《概率论与数理统计》第八章 回归分析
茆诗松《概率论与数理统计教程》(第2版)(课后习题 方差分析与回归分析)【圣才出品】

第8章 方差分析与回归分析一、方差分析1.在一个单因子试验中,因子A有三个水平,每个水平下各重复4次,具体数据如下:表8-1试计算误差平方和s e、因子A的平方和S A与总平方和S T,并指出它们各自的自由度.解:此处因子水平数r=3,每个水平下的重复次数m=4,总试验次数为n=mr=12.首先,算出每个水平下的数据和以及总数据和:T1=8+5+7+4=24.T2=6+10+12+9=37.T3=0+1+5+2=8.T=T l+T2+T3=24+37+8=69.误差平方和S e由三个平方和组成:于是而2.在一个单因子试验中,因子A有4个水平,每个水平下重复次数分别为5,7,6,8.那么误差平方和、A的平方和及总平方和的自由度各是多少?解:此处因子水平数r=4,总试验的次数n=5+7+6+8=26,因而有误差平方和的自由度因子A的平方和的自由度总平方和的自由度3.在单因子试验中,因子A有4个水平,每个水平下各重复3次试验,现已求得每个水平下试验结果的样本标准差分别为1.5,2.0,1.6,1.2,则其误差平方和为多少?误差的方差σ2的估计值是多少?解:此处因子水平数r=4,每个水平下的试验次数m=3,误差平方和S e由四个平方组成,它们分别为于是其自由度为,误差方差σ2的估计值为4.在单因子方差分析中,因子A有三个水平,每个水平各做4次重复试验.请完成下列方差分析表,并在显著性水平α=0.05下对因子A是否显著作出检验.表8-2 方差分析表解:补充的方差分析表如下所示:表8-3 方差分析表对于给定的显著性水平,查表知,故拒绝域为,由于,因而认为因子A是显著的.此处检验的p值为5.用4种安眠药在兔子身上进行试验,特选24只健康的兔子,随机把它们均分为4组,每组各服一种安眠药,安眠时间如下所示.表8-4 安眠药试验数据在显著性水平下对其进行方差分析,可以得到什么结果?解:这是一个单因子方差分析的问题,根据样本数据计算,列表如下:表8-5于是根据以上结果进行方差分析,并继续计算得到各均方以及F 比,列于下表:表8-6在显著性水平下,查表得,拒绝域为,由于故认为因子A (安眠药)是显著的,即四种安眠药对兔子的安眠作用有明显的差别.此处检验的p 值为6.为研究咖啡因对人体功能的影响,特选30名体质大致相同的健康男大学生进行手指叩击训练,此外咖啡因选三个水平:每个水平下冲泡l0杯水,外观无差别,并加以编号,然后让30位大学生每人从中任选一杯服下,2h后,请每人做手指叩击,统计员记录其每分钟叩击次数,试验结果统计如下表:表8-7请对上述数据进行方差分析,从中可得到什么结论?解:我们知道,对数据作线性变换不会影响方差分析的结果,这里将原始数据同时减去240,并作相应的计算,计算结果列入下表:表8-8于是可计算得到三个平方和把上述诸平方和及其自由度填入方差分析表,并继续计算得到各均方以及F比:表8-9若取查表知,从而拒绝域为,由于.故认为因子A(咖啡因剂量)是显著的,即三种不同剂量对人的作用有明显的差别.此处检验的p值为7.某粮食加工厂试验三种储藏方法对粮食含水率有无显著影响.现取一批粮食分成若干份,分别用三种不同的方法储藏,过一段时间后测得的含水率如下表:表8-10(1)假定各种方法储藏的粮食的含水率服从正态分布,且方差相等,试在下检验这三种方法对含水率有无显著影响;(2)对每种方法的平均含水率给出置信水平为0.95的置信区间.解:(1)这是一个单因子方差分析的问题,由所给数据计算如下表:表8-11三个平方和分别为。
概率论与数理统计(回归分析)

调整R方值 考虑到自变量数量的R方值,用 于比较不同模型之间的拟合优度。 调整R方值越接近于1,说明模型 拟合优度越好。
残差图 通过观察残差与实际观测值之间 的关系,判断模型是否符合线性 关系、是否存在异方差性等。
05
逻辑回归分析
逻辑回归模型
01
逻辑回归模型是一种用于解决 二分类问题的统计方法,基于 逻辑函数将线性回归的预测值 转换为概率形式。
多元非线性回归模型
在多个自变量X1, X2, ..., Xp的条件下,预测因变量Y的非线性数 学模型。模型形式为Y = f(β0, β1*X1, β2*X2, ... , βp*Xp),其
中f表示非线性函数。
多元逻辑回归模型
用于预测分类结果的多元回归模型,适用于因变量Y为二分 类或多分类的情况。
多重共线性问题
非线性回归模型是指因变量和自 变量之间的关系不是线性的,需 要通过变换或参数调整来拟合数 据。
形式
非线性回归模型通常采用指数函 数对数函数、多项式函数等形 式来表达。
适用范围
非线性回归模型适用于因变量和 自变量之间存在非线性关系的情 况,例如生物医学、经济学、社 会学等领域。
常用非线性回归模型
指数回归模型
线性回归模型假设因变量和自变 量之间存在一种线性关系,即当 一个自变量增加或减少时,因变 量也会以一种恒定的方式增加或 减少。
最小二乘法
01
02
03
最小二乘法是一种数学 优化技术,用于估计线
性回归模型的参数。
最小二乘法的目标是找 到一组参数,使得因变 量的观测值与预测值之
间的平方和最小。
最小二乘法的数学公式为: β=(XTX)^(-1)XTY,其中 X是自变量的数据矩阵,Y 是因变量的数据向量,β
魏宗舒《概率论与数理统计教程》(第2版)(章节题库 方差分析及回归分析)【圣才出品】

第8章 方差分析及回归分析1.今有某种型号的电池三批,它们分别是A、B、C三个工厂所生产的,为评比其质量,各随机抽取5只电池为样品,经试验得其寿命(h)如表8-1所示:表8-1试在显著性水平0.05下检验电池的平均寿命有无显著的差异,若差异是显著的,试求均值差和的置信水平为95%的置信区间。
解:以依次表示工厂A、B、C生产的电池的平均寿命。
提出假设:;:不全相等。
