Meta分析方法的统计过程
Meta_分析中的统计学过程

)* (#) )* ’+" )* +)$ )* +)" )* (,+ "* "$$ )* +,&
注: 取自 5,&6// 78 的资料
该数据资料在 M#@)0+ N7 = 软件中的计算结果见图 = 。
=7 >
合并统计量的假设检验
无论采用何种方法计算得到的
合并统计量, 都需要用假设检验 ! (-?&"(#$,$ "#$" . 的方法检验多 个独立研究的合并统计量是否具有统计学意义, 常用 " 检验 ( # , 根据 " 值得到该统计量的概率 ( 值。 若 ! ! 67 68 , 多个 "#$") !) 研究的合并统计量有统计学意义; 若 ! 5 67 68 , 多个研究的合 并统计量没有统计学意义。可信区间 ! ;&+%,:#+;# ,+"#’@0<, $% . 是 按一定的概率估计总体参数 ! 总体均数、总体率 . 所在的范围 ! 区间 . , 如: 是指总体参数在该范围 ! 区间 . 的可能 A8B 的 $%, 性为 A8B 。$% 主要有估计总体参数和假设检验两个用途。 若要 常用 $% 进行估计, 如均 利用样本资料得到的总体值 ! 参数 . 时, 数的 $%、 率和 &’ 的 $% 等。$% 的范围愈窄, 用样本指标估计总 体参数的可靠性就愈好; 反之其可靠性就愈差。 $% 可于假设检 验, A8B 的 $% 与 ! C 67 68 的假设检验等价, AAB 的 $% 与 ! C 67 6= 的假设检验等价。当实验效应指标为 &’ 或 ’’ 时,其值 等于 = 时实验效应无效, 此时其 A8B 的 $% 若包含了 = , 等价于 均大于 = 或 即无统计学意义; 若其上下限不包含 = ( ! 5 67 68 , 均小于 = ) , 等价于 ! D 67 68 , 即有统计学意义。当实验效应指 标为 ’(、)*( 或 +)* 时, 其值等于 6 时实验效应无效, 此时 其 A8B 的 $% 若包含了 6 , 等价于 ! 5 67 68 , 即无统计学意义; 均大于 6 或均小于 6 ) , 等价于 ! D 67 68 , 若其上下限不包含 6 ( 即有统计学意义。 E 实例分析 预防心肌梗死 F<#,$$ GH 等 ! " # 收集了关于阿司匹林 ( 0$?,’,+) 的资料, 符合纳入标准的研究共有 I 个, 其数据如表 E 所示。 从表中可见,在 I 个研究中,前 J 个研究的 &’ 的 A8B $% 都包含了 = ( 下限小于 = , 上限大于 = ) , 即无统计学意义, 都认为 阿司匹林预防心肌梗死无效,只有第 I 个研究的 A8B $% 的上 下限都小于 = ! 67 KEA L 67 AJJ . ,认为阿司匹林预防心肌梗死有 效。据此结果,很难得到阿司匹林预防心肌梗死是否有效的结 论,如果按传统的文献综述方法,根据 I 个研究中有 J 个研究 ( 在图 = 中可见该资料 /#"01 分析的以下内容: = . 图 = 左侧 ( 图 = 右侧所示为 I 个独立研究 所示为 I 个独立研究的数据; E) ( 的固定效应模型 &’ 值及 A8B $% 的计算结果; 图 = 中间所 >) 该图的竖线为无效线, 即 &’ C = , 示为 I 个独立研究的森林图, 每条横线为该研究的 A8B $% 上下限的连线,其线条长短直观 地表示了 $% 范围的大小,线条中央的小方块为 &’ 值的位置, 其方块大小为该研究权重大小。若某个研究 A8B $% 的线条横 跨为无效竖线, 即该研究无统计学意义, 反之, 若该横线落在无 ( 效竖线的左侧或右侧, 该研究有统计学意义; 图 = 中间底部 N) 所示为该 I 个研究的 /#"01 分析结果: ! 异质性检验 ( "#$" %&’ 该例 "$ C A7 A8 ,! C 67 => ; (#"#’&*#+#,"-)"$ 值和 ! 值, " 合并效 , 该例 &’ 合并 C 67 A6 ; 应量 &’ 合并 ( O&"0<) # 合并效应量 &’ 合并 的 A8B $%,该例 &’ 合并 A8B $% C 67 KN L 67 AJ ;$ 合并效应量 的检验 ( 即 " 值) 和 ! 值, 该例 # C O#$" %&’ &@#’0<< #%%#;") # 值( 可认为这 I 个阿司匹林 P >7 =I ,! C 67 66E 根据上述分析结果, 预防心肌梗死研究资料具有同质性 ( 异质性检验 "$ C A7 A8 , !C ,因此,合并效应量 &’ 采用固定效应模型, &’ 67 => ) 有效。 > !"#"!"$%"& 收稿日期: E66> P 6= P 6= 编辑: 刘 颖
