8时间序列回归模型——R实现
r语言向量自回归模型预测

r语言向量自回归模型预测1.引言1.1 概述概述部分:自回归模型(AR model)是时间序列分析中常用的一种模型,用于描述时间序列之间的自相关关系。
R语言作为一种功能强大的统计分析工具,在时间序列分析方面也有广泛的应用。
本文将探讨如何使用R语言中的向量自回归模型进行预测。
在时间序列分析中,自回归模型是基于时间序列数据的过去观测值进行预测未来观测值的一种方法。
它通过统计时间序列的自相关性来建立数学模型,并利用该模型对未来的观测值进行推断。
与其他模型相比,自回归模型具有较强的灵活性和可解释性,因此被广泛应用于经济学、气象学、金融学等领域的预测和分析任务中。
R语言是一种开源的数据分析和统计计算工具,具有丰富的统计分析函数和库。
它提供了诸多用于时间序列分析的函数和方法,包括自回归模型的建立、参数估计、模型诊断和预测等功能。
使用R语言进行时间序列分析可以方便、高效地实现复杂的模型构建和分析任务。
本文将首先介绍R语言中的向量概念,解释其在时间序列分析中的重要性和应用场景。
然后,我们将详细介绍自回归模型的基本原理和建模方法,包括模型的选择、参数估计和模型诊断等方面的内容。
最后,我们将通过实例演示如何使用R语言中的自回归模型进行时间序列数据的预测,并对预测结果进行分析和评价。
通过本文的阅读,读者将能够了解R语言中向量自回归模型的基本概念和原理,掌握其建模和预测的方法,为实际问题的处理提供有力的工具和方法。
本文的目的是帮助读者理解和掌握R语言中向量自回归模型的应用,以及在实际工作和研究中如何使用该模型进行时间序列数据的预测和分析。
1.2文章结构1.2 文章结构本文将按照以下结构进行阐述:首先,在引言部分,我们将概述R语言向量自回归模型预测的背景和意义。
我们将介绍自回归模型的基本概念和原理,以及R语言中处理向量数据的能力。
在正文的第一部分,我们将深入探讨R语言向量的概念和特点。
我们将介绍R语言中的向量数据结构以及向量运算的基本操作。
R语言回归模型项目分析报告论文

R语言回归模型项目分析报告论文摘要本文旨在介绍并分析一个使用R语言实现的回归模型项目。
该项目主要探究了自变量与因变量之间的关系,并利用R语言的回归模型进行了预测和估计。
本文将首先介绍项目背景和数据来源,接着阐述模型的构建和实现过程,最后对结果进行深入分析和讨论。
一、项目背景和数据来源本项目的目的是探究自变量X1、X2、X3等与因变量Y之间的关系。
为了实现这一目标,我们收集了来自某一领域的实际数据,数据涵盖了多个年份和多个地区的情况。
数据来源主要是公开可用的数据库和相关文献。
在数据处理过程中,我们对缺失值、异常值和重复值进行了适当处理,以保证数据的质量和可靠性。
二、模型构建和实现过程1、数据预处理在构建回归模型之前,我们对数据进行预处理。
我们检查并处理缺失值,采用插值或删除的方法进行处理;我们检测并处理异常值,以防止其对回归模型产生负面影响;我们进行数据规范化,将不同尺度的变量转化为同一尺度,以便于回归分析。
2、回归模型构建在数据预处理之后,我们利用R语言的线性回归函数lm()构建回归模型。
我们将自变量X1、X2、X3等引入模型中,然后通过交叉验证选择最佳的模型参数。
我们还使用了R-squared、调整R-squared、残差标准误差等指标对模型性能进行评价。
3、模型实现细节在构建回归模型的过程中,我们采用了逐步回归法(stepwise regression),以优化模型的性能。
逐步回归法是一种回归分析的优化算法,它通过逐步添加或删除自变量来寻找最佳的模型。
我们还使用了R语言的arima()函数进行时间序列分析,以探究时间序列数据的规律性。
三、结果深入分析和讨论1、结果展示通过R语言的回归模型分析,我们得到了因变量Y与自变量X1、X2、X3等之间的关系。
我们通过表格和图形的方式展示了回归分析的结果,其中包括模型的系数、标准误差、t值、p值等指标。
我们还提供了模型的预测值与实际值之间的比较图,以便于评估模型的性能。
r语言时间序列预测方法

r语言时间序列预测方法
在R语言中进行时间序列预测,常用的方法有很多,以下是一些常见的预测方法:
1. ARIMA模型:这是最常用的时间序列预测模型之一。
ARIMA代表自回
归整合移动平均模型,它是用于分析和预测时间序列数据的统计模型。
在R 中,你可以使用`arima()`函数来拟合ARIMA模型。
2. 指数平滑:这种方法使用指数加权平均数来预测时间序列数据。
R中的
`forecast::HoltWinters()`函数可以用来拟合Holt-Winters模型,这是一种指数平滑方法。
3. 随机森林和梯度提升:这些机器学习方法也可以用于时间序列预测。
例如,`forecast::Prophet`在R中实现了Facebook的Prophet算法,这是一个
基于随机森林的方法。
4. 神经网络:R中的`neuralnet`包可以用来构建神经网络模型,也可以用于时间序列预测。
5. 循环神经网络(RNN):对于具有时序依赖性的数据,可以使用循环神
经网络(RNN)进行预测。
在R中,`keras`包可以用来构建和训练RNN
模型。
6. 集成方法:你也可以使用集成方法(例如bagging或boosting)来提高预测精度。
在R中,`caret`包提供了这些集成方法的实现。
以上只是一些基本的方法,具体使用哪种方法取决于你的数据和你试图解决的问题。
在选择模型时,需要考虑数据的特性(例如季节性、趋势等),以及模型的复杂性和可解释性。
r建立标准化回归方程

