双口RAM应用实例
双口RAM在雷达数据处理中的应用

( e 7 3 I s iu e o I Ya g h u 2 5 01 Ch n ) Th 2 n tt t f CS C, n z o 2 0 , i a
Ab ta t Th s p pe e e t he s r t e o ua— r s r c : i a rpr s n s t t uc ur f d lpo t RAM ,nt o c s t i r du e he bus og c o y l i f du lp r a — o t RAM , nd i t o c sm anl h he y a d me h a n r du e i y t e t or n t od ofCPU t t i da a s orng, a a e — d t x c ng ng a a a s a i hr gh du lpo tRAM wo CPU n d t oc s o h a。 ha i nd d t h rng t ou a・ r ・ oft i a a pr e s roft e r 。
da e m i a . rt r n 1 Ke r s du lp r y wo d : a — o tRA M ; t ag i ; d e sar ir to og c; om p r t s or e un t a dr s b t a i n l i c a a or
双口R AM 有 2路 完全 独立 的 数据 总 线 、 地
收 稿 日期 :2 0 0 5一O 4—1 3Leabharlann 维普资讯 维普资讯
20 0 6年 8月
舰 船 电 子 对 抗
SH I PB( A RD ) ELECTR (N I C( U N TERM EASUR E ) C )
双口RAM在嵌入式系统调试中的应用

路 板面 积 。配台 IA总 线采 用 中 S
不仅可 满 足上 位 机 多任务控 制 系统 的需要
, ,
还
可 提 高本 系统 实时数 据 的处 理时 1l I 序 中 睦 时 效
。
I 7 3 ( ) 上位机 地址 DT 1 0U6 在
信方式, 或因结构复杂, 或因 传递
B
,
种 插 卡 式 可 编程 控 制 器 a该 嵌 入 式
I T 10 美 国I T 司采用 高 为与 上位机 共享 的通信 数据 区 如 图 D 73 是 D 公 P C实 质是 一个 智能 化 I L / O接 口卡 , 性 能 的 c s Mo 工艺生 产 的高速 1 K 2 所示 i 轰器件 的高集 成 度大大 简化
维普资讯
、
\
置 与 ] ■ 茸 结 E :
双 口 RAM 在 嵌 入 式 系 统 调 试 中 的 应 用
羲 毫 文 台 牡 曲 点 夼 t 渔 八 P 毒 辕 | 本 蛄 糕 采 特 , 甥 它 嵌 成 L 蜕 硬 I e
:: #
j
该片用别同的断志 芯 运 有 于 类 中标 进
行总线仲裁: 存储阵列中的 ×3E FH
和 ×3F F H单元被用做通信 “ 邮箱 ,
择调磷 竹萋席 怠媾了 _ 《 霉溉 箕罐虢攫神 强 鲥 调,
黪嚣 l中嘲貔蔫戮婚 . 谚 试 最。
j 嘲 R M ^ { 统 试 ≤ | 藏口 ^ j 或 摹 调 嵌
芯片却 独具特 点 :①具 有两套 完垒
卜 上 — — 003 、 8:04F - — — — 一 0.F 00003 — 0-F D 00-F - 0 - 1
00 00
~
双口RAM在DSP与ICCD通信系统中的应用

程 。针 对二 者 交换 数 据 的 仲 裁 方 式 , 出 了解 决 冲 突 争 端 的 方 法 。 整 体 系统 通 过 调 试 , 明 文 中采 取 的 中断 , 逻 提 证 忙
辑, 软件协调三种模式 , 有效解决 了两个 系统之 问的通信 争端。信 息处理 系统与 IC C D可 良好 协调 工作 , 系统 运行
SM E H H
输 出 L0 ,0 高 阻 数 据输 入
功 能 休 眠模 式 写 存 储 器
L
X
H
X
X
H
H
X
数据输 出
高 阻
读存储器
输 出不 允 许
( )两套完全独立 的数据 线 、 址线 、 写控 制线 , 1 地 读/ 允
许 两 个 C U对 双 端 口存 储 器 的 同 一 单元 进 行 同 时 存 取 ; P ( )有 两 套 完 全 独 立 的 中断 逻 辑 来 实 现 两 个 C U之 间 2 P
子系统之间的高速通信。
1 双 口 R M 器件 I T7 o A D O 7介绍
11 器件简介 .总线 ຫໍສະໝຸດ 称 描述 总线名称
描述
D 1 0 [5— 】
数据信号
C# E
片选信号
IT70 D 0 7是 美 国 IT公 司 采 用 高 性 能 的 C S工 艺 生 D MO
产的高速 3 2k×8bt i双端 口静态 R M, A 典型功 耗 8 0m ; 5 w 最大存取时 间:5n ; 1 s 工作 环境 : 5℃ ~+8 ; 一4 5 工作 电
口宽 度 , 址 线 l 地 2位 , 寻 址 空 间 应 为 3 8bt 可 2k× i 。
双口RAM在CAN与PROFIBUS-DP网关中的应用研究

两个 L C 1 8微控 制 器和 双 口 R M 设 计 C N 与 P O IU — P网 关 的方 案 ,介 绍 了利 用双 口 P23 A A R FB SD
R M 实现 双 C U之 间的 通信 的 实用 、高效 的方法 。这种设 计方 案对 其他 现 场 总线之 间的 网关设 A P
计具 有重要 的借鉴 意义 。 关键 词 :双 口 R M;P O IU — P A A R FB SD ;C N;总线
Ap l a in o u 1p r p i to fd a . o tRAM n t e CAN nd c i h a PROFI BUS. DP a e y g t wa
D P与 C N总线 网关 可 以实 现这 两种 不 同总线 之 间 A
d a P i e u e o u l o u lC U w t t s fd a — r RAM.T i e i r g a o t e ed u ae y b t e e hh pt h s d sg p o ms fr o r f l b s g t n r h i wa ewe n t h
P O IU 是 符 合 德 国 国家 标 准 D N 94 R FB S I 125和 欧洲标 准 E 5 10的 现 场 总线 , P O IU — P N07 由 R FB SD 、
P O I U .A和 P O IU —MS三个部 分 组成 , R FB S P R FB SF 广
灵活。
F ANG iz e , C L .h n HENG a g h ‘ W ANG o 1 Gu n . e , Ma .i ,L Gu . u V o h a ,
( .S a d n o ue c n eC ne ,ia 0 1 C ia 1 h n o gC mp t Si c e t J n2 04, hn ; r e r n 5 2 S a d n s tt f ih d sr ,ia 05 , hl ) .h n o gI t ueo g t n utyJn n2 3 3 C ia ni L I 5 l
IDT7007高速双端口RAM及其应用

