随机误差的正态分布.
简述随机误差正态分布的主要规律

简述随机误差正态分布的主要规律
随机误差正态分布是指测量结果的随机误差遵循高斯分布的规律。
其主要规律包括以下几点:
1. 平均数和方差呈正态分布:随机误差的正态分布以测量平均值为重心,其分布形状类似于一个钟形曲线。
随着测量次数的增加,随机误差的方差会趋近于平均值,使得正态分布的曲线更加平缓。
2. 极端值的出现概率较小:正态分布的规律表明,测量结果中极端值的出现概率较小,而大多数测量结果都分布在平均值附近。
3. 误差分布的离散程度与测量次数有关:随着测量次数的增加,随机误差的分布形状不变,但是其离散程度会越来越大。
这主要是因为多次测量的结果会趋近于平均值,使得随机误差的分布更加集中。
4. 误差分布的形状与测量方法有关:不同的测量方法可能会导致误差分布的形状不同。
例如,在回归分析中,残差的正态分布形状取决于回归模型的准确度。
随机误差正态分布的主要规律表明,测量结果的随机误差遵循高斯分布的规律,而随机误差的分布形状、离散程度和形状取决于测量方法和测量次数等因素。
单摆及随机误差正态分布

由传递公式求出
(T ± U )。
T
切勿先求出 5 个 Ti, 并求出相 应的 ST 及 UT。
∑ (t
tp
i
−t)
2
n −1 n
= 0.00626(s )
⋅ S t = 1.2 × S t = 0.00751(s )
U tB = 0.005(s )
2 2 U t = U tA + U tB = 0.0090(s )
Ug
2
2
2
2
批注 [BG9]: 不确定度的传递 中,必须写出相应的表达式注 [BG10]: 作为该实验的 最终结果,g 必须写为 (g
(
)
g = 9.781(1 ± 0.18% ) m ⋅ s −2
(
)
± U g )的形式。 上述 d、 l、
L、 t 由于是中间过程, 是否表
批注 [BG5]: 表述有何要求? 平均值及不确定度如何取 位?
(3)单摆摆长 L
L =l + d = 50.5200 + 1.9036 = 51.4718(cm) 2
2
U U L = U + d = 0.0910(cm) 2
2 l
批注 [BG6]: L 为间接量, 故L 的不确定度由传递公式给出。
⋅ S D = 1.2 × S D = 0.00201(cm )
U DB = 0.002(cm)
2 2 U D = U DA + U DB = 0.00283(cm )
D = (1.9036 ± 0.0028)(cm )
(2)摆线长 l
1 3 l = × ∑ l i = 50.5200(cm ) 3 i =1 Sl =
误差的统计概率

误差的统计概念一.随机误差的正态分布1. 正态分布随机误差的规律服从正态分布规律,可用正态分布曲线(高斯分布的正态概率密度函数)表示:(13)式中:y—概率密度;μ—总体平均值;σ—总体标准偏差。
正态分布曲线依赖于μ和σ两个基本参数,曲线随μ和σ的不同而不同。
为简便起见,使用一个新变数(u)来表达误差分布函数式:(14)u的涵义是:偏差值(x-μ)以标准偏差为单位来表示。
变换后的函数式为:(15)由此绘制的曲线称为“标准正态分布曲线”。
因为标准正态分布曲线横坐标是以σ为单位,所以对于不同的测定值μ及σ,都是适用的。
图1:两组精密度不同的测定值图2:标准正态分布曲线的正态分布曲线“标准正态分布曲线”清楚地反映了随机误差的分布性质:(1)集中趋势当x=μ时(u=0),,y此时最大,说明测定值x集中在μ附近,或者说,μ是最可信赖值。
(2)对称趋势曲线以x=μ这一直线为对称轴,表明:正负误差出现的概率相等。
大误差出现的概率小,小误差出现的概率大;很大误差出现的概率极小。
在无限多次测定时,误差的算术平均值极限为0 。
(3)总概率曲线与横坐标从-∝到+∝在之间所包围的面积代表具有各种大小误差的测定值出现的概率的总和,其值为1(100%)(16)用数理统计方法可以证明并求出测定值x出现在不同u区间的概率(不同u值时所占的面积)即x落在μ±uσ区间的概率:置信区间置信概率u= ± 1.00 x= μ± 1.00σ68.3%u= ± 1.96 x= μ± 1.96σ95.0%u= ± 3.00 x= μ± 3.00σ99.7%二. 有限数据随机误差的t分布在实际测定中,测定次数是有限的,只有和S,此时则用能合理地处理少量实验数据的方法—t分布1. t分布曲线(实际测定中,用、S代替μ、σ)t分布曲线与标准正态分布曲线相似,纵坐标仍为概率密度,纵坐标则是新的统计量t(17)无限次测定,u一定→P 就一定;有限次测定:t一定→P 随ν(自由度)不同而不同。
随机误差的正态分布

