文字的表示及处理
文字信息处理

• B:对象操作功能:版面上操作的对象可分为文字、 图形和图像三种,两种软件都提供了丰富的对象 操作功能。 • C:彩色版面设计功能:飞腾不仅可以对任何文字 和图形指定颜色,还可指定立体字的阴影颜色渐 变,指定线的颜色渐变等。 • D:输出及输出设备:PAGEMAKER的输出更开放 只要有设备的Windows驱动软件,就可输出,而 飞腾则一定要用方正RIP才可输出,电子文件只能 使用PS2格式。
三、照像排版
照像排版:运用照像原理,按预定要求,把需要排版的文字 通过光学系统准确拍摄到感光材料上,得到文字 的底片或照片。亦称“冷排”。 • 优点:无需庞大的字库及拣字装版空间,占地少,劳动强度 小,效率高; 无铅尘污染; 字型变化多。 • 照像排字机(照排机): 由光源、文字盘、照像系统组成。 即字库,相当于字模或照像时的原稿 • 照排技术的发展: 19世纪90年代开始使用 手动选字 自动选字 光学式 光机结合 阴极射线管 激光成像
–排版:PageMaker、 InDesign、QuarkXpress、 –图形:FreeHand、CorelDarw
1、计算机排版的发展
• (1)国外:1976年,蒙纳公司推出第一台激光照 排机;1986年开始出现桌面出版系统(Aldus公司 的Pagemaker1.0、苹果计算机和激光打印机、 Adobe公司的PostScript语言组成),在86-90期间 主要软件和产品有QuarkXpress2.0x、 Pagemaker3.0和ColorStudio. • 此后桌面出版系统和电子分色技术互相渗透,共同 发展.彩色桌面系统现在已发展成为包含有图形图 案设计、色彩管理、图文混排及特技处理、图像 创意等在内的计算机出版系统。 • 计算机排版的发展经历了从模拟到数字,从输入、 输出一体式到输入、输出分离式,从封闭系统到 开放系统。
电脑Word实验总结

电脑Word实验引言电脑Word是办公软件中最常用的文字处理工具之一,它提供了丰富的排版和编辑功能,使得我们可以方便地创建和编辑文档。
在本次实验中,我们对电脑Word进行了深入学习和探索,并通过实际操作掌握了一些常用的技巧和方法。
实验目的本次实验的主要目的是熟悉电脑Word的基本操作,掌握其常用功能,提高文档的排版和编辑能力。
通过本次实验,我们将能够更加高效和准确地使用电脑Word进行文档处理。
实验内容本次实验主要包括以下几个方面的内容:1.文字输入与编辑:学习使用电脑键盘输入文字,并掌握Word中文字的基本编辑功能,如剪切、复制、粘贴等。
2.格式设置:学习如何设置文字的字体、字号、颜色等格式,以及段落的对齐方式、行距等。
3.特殊符号与公式:学习如何插入特殊符号和数学公式,以便于在文档中表示复杂的内容和公式。
4.图片与表格:学习如何在Word文档中插入图片和表格,并对其进行格式化和调整。
5.目录与索引:学习如何创建文档的目录和索引,并进行相应的调整和更新。
实验过程在实验过程中,我们首先打开了电脑Word软件,并创建了一个新的文档。
然后,我们通过键盘输入了一段文本,并进行了基本的编辑操作,如剪切、复制、粘贴等。
接着,我们对文字进行了格式设置,包括字体、字号、颜色等。
此外,我们还学习了如何设置段落的对齐方式和行距。
在插入特殊符号和公式方面,我们通过Word中的插入功能,成功地插入了一些特殊符号和数学公式。
这些功能在写作科技文档和学术论文时非常有用。
在插入图片和表格方面,我们学习了如何在Word文档中插入图片,并对其进行调整和格式化。
同时,我们还学习了如何创建表格,并对表格进行相应的格式调整。
这对于创建报告和制作演示文稿非常有用。
最后,我们学习了如何创建文档的目录和索引,并进行相应的调整和更新。
这样可以使得文档更加结构化和易读。
实验通过本次实验,我对电脑Word的使用有了更深入的了解和掌握。
我学会了如何通过键盘输入文字,并进行基本的编辑操作,例如剪切、复制、粘贴等。
文字工作者请收藏,这套校对符号太全了!