PDF 文件使用 "pdfFactory Pro" 试用版本创建
来获得标志。一旦右边使用完毕而显示复位标志(置标志为 1),则左边立即置标 志为 0 以获得使用权,旗语通讯标志总是通过置位——测试的序列来进行的。旗
语通讯标志为低电平有效,申请标志应向锁存器写 0,释放标志时写 1。这八个锁 存器可通过 SEM、OE、R/W、A0~A2 像 RAM 单元一样来进行读写,只是读或
表 6 典型旗语通讯序列
功能
左端口
申请寄存
D0
器
右端口
申请寄存
D0
器
状态
旗语通讯
无动作
1
1
1
1
自由
左端口写
0
0
1
左端置标
1
志
无变化,右
右端口写
0
0
1
0
端保留申
请标志
右端获得
左端口写
1
1
0
0
标志
右端口写
1
1
1
旗语通讯
1
自由
PDF 文件使用 "pdfFactory Pro" 试用版本创建
INTL x
=H 功能
x
x
不相等
H
H
正常
H
x
相等
H
H
正常
x
H
相等
H
H
正常
L
L
表 5 旗语通讯读/写操作
输
相等 入
CE
R/W
OE
(2)
(2) 写禁止(3)
SEM
输出 I/O0-7
模式
H
Linux内核中双口RAM驱动开发及在大圆机控制系统中的应用

De v e l o pm e nt o f Du a l — po r t RAM Dr i v e r i n Li n u x Ke r n e l a nd Appl i c a t i o n i n Co nt r ol S y s t e m of Ci r c ul a r Ma c hi n e
W ANG Yi l i ,H 【 , Xu d o n g,H UAN G Bi n ( F a c u l t y o f Me c h a n i c a l E n g i n e e r i n g a n d Au t o m a t i o n , Z h  ̄ i n a g S c b T e c h Un i v e r s i t y ,Ha n g z h o u 3 1 0 0 1 8 , C h i n a )
d i a me t e r j a c q u a r d c i r c u l a r k n i t t i n g ma c h i n e .T h e e x p e r i me n t a l r e s u l t s h o ws t h a t t h e c o n t r o l
s y s t e m o f c i r c u l a r ma c h i n e c a n l o a d d u a l — — p o r t RA M d r i v e r a n d c o r r e c t l y i d e n t i f y d u a l _ ’ p o r t RAM wh e n s t a r t i n g;i t c a n r e a l i z e p a r a me t e r t r a n s f e r o f u p p e r a n d l o we r c o mp u t e r s t h r o u g h
基于FPGA的数据遗弃式双口RAM的设计及其在数据采样中的应用

Ke wo d : a d n d Du 1 o AM ; P y r s Ab n o e ; a . r R p t F GA; VHDL
0 引言 在 某些工程 中 ,需要及 时得 到 系统最 新一 段 时 问的数 据来诊 断或检测 系统 最新 的运作 状 态 ,因此 对 系统采 集和数 据存储 提 出 了新 的要求 。 文献 【—] 13 中所 实 现的系统 ,在一 定程 度上 提高 了采 样系 统 的 速 度 和精 确 度 , 中文献 [] 其 3还采 用 串行 FF IO双 口 R M 作 为采 样 系统 的数 据存 储 。FF 先 入 先 出 ) A IO(
双 口R AM 的数据存储结构是先进先出的数据存储 模式。这种数据存储模式 即不能存储最新 时问片的 数据 ,同时在高速的采样系统 中也容易造成数据的 堵塞 , 容易出现数据丢失的情况。 本文提 出采用 F G P A构建 的数据遗弃式 双 口 R M,不 断地 将数 据 从 双 口 R M 的 首 位存 入 A A R M, A 同时双 口R M 中数据在最高位遗弃。 A 这种遗
wi D9 6 w i pe e f bt D o v r rt o s- t ido i . edd t smpigss m a t A 7 , hc i a ic 一iA/ c n et 。oc nt c kn f g s e aa a l t t t h hs o1 6 e i a u h h p n ye h
基
于
-1 T
_ D
A 数 遗 式 口 A的 计 其 数 采 中 应 的据 弃双 R 设及在据 样的用 M
true dual port ram 的用法

true dual port ram 的用法
True Dual Port RAM的用法是指同时允许两个独立的数据写入或读取,并不会有数据冲突。
它是数字电路设计中的一种非常重要的电子器件,主要应用于数据缓冲、图像数据处理、信号生成等领域。
其被广泛地
应用于数据传输和处理芯片中。
True Dual Port RAM的设计基本结构类似于一种显存,但其有两个独
立的端口,分别由不同的控制线进行控制。
以Cypress公司的
CYD7446GN为例,其具有两个读取端口和两个写入端口。
其中,每个端口都可以独立地访问内存快,并且每个内存单元都由一个相应的读取
端口和写入端口控制。
这样可以让两个独立的设备同时访问同一块内存,彼此之间不会互相干扰。
True Dual Port RAM的应用非常广泛。
首先,它可以作为数据缓冲器
使用,让数据通过一条线路被多个处理器同时读取,以实现数据存取
的高效性。
其次,它还可用于图像和音频处理器中,被用于保持音频
和视频数据的像素值或颜色。
另外,True Dual Port RAM还可以用于
信号处理电路的数据保存和恢复,例如,车载系统中的雷达信号处理
模块,采样时,从两个端口同时读取数据。
总而言之,True Dual Port RAM的应用领域非常广泛,在工业、航空、航天、通信等各个领域都有广泛的应用。
其能够同时处理多条数据,
并且保证数据的正确性和独立性,为当今的数字电路设计提供了先进
而灵活的功能。
双端口RAM在高速电脑提花机中的应用

