的批准、发放使用、变更、报废和回收等作业纳入程序,按规定管理,受控文件不只限于设计部门制定的规范,详细说明产品或质量管理体系要求的所有文件都要列入控制范围内,这类文件应有标示,应有发放的记录,一旦原文的正本发生变更,则应及时回收扩散的副本,发放新文件,保证各个应用场所使用的是相应文件的有效版本,如公司内部使用的质量手册是受控文件。
非受控文件则不受文件变更的影响,如为了宣传的需要在投标时提供给顾客的质量手册是非受控文件,这类文件在原文件正本发生变更时,扩散的非受控副本可不收回。
9.1.3 文件分类1.按文件应用的对象,可分为与产品要求有关的文件(技术文件),如;图纸、技术标准、检验标准、工艺文件;与质量体系要求有关的文件(管理文件),如:质量手册、程序文件、作业指导书、质量审核报告等。
2.按文件的结构层次和使用性质,一个组织的质量管理体系所要求的典型文件包括:A、质量手册;B、程序文件;C、完成规定任务的作业指导书;D、收集和报告数据的标准表格;E、质量记录;F、质量计划。
9.1.4质量文件管理要求1.文件管理总要求(1)ISO9000:2000标准规定必须制定六个程序文件,它们是:文件控制程序、质量记录控制程序、不合格控制程序、内部审核程序、纠正措施程序和预防措施程序。
第9章习题及答案
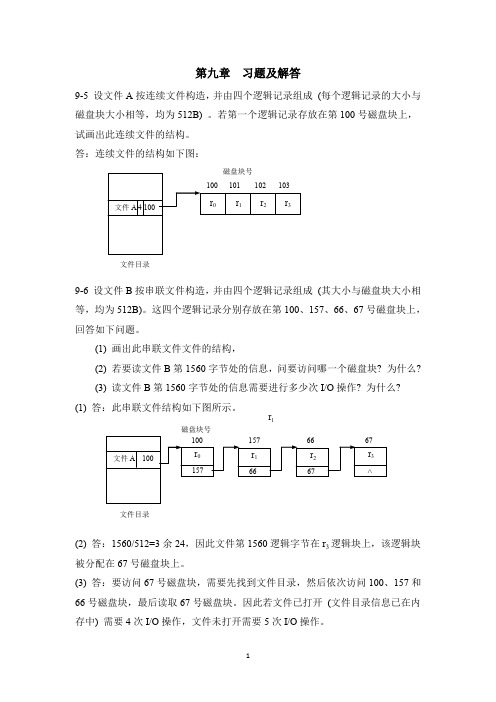
第九章 习题及解答9-5 设文件A 按连续文件构造,并由四个逻辑记录组成 (每个逻辑记录的大小与磁盘块大小相等,均为512B) 。
若第一个逻辑记录存放在第100号磁盘块上,试画出此连续文件的结构。
答:连续文件的结构如下图:9-6 设文件B 按串联文件构造,并由四个逻辑记录组成 (其大小与磁盘块大小相等,均为512B)。
这四个逻辑记录分别存放在第100、157、66、67号磁盘块上,回答如下问题。
(1) 画出此串联文件文件的结构,(2) 若要读文件B 第1560字节处的信息,问要访问哪一个磁盘块? 为什么? (3) 读文件B 第1560字节处的信息需要进行多少次I/O 操作? 为什么? (1) 答:此串联文件结构如下图所示。
(2) 答:1560/512=3余24,因此文件第1560逻辑字节在r 3逻辑块上,该逻辑块被分配在67号磁盘块上。
(3) 答:要访问67号磁盘块,需要先找到文件目录,然后依次访问100、157和66号磁盘块,最后读取67号磁盘块。
因此若文件已打开 (文件目录信息已在内存中) 需要4次I/O 操作,文件未打开需要5次I/O 操作。
文件目录文件目录 r 1磁盘块号9-16什么是“重名”问题? 二级文件目录结构如何解决这一问题?答:重名是指不同用户对不同文件起了相同的名字。
在二级文件目录结构中,每个用户建立用户文件目录,系统建立主目录,登记所有用户目录的信息,用目录名加文件名唯一标识每个文件解决重名问题。
9-18 假设两个用户共享一个文件系统,用户甲要用到文件a、b、c、e,用户乙要用到文件a、d、e、f。
已知:用户甲的文件a与用户乙的文件a实际上不是同一文件;用户甲的文件c与用户乙的文件f实际上是同一文件;甲、乙两用户的文件e是同一文件。
试拟定一个文件组织方案,使得甲、乙两用户能共享该文件系统而不致造成混乱。
答:如下图所示。
用户甲的主目录名为jia,有四个文件,文件名为a、b、c、e。
第九章_Ext2文件系统_ro机

第九章_Ext2文件系统_ro机第九章Ext2文件系统9.1基本概念在上一章中,我们把Ext2、Minix、Ext等实际可使用的文件系统称为具体文件系统.具体文件系统管理的是一个逻辑空间,这个逻辑空间就象一个大的数组,数组的每个元素就是文件系统操作的基本单位——逻辑块,逻辑块是从0开始编号的,而且,逻辑块是连续的.与逻辑块相对的是物理块,物理块是数据在磁盘上的存取单位,也就是每进行一次I/O操作,最小传输的数据大小.我们知道数据是存储在磁盘的扇区中的,那么扇区是不是物理块呢?或者物理块是多大呢?这涉及到文件系统效率的问题.如果物理块定的比较大,比如一个柱面大小,这时,即使是1个字节的文件都要占用整个一个柱面,假设Linux环境下文件的平均大小为1K,那么分配32K的柱面将浪费97%的磁盘空间,也就是说,大的存取单位将带来严重的磁盘空间浪费.另一方面,如果物理块过小,则意味着对一个文件的操作将进行更多次的寻道延迟和旋转延迟,因而读取由小的物理块组成的文件将非常缓慢!可见,时间效率和空间效率在本质上是相互冲突的.因此,最优的方法是计算出Linux环境下文件的平均大小,然后将物理块大小定为最接近扇区的整数倍大小.在Ext2中,物理块的大小是可变化的,这取决于你在创建文件系统时的选择,之所以不限制大小,也正体现了Ext2的灵活性和可扩充性,一是因为要适应近年来文件的平均长度缓慢增长的趋势,二是为了适应不同的需要.比如,如果一个文件系统主要用于BBS服务,考虑到BBS上的文章通常很短小,所以,物理块选的小一点是恰当的.通常,Ext2的物理块占一个或几个连续的扇区,显然,物理块的数目是由磁盘容量等硬件因素决定的.逻辑块与物理块的关系类似于虚拟内存中的页与物理内存中的页面的关系.具体文件系统所操作的基本单位是逻辑块,只在需要进行I/O操作时才进行逻辑块到物理块的映射,这显然避免了大量的I/O操作,因而文件系统能够变得高效.逻辑块作为一个抽象的概念,它必然要映射到具体的物理块上去,因此,逻辑块的大小必须是物理块大小的整数倍,一般说来,两者是一样大的.通常,一个文件占用的多个物理块在磁盘上是不连续存储的,因为如果连续存储,则经过频繁的删除、建立、移动文件等操作,最后磁盘上将形成大量的空洞,很快磁盘上将无空间可供使用.因此,必须提供一种方法将一个文件占用的多个逻辑块映射到对应的非连续存储的物理块上去,Ext2等类文件系统是用索引节点解决这个问题的,具体实现方法后面再予以介绍.为了更好的说明逻辑块和物理块的关系,我们来看一个例子.