Hadoop安装手册_Hadoop2.0-v1.6
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
hadoop2.2.0安装笔记

Hadoop 2.2 安装笔记测试环境:硬件:PC 机(12G内存, AMD phenomII x4 CPU,120G SSD硬盘)软件:win7 64位旗舰版操作系统vmware workstation 9.01SSH Secure Shell ClientCentOS-6.4-x86_64-minimaljdk-7u45-linux-x64hadoop-2.2.0第一步Linux 虚拟机安装和配置1.下载好linux操作系统镜像,建立三个空目录用来存放虚机2.建立三个虚拟机,1vcpu,2G内存,20G硬盘。
网络连接模式设置为桥接3.挂载iso镜像,安装系统,主机名分别设置为h1.hadooph2.hadooph3.hadooproot的密码都设成了hadoop由于使用的是centos最小安装镜像,所以各种设置采用默认的即可。
centos 最小安装版镜像地址/centos/6.4/isos/x86_64/4.修改三台虚机的网络配置,设置静态IP(物理机的ip为192.168.1.xx)h1 192.168.1.21h2 192.168.1.22h3 192.168.1.23重启虚机网络service network restart5.关闭防火墙:(非常重要)在三台机器上运行chkconfig iptables off (重启后生效)6.修改三台机器的/etc/hosts文件,加入以下三行192.168.1.21 h1 h1.hadoop192.168.1.22 h2 h2.hadoop192.168.1.23 h3 h3.hadoop7.安装完成后关机,快照。
(防止误操作)第二步,安装JDK1.下载JDK,使用secure file transfer工具上传到三台虚机(由于使用的是centos,我下载的RPM包)JDK下载地址/technetwork/java/javase/downloads/jdk7-downloads-1 880260.html2.在每台虚机上安装JDK[root@h3 ~]# rpm -ivh jdk-7u45-linux-x64.rpm第三步配置SSH 互信1.在每一台机器上创建RSA公钥2.将三台机器的公钥文件id_rsa.pub合并,并拷回每台机器的~/.ssh/,重命名为authorized_keysh1[root@h1 .ssh]# scp ~/.ssh/id_rsa.pub root@h2:~/.ssh/authorized_keysh2[root@h2 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys[root@h2 ~]# scp ~/.ssh/authorized_keys root@h3:~/.ssh/authorized_keysh3[root@h3 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys[root@h3 ~]# scp ~/.ssh/authorized_keys root@h1:~/.ssh/[root@h3 ~]# scp ~/.ssh/authorized_keys root@h2:~/.ssh/3.用每一台机器ssh连接另外两台,确保不用输入密码[root@h1 ~]# ssh h2Last login: Tue Jan 1 17:33:24 2008 from h3[root@h2 ~]# exitlogoutConnection to h2 closed.[root@h1 ~]# ssh h3Last login: Tue Jan 1 17:33:08 2008 from h2[root@h3 ~]# exitlogoutConnection to h3 closed.注意第一次建立连接时会有一个提示,以后就不会有了[root@h1 ~]# ssh h3The authenticity of host 'h3 (192.168.1.23)' can't be established.RSA key fingerprint is ba:26:62:1f:f7:46:24:cd:f9:95:c3:55:82:eb:4e:5a.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'h3,192.168.1.23' (RSA) to the list of known hosts. Last login: Tue Jan 1 17:18:53 2008 from 192.168.1.104第四步安装hadoop1.下载hadoop,由于2.2.x已经发布了稳定版,所以我下载了这个版本下载地址/apache/hadoop/common/hadoop-2.2.0/2.将hadoop-2.2.0.tar.gz 上传到h1节点3.解压安装包[root@h1 ~]# tar -zxvf hadoop-2.2.0.tar.gz4.修改hadoop-env.sh 文件[root@h1 hadoop]# vi /root/hadoop-2.2.0/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.7.0_455.修改core-site.xml文件[root@h1 hadoop]# vi core-site.xml<configuration><property><name></name><value>hdfs://h1:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop/tmp</value></property></configuration>6.建立hadoop临时目录(同样也要在节点2和节点3上建立)[root@h1 hadoop]# mkdir -p ~/hadoop/tmp7.修改 hdfs-site.xml文件[root@h1 hadoop]# vi hdfs-site.xml<configuration><property><name>dfs.replication</name><value>2</value></property></configuration>8.修改mapred-site.xml文件[root@h1 hadoop]# cp mapred-site.xml.template mapred-site.xml [root@h1 hadoop]# vi mapred-site.xml<configuration><property><name>mapred.job.tracker</name><value>h1:9001</value></property></configuration>9.修改masters文件[root@h1 hadoop]# vi mastersh110.修改slaves文件[root@h1 hadoop]# vi slavesh2h311.将hadoop-2.2.0拷贝到节点2和3[root@h1 ~]# scp -r hadoop-2.2.0 root@h2:~[root@h1 ~]# scp -r hadoop-2.2.0 root@h3:~12.格式化name node[root@h1 bin]# ~/hadoop-2.2.0/bin/hadoop namenode -format13.启动hadoop集群[root@h1 bin]# ./start-all.sh14.验证集群状态h1h2h3总结:1.整个安装步骤基本顺利,hadoop采用了java虚拟机,所以相对于其他系统简单很多。