双端口RAM在高速电脑提花机中的应用黄金波(桂林空军学院541003)摘 要 介绍了双端口RAM ID T7005的仲裁方法,以及ID T7005在提花机控制系统中的应用,较好地解决了提花机实时、高速选针控制与在线花型修改的矛盾,使大提花机的伺服系统轻松实现8000纬/mi n(1344针)以上,对各种提花机均能满足要求。
关键词 提花机 双端口RAM 工控机 单片机1 前言在高速大提花机伺服系统中,采用单个CPU (通常是工控机)实现对提花选针的实时控制,同时又要实现在线花型的显示、局部放大、编辑修改,有时还要实现组网生产管理而必须与管理中心服务器进行通信,这给伺服系统的设计带来很大的困难。
一方面要求硬件设计要采用速度较高的工控主板,使伺服系统硬件成本大幅度上升;另一方面使软件的开发难度增大,且受系统资源限制,软件在运行时必然要频繁地打开、关闭花型文件等,使软件的运行效率较低,难以实现大提花机的多任务、实时高速的伺服控制。
采用多CPU架构是解决这类问题最有效的方法。
本系统采用工控机主板+单片机模式进行设计,工控机负责人机交互,磁盘文件的管理,花型文件的显示、局部放大、编辑修改,数据的预处理,织机的状态显示,工控机与单片机的数据通信及与网络管理中心服务器的通信等任务;单片机负责提花龙头选针控制,织机的伺服控制等实时性任务。
由于花型文件较大时(比如达到8M),将系统设计成开机时一次性传送整个文件是不经济的,而且难以实现在线修改后传送。
因此,合理地解决工控机与单片机间的数据通信是本系统设计中的关键。
CPU之间的通信可采用以下几种方式:串行通信;并行通信;利用共享式存储器实现。
串行通信时要占用双方CPU时间,并行通信是在CPU之间增加缓冲器或锁存器实现双机通信,由于通信的数据量较大且要求实时,工控机的负担并没有因为增加单片机而得到明显减轻,这两种方式对解决本问题效果不理想。
共享式存储器有用普通存储器构成的DMA方式和用多端口存储器构成的新的通信方式,采用DMA方式能够达到数据的高速传输,但不能同时访问存储器,CPU必须等待总线,不利于实时控制;利用多端口存储器,例如双口RAM和F IFO 就是常用的两种多端口的存储器,它允许多CPU同时访问存储器,大大提高了通信效率,同时CPU间运行时的相互牵制达到最小,是解决本问题最理想图 主界面设置界面设计具有故障自动显示功能,电气参数和工艺参数可进行加密设置,即可设置使用者的优先权。
fpga双端口bram的用法

FPGA双端口BRAM的用法在现代的数字设计领域中,FPGA(Field-Programmable Gate Array)技术已经得到了广泛的应用。
FPGA是一种可编程的逻辑器件,可以通过编程来实现不同的数字电路功能。
而BRAM(Block RAM)是FPGA中的一种重要资源,用于存储数据和临时变量。
在FPGA设计中,双端口BRAM是一种非常有用的资源,能够提高设计的性能和灵活性。
1. 双端口BRAM的基本概念双端口BRAM是指具有两个读写端口的块RAM。
这意味着它可以同时进行读和写操作,而不会出现数据冲突。
这种特性使得双端口BRAM非常适合在FPGA设计中用于存储和处理大量的数据。
在图像处理、信号处理和深度学习等领域,双端口BRAM可以有效地提高算法的性能和并行处理能力。
2. 双端口BRAM的应用双端口BRAM在FPGA设计中有多种应用方式,可以用于实现数据缓冲、数据通路和状态机等功能。
在数据缓冲方面,双端口BRAM可以用于存储输入和输出数据,同时进行读写操作,以实现数据的缓冲和流水线处理。
在数据通路方面,双端口BRAM可以用于实现数据的交换和共享,以便多个模块能够同时访问和处理数据。
在状态机方面,双端口BRAM可以用于存储状态变量和控制信号,以实现复杂的状态机和状态转换逻辑。
3. 如何使用双端口BRAM在FPGA设计中,使用双端口BRAM需要首先进行资源分配和位置区域映射。
然后需要进行读写控制和数据流控制,以确保数据的正确读写和流水线处理。
需要根据具体的应用场景和性能要求,进行数据路径和控制逻辑的优化和调整。
使用双端口BRAM需要充分理解其工作原理和时序要求,以确保设计的正确性和稳定性。
4. 个人观点和总结作为FPGA设计领域的一名从业者,我认为双端口BRAM是一种非常有价值的资源,能够大大提高FPGA设计的性能和灵活性。
通过合理的应用和设计,双端口BRAM可以在信号处理、图像处理和人工智能等领域起到重要作用,为项目的成功实现提供了有力支持。
双端口存储器实验步骤

双端口存储器实验步骤一、实验目的双端口存储器是一种非常重要的存储器类型,本实验旨在通过实际操作了解双端口存储器的工作原理和应用。
二、实验原理双端口存储器是指具有两个独立的数据输入/输出端口的存储器。
其中一个端口可以用于读取和写入数据,而另一个端口只能用于读取数据。
双端口存储器通常用于需要高速并发访问的应用中,例如视频处理、音频处理等。
三、实验设备1. FPGA开发板2. Quartus II软件3. 双端口RAM芯片四、实验步骤1. 设计电路图首先,需要使用Quartus II软件设计电路图。
在电路图中添加一个双端口RAM模块,并将其连接到FPGA开发板上。
确保电路图正确无误,并生成可编程文件。
2. 编写Verilog代码接下来,需要编写Verilog代码来控制RAM模块的读写操作。
代码需要包括以下内容:- 地址信号:用于指定要访问的内存地址。
- 数据信号:用于传输要写入或读取的数据。
- 读/写信号:用于指定当前操作是读还是写。
- 时钟信号:用于同步各个模块之间的操作。
3. 烧录可编程文件将生成的可编程文件烧录到FPGA开发板上,确保烧录成功。
4. 进行测试使用示波器等测试工具,对RAM模块进行读写测试。
确保数据能够正常读取和写入,并且能够在不同端口之间进行并发访问。
五、实验注意事项1. 在设计电路图和编写代码时,需要仔细阅读芯片的数据手册,并按照要求正确配置各个信号。
2. 在进行测试时,需要注意时钟信号的频率和稳定性,以确保数据传输的准确性。
3. 如果出现问题,应该及时检查电路图、代码和硬件连接,并进行排查。
继电保护装置中的双口RAM

