JAVA动态生成word和pdf
java生成word文件并下载

import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.BufferedWriter;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import .URLEncoder;import java.util.Map;import javax.servlet.http.HttpServletResponse;import org.apache.log4j.Logger;import freemarker.template.Configuration;import freemarker.template.Template;/*** @Desc:word 操作工具类*/public class WordUtil {private static Logger log = Logger.getLogger(WordUtil.class);/*** @Desc :生成word 文件* @param dataMap word 中需要展示的动态数据,用map 集合来保存* @param templateName word 模板名称,例如:test.ftl* @param filePath 文件生成的目标路径,例如:D:/wordFile/* @param fileName 生成的文件名称,例如:test.doc*/public static void createWord(Map<String, Object> dataMap,String templateName,String filePath,String fileName){try {// 创建配置实例Configuration configuration = new Configuration();// 设置编码configuration.setDefaultEncoding("UTF-8");//ftl 模板文件File file = new File(filePath); configuration.setDirectoryForTemplateLoading(file);// 获取模板Template template = configuration.getTemplate(templateName);// 输出文件File outFile = new File(filePath + File.separator + fileName);// 如果输出目标文件夹不存在,则创建if (!outFile.getParentFile().exists()){ outFile.getParentFile().mkdirs();}// 将模板和数据模型合并生成文件Writer out = new BufferedWriter(new OutputStreamWriter(newFileOutputStream(outFile),"UTF-8"));// 生成文件template.process(dataMap, out);// 关闭流out.flush();out.close();} catch (Exception e) {log.error(" 生成word 文档(WordUtil) 出错:【msg:"+e.getMessage()+" 】,文件名:" + fileName);e.printStackTrace();}/**文件下载* @param path 文件路径全路径,包含文件名* @param response* @return*/public static HttpServletResponse downFile(String path, HttpServletResponse response) { try { // path 是指欲下载的文件的路径。
[原创]java实现word转pdf
![[原创]java实现word转pdf](https://img.taocdn.com/s3/m/a6ae1fe56394dd88d0d233d4b14e852458fb39dd.png)
[原创]java实现word转pdf 最近遇到⼀个项⽬需要把word 转成pdf,百度了⼀下⽹上的⽅案有很多,⽐如虚拟打印、给word 装扩展插件等,这些⽅案都依赖于ms word 程序,在java代码中也得使⽤诸如jacob或jcom这类java com bridge,使得服务器开发受限于win平台,⽽且部署起来也很⿇烦。
后来在某论坛看到了⼀个openoffice+jodconverter的转换⽅案,可以完成word到PDF的转换⼯作,服务器开发端需要安装openoffice,但是需求⼀步额外的操作--需要在服务器开发上的某个端⼝提供⼀个openoffice服务,这对部署起来显得⿇烦了点,貌似也不太安全。
偶然机会发现了PageOffice组件也可以实现word转pdf功能。
⽽且不只是简单的把word转为pdf格式,还可以⽀持动态填充数据到word模板⽂件然后再转为pdf⽂件。
以下为官⽹介绍: 调⽤PageOffice组件的FileMaker对象实现动态填充数据到word模板并转为pdf的核⼼代码如下:FileMakerCtrl fmCtrl = new FileMakerCtrl(request);fmCtrl.setServerPage(request.getContextPath()+"/poserver.zz");WordDocument doc = new WordDocument();doc.openDataRegion("PO_company").setValue("北京某某有限公司");//给数据区域赋值,即把数据填充到模板中相应的位置fmCtrl.setSaveFilePage("/savepdf"); //保存pdf的action或RequestMapping⽅法fmCtrl.setWriter(doc);fmCtrl.fillDocumentAsPDF("doc/template.doc", DocumentOpenType.Word, "123.pdf");//填充word模板并转为pdf 保存pdf的action或RequestMapping⽅法(/savepdf)的代码:FileSaver fs = new FileSaver(request, response);fs.saveToFile(request.getSession().getServletContext().getRealPath("doc") +"/"+ fs.getFileName());fs.close(); ⽰例源码及效果:/dowm/,下载PageOffice for Java,解压后,拷贝Samples4⽂件夹到Tomcat的Webapps⽬录下,访问:http://localhost:8080/Samples4/index.html,查看⽰例:⼆、34、FileMaker转换单个⽂档为PDF(以Word为例)。
Java生成PDF文档(表格、列表、添加图片等)

Java⽣成PDF⽂档(表格、列表、添加图⽚等)1 import java.awt.Color;2 import java.io.FileOutputStream;3 import com.lowagie.text.Cell;4 import com.lowagie.text.Chapter;5 import com.lowagie.text.Document;6 import com.lowagie.text.Font;7 import com.lowagie.text.Image;8 import com.lowagie.text.List;9 import com.lowagie.text.ListItem;10 import com.lowagie.text.PageSize;11 import com.lowagie.text.Paragraph;12 import com.lowagie.text.Section;13 import com.lowagie.text.Table;14 import com.lowagie.text.pdf.BaseFont;15 import com.lowagie.text.pdf.PdfWriter;16 public class ITextDemo {17 public boolean iTextTest() {18 try {19 /** 实例化⽂档对象 */20 Document document = new Document(PageSize.A4, 50, 50, 50, 50);21 /** 创建 PdfWriter 对象 */22 PdfWriter.getInstance(document,// ⽂档对象的引⽤23 new FileOutputStream("d://ITextTest.pdf"));//⽂件的输出路径+⽂件的实际名称24 document.open();// 打开⽂档25 /** pdf⽂档中中⽂字体的设置,注意⼀定要添加iTextAsian.jar包 */26 BaseFont bfChinese = BaseFont.createFont("STSong-Light",27 "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);28 Font FontChinese = new Font(bfChinese, 12, Font.NORMAL);//加⼊document:29 /** 向⽂档中添加内容,创建段落对象 */30 document.add(new Paragraph("First page of the document."));// Paragraph添加⽂本31 document.add(new Paragraph("我们是害⾍", FontChinese));32 /** 创建章节对象 */33 Paragraph title1 = new Paragraph("第⼀章", FontChinese);34 Chapter chapter1 = new Chapter(title1, 1);35 chapter1.setNumberDepth(0);36 /** 创建章节中的⼩节 */37 Paragraph title11 = new Paragraph("表格的添加", FontChinese);38 Section section1 = chapter1.addSection(title11);39 /** 创建段落并添加到⼩节中 */40 Paragraph someSectionText = new Paragraph("下⾯展⽰的为3 X 2 表格.",41 FontChinese);42 section1.add(someSectionText);43 /** 创建表格对象(包含⾏列矩阵的表格) */44 Table t = new Table(3, 2);// 2⾏3列45 t.setBorderColor(new Color(220, 255, 100));46 t.setPadding(5);47 t.setSpacing(5);48 t.setBorderWidth(1);49 Cell c1 = new Cell(new Paragraph("第⼀格", FontChinese));50 t.addCell(c1);51 c1 = new Cell("Header2");52 t.addCell(c1);53 c1 = new Cell("Header3");54 t.addCell(c1);55 // 第⼆⾏开始不需要new Cell()56 t.addCell("1.1");57 t.addCell("1.2");58 t.addCell("1.3");59 section1.add(t);60 /** 创建章节中的⼩节 */61 Paragraph title13 = new Paragraph("列表的添加", FontChinese);62 Section section3 = chapter1.addSection(title13);63 /** 创建段落并添加到⼩节中 */64 Paragraph someSectionText3 = new Paragraph("下⾯展⽰的为列表.", FontChinese);65 section3.add(someSectionText3);66 /** 创建列表并添加到pdf⽂档中 */67 List l = new List(true, true, 10);// 第⼀个参数为true,则创建⼀个要⾃⾏编号的列表,68 // 如果为false则不进⾏⾃⾏编号69 l.add(new ListItem("First item of list"));70 l.add(new ListItem("第⼆个列表", FontChinese));71 section3.add(l);72 document.add(chapter1);73 /** 创建章节对象 */74 Paragraph title2 = new Paragraph("第⼆章", FontChinese);75 Chapter chapter2 = new Chapter(title2, 1);76 chapter2.setNumberDepth(0);77 /** 创建章节中的⼩节 */78 Paragraph title12 = new Paragraph("png图⽚添加", FontChinese);79 Section section2 = chapter2.addSection(title12);80 /** 添加图⽚ */81 section2.add(new Paragraph("图⽚添加: 饼图", FontChinese));82 Image png = Image.getInstance("D:/pie.png");//图⽚的地址83 section2.add(png);84 document.add(chapter2);85 document.close();86 return true;87 } catch (Exception e2) {88 System.out.println(e2.getMessage());89 }90 return false;91 }92 public static void main(String args[]) {93 System.out.println(new ITextDemo().iTextTest());94 }95 }。
java使用模板生成word文件
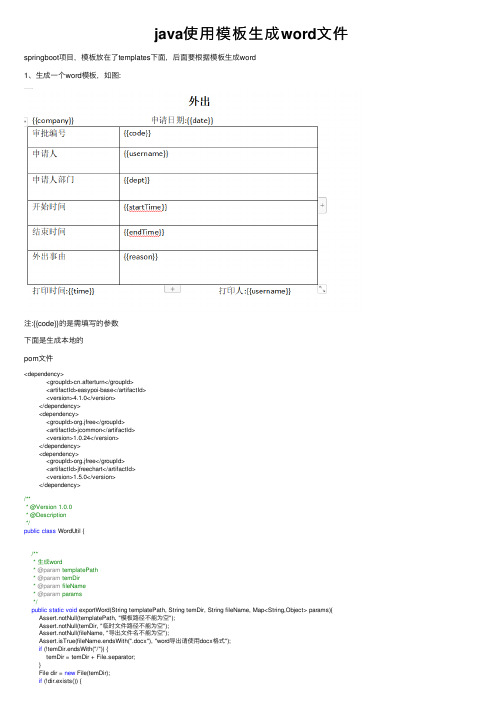
java使⽤模板⽣成word⽂件springboot项⽬,模板放在了templates下⾯,后⾯要根据模板⽣成word1、⽣成⼀个word模板,如图:注:{{code}}的是需填写的参数下⾯是⽣成本地的pom⽂件<dependency><groupId>cn.afterturn</groupId><artifactId>easypoi-base</artifactId><version>4.1.0</version></dependency><dependency><groupId>org.jfree</groupId><artifactId>jcommon</artifactId><version>1.0.24</version></dependency><dependency><groupId>org.jfree</groupId><artifactId>jfreechart</artifactId><version>1.5.0</version></dependency>/*** @Version 1.0.0* @Description*/public class WordUtil {/*** ⽣成word* @param templatePath* @param temDir* @param fileName* @param params*/public static void exportWord(String templatePath, String temDir, String fileName, Map<String,Object> params){Assert.notNull(templatePath, "模板路径不能为空");Assert.notNull(temDir, "临时⽂件路径不能为空");Assert.notNull(fileName, "导出⽂件名不能为空");Assert.isTrue(fileName.endsWith(".docx"), "word导出请使⽤docx格式");if (!temDir.endsWith("/")) {temDir = temDir + File.separator;}File dir = new File(temDir);if (!dir.exists()) {dir.mkdirs();}try {XWPFDocument doc = WordExportUtil.exportWord07(templatePath, params);String tmpPath = temDir + fileName;FileOutputStream fos = new FileOutputStream(tmpPath);doc.write(fos);fos.flush();fos.close();} catch (Exception e) {e.printStackTrace();}}}/*** @Version 1.0.0* @Description*/public class WordDemo {public static void main(String[] args) {Map<String,Object> map = new HashMap<>();map.put("username", "张三");map.put("company","xx公司" );map.put("date","2020-04-20" );map.put("dept","IT部" );map.put("startTime","2020-04-20 08:00:00" );map.put("endTime","2020-04-20 08:00:00" );map.put("reason", "外出办公");map.put("time","2020-04-22" );WordUtil.exportWord("templates/demo.docx","D:/" ,"⽣成⽂件.docx" ,map );}}2、下⾯是下载word⽂件/*** 导出word形式* @param response*/@RequestMapping("/exportWord")public void exportWord(HttpServletResponse response){Map<String,Object> map = new HashMap<>();map.put("username", "张三");map.put("company","杭州xx公司" );map.put("date","2020-04-20" );map.put("dept","IT部" );map.put("startTime","2020-04-20 08:00:00" );map.put("endTime","2020-04-20 08:00:00" );map.put("reason", "外出办公");map.put("time","2020-04-22" );try {response.setContentType("application/msword");response.setCharacterEncoding("utf-8");String fileName = URLEncoder.encode("测试","UTF-8" );//String fileName = "测试"response.setHeader("Content-disposition","attachment;filename="+fileName+".docx" ); XWPFDocument doc = WordExportUtil.exportWord07("templates/demo.docx",map); doc.write(response.getOutputStream());} catch (Exception e) {e.printStackTrace();}//WordUtil.exportWord("templates/demo.docx","D:/" ,"⽣成⽂件.docx" ,map );} 。
Java 转PDF为Word、图片、html、XPS、SVG、PDFA