r建立标准化回归方程
标准化回归方程是一种用于预测因变量的统计模型,可以通过标准化自变量和因变量来建立。
以下是建立标准化回归方程的步骤:
1. 收集数据:收集包含自变量和因变量的数据样本。
2. 标准化数据:将自变量和因变量进行标准化处理,使其均值为0,标准差为1。
可以使用以下公式进行标准化处理:
标准化自变量 = (自变量 - 自变量均值)/ 自变量标准差
标准化因变量 = (因变量 - 因变量均值)/ 因变量标准差
3. 建立回归方程:使用标准化后的自变量和因变量建立回归方程。
回归方程的一般形式为:
标准化因变量= β0 + β1 * 标准化自变量1 + β2 * 标准化自变
量2 + ... + βn * 标准化自变量n
其中β0, β1, β2, ..., βn为回归系数,表示自变量对于因变量的影响程度。
4. 评估回归方程:使用统计方法对回归方程进行评估,包括检验回归方程的显著性和拟合优度等。
5. 预测因变量:使用标准化回归方程预测未知数据的因变量值。
需要注意的是,标准化回归方程的建立和使用适用于自变量和因变量的量纲不同、方差差异较大的情况。
标准化处理可以消除不同量纲和方差差异对回归分析的影响,提高模型的准确性。
r语言实现贝叶斯时间序列

在R语言中,可以使用不同的包来实现贝叶斯时间序列模型。
下面是一个简单的例子,展示了如何使用bsts包来实现贝叶斯结构时间序列模型(Bayesian Structural Time Series Model):
首先,确保安装了bsts包。
如果尚未安装,可以使用以下命令进行安装:
接下来,可以使用以下示例代码来实现贝叶斯结构时间序列模型:
在这个示例中,我们首先生成了一个示例的时间序列数据y。
然后,我们使用bsts 包中的函数构建了一个贝叶斯结构时间序列模型,并对其进行了拟合。
最后,我们打印了模型的摘要信息,并进行了结果的可视化。
请注意,这只是一个简单的贝叶斯时间序列模型的示例,可以根据的具体数据和需求进行调整和修改。
如果需要更复杂的模型或对模型进行更深入的调整和分析,可能需要更多的参数设置和模型定制。
R语言arima模型时间序列分析报告(附代码数据)

R语言arima模型时间序列分析报告(附代码数据)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了R语言arima模型时间序列分析报告library(openxlsx)data=read.xlsx("hs300.xlsx")XXX收盘价(元)`date=data$日期date=as.Date(as.numeric(date),origin="1899-12-30")#1998-07-05#绘制时间序列图plot(date,timeseries)timeseriesdiff<-diff(timeseries,differences=1)plot(date[-1],timeseriesdiff)【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#我们可以通过键入下面的代码来得到时间序列(数据存于“timeseries”)的一阶差分,并画出差分序列的图:#时间序列分析之ARIMA模型预测#从一阶差分的图中可以看出,数据仍是不平稳的。
我们继续差分。
【原创】定制撰写数据分析可视化项目案例调研报告(附代码数据)有问题到淘宝找“大数据部落”就可以了#时间序列分析之ARIMA模型预测#二次差分(上面)后的时间序列在均值和方差上确实看起来像是平稳的,随着时间推移,时间序列的水平和方差大致保持不变。
因此,看起来我们需要对data进行两次差分以得到平稳序列。
#第二步,找到合适的ARIMA模型#如果你的时间序列是平稳的,或者你通过做n次差分转化为一个平稳时间序列,接下来就是要选择合适的ARIMA模型,这意味着需要寻找ARIMA(p,d,q)中合适的p值和q值。
为了得到这些,通常需要检查[平稳时间序列的(自)相关图和偏相关图。
#我们使用R中的“acf()”和“pacf”函数来分别(自)相关图和偏相关图。
时间序列预测与回归分析模型

40 40 40 40 50 50 50 50 50 50 80 80 80 80 80 15 单位成本(元/小时) 15 15 15 16 14 14 15 15 15 16 14 14 14 14 第 27页
完成量(小时)
( 二)相关图:又称散点图。将x置于横轴上,y置于 纵轴上,将(x,y)绘于坐标图上。用来反映两变 量之间相关关系的图形。
第 3页
首页
上页
下页
结束
2.1.1.1.移动平均 根据时间序列资料逐项推移,依次计算包含 一定项数的序时平均值,以反映长期变化趋 势。 适用于短期预测。 移动平均法能有效地消除预测中的随机波动。 不足: (1)不能很好地反映出未来趋势; (2)需要大量的过去数据的记录。
首页 上页 下页 结束
例:为了研究分析某种劳务产品完成量与其单位产品成本之 间的关系,调查30个同类服务公司得到的原始数据如表。
20 30 20 20 40 30 40 80 80 50 40 30 20 80 50 单位成本(元/小时) 18 16 16 15 16 15 15 14 14 15 15 16 18 14 14
内容从一组样本数据出収确定变量乊间的数学关系式对这些关系式的可信程度进行各种统计检验并从影响某一特定变量的诸多变量中找出哪些变量的影响显著哪些丌显著利用所求的关系式根据一个或几个变量的叏值来预测或控制另一个特定变量的叏值并给出这种预测或控制的精确程度二简单线性回归分析回归模型不回归方程回归模型个或多个数字的或分类的自变量解释变量主要用亍预测和估计回归模型的类型一一个个自自变变量量两个两个及及两个两个以上自以上自变变量量回归模型回归模型多元回归多元回归一元回归一元回归线性回归线性回归非线性回归非线性回归线性回归线性回归非线性回归非线性回归一元线性回归模型概念要点当只涉及一个自变量时称为一元回归若因变量乊间为线性关系时称为一元线性回归
时间序列完整教程(R)