假设用户要对一个已有文件进行写操作,用户进程必须先打开这个文件,file结构记录了该文件的当前位置.然后用户把一个指向用户内存区的指针和请求写的字节数传送给系统,请求写操作,这时系统要进行两次映射.一组字节到逻辑块的映射.这个映射过程就是找到起始字节到结束字节所占用的所有逻辑块号.这是因为在逻辑空间,文件传输的基本单位是逻辑块而不是字节.逻辑块到物理块的映射.这个过程必须要用到索引节点结构,该结构中有一个物理块指针数组,以逻辑块号为索引,通过这些指针找到磁盘上的物理块,具体实现将在介绍Ext2索引节点时再进行介绍.图9.1是由一组请求的字节到物理块的映射过程示意图.图9.1一组字节映射到物理块的示意图有了逻辑块和物理块的概念,我们也就知道通常所说的数据块是指逻辑块,以下没有特别说明,块或数据块指的是逻辑块.在Ext2中,还有一个重要的概念:片,它的作用是什么? 每个文件必然占用整数个逻辑块,除非每个文件大小都恰好是逻辑块的整数倍,否则最后一个逻辑块必然有空间未被使用,实际上,每个文件的最后一个逻辑块平均要浪费一半的空间,显然最终浪费的还是物理块.在一个有很多文件的系统中,这种浪费是很大的.Ext2使用片来解决这个问题.片也是一个逻辑空间中的概念,其大小在1K至4K之间,但片的大小总是不大于逻辑块.假设逻辑块大小为4K,片大小为1K,物理块大小也是1K,当你要创建一个3K大小的文件时,实际上分配给你了3个片,而不会给你一个逻辑块,当文件大小增加到4K时,文件系统则分配一个逻辑块给你,而原来的四个片被清空.如果文件又增加到5K时,则占用1个逻辑块和1个片.上述三种情况下,所占用的物理块分别是3个、4个、5个,如果不采用片,则要用到4个、4个、8个物理块,可见,使用片,减少了磁盘空间的浪费.当然,在物理块和逻辑块大小一样时,片就没有意义了.由上面分析也可看出:物理块大小100>12,所以要用到一次间接块,在一次间接块中查找第88项,此项内容就是对应的物理块的地址.而如果要找第1000个逻辑块对应的物理块,由于1000>256+12,所以要用到二次间接块了.索引节点的标志取下列几个值的可能组合.EXT2_SECRM_FL0x00000001完全删除标志.设置这个标志后,删除文件时,随机数据会填充原来的数据块.EXT2_UNRM_FL0x00000002可恢复标志.设置这个标志后,删除文件时,文件系统会保留足够信息,以确保文件仍能恢复EXT2_COMR_FL0x00000004压缩标志.设置这个标志后,表明该文件被压缩过.当访问该文件时,文件系统必须采用解压缩算法进行解压.EXT2_SYNC_FL0x00000008同步更新标志.设置该标志后,则该文件必须和内存中的内容保持一致,对这种文件进行异步输入、输出操作是不允许的.这个标志仅用于节点本身和间接块.数据块总是异步写入磁盘的.除了这几个常用标志外,还有12个标志就不一一介绍了.索引节点在磁盘上是经过编号的.其中,有一些节点有特殊用途,用户不能使用.这些特殊节点也在include/Linux/ext2_fs.h中定义.#defineEXT2_BAD_INO1该节点所对应的文件中包含着该文件系统中坏块的链接表#defineEXT2_ROOT_INO2该文件系统的根目录所对应的节点#defineEXT2_IDX_INO3ACL节点#defineEXT2_DATA_INO4ACL节点#defineEXT2_BOOT_LOADER_INO5用于引导系统的文件所对应的节点#defineEXT2_UNDEL_DIR_INO6文件系统中可恢复的目录对应的节点没有特殊用途的第一个节点号为11#defineEXT2_FIRST_INO11文件的类型、访问权限、用户标识号、用户组标识号等将在后面介绍.与Ext2超级块类似,当磁盘上的索引节点调入内存后,除了要填写VFS的索引节点外,系统还要根据它填写另一个数据结构,该结构叫ext2_inode_info,其作用也是为了存储特定文件系统自己的特性,它在include/Linux/ext2_fs_i.h中定义如下:structext2_inode_info{__u32i_data[15]数据块指针数组*/__u32i_flags;打开文件的方式*/__u32i_faddr;片的地址*/__u8i_frag_no;如果用到片,则是第一个片号*/__u8i_frag_size;片大小*/__u16i_osync;同步*/__u32i_file_acl;文件访问控制链表*/__u32i_dir_acl;目录访问控制链表*/__u32i_dtime;文件的删除时间*/__u32i_block_group;索引节点所在的块组号*//******以下四个域是用于操作预分配块的*__u32i_next_alloc_block;__u32i_next_alloc_goal;__u32i_prealloc_block;__u32i_prealloc_count;__u32i_dir_start_lookupinti_new_inode:1/*Isafreshlyallocatedinode*/};VFS索引节点中是没有物理块指针数组的域,这个Ext2特有的域在调入内存后,就必须保存在ext2_inode_info这个结构中.此外,片作为Ext2比较特殊的地方,在ext2_inode_info中也保存了一些相关的域.另外,Ext2在分配一个块时通常还要预分配几个连续的块,因为它判断这些块很可能将要被访问,所以采用预分配的策略可以减少磁头的寻道时间.这些用于预分配操作的域也被保存在ext2_inode_info结构中.9.2.4组描述符块组中,紧跟在超级块后面的是组描述符表,其每一项称为组描述符,是一个叫ext2_group_desc的数据结构,共32字节.