cadence upf 低功耗流程的仿真验证
Cadence综合技术提供新的方法来实现低功耗

Cadence综合技术提供新的方法来实现低功耗Cadence 设计系统公司今天发布了专为Cadence Encounter RTL Compiler 综合技术实现新的低功耗能力,可提升芯片质量(QoS)。
Encounter RTL Compiler 现在通过将多目标全局优化扩展到动态及泄漏功耗优化,以一种全新的方式实现了低功耗。
该单一过程解决方案改进了电源、时序和面积以求获得更高质量的芯片。
Encounter RTL Compiler 的整个低功耗综合解决方案在所有目标的同步优化上是独一无二的,带来了最快的芯片实现途径。
从事纳米规模设计的工程师们对功耗最为关注,并且功耗业已成为众多项目中最主要的优化对象。
在数字化实现流程中,大多数泄漏功耗优化是在RTL 到门级综合过程中实现的。
Encounter RTL Compiler 独一无二的、针对功耗、速度以及面积的单通路方法意味着更高的QoS 以及简化的设计流。
QoS 通过布线衡量一个设计的物理特性,主要包括改进的面积利用率、更高的性能以及更低的功耗。
不再需要在多次运行及多种工具中进行试验和错误纠正折衷。
“我们将在接下来的设计中使用Encounter RTL Compiler 的电源优化工具。
我们已经通过SoC Encounter 研究出一套基于Encounter RTL Compiler 的泄漏缩减方法,该方法能够帮我们实现高达600MHz 的目标速度,同时还能极大程度地减少泄漏功耗。
这绝对可以称得上是一举两得。
”SandbridgeTechnoloies公司的物理设计师Jeff Turlip 如是说。
Cadence 公司副总裁Chi-Ping Hsu 指出:“借助新低功耗方法,Encounter RTL Compiler 将继续改进其能力生产出质量最好的芯片,实现最快的运行时间和最高的容量。
我们很高兴能够提供全局综合技术以便在整个设计链中帮助我们的客户实现低功耗设计。
Cadence混合信号低功耗设计流程助力Silicon Labs降低MCU功耗

Cadence混合信号低功耗设计流程助力Silicon Labs降低
MCU功耗
佚名
【期刊名称】《单片机与嵌入式系统应用》
【年(卷),期】2013(13)11
【摘要】Cadence设计系统公司宣布,SiliconLabs采用完整的Cadence混合信号低功耗设计流程,使其最新款节能型基于ARM微控制器(MCU)的功耗大幅降低。
搭载了ARMCortex—M4核心的新款EFM32WonderGecko,功耗显著降低,即使运行在更高的温度,也能延长电池使用时间。
这款微控制器瞄准对功耗敏感的应用场合,例如智能能源和自动化领域,无论在活动还是在睡眠模式下均可实现低功耗运行。
【总页数】1页(P87-87)
【关键词】Cadence设计系统公司;低功耗运行;设计流程;混合信号;ARM微控制器;MCU;电池使用时间;睡眠模式
【正文语种】中文
【中图分类】TP368.1
【相关文献】
1.SMIC推出基于CPF的CADENCE低功耗数字参考流程SMIC加盟PFI;向在SMIC投产90纳米低功耗芯片的客户,提供新设计解决方案 [J],
2.Power Architecture助力IC设计突破障碍/MIPS授权国家IC设计深圳产业化
基地低功耗内核/凌讯科技90nm芯片采用Cadence低功耗解决方案 [J],
3.Silicon Labs低功耗无线MCU进军智能家居/智能仪表市场 [J], 韩霜
4.Silicon Labs针对物联网推出最低功耗和最小尺寸的无线MCU [J],
5.Cadence混合信号低功耗设计流程 [J],
因版权原因,仅展示原文概要,查看原文内容请购买。
一种低功耗系统芯片的实现流程

一种低功耗系统芯片的实现流程摘要:随着半导体工艺技术的进步,系统芯片的集成度越来越高,功耗成为重点考虑的因素之一,尤其用于便携式设备中。
本文描述了一种多电源、多电压低功耗系统芯片的实现流程。
该流程基于IEEE1801(UPF)标准,采用Synopsys和MentorGraphics公司的EDA 工具,方便地实现了RTL-GDSII的整个过程。
关键词:低功耗;可测性设计;多电源多电压;电源关断0 引言随着CMOS半导体工艺的进步,集成电路进入系统芯片(System on Chip,SoC)设计时代,极大地提高了集成度和时钟频率,导致芯片的功耗急剧增加。
功耗成为集成电路设计中除面积和时序之外的又一个重要因素,因此低功耗设计成为学术界和产业界关注的焦点。
低功耗技术的引入,给芯片的设计和实现提出了新的挑战。
这些挑战包括电压域的划分、EDA工具之间数据的交换和管理等。
本文基于IEEEl801标准Uni-fied Power Format(UPF),采用Synopsys和Mentor Graphics的EDA工具实现了包括可测性设计在内的“从RTL到GDSII”的完整低功耗流程设计。
本论文第1部分描述了低功耗技术和术语。
第2部分描述了本文设计的系统芯片的情况。
第3部分描述了整个设计的流程和采用的EDA工具。
第4部分为总结。
1 低功耗技术数字CMOS电路的功耗主要有三个来源,分别是开关功耗Pswitching、短路功耗Pshort-circuit和泄漏功耗Pleakage,分为动态功耗(Psw itching+Pshort-circuit)和静态功耗(Pleakage)两大类,如式(1)所示。
其中,α是开关活动因子,CL是有效电容,VDD是工作电压,fclk是时钟频率,ISC是平均短路电流,Ileak是平均漏电流。
目前提出了各种降低功耗的方法,主流的技术有门控时钟(Clock-Gating)、多阈值电压(Multi-threshold),先进的技术包括多电压(Mulit-Voltage,MV)电源关断(MTCMOS Pwr Gating)、多电压和带状态保持功能的电源关断(MV&Pwr Gating with State Retention)、低电压待机(Low-VDD Stan-dby)、动态或自适应电压和频率调整(Dynamic or Adaptive Voltage&Frequency Scaling,DVS、DVFS、AVS、AVFS)、阱偏置(Well Biasing,VTCMOS)等。
Cadence Incisive Enterprise Simulator将低功耗验证效率提升30%

Cadence Incisive Enterprise Simulator 将低功耗验证
效率提升30%
中国,2013 年5 月14 日,全球电子设计创新领先企业Cadence 设计系统公司(NASDAQ:CDNS),近日推出新版本Incisive Enterprise Simulator,该版本将复杂SoC 的低功耗验证效率提高了30%。
13.1 版的Cadence® Incisive® Enterprise Simulator 致力于解决低功耗验证的问题,包括高级建模、调试、功率格式支持,并且为当今最复杂的SoC 提供了
更快的验证方式。
Incisive SimVision Debugger 的最新调试功能对复杂的文本式功率意图标准提供了简单明了的交互式调试方式。
其他仿真器的改进包括额外的SystemVerilog 支持,更快的编译连接,使得仿真工作更快完成。
对CPF 的改良支持以及新增的IEEE 1801 支持将会让所有低功耗工程师都能享受到这些
改良成果。
我们成功地运行了Unified Power Format(IEEE 1801/UPF)仿真,用Incisive Enterprise Simulator 识别功耗域,确认隔离以及更多。
ST Microelectronics 研发设计经理David Vincenzoni 说。
该工具性能非常出色,我们对Cadence 表示喝彩,他们增加了全新的高级验证能力,以及IEEE
1801 支持,这将有助于加快低功耗SoC 的完成。
Cadence InciSive Enterprise SimuIator将低功耗验证效率提升30%