由已知得S T,S A,S E的自由度分别为n-1=15-1=14,s-1=2,n-s=15-3=12,从而得方差分析如表8-2所示:表8-2因=17.07>3.89=(2,14),故在显著性水平0.05下拒绝,认为平均寿命的差异是显著的。
由已知得,极限误差E为从而分别得和的一个置信水平为95%的置信区间为(±5.85)=(6.75,18.45),(±5.85)=(-7.65,4.05),(±5.85)=(-20.25,-8.55)。
2.为了寻找飞机控制板上仪器表的最佳布置,试验了三个方案,观察领航员在紧急情况的反应时间(以秒计),随机地选择28名领航员,得到他们对于不同的布置方案的反应时间如表8-3所示:表8-3试在显著性水平0.05下检验各个方案的反应时间有无显著差异,若有差异,试求的置信水平为0.95的置信区间。
解:提出假设::不全相等已知得又的自由度分别为n -1=28-1=27,s -1=3-1=2,n -s =28-3=25,从而得方差分析如表8-4所示:表8-4因=11.3>3.39=(2,14),故在显著性水平=0.05下拒绝,认为差异是显著的。
以下来求置信水平为1-=0.95的置信区间,今2.0595,则从而分别得的一个置信水平为0.95的置信区间为(±1.78)=(0.72,4.28),(±1.95)=(2.55,6.45),(±1.78)=(0.22,3.78)。
概率论与数理统计(茆诗松)第二版课后第八章习题参考答案

σ
r
(2) E( S A ) = (r − 1)σ 2 + m ∑ ai2 ,且当 H0:a 1 = a 2 = … = a r = 0 成立时,
i =1
σ2
SA
~ χ 2 (r − 1) ;
(3)Se 与 SA 相互独立. 证:根据第五章的定理结论知: 设 X1 , X 2 , …, Xn 相互独立且都服从正态分布 N (µ , σ 2 ),记 X =
i =1 j =1 r m
1
σ2
故
(Y ∑∑ = =
i 1 j 1
r
m
ij
− Yi⋅ ) 2 ~ χ 2 (rm − r ) ,
σ
Se
2
=
1
σ
2
(Y ∑∑ = =
i 1 j 1
r
m
ij
− Yi⋅ ) 2 ~ χ 2 (n − r ) ,即得 E(S e) = (n − r)σ 2;
4
(2) S A = m∑ (Yi⋅ − Y ) 2 = m∑ (ai + ε i⋅ − ε ) 2 = m∑ ai2 + m∑ (ε i⋅ − ε ) 2 + 2m∑ ai (ε i⋅ − ε ) ,
j =1
m
Ti 1 m = ∑ Yij , i = 1, 2, …, r, m m j =1
r r m 1 1 r m 1 r T = ∑ Ti = ∑∑ Yij , Y = T = Y = Yi⋅ , ∑∑ ij r ∑ n rm i =1 j =1 i =1 i =1 j =1 i =1
用 Yi⋅ 作为µ i 的点估计,Y 作为µ 的点估计.又记 ε i⋅ 表示第 i 个总体下随机误差平均值,ε 表示总的随机误 差平均值,即
概率论与数理统计_第八章

χ2 检验法
2 H1 : 2 0
2 21 / 2 (n), 或 2 2 / 2 (n)
概率论与数理统计
二、双正态总体
设有两个正态总体 2 x ~ N (1 ,12 ), y ~ N (2 , 2 ),
x1 , x2 ,...,xn1 ; y1 , y2 ,, yn2 分别是来自两个正态总体的独立
尽管主观上希望犯两类错误的概率都很小。但 在样本容量一定的情况下,不能同时控制犯两类错误 的概率。 一般,称控制犯第一类错误概率的检验问题为 显著性检验问题。为此,给定一个较小的正数α (0< α <1),使有
P{拒绝H 0 | H 0为真}
在此条件下确定k的值.
概率论与数理统计
小概率 事件
左边检验 拒绝域
H 0 : 0 ;
H1 : 0
t t (n 1)
H 0 : 0 ; H1 : 0
右边检验 拒绝域
t t (n 1)
概率论与数理统计
2、方差检验( χ2 检验法) 均值未知,方差检验( 检验法) 设总体x~N(μ,σ2),其中μ , σ2均未知,在显著性水
第八章 参数假设检验
假设检验的思想 正态总体均值的检验
正态总体方差的检验
概率论与数理统计
简 介
参数估计的方法是通过分析样本而估计总体参数
的取值(点估计)或总体参数落在什么范围(区间估计),
而有些实际问题中,我们不一定要了解总体参数的取
值或范围,而只想知道总体的参数有无明显变化,或
是否达到既定的要求,或两个总体的某个参数有无明
2
平α(0< α<1)下求双边检验问题 2 2 H0 : 2 0 ; H1 : 2 0
概率论课件_高教版_第八章_方差分析与回归分析

MS A 168.00 F 20.56 MS e 8.17
查附表在f1=3,f2=12时, F0.05=3.49,F0.01=5.95 实得 F> F0.01或 P<0.01,说明药剂处理有统计意义。
四、单因素方差分析模型参数的估计 当方差分析结果为否定原假设时,就需要估计模型的有 关参数 ,下面就讨论方差分析模型参数的估计。 单因素方差分析的模型 为 xij i ij i 1,2, , r 2 ~ N ( 0 , ), 且相互独立 j 1,2, , m ij 其中为总以平均效应, i为因素A的第i个水平Ai 对试验指标 的作用; ij为随机因素对试验指标 值的影响。需要估计的 参数 有 , i , 2。不难证明这些参数的 极大似然估计量为: 1 r m 1 m 1 r m ˆ i xij ˆ xij xij rm i 1 j 1 m j rm i 1 j 1 1 r m 1 2 2 ˆ ˆ) ( xij SSe rm i 1 j 1 rm
Tr
T
xr
x
其中xij是因素A第i水平下第j次重复试验结果 , m r m r T T Ti xij xi T xij Ti x . m rm j 1 i 1 j 1 i 1
单因素方差分析的统计模型