1.3
0.3
0.1179
1.4
0.4
0.1554
1.5
0.5
0.1915
1.6
0.6
0.2258
1.7
0.7
0.2580
1.8
0.8
0.2881
1.9
0.9
0.3159
1.96
1.0
0.3413
2.0
1
u u2
e 2 du
2 0
面积
u
0.3643
2.1
0.3849
2.2
0.4032
2.3
0.4192
频率分布图
规律
1. 测量过程中随机误差的存在,使分析结 果高低不齐,即测量数据具有分散的特性。
随机误差分布符合正态分布因此

△x
0.01 0.02 0.03 0.04 0.05 0.06
图2.2 误差频率分布图
(1)高斯误差定律 正态分布的分布密度函数为:
f (x)
1
( x )2
e 2 2 ( x )(2-1)
2
式中 、 为参数,可记为 x~N( , 2 )。其分布函数为:
x
F(x)
1
(x)2
e 2 2 dx
随机误差分布符合正态分布因此
在第1章中给出了一个实际测量结果的例子,以误差作为横坐标,以频率数 f 作为纵坐标,将所得数据画成频率分布的直方图,如图2.1 所示。
f i 18% 16%
14%
12%
10%
8%6%4%2%0%-0.06 -0.05 -0.04 -0.03 -0.02 -0.01 0
0.01
一般的正态分布可以通过适当变换化为标准正态分布。
若x~ N(,2) , 令Z=x, 则Z~ N( 0, 1) 符 合 标 准 正 态 分 布 , 如 下 式 :
F(x)(x)(Z) Z
1
Z2
e2dZ
2
(2-4)
( 2-4)其值见附表1。分布图见图2.3-1 19世纪德国的科学家高斯研究大量的测量数据时发现,随机误差分布符合正态分布。因此,在误差理论中将正态分布又称为高斯分布,图 2.3中的曲线称为高斯曲线,其分布密度函数及概率分布函数分别表示为:
准 误 差 为 σ, 服 从 正 态 分 布 的 随 机 变 量 可 表 示 x 为~ N ( a, ( )2) , 按 正 态 分 布 概 率 积 分
2
(2-2)
F(x)的图形关于中心轴对称,由此可以得出:
(2-3)
§1—2随机误差的正态分布