第五讲 Meta-分析简介

合计
传统文献综述的特点
在医学研究中,传统的文献综述在处 理同一问题的多个结果报道时,通常是 平等(等权重方法)对待每个研究结果 而得出结论。这种文献综述主要是以某 类结果的文献数量的多少得出结论,一 般不进行文献评价,也不考虑文献的质 量。
传统文献综述的主要问题
传统文献综述的结果必然存在两个问题: 一是多个同类研究的质量不相同
80年代末该方法传入我国,又称荟萃分析、汇 总分析等。
实例一
6个抗高血压药物对老年心血管疾病的治疗性研究
抗高血压药 K个研究 ANBP HNT Kuramoto SHEP-PS STOP VS 合计 死亡数 治疗总数 (n) (N) 31 28 4 33 84 9 189 293 101 44 443 812 38 1731 安慰剂 死亡数 治疗总数 (n) (N) 40 34 9 14 152 25 274 289 99 47 108 815 43 1401 OR 0.74 0.73 0.42 0.54 0.50 0.22 OR的95%CI 下限 0.45 0.40 0.12 0.28 0.38 0.09 上限 1.21 1.34 1.49 1.05 0.67 0.59
二是各个研究的样本含量的大小不相同
因此,传统文献综述所采用的等权重方法很难 保证研究结果的真实性、可靠性和科学性,尤 其当多个研究的结果不一致时,其结论容易使 人产生误解或困惑。
Meta-分析的统计目的
对多个同类独立研究的结果进行汇总 和合并分析,以达到增大样本含量,提 高检验效能的目的,尤其是当多个研究 结果不一致或都没有统计学意义时,采 用Meta-分析可得到接近真实情况的统 计分析结果。
临床意义
若95%可信区间与无效线相交,可认为试验组效 应量与对照组相等,试验因素无效。 若95%可信区间不与无效线相交,且落在无效线 右侧 若所研究的事件是不利事件(如发病、死亡 等),该试验因素为有害因素(危险因素) 若研究者所研究的事件是有益事件(如有效 、生存等)时,试验因素为有益因素(保护 因素)
meta 效应值计算

meta 效应值计算
Meta效应值(meta-effect value)通常是指在统计学和研究合成的文献中,对于一组研究的效应值(effect sizes)进行汇总和分析的过程。
Meta分析是一种将多个独立研究的结果进行整合和综合的方法,以获得更全面、准确的结论。
Meta效应值计算涉及以下几个步骤:
一、效应值提取:从各个研究中提取相关的效应值。
效应值通常是用于度量研究结果的指标,比如风险比、比率、标准化平均差异等。
二、权重分配:为每个研究的效应值分配权重。
通常,较大的研究、研究设计更好的研究或效应值的不确定性较小的研究将被赋予较大的权重。
三、Meta效应值计算:利用加权平均等方法,将各个研究的效应值合并为一个汇总的效应值。
这个Meta效应值用于代表整体的效应。
四、不确定性评估:评估合并效应值的不确定性,通常通过计算置信区间来反映。
Meta效应值计算可以应用于各个学科,包括医学、心理学、教育研究等。
它使研究者能够更全面地了解一组独立研究的整体效应,并提供更准确的结论,同时考虑了研究的变异性和规模。
meta分析的基本流程及质量评价

meta分析的基本流程及质量评价下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!一、确定研究问题和选择研究类型1.1 确定研究问题:在开始meta分析前,需要明确研究问题或研究假设。
Meta分析的统计过程

47
0.7365 0.7333
0.4222
下限 0.4467 0.4018
0.1199
上限 1.2144 1.3382
1.4866
SHEP-PS 33
433
STOP
84
812
VS
9
38
14 108 152 815 25 43
0.5404 0.5033 0.2234
0.2782 0.3779 0.0853
1.0499 0.6703 0.5850
合计
189 1731
274 1401
选自Cochrance手册摘要和Cochrance图书馆
实例二 饮食对痛风的影响研究
第i个 研究
有饮食计划组
n1
X1
s1
无饮食计划组
n2
X2
P值 s2
1
17
35.00 9.00
