均数的抽样误差与总体均数估计2010.
医学统计学复习题

抽样误差与总体均数的估计1. ( C )A. 总体均数B。
总体均数离散程度C。
样本均数的标准差D。
个体变量值的离散程度E。
总体标准差2.抽样研究中,S为定值,若逐渐增大样本含量,则样本( B )A。
标准误增大B。
标准误减小C. 标准误不改变D。
标准误的变化与样本含量无关E。
标准误为零3. 关于以0为中心的t分布,叙述错误的是( E )A。
t分布是一簇曲线B. t分布是单峰分布C。
当v→∞时,t→μD。
t分布以0为中心,左右对称E。
相同v时,∣t∣越大,p越大4.均数标准误越大,则表示此次抽样得到的样本均数( C )A。
系统误差越大B。
可靠程度越大C。
抽样误差越大D。
可比性越差E. 测量误差越大5。
要减小抽样误差,最切实可行的办法是( A )A. 适当增加观察例数B。
控制个体变异C。
严格挑选观察对象D. 考察总体中每一个个体E. 提高仪器精度6。
”假设已知某地35岁以上正常成年男性的收缩压的总体均数为120。
2mmHg, 标准差为11。
2 mmHg ,后者反映的是”( E )A. 总体均数不同B。
抽样误差C。
抽样误差或总体均数不同D. 系统误差E. 个体变异7。
”已知某地35岁以上正常成年男性的收缩压的总体均数为120。
2mmHg,标准差为11。
2 mmHg 。
从该地随机抽取20名35岁以上正常成年男性,测得其平均收缩压为112。
8mmHg.则112。
8mmHg 与120。
2mmHg 不同的原因是”( B )A。
个体变异B. 抽样误差C. 总体均数不同D。
抽样误差或总体均数不同E. 系统误差8. ”已知某地35岁以上正常成年男性的收缩压的总体均数为120.2mmHg,标准差为11.2 mmHg 。
从该地随机抽取10名7岁正常男孩,测得其平均收缩压为90。
5 mmHg ,标准差为10。
4mmHg,则90.5mmHg 与120。
2mmHg不同,原因是”( C )A. 个体变异B。
抽样误差C。
总体均数不同D。
总体均数的估计和假设检验PPT课件

5、t’检验
当方差不齐时,两小样本均数的比较用t’
检验。 检验统计量:t'
x1 x2 s12 s22 n1 n2
临界值:
t'
s2 x1
t ,v1
s2
s2 x2
s2
t ,v2
x1
x2
如果t’ >t’α,则P<α,则拒绝原假设。
6、z检验
当样本含量较大时,可用z检验来进行
两样本均数的比较。它是用于两大样本均 数的比较,目的是推断两总体均数是否相 同。所用公式:
4、成组t检验
(3) 资料要求:两样本来自正态或近似正态 分布,并且两组总体方差相等。
(4) 对数正态分布的资料,在进行t检验时,
要先把数据进行对数转换,用对数值作为
新变量进行成组t检验。
4、成组t检验
(4) 公式: H0: μ1= μ2 H1:μ1 ≠ μ2
t x1 x2 s
x1 x2
(1) 小样本资料的估计(未知)
P(t ,<t<t , ) 1
由1-αx时 t,,计( 算sn )总<体<均x数的t,可( 信sn区)可间得的到通当式可为信:度
即:x
t
,
s x
例2:试求例1中该地1岁婴儿血红蛋白平 均值的95%的可信区间。
s
由ν于 =nn= -215=,24s=,11α.取9g双/L尾, 0s.x 05,n查t2界.3值8 g表/ L得:
准差s2=1.626 mg/dl,配对t检验结果,t =-
3.098,P<0.05,故认为脑病病人尿中类固醇排出 量高于正常人。
表3 正常人和脑病病人尿中类固醇排出量 (mg/dl)
正常人
2.90 5.41 5.48 4.60 4.03 5.10 4.97 4.24 4.37 3.05 2.78脑ຫໍສະໝຸດ 病人差别是由抽样误差引起的。
样本均数的抽样误差