Java 将PDF 转为Word、图片、SVG、XPS、Html、PDF/A本文将介绍通过Java编程来实现PDF文档转换的方法。
包括:PDF转为WordPDF转为图片PDF转为HtmlPDF转为SVG将PDF每一页转为单个的SVG将一个包含多页的PDF文档转为一个SVGPDF转为XPSPDF转为PDF/A使用工具:Free Spire.PDF for Java(免费版)Jar文件获取及导入:方法1:通过官网下载jar文件包。
下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入Java程序。
方法2:可通过maven仓库安装导入。
参考导入方法。
Java代码示例【示例1】PDF 转WordPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToWord.docx",FileFormat.DOCX);【示例2】PDF转图片支持的图片格式包括Jpeg, Jpg, Png, Bmp, Tiff, Gif, EMF等。
这里以保存为Png格式为例。
import com.spire.pdf.*;import javax.imageio.ImageIO;import java.awt.image.BufferedImage;import java.io.File;import java.io.IOException;public class PDFtoimage {public static void main(String[] args) throws IOException {PdfDocument pdf = new PdfDocument("test.pdf");BufferedImage image;for(int i = 0; i< pdf.getPages().getCount();i++){image = pdf.saveAsImage(i);File file = new File( String.format("ToImage-img-%d.png", i)); ImageIO.write(image, "PNG", file);}pdf.close();}}【示例3】PDF转HtmlPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToHTML.html", FileFormat.HTML);【示例4】PDF转SVG1.转为单个svgPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToSVG.svg", FileFormat.SVG);2.多页pdf转为一个svgPdfDocument pdf = new PdfDocument("sampe.pdf");pdf.getConvertOptions().setOutputToOneSvg(true);pdf.saveToFile("ToOneSvg.svg",FileFormat.SVG);【示例5】PDF 转XPSPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToXPS.xps", FileFormat.XPS);【示例6】PDF转PDF/Aimport com.spire.pdf.*;import com.spire.pdf.graphics.PdfMargins;import java.awt.geom.Dimension2D;public class PDFtoPDFA {public static void main(String[]args){//加载测试文档PdfDocument pdf = new PdfDocument();pdf.loadFromFile("test.pdf");//转换为Pdf_A_1_B格式PdfNewDocument newDoc = new PdfNewDocument();newDoc.setConformance(PdfConformanceLevel.Pdf_A_1_B);PdfPageBase page;for ( int i=0;i< pdf.getPages().getCount();i++) {page = pdf.getPages().get(i);Dimension2D size = page.getSize();PdfPageBase p = newDoc.getPages().add(size, new PdfMargins(0)); page.createTemplate().draw(p, 0, 0);}//保存结果文件newDoc.save("ToPDFA.pdf");newDoc.close();}}(本文完)。
JAVA不使用POI,用PageOffice动态导出Word文档

JAVA不使用POI,用PageOffice动态导出Word文档很多情况下,软件开发者需要从数据库读取数据,然后将数据动态填充到手工预先准备好的Word模板文档里,这对于大批量生成拥有相同格式排版的正式文件非常有用,这个功能应用PageOffice的基本动态填充功能即可实现。
但若是用户想动态生成一个没有固定模版的公文时,换句话说,没有办法事先准备一个固定格式的模板时,就需要开发人员在后台用代码实现Word文档的从零到图文并茂的动态生成功能了。
这里的“零”指的是Word空白文档。
那如何实现Word文档的从无到有呢,下面我就把自己实现这一功能的过程介绍一下。
例如,我想打开一个Word文档,里面的内容为:标题(粗体、黑体、字体大小为20、居中显示)、第一段内容(内容(略)、字体倾斜、字体大小为10、中文“楷体”、英文“Times New Roman”、红色、最小行间距、左对齐、首行缩进)、第二段内容(内容(略)、字体大小为12、黑体、1.5倍行间距、左对齐、首行缩进、插入图片)、第三段内容(内容(略)、字体大小为14、华文彩云、2倍行间距、左对齐、首行缩进)第一步:请先安装PageOffice的服务器端的安装程序,之后在WEB项目下的“WebRoot/WEB-INF/lib”路径中添加pageoffice.cab和pageoffice.jar(在网站的“下载中心”中可下载相应的压缩包,解压之后直接将pageoffice.cab和pageoffice.jar文件拷贝到该目录下就可以了)文件。
第二步:修改WEB项目的配置文件,将如下代码添加到配置文件中:<!-- PageOffice Begin --><servlet><servlet-name>poserver</servlet-name><servlet-class>com.zhuozhengsoft .pageoffice.poserver.Server</servlet-class></servlet><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/poserver.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/pageoffice.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/popdf.cab</url-pattern></servlet-mapping><servlet-mapping><servlet-name>poserver</servlet-name><url-pattern>/sealsetup.exe</url-pattern></servlet-mapping><servlet><servlet-name>adminseal</servlet-name><servlet-class>com.zhuozhengsoft.pageoffice.poserver.AdminSeal </servlet-class></servlet><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/adminseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/loginseal.do</url-pattern></servlet-mapping><servlet-mapping><servlet-name>adminseal</servlet-name><url-pattern>/sealimage.do</url-pattern></servlet-mapping><mime-mapping><extension>mht</extension><mime-type>message/rfc822</mime-type></mime-mapping><context-param><param-name>adminseal-password</param-name><param-value>123456</param-value></context-param><!-- PageOffice End -->第三步:在WEB项目的WebRoot目录下添加文件夹存放word模板文件,在此命名为“doc”,将要打开的空白Word文件拷贝到该文件夹下,我要打开的Word文件为“test.doc”。
Java模板动态生成word文件的方法步骤