N a n o Y i e l d 高 良率解 决方 案
概伦 电子 科技 有限 公 司宣布 中芯 国际集 成 电路
视 频编码器 l P已可支持 V P 8技术
I m a g i n a t i o n T e c h n o l o g i e s日 前宣布 , 已在其领先
L I M b u s  ̄和 I 2 S 接 口,用 以为智能手 机和 更快完成。对 C P F的改良支持 以及新增的 I E E E 的同步 S
h t t p: / / www. c i c ma g . c o m
l 圆 圈
! 璺 箜 ! 垒 ! 塑 3
证的问题 , 包括高级建模 、 调试 、 功率格式支持 , 并且
为 当今最 复 杂的 S o C提供 了更快 的验 证 方式 。
全新高性价 比 H D音频 中枢
欧胜微电子有限公司 日 前宣布 :推 出产品代码
为 WM8 9 9 7的一 款 高度 灵 活 的 高 清 晰 度 音 频 中枢
I n c i s i v e S i m V i s i o n D e b u g g e r 的最新调试功能对
电子 )
应用提供高性能 、高品质的视频编码 / 解码解决方
案。 它 的出货 量 已超 过 5亿 , 遥 遥领 先于 业界 其他 方 案。P o w e r V R E 4 5 0 0 MP 视 频 编 码 器 是 I m a g i n —
进工艺制程开发中的 S R A M进行优化。 ( 来 自概伦 a t i o n V X E S e r i e s 4系列 产 品 的成 员 , 可 处 理所 有 主 要
功耗 验证 效率提 高 了 3 0 %。 1 3 . 1 版的 C a d e n c e  ̄
低功耗验证方法学

低功耗验证方法学
低功耗验证方法学是一个非常重要的领域,它涉及到在集成电路设计中如何有效地验证低功耗电路的正确性和可靠性。
在当今的电子产品中,低功耗设计已经成为一种趋势,因为它可以显著地降低能耗和延长电池寿命。
因此,低功耗验证方法学变得尤为重要。
在低功耗验证中,有几种常见的方法,包括仿真、形式化验证和硬件验证。
这些方法都有其优点和缺点,并且需要根据具体的需求进行选择。
仿真是一种通过模拟电路行为来验证其功能的方法。
在低功耗验证中,仿真可以帮助验证电路中低功耗模式的正确性,但是仿真速度较慢,需要大量的计算资源,而且在某些情况下可能无法覆盖所有可能的状态。
形式化验证是一种基于逻辑推理的方法,它可以通过数学方法来证明电路的正确性。
形式化验证可以帮助验证电路中低功耗模式的正确性,而且可以避免仿真中可能存在的遗漏问题,但是它需要对电路进行严格的建模和证明,因此可能需要大量的时间和资源。
硬件验证是一种基于实际物理硬件的验证方法,它可以直接验证电路的正确性。
在低功耗验证中,硬件验证可以帮助验证电路中低功耗模
式的正确性,并且可以提供更高的可靠性和准确性,但是需要更高的成本和时间。
总的来说,低功耗验证方法学是一个充满挑战和机遇的领域,需要持续地发展和创新,以满足不断变化的市场需求和技术要求。
CADENCE仿真步骤

CADENCE仿真步骤
Cadence是一款电路仿真软件,它可以帮助设计师创建、分析和仿真
电子电路。
本文将介绍Cadence仿真的步骤。
1.准备仿真结构:第一步是准备仿真结构。
我们需要编写表示电路的Verilog或VHDL代码,然后将它们编译到Cadence Integrated Circuit (IC) Design软件中。
这会生成许多文件,包括netlist和verilog等文件,这些文件将用于仿真。
2.定义仿真输入输出信号:接下来,我们需要定义仿真的输入信号和
输出信号。
输入信号可以是电压、电流、时间和其他可测量的变量。
我们
需要定义输入信号的模拟和数字值,以及输出信号的模拟和数字值。
3.定义参数:参数是仿真中用于定义仿真设计的变量,这些变量可以
是仿真中电路的物理参数,如电阻、电容、时延、输入电压等,也可以是
算法参数,如积分步长等。
4.运行仿真:在所有参数和信号都设置完成后,我们可以运行仿真。
在运行仿真之前,可以使用自动参数检查来检查参数是否正确。
然后,使
用“开始仿真”命令即可启动仿真进程。
5.结果分析:在仿真结束后,我们可以使用结果分析器来查看输出信
号的模拟和数字值,以及仿真中电路的其他特性,如暂态分析、稳态分析、功率分析等。
以上就是Cadence仿真步骤。
Cadence仿真流程
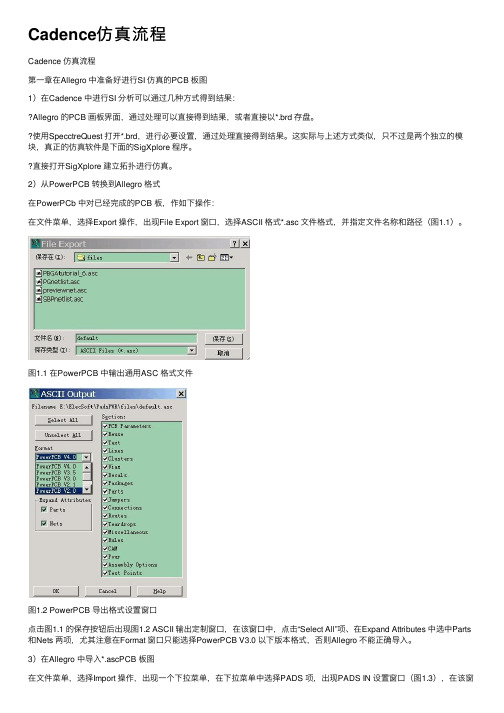
Cadence仿真流程Cadence 仿真流程第⼀章在Allegro 中准备好进⾏SI 仿真的PCB 板图1)在Cadence 中进⾏SI 分析可以通过⼏种⽅式得到结果:Allegro 的PCB 画板界⾯,通过处理可以直接得到结果,或者直接以*.brd 存盘。
使⽤SpecctreQuest 打开*.brd,进⾏必要设置,通过处理直接得到结果。
这实际与上述⽅式类似,只不过是两个独⽴的模块,真正的仿真软件是下⾯的SigXplore 程序。
直接打开SigXplore 建⽴拓扑进⾏仿真。
2)从PowerPCB 转换到Allegro 格式在PowerPCb 中对已经完成的PCB 板,作如下操作:在⽂件菜单,选择Export 操作,出现File Export 窗⼝,选择ASCII 格式*.asc ⽂件格式,并指定⽂件名称和路径(图1.1)。
图1.1 在PowerPCB 中输出通⽤ASC 格式⽂件图1.2 PowerPCB 导出格式设置窗⼝点击图1.1 的保存按钮后出现图1.2 ASCII 输出定制窗⼝,在该窗⼝中,点击“Select All”项、在Expand Attributes 中选中Parts 和Nets 两项,尤其注意在Format 窗⼝只能选择PowerPCB V3.0 以下版本格式,否则Allegro 不能正确导⼊。
3)在Allegro 中导⼊*.ascPCB 板图在⽂件菜单,选择Import 操作,出现⼀个下拉菜单,在下拉菜单中选择PADS 项,出现PADS IN 设置窗⼝(图1.3),在该窗⼝中需要设置3 个必要参数:图1.3 转换阿三次⽂件参数设置窗⼝i. 在的⼀栏那填⼊源asc ⽂件的⽬录ii. 在第⼆栏指定转换必须的pads_in.ini ⽂件所在⽬录(也可将此⽂件拷⼊⼯作⽬录中,此例)iii. 指定转换后的⽂件存放⽬录然后运⾏“Run”,将在指定的⽬录中⽣成转换成功的.brd ⽂件。
cadence仿真步骤