Hadoop安装手册

Hadoop目录1Centos ··········································· 错误!未定义书签。
1.1安装环境 (3)1.2初始环境配置 (3)1.2.1设置centos开机自启动网络 (3)1.2.2关闭防火墙 (4)1.2.3关闭selinux (5)1.2.4修改hosts (5)1.3安装JDK (6)1.3.1安装 (6)1.3.2设置环境变量 (7)1.4添加用户 (8)1.5复制虚拟机 (8)1Hadoop1.1.2安装1.1安装环境操作系统:Centos6.5 64位Hadoop:hadoop-1.1.2Jdk:jdk-7u511.2初始环境配置1.2.1设置centos开机自启动网络[root@localhost network-scripts]# cd /etc/sysconfig/network-scripts[root@localhost network-scripts]# lsifcfg-eth0 ifdown-bnep ifdown-ipv6 ifdown-ppp ifdown-tunnel ifup-bnep ifup-ipv6 ifup-plusb ifup-routes ifup-wireless network-functionsifcfg-lo ifdown-eth ifdown-isdn ifdown-routes ifup ifup-eth ifup-isdn ifup-post ifup-sit init.ipv6-global network-functions-ipv6ifdown ifdown-ippp ifdown-post ifdown-sit ifup-aliases ifup-ippp ifup-plip ifup-ppp ifup-tunnel net.hotplug第3页/共53页[root@localhost network-scripts]# vi ifcfg-eth0DEVICE=eth0HWADDR=00:0C:29:09:8B:B0TYPE=EthernetUUID=3192d1fe-8ff3-411f-81b7-8270e86f5959ONBOOT=yesNM_CONTROLLED=yesBOOTPROTO=dhcp1.2.2关闭防火墙关闭防火墙[root@master01 /]# service iptables stopiptables:将链设置为政策 ACCEPT:filter [确定]iptables:清除防火墙规则: [确定]iptables:正在卸载模块: [确定]设置开机不启用[root@master01 /]# chkconfig iptables off第4页/共53页1.2.3关闭selinux[root@master01 /]# vi /etc/selinux/config# This file controls the state of SELinux on the system.# SELINUX= can take one of these three values:# enforcing - SELinux security policy is enforced.# permissive - SELinux prints warnings instead of enforcing.# disabled - No SELinux policy is loaded.SELINUX=disabled# SELINUXTYPE= can take one of these two values:# targeted - Targeted processes are protected,# mls - Multi Level Security protection.#SELINUXTYPE=targeted1.2.4修改hosts[root@master01 etc]# vi /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.239.100 master01第5页/共53页192.168.239.101 slave01192.168.239.102 slave021.3安装JDK1.3.1安装cd /home/nunchakus[root@localhost nunchakus]# lsjdk-7u51-linux-x64.rpm[root@localhost nunchakus]# rpm -ivh jdk-7u51-linux-x64.rpmPreparing... ########################################### [100%] 1:jdk ########################################### [100%] Unpacking JAR files...rt.jar...jsse.jar...charsets.jar...tools.jar...localedata.jar...jfxrt.jar...[root@localhost nunchakus]# lsjdk-7u51-linux-x64.rpm[root@localhost nunchakus]# cd /usr[root@localhost usr]# lsbin etc games include java lib lib64 libexec local sbin share src tmp [root@localhost usr]# cd java[root@localhost java]# lsdefault jdk1.7.0_51 latest第6页/共53页1.3.2设置环境变量[root@localhost ~]# vi /etc/profile末尾加入export JAVA_HOME=/usr/java/jdk1.7.0_51export JAVA_BIN=/usr/java/jdk1.7.0_51/binexport PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH让/etc/profile文件修改后立即生效,可以使用如下命令:# . /etc/profile注意: . 和/etc/profile 有空格.重启测试[root@localhost ~]# java -version第7页/共53页java version "1.7.0_45"OpenJDK Runtime Environment (rhel-2.4.3.3.el6-x86_64 u45-b15)OpenJDK 64-Bit Server VM (build 24.45-b08, mixed mode)1.4添加用户[root@master01 /]# useradd hadoop[root@master01 /]# passwd hadoop更改用户hadoop 的密码。
HADOOP2.2安装部署手册