Java模板动态⽣成word⽂件的⽅法步骤最近项⽬中需要根据模板⽣成word⽂档,模板⽂件也是word⽂档。
当时思考⼀下想⽤POI API来做,但是觉得⽤起来相对复杂。
后来⼜找了⼀种⽅式,使⽤freemarker模板⽣成word⽂件,经过尝试觉得还是相对简单易⾏的。
使⽤freemarker模板⽣成word⽂档主要有这么⼏个步骤1、创建word模板:因为我项⽬中⽤到的模板本⾝是word,所以我就直接编辑word⽂档转成freemarker(.ftl)格式的。
2、将改word⽂件另存为xml格式,注意使⽤另存为,不是直接修改扩展名。
3、将xml⽂件的扩展名改为ftl4、编写java代码完成导出使⽤到的jar:freemarker.jar (2.3.28) ,其中Configuration对象不推荐直接new Configuration(),仔细看Configuration.class⽂件会发现,推荐的是 Configuration(Version incompatibleImprovements) 这个构造⽅法,具体这个构造⽅法⾥⾯传的就是Version版本类,⽽且版本号不能低于2.3.0闲⾔碎语不再讲,直接上代码public static void exportDoc() {String picturePath = "D:/image.png";Map<String, Object> dataMap = new HashMap<String, Object>();dataMap.put("brand", "海尔");dataMap.put("store_name", "海尔天津");dataMap.put("user_name", "⼩明");//经过编码后的图⽚路径String image = getWatermarkImage(picturePath);dataMap.put("image", image);//Configuration⽤于读取ftl⽂件Configuration configuration = new Configuration(new Version("2.3.0"));configuration.setDefaultEncoding("utf-8");Writer out = null;try {//输出⽂档路径及名称File outFile = new File("D:/导出优惠证明.doc");out = new BufferedWriter(new OutputStreamWriter(newFileOutputStream(new File("outFile")), "utf-8"), 10240);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (FileNotFoundException e) {e.printStackTrace();}// 加载⽂档模板Template template = null;try {//指定路径,例如C:/a.ftl 注意:此处指定ftl⽂件所在⽬录的路径,⽽不是ftl⽂件的路径configuration.setDirectoryForTemplateLoading(new File("C:/"));//以utf-8的编码格式读取⽂件template = configuration.getTemplate("导出优惠证明.ftl", "utf-8");} catch (IOException e) {e.printStackTrace();throw new RuntimeException("⽂件模板加载失败!", e);}// 填充数据try {template.process(dataMap, out);} catch (TemplateException e) {e.printStackTrace();throw new RuntimeException("模板数据填充异常!", e);} catch (IOException e) {e.printStackTrace();throw new RuntimeException("模板数据填充异常!", e);} finally {if (null != out) {try {out.close();} catch (IOException e) {e.printStackTrace();throw new RuntimeException("⽂件输出流关闭异常!", e);}}}}因为很多时候我们根据模板⽣成⽂件需要添加⽔印,也就是插⼊图⽚/**** 处理图⽚* @param watermarkPath 图⽚路径 D:/image.png* @return*/private String getWatermarkImage(String watermarkPath) {InputStream in = null;byte[] data = null;try {in = new FileInputStream(watermarkPath);data = new byte[in.available()];in.read(data);in.close();} catch (Exception e) {e.printStackTrace();}BASE64Encoder encoder = new BASE64Encoder();return encoder.encode(data);}注意点:插⼊图⽚后的word转化为ftl模板⽂件(ps:⽔印图⽚可以在word上调整到⾃⼰想要的⼤⼩,然后在执⾏下⾯的步骤)1、先另存为xml2、将xml扩展名改为ftl3、打开ftl⽂件, 搜索w:binData 或者 png可以快速定位图⽚的位置,图⽚已经编码成0-Z的字符串了, 如下:5、将上述0-Z的字符串全部删掉,写上${image}(变量名随便写,跟dataMap⾥的key保持⼀致)后保存6、也是创建⼀个Map, 将数据存到map中,只不过我们要把图⽚⽤代码进⾏编码,将其也编成0-Z的字符串,代码请看上边⾄此⼀个简单的按照模板⽣成word并插⼊图⽚(⽔印)功能基本完成。
java根据模板动态生成PDF实例