/ E CL L
左端口 / L OE X
A2.0 l AL L 1 F FF
/NT I L X
R WR / X
/ E CR X
右 端 口 / E OR X
A2・ 0 l AR R X
/ NT I R L
功能 设 置 / NT I R
双 口存 储 器 ,它 有 两 套 地 址
图 1 MC 8 3 6 3 2与,  ̄s 2 w 4 r 3o o接口示意 图
维普资讯
《 气自 化 2 6 电 动 ) 0年第2卷第2 0 8 期
微 电脑 应 用
表 1 邮箱 中 断真 值 表
R /WL L
O t 数 据 缓 冲器 , 加 上 一 u) 再
1 S 2 F4 ¨ 3 0 2o
些必要的控制信号线 ,这样
处 理 器 之 间 可 以 按 照 先 进
先 出的顺序原则 , 通过 FF IO
器 件 实 现 相 互 通 讯 。但 是 这 种 方 式 主 要 适 合 于 每 次 所 要 交 换 的 数 据 较 少 、要 求 处 理 器 问 的 数 据 交 换 尽 可 能
线和两套数据线 ,有关控制逻辑保证 每时每刻 只有一套地址线和
一
套数据线通过带三态的缓 冲器对全局存储器进行读 、 写操作 。
在我们研制 的继 电保护 系统 中 , 采用 摩托罗拉3 位 高性 能单 2 片机 MC 8 3 负责对 整个 系统 中运行 的各个 任 务的 管理 和调 6 3 2,
度, 人机 对话 , 开关 量 的采 集 、 出等任 务 ; 输 而数 据 采集模 块 的 C U则采用 德州 仪器公 司 T 3 0 2 0 D P 模 块 的具 体工 作流 P MS 2 F 4 S 。 程分 两路 : 一路是 经开关柜 在线检测 电路 , 进入 D P内置 的两片 S A D转 换器进行转 换 ; 另一路 由外 部二次侧 电压 、 电流 经过电压 、 电流互 感器 , 信号调理 电路 , 转换为 ± V交 流信号 , 5 再经 过 A/ D 转换 器 MA 2 模数转 换 , 换结果 由 D P读 取 。 X15 转 S 然后 再 由 D P S 进行 各种必 要 的计 算处理 , 并将 结果送 到双 E R M 供 MC 8 3 1 A 632 使用 。 C 8 3 需要使 用大量 由 D P处理完 成 的各种数据 , M 632 S 由于 有 实时处 理的要 求 , S D P不 能被 动地用作 从处理 器 , MC 8 3 在 6 32
实验二双端口存储器原理实验

实验二双端口存储器原理实验实验目的:1.了解双端口存储器的工作原理;2.了解双端口存储器的读写时序;3.掌握双端口存储器的控制方式。
实验器材:1.双端口RAM芯片;2.数字逻辑实验箱;3.示波器。
实验原理:双端口存储器是一种具有两个访问端口的存储器,其中一个端口用于读数据,另一个端口用于写数据。
两个端口可以同时进行读写操作,且可以独立操作,互不干扰。
双端口存储器广泛应用于多核处理器、高速路由器、交换机等领域,其性能优越,能提供更高的并行处理能力。
双端口存储器的读写时序如下:1.读操作时序:1)使能端CE1置低,选中读数据的端口;2)地址信号输入地址端口AD1;3)等待一段时间,取数据端口的读数据。
2.写操作时序:1)使能端CE2置低,选中写数据的端口;2)地址信号输入地址端口AD2;3)数据输入数据端口D;4)等待一段时间,完成写操作。
实验步骤:1.连接双端口RAM芯片到数字逻辑实验箱上,确保电路连接正确;2.连接示波器到仪表箱,用于监测信号波形;3.按照双端口存储器的读写时序,设置实验箱上的信号发生器;4.编写控制代码,控制实验箱上的信号发生器模拟读写操作;5.观察示波器上的波形,验证读写操作的正确性;6.分析实验结果,总结双端口存储器的工作原理和性能。
实验注意事项:1.操作实验箱时要小心谨慎,防止损坏实验箱和芯片;2.实验过程中需要观察示波器上的波形,确保信号发生器的设置正确;3.根据实验目的和步骤设定实验结果的收集和分析方式;4.实验后及时关闭实验箱和示波器,保持实验室整洁。
实验结果与分析:根据实验步骤设置好实验箱上的信号发生器,并编写相应的控制代码后,进行实验。
通过示波器监测到的信号波形可以验证读写操作的正确性。
实验结果的收集和分析主要包括以下内容:1.读操作时序的验证:通过示波器观察到CE1端信号在读操作开始时置低,地址信号AD1输入正确,数据端口读数据正确。
2.写操作时序的验证:通过示波器观察到CE2端信号在写操作开始时置低,地址信号AD2输入正确,数据端口D输入正确。
Xilinx IP core之RAM用法指南
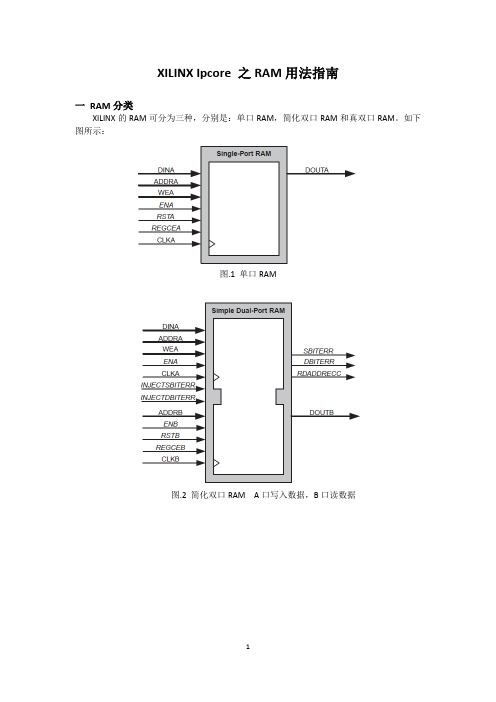
XILINX Ipcore 之RAM用法指南一RAM分类XILINX的RAM可分为三种,分别是:单口RAM,简化双口RAM和真双口RAM。
如下图所示:图.1 单口RAM图.2 简化双口RAM A口写入数据,B口读数据图.3 真双口RAM A,B任意一个口都可以读写数据,可从A写入,B读数据二选择数据位宽和深度Block RAM的数据位宽为1-1152bit,深度取决于所选择FPGA器件中block的数量。
超出地址范围之外的写操作,写进去的数据不会与存储器件中的数据冲突。
读超出地址范围之外数据将会返回无效数据。
注意,当对超出范围的地址进行操作的时候,不能置位set或reset 信号,因为这仍然会读出无效数据。
三操作模式每个端口的操作模式决定了此端口的读和写之间关系。
端口A和B可以独立配置为以下三种模式中任一模式:写优先模式,读优先模式,不改变模式。
这些模式详解见下面。
当A和B端口地址有冲突时,操作模式就会影响A和B口之间关系。
1.写优先模式(write first mode):在写优先模式中,输入数据被自动写入存储器件中,并且出现在数据输出端口。
时序见下图。
这种传输模式增强了在同一端口写操作时使用数据输出总线的灵活性。
图.4 写优先操作模式2.读优先模式(read first mode):在读优先模式中,预先存储在写地址中的数据会被输出,而输入数据被存入存储器件中。
这种模式见下图。
图.5 读优先模式3.不改变模式:在不改变模式中,输出锁存在写操作时候保持不变,见下图。
在同一端口的写操作不会对数据输出端口产生影响,输出仍然是以前的读数据。
图.6 不改变模式四数据位宽比例Block RAM产生器支持端口A和B的位宽不同。
即DINA,DINB,DOUA,DOUTB位宽可以互不相同。
支持1:32到32:1之间的比例,端口A的宽度最大可达端口B的32倍,反之亦然。
例如一个A口位宽32bit深度2048的真双口RAM,如果B端口宽度为8bit深度为8192。
利用双口RAM实现DSP与上位机的数据交换