CDNLive! Paper – Signal Integrity (SI) for Dual Data Rate (DDR) InterfacePrithi Ramakrishnan iDEN Subscriber Group Plantation, FlPresented atIntroductionThe need for Signal Integrity (SI) analysis for printed circuit board (PCB) design has become essential to ensure first time success of high-speed, high-density digital designs. This paper will cover the usage of Cadence’s Allegro PCB SI tool for the design of a dual data rate (DDR) memory interface in one of Motorola’s products. Specifically, this paper will describe the following key phases of the high-speed design process: Design set-up Pre-route SI analysis Constraint-driven routing Post-route SI analysisDDR interfaces, being source synchronous in nature, feature skew as the fundamental parameter to manage in order to meet setup and hold timing margins. A brief overview of source synchronous signaling and its challenges is also presented to provide context.Project BackgroundThis paper is based on the design of a DDR interface in an iDEN Subscriber Group phone that uses the mobile Linux Java platform. The phone is currently in the final stages of system and factory testing, and is due to be released in the market at the end of August 2007 for Nextel international customers. The phone has a dual-core custom processor with an application processor (ARM 11) and a baseband processor (StarCore) running at 400MHz and 208MHz respectively. The processor has a NAND and DDR controller, both supporting 16-bit interfaces. The memory device used is a multi-chip package (MCP) with stacked NAND (512Mb) and DDR (512Mb) parts. The NAND device is run at 22MHz and the DDR at 133MHz. The interface had to be supported over several memory vendors, and consequently had to account for the difference in timing margins, input capacitances, and buffer drive strengths between different dies and packages. As customer preference for smaller and thinner phones grows, the design and placement of critical components and modules has become more challenging. In addition to incorporating various sections such as Radio Frequency (RF), Power Management, DC, Audio, Digital ICs, and sub-circuits of these modules, design engineers must simultaneously satisfy the rigid placement requirements for components such as speakers, antennas, displays, and cameras. As such, there are very few options and little flexibility in terms of placement of the components. This problem was further accentuated by the fact that several layers of the 10 layer board (3-4-3 structure with one ground plane and no power planes) were reserved for power, audio, and other high frequency (RF) nets, leaving engineers with few layers to choose from for digital circuitry.Figure 1. Memory Interface routes With the DDR interface data switching at 266MHz, we had very tight margins — 600ps for data/DQS lines, 280ps for the address lines, and 180ps for control lines. However, with the NAND interface we had larger margins that were on the order of a few tens of nanoseconds. In these situations, choosing a higher drive strength and using terminators of appropriate values (to meet rise times and avoid overshoot/undershoot) has become a common practice in DDR designs. However, due to the lack of space on the board, we were not in a position to use terminators. Therefore, we used programmable buffers on our processor, and with the help of Cadence SI tools were able to fine-tune the design. Our group migrated from using Mentor Graphics to Cadence SI during this project. As one might expect, this made the task of designing a high speed DDR interface even more challenging. To help overcome this, we worked extensively with Cadence Services, where Ken Willis supported us on the SI portion of the design.The Source Synchronous Design ChallengeBefore discussing the specifics of the Motorola DDR interface, a brief overview of source synchronous signaling is provided here for context. Historically, digital interfaces have utilized “common clock” signaling, as shown in the figure below.Clock DriverTcoInterconnect Delay D0 D1 D2 D0 D1 D2DriveReceiveFigure 2. Common clock designWith common clock interfaces, the clock signal is provided to the driving and receiving components from an external component. The magnitude of the driver’s Tco (time from clock to output valid) and the interconnect delay between the driving and receiving components becomes a limiting factor in the timing of the interface. From a practical standpoint, it becomes increasingly challenging to implement interfaces of this type above several hundred megahertz. In order to accommodate requirements for faster data rates, source synchronous signaling emerged as the new paradigm. This is illustrated in the figure below.StrobeD 0 D 1D 0 D 1DriveReceiveFigure 3. Source synchronous design.In a source synchronous interface, the “clock” is provided locally by the driving component, and is generally called a “strobe” signal. The relationship between the strobe and its associated data bits is known as it leaves the driving component, with setup and hold margins pre-established as the signals are put onto the bus.TsetupTholdFigure 4. Timing diagram. This essentially takes the driver’s Tco as well as the magnitude of the interconnect delay between the driving and receiving chip out of the timing equation altogether. The timing challenge then becomes to manage the skew between the data and strobe signals such that the setup and hold requirements at the receiving end are still met.Technical ApproachThe general technical approach used in this project can be broken down into the following key phases of the high-speed design process: Design set-up Pre-route SI analysis Constraint-driven routing Post-route SI analysisFirst the PCB design database is set up to enable analysis with Allegro PCB SI. Before routing is performed, initial trade-offs are examined at the placement stage, and constraints are captured to facilitate constraint-driven routing. When routing is completed, detailed analysis is performed, interconnect delays extracted, and setup/hold margins are computed. Any adjustments required are fed back to the layout designer, and the postroute analysis is repeated. This basic process is diagrammed below.Design Setup SI Models Pre-Route AnalysisStartConstraints RoutingPost-Route AnalysisnoMargins OK?yes EndFigure 5. SI design process flow. Detail on the major design phases are provided in the subsequent sections. Design Setup By virtue of its direct integration with the Allegro PCB layout database, Allegro SI analysis requires that the design be set up to facilitate the automated extraction, circuit building, netlisting, simulation, and analysis that it performs. This essentially means adding the needed intelligence to the physical Allegro database that allows the tool to do its job. This setup involves the following: Cross section DC nets Device definitions SI models By definition, SI analysis involves the modeling of interconnect parasitics. In order to do this accurately, the tool needs to know the properties and characteristics of the materials used in the PCB stack-up. This information is defined in the Cross Section form, as shown below.It is crucial to get this data correct, as it will be fed to the 2D field solver to model interconnect parasitics during the extraction process. The best source for this detailed information is generally from the PCB fabricator. Layer thickness, dielectric constant, and loss tangent are all critical parameters for the cross section definition. In order for circuit extraction to be done properly, the tool needs to know about DC nets in the design, and what their associated voltage levels are. This accomplishes two main things in the setup; a) enables voltage sources to be injected properly in the extracted circuits, and b) avoids having the tool needlessly trying to extract extremely large DC nets, and hanging up the analysis process. Take the example of a parallel resistor termination. Allegro SI will encounter the resistor as it walks the signal net to be extracted. The tool will look up the SI model assigned to this resistor, splice in the resistor subcircuit, and continue extracting whatever is on the other side of the resistor. If this is a large DC net (ex. VTT), the desire is for the tool to put a voltage source at the 2nd resistor pin, complete the circuit, and simulate the signal. To do this properly, the tool relies on a VOLTAGE property to exist on the DC net, with a numeric value defined. In the absence of the VOLTAGE property, the tool will simply continue to extract, which in the case of a 2000 pin ground net, would be a large waste of computational time. To identify DC nets, clicking “Logic > Identify DC Nets” will spawn the following form.All DC nets in the design should be identified, to fully optimize SI analysis. These can be identified up front in the schematic, as well as in the physical layout as shown here. The next step in the design set-up process is to verify that the logical “CLASS” and “PINUSE” attributes for the devices in the design are defined appropriately. These attributes originate from the schematic symbol libraries and are passed into the Allegro physical layout environment. In an ideal methodology, these libraries would be defined properly and would require no edits. However, this is not always the case, and as these attributes have a bearing on the behavior of the SI analysis, it is worth mention here. The “CLASS” attribute is used to distinguish between different types of components in the PCB design. Legal values of “CLASS” are listed below: IC – This is used for digital integrated circuits, which contain drivers and/or receivers. These types of components are modeled with an SI model of the type “IbisDevice”. When the automated circuit building algorithms in Allegro PCB SI encounter a model of this type, it looks up the buffer model (driver, receiver, or bidirectional) assigned to the pin in question, and inserts it into the circuit along with its associated package parasitics. IO – A component with CLASS = IO is intended for components that connect off-card to other physical layout designs, such as connectors. These components can be associated with a “DesignLink”, which provides netlisting to other physical designs and enables multi-board SI analysis. So circuit building algorithms expect to jump from a device of CLASS=IO to a similar device on a different physical layout. DISCRETE – For devices of this class, circuit building algorithms expect to traverse “through” the component, from one pin to another, inserting a subcircuit in-between. A good example of this would be a series resistor.If CLASS attributes are not set up properly in the source schematic libraries, they can be edited in the physical layout database for analysis by using the form shown below, launched from the “Logic > Parts List” menu pick.The “PINUSE” attribute also impacts the behavior of the SI analysis, as the tool uses this information to determine if a pin is a driver, receiver, bidirectional, or passive pin. As with the “CLASS” attribute, in an ideal methodology this is defined properly in the schematic libraries, and no editing is required in physical layout. “PINUSE” can be modified in two main ways for SI purposes. The most straightforward way is to ensure that the IOCell models used in the IbisDevice models assigned to components have the appropriate Model Type for the signals they are associated to. When SI models are assigned to components, the tool will check for conflicts between the model and the PINUSE it finds for the component in the design, and will use the SI model to automatically override the PINUSE found in the drawing. So if the correct pin types are found in the SI models, the layout will automatically inherit those settings. For components not explicitly modeled, their PINUSE can be set using the form shown below, launched from the “Logic > Pin Type” menu pick.Signal Integrity (SI) models can be assigned using the “Signal Model Assignment” form, shown below.Upon clicking “OK” the selected models will be assigned to the components and saved directly in the layout database. As mentioned previously, “PINUSE” attributes will be synced up, with the SI models superseding attributes in the original layout drawing.Pre-Route SI AnalysisPerforming pre-route analysis is a key part of the high-speed design process. Once critical component placement has been done, Manhattan distances can be used to estimate trace lengths, and can provide a realistic picture of how routed interconnect will potentially perform.Before simulations are run for critical signals, the timing of the interface must be well understood. To accomplish this, we will first sketch timing diagrams for each signal group and then extract a representative signal for analysis. Next, we will explore Z0, layer assignments, drive strength, route lengths, spacing, and terminations for these nets.To sketch the timing diagrams, we first analyze the memory interface. The memory interface consists of both DDR and NAND signals and has around seventy nets. To simplify the analysis of the interface, we first divide these nets based on function and then simulate one net from each group. Accordingly, we select one signal from each of the following groups —clock_ddr, strobe_ddr , data_ddr, control_ddr, address_ddr, control_nand, and data_nand — for our pre-route simulations.To understand the timing relations in the interface, we should look at the following operations between the memory device and the processor — read, write, address write, and control operations. Next, we identify the nets involved and the clocking reference signal for each of these operations. We then calculate the worst case slack available from the setup and hold numbers available in the data sheets. In particular, we adopted the worst case numbers across four different memory vendors, to ensure robustness of the manfactured system in the field..1.ReadDuring the read operation, the memory drives the data and DQS lines. The processor has a delay line (a series of buffers which can be tapped at different points), which is used to delay the DQS signal so that it samples the data at quarter of the cycle. The processor also offers programming options that allow us to apply an offset to the quarter cycle, enabling us to meet our setup and hold times. Hence, the processor self-corrects forstrobe/data skew using this delay line. The granularity of this delay