hadoop基本命令_建表-删除-导数据
hadoop建表语句

hadoop建表语句Hadoop是目前最流行的分布式数据处理平台之一,可以处理非常大规模的数据集。
在Hadoop中建表是非常常见的操作,下面是Hadoop建表语句的相关内容:1. 创建表创建表的语法如下:CREATE TABLE table_name (column1 datatype1,column2 datatype2,column3 datatype3,...);其中,table_name是要创建的表的名称,column是表的列名,datatype是列的数据类型。
2. 删除表删除表的语法如下:DROP TABLE table_name;其中,table_name是要删除的表的名称。
3. 添加列添加列的语法如下:ALTER TABLE table_name ADD COLUMN column_name datatype;其中,table_name是要添加列的表的名称,column_name是要添加的列名,datatype是列的数据类型。
4. 删除列删除列的语法如下:ALTER TABLE table_name DROP COLUMN column_name;其中,table_name是要删除列的表的名称,column_name是要删除的列名。
5. 修改列修改列的语法如下:ALTER TABLE table_name CHANGE COLUMN old_column_name new_column_name datatype;其中,table_name是要修改列的表的名称,old_column_name是要修改的旧列名,new_column_name是要修改的新列名,datatype是列的数据类型。
总之,Hadoop建表语句是非常基础的操作,在使用Hadoop进行数据处理时需要熟练掌握。
大数据CDA考试(习题卷10)

大数据CDA考试(习题卷10)第1部分:单项选择题,共47题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]以下哪个部分不是一篇数据分析报告必须有的。
( )A)标题B)正文C)结论与建议D)附录答案:D解析:2.[单选题]关于相关关系有误的是()。
A)按相关的程度分为完全相关、不完全相关和不相关B)按相关的特点分为单相关和多相 关C)按相关的方向分为正相关和负相关D)按相关的形式分为线性相关和非线性相关。
答案:B解析:3.[单选题]数据挖掘中Naive Bayes于什么方法?()A)聚类B)分类C)时间序列D)关联规则答案:B解析:4.[单选题]下哪种不是Hive支持的数据类型()。
A)tructB)ntC)apD)ong答案:D解析:5.[单选题]下列哪种方法不能用于检验一元线性回归残差是否服从正态分布( )A)PP图B)SW检验C)KS检验D)ADF检验答案:D解析:ADF检验一般用于时序模型6.[单选题]下列有关数据分析说法正确的是( )。
A)数据分析规定其操作流程分为5步B)SEMMA是数据挖掘项目方法论的名称C)数据分析只是针对大数据情形,小数据是没有意义的D)数据分析中模型的精度是第一位的答案:B解析:A项,没有明确规定的步骤数量;C项两类数据各有用处;D项,数据分析需要权衡成本、精度、效率等。
7.[单选题]Java编程所必须的默认引用包为()A)java.sys包B)ng 包C)java.util 包D)以上都不是答案:B解析:8.[单选题]下列涉及通配符的操作,范围最大的是( )A)nameB)nameC)nameD)name答案:C解析:%匹配多个字符,_匹配一个字符。
9.[单选题]检验单总体均值的过程中,如果是小样本,但总体标准差已知,检验统计量应该选择( )。
A)B)C)D)答案:A解析:见单总体均值检验概念10.[单选题]对于Hive 中关于普通表和外部表描述不正确的是?A)默认创建普通表B)删除外部表时,只除外部表数据而 不删除元数据C)外部实质是将已存在于HDFS 上的文件路径跟表关联起来D)删除普通表时,元数据和数据同时 被删除答案:C解析:11.[单选题]为AB类的一个无形式参数无返回值的方法methiod 书写方法头,使得使用类名 AB作为前级就可以调用它,该方法头的形式为()。
大学生大数据技术原理与应用章节测验期末考试答案