b.
-
0
+
x
X -
2.正态分布曲线的讨论
特点:
y: 概率密度 x: 测量值 μ: 总体平均值 x-μ: 随机误差 σ : 总体标准偏差
(1)y极大值在 x = μ 处;
于x = μ 对称;
x 轴为渐近线.
(2)拐点在 x = μ ± σ 处.
表示为N(, 2)
(1)测定值的正态分布
(u )du 1
同理,由标准正态分布曲线方程还 可求得在无限多次测量中,某一范围内测 量值或随机误差出现的机会(概率)的最 终趋势是多少. 2 u 即 u2 1
P
u1
2
e 2 du
标准正态分布曲线 N (0,1)
0.4 0.3 0.2 0.1 0 -4
-3 -2 - -3 -2 -
对称性: 曲线以x =这条直线为对称轴.
表明测量数据具有明显的向 总体平均值集中的趋势;
决定正态分布曲线的中心位置。
测量值出现正,负误差的机会相等. 单峰性:
1 y 2π
x =时,y值最大,表现为一个峰形.
σ决定正态分布曲线的形状;
σ越小,数据越集中,测定值落在
附近的概率越大。
当 σ ,µ 确定,正态分布曲线的位置和形状也确定,
P=95.5% ½ a
=0.47%
y
-3
-2
-1
0
1
2
3
u
α=4.5%
P 置信度
a 显著性水平
P+ a = 1
-3
-2
-1
0
68.3% 95.5% 99.7%
0
2 3 + +2 +3
随机误差概率密度正态分布
ƒ(0)
置信概率
1/2α
P= φ(z)=1-α
1/2α
置信区间 ±(L) 图1—5 置信区间与置信概率
δ
Z
0
φ(Z)
0.00000 0.07966 0.15852
Z
0.9 1.0 1.1
φ(Z)
0.63188 0.68269 0.72867
Z
1.9 1.96 2.0
φ(Z)
0.94257 0.95000 0.95450
拐点坐标:
1 f (0) f max ( ) σ 2 1 f g ( ) f ( ) 2e
概率:
P{,}
f ( )d 1
一、算是平均值与数学期望值 1. 算是平均值:
x
x
i 1
n
i
n
2. 随机变量的数学期望定义为随机变量的一阶 原点距,记为:
h
1
2
ƒ(δ)
ƒ(δ) σ<σ´<σ´´ h>h´>h´´ ƒ(δ)dδ
拐点
ƒ´(δ)
ƒ´´(δ)
1/(σ√2πe)
1/(σ√2π)
- σ´´- σ´
-σ
σ
σ´
σ´´
δ
随机误差正态分布曲线图
3、σ(曲线的拐点)的大小说明了测量值的 离散性, 故等精度测量是一种σ值相同的测 量。 4、正态分布曲线的关键点 峰点坐标: 0( xi x0 )
( x x0 ) 2 1 Dx ( x x0 ) f ( x)dx exp[ ( x x0 ) 2 ]dxlim
随机误差的正态分布特点

随机误差的正态分布特点1.均值:正态分布的均值为μ,表示数据的中心位置。
在随机误差中,均值可以理解为误差的总体偏差。
如果误差呈现正态分布,均值为0,则表示误差的总体平均值接近于真值,没有系统性偏差。
2.方差:正态分布的方差为σ^2,表示数据的分布范围。
在随机误差中,方差可以理解为误差的离散程度。
方差越大,数据点越分散,说明误差范围更广,反之亦然。
随机误差的正态分布特点是方差相等,即具有同一水平的离散程度。
3.形状:正态分布的形状呈钟形曲线,两侧对称。
随机误差的正态分布特点是呈正态分布曲线,即误差集中在均值附近,偏离均值的概率较小。
该特点反映了随机误差的分布规律,即大部分误差相对较小,极端误差的发生概率较低。
4.中心极限定理:中心极限定理指出,当样本容量足够大时,不论总体分布形态如何,样本的均值分布将近似服从正态分布。
这意味着随机误差的正态分布特点成为了统计学中很重要的前提条件。
由于中心极限定理的存在,可以使用正态分布来进行统计推断和置信区间估计等分析。
在实际应用中,随机误差的正态分布特点有着重要的意义:1.基于随机误差的正态分布特点,可以进行参数估计和假设检验等统计推断。
通过对误差进行统计分析,可以对总体特征进行估计,并利用置信区间判断总体特征是否显著。
2.正态分布的特点使得随机误差具有较好的可控性和可预测性。
通过对误差的分布特征的研究,可以提供对误差的限制和控制方法,从而提高实验的精度。
3.正态分布假设简化了许多统计模型的建立和推断过程。
在许多情况下,我们可以假设随机误差符合正态分布,从而简化了模型的复杂度和计算的难度。
然而,需要注意的是,随机误差的正态分布特点并不意味着所有数据都遵循正态分布。
实际数据可能会受到多种因素的影响,导致偏离正态分布。
因此,在实际应用中,需要通过实际数据分布的分析和统计检验来验证数据是否符合正态分布。
同时,也需要对数据进行预处理和适当的转换,以满足正态分布的假设前提条件。
1002随机误差