利 用双口 R AM 实坝 D P与 上位栅 的数据 交换 S
陈 必 然 /海装 重 庆 局
[ 摘 要 ]介绍 了 T S 2 V 50 和 IT 0 6 M 3 0C 4 2 D 7 2 1的性能特点 ,提 出了 DP与上位机数据 交换 实现方 法,给出 了接 口设计 方案并对工程 S 实现的关键技术进行 了分析。 [ 关键词 ]D P 双 口 R M 数据交换 S A
U p r C m u e .T e i t r a e d s g c e e i g v n a d t e k y t c n q e o e l i g a n i e r i a ay e . p e o p t r h n e' c e i n s h m s i e n h e e h i u f r a i n t e g n e s n lz d f z
用双 口 R M 方 式来 实 现 D P与上 位 机 的数 据 交 换 的方法 ,较 A S 易实 现 。C 4 2 行速 度 快 ,具有 1n ( 0 M P ) 50 运 0 s 10 IS 指令 周期 , 工作 电压 为 3 V, . 因此 它 与双 口R M 的接 口具有 一 定特 殊性 。 3 A 】 ]T 0 6 是 1KX1bt 双端 口静 态 R M,允 许 两 个 端 D 72 1 6 i的 6 A 口同时对 内存 进行 访 问 ;最小 访 问时 间 为 1n ;利用 M S 择 5s /选 可将 数 据总 线 扩展 至 3 位 或 更 高 ;具有 B s 和 中断 标 志 ;具 2 uy 有 片 内读 写 冲突 仲裁逻 辑 ;工 作 电压 5 口 V】 。 I T06 D 72 1的 中断 功 能 :当左 端 口向 3 F H单 元 写 入 数 据 FF 时 ,右 端 口 IT N R引 脚 产生 中断 ,右 端 口对该 单 元访 问后 ,中 断被 释放 ;当右 端 口向 3 F H写 人数 据 时 ,左端 口 IT FE N L引脚 产 生 中断 ,左 端 口对该 单元 访 问后 ,中断被 释放 。 利 用 IT 06 D 72 1的 中断 功 能 ,D P可 很 容 易 地 与 上位 机 进 S 三 、建议 采取 的几 种 安全对 策 1 、网络 分 段 。 网络 分 段 通 常被 认 为 是 控制 网络 广 播 风暴 的一种 基本 手 段 ,但 其实 也 是保 证 网络 安全 的一项 重要 措 施 。 其 目的就是 将 非法 用 户 与敏感 的 网络 资 w rs S K y od ]D P
双口RAM原理及应用实例PPT

双口RAM在FPGA中的实现
选用Xilinx公司的Spartan-6 FPGA器件, 基于低功耗45 nm、9-金属铜层、双栅极氧 化层工艺技术,提供高级功耗管理技术, 150 000个逻辑单元,集成式PCI Express模 块,高级存储器支持。250 MHz DSPslice和 3.125 Gb/s低功耗收发器。 通过Verilog HDL语言对双口RAM功能的 描述就能在一片FPGA器件内实现8位16字 节的双口RAM,并进行读写操作控制。双 口RAM读写操作控制采用Verilog HDL代码。
FPGA(Field-Programmable Gate Array),即现场可编程门阵列,它是在PAL、 GAL、CPLD等可编程器件的基础上进一步 发展的产物。它是作为专用集成电路 (ASIC)领域中的一种半定制电路而出现 的,既解决了定制电路的不足,又克服了 原有可编程器件门电路数有限的缺点。
FPGA采用了逻辑单元阵列LCA(Logic Cell Array) 这样一个概念,内部包括可配置逻辑模块CLB (Configurable Logic Block)、输入输出模块IOB (Input Output Block)和内部连线(Interconnect) 三个部分。 现场可编程门阵列(FPGA)是可编程器件,与传 统逻辑电路和门阵列(如PAL,GAL及CPLD器件)相比, FPGA具有不同的结构。FPGA利用小型查找表 (16×1RAM)来实现组合逻辑,每个查找表连接到一 个D触发器的输入端,触发器再来驱动其他逻辑电路或 驱动I/O,由此构成了既可实现组合逻辑功能又可实现 时序逻辑功能的基本逻辑单元模块,这些模块间利用 金属连线互相连接或连接到I/O模块。FPGA的逻辑是 通过向内部静态存储单元加载编程数据来实现的,存 储在存储器单元中的值决定了逻辑单元的逻辑功能以 及各模块之间或模块与I/O间的联接方式,并最终决定 了FPGA所能实现的功能,FPGA允许无限次的编程。
实验二 双端口存储器原理实验