大数据技术原理与应用第1章大数据概述1单选(2分)第三次信息化浪潮的标志是:A.个人电脑的普及B.云计算、大数据、物联网技术的普及C.虚拟现实技术的普及D.互联网的普及正确答案:B你选对了2单选(2分)就数据的量级而言,1PB数据是多少TB?A.2048B.1000C.512D.1024正确答案:D你选对了3单选(2分)以下关于云计算、大数据和物联网之间的关系,论述错误的是:A.云计算侧重于数据分析B.物联网可借助于云计算实现海量数据的存储C.物联网可借助于大数据实现海量数据的分析D.云计算、大数据和物联网三者紧密相关,相辅相成正确答案:A你选对了4单选(2分)以下哪个不是大数据时代新兴的技术:A.SparkB.HadoopC.HBaseD.MySQL正确答案:D你选对了5单选(2分)每种大数据产品都有特定的应用场景,以下哪个产品是用于批处理的:A.MapReduceB.DremelC.StormD.Pregel正确答案:A你选对了6单选(2分)每种大数据产品都有特定的应用场景,以下哪个产品是用于流计算的:A.GraphXB.S4C.ImpalaD.Hive正确答案:B你选对了7单选(2分)每种大数据产品都有特定的应用场景,以下哪个产品是用于图计算的:A.PregelB.StormC.CassandraD.Flume正确答案:A你选对了8单选(2分)每种大数据产品都有特定的应用场景,以下哪个产品是用于查询分析计算的:A.HDFSB.S4C.DremelD.MapReduce正确答案:C你选对了9多选(3分)数据产生方式大致经历三个阶段,包括:A.运营式系统阶段B.感知式系统阶段C.移动互联网数据阶段D.用户原创内容阶段正确答案:ABD你选对了10多选(3分)大数据发展三个阶段是:A.低谷期B.成熟期C.大规模应用期D.萌芽期正确答案:BCD你选对了11多选(3分)大数据的特性包括:A.价值密度低B.处理速度快C.数据类型繁多D.数据量大正确答案:ABCD你选对了12多选(3分)图领奖获得者、著名数据库专家Jim Gray博士认为,人类自古以来在科学研究上先后经历哪几种范式:A.计算科学B.数据密集型科学C.实验科学D.理论科学正确答案:ABCD你选对了13多选(3分)大数据带来思维方式的三个转变是:A.效率而非精确B.相关而非因果C.精确而非全面D.全样而非抽样正确答案:ABD你选对了14多选(3分)大数据主要有哪几种计算模式:B.图计算C.查询分析计算D.批处理计算正确答案:ABCD你选对了15多选(3分)云计算的典型服务模式包括三种:A.SaaSB.IaaSC.MaaSD.PaaS正确答案:ABD你选对了第2章大数据处理架构Hadoop1单选(2分)启动hadoop所有进程的命令是:A.start-dfs.shB.start-all.shC.start-hadoop.shD.start-hdfs.sh正确答案:B你选对了2单选(2分)以下对Hadoop的说法错误的是:A.Hadoop是基于Java语言开发的,只支持Java语言编程B.Hadoop2.0增加了NameNode HA和Wire-compatibility两个重大特性C.Hadoop MapReduce是针对谷歌MapReduce的开源实现,通常用于大规模数据集的并行计算D.Hadoop的核心是HDFS和MapReduce正确答案:A你选对了3单选(2分)以下哪个不是Hadoop的特性:A.成本高B.支持多种编程语言C.高容错性正确答案:A你选对了4单选(2分)以下名词解释不正确的是:A.Zookeeper:针对谷歌Chubby的一个开源实现,是高效可靠的协同工作系统B.HBase:提供高可靠性、高性能、分布式的行式数据库,是谷歌BigTable的开源实现C.Hive:一个基于Hadoop的数据仓库工具,用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储D.HDFS:分布式文件系统,是Hadoop项目的两大核心之一,是谷歌GFS的开源实现正确答案:B你选对了5多选(3分)以下哪些组件是Hadoop的生态系统的组件:A.HBaseB.OracleC.HDFSD.MapReduce正确答案:ACD你选对了6多选(3分)以下哪个命令可用来操作HDFS文件:A.hadoop fsB.hadoop dfsC.hdfs fsD.hdfs dfs正确答案:ABD你选对了第3章分布式文件系统HDFS1单选(2分)HDFS的命名空间不包含:A.字节B.文件C.块D.目录正确答案:A你选对了2单选(2分)对HDFS通信协议的理解错误的是:A.客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的B.客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互C.名称节点和数据节点之间则使用数据节点协议进行交互D.HDFS通信协议都是构建在IoT协议基础之上的正确答案:D你选对了3单选(2分)采用多副本冗余存储的优势不包含:A.保证数据可靠性B.容易检查数据错误C.加快数据传输速度D.节约存储空间正确答案:D你选对了4单选(2分)假设已经配置好环境变量,启动Hadoop和关闭Hadoop的命令分别是:A.start-dfs.sh,stop-hdfs.shB.start-hdfs.sh,stop-hdfs.shC.start-dfs.sh,stop-dfs.shD.start-hdfs.sh,stop-dfs.sh正确答案:C你选对了5单选(2分)分布式文件系统HDFS采用主从结构模型,由计算机集群中的多个节点构成的,这些节点分为两类,一类存储元数据叫,另一类存储具体数据叫 :A.名称节点,主节点B.从节点,主节点C.名称节点,数据节点D.数据节点,名称节点正确答案:C你选对了6单选(2分)下面关于分布式文件系统HDFS的描述正确的是:A.分布式文件系统HDFS是Google Bigtable的一种开源实现B.分布式文件系统HDFS是谷歌分布式文件系统GFS(Google File System)的一种开源实现C.分布式文件系统HDFS比较适合存储大量零碎的小文件D.分布式文件系统HDFS是一种关系型数据库正确答案:B你选对了7多选(3分)以下对名称节点理解正确的是:A.名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问B.名称节点用来负责具体用户数据的存储C.名称节点通常用来保存元数据D.名称节点的数据保存在内存中正确答案:ACD你选对了8多选(3分)以下对数据节点理解正确的是:A.数据节点通常只有一个B.数据节点用来存储具体的文件内容C.数据节点的数据保存在磁盘中D.数据节点在名称节点的统一调度下进行数据块的创建、删除和复制等操作正确答案:BCD你选对了9多选(3分)HDFS只设置唯一一个名称节点带来的局限性包括:A.集群的可用性B.性能的瓶颈C.命名空间的限制D.隔离问题正确答案:ABCD你选对了10多选(3分)以下HDFS相关的shell命令不正确的是:A.hadoop dfs mkdir <path>:创建<path>指定的文件夹B.hdfs dfs -rm <path>:删除路径<path>指定的文件C.hadoop fs -copyFromLocal <path1> <path2>:将路径<path2>指定的文件或文件夹复制到路径<path1>指定的文件夹中D.hadoop fs -ls <path>:显示<path>指定的文件的详细信息正确答案:AC你选对了第4章分布式数据库HBase1单选(2分)HBase是一种数据库A.行式数据库B.关系数据库C.文档数据库D.列式数据库正确答案:D你选对了2单选(2分)下列对HBase数据模型的描述错误的是:A.每个HBase表都由若干行组成,每个行由行键(row key)来标识B.HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳C.HBase中执行更新操作时,会删除数据旧的版本,并生成一个新的版本D.HBase列族支持动态扩展,可很轻松地添加一个列族或列正确答案:C你选对了3单选(2分)下列说法正确的是:A.如果不启动Hadoop,则HBase完全无法使用B.HBase的实现包括的主要功能组件是库函数,一个Master主服务器和一个Region服务器C.如果通过HBase Shell插入表数据,可以插入一行数据或一个单元格数据D.Zookeeper是一个集群管理工具,常用于分布式计算,提供配置维护、域名服务、分布式同步等正确答案:D你选对了4单选(2分)在HBase数据库中,每个Region的建议最佳大小是:A.2GB-4GBB.100MB-200MBC.500MB-1000MBD.1GB-2GB正确答案:D你选对了5单选(2分)HBase三层结构的顺序是:A.Zookeeper文件,.MEATA.表,-ROOT-表B.-ROOT-表,Zookeeper文件,.MEATA.表C.Zookeeper文件,-ROOT-表,.MEATA.表D..MEATA.表,Zookeeper文件,-ROOT-表正确答案:C你选对了6单选(2分)客户端是通过级寻址来定位Region:A.三B.二C.一D.四正确答案:A你选对了7单选(2分)关于HBase Shell命令解释错误的是:A.create:创建表B.put:向表、行、列指定的单元格添加数据C.list:显示表的所有数据D.get:通过表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值正确答案:C你选对了8多选(3分)下列对HBase的理解正确的是:A.HBase是针对谷歌BigTable的开源实现B.HBase是一种关系型数据库,现成功应用于互联网服务领域C.HBase是一个行式分布式数据库,是Hadoop生态系统中的一个组件D.HBase多用于存储非结构化和半结构化的松散数据正确答案:AD你选对了9多选(3分)HBase和传统关系型数据库的区别在于哪些方面:A.数据操作B.数据索引C.数据模型D.存储模式正确答案:ABCD你选对了10多选(3分)访问HBase表中的行,有哪些方式:A.通过某列的值区间B.全表扫描C.通过一个行健的区间来访问D.通过单个行健访问正确答案:BCD你选对了第5章 NoSQL数据库1单选(2分)下列关于NoSQL数据库和关系型数据库的比较,不正确的是:A.NoSQL数据库很容易实现数据完整性,关系型数据库很难实现数据完整性B.NoSQL数据库缺乏统一的查询语言,而关系型数据库有标准化查询语言C.NoSQL数据库的可扩展性比传统的关系型数据库更好D.NoSQL数据库具有弱一致性,关系型数据库具有强一致性正确答案:A你选对了2单选(2分)以下对各类数据库的理解错误的是:A.键值数据库的键是一个字符串对象,值可以是任意类型的数据,比如整型和字符型等B.文档数据库的数据是松散的,XML和JSON 文档等都可作为数据存储在文档数据库中C.图数据库灵活性高,支持复杂的图算法,可用于构建复杂的关系图谱D.HBase数据库是列族数据库,可扩展性强,支持事务一致性正确答案:D你选对了3单选(2分)下列数据库属于文档数据库的是:A.MySQLB.RedisC.MongoDBD.HBase正确答案:C你选对了4单选(2分)NoSQL数据库的三大理论基石不包括:A.最终一致性B.BASEC.ACIDD.CAP正确答案:C你选对了5多选(3分)关于NoSQL数据库和关系数据库,下列说法正确的是:A.NoSQL数据库可支持超大规模数据存储,具有强大的横向扩展能力B.NoSQL数据库和关系数据库各有优缺点,但随着NoSQL的发展,终将取代关系数据库C.大多数NoSQL数据库很难实现数据完整性D.关系数据库有关系代数理论作为基础,NoSQL数据库没有统一的理论基础正确答案:ACD你选对了6多选(3分)NoSQL数据库的类型包括:A.键值数据库B.列族数据库C.文档数据库D.图数据库正确答案:ABCD你选对了7多选(3分)CAP是指:A.一致性B.可用性C.持久性D.分区容忍性正确答案:ABD你选对了8多选(3分)NoSQL数据库的BASE特性是指:A.软状态B.持续性C.最终一致性D.基本可用正确答案:ACD你选对了第6章云数据库1单选(2分)下列Amazon的云数据库属于关系数据库的是:A.Amazon SimpleDBB.Amazon DynamoDBC.Amazon RDSD.Amazon Redshift正确答案:C你选对了2单选(2分)下列关于UMP系统的说法不正确的是:A.Controller服务器向UMP集群提供各种管理服务,实现集群成员管理、元数据存储等功能B.Agent服务器部署在运行MySQL进程的机器上,用来管理每台物理机上的MySQL实例C.UMP系统是低成本和高性能的MySQL云数据库方案D.Mnesia是UMP系统的一个组件,是一个分布式数据库管理系统,且不支持事务正确答案:D你选对了3多选(3分)UMP依赖的开源组件包括A.LVSB.ZooKeeperC.MnesiaD.RabbitMQ正确答案:ABCD你选对了4多选(3分)在UMP系统中,Zookeeper主要发挥的作用包括:A.监控所有MySQL实例B.负责集群负载均衡C.提供分布式锁,选出一个集群的“总管”D.作为全局的配置服务器正确答案:ACD你选对了5多选(3分)UMP系统设计了哪些机制来保证数据安全:A.记录用户操作日志B.数据访问IP白名单C.SSL数据库连接D.SQL拦截正确答案:ABCD你选对了第7章 MapReduce1单选(2分)下列说法错误的是:A.Map函数将输入的元素转换成<key,value>形式的键值对B.Hadoop框架是用Java实现的,MapReduce应用程序则一定要用Java来写C.MapReduce框架采用了Master/Slave架构,包括一个Master和若干个SlaveD.不同的Map任务之间不能互相通信正确答案:B你选对了2单选(2分)在使用MapReduce程序WordCount进行词频统计时,对于文本行“hello hadoop hello world”,经过WordCount程序的Map函数处理后直接输出的中间结果,应是下面哪种形式:A.<"hello",1,1>、<"hadoop",1>和<"world",1>B.<"hello",2>、<"hadoop",1>和<"world",1>C.<"hello",<1,1>>、<"hadoop",1>和<"world",1>D.<"hello",1>、<"hello",1>、<"hadoop",1>和<"world",1>正确答案:D你选对了3单选(2分)对于文本行“hello hadoop hello world”,经过WordCount的Reduce函数处理后的结果是:A.<"hello",<1,1>><"hadoop",1><"world",1>B.<"hello",1><"hello",1><"hadoop",1><"world",1>C.<"hello",1,1><"hadoop",1><"world",1>D.<"hello",2><"hadoop",1><"world",1>正确答案:B你选对了4多选(3分)下列关于传统并行计算框架(比如MPI)和MapReduce并行计算框架比较正确的是:A.前者所需硬件价格贵,可扩展性差,后者硬件便宜,扩展性好B.前者相比后者学习起来更难C.前者是共享式(共享内存/共享存储),容错性差,后者是非共享式的,容错性好D.前者适用于实时、细粒度计算、计算密集型,后者适用于批处理、非实时、数据密集型正确答案:ABCD你选对了5多选(3分)MapReduce1.0的体系结构主要由哪几个部分组成:A.JobTrackerB.TaskTrackerC.ClientD.Task正确答案:ABCD你选对了第8章 Hadoop再探讨1单选(2分)下列说法正确的是:A.HDFS HA可用性不好B.第二名称节点是热备份C.HDFS HA提供高可用性,可实现可扩展性、系统性能和隔离性D.第二名称节点无法解决单点故障问题正确答案:D你选对了2单选(2分)HDFS Federation设计不能解决“单名称节点”存在的哪个问题:A.单点故障问题B.HDFS集群扩展性C.性能更高效D.良好的隔离性正确答案:A你选对了3多选(3分)下列哪些是Hadoop1.0存在的问题:A.抽象层次低B.表达能力有限C.开发者自己管理作业之间的依赖关系D.执行迭代操作效率低正确答案:ABCD你选对了下列对Hadoop各组件的理解正确的是:A.Oozie:工作流和协作服务引擎B.Pig:处理大规模数据的脚本语言C.Kafka:分布式发布订阅消息系统D.Tez:支持DAG作业的计算框架正确答案:ABCD你选对了5多选(3分)对新一代资源管理调度框架YARN的理解正确的是:A.YARN既是资源管理调度框架,也是一个计算框架B.MapReduce2.0是运行在YARN之上的计算框架,由YARN来为MapReduce提供资源管理调度服务C.YARN可以实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架D.YARN的体系结构包含三个组件:ResourceManager,NodeManager,ApplicationMaster正确答案:BCD你选对了第9章数据仓库Hive1单选(2分)下列有关Hive和Impala的对比错误的是:A.Hive与Impala中对SQL的解释处理比较相似,都是通过词法分析生成执行计划B.Hive与Impala使用相同的元数据C.Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询D.Hive在内存不足以存储所有数据时,会使用外存,而Impala也是如此正确答案:D你选对了2单选(2分)下列关于Hive基本操作命令的解释错误的是:A.create table if not exists usr(id bigint,name string,age int);//如usr表不存在,创建表usr,含三个属性id,name,ageB.load data local inpath ‘/usr/local/data’ overwrite into table usr; //把目录’/usr/local/data’下的数据文件中的数据以追加的方式装载进usr表C.create database userdb;//创建数据库userdbD.insert overwrite table student select * from user where age>10; //向表usr1中插入来自usr表的age大于10的数据并覆盖student表中原有数据正确答案:B你选对了下列说法正确的是:A.Impala和Hive、HDFS、HBase等工具可统一部署在一个Hadoop平台上B.数据仓库Hive不需要借助于HDFS就可完成数据的存储C.Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据D.HiveQL语法与传统的SQL语法很相似正确答案:ACD你选对了4多选(3分)Impala主要由哪几个部分组成:A.HiveB.ImpaladC.State StoreD.CLI正确答案:BCD你选对了5多选(3分)以下属于Hive的基本数据类型是:A.BINARYB.STRINGC.FLOATD.TINYINT正确答案:ABCD你选对了第10章 Spark1单选(2分)Spark SQL目前暂时不支持下列哪种语言:A.PythonB.JavaC.ScalaD.Lisp正确答案:D你选对了2单选(2分)RDD操作分为转换(Transformation)和动作(Action)两种类型,下列属于动作(Action)类型的操作的是:A.groupByB.filterC.countD.map正确答案:C你选对了3单选(2分)下列说法错误的是:A.在选择Spark Streaming和Storm时,对实时性要求高(比如要求毫秒级响应)的企业更倾向于选择流计算框架StormB.RDD采用惰性调用,遇到“转换(Transformation)”类型的操作时,只会记录RDD生成的轨迹,只有遇到“动作(Action)”类型的操作时才会触发真正的计算C.Spark支持三种类型的部署方式:Standalone,Spark on Mesos,Spark on YARND.RDD提供的转换接口既适用filter等粗粒度的转换,也适合某一数据项的细粒度转换正确答案:D你选对了4单选(2分)下列关于常见的动作(Action)和转换(Transformation)操作的API解释错误的是:A.filter(func):筛选出满足函数func的元素,并返回一个新的数据集B.map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集C.count():返回数据集中的元素个数D.take(n):返回数据集中的第n个元素正确答案:D你选对了5单选(2分)下列大数据处理类型与其对应的软件框架不匹配的是:A.复杂的批量数据处理:MapReduceB.基于历史数据的交互式查询:ImpalaC.基于实时数据流的数据处理:StormD.图结构数据的计算:Hive正确答案:D你选对了6多选(3分)Apache软件基金会最重要的三大分布式计算系统开源项目包括:A.OracleB.HadoopC.StormD.Spark正确答案:ABC你选对了7多选(3分)Spark的主要特点包括:A.运行模式多样B.运行速度快C.通用性好D.容易使用正确答案:ABCD你选对了8多选(3分)下列关于Scala的说法正确的是:A.Scala运行于Java平台,兼容现有的Java程序B.Scala具备强大的并发性,支持函数式编程C.Scala是一种多范式编程语言D.Scala是Spark的主要编程语言,但Spark还支持Java、Python、R作为编程语言正确答案:ABCD你选对了9多选(3分)Spark的运行架构包括:A.运行作业任务的工作节点 Worker NodeB.每个工作节点上负责具体任务的执行进程 ExecutorC.每个应用的任务控制节点 DriverD.集群资源管理器 Cluster Manager正确答案:ABCD你选对了第11章流计算1单选(2分)流计算秉承一个基本理念,即数据的价值随着时间的流逝而,如用户点击流:A.降低B.不确定C.不变D.升高正确答案:A你选对了2单选(2分)Hadoop运行的是MapReduce任务,类似地,Storm运行的任务叫做A.SpoutB.BoltC.TupleD.Topology正确答案:D你选对了3多选(3分)对于一个流计算系统来说,它应达到如下哪些需求:A.海量式B.高性能C.分布式D.实时性正确答案:A、B、C、D你选对了4多选(3分)数据采集系统的基本架构包括哪些部分:A.ControllerB.StoreC.AgentD.Collector正确答案:B、C、D你选对了5多选(3分)以下哪些是开源的流计算框架:A.Facebook PumaB.Yahoo! S4C.IBM InfoSphere StreamsD.Twitter Storm正确答案:B、D你选对了6多选(3分)下面哪几个属于Storm中的Stream Groupings的分组方式:A.按照字段分组B.广播发送C.随机分组D.全局分组正确答案:A、B、C、D你选对了第12章 Flink1单选(2分)以下哪个不是Flink的优势:A.同时支持高吞吐、低延迟、高性能B.不支持增量迭代C.同时支持流处理和批处理D.支持有状态计算正确答案:B你选对了2单选(2分)在Flink中哪个是基于批处理的图计算库:A.SQL&Table库B.FlinkMLC.GellyD.CEP正确答案:C你选对了3多选(3分)下面关于Flink的说法正确的是:A.Flink起源于Stratosphere 项目,该项目是在2010年到2014年间由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合开展的B.Flink可以同时支持实时计算和批量计算C.Flink不是Apache软件基金会的项目D.Flink是Apache软件基金会的5个最大的大数据项目之一正确答案:A、B、D你选对了4多选(3分)Flink的主要特性包括:A.精确一次的状态一致性保障B.批流一体化C.精密的状态管理D.事件时间支持正确答案:A、B、C、D你选对了5多选(3分)下面论述正确的是:A.Spark Streaming通过采用微批处理方法实现高吞吐和容错性,但是牺牲了低延迟和实时处理能力B.Storm虽然可以做到低延迟,但是无法实现高吞吐,也不能在故障发生时准确地处理计算状态C.流处理架构需要具备低延迟、高吞吐和高性能的特性,而目前从市场上已有的产品来看,只有Flink 可满足要求D.Flink实现了Google Dataflow流计算模型,是一种兼具高吞吐、低延迟和高性能的实时流计算框架,并且同时支持批处理和流处理正确答案:A、B、C、D你选对了6多选(3分)Flink常见的应用场景包括:A.数据流水线应用B.事件驱动型应用C.地图应用D.数据分析应用正确答案:A、B、D你选对了7多选(3分)Flink核心组件栈分为哪三层:A.物理部署层B.Runtime核心层C.Core层D.API&Libraries层正确答案:A、B、D你选对了8多选(3分)Flink有哪几种部署模式:A.运行在GCE(谷歌云服务)和EC2(亚马逊云服务)上B.YARN集群模式C.Standalone集群模式D.Local模式正确答案:A、B、C、D你选对了9多选(3分)Flink系统主要由两个组件组成,分别为:A.JobManagerB.JobSchedulerC.TaskSchedulerD.TaskManager正确答案:A、D你选对了10多选(3分)在编程模型方面,Flink 提供了不同级别的抽象,以开发流或批处理作业,主要包括哪几个级别的抽象:A.DataStream API(有界或无界流数据)以及 DataSet API(有界数据集)B.Table APIC.状态化的数据流接口D. SQL正确答案:A、B、C、D你选对了第13章图计算1单选(2分)Pregel是一种基于模型实现的并行图处理系统:A.TSPB.STPC.BSPD.SBP正确答案:C你选对了2单选(2分)谷歌在后Hadoop时代的新“三驾马车”不包括:A.CaffeineB.DremelC. PregelD.Hama正确答案:D你选对了3多选(3分)下列哪些是以图顶点为中心的,基于消息传递批处理的并行图计算框架:A.HamaB.GiraphC.PregelD.Neo4j正确答案:A、B、C你选对了4多选(3分)以下关于Pregel图计算框架说法正确的是:A.通常只对满足交换律和结合律的操作才会开启Combiner功能B.Pregel采用检查点机制来实现容错C.对于全局拓扑改变,Pregel采用了惰性协调机制D.Aggregator提供了一种全局通信、监控和数据查看的机制正确答案:A、B、C、D你选对了第14章大数据在不同领域的应用1单选(2分)下列说法错误的是:A.ItemCF算法推荐的是那些和目标用户之前喜欢的物品类似的其他物品B.基于用户的协同过滤算法(简称UserCF算法)是目前业界应用最多的算法erCF算法推荐的是那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品erCF算法的推荐更偏向社会化,而ItemCF算法的推荐更偏向于个性化正确答案:B你选对了2多选(3分)推荐方法包括哪些类型:A.专家推荐B.协同过滤推荐C.基于内容的推荐D.基于统计的推荐正确答案:A、B、C、D你选对了期末试卷1单选(2分)数据产生方式的变革主要经历了三个阶段,以下哪个不属于这三个阶段:A.运营式系统阶段B.感知式系统阶段C.数据流阶段D.用户原创内容阶段正确答案:C你选对了2单选(2分)第三次信息化浪潮的发生标志是以下哪种技术的普及:A.互联网B.CPUC.物联网、云计算和大数据D.个人计算机正确答案:C你选对了3单选(2分)在Flink中哪个是基于批处理的图计算库:A.SQL&Table库B.CEPC. GellyD. FlinkML正确答案:C你选对了4单选(2分)Hadoop的两大核心是和A.MapReduce; HBaseB. HDFS; HBaseC.HDFS; MapReduceD.GFS; MapReduce正确答案:C你选对了5单选(2分)HDFS默认的一个块大小是A.64MBB.8KBC. 32KBD.16KB正确答案:A你选对了6单选(2分)在分布式文件系统HDFS中,负责数据的存储和读取:A.数据节点B.第二名称节点C.名称节点D.主节点正确答案:A你选对了7单选(2分)上传当前目录下的本地文件file.txt到分布式文件系统HDFS的“/path”目录下的Shell命令是:A.hdfs dfs -put /path file.txtB.hadoop dfs -put /path file.txtC.hdfs fs -put file.txt /pathD.hdfs dfs -put file.txt /path正确答案:D你选对了8单选(2分)在HDFS根目录下创建一个文件夹/test,且/test文件夹内还包含一个文件夹dir,正确的shell命令是:A.hadoop fs -mkdir -p /test/dirB.hdfs fs -mkdir -p /test/dirC.hadoop dfs -mkdir /test/dirD.hdfs dfs *mkdir -p /test/dir正确答案:A你选对了9单选(2分)下列有关HBase的说法正确的是:A.在向数据库中插入记录时,HBase和关系数据库一样,每次都是以“行”为单位把整条记录插入数据库B.HBase是针对谷歌BigTable的开源实现,是高可靠、高性能的图数据库C.HBase是一种NoSQL数据库。
Hadoop基础(试卷编号151)