14 3.08
0.07
2
0.0133
频率密度 fi / x
11 8 8 7 5 3 1
x 3.01
fivi 0
n=150 fi 0.9999
10
2、统计直方图 根据表1-1的数据可按下列步骤作出统计直方图。
以xi为横坐标,以fi 或 fi /x为纵坐标建立坐标系。
2 i
vi2
n
2 x
2
x
vi
vi2
n
2 x
i1
i1
i1
i1
n
n
i
vi
n x
i 1
i 1
n
n
n
i vi i
i1 i1 i1
x
n
n
n
n
2
i
n
i2
n
2 i j
2 x
i 1
n
i1 n2
1
2
单峰性
A、对称性 f ( ) 0 f ( ) f ( )
B、抵偿性 C、单峰性 D、有界性
n
随着测量次数的增加, lim
i
i 1
0
n n
δ=0时, fmax ( ) f (0) f ( ) f (0)
随机误差δ出现在一个有限的区间
内,即[-kσ,+kσ]的可能性较大。
1879.64
li
vi
-0.01
0
+0.04
+0.05
-0.05
-0.04
+0.04
随机误差的正态分布特点

随机误差的正态分布特点随机误差是指在测量或实验中出现的不可预测的偶然性误差,通常表现为数据点在期望值周围上下波动,呈现出一种无规律的分布。
而正态分布则是一种常见的连续概率分布,具有钟形曲线的特征,其均值、中位数和众数重合,且对称分布。
正态分布的特点是具有明显的中心对称性,即均值位于分布的中心,而标准差决定了分布的扁平程度。
在正态分布中,68%的数据落在均值加减一个标准差的范围内,95%的数据落在均值加减两个标准差的范围内,99.7%的数据落在均值加减三个标准差的范围内。
这种特性使得正态分布在统计学中应用广泛,特别适合描述大量独立测量所得数据的分布情况。
当随机误差服从正态分布时,意味着在测量或实验中产生的误差是无偏的,即随机误差在正负方向上等概率出现,不会对结果产生系统性的影响。
这种误差分布的特性有助于科学家们更好地理解和评估实验数据的可靠性,从而提高实验的准确性和可重复性。
在实际应用中,随机误差的正态分布特点常常体现在各种测量和调查中。
例如,在物理实验中,测量仪器的精度限制和环境因素的干扰可能导致随机误差的产生,而这些误差往往呈现出正态分布的特征。
在社会调查中,由于受访者个体差异和调查方法的局限性,随机误差也会以正态分布的形式存在,影响着统计数据的准确性和可信度。
中心扩展是指正态分布曲线在均值处向两侧逐渐变陡,形成一个逐渐扩展的中心区域。
这种特点表明大多数数据点集中在均值附近,而远离均值的数据点数量逐渐减少。
中心扩展的特性使得正态分布在描述数据集中心趋势和变异程度时具有重要意义,有助于科学家们更好地分析和解释数据的分布规律。
在实际应用中,中心扩展的特点常常被用于判断数据的离群值和异常情况。
当数据点偏离均值较远时,可能表明存在异常情况或特殊情形,需要进一步检查和验证。
通过观察正态分布曲线的中心扩展情况,可以更直观地了解数据的分布情况,从而有效识别异常值并减少误判的可能性。
总的来说,随机误差的正态分布特点体现了数据分布的一种普遍规律,具有中心对称和中心扩展的特性。
随机误差的正态分布