HA D O O P2.2安装部署手册XXXXX公司2014年5月版本号更新人更新日期V1.0Box2014-5-15目录目录 (I)第1章基础环境 (1)1.1集群规划 (1)1.1.1.修改主机名 (1)1.1.2.职责划分 (1)第2章软件版本 (2)2.1软件 (2)2.2文件目录规划 (2)第3章基础配置 (3)3.1集群SSH无密码互信 (3)3.2配置系统环境变量 (3)第4章HADOOP安装 (4)4.1配置文件修改 (4)4.1.1修改$HADOOP_HOME/etc/Hadoop/hadoop-env.sh (4)4.1.2修改$HADOOP_HOME/etc/Hadoop/slaves (4)4.1.3修改$HADOOP_HOME/etc/Hadoop/core-site.xml (4)4.1.4修改$HADOOP_HOME/etc/Hadoop/hdfs-site.xml (5)4.1.5修改$HADOOP_HOME/etc/Hadoop/mapred-site.xml (6)4.1.6修改$HADOOP_HOME/etc/Hadoop/yarn-site.xml (7)4.1.7分发到各结点 (9)4.2格式化HDFS (9)4.3启动HDFS、YARN (9)4.4检查集群运行状态 (9)第5章ZOOKEEPER安装 (9)5.1修改配置 (9)5.2分发到各结点 (10)5.3启动ZOOKEEPER (10)第6章HBASE安装 (10)6.1修改配置 (10)6.1.1修改$HBASE_HOME/conf/hbase-env.sh (10)6.1.2修改$HBASE_HOME/conf/RegionServer (10)6.1.3修改$HBASE_HOME/conf/hbase-site.xml (11)6.2分发到各结点 (12)6.3启动HBASE (12)第7章安装HIVE (12)7.1安装MYSQL (12)7.1.1检查是否已经安装过MYSQL (12)7.1.2安装MYSQL (13)7.1.3配置MYSQL (13)7.1.4修改root密码 (14)7.1.5创建hive元数据数据库 (14)7.2修改HIVE配置 (15)7.2.1修改$HIVE_HOME/conf/hive-site.xml (15)7.3开启HIVE服务 (16)第8章安装SPARK (17)8.1修改配置 (17)8.1.1修改$SPARK_HOME/spark-env.sh (17)8.1.2修改slaves (17)8.2分发到各结点 (17)8.3启动spark (17)第9章安装SHARK (18)9.1修改配置 (18)9.2进入SHARK控制台 (18)附录A:HADOOP-HBASE兼容表 (18)附录B:问题清单 (19)第1章基础环境[root@ip-172-167-15-226~]#lsb_release-aLSBVersion::core-4.0-amd64:core-4.0-noarch:graphics-4.0-amd64:graphics-4.0-noarch:printing-4.0-amd6 4:printing-4.0-noarchDistributor ID:RedHatEnterpriseServerDescription:Red Hat Enterprise Linux Server release6.2(Santiago)Release: 6.2Codename:Santiago1.1集群规划1.1.1.修改主机名vi/etc/sysconfig/networkHOSTNAME=hadoo201vi/etc/hosts#for hadoop2cluster#pengyq2014.5.13172.167.15.226hadoop201172.167.15.227hadoop202172.167.15.228hadoop203172.167.15.230hadoop204172.167.15.231hadoop2051.1.2.职责划分hadoop201作为namenode、seconderynamenode、HMaster、Spark Masterhadoop202,hadoop203,hadoop204,hadoop205为DataNode、RegionServer、Spark Slaver五台机器都作为Zookeeper节点第2章软件版本2.1软件版本兼容请参照附录A[hadoop@hadoop201hadoop2_cluster]$lsjdk1.7.0_55#JAVA运行基础环境hadoop-2.2.0Zookeeper-3.4.6#hbase依赖(使用hbase0.98.2自带zk安装遇到了问题,所以独立安装zk群)hbase-0.98.2apache-hive-0.13.0-binscala-2.11.0#spark依赖spark-0.9.1-bin-hadoop2shark-0.9.1-bin-hadoop22.2文件目录规划/Hadoop/home/hadoop2_cluster/jdk1.7.0_55/hadoop-2.2.0/Zookeeper-3.4.6/hbase-0.98.2/apache-hive-0.13.0-bin/scala-2.11.0/spark-0.9.1-bin-hadoop2/shark-0.9.1-bin-hadoop2/workspace/dfs/data/#hdfs数据name/#namenode数据hive/#hive querylogmapred/#mapreduce日志tmp/zookeeper/#zookeeper datadir/opt/mysql_data/mysql#mysql数据存放目录第3章基础配置3.1集群SSH无密码互信生成SSH密钥ssh-keygen#分发公钥到受控节点ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop202ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop203ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop204ssh-copy-id-i~/.ssh/id_rsa.pub hadoop@hadoop205出现的问题:Permission denied(publickey,gssapi-with-mic).修改了/etc/ssh/sshd_config中的"PasswordAuthentication"参数值为"no",修改回"yes",重启sshd服务即可。
hadoop2.0安装

Hadoop2.0配置SSH安装在线安装ssh #sudo apt-get install openssh-serveropenssh-client手工安装ssh存储ssh密码#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa#cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys#sudo chmod go-w $HOME $HOME/.ssh#sudo chmod 600 $HOME/.ssh/authorized_keys#sudo chown `whoami` $HOME/.ssh/authorized_keys测试连接本地服务,无密码登陆,则说明ssh服务安装配置正确#ssh localhost#exit安装JDK安装必须1.6或者1.6以上版本。
#sudo mkdir /usr/java#cd /usr/java#sudo wget/otn-pub/java/jdk/6u31-b04/jdk-6u31-linux-i586.bin #sudo chmod o+w jdk-6u31-linux-i586.bin#sudo chmod +x jdk-6u31-linux-i586.bin#sudo ./jdk-6u31-linux-i586.bin修改环境变量/etc/profile文件中增加如下代码export JA V A_HOME=/usr/java/jdk1.6.0_24export PATH=$PATH:/usr/java/jdk1.6.0_24/binexport CLASSPA TH=/usr/java/jdk1.6.0_24/lib/dt.jar:/usr/java/jdk1.6.0_24/lib/tools.jar#source /etc/profile测试# java -version显示java版本,则证明安装配置正确安装hadoop选择一个linux系统,下载并解压hadoop2.0.x并解压到/home/hadoop-2.0.0-alpha。