Hadoop基础(试卷编号151)1.[单选题]下列关于Hadoop和Spark说法错误的是()。
A)二者都支持流式计算B)二者都支持批量计算C)二者都支持机器学习D)二者都支持SQL语句查询答案:A解析:2.[单选题]测试 Sqoop 是否能够正常连接 MySQL 数据库命令是( )A)sqoop list-database --connect jdbc:mysql://127.0.0.1:3306/ --username root - PB)sqoop list-databases --connection jdbc:mysql://127.0.0.1:3306/ --username root - PC)sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -LD)sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root - P答案:D解析:3.[单选题]下面哪个命令是用来定义shell的全局变量:A)exportfsB)aliasC)exportsD)export答案:D解析:4.[单选题]关于Hadoop下列说法错误的是()A)HDFS采用了Master/Slave的架构模型B)Namenode负责维护文件系统的命名空间C)Datanode执行比如打开、关闭、重命名文件操作D)HDFS暴露了文件系统的命名空间,允许用户以文件的形式在上面存储数据答案:C解析:5.[单选题]关干HiveSQL运行原理,描述不正确的选项有?(A)C)对于selectcount(*)fromtable操作,一定会启reduce任务D)对于select*fromtable语句不会启MapReduce答案:A解析:6.[单选题]调用Zookeeper对象创建的节点,不包括()。
Hadoop基本命令详解