line is 30 ps; that is, each of the buffers of the delay line contributes 30 ps of delay. The data lines 0-7 are clocked with respect to the DQS0 strobe signal, and the data lines 8-15 are clocked with respect to DQS1. Data and strobe lines should be clustered, with the matching constraints determined by the write cycle.2.WriteFigure 7. Write operation at memory interface.During the write operation, both data and DQS are driven by the processor. Data is latched at both the positive and the negative edges of the DQS signals. Here again, data bits 0-7 are clocked by DQS0 and data bits 8-15 are clocked by DQS1. The setup and hold times available as these signals come out of the DDR controller are 1.58ns and 1.7ns respectively and the corresponding times required at the memory to ensure correct operation is 0.9ns. Hence, the slack available for routing is the lesser of 1.58ns – 0.9ns or 1.7ns – 0.9ns, which comes out to be 0.68ns. This amounts to an allowable ~85mm mismatch between the data lines. In addition, we need to make sure that length of the DQS lines is around the average of all the data lines. The data mask signals DQM0 and DQM1 also come into play during the write operation and we should group them along with the respective data lines.3.Address busFigure 8. Address bus operation at memory interface.Both address and clock lines are driven by the processor. The address bits 0-12 are clocked by the differential clock and latched at the positive edge of the clock. The setup and hold times available for these signals from the DDR controller are 1.78ns and 4.22ns respectively and the corresponding times required at the memory to ensure correct operation is 1.5ns for both. Hence the worst case slack for routing is 0.28ns and we have to try to match our signals to meet these numbers. The 0.28ns slack amounts to ~14mm mismatch between the address lines and the clock.4.Control linesFigure 9. Control lines at memory interface.The control signals are clocked by the differential clock and latched at the positive edge of the clock. The setup and hold times coming out of the DDR controller are 1.64ns and 4.04ns respectively. The setup and hold times required at the memory to ensure correct operation is 1.5ns. Hence, the worst case slack for routing is 0.14ns and we have to try and match our signals to meet these numbers. The 0.14 ns slack amounts to ~7mm mismatch between the control lines and the clock.In addition, CLK to DQS skew is around 600 ps. With regards to the NAND lines, setup and hold numbers are in the order of tens of ns and hence routing them as short as possible based on their Manhattan lengths would suffice.To complete pre-route analysis, SigXplorer must be setup for these tasks:a. Extract a topology file for single net analysis. To bring up the net in SigXplorer, it is essential that the models are assigned, as described in Section 2, to each of the drivers, receivers, and components in the signal path.b. Set up parameters for extraction and simulate using SigXplorer.c. Perform measurements using SigWaveThe following screenshots of SigXplorer show this process in detail.Figure 10. SigXplorer screenshots.Since at this point none of the nets in the design are routed we need to set the percent Manhattan section for unrouted interconnect models. We should then select the net, as shown in the next screenshot, for analysis.Analyze Æ SI/EMI Sim Æ PreferencesThe speed at which the signal travels in the trace, where C is 3 x 108 m/s and E reff is the effective dielectric constant seen in the interconnectSets the default lengthfor unrouted transmission linesAt this point, it is important to check if your driver and receiver pins are set correctly. The net chosen in the above example is a data net, it is bi-directional, hence it can be driven both by the memory device as well as the processor. The view topology icon can be clicked to export this net in SigXplorer.The tool extracts the net along with drivers, receivers and strip lines on various layers of the board. Before you start the simulation, you must set the stimulus frequency, pulse step offset, and cycle count. This can be set in the following GUI.Analyze Æ PreferencesBoth the memory device and the processor have programmable drive strengths. The buffer model can bechanged to pick up the various drive strengths that are available in the dml models of the devices till we observe satisfactory waveforms in SigWave.Analyze Æ SI/EMI Sim Æprobeinvokes SigXplorerMake sure you check you driver and load pinsSigXplorer allows you to sweep any of the parameters such as the thickness, length, drive strengths and displays corresponding settle/switch delays, monotonicity, and glitch tolerance for the corresponding simulation. It also allows adding components such as resistors and capacitors and let’s us sweep their values. We added a resistor in series with our clock in or to get rid of ringing in the rising edge. The tool let us determine what values were suitable for this resistor. As shown in the next figure the waveform corresponding to our simulation can bebrought up on SigWave.driverreceiverYou can observe the rise/fall times, look for noise margins, overshoot/undershoot of the receiver waveform. The constraints we develop in the pre-route simulation will be used by the routing tool to ensure correct first time results. This leads to our next section; Constraint-driven routing.Constraint-driven routingOnce pre-route analysis has been done, and trade-offs have been examined, signal wiring constraints need to be developed to drive the constraint-driven routing process. With the DDR interface being point-to-point between the processor and memory, we translated our timing requirements into length constraints to make the routing as straightforward as possible. We also assigned layer constraints for our DDR signals. Both the length and the layer constraints can be directly applied to the constraint manager before the routing process starts.For our particular design, we determined the following layer assignments from the results of the pre-route simulations, taking into account the layer’s characteristic impedance per our stack-up:Layer 6 Æ ground planeLayer 7 Æ clock, add, ctrlLayer 8 Æ data, strobeLayer 9 Æ NAND interfaceBefore we set up our design for auto-routing, we routed the differential clock lines manually on the layers closest to the ground plane. For the rest of the nets, the layer constraints can be created as shown in the following snapshots of the constraint manager.Electrical Constraint Set Æ WiringRight click on board Æ Create new constraintName the constraint (ex. ECSET1)We choose one layer with horizontal orientation and one with vertical for each of our layer sets. You can form groups from the available layer sets and create a new constraint. This constraint, which we define as ECSET1, can be easily read back in the constraint manager and applied to the relevant net group, as shown in the following snapshot.We determined from pre-route analysis the slack available for each of our net groups; however, before we translate these into length constraints it is important to get a report of the Manhattan lengths of each of these signals. To illustrate this, we will focus on the address signals. The Manhattan report of the address lines showed that the shortest lines were 6mm and the longest were 17mm. Accordingly, the minimum length constraint must be longer than 6mm and the maximum length constraint must be longer than 17mm. Additionally, from our timing diagrams, we determined that the maximum spread can be no more than 14mm. Following these restrictions, we set the minimum and maximum length limits for the address line are 11.99 mmto 18.99 mm (shown in the constraint editor window below). Based on the layout designer's recommendations, we were able to constrain a bit tighter (7mm margin) and produce better margins.To enter the length constraint, we open the Net Æ Routing ÆTotal etch length section of the constrain manager. We followed this procedure for all the other net groups. The snapshot that follows shows length constraints associated with the address lines. Here, the key is to not to over-constrain your design, but at the same time have enough constraints so the timing and signal integrity parameters are met. Over-constraining the design severely inhibits the auto-router and may leave large portions of the design (as much as 90%) un-routed.Post-Route SI AnalysisOnce the design is fully routed, detailed simulations can be run for post-route verification. The goal at this phase is to determine final margins over all corners, and find and correct any SI or timing-related issues before the board is released for fabrication. Before starting simulation, it is important to verify that the design is properly routed and that it meets the specifications/constraints. In particular, it is essential to verify that the design does not include dangling and partially-routed/un-routed nets. We must also verify that all the nets meet the length constraints assigned to them. The Constraint Manager window helps identify nets that are in violation (shown in red) and nets that are in compliance (in green). For convenience and clarity, the Constraint Manager also reports the actual route length and the Manhattan lengths for each net.The next step is to bring up the physical layout and visually inspect the nets to ensure that each net is routed in its appropriate layer, or run DRCs if the signals were explicitly limited to specific layers in Physical Constraint Sets. When test points are associated with a net, we must manually verify that the points are in line with the nets (and are not stubs hanging off the nets). Note that when using the simpler Total_Etch_Length constraint, the auto-router can meet routing length constraints for the net, even when there are stubs in the design. These stubs can produce undesirable effects such as reflections and hence this step is important. If there are too manycritical signals to check manually on larger designs, this check can be automated by using an explicit topology and stub length constraints. After manual inspection, we begin post–route simulation and generate reports to analyze the design. We then export the reports to an Excel spreadsheet to facilitate analysis.We generated both delay and reflection reports. The delay report provides information on timing parameters such as propagation delay, switch and settle rise and fall times. The reflection report presents data on signal integrity parameters such as overshoot, undershoot, noise margin, monotonicity, and glitch. Preparing the design for post-route simulation involves the selection of various options in the SI\EMI Sim preferences list. The following screen display describes this process.In the form above, we set up the frequency of the stimulus and the duty cycle. We also set up V meas as thereference for delay calculations. Choosing the reference as V meas , rather than V IH and V IL , makes analysis much easier and is in accordance with the memory datasheet. We chose V meas as 0.9V which is half of the peak-to-peak voltage swing (1.8V).Now that the design is routed, we need to set the parameters for routed interconnects. Here you can specify the minimum coupling distance for nets for the tool to recognize it as a differential pair. This can be done by invoking Analyze Æ SI ÆPref ÆInterconnect Models.Analyze Æ SI/EMI Sim Æ preferencesThe preceding screenshot shows the option that allows us to select the delay and reflection reports. In this form, we also choose all three simulation modes — fast, typical, and slow — to cover all corner cases. In our experience, running typical mode simulations were not enough to determine final timing margins over process, voltage, and temperature. So, we exported the reports to an Excel spread sheet and analyzed the results. Reflection and delay reports simulate only a primary net and none of its neighbors. As a result, these reports do not take into consideration the parasitics of the power and ground pins.Timing > Control typNote:All timings in ns unless labelled otherwise.Component Timingdriving to MemoryTsetup 1.64Tsetup 1.5Thold 4.04Thold 1.5Skew_max = 1.64 - 1.5 = 140ps between clock and controlSkew_max=0.14Clock/Strobe RelationshipsSdram_Ctrl<6:7> is differential clockInterconnect TimingXNet Drvr Rcvr PropDly SettleRise SettleFall AvgSettleSDRAM_CTRL<6>U800 V2_UU2164 C7_U2160.142029 1.13851 1.20538 1.172XNet Drvr Rcvr PropDly SettleRise SettleFall MinSettle MaxSettle MinSettleSkew MaxSettleSkew MaxSkew MarginSDRAM_CTRL<0>U800U21640.1118 1.191 1.235 1.104 1.2350.0680.0630.0680.072SDRAM_CTRL<10>U800U21640.1254 1.165 1.207SDRAM_CTRL<11>U800U21640.1114 1.141 1.187SDRAM_CTRL<12>U800U21640.1217 1.178 1.221SDRAM_CTRL<13>U800U21640.1067 1.114 1.153SDRAM_CTRL<14>U800U21640.09823 1.104 1.143SDRAM_CTRL<2>U800U21640.1274 1.163 1.205SDRAM_CTRL<3>U800U21640.09163 1.108 1.153SDRAM_CTRL<8>U800U21640.1081 1.137 1.182SDRAM_CTRL<4>U800U21640.06959 1.143 1.247SDRAM_CTRL<5>U800U21640.0862 1.169 1.285The preceding spreadsheet was created with data from delay reports and was used to analyze the control lines with respect to the clock. The clock signal in our design is called SDRAM_CTRL<6>. The sheet also lists the driver (U800, the processor), receiver (U2164, memory device), propagation delay (0.142029 ns), settle rise (1.13851 ns), and settle fall (1.20538 ns) values. The average settle delay (1.172 ns) is calculated by averaging the settle rise and settle fall numbers.The control nets SDRAM<0> to SDRAM_CTRL <14> are listed next to the corresponding drivers, receivers, propagation delays, settle rise and settle fall delays. We then look for the minimum and maximum delays of all the settle rise and settle fall delays. These are listed under maximum settle delay (1.235 ns) and minimum settle delay (1.104 ns) respectively. Using these numbers, we calculate the maximum settle skew (0.063 ns), which is the difference between the maximum settle delay (1.235ns) and the average settle time (1.172 ns) of the clock signal. We also calculate the minimum settle skew (0.063 ns), which is the difference between the minimum settle delay (1.104ns) and the average settle time (1.172 ns) of the clock signal. Subtracting the maximum of these two skews, which in our case is 0.068 ns, from the total skew available (0.140 ns) gives the margin (0.072 ns) for these nets.。
Mentor Graphics 使用UPF逐步求精方法推动新一代低功耗验证