系统误差与随机误差的比较
项目
系统误差
随机误差
产生原因 固定的因素
不定的因素
分类
方法误差、仪器与试剂 误差、主观误差
性质
重现性、单向性(或周 服从概率统计规律、
期性)、可测性
不可测性
影响 准确度
精密度
消除或减 小的方法
校正
增加测定的次数
系统误差的检查与校正方法
(1)方法误差:检查与校正 对照试验选择、改进实验方法。 (2)仪器和试剂误差:检查与校正,空白试验-空白值,空白 校正。
第四章 误差与实验数据的处理
上饶师范学院化学化工学院
• 定量分析பைடு நூலகம்准确获取试样中物质的含量
分析方法 仪器和试剂 工作环境 分析者等
误差:分析结果与真值之差。 误差是客观存在不可避免
对试样准确测量
分析工作者的任务
对分析结果的可靠性 和准确性作出评价
对产生误差的原因进 行分析提出改进措施
第一节 误差的基本概念
23%
1.805 1.835 16
16%
1.835 1.865
6
6%
1.865 1.895
2
2%
∑
100
100%
频率
0.3
0.2
0.1
0.0
测定值
频率分布直方图
二、正态分布
正态分布N (, 2) 的概率密度函数:
y f (x)
1
e
(
x)2 2 2
2
特点: 总体平均值:无限次测量值集中的趋势。y
绝对误差为:Ea=X-T
相对误差(Er):表示误差在真实值中所占的百分率
误差函数 正态分布

误差函数正态分布
误差函数正态分布是一种常见的概率分布,它在统计学和机器学习中被广泛应用。
误差函数正态分布通常用于描述随机变量的分布,它的形状类似于钟形曲线,因此也被称为钟形曲线分布。
误差函数正态分布的概率密度函数可以表示为:
f(x) = (1/σ√(2π)) * e^(-(x-μ)²/2σ²)
其中,μ是分布的均值,σ是标准差。
这个公式描述了随机变量x 的概率密度函数,即在给定的均值和标准差下,x取某个值的概率。
误差函数正态分布在机器学习中的应用非常广泛,特别是在神经网络中。
在神经网络中,误差函数通常用于衡量模型的预测结果与真实结果之间的差异。
误差函数正态分布可以用来描述这种差异的分布情况,从而帮助我们更好地理解模型的性能。
误差函数正态分布还可以用于模型的优化。
在训练神经网络时,我们通常使用梯度下降算法来最小化误差函数。
误差函数正态分布可以帮助我们更好地理解梯度下降算法的收敛性和稳定性,从而更好地优化模型。
误差函数正态分布是一种非常重要的概率分布,它在统计学和机器学习中都有广泛的应用。
通过对误差函数正态分布的研究,我们可以更好地理解模型的性能和优化方法,从而提高模型的准确性和稳
定性。
随机误差的正态分布曲线

误差的表示方法
• 绝对误差:测量值与真实值间的差值
xL
• 相对误差:绝对误差与真实值(或测量值)之比 定义:= 100% 实际:= 100% L x • 引用误差:绝对误差与仪表满量程之比
= 100% xm
9
仪表精度等级的确定
• 依据引用误差,如0.5级表代表其引用误差最大为 0.5% • 我国的仪表等级分为0.1、0.2、0.5、1.0、1.5、 2.5和5.0共七个等级。 • 选用仪表时,一般使其最好能工作在不小于满刻 度值2/3的区域。
• 由于2.0%>1.5%,因此,该电流表已不合格,但 可做精度为2.5级表使用。
11
18.2 测量误差的处理 18.2.1随机误差的统计处理
• 1、随机误差的正态分布曲线
– 单峰性:绝对值小的随机误差出现的概率ቤተ መጻሕፍቲ ባይዱ于绝对值大的随机误差出现
的概率。
– 有界性:随机误差的绝对值是有限的。 – 对称性:随着测量次数的增加,绝对值相等、符号相反的随机误差的出
• 若总的误差已确定,要确定各环节的误差大小以保证总的 误差不超过允许值,这一过程称为误差的分配 • 误差分配有助于在进行测量工作前,根据给定的允许测量 总误差来选择测量方案,合理进行误差分配,确定各环节 误差,以保证测量精度。误差分配应考虑测量过程中所有 误差组成项的分配问题。 • 误差的分配一般地说有无穷多个方案,因此往往在某些假 设条件下进行分配。
– 理论真值是在理想情况下表征一个物理量真实状态或属性的值, 它通常客观存在但不能实际测量得到,或者是根据一定的理论所 定义的数值(如三角形三内角之和为180度)。 – 约定真值是为了达到某种目的按照约定的办法所确定的值(如光 速为30万公里每秒),或以高精度等级仪器的测量值约定为低精 度等级仪器测量值的真值。
随机误差的正态分布