18
24.00 8.00 P<0.05
2
15
43.00 10.00
关于随机效应模型(1)
随机效应模型一种对异质性资料 进行Meta分析的方法,但是,该法不 能控制混杂,也不能校正偏倚或减少 异质性,更不能消除产生异质性的原 因。
目前,随机效应模型多采用D-L 法(DerSimonian&Laird法)。
关于随机效应模型(2)
D-L法是1986年,由DerSimonian和 Laird首先提出,该法不仅可用于分类变 量,也适用于数值变量。D-L法主要是对 权重W进行校正,即将各式中的Wi按下 式进行计算:
若异质性检验检验结果为P>0.10时, 多个研究具有同质性,可选择固定效应 模型(fixed effect model);
Meta分析的统计过程

Meta分析的统计过程引言Meta分析是一种统计分析方法,用于合并和综合研究文献中的统计数据,以产生更准确、可靠和有说服力的结论。
它对多个独立研究的结果进行整合,从而提高统计成效和推广性。
本文将介绍Meta分析的统计过程,并提供相应的Markdown文本格式输出。
数据收集Meta分析的第一步是收集与研究主题相关的研究文献。
这可以通过文献检索数据库,如PubMed或Scopus进行。
收集到的文献应进行筛选,选择与研究目的最为相关的研究,以防止潜在的偏差。
数据提取在Meta分析中,需要提取每个研究的统计数据。
常见的统计数据包括均值、标准差、样本量和相应的效应量。
这些数据将用于计算汇总效应量和其可信区间。
在数据提取过程中,应注意保持数据的一致性和准确性。
效应量计算Meta分析的核心是计算汇总效应量及其误差估计。
根据具体的研究设计和效应量类型,可以选择不同的计算方法。
常见的效应量包括标准化平均差(SMD)、风险比(RR)和比率差(RD)等。
计算汇总效应量时,需要考虑各个研究的样本量权重,以提高结果的可靠性。
效应量的统计分析在Meta分析中,需要进行统计分析以评估汇总效应量的显著性。
通常使用Z检验或T检验来计算汇总效应量与零假设之间的统计差异。
此外,还可以计算Q统计量和I^2统计量,以评估研究间异质性的程度。
辅助分析可以帮助研究者更好地理解研究结果和异质性源。
效应量的可信区间估计除了汇总效应量,Meta分析还需要估计汇总效应量的可信区间。
常用的方法是计算95%的可信区间,用于描述汇总效应量的精确性。
根据不同的效应量类型,可以选择不同的估计方法,如固定效应模型或随机效应模型。
可信区间的大小将给出一个效应量真值的范围。
效应量的整合与解释Meta分析的最终目标是整合研究结果并给出结论。
通过汇总效应量和可信区间,可以得出关于研究主题的定量结论。
此外,还可以对汇总效应量的大小和方向进行解释,以帮助读者更好地理解研究结果。
系统综述 meta分析的实施步骤

系统综述:meta分析的实施步骤1. 简介Meta分析是一种系统综述的方法,通过整合多个独立研究的结果,以统计的方式评估研究之间的一致性和差异性。
Meta分析的目的是通过合并数据,提供一个更为准确和可靠的效应估计,从而为决策者提供科学依据。
2. 步骤2.1. 确定研究问题在进行meta分析之前,首先需要明确研究的目标和问题。
确定研究问题可以帮助研究者明确自己需要合并哪些研究的数据,以及需要评估什么样的效应。
2.2. 确定包含和排除标准确定包含和排除标准是指确定符合研究问题的研究并筛选出合适的研究。
通常,这些标准包括研究类型、样本量、研究设计等。
这一步骤的目的是确保所选研究的质量和可比性。
2.3. 搜索和筛选研究在这一步骤中,需要对相关数据库进行搜索,并根据确定的包含和排除标准对检索到的研究进行筛选。
筛选研究的过程可以包括初筛、全文阅读和最终筛选。
只有符合研究问题和标准的研究才会被保留下来。
2.4. 提取数据一旦确定了符合研究问题和标准的研究,就需要从每个研究中提取所需的数据。
通常,需要提取的数据包括样本量、效应量和相关的统计指标。
提取数据的过程需要按照统一的数据提取表格或表单进行。
2.5. 进行数据分析在完成数据提取后,可以开始进行数据的统计分析。
常用的分析方法包括计算效应量的加权平均、计算异质性和进行子组分析等。
这些分析方法可以帮助研究者判断研究之间的差异和一致性。
2.6. 评估偏倚风险评估偏倚风险是meta分析中非常重要的一步,它可以帮助研究者判断所选研究的质量和可信度。