实验二双端口存储器原理实验一、实验目的(1)了解双端口静态随机存储器IDT7132的工作特性及使用方法。
(2)了解半导体存储器怎样存储和读出数据。
(3)了解双端口存储器怎样并行读写,产生冲突的情况如何。
二、实验电路图7 双端口存储器实验电路图图7示出了双端口存储器的实验电路图。
这里使用了一片IDT7132(U36)(2048×8位),两个端口的地址输入A8—A10引脚接地,因此实际使用存储容量为256字节。
左端口的数据部分连接数据总线DBUS7—DBUS0,右端口的数据部分连接指令总线INS7—INS0。
一片GAL22V10(U37)作为左端口的地址寄存器(AR1),内部具有地址递增的功能。
两片4位的74HC298(U28、U27)作为右端口的地址寄存器(AR2H、AR2L),带有选择输入地址源的功能。
使用两组发光二极管指示灯显示地址和数据:通过开关IR/DBUS 切换显示数据总线DBUS和指令寄存器IR的数据,通过开关AR1/AR2切换显示左右两个端口的存储地址。
写入数据由实验台操作板上的二进制开关SW0—SW7设置,并经过SW_BUS三态门74HC244(U38)发送到数据总线DBUS上。
指令总线INS的指令代码输出到指令寄存器IR(U20),这是一片74HC374。
存储器IDT7132有6个控制引脚:CEL#、LRW、OEL#、CER#、RRW、OER#。
CEL#、LRW、OEL#控制左端口读、写操作,CER#、RRW、OER#控制右端口读、写操作。
CEL#为左端口选择引脚,低有效。
当CEL# =1时,禁止左端口读、写操作;当CEL# =0 时,允许左端口读、写操作。
当LRW为高时,左端口进行读操作;当LRW为低时,左端口进行写操作。
当OEL#为低时,将左端口读出的数据放到数据总线DBUS上;当OEL#为高时,禁止左端口读出的数据放到数据总线DBUS上。
CER#、RRW、OER#控制右端口读、写操作的方式与CEL#、LRW、OER#控制左端口读、写操作的方式类似,不过右端口读出的数据放到指令总线上而不是数据总线上。
基于FPGA的双口RAM实现及应用