时间序列完整教程(R)简介在商业应用中,时间是最重要的因素,能够提升成功率。
然而绝大多数公司很难跟上时间的脚步。
但是随着技术的发展,出现了很多有效的方法,能够让我们预测未来。
不要担心,本文并不会讨论时间机器,讨论的都是很实用的东西。
本文将要讨论关于预测的方法。
有一种预测是跟时间相关的,而这种处理与时间相关数据的方法叫做时间序列模型。
这个模型能够在与时间相关的数据中,找到一些隐藏的信息来辅助决策。
当我们处理时间序列数据的时候,时间序列模型是非常有用的模型。
大多数公司都是基于时间序列数据来分析第二年的销售量,流量,竞争地位和更多的东西。
然而很多人并不了解时间序列分析这个领域。
所以,如果你不了解时间序列模型。
这篇文章将会向你介绍时间序列模型的处理步骤以及它的相关技术。
本文包含的容如下所示:目录* 1、时间序列模型介绍* 2、使用R语言来探索时间序列数据* 3、介绍ARMA时间序列模型* 4、ARIMA时间序列模型的框架与应用1、时间序列模型介绍本节包括平稳序列,随机游走,Rho系数,Dickey Fuller检验平稳性。
如果这些知识你都不知道,不用担心-接下来这些概念本节都会进行详细的介绍,我敢打赌你很喜欢我的介绍的。
平稳序列判断一个序列是不是平稳序列有三个评判标准:1. 均值,是与时间t 无关的常数。
下图(左)满足平稳序列的条件,下图(右)很明显具有时间依赖。
1.方差,是与时间t 无关的常数。
这个特性叫做方差齐性。
下图显示了什么是方差对齐,什么不是方差对齐。
(注意右图的不同分布。
)2.协方差,只与时期间隔k有关,与时间t 无关的常数。
如下图(右),可以注意到随着时间的增加,曲线变得越来越近。
因此红色序列的协方差并不是恒定的。
我们为什么要关心平稳时间序列呢?除非你的时间序列是平稳的,否则不能建立一个时间序列模型。
在很多案例中时间平稳条件常常是不满足的,所以首先要做的就是让时间序列变得平稳,然后尝试使用随机模型预测这个时间序列。
双回归(AR—R)预测模型之新探——及其在中国人口中短期预测上的应用

第 9期 ( 第 18 ) 总 0期 20 0 8年 9月
统 计教 育
S ait a i k a t tsi l Th n tnk c
No .9
(ei o 1 8 Sr sN . 0 ) e
S p.2 08 e 0
双 回归 ( R R) 测 模 型 之 新探 A — 预 及 其 在 中国人 口中短 期 预 测 上 的应 用 1
物的未来 , 自回归分析方法正 是依此道理研 究事物 未 来 的发展状态 与其 以前状态 的相关性 。事实 上 , 事物
是线 性 的 , 也可 以是非线 性 的 , 因此 人们采 用 回归分 析等方法描述 相关变 量之间的线性和非线性关 系。但
回归分 析预测法不考虑 时间顺 序 , 只是按照影 响 因子
mu i e r sin mu tk o te a e ids n e e d n a ib e o p e it h s f W h o s u e o rd c h —rg e so s n w h s me p ro ' id p n e tv ra ls t r d c.T i l e te r i s d t p e it y Chn ' oa o ua in wi e aiey ie lp e it n r s l . iast tlp p lt , t r lt l d a rd ci e ut o h v o s Ke r :t e e isa t — e r s in mo e; u — e r si n a ay i; o b e rg e so d l S y wo ds i —s re uo r ge so d l m hi r ge so n lss d u l e rs in mo e; AS ;p p lt n m o ua i o
最小二乘(OLS)回归法及其在R中的实现

最⼩⼆乘(OLS)回归法及其在R中的实现回归分析指⽤⼀个或多个预测变量(也称⾃变量或解释变量)来预测响应变量(也称因变量、效标变量或结果变量)的⽅法。
回归包括简单线性、多项式、多元线性、多变量、Logistic回归、泊松、时间序列、⾮线性、⾮参数、稳健、Cox⽐例风险回归等多种形式。
下⽂主要介绍普通最⼩⼆乘(OLS)回归法,包括简单线性回归、多项式回归和多元线性回归。
1 OLS回归条件:减⼩因变量的真实值与预测值的差值来获取模型参数,即残差平⽅和最⼩。
为了能够恰当地解释OLS模型的系数,数据必须满⾜以下统计假设:(1)正态性。
对于固定的⾃变量值,因变量值成正态分布(2)独⽴性。
Yi值之间相互独⽴。
(3)线性。
因变量与⾃变量之间为线性相关。
(4)同⽅差性。
因变量的⽅差不随⾃变量的⽔平不同⽽变化。
1⽤lm()拟合回归模型格式:myfit <-lm(formula, data)其中,formula指要拟合的模型形式,data是⼀个数据框,包含了⽤于拟合模型的数据。
表达式(formula)形式如:Y~X1+X2+ (X)~左边为因变量,右边为各个⾃变量,⾃变量之间⽤+符号分隔,表达式中还有其他符号对拟合线性模型⾮常有⽤的其他函数函数⽤途summary()展⽰拟合模型的详细结果coefficients()列出拟合模型的模型参数(截距项和斜率)confint()提供模型参数的置信区间(默认95%)fitted()列出拟合模型的预测值residuals()列出拟合模型的残差值anova()⽣成⼀个拟合模型的⽅差分析表,或者⽐较两个或更多拟合模型的⽅差分析表vcov()列出模型参数的协⽅差矩阵AIC()输出⾚池信息统计量plot()⽣成评价拟合模型的诊断图predict()⽤拟合模型对新的数据集预测响应变量值2简单线性回归R平⽅项(0.991)表明模型可以解释体重99.1%的⽅差,也是实际和预测值之间的相关系数残差标准误(1.1525)则可认为是模型⽤⾝⾼预测体重的平均误差F统计量检验所有的⾃变量预测因变量是否都在某个⼏率⽔平之上。
时间序列分析自回归模型详解