试验数据xij满足 xij i ij i 1,2,, r 2 ~ N ( 0 , ),且相互独立 j 1,2,, m ij 其中为总以平均效应, i为因素A的第i个水平Ai 对试验指 标的作用 ; ij为随机因素对试验指标 值的影响。
鸡重/g-1000
60 80 1 2 12 9 28
Ti
概率论与数理统计教程-魏宗舒-课后习题解答答案-7-8章

概率论与数理统计教程-魏宗舒-课后习题解答答案-7-8章概率论与数理统计教程-魏宗舒-课后习题解答答案-7-8章第七章假设检验7.1 设总体2(,)N ξµσ~,其中参数µ,2σ为未知,试指出下⾯统计假设中哪些是简单假设,哪些是复合假设:(1)0:0,1H µσ==;(2)0:0,1H µσ=>;(3)0:3,1H µσ<=;(4)0:03H µ<<;(5)0:0H µ=.解:(1)是简单假设,其余位复合假设 7.2 设1225,,,ξξξ取⾃正态总体(,9)N µ,其中参数µ未知,x 是⼦样均值,如对检验问题0010:,:H H µµµµ=≠取检验的拒绝域:12250{(,,,):||}c x x x x c µ=-≥,试决定常数c ,使检验的显著性⽔平为0.05解:因为(,9)N ξµ~,故9(,)25N ξµ~ 在0H 成⽴的条件下,00053(||)(||)53521()0.053cP c P c ξµξµ-≥=-≥??=-Φ=55()0.975,1.9633c cΦ==,所以c =1.176。
7.3 设⼦样1225,,,ξξξ取⾃正态总体2(,)N µσ,20σ已知,对假设检验0010:,:H H µµµµ=>,取临界域12n 0{(,,,):|}c x x x c ξ=>,(1)求此检验犯第⼀类错误概率为α时,犯第⼆类错误的概率β,并讨论它们之间的关系;(2)设0µ=0.05,20σ=0.004,α=0.05,n=9,求µ=0.65时不犯第⼆类错误的概率。
解:(1)在0H 成⽴的条件下,200(,)nN σξµ~,此时00000()P c P ξαξ=≥=10,由此式解出010c αµ-=+在1H 成⽴的条件下,20(,)nN σξµ~,此时101010()(P c P αξβξµ-=<=<=Φ=Φ=Φ由此可知,当α增加时,1αµ-减⼩,从⽽β减⼩;反之当α减少时,则β增加。
概率论与数理统计课件--一元回归分析.ppt

相关关系举例
例如:在气候、土壤、水利、种子和耕作技术等条件基本 相同时,某农作物的亩产量 Y 与施肥量 X 之间有一定的关系, 但施肥量相同,亩产量却不一定相同。亩产量是一个随机变量。
又如:人的血压 Y 与年龄 X 之间有一定的依赖关系,一 般来说,年龄越大,血压越高,但年龄相同的两个人的血压不 一定相等。血压是一个随机变量。
相关关系问题
在现实问题中,处于同一个过程中的一些变量, 往往是相互依赖和相互制约的,它们之间的相互关系 大致可分为两种:
(1)确定性关系——函数关系;
(2)非确定性关系——相关关系;
相关关系表现为这些变量之间有一定的依赖关系, 但这种关系并不完全确定,它们之间的关系不能精确 地用函数表示出来,这些变量其实是随机变量,或至 少有一个是随机变量。
(3)利用所得到的经验公式进行预测和控制。
一元线性回归模型
设随机变量Y依赖于自变量x,作n次独立试验,
得n对观测值:(x 1 ,y 1 )(x 2 ,y 2 ) (x n ,y n )
称这n对观测值为容量为n的一个子样,若把这n对观
测值在平面直角坐标系中描点,得到试验的散点图.
如果试验的散点图中各点呈直线状,则假设这批数
因此,统计学上讨论两变量的相关关系时,是设法
确定:在给定自变量 X x 的条件下,因变量 Y的
条件数学期望 E (Y | x)
回归分析的概念
研究一个随机变量与一个(或几个)可控变量之间 的相关关系的统计方法称为回归分析。
引进回归函数 (x)E(Y|x)
y(x)E (Y|x)称为回归方程
回归方程反映了因变量Y随自变量 x的变化而变化
n
n
( yi y )2 ( yi yi )2
概率论与数理统计--第八章 方差分析与回归分析

定理8.1.1 在上述符号下,总平方和ST可以分解为因子平方和SA与误差平方和Se之和,其自由度也有相应分解公式,具体为: ST =SA +Se , fT =fA +fe (8.1.16) (8.1.16)式通常称为总平方和分解式。
在水平Ai下的试验结果yij与该水平下的指标均值 i 一般总是有差距的,记 ij = yiji, ij 称为随机误差。于是有 yij = i +ij (8.1.2) (8.1.2)式称为试验结果 yij 的数据结构式。
第八章 方差分析与回归分析
§8.1 方差分析 §8.2 多重比较 §8.3 方差齐性分析 §8.4 一元线性回归 §8.5 一元非线性回归
§8.1 方差分析
8.1.1 问题的提出 实际工作中我们经常碰到多个正态总体均值的比较问题,处理这类问题通常采用所谓的方差分析方法。
例8.1.1 在饲料养鸡增肥的研究中,某研究所提出三种饲料配方:A1是以鱼粉为主的饲料,A2是以槐树粉为主的饲料,A3是以苜蓿粉为主的饲料。为比较三种饲料的效果,特选 24 只相似的雏鸡随机均分为三组,每组各喂一种饲料,60天后观察它们的重量。试验结果如下表所示:
表8.1.1 鸡饲料试验数据
饲料A
鸡 重(克)
A1
1073
1009
1060
1001
1002
1012
1009
1028
A2
1107
1092
990
1109
1090
1074
1122
《概率论与数理统计》教学课件(共8章)第8章 回归分析与方差分析

值而定,即y的数学期望是x的函数,记为μ(x)。μ(x)称为y关于x的回归函数,简称为y关于x的回归。
根据μ(x)的不同形式,回归分析分为线性回归和非线性回归,其中线性回归又分为一元线性回归和多
元线性回归。
8.1
∧
b−t (n−2)
α
2
∧
σ
Lxx
∧
,b + t (n−2)
α
2
∧
σ
Lxx
.