文字工作者请收藏,这套校对符号太全了!1字符的改动共有4个符号,分别是改正符、删除符、增补符、改正上下角符。
改正符形态为一线连两圈。
将拟改正的内容和改正的内容分别圈起,用一根线连起来。
当改正的字符较多,圈起有困难时,可用线在页边画清改正的范围。
一般情况下,改正符的位置位于行间,不到页边。
在校对中,遇到必须更换的损、坏、污字,也要用改正符号画出。
删除符形态为一个圈连一根旋转着的线。
表示被圈中的内容被删除。
增补符的形态类似顺时针旋转90°的单书名号,用时插入到要增补内容的位置,然后将增补内容圈起,两者用线相连。
只有当增补内容较多,无法圈住时,增补内容才可出现在页边。
改正上下角符的形态与改正符相似,只是改正的圈变成了方形。
修改后的内容在方形中的位置有上中下三种,分别表示上角、居中、下角。
比如M是表示平方米,如果“2”字没有上标,成了M2,就运用这个符号进行修改。
2字符方向位置的移动一是转正符。
用于将横卧的字符扶正。
形态为一根直线,尾端呈螺旋状。
二是对调符。
将内容在行间对调。
形态为一个横卧的“S”状;如果对调内容相隔较远,则将横卧的“S”的中间段对应延长。
三是接连符。
一根线连接相邻两行内容的首末,线末端的箭头表示连接的方向和位置,表示两行接连成一行,不需要另起行。
四是另起段符。
形态和用法是:一个左括号位于被起段内容的前端,一根短竖线位于将起段位臵,中间用线相连,线末端的箭头表示转移方向。
五是转移符。
根据不同情况,又细分为三种。
一种在行间附近转移,形态类似于增补符,差别在于圈圈中的内容不是自己增添的,而是已有的;一种用于相邻行首末衔接字符的转移;一种是用于相邻页首末衔接字符的转移。
六是上下移动符。
主要用于文字上靠或下靠的情况,保持一行字符的水平齐整。
有两种形态,一种类似于城墙剁口,开口向下或向上,缺口左右有一条水平线,表示将剁口罩住的字符上或下移至水平线位臵;另一种是先划一条短水平线,再画一个向上或向下的箭头,箭头紧抵短线,表示字符将上或下移动到短线处。
计算机中的字是如何处理的
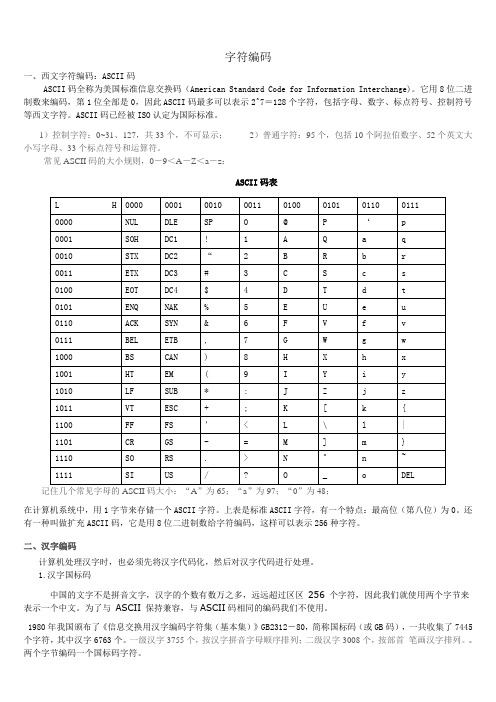
字符编码一、西文字符编码:ASCII码ASCII码全称为美国标准信息交换码(American Standard Code for Information Interchange)。
它用8位二进制数来编码,第1位全部是0,因此ASCII码最多可以表示2^7=128个字符,包括字母、数字、标点符号、控制符号等西文字符。
ASCII码已经被ISO认定为国际标准。
1)控制字符:0~31、127,共33个,不可显示;2)普通字符:95个,包括10个阿拉伯数字、52个英文大小写字母、33个标点符号和运算符。
常见ASCII码的大小规则,0-9<A-Z<a-z:ASCII码表记住几个常见字母的ASCII码大小:“A”为65;“a”为97;“0”为48;在计算机系统中,用1字节来存储一个ASCII字符。
上表是标准ASCII字符,有一个特点:最高位(第八位)为0。
还有一种叫做扩充ASCII码,它是用8位二进制数给字符编码,这样可以表示256种字符。
二、汉字编码计算机处理汉字时,也必须先将汉字代码化,然后对汉字代码进行处理。
1.汉字国标码中国的文字不是拼音文字,汉字的个数有数万之多,远远超过区区256 个字符,因此我们就使用两个字节来表示一个中文。
为了与ASCII 保持兼容,与ASCII码相同的编码我们不使用。
1980年我国颁布了《信息交换用汉字编码字符集(基本集)》GB2312-80,简称国标码(或GB码),一共收集了7445个字符,其中汉字6763个。
一级汉字3755个,按汉字拼音字母顺序排列;二级汉字3008个,按部首笔画汉字排列。
两个字节编码一个国标码字符。
2.汉字的机内表示:机内码:计算机在信息处理时表示汉字的编码,称作机内码。
现在我国都用国标码(GB2312)作为机内码。
中国的台湾省也在使用中文,但是由于历史的原因,那里没有使用大陆的简体中文,还在使用着繁体的中文,并且他们自己也制定了一套表示繁体中文的字符编码,称为BIG5,不幸的是,虽然他们的也使用两个字节来表示一个汉字,但他们没有象我们兼容ASCII 一样兼容大陆的简体中文,他们使用了大致相同的编码范围来表示繁体的汉字。
word文字处理基本操作剖析