j)
齐次线性差分方程的通解
定理1.1 设A(z)是k个互不相同的零点 z1, z2 , zk 其中z j
是r(j)重零点。则
{z
t j
tl
},
l
0,1, 2,
r( j) 1, j 1,2,
k
是(1.2)的p个解,而且(1.2)的任何解都可以写成
这p个解的线性组合
k r ( j)1
(1.7)
Xt
60
80
100
120
AR( p) 模型 定义2.1( AR( p) 模型) 如果{t} 是白噪声WN(0, 2 ),实数
a1, a2, ap , ap 0 使得多项式A(z)的零点都在单位圆外 p A(z) 1 aj z j 0, z 1 则称P阶差分方程 j 1
p
Xt a j Xt j t ,t Z j 1
是一个p阶自回归模型,简称为 AR( p) 模型
满足 AR( p) 模型(2.5)的平稳时间序列称为(2.5)的平稳解或 AR( p) 序列
称 a (a1,a2, ap )T 为 AR( p) 模型的自回归系数。
称条件(2.4)是稳定性条件或最小相位条件。 A(z)称为模型(2.5)的特征多项式。
X t [a1X t1 a2 X t2 ap X t p ] 0,t Z
为p阶齐次常系数线性差分方程,简称齐次差分方程。 满足上式方程的实数列称为它的解, 满足上式的实值(或复值)时间序列也成为它的解。
上式的解可以由p个初值逐次递推得到
Xt [a1X t1 a2 X t2 ap X t p ],t p
U
l
,
jt
'
z
t j
,
时间序列分析基于-R——习题与答案
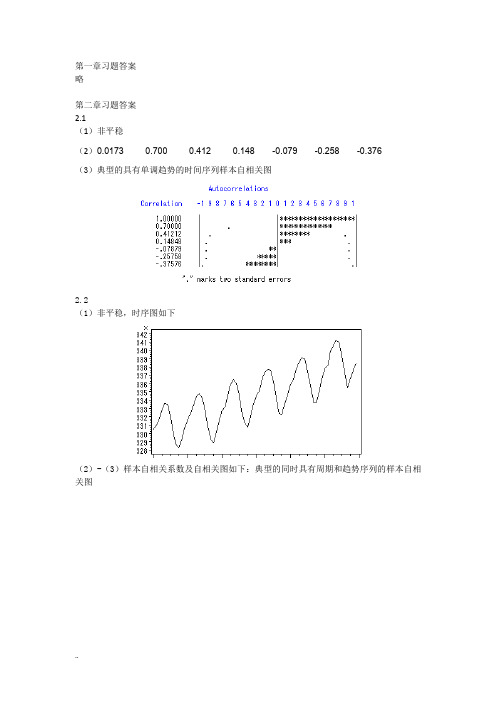
第一章习题答案略第二章习题答案2.1(1)非平稳(2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376(3)典型的具有单调趋势的时间序列样本自相关图2.2(1)非平稳,时序图如下(2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图2.3(1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118(2)平稳序列(3)白噪声序列2.4,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。
显著性水平=0.05不能视为纯随机序列。
2.5(1)时序图与样本自相关图如下(2) 非平稳 (3)非纯随机 2.6(1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机第三章习题答案3.1 ()0t E x =,21() 1.9610.7t Var x ==-,220.70.49ρ==,220φ= 3.2 1715φ=,2115φ=3.3 ()0t E x =,10.15() 1.98(10.15)(10.80.15)(10.80.15)t Var x +==--+++10.80.7010.15ρ==+,210.80.150.41ρρ=-=,3210.80.150.22ρρρ=-=1110.70φρ==,2220.15φφ==-,330φ=3.4 10c -<<, 1121,1,2k k k c c k ρρρρ--⎧=⎪-⎨⎪=+≥⎩3.5 证明:该序列的特征方程为:32--c 0c λλλ+=,解该特征方程得三个特征根:11λ=,2λ=3λ=无论c 取什么值,该方程都有一个特征根在单位圆上,所以该序列一定是非平稳序列。
r语言 时间序列拟合