它是用来描述某个块组的整体信息的. structext2_group_desc{__u32bg_block_bitmap;/*组中块位图所在的块号*/__u32bg_inode_bitmap;组中索引节点位图所在块的块号*/__u32bg_inode_table;/*组中索引节点表的首块号*/__u16bg_free_blocks_count;/*组中空闲块数*/__u16bg_free_inodes_count;/*组中空闲索引节点数*/__u16bg_used_dirs_count;/*组中分配给目录的节点数*/__u16bg_pad;填充,对齐到字*/__u32[3]bg_reserved;用null填充12个字节*/}每个块组都有一个相应的组描述符来描述它,所有的组描述符形成一个组描述符表,组描述符表可能占多个数据块.组描述符就相当于每个块组的超级块,一旦某个组描述符遭到破坏,整个块组将无法使用,所以组描述符表也像超级块那样,在每个块组中进行备份,以防遭到破坏.组描述符表所占的块和普通的数据块一样,在使用时被调入块高速缓存.9.2.5位图在Ext2中,是采用位图来描述数据块和索引节点的使用情况的,每个块组中都有两个块,一个用来描述该组中数据块的使用情况,另一个描述该组中索引节点的使用情况.这两个块分别称为数据块位图块和索引节点位图块.数据位图块中的每一位表示该组中一个块的使用情况,如果为0,则表示相应数据块空闲,为1,则表示已分配,索引节点位图块的使用情况类似.Ext2在安装后,用两个高速缓存分别来管理这两种位图块.每个高速缓存最多同时只能装入Ext2_MAX_GROUP_LOADED个位图块或索引节点块,当前该值定义为8,所以也应该采用一些算法来管理这两个高速缓存,Ext2中采用的算法类似于LRU算法.前面说过,ext2_sp_info结构中有四个域用来管理这两个高速缓存,其中s_block_bitmap_number[]数组中存有进入高速缓存的位图块号,而s_block_bitmap[]数组则存储了相应的块在高速缓存中的地址.s_inode_bitmap_number[]和s_inode_bitmap[]数组的作用类似上面.我们通过一个具体的函数来看Ext2是如何通过这四个域管理位图块高速缓存的.在Linux/fs/ext2/balloc.c 中,有一个函数load__block_bitmap,它用来调入指定的数据块位图块,下面是它的执行过程:如果指定的块组号大于块组数,出错,结束;通过搜索s_block_bitmap_number[]数组可知位图块是否已进入高速缓存,如果已进入,则结束,否则,继续; 如果块组数不大于Ext2_MAX_GROUP_LOADED,高速缓存可以同时装入所有块组的数据块位图块,不用采用什么算法,只要找到s_block_bitmap_number[]数组中第一个空闲元素,将块组号写入,然后将位图块调入高速缓存,最后将它在高速缓存中的地址写入s_block_bitmap[]数组中;如果块组数大于Ext2_MAX_GROUP_LOADED,则需要采用以下算法;首先通过s_block_bitmap_number[]数组判断高速缓存是否已满,若未满,则操作过程类似上一步,不同之处在于需要将s_block_bitmap_number[]数组各元素依次后移一位,而用空出的第一个元素存储块组号,s_block_bitmap[]也要做相同处理;如果高速缓存已满,则将s_block_bitmap[]数组最后一项所指的位图块从高速缓存中交换出去,然后调入所指定的位图块,最后对这两个数组作和上面相同的操作;可以看出,这个算法很简单,就是对两个数组的简单操作,只是在块组数大于Ext2_MAX_GROUP_LOADED时,要求数组的元素按最近访问的先后次序排列,显然,这样也是为了更合理的进行高速缓存的替换操作.9.2.6索引节点表及实例分析在两个位图块后面,就是索引节点表了,每个块组中的索引节点都存储在各自的索引节点表中,并且按索引节点号依次存储.索引节点表通常占好几个数据块,索引节点表所占的块使用时也像普通的数据块一样被调入块高速缓存.有了以上几个概念和数据结构后,我们分析一个具体的例子,来看看这些数据结构是如何配合工作的.在fs/ext2/inode.c中,有一个ext2_read_inode,用来读取指定的索引节点信息.其代码如下:voidext2_read_inode{structbuffer_head*bh;structext2_inode*raw_inode; unsignedlongblock_group; unsignedlonggroup_desc; unsignedlongdesc; unsignedlongblock; unsignedlongoffset;structext2_group_desc *gdp;if)||inode->i_ino>le32_to_cpu){ext2_error;gotobad_inode;}block_group/EXT2_INODES_PER_GROUP;if{ext2_error;gotobad_inode;}group_desc=block_group>>EXT2_DESC_PER_BLOCK_BITS; desc=block_group&1);bh=inode->i_sb->u.ext2_sb.s_group_desc[group_desc]; if{ext2_error;gotobad_inode;}gdp=bh->b_data;/**Figureouttheoffsetwithintheblockgroupinodetable*/offset=%EXT2_INODES_PER_GROUP) *EXT2_INODE_SIZE;block=le32_to_cpu+);if)){ext2_error;gotobad_inode;}offset&=-1);raw_inode=;inode->i_mode =le16_to_cpu; inode->i_uid=le16_to_cpu;inode->i_gid =le16_to_cpu; if)){inode->i_uid |=le16_to_cpui_gid|=le16_to_cpui_nlink=le16_to_cpu; inode->i_size =le32_to_cpu; inode->i_atime =le32_to_cpu; inode->i_ctime =le32_to_cpu;inode->i_mtime=le32_to_cpu;inode->u.ext2_i.i_dtime =le32_to_cpu;/*Wenowhaveenoughfieldstocheckiftheinodewasactiveornot.Thisis needed because nfsd might tryto access dead inodes *the testisthat same one thate2fsck usesNeilBrown 1999oct15*/if){/*thisinodeisdeleted*/brelse;gotobad_inode;}inode->i_blksize =PAGE_SIZE;/*ThistheoptimalIOsize,notthefsblocksize*/inode->i_blocks=le32_to_cpu;inode->i_version=++event;inode->u.ext2_i.i_flags =le32_to_cpu;inode->u.ext2_i.i_faddrle32_to_cpu;inode->u.ext2_i.i_frag_no =raw_inode->i_frag;inode->u.ext2_i.i_frag_size =raw_inode->i_fsize; inode->u.ext2_i.i_file_acl =le32_to_cpu;if)inode->i_size|=le32_to_cpu)u.ext2_i.i_dir_acl=le32_to_cpu;inode->i_generation=le32_to_cpu;inode->u.ext2_i.i_prealloc_count =0;inode->u.ext2_i.i_block_group =block_group;/**NOTE!Thein-memoryinodei_dataarrayisinlittle-endianorder*evenonbig-endianmachines: wedoNOT byteswap theblock numbers! */for/* Nothingtodo*/;elseif){inode->i_op=&ext2_file_inode_operations; inode->i_fop=&ext2_file_operations;inode->i_mapping->a_ops=&ext2_aops;}elseif){inode->i_op=&ext2_dir_inode_operations; inode->i_fop=&ext2_dir_operations; inode->i_mapping->a_ops=&ext2_aops;}elseif){ifinode->i_op=&ext2_fast_symlink_inode_operations; else{inode->i_op=&page_symlink_inode_operations; inode->i_mapping->a_ops=&ext2_aops;}}elseinit_special_inode);brelse;inode->i_attr_flags=0;if{inode->i_attr_flags|=A TTR_FLAG_SYNCRONOUS; inode->i_flags|=S_SYNC;}if{inode->i_attr_flags|=A TTR_FLAG_APPEND;inode->i_flags|=S_APPEND;}if{inode->i_attr_flags|=A TTR_FLAG_IMMUTABLE; inode->i_flags|=S_IMMUTABLE;}if{inode->i_attr_flags|=A TTR_FLAG_NOA TIME; inode->i_flags|=S_NOATIME;}return;bad_inode:make_bad_inode;return;}这个函数的代码有200多行,为了突出重点,下面是对该函数主要内容的描述:如果指定的索引节点号是一个特殊的节点号,或者小于第一个非特殊用途的节点号,即EXT2_FIRST_INO ,或者大于该文件系统中索引节点总数,则输出错误信息,并返回;用索引节点号整除每组中索引节点数,计算出该索引节点所在的块组号;即block_group=/Ext2_INODES_PER_GROUP找到该组的组描述符在组描述符表中的位置.因为组描述符表可能占多个数据块,所以需要确定组描述符在组描述符表的哪一块以及是该块中第几个组描述符. 即:group_desc=block_group>>Ext2_DESC_PER_BLOCK_BITS表示块组号整除每块中组描述符数,计算出该组的组描述符在组描述符表中的哪一块.我们知道,每个组描述符是32字节大小,在一个1K大小的块中可存储32个组描述符.块组号与每块中组的描述符数进行”与”运算,得到这个组描述符具体是该块中第几个描述符.即desc=block_group&-1).有了group_desc和desc,接下来在高速缓存中找这个组描述符就比较容易了:即:bh=inode->i_sb->u.ext2_sb.s_group_desc[group_desc],首先通过s_group_desc[]数组找到这个组描述符所在块在高速缓存中的缓冲区首部;然后通过缓冲区首部找到数据区,即gdp=bh->b_data.找到组描述符后,就可以通过组描述符结构中的bg_inode_tabl找到索引节点表首块在高速缓存中的地址:offset=%Ext2_INODES_PER_GROUP)*Ext2_INODE_SIZE,计算该索引节点在块中的偏移位置;block=le32_to_cpu+),计算索引节点所在块的地址;代码中le32_to_cpu、le16_to_cpu按具体CPU的要求进行数据的排列,在i386处理器上访问Ext2文件系统时这些函数不做任何事情.