word文字处理基本操作1. 新建/ 打开文档当直接启动Word 时,Word 自动新建一个标题为“文档1”的空白文档,用户也可使用“文件”|“新建”新建文档。
当新建文档时,“新建文档”任务窗格会提供多种文档模板来新建所需文档,如“报告”、“备忘录”、“信函和传真”等。
用户可通过双击Word 文档启动Word 并打开该文档,也可使用“文件”| “打开”打开文档。
2. 输入文档内容新建/打开文档后,在文档编辑区中可输入文档内容。
·输入中英文当关闭中文输入法时,可通过键盘输入英文;当打开中文输入法时,可输入中文。
用户可通过语言栏或Ctrl+空格键,切换中英文输入法。
·输入数字打开Num Lock,可使用数字小键盘输入数字。
·输入符号当输入某些键盘上没有的字符时,可使用“插入”|“特殊符号”或“符号”,如特殊字符§和?(字体wingdings3)。
·输入日期和时间使用“插入”|“日期和时间”,可输入日期和时间。
如选择了“日期和时间”对话框中的“自动更新”,则每次打开文档时,日期和时间都自动更新为当前系统时间。
·制作超链接使用“插入”| “超级链接”,可在文档中制作某个Web 站点或文档的超链接。
·自动替换选择“工具”|“自动更正选项”|“自动更正”,并选中“键入时自动替换”,就可使用自动替换简化文本输入。
例如,在文档中经常输入“Microsoft Office 2003”,可在“替换”框中输入“M3”,在“替换为”框中输入“Microsoft Office 2003”,单击“添加”将此条目添加到自动更正条目中。
此后,在文档中输入“M3”并回车,Word 就会自动更正为“Microsoft Office 2003”。
·插入/改写模式在插入模式下,输入的文本插入到光标位置。
在改写模式下,输入的文本替换光标后边的文本。
如状态栏中的“改写”为深色,表示当前处于改写模式,否则处于插入模式。
《多媒体技术及应用》第3章 文本处理技术

1.扫描 2.纠偏和翻转 3.识别
第20页
3.4 处理文本信息
文本信息处理是指根据不同的要求和使用目的, 选择相适应的文本格式,进行内容、形式(版面)、 风格等的编辑与设计工作,并通过设计特殊图符 和效果来美化文本。
第3章 文本处理技术 概述
文本(Text)是多媒体信息最基本的表示形式之一,可以清 楚、准确地表达思想,描述概念,叙述事实等。它是人们 最熟悉的信息表示方式,例如,文章,书等都以文本形式 出现。
文本的最显著的特点是在组织上是线性的和顺序的。在计 算机系统中,文字和数值都是用二进制编码表示的,文字 信息和数值信息统称为文本信息。
当超文本中的内容不仅包含文本块,而且还包含图片、声 音、视频、动画等多种媒体信息,且通过超级链接实现各 种媒体信息的组合使用时,则这种超文本又被称为超媒体。 目前流行于Internet上的网页大多是超媒体。
第14页
常用文本的存储类型
第15页
3.3 获取文本信息
文本信息的获取主要是指利用不同的设备和输入途径,快速 准确地输入文本信息的方法。
第3页
3.1.1 西文编码
ASCII码
►西文采用ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)表 示,包括数字、字母、特殊符号等。
►ASCII码用7位二进制数表示一个字符,共能表示 27=128个不同的字符,包括了计算机处理信息常用的 26个英文大写字母A-Z,26个英文小写字母a-z,数字 符号0-9,算术与逻辑运算符号、标点符号等。
第4章 文字处理

D.各栏之间的间距是固定不变的
答案:C
解析:
本题考査文字处理基础知识。
Word2007中,对文字块分栏时,各可以设置不同的栏宽。
8.在word 2007中,段落对齐方式不包括()。
A.分散对齐
B.两端对齐
C.居中对齐
D.上下对齐
答案:D
解析:
本题考查文字处理基础知识。
在Word 2007中,段落对齐方式包括:左对齐、右对齐、居中、两端对齐、分散对齐(在左右边距之间均匀分布文本)。
答案:A
解析:
本题考査办公软件使用知识。
打印页中“-”表示连续打印,“,”表示单独打印。如2-6页表示打印的是第2页,第3页,第4页,第5页和第6页,即第2页到第6页,而如果是“2,6”的话,则表示打印第2页和第6页。
7.下列关于Word 2007分栏的功能的描述中正确的是()。
A.最多可以设6栏
B.各栏的间距可以不同
A.只能打开一个文档窗口
B.可以同时打开多个文档窗口,被打开的窗口都是活动窗口
C.可以同时打开多个文档窗口,但其中只有一个是活动窗口
D.可以同时打开多个文档窗口,但在屏幕上只能见到-一个文档窗口
答案:C
解析:
本题考査办公软件基础知识。
目前的办公软件一般都能同时打开多个文档窗口,但只有一个是当前活动窗口。
A. docx
B. wps
C. ppt
D. PDF
答案:D
解析:
PDF文件以PostScript语言图象模型为基础,无论在哪种打印机上都可保证精确的颜色和准确的打印效果,即PDF会忠实地再现原稿的每一个字符、颜色以及图象。PF文件格式与操作系统平台无关,也就是说,PDF文件不管是在Windows,Unix还是在苹果公司的Mac OS操作系统中都是通用的。这一特点使它成为在Internet上进行电子文档发行和数字化信息传播的理想文档格式。PDF不管是什么电脑、什么版本都保持格式一致,且一般不支持随意更改内容。
文本与文本处理