Mentor Graphics 使用UPF 逐步求精方法推动新一
代低功耗验证
俄勒冈州威尔逊维尔,2015 年9 月11 日
Mentor Graphics 公司(纳斯达克代码:MENT)今天宣布支持低功率
逐步求精方法,通过采用Questa Power Aware SimulaTIon 和Visualizer Debug Environment 的新功能以显着提升采用ARM®技术的低功率设计的验证复用和生产率。
UPF 规定低功耗设计意图应与设计区分开,且应用于芯片设计的验
证和实施阶段。
随着复杂的电源管理要求不断增多,强调实施的传统低功耗
方法已开始受到动摇。
逐步求精方法在设计周期的早期便以更抽象的方式定
义低功耗设计意图,并在设计进入实施阶段时对其进行更具体的完善和加
强。
这样可提升整体验证流程和验证结果在每一步的复用。
逐步求精方法注
重将UPF 分为用于IP/块的约束UPF、用于验证的配置UPF 以及实施UPF。
这样可从多个来源开发软IP 和子系统(及其低功率设计意图),然后
快速地一起进行验证以保持功耗验证的一致性。
逐步求精方法由ARM 高级首席研究工程师兼IEEE1801 主席John。
Cadence推进低功耗规范 统一功耗设计验证

V r g硬件描述语 言) ei l o 的连接 , 从而实 C d n e数 字 I 工 具 支 持 , 括 验 证 和 最短 的开发时间掌握低 功耗设计技 aec C 包 C d n e推 出 了低 功 耗 设 计 方 法 学 现 了 自动 化流程; 而在功耗 部分, 因缺 方 面 的 Ics eD s n e m 和 Ic — 术 , a e c n iv e i a i g T n i s
完整 的流程实施 ,或 选择单独 的模块 使用 。 使用 S2的通用功 耗格式 (P ) i C F 在 整 个 流程 中提 供 单 一 的 低功 耗 意 图规 范 ,帮助低功 耗设计 小组快速地 在 多 个 工 程 小 组 中部 署 高 度 自动 化 的低 功 耗 设 计流 程 并 获 得 更 高 的 生
针对 这 一 现 状 ,C d n e设 计 公 于 l a ec C物理设计的 S C E c u tr o n o ne 系统 中 , 过 C F读 通 P 出的 功 耗 意 图可
以用来建立电源
域 , 并 在标 准 单 元 布 局 旁插 入 电 平 转换 器 和 隔 离
单元。
维普资讯
C d ne a e c 推进低功耗规范统一功耗设计验证
■ 记者 : 陈楠
伴随着高端电子产 品的需求增加 , 功耗的相关信息 与仿真 、验证 、综合 、 在实现方面 , n o ne R1 C m— E c u tr 1 o _ue 数字 实 a ec n otr 现 工程 副 总裁 吕丰 荣先 生表 示 :“ 半
导体 产 业经 过 数十 年 的发 展、变革 ,
对于低 功耗 的设计要 求越来越 高, C d n e 致 力 于推 进 低 功耗 设计 规 aec 范 的标 准 化 流 程,并 相 信 未来 5 1 —0
如何进行电路的仿真和验证