样本均数的抽样误差均数的抽样误差:从同一总体中随机抽取若干个观察单位数相等的样本,由于抽样引起样本均数与总体均数及样本均数之间的差异称作均数的抽样误差,其大小可用均数的标准差描述,医学|教育|网搜集整理样本均数的标准差称为标准误。
抽样误差在抽样研究中不可避免。
标准误越大,均数的抽样误差就越大,说明样本均数与总体均数的差异越大。
样本均数:样本均数又称样本均值,均值是指在一组数据中所有数据之和再除以数据的个数。
它是反映数据集中趋势的一项指标,属数学领域。
均值是指在一组数据中所有数据之和再除以数据的个数。
它是反映数据集中趋势的一项指标。
例如 1、2、3、4 四个数据的均值为(1+2+3+4)/4=2.5。
样本(sample),是指从总体中抽出的一部分个体。
样本中所包含个体数目称样本容量或含量,用符号N或n表示。
总体(population)是指客观存在的,并在同一性质的基础上结合起来的许多个别单位的整体,即具有某一特性的一类事物的全体,又叫母体或全域。
简单地说,总体也就是我们所研究的性质相同个体的总和。
样本是受审查客体的反映形象或其自身的一部分。
按一定方式从总体中抽取的若干个体,用于提供总体的信息及由此对总体作统计推断。
又称子样。
例如因为人力和物力所限,不能每年对全国的人口进行普查,但可以通过抽样调查的方式来得到需要的信息。
从总体中抽取样本的过程叫抽样。
最常用的抽样方式是简单随机抽样,按这种方式抽样,总体中每个个体都有同等的机会被抽入样本,这样得到的样本称简单随机样本。
样本的平均值称样本均值,样本偏离样本均值的平方的平均值称为样本方差,在数理统计中,常常用样本均值来估计总体均值,用样本方差来估计总体方差。
总体均数估计与假设检验
t 检验
t-test
三、t检验和Z检验(参数检验)
以t分布为基础的检验称为t检验。 t分布的发现使得小样本统计推断成为 可能。因而,它被认为是统计学发展历 史中的里程碑之一。
在医学统计学中,t检验是重要的 假设检验方法之一。常用于两个均数之 间差别的比较,并根据资料的分布情况 及设计类型,选择不同的t检验方法。
配对样本t检验
Paired design t-test
关系:随着样本含量增加,都减小。
联系:都是表示变异度的指标,当样本量一定时,两者成正比。
标准误用途
衡量样本均数的可靠性:标准误越小,表明 样本均数越可靠;
参数估计:估计总体均数的置信区间(区 域);
假设检验:用于总体均数的假设检验(比 较)。
二、t分布:
标准正态分布
开创了小样本统计的新纪元,t分布主要用于总体均数的 区间估计和t检验!
假设检验(Hypothesis test)
假设检验的推断原理 假设检验的基本步骤 t检验和Z检验 两样本总体方差齐性检验 正态性检验 假设检验的两类错误 注意事项
一、假设检验的推断原理
上面介绍过的区间估计方法是统计 推断的内容之一,假设检验是统计推 断的另一重要内容。正是应用统计推 断的理论和方法,人们才能顺利地通 过有限的样本信息去把握总体特征, 实现抽样研究的目的。
s / n 25.74 36
在H0成立的前提下,当前t值出现的概率有多 大???
如何给出这个量的界限?
小概率事件在一次试验 中基本上不会发生 !
从附表2中查出在显著性水平 =0.05(双侧),自由度为35所 对应的t界值=2.318,即为拒绝 域与接受域的界限。如果计算
均数的抽样误差与总体均数的估计