因为不同的处理器在存取数据时在字节的排列次序上有所谓”bigending”和”littleending”之分.例如,i386就是”littleending”处理器,它在存储一个16位数据0x1234时,实际存储的却是0x3412,对32位数据也是如此.这里索引节点号与块的长度都作为32位或16位无符号整数存储在磁盘上,而同一磁盘既可以安装在采用”little ending”方式的CPU机器上,也可能安装在采用”big ending”方式的CPU机器上,所以要选择一种形式作为标准.事实上,Ext2采用的标准为”littleending”,所以,le32_to_cpu、le16_to_cpu函数不作任何转换.计算出索引节点所在块的地址后,就可以调用sb_bread通过设备驱动程序读入该块.从磁盘读入的索引节点为ext2_Inode数据结构,前面我们已经看到它的定义.磁盘上索引节点中的信息是原始的、未经加工的,所以代码中称之为raw_inode,即raw_inode=与磁盘索引节点ext2_inode相对照,内存中VFS的inode结构中的信息则分为两部分,一部分是属于VFS层的,适用于所有的文件系统;另一部份则属于具体的文件系统,这就是inode中的那个union,因具体文件系统的不同而赋予不同的解释.对Ext2来说,这部分数据就是前面介绍的ext2_inode_info结构.至于代表着符号链接的节点,则并没有文件内容,所以正好用这块空间来存储链接目标的路径名.ext2_inode_info结构的大小为60个字节.虽然节点名最长可达255个字节,但一般都不会太长,因此将符号链接目标的路径名限制在60个字节不至于引起问题.代码中inode->u.*设置的就是Ext2文件系统的特定信息.接着,根据索引节点所提供的信息设置inode结构中的inode_operations结构指针和file_operations结构指针,完成具体文件系统与虚拟文件系统VFS之间的连接.目前2.4版内核并不支持存取控制表ACL,因此,代码中只是为之留下了位置,而暂时没做任何处理.另外,通过检查inode结构中的mode域来确定该索引节点是常规文件、目录、符号链接还是其他特殊文件而作不同的设置或处理.例如,对Ext2文件系统的目录节点,就将i_op和i_fop分配设置为ext2_dir_inode_operations和ext2_dir_operations.而对于Ext2常规文件,则除i_op和i_fop以外,还设置了另一个指针a_ops,它指向一个address_apace_operation结构,用于文件到内存空间的映射或缓冲.对特殊文件,则通过init_special_inode函数加以检查和处理.从这个读索引节点的过程可以看出,首先要寻找指定的索引节点,要找索引节点,必须先找组描述符,然后通过组描述符找到索引节点表,最后才是在这个索引节点表中找索引节点.当从磁盘找到索引节点以后,就要把其读入内存,并存放在VFS索引节点相关的域中.从这个实例的分析,读者可以仔细体会前面所介绍的各种数据结构的具体应用.9.2.7Ext2的目录项及文件的定位文件系统一个很重要的问题就是文件的定位,如何通过一个路径来找到一个文件的具体位置,这就要依靠ext2_dir_entry这个结构.1.Ext2目录项结构在Ext2中,目录是一种特殊的文件,它是由ext2_dir_entry这个结构组成的列表.这个结构是变长的,这样可以减少磁盘空间的浪费,但是,它还是有一定的长度方面的限制,一是文件名最长只能为255个字符.二是尽管文件名长度可以不限,但系统自动将之变成4的整数倍,不足的地方用null字符填充.目录中有文件和子目录,每一项对应一个ext2_dir_entry.该结构在include/Linux/ext2_fs.h中定义如下:/**Structureofadirectoryentry*/#defineEXT2_NAME_LEN255structext2_dir_entry{__u32inode;Inodenumber*/__u16rec_len;Directoryentrylength*/__u16name_len;Namelength*/charname[EXT2_NAME_LEN]Filename*/};这是老版本的定义方式,在ext2_fs.h中还有一种新的定义方式:/**Thenewversionofthedirectory entry.SinceEXT2structures are*storedinintelbyteorder,andthename_lenfieldcouldneverbe*than255chars,it’ssafetoreclaimtheextrabyteforthe*file_typefield.*/structext2_dir_entry_2{__u32inode;Inode number*/__u16rec_len;Directorylength*/__u8name_len;Namelength*/__u8file_type;charname[EXT2_NAME_LEN]Filename*/};其二者的差异在于,一是新版中结构名改为ext2_dir_entry_2;二是老版本中ext2_dir_entry中的name_len为无符号短整数,而新版中则改为8位的无符号字符,腾出一半用作文件类型.目前已定义的文件类型为:**Ext2directorytypes.Onlythelow3bitsareused.The*otherbitsarereservedfornow.