如何进行电路的仿真和验证电路仿真和验证是电子设计中非常重要的环节,它可以帮助工程师评估电路的性能、发现问题并进行优化。
本文将介绍如何进行电路的仿真和验证,帮助读者对该过程有一个清晰的了解。
一、电路仿真的基本概念和方法电路仿真是通过使用计算机软件来模拟电路运行的过程,以获取电路的性能参数和波形。
下面是进行电路仿真的一般步骤:1. 设计电路原理图:首先,需要使用电子设计自动化软件(如Cadence、Altium等)来设计电路的原理图,包括电路中的元件和它们之间的连接关系。
2. 编写仿真模型:为了进行仿真,需要为电路中的每个元件编写仿真模型。
这些模型能够准确地描述元件的特性和行为,对于常见的元件(如电阻、电容、电感等),可以使用编程语言(如Verilog-A、SPICE等)来编写模型。
3. 设置仿真参数:在进行电路仿真之前,需要设置仿真的参数,包括工作电压、工作温度、仿真时间等。
这些参数会影响电路的仿真结果,需要根据实际情况进行设置。
4. 运行仿真:在设置好仿真参数后,可以通过仿真软件来运行仿真。
仿真软件会根据仿真模型和参数计算电路的电流、电压、功率等参数,并生成电路的波形图。
5. 仿真结果分析:当仿真完成后,需要对仿真结果进行分析。
通过观察波形图和参数值,可以评估电路的性能如增益、带宽等,并发现潜在的问题。
二、电路验证的重要性和方法电路验证是在实际电路制作之前对设计的电路进行验证,以确保其功能和性能的正确性。
下面是进行电路验证的常用方法:1. 逻辑验证:逻辑验证主要用于数字电路设计。
通过使用逻辑仿真工具(如ModelSim、ISE等),可以对电路进行逻辑仿真,验证其逻辑功能是否符合设计要求。
2. 物理验证:物理验证主要用于模拟电路设计。
通过使用物理仿真工具(如HSpice、Spectre等),可以对电路进行物理仿真,验证其电流、电压、功率等物理参数是否满足设计要求。
3. 实验验证:实验验证是通过在实际电路中搭建和测试,验证电路的性能和特性。
关于EDA工具整合低功耗设计、验证和提高生产力的设计