Hadoop基本命令详解调⽤⽂件系统(FS)Shell命令应使⽤bin/hadoop fs <args>的形式。
所有的的FS shell命令使⽤URI路径作为参数。
URI路径详解点击这⾥。
1、cat说明:将路径指定⽂件的内容输出到stdout。
⽤法:hadoop fs -cat URI [URI …]范例:hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2hadoop fs -cat file:///file3/user/hadoop/file4返回值:成功返回0,失败返回-1。
2、chgrp说明:改变⽂件所属的组。
使⽤-R将使改变在⽬录结构下递归进⾏。
命令的使⽤者必须是⽂件的所有者或者超级⽤户。
⽤法:hadoop fs -chgrp [-R] GROUP URI [URI …]范例:hadoop fs -chgrp -R hadoop /user/hadoop/3、chmod说明:改变⽂件的权限。
使⽤-R将使改变在⽬录结构下递归进⾏。
命令的使⽤者必须是⽂件的所有者或者超级⽤户。
⽤法:hadoop fs -chmod [-R] URI [URI …]范例:hadoop fs -chmod -R 744 /user/hadoop/4、chown说明:改变⽂件的拥有者。
使⽤-R将使改变在⽬录结构下递归进⾏。
命令的使⽤者必须是超级⽤户。
⽤法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]范例:hadoop fs -chmod -R hadoop /user/hadoop/5、copyFromLocal(本地到hdfs)说明:除了限定源路径是⼀个本地⽂件外,和put命令相似。
⽤法:hadoop fs -copyFromLocal <localsrc> URI6、copyToLocal(hdfs到本地)说明:除了限定⽬标路径是⼀个本地⽂件外,和get命令类似。
sqoop常用命令