hadoop实战系列之hadoop安装教程-北风网课件

配置操作系统的环境变量,以便可以在任何位置运行Hadoop命令。
Hadoop安装步骤
1
解压Hadoop软件包
使用解压工具解压下载的Hadoop软件包到目标文件夹。
2
配置Hadoop环境
修改Hadoop配置文件和环境变量,以适应你的环境和需求。
3
启动Hadoop集群
依次启动NameNode和DataNode,然后启动ResourceManager和NodeManager。
常见问题解答
如何解决Hadoop启动失败问题
检查日志和配置文件,确保正确配置并解决可能的故障。
如何解决Hadoop集群无法连接的问题
检查网络设置并确保各个节点之间可以互相通信。
总结
1 Hadoop的优势和劣势
2 安装Hadoop的难点和注意事项
Hadoop具有高性能、可扩展性和容错性,但 也需要大量的配置和维护工作。
4
检验Hadoop集群是否启动成功
运行一些简单的命令来验证Hadoop集群是否正常运行。
Hadoop集群管理工具
Hadoop集群管理工具介绍
介绍各种Hadoop集群管理工具,如Ambari、 Cloudera等。
使用Ambari管理Hadoop集群
详细介绍如何使用Ambari对Hadoop集群进行管理。
Hadoop实战系列之 Hadoop安装教程-北风网 课件
Hadoop是一个开源的分布式计算平台,用于存储和处理大规模数据集。本课 件将介绍Hadoop的安装过程和常见问题解答。
介绍
Hadoop是什么
Hadoop是一个开源的分布式 计算平台,用于存储和处理 大规模数据பைடு நூலகம்。
hadoop安装指南及基本命令

Hadoop安装指南安装JDK(参考jdk的安装文档)关闭防火墙:(1)重启后永久性生效:开启:chkconfig iptables on 关闭:chkconfig iptables off (2)即时生效,重启后失效:开启:service iptables start 关闭:service iptables stop设置DNS解析Hadoop集群之间通过主机名互相访问,所以在安装时需要设置dns解析Vi /etc/hosts 在最后一行加上IP地址和主机名,中间一空格隔开设置SSH免密码登陆:命令“ssh-keygen –t rsa”表示使用rsa加密方式生成密钥,回车后会提示三次输入信息,直接回车就OK命令“cp id_rsa.pub authorized_keys”用于生成授权文件验证ssh无密码登陆命令:ssh localhost安装hadoop安装程序包将hadoop-1.1.2.tar.gz 放在usr/hadopp目录下命令: tar –xzvf Hadoop-1.1.2.tar.gz设置环境变量Vi /etc/profile 在最后面输入:Export HADOOP_HOME=/usr/Hadoop/Hadoop-1.1.2Export PATH=$PATH:$HADOOP_HOME/bin修改hadoop配置文件1.hadoop-env.shexport JAVA_HOME=/usr/local/jdk/2.core-site.xml<configuration><property><name></name><value>hdfs://hadoop0:9000</value><description>change your own hostname</description> </property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property></configuration>3.hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property></configuration>4.mapred-site.xml<configuration><property><name>mapred.job.tracker</name><value>hadoop0:9001</value><description>change your own hostname</description></property></configuration>Hadoop集群环境的搭建1、准备机器一台master,若干台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,当前准备三台机器:对三台机器分别安装hadoop环境,SSH秘密登陆和DNS 解析。
Hadoop集群安装详细步骤亲测有效

Hadoop集群安装详细步骤亲测有效第一步:准备硬件环境- 64位操作系统,可以是Linux或者Windows-4核或更高的CPU-8GB或更高的内存-100GB或更大的硬盘空间第二步:准备软件环境- JDK安装:Hadoop运行需要Java环境,所以我们需要先安装JDK。
- SSH配置:在主节点和从节点之间建立SSH连接是Hadoop集群正常运行的前提条件,所以我们需要在主节点上生成SSH密钥,并将公钥分发到从节点上。
第四步:配置Hadoop- core-site.xml:配置Hadoop的核心参数,包括文件系统的默认URI和临时目录等。
例如,可以将`hadoop.tmp.dir`设置为`/tmp/hadoop`。
- hdfs-site.xml:配置Hadoop分布式文件系统的参数,包括副本数量和块大小等。
例如,可以将副本数量设置为`3`。
- yarn-site.xml:配置Hadoop的资源管理系统(YARN)的参数。
例如,可以设置YARN的内存资源分配方式为容器的最大和最小内存均为1GB。
- mapred-site.xml:配置Hadoop的MapReduce框架的参数。
例如,可以设置每个任务容器的内存限制为2GB。
第五步:格式化Hadoop分布式文件系统在主节点上执行以下命令,格式化HDFS文件系统:```hadoop namenode -format```第六步:启动Hadoop集群在主节点上执行以下命令来启动Hadoop集群:```start-all.sh```此命令将启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager。
第七步:测试Hadoop集群可以使用`jps`命令检查Hadoop的各个进程是否正常运行,例如`NameNode`、`DataNode`、`ResourceManager`和`NodeManager`等进程都应该在运行中。
Hadoop 2.0安装部署方法

✓ 步骤1:下载JDK 1.6(注意区分32位和64位) ✓ 步骤2:安装JDK 1.6(以32位为例)
chmod +x jdk-6u45-linux-i586.bin ./jdk-6u45-linux-i586.bin
✓ 步骤3:验证是否安装成功
以上整个过程与实验环境基本一致,不同的是步骤2中配置文件设置内容以 及步骤3的详细过程。
30
HDFS 2.0的HA配置方法(主备NameNode)
注意事项:
1 主备NameNode有多种配置方法,本课程使用Journal Node方式。为此 ,需要至少准备3个节点作为Journal Node,这三个节点可与其他服务,比 如NodeManager共用节点 2主备两个NameNode应位于不同机器上,这两台机器不要再部署其他 服 务,即它们分别独享一台机器。(注:HDFS 2.0中无需再部署和配置 Secondary Name,备NameNode已经代替它完成相应的功能) 3 主备NameNode之间有两种切换方式:手动切换和自动切换,其中, 自动切换是借助Zookeeper实现的,因此,需单独部署一个Zookeeper集群 (通常为奇数个节点,至少3个)。本课程使用手动切换方式。
Hadoop 2.0安装部署方法
Open Passion Value
目录
1. Hadoop 2.0安装部署流程 2. Hadoop 2.0软硬件准备 3. Hadoop 2.0安装包下载 4. Hadoop 2.0测试环境(单机)搭建方法 5. Hadoop 2.0生产环境(多机)搭建方法 6. 总结
✓ yarn-site.xml:
hadoop2.6完全分布式安装

系统准备Hadoop完全分布式安装,服务器最好都是基数,我用了三台虚拟机。
hadoop2.6.0完全分布式masterhadoop2.6.0完全分布式salves01hadoop2.6.0完全分布式salves02系统环境设置修改虚拟机的主机名称代码如下:1、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=masterGAREWAY=192.168.83.22、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves01GAREWAY=192.168.83.23、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves02GAREWAY=192.168.83.2配置IP地址1、修改第一台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.100GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.22、修改第二台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.101GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.23、修改第三台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.102GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.2service network restart //使配置的ip起作用修改主机名和IP的映射关系以及其他虚拟机的关系(hosts)vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.83.100 master192.168.83.101 salves01192.168.83.102 salves02三台虚拟机都需要配置,三台虚拟机的hosts一样关闭防火墙三台虚拟机都需要关闭防火墙重启系统安装jdk准备jdk在网上下载64位的jdk,下载好了之后上传到虚拟机中在Ubuntu下切换到root用户解压jdk(jdk-7u55-linux-x64.tar.gz)代码如下:配置坏境变量代码如下:重启/etc/profile代码如下:查看是否配置成功(jdk的版本) java –version统默认自己配置的jdk代码如下:配置ssh免密码登录代码如下:ssh-keygen -t rsa//创建keycat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys//把key写在authorized_keys中ll ~/.ssh/authorized_keys//查看是否有这个文件chmod 600 authorized_keys//给这个文件赋予权限ssh localhost //执行切换,看是否是免密码登录把三台服务器中的id_rsa.pub(key),分别加入三台服务器中的authorized_keys文件中,打通三台服务器免密码登录。
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
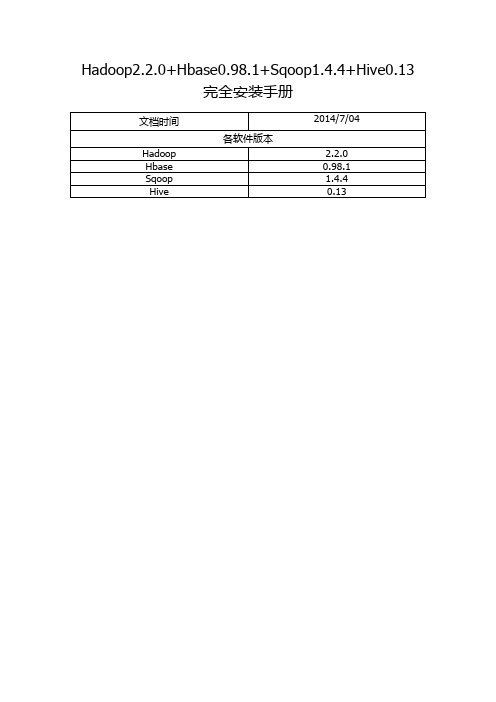
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
1 Hadoop安装手册Hadoop2.0

Hadoop2.0安装手册目录第1章安装VMWare Workstation 10 (4)第2章VMware 10安装CentOS 6 (10)2.1 CentOS系统安装 (10)2.2 安装中的关键问题 (13)2.3 克隆HadoopSlave (17)2.4 windows中安装SSH Secure Shell Client传输软件 (19)第3章CentOS 6安装Hadoop (23)3.1 启动两台虚拟客户机 (23)3.2 Linux系统配置 (24)3.2.1软件包和数据包说明 (25)3.2.2配置时钟同步 (25)3.2.3配置主机名 (26)3.2.5使用setup 命令配置网络环境 (27)3.2.6关闭防火墙 (29)3.2.7配置hosts列表 (30)3.2.8安装JDK (31)3.2.9免密钥登录配置 (32)3.3 Hadoop配置部署 (34)3.3.1 Hadoop安装包解压 (34)3.3.2配置环境变量hadoop-env.sh (34)3.3.3配置环境变量yarn-env.sh (35)3.3.4配置核心组件core-site.xml (35)3.3.5配置文件系统hdfs-site.xml (35)3.3.6配置文件系统yarn-site.xml (36)3.3.7配置计算框架mapred-site.xml (37)3.3.8 在master节点配置slaves文件 (37)3.3.9 复制到从节点 (37)3.4 启动Hadoop集群 (37)3.4.1 配置Hadoop启动的系统环境变量 (38)3.4.2 创建数据目录 (38)3.4.3启动Hadoop集群 (38)第4章安装部署Hive (44)4.1 解压并安装Hive (44)4.2 安装配置MySQL (45)4.3 配置Hive (45)4.4 启动并验证Hive安装 (46)第5章安装部署HBase (49)5.1 解压并安装HBase (49)5.2 配置HBase (50)5.2.1 修改环境变量hbase-env.sh (50)5.2.2 修改配置文件hbase-site.xml (50)5.2.3 设置regionservers (51)第1章安装VMWare Workstation 105.2.4 设置环境变量 (51)5.2.5 将HBase安装文件复制到HadoopSlave节点 (51)5.3 启动并验证HBase (51)第6章安装部署Mahout (54)6.1 解压并安装Mahout (54)6.2 启动并验证Mahout (55)第7章安装部署Sqoop (57)7.1 解压并安装Sqoop (57)7.2 配置Sqoop (58)7.2.1 配置MySQL连接器 (58)7.2.2配置环境变量 (58)7.3 启动并验证Sqoop (59)第8章安装部署Spark (61)8.1 解压并安装Spark (61)8.2 配置Hadoop环境变量 (62)8.3 验证Spark安装 (62)第9章安装部署Storm (66)安装Storm依赖包 (66)9.1安装ZooKeeper集群 (66)9.1.1解压安装 (66)9.1.2配置ZooKeeper属性文件 (67)9.1.3 将Zookeeper安装文件复制到HadoopSlave节点 (68)9.1.3启动ZooKeeper集群 (68)9.2安装Storm (69)9.2.1 解压安装 (69)9.2.2修改storm.yaml配置文件 (70)9.2.3 将Storm安装文件复制到HadoopSlave节点 (70)9.2.4启动Storm集群 (70)9.2.5向Storm集群提交任务 (71)第10章安装部署Kafka (73)10.1. 