功能 仿 真验 证 该 设 计 的正 确 性 , 设 计 能减 小 电路设 计 的复 杂 性 , 强设 计 的灵 活 性 和 资 源 的 可配 置 性 能 . 该 增 降低 设 计
成 本 . 短 开 发周 期 。 缩 关键 词 :双 口 R M;F GA;数 据 采 集 ;仿 真 ;V rlgHDL A P ei o
随 着 电 子技 术 的 飞速 发 展 , 大量 的高 速 数 据 采 集 和在 线 测 试对 现 代 工业 测 控 系 统 和 仪 器 仪表 的 功 能 和 性 能 提 更 高
仲裁 控 制 。 内部 仲 裁 逻辑 控 制 提 供 以下 功 能 : 同一 地 址 单 对 元 访 问 的 时 序 控 制 ; 储 单 元 数 据 块 的 访 问权 限 分 配 : 令 存 信
要 求 。C U 并行 工 作 ( 单 片 机 系统 ) P 双 方式 得 到 广泛 应 用 。为
了使 2个 单 片机 能 够 快 速 有 效 交 换 信 息 ,充 分 利 用 系 统 资
源 , 用 双 口 R M 实 现存 储 器 共 享 是 目前 较 为 流行 的方 法 。 采 A
交 换 逻 辑 ( 如 中断 信 号 ) 。 口 R M 可 用 于 提高 R M 的 例 等 双 A A
a q i t n s se T e f n t n smu ain r s l r v e c re t e s o e d sg . e d s n r d c s te c mpe i f c s i y tm. h u ci i l t e u t p o e t o rc n s ft e i nT e i e u e h o lx t o u io o o s h h h g y cr u td s , n n a c s d sg e i i t n o f u a i t f r s u c s r d c s t e d s n c s a d s o tn h i i e i a d e h n e e in f x bl y a d c n g r b l y o e o r e , u e h e i o t n h r s t e c n g l i i i e g e
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
双端口RAM在高速数据采集中的应用利用传统方法设计的高速数据采集系统由于集成度低、电路复杂,高速运行电路干扰大,电路可靠性低,难以满足高速数据采集工作的要求。
应用FPGA可以把数据采集电路中的数据缓存、控制时序逻辑、地址译码、总线接口等电路全部集成进一片芯片中,高集成性增强了系统的稳定性,为高速数据采集提供了理想的解决方案。
下面以一个高速数据采集系统为例介绍双端口RAM的应用。
该系统要求实现对频率为5MHz的信号进行采样,系统的计算处理需要对信号进行波形分析,信号采样时间为25μs。
根据设计要求,为保证采样波形不失真,A/D采样频率用80MHz,采样精度为8位数据宽度。
计算得出存储容量需要2K字节。
其系统结构框图如图3所示,图4给出了具体电路连接图。
根据设计要求,双端口RAM的LPM_WIDTH参数设置为8,LPM_WIDTHAD 参数设置为11(211=2048),使用读写使能端及读写时钟。
ADCLK、WRCLK和地址发生器的计数频率为80MHz。
A/D转换值对双端口RAM的写时序为顺序写方式,每完成一次A/D转换,存储一次数据,地址加1指向下一单元,因此写地址发生器(RAM_CONTROL)采用递增计数器实现,计数频率与ADCLK、WRCLK一致以保证数据写入时序的正确性。
写操作时序由地址和时钟发生器、A/D转换时钟和双端口RAM的写时钟产生。
停止采样时AD_STOP有效,写地址发生器停止计数,同时停止对RAM的写操作。
将地址发生器的计数值接至DSP总线可以获取采样的首尾指针。
地址发生器单元一般用(VHDL)语言编程实现,然后生成符号文件RAM_CONTROL在上层文件调用。
其部分VHDL语言程序如下:对双端口RAM的读操作采用存储器映像方式,其读出端口接DSP的外扩RAM 总线,DSP可随机读取双端口RAM的任一单元数据,以方便波形分析。
由于LPM_RAM_DP模块的读端数据总线q不具有三态特性,因此调用三态缓冲器74244,通过其将输出数据连接到DSP数据总线上。
在高速数据采集电路中,数据缓存也可以用FIFO或单端口RAM实现。
用FIFO 进行数据缓存,由于其已经把地址发生部分集成在模块单元内,因此省去了一部分程序编写,但是DSP却不能任意地访问FIFO的存储单元,只能是顺序写入/读出数据,这样设计,系统的灵活性就大大降低。
如果DSP的分析计算需要特定单元的数据,则系统的效率和速度会因为无效数据的读取而降低。
使用单端口RAM进行数据缓存同样存在一些问题。
由RAM侧看,DSP和A/D转换器是挂在一条总线上的,当从RAM向DSP传输数据的时候,A/D转换器就不能有数据传到该总线上,否则会产生总线冲突,引起芯片损坏。
解决这个问题就需要增加电路。
应用双端口RAM就不存在这个问题,而且使系统结构划分更明确,符合模块化设计思想。
结语综上所述,利用FPGA芯片的高速工作特性,以及其内部集成嵌入式阵列和大规模逻辑阵列的特点,设计存储器,三态缓存器、地址发生器、以及复杂的时序逻辑电路等,应用于高速数据采集电路中可以使电路大大简化,性能提高。
同时由于FPGA可实现在系统编程(ISP),使系统具有可在线更新、升级容易等特点,是一种较为理想的系统及电路实现方法。
在FPGA中构造存储器许多系列的FPGA芯片内嵌了存储阵列,如ALTERA EPlK50芯片内嵌了5K字节的存储阵列。
因此,在FPGA中实现各种存储器,如单/双端口RAM、单/双端口ROM、先进先出存储器FIFO等非常方便,而且具有诸多优点。
其硬件可编程的特点允许开发人员灵活设定存储器数据的宽度、存储器的大小、读写控制逻辑等,尤其适用于各种特殊存储要求的场合。
FPGA/FPGA器件可工作于百兆频率以上,其构造的存储器存取速度也可达百兆次/秒以上,这样构成的高速存储器能够胜任存储数据量不太大,但速度要求很高的工作场合。
FPGA中构造存储器主要有两种方法实现。
一是通过硬件描述语言如VHDL、AHDL、Verilog HDL等编程实现。
二是调用MAX+PLUSⅡ自带的库函数实现。
调用库函数方法构造存储器较硬件描述语言输入方式更为方便、灵活、快捷和可靠,故也更常用之。
利用库函数构造双端口RAM在MAX+PLUSⅡ中有几个功能单元描述库。
prim逻辑元库,包括基本逻辑单元电路,如与、或、非门,触发器、输入、输出引脚等;mf宏功能库,包括TTL数字逻辑单元如74系列芯片;而下文将要详细介绍的参数化双端口RAM模块所在的参数化模块库(mega-lpm)中,包括各种参数化运算模块(加、减、乘、除)、参数化存储模块(单、双端口RAM、ROM、FIFO等)以及参数化计数器、比较器模块等等。
库中的这些元件功能逻辑描述经过了优化验证,是数字电路设计中的极好选择。
mega-lpm库中共有五种参数化双端口RAM模块:ALTDPRAM、LPM_RAM_DP、CSDPRAM、LPM_RAM_DQ和LPM_RAM_IO。
其中ALTDPRAM和LPM_RAM_DP模块读写有两套总线,读和写有各自的时钟线、地址总线、数据总线和使能端,可同时进行读写操作。
除此之外,ALTDPRAM模块还有一个全局清零端口。
CSDPRAM模块则有a、b两组写端时钟线、地址总线、数据总线和使能端,可同时对RAM进行写操作,但对RAM读、写只能分时进行。
LPM_RAM_DQ模块相对简单,读与写共用一组地址总线,有各自的数据线和时钟线。
LPM_RAM_IO模块只有一组地址总线和数据总线。
mega-1pm函数库中的双端口RAM模块全是参数化调用,这为设计带来极大的方便。
通过对各种参数的取舍、参数设置和组合,再结合读写控制逻辑就可以构造出设计需要的存储器模块。
双端口RAM常见的应用模式主要有以下两种:1.存储器映像方式。
该方式可以随意对存储器的任何单元进行读写操作。
其主要应用于多CPU的共享数据存储、数据传送等。
该方式中,读、写控制线、地址总线和数据总线有两套。
根据两端口之间数据的传送方向为单向或双向,又有单向数据总线和双向数据总线之分。
2.顺序写方式。
该方式对RAM的写操作只能顺序写入。
这种情况适用于对象特性与时间紧密相关或传送数据与顺序密切相关的场合,如文件传送、时序过程、波形分析等。
根据写控制逻辑的不同,可对RAM进行循环写入或一次写入方式。
该方式下的读操作可以是存储器映像读或顺序读,前一种有较大的灵活性,而后一种则类似于FIFO形式。
在读、写使用独立的地址总线和数据总线时,可以同时对RAM不同单元进行读写操作。
根据不同控制逻辑的要求,对读写时钟、时钟使能端口可以适时设置,以满足控制需要。
我用的FPGA芯片是EP1C6Q240C6,其内部静态RAM容量Up to 294,912 RAM bits (36,864 bytes)如果作为采集图像的中间缓存,分辨率为1280*1024的一帧图像,图像数据量为1280*1024*8bit(RAW DATA)= 10485760 bit = 1310720 bytes,远远大于RAM的容量,那么就采用双口RAM存储1行的图像数据。