sqoop常用命令sqoop是一个用于在Hadoop和关系型数据库之间传输数据的工具,它提供了一系列常用命令来进行数据导入和导出操作。
本文将介绍sqoop的常用命令,帮助读者了解如何使用sqoop进行数据传输。
1. import命令import命令用于将关系型数据库中的数据导入到Hadoop中的Hive表或HDFS文件中。
使用该命令时,需要指定数据库连接信息、表名、目标路径等参数。
例如,以下命令将数据库中的表数据导入到Hive表中:```sqoop import --connect jdbc:mysql://localhost:3306/db --username user --password pass --table table --hive-import --hive-table hive_table```2. export命令export命令用于将Hive表或HDFS文件中的数据导出到关系型数据库中的表中。
使用该命令时,需要指定数据库连接信息、目标表名、数据源路径等参数。
例如,以下命令将Hive表的数据导出到数据库表中:```sqoop export --connect jdbc:mysql://localhost:3306/db --username user --password pass --table table --export-dir hdfs://localhost:9000/path```3. eval命令eval命令用于执行SQL语句并将结果打印到控制台。
使用该命令时,需要指定数据库连接信息和要执行的SQL语句。
例如,以下命令执行SQL语句并打印结果:```sqoop eval --connect jdbc:mysql://localhost:3306/db --username user --password pass --query "SELECT * FROM table"```4. list-tables命令list-tables命令用于列出数据库中的所有表名。
hadoop 操作手册

hadoop 操作手册Hadoop 是一个分布式计算框架,它使用 HDFS(Hadoop Distributed File System)存储大量数据,并通过 MapReduce 进行数据处理。
以下是一份简单的 Hadoop 操作手册,介绍了如何安装、配置和使用 Hadoop。
一、安装 Hadoop1. 下载 Hadoop 安装包,并解压到本地目录。
2. 配置 Hadoop 环境变量,将 Hadoop 安装目录添加到 PATH 中。
3. 配置 Hadoop 集群,包括 NameNode、DataNode 和 JobTracker 等节点的配置。
二、配置 Hadoop1. 配置 HDFS,包括 NameNode 和 DataNode 的配置。
2. 配置 MapReduce,包括 JobTracker 和 TaskTracker 的配置。
3. 配置 Hadoop 安全模式,如果需要的话。
三、使用 Hadoop1. 上传文件到 HDFS,使用命令 `hadoop fs -put local_file_path/hdfs_directory`。
2. 查看 HDFS 中的文件和目录信息,使用命令 `hadoop fs -ls /`。
3. 运行 MapReduce 作业,编写 MapReduce 程序,然后使用命令`hadoop jar my_` 运行程序。
4. 查看 MapReduce 作业的运行结果,使用命令 `hadoop fs -cat/output_directory/part-r-00000`。
5. 从 HDFS 中下载文件到本地,使用命令 `hadoop fs -get/hdfs_directory local_directory`。
6. 在 Web 控制台中查看 HDFS 集群信息,在浏览器中打开7. 在 Web 控制台中查看 MapReduce 作业运行情况,在浏览器中打开四、管理 Hadoop1. 启动和停止 Hadoop 集群,使用命令 `` 和 ``。
hadoop的基本操作命令

hadoop的基本操作命令Hadoop的基本操作命令Hadoop是一个分布式计算框架,常用于大数据处理。
本文将介绍Hadoop的基本操作命令,包括文件系统操作、作业管理、信息查看等。
一、文件系统操作1.创建目录在Hadoop中,可以使用mkdir命令创建目录。
具体用法如下:hadoop fs -mkdir /path/to/directory其中,/path/to/directory是要创建的目录路径。
2.上传文件使用put命令上传本地文件到Hadoop文件系统中。
用法如下:hadoop fs -put /path/to/local/file /path/to/hdfs/directory其中,/path/to/local/file是要上传的本地文件路径,/path/to/hdfs/directory是要上传到的Hadoop文件系统路径。
3.下载文件使用get命令将Hadoop文件系统中的文件下载到本地。
用法如下:hadoop fs -get /path/to/hdfs/file /path/to/local/directory其中,/path/to/hdfs/file是要下载的Hadoop文件系统文件路径,/path/to/local/directory是要下载到的本地文件夹路径。
4.列出目录内容使用ls命令列出指定目录下的文件和子目录。
用法如下:hadoop fs -ls /path/to/directory其中,/path/to/directory是要列出内容的目录路径。
5.删除文件或目录使用rm命令删除指定的文件或目录。
用法如下:hadoop fs -rm /path/to/file或hadoop fs -rm -r /path/to/directory其中,/path/to/file是要删除的文件路径,/path/to/directory是要删除的目录路径。
二、作业管理1.提交作业使用jar命令提交作业。
hadoop常用指令