均数的抽样误差和总体均数估计

在医学、生物学、经济学和社会科学 等领域中,均数的抽样误差和总体均 数估计都是重要的统计工具,用于指 导研究和决策。
02
均数的抽样误差
抽样误差的定义
抽样误差是由于从总体中随机抽取样本而产生的误差,它反映了样本均数 与总体均数之间的差异。
抽样误差是不可避免的,因为每个样本都是独特的,不可能完全复制总体。
研究结论
01
抽样误差是衡量样本均数与总体均数接近程度的重要
指标,其大小直接影响到总体均数的估计精度。
02
在大样本条件下,样本均数的抽样误差通常较小,能
够较好地反映总体均数的真实情况。
03
通过增加样本量或提高样本代表性,可以减小抽样误
差,提高总体均数估计的准确性。
对未来研究的建议
01
进一步研究不同抽样方法对均数抽样误差的影响,以便在实际 应用中选择合适的抽样方法。
市场调研
市场调研中,企业通过抽样调查了解 消费者需求、市场趋势等信息,进而 估计总体均数,制定营销策略。
医学研究中均数估计的应用
临床试验
在临床试验中,研究者通过随机抽样方 法选取一定数量的患者作为样本,根据 样本数据估计总体均数,进而评估药物 疗效。
VS
流行病学研究
流行病学研究中,研究者通过抽样调查方 法了解疾病在人群中的分布情况,估计总 体均数,为制定疾病防控策略提供依据。
均数的抽样误差和总体均 数估计
• 引言 • 均数的抽样误差 • 总体均数的估计 • 样本大小与均数估计精度 • 实际应用案例 • 结论与展望
01
引言
主题简介
均数的抽样误差
指通过样本均数来估计总体均数时所存在的误差范围。
总体均数估计
第三章 总体均数的估计与假设检验

Sd
d
d Sd / n
2
(
d)
n
n 1
S d 0.1087 t 2.7424 0.1087/ 10 7.925
v 10 1 9
3)确定P值,作出推断结论 T0.05,9=2.262, 7.925>2.262,故P<0.05.可以认为两种 方法对脂肪含量的测定结果不同。
167.41, 2.74
165.56, 6.57
168.20, 5.36 n j=10
…. 165.69, 5.09
将上述100个样本均数看成新变量值,则这个 100个样本均数构成一新分布,绘制直方图
样本均数的抽样分布具有如下特点:
1) 各样本均数未必等于总体均数
2) 各样本均数间存在差异
3) 样本均数的分布很有规律,围绕着总体均 数,中间多,两边少,左右基本对称,也 服从正态分布
假设检验的基本步骤:
1、建立检验假设
H0: 检验假设, 无效假设,零假设 μ=μ0
H1: 备择假设,对立假设
μ≠μ0
2、确定检验水准 α=0.05 单双侧
3、选定检验方法和计算检验统计量
4、确定P值和作出推论结论。
P值是指从H0所规定的总体进行随机抽样,获 得大于(或等于及小于)现有样本获得的检验 统计量值的概率。
(1012/L)
血红蛋白 (g/L)
女
男 女
255
360 255
4.18
134.5 117.6
0.29
7.1 10.2
4.33
140.2 124.7
*标准值:使用内科学(1976年)所载均数(转位法定单位)
1)说明女性的红细胞数与血红蛋白的变异程度何者为大? 2)抽样误差是? 3)试估计该地健康成年女性红细胞数的均数? 4) 该地健康成年男女血红蛋白含量是否不同? 5)该地男性两项血压指标是否均低于上表的标准值(若测 定方法相同)?
医学统计学正态分布习题及答案

1.96
二、是非题
1.对于偏态分布资料, 1.96
范围内也包含了95%的变量值( )
答案:错
2.正态分布在横轴上的位置由均数决定 ()
答案:对
3.任何一个正态分布都可以通过标准化 变换转化为标准正态分布( )
答案:对
4.设随机变量的值在(0,+)范围中, 从该变量值的总体中抽样,若样本的标 准差大于样本均数,则可推断不服从正 态分布( )
4.在排放的工业废水中规定有害物质含 量不能超过0.005。现从某企业排出的废 水中抽取10份水样,测出有害物质的平 均含量为:0.0053,标准差为:0.0004。
假设某企业排出的废水符合标准,从该 企业排出的废水中抽到的含量为10的样 本是否小概率事件?
5.某医院要求除内科之外的各科室住院 病人的平均住院日均不超过20天。该院 某科对科室全部病人计算出平均住院日 为15天。科主任认为:该科室目前已达 到了医院的要求。这个看法是否正确?
10.某市500名10岁正常男孩中,有95% 的人体重在 18~30kg范围内,由此可知 此500名男孩体重的标准差等于( ) kg
A 2.000
B 2.326
C 6.122
D 3.061
E 6.000 答案:D
11.对于服从标准正态分布的变量,有 ()
A 的概率是0.10 B 的概率是0.025 C 的概率是0.05 D 的概率是0.01 E 的概率是0.005 答案:B
二、是非判断题
1.对于一个含量为n样本,为了推断该 样本是否取自均数为μ0的总体,需要对 该样本的均数与μ0之间的差别是否是抽 样误差进行假设检验( )
2.从均数为μ0的总体中抽取一个含量为 n样本,必须对样本均数与μ0之间的差别 是否是抽样误差进行假设检验( )
均数的抽样误差PPT课件