字体(宋体、楷体、黑体、仿宋、隶书···)
字符的修饰
字符的形状(字形):正常、加粗、倾斜、加粗倾斜
字形的修饰:下划线、着重号、上下标、删除线···
字符的颜色
字符的宽度
字符的间距
字符的效果
字符的排列方向
Demo1
29
设置段落的格式
什么是段落?用“回车”相互隔开的一组文字
段落格式的设置:
字符信息的输入
人工输入
自动识别输入
键盘输入 联机手写输入 语音输入
印刷体识别
手写体识别
– 技术上非常困难,还无法实用 –目前准备先突破工整的楷书手写体的识别!
22
汉字的键盘输入
汉字与键盘上的键无法一一对应,因此必须使用 几个键来表示一个汉字,这就称为汉字的“键盘输 入编码” 优秀的汉字键盘输入编码应具有的特点:
美国标准信息交换码(ASCII码):
ASCII字符集包含96个可打印字符和32个控制字符 采用7个二进位进行编码 计算机中使用1个字节存储1个ASCII 字符
0 X XX X XX X 存在问题:
字符集太小(只有128个字符) 不同国家和地区使用不同的字符集及其编码,互不兼容
7
汉字如何编码?
国家标准GB2312-1980 汉字扩充规范 GBK (已被GB 18030取代) 国家标准GB18030-2005 港澳台使用的汉字编码字符集CNS 11643 (BIG
5,俗称“大五码”) UCS/Unicode多文种大字符集
Unicode的UTF-8 Unicode的UTF-16
文本处理举例: 字数统计,词频统计,简/繁体相互转换,汉字/拼音相互转换 词语排序,词语错误检测,文句语法检查 自动分词,词性标注,词义辨识,大陆/台湾术语转换 关键词提取,文摘自动生成,文本分类 文本检索(关键词检索、全文检索),文本过滤 文语转换(语音合成) 文种转换(机器翻译) 篇章理解,自动问答,自动写作等 文本压缩,文本加密,文本著作权保护
公文修改符号及其用法

公文修改符号及其用法公文是指国家机关、团体、企事业单位等正式机构用于内外部沟通、传递信息、处理事务的正式文件。
在撰写和修改公文时,使用恰当的符号和标记非常重要,这有助于确保信息的准确传达以及降低可能出现的歧义和误解。
本文将介绍一些常见的公文修改符号及其用法。
一、删除符号1. 删除线(——):将需要删除的文字或段落用删除线划掉。
这个符号通常用于删除不必要或错误的信息。
2. 删除号(×):写在需要删除的文字或段落上方,表示该部分需要删除。
删除号与删除线的作用类似,但删除号更直接明了。
二、添加符号1. 插入符号(∧):插入符号写在需要添加的文字上方,表示该部分需要添加到原文中。
它可以用于添加遗漏的信息或修改原文的错误之处。
2. 下划线(__):在需要添加的文字下方加上下划线,表示该部分需要添加到原文中。
下划线的作用与插入符号相似,可根据个人习惯选择使用。
三、修改符号1. 替换符号(→):用替换符号表示原文需要替换的部分,并在符号后面写上替代内容。
这个符号用于修改原文中不准确或不恰当的表达。
2. 重复符号(⇔):在需要重复的文字或段落两侧加上重复符号,表示该部分需要在原文中重复出现。
它常用于公文中需要重复提及的信息或重要指示。
四、引用符号1. 引号(“”):将需要引用的文字或段落以引号括起来,表示该部分为他人的观点、引述或引文。
在正式公文中,引述的内容应注明出处,以确保信息的准确性和知识产权的尊重。
2. 斜体字(斜体):将需要引用的文字或段落以斜体字体表示。
斜体的使用可以突出引用部分,使之与正文有所区别。
五、其他符号1. 添加注释符号(*):使用小星号或其他符号在文字或段落旁边加上注释,以进一步解释或补充相关信息。
注释部分通常放在页面底部或另页注释部分。
2. 上标(^):在需要上标的地方加上上标符号,并在上标符号后面写上需要上标的内容。
上标常用于公式、化学式、脚注等地方。
以上所介绍的公文修改符号只是其中一部分,实际使用中还有其他符号和标记。
高中信息技术文字及其处理技术教案

页面大小与方向 页边距设置
页眉页脚设置 打印输出
根据需求设置页面大小(如A4、 B5等)和方向(横向或纵向)。
添加页眉页脚以显示文档标题、 页码等信息。
2024/1/27
16
04
图文混排与表格制作技术
Chapter
2024/1/27
17
插入图片和图形对象
构。
设置表格格式
03
设置表格边框、底纹、字体等格式,美化表格外观。
20
表格数据处理与呈现
01
02
03
04
输入和编辑数据
在表格中输入数据,对数据进 行修改、删除等操作。
数据排序和筛选
对表格数据进行排序和筛选, 方便查找和分析数据。
数据计算和统计
使用公式和函数对数据进行计 录制的宏命令 ,以及如何在文档中插入和运 行宏。
宏命令编辑与调试
介绍如何编辑和调试宏命令, 以解决录制过程中出现的问题
。
23
邮件合并功能实现批量处理
邮件合并概念
解释邮件合并的概念,说明其在批量 处理中的应用场景。
数据源准备
介绍如何准备数据源,包括创建数据 源文件、编辑数据源内容等。
2024/1/27
语音输入设备
介绍常用的语音输入设备 ,如麦克风、耳机等。
语音输入软件
推荐一些优秀的语音输入 软件,并分析其特点和适 用范围。
9
手写输入方法
手写识别技术
了解手写识别技术的基本原理和 应用场景。
手写输入设备
介绍常用的手写输入设备,如手 写板、触控屏等。
手写输入软件
推荐一些优秀的手写输入软件, 并分析其特点和适用范围。
古人书写对于错字掉字的处理