例如,例1中b的置信度为0.95的置信区间为
0.8706−2.3646 ×
=(0.8346, 0.9066).
0.9408
4060
, 0.8706 + 2.3646 ×
0.9408
4060
8.1
一元线性回归
8. 1. 6
利用回归方程进行预测
8. 1. 4
线性假设的显著性检验
∧
引理 对于一元线性回归,有b~N(b,σ2/Lxx)。
n
n
∧ ∑ (xi −x)(yi −y) ∑ (xi −x)yi
∧
证 因为b=i=1 n
=i=1
,所以b是y1,y2,…,yn的线性组合,而y1,y2,…,yn是独立的正
n
∑ (xi−x)2
∑ (xi −x)2
8. 1. 4
线性假设的显著性检验
n
n
∑ (xi−x)2 D(yi) ∑ (xi −x)2σ2
∧
D(b)=i=1n
= i=1
n
2
2
[ ∑ (xi −x) ]
[ ∑ (xi −x)2 ] 2
数学英语词汇(概率论与数理统计)
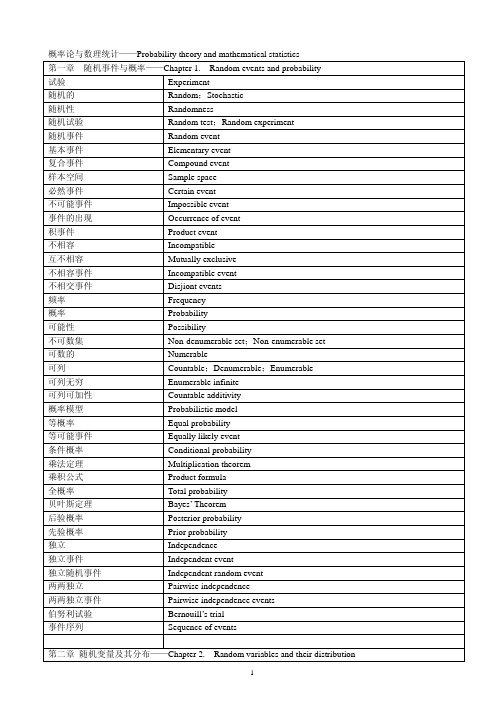
概率论与数理统计——Probability theory and mathematical statistics第一章随机事件与概率——Chapter 1. Random events and probability试验 Experiment随机的 Random;Stochastic随机性 Randomnesstest;Random experiment随机试验 Randomevent随机事件 Randomevent基本事件 Elementaryevent复合事件 Compoundspace样本空间 Sampleevent必然事件 Certainevent不可能事件 Impossible事件的出现Occurrence of eventevent积事件 Product不相容 Incompatibleexclusive互不相容 Mutuallyevent不相容事件 Incompatibleevents不相交事件 Disjiont频率 Frequency概率 Probability可能性 Possibilityset;Non-enumerable set不可数集 Non-denumerable可数的 Numerable可列 Countable;Denumerable;Enumerableinfinite可列无穷 Enumerableadditivity可列可加性 Countablemodel概率模型 Probabilisticprobability等概率 Equal等可能事件Equally likely event条件概率 Conditionalprobabilitytheorem乘法定理 Multiplicationformula乘积公式 Product全概率 TotalprobabilityTheorem贝叶斯定理 Bayes’后验概率 Posteriorprobabilityprobability先验概率 Prior独立 Independence独立事件 Independentevent独立随机事件Independent random eventindependence两两独立 Pairwise两两独立事件Pairwise independence eventstrial伯努利试验 Bernouill’sevents事件序列 Sequenceof第二章随机变量及其分布——Chapter 2. Random variables and their distribution分布 Distributiondistribution概率分布 Probabilityvariable随机变量 Random离散 Discrete离散随机变量Discrete random variabledistribution离散分布 Discretedistribution一维概率分布 One-dimensionalprobability连续随机变量Continuous random variable连续分布 Continuousdistributionfunction密度函数 Densityfunction分布函数 Distributiondistribution两点分布 Two-pointdistribution零一分布 Zero-onedistribution二项分布 Binomialdistribution超几何分布 Hypergeometrydistribution泊松分布 Poisson均匀分布 Uniformdistributiondistribution指数分布 Exponentialdistribution正态分布 Normal高斯分布 Gaussiandistributiondistributionnormal标准正态分布 Standarddistribution几何分布 GeometricdistributionΓ分布 Gammadistribution瑞利分布 Rayleigh第三章二维随机变量及其分布——Chapter 3. Two-dimension random variables and their distributionvector随机向量 Random联合分布 Jointdistributionn维概率分布n-dimensional probability distributiondistribution边缘分布 Marginal联合分布函数Joint distribution function联合概率分布Joint probability distributiondistributionprobability条件概率分布 Conditional条件概率函数Conditional probability functiondensity联合密度 Joint联合概率密度Joint probability densitydensity边缘密度 Marginalprobabilitydensity条件概率密度 Conditional二元正态分布Bivariate normal distributionnormaldistribution多元正态分布 Multivariate多维正态分布Multidimensional normal distributionn维正态分布n-dimensional normal distribution随机变量独立性Independence of random variable独立随机变量Independent random variable卷积 Convolution第四章数字特征——Chapter 4. Numeric characteristic期望 Expectationexpectation数学期望 Mathematicalvector均值向量 Mean方差 Variancedeviation标准差 Standard偏差 Deviation标准化随机变量Standardized random variable协方差 Covariancematrix协方差矩阵 Covariance相关系数 Correlationcoefficient;Related coefficient不相关 Irrelevancecorrelation负相关 Negative矩 Momentmoment中心矩 Centralmoment一阶矩 First峰度 Leptokurtosisfunction矩函数 Moment矩母函数Moment generating functioninequality切比雪夫不等式 Chybyshevprobability依概率收敛 Convergenceinconvergence弱收敛 Weak大数定律Law of large number弱大数定律Weak