第二个要素是“精确性”,常用可信区间的长度(CL,CU)来表示,当
然长度越小越好。精确性与变量的变异度大小、样本例数和1- 的取值 有关。当1- 的取值确定后,可信区间的长度受限于个体变异和样本含
量,个体变异越大区间越宽,样本越小区间越宽,反之区间越窄。
例:某年级学生总人数800人,通过计算其中50人 的医学统计学考试成绩来估计其总体均数。
抽样n=50, X =75.00。估计μ= ?。
①μ=75.00
可能性
②μ=70.00~80.00 可能性
③μ=65.00~85.00 可能性
24
二、t 检验
统计分析
统计描述
是用统 计指标、统计表 和统计图描述资 料的分析规律及 其数量特征。
统计推断
包括“总体 参数估计”和“ 假设检验”两个 内容。
本例自由度:ν-1=25-1=24; t0.05,24,经查表得t0.05,24 = 2.064 则
S X + t0.05,24 × X =73.6 + 2.064×6.5/ 25 = 76.3次/分
X
-
t0.05,24
×
S X
=
73.6
-
2.064×6.5/
25 = 70.9次/分
即该地区正常男子脉搏总体均数的95%可信区间为:
可能高,也可能低
双侧检验
肯定不会低(或高)
单侧检验
H1 : μ>μ0 μ<μ0 μ1 >μ2 μ1< μ2
33
17
2)小样本可信区间估计--t分布法:
x
总体均数95%可信区间估计计算公式:
X
t
0.05,
S X
总体均数99%可信区间估计计算公式:
计量资料的统计推断

2018/6/22
Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106
均数
8
6.
19
2、均数的标准误
均数的标准误 (standard error of mean):样本均数的标准差,它反映了 样本均数间的离散程度。 意 义:反映抽样误差的大小。标准误越 小,抽样误差越小,用样本均数估计总体 均数的可靠性越大。
5
样本均数分布示意图:
样本 1 x1 样本 2 样本 3
x2
x3
总体 X
μσ
样本 4 样本 5
x4
x5 x.....
样本均数 X
若 总 体 服 从 正 态 分 布 或 抽 样 例 数 足 够 大
样本 6
x6
N ,
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106
某地成年男子红细胞数的抽样调查, n=144人,均数为5.38×1012/L, s=0.44×1012/L,求其标准误。
s 0.44 12 sx n 144 0.037(10 / L)
2008执考:若不知总体标准差,反映均数 抽样误差大小的指标,用: A. S B. sx C.SP D.σp E. x
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106 11
3、标准误与标准差的区别与联系 标准差 标准误
意义 衡量均数的标准差,衡 量样本均数的离散程度, 反映了抽样误差的大小。
s
( x x ) n 1
2018/6/22 Plan 1-2-3-4-5-6-7-9:1-18-26-40-63-81-89-97-106 4
2计量资料统计分析

(
xxi2
( x)2
xi )2 n
x2 (
x)2 n
n 1
n 1n 1
n 1
式中n-1称为自由度
(四)标准差
1、直接法:
S (x x)2
n 1
x2
( x)2
n
n 1
例:三组同年龄、同性别儿童的体重(kg) 甲组 26 28 30 32 34 乙组 24 27 30 33 36 丙组 26 29 30 31 34
5
3.85
125
96.15
156~
3
2.31
128
98.46
160~164
2
1.54
130
100.00
合计
130 100.00
—
—
二、集中趋势指标
包括:算术均数、几何均数、中位数 意义:
1. 反映一组同质变量值的平均 水平或分布的集中位置。
2. 作为一组资料的代表值,便 于组间的分析比较。
(一)算术均数
G
lg
1
lg
10
lg
100
lg
1000 5
lg
10000
lg
100000
lg 13 1000
5个人的平均血清抗体效价为1:1000
2、加权法
G
lg
1
f lg f
x
lg 1
f1
lg
x1
f2 f1
lg x2 f2 fk
fk
lg
xk
3、几何均数的应用
医学统计学计量资料的统计推断