关于EDA工具整合低功耗设计、验证和提高生产力
的设计
整合低功耗设计、验证和提高生产力的EDA工具将领先的设计、验证和实现技术与CPF相集成
Cadence Low-Power Solution是用于低功耗芯片的逻辑设计、验证和实现的完全集成的、标准化的流程,将领先的设计、验证和实现技术与
Si2Common Power Format(CPF)相集成,为IC工程师提供端到端的低功耗设计方案。
CPF是在设计过程初期详细定义节约功耗技术的标准化格式。
通过在整个设计过程中保存低功耗设计意图,该解决方案避免了费力的人工操作,大大降低了与功耗相关的芯片故障,并在设计过程初期提供功耗的可预测性。
Cadence Low-Power SoluTIon通过在CPF规范中建立一个设计功耗意图的单一的表示法,解决在低功耗设计中多种设计方式混用所带来的问题。
这种表现法跨越了逻辑设计师、验证工程师和实现工程师所使用的Cadence LogicDesign Team SoluTIon和DigitalImplementaTIon解决方案,包括计划和以指标为驱动的流程管理、仿真、逻辑综合、等效验证、测试、布局、布线和电压降分布分析。
能够让由多类型专家构成的整个项目团队以包含了低功耗意图的共同的设计角度开始工作,还大幅提高了设计可预测性,并将芯片故障的风险降到最低。
UPF低功耗设计

Thursday, November 18, 2010 基于IEEE1801(UPF)标准的低功耗设计实现流程Low-power Implementation Flow Based IEEE1801 (UPF)郭军, 廖水清, 张剑景华为通信技术有限公司**************************************************************AbstractPower consumption is becoming an increasingly important aspect of ASIC design. There are several different approaches that can be used to reduce power. However, it is important to use these low-power technology more effectively in IC design implementation and verification flow. In our latest low-power chip, we completed full implementation and verification flow from RTL to GDSII successfully and effectively by adopting IEEE1801 Unified Power Format (UPF). This paper will focus on UPF application in design implementation with Synopsys low power solution. It will highlight that how to describe our low-power intent using UPF and how to complete the design flow. This paper first illustrates current low-power methodology and UPF’s concept. Then, it discussed UPF application in detail. Finally, it gives our conclusion.Key words: IEEE1801, UPF, Low-Power, Shut-Down, Power Gating, Isolation, IC-Compiler摘要目前除了时序和面积,功耗已经成为集成电路设计中日益关注的因素。
CADENCE仿真流程

CADENCE仿真流程第一章进行SI仿真的PCB板图的准备仿真前的准备工作主要包括以下几点:1、仿真板的准备●原理图设计;●PCB封装设计;●PCB板外型边框(Outline)设计,PCB板禁止布线区划分(Keepouts);●输出网表(如果是用CADENCE的Concept HDL设计的原理图,可将网表直接Expot 到BRD文件中;如果是用PowerPCB设计的板图,转换到allegro中的板图,其操作见附录一的说明);●器件预布局(Placement):将其中的关键器件进行合理的预布局,主要涉及相对距离、抗干扰、散热、高频电路与低频电路、数字电路与模拟电路等方面;●PCB板布线分区(Rooms):主要用来区分高频电路与低频电路、数字电路与模拟电路以及相对独立的电路。
元器件的布局以及电源和地线的处理将直接影响到电路性能和电磁兼容性能;2、器件模型的准备●收集器件的IBIS模型(网上下载、向代理申请、修改同类型器件的IBIS模型等)●收集器件的关键参数,如T co、Tsetup、Tholdup等及系统有关的时间参数T clock、Tskew、Tjitter●对IBIS模型进行整理、检查、纠错和验证。
3、确定需要仿真的电路部分,一般包括频率较高,负载较多,拓扑结构比较复杂(点到多点、多点到多点),时钟电路等关键信号线第二章IBIS模型的转化和加载CADENCE中的信号完整性仿真是建立在IBIS模型的基础上的,但又不是直接应用IBIS 模型,CADECE的软件自带一个将IBIS模型转换为自己可用的DML(Device Model Library)模型的功能模块,本章主要就IBIS模型的转换及加载进行讲解。
1、IBIS模型到DML模型的转换在Allegro窗口中选择Analyse\SI/EMI SIM\Library,打开“signal analyze library browser”窗口,在该窗口的右下方点击“Translate →”按钮,在出现的下拉菜单中选择“ibis2signois”项,出现“Select IBIS Source File”窗口(图1),选择想要进行转换的源IBIS文件,按下“打开”按钮,出现转换后文件名及路径设置窗口(缺省设置为和源IBIS文件同名并同路径放置,但此处文件名后缀为dml),设置后按下“保存”按钮,出现保存确定窗口(图2),点击OK按钮即可,随后会出现一个“messages”窗口,该窗口中的报告文件说明在模型转换过程中出现的问题,对其中的“warning”可不用在意,但如果出现“error”则必须进行修改后重新进行模型格式转化直到没有“error”出现为止,此时转换得到的dml文件才是有效的。
CADENCE仿真步骤

CADENCE仿真步骤1.电路设计:首先,需要使用电路设计软件(例如OrCAD)绘制电路原理图。
在设计电路时,应该合理选择电路元件,确保其参数和规格满足设计要求。
2.创建电路网络:在CADENCE中创建电路网络是第一步。
通过将电路原理图导入到CADENCE中,可以建立电路的模型。
在建立电路网络时,应定义元件的参数值,并将其连接起来。
3.定义仿真设置:在进行仿真之前,需要设置仿真参数。
这些参数包括仿真类型(例如直流、交流、蒙特卡罗等)、仿真步长、仿真时间等。
此外,还可以设置其他参数,如故障分析、参数扫描等。
4. 运行仿真:设置好仿真参数后,可以开始运行仿真了。
CADENCE 提供了多种仿真工具,如PSpice、Spectre等,可以根据不同的需求选择适合的工具。
在仿真过程中,CADENCE会使用电路元件的模型计算电路参数,根据仿真设置提供的信息生成相应的结果。
5.分析仿真结果:一旦仿真完成,CADENCE会生成仿真结果文件。
通过分析仿真结果,可以评估电路设计的性能。
常见的仿真结果包括电流、电压、功耗、频率响应等。
可以将仿真结果与预期结果进行比较,找出设计中的问题并进行优化。
6.优化电路设计:根据仿真结果,可以对电路设计进行调整和优化。
优化可以包括选择不同的元件、调整元件参数、改变电路拓扑等。
通过不断迭代仿真和优化,可以逐步改进电路设计,使其达到预期的性能指标。
7.验证仿真结果:当设计经过一系列的优化后,需要验证仿真结果是否可靠。
一种常用的验证方法是进行物理验证,即将最终的电路设计制作出来并测量其实际性能。
通过比较实际测量结果与仿真结果,可以验证仿真的准确性,并进行必要的修正。
8. 导出设计文件:一旦电路设计完成并验证通过,就可以将设计文件导出,准备进一步的生产制造。
将设计文件导出为标准的格式(如Gerber文件),可以将其发送给制造商进行生产。
总结:CADENCE仿真步骤包括电路设计、创建电路网络、定义仿真设置、运行仿真、分析仿真结果、优化电路设计、验证仿真结果和导出设计文件。
upf验证流程(一)