lpm_ram_dp 参数化双端口RAM 宏模块// synopsys translate_off`timescale 1 ps / 1 ps// synopsys translate_onmodule dpram16k_1to512_32 (data,wren,wraddress,rdaddress,wrclock,rdclock,wr_aclr,rd_aclr,q);input [0:0] data;input wren;input [13:0] wraddress;input [8:0] rdaddress;input wrclock;input rdclock;input wr_aclr;input rd_aclr;output [31:0] q;wire [31:0] sub_wire0;wire [31:0] q = sub_wire0[31:0];altsyncram altsyncram_component (.wren_a (wren),.aclr0 (wr_aclr),.clock0 (wrclock),.aclr1 (rd_aclr),.clock1 (rdclock),.address_a (wraddress),.address_b (rdaddress),.data_a (data),.q_b (sub_wire0)// synopsys translate_off,.addressstall_a (),.addressstall_b (),.byteena_a (),.byteena_b (),.clocken0 (),.clocken1 (),.data_b (),.q_a (),.rden_b (),.wren_b ()// synopsys translate_on);defparamaltsyncram_component.intended_device_family = "Cyclone",altsyncram_component.operation_mode = "DUAL_PORT",altsyncram_component.width_a = 1,altsyncram_component.widthad_a = 14,altsyncram_component.numwords_a = 16384, //2^14 = 16384altsyncram_component.width_b = 32,altsyncram_component.widthad_b = 9,altsyncram_component.numwords_b = 512, //2^9 = 512altsyncram_component.lpm_type = "altsyncram",altsyncram_component.width_byteena_a = 1,altsyncram_component.outdata_reg_b = "UNREGISTERED",altsyncram_component.indata_aclr_a = "CLEAR0",altsyncram_component.wrcontrol_aclr_a = "CLEAR0",altsyncram_component.address_aclr_a = "CLEAR0",altsyncram_component.address_reg_b = "CLOCK1",altsyncram_component.address_aclr_b = "CLEAR1",altsyncram_component.outdata_aclr_b = "NONE",altsyncram_component.power_up_uninitialized = "FALSE";endmodule//双端口RAM的设计与测试(verilog)以下是用verilog语言写的同步双端口设计文件(来自Actel官方文件中)写的很精炼编程风格也不错,该文档中注释的相当明确自己综合和仿真测试过,没问题测试测试写的比设计长多了,写的很好值得学习,也可以直接用在你的设计中`timescale 1 ns/100 psmodule test;parameter width = 8; // bus widthparameter addr = 8; // # of addr linesparameter numvecs = 20; // actual number of vectorsparameter Clockper = 1000; // 100ns periodreg [width-1:0] Data;reg [addr-1:0] WAddress, RAddress;reg Clock, WE, RE,rst; //addition rstreg [width-1:0] data_in [0:numvecs-1];reg [width-1:0] data_out [0:numvecs-1];wire [width-1:0] Q;integer i, j, k, numerrors;ram u0(.data(Data), .q(Q), .clk(Clock),.rst(rst),.wen(WE),.ren(RE), .waddr(WAddress), .raddr(RAddress));initialbegin// sequential test patterns entered at neg edge Clock data_in[0]=8'h00; data_out[0]=8'hxx;data_in[1]=8'h01; data_out[1]=8'hxx;data_in[2]=8'h02; data_out[2]=8'hxx;data_in[3]=8'h04; data_out[3]=8'hxx;data_in[4]=8'h08; data_out[4]=8'hxx;data_in[5]=8'h10; data_out[5]=8'hxx;data_in[6]=8'h20; data_out[6]=8'hxx;data_in[7]=8'h40; data_out[7]=8'hxx;data_in[8]=8'h80; data_out[8]=8'hxx;data_in[9]=8'h07; data_out[9]=8'h01;data_in[10]=8'h08; data_out[10]=8'h02;data_in[11]=8'h09; data_out[11]=8'h04;data_in[12]=8'h10; data_out[12]=8'h08;data_in[13]=8'h11; data_out[13]=8'h10;data_in[14]=8'h12; data_out[14]=8'h20;data_in[15]=8'h13; data_out[15]=8'h40;data_in[16]=8'h14; data_out[16]=8'h80;data_in[17]=8'haa; data_out[17]=8'h80;data_in[18]=8'h55; data_out[18]=8'haa;data_in[19]=8'haa; data_out[19]=8'h55;endinitialbeginrst=0;Clock = 0;WE = 0;RE = 0;WAddress = 0;RAddress = 0;Data = 0;numerrors = 0;#200 rst=1; //there rst reset to ram#200 rst=0;endalways#(Clockper / 2) Clock = ~Clock;initialbegin#2450 WE = 1;#8000 WE = 0;RE = 1;#8000 RE = 0;WE = 1;#1000 RE = 1;endinitialbegin#1450;for (k = 0; k <= width; k = k + 1)#1000 WAddress = k;WAddress = 0;endinitialbegin#9450;for (j = 0; j <= width; j = j + 1)#1000 RAddress = j;RAddress = 0;endinitialbegin$display("\nBeginning Simulation...");//skip first rising edgefor (i = 0; i <= numvecs-1; i = i + 1)begin@(negedge Clock);// apply test pattern at neg edgeData = data_in;@(posedge Clock)#450; //45 ns later// check result at posedge + 45 ns$display("Pattern#%d time%d: WE=%b; Waddr=%h; RE=%b; Raddr=%h; Data=%h; Expected Q=%h;Actual Q=%h", i, $stime, WE, WAddress, RE, RAddress,Data, data_out, Q);if ( Q !== data_out )begin$display(" ** Error");numerrors = numerrors + 1;endendif (numerrors == 0)$display("Good! End of Good Simulation.");elseif (numerrors > 1)$display("%0d ERRORS! End of Faulty Simulation.",numerrors);else$display("1 ERROR! End of Faulty Simulation.");#1000 $finish; // after 100 ns laterendendmodule设计为了方便,我将其设计代码也放在这儿,你可以直接用综合和仿真`timescale 1 ns/100 ps//#############################################//# Behavioral dual-port SRAM description ://# Active High write enable (WE)//# Active High read enable (RE)//# Rising clock edge (Clock)//#############################################module reg_dpram(Data, Q, Clock, WE, RE, WAddress, RAddress);parameter width = 8;parameter depth = 8;parameter addr = 3;input Clock, WE, RE;input [addr-1:0] WAddress, RAddress;input [width-1:0] Data;output [width-1:0] Q;reg [width-1:0] Q;reg [width-1:0] mem_data [depth-1:0];// ############################################// # Write Functional Section// ############################################always @(posedge Clock)beginif(WE)mem_data[WAddress] = #1 Data;end//############################################# //# Read Functional Section//############################################# always @(posedge Clock)beginif(RE)Q = #1 mem_data[RAddress];endendmodule。