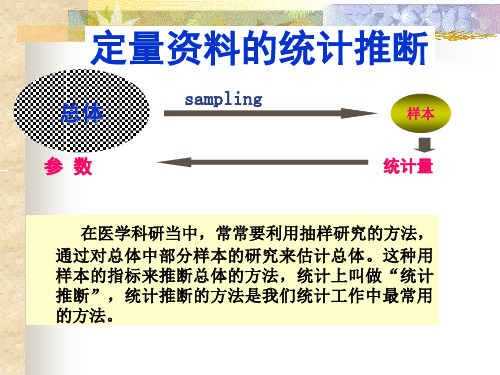
医学统计学计量资料的统计推断主要内容:标准误t 分布总体均数的估计假设检验均数的 t检验、u 检验、方差分析几个重要概念的回顾:计量资料:总体:样本:统计量:参数:统计推断:参数估计、假设检验第一节均数的抽样误差与总体均数的估计欲了解某地2000年正常成年男性血清总胆固醇的平均水平,随机抽取该地200名正常成年男性作为样本。
由于存在个体差异,抽得的样本均数不太可能恰好等于总体均数。
一、均数的抽样误差与标准误一、均数的抽样误差与标准误抽样误差:由于抽样引起的样本统计量与总体参数之间的差异X数理统计推理和中心极限定理表明:1、从正态总体N(??,??2)中,随机抽取例数为n的样本,样本均数??X 也服从正态分布;即使从偏态总体抽样,当n足够大时??X也近似正态分布。
2、从均数为??,标准差为??的正态或偏态总体中抽取例数为n的样本,样本均数??X的总体均数也为??,标准差为X标准误含义:样本均数的标准差计算:(标准误的估计值)注意: X 、S??X均为样本均数的标准误标准误意义:反映抽样误差的大小。
标准误越小,抽样误差越小,用样本均数估计总体均数的可靠性越大。
标准误用途:衡量抽样误差大小估计总体均数可信区间用于假设检验二 t 分布对正态变量样本均数??X做正态变换(u变换):X 常未知而用S??X估计,则为t变换:二、 t 分布t值的分布即为t分布t 分布的曲线:与??有关t分布与标准正态分布的比较1、二者都是单峰分布,以0为中心左右对称2、t分布的峰部较矮而尾部翘得较高说明远侧的t值个数相对较多即尾部面积(概率P值)较大。
当ν逐渐增大时,t分布逐渐逼近标准正态分布,当ν→??时,t分布完全成为标准正态分布t 界值表(附表9-1 )t??/2,??:表示自由度为??,双侧概率P为??时t的界值t分布曲线下面积的规律:中间95%的t值:- t0.05/2,?? ?? t0.05/2,??中间99%的t值:- t0.01/2,?? ?? t0.01/2,??单尾概率:一侧尾部面积双尾概率:双侧尾部面积(1) 自由度(ν)一定时,p与t成反比;(2) 概率(p)一定时,ν与t成反比;三总体均数的估计统计推断:用样本信息推论总体特征。
医学统计:均数的抽样误差与总体均数估计