常用的评估偏倚风险的工具包括Cochrane Collaboration’s risk of bias tool和Newcastle-Ottawa Quality Assessment Scale等。
2.7. 进行结果的解释和展示完成数据分析后,需要对结果进行解释和展示。
可以通过表格、图形和描述性文字等方式来呈现结果。
此外,还可以进行敏感性分析和亚组分析等进一步分析,以检验结果的稳定性和可靠性。
META分析流程(超级实用)

visualinspectionfunnelplotscancerdiagnosiscancerdeathendpointsbias75阳性结果更易被发表研究者可能终止阴性结果或结果模糊的研究偏向于研究组的错误设计阴性结果发表延迟不容易发表成英文文献阳性结果更易被发表研究者可能终止阴性结果或结果模糊的研究偏向于研究组的错误设计阴性结果发表延迟不容易发表成英文文献产生原因publicationbias76好的meta分析应包括所有与课题有关的可获得的资料但应尽最大可能收集未发表的研究先行将所有的rct进行登记通过这一系统随访并获得所有研究的结果是解决发表偏倚的根本途应用统计学方法计算拒绝结论所需的未发表研究数量的大小评估发表偏倚对研究结果的影响好的meta分析应包括所有与课题有关的可获得的资料但应尽最大可能收集未发表的研究先行将所有的rct进行登记通过这一系统随访并获得所有研究的结果是解决发表偏倚的根本途应用统计学方法计算拒绝结论所需的未发表研究数量的大小评估发表偏倚对研究结果的影响解决办法publicationbias77publicationbias偏倚的识别漏斗图分析funnelplots计算失效安全数failsafenumbernfs漏斗图分析funnelplots计算失效安全数failsafenumbernfs78漏斗图分析funnelplots
7
Meta分析之选题
4 .问题清楚,回答明确 提出的问题应该是选择题式的,而不应是开放式
Meta分析

Revman(Review manager)简介 实例应用
敏感性分析 结果的讨论与分析
一、连续型变量资料的Meta分析
对于连续型变量资料, 对于连续型变量资料,Meta分析的效应尺度常 分析的效应尺度常 有均数之差(MD)及比较优势(OR)等。 有均数之差( )及比较优势( )
固定效应模型一般采用 固定效应模型一般采用Inverse-variance法(倒方差加权法); 一般采用 法 倒方差加权法); 随机效应模型则是在 法基础上, 随机效应模型则是在Invernse-variace法基础上,采用 则是在 法基础上 DerSimonian-Laird法,引入校正因子对固定效应模型中的权重 法 进行校正后再计算合并效应量及其95%置信区间。 置信区间。 进行校正后再计算合并效应量及其 置信区间
实例
三、诊断试验的Meta分析 诊断试验的Meta分析 Meta
M-H 法 M-H 法是分类变量固定效应模型常用的统计方法,可用于 OR、
RR、RD 等效应指标的合并。 (1 )合并效应量 OR 、相应权重 wMH,i 及其标准误 SE OR )}的计 算 {ln( MH MH
OR MH
∑w OR = ∑w
MH,i i MH,i
bici wMH,i = Ni
1 E F +G H + 2 SE OR )}= 2 + {ln( MH 2 R R×S S
(3)合并效应量 RD 、相应权重 wMH,i 及其标准误 SE{RD }的计算 MH MH
RDMH = wMH,i RD i wMH,i
wMH,i =
n1i n2i J SE{RDMH} = Ni K2
其中, J = ∑
ai bi n2i + ci di n1i
Meta分析的统计过程刘关键

可编辑ppt
4
二、Meta分析的定义
可编辑ppt
5
Meta-Analysis is a systematic review that uses quantitative methods to summarize the results. Meta分析是运用定量方法去概括(总 结)多个研究结果的系统评价。
可编辑ppt
13
Meta分析与系统评价(一)
在系统评价(systematic review)
中,当数据资料适合使用Meta分析时,
用Meta分析可以克服传统文献综述的两
大问题,其分析结果的可靠性更高;当
数据资料不适合做Meta分析时,系统评
价只能解决文献评价的问题,不能解决
样本含量的问题,因此,对其分析结论
numerical estimate.