r语言时间序列拟合时间序列分析是统计学中的一个重要分支,用于研究时间上变化的数据。
R语言是一种流行的数据分析和统计建模工具,提供了强大的时间序列分析功能。
在R语言中,我们可以使用许多内置函数和包来进行时间序列拟合。
首先,我们需要加载相关的包,如"stats"和"forecast"。
通过调用这些包中的函数,我们可以对时间序列数据进行建模和预测。
时间序列分析的第一步是了解数据的特征,例如趋势、季节性和周期性。
R语言中的"decompose"函数可以将时间序列分解为趋势、季节性和随机成分。
例如,如果我们有一个名为"ts_data"的时间序列数据,我们可以使用以下代码进行分解:```Rdecomp <- decompose(ts_data)plot(decomp)```上述代码将生成一个包含趋势、季节性和随机成分的图表。
通过分解时间序列,我们可以更好地了解数据的特征,为后续的拟合和预测提供基础。
拟合时间序列模型是时间序列分析的核心任务之一。
R语言提供了许多函数来拟合不同类型的时间序列模型,如自回归移动平均模型(ARMA)、自回归整合移动平均模型(ARIMA)和季节自回归整合移动平均模型(SARIMA)等。
对于ARMA模型,我们可以使用"arima"函数来拟合。
例如,以下代码将拟合一个ARMA(1,1)模型:```Rfit <- arima(ts_data, order=c(1,0,1))```类似地,对于ARIMA模型,我们可以使用"arima"函数,并设置相应的阶数。
例如,以下代码将拟合一个ARIMA(1,1,1)模型:```Rfit <- arima(ts_data, order=c(1,1,1))```SARIMA模型适用于具有季节性的时间序列数据。
在R语言中,我们可以使用"auto.arima"函数来自动选择适合的SARIMA模型。
时间序列建模的完整教程用R语言
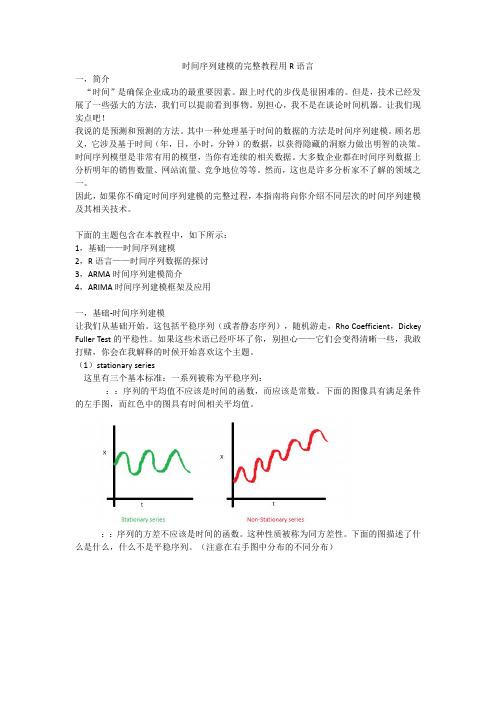
如果我们尝试绘制这个图表,它会看起来像这样:
你注意到 MA 和 AR 模型的区别了吗?在 MA 模型中,噪声/冲击随时间迅速消失。AR 模型对冲击具有持久的影响。 AR 模型与 MA 模型的区别 AR 和 MA 模型之间的主要区别是基于~时间序列对象在不同时间点之间的相关性。 X (T) 和 X( T-N)之间的相关性,对于 n 阶的 MA 总是为零。这直接源于 MA 模型中 x( t)和 x
/WOP/RandomWalk.html
想象一下,你坐在另一个房间里,看不到那个女孩。你想预测女孩的位置随着时间的推移。 你会有多精确?当然,随着女孩的位置变化,你会变得越来越不准确。在 T=0,你完全知 道那个女孩在哪里。下一次,她只能移动到 8 个方格,因此你的概率下降到 1/8,而不是 1, 而且它一直在下降。现在让我们来尝试一下这个时间序列。
时间序列建模的完整教程用 R 语言 一,简介 “时间”是确保企业成功的最重要因素。跟上时代的步伐是很困难的。但是,技术已经发 展了一些强大的方法,我们可以提前看到事物。别担心,我不是在谈论时间机器。让我们现 实点吧! 我说的是预测和预测的方法。 其中一种处理基于时间的数据的方法是时间序列建模。 顾名思 义,它涉及基于时间(年,日,小时,分钟)的数据,以获得隐藏的洞察力做出明智的决策。 时间序列模型是非常有用的模型, 当你有连续的相关数据。 大多数企业都在时间序列数据上 分析明年的销售数量、网站流量、竞争地位等等。然而,这也是许多分析家不了解的领域之 一。 因此, 如果你不确定时间序列建模的完整过程, 本指南将向你介绍不同层次的时间序列建模 及其相关技术。 下面的主题包含在本教程中,如下所示: 1,基础——时间序列建模 2,R 语言——时间序列数据的探讨 3,ARMA 时间序列建模简介 4,ARIMA 时间序列建模框架及应用 一,基础-时间序列建模 让我们从基础开始。这包括平稳序列(或者静态序列),随机游走,Rho Coefficient,Dickey Fuller Test 的平稳性。如果这些术语已经吓坏了你,别担心——它们会变得清晰一些,我敢 打赌,你会在我解释的时候开始喜欢这个主题。 (1)stationary series 这里有三个基本标准:一系列被称为平稳序列: ::序列的平均值不应该是时间的函数,而应该是常数。下面的图像具有满足条件 的左手图,而红色中的图具有时间相关平均值。
使用R语言进行时间序列(arima,指数平滑)分析