古⼈书写对于错字掉字的处理问:古⼈在抄写⽂章、写信等书写活动中,偶尔也会出现错字、掉字现象。
他们⼀般都怎么处理?答:如果不是特别正式的东西,通⾏的总原则是:在错字右边点上三个⼩点,表⽰这个字不要了。
有时也可能是两个点、四个点,有时还是⼀个很⼩的“⼘”字,都是⼀个意思,表⽰被标记成这种符号的字,都不能算⼊正⽂内容当中。
⽽掉字了呢,则是在上⼀字的右下⾓处补上即可。
问:能不能给我们举些具体例⼦?答:好的。
我们来看下⾯两幅图。
第⼀图是⽶芾的《苕溪诗帖》局部(所有图⽚已将错字、掉字情况加重颜⾊,后同)。
从帖⽂内容看,是⽼⽶⾃⼰已经写好了诗,然后⽐较正式地书写⼀次。
写完“会”字时,他发现这个字写错了,于是在旁边写了个很⼩的“⼘”字,这就是表⽰这个字是误写,不要了。
第⼆图是苏轼的《黄州寒⾷帖》局部,他写完“何殊少年⼦”后,发现殊下⾯少个“病”字,于是在“殊”的右下⾓处补上,⽽且发现“⼦”这个字是多余的,于⼜在旁边加上⼩点,表⽰不要了。
问:《兰亭序》第四⾏“有”右下⾓加了“崇⼭”两字,也是上⾯所说的补字情况吧?答:是的(见下图)。
但《兰亭序》的真伪⼀直存在着争议,我个⼈认为,这两个补字,以及后半部分的故意涂抹,都是有意作假的有⼒证据。
关于这个问题,专写⽂章都得⼏千甚⾄上万字,我们这⼉不是写学术论⽂,就不具体谈这个事情了。
问:说到涂抹,那古代正式书写时,是否也会涂抹掉⼀些字?答:很少很少出现,原因就是为了保持⽂章页⾯的整体⽐较⼲净。
除⾮是完全的草稿,否则很少会涂抹。
问:纯草稿的书法作品,都有哪些?答:最著名的当然就是颜真卿的《祭侄⽂稿》(见下图),因为这就是草稿,所以涂抹的地⽅很多。
这也符合我们写⽂章的基本⽅式。
此外,王铎也有⼤量作诗的草稿传世,你去看⼀看,简直没法认读,因为他是⾃⼰在做律诗,得反复“推敲”很多字,所以就改啊改,最后纸张都涂得不像样⼦了。
最后这些⽂字该如何排序,其实也只有他⾃⼰知道。
问:也就是说,绝⼤部分流传下来的书法作品,都是先有了稿件,然后再⽤⽑笔抄写?答:基本上是这样的。
简述栅格化文字的含义

简述栅格化文字的含义
栅格化文字是指将文字以像素点的形式表示,每个字母或字符都被分解为一个个的像素格子。
这种表示方式常用于计算机图形学和数字艺术中,通过将文字转换为像素点的形式,可以实现对文字的各种处理和变换。
栅格化文字的主要目的是将连续的曲线和线条转化为离散的像素点,从而可以更方便地在计算机屏幕上显示和处理。
通过将文字划分为像素格子,可以将其存储为二维数组或位图,每个像素点用一个二进制数或颜色值来表示。
这种离散的表示方式使得文字可以被计算机直接处理和呈现,例如在屏幕上显示、打印或进行图像处理等。
在栅格化文字中,每个像素格子的大小是固定的,通常以像素为单位。
栅格化的过程中,需要考虑到字体的大小和清晰度,以确保栅格化后的文字能够清晰可见,并尽量减少失真和锯齿等视觉上的问题。
栅格化文字的应用非常广泛。
在计算机图形学中,栅格化文字可以用于生成二维和三维图形中的文字标签、标题和注释等,使其与图形元素融合在一起。
在数字艺术中,栅格化文字可以用于创建像素艺术、游戏界面、动画和电子音乐等。
此外,栅格化文字还可以用于OCR(光学字符识别)技术中,将印刷或手写文字转化为可编辑的电子文本,用于文档扫描和文字识别等应用。
总而言之,栅格化文字是一种将连续的文字形状转化为离散的像素点表示的技术,
它在计算机图形学和数字艺术等领域有着广泛的应用。
通过栅格化,文字可以方便地在计算机中处理和显示,从而实现各种文字相关的功能和效果。
汉字的显示原理