Meta分析是文献评价中,将若干
个研究结果合并成一个单独数字估计
的统计方法。
《The Cochrane Library》第3页的定
义。
可编辑ppt
7
三、Meta分析的统计目的
可编辑ppt
8
实例一 抗高血压药物对老年心血管疾病的治疗 性研究
抗高血压药
死亡数 K个研究
可编辑ppt
10
传统文献综述的特点
在医学研究中,传统的文献综述 在处理同一问题的多个结果报道时, 通常是平等(等权重方法)对待每个 研究结果而得出结论。这种文献综述 一般不进行文献评价,也不考虑文献 的质量,主要是以某类文献数量的多 少得出结论。
可编辑ppt
11
传统文献综述的主要问题
传统文献评价的结果必然存在两个问题:
84
812
Meta分析的统计学方法_杨娟
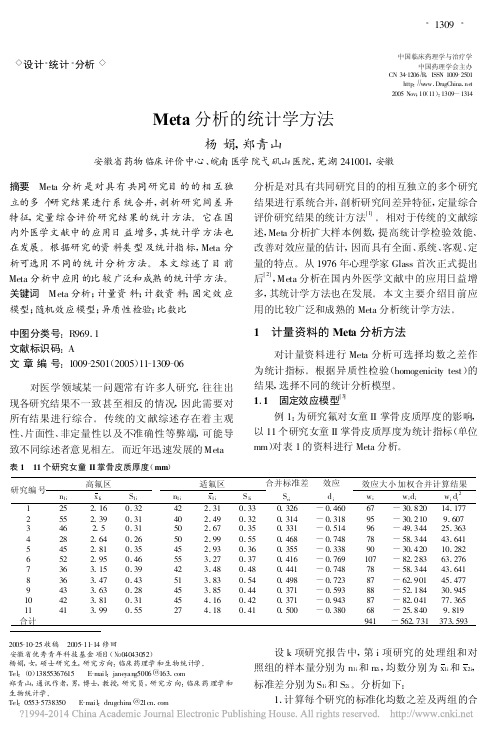
例 1 :为研究氟对女童 II 掌骨皮质厚度的影响 , 以 11 个研究女童 II 掌骨皮质厚度为统计指标(单位 mm)对表 1 的资料进行 Meta 分析 。
若
Sd
2
<S
2 e
,
则随机效应模型退化为固定效应
模型 。在区间估计时 , 随机效应模型比固定效应模
型估计更精确(区间宽度更窄)。
2 计数资料的 Meta 分析方法
对于计数资料 , 主要讨论四格表资料的 Meta 分 析 。能够形成四格表资料的研究方法最常见的有随 机化临床试验 、病例-对照研究 、队列研究和诊断试 验评价等 。 这些研究的数据基本格式见表 2 。另外 等级资料转换 成二分类资料后也可用 计数资料的
表 4 激素预防新生儿肺透明膜病 Peto 法计算合 并所需要的中间值
研 究编号
Oi
1
35
2
1
3
16
4
3
5
9
6
3
7
1
8
4
9
32
10
5
11
7
12
1
13
5
14
6
合计
35
Ei 47 .367 3 .183
19 5 .276 8 .461 8 .325 3 .89 8 .438 32 .544 4 .397 9 .878 1 .043 5 .425 7 .149
分析是对具有共同研究目的的相互独立的多个研究
结果进行系统合并 , 剖析研究间差异特征 , 定量综合 评价研究结果的统计方法[ 1] 。 相对于传统的文献综 述 ,Meta 分析扩大样本例数 , 提高统计学检验效能 、 改善对效应量的估计 , 因而具有全面 、系统 、客观 、定 量的特点 。从 1976 年心理学家 Glass 首次正式提出 后[ 2] ,Meta 分析在国内外医学文献中的应用日益增 多 , 其统计学方法也在发展 。 本文主要介绍目前应 用的比较广泛和成熟的 Meta 分析统计学方法 。
Me 分析的统计过程

怎样做?