law of large numberslimitTheorem中心极限定理 Centraldistribution极限分布 Limiting第五章数理统计的基本概念——Chapter 5. Fundamental concept of mathematical statistics 统计 Statistic总体 Population;Ensemble;Totalitydistribution总体分布 Populationparameter总体参数 Population随机抽样法Method of random samplingprocession数据处理 Datavalue观测值 Observedinterval组距 Classlimits组限 Classmean组平均 Classmidpoint组中值 Classerror分组误差 Grouping直方图 Histogramvariance经验方差 Empiricalfunction经验分布函数 Empiricaldistributionpopulation正态总体 Normalaverage简单平均 Simple平均值 Mean;Mean value;Average权 Weightaverage;Weighted mean加权平均值 Weighted总体均值 Populationmean;Ensemble averagevariance总体方差 Population离差平方和Sum of squares of deviationsmoment总体矩 Populationmoment总体中心矩 Populationcentral样本 Sampleaverage样本均值 Sample样本相关系数 Samplecoefficientcorrelationmean样本均值 Samplemoment样本矩 Samplepoint样本点 Samplesize样本容量 Samplespace样本空间 Sample样本标准差Sample standard deviationvariance样本方差 Sample抽样 Samplinginspection抽样检验 Sampling均方根 Root-mean-squaresquaredeviation均方差 Mean众数 Mode分位数 Quantile峰值 Peakχ 2分布Chi square distributiont分布 t-distribution临界值 Marginalvalueoffreedom自由度 Degree无限自由度Infinite degree of freedomstatistics充分统计量 Sufficient第六章参数估计——Chapter 6. Parameter estimation总体参数Parameter of population估计 Estimate估计量 Estimatorestimation点估计 Point矩法Method of momentestimation 矩估计法 Momentofmethodfunction似然函数 Likelihoodequation似然方程 Likelihoodlikelihood最大似然 Maximum最大似然法Method of maximum likelihoodestimate最大似然估计 Maximumlikelihood相关的估计量Estimate of correlationestimates充分估计量 Sufficient无偏的 Unbiased无偏性 Unbiasedness;Without bias无偏估计 Unbiasedestimate;Unbiased estimation有效性 Validityestimation有效估计 Efficiency有效估计量 Efficiencyestimatorerrorsquare均方误差 Mean最小方差估计Minimum variance estimation一致最小方差无偏估计Uniformly minimum variance unbiased estimationestimation;Estimate by a interval区间估计 Intervalinterval;Fiducial interval置信区间 Confidencelevel置信水平 Confidenceconfidenceof置信度 Degreelimit置信限 Fiducial总体比例估计Estimate of population proportion总体方差估计Estimate of population variance第七章假设检验——Chapter 7. Hypothesis testing假设 Hypothesis统计假设 Statisticalhypothesistesting;Test of hypothesis;Testing of hypothesis 假设检验 Hypothesis小概率事件Event of small probabilitystatistics检验统计量 Testtest双侧检验 Two-sidesofacceptance;Acceptance region接受域 Region拒绝域Region of rejection显著水平Level of significance;Significance level第八章回归分析——Chapter 8. Regression analysis回归 Regression回归分析 Regressionanalysisequation回归方程 Regression回归系数估计Estimate of regression coefficient线性回归 Linearregression拟和 Fittingmethod;Minimum squares method最小二乘法 Leastsquare残差 Residual残差平方和Residual sum of squares;Square sum of residues方差分析 Varianceanalysis曲线拟和Fitting of a curve多项式拟和Fitting of a polynomial直线拟和Fitting of a straight linefit拟和优度 Goodnessof拟和优度检验Goodness of fit testregression非线性回归 Nonlinearanalysis 非线性回归分析 Nonlinearregression。
概率论 第八章 回归分析

注:依据对变量 X 与 Y 进行n 次独立观察得到的样本 (X1 ,Y1 ), ( X2 ,Y2 ), , ( Xn , Yn) , 对 β0 , β1 进行估计时, 还须注意X 与 Y间线性关系的强弱
(a) (a) (b)中X 与 Y间
(b) 线性关系强
(a) (b)
(c) (d)中X 与 Y间
3、 X为自变量:有时是随机的,如从总体中随机抽取 一个个体,测其Y和X值,这时所以Y和X都是随机变量; 有时是非随机的,如货币储蓄量与利率,利率可人为给 定。本章中,如无特别声明,一律设X为非随机变量。
三、回归方程:回归模型 Y= f(X)+e 中, 当X为非随机变量时, f(X) 也是非随机变量,而 E e =0, 于 是有 EY= f(X) ,所以可以用f(X) 作为Y的近似。 当X为随机变量时, 求Y对X的条件期望,也有 E(Y|X)= f(X) 记 y=f(x) 则称 y=f(x) 为 Y对X的回归方程
1n 1n 1 n Y EY Y EY (Y ei i i i EY i) ni ni ni1 n i1 1 1
得到
ˆ ,Y ˆ ˆ Cov ( ) E ( E )( Y E Y ) 1 1 1
又因