汉字的显示原理汉字的显示原理涉及到计算机技术和文字编码两个方面。
计算机是一种只认识二进制数字的电子设备,而汉字属于复杂的字符集,在计算机中需要通过文字编码来表示显示。
以下是汉字显示原理的详细解释:1. 文字编码:文字编码是将文字字符映射为计算机可以识别和处理的二进制数字的一种方法。
最常见的文字编码系统之一是ASCII码(American Standard Code for Information Interchange),它是美国制定的一个字符集,只包含了拉丁字母和基本的标点符号,不包含汉字。
由于ASCII码的局限性,无法表示汉字等特殊字符,因此出现了许多国家和地区特定的文字编码系统,如GB2312、GBK、GB18030等,分别用于表示简体中文及常用汉字。
2. Unicode编码:为了解决不同国家和地区文字编码的混乱局面,Unicode(统一码)横空出世。
Unicode是一种国际字符集,为世界上所有的字符提供了统一的编码方案,包括汉字、拉丁字母、数字、标点符号等。
Unicode目前包括了超过13万个字符,其中包括汉字及其他各种语言的字符。
Unicode编码采用的是32位的编码方案,即每个字符用4个字节表示。
为了节省存储空间和传输带宽,在实际使用中,通常会使用Unicode的子集UTF-8(8-bit Unicode Transformation Format)进行存储和传输。
UTF-8是一种变长编码方案,根据字符的不同,使用1到4个字节来表示字符。
对于英文字母和数字等基本字符,UTF-8只需要1个字节表示,而对于汉字等特殊字符,需要3个或4个字节表示。
3. 字库与字形:计算机中的汉字显示需要依靠字库和字形来完成。
字库是存储了一定数量的汉字和其他字符的数据库,字形是对于每个字的形状和样式的描述。
字库和字形的关系是一对多的关系,即每个字可以对应多种不同的字形。
在早期的计算机中,字库和字形主要采用点阵字库的方式来存储,即每个文字在一个字格中使用二进制的点阵表示。
第 4 章 文字处理与编辑排版

第 4 章文字处理与编辑排版一、字符的ASCII 编码在机器中的表示方法准确地描述应该是:使用8 位二进制代码, 1 。
1 . A )最右边一位为1 B )最左边一位为1 C )最右边一位为0 D )最左边一位为0二、在微型计算机中,应用最普遍的英文字符编码是 2 ;汉字字符编码是 3 。
2 . A ) BSC 码 B ) ASCII 码 C )汉字编码 D )反码3 . A ) GB2312- 80 B ) BSC 码 C ) ASCII 码 D )汉字编码三、在微机汉字系统中GB2312-80 用 4 位二进制表示1 个符号;而微机汉字系统的机内码的两个字节中,每个字节的最高位分别是 5 。
4 . A )8 B ) 16 C ) 4 D ) 75 . A ) l 和 1 B ) l 和0 C ) 0 和 1 D ) 0 和0四、输入汉字时,计算机的输入法软件按照 6 将输入编码转换成机内码;存储和处理汉字时,采用的是7 。
6 . A )字形码 B )国标码 C )区位码 D )输入码7 . A )字形码 B )国标码 C )机内码 D )输入码五、根据键入技术来分类,汉字的输入大致可分为8 类;五笔字型码属于9 。
重码是指同一个编码对应10 个汉字。
8 . A ) 4 B ) 3 C ) 5 D ) 29 . A )音形混合码 B )双拼码 C )全拼码 D )形码lo . A )多 B ) 3 C ) 2 D ) l六、汉字字库或汉字字模简称11 ;若汉字固化在ROM 或EPROM 中,则称为12 字库。
11 . A )汉字库 B )软库 C )硬库 D )字典12 . A )固定 B )硬 C )规范 D )软七、汉字字模是汉字的13 ;标准汉字库的容量取决于14 的大小;24 * 24 点阵字形用15 个字节存储一个汉字。
13 . A ) ASCII 码 B )机内码 C )点阵字形信息 D )国标码14 . A )汉字的字模 B )字模点阵 C )汉字笔划数量 D )以上都不是15 . A ) 128 B ) 32 C ) 288 D ) 72八、存储一个汉字字形的16×16 点阵和存储一个英文字母字形的8×8 点阵,所占字节数的比值为【①】。
〖2021年整理〗《Word文字处理初步》课后练习

第十课Word——文字处理初步学习要点1、初识Word界面。
2、打开、保存文档。
3、字体、段落、格式的设置。
4、查找与替换文本。
5、移动文本。
一、填空题1、字体是指字符的轮廓特征。
常用的中文字体包括宋体、黑体、幼圆、隶书等。
2、字号是指字符的大小。
一种是使用西方的计量单位磅,以阿拉伯数字形式表示,称为数字法,数字越大,字符也越大。
另一种是适应中文排版需要的标准初号到八号字,称为中文法。
号数越大,字符越小。
3、字形即字符的形状,在Word中包括字符加粗、倾斜、下划线等属性。
4、“植物舞蹈家”设定为“黑体”、“小三”号、“加粗”,分别应该在1、3、2处进行设定。
5、在Word中,段落是指以回车键结束的一串文本。
6、Word提供了左对齐、两端对齐、居中对齐、右对齐、分散五种对齐方式。
7、某文件正文设定为“首行缩进4字符”、“两端对齐”、“左右缩进2字符”、“段前、段后间距1行”、“行距倍”格式,分别应该在(如图)3、1、2、4、5处进行设定。
8、当编辑文件时出现了误操作,可以用“常用”工具栏中的撤消命令,也可以使用快捷键CtrZ。
9、剪贴板是文档进行信息传输的中间媒介,是信息的临时存储“仓库”,可以存放多种形式的数据,如文本、图像、数值、文件等,可以对该数据进行复制或移动操作。
10、如果同一个错误在文中反复出现多次,可以利用查找与替换进行修改。
如要把某文件中的“通海一中”全部改成“通海六中”,(如图)1处通海一中填写,2处填写通海六中。
11、Word提供了五种文档的查看方式:普通视图、Web版式视图、页面视图、大纲视图、阅读版式。
其中“所见即所得”的是页面视图。
文字的功能及文字的表达