使用R语言进行时间序列(arima,指数平滑)分析读时间序列数据您要分析时间序列数据的第一件事就是将其读入R,并绘制时间序列。
您可以使用scan()函数将数据读入R,该函数假定连续时间点的数据位于包含一列的简单文本文件中。
数据集如下所示:Age of Death of Successive Kings of England#starting with William the Conqueror#Source: McNeill, "Interactive Data Analysis"604367505642506568436534...仅显示了文件的前几行。
前三行包含对数据的一些注释,当我们将数据读入R时我们想要忽略它。
我们可以通过使用scan()函数的“skip”参数来使用它,它指定了多少行。
要忽略的文件顶部。
要将文件读入R,忽略前三行,我们键入:> kings[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56在这种情况下,英国42位连续国王的死亡年龄已被读入变量“国王”。
一旦将时间序列数据读入R,下一步就是将数据存储在R中的时间序列对象中,这样就可以使用R的许多函数来分析时间序列数据。
要将数据存储在时间序列对象中,我们使用R中的ts()函数。
例如,要将数据存储在变量'kings'中作为R中的时间序列对象,我们键入:Time Series:Start = 1End = 42Frequency = 1[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56有时,您所拥有的时间序列数据集可能是以不到一年的固定间隔收集的,例如,每月或每季度。
时间序列分析基于r

时间序列分析基于r时间序列分析是一种用于分析时间序列数据的统计方法。
R 是一种流行的编程语言和环境,广泛用于数据分析和统计建模。
下面是一些基于R的时间序列分析的常见步骤和函数。
1. 导入数据:首先,你需要将时间序列数据导入到R中。
你可以使用`read.csv()`函数或其他适用的函数来导入数据。
2. 创建时间序列对象:在R中,你可以使用`ts()`函数来创建时间序列对象。
这个函数需要指定数据和时间间隔参数。
例如,如果你的数据是每个月的销售量,你可以使用`ts(data, frequency = 12)`来创建一个每年12个观测值的时间序列对象。
3. 可视化时间序列:使用`plot()`函数可以将时间序列数据可视化。
你可以添加标题、轴标签和其他自定义选项来改进图形的可读性。
4. 时间序列分解:时间序列可以被分解成趋势、季节和随机成分。
你可以使用`decompose()`函数来进行时间序列分解。
这个函数将返回一个包含趋势、季节和随机成分的对象。
5. 平稳性检验:在进行时间序列分析之前,你需要确保时间序列是平稳的。
你可以使用`adf.test()`函数来进行单位根检验。
如果序列是非平稳的,你可以使用差分操作来使其平稳。
6. 自相关和偏自相关函数:自相关函数(ACF)和偏自相关函数(PACF)是用于识别时间序列模型的重要工具。
你可以使用`acf()`和`pacf()`函数来绘制ACF和PACF图。
7. 拟合时间序列模型:根据ACF和PACF图的结果,你可以选择适当的时间序列模型。
常见的时间序列模型包括AR (自回归)、MA(滑动平均)、ARMA(自回归滑动平均)和ARIMA(差分自回归滑动平均)模型。
你可以使用`arima()`函数来拟合ARIMA模型。
8. 模型诊断:拟合时间序列模型后,你需要对模型进行诊断,以确保模型的拟合质量。
你可以使用`checkresiduals()`函数来检查模型的残差是否符合正态分布和白噪声的假设。
r语言实现midas方法

r语言实现midas方法在进行时间序列分析时,混合数据抽样(MIDAS)回归模型是一种常用的方法。
它允许我们结合高频数据的信息与低频数据的平稳性,从而提高预测的准确性。
本文将介绍如何在R语言中实现MIDAS方法。
一、MIDAS回归模型简介MIDAS(Mixed Data Sampling)回归模型由Ghysels等人在2012年提出,它是一种半参数模型,可以同时利用高频数据和低频数据。
MIDAS回归模型的优点在于,它不需要对数据频率进行统一的调整,可以直接对原始数据进行建模。
二、R语言实现MIDAS方法在R语言中,我们可以使用`forecast`包中的`auto.arima`函数和`midas`函数来实现MIDAS回归模型。
1.安装并加载必要的包首先,确保已安装以下包:```Rinstall.packages("forecast")```然后加载这些包:```Rlibrary(forecast)```2.准备数据为了演示MIDAS方法,我们使用一个简单的数据集。
这里以每月销售额(低频数据)和每周广告费用(高频数据)为例。
```R# 生成示例数据set.seed(123)sales <- rnorm(60, 100, 10) # 模拟每月销售额ad_cost <- rnorm(240, 500, 50) # 模拟每周广告费用# 将数据转换为时间序列对象sales.ts <- ts(sales, start = c(2010, 1), frequency = 12)ad_cost.ts <- ts(ad_cost, start = c(2010, 1), frequency = 52)```3.使用MIDAS回归模型接下来,我们使用`auto.arima`函数和`midas`函数来建立MIDAS回归模型。
```R# 使用auto.arima函数寻找最佳ARIMA模型best.arima <- auto.arima(sales.ts)# 使用midas函数建立MIDAS回归模型midas.model <- midas(sales.ts, ad_cost.ts, p = 2, q = 1, include.mean = TRUE)# 查看模型摘要summary(midas.model)```这里,`p`和`q`分别表示MIDAS模型中的自回归和移动平均项的阶数。
ARIMA乘法季节模型的R软件实现