HDFS 常用文件操作命令前言HDFS命令基本格式:hadoop fs -cmd < args >ls 命令hadoop fs -ls /列出hdfs文件系统根目录下的目录和文件hadoop fs -ls -R /列出hdfs文件系统所有的目录和文件put 命令hadoop fs -put < local file > < hdfs file >hdfs file的父目录一定要存在,否则命令不会执行hadoop fs -put < local dir >...< hdfs dir >hdfs dir 一定要存在,否则命令不会执行hadoop fs -put - < hdsf file>从键盘读取输入到hdfs file中,按Ctrl+D结束输入,hdfs file不能存在,否则命令不会执行moveFromLocal 命令hadoop fs -moveFromLocal < local src > ... < hdfs dst >与put相类似,命令执行后源文件local src 被删除,也可以从从键盘读取输入到hdfsfile中copyFromLocal 命令hadoop fs -copyFromLocal < local src > ... < hdfs dst >与put相类似,也可以从从键盘读取输入到hdfs file中get 命令hadoop fs -get < hdfs file > < local dir>local file不能和hdfs file名字不能相同,否则会提示文件已存在,没有重名的文件会复制到本地hadoop fs -get < hdfs dir > ... < local dir >拷贝多个文件或目录到本地时,本地要为文件夹路径注意:如果用户不是root,local 路径要为用户文件夹下的路径,否则会出现权限问题,moveToLocal 命令当前版本中还未实现此命令copyToLocal 命令hadoop fs -copyToLocal < local src > ... < hdfs dst >与get相类似rm 命令hadoop fs -rm < hdfs file > ...hadoop fs -rm -r < hdfs dir>...每次可以删除多个文件或目录mkdir 命令hadoop fs -mkdir < hdfs path>只能一级一级的建目录,父目录不存在的话使用这个命令会报错hadoop fs -mkdir -p < hdfs path>所创建的目录如果父目录不存在就创建该父目录getmerge 命令hadoop fs -getmerge < hdfs dir > < local file >将hdfs指定目录下所有文件排序后合并到local指定的文件中,文件不存在时会自动创建,文件存在时会覆盖里面的内容hadoop fs -getmerge -nl < hdfs dir > < local file >加上nl后,合并到local file中的hdfs文件之间会空出一行cp 命令hadoop fs -cp < hdfs file > < hdfs file >目标文件不能存在,否则命令不能执行,相当于给文件重命名并保存,源文件还存在hadoop fs -cp < hdfs dir >... < hdfs dir >目标文件夹要存在,否则命令不能执行mv 命令hadoop fs -mv < hdfs file > < hdfs file >目标文件不能存在,否则命令不能执行,相当于给文件重命名并保存,源文件不存在hadoop fs -mv < hdfs dir >... < hdfs dir >源路径有多个时,目标路径必须为目录,且必须存在。
hadoop基本命令_建表-删除-导数据
HADOOP表操作1、hadoop简单说明hadoop 数据库中的数据是以文件方式存存储。
一个数据表即是一个数据文件。
hadoop目前仅在LINUX 的环境下面运行。
使用hadoop数据库的语法即hive语法。
(可百度hive语法学习)通过s_crt连接到主机。
使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。
2、使用hive 进行HADOOP数据库操作3、hadoop数据库几个基本命令show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。
usezb_dim;show tables;4、在hadoop数据库上面建表;a1: 了解hadoop的数据类型int 整型; bigint 整型,与int 的区别是长度在于int;int,bigint 相当于oralce的number型,但是不带小数点。
doubble 相当于oracle的numbe型,可带小数点;string 相当于oralce的varchar2(),但是不用带长度;a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。
create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符a2.1 查看建表结构: describeA2.2 往表里面插入数据。
由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
数据文件的生成,第一步,在EXECLE中按表的顺序依次放入要需要的数据,然后复制到UE编码器中生成文件,保存格式为TXT。
《大数据Hadoop基础》课程标准

《大数据Hadoop基础》课程标准一、课程说明课程编码〔37601〕承担单位〔计算机信息学院〕制定〔〕制定日期〔2022年11月16日〕审核〔专业指导委员会〕审核日期〔2022年11月26日〕批准〔二级学院(部)院长〕批准日期〔2022年11月28日〕(1)课程性质:《大数据应用技术基础》由Hadoop开发基础、分布式存储HDFS开发基础和分布式计算Map Reduce开发基础三部分组成,它是由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架;Hadoop以一种可靠、高效、可伸缩的方式进行数据处理,能够处理PB级数据。
从学科性质上讲,它既是大数据技术与应用专业的基础课程,又是大数据技术与应用专业的专业核心课程,它为大数据技术与应用专业后继课程的学习提供必要的理论与实践基础。
(2)课程任务:通过本门课程的学习,使学生知道Hadoop框架最核心的设计是:HDFS和Map Reduce;HDFS是部署在Hadoop集群的底层为海量的数据提供了存储,而Map Reduce为海量的数据提供了计算;而且能够理解并掌握HDFS文件系统的存储原理、两种访问HDFS文件系统的模式以及理解Hadoop集群的计算框架Map Reduce的工作原理,为《Hadoop基础实战》、《数据的可视化》和《Spark数据计算》等课程的学习提供理论依据和实战基础。
(3)课程衔接:《大数据应用技术基础》的先修课程为《Java程序设计》、《Linux系统管理》等,这些课程的学习将为本课程的学习奠定了理论基础。
《大数据应用技术基础》的后续课程是《Hadoop基础实战》、《数据的可视化》和《Spark 数据计算》等,通过该课程的学习可为这些课程内容的学习奠定良好的理论和实战基础,在教学中起到承上启下的作用。
二、学习目标通过本门课程的学习,首先,使学生知道Hadoop集群的基本架构,理解并掌握Hadoop 集群搭建的三种模式;其次,知道HDFS是部署在Hadoop集群的一个分布式文件存储系统,理解并掌握HDFS文件系统的存储原理以及两种访问HDFS文件系统的模式;最后,理解Hadoop集群的计算框架Map Reduce的工作原理,并且掌握map Reduce分析年气象数据和英语单词统计,从而提高学生的发现问题、分析问题和解决问题的能力。
hdfs的文件操作命令以及mapreduce程序设计

hdfs的文件操作命令以及mapreduce程序设计Hadoop分布式文件系统(HDFS)是Hadoop框架的一部分,用于存储和处理大规模数据集。
以下是HDFS的一些常见文件操作命令:1. 查看文件和目录:- `hadoop fs -ls <path>`:列出指定路径下的文件和目录。
- `hadoop fs -du <path>`:查看指定路径下的文件和目录的大小。
2. 创建和删除目录:- `hadoop fs -mkdir <path>`:创建一个新目录。
- `hadoop fs -rmr <path>`:递归删除指定路径下的所有文件和目录。
3. 文件复制和移动:- `hadoop fs -cp <src> <dest>`:将源路径中的文件复制到目标路径。
- `hadoop fs -mv <src> <dest>`:将源路径中的文件移动到目标路径。
4. 文件上传和下载:- `hadoop fs -put <localSrc> <dest>`:将本地文件上传到HDFS中的指定路径。
- `hadoop fs -get <src> <localDest>`:将HDFS中的文件下载到本地目录。
5. 查看文件内容:- `hadoop fs -cat <path>`:显示指定路径下文件的内容。
- `hadoop fs -tail <path>`:显示指定文件的最后几行内容。
上述命令可以在命令行中使用。
此外,Hadoop还提供了Java 编程接口(API)和命令行工具(如`hadoop jar`)来编写和运行MapReduce程序。
以下是使用Java编写的简单MapReduce程序的示例:```javaimport org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {String[] words = value.toString().split(" ");for (String w : words) {word.set(w);context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Job job = Job.getInstance();job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}```该示例是一个简单的词频统计程序。
《Hadoop系统搭建及项目实践》课后习题答案

项目1 Hadoop基础知识1.Hadoop是由哪个项目发展来的?答:2002年,开源组织Apache成立开源搜索引擎项目Nutch,但在Nutch开发过程中,始终无法有效地将计算任务分配到多台计算机上。
2004年前后,Google陆续发表三大论文GFS、MapReduce和BigTable。
于是Apache在其Nutch里借鉴了GFS和MapReduce思想,实现了Nutch版的NDFS和MapReduce。
但Nutch项目侧重搜索,而NDFS和MapReduce则更像是分布式基础架构,因此,2006年,开发人员将NDFS和MapReduce移出Nutch,形成独立项目,称为Hadoop。
2.Hadoop主要有哪些版本?答:目前Hadoop的发行版除了Apache的开源版本之外,还有华为发行版、Intel发行版、Cloudera发行版(CDH)、Hortonworks发行版(HDP)、MapR等,所有这些发行版均是基于Apache Hadoop衍生出来的。
Apache Hadoop版本分为两代,第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。
第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x 最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x增加了NameNode HA等新的重大特性。
第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNodeHA和Wire-compatibility两个重大特性。
3.简要描述Hadoop的体系结构,分析1.x与2.x版本间的区别。
答:Hadoop 2.x相比Hadoop 1.x最大的变化是增加了YARN组件,YARN是一个资源管理和任务调度的框架,主要包含三大模块:ResourceManager(RM)、NodeManager(NM)和ApplicationMaster(AM)。
熟悉常用的hbase操作实验报告 -回复