java根据模板动态⽣成PDF实例⼀、需求说明:根据业务需要,需要在服务器端⽣成可动态配置的PDF⽂档,⽅便数据可视化查看。
⼆、解决⽅案:iText+FreeMarker+JFreeChart⽣成可动态配置的PDF⽂档iText有很强⼤的PDF处理能⼒,但是样式和排版不好控制,直接写PDF⽂档,数据的动态渲染很⿇烦。
FreeMarker能配置动态的html模板,正好解决了样式、动态渲染和排版问题。
JFreeChart有这⽅便的画图API,能画出简单的折线、柱状和饼图,基本能满⾜需要。
三、实现功能:1、能动态配置PDF⽂档内容2、能动态配置中⽂字体显⽰3、设置⾃定义的页眉页脚信息4、能动态⽣成业务图⽚5、完成PDF的分页和图⽚的嵌⼊四、主要代码结构说明:1、component包:PDF⽣成的组件对外提供的是PDFKit⼯具类和HeaderFooterBuilder接⼝,其中PDFKit负责PDF的⽣成,HeaderFooterBuilder负责⾃定义页眉页脚信息。
2、builder包:负责PDF模板之外的额外信息填写,这⾥主要是页眉页脚的定制。
3、chart包:JFreeChart的画图⼯具包,⽬前只有⼀个线形图。
4、test包:测试⼯具类5、util包:FreeMarker等⼯具类。
五、关键代码说明:1、模板配置<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "/TR/xhtml1/DTD/xhtml1-strict.dtd"><html xmlns="/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/><meta http-equiv="Content-Style-Type" content="text/css"/><title></title><style type="text/css">body {font-family: pingfang sc light;}.center{text-align: center;width: 100%;}</style></head><body><!--第⼀页开始--><div class="page" ><div class="center"><p>${templateName}</p></div><div><p>iText官⽹:${ITEXTUrl}</p></div><div><p>FreeMarker官⽹:${freeMarkerUrl}</p></div><div><p>JFreeChart教程:${JFreeChartUrl}</p></div><div>列表值:</div><div><#list scores as item><div><p>${item}</p></div></#list></div></div><!--第⼀页结束--><!---分页标记--><span style="page-break-after:always;"></span><!--第⼆页开始--><div class="page"><div>第⼆页开始了</div><!--外部链接--><p>百度图标</p><div><img src="${imageUrl}" alt="百度图标" width="270" height="129"/></div><!--动态⽣成的图⽚--><p>⽓温变化对⽐图</p><div><img src="${picUrl}" alt="我的图⽚" width="500" height="270"/></div></div><!--第⼆页结束--></body></html>2、获取模板内容并填充数据/*** @description 获取模板*/public static String getContent(String fileName,Object data){String templatePath=getPDFTemplatePath(fileName);//根据PDF名称查找对应的模板名称String templateFileName=getTemplateName(templatePath);String templateFilePath=getTemplatePath(templatePath);if(StringUtils.isEmpty(templatePath)){throw new FreeMarkerException("templatePath can not be empty!");}try{Configuration config = new Configuration(Configuration.VERSION_2_3_25);//FreeMarker配置config.setDefaultEncoding("UTF-8");config.setDirectoryForTemplateLoading(new File(templateFilePath));//注意这⾥是模板所在⽂件夹,不是⽂件 config.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);config.setLogTemplateExceptions(false);Template template = config.getTemplate(templateFileName);//根据模板名称获取对应模板StringWriter writer = new StringWriter();template.process(data, writer);//模板和数据的匹配writer.flush();String html = writer.toString();return html;}catch (Exception ex){throw new FreeMarkerException("FreeMarkerUtil process fail",ex);}}3、导出模板到PDF⽂件/*** @description 导出pdf到⽂件* @param fileName 输出PDF⽂件名* @param data 模板所需要的数据**/public String exportToFile(String fileName,Object data){String htmlData= FreeMarkerUtil.getContent(fileName, data);//获取FreeMarker的模板数据if(StringUtils.isEmpty(saveFilePath)){saveFilePath=getDefaultSavePath(fileName);//设置PDF⽂件输出路径}File file=new File(saveFilePath);if(!file.getParentFile().exists()){file.getParentFile().mkdirs();}FileOutputStream outputStream=null;try{//设置输出路径outputStream=new FileOutputStream(saveFilePath);//设置⽂档⼤⼩Document document = new Document(PageSize.A4);//IText新建PDF⽂档PdfWriter writer = PdfWriter.getInstance(document, outputStream);//设置⽂档和输出流的关系//设置页眉页脚PDFBuilder builder = new PDFBuilder(headerFooterBuilder,data);builder.setPresentFontSize(10);writer.setPageEvent(builder);//输出为PDF⽂件convertToPDF(writer,document,htmlData);}catch(Exception ex){throw new PDFException("PDF export to File fail",ex);}finally{IOUtils.closeQuietly(outputStream);}return saveFilePath;}4、测试⼯具类public String createPDF(Object data, String fileName){//pdf保存路径try {//设置⾃定义PDF页眉页脚⼯具类PDFHeaderFooter headerFooter=new PDFHeaderFooter();PDFKit kit=new PDFKit();kit.setHeaderFooterBuilder(headerFooter);//设置输出路径kit.setSaveFilePath("/Users/fgm/Desktop/pdf/hello.pdf”);//设置出书路径String saveFilePath=kit.exportToFile(fileName,data);return saveFilePath;} catch (Exception e) {log.error("PDF⽣成失败{}", ExceptionUtils.getFullStackTrace(e));return null;}}public static void main(String[] args) {ReportKit360 kit=new ReportKit360();TemplateBO templateBO=new TemplateBO();//配置模板数据templateBO.setTemplateName("Hello iText! Hello freemarker! Hello jFreeChart!");templateBO.setFreeMarkerUrl("/chm/freemarker2_3_24/ref_directive_if.html");templateBO.setITEXTUrl("/examples-itext5");templateBO.setJFreeChartUrl("/jfreechart/jfreechart_referenced_apis.html");templateBO.setImageUrl("https:///5aV1bjqh_Q23odCf/static/superman/img/logo/bd_logo1_31bdc765.png"); List<String> scores=new ArrayList<String>();scores.add("90");scores.add("95");scores.add("98");templateBO.setScores(scores);List<Line> lineList=getTemperatureLineList();TemperatureLineChart lineChart=new TemperatureLineChart();String picUrl=lineChart.draw(lineList,0);//⾃定义的数据画图templateBO.setPicUrl(picUrl);String path= kit.createPDF(templateBO,"hello.pdf");System.out.println(path);}六、⽣成效果图:七、项⽬完整代码⼋、遇到的坑:1、FreeMarker配置模板⽂件样式,在实际PDF⽣成过程中,可能会出现⼀些不⼀致的情形,⽬前解决⽅法,就是换种⽅式调整样式。
Javafreemarker生成word模板文件(如合同文件)及转pdf文件方法
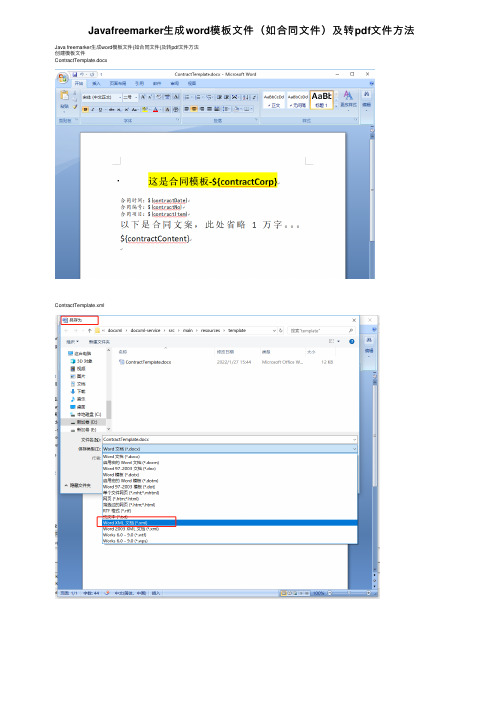
Javafreemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法Java freemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法创建模板⽂件ContractTemplate.docxContractTemplate.xml导⼊的Jar包compile("junit:junit")compile("org.springframework:spring-test")compile("org.springframework.boot:spring-boot-test")testCompile 'org.springframework.boot:spring-boot-starter-test'compile 'org.freemarker:freemarker:2.3.28'compile 'fakepath:aspose-words:19.5jdk'compile 'fakepath:aspose-cells:8.5.2'Java⼯具类 xml⽂档转换 Word XmlToDocx.javapackage com.test.docxml.utils;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.InputStream;import java.util.Enumeration;import java.util.zip.ZipEntry;import java.util.zip.ZipFile;import java.util.zip.ZipOutputStream;/*** xml⽂档转换 Word*/public class XmlToDocx {/**** @param documentFile 动态⽣成数据的docunment.xml⽂件* @param docxTemplate docx的模板* @param toFilePath 需要导出的⽂件路径* @throws Exception*/public static void outDocx(File documentFile, String docxTemplate, String toFilePath,String key) throws Exception { try {File docxFile = new File(docxTemplate);ZipFile zipFile = new ZipFile(docxFile);Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();FileOutputStream fileOutputStream = new FileOutputStream(toFilePath);ZipOutputStream zipout = new ZipOutputStream(fileOutputStream);int len = -1;byte[] buffer = new byte[1024];while (zipEntrys.hasMoreElements()) {ZipEntry next = zipEntrys.nextElement();InputStream is = zipFile.getInputStream(next);// 把输⼊流的⽂件传到输出流中如果是word/document.xml由我们输⼊zipout.putNextEntry(new ZipEntry(next.toString()));if ("word/document.xml".equals(next.toString())) {InputStream in = new FileInputStream(documentFile);while ((len = in.read(buffer)) != -1) {zipout.write(buffer, 0, len);}in.close();} else {while ((len = is.read(buffer)) != -1) {zipout.write(buffer, 0, len);}is.close();}}zipout.close();} catch (Exception e) {e.printStackTrace();}}}Java⼯具类 word⽂档转换 PDF WordToPdf.javapackage com.test.docxml.utils;import com.aspose.cells.*;import com.aspose.cells.License;import com.aspose.words.*;import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;/*** word⽂档转换 PDF*/public class WordToPdf {/*** 获取license许可凭证* @return*/private static boolean getLicense() {boolean result = false;try {String licenseStr = "<License>\n"+ " <Data>\n"+ " <Products>\n"+ " <Product>Aspose.Total for Java</Product>\n"+ " <Product>Aspose.Words for Java</Product>\n"+ " </Products>\n"+ " <EditionType>Enterprise</EditionType>\n"+ " <SubscriptionExpiry>20991231</SubscriptionExpiry>\n"+ " <LicenseExpiry>20991231</LicenseExpiry>\n"+ " <SerialNumber>23dcc79f-44ec-4a23-be3a-03c1632404e9</SerialNumber>\n"+ " </Data>\n"+ " <Signature>0nRuwNEddXwLfXB7pw66G71MS93gW8mNzJ7vuh3Sf4VAEOBfpxtHLCotymv1PoeukxYe31K441Ivq0Pkvx1yZZG4O1KCv3Omdbs7uqzUB4xXHlOub4VsTODzDJ5MWHqlRCB1HHcGjlyT2sVGiovLt0Grvqw5+QXBuin + "</License>";InputStream license = new ByteArrayInputStream(licenseStr.getBytes("UTF-8"));License asposeLic = new License();asposeLic.setLicense(license);result = true;} catch (Exception e) {e.printStackTrace();}return result;}/*** word⽂档转换为 PDF* @param inPath 源⽂件* @param outPath ⽬标⽂件*/public static File doc2pdf(String inPath, String outPath) {//验证License,获取许可凭证if (!getLicense()) {return null;}//新建⼀个PDF⽂档File file = new File(outPath);try {//新建⼀个IO输出流FileOutputStream os = new FileOutputStream(file);//获取将要被转化的word⽂档Document doc = new Document(inPath);// 全⾯⽀持DOC, DOCX,OOXML, RTF HTML,OpenDocument,PDF, EPUB, XPS,SWF 相互转换doc.save(os, com.aspose.words.SaveFormat.PDF);os.close();} catch (Exception e) {e.printStackTrace();}return file;}public static void main(String[] args) {doc2pdf("D:/1.doc", "D:/1.pdf");}}Java单元测试类 XmlDocTest.javapackage com.test.docxml;import com.test.docxml.utils.WordToPdf;import com.test.docxml.utils.XmlToDocx;import freemarker.template.Configuration;import freemarker.template.Template;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.core.io.ClassPathResource;import org.springframework.core.io.Resource;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import org.springframework.test.context.web.WebAppConfiguration;import java.io.File;import java.io.PrintWriter;import java.io.Writer;import java.nio.charset.Charset;import java.util.HashMap;import java.util.Locale;import java.util.Map;/*** 本地单元测试*/@RunWith(SpringJUnit4ClassRunner.class)//@RunWith(SpringRunner.class)@SpringBootTest(classes= TemplateApplication.class)@WebAppConfigurationpublic class XmlDocTest {//短租@Testpublic void testContract() throws Exception{String contractNo = "1255445544";String contractCorp = "银河宇宙⽆敌测试soft";String contractDate = "2022-01-27";String contractItem = "房地产交易中⼼";String contractContent = "稳定发展中的⽂案1万字";//doc xml模板⽂件String docXml = "ContractTemplate.xml"; //使⽤替换内容//xml中间临时⽂件String xmlTemp = "tmp-ContractTemplate.xml";//⽣成⽂件的doc⽂件String toFilePath = contractNo + ".docx";//模板⽂档String docx = "ContractTemplate.docx";//⽣成pdf⽂件String toPdfFilePath = contractNo + ".pdf";;String CONTRACT_ROOT_URL = "/template";Resource contractNormalPath = new ClassPathResource(CONTRACT_ROOT_URL + File.separator + docXml);String docTemplate = contractNormalPath.getURI().getPath().replace(docXml, docx);//设置⽂件编码(注意点1)Writer writer = new PrintWriter(new File(xmlTemp),"UTF-8");Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);configuration.setEncoding(Locale.CHINESE, Charset.forName("UTF-8").name());//设置配置(注意点3)configuration.setDefaultEncoding("UTF-8");String filenametest = contractNormalPath.getURI().getPath().replace(docXml, "");System.out.println("filenametest=" + filenametest);configuration.setDirectoryForTemplateLoading(new File(filenametest));// Template template = configuration.getTemplate(ContractConstants.CONTRACT_NORMAL_URL+orderType+type+".xml"); //设置模板编码(注意点2)Template template = configuration.getTemplate(docXml,"UTF-8"); //绝对地址Map paramsMap = new HashMap();paramsMap.put("contractCorp",contractCorp);paramsMap.put("contractDate",contractDate);paramsMap.put("contractNo",contractNo);paramsMap.put("contractItem",contractItem);paramsMap.put("contractContent",contractContent);template.process(paramsMap, writer);XmlToDocx.outDocx(new File(xmlTemp), docTemplate, toFilePath, null);System.out.println("do finish");//转成pdfWordToPdf.doc2pdf(toFilePath,toPdfFilePath);}}创建成功之后的⽂件如下:。
Java使用IText(VM模版)导出PDF,IText导出word(二)