2 n 0 i j 所以 ˆ ,Y E ( e E (X X ) 0 Cov ( ) iej) 2 i 1 i j nL XX i 1
ˆX ˆ ˆ Y X E ( Y ) E Y X E E 1 1 1 E 0
(2) ˆ 1 与 Y 不相关 证: 1n
n n L L 1 XY ˆ ˆ XY [ ( X X ) Y ( X X ) E Y ] E E i i i i 1 1 L L L i 1 i 1 XX XX XX n 1 n 1 [ ( X X )( Y E Y (X ) e i i i)] i X i L L XX i 1 XX i 1 n n 1 E [( ( X X ) e )( e )] i i i nL XX i 1 i 1
《概率论与数理统计》习题及答案 第八章

《概率论与数理统计》习题及答案第 八 章1.设12,,,n X X X 是从总体X 中抽出的样本,假设X 服从参数为λ的指数分布,λ未知,给定00λ>和显著性水平(01)αα<<,试求假设00:H λλ≥的2χ检验统计量及否定域. 解 00:H λλ≥选统计量 200122nii XnX χλλ===∑记212nii Xχλ==∑则22~(2)n χχ,对于给定的显著性水平α,查2χ分布表求出临界值2(2)n αχ,使22((2))P n αχχα≥=因 22χχ>,所以2222((2))((2))n n ααχχχχ≥⊃≥,从而 2222{(2)}{(2)}P n P n αααχχχχ=≥≥≥ 可见00:H λλ≥的否定域为22(2)n αχχ≥.2.某种零件的尺寸方差为21.21σ=,对一批这类零件检查6件得尺寸数据(毫米):32.56, 29.66, 31.64, 30.00, 21.87, 31.03。
设零件尺寸服从正态分布,问这批零件的平均尺寸能否认为是32.50毫米(0.05α=).解 问题是在2σ已知的条件下检验假设0:32.50H μ= 0H 的否定域为/2||u u α≥ 其中29.4632.502.45 6.771.1X u -==⨯=-0.0251.96u =,因|| 6.77 1.96u =>,所以否定0H ,即不能认为平均尺寸是32.5毫米。
3.设某产品的指标服从正态分布,它的标准差为100σ=,今抽了一个容量为26的样本,计算平均值1580,问在显著性水平0.05α=下,能否认为这批产品的指标的期望值μ不低于1600。
解 问题是在2σ已知的条件下检验假设0:1600H μ≥0H 的否定域为/2u u α<-,其中 158016005.1 1.02100X u -==⨯=-.0.051.64u -=-.因为0.051.02 1.64u u =->-=-,所以接受0H ,即可以认为这批产品的指标的期望值μ不低于1600.4.一种元件,要求其使用寿命不低于1000小时,现在从这批元件中任取25件,测得其寿命平均值为950小时,已知该元件寿命服从标准差为100σ=小时的正态分布,问这批元件是否合格?(0.05α=)解 设元件寿命为X ,则2~(,100)X N μ,问题是检验假设0:1000H μ≥. 0H 的否定域为0.05u u ≤-,其中95010005 2.5100X u -==⨯=-0.05 1.64u = 因为0.052.5 1.64u u =-<-= 所以否定0H ,即元件不合格.5.某批矿砂的5个样品中镍含量经测定为(%)X : 3.25,3.27,3.24,3.26,3.24设测定值服从正态分布,问能否认为这批矿砂的镍含量为3.25(0.01)α=?解 问题是在2σ未知的条件下检验假设0: 3.25H μ=0H 的否定域为 /2||(4)t t α>522113.252,(5)0.00017,0.0134i i X S X X S ===-⨯==∑0.005(4) 4.6041t =3.252 3.252.240.3450.013X t -==⨯=因为0.005||0.345 4.6041(4)t t =<=所以接受0H ,即可以认为这批矿砂的镍含量为3.25.6.糖厂用自动打包机打包,每包标准重量为100公斤,每天开工后要检验一次打包机工作是否正常,某日开工后测得9包重量(单位:公斤)如下: 99.3,98.7,100.5,101.2,98.3,99.7,99.5,102.1,100.5 问该日打包机工作是否正常(0.05α=;已知包重服从正态分布)?解 99.98X =,92211(()) 1.478i i S X X ==-=∑, 1.21S =,问题是检验假设0:100H μ=0H 的否定域为/2||(8)t t α≥. 其中99.9810030.051.21X t -==⨯=-0.025(8) 2.306t =因为0.025||0.05 2.306(8)t t =<= 所以接受0H ,即该日打包机工作正常.7.按照规定,每100克罐头番茄汁中,维生素C 的含量不得少于21毫克,现从某厂生产的一批罐头中抽取17个,测得维生素C 的含量(单位:毫克)如下 22,21,20,23,21,19,15,13,16, 23,17,20,29,18,22,16,25.已知维生素C 的含量服从正态分布,试检验这批罐头的维生素含量是否合格。
概率论与数理统计(魏宗舒)第八章答案

第八章 方差分析和回归分析8.4 考察温度对某一化工产品得率的影响,选了五种不同的温度,在同一温度下做了三次实验,测得其得率如下,试分析温度对得率有无显著影响。
解 把原始数据均减去90后可列出如下计算表和方差分析表,r 表示因子水平数,t 为重复实验次数。
5,3,15r t n rt ====222308,810,9.6ij i j ij i i j iy y y n ⎛⎫⎪⎝⎭===∑∑∑∑∑ 18109.6260.433089.6298.438A T e T A S S S S S =⨯-==-==-=方差分析表由于17.16F =>,所以在0.01α=上水平上认为温度对得率有显著影响。
8.8 下面记录了三位操作工分别在四台不同机器上操作三天的日 产量:试在显著性水平0.05α=下检验: (1) 操作工之间有无显著性差异? (2) 机器之间的差异是否显著?(3)操作工与机器的交互作用是否显著?解 用r 表示机器的水平数,s 表示操作工的水平数,t 表示重复实验次数,列出计算表和方差分析表:4,3,3,36r s t n rst =====211065ijkijky=∑∑∑, 2.33071ik ijy =∑∑2..98307i iy=∑, 2..131369j jy =∑,2()10920.25ijk y n=∑∑∑19830710920.25 2.759A S =⨯-=1131********.2527.1712B S =⨯-=13307110920.25 2.7527.1773.503A B S ⨯=⨯---=1106510920.25144.75T S =-=144.75 2.7527.1777.5041.33e S =---=方差分析表由于7.90 3.40,7.12 2.51B A B F F ⨯=>=>,所以在0.05α=水平上,操作工有显著差异,机器之间无显著差异,交互作用有显著差异。
[课件]概率统计 回归分析PPT
![[课件]概率统计 回归分析PPT](https://img.taocdn.com/s3/m/1c5275dd04a1b0717fd5dde7.png)
(四)线性假设的显著性检验
采用最小二乘法估计参数a和b,并不需要事先知道Y与x之间 一定具有相关关系,即使是平面图上一堆完全杂乱无章的散 点,也可以用公式求出回归方程。因此μ(x)是否为x的线性函 数,一要根据专业知识和实践来判断,二要根据实际观察得 到的数据用假设检验方法来判断。
n
n
( xi )a ( xi 2 )b xi yi .