2 有效数4时舍; 尾数≥6时入
尾数=5时, 若后面数为0, 舍5成双;若5后面还有 不是0的任何数皆入
例 下列值修约为四位有效数字 0.324 74 0.324 75 0.324 76 0.324 85 0.324 851
0.324 7 0.324 8 0.324 8 0.324 8 0.324 9
它是由某些无法控制和避免的偶然因素造成 的。如:测定时环境温度、湿度、气压的微小波 动,仪器性能的微小变化,或个人一时的辨别的 差异而使读数不一致等。 如:天平和滴定管最后一位读数的不确定性。
它的特点:大小和方向都不固定,也无法测量 或校正。
10
除这两种误差外,往往可能由于工作上粗枝大 叶不遵守操作规程等而造成的“过失误差”。 过失
对数关系
若 R=mlgA, 则
ER
0.434m
EA A
分析结果的相对误差是测量值的相对误差 的指数倍。
28
(二)偶然误差 1、加减法 若 R=A+B-C, 则 SR2=SA2+SB2+SC2 若 R=aA+bB-cC+…, 则 SR2=a2SA2+b2SB2+c2SC2+…
分析结果的标准偏差的平方是各测量步骤标 准偏差的平方总和。
64若以样本平均值来估计总体平均值可能存在的区间可按下式进行估算对于少量测量数据必须根据t分布进行统计处理按t的定义可得出65它表示在一定置信度下以平均值为中心包括总体平均值的范围即平均值的置信区间
§3.1 分析化学中的误差
一、基本概念
1.真值 某一物理量本身具有的客观存在的真实数值,即 为该量的真值。一般说来,真值是未知的,但下 列情况的真值可以认为是知道的: a.理论真值 如某化合物的理论组成
随机误差出现的规律

随机误差出现的规律
随机误差是在测量或实验过程中不可避免的一种误差。
它是由于各种不确定因
素的影响导致的测量结果与真实值之间的偏差。
虽然"随机"一词暗示了它的无规律性,但实际上随机误差具有一定的规律。
首先,随机误差呈现出正态分布的特点。
正态分布是一种常见的概率分布模式,也被称为高斯分布。
它的特点是将大量的观测值分布在均值附近,并向两侧逐渐减少。
在测量中,随机误差的分布通常符合这种形态。
其次,随机误差的出现通常受到多个因素的影响。
例如,环境条件的变化、测
量仪器的精度、实验人员的技巧水平等因素都可能对随机误差产生影响。
这些因素相互作用,使得随机误差不可完全预测和消除。
另外,随机误差具有独立性。
这意味着一个测量值的误差与其他测量值的误差
之间是相互独立的。
也就是说,一个误差的出现并不会直接导致其他误差的出现。
这种独立性使得我们能够通过多次测量来减小随机误差的影响,通过取平均值等方法提高测量结果的精确度。
最后,随机误差具有一定的范围和趋势。
尽管它的出现是随机的,但通过大量
的数据分析,我们可以发现误差值的范围和变化趋势。
这可以帮助我们更好地理解和处理随机误差,提高测量和实验的可靠性。
总结来说,随机误差虽然是一种难以避免的误差,但其出现具有一定的规律性。
通过理解和掌握随机误差的规律,我们可以采取相应的措施来减小其影响,提高测量结果的准确性和可信度。
随机误差