*/enum{EXT2_FT_UNKNOWN, /*未知*/EXT2_FT_REG_FILE,/*常规文件*/EXT2_FT_DIR,/*目录文件*/EXT2_FT_CHRDEV,/*字符设备文件*/EXT2_FT_BLKDEV,/*块设备文件*/EXT2_FT_FIFO,/*命名管道文件*/EXT2_FT_SOCK,/*套接字文件*/EXT2_FT_SYMLINK,/*符号连文件*/EXT2_FT_MAX/*文件类型的最大个数*/};2.各种文件类型如何使用数据块我们说,不管哪种类型的文件,每个文件都对应一个inode结构,在inode结构中有一个指向数据块的指针i_blaock,用来标识分配给文件的数据块.但是Ext2所定义的文件类型以不同的方式使用数据块.有些类型的文件不存放数据,因此,根本不需要数据块,下面对不同文件类型如何使用数据块给予说明.常规文件常规文件时最常用的文件.常规文件在刚创建时是空的,并不需要数据块,只有在开始有数据时才需要数据块;可以用系统调用truncate清空一个常规文件.目录文件Ext2以一种特殊的方式实现了目录,这种文件的数据块中存放的就是ext2_dir_entry_2结构.如前所述,这个结构的最后一个域是可变长度数组,因此该结构的长度是可变的.在ext2_dir_entry_2结构中,因为rec_len域是目录项的长度,把它与目录项的起始地址相加就得到下一个目录项的起始地址,因此说,rec_len可以被解释为指向下一个有效目录项的指针.为了删除一个目录项,把ext2_dir_entry_2的inode域置为0并适当增加前一个有效目录项rec_len域的值就可以了.符号连如果符号连的路径名小于60个字符,就把它存放在索引节点的i_blaock域,该域是由15个4字节整数组成的数组,因此无需数据块.但是,如果路径名大于60个字符,就需要一个单独的数据块.设备文件、管道和套接字这些类型的文件不需要数据块.所有必要的信息都存放在索引节点中.3.文件的定位文件的定位是一个复杂的过程,我们先看一个具体的例子,然后再结合上面的数据结构具体介绍一下如何找到一个目录项的过程.如果要找的文件为普通文件,则可通过文件所对应的索引节点找到文件的具体位置,如果是一个目录文件,则也可通过相应的索引节点找到目录文件具体所在,然后再从这个目录文件中进行下一步查找,来看一个具体的例子.假设路径为/home/user1/file1,home和user1是目录名,而file1为文件名.为了找到这个文件,有两种途径,一是从根目录开始查找,二是从当前目录开始查找.假设我们从根目录查找,则必须先找到根目录的节点,这个节点的位置在VFS中的超级块中已经给出,然后可找到根目录文件,其中必有home所对应的目录项,由此可先找到home节点,从而home的目录文件,然后依次是user1的节点和目录文件,最后,在该目录文件中的file1目录项中找到file1的节点,至此,已经可以找到file1文件的具体所在了.目录中还有两个特殊的子目录:”.”和”..”,分别代表当前目录和父目录.它们是无法被删除的,其作用就是用来进行相对路径的查找.现在,我们来分析一下fs/ext2/dir.c中的函数ext2_find_entry,该函数从磁盘上找到并读入当前节点的目录项,其代码及解释如下:/**ext2_find_entry**findsanentryinthespecifieddirectorywiththewantedname.It* returns the pagein which the entry was found, andthe entry itself*.Pageis returned mapped andunlocked.*Entryisguaranteedtobevalid.*/typedefstructext2_dir_entry_2ext2_dirent; structext2_dir_entry_2*ext2_find_entry{constchar*name=dentry->d_;/*目录项名*/intnamelen=dentry->d_name.len;/*目录项名的长度*/ unsignedreclen=EXT2_DIR_REC_LEN;/*目录项的长度*/ unsignedlongstart,n;unsignedlongnpages=dir_pages;/*把以字节为单位的文件大小转换为物理页面数*/。
第9章-(1)文件权限设定PPT课件

-rw-r--r-- 1 root users 68495 Jun 25 08:53 install.log
[root@www ~]# chgrp testing install.log
chgrp: invalid group name `testing' <== 发生错误讯息啰~ 找不到这个群组名~
➢ 『王大毛家』就是所谓的『群组』啰, 至于三兄弟就是分别为三 个『使用者』,而这三个使用者是在同一个群组里面的喔! 而三 个使用者虽然在同一群组内,但是我们可以设定『权限』, 好让 某些用户个人的信息不被群组的拥有者查询,以保有个人『私人 的空间』啦! 而设定群组共享,则可让大家共同分享!
3. 其他人的概念
➢ 使用者的意义:由于王家三人各自拥有自己的房间,所以, 王二 毛虽然可以进入王三毛的房间,但是二毛不能翻三毛的抽屉喔! 那样会被三毛K的! 因为抽屉里面可能有三毛自己私人的东西, 例如情书啦,日记啦等等的,这是『私人的空间』,所以当然不 能让二毛拿啰!
➢ 群组的概念:由于共同拥有客厅,所以王家三兄弟可以在客厅打 开电视机啦、翻阅报纸啦、坐在沙发上面发呆啦等等的! 反正, 只要是在客厅的玩意儿,三兄弟都可以使用喔! 因为大家都是一 家人嘛!
[root@www ~]# ls -l
-rw-r--r-- 1 root root 68495 Jun 25 08:53 install.log
提示:
➢ chown也可以使用『chown user.group file』,亦即在拥 有者与群组间加上小数点『.』也行!
➢ 也使用冒号『:』来隔开拥有者与群组!