熟悉常用的hbase操作实验报告-回复熟悉常用的HBase操作实验报告HBase是一个开源的非关系型分布式数据库,它是基于Hadoop的分布式文件系统HDFS来存储数据,并采用Google的Bigtable作为数据模型。
HBase具有高可用性、高可靠性和高扩展性的特点,适合存储海量数据和进行实时查询。
在本次实验中,我们将熟悉HBase的常用操作,包括创建表、插入数据、查询数据和删除数据等。
一、实验准备为了完成这个实验,我们需要安装好HBase的环境,并启动HBase服务。
同时,需要编写Java代码来执行HBase的操作。
二、创建表在HBase中,表由行(row)和列(column)组成。
我们首先需要创建一个表,来存储我们的数据。
1. 打开HBase的Shell界面,输入以下命令来创建名为“student”的表:create 'student', 'info'上述命令中,“student”是表的名称,“info”是表中的列族名称。
2. 使用Java代码来创建表,首先需要导入HBase的相关包:import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;然后,编写创建表的代码:Configuration conf = HBaseConfiguration.create(); HBaseAdmin admin = new HBaseAdmin(conf); HTableDescriptor tableDescriptor = newHTableDescriptor(TableName.valueOf("student")); tableDescriptor.addFamily(new HColumnDescriptor("info")); admin.createTable(tableDescriptor);上述代码中,我们使用了HBaseAdmin类的createTable方法来创建表。
hdoop的hdfs中的常用操作命令

hdoop的hdfs中的常用操作命令Hadoop的HDFS(Hadoop Distributed File System)中常用的操作命令包括:1. ls:列出HDFS上的文件和目录`hadoop fs -ls <path>`2. mkdir:创建一个新目录`hadoop fs -mkdir <path>`3. cp:将文件从本地文件系统复制到HDFS或者在HDFS之间复制文件`hadoop fs -cp <source> <destination>`4. mv:将文件从一个位置移动到另一个位置(可以在HDFS内部或者HDFS与本地文件系统之间移动)`hadoop fs -mv <source> <destination>`5. rm:删除指定的文件或目录`hadoop fs -rm <path>`6. cat:将文件的内容打印到控制台上`hadoop fs -cat <path>`7. tail:显示文件的最后几行`hadoop fs -tail <path>`8. get:将文件从HDFS复制到本地文件系统`hadoop fs -get <source> <destination>`9. put:将文件从本地文件系统复制到HDFS`hadoop fs -put <source> <destination>`10. chmod:更改文件的权限`hadoop fs -chmod <mode> <path>`以上是HDFS中常用的操作命令。
可以使用命令`hadoop fs -help`查看更多的HDFS命令及其用法。
Hadoop常用命令及范例

Hadoop常⽤命令及范例 hadoop中的zookeeper,hdfs,以及hive,hbase都是hadoop的组件,要学会熟练掌握相关的命令及其使⽤规则,下⾯就是⼀些常⽤命令及对hbase和hive的操作语句,同时也列出了⼀些范例。
start-dfs.sh NameNode 进程启动:hadoop-daemon.sh start namenode DataNode 进程启动:hadoop-daemon.sh start datanode HA ⾼可⽤环境中需要启动的进程: zookeeper: zkServer.sh start 启动 zkServer.sh stop 停⽌ zkServer.sh status 查看状态 leader follwer journalnode 集群命令 hadoop-daemon.sh start journalnode 启动 hadoop-daemon.sh stop journalnode 停⽌ ZKFC 启动 zkfc 进程: hadoop-daemon.sh start zkfc 停⽌ zkfc 进程: hadoop-daemon.sh stop zkfc 1. shell命令管理和 HDFS 的⽂件管理。
(1)启动 Zookeeper zkServer.sh start (2)启动 HDFS 的命令 start-dfs.sh (3)启动 Yarn 的命令 start-yarn.sh (4)显⽰ HDFS 中/data/test ⽬录信息 hadoop fs -mkdir /data/test hadoop fs -lsr /data/test (5)将本地⽂件/tmp/log.txt ⽂件上传到/data/test ⽬录中 hadoop fs -put /tmp/log.txt /data/test (6)设置⽂件/data/test/log.txt 的副本数为 3 hadoop fs -setrep -w 3 /data/test/log.txt (7)显⽰/data/test/log.txt ⽂件内容 hadoop fs -cat /data/test/log.txt (8)将/data/test/log.txt ⽂件移动到集群/user/hadoop ⽬录下 hadoop fs -mkdir /user/hadoop hadoop fs -mv /data/test/log.txt /user/hadoop (9)将/data/test/log.txt ⽂件下载到/home/hadoop ⽬录下 hadoop fs -copyToLocal /data/test/log.txt /home/hadoop/ (10)关闭 HDFS 命令 stop-dfs.sh (11)停⽌ Zookeeper zkServer.sh stop 2.将学⽣数据存储到 Hive 数据仓库中,信息包括(学号,姓名,性别,年龄,联系⽅式, 邮箱),创建表语法如下: 启动 hive 前切记要先启动 mysql 数据库 create table student(sno string ,name string ,sex string ,age int ,phone string, email string) row format delimited fields terminated by ',' ;(1)将本地数据“/tmp/student.dat”加载到 student 表,写出操作语句 load data local inpath '/tmp/student.dat' overwrite into table student; (2)写 HQL 语句查询全部学⽣信息 select * from student; (3)写 HQL 语句查询各个年龄及对应学⽣数量 (4) select age,count(*) from student group by age; (5)写 HQL 语句查询全部学⽣的姓名和性别 select name,sex from student; (6)写 HQL 语句查询年龄为 18 的学⽣姓名和联系⽅式 select name,phone from student where age=18; (7)写 HQL 语句查看 student 表结构 describe student; (8)写 HQL 语句删除 student 表 drop table student; (9)导出⽣地/home/hadoop/out ⽬录,写出语 from student insert overwrite local directory '/home/hadoop/out' select *; 3.员⼯表 employee 包含两个列族 basic 和 info,使⽤ shell 命令完成以下操作。
hadoop命令大全

hadoop命令⼤全启动与关闭启动Hadoop1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/start-all.sh关闭Hadoop1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/stop-all.sh⽂件操作Hadoop使⽤的是HDFS,能够实现的功能和我们使⽤的磁盘系统类似。
并且⽀持通配符,如*。
查看⽂件列表查看hdfs中/user/admin/aaron⽬录下的⽂件。
1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/hadoop fs -ls /user/admin/aaron这样,我们就找到了hdfs中/user/admin/aaron⽬录下的⽂件了。
我们也可以列出hdfs中/user/admin/aaron⽬录下的所有⽂件(包括⼦⽬录下的⽂件)。
1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/hadoop fs -lsr /user/admin/aaron创建⽂件⽬录查看hdfs中/user/admin/aaron⽬录下再新建⼀个叫做newDir的新⽬录。
1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/hadoop fs -mkdir /user/admin/aaron/newDir删除⽂件删除hdfs中/user/admin/aaron⽬录下⼀个名叫needDelete的⽂件1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/hadoop fs -rm /user/admin/aaron/needDelete删除hdfs中/user/admin/aaron⽬录以及该⽬录下的所有⽂件1. 进⼊HADOOP_HOME⽬录。
2. 执⾏sh bin/hadoop fs -rmr /user/admin/aaron上传⽂件上传⼀个本机/home/admin/newFile的⽂件到hdfs中/user/admin/aaron⽬录下1. 进⼊HADOOP_HOME⽬录。
hadoop基本命令

hadoop基本命令
Hadoop是一个开源的分布式计算系统,用于大规模数据处理。
以下是Hadoop的基本命令:
1. hdfs命令:用于管理Hadoop分布式文件系统(HDFS),如创建、删除、移动和复制文件或目录。
2. mapred命令:用于管理Hadoop的MapReduce作业,如提交、监视和控制作业。
3. yarn命令:用于管理Hadoop的资源管理器(YARN),如查看节点状态、启动和停止节点等。
4. dfsadmin命令:用于管理HDFS的管理员操作,如关闭节点、恢复数据等。
5. fsck命令:用于检查HDFS文件系统的完整性和一致性。
6. distcp命令:用于在不同的Hadoop或非Hadoop集群之间复制大量数据。
7. hadoop命令:用于执行Hadoop相关的命令和操作。
以上是Hadoop的基本命令,可以通过这些命令来管理和操作Hadoop集群和数据。
- 1 -。
Hadoop命令大全