安装Kafka (73)10.1.1下载Kafka安装文件 (73)10.2. 配置Kafka (73)10.3. 启动Kafka (74)第1章安装VMWare Workstation 10第1章安装VMWare 10主要内容安装VMWare Workstation 10第1章安装VMWare Workstation 10 在软件包中找到“software\vmware”目录并进入该目录,如下所示:点击“VMware-workstation-full-10.0.0-1295980.exe”安装2等待安装软件检测和解压以后,出现如下界面,直接单击下一步即可。
hadoop 操作手册

hadoop 操作手册Hadoop 是一个分布式计算框架,它使用 HDFS(Hadoop Distributed File System)存储大量数据,并通过 MapReduce 进行数据处理。
以下是一份简单的 Hadoop 操作手册,介绍了如何安装、配置和使用 Hadoop。
一、安装 Hadoop1. 下载 Hadoop 安装包,并解压到本地目录。
2. 配置 Hadoop 环境变量,将 Hadoop 安装目录添加到 PATH 中。
3. 配置 Hadoop 集群,包括 NameNode、DataNode 和 JobTracker 等节点的配置。
二、配置 Hadoop1. 配置 HDFS,包括 NameNode 和 DataNode 的配置。
2. 配置 MapReduce,包括 JobTracker 和 TaskTracker 的配置。
3. 配置 Hadoop 安全模式,如果需要的话。
三、使用 Hadoop1. 上传文件到 HDFS,使用命令 `hadoop fs -put local_file_path/hdfs_directory`。
2. 查看 HDFS 中的文件和目录信息,使用命令 `hadoop fs -ls /`。
3. 运行 MapReduce 作业,编写 MapReduce 程序,然后使用命令`hadoop jar my_` 运行程序。
4. 查看 MapReduce 作业的运行结果,使用命令 `hadoop fs -cat/output_directory/part-r-00000`。
5. 从 HDFS 中下载文件到本地,使用命令 `hadoop fs -get/hdfs_directory local_directory`。
6. 在 Web 控制台中查看 HDFS 集群信息,在浏览器中打开7. 在 Web 控制台中查看 MapReduce 作业运行情况,在浏览器中打开四、管理 Hadoop1. 启动和停止 Hadoop 集群,使用命令 `` 和 ``。
Hadoop安装配置手册

Hadoop安装与配置手册(ver 0.1)骆卫华中科院计算所多语言交互技术实验室2008-8-26目录Hadoop安装与配置手册(ver 0.1) (1)1前言 (2)2获取Hadoop (2)3安装Hadoop (2)3.1先决条件 (2)3.2安装 (4)4配置Hadoop (4)5运行简单的例子 (9)6补充说明 (9)7推荐资源 (13)8参考文献 (13)1前言Hadoop是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来专门负责分布式存储以及分布式运算的项目。
简单地说,Hadoop是一个实现可靠、可扩展、分布式运算的开源软件平台,它也是Google著名的分布式文件系统Google File System和分布式并行开发框架MapReduce的开源版本。
Hadoop由三个相对独立,而又相辅相成的软件组成,包括:(1) Hadoop Core,是Hadoop的核心,提供了一个分布式文件系统(HDFS),并支持MapReduce分布式计算框架;(2) Hbase,构造在Hadoop Core之上,提供一个可扩展、分布式的数据库系统;(3) ZooKeeper,是一个高可用、高可靠的协同工作系统,分布式程序可以用ZooKeeper 保存并更新关键共享状态。
Hadoop的官方网址是。
它拥有三个不同的mailing list,分别是Users(普通用户)、Developers(有兴趣参加Hadoop开发的人)和Commits(关注Hadoop版本变化信息的人),可以通过/core/mailing_lists.html订阅。
想了解更多Hadoop的信息,可以通过访问其Wiki网页/hadoop来达到目的。
Hadoop支持的平台包括Linux和Windows(Windows需安装Cygwin),目前已知在Unix BSD和Mac OS/X上也能运行。
但官方说法是,GNU/Linux是一个经过验证的开发和生产平台,而Win32上尚未经过严格的测试,因此可以做开发平台,但不推荐作为生产平台。
hadoop单机安装手册

hadoop单机安装手册目录一、搭建java环境 (2)(1)安装jdk (2)(2)配置JAVA环境变量 (2)(3)设权 (2)(4)测试java (2)二、安装SSH免登陆 (2)(1)设置不用登陆密码 (2)(2)完成后登录不用输入密码,第一次需要输入回车键。
(3)三、安装hadoop (3)(1)下载hadoop安装包 (3)(2)设制bin目录下脚本权限 (3)(3)修改配置 (3)(3)测试 (3)四、测试wordcount实例 (3)(1)新建文件夹并在文件夹中建立文本 (3)(2)统计文本中的单词并输出到指定文件夹 (4)(3)输出结果 (4)五、常见问题 (4)(1)连接失败 (4)(2)实例无法运行 (4)一、搭建java环境(1)安装jdkyum install -y java-1.6.0*(2)配置JAVA环境变量vim /etc/environment添加以下两条64位版本CLASSPATH=.:/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre/libJAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre32位版本CLASSPATH=.:/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0/jre/libJAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0/jre(3)设权chmod +x /etc/environmentsource /etc/environment(4)测试javajava -version 应该为java1.6.0二、安装SSH免登陆(1)设置不用登陆密码cd /rootssh-keygen -t dsa -P '' -f ~/.ssh/id_dsacat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keysssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys(2)完成后登录不用输入密码,第一次需要输入回车键。