➢ 此外,chown也能单纯的修改所属群组!例如『chown
WSA 第九章 知识点

第九章文件服务器知识点Edit by LCHSH1. 哪些帐户组可以创建共享文件夹?在域控制器上,Administrators组、Server Operators组的成员有创建共享文件夹的权限。
在成员服务器或者独立服务器上,Administrators组、Power Users组的成员有创建共享文件夹的权限。
2. 什么是共享名?共享名是其他计算机在网络中查看此共享文件夹资源时看到的名称,此名称可以和文件夹名称相同或者不同。
但是每台计算机上的共享名称必须不能重复。
每一个文件夹可以建立多个共享,每个共享可以设置不同的共享名、描述、用户数、权限。
3. 设置共享时,“用户数限制”指的是什么?此项可以限制同时访问此共享文件夹的用户数量,注意,这里是同时访问的人数,不是总共访问的人数。
此项的默认设置是最多用户,最多用户是指同时能够访问此台计算机的用户数,是由此台计算机购买的授权决定的。
4. 通过哪些方法可以访问共享文件夹?可以通过“网上邻居”、“UNC路径”、“映射网络驱动器”来实现对共享文件夹的访问。
5. 有哪些方法可以把共享文件夹映射成网络驱动器?对于经常使用的共享文件夹,可以将其映射成网络驱动器,方便访问。
在客户端上进行映射操作:①右击共享的文件夹--→“映射网络驱动器”。
②右击“网上邻居”--→“映射网络驱动器”。
③右击“我的电脑”--→“映射网络驱动器”。
④net use X: \\计算机名\共享名。
(其中“X”代表盘符)6. 什么是共享权限?共享权限是控制用户通过网络访问共享文件夹的手段,共享权限仅当用户通过网络访问时才有效。
8. 域用户帐户登录成员计算机时,对成员计算机上的文件夹和文件有什么样的NTFS权限?用域帐户登录域中的计算机时,对此计算机上的文件和文件夹也有相应的NTFS权限,那么,这些权限到底是什么呢?对某文件夹点右键,选“共享和安全”,点“安全”选项卡,发现ACL列表中并没有域用户帐户或组。
第9章 文件共享与NTFS权限.ppt

同步处理
在网络联机正常时,您所存取的文件仍然是网络计算机内的文件。系统会自 动同步您的脱机文件,当网络文件内容有变更时,它会被复制到您的计算机 的缓存区内,反之亦然 若您有需要立刻同步的话,可手动同步
对着脱机文件右键单击同步 或是点击前面图上方菜单中的同步处理
若您计算机与网络计算机正常联机中,但是链接速度却很慢,影响到您编辑网 络文件的话,此时只要点击前面图上方的脱机工作就可以编辑本机快取区内的 文件副本。 等文件编辑完成后,点击在线工作来执行同步工作,以便将较新版的本机文件 副本复制到网络计算机内。
Windows Server 2008共享权限
右键单击一个文件,选择“共享”。 右键单击一个文件,选择“属性”,切换到“共享选项卡”,点击“共享”。 高级共享。
Windows Server 2008共享权限
读取、参与者和共有者3种权限的意义如下:
权限设置 读取 参与者
公有者
所拥有的权限 读取档案或子文件夹 执行程序 有读取的所有权限 新增文件和子文件夹 修改文件内容更改文件或子文件属性 最大权限,可执行所有操作
用户从该共享打开的所有 文件和程序将自动在脱机 状态下可用
该共享上的文件或程序在 脱机状态下不可用
用途
该选项允许用户对文件加注脱机访问标记。这是所有共享的默认设置,不过只有加上 脱机访问标记的文件才是激活的,有标记的文件才有缓存。
该选项允许自动缓存文件夹中每个打开的文件。可以节省带宽,因为只有实际使用过 的文件才得到缓存。对于窄带宽,比较有用。
如果网络上的计算机都支持并启动网络探索功能,当其中 一PC新增了共享文件夹,便会主动广播相关讯息,让其它的计 算机知道这些新增的网络资源。
注意:网络探索默认是关闭的
vb学习教程第9章 文件1

数据项
二、文件分类
根据访问文件的方式将文件分成3类: 顺序文件 随机文件 二进制文件。
1.顺序文件
顺序文件(Sequential File)是普通的文本文件。顺序 文件中的记录按顺序一个接一个地排列。读写文件存取记 录时,都必须按记录顺序逐个进行。一行一条记录(一项 数据),记录可长可短,以“换行”字符为分隔符号。
1.常用属性
(1)Path属性 用于返回和设置文件列表框当前目录,设计时不可用。 说明:当Path值的改变时,会引发一个PathChange事件。
(2)Filename属性
用于返回或设置被选定文件的文件名,设计时不可用。
说明:Filename属性不包括路径名。 例如:要从文件列表框(File1)中获得全路径的文件名 Fname$,用下面的程序代码: If Else
9.2.2 目录列表框(DirListBox)
目录列表框(DirListBox) 控件用来当前驱动器目录结构及 当前目录下的所有子文件夹(子 目录)。供用户选择其中一个目 录为当前目录。
1.常用属性
Path属性是目录列表框控件的最常用的属性,用于返回 或设置当前路径。该属性在设计时是不可用的。 使用格式:Object.Path [= <字符串表达式>] 其中: Object:对象表达式,其值是目录列表框的对象名。
9.3 顺序文件
在程序中对文件的操作,通常按3个步骤进行: 打开文件
读出或写入
关闭文件
9.3.1 顺序文件的打开与关闭
1。打开顺序文件 其使用格式如下: Open FileName For [Input | Output | Append] [Lock]As filenumber [Len = Buffersize] 各参数的意义(见教材Pg. 230)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第九章文件一、单项选择题【9.1】要打开一个已存在的非空文件"file"用于修改,选择正确的语句____。
A) fp=fopen("file", "r"); B) fp=fopen("file", "a+");C) fp=fopen("file", "w"); D) fp=fopen('file", "r+");【9.2】当顺利执行了文件关闭操作时,fclose函数的返回值是。
A) -1 B) TRUE C) 0 D) 1【9.3】fscanf函数的正确调用形式是。
A) fscanf (文件指针, 格式字符串, 输出列表);B) fscanf (格式字符串, 输出列表, 文件指针);C) fscanf (格式字符串, 文件指针, 输出列表);D) fscanf (文件指针, 格式字符串, 输入列表);【9.4】使用fgetc函数,则打开文件的方式必须是。
A) 只写 B) 追加 C) 读或读/写 D) 参考答案B和C都正确【9.5】C语言中标准输入文件stdin是指。
A) 键盘 B) 显示器 C) 鼠标 D) 硬盘二、程序填空题【9.6】下面程序的功能是统计文件中的字符的个数。
#include <stdio.h>main(){ long num=0;① *fp;if((fp=fopen("fname.dat", "r"))==NULL){ printf("Can't open the file! ");exit(0);}while( ② ){ fgetc(fp);num++;}printf("num=%d\n",num);fclose(fp);}【9.7】下面程序的功能是把从键盘输入的文件(用 @ 作为文件结束标志)复制到一个名为second.txt的新文件中。