文字的功能及文字的表达文字的许多功能和用途,是由人类为满足生存、生活的需要逐渐开发出来的。
如木头本没有什么用处一样,它点火、造船、造农具、造房子、造箱子的功能是人类对它创造性使用的结果。
那么,文字功能是怎样在人类生存生活的需要下,逐渐发展成现在的样子的呢?远古的人类通过“结绳记事”,但只能大概地、比较性地表示“物”的大小和多少,无法表示“物”的具体形状。
后来容易识别“物”,人们就创造了“画”。
这个“画”就是仓颉用来表示“物”的原始文字。
如果说“画”是文字的雏形(字画同源),最初的文字是只具有“形”的要素,它的功能只具有记录的功能。
但有时“画”在眼前,有时不在眼前。
人们不可能天天拿着“画”来进行交流。
当“画”不在眼前时,用打手势或体态说明,是很困难的。
如果给“画”一个固定的声音,有一个能够叫出来的名子,就简单多了。
这样“画”就不仅有了视觉的形,也有了一个和它对应的声音的表达。
从此,文字就有了交流的功能。
汉字的“形”和“音”,使“画”变成了一种抽象的符号。
这些抽象的符号在人类长期的使用过程中被固定下来,成为一种公认的约定的能代表一定的“物”的符号。
这样文字就具足了“音、形、义”三个基本要素。
如果文字的“记录、记载、交流”仅仅停留在对“物”形状的表达上还是不行的,要知道这个“物”的位置、方向、作用、性质、功能等,还必须有“指示字”。
如“上、下、前、后、左、右、内、外”等字。
指示字表明文字说明事物功能。
在人类日常生活交流的过程中,只对“物”加以说明是不够的,世上的“物”都是相互联系变化的。
这就需要把“物”的发展变化的过程表达出来,这就是叙事。
人类最初的叙事记录是用字表达的。
如牧、放、解等字。
这就是会意字。
会意字是文字叙事的功能。
事物的发展变化都有一定道理的。
也就是说“物”的发展变化都有其内在的规律,人类对规律的说明就是说理。
说理即是表达思想,没有虚词不行。
在日常生活中,不仅需要记载、记录、说明、叙事、说理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
文字的表示及处理
4.GB18030-2000编码 GB18030-2000编码标准在GB2312和 GBK编码标准的基础上进行了扩充,采用 单字节、双字节和四字节三种方式对字 符编码,因此该标准的汉字有27000多个。 包括全部中、日、韩统一字符集和CJK汉 字扩充的所有字符。
22(52)
使用7个二进位对字符进行编码。
2(52)
文字的表示及处理
基本的ASCII字符集共有128个字符
95个可打印字符(常用字母、数字、标点符号) 33个控制字符(不可直接显示或打印)
特殊字符的ASCII码 空格(32)、A(65)、a(97)、0(48)
下面为ASCII代码表:
3(52)
文字的表示及处理
34(52)
文字的表示及处理
汉字字型码:用于汉字在显示器或者
打印机上输出.
汉字字型码表示形式分类:
点阵表示形式
矢量表示形式
35(52)
文字的表示及处理
汉字字型表示形式:
点阵描述
汉字字型码用点阵表示 16*16(占32个字节)、 24*24、48*48等 汉字矢量表示存储描述汉 字轮廓特征的信息。如: Windows中TrueType技术即 为该表示形式。
20行
大
13(52)
文字的表示及处理
1.GB2312-80汉字编码 国标交换码 (国标码):
问题:信息通信中,汉字的区位码与通信 使用的控制码(00H~1FH)发生冲突。 解决方案:为了避免汉字区位码与通信控 制码的冲突,每个汉字的区号和位号必须 分别加上32。得到的代码称为汉字的“国 标交换码”
6(52)
文字的表示及处理
要求:
1.会比较ASCII字符的大小(按其ASCII码值)
空格<0~9<A ~Z <a~z 2.会推算同组字符ASCII码值 如A的ASCII值(十进制)为65,则B、C… 的ASCII值分别为66、67…
7(52)
文字的表示及处理
2.EBCDIC码
定义方式:
用8位二进制数位表示一个字符的扩
17(52)
文字的表示及处理
2.GBK汉字内码扩展规范 问题:GB2312-80只有6763个汉字,使用时 功能不够。 解决方法:1995年发布GBK,全称为《汉字内码
扩展规范》GBK字符集中一共有21003个汉字和 883个图形符号,它与GB2312国标汉字字符集及 其内码保持兼容。
组成:共收入21886个汉字和图形符号 (21003个汉字,883个图形符号)
小词汇量/中词汇/大词汇量语音识别
特定人/限定人/非特定人语音识别
最高目标:非特定人大词汇量的连续语音识 别技术
31(52)
文字的表示及处理
(4)脱机文字识别
脱机文字识别:对已经印刷或写完的文字
进行识别, 自动输入计算机并转换为数字文本
形 式 的 一 种 技 术 , 也 叫 做 汉 字 OCR ( Optical
文字的表示及处理
3.5 文字的表示及处理
主要内容: 西文字符编码 汉字编码 汉字的输入和输出 文本处理
1(52)
文字的表示及处理
一、西文字符编码
1. ASCII码
ASCII码,即美国标准信息交换码
(American Standard Code for Information Interchange),
解决方法:使表示GB2312汉字的两个字节的最