upf验证流程(一)UPF验证什么是UPF验证?UPF(Unified Power Format)是一种用于描述芯片功率管理策略的行业标准格式。
UPF验证是指对设计中的UPF文件进行验证,以确保设计在不同功率管理模式下的正确性和可靠性。
UPF验证的流程UPF验证通常包括以下几个关键步骤: 1. UPF文件分析:首先,对设计中的UPF文件进行详细分析,了解该设计中的不同功率管理模式和约束条件。
2.UPF文件读入:将UPF文件读入到验证环境中,以便在后续的验证过程中使用。
3.功能验证:对UPF文件中定义的不同功率管理模式进行功能验证,以确保设计在不同模式下的正确性。
这包括检查是否正确实施了电源管理策略,以及各个模式之间的切换是否正确。
4.约束验证:验证UPF文件中定义的约束条件是否满足。
例如,检查电源域划分是否正确,电源域之间的约束是否满足,以及时序约束是否符合要求。
5.电源域检查:对设计中的电源域进行检查,以确保其在不同功率管理模式下的正确性。
这包括电源域之间的电源切换、电源间干扰等方面。
6.仿真验证:通过对UPF文件进行仿真验证,检查设计在不同功率管理模式下的性能。
这包括电源开关的正确性、功耗的控制以及电源切换的时间等方面。
7.模拟验证:在实际硅片上进行模拟验证,以验证设计在不同功率管理模式下的正确性和可靠性。
这可以帮助发现在仿真验证中可能存在的问题,并提供更准确的性能评估。
结论UPF验证是确保芯片设计在不同功率管理模式下正确性和可靠性的重要步骤。
通过对UPF文件进行功能验证、约束验证、电源域检查、仿真验证和模拟验证等流程,可以有效减少在实际制造过程中可能出现的问题,提高芯片的功耗控制能力和可靠性。
UPF验证的工具UPF验证通常借助以下一些工具来完成:1.UPF文件解析工具:用于解析和分析设计中的UPF文件,提取其中的信息并进行后续处理。
常用的工具有UPFAnalyzer和UPF Parser等。
CADENCE仿真步骤

Cadence SPECCTRAQuest 仿真步骤[摘要]本文介绍了Cadence SPECCTRAQuest在高速数字电路的PCB设计中采用的基于信号完整性分析的设计方法的全过程。
从信号完整性仿真前的环境参数的设置,到对所有的高速数字信号赋予PCB板级的信号传输模型,再到通过对信号完整性的计算分析找到设计的解空间,这就是高速数字电路PCB板级设计的基础。
[关键词]板级电路仿真 I/O Buffer Information Specification(IBIS)1 引言电路板级仿真对于今天大多数的PCB板级设计而言已不再是一种选择而是必然之路。
在相当长的一段时间,由于PCB仿真软件使用复杂、缺乏必需的仿真模型、PCB仿真软件成本偏高等原因导致仿真在电路板级设计中没有得到普及。
随着集成电路的工作速度不断提高,电路的复杂性不断增加之后,多层板和高密度电路板的出现等等都对PCB板级设计提出了更新更高的要求。
尤其是半导体技术的飞速发展,数字器件复杂度越来越高,门电路的规模达到成千上万甚至上百万,现在一个芯片可以完成过去整个电路板的功能,从而使相同的PCB 上可以容纳更多的功能。
PCB已不仅仅是支撑电子元器件的平台,而变成了一个高性能的系统结构。
这样,信号完整性在PCB板级设计中成为了一个必须考虑的一个问题。
传统的PCB板的设计依次经过电路设计、版图设计、PCB制作等工序,而PCB的性能只有通过一系列仪器测试电路板原型来评定。
如果不能满足性能的要求,上述的过程就需要经过多次的重复,尤其是有些问题往往很难将其量化,反复多次就不可避免。
这些在当前激烈的市场竞争面前,无论是设计时间、设计的成本还是设计的复杂程度上都无法满足要求。
在现在的PCB板级设计中采用电路板级仿真已经成为必然。
基于信号完整性的PCB仿真设计就是根据完整的仿真模型通过对信号完整性的计算分析得出设计的解空间,然后在此基础上完成PCB设计,最后对设计进行验证是否满足预计的信号完整性要求。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cadenceupf低功耗流程的仿真验证
本文是记录项目过程中遇到的奇巧淫技,如有遗漏或者不足,请大家改正和补充,谢谢。
随着深亚微米技术的普及与发展,leakage功耗在整个功耗中的比重越来越大,比如45nm下,已
经占到了60%以上,所以低功耗解决方案应运而生。
目前已经有一套标准的低功耗设计流程,流
程有CPF(cadence主导)和UPF(synopsys主导)两种,但技术趋势是UPF会大一统,所以本篇
将为那些仍旧使用ncverilog而不是vcs仿真工具的苦逼们提供一些参考。
目前常用的降低低功耗的方法有四种:多电压域、时钟门控、电源关断和动态电压频率调整。
其
中的时钟门控对验证影响较小,大家应该都接触过,而剩下的三个对验证工作影响较大,需要用
到各个EDA厂商的低功耗解决方案。
闲话就说这么多,那么cadence如何使用upf来实现低功耗流程的仿真验证呢?
第一步,先得有UPF文件,根据设计需求,使用TCL建立脚本,建立和管理独立电压源、确定隔离、建立电平漂移等,一般是设计或者后端人员书写,验证工程师当然也可以写,具体内容参考IEEE 1801。
第二步,仿真case中添加电源上电过程,使用$supply_on函数给相应VDD上电。
第三步,将UPF嵌入到仿真命令中,即:
irun -lps_1801 sim.upf -lps_assign_ft_buf -lps_iso_verbose ...
或者
1 ncvlog ...
2 ncelab -lps_1801 sim.upf -lps_assign_ft_buf -lps_iso_verbose ...
3 ncsim ...
相关options解释如下:
①-lps_1801 filename: 指定符合IEEE 1801标准的UPF文件;
②-lps_assign_ft_buf: 指定assign赋值被当做buffer对待,而非默认的wire,好处是从always-on domain进入和穿过power-down domain的信号被force成x,便于debug;
③-lps_const_aon: 对处在power-down domain并且直接和always-on domain相连接的tie-high或
者tie-low constant,不使能corruption功能;默认不使用该功能;
④-lps_enum_rand_corrupt:对于用户定义的enum类型数据,在电源关断后,随机从枚举列表中
选择一个值作为变量值;和该命令相类似的还有-lps_enum_right, -lps_implicit_pso等,因为不常用,就不一一介绍了;
⑤-lps_iso_verbose: 使能isolation的log功能,这个一般需要加上;
⑥...
其它的options请参考cadence的low-power simulation guide。
最后,运行仿真即可。
最后说一下low power流程验证正确性和完备性的确认方法。
①增加的low power流程不能影响芯片本身功能的正确性,比如通过电源关断来降低芯片功耗,
则关断再打开后,芯片还可以正常work。
这部分可以利用原有的self-check验证环境来确认。
②利用log文件分析,上述仿真命令-lps_verbose和UPF文件会为仿真输出与low power相关的
warning, error以及assertion信息,通过log文件可以check流程的正确性;
③自动的assertion checker分析,使用-lps_verify选项可以自动检查电源关断顺序(隔离->复位->断电)和电源打开过程(上电->解复位->解隔离),如不满足该时序要求,会自动报错;
④利用覆盖率保证验证完备性,使用-lps_vplan选项依据UPF文件生成low power验证计划,通过simvision提供的coverage接口,得到low power相关的功能覆盖率;。