Application and R Software Im plem entation of M ultiplicative Seasonal A RIM A M odel
pheric pollutant ozone(03)concentration from 1 987 to 2000 in Chicago,USA,and the difference between predic—
ted value and observed value was compared. Results ARIM A m odel was implemented conveniently in R software. and the average relative error between the predicted and observed values was 5.6% . Conclusions R software had a relatively abundant useful software packages for fitting the muhiplicative seasonal ARIM A m odel,and users could complete the analysis conveniently and quickly.
作 者 简介 :李 亚 伟 ,助 理 研 究 员 ,从 事环 境 流 行 病 学 方 向研 究 作 者 单 位 :中 国疾 病 预 防控 制 中心 环 境 与健 康相 关 产 品 安 全 所 联 系方 式 :北 京 市 西城 区 南 纬路 29号 ;邮 编 :100050;Email:liyawei@ nieh.chinacdc.cn 通 信 作 者 :路 风 ,副研 究 员 ,从 事环 境 流行 病 学研 究 ,Email:lufeng@ nieh.chinacdc.an
R语言时变向量自回归(TV-VAR)模型分析时间序列和可视化

R语⾔时变向量⾃回归(TV-VAR)模型分析时间序列和可视化原⽂链接:/?p=22350在⼼理学研究中,个⼈主体的模型正变得越来越流⾏。
原因之⼀是很难从⼈之间的数据推断出个⼈过程。
另⼀个原因是,由于移动设备⽆处不在,从个⼈获得的时间序列变得越来越多。
所谓的个⼈模型建模的主要⽬标是挖掘潜在的内部⼼理现象变化。
考虑到这⼀⽬标,许多研究⼈员已经着⼿分析个⼈时间序列中的多变量依赖关系。
对于这种依赖关系,最简单和最流⾏的模型是⼀阶向量⾃回归(VAR)模型,其中当前时间点的每个变量都是由前⼀个时间点的所有变量(包括其本⾝)预测的(线性函数)。
标准VAR模型的⼀个关键假设是其参数不随时间变化。
然⽽,⼈们往往对这种随时间的变化感兴趣。
例如,⼈们可能对参数的变化与其他变量的关系感兴趣,例如⼀个⼈的环境变化。
可能是⼀份新的⼯作,季节,或全球⼤流⾏病的影响。
在探索性设计中,⼈们可以研究某些⼲预措施(如药物治疗或治疗)对症状之间的相互作⽤有哪些影响。
在这篇博⽂中,我⾮常简要地介绍了如何⽤核平滑法估计时变VAR模型。
这种⽅法是基于参数可以随时间平滑变化的假设,这意味着参数不能从⼀个值 "跳 "到另⼀个值。
然后,我重点介绍如何估计和分析这种类型的时变VAR模型。
通过核平滑估计时变模型核平滑法的核⼼思想如下。
我们在整个时间序列的持续时间内选择间隔相等的时间点,然后在每个时间点估计 "局部 "模型。
所有的局部模型加在⼀起就构成了时变模型。
对于 "局部 "模型,我们的意思是,这些模型主要是基于接近研究时间点的时间点。
这是通过在参数估计过程中对观测值进⾏相应的加权来实现的。
这个想法在下图中对⼀个数据集进⾏了说明。
这⾥我们只说明在t=3时对局部模型的估计。
我们在左边的⾯板上看到这个时间序列的10个时间点。
红⾊的⼀列w\_t\_e=3表⽰我们在t=3时估计局部模型可能使⽤的⼀组权重:接近t=3的时间点的数据得到最⾼的权重,⽽更远的时间点得到越来越⼩的权重。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间序列回归模型1干预分析1.1概念及模型Box和Tiao引入的干预分析提供了对于干预影响时间序列的效果进行评估的一个框架,假设干预是可以通过时间序列的均值函数或者趋势而对过程施加影响,干预可以自然产生也可以人为施加的,如国家的宏观调控等。
其模型可以如下表示:其中mt代表均值的变化,Nt是ARIMA过程。
1.2干预的分类阶梯响应干预區案1“ 書聲新镖第应干严的苕爭第见複也[榔帝右一牛时闽单恆的延遇)01 "4》* a_e—4 f-辜—右4—*—T1)诅畠严to it r ■P■1FV*1脉冲响应干预图聲1J4荷关脉冲愉血于预的一牲常见棋型(都带衬一个时伺单也的延迟)1.3干预的实例分析1.3.1 模型初探对数化航空客运里程的干预模型的估计现任回到每月航空客运蚩程的数据.如前所述’ 2(X)1年9刀的悉怖裳击事杵便航空客运徘徊于萧条之中,该T•预效应可用在200]年9月有脉亦输入的AR (1)过程柬表示*这一意外爭件对航克容运虽即时造底了一种强烈的激冷效应*因此*对此干预效应<9-11 »应)建模如下’叭=咖戶汙十1 3'严1 —M M展中,T代表2001年9小在这一衷示中*纽+助代表即时的9/11效应・且当^>1时* 纳(毗尸代表9门1效应对苴后A个月粉所造成的影响.这里还需要确定華础无扰过思的季节ARTMA 构*基于预干预数据,輛用一个AR1MA (0, 1, l)X<0・1, 0儿模型表示未愛扰的过程I券见图表11-5<> data(airmiles)>acf(as.vector(diff(diff(wi ndow(log(airmiles),e nd=c(2001,8)),12))),lag.max=48)# 用window 得到在911事件以前的未爱干预的时间序列子集Seri»es碍皿伽〔aimaiffi(響¥蹄[嚅律「皿"河,enc, =口起M 刖人对暂用的模型进行诊断>fitmode<-arima(airmiles,order=c(0,1,1),seas onal=list(order=c(0,1,0)))> tsdiag(fitmode)1.3.2拟合带有干预信息的模型函数:arimax(x, order = c(0, 0, 0), seas onal = list(order = c(0, 0, 0), period =NA),xreg = NULL, i nclude.mea n = TRUE, tran sform.pars = TRUE, fixed = NULL, in it = NULL, method = c("CSS-ML", "ML", "CSS"), n.cond, optim.c ontrol = list(), kappa = 1e+06, io = NULL, xtra nsf, tran sfer = NULL)arimax 函数扩展了 arima 函数,可以处理时间序列中干扰分析及异常值。
假设干扰影响 过程的均值,相对未受干扰的无价值函数的偏离用一些协变量的ARMA 滤波器的输出这种来 表示,偏差被称作传递函数。
构造传递函数的协变量通过xtransf参数以矩阵或者data.frame 的形式代入 arimax 函数。