i 1 i 1 i 1
2 1 1 记 号 : y y x x x , i,x i,S x x i ni ni i
n
n
n
S x x y ,S y y y . x y i i y y i
ˆ ˆ ˆ 性 质 : a , ba 分 别 是 , b 的 无 偏 估 计 , 从 而 E ( Y ) a b x 。
1 ˆ 证 明 : 因 为 b S / SS x x Y , x y x x x x i i i 1 x x i
1 ˆ E ( b ) S x x E ( Y ) S x x ( a b x ) x x i i i i i
即 要 检 验 假 设 H : bH 0 ,1 : b 0 , 0
若原假设被拒绝,说明回归效果是显著的,否则, 若接受原假设,说明Y与x不是线性关系,回归方程 无意义。回归效果不显著的原因可能有以下几种:
(1)影响Y取值的,除了x,还有其他不可忽略的因素; (2)E(Y)与x的关系不是线性关系,而是其他关系; (3)Y与x不存在关系。
( 5 ) 回 归 函 数 ( x ) a b x 的 点 估 计 和 置 信 区 间 ;
概率论与数理统计的回归分析

概率论与数理统计的回归分析引言回归分析是概率论与数理统计中的重要内容之一。
它旨在研究自变量与因变量之间的关系,并通过建立数学模型来预测或解释因变量的变化。
本文将介绍回归分析的基本概念、原理以及应用。
回归分析的基本概念回归分析的基本概念包括以下几个方面:1. 自变量和因变量:自变量是研究对象中的一个或多个变量,其取值是研究者可以操纵和观察的;而因变量是自变量的取值所导致的响应或结果。
2. 线性回归和非线性回归:回归分析可以根据自变量与因变量之间的关系,分为线性回归和非线性回归两种类型。
线性回归是指自变量和因变量之间存在线性关系的情况,而非线性回归则是指自变量和因变量之间存在非线性关系的情况。
3. 最小二乘法:最小二乘法是进行回归分析时常用的一种方法。
它通过最小化观测值与模型预测值之间的残差平方和,来求解回归系数的估计值。
回归模型的建立和应用回归模型是回归分析的核心内容,它描述了自变量和因变量之间的数学关系。
常见的回归模型包括简单线性回归模型、多元线性回归模型和逻辑回归模型等。
回归分析在实际应用中有广泛的用途。
例如,在经济学中,可以使用回归分析来探索经济变量之间的关系;在医学研究中,可以使用回归分析来评估治疗方法对患者病情的影响。
结论回归分析是概率论与数理统计中的重要工具,它可以帮助我们理解自变量和因变量之间的关系,并预测或解释因变量的变化。
通过建立回归模型,可以进行深入的研究和分析。
回归分析的应用范围广泛,对于各个学科领域的研究具有重要意义。
总之,概率论与数理统计的回归分析对于揭示事物之间的关系和预测未来变化具有重要作用,可以为我们的研究和决策提供有力支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
n
lxx (xi x)2
其中
i1
n
lxy (xi x) ( yi y)
i1
即,最小二乘估计所得回归方程为: yˆ aˆ bˆx
从参数估计过程可见,回归方程的基本性质
1 2
Q ( y yˆ)2 最小 ( y yˆ) 0
3 回 归直线通过点 (x, y)
1
n
第八章 回归分析
• 一元线性回归 • 回归效果的检验 • 一元非线性回归 • 预测与控制 • 多元线性回归
回归:从一组样本数据出发,确定变量之间的数学关 系式 检验:对这些关系式的可信程度进行统计检验,从影 响某一特定变量的诸多变量中,找出哪些变量的影响显著, 哪些不显著 预测和控制:利用求得的关系式,根据一个或几个变 量的取值来预测或控制另一个特定变量的取值,并给出这 种预测或控制的精确程度
ε
i
~N (0,σ 2)
n
bˆ lxy lxx
( xi x ) yi
i1 n
( xi x )2
i1
aˆ y bˆx
D(bˆ) σ 2
lxx
D(aˆ) σ 2 ( 1 x 2 )
n lxx
D( yi ) σ 2
3、直线回归的变异来源
根据回归方程作回归直线, 可以发现,并不是所有散
点都恰好落在回归直线上,说明用 yˆ去估计 y 有偏差。
(1)( y y) 的分解
从左图可以看出:
(y y) (yˆ y) (y yˆ)
( y y) ( yˆ y) ( y yˆ)
上式两端平方,然后对所有n个点求和,有
( y y)2 [( yˆ y) ( y yˆ)]2
(2)
称 R2 = SSR / SST 为判定系数,它度量了经验回归方程 对观测数据的拟和程度。
0≤R2≤1,R2越大,因变量与自变量之间的相关性越强。
(2)线性回归的自由度
n
n
n
( yi y)2 ( ˆyi y )2 ( yi ˆyi )2
i 1
i 1
i 1
总平方和 = 回归平方和 + 剩余平方和
一、一元回归分析模型
例: 某市场在t 时刻黄瓜销量数据如下, 其中qt 表示t 时 刻的黄瓜销量, pt表示t 时刻的销售价格
pt:元 2.5 2.0 1.5 1.0 0.5 0
qt:斤 1 3 5 7 9 11
这是一个确定性关系: qt 11 4 pt
厦门大学经济学院-2012春季学期
若x、y之间的关系是随机的,例如
SST = SSR + SSE
与上面等式对应,y 的总自由 度d fy 划分为 回归自由度 dfR 与 差残自由度 dfE ,即
df y dfR dfE
df y dfR dfE
线性回归中 ,
(4)
回归自由度 dfR = 自变量个数,dfR 1 总自由度 dfy n 1
残差自由度 dfE n 2
如图
从散点图 可看出以下问题:
① 两个变量间有关或无关?若有关,两个变量间关系类 型,是直线型还是曲线型?