Java使⽤IText(VM模版)导出PDF,IText导出word(⼆)===============action===========================//退款导出wordpublic void exportWordTk() throws IOException{Long userId=(Long)ServletActionContext.getContext().getSession().get(Constant.SESSION_USER_ID);//获取⽣成Pdf需要的⼀些路径String tmPath=ServletActionContext.getServletContext().getRealPath("download/template");//vm 模板路径String wordPath=ServletActionContext.getServletContext().getRealPath("download/file");//⽣成word路径//wordPath+"/"+userId+"_"+fk+".doc"//数据Map map=new HashMap();//velocity模板中的变量map.put("date1",this.fk);map.put("date",new SimpleDateFormat("yyyy-MM-dd HH:mm").format(new Date()));String newFile=wordPath+"/tk_word_"+userId+".doc";File file=new File(newFile);if(!file.exists()){//设置字体,⽀持中⽂显⽰new PdfUtil().addFontAbsolutePath(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun.ttf"));//这个字体需要⾃⼰去下载PdfUtil.createByVelocityPdf(tmPath,"tk_word.vm", wordPath+"/tk_word_"+userId+".pdf", map);//导出PDFPdfUtil.createByVelocityDoc(tmPath,"tk_word.vm",newFile, map);//导出word}sendMsgAjax("dzz/download/file/tk_word_"+userId+".doc");}=================vm ⽂件模板(tk_word.vm)=====================<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><title></title><style type="text/css">body, button, input, select, textarea {color: color:rgb(0,0,0);font: 14px/1.5 tahoma,arial,宋体,sans-serif;}p{margin:0;padding:0;}.title{border-bottom:1px solid rgb(0,0,0);margin:0;padding:0;width:85%;height:25px;}li{list-style:none;}.li_left li{text-align:left;line-height:47px;font-size:14pt;}.li_left{width:610px;}.fnt-21{font-size:16pt;}table{width:90%;/*argin-left:25px;*/}div_cls{width:100%;text-align:center;}</style></head><body style="font-family: songti;width:100%;text-align:center;"><div style="text-align:center;"><b class="fnt-21"> 本组评审结果清单</b> </div> <table border="1" cellpadding="0" cellspacing="0" style="width:90%;margin-left:25px;"> <tr><td style="width:20%" align="center">申报单位</td><td style="width:10%" align="center">申报经费(万元)</td></tr></table><br/><div><ul style="float:right;margin-right:40px;"><li>$date</li><!--获取后天封装的数据--></ul></div></body></html>====================⼯具类======================package com.qgc.dzz.util;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.io.PrintWriter;import .URL;import java.util.ArrayList;import java.util.List;import java.util.Map;import java.util.UUID;import org.apache.struts2.ServletActionContext;import org.apache.velocity.Template;import org.apache.velocity.VelocityContext;import org.apache.velocity.app.VelocityEngine;import org.xhtmlrenderer.pdf.ITextFontResolver;import org.xhtmlrenderer.pdf.ITextRenderer;import com.lowagie.text.Document;import com.lowagie.text.DocumentException;import com.lowagie.text.Font;import com.lowagie.text.Image;import com.lowagie.text.Rectangle;import com.lowagie.text.pdf.BaseFont;import com.lowagie.text.pdf.PdfImportedPage;import com.lowagie.text.pdf.PdfReader;import com.lowagie.text.pdf.PdfWriter;public class PdfUtil {private static List<String> fonts = new ArrayList();//字体路径/*** 使⽤vm导出word* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param docPath ⽣成⽂件的路径,包含⽂件如:d://temp.doc* @param map 参数,传递到vm* @return*/public static boolean createByVelocityDoc(String localPath, String templateFileName, String docPath, Map<String, Object> map) {try{createFile(localPath,templateFileName,docPath, map);return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 导出pdf* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param pdfPath ⽣成⽂件的路径,包含⽂件如:d://temp.pdf* @param map 参数,传递到vm* @return*/public static boolean createByVelocityPdf(String localPath, String templateFileName, String pdfPath, Map<String, Object> map) {try{String htmlPath = pdfPath + UUID.randomUUID().toString() + ".html";createFile(localPath, templateFileName, htmlPath, map);//⽣成html 临时⽂件HTML2OPDF(htmlPath, pdfPath, fonts);//html转成pdfFile file = new File(htmlPath);file.delete();return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 合并PDF* @param writer* @param document* @param reader* @throws DocumentException*/public void addToPdfUtil(PdfWriter writer, Document document,PdfReader reader) throws DocumentException {int n = reader.getNumberOfPages();Rectangle pageSize = document.getPageSize();float docHeight = pageSize.getHeight();float docWidth = pageSize.getWidth();for (int i = 1; i <= n; i++) {document.newPage();PdfImportedPage page = writer.getImportedPage(reader, i);Image image = Image.getInstance(page);float imgHeight = image.getPlainHeight();float imgWidth = image.getPlainWidth();if (imgHeight < imgWidth) {float temp = imgHeight;imgHeight = imgWidth;imgWidth = temp;image.setRotationDegrees(90.0F);}if ((imgHeight > docHeight) || (imgWidth > docWidth)) {float hc = imgHeight / docHeight;float wc = imgWidth / docHeight;float suoScale = 0.0F;if (hc > wc)suoScale = 1.0F / hc * 100.0F;else {suoScale = 1.0F / wc * 100.0F;}image.scalePercent(suoScale);}image.setAbsolutePosition(0.0F, 0.0F);document.add(image);}}/*** html 转成 pdf ⽅法* @param htmlPath html路径* @param pdfPath pdf路径* @param fontPaths 字体路径* @throws Exception*/public static void HTML2OPDF(String htmlPath, String pdfPath,List<String> fontPaths)throws Exception{String url = new File(htmlPath).toURI().toURL().toString();//获取⽣成html的路径OutputStream os = new FileOutputStream(pdfPath);//创建输出流ITextRenderer renderer = new ITextRenderer();//itext 对象ITextFontResolver fontResolver = renderer.getFontResolver();//字体// //⽀持中⽂显⽰字体// fontResolver.addFont(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun_0.ttf"), // BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);if ((fontPaths != null) && (!fontPaths.isEmpty())) {URL classPath = PdfUtil.class.getResource("/");for (String font : fontPaths) {if (font.contains(":"))fontResolver.addFont(font, "Identity-H", false);else {fontResolver.addFont(classPath + "/" + font, "Identity-H",false);}}}renderer.setDocument(url);//设置html路径yout();renderer.createPDF(os);//html转换成pdfSystem.gc();os.close();System.gc();}public static boolean createFile(String localPath, String templateFileName,String newFilePath, Map<String, Object> map){try{VelocityEngine engine = new VelocityEngine();engine.setProperty("file.resource.loader.path", localPath);//指定vm路径Template template = engine.getTemplate(templateFileName, "UTF-8");//指定vm模板VelocityContext context = new VelocityContext();//创建上下⽂对象if (map != null){Object[] keys = map.keySet().toArray();for (Object key : keys) {String keyStr = key.toString();context.put(keyStr, map.get(keyStr));//传递参数到上下⽂对象}}PrintWriter writer = new PrintWriter(newFilePath, "UTF-8");//写⼊参数到vm template.merge(context, writer);writer.flush();writer.close();return true;} catch (Exception e) {e.printStackTrace();}return false;}public static Font FONT = getChineseFont();public static BaseFont BSAE_FONT = getBaseFont();/*** ⽀持显⽰中⽂* @return*/public static Font getChineseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}Font fontChinese = new Font(bfChinese);return fontChinese;}public static BaseFont getBaseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return bfChinese;}public void addFontAbsolutePath(String path) {this.fonts.add(path);}public void addFontClassPath(String path) {this.fonts.add(path);}public List<String> getFonts() {return this.fonts;}public void setFonts(List<String> fonts) {this.fonts = fonts;}}。
Java利用poi生成word(包含插入图片,动态表格,行合并)

//图片,如果是多个图片,就新建多个map Map<String,Object> picture1 = new HashMap<String, Object>(); picture1.put("width", 100); picture1.put("height", 150); picture1.put("type", "jpg"); picture1.put("content", WorderToNewWordUtils.inputStream2ByteArray(new FileInputStream("D:/docTest/p1.jpg"), true)); data.put("${picture1}",picture1);
data.put("${address}", "华东院"); /* data.put("${communityvalue}", ""); data.put("${safetycode}", "华东院"); data.put("${picture2}", ""); data.put("${picture3}", "");*/ data.put("${buildingvalue2}", "华东院"); /* data.put("${patrolPhoto1}", ""); data.put("${patrolPhoto2}", ""); data.put("${buildingvalue3}", "中国");*/
java生成word

java⽣成word当我们使⽤Java⽣成word⽂档时,通常⾸先会想到iText和POI,这是因为我们习惯了使⽤这两种⽅法操作Excel,⾃然⽽然的也想使⽤这种⽣成word⽂档。
但是当我们需要动态⽣成word时,通常不仅要能够显⽰word中的内容,还要能够很好的保持word中的复杂样式。
这时如果再使⽤IText和POI去操作,就好⽐程序员去搬砖⼀样痛苦。
这时候,我们应该考虑使⽤FreeMarker的模板技术快速实现这个复杂的功能,让程序员在喝咖啡的过程中就把问题解决。
实现思路是这样的:先创建⼀个word⽂档,按照需求在word中填好⼀个模板,然后把对应的数据换成变量${},然后将⽂档保存为xml⽂档格式,使⽤⽂档编辑器打开这个xml格式的⽂档,去掉多余的xml符号,使⽤Freemarker读取这个⽂档然后替换掉变量,输出word⽂档即可。
具体过程如下:1.创建带有格式的word⽂档,将该需要动态展⽰的数据使⽤变量符替换。
2. 将刚刚创建的word⽂档另存为xml格式。
3.编辑这个XMl⽂档去掉多余的xml标记,如图中蓝⾊部分 4.从官⽹最新的开发包,将freemarker.jar拷贝到⾃⼰的开发项⽬中。
5.新建DocUtil类,实现根据Doc模板⽣成word⽂件的⽅法1234 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36package com.favccxx.secret.util;import java.io.BufferedWriter;import java.io.File;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import java.util.Map;import freemarker.template.Configuration;import freemarker.template.DefaultObjectWrapper;import freemarker.template.Template;import freemarker.template.TemplateExceptionHandler;public class DocUtil {privateConfiguration configure = null;publicDocUtil(){configure= new Configuration();configure.setDefaultEncoding("utf-8");}/*** 根据Doc模板⽣成word⽂件* @param dataMap Map 需要填⼊模板的数据* @param fileName ⽂件名称* @param savePath 保存路径*/publicvoid createDoc(Map<String, Object> dataMap, String downloadType, StringsavePath){try{//加载需要装填的模板Templatetemplate = null;//加载模板⽂件configure.setClassForTemplateLoading(this.getClass(),"/com/favccxx/secret/templates"); //设置对象包装器configure.setObjectWrapper(newDefaultObjectWrapper());//设置异常处理器configure.setTemplateExceptionHandler(TemplateExceptionHandler.IGNORE_HANDLER); //定义Template对象,注意模板类型名字与downloadType要⼀致template= configure.getTemplate(downloadType + ".xml");//输出⽂档FileoutFile = new File(savePath);Writerout = null;3637 38 39 40 41 42 43 44 45 46 out= new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"utf-8")); template.process(dataMap,out);outFile.delete();}catch(Exception e) {e.printStackTrace();}}} 6.⽤户根据⾃⼰的需要,调⽤使⽤getDataMap获取需要传递的变量,然后调⽤createDoc⽅法⽣成所需要的⽂档。
java生成复杂pdf的方法