hadoop 1.2.0 版本的安装步骤

hadoop1.2.0 版本的安装说明作者:phoenix日期:20140423版本:Hadoop 1.2.0部署第一步:修改hostname192.168.10.235上面的修改步骤如下,其他的slave节点类似1.vim /etc/hosts192.168.10.235 hd235192.168.10.236 hd236192.168.10.234 hd234192.168.10.239 hd2392.vim /etc/sysconfig/network添加:HOSTNAME=hd2353.最好能够重启一下机器,这样有必要将hostname真正的修改过来注意:要关闭所有机器的防火墙第二步:ssh 免登录设置1.在做hd235上运行ssh-keygen -t rsa2.复制到slave节点上scp .ssh/id_rsa.pub 192.168.10.234:~/master_keysscp .ssh/id_rsa.pub 192.168.10.236:~/master_keysscp .ssh/id_rsa.pub 192.168.10.239:~/master_keys3.登录到slave节点,执行以下语句chmod 700 ~/.sshmv ~/master_keys ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys第三步:环境配置1.安装好配置JAVA,2.修改环境变量配置文件vim /etc/profile修改以下变量:(1)JAVA_HOME(2)HADOOP_HOME=/home/mafuli/hadoop/(3)JRE_HOME=$JAVA_HOME/jre(4)PATH=$HADOOP_HOME/bin:$PATH(5)PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH3.修改完毕之后重新加载配置文件source /etc/profile第四步:在hd235上解压文件,解压目录/home/mafuli/ (1)解压hadoop-1.2.0.tar.gztar –zxvf hadoop-1.2.0.tar.gz(2)重命名:mv hadoop-1.2.0.tar.gz Hadoop(3)创建dfs存放目录(slave机器上也要有此操作)mkdir hadoop_tmp第五步:修改配置文件1.core-site.xml<configuration><property><name></name><value>hdfs://192.168.10.235:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/mafuli/hadoop_tmp</value></property></configuration>2.hdfs-site.xml<configuration><property><name>dfs.replication</name><value>3</value></property></configuration>3.mapred-site.xml<configuration><property><name>mapred.job.tracker</name><value>192.168.10.235:9001</value></property></configuration>4.Hadoop-env.sh将EXPORT JAVA_HOME的注释去掉,同时修改正确的路径第六步:拷贝文件将hd235上面的hadoop文件夹复制到各个子目录中scp –r /home/mafuli/Hadoop 192.168.10.234:/home/mafuliscp –r /home/mafuli/Hadoop 192.168.10.236:/home/mafuliscp –r /home/mafuli/Hadoop 192.168.10.239:/home/mafuli第七步:启动1.cd /home/mafuli/hadoop/bin2../start-all.sh可以在hadoop/logs目录下查看日志情况访问192.168.10.235:50030和192.168.10.235:50070查看运行情况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop2.0安装手册目录第1章安装VMWare Workstation 10 (4)第2章VMware 10安装CentOS 6 (10)2.1 CentOS系统安装 (10)2.2 安装中的关键问题 (13)2.3 克隆HadoopSlave (17)2.4 windows中安装SSH Secure Shell Client传输软件 (19)第3章CentOS 6安装Hadoop (23)3.1 启动两台虚拟客户机 (23)3.2 Linux系统配置 (24)3.2.1软件包和数据包说明 (25)3.2.2配置时钟同步 (25)3.2.3配置主机名 (26)3.2.5使用setup 命令配置网络环境 (27)3.2.6关闭防火墙 (29)3.2.7配置hosts列表 (30)3.2.8安装JDK (31)3.2.9免密钥登录配置 (32)3.3 Hadoop配置部署 (34)3.3.1 Hadoop安装包解压 (34)3.3.2配置环境变量hadoop-env.sh (34)3.3.3配置环境变量yarn-env.sh (35)3.3.4配置核心组件core-site.xml (35)3.3.5配置文件系统hdfs-site.xml (35)3.3.6配置文件系统yarn-site.xml (36)3.3.7配置计算框架mapred-site.xml (37)3.3.8 在master节点配置slaves文件 (37)3.3.9 复制到从节点 (37)3.4 启动Hadoop集群 (37)3.4.1 配置Hadoop启动的系统环境变量 (38)3.4.2 创建数据目录 (38)3.4.3启动Hadoop集群 (38)第4章安装部署Hive (44)4.1 解压并安装Hive (44)4.2 安装配置MySQL (45)4.3 配置Hive (45)4.4 启动并验证Hive安装 (46)第5章安装部署HBase (49)5.1 解压并安装HBase (49)5.2 配置HBase (50)5.2.1 修改环境变量hbase-env.sh (50)5.2.2 修改配置文件hbase-site.xml (50)5.2.3 设置regionservers (51)第1章安装VMWare Workstation 105.2.4 设置环境变量 (51)5.2.5 将HBase安装文件复制到HadoopSlave节点 (51)5.3 启动并验证HBase (51)第6章安装部署Mahout (54)6.1 解压并安装Mahout (54)6.2 启动并验证Mahout (55)第7章安装部署Sqoop (57)7.1 解压并安装Sqoop (57)7.2 配置Sqoop (58)7.2.1 配置MySQL连接器 (58)7.2.2配置环境变量 (58)7.3 启动并验证Sqoop (59)第8章安装部署Spark (61)8.1 解压并安装Spark (61)8.2 配置Hadoop环境变量 (62)8.3 验证Spark安装 (62)第9章安装部署Storm (66)安装Storm依赖包 (66)9.1安装ZooKeeper集群 (66)9.1.1解压安装 (66)9.1.2配置ZooKeeper属性文件 (67)9.1.3 将Zookeeper安装文件复制到HadoopSlave节点 (68)9.1.3启动ZooKeeper集群 (68)9.2安装Storm (69)9.2.1 解压安装 (69)9.2.2修改storm.yaml配置文件 (70)9.2.3 将Storm安装文件复制到HadoopSlave节点 (70)9.2.4启动Storm集群 (70)9.2.5向Storm集群提交任务 (71)第10章安装部署Kafka (73)10.1. 