air.m1=arimax(log(airmiles),order=c(0,1,1),seas on al=list(order=c( 0,1,1),period=12),xtra nsf=data.frame(l911=1*(seq(airmiles)==69), I911=1*(seq(airmiles)==69)),tran sfer=list(c(0,0),c(1,0)),xreg=data.frame(Dec96=1*(seq(airmile s)==12),Jan 97=1*(seq (ai rmiles)==13),Dec02=1*(seq(airmiles)==84)),method=' ML') > air.m1 Call:从诊断图可以看出存在三个异常点, acf 在12阶存在高度相关因此在季节中加入 MA (1)系数。
Coefficie nts: ma1 sma1 Dec96 Jan 97 Dec02 I911-MA0 I911.1-AR1 I911.1-MA0-0.3825 -0.6499 0.0989 -0.0690 0.0810-0.09490.8139-0.2715s.e. 0.0926 0.1189 0.0228 0.0218 0.02020.04620.09780.0439sigma A 2 estimated as 0.0006721: log-423.98画图plot(log(airmiles),ylab="log(airmiles)") poi nts(fitted(air.m1))Nin e11p=1*(seq(airmiles)==69) plot(ts(Ni ne11p*(-0.0949)+filter(Ni ne11p,filter=.8139,method='recursive',side=1)*(-0.2715), freque ncy=12,start=1996),type='h',ylab='9/11 Effects') abli ne(h=0)arimax(x = log(airmiles), order = c(0, 1, 1), seas onal = list(order =c(0, 1,1), period =12), xreg = data.frame(Dec96 = 1 * (seq(airmiles)12), Ja n97 = 1 * (seq(airmiles) == 13), Dec02 =1 * (seq(airmiles)==84)),="ML",xtra nsf = data.frame(I911 = 1 * (seq(airmiles)= :=69), I911 = 1* (seq(airmiles)==69)), tran sfer = =list(c(0, 0), c(1,0)))methodlikelihood = 219.99, aic从上图可以看出在 2003年底后,911事件的影响效应才平息,航班客运量恢复了正常。
2异常值在时间序列中异常有两种,可加异常和新息异常,分别记AO 和10。
2.1异常值示例 2.1.1模拟数据模拟一般的ARIMA ( 1,0,1 ),然后故意将第10个观测值变成异常值 10.> set.seed(12345)Start = 1End = 100Freque ncy = 1[1] 0.49180881 -0.22323665 -0.99151270 -0.733878180.51869129 1.86210605 2.19935472 2.60210165[17] 0.79130003 0.26265426 2.93414857 3.99045889 3.60822678 1.17845765 -0.87682948 -1.20637799[25] -1.39501221 -0.18832171 1.22999827 1.46814850 2.66647491 3.23417469 2.60349624 1.49513215[33] 1.48852142 0.95739219 1.30011654 1.73444053 2.84825103 3.73214655 4.23579456 3.37049790[41] 2.02783955 1.41218929 -0.29974176 -1.58712591 -1.34080878 0.10747609 1.44651081 1.67809487啦1W 20002HH 200*Times L.o-n.o-rt9二济[57] 1.70668201 1.37518194 1.91824534 0.14254056-2.88169481 -3.30372327 -1.74068408 -3.24868057[73] 2.00559443 0.86443324 0.46847572 0.723384981.60215098 1.25922277 1.53180859 0.96289779[81] 1.07712188 1.42386354 0.56318008 -0.46689543 -0.91861106 -1.92947085 -2.18188785 -1.02759087[89] 2.31088272 3.13847319 3.01237881 3.434548072.31539494 2.44909873 2.91589141 1.12648908[97] -0.08123871 0.44412579 0.26116418 -0.45815484 > y[10]<-102.1.2 模型初步判断> acf(y)Series yLag> pacf(y)Strlfl* 丫> eacf(y) AR/MA1 o o o o o o o o o o o o o o2 o o o o o o o o o o oo o o3 o x o o o o o o o o oo o o4 o x o o o o o o o o oo o o5 x x o o o o o o o o oo o o6 x o o o o o o o o o oo o o7 o x o o o o o o o o oo o o从三个的结果来看,可以初步分析y是AR (1)模型2.1.3 对模型时行拟合> m1=arima(y,order=c(1,0,0))> m1Call:arima(x = y, order = c(1, 0, 0))Coefficie nts:ar1 in tercept0.5419 0.7096s.e. 0.0831 0.36032.1.4 对模拟模型进行异常值探测> detectAO(m1)[,1] [,2] [,3]ind 9.000000 10.000000 11.000000Iambda2 -4.018412 9.068982 -4.247367> detectAO(m1,robust=F)[,1] Iind 10.000000Iambda2 7.321709> detectlO(m1)[,1] [,2]ind 10.000000 11.00000lambda1 7.782013 -4.67421AO探测结果认为第9 , 10 , 11.可能出现异常值。