高 位 (b7) 都 置 为 “ 1” 。 这 种 汉 字 编 码 , 称 为
GB2312汉字的“机内码”
。
16(52)
文字的表示及处理
区位码 + 32 = 国标码
国标码+128 = 机内码 例如:“大”字 区位码:20 83 二进制表示为:00010100 01010011 国标交换码:52 115 (+32) 二进制表示为:00110100 01110011 机内码:180 243 (+128) 二进制表示为:10110100 11110011 (B4F3)
Character Recognition)。
分类: 印刷体OCR 和手写体OCR
32(52)
文字的表示及处理
汉字键盘输入方法的比较
类型
数字 编码 字音 编码
原理
举例
优点
缺点
使用一串数字来表示 电报码 汉字 区位码
仅使用10个数 难记忆 字键
把汉语的拼音作为汉 智能ABC 简单易学,适 重码多,需增加选择 字的输入编码 紫光 合于非专业人 操作,不会汉语拼音 微软拼音输入 员 或不知道读音时无法 使用 把汉字的部件或笔画 五笔字形 作为码元,按照汉字 表形码 结构及其切分规则作 郑码 为编码依据,确定每 个汉字的输入代码 重码少、输入 缺乏统一的规范,编 速度较快,适 码规则不易掌握 合于专业录入 员、打字员使 用 同上 同时要掌握音、形两 种取码方法或规则, 对普通用户比较困难
1.GB2312-80汉字编码
区位码: GB2312-80是一个二维代码 表,有94行、94列, 汉字在代码表中的 位置用它所处的行号、列号表示。
行号 区号
列号
位号
12(52)
文字的表示及处理
例如:
“大”字的区号20,位号83,
区位码是20 83
用2个字节表示为:
83列
00010100 01010011
轮廓点
直线
二次曲线
轮廓描述
36(52)
文字的表示及处理
字型库:简称字库,同一种字体的所有
字符(例如GB2312中的7000多字符)的形状描
述信息的集合。不同的字体(如宋体、仿宋、
楷体、黑体等)对应不同的字库。
37(52)
文字的表示及处理
三、文本编辑
1.文本的编辑
ቤተ መጻሕፍቲ ባይዱ
文本编辑的主要功能(了解)
19(52)
文字的表示及处理
3.UCS/Unicode汉字编码
目的:统一的多文本处理环境,实现所有字符 在同一字符集中统一编码
途径:UCS:ISO/IEC 10646 (通用多8位编码 字符集) Unicode:统一码或联合码,与UCS完全等 同的工业标准 优点:编码空间极大(4个字节),能容纳足 够多的各种字符集(13亿字符)
20(52)
文字的表示及处理
缺点:4字节的字符编码使存储空间浪费严重
克 服 : UCS-2 是 双 字 节 编 码 , 共 有 字 符 49194个,其中包括:
欧洲及中东地区使用的拉丁字母、音节文 字 各种标点符号、数学符号、技术符号、几 何形状、箭头及其他符号 中、日、韩(CJK)统一编码的汉字
运动按时间采样,发送到计算机中,由软件进行 识别,然后用该汉字(或符号)对应的代码进行 保存。
例如:
汉王笔
正识率 95℅ ~ 90℅,
速度 12字/秒
30(52)
文字的表示及处理
(3)汉字语音识别
目的:使计算机具有人的听觉,是模式识别的 分支
孤立词/连接词/连续语音识别
语音识别的分类(按照不同的应用及要求):
14(52)
文字的表示及处理
例如:
“大”字的区号20,位号83 区位码:20 83
二进制表示为:00010100 01010011
国标交换码:52 115 (+32)
二进制表示为:00110100 01110011
15(52)
文字的表示及处理
1.GB2312-80汉字编码
机内码:
问题:文本中的汉字与西文字符经常是混合在 一起使用的,汉字信息如不予以特别的标识, 它与单字节的标准ASCII码就会混淆不清。
18(52)
文字的表示及处理
GBK汉字内码扩充规范
GBK编码区分三个部分:
汉字区(21003个汉字)、图形符号区、用户自定义 区 GBK每一个字符都采用双字节表示
总体编码范围为:8140H—FEFEH,共23940个码位;
首字节范围:81H—FEH(二进制最高位为1); 尾字节范围:40H—FEH(二进制最高位可以为0或1);
9
文字的表示及处理
(2)第二部分:一级常用汉字,共3755个,
按汉语拼音排列
(3)第三部分:二级常用汉字,共3008个,
按偏旁部首排列
汉字共6763个 字符共7445个
10(52)
文字的表示及处理
1.GB2312-80汉字编码
GB2312-80字符集
1 2
1
位号 3 ………………
94
拉丁字母、俄 文、日文平假 名与片假名、 希腊字母、汉 语拼音等共682 个
7
8
9
A
B
C
D
E
F
0 1 2 3 4 5 6 7
控制字符
5(52)
文字的表示及处理
每个字符用标准规定的7位二进制数表示, 在机内占一个字节(最高位为0)。
如: 字符“A”的ASCII码为:
(01000001)2 或(65)10、(101)8、(41)16
字符“0”的ASCII码为:
(00110000)2 或(48)10、(60)8、(30)16
GB18030
保持向下兼容
编码不 兼容!
27484
FF
汉字
24(52)
文字的表示及处理