安装Kafka (73)10.1.1下载Kafka安装文件 (73)10.2. 配置Kafka (73)10.3. 启动Kafka (74)第1章安装VMWare Workstation 10第1章安装VMWare 10主要内容安装VMWare Workstation 10第1章安装VMWare Workstation 10 在软件包中找到“software\vmware”目录并进入该目录,如下所示:点击“VMware-workstation-full-10.0.0-1295980.exe”安装2等待安装软件检测和解压以后,出现如下界面,直接单击下一步即可。
选择我同意选项,直接下一步。
4典型安装和自定义安装,可根据自己的情况酌情选择。
这里我们选择自定义安装。
5选择自定义以后,根据自己的情况选择自己需要的功能。
这里我们选择全部。
6我们可以更改软件的安装路径,端口默认即可。
7 出现如下图的选择框框,一般不建议勾选。
8出现下图提示选择默认的即可。
9 单击下一步,即可安装。
点击“继续”按钮10软件安装成功,如下图所示。
安装完成后,要求输入注册码,打开压缩文件中的算号器,拷贝粘贴注册码输入注册码:点击输入后,出现:点击完成,VMware安装过程结束。
第2章VMware 10安装CentOS 6主要内容⏹CentOS系统安装⏹安装中的关键问题⏹克隆HadoopSlave⏹安装SSH Secure Shell Client传输软件第2章VMware 10安装CentOS 6第2章VMware 10安装CentOS 6 2.1 CentOS系统安装打开VMware Workstation 10点击文件->新建虚拟机选择典型(推荐)(T)选项,点击“下一步(N)>”选择“安装程序光盘映像文件(iso)(M)”,选择指定的CentOS系统的.iso文件,点击“下一步(N)>”填写下面的信息,点击“下一步(N)>”,全名:zkpk 用户名:zkpk 密码:zkpk 确认:zkpk虚拟机名称(V):HadoopMaster,选择安装位置,点击“下一步(N)>”这里的磁盘大小不要直接使用默认值,要调大该值,设置为30.0 使用默认,点击“下一步(N)>”正常情况下,安装CentOS6进入下面的界面:直接等待安装完成,系统自动重启输入密码zkpk登录进系统至此,CentOS系统安装完毕。
2.2 安装中的关键问题如果出现下面的界面,说明BIOS中没有打开VT-x功能,所以就不能用VT-x进行加速。
打开BIOS中的VT-x功能的操作如下:首先在开机自检Logo处按F2热键(不同品牌的电脑进入BIOS的热键不同,有的电脑是F1\F8\F12)进入BIOS,选择Configuration选项,选择Intel Virtual Technology并回车,如下图:将光标移动至Enabled处,并回车确定,如下图:此时该选项将变为Enabled,最后按F10热键保存并退出即可开启VT功能,如下图:2、Insyde BIOS机型的参考操作方法:(以Lenovo 3000 G460作为操作平台)首先在开机自检Logo处按F2热键进入BIOS,选择Configuration选项,选择Intel Virtual Technology并回车,如下图:将光标移动至Enabled处,并回车确定,如下图:此时该选项将变为Enabled,最后按F10热键保存并退出即可开启VT功能,如下图:如果修改该BIOS选项之后,仍然出现提示VT-x没有打开的情况,需要重启电脑重试。
如果仍然不可以,请使用下面的方式验证电脑的硬件配置。
如何测试自己电脑是否支持虚拟化?运行SecurAble软件,有三种情况。
1、如下图,说明支持64位系统,满足需求。
2、如下图,说明支持64位系统,但是虚拟化在BIOS中没有开启。
需要在BIOS中开启相关选项。
具体不同笔记本型号修改方法,请查询百度。
3、如果出现如下图的显示,请您更换笔记本。
SecurAble就是一款测试测试电脑能否支持Windows7的XP兼容模式的免费软件,另外SecurAble还可以测试你的机器硬件是否支持Hyper-V和KVM,要运行Hyper-v和KVM,物理主机厂的CPU必须支持虚拟化,而且主机要64位的,同时BIOS要开启硬件级别的数据执行保护(Hardward D.E.P),这些信息通过SecurAble 就可以找到答案。
2.3 克隆HadoopSlave点击下图所示的“克隆”选项点击“下一步”看到下面的界面使用默认选项,点击“下一步”,选择“创建完整克隆(F)”,点击“下一步”,如下图所示。
将虚拟机重命名为HadoopSlave,选择一个存储位置(占用空间10GB左右),点击完成点击“关闭”按钮后,发现“HadoopSlave”虚拟机已经在左侧的列表栏中2.4 windows中安装SSH Secure Shell Client传输软件在Hadoop In Action Experiment软件包下面的software目录中,包含一个SSH Secure Shell Client 3.2.9.RAR 的安装文件,该文件用于windows系统与Linux系统之间进行文件传输。
1.安装SSH Secure Shell Client在本机windows操作系统的任意位置,解压并点击安装SSH Secure Shell Client软件。
一路点击“NEXT”安装完成,在windows桌面上会看到如下图的快捷方式。
2. 打开并传输文件测试点击黄色文件夹快捷方式“SSH Secure File Transfer Client”,会出现如下图的弹窗:点击“Quick Connect”,弹出连接对话框输入已经安装的CentOS的主机名和用户名,如下图所示:假设安装的CentOS虚拟机的IP地址是192.168.190.165,用户名是zkpk 点击“Connect”,弹出输入密码的对话框输入密码zkpk,点击“OK”,会看到下面的对话框,表示连接成功。
第2章VMware 10安装CentOS 6上图中左侧是windows本机目录,右侧是Linux目录,拖拽文件即可实现复制。
第3章CentOS 6安装Hadoop主要内容⏹启动两台虚拟客户机⏹Linux系统配置⏹Hadoop配置部署⏹启动Hadoop集群第3章CentOS 6安装Hadoop3.1 启动两台虚拟客户机打开VMware Workstation10打开之前已经安装好的虚拟机:HadoopMaster和HadoopSlave,出现异常,选择“否”进入如果之前没有打开过两个虚拟机,请使用“文件”->“打开”选项,选择之前的虚拟机安装包(在一体软件包里面的)3.2 Linux系统配置以下操作步骤需要在HadoopMaster和HadoopSlave节点上分别完整操作,都使用root用户,从当前用户切换root用户的命令如下:su root输入密码:zkpk本节所有的命令操作都在终端环境,打开终端的过程如下图的Terminal菜单:终端打开后如下图中命令行窗口所示。