(x)
(b
1 a)B(g,
h)
x b
a a
g 1
1
x b
a a
h1
数学期望 bg ah
gh
标准方差 (b a) gh
(g h) g h 1
贝塔分布的性质与密度函数图
在给定分布界限a,b 下通
过参数g,h 取不同值,贝塔
0
1 a2 x2
a xa 其他
数学期望 E 0
f (x )
标准方差
a
2
置信因子 k a 2
服从反正弦分布的可能情形
度盘偏心引起的测角误差;
正弦(或余弦)振动引起的位移误差; -a
o
无线电中失配引起的误差。
a
x
瑞利分布
概率密度函数
f (x)
2、类型
▪正态分布统计检验
❖夏皮罗-威尔克检验 ❖偏态系数检验 ❖峰态系数检验
▪一般分布检验
❖皮尔逊检验
皮尔逊 2
检验( n 50
)
1、提出原假设
H0 : F (x) F0 (x)
▪把整个数轴分成m个区间
(, a1], (a1, a2 ],L L , (am1, )
▪总体X 的分布函数 F(x)未知 ▪ fi 频数,样本的观察值落
在区间 [3 ,3 ] 内的概率P 3
P 3 2(3) 1 20.9987 1 0.9974
随机误差服从正态分布,且标准偏差为 ,则 在该条件下,进行100次测量,可能有99次的随 机误差落在区间内[3 , 3 ]
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
测量值出现的区间
x=μ±1σ x=μ±1.96σ x=μ±2σ x=μ±2.58σ x=μ±3σ
概率
68.3% 95.0% 95.5% 99.0% 99.7%
例:已知某试样质量分数的标准值为1.75%, σ=0.10%;无系统误差。求:(1)分析结果落在 (1.75±0.15)%范围内的概率;(2)分析结果大于 2.00%的概率。
解:(1)
u x x 1.75% 0.15% 1.5
0.10% 0.10%
(2) 属于单边检验问题: u x 2.00% 1.75% 2.5
0.10%
阴影部分的概率为0.4938。正态分布曲线右侧的概率 为 0.5000 , 故 阴 影 部 分 以 外 的 概 率 为 0.5000 - 0.4938=0.62% , 即 分 析 结 果 大 于 2.00% 的 概 率 为 0.62%。
概率P为: p
(u) du
1
eu2 / 2du
2
大多数测量值集中在算术平均值的附近; 小误差出现的几率大,大误差出现的几率小,
特大误差出现的几率极小; 绝对值相等的正、负误差出现的几率趋于相
等。
表3-2 正态分布概率积分表
图 7-5 正态分布概率积分图
y f (x)
1
e( x )2 / 2 2
2
y:概率密度; x:测量值 μ:总体平均值,即无限次测定数据的平均值,无系 统误差时即为真值;反映测量值分布的集中趋势。
σ:总体标准偏差,反映测量值分布的分散程度; x-μ:随机误差
概率
正态分布曲线:以x-μ为横坐标建立的曲线。 曲线与横坐标-∞到+∞之间所夹的面积,代表 所有数据出现概率的总和,其值应为1,即概 率P为:
表3-1 频数分布表 图3-2 相对频数分布直方图
频数分布特点
1) 离散特性:全部数据是分散的、各异的, 具有波动性;但这种波动又是在平均值周围 波动,或比平均值稍大些、或稍小些。所以 用标准偏差来衡量。
总体标准偏差:测量次数为无限多次时
σ x 2 n
2. 正态分布
测量数据一般符合正态分布规律,即高斯分布,正态 分布曲线数学表达式为:
1
p f (x) dx
ex 2 / 2 2 dx 1
2
设:
u x
y φ (u)
1
u2
e2
2
标准正态分布曲线
定义:横坐标改为u,纵坐标为概率密度得 到的曲线。曲线与横坐标所夹的面积,代表 所有数据出现的概率总和,其值应为1。