java生成复杂pdf的方法摘要:1.Java 生成复杂PDF 的方法1.1.Java 的优势1.2.生成复杂PDF 的方法1.2.1.使用iText 库1.2.2.使用Apache PDFBox 库1.2.3.使用Java 内置的PDF 支持1.3.选择合适的库1.4.总结正文:Java 作为一种广泛应用的编程语言,具有跨平台、可移植性强等优势。
在生成复杂PDF 方面,Java 同样具有很好的表现。
本文将介绍几种Java 生成复杂PDF 的方法。
首先,Java 的优势在于其跨平台性,这意味着在编写代码时,可以忽略底层操作系统和硬件的差异,从而更专注于业务逻辑。
此外,Java 有着丰富的开源库,可以帮助开发者轻松实现各种功能。
在生成复杂PDF 方面,Java 有多种方法可供选择。
其中,使用iText 库、Apache PDFBox 库以及Java 内置的PDF 支持是最常见的几种方式。
iText 库是一个功能强大的Java PDF 库,可以轻松地创建、编辑和处理PDF 文件。
它提供了丰富的API,支持各种PDF 对象的创建和操作。
使用iText 库,可以方便地实现复杂PDF 的生成,例如添加图片、表格、超链接等。
同时,iText 库还支持将PDF 文件转换为其他格式,如HTML、XML 等。
Apache PDFBox 库是另一个常用的Java PDF 库,它提供了一组工具,用于处理PDF 文档。
与iText 库相比,PDFBox 库更注重底层操作,可以实现对PDF 文件的无缝解析。
通过PDFBox 库,可以提取PDF 文件中的文本、图片等元素,并对其进行操作。
这使得Apache PDFBox 库在处理复杂PDF 时具有较高的灵活性。
此外,Java 内置的PDF 支持也是一个值得关注的领域。
随着Java 7 的发布,Java 引入了PDF 支持,使得开发者可以直接在Java 代码中处理PDF 文件。
java openoffice用法

java openoffice用法OpenOffice是一款开源、跨平台的办公套件,提供了文字处理、电子表格、演示文稿等多种功能。
Java OpenOffice用法是指使用Java编程语言与OpenOffice进行交互,实现自动化文档操作、数据处理等功能。
Java OpenOffice的常见用途包括:1. 文档生成与处理:使用Java OpenOffice可以生成各种类型的文档,如Word文档、PDF文档等。
通过Java代码,可以控制文档格式、内容、样式等,实现自动化的文档生成。
同时,Java OpenOffice还可以对已有文档进行编辑、修改、合并等操作。
2. 数据导入与导出:通过Java OpenOffice,可以将数据库或其他数据源中的数据导入到OpenOffice文档中,实现数据的格式化展示。
反之,也可以将OpenOffice文档中的数据导出到数据库或其他数据源中,实现数据的持久化存储。
3. 批量处理与自动化:Java OpenOffice提供了一系列的API,可以对大量的文档进行批量处理。
比如,可以通过Java代码自动化地将多个文档合并为一个文档,或者将一个文档分割为多个文档。
这样,可以大大提高工作效率,并减少手动操作的时间和错误。
4. 模板管理:Java OpenOffice支持使用模板来创建文档,通过Java代码可以动态地填充模板中的变量和内容。
这样,可以快速地生成符合特定格式要求的文档。
同时,还可以实现模板的更新和管理,方便灵活地应对不同的需求。
5. 图表和图形操作:Java OpenOffice能够创建各种类型的图表和图形,并对其进行自定义。
通过Java代码,可以更改图表的样式、颜色、标签等,并将其插入到文档中或导出为图片文件。
6. 导出为其他格式:Java OpenOffice不仅可以导出为常见的文档格式,还可以将文档导出为HTML、XML、纯文本等格式。
这样,可以方便地将文档共享给其他系统或进行进一步处理。
Java 将Word转为PDF、html、图片、XPS(基于Spire.Cloud.SDK for Java)

Java 将Word转为PDF/Html/图片/XPS/SVG(基于Spire.Cloud.SDK for Java)Spire.Cloud.SDK for Java API提供了ConverApi接口支持将Word文档转换为多种文档格式,包括将Word转为PDF、Html、位图Bitmap(JPEG/BMP/ PNG)、矢量图Vectorgraph(支持WMF/SVG)、XPS、PostScript、PCL、dotx、dotm、docm、odt、wordxml、wordml、doc、docx、rtf、epub等等。
下面将详细介绍如何来实现转换。
步骤一、导入jar文件创建Maven项目程序,通过maven仓库下载导入。
以IDEA为例,新建Maven项目,在pom.xml文件中配置maven仓库路径,并指定spire.cloud.sdk的依赖,如下:<repositories><repository><id>com.e-iceblue</id><name>cloud</name><url>/repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId> cloud </groupId><artifactId>spire.cloud.sdk</artifactId><version>3.5.0</version></dependency><dependency><groupId> com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.1</version></dependency><dependency><groupId> com.squareup.okhttp</groupId><artifactId>logging-interceptor</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okhttp </groupId><artifactId>okhttp</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okio </groupId><artifactId>okio</artifactId><version>1.6.0</version></dependency><dependency><groupId> io.gsonfire</groupId><artifactId>gson-fire</artifactId><version>1.8.0</version></dependency><dependency><groupId>io.swagger</groupId><artifactId>swagger-annotations</artifactId><version>1.5.18</version></dependency><dependency><groupId> org.threeten </groupId><artifactId>threetenbp</artifactId><version>1.3.5</version></dependency></dependencies>完成配置后,点击“Import Changes” 即可导入所有需要的jar文件。
详解Java生成PDF文档方法

详解Java⽣成PDF⽂档⽅法最近项⽬需要实现PDF下载的功能,由于没有这⽅⾯的经验,从⽹上花了很长时间才找到相关的资料。
整理之后,发现有如下⼏个框架可以实现这个功能。
1. 开源框架⽀持1. iText,⽣成PDF⽂档,还⽀持将XML、Html⽂件转化为PDF⽂件;2. Apache PDFBox,⽣成、合并PDF⽂档;3. docx4j,⽣成docx、pptx、xlsx⽂档,⽀持转换为PDF格式。
⽐较:1. iText开源协议为AGPL,⽽其他两个框架协议均为Apache License v2.0。
2. 使⽤PDFBox⽣成PDF就像画图似的,⽂字和图像根据页⾯坐标画上去的,需要根据字数⼿动换⾏。
3. docx4j⽤来⽣成docx⽂档,提供了将WORD⽂档转换为PDF⽂档的功能,并不能直接⽣成PDF⽂档。
2. 实现⽅案—格式复杂格式简单数据量⼤docx4j+freemarker docx4j或PDFBox数据量⼩docx4j PDFBox2.1 纯数据⽣成PDF1.docx4j,适⽤于⽣成格式简单或格式复杂且数据量⼩的PDF⽂档;2.Apache PDFBox,适⽤于⽣成格式简单且数据量⼩的PDF⽂档。
1.docx4jdocx4j是⼀个开源Java库,⽤于创建和操作Microsoft Open XML(Word docx,Powerpoint pptx和Excel xlsx)⽂件。
它类似于Microsoft的OpenXML SDK,但适⽤于Java。
docx4j使⽤JAXB来创建内存中的对象表⽰,程序员需要花时间了解JAXB和Open XML⽂件结构。
// word对象WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage();// ⽂档主体MainDocumentPart mainDocumentPart = wordMLPackage.getMainDocumentPart();// 换⾏符Br br = objectFactory.createBr();// 段落P p = objectFactory.createP();// 段落设置PPr ppr = objectFactory.createPPr();// ⽂字位置Jc jc = new Jc();jc.setVal(je);ppr.setJc(jc);// ⾏设置RPr rpr = objectFactory.createRPr();// 字体设置RFonts rFonts = objectFactory.createRFonts();rFonts.setAscii("Times New Roman");rFonts.setEastAsia("宋体");rpr.setRFonts(rFonts);// ⾏R r = objectFactory.createR();// ⽂本Text text = objectFactory.createText();text.setValue("这是⼀段普通⽂本");r.setRPr(rpr);r.getContent().add(br);r.getContent().add(text);p.getContent().add(r);p.setPPr(ppr);// 添加到正⽂中mainDocumentPart.addObject(p);// 导出//..2.Apache PDFBox Apache PDFBox是处理PDF⽂档的⼀个开源的Java⼯具。
Java实现word模板转为pdf