1./ 了解正在进行的临床 试验。
2.每年国内、国外相应领域的会议,相当重要的途径,目 前很多未发表的、进行中有初步结果或者有中期报告的临 床试验接出于此。肿瘤方面如CSCO,ASCO,ESMO, 更专科的子领域如 World Conference on lung cancer 。
6 有合适的原始论文。
巧妇难为无米之炊,meta分析的“米”就是原始 论文。原始论文要适合做meta分析,例如研究危 险因素的就应当是病例对照研究和队列研究;要 提供必要的信息,例如研究危险因素的就要能够 提取出四格表资料;数目也不能太少,否则达不 到汇总的效果,如果数目太多,当然没有什么不 好,而且结果会更可靠,只是研究所需时间要增 加而已。还有质量要高,设计要科学。
4 问题清楚,回答明确。
提出的问题应该是选择题式的,如:A和B 两种疗法治疗C病哪种更好?而不应是开放 式的,例如,乳腺癌应该采取什么样的治 疗方法?正确的提法应该是:二期乳腺癌 患者采用保乳手术和根治术,哪种方法更 好?
5 有明确的效应指标
对于危险因素,可以以OR/RR值为效应指 标,对于肿瘤的治疗,可以以×年生存率 为效应指标等等。
多沟通一些,每个人都获得更广阔的空间!
--我最近发现,可以试着写信给该方面的专 家,如入选高质量研究的作者,一般他们 也很客气的,会告诉你是否还有其它人或 他自己正在做的工作。毕竟他们对这方面 也很了解。
未发表文献(灰色文献gray literature)的检索有: ①尚未完成的研究在Cochrane临床对照试验数据库(The
信息收集流程图
获得全文的常见方法: 1、各个医学院校的图书馆都购买了不同程度的医学数据库版权,从 各个学校校园网上网进入数据库可以得到诸如springlink ovid等数据 库的全文。 2、代理服务器,在诸如小木虫,叩诊锤等各个专业的网站里有些前 辈会共享他们的代理服务器,同时诸如BMJ等杂志也会提供一些代理 服务器也是向中国用户开放的,改变代理服务器设置可以帮助你从网 上得到全文,但使用这种方法时候请注意下载时请下载必要的文章, 以前经常有代理服务器因为批量下载端口被封的情况,以至于端口越 来越难得,而且大量端口被收回后大家分享端口的积极性也就越来越 差,所以尽管是免费的午餐,请大家珍惜。 3、google学术 搜索全文的功能里google学术绝对是不差于 pubmed的利器。 3、图书馆查询,大部分图书馆提供付费和免费的查询,这里面协和 图书馆和301的军事医学科学院图书馆可能是比较全的,其他学校图 书馆能查到常见文献,但做meta是往往不够给力。 4、直接向作者索要,文章的摘要已经提供了作者的联系方式,所以 联系第一作者和通讯作者(最后一个)也是获得全文的途径之一,这 里大家不要觉得人家怎么会给你,人家会保密什么的,首先,已经发 表的文章,也就没啥保密的需要了,而引用次数已经成为衡量文章重 要性的标准,所以大部分西方作者乐于为你提供全文,从而为自己增 加引用次数,这是个互利的过程,至少目前为止,我索要的文章还没 被拒绝过。
Meta分析的简单介绍---文本资料

吉林大学白求恩第一医院 结直肠肛门外科 张婷
“Meta”一词源于希腊文,意为“more comprehensive”,即“更广泛、更全面”
上个世纪60年代开始,在医学文献中,陆续出 现许多对多个独立研究的统计量进行合并的报 道。 英国心理学家G.V.Glass,在1976年首先将这 种多个同类研究的统计量合并方法称为 “Meta-Analysis”。该方法现在已广泛应用于 医学和健康领域,尤其是针对疾病的诊断、治 疗、预防和病因等问题的综合评价。
RR和OR的森林图
RR和OR的森林图(forest plots) 无效线竖线的横轴尺度为1; 每条横线为该研究的95%可信区间上下限的 连线; 线条长短直观地表示了可信区间范围的大小; 线条中央的小方块为RR或OR值的位置,其 方块大小为该研究权重大小。 若某个研究的95%可信区间的线条横跨过无 效竖线,即该研究无统计学意义,反之,若 该横线落在无效竖线的左侧或右侧,该研究 有统计学意义。
异质性定义
广义上用于描述试验的参与者、试验 的干预措施和多个研究测量结果的变 异,即各研究的内在真实性的变异。
种类: 临床异质性 方法异质性 统计学异质性
统计学异质性
是指干预效果的评价在不同试验间的变异, 它是研究间的临床和方法学上变异联合作用 的结果。 通常将Meta分析的统计学异质性简称为“异 质性”,它是以各研究之间可信区间(CI) 的重合程度来度量异质性的大小; 多个研究间的CI重合程度越大,存在统计学 异质性的可能性就越小,反之,各研究间存 在统计学异质性的可能性就越大。 异质性分析的意义:Meta分析的核心计算是 合并(相加),按统计原理,只有同质的资 料才能进行合并或比较等统计分析,反之则 不能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