|μ |
面积
|μ |
面积
|μ |
面积
0.0
0.0000
1.0
0.3413
2.0
0.4773
0.1
0.03981.10.36Fra bibliotek32.1
0.4821
0.2
0.0793
1.2
0.3849
2.2
0.4861
0.3
0.1179
1.3
0.4032
2.3
0.4893
0.4
0.1554
1.4
0.4192
2.4
0.4918
3.3.1 随机误差的正态分布
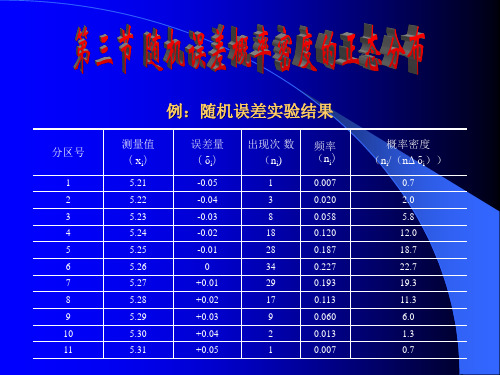
1. 频数分布:测定某样品100次,因有偶然误 差存在,故分析结果有高有低,有两头小、 中间大的变化趋势,即在平均值附近的数据 出现机会最多。
表3-1 频数分布表 图3-2 相对频数分布直方图
3.3.1 随机误差的正态分布
1. 频数分布:测定某样品100次,因有偶然误 差存在,故分析结果有高有低,有两头小、 中间大的变化趋势,即在平均值附近的数据 出现机会最多。
(1) t分布曲线
正态分布是无限次测量 数据的分布规律。对于有 限次测量数据则用t 分布曲
线处理。用s代替σ,纵坐
标仍为概率密度,但横坐 标则为统计量t。
x
t s
x
图3-6 t分布曲线 f=1, 5, ∞
t分布曲线的意义:
t分布曲线下面一定区间内的积 分面积,就是该区间内随机误差出 现的概率。
置信度P:在某一t值时,测定值落在(μ±ts)范围内的 概率。落在此范围之外的概率为(1-P),称为显著性水 准α。 ta, f :t值与置信度P及自由度f关系。
例:t0·05, 10表示置信度为95%,自由度为10时的t值。
t0·01, 5表示置信度为99%,自由度为5时的t值。
→ 对于少量测量数据,即当 n有限时,必须
3.3.2 总体平均值的估计
1. 平均值的标准偏差:
1.0
S (单位为S)
sx
s n
x
n
0.8 0.6
X
表明:平均值的标准偏差 0.4
随着n的增大而减小;即平 0.2
均值的精密度会提高。当 n>5时变化很慢。
0.0
n
0 2 4 6 8 10
平均值的平均 偏差:
x
n
dx
d n
2. 少量实验数据的统计处理
t分布曲线与标准正态分布曲线的区别
t值与u值的区别:用有限次测定的s代替了总体 σ。
前者随f的不同而不同。 前者比后者更“矮胖”,说明有限次测定值的
分布更分散。
t积分,是先设定P,已知f,查t值,此时P对应 了正负t曲线下的面积;u积分,是已知μ和σ
值,求 u , 再查P值。
(2) 平均值的置信区间
1
p f (x) dx
ex 2 / 2 2 dx 1
2
设:
u x
y φ (u)
1
u2
e2
2
概率
正态分布曲线:以x-μ为横坐标建立的曲线。 曲线与横坐标-∞到+∞之间所夹的面积,代表 所有数据出现概率的总和,其值应为1,即概 率P为:
根据t分布进行统计处理:
x ts x ts
x
n
含义:表示在一定置信度下,以平均值为中
心,包括总体平均值的范围。这就叫平均值
的置信区间。
例:测定未知试样中Cl-的质量分数,4次结果 为47.64%,47.69%,47.52%,47.55%。计算 置信度为90%,95%和99%时,总体平均值μ 的置信区间。 解:
0.5
1.5
0.4332
2.5
0.4938
0.6
0.1915
1.6
0.4452
2.6
0.4953
0.7
0.2258
1.7
0.4554
2.7
0.4965
0.8
0.2580
1.8
0.4641
2.8
0.4974
0.9
0.2881
1.9
0.4713
2.9
0.4987
0.3519
随机误差出现的区间 (以σ为单位)