的标准差与总体标准差的关系
样本均数的分布规律:
①以特定的样本量 n 从正态总体 N(,2)中抽取样本,所得样
本均数 x 的分布为正态分布。 ②样本均数的均数等于原正态分布的总体均数,即 x 。
③样本均数的变异程度小于原变量的变异程度,即 x 。
④样本均数的标准差为: x / n
中心极限定理和正态分布推理
中心极限定理:也称大数定理,从正态分布 N(, 2 ) X
总体中以固定 n 抽样时,样本均数 X 的分布仍服从正态
分布 N (, 2 ) 。
X
~
N
,
2
n
正态分布推理:当样本含量 n 足够大时,即使从偏态分
样本均数(cm) 从正态总体N(1554,53)中以n=20抽样10000次
样本均数的分布
从正态总体N(155.4,5.3)中以样本量n=20抽样10000次样本均数 X 的描述结果
样本个数 10000
X 的均值 155.4102561
X 的标准差 1.2028796
最小值 150.2155347
最大值 160.9946597
抽样误差在抽样研究中是不可避免的,但只要严格遵循 随机化抽样的原则,就能估计抽样误差的大小。
第一节 均数的抽样误差和总体均数的估计
由于变异的存在,抽样研究所造成的样本均数与总体均数 的差异,以及各样本均数间的差异称为均数的抽样误差。
抽样误差在抽样研究中是不可避免的,但只要严格遵循随 机化抽样的原则,就能估计抽样误差的大小。
6 10000
2000
1500
1000
500
0
149 150 151 152 153 154 155 156 157 158 159 160 161
医学统计学总体均数的估计和假设检验

3.106
3.055
3.012 2.977 2.947 2.921 2.898 2.878 2.861 2.845 2.750 2.704 2.678 2.626
2.58
3.497
3.428
3.372 3.326 3.286 3.252 3.222 3.197 3.174 3.153 3.030 2.971 2.937 2.871 2.8070
t x
sX
统计量是t的分布就是t分布。
t分布的特征: ① 以0为中心,左右对称呈单峰分布; ② t分布是一簇曲线,分布参数为自由度υ。 ③ t分布的形状与样本例数n有关,高峰比正态分
布略低,两侧尾部翘得比正态分布略高。越大, 曲线越近正态分布,当ν=∞时,t分布即为z分布。 由于t分布是一簇曲线,为了便于应用,统计学 家编制了表4-4-1 t界值表。
3)与例数的关系不同:当样本含量足够大时,标准 差趋向稳定。而标准误随例数的增大而减小,甚至趋 向于0。若样本含量趋向于总例数,则标准误接近于0。
联系;二者均为变异指标,如果把总体中各样本均 数看成一个变量,则标准误可称为样本均数的标准差。 当样本含量不变时,均数的标准误与标准差成正比。 两者均可与均数结合运用,但描述的内容各不相同。
活量的95%的可信区间。
本例n=5, =4,t0.05,4=2.776
x t0.05sx =2.44±2.776×0.33/ 5 =2.03~2.85(L)
该地17岁女中学生肺活量均数的95%可信区间为2.03L~2.85L。
例4-4-3 由例4-2-1 101名30~49岁健康男子血清总 胆固醇 X 4.735mmol·L-1,S=0.88 mmol·L-1,求该 地健康男子血清总胆固醇值均数的95%可信区间。
统计学--第三章总体均数的估计与假设检验

总体均数的估计 与假设检验
课件
1
统计推断的目的:
用样本的信息去推论总体。
医学研究中大多数是无限总体, 即使是有限总体,但也经常受各种条 件的限制,不可能直接获得总体的信 息。
课件本科生卫生学(5)
2
第一节 均数的抽样误差与标准误
• 抽样误差(sampling
error):因各样本 包含的个体不同,所得的各个样本统计量 (如均数)往往不相等,这种由于个体差 异和抽样造成的样本统计量与总体参数的 差异,称为抽样误差。
均数的95%可信区间为3.47~ 3.81(mmol / L) 95%参考值范围为1.29~ 5.99(mmol / L)
S 1.20 X u / 2 S X X 1.96 3.64 1.96 n 200 (3.47, 3.81)
X 1.96S 3.64 1.961.20 (1.29, 5.99) 32 课件本科生卫生学(5)
t分布的应用: 总体均数的区间估计 t检验
课件本科生卫生学(5) 18
第三节 总体均数的置信区间估计 confidence interval
可信区间的概念 总体均数可信区间的计算 均数可信区间与参考值范围的区别
课件本科生卫生学(5)
19
一、可信区间的概念
统计推断:参数估计与假设检验。 参数估计: parametric estimation,用样本统 计量估计总体参数的方法。 点(值)估计:point estimation,直接用样 本统计量作为总体参数的估计值。方法简 单但未考虑抽样误差大小。 区间估计:interval estimation,按预先给定 的概率95%,或(1-),确定的包含未知总 体参数的可能范围。考虑了抽样误差。