② 两个变量间直线关系的性质,正相关还是负相关?相 关程度密切还是不密切? 散点图直观地、定性地表示了两个变量之间的关系。 为了探讨它们之间的规律性,还必须根据观测值将关
系定量地表达出来。
若散点呈直线趋势,又由于因变量y的实际观测值总有 随机误差, y 与 x的关系可用一元线性回归模型描述
0
Q b
n
2 [ yi
i1Biblioteka (a bxi )]xi0
na nxb ny
n
正规方程组
nxa ( xi2 )b
i1
n
xi yi i1
n nx
D
nx
xi 2 n(
n
xi 2 nx 2 ) n (xi x)2 0
i 1
所以,方程组有解:
aˆ
bˆ
y
bˆx lxy
线性组合,根据正态分布的性质,它们也一定是正态的。
aˆ y bˆx bˆ lxy
lxx
n
lxy (xi x) ( yi y) i1
n
(xi x) yi i1
n
lxx (xi x)2 i1
厦门大学经济学院-2012春季学期
2.a, b 点估计的方差 yi a bxi εi
pt
qt
0
2.5
1
2
2
2.0
3
4
…
…
10
0
11
12
这时,方程的形式为
qt 11 4 pt ε t
概率 0.25 0.50 0.25 0.25 0.50 0.25 … 0.25 0.50 0.25
厦门大学经济学院-2012春季学期
qt 11 4 pt
t
其中,ε t 为随机变量。
t
概率
-1
0.25
n i1
yˆi
1 n
n i1
(aˆ bˆxi )
aˆ bˆ 1 n
n i1
xi
aˆ bˆx y
例 某市场连续12天白菜的价格和销量调查数据如下:
价格 (元/斤)xi
1.00 0.90 0.80 0.70 0.70 0.70 0.70 0.65 0.60 0.60 0.55 0.50
销量 Y(斤) yi
因此 ,
回归均方 MSE SSE / dfR
残差均方 MSR SSR / dfE
(2) y =a + b x + ε ,ε~N(0,σ2) 中 σ2的估计值。
剩余平方和 Q ( y yˆ)2 的大小表示了实测点
与回归直线偏离的程度。
由于 Q 的自由度为 n-2 。 剩余均方为: MSR SSR / dfE
对可选的几个回归方程形式,常用比选准则有:
1. 可决系数
R2 1 SSE , R2 1 , SST
R2 大,表示观测值, yi 与拟合值 yˆi 比较靠近,
也就意味着从整体上看, n个点的散布离曲线较近,
因此选 R2 较大的方程为好。
2. 剩余标准差 s SSE /(n 2)
s 是一元线性回归方程中对 的估计,将S 看成
55 70 90 100 90 105 80 110 125 115 130 130
试求:白菜销量对价格的回归方程.
厦门大学经济学院-2012春季学期
二、回归的估计效果
1.a, b 的点估计 yˆ aˆ bˆx
(1)估计量 aˆ ,bˆ 分别是a,b的无偏估计量;
(2)由于 aˆ ,bˆ 均为相互独立的正态变量 y1, y2,, yn 的
b
SSxy
b2
SSx
SSxy SSx
SSxy
SSxy SSx
2
SSx
=0
所以, ( y y)2 ( yˆ y)2 ( y yˆ)2 (1)
( y y)2 反映 y 的总变异程度,称为总离差平方和,记
为SST;
( yˆ y)2反映y 与x 的直线关系引起的 y的变异程度,即
回归自变量变差的贡献,称为回归离差平方和,记为SSR;
性 关
产量和施肥量
系 商品价格和需求量
实变量
变量取值 非确定
Y
随机变量
如果对于任何已知的x值,变量y按某个概率取某些特殊 的值,则x和y之间的关系为随机的
回归基本思想
(x, y)
采集样本信息(xi,yi)
回归分析 散点图
回归方程的 显著性检验
回归方程
对现实进行预测与控制
厦门大学经济学院-2012春季学期
是σ2的无偏估计值。
即便x和y不存在线性关系, 但根据 n 对观测值(xi,yi)
总可求得一个回归方程 yˆ = a + bx
显然,这样的回归方程,反应的线性关系并不真实。
线性回归方程所反应的变量间的线性关系是否真实? 取决于变量 x 与 y 间是否存在直线关系。
以下,作出统计推断和检验。
二. 回归方程的检验方法
把所有直线中最接近散点图中全部散点的直线用来
表示x 与y 的直线关系,这条直线称为回归直线。
n
n
对于 Q(a,b) εi2 [ yi (a bxi )]2
i1
i1
二元函数Q(a,b) 的最小值点 (aˆ,bˆ) 称为a,b
的最小二乘估计(简记为OLSE )
Q
a
n
2
i1
( yi
(a
bxi ))
E ( y y)2 - E(bˆ2 (xi x)2 )
E(
lyy)
-
E(bˆ2lxx)
(n
1)σ
2
b2lxx
-
σ
(
2
b2 )lxx)
lxx
(n 2) σ 2
E(Q(/ n 2)) σ 2
作业 习题 8.1:4
对于方程 y =a + b x + ε ,ε~N (0, σ2 ) , Q /(n -2)
厦门大学经济学院-2012春季学期
3. t检验
(1) 提出原假设和备择假设
H0: b = 0; H1: b ≠ 0
(2) 选择检验统计量,
前一节已经证明: D(bˆ) σ 2
Z
bˆ b Sbˆ
bˆ Sbˆ
lxx
~
t(n
2)
(
H
成立时)
0
(3) 对于给定的显著性水平α, 当 P{| t(n 2) || Z |}
厦门大学经济学院-2012春季学期
一个自变量
一元回归
回归模型
两个及两个以上 自变量