合并统计量的计算
当多个独立研究的例数不等时,它 们的综合效应不等于这多个单独效应的 平均数。如三个均数的总均数不等于这 三个均数之和除以3。
所以,怎样合理的对多个独立研究 效应进行合并,是Meta分析统计过程的 主要问题之一。
合并统计量的两种统计模型
固定效应模型(fixed effect model): 若多个研究具有同质性(无异质性)时, 可使用固定效应模型。
1.单个研究的统计量
根据资料类型选择单个研究的统计量d1 (1)分类变量可选择的统计量 比值比,OR(odds ratio) 相对危险度,RR(relative risk) 率差,RD(rate difference)
(2)数值变量可选择加权均数差 (WMD)或标准化均数差(SMD) 为统计量。
Meta-Analysis is statistical technique for assembling the results of several studies in a review into a single numerical estimate.
Meta分析是文献评价中,将若干 个研究结果合并成一个单独数字估计 的统计方法。
Meta分析的统计过程
一、概述
60年代开始,在医学文献中, 陆续出现了对多个独立研究的统 计量进行合并的报道。
76年G.V.Glass首先将合并统计 量对文献进行综合分析研究的这 类方法称为Meta-Analysis。
80年代末该方法传入我国, 中文译名有荟萃分析、二次分析、 汇总分析、集成分析等。但无论 何种中文译名都有不足之处。因 此,很多学者建议仍然使用〝 Meta分析〞这一名称。
9
47
0.7365 0.7333
0.4222
下限 0.4467 0.4018
0.1199
上限 1.2144 1.3382
1.4866
SHEP-PS 33
433
STOP
84
812
VS
9
38
14 108 152 815 25 43
0.5404 0.5033 0.2234
述的主要问题
传统文献评价的结果必然存在两个问题: 一是多个研究的质量不相同 二是各个研究的样本含量的大小(权重)
不相等。 因此,传统文献综述的方法很难保证
研究结果的真实性、可靠性和科学性,尤 其当多个研究的结果不一致时,让人容易 产生困惑或误解。
Meta分析的统计目的
对多个同类独立研究的结果进行汇 总和合并分析,以达到增大样本含量, 提高检验效能的目的,尤其是当多个研 究结果不一致或都没有统计意义时,采 用Meta分析可得到更加接近真实情况的 统计分析结果。
若异质性检验检验结果为P>0.10时, 多个研究具有同质性,可选择固定效应 模型(fixed effect model);
若多个研究结果为P≤0.10时,多个 研究不具有同质性,首先应进行异质性 分析和处理,若仍无法消除异质性的资 料,可选择随机效应模型(random effect model)。
1.0499 0.6703 0.5850
合计
189 1731
274 1401
选自Cochrance手册摘要和Cochrance图书馆
实例二 饮食对痛风的影响研究
第i个 研究
有饮食计划组
n1
X1
s1
无饮食计划组
n2
X2
s2
P值
1
17
35.00 9.00
18
24.00 8.00 P<0.05
2
15
43.00 10.00
Meta分析与系统评价(二)
没有按系统评价标准操作规范实 施,或未经严格文献评价的研究,即 使用了Meta分析也不一定是系统评价 的研究,更难说是高质量的研究。
四、Meta分析的统计过程
Meta分析的计算的主要步骤:
1.计算每个研究的效应量及方差 2.计算每个研究效应量的权重 3.计算合并效应量 4.异质性检验 5.合并效应量的可信区间 6.合并效应量的检验
数值变量 (Continuous)
个案资料 (individual)
合并统计量
模型
Summary statistic OR(odds ratio)
Model 固定 固定
随机
RR(relative risk)
RD(relative difference)
固定 随机 固定 随机
WMD(Weighted 固定 Mean Difference)
二、Meta分析的定义
Meta-Analysis is a systematic review that uses quantitative methods to summarize the results. Meta分析是运用定量方法去概括(总 结)多个研究结果的系统评价。