#include <stdio.h>FILE *fp;main(){ char ch;if((fp=fopen( ① ))==NULL)exit(0);while((ch=getchar())!='@')fputc(ch,fp);② ;}【9.8】下面程序的功能是将磁盘上的一个文件复制到另一个文件中,两个文件名在命令行中给出(假定给定的文件名无误)。
#include <stdio.h>main(int argc,char *argv[]){ FILE &f1,*f2;if(argc< ① ){ printf("The command line error! ");exit(0);}f1=fopen(argv[1], "r");f2=fopen(arhv[2], "w");while( ② )fputs(fgetc(f1), ③ );④ ;⑤ ;}【9.9】下面程序的功能是键盘上输入一个字符串,把该字符串中的小写字母转换为大写字母,输出到文件test.txt中,然后从该文件读出字符串并显示出来。
#include <stdio.h>main(){ char str[100];int i=0;FILE *fp;if((fp=fopen("test.txt", ① ))==NULL){ printf("Can't open the file.\n");exit(0);}printf("Input a string:\n");gets(str);while(str[i]){ if(str[i]>= 'a'&&str[i]<= 'z')str[i]= ② ;fputc(str[i],fp);i++;}fclose(fp);fp=fopen("test.txt", ③ );fgets(str,strlen(str)+1,fp);printf("%s\n",str);fclose(fp);}【9.10】下面程序的功能是将从终端上读入的10个整数以二进制方式写入名为"bi.dat"的新文件中。
#include <stdio.h>FILE *fp;main(){ int i, j;if(( fp=fopen( ① , "wb" )) == NULL )exit (0);for( i=0;i<10;i++ ){ scanf("%d", &j );fwrite( ② , sizeof(int), 1, ③ );}fclose( fp);}【9.11】以字符流形式读入一个文件,从文件中检索出六种C语言的关键字,并统计、输出每种关键字在文件中出现的次数。
本程序中规定:单词是一个以空格或'\t'、 '\n'结束的字符串。
#include <stdio.h>#include <string.h>FILE *cp;char fname[20], buf[100];int num;struct key{ char word[10];int count;}keyword[]={ "if", 0, "char", 0, "int", 0,"else", 0, "while", 0, "return", 0};char *getword (FILE *fp){ int i=0;char c;while((c=getc(fp)) != EOF && (c==' '||c=='\t'||c=='\n')) ;if( c==EOF ) return (NULL) ;else buf[i++]=c;while((c = ① && c!= ' ' && c!= '\t' && c!= '\n' )buf[i++] = c;buf[i]= '\0';return(buf);}lookup(char *p){ int i;char *q, *s;for(i=0;i<num;i++){ q = ② ;s=p;while( *s && (*s==*q) ){ ③}if( ④ ){ keyword[i].count++;break;}}return;}main(){ int i;char *word;printf("Input file name:");scanf("%s", fname);if((cp=fopen(fname, "r")) ==NULL ){ printf("File open error: %s\n", fname);exit(0);}num = sizeof(keyword) / sizeof(struct key);while( ⑤ )lookup(word);fclose(cp);for(i=0;i<num;i++)printf("keyword:%-20scount=%d\n",keyword[i].word,keyword[i].cou nt);}【9.12】下面程序的功能是从键盘接受姓名(例如:输入"ZHANG SAN"),在文件"try.dat"中查找,若文件中已经存入了刚输入的姓名,则显示提示信息;若文件中没有刚输入的姓名,则将该姓名存入文件。
要求:⑴若磁盘文件"try.dat",已存在,则要保留文件中原来的信息;若文件"try.dat"不存在,则在磁盘上建立一个新文件;⑵当输入的姓名为空时(长度为0),结束程序。
#include <stdio.h>main(){ FILE *fp;int flag;char name[30], data[30];if((fp=fopen("try.dat", ①))==NULL ){ printf("Open file error\n");exit(0);}do{ printf("Enter name:");gets(name);if( strlen(name)==0 )break;strcat(name, "\n");②;flag=1;while( flag && (fgets(data, 30, fp) ③) )if( strcmp(data, name) == 0 )④ ;if( flag )fputs(name, fp);elseprintf("\tData enter error !\n");} while( ⑤ );fclose(fp);}【答案:】【9.1】答案:D注释:函数fopen中的第二参数是打开模式,"r"模式是只读方式,不能写文件;"a+"模式是读/追加方式,允许从文件中读出数据,但所有写入的数据均自动加在文件的末尾;"w"模式是写方式,允许按照用户的要求将数据写入文件的指定位置,但打开文件后,首先要将文件的内容清空。
"r+"模式是读/写方式,不但允许读文件,而且允许按照用户的要求将数据写入文件的指定位置,且在打开文件后,不会将文件的内容清空。
本题的要求是"修改"文件的内容,因此只能选择答案D。
【9.2】答案:C【9.3】答案:D【9.4】答案:C【9.5】答案:A【9.6】答案:① FILE ② !feof(fp)注释:FILE 是文件结构类型名。
feof()是测试文件结束标志的函数。
【9.7】答案:① "second.txt" ② fclose(fp)【9.8】答案:① 3 ② !feof(f1)或feof(f1)==0 ③ f2 ④ fclose(f2) ⑤ fclose(f1)注释:程序中使用了带参数的main函数,其中整型参数argc为命令行中字符串的个数,此程序运行时输入的字符串有可运行程序名、文件1和文件2,故argc不应小于3。