分类:Hadoop命令⼤全2011-03-01 15:046852⼈阅读(0)1、列出所有Hadoop Shell⽀持的命令$ bin/hadoop fs -help2、显⽰关于某个命令的详细信息$ bin/hadoop fs -help command-name3、⽤户可使⽤以下命令在指定路径下查看历史⽇志汇总$ bin/hadoop job -history output-dir这条命令会显⽰作业的细节信息,失败和终⽌的任务细节。
4、关于作业的更多细节,⽐如成功的任务,以及对每个任务的所做的尝试次数等可以⽤下⾯的命令查看$ bin/hadoop job -history all output-dir5、格式化⼀个新的分布式⽂件系统:$ bin/hadoop namenode -format6、在分配的NameNode上,运⾏下⾯的命令启动HDFS:$ bin/start-dfs.shbin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves⽂件的内容,在所有列出的slave上启动DataNode守护进程。
7、在分配的JobTracker上,运⾏下⾯的命令启动Map/Reduce:$ bin/start-mapred.shbin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves⽂件的内容,在所有列出的slave上启动TaskTracker守护进程。
8、在分配的NameNode上,执⾏下⾯的命令停⽌HDFS:$ bin/stop-dfs.shbin/stop-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves⽂件的内容,在所有列出的slave上停⽌DataNode守护进程。
9、在分配的JobTracker上,运⾏下⾯的命令停⽌Map/Reduce:$ bin/stop-mapred.shbin/stop-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves⽂件的内容,在所有列出的slave上停⽌TaskTracker守护进程。
hbase基础建表语句

hbase基础建表语句在Hadoop⽬录下的HBASE下执⾏命令 ./hbase shell 进⼊hbase环境创建hbase 数据库表 create "表名", "字段A","字段B"。
删除表⾸先desable "表名" 然后drop "表名"查看表机构 desc "表名"查看所有表名 list查看表数据 scan "表名"---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------⼀. 介绍HBase是⼀个分布式的、⾯向列的开源数据库,源于google的⼀篇论⽂《bigtable:⼀个结构化数据的分布式存储系统》。
HBase是Google Bigtable的开源实现,它利⽤Hadoop HDFS作为其⽂件存储系统,利⽤Hadoop MapReduce来处理HBase中的海量数据,利⽤Zookeeper作为协同服务。
HBase以表的形式存储数据。
表有⾏和列组成。
列划分为若⼲个列族/列簇(column family)。
如上图所⽰,key1, key2, key3是三条记录的唯⼀的row key值,column-family1, column-family2, column-family3是三个列族,每个列族下⼜包括⼏列。
⽐如 column-family1这个列族下包括两列,名字是column1和column2。
t1:abc,t2:gdxdf是由row key1和column-family1-column1唯⼀确定的⼀个单元cell。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HADOOP表操作
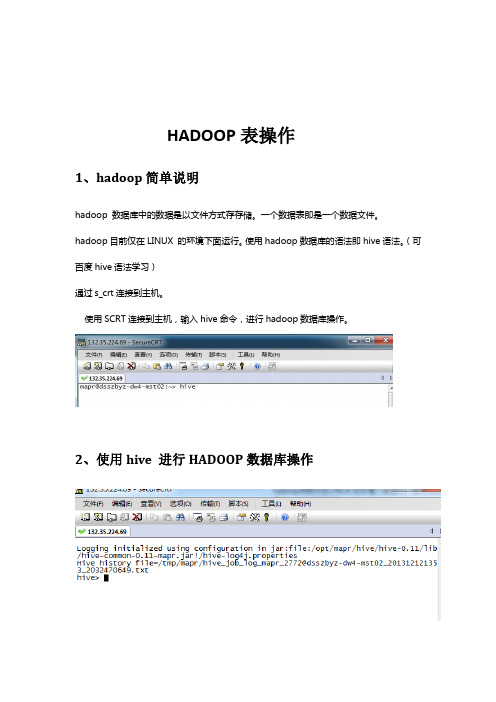
1、hadoop简单说明
hadoop 数据库中的数据是以文件方式存存储。
一个数据表即是一个数据文件。
hadoop目前仅在LINUX 的环境下面运行。
使用hadoop数据库的语法即hive语法。
(可百度hive语法学习)
通过s_crt连接到主机。
使用SCRT连接到主机,输入hive命令,进行hadoop数据库操作。
2、使用hive 进行HADOOP数据库操作
3、hadoop数据库几个基本命令
show datebases; 查看数据库内容; 注意:hadoop用的hive语法用“;”结束,代表一个命令输入完成。
usezb_dim;
show tables;
4、在hadoop数据库上面建表;
a1: 了解hadoop的数据类型
int 整型; bigint 整型,与int 的区别是长度在于int;
int,bigint 相当于oralce的number型,但是不带小数点。
doubble 相当于oracle的numbe型,可带小数点;
string 相当于oralce的varchar2(),但是不用带长度;
a2: 建表,由于hadoop的数据是以文件有形式存放,所以需要指定分隔符。
create table zb_dim.dim_bi_test_yu3(id bigint,test1 string,test2 string)
row format delimited fields terminated by '\t' stored as textfile; --这里指定'\t'为分隔符
a2.1 查看建表结构: describe
A2.2 往表里面插入数据。
由于hadoop的数据是以文件存在,所以插入数据要先生成一个数据文件,然后使用SFTP将数据文件导入表中。
数据文件的生成,第一步,在EXECLE中按表的顺序依次放入要需要的数据,然后复制到UE编码器中生成文件,保存格式为TXT。
注意:文件中的分隔符必须与建表时指定的分隔一致。
保存文件时生成的格式。
A2.2.1: 通过4A打开SFTP 导入文件。
A2.2.2: 将数据文件写入表内。
load data local inpath'/home/mapr/yu_dim_test.txt' overwrite into table zb_dim.dim_bi_test_yu3;
A2.2.3查看导入的内容。
注意:由于hadoop是库的数据是以文件存的,与oarlce中的追加一条记录,删除一条记录不一样,只能再覆盖文件。
A2.2.4 : 将一个表的数据导入另一个表。
例:将zb_dim.dim_bi_test_yu3 表中的数据导入
zb_dim.dim_bi_yu_test_yu;
注意:源表必须有数据才能使用insert overwrite table 将源表的数据写入目标表。
insert overwrite table zb_dwa.dwa_s_m_acc_al_charge_"$v_prov"
partition(month_id='"$v_month"') SELECT
ER_ID, T.SERVICE_TYPE, '', '', SUM(T.BEF_FEE), 0, 0, SUM(T.FEE), '"$v_prov"' FROM
ZB_DWD.DWD_M_ACC_AL_CHARGE_"$v_prov" T WHERE T.MONTH_ID = '"$v_month"' GROUP BY ER_ID, T.SERVICE_TYPE(有分区)
insert overwrite table zb_dim. dim_bi_yu_test_yu SELECT id,test1,test2 FROM zb_dim.dim_bi_test_yu3
查看写入的内容:
A2.3: DROP 表。