《Evidence-Based Medicine》David Sackett等,第247页的定义。
关于随机效应模型(1)
随机效应模型一种对异质性资料 进行Meta分析的方法,但是,该法不 能控制混杂,也不能校正偏倚或减少 异质性,更不能消除产生异质性的原 因。
目前,随机效应模型多采用D-L 法(DerSimonian&Laird法)。
关于随机效应模型(2)
D-L法是1986年,由DerSimonian和 Laird首先提出,该法不仅可用于分类变 量,也适用于数值变量。D-L法主要是对 权重W进行校正,即将各式中的Wi按下 式进行计算:
《The Cochrane Library》第3页的定 义。
三、Meta分析的统计目的
实例一 抗高血压药物对老年心血管疾病的治疗 性研究
抗高血压药
死亡数 K个研究
治疗 总数
安慰剂
死亡数 治疗 总数
OR的95%CI OR
ANBP
31
293
HNT
28
101
Kuramoto
4
44
40 289 34 99
若P≤0.05, 多个研究的合并效应量有 统计学意义;
若P>0.05,多个研究的合并效应量 没有统计学意义。
6.合并效应量的可信区间
可信区间(confidence interval, CI)是 按一定的概率估计总体参数(总体均数、 总体率)所在的范围(区间),如:95 %的CI,是指总体参数在该范围(区间) 的可能性为95%。
Q
Wi (d i d )2
Wi
d
2 i
(
Wi di )2 Wi
Wi为每个研究的权重,第i个研究的 权重Wi按下式计算:
1 Wi Var(di )
该检验统计量Q服从自由度为K-1
的卡方( 2)分布,因此,当计算得
到Q后,需由卡方分析获取概率,故又 将此检验叫做卡方检验(Chi-square test)。
在Cochrane系统评价中,只要I2不 大于70%,其异质性可以接受。
异质性分析与处理的方法
当异质性检验出现P≤0.10时,首 先应找出产生异质性的原因,如疗程 长短、用药剂量、病情轻重、对照选 择等是否相同。
由上述原因引起的异质性,可使 用亚组分析(subgroup analysis)、 Breslow-Day法和回归近似法。
随机效应模型(random effect model): 若多个研究不具有同质性时,先对异质 性原因进行处理,若异质性分析与处理 后仍无法解决异质性时,可使用随机效 应模型。
(1)分类变量(category dichotomous) 固定效应模型,指标RR、OR (1)standard odds ratio法 (2)Mantel-Haenzel法 (3)Peto法 随机效应模型,指标RR、OR 如:DerSimonian&Laird(D-L)法
16
37.00 7.00 P>0.05
3
18
40.00 2.30
19
32.00 2.54 P<0.05
合计
50
53
选自Cochrance协作系统评价员学习资料1.1版,2002年11月
传统文献综述的特点
在医学研究中,传统的文献综述 在处理同一问题的多个结果报道时, 通常是平等(等权重方法)对待每个 研究结果而得出结论。这种文献综述 一般不进行文献评价,也不考虑文献 的质量,主要是以某类文献数量的多 少得出结论。
随机
SMD (Standardised Mean Difference)
OR(odds ratio)
固定 随机 固定
计算方法
Method Peto法 Mantel-Haenzel法 D-L法 Mantel-Haenzel法 D-L法 Mantel-Haenzel法 D-L法 倒方差法(inverse variance) D-L法 倒方差法 D-L法
因此,Meta分析过程需要对多个研 究的结果进行异质性分析,尽可能地消 除导致异质的原因,使之到同质。
异质性检验
异质性检验(tests for heterogeneity) 又称同质性检验(tests for homogeneity)。
用假设检验的方法检验多个独立研究 是否具有异质性(同质性)。
异质性检验的方法,目前,多用下式计算:
I2及计算
在Revman4.2及以后的软件中,出 现了新的异质性指标,即I2。其计算公 式如下:
I 2 Q (k 1) 100% Q
式中的Q为异质性检验的卡方值 2,K
为纳入Meta分析的研究个数。
I2的意义
在Revman中,I2可用于衡量多个 研究结果间异质性程度大小的指标。 这个指标用于描述由各个研究所致的, 而非抽样误差所引起的变异(异质性) 占总变异的百分比。