Java实现word模板转为pdf1. pom相关依赖⼯具poi-tl (操作word⽂档模板) + jacob (将操作后的word模板转为pdf)<!-- poi-tl的pom依赖 --><dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.9.1</version></dependency><!-- jacob的pom依赖(需⾃⾏导⼊.jar包) --><dependency><groupId>com.jacob</groupId><artifactId>jacob</artifactId><version>1.17</version><scope>system</scope><systemPath>${project.basedir}/src/main/resources/lib/jacob.jar</systemPath></dependency>2. 对word模板进⾏插⼊数据操作使⽤poi-tl操作word需要创建⼀个⽤于向word插⼊数据的Map<String, Object>集合, word模板中标签格式为"{{标签}}", 其中标签内容为Map<String, Object> 的key.// 项⽬根路径String abPath = new File("").getAbsolutePath() + "/src/main/resources";// 创建⽤于插⼊数据的MapMap<String, Object> map = new HashMap<>();map.put(<k>, <v>);...// 填充word⽂档XWPFTemplate template = pile(abPath + "<模板路径>").render(map);// 输出⽂档template.writeAndClose(new FileOutPutStream("<输出路径>"));3. 对word模板的表格执⾏插⼊数据操作(动态表格)使⽤poi-tl操作word的表格,动态的插⼊数据,需要⽤到poi-tl的可选插件进⾏⾃定义渲染策略, ⾸先在word需要操作的表格中的任意单元格添加标签“{{标签}}”⾃定义渲染策略/*** ⾃定义渲染策略** @author*/public class DetailTablePolicy extends DynamicTableRenderPolicy {// 表格起始⾏⾏数int tableStartRow = 1;/*** ⾃定义渲染策略** @data 传⼊的封装好的数据*/@Overridepublic void render(XWPFTable table, Object data) throws Exception {// 如果数据为空,直接返回if (null == data) return;// 封装数据List的数据封装对象NdrwhkhzbData detailData = (NdrwhkhzbData) data;// 获取当前列表⾏⾼int height = table.getRow(2).getHeight();// 从封装对象中获取数据集合List<RowRenderData> datas = detailData.getNdrwhkhzbs();if (null != datas) {// 循环移除空⽩表格中数据数量的空⽩⾏for (int i = 1; i < datas.size() + 2; i++) {table.removeRow(i);}// 循环插⼊数据for (int i = 0; i < datas.size(); i++) {// 新增⼀⾏空⽩⾏XWPFTableRow insertNewTableRow = table.insertNewTableRow(tableStartRow);// 设置⾏⾼insertNewTableRow.setHeight(height);// 循环添加单元格(4为每⾏单元格数量)for (int j = 0; j < 4; j++) {insertNewTableRow.createCell();}// 填充表格TableRenderPolicy.Helper.renderRow(table.getRow(tableStartRow), datas.get(i));}}}}把⾃定义渲染策略当做⼯具类, 在主逻辑中直接配置使⽤/*** 操作年度任务和考核指标表** @throws IOException 输⼊输出流异常*/private void createNdrwhkhzb(Integer uid, String dirPath) throws IOException {PageData datas = new PageData();NdrwhkhzbData detailTable = new NdrwhkhzbData();List<RowRenderData> nds = new ArrayList<>();// 根据uid查询年度任务和考核指标数据List<NdrwhkhzbEntity> list = ndrwhkhzbService.selectNdrwhkhzbByUid(uid);for (NdrwhkhzbEntity ndrwhkhzbEntity : list) {RowRenderData rrd = Rows.of(ndrwhkhzbEntity.getNd(), ndrwhkhzbEntity.getNdrw(), ndrwhkhzbEntity.getNdkhzb(), ndrwhkhzbEntity.getZyrwdsjjd()).center().create();nds.add(rrd);}detailTable.setNdrwhkhzbs(nds);datas.setNdrwhkhzbData(detailTable);// 配置表格Configure config = Configure.builder().bind("detail_table", new DetailTablePolicy()).build();// 调⽤渲染策略进⾏填充XWPFTemplate template =pile(dirPath + "/" + uid + "_Complete.docx", config).render(datas);// 写⼊表格中template.writeToFile(dirPath + "/" + uid + "_Complete.docx");}⽤到的⼀些实体类// PageDatapublic class PageData {@Name("detail_table")private NdrwhkhzbData ndrwhkhzbData;public NdrwhkhzbData getNdrwhkhzbData() {return ndrwhkhzbData;}public void setNdrwhkhzbData(NdrwhkhzbData ndrwhkhzbData) {this.ndrwhkhzbData = ndrwhkhzbData;}}// NdrwhkhzbDatapublic class NdrwhkhzbData {private List<RowRenderData> ndrwhkhzbs;public List<RowRenderData> getNdrwhkhzbs() {return ndrwhkhzbs;}public void setNdrwhkhzbs(List<RowRenderData> ndrwhkhzbs) {this.ndrwhkhzbs = ndrwhkhzbs;}}4. 将编辑好的Word转为pdf格式(jacob)这⾥将word转为pdf时需要⽤到jacob, 这⾥需要将jacob的dll⽂件放到jdk和jre的bin⽬录下, 下载的jacob中dll⽂件⼀般为两个版本, X86为32位, X64为64位, 根据⾃⼰安装的jdk版本添加所对应的dll⽂件/** 将 .docx 转换为 .pdf*/ActiveXComponent app = null;String wordFile = dirPath + "/" + uid + "_Complete.docx";String pdfFile = dirPath + "/" + dirName + ".pdf";System.out.println("开始转换...");// 开始时间long start = System.currentTimeMillis();try {// 打开wordapp = new ActiveXComponent("Word.Application");// 设置word不可见,很多博客下⾯这⾥都写了这⼀句话,其实是没有必要的,因为默认就是不可见的,如果设置可见就是会打开⼀个word⽂档,对于转化为pdf明显是没有必要的 //app.setProperty("Visible", false);// 获得word中所有打开的⽂档Dispatch documents = app.getProperty("Documents").toDispatch();System.out.println("打开⽂件: " + wordFile);// 打开⽂档Dispatch documentP = Dispatch.call(documents, "Open", wordFile, false, true).toDispatch(); // 如果⽂件存在的话,不会覆盖,会直接报错,所以我们需要判断⽂件是否存在File target = new File(pdfFile);if (target.exists()) {target.delete();}System.out.println("另存为: " + pdfFile);// 另存为,将⽂档报错为pdf,其中word保存为pdf的格式宏的值是17Dispatch.call(documentP, "SaveAs", pdfFile, 17);// 关闭⽂档Dispatch.call(documentP, "Close", false);// 结束时间long end = System.currentTimeMillis();System.out.println("转换成功,⽤时:" + (end - start) + "ms");} catch (Exception e) {e.getMessage();System.out.println("转换失败" + e.getMessage());} finally {// 关闭officeapp.invoke("Quit", 0);}5. 通过lo流将⽣成好的⽂件传到浏览器下载/** 下载pdf*/String fileName = dirName + ".pdf";File file = new File(dirPath + "/" + fileName);if (file.exists()) {BufferedInputStream bis = null;FileInputStream fis = null;try {response.setHeader("Content-disposition", "attachment; filename=" + fileName);byte[] buff = new byte[2048];fis = new FileInputStream(file);bis = new BufferedInputStream(fis);OutputStream os = response.getOutputStream();int i = bis.read(buff);while (i != -1) {os.write(buff, 0, i);i = bis.read(buff);}os.close();} catch (Exception e) {e.printStackTrace();} finally {assert fis != null;fis.close();assert bis != null;bis.close();}}6. 最后的Controller整体代码package org.example.controller;import com.deepoove.poi.XWPFTemplate;import com.deepoove.poi.config.Configure;import com.deepoove.poi.data.Includes;import com.deepoove.poi.data.RowRenderData;import com.deepoove.poi.data.Rows;import com.jacob.activeX.ActiveXComponent;import .Dispatch;import org.example.entity.*;import org.example.service.*;import org.example.utils.DetailTablePolicy;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.context.annotation.Scope;import org.springframework.stereotype.Controller;import org.springframework.util.DigestUtils;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.ResponseBody;import javax.servlet.http.HttpServletResponse;import javax.servlet.http.HttpSession;import java.io.*;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;/*** 创建pdf控制器** @author: yoojyn* @data: 2021/1/11*/@Controller@RequestMapping("/createPdfController")public class CreatePdfController {@Autowiredprivate IKtfmService ktfmService;@Autowiredprivate IKtjbxxService ktjbxxService;@Autowiredprivate IKtbyxfxService ktbyxfxService;@Autowiredprivate IZtmbhkhzbService ztmbhkhzbService;@Autowiredprivate INdrwhkhzbService ndrwhkhzbService;@Autowiredprivate IKtjfysjsmService ktjfysjsmService;@Autowiredprivate IXjxhkxxfxService xjxhkxxfxService;/*** ⽣成word⽂件** @param session 作⽤域*/@Scope("prototype")@ResponseBody@RequestMapping("/createPdf")public void createPdf(HttpSession session, HttpServletResponse response) {// 获取当前⽤户idUserinfo loginedUser = (Userinfo) session.getAttribute("loginedUser");Integer uid = loginedUser.getUid();String dirName = DigestUtils.md5DigestAsHex((uid + "_国家重⼤专项任务合同申报").getBytes());String dirPath = "D:/" + dirName;String abPath = new File("").getAbsolutePath() + "/src/main/resources";try {// 创建⽤于存储中间⽂件的⽂件夹new File(dirPath).mkdirs();// 创建⽤于存储数据的map集合Map<String, Object> map = new HashMap<>();// 获取封⾯数据createKtfm(uid, map);// 获取基本信息数据createJbxx(uid, map);// 获取必要性分析createByxfx(uid, map);// 获取总体⽬标和考核指标createZtmbhkhzb(uid, map);// 获取经费预算及说明createJfysjsm(uid, map);// 查询附件XjxhkxxfxEntity xjxhkxxfxEntity = xjxhkxxfxService.selectXjxhkxxfxByUid(uid);// 设置下⼀步处理表格要⽤到的标签map.put("page9",Includes.ofLocal(abPath + "/static/file/upload/" + xjxhkxxfxEntity.getFilename()).create());map.put("detail_table", "{{detail_table}}");// 填充⽂档XWPFTemplate template = pile(abPath + "/static/file/moban/moban.docx").render(map);// 输出⽂档template.writeAndClose(new FileOutputStream(dirPath + "/" + uid + "_Complete.docx"));// 操作年度任务和考核指标表createNdrwhkhzb(uid, dirPath);} catch (IOException e) {e.printStackTrace();}try {/** 将 .docx 转换为 .pdf*/ActiveXComponent app = null;String wordFile = dirPath + "/" + uid + "_Complete.docx";String pdfFile = dirPath + "/" + dirName + ".pdf";System.out.println("开始转换...");// 开始时间long start = System.currentTimeMillis();try {// 打开wordapp = new ActiveXComponent("Word.Application");// 设置word不可见,很多博客下⾯这⾥都写了这⼀句话,其实是没有必要的,因为默认就是不可见的,如果设置可见就是会打开⼀个word⽂档,对于转化为pdf明显是没有必要的 //app.setProperty("Visible", false);// 获得word中所有打开的⽂档Dispatch documents = app.getProperty("Documents").toDispatch();System.out.println("打开⽂件: " + wordFile);// 打开⽂档Dispatch documentP = Dispatch.call(documents, "Open", wordFile, false, true).toDispatch(); // 如果⽂件存在的话,不会覆盖,会直接报错,所以我们需要判断⽂件是否存在File target = new File(pdfFile);if (target.exists()) {target.delete();}System.out.println("另存为: " + pdfFile);// 另存为,将⽂档报错为pdf,其中word保存为pdf的格式宏的值是17Dispatch.call(documentP, "SaveAs", pdfFile, 17);// 关闭⽂档Dispatch.call(documentP, "Close", false);// 结束时间long end = System.currentTimeMillis();System.out.println("转换成功,⽤时:" + (end - start) + "ms");} catch (Exception e) {e.getMessage();System.out.println("转换失败" + e.getMessage());} finally {// 关闭officeapp.invoke("Quit", 0);}/** 下载pdf*/String fileName = dirName + ".pdf";File file = new File(dirPath + "/" + fileName);if (file.exists()) {BufferedInputStream bis = null;FileInputStream fis = null;try {response.setHeader("Content-disposition", "attachment; filename=" + fileName);byte[] buff = new byte[2048];fis = new FileInputStream(file);bis = new BufferedInputStream(fis);OutputStream os = response.getOutputStream();int i = bis.read(buff);while (i != -1) {os.write(buff, 0, i);i = bis.read(buff);}os.close();} catch (Exception e) {e.printStackTrace();} finally {assert fis != null;fis.close();assert bis != null;bis.close();}}} catch (Exception e) {e.printStackTrace();} finally {delDir(new File(dirPath));}}/*** 删除⽂件夹** @param file ⽂件夹对象*/private void delDir(File file) {if (file.isFile()) {file.delete();}if (file.isDirectory()) {File[] files = file.listFiles();for (File f : files) {f.delete();}file.delete();}}/*** 储存经费预算及说明** @param uid ⽤户id* @param map 储存数据的map集合*/private void createJfysjsm(Integer uid, Map<String, Object> map) {// 根据⽤户编号查询经费预算及说明KtjfysjsmEntity ktjfysjsmEntity = ktjfysjsmService.getDatesByUid(uid);// 添加到map集合map.put("zjzyczzj", ktjfysjsmEntity.getZjzyczzj());map.put("zjdfczzj", ktjfysjsmEntity.getZjdfczzj());map.put("zjdwzczj", ktjfysjsmEntity.getZjdwzczj());map.put("zjqt", ktjfysjsmEntity.getZjqt());}/*** 操作年度任务和考核指标表** @throws IOException 输⼊输出流异常*/private void createNdrwhkhzb(Integer uid, String dirPath) throws IOException {PageData datas = new PageData();NdrwhkhzbData detailTable = new NdrwhkhzbData();List<RowRenderData> nds = new ArrayList<>();// 根据uid查询年度任务和考核指标数据List<NdrwhkhzbEntity> list = ndrwhkhzbService.selectNdrwhkhzbByUid(uid);for (NdrwhkhzbEntity ndrwhkhzbEntity : list) {RowRenderData rrd = Rows.of(ndrwhkhzbEntity.getNd(), ndrwhkhzbEntity.getNdrw(), ndrwhkhzbEntity.getNdkhzb() , ndrwhkhzbEntity.getZyrwdsjjd()).center().create();nds.add(rrd);}detailTable.setNdrwhkhzbs(nds);datas.setNdrwhkhzbData(detailTable);Configure config = Configure.builder().bind("detail_table", new DetailTablePolicy()).build();XWPFTemplate template =pile(dirPath + "/" + uid + "_Complete.docx", config).render(datas);template.writeToFile(dirPath + "/" + uid + "_Complete.docx");}/*** 储存总体⽬标和考核指标** @param uid ⽤户id* @param map 储存数据的map集合*/private void createZtmbhkhzb(Integer uid, Map<String, Object> map) {// 根据⽤户编号查询总体⽬标和考核指标ZtmbhkhzbEntity ztmbhkhzbEntity = ztmbhkhzbService.selectZtmbhkhzbByUid(uid);// 添加到map集合map.put("page6", ztmbhkhzbEntity.getZtmbhkhzb());}/*** 储存必要性分析数据** @param uid ⽤户id* @param map 储存数据的map集合*/private void createByxfx(Integer uid, Map<String, Object> map) {// 根据⽤户编号查询必要性分析数据KtbyxfxEntityWithBLOBs ktbyxfxEntity = ktbyxfxService.selectKtbyxfxByUid(uid);// 添加到map集合map.put("page5_ktyzx", ktbyxfxEntity.getKtyzx());map.put("page5_ktysfgc", ktbyxfxEntity.getKtysf());map.put("page5_ktyq", ktbyxfxEntity.getKtyq());}/*** 储存基本信息数据** @param uid ⽤户编号* @param map 储存数据的map集合*/private void createJbxx(Integer uid, Map<String, Object> map) {// 根据⽤户编号查询基本信息数据KcjbxxEntity kcjbxxEntity = ktjbxxService.selectKtjbxxByUid(uid);// 添加到map集合map.put("page3_ktmc", kcjbxxEntity.getKtmc());map.put("page3_ktmj", kcjbxxEntity.getKtmj());map.put("page3_yjwcsj", kcjbxxEntity.getYjwcsj());map.put("page3_kyhdlx", kcjbxxEntity.getKthdlx());map.put("page3_yqcglx", kcjbxxEntity.getYqcglx());map.put("page3_dwmc", kcjbxxEntity.getDwmc());map.put("page3_dwxz", kcjbxxEntity.getDwxz());map.put("page3_txdz", kcjbxxEntity.getTxdz());map.put("page3_yzbm", kcjbxxEntity.getYzbm());map.put("page3_szdq", kcjbxxEntity.getSzdq());map.put("page3_dwzgbm", kcjbxxEntity.getDwzgbm());map.put("page3_lxdh", kcjbxxEntity.getLxdh());map.put("page3_zzjgdm", kcjbxxEntity.getZzjgdm());map.put("page3_czhm", kcjbxxEntity.getCzhm());map.put("page3_dwclsj", kcjbxxEntity.getDwclsj());map.put("page3_dzxx", kcjbxxEntity.getDzxx());}/*** 储存课题封⾯数据** @param uid ⽤户编号* @param map 储存数据的map集合*/private void createKtfm(Integer uid, Map<String, Object> map) {// 根据⽤户编号查询封⾯数据KtfmEntity ktfmEntity = ktfmService.selectKtfmByUid(uid);// 添加到map集合map.put("page1_zxmc", "5G总体及关键器件");map.put("page1_xmbh", "2016ZX03001_001");map.put("page1_xmmc", "新⼀代宽带⽆线移动通信⽹");map.put("page1_ktbh", "2016ZX03001_001_002");map.put("page1_ktmc", "5G⾼性能基站A/D、D/A转换器试验样⽚研发");map.put("page1_zrdw", "program_test");map.put("page1_ktzz", ktfmEntity.getKtfzr());map.put("page1_ktnx1", "2016-01-01");map.put("page1_ktnx2", "2017-12-31");map.put("page1_tbrq", "2020-12-28");map.put("page1_nian", "⼆⼀");map.put("page1_yue", "⼀");}}以上就是Java 实现word模板转为pdf的详细内容,更多关于Java word模板转为pdf的资料请关注其它相关⽂章!。
easypoi模板指令

easypoi模板指令Easypoi是一款Java的开源框架,用于快速生成Excel、Word、Pdf等文档,并且支持模板导出的功能。
其中,模板指令是一个非常重要的组成部分,掌握了模板指令的使用方法,可以大大提高文档生成的效率和质量。
1. 模板指令的概念模板指令是一种特殊的标记,用于在Excel、Word、Pdf等文档中标识出需要动态生成的数据。
在Easypoi框架中,模板指令由“#”和“$”两个符号组成,其中“#”代表模板指令的开始,而“$”代表模板指令的结束。
2. 模板指令的类型Easypoi框架支持多种类型的模板指令,包括普通文本、图片、表格等。
其中,普通文本指令用于输出单个文本数据,图片指令用于插入图片,而表格指令则用于生成表格数据。
3. 模板指令的使用方法使用模板指令的方法非常简单,只需要在Excel、Word、Pdf等文档中添加相应的标记即可。
例如,在Excel中,可以使用“#$”指令输出一个名为“”的字段值。
在Word中,可以使用“#foreach(item:list)”和“$end”指令生成一个循环区域,用于输出列表数据。
4. 模板指令的高级应用除了基本的模板指令之外,Easypoi框架还支持一些高级的指令,包括条件判断、函数调用、样式设置等。
例如,在Excel中,可以使用“#if(condition)”和“$endif”指令进行条件判断,而在Word 中,可以使用“#style”指令设置文本样式。
总之,掌握了Easypoi框架中的模板指令,可以大大提高文档生成的效率和质量。
因此,在使用Easypoi框架时,建议仔细学习和掌握模板指令的使用方法,以充分发挥框架的优势。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
java生成word的几种方案
1、Jacob是Java-COM Bridge的缩写,它在Java与微软的COM组件之间构建一座桥梁。
使用Jacob自带的DLL动态链接库,并通过JNI的方式实现了在Java平台上对COM程序的调用。
DLL动态链接库的生成需要windows平台的支持。
2、Apache POI包括一系列的API,它们可以操作基于MicroSoft OLE 2 Compound
Document Format的各种格式文件,可以通过这些API在Java中读写Excel、Word 等文件。
他的excel处理很强大,对于word还局限于读取,目前只能实现一些简单文件的操作,不能设置样式。
3、Java2word是一个在java程序中调用MS Office Word 文档的组件(类库)。
该组件提
供了一组简单的接口,以便java程序调用他的服务操作Word 文档。
这些服务包括:打开文档、新建文档、查找文字、替换文字,插入文字、插入图片、插入表格,在书签处插入文字、插入图片、插入表格等。
填充数据到表格中读取表格数据,1.1版增强的功能:指定文本样式,指定表格样式。
如此,则可动态排版word 文档。
4、iText操作Excel还行。
对于复杂的大量的word也是噩梦。
用法很简单, 但是功能很少, 不
能设置打印方向等问题。
5、JSP输出样式基本不达标,而且要打印出来就更是惨不忍睹。
6、用XML做就很简单了。
Word从2003开始支持XML格式,大致的思路是先用office2003
或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。
经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。
java生成pdf方案总结
1. Jasper Report生成pdf:设计思路是先生成模板,然后得到数据,最后将两者整合得到结果。
但是Jasper Report的问题在于,其生成模板的方式过于复杂,即使有IDE的帮助,我们还是需要对其中的众多规则有所了解才行,否则就会给调试带来极大的麻烦。
2. openoffice生成pdf:openoffice是开源软件且能在windows和linux平台下运行。
3. itext + flying saucer生成pdf:itext和flying saucer都是免费开源的,且与平台无关,结合css和velocity技术,可以很好的实现。
一般使用第三种方案比较多,它实现的步骤是非常简单的。
JAVA生成word优缺点对比
JAVA生成pdf优缺点对比。